Yue Wang's personal website
wangyueft / detr3d Goto Github PK
View Code? Open in Web Editor NEWLicense: MIT License
License: MIT License
Yue Wang's personal website























































































































Hello,
Could you provide the results on the NuScenes train, validation and test splits in JSON format? I plan to use this as the input for a tracking algorithm.
Best regards,
when i run the code
tools/dist_test.sh projects/configs//detr3d/detr3d_vovnet_gridmask_det_final_trainval_cbgs.py /path/to/ckpt 1 --eval=bbox
i got this error at last:
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank: 0 (pid: 71517) of binary: /home/xxx/bin/python
Traceback (most recent call last):
File "/home/xxx/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/xxx/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/launch.py", line 193, in <module>
main()
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/launch.py", line 189, in main
launch(args)
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/launch.py", line 174, in launch
run(args)
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/run.py", line 713, in run
)(*cmd_args)
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/launcher/api.py", line 131, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/home/xxx/lib/python3.7/site-packages/torch/distributed/launcher/api.py", line 261, in launch_agent
failures=result.failures,
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
tools/test.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2022-02-22_20:41:39
host : k8s-deploy-xxx-xxx-xxx-xxx
rank : 0 (local_rank: 0)
exitcode : -9 (pid: 71517)
error_file: <N/A>
traceback : Signal 9 (SIGKILL) received by PID 71517
============================================================
i dont'k know why... what's happened?
at detr3dhead class you make pred box tensor z = z - h/2
make gt z = z - h/2, by use
gt_bboxes_3d = LiDARInstance3DBoxes(gt_bboxes_3d, box_dim=gt_bboxes_3d.shape[-1], origin=(0.5, 0.5, 0.5)).convert_to(self.box_mode_3d)
but in pred
the default LiDARInstance3DBoxes is origin=(0.5, 0.5, 0) .
So, in detr3dhead get_bboxes, should be bboxes[:, 2] = bboxes[:, 2]
And if I change bboxes[:, 2] = bboxes[:, 2] - bboxes[:, 5] * 0.5 to bboxes[:, 2] = bboxes[:, 2],
The eval of [DETR3D, ResNet101 w/ DCN] (https://github.com/WangYueFt/detr3d/blob/main/projects/configs/detr3d/detr3d_res101_gridmask.py)
Evaluating bboxes of pts_bbox
mAP: 0.3460
mATE: 0.7654
mASE: 0.2678
mAOE: 0.3933
mAVE: 0.8726
mAAE: 0.2100
NDS: 0.4221
So, am I wrong or right?
Hi,
I have installed mmdtection3d properly and I have all the pre-trianed model and weights at hand. when I run the test in tools, I get the following error:
File "tools/test.py", line 250, in
main()
File "tools/test.py", line 142, in main
plg_lib = importlib.import_module(_module_path, package = _module_dir[0])
File "/opt/conda/lib/python3.7/importlib/init.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "", line 1006, in _gcd_import
File "", line 983, in _find_and_load
File "", line 953, in _find_and_load_unlocked
File "", line 219, in _call_with_frames_removed
File "", line 1006, in _gcd_import
File "", line 983, in _find_and_load
File "", line 965, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'projects'
Any suggestion?
Hi,
Thanks for this amazing work. I was going through the code and saw that you've kept use_lidar=true here for DETR3D
https://github.com/WangYueFt/detr3d/blob/main/projects/configs/detr3d/detr3d_res101_gridmask.py#L23
I was expecting since its an image-based method, it should be kept false, and also the file should look similar to-
https://github.com/open-mmlab/mmdetection3d/blob/master/configs/_base_/datasets/nus-mono3d.py
Thanks
Hello ,when i use tools/dist_train.sh
open-mmlab/lib/python3.7/multiprocessing/reduction.py", line 60, in dump ForkingPickler(file, protocol).dump(obj) TypeError: can't pickle dict_keys objects ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 702440) of binary:

From your result in the paper, fps of your model is smaller than other models with nms. And from my understanding, bigger fps means better performance, but you said your model is more efficient. Could you explain it why your model is more efficient with smaller fps?
Hello, thanks for your excellent work.
I have some questions about your work, In detr3d_head.py, the prediction coordinate is :
tmp[..., 0:2] += reference[..., 0:2]
tmp[..., 0:2] = tmp[..., 0:2].sigmoid()
tmp[..., 4:5] += reference[..., 2:3]
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])
tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])
tmp[..., 4:5] = (tmp[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])According to the above setting, the tmp[...,:2] is x,y, and the 4th dim is z.
But in ground truth setting:
The gt_bboxes_3d[...,:3] is x,y,z which is conflict with the prediction bboxes of dimension setting.
if self.with_velocity:
gt_velocity = info['gt_velocity'][mask]
nan_mask = np.isnan(gt_velocity[:, 0])
gt_velocity[nan_mask] = [0.0, 0.0]
gt_bboxes_3d = np.concatenate([gt_bboxes_3d, gt_velocity], axis=-1)How to explain it?
Hello!
First of all, thanks so much for your great efforts, it's really amazing to have DETR3D here! I see that you didn't report any results on KITTI-object in your paper since nuScenes provides more sequential data that benefits the use of transformer-ish architecture. So I would like to ask whether you ran some test on KITTI dataset, or if someone else has reproduced the method on KITTI, which would be really appreciated.
Kind regards.
thanks!
Hi, I'm a trying to train detr3D on Nuscenes, but I meet a puzzled training procedure.
It's strange that the training time will continue some weeks, and I find that the GPU-util is strange,too. I use 4 RTX A6000 to train the model, sometimes one or two GPUs' util will be 0(for a long time).
After check, I can train fcos3d as usual.
Could anyone please help me with the question? A lot of thanks!


Hello, any details for the training schedule of this pretrained fcos3d checkpoint?
According to my experiment result, the prediction result of with_box_refine=False is better than that of with_box_refine=True. mAP of with_box_refine=False is 0.365, and mAP of with_box_refine=True is 0.35. I didn't see any related discussion on this comparison in the paper. Is there any explanation for this? Thank you!
Hi, thanks for your great work! I am trying to reproduce the performance of Object DGCNN. However, the final results of voxel-based one is 5 points below the reported one. Here is the log:
2021-12-06 10:15:40,069 - mmdet - INFO - Epoch(val) [20][753] ...pts_bbox_NuScenes/NDS: 0.6263, pts_bbox_NuScenes/mAP: 0.5352
I notice that there is a shape mismatch between the pretrained backbone(provided in your google-drive) and the initialized one in object DGCNN:
size mismatch for pts_backbone.blocks.0.0.weight: copying a param with shape torch.Size([64, 64, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 256, 3, 3]).
size mismatch for pts_backbone.blocks.0.1.weight: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.1.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.1.running_mean: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.1.running_var: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.3.weight: copying a param with shape torch.Size([64, 64, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 128, 3, 3]).
size mismatch for pts_backbone.blocks.0.4.weight: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.4.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.4.running_mean: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.4.running_var: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.6.weight: copying a param with shape torch.Size([64, 64, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 128, 3, 3]).
size mismatch for pts_backbone.blocks.0.7.weight: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.7.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.7.running_mean: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.7.running_var: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.9.weight: copying a param with shape torch.Size([64, 64, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 128, 3, 3]).
size mismatch for pts_backbone.blocks.0.10.weight: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.10.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.10.running_mean: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.0.10.running_var: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for pts_backbone.blocks.1.0.weight: copying a param with shape torch.Size([128, 64, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 128, 3, 3]).
size mismatch for pts_backbone.blocks.1.1.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.1.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.1.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.1.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.3.weight: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for pts_backbone.blocks.1.4.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.4.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.4.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.4.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.6.weight: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for pts_backbone.blocks.1.7.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.7.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.7.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.7.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.9.weight: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for pts_backbone.blocks.1.10.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.10.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.10.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.10.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.12.weight: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for pts_backbone.blocks.1.13.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.13.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.13.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.13.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.15.weight: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for pts_backbone.blocks.1.16.weight: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.16.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.16.running_mean: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for pts_backbone.blocks.1.16.running_var: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([256]).
Is this normal?
Hello, can you please explain what is the function of grid mask? Is it a way of augmentation? Have you tested the result with use_grid_mask=False?
Thanks a lot!
Hello
Could you share your onnx export script, which can help us a lot.
Thanks!
I have reproduced your excellent work DETR3D but met some trouble, I didn't find the config parameter to change the batch_size of the model. Should it be added to the config.py (like detr3d_res101_gridmask.py)? I will appreciate it to your kindness to answer my question.
Hello! This is a wonderful work! Thank you for sharing! I have a simple question regarding the CBGS. In the original CBGS, there are mainly two technologies, one is duplicate sampling to alleviate the class imbalance, another is ground truth data augmentation through random adding ground truth from other frames. Just want to confirm, for DETR3D, only duplicate sampling is applied in the CBGS, am I right? Because DETR3D is a image-based network, adding new targets is not as easy as in point clouds.

When reproduce detr3d, I find that whether use official provided model or train myself, the mAOE and mAOS metric is always too large.
Could someone give me any suggestion?
Hi, thank you for your excellent work! I try to reproduce the results of "resnet-101 with fcos3d initialized backbone" in the config. The data is created by the "create_data.py" in this repo, the produced "train.pkl" and "val.pkl" are used for training. The mAP and mAAE, mAVE, mATE are similar to the results of the paper, but why mAOE and mASE are 0.7, 1.6, they are twice difference with the paper produced? Looking forward to your reply, thank you!
Hi, when i Modified the backbone network to resnet50, and download it's pretrained model from Net, the model does not converge, when I put the res101(download from your ‘readme’) back on, it works again,I dont know why,hope for your reply。
'pts_bbox_NuScenes/NDS': 0.8238093679962551, 'pts_bbox_NuScenes/mAP': 0.83450670209427}
Per-class results:
Object Class AP ATE ASE AOE AVE AAE
car 0.873 0.256 0.114 0.033 0.260 0.195
truck 0.832 0.327 0.115 0.033 0.191 0.216
bus 0.842 0.323 0.104 0.027 0.293 0.245
trailer 0.778 0.395 0.116 0.041 0.136 0.124
construction_vehicle 0.783 0.405 0.173 0.079 0.137 0.322
pedestrian 0.805 0.380 0.203 0.181 0.245 0.136
motorcycle 0.821 0.337 0.150 0.085 0.347 0.213
bicycle 0.871 0.271 0.169 0.079 0.155 0.009
traffic_cone 0.877 0.241 0.162 nan nan nan
barrier 0.862 0.289 0.110 0.050 nan nan
Compared with the index mAP=34.6 in the paper, 83.4 is extremely abnormal when the training model provided by the author is tested on the verification set. Has anyone ever been in that situation?
Environment: 4xRTX3090.
Failure: train detr3d with resnet101 backbone dominates each card with 21GB memory. Train detr3d with vovnet backbone exceeds the memory limit. image_per_gpu is set to 1.
I read from your paper that your experiment uses 8xRTX3090. How should I adjust for adaption of my training process?
Could you provide the code for kownledge distillation?
Hi,
I run train.py and get the error below
tools/dist_train.sh /home_shared/jongwoo/detr3d/projects/configs/detr3d/detr3d_res101_gridmask.py 8
Traceback (most recent call last): File "tools/train.py", line 248, in <module> main() File "tools/train.py", line 237, in main train_model( File "/home_shared/jongwoo/detr3d/mmdetection3d/mmdet3d/apis/train.py", line 28, in train_model train_detector( File "/home_shared/jongwoo/miniconda3/envs/cuda11_1/lib/python3.8/site-packages/mmdet/apis/train.py", line 158, in train_detector cfg.device, File "/home_shared/jongwoo/miniconda3/envs/cuda11_1/lib/python3.8/site-packages/mmcv/utils/config.py", line 48, in __getattr__ raise ex **AttributeError: 'ConfigDict' object has no attribute 'device'**
I am using Ubuntu 18.04.5 LTS and I train with a single node and 8 GPUs. This device issue happens only when I run training.
I can run dist_test.sh without any problem. I can successfully run the following code.
nohup tools/dist_test.sh /home_shared/jongwoo/detr3d/projects/configs/detr3d/detr3d_res101_gridmask.py /home_shared/jongwoo/detr3d/pretrain_weight/detr3d_resnet101.pth 8 --eval=bbox &
I have read the mmdet3d doc and run the visualize_results.py script.But I can only get ***.obj file.
How can I visualize results on images?
Hi, Could you please tell me what is the external data you used (showing on the rankings of nuscenes)? Public or private datasets?

hi, thank you for your work, i have a problem in feature_sampling function, the following code
reference_points_cam = (reference_points_cam - 0.5) * 2
why need multiply 2?
Thank you for reply!
Dear authors,
Thank you for your amazing work! I read your code and find you implemented two-stage detection. Do you have two-stage experimental results?
Hi,
Thx for your great work! I'm trying to rerun the training process of DETR3D on a 8-V100 machine using the default setting of detr3d_res101_gridmask_cbgs.py and the estimation of the training time is 8 days (I notice that the training epoch in paper is 12 while the code is 24, so for you the time should be 36h in this config?), which is 5.4x longer than the time you reported in the paper. Is this normal? I think 3090 should not be 5.4x faster than V100...
Hi,
I was trying to test for different image encoder backbones.
The config file I am using was detr3d_res101_gridmask.py (https://github.com/WangYueFt/detr3d/blob/main/projects/configs/detr3d/detr3d_res101_gridmask.py).
I only change load_from='ckpts/fcos3d.pth' to load_from = None, then the model diverges.
I change image backbone from ResNet 101 to 50 (pretrained using torchvision or detectron2 caffe) all diverges.
Do I have to use the exact given setting or did I do something wrong? How to change image encoder backbones or train it from scratch?

Hello,
Im trying to run the train.py file with the detr3d_res101_gridmask.py configuration but Im not able to build the Detr3D model using mmdetection3d. Do I have to do anything extra in order to allow mmdet3d to build Detr3d? Here is my error:
Traceback (most recent call last): File "/opt/conda/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/opt/conda/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/root/.vscode-server/extensions/ms-python.python-2022.6.3/pythonFiles/lib/python/debugpy/__main__.py", line 45, in <module> cli.main() File "/root/.vscode-server/extensions/ms-python.python-2022.6.3/pythonFiles/lib/python/debugpy/../debugpy/server/cli.py", line 444, in main run() File "/root/.vscode-server/extensions/ms-python.python-2022.6.3/pythonFiles/lib/python/debugpy/../debugpy/server/cli.py", line 285, in run_file runpy.run_path(target_as_str, run_name=compat.force_str("__main__")) File "/opt/conda/lib/python3.7/runpy.py", line 263, in run_path pkg_name=pkg_name, script_name=fname) File "/opt/conda/lib/python3.7/runpy.py", line 96, in _run_module_code mod_name, mod_spec, pkg_name, script_name) File "/opt/conda/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/Development_detr3d/tools/train.py", line 250, in <module> main() File "/Development_detr3d/tools/train.py", line 209, in main test_cfg=cfg.get('test_cfg')) File "/Development_detr3d/mmdetection3d/mmdet3d/models/builder.py", line 84, in build_model return build_detector(cfg, train_cfg=train_cfg, test_cfg=test_cfg) File "/Development_detr3d/mmdetection3d/mmdet3d/models/builder.py", line 58, in build_detector cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg)) File "/opt/conda/lib/python3.7/site-packages/mmcv/utils/registry.py", line 212, in build return self.build_func(*args, **kwargs, registry=self) File "/opt/conda/lib/python3.7/site-packages/mmcv/cnn/builder.py", line 27, in build_model_from_cfg return build_from_cfg(cfg, registry, default_args) File "/opt/conda/lib/python3.7/site-packages/mmcv/utils/registry.py", line 45, in build_from_cfg f'{obj_type} is not in the {registry.name} registry') KeyError: 'Detr3D is not in the models registry'
Hi, May I ask about the detail of dd3d_det_final.pth? Is this model checkpoint pretrained on their private dataset and then on nuScenes trainval?
Hi, thanks so much for sharing such great work!
I have some questions about the parameter settings of the experiment. In the paper, the training epoch is 12 with an initial LR 1e-4, but the epoch is 24 in code with an initial LR 2e-4.
Do all the experiments (Table 1 & Table 2) in the paper under the setup mentioned in the paper (epoch 12)?
(I understand that CBGS will extend the training time)
Could you report an experimental config from the paper? One might expect to do a comparison experiment with you in the same experimental configuration.
The released code with epoch 24 and initial LR 2e-4, are there any results under such a setup? How much can it improve over when set epoch to 12 with an initial LR 1e-4?
python ./tools/test.py /media/yinwenbing/disk1/detr3d/projects/configs/detr3d/detr3d_res101_gridmask.py
/media/yinwenbing/disk1/detr3d/ckp/detr3d_resnet101.pth
--show --show-dir ./data/result/detr3d
I run ang get this error:
Traceback (most recent call last):
File "./tools/test.py", line 249, in
main()
File "./tools/test.py", line 219, in main
outputs = single_gpu_test(model, data_loader, args.show, args.show_dir)
File "/media/yinwenbing/disk1/detr3d/mmdetection3d/mmdet3d/apis/test.py", line 47, in single_gpu_test
model.module.show_results(data, result, out_dir=out_dir)
File "/media/yinwenbing/disk1/detr3d/mmdetection3d/mmdet3d/models/detectors/mvx_two_stage.py", line 467, in show_results
if isinstance(data['points'][0], DC):
KeyError: 'points'
Hi, in the log you provide, the loaded pretrained model is called pgd.pth while the provided model is fcos3d.pth, are these two models the same?
Hi,
When I did the experiment on NuScenesDataset, I found that an error was reported in the configuration file detr3d_vovnet_gridmask_det_final_trainval_cbgs.py and there was no such file in the NuScenesDataset. ann_file=data_root + 'nuscenes_infos_trainval.pkl'(line 192), maybe it should be ann_file=data_root + 'nuscenes_infos_train.pkl'?

I used demo/mono_det demo.py from mmdetection 3d but got keyError: 'img'. Could you please tell me how you tested it?
Thank you for your great work.
The paper compares FCOS3D and Detr3D in the overlap region. How to test the nuscenes only in the overlap region?Thank you very much!
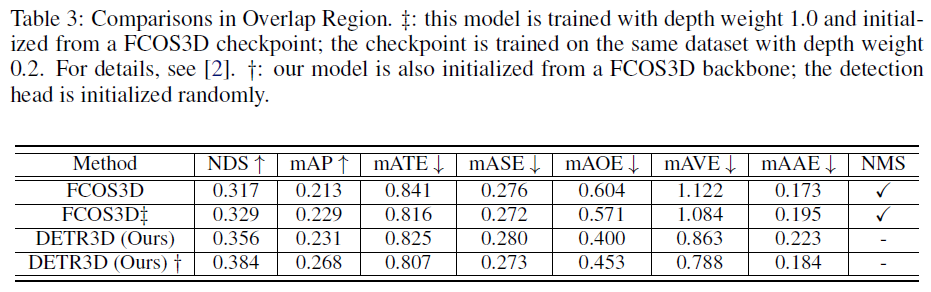
Thanks for releasing the wonderful work.
In the readme:
| Backbone | mAP | NDS | Download |
|---|---|---|---|
| DETR3D, ResNet101 w/ DCN | 34.7 | 42.2 | model | log |
| above, + CBGS | 34.9 | 43.4 | model | log |
| DETR3D, VoVNet on trainval, evaluation on test set | 41.2 | 47.9 | model | log |
If I understand correctly, the number of above+CBGS is for the validation set, while the number of DETR3D, VoVNet on trainval is for test set. So I am wondering have you evaluated the results of above + CBGS on the test set? I wonder how much gap it will have for the results on val set and test set
why only set num_points == 1 in code ? Whether num_points > 1 will be better ?
Dear Authors,
Thanks for your wonderful work on 3D object detection. I am wondering that have you implemented detr3d on the KITTI dataset? I reimplemented it but observed strong overfitting on the KITTI dataset:


Best,
Qing LIAN
hi
thx for the great job , can someone tell me the detail rely version about this repo?
i try to follow the mmdetection3d but all failed.
pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0
mmcv=1.4.0 mmsegmentation=0.14.1 mmdet=2.14.0
not works
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.