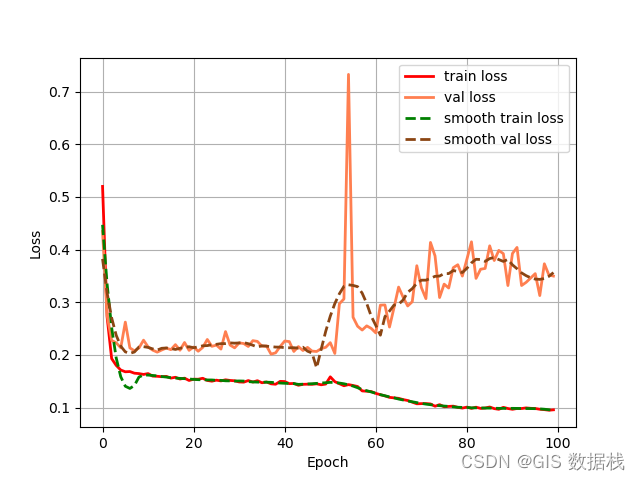
所有的图片都是跳过了,导致所有评价指标都是0
Num classes 4
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/17457--E2-2-2019-9-53.png, miou_out_66/detection-results/17457--E2-2-2019-9-53.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/12336--F2-1-2021-7-17.png, miou_out_66/detection-results/12336--F2-1-2021-7-17.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/7450--E2-2-2021-7-12.png, miou_out_66/detection-results/7450--E2-2-2021-7-12.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/16970--D3-1-2020-6-35.png, miou_out_66/detection-results/16970--D3-1-2020-6-35.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/22019--G3-1-2020-7-51.png, miou_out_66/detection-results/22019--G3-1-2020-7-51.png