bubbliiiing / deeplabv3-plus-pytorch Goto Github PK
View Code? Open in Web Editor NEW这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。
License: MIT License
这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。
License: MIT License
1.目前程式我只要將pretrained設定為True會跳出這個錯誤,請問如何解決?(我已經預先下載好.pth檔並且放在model_data)

2.請問要如何在程式新增計算dice值?
最近在标注数据集准备训练,请问2007与2012的语义分割数据集有何区别???
ASPP模块中第五个分支使用了2次torch.mean进行卷积,这样是等效于AdaptiveAvg Pool2d吗?

我换了weight 发现训练的时候一开始十几个epoch miou都不变的。。。 为啥啊
请问下面这条公式出处是哪里呀?或者是作者您写的吗?
deeplabv3-plus-pytorch/train.py
Line 413 in 9161327
ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 256, 1, 1])
用voc训练集训练出来的模型,预测时全黑
`# ---------------------------------------------------#
pr = pr.argmax(axis=-1)`
这个pr是全0的,用预训练模型继续训练,也会出现黑点越来越多的情况,请问这是什么原因呢
up主你好,你的Deeplabv3+用的是voc数据集,
由于没有找到cityscape转voc的脚本
所以直接将cityscape转成coco数据集放进去训练,但结果moiu只有40左右
问题①:想问一下需不需要先cityscape转coco,然后再coco转voc进行训练?
问题②:用你提供的voc_mobilenetv2预训练权重会不会对cityscape效果造成影响?



小白想问问怎么得到分割目标的最小外接矩形或者坐标点呢?
博主好,用自己的数据集,预测出来的图只是比原图变暗了一点,没有显示标注的部分,是哪里需要更改吗?
大佬您好,我在训练自己数据集的时候遇到了一个问题,我设置num_classes为2(只需分割一个种类),但是在载入预训练模型时,始终无法载入 Fail To Load Key: ['cls_conv.weight', 'cls_conv.bias'] ……Fail To Load Key num: 2 这两个键,请问一下有没有上面解决办法?
再次感谢作者的代码,我想参考您yolov4中ghostnet和mobilenetv3替换该代码的mobilenetv2,麻烦作者给一些建议,谢谢你
如题
您好,我训练的是自己的数据集,计算miou时发现moiu_out文件下的detection-results文件中的预测结果全是黑的,请问这是什么原因呢
老师好,想请问一下,默认导出onnx之后,模型输出是三通道的RGB图像,怎么将输出改为0或1的标签呀,比如我就对两个类进行分割(背景和目标),然后我希望输出二值图(背景为0,目标为1),就好像训练的数据集的标签一样
模型转onnx格式之后,输出是3通道的float图,仔细观察后通道1和通道2都有点奇怪,通道3是我想要的(需要格式转换),怎么控制网络直接输出灰度标签呢
倒数第二行代码:
print('Total Loss: %.3f || Val Loss: %.3f ' % (loss / (epoch_step + 1), val_loss / (epoch_step_val + 1)))
前面应该是total_loss吧?如下:
print('Total Loss: %.3f || Val Loss: %.3f ' % (total_loss / (epoch_step + 1), val_loss / (epoch_step_val + 1)))

这是初始化的时候,里面都是nan
然后训练的时候会大概率返回的low_level_features都是0,偶然会有值。导致最后计算的loss都是nan;或者无法下降。
是什么原因可能导致吗?自学初学者,基础不扎实,不明白是哪里的问题。求解
请问deeplabv3支持的最大图片输入宽高是多少?谢谢
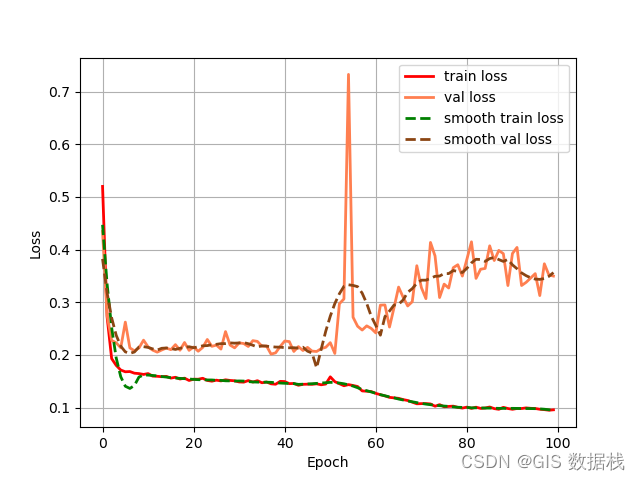
在xception主干网络下 到50epoch后loss非常不平滑,请问下这是怎么回事呢?
请问下,这个需要python哪个版本。我运行安装的时候老是提示这个问题
Could not find a version that satisfies the requirement scipy==1.2.1 (from -r requirements.txt (line 1)) (from versions: )
No matching distribution found for scipy==1.2.1 (from -r requirements.txt (line 1))
博主大大您好,请问如果想要更换除mobilenet和xception以外的其他backbone,应该在代码中怎样操作实现呢?
up主你好,对于非voc数据想在deeplabv3+中训练的话,是不是得将它们先转成voc数据集的格式?
因此我用了你提供的那个segmentation-format-fix-main/Convert_SegmentationClass.py文件将彩色标签文件转成黑色标签开始训练,可以成功训练,但是预测没有效果,想问一下是不是数据集格式转换的问题以及如何排查问题,这个问题卡了好久,谢谢!
你好!请问有所对应的网络结构图吗?我看到的结构图中,只有1个dropout层,而你的代码里有2个
再次感谢您提供的代码和讲解
关于数据增强,我有几点疑问:
1、代码中的数据增强方式会给图像加上灰边,这些灰色的像素点在训练的时候是怎么处理的呢?会计算进loss中吗?
2、代码中没有对旋转操作,是因为旋转对训练的提高效果不明显吗?
3、数据增强是为了有更丰富的训练数据,那么对一张图像进行各种变换后保存起来,用这些数据对网络进行训练是否能达到更好的效果呢?
DeepLabv3+的论文中报告的MIoU大多在80以上,请问这其中的差距是什么原因造成的?怎样才能达到论文中的效果?
请问我使用自己的数据进行训练时,会出现跑到中途就卡住,然后就自动结束进程,请问知道是什么原因吗?

所有的图片都是跳过了,导致所有评价指标都是0
Num classes 4
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/17457--E2-2-2019-9-53.png, miou_out_66/detection-results/17457--E2-2-2019-9-53.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/12336--F2-1-2021-7-17.png, miou_out_66/detection-results/12336--F2-1-2021-7-17.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/7450--E2-2-2021-7-12.png, miou_out_66/detection-results/7450--E2-2-2021-7-12.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/16970--D3-1-2020-6-35.png, miou_out_66/detection-results/16970--D3-1-2020-6-35.png
Skipping: len(gt) = 786432, len(pred) = 262144, /gpfs/home/cuilulu_stu/deeplabv3-plus-pytorch-main/VOCdevkit/VOC2007/SegmentationClass/22019--G3-1-2020-7-51.png, miou_out_66/detection-results/22019--G3-1-2020-7-51.png
博主大大,我按照文档指示对VOC数据集进行训练,但是耗时很长,是什么原因噻?
博主大大,请教一下,这个是怎么造成的呢
使用xception作为主干网络。
哥,对于您写的代码:
1、当pretrained=True 且model_path="model_data/xception_pytorch_imagenet.pth"
2、当pretrained=False且model_path="model_data/xception_pytorch_imagenet.pth"
3、当pretrained=True且model_path=""
对于以上三种情况,都只是加载了主干网络xception的预训练权重,是这样吗
如何对不同的像素区域打上对应的label
你好 想加入mae(绝对误差指标)但是输出图片通道数为num_class,而我单纯就是二分类怎么解决呢
作者大大,您好,我想请问一下关于调整原来的mobilenetv2下采样次数时,函数:
def _nostride_dilate(self, m, dilate): classname = m.__class__.__name__ if classname.find('Conv') != -1: if m.stride == (2, 2): m.stride = (1, 1) if m.kernel_size == (3, 3): m.dilation = (dilate//2, dilate//2) m.padding = (dilate//2, dilate//2) else: if m.kernel_size == (3, 3): m.dilation = (dilate, dilate) m.padding = (dilate, dilate)
为什么要调整padding和dilation为不同的值,这一步不是很懂,希望得到各位大佬的指点。
m.dilation = (dilate//2, dilate//2) m.padding = (dilate//2, dilate//2)
这里我可以理解为保持卷积前后的size保持不变,但是不是很懂为什么后面其他层要调整padding和dilation的大小,是为了获得更大的感受野?不调整可不可以?
小白勿喷!!!
| num_classes | 21|
| backbone | xception|
| model_path | /home/neaucs2/usr/tc/yzq/deeplabv3-plus-pytorch/model_data/deeplab_xception.pth|
| input_shape | [512, 512]|
| Init_Epoch | 0|
| Freeze_Epoch | 50|
| UnFreeze_Epoch | 250|
| Freeze_batch_size | 16|
| Unfreeze_batch_size | 8|
| Freeze_Train | False|
| Init_lr | 0.007|
| Min_lr | 7.000000000000001e-05|
| optimizer_type | sgd|
| momentum | 0.9|
| lr_decay_type | cos|
| save_period | 5|
| save_dir | logs|
| num_workers | 4|
| num_train | 10582|
| num_val | 1449|`
可以使用数据集cityscapes来训练吗?
您好,非常好的一个仓库!请问是否有mobilenetV3版本的网络权重

if self.mix_type == 0:
seg_img = np.zeros((np.shape(pr)[0], np.shape(pr)[1], 3))
for c in range(self.num_classes):
seg_img[:, :, 0] += ((pr[:, :] == c ) * self.colors[c][0]).astype('uint8')
seg_img[:, :, 1] += ((pr[:, :] == c ) * self.colors[c][1]).astype('uint8')
seg_img[:, :, 2] += ((pr[:, :] == c ) * self.colors[c][2]).astype('uint8')
请问如果我想得到这个猫的左上方坐标和右下方坐标该怎么print呢
首先感谢提供多种版本的代码。
我注意到同样是VOC12数据集,deeplabv3-plus-tf2/deeplabv3-plus-keras在测试集上的结果显著优于deeplabv3-plus-pytorch版本。
是否因为前者使用的是dice_loss_with_CE而后者只使用DiceLoss进行训练?还是有其它别的原因?
你的注释写的也太详细了,我追的女孩子看你的代码都不需要我了,555555~

ASPP模块中第五个分支使用了2次torch.mean进行卷积,这样是等效于AdaptiveAvg Pool2d吗?
@bubbliiiing up,我自己从新训练了你的deeplabv3+网络,也是采用的冻结训练,但是解冻后miou突然下降很多,请问这是什么问题?
下面是训练过程中的miou:
0
78.31419775054849
81.50547537615232
27.105109248288006
47.354731057269554
47.7181748097358
54.851383176103475
54.9375840188487
52.765164041864956
81.50之后就是解冻阶段。
首先谢谢您的代码,让我受益匪浅。我想请教一下训练中每一代的f_score是什么值?谢谢大佬
需要在其它平台推理,怎么把模型转换为onnx模型
我替换为自己的数据集进行训练,但是一直遇到ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 256, 1, 1]),这个报错,百度了都说是batch_size可能多出来了,把drop_last设置为true就好了。可是我看你的代码里是设置的true啊,请问up怎么解决呢,我这边cuda:10.1 pytorch:1.2.0
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.