ahojnnes / local-feature-evaluation Goto Github PK
View Code? Open in Web Editor NEWComparative Evaluation of Hand-Crafted and Learned Local Features
Comparative Evaluation of Hand-Crafted and Learned Local Features



















































































































I have received the following error.
As I looked at the details, it seems that the error is related to the command lines of Ceres Solver which I have just recently updated (please see the figure below).
Therefore, I guess that your developed package is relying on a certain Ceres's commit (about 2 years ago...).
Can you share the commit id of the Ceres solver, so I can checkout the commit and works with your repo.?
src/CMakeFiles/colmap.dir/build.make:128: recipe for target 'src/CMakeFiles/colmap.dir/base/camera.cc.o' failed
make[2]: *** [src/CMakeFiles/colmap.dir/base/camera.cc.o] Error 1
CMakeFiles/Makefile2:853: recipe for target 'src/CMakeFiles/colmap.dir/all' failed
make[1]: *** [src/CMakeFiles/colmap.dir/all] Error 2
Makefile:149: recipe for target 'all' failed
make: *** [all] Error 2

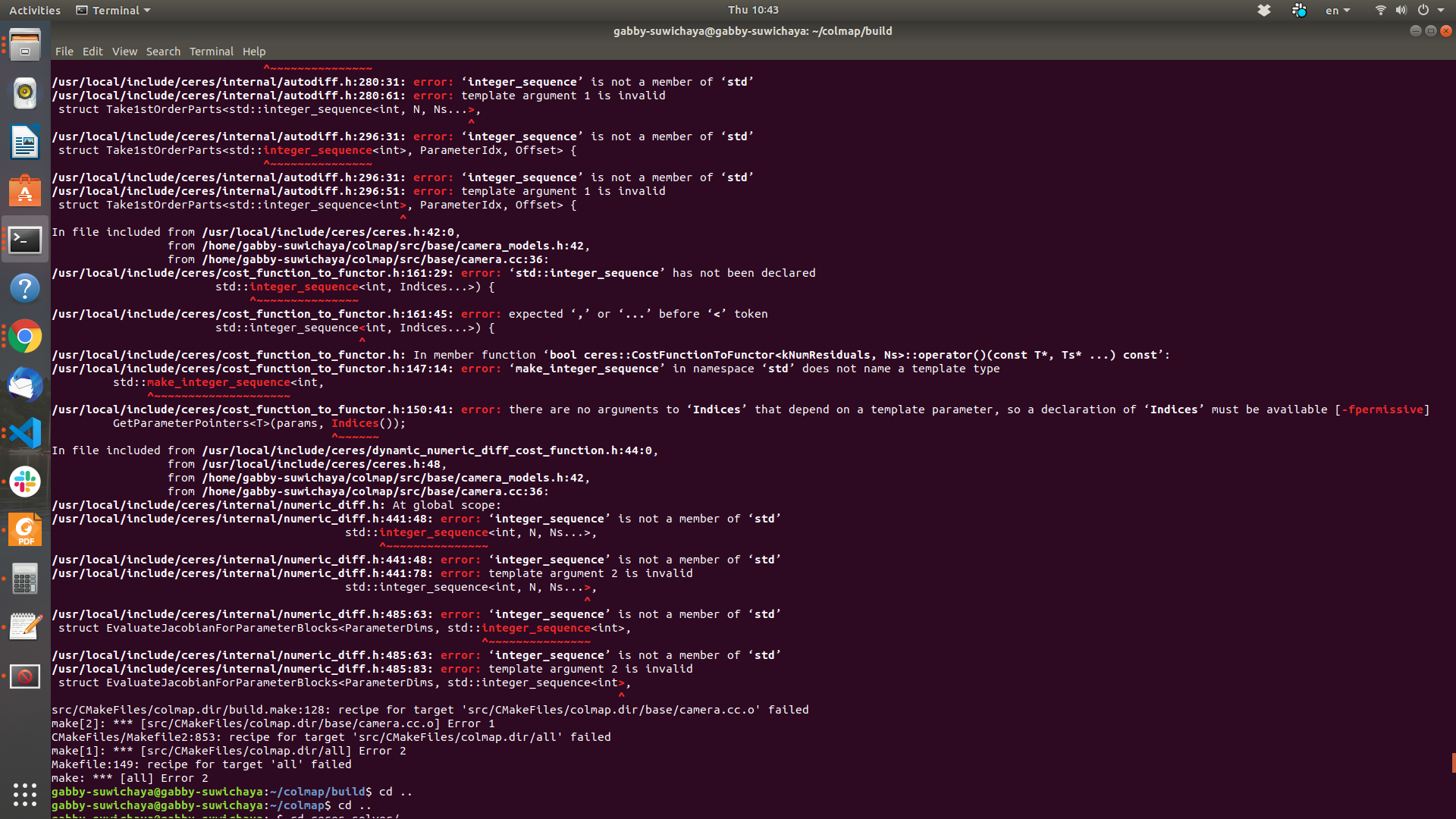
Hi,
when I am building the "colmap", I met the problem below:
CMake Error at CMakeLists.txt:87 (find_package):
By not providing "FindCeres.cmake" in CMAKE_MODULE_PATH this project has
asked CMake to find a package configuration file provided by "Ceres", but
CMake did not find one.
Could not find a package configuration file provided by "Ceres" with any of
the following names:
CeresConfig.cmake
ceres-config.cmake
Add the installation prefix of "Ceres" to CMAKE_PREFIX_PATH or set
"Ceres_DIR" to a directory containing one of the above files. If "Ceres"
provides a separate development package or SDK, be sure it has been
installed.
-- Configuring incomplete, errors occurred!
How to solve it?
Hi, thanks for your code!
After reading the code and your paper, I have some questions.
When I want to run 'matches_importer' ,I found I don't have this txt.
I am not sure to understand how to extract the statistics after dense reconstruction like in INSTRUCTION.md

Can anyone show me how to do step by step? And if I use COLMAP GUI to reconstruct the sparse or dense model, how can I extract the statistics? Thank you.
It seems like colmap does not have vocab_tree_retriever_float.cc or vocab_tree_builder_float.cc, as described in the current version of the instructions when using large datasets.
I could only find versions without the "float" notation (eg, I can find vocab_tree_retriever but not vocab_tree_retriever_float).
I suppose one can use the non-float ones, but I would guess the performance would suffer a bit since the non-float ones perform quantization, while the "float" ones mentioned in the instructions probably perform no quantization (this is my guess).
Hello. I have tried to use the approximate_matching. However, I constantly get the error at system(command) in Matlab (Matlab 2018b, Ubuntu 18.04)..
[status, output] = system(command);
The error is shown as follows:
86 if num_images < 2 % 2000
Running command: /home/userxx/colmap/build/src/tools/vocab_tree_retriever_float
Running command: --database_path
Running command: /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/database.db
Running command: --descriptor_path
Running command: /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/descriptors
Running command: --vocab_tree_path
Running command: /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/Oxford5k/vocab-tree.bin
Error using matlab.system.internal.executeCommand
Arguments must contain a character vector.
Error in dos (line 66)
[varargout{1:nargout}] = matlab.system.internal.executeCommand(varargin{:});
Error in approximate_matching (line 11)
[status, output] = system(command);
Error in matching_pipeline_file (line 90)
approximate_matching
Because Oxford5k is quite large, so I tried running this by using Fountain dataset (by setting the number of the image to a low number such as 2).
PS. Also, before running this code ("approximate_matching.m"), I have executed the following two colmap command (according to the instruction https://github.com/ahojnnes/local-feature-evaluation/blob/master/INSTRUCTIONS.md) which seems to work fine...
./colmap/build/src/tools/vocab_tree_builder_float
--descriptor_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/descriptors
--database_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/database.db
--vocab_tree_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/Oxford5k/vocab-tree.bin
And
./colmap/build/src/tools/vocab_tree_retriever_float \
--descriptor_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/descriptors
--database_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/database.db
--vocab_tree_path /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/Oxford5k/vocab-tree.bin
> /Fountain/d2_netD2-Net-nophototourism-FP32-detThr0-max-global_ApproxMatch_Scr1p00_Mtch0p95_TESTFORApprox/retrieval.txt
Results:
Loading descriptors...
=> Loaded a total of 190278 descriptors
Building index for visual words...
=> Quantized descriptor space using 64516 visual words
Saving index to file...
Hi,
I am testing my descriptor on the benchmark, but I meet a problem when import feature matches to colmap
the error on Fountain is
==============================================================================
Custom feature matching
==============================================================================
Matching block [1/1]F1011 02:58:27.932655 3451297 database.cc:153] Check failed: matrix.size() * sizeof(typename MatrixType::Scalar) == num_bytes (44408 vs. 88816)
*** Check failure stack trace: ***
@ 0x7fddebffc1c3 google::LogMessage::Fail()
@ 0x7fddec00125b google::LogMessage::SendToLog()
@ 0x7fddebffbebf google::LogMessage::Flush()
@ 0x7fddebffc6ef google::LogMessageFatal::~LogMessageFatal()
@ 0x55bb5c715889 colmap::(anonymous namespace)::ReadDynamicMatrixBlob<>()
@ 0x55bb5c716972 colmap::Database::ReadMatches()
@ 0x55bb5c7ae0d5 colmap::FeatureMatcherCache::GetMatches()
@ 0x55bb5c7b26aa colmap::SiftFeatureMatcher::Match()
@ 0x55bb5c7b7363 colmap::ImagePairsFeatureMatcher::Run()
@ 0x55bb5c94ca51 colmap::Thread::RunFunc()
@ 0x7fddea3f1de4 (unknown)
@ 0x7fddea517609 start_thread
@ 0x7fddea09d293 clone
/home/kunbpc/Installed/colmap/build/src/exe/colmap: /usr/local/lib/libtiff.so.5: no version information available (required by /lib/x86_64-linux-gnu/libfreeimage.so.3)
ERROR: Failed to parse options - unrecognised option '--export_path'.
Warning: Could not reconstruct any model
and my code is
subprocess.call([paths.colmap_path,
"matches_importer",
"--database_path",
paths.database_path,
"--match_list_path",
paths.match_list_path,
"--match_type", "pairs"])
I have checked the numpy shape of my matches, it is (x,2), and I apply exhaustive matching by a nested for loop, which is
image_names = list(images.keys())
image_pairs = []
image_pair_ids = set()
for idx_total, image_name1 in enumerate(tqdm(image_names[:-1])):
# read descriptors for image1
feature_path1 = paths.features_path/'{}.{}_local'.format(image_name1, configs['method_postfix'])
descriptors1 = np.load(feature_path1)['descriptors']
descriptors1 = torch.from_numpy(descriptors1).to(device)
bar = tqdm(image_names[idx_total+1:])
for idx_sub, image_name2 in enumerate(bar):
image_pairs.append((image_name1, image_name2))
image_id1, image_id2 = images[image_name1], images[image_name2]
image_pair_id = image_ids_to_pair_id(image_id1, image_id2)
if image_pair_id in image_pair_ids:
continue
# read descriptors for image2
feature_path2 = paths.features_path/'{}.{}_local'.format(image_name2, configs['method_postfix'])
descriptors2 = np.load(feature_path2)['descriptors']
descriptors2 = torch.from_numpy(descriptors2).to(device)
matches = matcher(descriptors1, descriptors2, **configs['matcher_config'])
image_pair_ids.add(image_pair_id)
if image_id1 > image_id2:
matches = matches[:, [1, 0]]
matches_str = matches.tostring()
cursor.execute("INSERT INTO matches(pair_id, rows, cols, data) "
"VALUES(?, ?, ?, ?);",
(image_pair_id, matches.shape[0], matches.shape[1],
matches_str))
connection.commit()
The error code said there is something half the size of that it should be, but I have no idea about what it is and what's wrong with it.
I also submitted the same issue on colmap repository.
When i use the command:
python3 scripts/reconstruction_pipeline.py --dataset_path data/Fountain/ --colmap_path ../colmap/build/src/exe
to eval the descriptor,error occurs:
Traceback (most recent call last):
File "scripts/reconstruction_pipeline.py", line 277, in
main()
File "scripts/reconstruction_pipeline.py", line 243, in main
matching_stats = import_matches(args)
File "scripts/reconstruction_pipeline.py", line 114, in import_matches
"--match_type", "pairs"])
File "/usr/lib/python3.5/subprocess.py", line 557, in call
with Popen(*popenargs, **kwargs) as p:
File "/usr/lib/python3.5/subprocess.py", line 947, in init
restore_signals, start_new_session)
File "/usr/lib/python3.5/subprocess.py", line 1551, in _execute_child
raise child_exception_type(errno_num, err_msg)
FileNotFoundError: [Errno 2] No such file or directory: '../colmap/build/src/exe/matches_importer'
But i can use the command "colmap matches_importer --dataset_path data/Fountain --match_list_path data/Fountain/image-pairs.txt" correctly.
How to fix it? Looking forward to your apply!
Traceback (most recent call last):
File "scripts/reconstruction_pipeline.py", line 304, in
main()
File "scripts/reconstruction_pipeline.py", line 270, in main
matching_stats = import_matches(args)
File "scripts/reconstruction_pipeline.py", line 144, in import_matches
cursor.execute("SELECT count(*) FROM two_view_geometries WHERE rows > 0;")
sqlite3.OperationalError: no such table: two_view_geometries.
I've finished reconstruction_pipeline.py but got this error._
Hello, I think it misses some files on this project. After running matching_pipeline.m (it misses pdist2.m to compute eculidean distance of descriptors, I used my own), I obtained some files in 'descriptors', 'keypoints', 'matches' as you described in the instruction. However, I can not continue the evaluation by using the python script 'reconstruction_pipeline.py', as it requires to input the database file, which I haven't find after running the matching_pipeline. I do found there is 'DATABASE_PATH' defined in the 'matching_pipeline.m', but I didn't find where it is used. Can you help me to fix the problem?
I don not have this execuate './colmap/build/src/exe/matches_importer ',and how to get it?
CMake Error at CMakeLists.txt:87 (find_package):
By not providing "FindCeres.cmake" in CMAKE_MODULE_PATH this project has
asked CMake to find a package configuration file provided by "Ceres", but
CMake did not find one.
Could not find a package configuration file provided by "Ceres" with any of
the following names:
CeresConfig.cmake
ceres-config.cmake
Add the installation prefix of "Ceres" to CMAKE_PREFIX_PATH or set
"Ceres_DIR" to a directory containing one of the above files. If "Ceres"
provides a separate development package or SDK, be sure it has been
installed.
-- Configuring incomplete, errors occurred!
See also "/home/wsw/文档/local-feature-evaluation-master/colmap/build/CMakeFiles/CMakeOutput.log".
Hi ahojnnes,


the result of Fountain is normal.
but the result of the Herzjesu and southbuilding's dense points is too small...
How can I solve the problem?
Hi,
I was able to follow all steps from the instructions but am having a problem importing features/matches into colmap.
(I am using my own detector/descriptor, but I made sure the writing format is correct, by reading with the provided MATLAB functions and similarly by checking that the read_matrix function from colmap_import.py reads the features properly).
When running
python scripts/colmap_import.py --dataset_path path/to/FountainI get
Importing features for 0010.png
Traceback (most recent call last):
File "scripts/colmap_import.py", line 94, in <module>
main()
File "scripts/colmap_import.py", line 65, in main
memoryview(keypoints)))
sqlite3.InterfaceError: Error binding parameter 3 - probably unsupported type.
I have investigated quite a bit, but still cannot figure out what the problem is. It looks like the issue is with memoryview(keypoints). Could this potentially be a python version problem? (are you using python 2.7?)
Another thing I am thinking is: is the command (ie, the one that ends in line 65 of colmap_import.py) trying to just write the address of keypoints into data? I am not familiar with SQL, so apologies if this is a dumb question. If this is the case, maybe I could somehow cast the memory address returned by memoryview(keypoints) into an int before passing it into the cursor.execute call?
BTW, when I print as print(memoryview(keypoints)) (right before the error), I get: <memory at 0x7f39516b4478> -- does this look like what this should be?
Thanks for the help!
I'm trying to run this benchmark using databases Herzjesu and Fountain but got the following error on both:
Computing features for 0000.png [1/11] -> skipping, already exist
Computing features for 0006.png [7/11] -> skipping, already exist
Computing features for 0004.png [5/11] -> skipping, already exist
Computing features for 0009.png [10/11] -> skipping, already exist
Computing features for 0001.png [2/11] -> skipping, already exist
Computing features for 0008.png [9/11] -> skipping, already exist
Computing features for 0003.png [4/11] -> skipping, already exist
Computing features for 0005.png [6/11] -> skipping, already exist
Computing features for 0010.png [11/11] -> skipping, already exist
Computing features for 0007.png [8/11] -> skipping, already exist
Computing features for 0002.png [3/11] -> skipping, already exist
Matching block [1/1, 1/1]Warning: Converting non-floating point data to single.
> In pdist2 (line 228)
In match_descriptors (line 18)
In exhaustive_matching (line 57)
In matching_pipeline (line 81)
Error using pdist2mex
X and Y inputs to PDIST2MEX must both be double, or both be single.
Error in pdist2 (line 352)
D = pdist2mex(X',Y',dist,additionalArg,smallestLargestFlag,radius);
Error in match_descriptors (line 18)
dists = pdist2(descriptors1, descriptors2, 'euclidean');
Error in exhaustive_matching (line 57)
matches = match_descriptors(descriptors(oidx1), ...
Error in matching_pipeline (line 81)
exhaustive_matching
I've installed all Dependencies, downloaded Databases keypoints and configured TODO Variables in matching_pipeline.m script. Any ideia about this problem? Best regards.
First of all thank you for your excellent work. I was wondering if you could provide your RANSAC configuration for evaluation? I didn't find them either in the original paper or this repo, or are you using the default configuration? I'm asking this because I find default configuration fails to discard many visually unreliable inlier image pairs, and very strangely it seems to me 'min_inlier_ratio' is not working at all - pairs that should be discarded by this ratio test still appear in the inlier pair list. Is it a COLMAP issue or am I doing something wrong?
Thank you very much.
Hello,
I'm trying to add custom datasets to your benchmark. My goal is to determine which method (SIFT, ...) is best for my specific application.
To do so, I tried to generate the file database.db associated with custom dataset. However, i can not figure out what params in the table cameras should contain (apparently it is binary data). Since i had no idea which kind of data i had to put here, i set NULL for every camera_id.
I generated descriptors, keypoints and matches successfully thanks to scripts/matching_pipeline.m (this script do not use database). However, when I try to run scripts/reconstruction_pipeline.py on my custom dataset, i get the following errors:
==============================================================================
Loading database
==============================================================================
Loading cameras...F0917 10:12:14.569028 5185 database.cc:207] Check failed: num_params == camera.NumParams() (0 vs. 4)
*** Check failure stack trace: ***
@ 0x7fd04f1b25cd google::LogMessage::Fail()
@ 0x7fd04f1b4433 google::LogMessage::SendToLog()
@ 0x7fd04f1b215b google::LogMessage::Flush()
@ 0x7fd04f1b4e1e google::LogMessageFatal::~LogMessageFatal()
@ 0x6426a9 colmap::(anonymous namespace)::ReadCameraRow()
@ 0x647cd2 colmap::Database::ReadAllCameras()
@ 0x64b87d colmap::DatabaseCache::Load()
@ 0x6ad367 colmap::IncrementalMapperController::LoadDatabase()
@ 0x6b0fba colmap::IncrementalMapperController::Run()
@ 0x7f4eec colmap::Thread::RunFunc()
@ 0x7fd04bb79c80 (unknown)
@ 0x7fd04e3a86ba start_thread
@ 0x7fd04b2df41d clone
@ (nil) (unknown)
Warning: Could not reconstruct any model
==============================================================================
Raw statistics
==============================================================================
{'num_inlier_matches': None, 'num_images': 43, 'num_inlier_pairs': 0}
None
==============================================================================
Formatted statistics
==============================================================================
Traceback (most recent call last):
File "scripts/reconstruction_pipeline.py", line 297, in <module>
main()
File "scripts/reconstruction_pipeline.py", line 293, in main
matching_stats["num_inlier_matches"]])) + " |")
TypeError: 'NoneType' object is not subscriptable
Do you have any idea what i did wrong here? Or anything i should consider to add a custom dataset to your benchmark?
I followed the instruction to reproduce the statistic result on the Gendarmenmarkt dataset. After conducting feature matching, it comes to
python scripts/reconstruction_pipeline.py
--dataset_path path/to/Fountain
--colmap_path path/to/colmap/build/src/exe
This script has already run over 3 days, so I think there might be something wrong?
I checked the task manager, and found that two threads are running:
~/colmap/build/src/exe/dense_fuser --workspace_path ~/data/Gendarmenmarkt/dense/0 --input_type photometric --output_path ~/data/Gendarmenmarkt/dense/0
~/colmap/build/src/exe/dense_fuser --workspace_path ~/data/Gendarmenmarkt/dense/0 --input_type photometric --output_path ~/data/Gendarmenmarkt/dense/0/fused.
Is this normal? Otherwise, how can I accelerate the process?
Hi Dr. Schönberger,
We ran this benchmark for our new descriptor R2D2, and a pretrained version of SuperPoint. Should we add the results to the readme ?
Cheers,
Noe Pion from Naver Labs Europe
Hi, Thanks for your work!
I followed your instruction, and almost everything went well. However, when I did
cd colmap/build
cmake .. -DTEST_ENABLED=OFF
make -j8'
In make -j8, an error ocuured as in
[ 93%] Building CXX object src/tools/CMakeFiles/vocab_tree_retriever_float.dir/vocab_tree_retriever_float.cc.o
[ 95%] Built target inverted_file_entry_test
/home/phantom/projects/local-feature-evaluation/colmap/src/tools/vocab_tree_retriever_float.cc:17:26: fatal error: base/feature.h: No such file or directory
compilation terminated.
src/tools/CMakeFiles/vocab_tree_retriever_float.dir/build.make:62: recipe for target 'src/tools/CMakeFiles/vocab_tree_retriever_float.dir/vocab_tree_retriever_float.cc.o' failed
make[2]: *** [src/tools/CMakeFiles/vocab_tree_retriever_float.dir/vocab_tree_retriever_float.cc.o] Error 1
CMakeFiles/Makefile2:6243: recipe for target 'src/tools/CMakeFiles/vocab_tree_retriever_float.dir/all' failed
make[1]: *** [src/tools/CMakeFiles/vocab_tree_retriever_float.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
For information, there was no feature.h in colmap/src/base/.
Could you please help with this?
Hi,
TFeat have 3 version of pretrained models provided on https://github.com/vbalnt/tfeat which pretrained model did you use in your evaluations.
Hi,
I could reproduce the result on Fountain, Herz-jesu, South-Building but cannot reproduce the result for Madrid Metropolis. The number of inliers-pairs and inlier -matches are way too many with lots of false positives. Is it a problem with inlier matching code?
Thanks so much for leasing this evaluation metrics. I just wonder if you have any full python implementation for the evaluation.
In function match_descriptors() (line 18), the function pdist2() is called with 'squaredeuclidean' argument, but it is not in the list of valid methods (line 142). It should be replaced by 'euclidean' or 'seuclidean', right?
I would like to ask if there is any process guidance instructions about running with python code in the repository code. I only found the guidance file of running with matlab in the repository, and I want a readme file that can make python code run!!!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.