Haofei Xu · Jing Zhang · Jianfei Cai · Hamid Rezatofighi · Fisher Yu · Dacheng Tao · Andreas Geiger
Paper | Slides | Project Page | Colab | Demo

A unified model for three motion and 3D perception tasks.
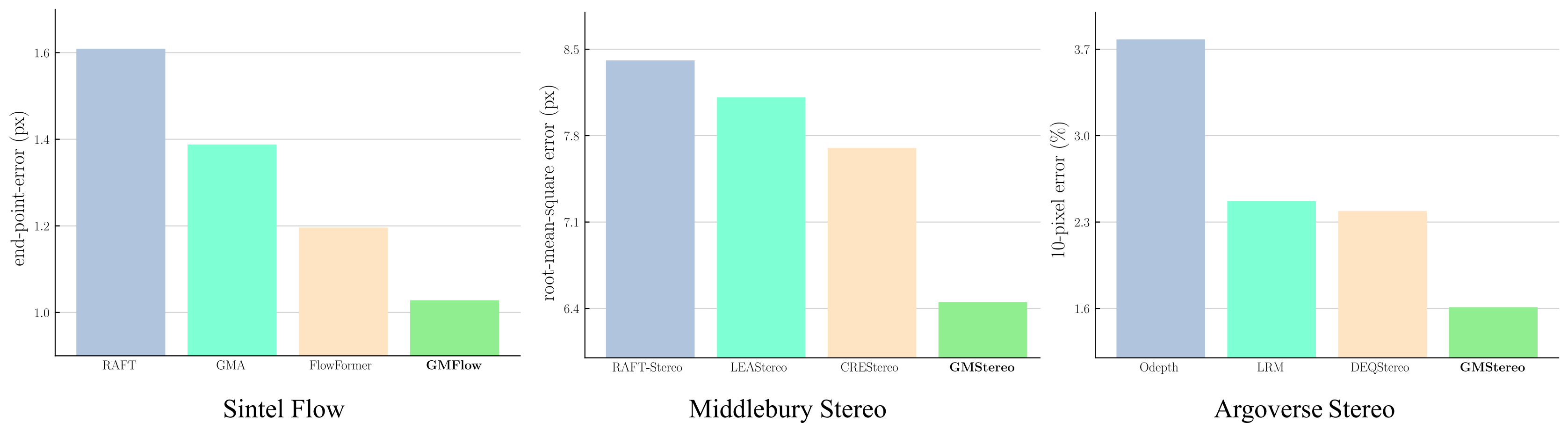
We achieve the 1st places on Sintel (clean), Middlebury (rms metric) and Argoverse benchmarks.
This project is developed based on our previous works:
-
GMFlow: Learning Optical Flow via Global Matching, CVPR 2022, Oral
-
High-Resolution Optical Flow from 1D Attention and Correlation, ICCV 2021, Oral
-
AANet: Adaptive Aggregation Network for Efficient Stereo Matching, CVPR 2020
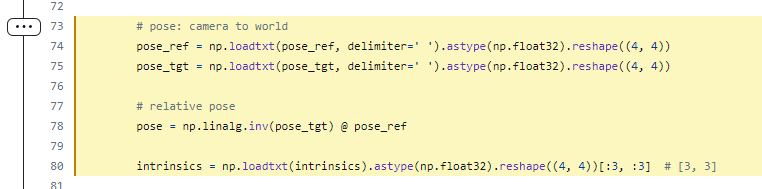
Our code is developed based on pytorch 1.9.0, CUDA 10.2 and python 3.8. Higher version pytorch should also work well.
We recommend using conda for installation:
conda env create -f conda_environment.yml
conda activate unimatch
Alternatively, we also support installing with pip:
bash pip_install.sh
A large number of pretrained models with different speed-accuracy trade-offs for flow, stereo and depth are available at MODEL_ZOO.md.
We assume the downloaded weights are located under the pretrained directory.
Otherwise, you may need to change the corresponding paths in the scripts.
Given an image pair or a video sequence, our code supports generating prediction results of optical flow, disparity and depth.
Please refer to scripts/gmflow_demo.sh, scripts/gmstereo_demo.sh and scripts/gmdepth_demo.sh for example usages.
kitti_demo.mp4
The datasets used to train and evaluate our models for all three tasks are given in DATASETS.md
The evaluation scripts used to reproduce the numbers in our paper are given in scripts/gmflow_evaluate.sh, scripts/gmstereo_evaluate.sh and scripts/gmdepth_evaluate.sh.
For submission to KITTI, Sintel, Middlebury and ETH3D online test sets, you can run scripts/gmflow_submission.sh and scripts/gmstereo_submission.sh to generate the prediction results. The results can be submitted directly.
All training scripts for different model variants on different datasets can be found in scripts/*_train.sh.
We support using tensorboard to monitor and visualize the training process. You can first start a tensorboard session with
tensorboard --logdir checkpoints
and then access http://localhost:6006 in your browser.
@article{xu2023unifying,
title={Unifying Flow, Stereo and Depth Estimation},
author={Xu, Haofei and Zhang, Jing and Cai, Jianfei and Rezatofighi, Hamid and Yu, Fisher and Tao, Dacheng and Geiger, Andreas},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023}
}
This work is a substantial extension of our previous conference paper GMFlow (CVPR 2022, Oral), please consider citing GMFlow as well if you found this work useful in your research.
@inproceedings{xu2022gmflow,
title={GMFlow: Learning Optical Flow via Global Matching},
author={Xu, Haofei and Zhang, Jing and Cai, Jianfei and Rezatofighi, Hamid and Tao, Dacheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8121-8130},
year={2022}
}
This project would not have been possible without relying on some awesome repos: RAFT, LoFTR, DETR, Swin, mmdetection and Detectron2. We thank the original authors for their excellent work.