

![]()




EnvPool is a C++-based batched environment pool with pybind11 and thread pool. It has high performance (~1M raw FPS with Atari games, ~3M raw FPS with Mujoco simulator on DGX-A100) and compatible APIs (supports both gym and dm_env, both sync and async, both single and multi player environment). Currently it supports:
- Atari games
- Mujoco (gym)
- Classic control RL envs: CartPole, MountainCar, Pendulum, Acrobot
- Toy text RL envs: Catch, FrozenLake, Taxi, NChain, CliffWalking, Blackjack
- ViZDoom single player
- DeepMind Control Suite
- Box2D
- Procgen
- Minigrid
Here are EnvPool's several highlights:
- Compatible with OpenAI
gymAPIs, DeepMinddm_envAPIs, andgymnasiumAPIs; - Manage a pool of envs, interact with the envs in batched APIs by default;
- Support both synchronous execution and asynchronous execution;
- Support both single player and multi-player environment;
- Easy C++ developer API to add new envs: Customized C++ environment integration;
- Free ~2x speedup with only single environment;
- 1 Million Atari frames / 3 Million Mujoco steps per second simulation with 256 CPU cores, ~20x throughput of Python subprocess-based vector env;
- ~3x throughput of Python subprocess-based vector env on low resource setup like 12 CPU cores;
- Comparing with existing GPU-based solution (Brax / Isaac-gym), EnvPool is a general solution for various kinds of speeding-up RL environment parallelization;
- XLA support with JAX jit function: XLA Interface;
- Compatible with some existing RL libraries, e.g., Stable-Baselines3, Tianshou, ACME, CleanRL, or rl_games.
- Stable-Baselines3
Pendulum-v1example; - Tianshou
CartPoleexample,Pendulum-v1example, Atari example, Mujoco example, and integration guideline; - ACME
HalfCheetahexample; - CleanRL
Pong-v5example (Solving Pong in 5 mins (tracked experiment)); - rl_games Atari example (2 mins Pong and 15 mins Breakout) and Mujoco example (5 mins Ant and HalfCheetah).
- Stable-Baselines3
Check out our arXiv paper for more details!
EnvPool is currently hosted on PyPI. It requires Python >= 3.7.
You can simply install EnvPool with the following command:
$ pip install envpoolAfter installation, open a Python console and type
import envpool
print(envpool.__version__)If no error occurs, you have successfully installed EnvPool.
Please refer to the guideline.
The tutorials and API documentation are hosted on envpool.readthedocs.io.
The example scripts are under examples/ folder; benchmark scripts are under benchmark/ folder.
We perform our benchmarks with ALE Atari environment PongNoFrameskip-v4 (with environment wrappers from OpenAI Baselines) and Mujoco environment Ant-v3 on different hardware setups, including a TPUv3-8 virtual machine (VM) of 96 CPU cores and 2 NUMA nodes, and an NVIDIA DGX-A100 of 256 CPU cores with 8 NUMA nodes. Baselines include 1) naive Python for-loop; 2) the most popular RL environment parallelization execution by Python subprocess, e.g., gym.vector_env; 3) to our knowledge, the fastest RL environment executor Sample Factory before EnvPool.
We report EnvPool performance with sync mode, async mode, and NUMA + async mode, compared with the baselines on different number of workers (i.e., number of CPU cores). As we can see from the results, EnvPool achieves significant improvements over the baselines on all settings. On the high-end setup, EnvPool achieves 1 Million frames per second with Atari and 3 Million frames per second with Mujoco on 256 CPU cores, which is 14.9x / 19.6x of the gym.vector_env baseline. On a typical PC setup with 12 CPU cores, EnvPool's throughput is 3.1x / 2.9x of gym.vector_env.
| Atari Highest FPS | Laptop (12) | Workstation (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For-loop | 4,893 | 7,914 | 3,993 | 4,640 |
| Subprocess | 15,863 | 47,699 | 46,910 | 71,943 |
| Sample-Factory | 28,216 | 138,847 | 222,327 | 707,494 |
| EnvPool (sync) | 37,396 | 133,824 | 170,380 | 427,851 |
| EnvPool (async) | 49,439 | 200,428 | 359,559 | 891,286 |
| EnvPool (numa+async) | / | / | 373,169 | 1,069,922 |
| Mujoco Highest FPS | Laptop (12) | Workstation (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For-loop | 12,861 | 20,298 | 10,474 | 11,569 |
| Subprocess | 36,586 | 105,432 | 87,403 | 163,656 |
| Sample-Factory | 62,510 | 309,264 | 461,515 | 1,573,262 |
| EnvPool (sync) | 66,622 | 380,950 | 296,681 | 949,787 |
| EnvPool (async) | 105,126 | 582,446 | 887,540 | 2,363,864 |
| EnvPool (numa+async) | / | / | 896,830 | 3,134,287 |
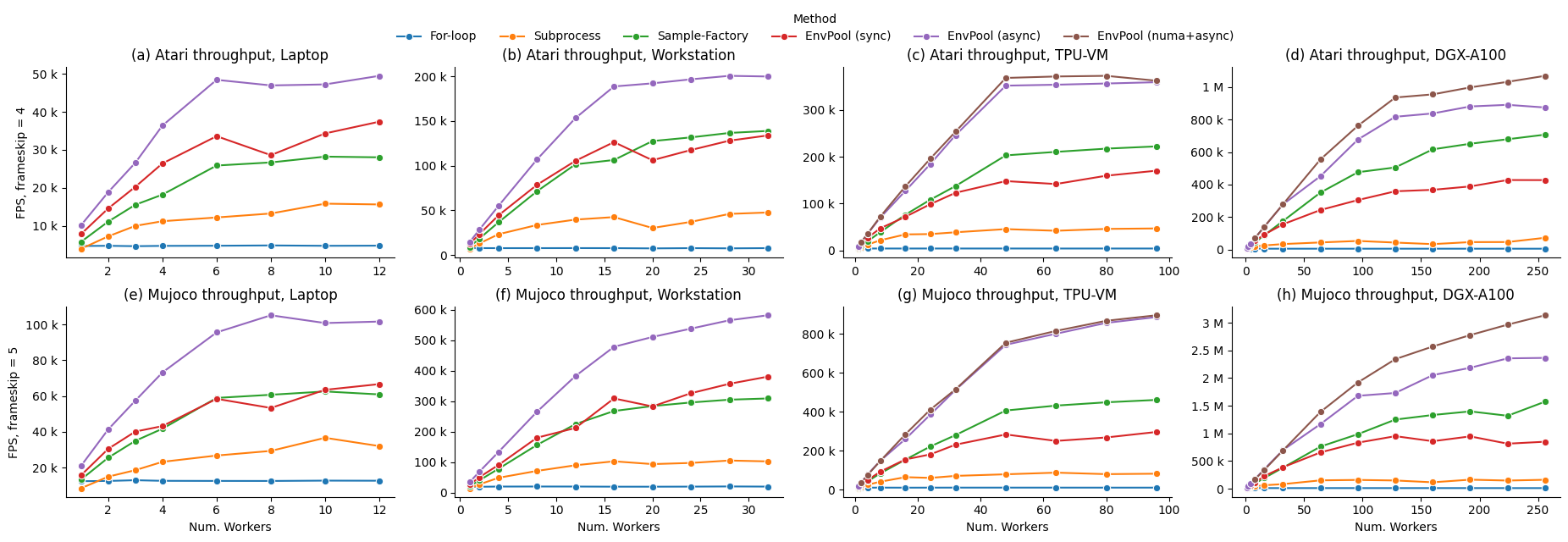
Please refer to the benchmark page for more details.
The following content shows both synchronous and asynchronous API usage of EnvPool. You can also run the full script at examples/env_step.py
import envpool
import numpy as np
# make gym env
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
# or use envpool.make_gym(...)
obs = env.reset() # should be (100, 4, 84, 84)
act = np.zeros(100, dtype=int)
obs, rew, term, trunc, info = env.step(act)Under the synchronous mode, envpool closely resembles openai-gym/dm-env. It has the reset and step functions with the same meaning. However, there is one exception in envpool: batch interaction is the default. Therefore, during the creation of the envpool, there is a num_envs argument that denotes how many envs you like to run in parallel.
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)The first dimension of action passed to the step function should equal num_envs.
act = np.zeros(100, dtype=int)You don't need to manually reset one environment when any of done is true; instead, all envs in envpool have enabled auto-reset by default.
import envpool
import numpy as np
# make asynchronous
num_envs = 64
batch_size = 16
env = envpool.make("Pong-v5", env_type="gym", num_envs=num_envs, batch_size=batch_size)
action_num = env.action_space.n
env.async_reset() # send the initial reset signal to all envs
while True:
obs, rew, term, trunc, info = env.recv()
env_id = info["env_id"]
action = np.random.randint(action_num, size=batch_size)
env.send(action, env_id)In the asynchronous mode, the step function is split into two parts: the send/recv functions. send takes two arguments, a batch of action, and the corresponding env_id that each action should be sent to. Unlike step, send does not wait for the envs to execute and return the next state, it returns immediately after the actions are fed to the envs. (The reason why it is called async mode).
env.send(action, env_id)To get the "next states", we need to call the recv function. However, recv does not guarantee that you will get back the "next states" of the envs you just called send on. Instead, whatever envs finishes execution gets recved first.
state = env.recv()Besides num_envs, there is one more argument batch_size. While num_envs defines how many envs in total are managed by the envpool, batch_size specifies the number of envs involved each time we interact with envpool. e.g. There are 64 envs executing in the envpool, send and recv each time interacts with a batch of 16 envs.
envpool.make("Pong-v5", env_type="gym", num_envs=64, batch_size=16)There are other configurable arguments with envpool.make; please check out EnvPool Python interface introduction.
EnvPool is still under development. More environments will be added, and we always welcome contributions to help EnvPool better. If you would like to contribute, please check out our contribution guideline.
EnvPool is under Apache2 license.
Other third-party source-code and data are under their corresponding licenses.
We do not include their source code and data in this repo.
If you find EnvPool useful, please cite it in your publications.
@inproceedings{weng2022envpool,
author = {Weng, Jiayi and Lin, Min and Huang, Shengyi and Liu, Bo and Makoviichuk, Denys and Makoviychuk, Viktor and Liu, Zichen and Song, Yufan and Luo, Ting and Jiang, Yukun and Xu, Zhongwen and Yan, Shuicheng},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {22409--22421},
publisher = {Curran Associates, Inc.},
title = {Env{P}ool: A Highly Parallel Reinforcement Learning Environment Execution Engine},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/8caaf08e49ddbad6694fae067442ee21-Paper-Datasets_and_Benchmarks.pdf},
volume = {35},
year = {2022}
}This is not an official Sea Limited or Garena Online Private Limited product.







































































































































