Code repository for the paper:
Convolutional Mesh Regression for Single-Image Human Shape Reconstruction
Nikos Kolotouros, Georgios Pavlakos, Kostas Daniilidis
CVPR 2019
[paper] [project page]
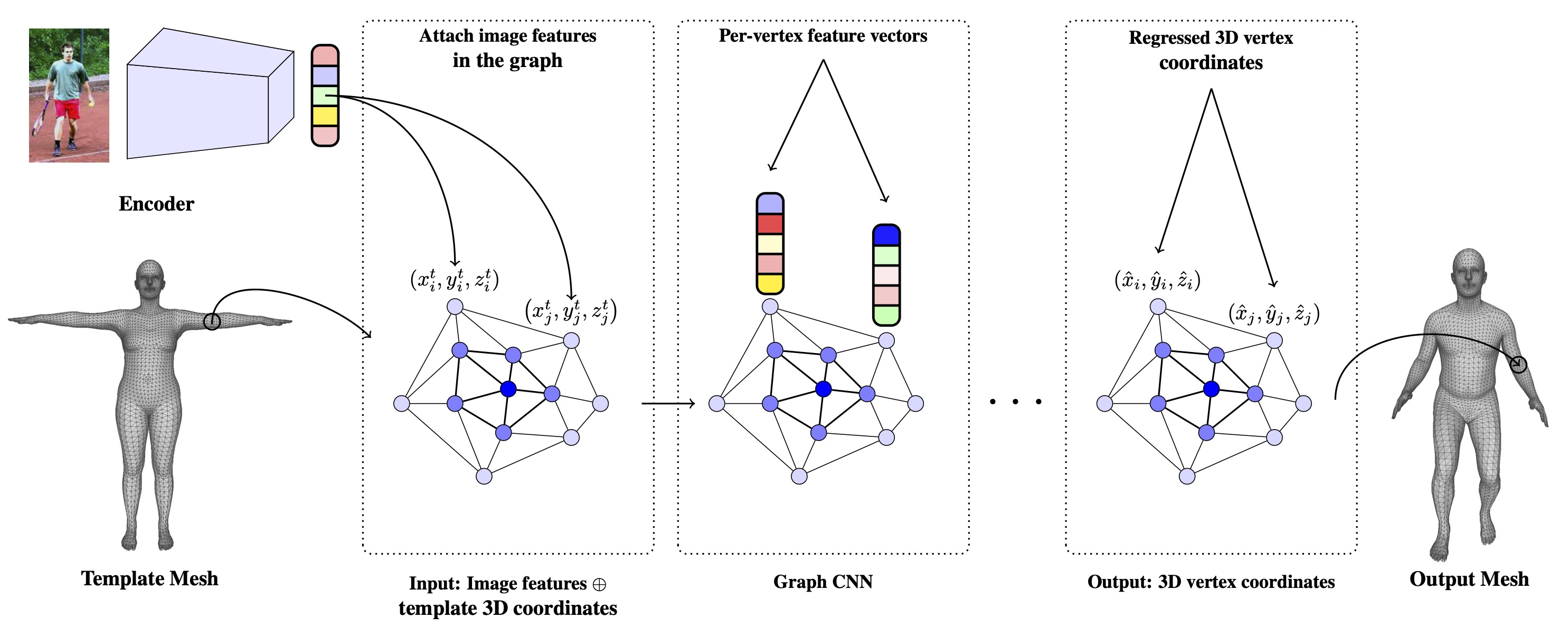
If you want to run the inference code and these instructions are not compatible with your setup, we have updated the installation procedure and inference code to be compatible with recent cuda/pytorch versions. Please check the cuda11_fix branch.
We recommend using the docker image that has all the dependencies pre-installed. You can pull the docker image by doing docker pull chaneyk/graphcmr.
We also provide the Dockerfile used to build the docker image in the docker folder.
We want to thank Ken Chaney for helping us support this functionality.
Alternatively, we suggest creating a new virtual environment for a clean installation of all the relevant dependencies. Although our code is fully compatible with Python 3, the visualizations depend on OpenDR that only works with Python 2. So currently only Python 2 is supported. We plan to drop this dependency in the future.
virtualenv cmr
source cmr/bin/activate
pip install -U pip
pip install -r requirements.txt
After finishing with the installation, you can continue with running the demo/evaluation/training code. In case you want to evaluate our approach on Human3.6M, you also need to manually install the pycdf package of the spacepy library to process some of the original files. If you face difficulties with the installation, you can find more elaborate instructions here.
To be able to run our code you need to also fetch some additional files. The recommended way of doing it is by running
./fetch_data.sh
Running the above command will fetch the pretrained models. We provide 2 pretrained models, one trained on Human3.6M + UP-3D and another one that also incorporates in the training images with 2D ground truth joints only (i.e., images from the LSP, MPII and COCO datasets).
Moreover, the command will fetch the neutral SMPL model from the Unite the People repository. The model falls under the SMPLify license. If you find this model useful for your research, please follow the corresponding citing insturctions.
To run our method, you need a bounding box around the person. The person needs to be centered inside the bounding box and the bounding box should be relatively tight. You can either supply the bounding box directly or provide an OpenPose detection file. In the latter case we infer the bounding box from the detections.
In summary, we provide 3 different ways to use our demo code and models:
- Provide only an input image (using
--img), in which case it is assumed that it is already cropped with the person centered in the image. - Provide an input image as before, together with the OpenPose detection .json (using
--openpose). Our code will use the detections to compute the bounding box and crop the image. - Provide an image and a bounding box (using
--bbox). The expected format for the json file can be seen inexamples/im1010_bbox.json.
Example with OpenPose detection .json
python demo.py --checkpoint=data/models/model_checkpoint_h36m_up3d_extra2d.pt --img=examples/im1010.jpg --openpose=examples/im1010_openpose.json
Example with predefined Bounding Box
python demo.py --checkpoint=data/models/model_checkpoint_h36m_up3d_extra2d.pt --img=examples/im1010.jpg --bbox=examples/im1010_bbox.json
Example with cropped and centered image
python demo.py --checkpoint=data/models/model_checkpoint_h36m_up3d_extra2d.pt --img=examples/im1010.jpg
Running the previous command will save the results in examples/im1010_{gcnn,smpl,gcnn_side,smpl_side}.png. The files im1010_gcnn and im1010_smpl show the overlayed reconstructions of the non-parametric and parametric shapes respectively. We also render side views, saved in im1010_gcnn_side.png and im1010_smpl_side.png.
Besides the demo code, we also provide code to evaluate our models on the datasets we employ for our empirical evaluation. Before continuing, please make sure that you follow the details for data preprocessing.
Example usage:
python eval.py --checkpoint=data/models/model_checkpoint_h36m_up3d.pt --config=data/config.json --dataset=h36m-p1 --log_freq=20
Running the above command will compute the MPJPE and Reconstruction Error on the Human3.6M dataset (Protocol I). The --dataset option can take different values based on the type of evaluation you want to perform:
- Human3.6M Protocol 1
--dataset=h36m-p1 - Human3.6M Protocol 2
--dataset=h36m-p2 - UP-3D
--dataset=up-3d - LSP
--dataset=lsp
Due to license limitiations, we cannot provide the SMPL parameters for Human3.6M (recovered using MoSh). Even if you do not have access to these parameters, you can still use our training code using data from UP-3D (full shape ground truth) and other in-the wild datasets (e.g., LSP, MPII, COCO that provide 2D keypoint ground truth). Again, make sure that you follow the details for data preprocessing.
Example usage:
python train.py --name train_example --pretrained_checkpoint=data/models/model_checkpoint_h36m_up3d.pt --config=data/config.json
You can view the full list of command line options by running python train.py --help. The default values are the ones used to train the models in the paper.
Running the above command will start the training process. It will also create the folders logs and logs/train_example that are used to save model checkpoints and Tensorboard logs.
If you start a Tensborboard instance pointing at the directory logs you should be able to look at the logs stored during training.
If you find this code useful for your research, please consider citing the following paper:
@Inproceedings{kolotouros2019cmr,
Title = {Convolutional Mesh Regression for Single-Image Human Shape Reconstruction},
Author = {Kolotouros, Nikos and Pavlakos, Georgios and Daniilidis, Kostas},
Booktitle = {CVPR},
Year = {2019}
}





























































































































