![]()

Causal machine learning enables individuals and organizations to make better data-driven decisions. In particular, causal ML allows us to answer “what if” questions about the effect of potential actions on outcomes.
Causal ML is a nascent area, we aim to enable a scalable, flexible, real-world applicable end-to-end causal inference framework. In perticular, we bridge between causal discovery, causal inference, and deep learning to achieve the goal. We aim to develop technology can automate causal decision-making using existing observational data alone, output both the discovered causal relationships and estimate the effect of actions simultaneously.
Causica is a deep learning library for end-to-end causal inference, including both causal discovery and inference. It implements deep end-to-end inference framework [2] and different alternatives.
This project splits the interventional decision making from observational decision making Azua repo found here Azua.
This codebase has been heavily refactored, you can find the previous version of the code here.
The Causica repo is on PyPI so you can be pip installed:
pip install causica
Real-world data-driven decision making requires causal inference to ensure the validity of drawn conclusions. However, it is very uncommon to have a-priori perfect knowledge of the causal relationships underlying relevant variables. DECI allows the end user to perform causal inference without having complete knowledge of the causal graph. This is done by combining the causal discovery and causal inference steps in a single model. DECI takes in observational data and outputs ATE and CATE estimates.
For more information, please refer to the paper.
Model Description
DECI is a generative model that employs an additive noise structural equation model (ANM-SEM) to capture the functional relationships among variables and exogenous noise, while simultaneously learning a variational distribution over causal graphs. Specifically, the relationships among variables are captured with flexible neural networks while the exogenous noise is modelled as either a Gaussian or spline-flow noise model. The SEM is reversible, meaning that we can generate an observation vector from an exogenous noise vector through forward simulation and given a observation vector we can recover a unique corresponding exogenous noise vector. In this sense, the DECI SEM can be seen as a flow from exogenous noise to observations. We employ a mean-field approximate posterior distribution over graphs, which is learnt together with the functional relationships among variables by optimising an evidence lower bound (ELBO). Additionally, DECI supports learning under partially observed data.
Simulation-based Causal Inference
DECI estimates causal quantities (ATE) by applying the relevant interventions to its learnt causal graph (i.e. mutilating incoming edges to intervened variables) and then sampling from the generative model. This process involves first sampling a vector of exogenous noise from the learnt noise distribution and then forward simulating the SEM until an observation vector is obtained. ATE can be computed via estimating an expectation over the effect variable of interest using MonteCarlo samples of the intervened distribution of observations.
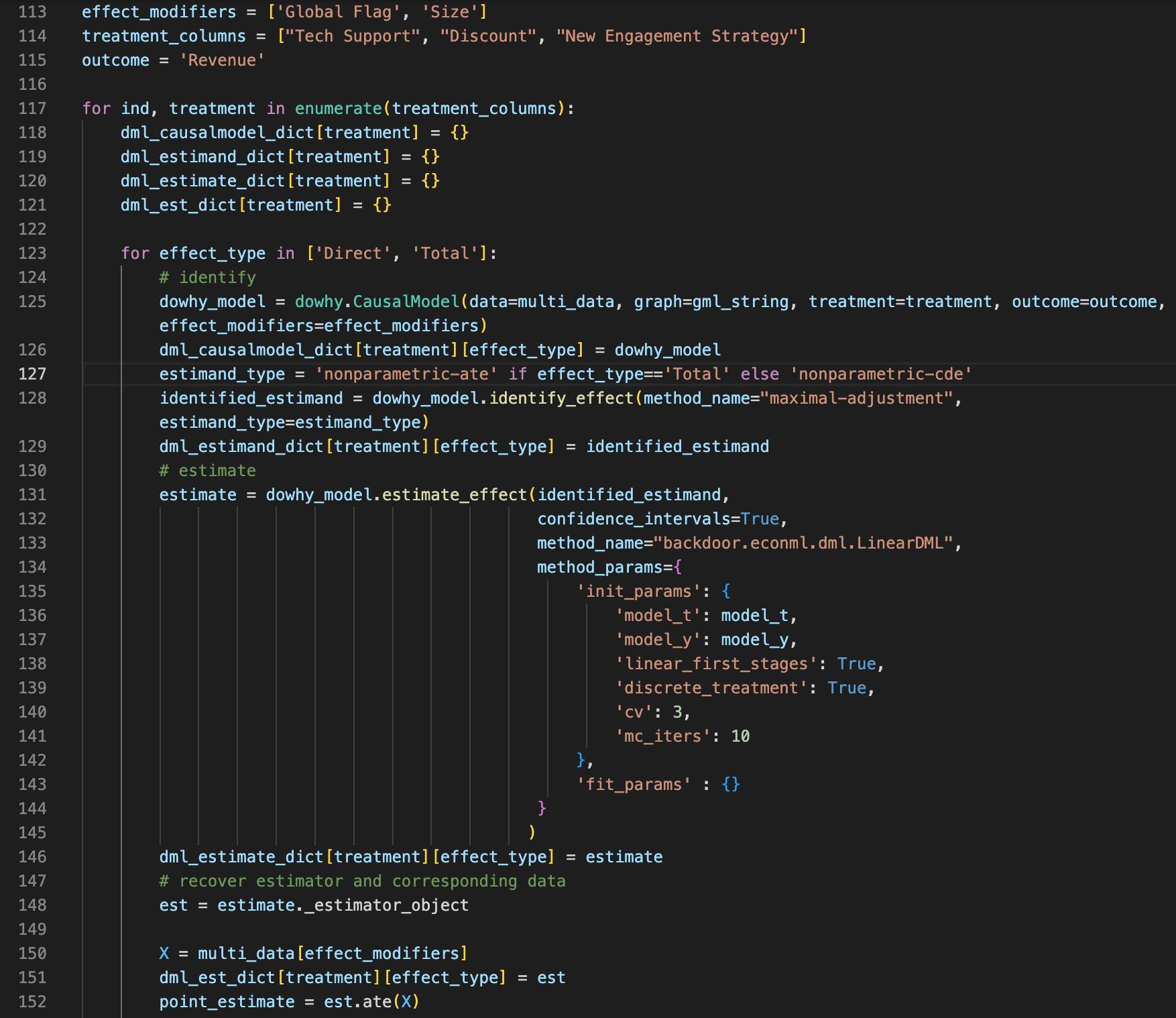
The best place to start is the examples/multi_investment_sales_attribution.ipynb notebook. This explains how to fit a model using PyTorch Lightning and test ATE and ITE results.
For a more detailed introduction to the components and how they fit together, see the notebook examples/csuite_example.ipynb, for how to train a DECI model and check the causal discovery.
This will download the data from the CSuite Azure blob storage and train DECI on it. See here for more info about CSuite datasets. The notebook will work on any of the available CSuite datasets.
Specifying a noise model
The noise exogenous model can be modified by changing the noise_dist field within TrainingConfig, either Gaussian or Spline are allowed.
The Gaussian model has Gaussian exogenous noise distribution with mean set to 0 while its variance is learnt.
The Spline model uses a flexible spline flow that is learnt from the data. This model provides most gains in heavy-tailed noise settings, where the Gaussian model is at risk of overfitting to outliers, but can take longer to train.
Using a known Causal graph
To use DECI to learn the functional relationships, remove the variational distribution terms from the loss and replace the sample with the known graph.
Example using the CLI
An example of how to run a training job with the noise distribution specified in the config src/causica/config/lightning/default_gaussian.yaml and the data configuration specified in src/causica/config/lightning/default_data.yaml:
python -m causica.lightning.main \
--config src/causica/config/lightning/default_gaussian.yaml --data src/causica/config/lightning/default_data.yaml
For now, we have removed Rhino and DDECI from the codebase but they will be added back. You can still access the previously released versions here.
If you have used the models in our code base, please consider to cite the corresponding papers:
[1], (VISL) Pablo Morales-Alvarez, Wenbo Gong, Angus Lamb, Simon Woodhead, Simon Peyton Jones, Nick Pawlowski, Miltiadis Allamanis, Cheng Zhang, "Simultaneous Missing Value Imputation and Structure Learning with Groups", ArXiv preprint
[2], (DECI) Tomas Geffner, Javier Antoran, Adam Foster, Wenbo Gong, Chao Ma, Emre Kiciman, Amit Sharma, Angus Lamb, Martin Kukla, Nick Pawlowski, Miltiadis Allamanis, Cheng Zhang. Deep End-to-end Causal Inference. Arxiv preprint (2022)
[3], (DDECI) Matthew Ashman, Chao Ma, Agrin Hilmkil, Joel Jennings, Cheng Zhang. Causal Reasoning in the Presence of Latent Confounders via Neural ADMG Learning. ICLR (2023)
[4], (Rhino) Wenbo Gong, Joel Jennings, Cheng Zhang, Nick Pawlowski. Rhino: Deep Causal Temporal Relationship Learning with History-dependent Noise. ICLR (2023)
We use Poetry to manage the project dependencies, they're specified in the pyproject.toml. To install poetry run:
curl -sSL https://install.python-poetry.org | python3 -
To install the environment run poetry install, this will create a virtualenv that you can use by running either poetry shell or poetry run {command}. It's also a virtualenv that you can interact with in the normal way too.
More information about poetry can be found here
We use mlflow for logging metrics and artifacts. By default it will run locally and store results in ./mlruns.




![microsoft-github-operations[bot] avatar](https://avatars.githubusercontent.com/in/41902?v=4 "microsoft-github-operations[bot]")