🤖🔬 PathML: Tools for computational pathology

![]()
![]()
⭐ PathML objective is to lower the barrier to entry to digital pathology
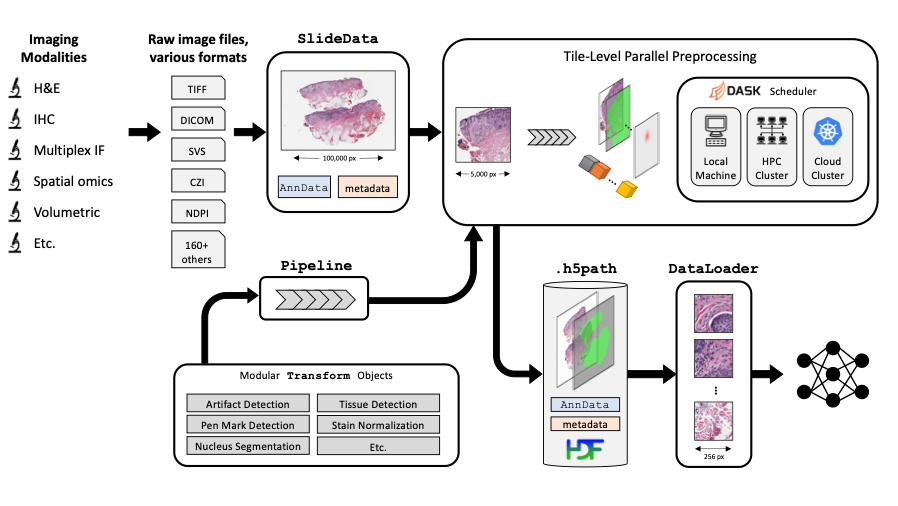
Imaging datasets in cancer research are growing exponentially in both quantity and information density. These massive datasets may enable derivation of insights for cancer research and clinical care, but only if researchers are equipped with the tools to leverage advanced computational analysis approaches such as machine learning and artificial intelligence. In this work, we highlight three themes to guide development of such computational tools: scalability, standardization, and ease of use. We then apply these principles to develop PathML, a general-purpose research toolkit for computational pathology. We describe the design of the PathML framework and demonstrate applications in diverse use cases.
🚀 The fastest way to get started?
docker pull pathml/pathml && docker run -it -p 8888:8888 pathml/pathml
done, what analyses can I write now? 👉 
| |
This AI will:
More usage examples here. |
📖 Official PathML Documentation
View the official PathML Documentation on readthedocs
🔥 Examples! Examples! Examples!
↴ Jump to the gallery of examples below
![]()
There are several ways to install PathML:
pip installfrom PyPI (recommended for users)- Clone repo to local machine and install from source (recommended for developers/contributors)
- Use the PathML Docker container
- Install in Google Colab
Options (1), (2), and (4) require that you first install all external dependencies:
- openslide
- JDK 8
We recommend using conda for environment management. Download Miniconda here
Create conda environment, this step is common to all platforms (Linux, Mac, Windows):
conda create --name pathml python=3.8
conda activate pathml
Install external dependencies (for Linux) with Apt:
sudo apt-get install openslide-tools g++ gcc libblas-dev liblapack-dev
Install external dependencies (for MacOS) with Brew:
brew install openslide
Install external dependencies (for Windows) with vcpkg:
vcpkg install openslide
Install OpenJDK 8, this step is common to all platforms (Linux, Mac, Windows):
conda install openjdk==8.0.152
Optionally install CUDA (instructions here)
Install PathML from PyPI:
pip install pathml
Clone repo:
git clone https://github.com/Dana-Farber-AIOS/pathml.git
cd pathml
Create conda environment:
conda env create -f environment.yml
conda activate pathml
Optionally install CUDA (instructions here)
Install PathML from source:
pip install -e .
First, download or build the PathML Docker container:

-
Step 1: download PathML container from Docker Hub
docker pull pathml/pathml:latestOptionally specify a tag for a particular version, e.g.
docker pull pathml/pathml:2.0.2. To view possible tags, please refer to the PathML DockerHub page. -
Alternative Step 1 if you have custom hardware: build docker container from source
git clone https://github.com/Dana-Farber-AIOS/pathml.git cd pathml docker build -t pathml/pathml . -
Step 2: Then connect to the container:
docker run -it -p 8888:8888 pathml/pathml
The above command runs the container, which is configured to spin up a jupyter lab session and expose it on port 8888.
The terminal should display a URL to the jupyter lab session starting with http://127.0.0.1:8888/lab?token=<.....>.
Navigate to that page and you should connect to the jupyter lab session running on the container with the pathml
environment fully configured. If a password is requested, copy the string of characters following the token= in the
url.
Note that the docker container requires extra configurations to use with GPU.
Note that these instructions assume that there are no other processes using port 8888.
Please refer to the Docker run documentation for further instructions
on accessing the container, e.g. for mounting volumes to access files on a local machine from within the container.
To get PathML running in a Colab environment:
import os
!pip install openslide-python
!apt-get install openslide-tools
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
!update-alternatives --set java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
!java -version
!pip install pathml
PathML Tutorials we published in Google Colab
- PathML Tutorial Colab #1 - Load an SVS image in PathML and see the image descriptors
- Now that you have PathML installed, all our other examples would work too - Only make sure you select an appropriately sized backend or VM in CoLab (i.e., RAM, CPU, Disk, and GPU if necessary)
Thanks to all of our open-source collaborators for helping maintain these installation instructions!
Please open an issue for any bugs or other problems during installation process.
To use GPU acceleration for model training or other tasks, you must install CUDA. This guide should work, but for the most up-to-date instructions, refer to the official PyTorch installation instructions.
Check the version of CUDA:
nvidia-smi
Install correct version of cudatoolkit:
# update this command with your CUDA version number
conda install cudatoolkit=11.0
After installing PyTorch, optionally verify successful PyTorch installation with CUDA support:
python -c "import torch; print(torch.cuda.is_available())"
Jupyter notebooks are a convenient way to work interactively. To use PathML in Jupyter notebooks:
PathML relies on Java to enable support for reading a wide range of file formats.
Before using PathML in Jupyter, you may need to manually set the JAVA_HOME environment variable
specifying the path to Java. To do so:
- Get the path to Java by running
echo $JAVA_HOMEin the terminal in your pathml conda environment (outside of Jupyter) - Set that path as the
JAVA_HOMEenvironment variable in Jupyter:import os os.environ["JAVA_HOME"] = "/opt/conda/envs/pathml" # change path as needed
conda activate pathml
conda install ipykernel
python -m ipykernel install --user --name=pathml
This makes the pathml environment available as a kernel in jupyter lab or notebook.
Now that you are all set with PathML installation, let's get started with some analyses you can easily replicate:
If you use PathML please cite:
So far, PathML was referenced in 20+ manuscripts:
- H. Pakula et al. Nature Communications, 2024
- B. Ricciuti et al. Journal of Clinical Oncology, 2024
- A. Song et al. Nature Reviews Bioengineering, 2023
- I. Virshup et al. Nature Bioengineering, 2023
- A. Karargyris et al. Nature Machine Intelligence, 2023
- S. Pati et al. Nature Communications Engineering, 2023
- C. Gorman et al. Nature Communications, 2023
- J. Nyman et al. Cell Reports Medicine, 2023
- A. Shmatko et al. Nature Cancer, 2022
- J. Pocock et al. Nature Communications Medicine, 2022
- S. Orsulic et al. Frontiers in Oncology, 2022
- J. Linares et al. Molecular Cell, 2021
- the list continues here 🔗
This is where in the world our most enthusiastic supporters are located:

|
and this is where they work:

|
Source: https://ossinsight.io/analyze/Dana-Farber-AIOS/pathml#people
PathML is an open source project. Consider contributing to benefit the entire community!
There are many ways to contribute to PathML, including:
- Submitting bug reports
- Submitting feature requests
- Writing documentation and examples
- Fixing bugs
- Writing code for new features
- Sharing workflows
- Sharing trained model parameters
- Sharing
PathMLwith colleagues, students, etc.
See contributing for more details.
The GNU GPL v2 version of PathML is made available via Open Source licensing. The user is free to use, modify, and distribute under the terms of the GNU General Public License version 2.
Commercial license options are available also.
Questions? Comments? Suggestions? Get in touch!



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

























































































































