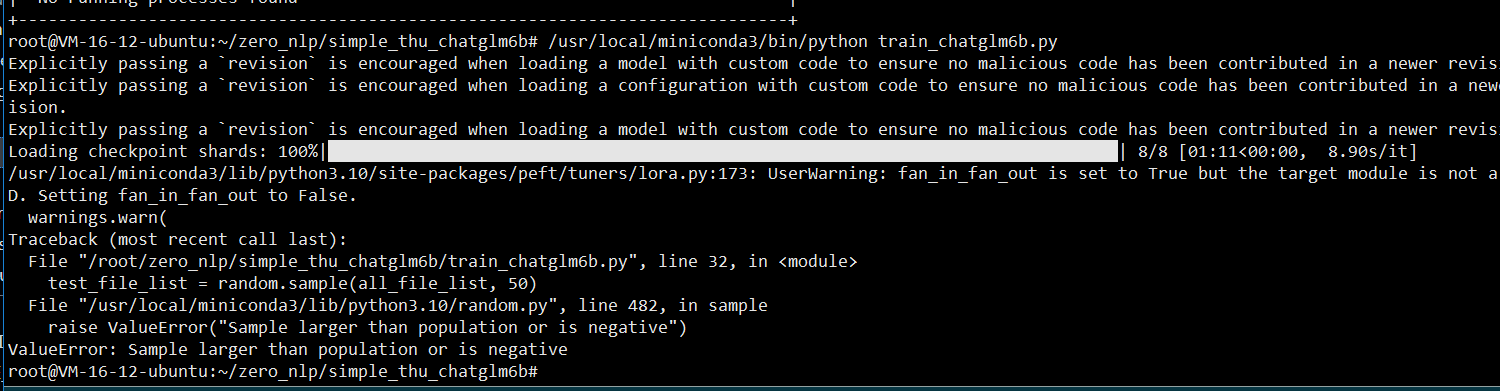
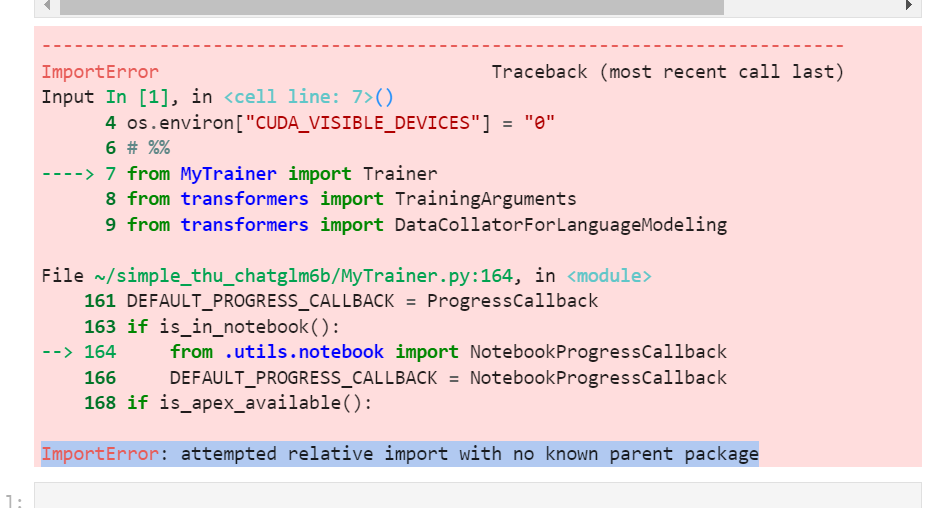
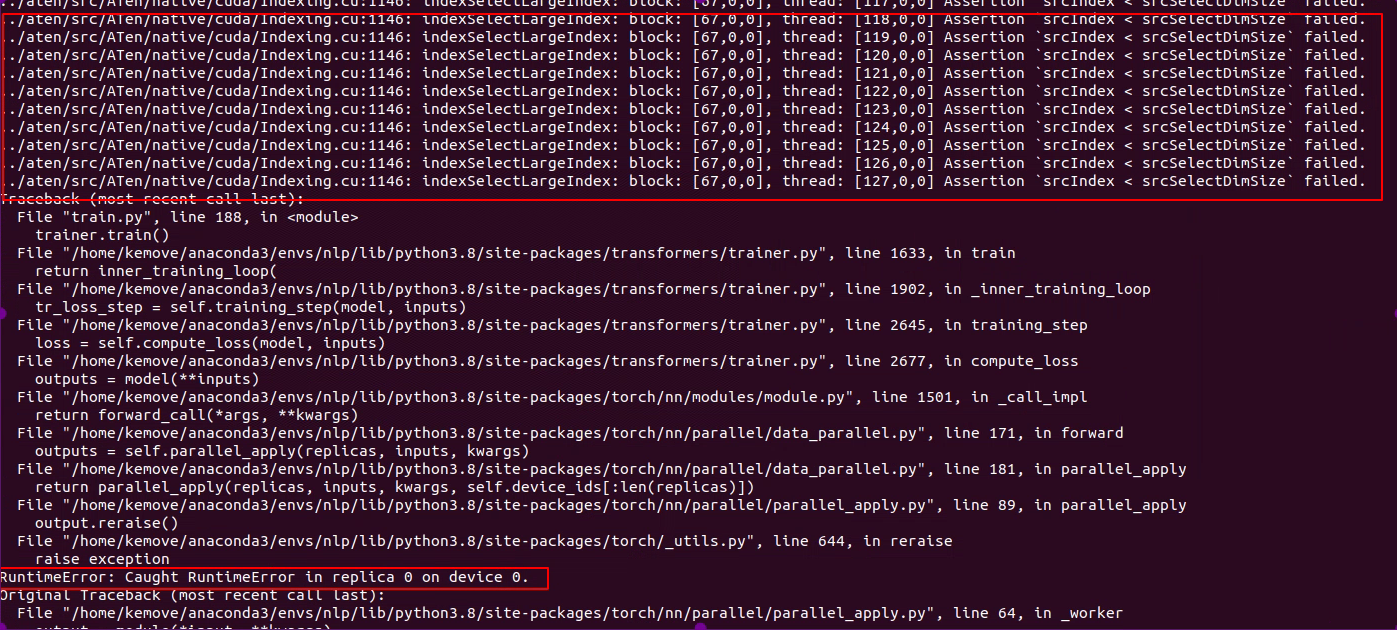
首先非常赞赏你对clip方面研究的热情,关于微调方案,我这边image部分使用的原open ai的model,text部分使用的taiyi text_encoder 并冻结了一部分层:
from torch.utils.data import Dataset, DataLoader
import torch
from transformers import CLIPModel, CLIPProcessor, BertForSequenceClassification
from transformers import BertForSequenceClassification, BertConfig, BertTokenizer
import clip
from torch import nn, optim
import pandas as pd
from PIL import Image
import os
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 加载模型
img_encoder, preprocess = clip.load('ViT-B/32', device=device, jit=False)
#
text_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese")
text_encoder = BertForSequenceClassification.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese").to(device)
# clip.model.convert_weights(img_encoder)
class image_caption_dataset(Dataset):
def __init__(self, img_ls,tit_ls):
self.img_ls = img_ls
self.tit_ls = tit_ls
def __len__(self):
return len(self.img_ls)
def __getitem__(self, idx):
image = preprocess(Image.open( “"), stream=True).raw))
title = self.tit_ls[idx]
return image, title
def convert_models_to_fp32(model):
for p in model.parameters():
p.data = p.data.float()
p.grad.data = p.grad.data.float()
# list_image_path = ['./imgs/0.jpeg','./imgs/1.jpeg','./imgs/2.jpeg','./imgs/3.jpeg' ]
# list_txt = ['a good cat toy is colorful' , 'a cat toy on the desk', "there is a cat toy on the sofa", "a photo of cat toy" ]
#加载数据集
dataset = image_caption_dataset(img_ls,tit_ls)
train_dataloader = DataLoader(dataset, batch_size=32)
#设置参数
loss_img = nn.CrossEntropyLoss().to(device)
loss_txt = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam([{'params': img_encoder.parameters()}, {'params': text_encoder.parameters()}], lr=5e-5, betas=(0.9, 0.98), eps=1e-6, weight_decay=0.2)
for name, param in list(text_encoder.named_parameters())[:-20]:
# print(name)
param.requires_grad = False
for i in range(500):
k = 1
for batch in train_dataloader:
list_image, list_txt = batch # list_images is list of image in numpy array(np.uint8), or list of PIL images
#list_image = list_image.to(device)
texts = text_tokenizer(list_txt, padding=True, return_tensors='pt')['input_ids'].to(device)
images = list_image.to(device)
# logits_per_image, logits_per_text = model(images, texts)
logits_per_image = img_encoder.encode_image(images)
logits_per_text = text_encoder(texts).logits
if device == "cpu":
ground_truth = torch.arange(len(list_image)).long().to(device)
else:
#ground_truth = torch.arange(batch_size).half().to(device)
ground_truth = torch.arange(len(list_image), dtype=torch.long, device=device)
#反向传播
total_loss = (loss_img(logits_per_image, ground_truth) + loss_txt(logits_per_text, ground_truth)) / 2
k += 1
if k%10==0:
print(k,":",total_loss)
optimizer.zero_grad()
total_loss.backward()
if device == "cpu":
optimizer.step()
else:
# convert_models_to_fp32(model)
optimizer.step()
# clip.model.convert_weights(img_encoder)
print('[%d] loss: %.3f' %(i + 1, total_loss))
# torch.save(model, './model/model1.pkl')
希望上面代码对大家clip方面的工作或研究有帮组,有其它更好的方案也期望能进行改善