Comments (19)
 cywjava
commented on May 14, 2024
1
cywjava
commented on May 14, 2024
1
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
from zero_nlp.
 xiamaozi11
commented on May 14, 2024
1
xiamaozi11
commented on May 14, 2024
1
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
from zero_nlp.
 1006076811
commented on May 14, 2024
1
1006076811
commented on May 14, 2024
1
RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with
TORCH_USE_CUDA_DSAto enable device-side assertions.
同学我也遇到这个问题,有什么解决方案吗
from zero_nlp.
cywjava
commented on May 14, 2024
File "/home/thudm/.cache/huggingface/modules/transformers_modules/local/modeling_chatglm.py", line 864, in forward
logger.warning_once(
AttributeError: 'Logger' object has no attribute 'warning_once'
小白调试,一步一个坑。。。
为什么没有使用你修改后的文件呢。。。
from zero_nlp.
 pollymars
commented on May 14, 2024
pollymars
commented on May 14, 2024
File "/home/thudm/.cache/huggingface/modules/transformers_modules/local/modeling_chatglm.py", line 864, in forward logger.warning_once( AttributeError: 'Logger' object has no attribute 'warning_once' 小白调试,一步一个坑。。。 为什么没有使用你修改后的文件呢。。。
这个bug我也遇到过,我是把warning_once改成info了
from zero_nlp.
cywjava
commented on May 14, 2024
File "/home/thudm/.cache/huggingface/modules/transformers_modules/local/modeling_chatglm.py", line 864, in forward logger.warning_once( AttributeError: 'Logger' object has no attribute 'warning_once' 小白调试,一步一个坑。。。 为什么没有使用你修改后的文件呢。。。
这个bug我也遇到过,我是把warning_once改成info了
改成info 的确可以,已经正常运行起来了,用了四张P40
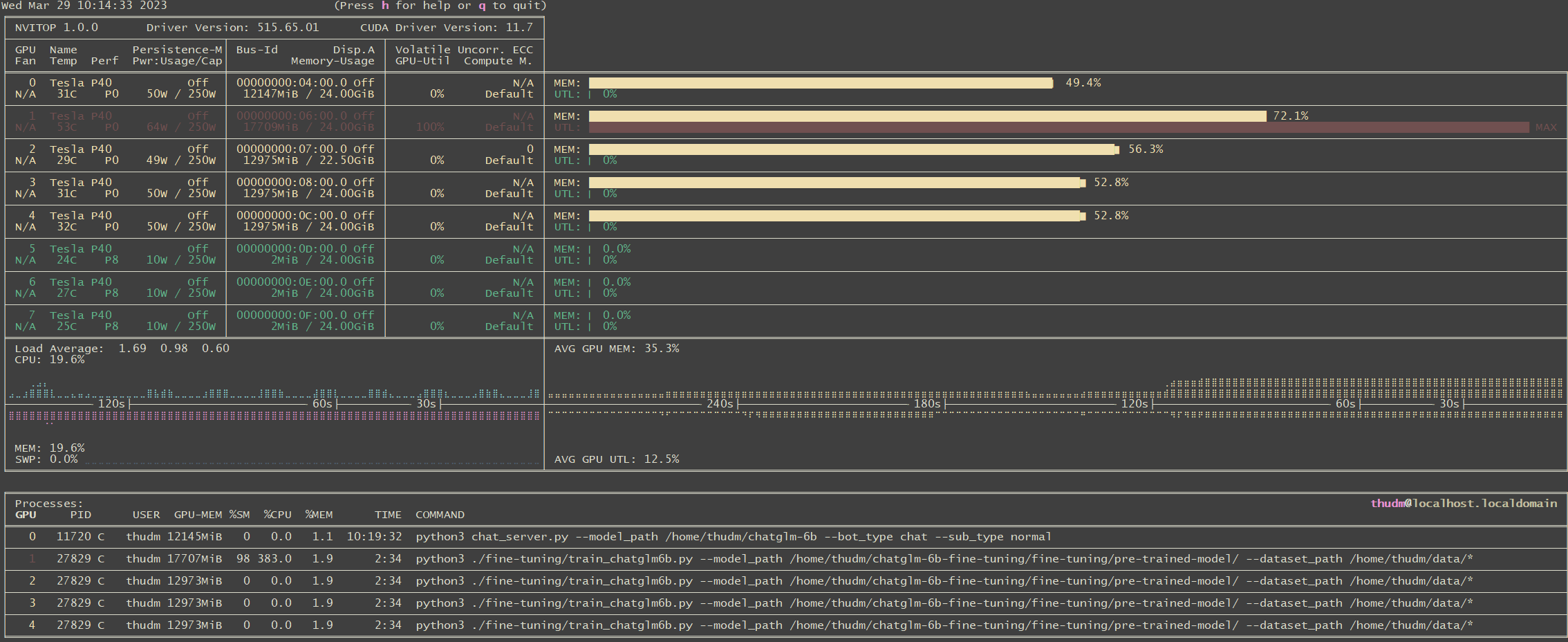
from zero_nlp.
xiamaozi11
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
from zero_nlp.
cywjava
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了
from zero_nlp.
xiamaozi11
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了
能说下改哪里么
from zero_nlp.
xiamaozi11
commented on May 14, 2024
ok
from zero_nlp.
 zhangzai666
commented on May 14, 2024
zhangzai666
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错:
RuntimeError: Caught RuntimeError in replica 1 on device 1.
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
这个遇到过么,怎么改一下啊
from zero_nlp.
cywjava
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错: RuntimeError: Caught RuntimeError in replica 1 on device 1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) 这个遇到过么,怎么改一下啊
你用他这个目录下的文件,把原来的bin复制进来,还有那个词表文件 ice_txt.bin 就行了。
from zero_nlp.
zhangzai666
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错: RuntimeError: Caught RuntimeError in replica 1 on device 1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) 这个遇到过么,怎么改一下啊
感谢您的回答,现在又报了新的错误。
ValueError: Caught ValueError in replica 1 on device 1.
ValueError: 150001 is not in list
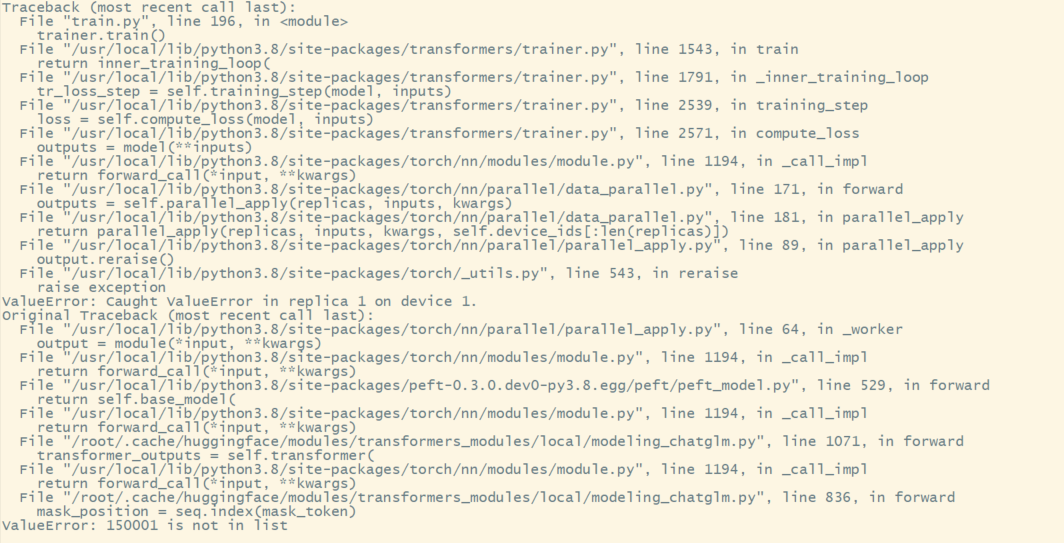
from zero_nlp.
cywjava
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错: RuntimeError: Caught RuntimeError in replica 1 on device 1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) 这个遇到过么,怎么改一下啊
感谢您的回答,现在又报了新的错误。 ValueError: Caught ValueError in replica 1 on device 1. ValueError: 150001 is not in list
你试试设置 export CUDA_VISIBLE_DEVICES=0
from zero_nlp.
zhangzai666
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错: RuntimeError: Caught RuntimeError in replica 1 on device 1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) 这个遇到过么,怎么改一下啊
感谢您的回答,现在又报了新的错误。 ValueError: Caught ValueError in replica 1 on device 1. ValueError: 150001 is not in list
你试试设置 export CUDA_VISIBLE_DEVICES=0
还是不行,看这个意思是列表没有1500001这个元素,上面报错好像是显卡显存问题,我有4张40G的显卡,按理说不应该。这个是因为多卡训练的问题么,代码我还没仔细看,直接报了很多错
from zero_nlp.
cywjava
commented on May 14, 2024
多张训练,为何总是第一张卡负载90%多,其它闲着呢。然而我的GPT2模型训练时,使用多卡,就不会有这样的问题。
from zero_nlp.
 yuanzhoulvpi2017
commented on May 14, 2024
yuanzhoulvpi2017
commented on May 14, 2024
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select)
同学改好了么
好了,正常跑起来了能说下改哪里么
你要用他提供thuglm下的几个py文件
大神问一下,微调的时候报错: RuntimeError: Caught RuntimeError in replica 1 on device 1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) 这个遇到过么,怎么改一下啊
感谢您的回答,现在又报了新的错误。 ValueError: Caught ValueError in replica 1 on device 1. ValueError: 150001 is not in list
你试试设置 export CUDA_VISIBLE_DEVICES=0
还是不行,看这个意思是列表没有1500001这个元素,上面报错好像是显卡显存问题,我有4张40G的显卡,按理说不应该。这个是因为多卡训练的问题么,代码我还没仔细看,直接报了很多错
是不是词表下载的不对?
from zero_nlp.
 xiaoweiweixiao
commented on May 14, 2024
xiaoweiweixiao
commented on May 14, 2024
RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with
TORCH_USE_CUDA_DSAto enable device-side assertions.同学我也遇到这个问题,有什么解决方案吗
RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with
TORCH_USE_CUDA_DSAto enable device-side assertions.
我也遇到这个问题了,你们解决了吗?

from zero_nlp.
yuanzhoulvpi2017
commented on May 14, 2024
添加了单机多卡训练代码,链接放在这里,https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/Chatglm6b_ModelParallel
from zero_nlp.
Related Issues (20)
- chatGLMv2-6b p-tuning 和 LoRA数据预处理的方法是一样的吗 ?
- ChatGLM2 lora finetuning 加载 lora 参数:RuntimeError: Expected 4-dimensional input for 4-dimensional weight [3072, 32, 1, 1], but got 3-dimensional input of size [1, 64, 4096] instead HOT 4
- 4张3080ti跑chatglm2-6b-lora报oom HOT 5
- 求助:chatglm2 lora训练error:RuntimeError: Expected is_sm80 to be true, but got false. HOT 2
- 训练的时候报错ValueError: The current `device_map` had weights offloaded to the disk. HOT 11
- 训练出错
- 两张4090单机多卡跑,咋感觉越跑越慢了,比单卡慢 HOT 2
- 请问有部署或者运行的文档吗?在哪里可以看?
- 实时微调可以通过加入传统RL实现吗
- 请问如果单纯使用zeroth-order向前优化少量batch(只要体现出一定的优化效果)的话要怎么实现 HOT 2
- lora推理中只能指定一个输入吗?有办法实现batch_size的推理吗
- 救命!!ChatGlm-v2-6b_Lora该怎么设置epoch?? HOT 1
- 大佬,可以多个多个lora叠加使用吗?
- chatglm_v2_6b_lora多卡如何设置,没有找到 HOT 2
- 能出一个ChatGLM
- 能出一个ChatGLM的教程吗
- Segment Fault 是哪的问题?
- 大佬 chinese_llama 还可以用吗 HOT 1
- 出个chatglm3的吧 微调后 推理老是出问题 HOT 1
- internlm-sft 单机多卡微调 GPU 利用率低 HOT 5
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from zero_nlp.