xline-kv / xline Goto Github PK
View Code? Open in Web Editor NEWA geo-distributed KV store for metadata management
Home Page: https://xline.cloud
License: Apache License 2.0
A geo-distributed KV store for metadata management
Home Page: https://xline.cloud
License: Apache License 2.0




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")























































































































Currently, heartbeat and append entries are separated -- heartbeat will be triggered every 150ms. However, when the server is busy, there will be many append entries triggered in between two heartbeats. These append entries alone can keep the follower alive. Therefore, these heartbeats can be optimized out.
Originally posted by @rogercloud in #85 (comment)
this loop may be blocked by slow requests, and it cannot ensure that the same command will call sync after calling execute
Server will start tokio async task during Server::new().
When server is stopped, need to abort the async task.
Example
If speculative execution is feasible but the result of speculative execution is lost, then the proposal will fail because slow path doesn't carry execution result. We should put execution result in the wait sync request in this situation.
Create a Snapshot through the StorageApi's interface, which returns a Snapshot structure. The specific implementation is determined by the underlying storage engine and must implement the AsyncRead and AsyncWrite traits for reading and writing Snapshot-related files.
Snapshots are sent in two situations:
When the Follower receives the InstallSnapshot RPC, it writes the Snapshot to its local storage and then applies the Snapshot to the local storage through the StorageApi's apply_snapshot interface, which is implemented by the underlying storage engine.
The Snapshot file obtained by the user is only used for disaster recovery and is recovered to obtain the business data through a separate tool.
message InstallSnapshotRequest {
uint64 term = 1;
uint64 leader_id = 2;
uint64 last_included_index = 3;
uint64 last_included_term = 4;
uint64 offset = 5;
bytes data = 6;
bool done = 7;
}
message InstallSnapshotResponse {
uint64 term = 1;
}
service Protocol {
...
rpc InstallSnapshot (stream InstallSnapshotRequest) returns (InstallSnapshotResponse);
}trait StorageApi {
type Error: std::error::Error + Send + Sync + 'static;
type Snapshot: Snapshot;
...
fn snapshot(&self) -> Result<Self::Snapshot,Self::Error>;
fn apply_snapshot(&self, snapshot: Self::Snapshot) -> Result<(),Self::Error>;
}
trait Snapshot: Read + Write {
fn size(&self) -> u64;
}we will persist term and other metadata directly, do we need to create snapshots for them regularly? Or do we only need to regularly compact the log?
Now we may store several cmds in one log entry. Store them separately.
Originally posted by @rogercloud in #85 (comment)
Command duplication can occur in many situations: client retry, optimistic recovery, etc. We need to add a mechanism to prevent the command from being executed twice.
Originally posted by @rogercloud in #86 (comment)
Right now DB is implemented as a in-memory hashmap. To be able to substitute different DB backends, need to abstract DB interfaces as a trait and allow others DB backends to implement.
Currently, the state of our curp server is filled with many things. It is very maintainable since we will soon add persistent support to the project. And a big lock of state is not efficient either. We should refactor curp's state now.
In addition, we need to add index to our log entry since it will be utilized when snapshot is enabled.
We can divide the state into following sections:
PersistedState that needs to be persisted on disk: term, voted_for.VolatileState that stores only in memory: commitIndex, lastApplied, leader_id, next_index, match_index, and timeout utils.Logs that needs to be persisted on disk.Other structures that exist in current State are all shared references. They can be moved out into a new structure called Shared.
Our ExecuteError now has only two members, but in actual situations, other errors may occur in the executor, but in Curp, it is impossible to know the errors that will occur in the upper layer, so a solution is needed to allow Corp users to define their own errors type.
ExecuteError only contain the message but not the type, which is similar to our current implementation, but the upper layer will not be able to judge the type of the error.CommandExecutor trait, But because many places in Curp used ExecuteError, here will be complicated changes.Currently, our curp server will abort all the background tasks via a Shutdown instance. When a Protocol instance is dropped, it will send a message to notify a background task to abort other tasks. Some relevant codes are shown below:
/// Shutdown broadcast wrapper
#[derive(Debug)]
pub(crate) struct Shutdown {
/// `true` if the shutdown signal has been received
shutdown: bool,
/// The receive half of the channel used to listen for shutdown.
notify: broadcast::Receiver<()>,
}
impl<C: 'static + Command> Drop for Protocol<C> {
#[inline]
fn drop(&mut self) {
// TODO: async drop is still not supported by Rust(should wait for bg tasks to be stopped?), or we should create an async `stop` function for Protocol
let _ = self.stop_tx.send(()).ok();
}
}However, we don't need to record this shutdown bool variable, since this shutdown channel will only be notified once. Thus, we can use an event listener to replace the Shutdown struct.
Replace the reachable with an injected function. Currently, we use an atomic bool to control whether the server is reachable. We can extend the logic to a function that could help us test in other ways.
Currently, the GC_INTERVAL is still hard-coded in the curp/src/server/gc.rs, like:
/// How often we should do gc
const GC_INTERVAL: Duration = Duration::from_secs(20);
/// Run background GC tasks for Curp server
pub(super) fn run_gc_tasks<C: Command + 'static>(cmd_board: CmdBoardRef<C>, spec: SpecPoolRef<C>) {
let _spec_pool_gc = tokio::spawn(gc_spec_pool(spec, GC_INTERVAL));
let _cmd_board_gc = tokio::spawn(gc_cmd_board(cmd_board, GC_INTERVAL));
}In fact, since the gc interval may be changed in some situations, we should put it into the ServerTimeout in the config.rs file and make it configurable, as other configuration field does.
cargo build --release
Compiling console v0.15.2
error: unnecessary parentheses around match arm expression
--> curp/src/bg_tasks.rs:191:28
|
191 | Ok(req) => (req),
| ^ ^
|
note: the lint level is defined here
--> curp/src/lib.rs:41:5
|
41 | warnings, // treat all wanings as errors
| ^^^^^^^^
= note: #[deny(unused_parens)] implied by #[deny(warnings)]
help: remove these parentheses
|
191 - Ok(req) => (req),
191 + Ok(req) => req,
|
Compiling indicatif v0.17.2
error: could not compile curp due to previous error
warning: build failed, waiting for other jobs to finish...
rustc -V
rustc 1.65.0 (897e37553 2022-11-02)
protoc --version
libprotoc 3.21.11
uname -a
Darwin bcd07439fa51 22.1.0 Darwin Kernel Version 22.1.0: Sun Oct 9 20:15:09 PDT 2022; root:xnu-8792.41.9~2/RELEASE_ARM64_T6000 arm64
Currently, configurations like HEATBEAT_INTERVAL, N_EXECUTE_WORKERS, or ELECTION_TIMEOUT are hardcoded in the code. Make it configurable by developing something like a server builder pattern.
Ideally, Protocol in server.rs should accept commands from clients and hand them to SyncManager where we use Raft to sync between different servers. Currently, however, they are interleaved with each other: Protocol also handles some of the RPCs used in Raft while SyncManager will remove executed commands from the speculative commands pool.
Our Range request is slower than etcd now, etcd's range request doesn't go through the consensus protocol, just ask the leader for a committed index, and then wait for the applied index of the current node to catch up with the committed index. and they can be batched when asking for index from leader. but in our current implementation, all Range requests use the curp protocol.
Xline
etcd

When I tested the method test_kv_put() in xline/tests/kv_test.rs, it have a wrong.
Currently, the sync of commands that can be executed speculatively will be postponed until the execution is finished. This is to preserve the execution order. For example, if a=1 and a=2 arrive sequentially. Only after a=1 finishes speculative execution will a=1 be synced. Only then will a=2 be synced and executed due to the key-based channel.
The postponement is unnecessary. We can add another mechanism to preserve the execution order. For example, store the execution order in a channel and spawn an execution task.
Originally posted by @rogercloud in #86 (comment)
./quick_start.sh
stopping
"docker stop" requires at least 1 argument.
See 'docker stop --help'.
Usage: docker stop [OPTIONS] CONTAINER [CONTAINER...]
Stop one or more running containers
stopped
container starting
Unable to find image 'gcr.io/etcd-development/etcd:v3.5.5' locally
bca9b7f8162a07cf747235b906ce7c7897cdf61abacad40ebf4bccce5577f4c8
162a701933e3b6f8a3d4debc799bcb173cb9dfc5726cf2a872347fbf52946ffc
c5d27f380aee918358c0c6c29bf5b3a93a46c757cc0e378e3e88dfdbcc6364e0
v3.5.5: Pulling from etcd-development/etcd
fa223d8c149d: Pull complete
a25d580da1fd: Pull complete
b5dd3f73ef5b: Pull complete
2767fb7dc720: Pull complete
4cbd5560d3c8: Pull complete
14776ed116ad: Pull complete
Digest: sha256:89b6debd43502d1088f3e02f39442fd3e951aa52bee846ed601cf4477114b89e
Status: Downloaded newer image for gcr.io/etcd-development/etcd:v3.5.5
b6b53140265b4516b16da915496b7cd05a018920492b4c73aefa5d36f525e370
container started
cluster starting
Error response from daemon: OCI runtime exec failed: exec failed: unable to start container process: exec /usr/local/bin/xline: exec format error: unknown
Error response from daemon: OCI runtime exec failed: exec failed: unable to start container process: exec /usr/local/bin/xline: exec format error: unknown
Error response from daemon: OCI runtime exec failed: exec failed: unable to start container process: exec /usr/local/bin/xline: exec format error: unknown
command is: docker exec -e RUST_LOG=debug -d node2 /usr/local/bin/xline --name node2 --cluster-peers 172.20.0.3:2379 172.20.0.5:2379 --self-ip-port 172.20.0.4:2379 --leader-ip-port 172.20.0.3:2379
command is: docker exec -e RUST_LOG=debug -d node1 /usr/local/bin/xline --name node1 --cluster-peers 172.20.0.4:2379 172.20.0.5:2379 --self-ip-port 172.20.0.3:2379 --leader-ip-port 172.20.0.3:2379 --is-leader
command is: docker exec -e RUST_LOG=debug -d node3 /usr/local/bin/xline --name node3 --cluster-peers 172.20.0.3:2379 172.20.0.4:2379 --self-ip-port 172.20.0.5:2379 --leader-ip-port 172.20.0.3:2379
cluster started
docker -v
Docker version 20.10.17-rd, build c2e4e01
uname -a
Darwin bcd07439fa51 22.1.0 Darwin Kernel Version 22.1.0: Sun Oct 9 20:15:09 PDT 2022; root:xnu-8792.41.9~2/RELEASE_ARM64_T6000 arm64
rustc -V
rustc 1.61.0 (fe5b13d68 2022-05-18)
In concurrent tests of Curp, add verification instead of just observing logs.
Originally posted by @rogercloud in #66 (comment)
We can use GitHub Action to generate a rust doc and then push it to a gh-pages branch, so we can have a doc site, like tikv or casbin-rs
In the current implementation, we traverse a KeyRange vector that may have duplicates
When I executed the cargo build --release as described in the Contribution Guide document, it showed me a proto compile error as follows:
$ cargo build --release
Compiling curp v0.1.0 (/home/Xline/curp)
error: failed to run custom build command for `curp v0.1.0 (/home/Xline/curp)`
Caused by:
process didn't exit successfully: `/home/Xline/target/release/build/curp-755359d522eb8104/build-script-build` (exit status: 101)
--- stderr
thread 'main' panicked at 'Failed to compile proto, error is Custom { kind: Other, error: "protoc failed: message.proto: This file contains proto3 optional fields, but --experimental_allow_proto3_optional was not set.\n" }', curp/build.rs:4:29
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceI will issue a pr to solve this problem.
I run commands in the Contribution Guide step by step and I am stuck in the Send Etcd requests section. The error log is as down below.
$ docker exec node4 /bin/sh -c "/usr/local/bin/etcdctl --endpoints=\"http://172.20.0.3:2379\" put A 1"
OK
$ docker exec node4 /bin/sh -c "/usr/local/bin/etcdctl --endpoints=\"http://172.20.0.3:2379\" get A 1"
{"level":"warn","ts":"2022-12-27T09:18:09.831Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0002b4000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = Unknown desc = malformed header: missing HTTP content-type"}
Error: rpc error: code = Unknown desc = malformed header: missing HTTP content-typeWhen server receives requests, we cannot make sure the request is always valid.
Need to filter out invalid requests before handle them.
Refer to https://github.com/etcd-io/etcd/blob/main/server/etcdserver/api/v3rpc/key.go#L143
Garbage collection logic is still missing.
One-line summary
I cannot modify an existing key after using the etcdctl watch command to watch it.
What did I expect to happen?
I should have successfully modified an existing key-value pair whether I watch it or not.
How to reproduce this issue?
step 1. build an environment (run the quick_start.sh script)
step 2. refer to the Relevant log output down below.
0.1.0 (Default)
1. Modified an existing key without watching it, all modified ops can work properly.
$ docker exec -it node4 bash
root@e97cceaf264a:/# alias etcdctl='/usr/local/bin/etcdctl --endpoints="http://172.20.0.3:2379"'
root@e97cceaf264a:/# etcdctl put hello world1
OK
root@e97cceaf264a:/# etcdctl put hello world2
OK
root@e97cceaf264a:/# etcdctl put hello world3
OK
root@e97cceaf264a:/# etcdctl put hello world4
OK
root@e97cceaf264a:/# etcdctl put hello world5
OK
root@e97cceaf264a:/# etcdctl put hello world6
OK
root@e97cceaf264a:/# etcdctl put hello world7
OK
root@e97cceaf264a:/# etcdctl put hello world8
OK
root@e97cceaf264a:/# etcdctl put hello world9
OK
root@e97cceaf264a:/# etcdctl put hello world10
OK
2. Modified an existing key after watching it, the most ops after the watch op failed.
$ docker exec -it node4 bash
root@2cb3d250295f:/# alias etcdctl='/usr/local/bin/etcdctl --endpoints="http://172.20.0.3:2379"'
root@2cb3d250295f:/# etcdctl put hello world1
OK
root@2cb3d250295f:/# etcdctl put hello world2
OK
root@2cb3d250295f:/# etcdctl put hello world3
OK
root@2cb3d250295f:/# etcdctl put hello world4
OK
root@2cb3d250295f:/# etcdctl put hello world5
OK
root@2cb3d250295f:/# etcdctl watch hello -w=json --rev=1
{"Header":{"revision":6},"Events":[{"kv":{"key":"aGVsbG8=","create_revision":2,"mod_revision":2,"version":1,"value":"d29ybGQx"}},{"kv":{"key":"aGVsbG8=","create_revision":2,"mod_revision":3,"version":2,"value":"d29ybGQy"}},{"kv":{"key":"aGVsbG8=","create_revision":2,"mod_revision":4,"version":3,"value":"d29ybGQz"}},{"kv":{"key":"aGVsbG8=","create_revision":2,"mod_revision":5,"version":4,"value":"d29ybGQ0"}},{"kv":{"key":"aGVsbG8=","create_revision":2,"mod_revision":6,"version":5,"value":"d29ybGQ1"}}],"CompactRevision":0,"Canceled":false,"Created":false}
^C
root@2cb3d250295f:/# etcdctl put hello world6
OK
root@2cb3d250295f:/# etcdctl put hello world7
OK
root@2cb3d250295f:/# etcdctl put hello world8
{"level":"warn","ts":"2023-01-14T03:29:53.423Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000244000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = Unknown desc = malformed header: missing HTTP content-type"}
Error: rpc error: code = Unknown desc = malformed header: missing HTTP content-type
root@2cb3d250295f:/# etcdctl put hello world9
{"level":"warn","ts":"2023-01-14T03:30:01.802Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001f6a80/172.20.0.3:2379","attempt":0,"error":"rpc error: code = Unknown desc = malformed header: missing HTTP content-type"}
Error: rpc error: code = Unknown desc = malformed header: missing HTTP content-type
root@2cb3d250295f:/# etcdctl put hello world10
{"level":"warn","ts":"2023-01-14T03:30:09.523Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000234000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = Unknown desc = malformed header: missing HTTP content-type"}
Error: rpc error: code = Unknown desc = malformed header: missing HTTP content-type
root@2cb3d250295f:/# etcdctl put hello world11
{"level":"warn","ts":"2023-01-14T03:38:58.177Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000452a80/172.20.0.3:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
root@2cb3d250295f:/# etcdctl put hello world11
{"level":"warn","ts":"2023-01-14T03:39:05.726Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000234000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
root@2cb3d250295f:/# etcdctl put hello world12
{"level":"warn","ts":"2023-01-14T03:40:00.185Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc00024e000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
root@2cb3d250295f:/# etcdctl put hello1 world1
OK
root@2cb3d250295f:/# etcdctl put hello1 world2
{"level":"warn","ts":"2023-01-14T03:40:22.492Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000236000/172.20.0.3:2379","attempt":0,"error":"rpc error: code = Unknown desc = malformed header: missing HTTP content-type"}
Error: rpc error: code = Unknown desc = malformed header: missing HTTP content-typeXline is designed to be compatible with etcd API, including the kv API, watch API, auth API, etc. Currently, xline uses etcdctl to verify these APIs validation manually. We need to automate these tests to improve efficiency of testing.
Currently, we use a big RwLock to protect the state. Replace it with fine-grained locking.
Given that the version of the default protobuf-compiler provided in ubuntu is out-of-date, adding a protoc version requirement in the quick start doc can help developers avoid some compile errors. #115
Create a testing framework that will allow us to manually crash and recover servers as needed, as well as evaluate their consistency.
file an issue to track writing the configurations and their default values in the doc.
Heartbeat may wipe newly replicated logs.
0.1.0 (Default)
No response
Currently, our gc process mainly relies on running gc_task every GC_INTERVAL. In some extreme cases, it threatens to lose those completed-but-yet-to-sync commands.
For instance, a client sends a request to a leader and the leader executes this command in the fast path. But before syncing the command execution result to others, it crashes. And for some unknown reason, the cluster cannot reach the same page about who is the next leader. After GC_INTERVAL, this command is removed from spec_pool via the gc task. After ten seconds or so, the new leader is finally elected. But unfortunately, the speculatively executed command is gone. The new leader cannot recover it from the spec_pool.
Currently, our code uses a real system time timeout mechanism, which is straight forward and easy to understand. However, obtaining system time is not efficient. We need to update last_rpc_time every time we receive a new append_entries, which could lead to performance issue when the server is busy.
Etcd offers a more clever timeout detection mechanism based on tick. A task is spawned to periodically perform tick operation. Every tick is 1 heartbeat interval. A tick will increase election_timeout and heartbeat_timeout by 1. A broadcast of heartbeats(for leader) or a new round of election(for follower) will be performed when timeout.
I believe adopting this method will improve curp’s performance as well as readability(since all periodically executed operations will be in one place).
last_rpc_time. Add heartbeat_timeout and election_timeout tick count.bg_election and bg_heartbeat.we need to redirect lease keep alive stream to the leader in lease service, the current implementation doesn't look very good, maybe we can use proxy pattern to refactor it?
When we call watch in kvwatcher.rs, the following things will happen:
However, these two steps are not atomic operation. So if a new event occur after 1 but before 2, then we will lose this event.
0.1.0 (Default)
Not yet produced.Currently, our curp server has the following pain points that might slow down our later developments:
LockGuard scope issue. Given that LockGuard must be released at the await point, we must take special care in how we structure the code, which results in opaque and nested code that is difficult both for the developer to write and for reviewers to read. Things would go more smoothly if we could divide our code into two parts: the non-async (update of curp's state) component and the async (transport, io) half.As a solution, I suggest introducing a new abstraction layer called RawCurp. RawCurp can be viewed as a state machine. It is purely non-async. So the receiving and sending of requests and responses will be handled outside of RawCurp.
It looks like this:
pub(super) struct RawCurp<C: Command> {
/// Curp state
st: RwLock<State>,
/// Additional leader state
lst: RwLock<LeaderState>,
/// Additional candidate state
cst: Mutex<CandidateState<C>>,
/// Curp logs
log: RwLock<Log<C>>,
/// Relevant context
ctx: Context<C>,
}
impl<C: 'static + Command> RawCurp<C> {
/// Handle `append_entries`
/// Return Ok(term) if succeeds
/// Return Err(term, hint_next_index_for_leader) if fails
pub(super) fn handle_append_entries(
&self,
term: u64,
leader_id: String,
prev_log_index: usize,
prev_log_term: u64,
entries: Vec<LogEntry<C>>,
leader_commit: usize,
) -> Result<u64, (u64, usize)>;
/// Handle `append_entries` response
/// Return Ok(append_entries_succeeded)
/// Return Err(()) if self is no longer the leader
pub(super) fn handle_append_entries_resp(
&self,
follower_id: &ServerId,
last_sent_index: Option<usize>, // None means the ae is a heartbeat
term: u64,
success: bool,
hint_index: usize,
) -> Result<bool, ()>;
// other handlers ...
pub(super) fn tick(&self) -> TickAction;
}Before refactoring: Protocol, State, bg_tasks are messed up together
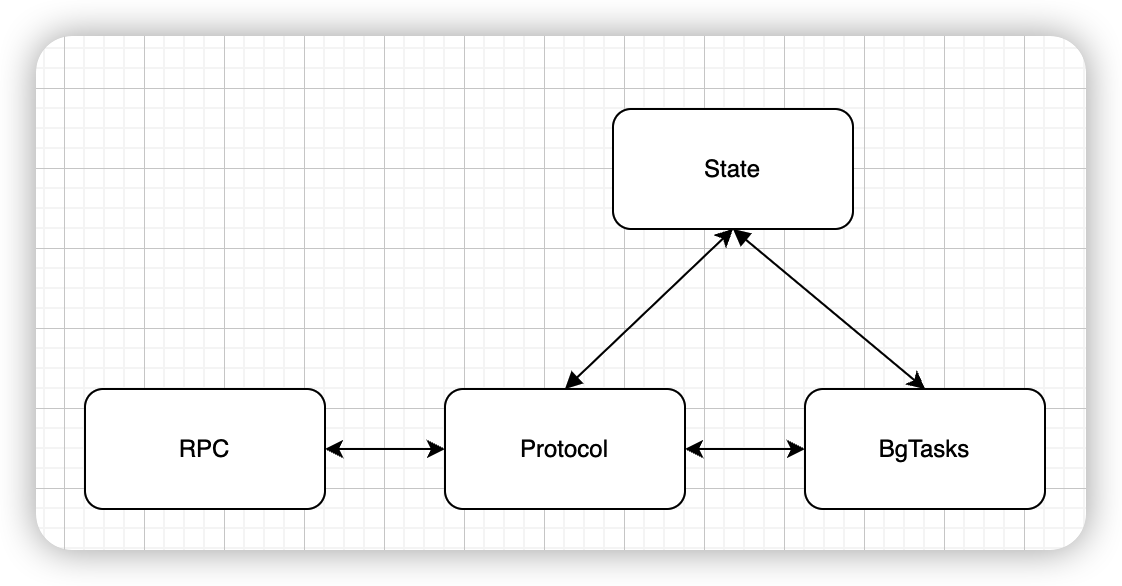
After refactoring:
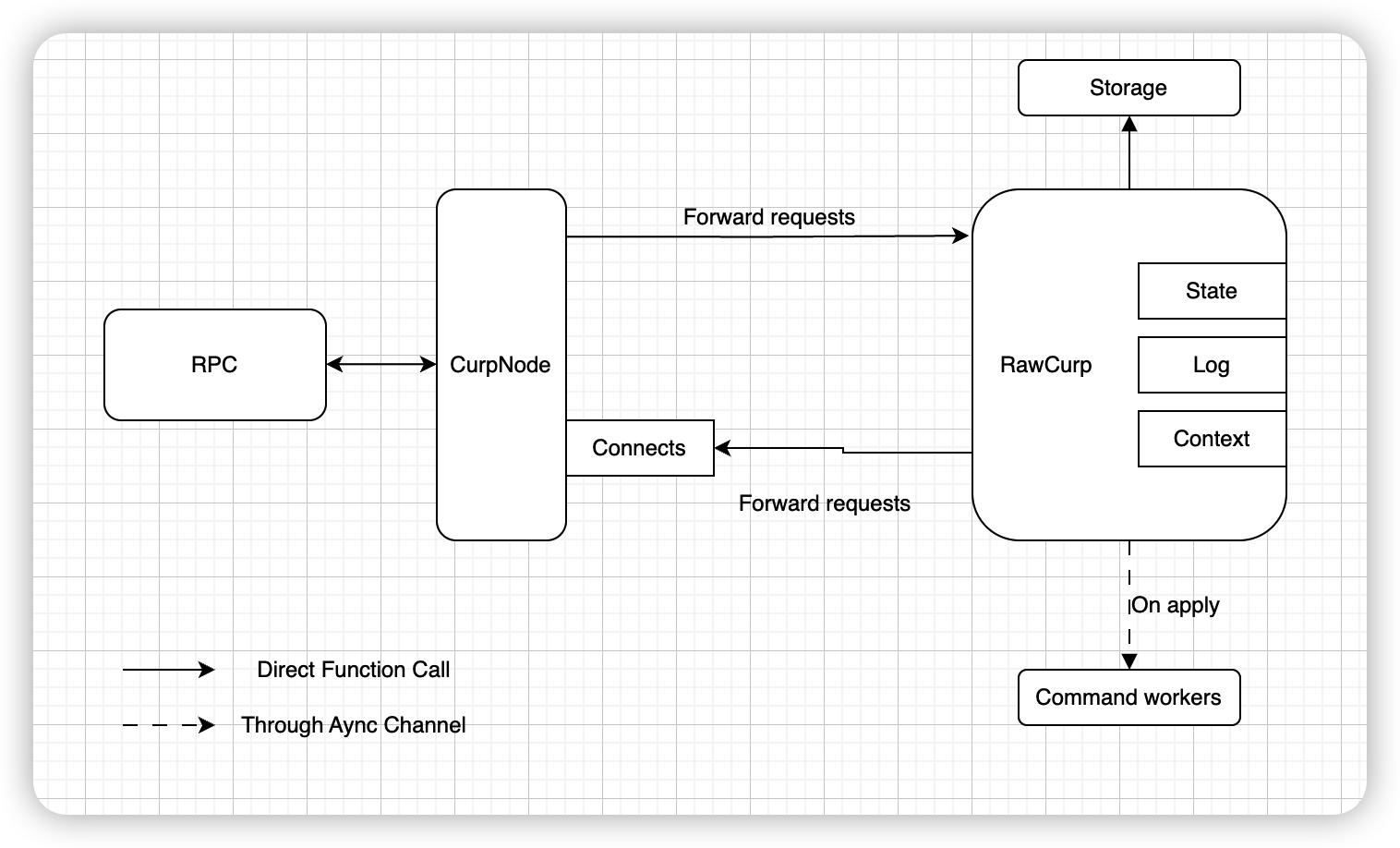
CurpNode will handle all transport-related functionalities and error handlings, while RawCurp only needs to take care of internal structures and their consistencies.
I plan to deliver this refactor in 4 prs.
RawCurp without removing the bg_tasks: I will try my best to reserve the current bg_tasks interface and replace the inner code with the RawCurp. This will help reduce the burden of reviewers.bg_tasks; refactor LogEntry: only one cmd for each log entry and it should contain index; improve error handling.P.S. Although I will remove the bg_tasks in the end, it doesn't mean that there will be no background tasks in CurpNode. In fact, there will still be bg_tick and bg_leader_calibrate_follower, but since most logics are handled in the curp module, there will be not much code.
RawCurpRawCurp has 4 locks:
//! Lock order should be:
//! 1. self.st
//! 2. self.ctx || self.ltx (there is no need for grabbing both)
//! 3. self.log
pub(super) struct RawCurp<C: Command> {
/// Curp state
st: RwLock<State>,
/// Additional leader state
lst: RwLock<LeaderState>,
/// Additional candidate state
cst: Mutex<CandidateState<C>>,
/// Curp logs
log: RwLock<Log<C>>,
/// Relevant context
ctx: Context<C>,
}
pub(super) struct State {
/* persisted state */
/// Current term
pub(super) term: u64,
/// Candidate id that received vote in current term
pub(super) voted_for: Option<ServerId>,
/* volatile state */
/// Role of the server
pub(super) role: Role,
/// Cached id of the leader.
pub(super) leader_id: Option<ServerId>,
}
pub(super) struct CandidateState<C> {
/// Collected speculative pools, used for recovery
pub(super) sps: HashMap<ServerId, Vec<Arc<C>>>,
/// Votes received in the election
pub(super) votes_received: u64,
}
pub(super) struct LeaderState {
/// For each server, index of the next log entry to send to that server
pub(super) next_index: HashMap<ServerId, usize>,
/// For each server, index of highest log entry known to be replicated on server
pub(super) match_index: HashMap<ServerId, usize>,
}
pub(super) struct Log<C: Command> {
/// Log entries, should be persisted
pub(super) entries: Vec<LogEntry<C>>,
/// Index of highest log entry known to be committed
pub(super) commit_index: usize,
/// Index of highest log entry applied to state machine
pub(super) last_applied: usize,
}| Function | Lock | st | lst | cst | log | Notes |
|---|---|---|---|---|---|
| tick(leader) | 1 | 0 | 0 | 1 | grab and release state read lock to check role, grab log read lock to generate heartbeats |
| tick(candidate/follower) | 1 | 0 | 1 | 1 | grab and release state read lock to check role, grab candidate state write lock and log read lock to become candidate and generate votes |
| handle_append_entries | 1 | 0 | 0 | 1 | grab upgradable read state lock to check term(upgrade to write if term is updated), while holding the state log, grab log write lock to append new logs |
| handle_append_entries_resp | 1 | 1 | 0 | 1 | grab and release state read lock to check role, grab and release leader state write lock to update match_index for follower, grab and release leader state read lock and log read lock to check if commit_index updated, if can grab log write lock to update commit index |
| handle_vote | 1 | 0 | 0 | 1 | grab state write lock to vote, grab log read lock to check if candidate's log is up-to-date |
| handle_vote_resp | 1 | 1 | 1 | 1 | grab state and cadidate write lock to handle vote response. If election succeeds, will release candidate lock, and grab leader state write log(to reset next_index) and log write lock(to recover commands) |
Inline variables in a format string and eliminate these warnings.
cargo clippy
Checking curp v0.1.0 (/home/jiawei/Xline/curp)
error: variables can be used directly in the `format!` string
--> curp/src/client.rs:252:58
|
252 | return Err(ProposeError::SyncedError(format!("{:?}", e)));
| ^^^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
note: the lint level is defined here
--> curp/src/lib.rs:44:5
|
44 | clippy::pedantic,
| ^^^^^^^^^^^^^^^^
= note: `#[deny(clippy::uninlined_format_args)]` implied by `#[deny(clippy::pedantic)]`
help: change this to
|
252 - return Err(ProposeError::SyncedError(format!("{:?}", e)));
252 + return Err(ProposeError::SyncedError(format!("{e:?}")));
|
error: variables can be used directly in the `format!` string
--> curp/src/server/mod.rs:167:17
|
167 | format!("0.0.0.0:{}", port)
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
help: change this to
|
167 - format!("0.0.0.0:{}", port)
167 + format!("0.0.0.0:{port}")
|
error: variables can be used directly in the `format!` string
--> curp/src/server/mod.rs:169:60
|
169 | .map_err(|e| ServerError::ParsingError(format!("{}", e)))?,
| ^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
help: change this to
|
169 - .map_err(|e| ServerError::ParsingError(format!("{}", e)))?,
169 + .map_err(|e| ServerError::ParsingError(format!("{e}")))?,
|
error: variables can be used directly in the `format!` string
--> curp/src/server/mod.rs:403:45
|
403 | tonic::Status::invalid_argument(format!("propose cmd decode failed: {}", e))
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
help: change this to
|
403 - tonic::Status::invalid_argument(format!("propose cmd decode failed: {}", e))
403 + tonic::Status::invalid_argument(format!("propose cmd decode failed: {e}"))
|
error: variables can be used directly in the `format!` string
--> curp/src/server/mod.rs:483:45
|
483 | tonic::Status::invalid_argument(format!("wait_synced id decode failed: {}", e))
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
help: change this to
|
483 - tonic::Status::invalid_argument(format!("wait_synced id decode failed: {}", e))
483 + tonic::Status::invalid_argument(format!("wait_synced id decode failed: {e}"))
|
error: variables can be used directly in the `format!` string
--> curp/src/server/mod.rs:584:50
|
584 | .map_err(|e| tonic::Status::internal(format!("encode or decode error, {}", e)))?;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args
help: change this to
|
584 - .map_err(|e| tonic::Status::internal(format!("encode or decode error, {}", e)))?;
584 + .map_err(|e| tonic::Status::internal(format!("encode or decode error, {e}")))?;
|
error: could not compile `curp` due to 6 previous errorsAdd a test to cover the situation in this PR.
Originally posted by @rogercloud in #86 (comment)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.