This project aims to accurately recognize user's action in a series of video frames through combination of convolution neural nets, and long-short term memory neural nets.
-
This project explores prominent action recognition models with UCF-101 dataset
-
Perfomance of different models are compared and analysis of experiment results are provided
rnn_practice: Practices on RNN models and LSTMs with online tutorials and other useful resources
data: Training and testing data. (NOTE: please don't add large data files to this repo, add them to .gitignore)
models: Defining the architecture of models
utils: Utils scripts for dataset preparation, input pre-processing and other helper functions
train_CNN: Training CNN models. The program loads corresponding models, sets the training parameters and initializes network training
process_CNN: Processing video with CNN models. The CNN component is pre-trained and fixed during the training phase of LSTM cells. We can utilize the CNN model to pre-process frames of each video and store the intermediate results for feeding into LSTMs later. This procedure improves the training efficiency of the LRCN model significantly
train_RNN: Training the LRCN model
predict: Calculating the overall testing accuracy on the entire testing set
- Fine-tuned ResNet50 and trained solely with single-frame image data. Each frame of the video is considered as an image for training and testing, which generates a natural data augmentation. The ResNet50 is from keras repo, with weights pre-trained on Imagenet. ./models/finetuned_resnet.py

-
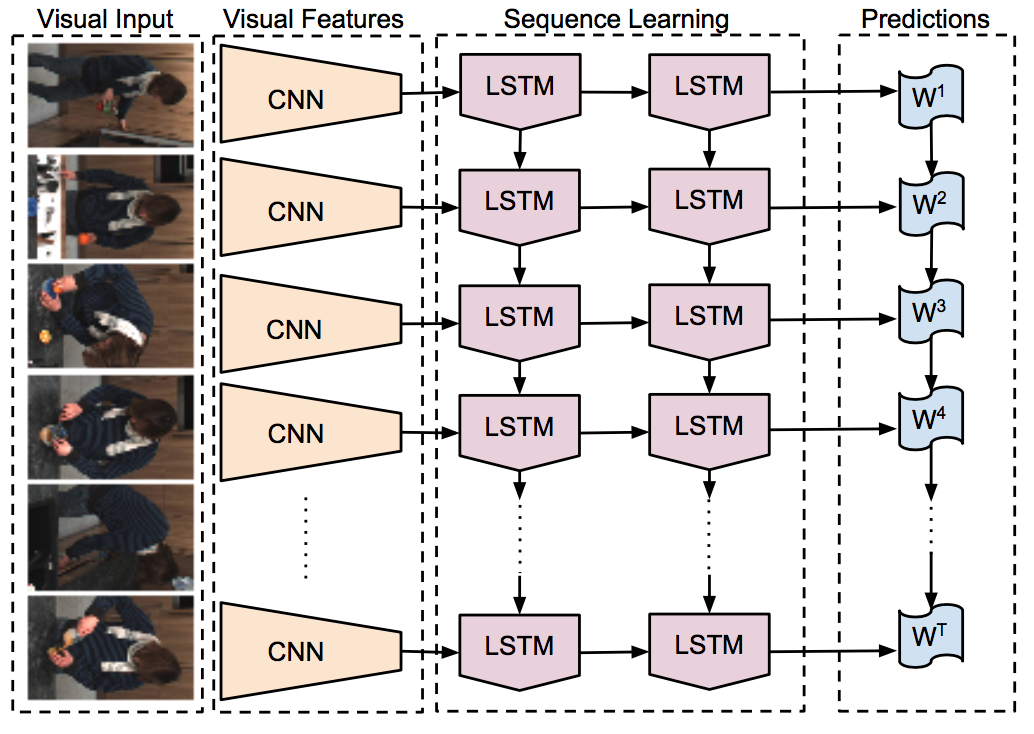
LRCN (CNN feature extractor, here we use the fine-tuned ResNet50 and LSTMs). The input of LRCN is a sequence of frames uniformly extracted from each video. The fine-tuned ResNet directly uses the result of [1] without extra training (C.F.Long-term recurrent convolutional network).
Produce intermediate data using ./process_CNN.py and then train and predict with ./models/RNN.py
- Simple CNN model trained with stacked optical flow data (generate one stacked optical flow from each of the video, and use the optical flow as the input of the network). ./models/temporal_CNN.py

- Two-stream model, combines the models in [2] and [3] with an extra fusion layer that output the final result. [3] and [4] refer to this paper ./models/two_stream.py

If you use this code or ideas from the paper for your research, please cite the following papers:
@inproceedings{lrcn2014,
Author = {Jeff Donahue and Lisa Anne Hendricks and Sergio Guadarrama
and Marcus Rohrbach and Subhashini Venugopalan and Kate Saenko
and Trevor Darrell},
Title = {Long-term Recurrent Convolutional Networks
for Visual Recognition and Description},
Year = {2015},
Booktitle = {CVPR}
}
@article{DBLP:journals/corr/SimonyanZ14,
author = {Karen Simonyan and
Andrew Zisserman},
title = {Two-Stream Convolutional Networks for Action Recognition in Videos},
journal = {CoRR},
volume = {abs/1406.2199},
year = {2014},
url = {http://arxiv.org/abs/1406.2199},
archivePrefix = {arXiv},
eprint = {1406.2199},
timestamp = {Mon, 13 Aug 2018 16:47:39 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/SimonyanZ14},
bibsource = {dblp computer science bibliography, https://dblp.org}
}













































































































