

The open-source tool for building high-quality datasets and computer vision models
Website • Docs • Try it Now • Tutorials • Examples • Blog • Community

![]()

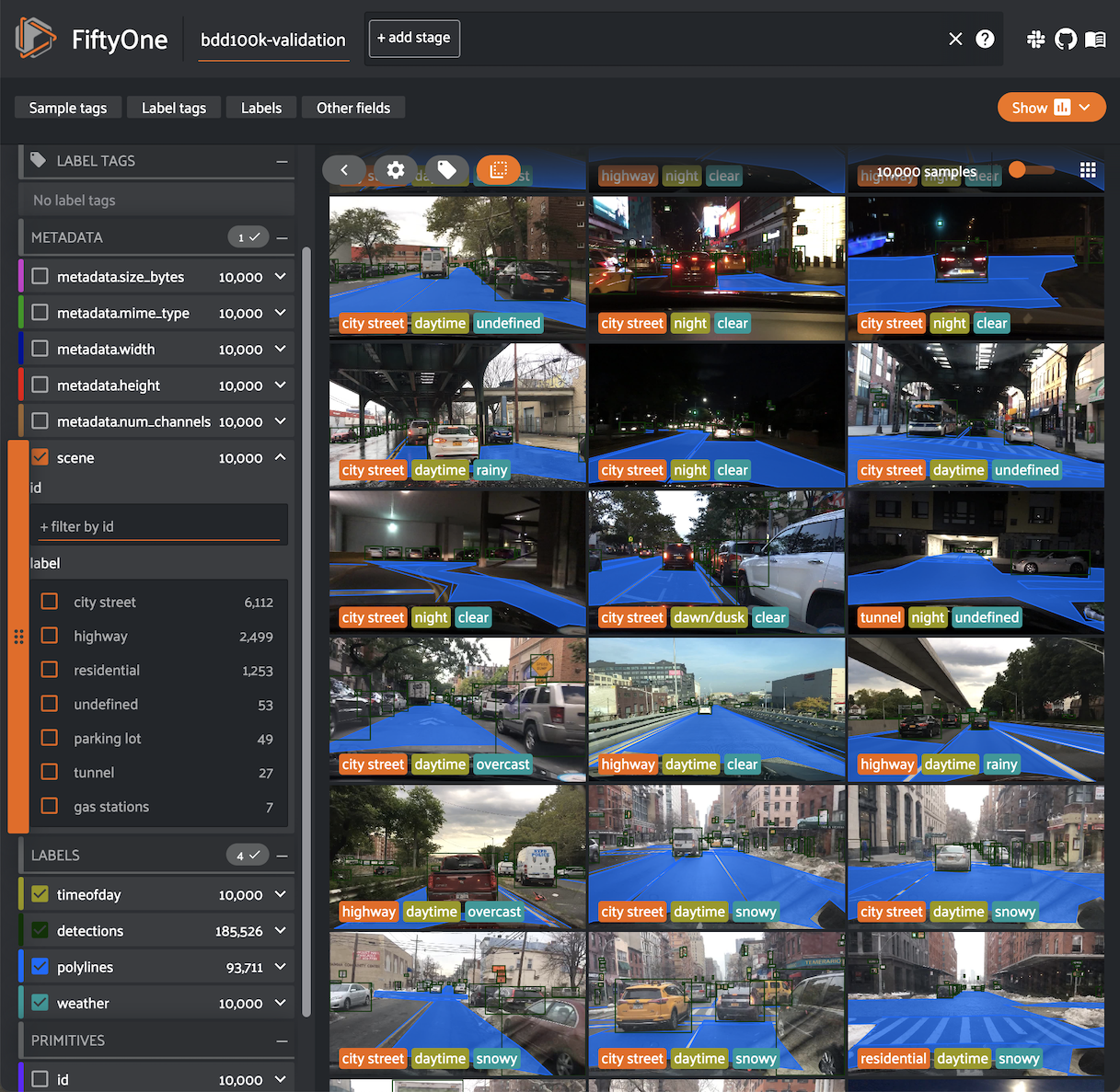
Nothing hinders the success of machine learning systems more than poor quality data. And without the right tools, improving a model can be time-consuming and inefficient.
FiftyOne supercharges your machine learning workflows by enabling you to visualize datasets and interpret models faster and more effectively.
Use FiftyOne to get hands-on with your data, including visualizing complex labels, evaluating your models, exploring scenarios of interest, identifying failure modes, finding annotation mistakes, and much more!
You can get involved by joining our Slack community, reading our blog on Medium, and following us on social media:
You can install the latest stable version of FiftyOne via pip:
pip install fiftyoneConsult the installation guide for troubleshooting and other information about getting up-and-running with FiftyOne.
Dive right into FiftyOne by opening a Python shell and running the snippet below, which downloads a small dataset and launches the FiftyOne App so you can explore it:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
session = fo.launch_app(dataset)Then check out this Colab notebook to see some common workflows on the quickstart dataset.
Note that if you are running the above code in a script, you must include
session.wait() to block execution until you close the App. See
this page
for more information.
Full documentation for FiftyOne is available at fiftyone.ai. In particular, see these resources:
Check out the fiftyone-examples repository for open source and community-contributed examples of using FiftyOne.
FiftyOne is open source and community contributions are welcome!
Check out the contribution guide to learn how to get involved.
The instructions below are for macOS and Linux systems. Windows users may need to make adjustments. If you are working in Google Colab, skip to here.
You will need:
- Python (3.8 - 3.11)
- Node.js - on Linux, we recommend using nvm to install an up-to-date version.
- Yarn - once Node.js is installed, you can
enable Yarn via
corepack enable - On Linux, you will need at least the
opensslandlibcurlpackages. On Debian-based distributions, you will need to installlibcurl4orlibcurl3instead oflibcurl, depending on the age of your distribution. For example:
# Ubuntu
sudo apt install libcurl4 openssl
# Fedora
sudo dnf install libcurl opensslWe strongly recommend that you install FiftyOne in a virtual environment to maintain a clean workspace. The install script is only supported in POSIX-based systems (e.g. Mac and Linux).
First, clone the repository:
git clone https://github.com/voxel51/fiftyone
cd fiftyoneThen run the install script:
bash install.bashNOTE: If you run into issues importing FiftyOne, you may need to add the
path to the cloned repository to your PYTHONPATH:
export PYTHONPATH=$PYTHONPATH:/path/to/fiftyoneNOTE: The install script adds to your nvm settings in your ~/.bashrc or
~/.bash_profile, which is needed for installing and building the App
NOTE: When you pull in new changes to the App, you will need to rebuild it,
which you can do either by rerunning the install script or just running
yarn build in the ./app directory.
To upgrade an existing source installation to the bleeding edge, simply pull
the latest develop branch and rerun the install script:
git checkout develop
git pull
bash install.bashIf you would like to
contribute to FiftyOne,
you should perform a developer installation using the -d flag of the install
script:
bash install.bash -dAlthough not required, developers typically prefer to configure their FiftyOne installation to connect to a self-installed and managed instance of MongoDB, which you can do by following these simple steps.
You can install from source in Google Colab by running the following in a cell and then restarting the runtime:
%%shell
git clone --depth 1 https://github.com/voxel51/fiftyone.git
cd fiftyone
bash install.bashRefer to these instructions to see how to build and run Docker images containing source or release builds of FiftyOne.
Voxel51 is currently in the process of implementing a Storybook which contains examples of its basic UI components. You can access the current storybook instances by running yarn storybook in /app/packages/components. While the storybook instance is running, any changes to the component will trigger a refresh in the storybook app.
%%shell
cd /app/packages/components
yarn storybookSee the docs guide for information on building and contributing to the documentation.
You can uninstall FiftyOne as follows:
pip uninstall fiftyone fiftyone-brain fiftyone-db fiftyone-desktopSpecial thanks to these amazing people for contributing to FiftyOne! 🙌
If you use FiftyOne in your research, feel free to cite the project (but only if you love it 😊):
@article{moore2020fiftyone,
title={FiftyOne},
author={Moore, B. E. and Corso, J. J.},
journal={GitHub. Note: https://github.com/voxel51/fiftyone},
year={2020}
}





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")






















































































































































































