由于误操作,将仓库设置为私有导致之前500star丢失,欢迎大家从新star github地址:https://github.com/scxwhite/hera


目前接入hera的公司(点我接入):
- 杭州二维火科技有限公司
- 杭州涂鸦科技有限公司
- 北京高因科技(居理新房)有限公司
- 盈亚科技有限公司
- 北京智融时代信息技术有限公司
- 卓尔智联集团(02098·HK)
- 北京果敢时代科技有限公司(大V店)
- 中通天鸿-**领先的云计算呼叫中心平台及人工智能科技公司
- 杭州-呆萝卜
- 微神马科技(大连)有限公司
- 上海骅天技术服务有限公司
- 浙江格家网络技术有限公司
- 紫梧桐(北京)资产管理有限公司 (蛋壳公寓)
- 海拍客
- 摩比神奇(北京)信息技术有限公司
- 杭州富聊科技有限公司
- 来伊份大数据--------新鲜零食 来自上海 全国2800家专卖店
- 广东步步高教育电子有限公司
- 浙江慧度资产管理有限公司
- 持续更新中。。欢迎大家自荐
个人微信(已满99人,需要我拉你进去)

开源不易,感谢支持
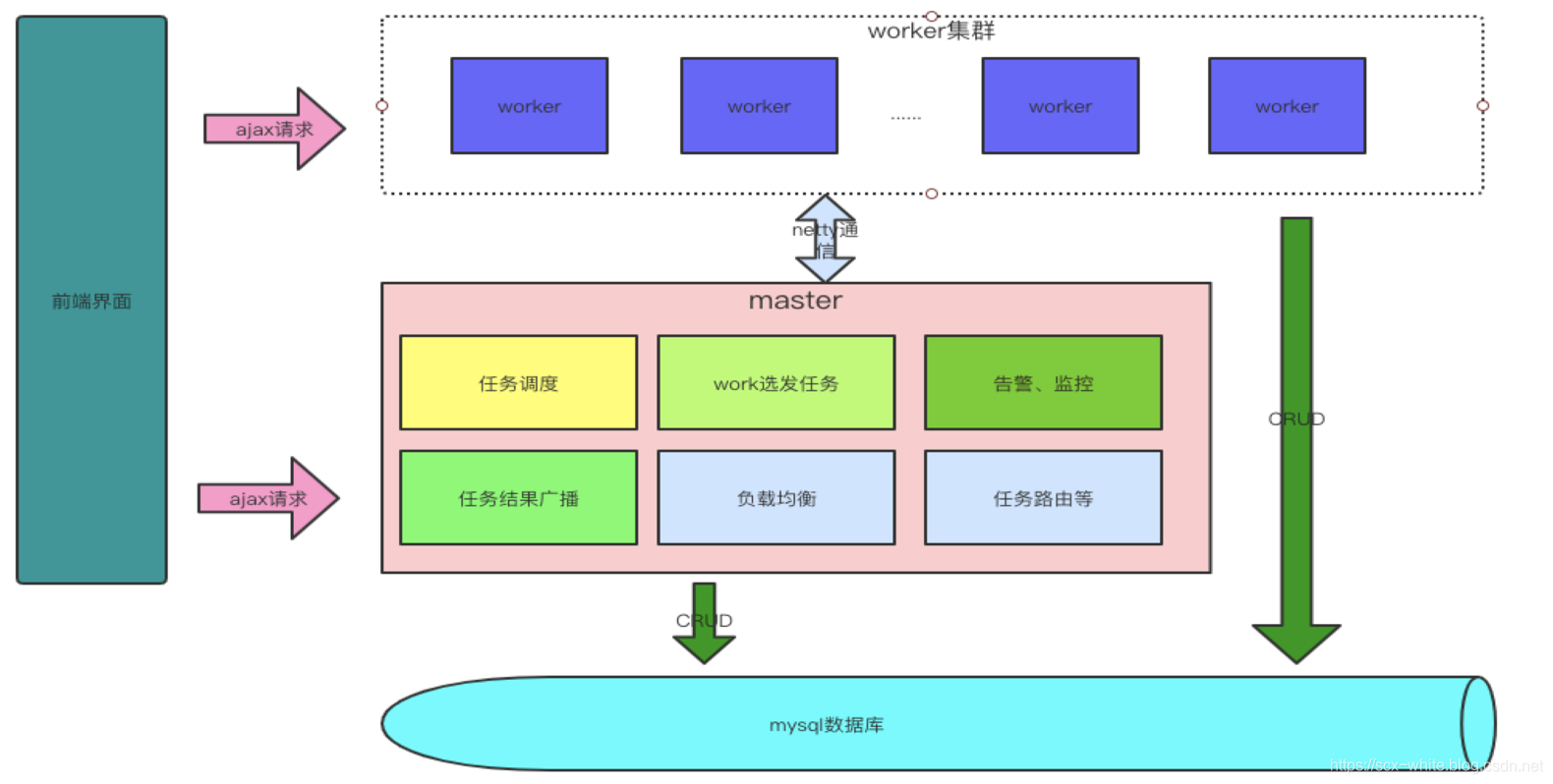
在大数据平台,随着业务发展,每天承载着成千上万的ETL任务调度,这些任务集中在hive,shell脚本调度。怎么样让大量的ETL任务准确的完成调度而不出现问题,甚至在任务调度执行中出现错误的情况下,任务能够完成自我恢复甚至执行错误告警与完整的日志查询。hera任务调度系统就是在这种背景下衍生的一款分布式调度系统。随着hera集群动态扩展,可以承载成千上万的任务调度。它是一款原生的分布式任务调度,可以快速的添加部署wokrer节点,动态扩展集群规模。支持shell,hive,spark脚本调度,可以动态的扩展支持python等服务器端脚本调度。
hera分布式任务调度系统是根据前阿里开源调度系统(
zeus)进行的二次开发,其中zeus大概在2014年开源,开源后却并未进行维护。我公司(二维火)2015年引进了zeus任务调度系统,一直使用至今年11月份,在我们部门乃至整个公司发挥着不可替代的作用。在我使用zeus的这一年多,不得不承认它的强大,只要集群规模于配置适度,他可以承担数万乃至十万甚至更高的数量级的任务调度。但是由于zeus代码是未维护的,前端更是使用GWT技术,难于在zeus上面进行维护。我与另外一个小伙伴(花名:凌霄,现在阿里淘宝部门)于今年三月份开始重写zeus,改名赫拉(hera)
***项目地址:[email protected]:scxwhite/hera.git ***
hera系统只是负责调度以及辅助的系统,具体的计算还是要落在hadoop、hive、yarn、spark等集群中去。所以此时又一个硬性要求,如果要执行hadoop,hive,spark等任务,我们的hera系统的worker一定要部署在这些集群某些机器之上。如果仅仅是shell,那么也至少需要linux系统。对于windows系统,可以把自己作为master进行调试。
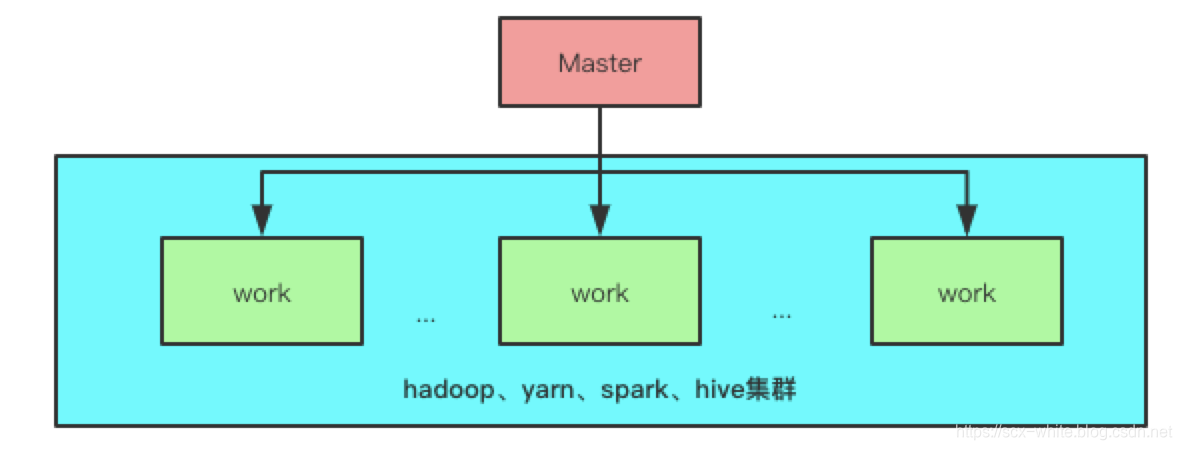
hera系统本身严格的遵从主从架构模式,由主节点充当着任务调度触发与任务分发器,从节点作为具体的任务执行器.架构图如下:
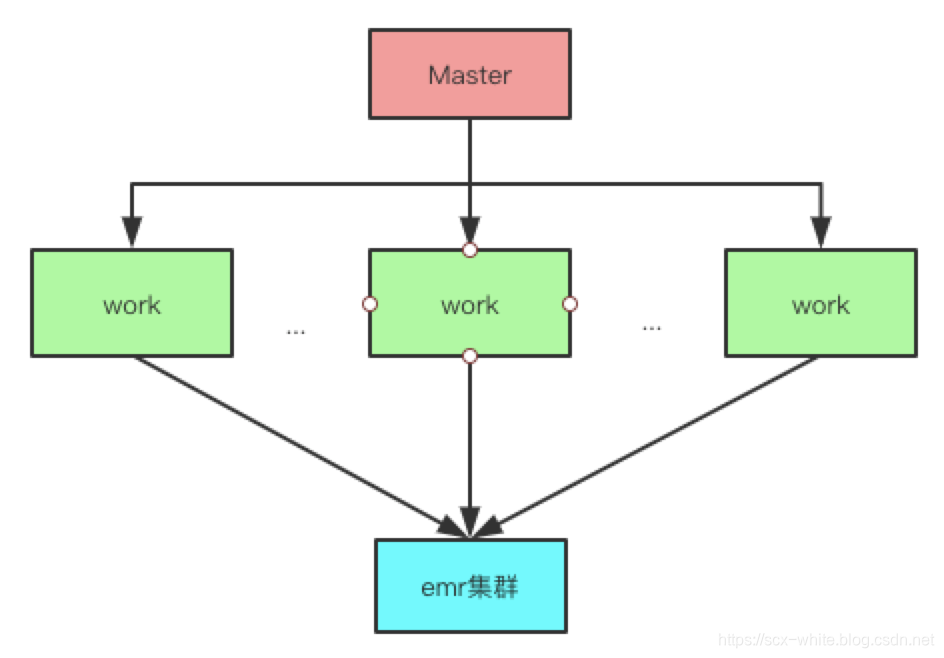
hera 在 2.4 版本以上也支持了emr 集群,即允许任务执行在阿里云、亚马逊的 emr 机器之上,架构图如下:
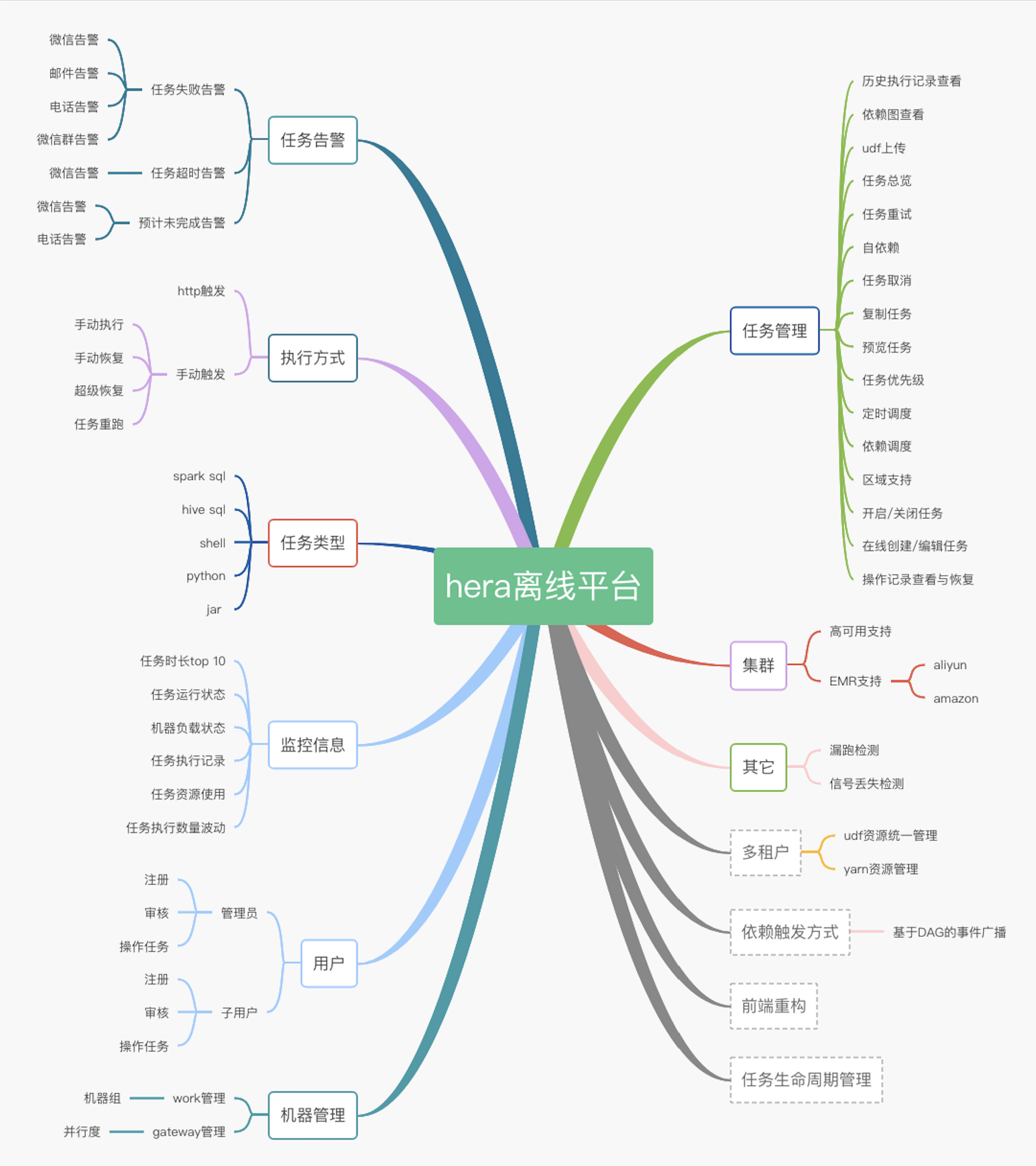
- 支持任务的定时调度、依赖调度、手动调度、手动恢复、超级恢复、重跑历史
- 支持丰富的任务类型:
shell,hive,python,spark-sql,java - 可视化的任务
DAG图展示,任务的执行严格按照任务的依赖关系执行 - 某个任务的上、下游执行状况查看,通过任务依赖图可以清楚的判断当前任务为何还未执行,删除该任务会影响那些任务。
- 支持上传文件到
hdfs,支持使用hdfs文件资源 - 支持日志的实时滚动
- 支持任务失败自动恢复
- 实现集群HA,机器宕机环境实现机器断线重连与心跳恢复与
hera集群HA,节点单点故障环境下任务自动恢复,master断开,worker抢占master - 支持对
master/work负载,内存,进程,cpu信息的可视化查看 - 支持正在等待执行的任务,每个
worker上正在执行的任务信息的可视化查看 - 支持实时运行的任务,失败任务,成功任务,任务耗时
top10的可视化查看 - 支持历史执行任务信息的折线图查看 具体到某天的总运行次数,总失败次数,总成功次数,总任务数,总失败任务数,总成功任务数
- 支持关注自己的任务,自动调度执行失败时会向负责人发送邮件
- 对外提供
API,开放系统任务调度触发接口,便于对接其它需要使用hera的系统 - 组下任务总览、组下任务失败、组下任务正在运行
- 支持
map-reduce任务和yarn任务的实时取消。 - 支持任务超时提醒
- 支持用户与组的概念
- 支持任务操作历史记录查看与恢复
- 支持任务告警定位到个人
- 告警类型支持邮箱以及自定义的钉钉、企业微信、短信、电话等
- 支持任务各种条件的模糊搜索
- 支持阿里云emr的自动创建、销毁
- 支持亚马逊emr的自动创建、销毁、弹性伸缩
- (还有更多,等待大家探索)
当使用git把hera克隆到本地之后,首先在hera/hera-admin/resources目录下找到hera.sql文件,在自己的数据库中新建这些必要的表,并插入初始化的数据(如果你目前使用的是低版本的hera,那么你可以到 update 目录查看是否有你的 hera 版本升级的 ddl ,如果有请根据你的版本依次执行 ddl 语句)
此时可以在hera/hera-admin/resources目录下找到application.yml文件。在文件里修改数据源hera的数据源(修改druid.datasource下的配置)即可进行下面的操作。
## 省略部分
druid:
datasource:
username: root #数据库用户名
password: moye #数据库密码
driver-class-name: com.mysql.jdbc.Driver #数据库驱动
url: jdbc:mysql://localhost:3306/hera?characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
## 省略部分
[注:2.4.1及以上版本已经集成启动和关闭的sh]
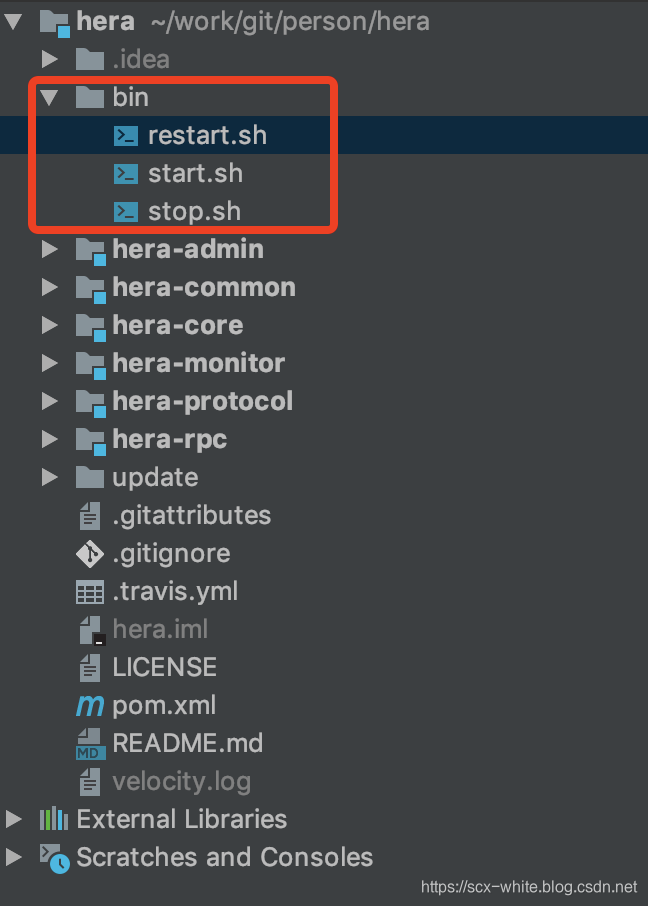
如果你的 hera 使用的是 2.4.1 版本以上的,使用maven执行 mvn clean package -Dmaven.test.skip=true -Pdev
打包后在根目录会出现如图所示的压缩包
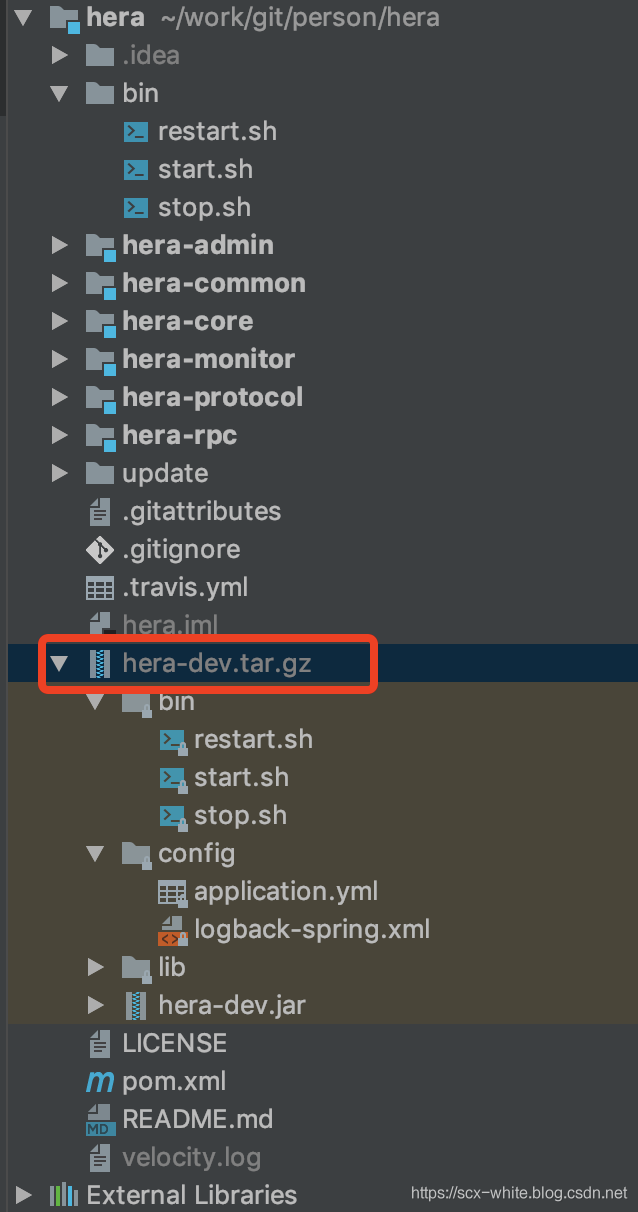
你可以通过 ssh 把该包上传到服务器,解压该tar.gz包。然后修改 config 目录下的application.yml 配置文件,在 bin 目录里执行 start.sh 脚本即可成功启动hera。
mvn clean package -Dmaven.test.skip=true -Pdev
打包后可以进入hera-admin/target目录下查看打包后的hera-dev.jar 。此时可以简单使用java -server -Xms4G -Xmx4G -Xmn2G -jar hera.jar 启动项目,此时即可在浏览器中输入
localhost:8080/hera/login/admin
即进入登录界面,账号为hera 密码为biadmin,点击登录即进入系统。
注:目前hera有用户账户和组账户之分,默认跳转的登录地址为用户账户,需要用户注册(用户需要归属于一个组账户),然后hera组账户在用户管理里页面审核通过后即可登录用户账户。
顺便附上我的启动脚本
#!/bin/sh
JAVA_OPTS="-server -Xms4G -Xmx4G -Xmn2G -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:CMSFullGCsBeforeCompaction=5 -XX:+CMSParallelInitialMarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/opt/logs/spring-boot/gc.log -XX:MetaspaceSize=128m -XX:+UseCMSCompactAtFullCollection -XX:MaxMetaspaceSize=128m -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/logs/spring-boot/dump"
log_dir="/opt/logs/spring-boot"
log_file="/opt/logs/spring-boot/all.log"
jar_file="/opt/app/spring-boot/hera.jar"
#日志文件夹不存在,则创建
if [ ! -d "${log_dir}" ]; then
echo "创建日志目录:${log_dir}"
mkdir -p "${log_dir}"
echo "创建日志目录完成:${log_dir}"
fi
#父目录下jar文件存在
if [ -f "${jar_file}" ]; then
#启动jar包 错误输出的error 标准输出的log
nohup java $JAVA_OPTS -jar ${jar_file} 1>"${log_file}" 2>"${log_dir}"/error.log &
echo "启动完成"
exit 0
else
echo -e "\033[31m${jar_file}文件不存在!\033[0m"
exit 1
fi关闭的脚本
#!/bin/bash
pid=`ps aux| grep java | grep hera | awk '{print $2}'`
[ ! $pid ] && echo "找不到hera的进程,请确认hera已经启动" && exit 0
res=`kill -9 $pid`
echo 关闭hera成功,pid:$pid
默认登陆地址为:http://localhost:8080/hera 下面需要做的是在worker管理这里添加执行任务的机器IP,然后选择一个机器组(组的概念:对于不同的worker而言环境可能不同,可能有的用来执行spark任务,有的用来执行hadoop任务,有的只是开发等等。当创建任务的时候根据任务类型选择一个组,要执行任务的时候会发送到相应的组的机器上执行任务)。
对于执行work的机器ip调试时可以是master,生产环境建议不要让master执行任务。如果要执行map-reduce或者spark任务,要保证你的work具有这些集群的客户端。
那么我们就在work管理页面增加要执行的work地址以及机器组。
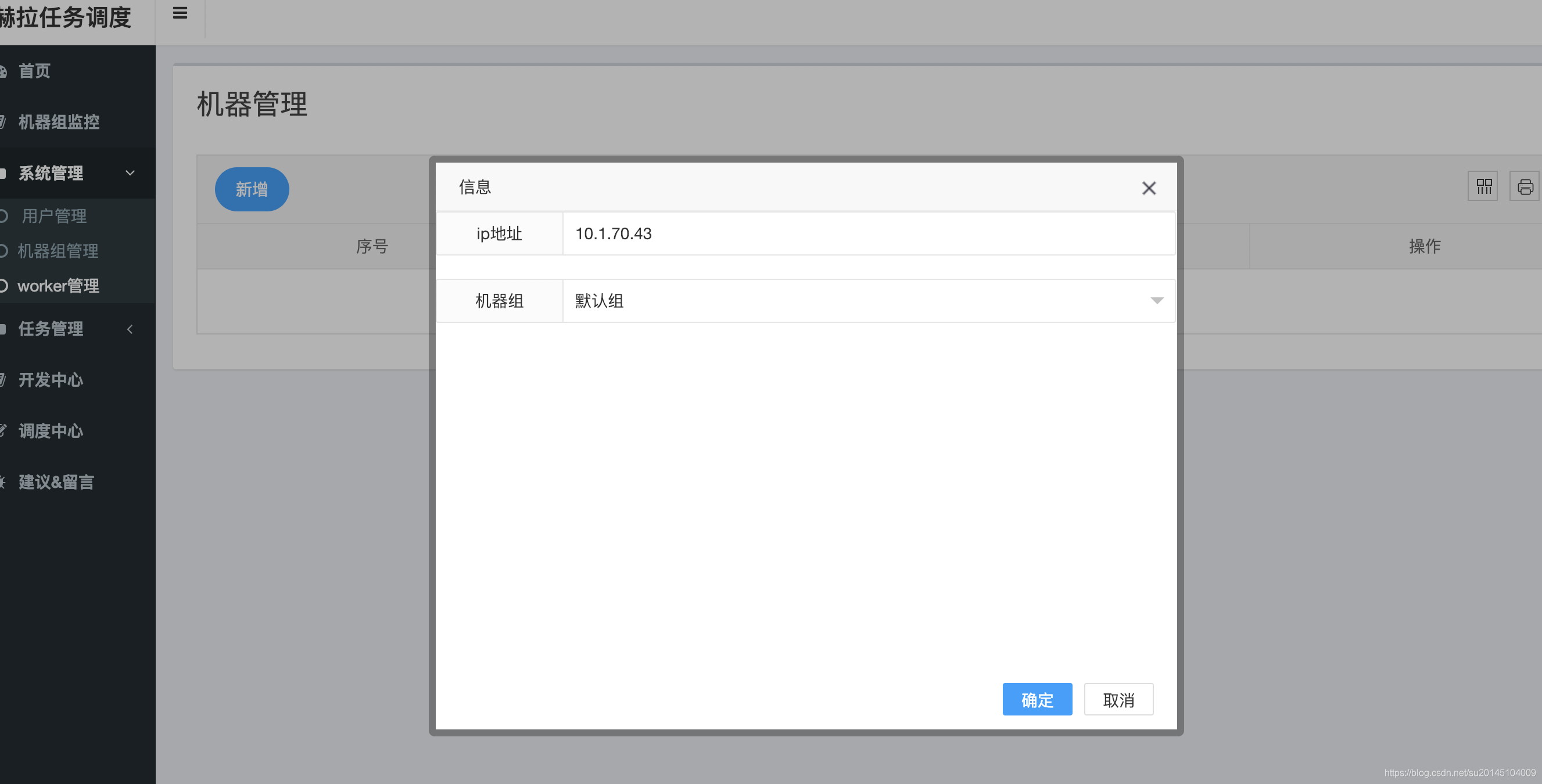
此时有30分钟的缓冲时间,master 才会检测到该 work 加入。为了测试,此时我们可以通过重启 master 来立刻使该 work加入执行组(后面会增加一键刷新work` 信息)。
此时要注意,我们的 work 也一定也要安装 hera 应用并启动。
重启后我们可以进入调度中心 ,在搜索栏里搜索 1 ,然后按回车
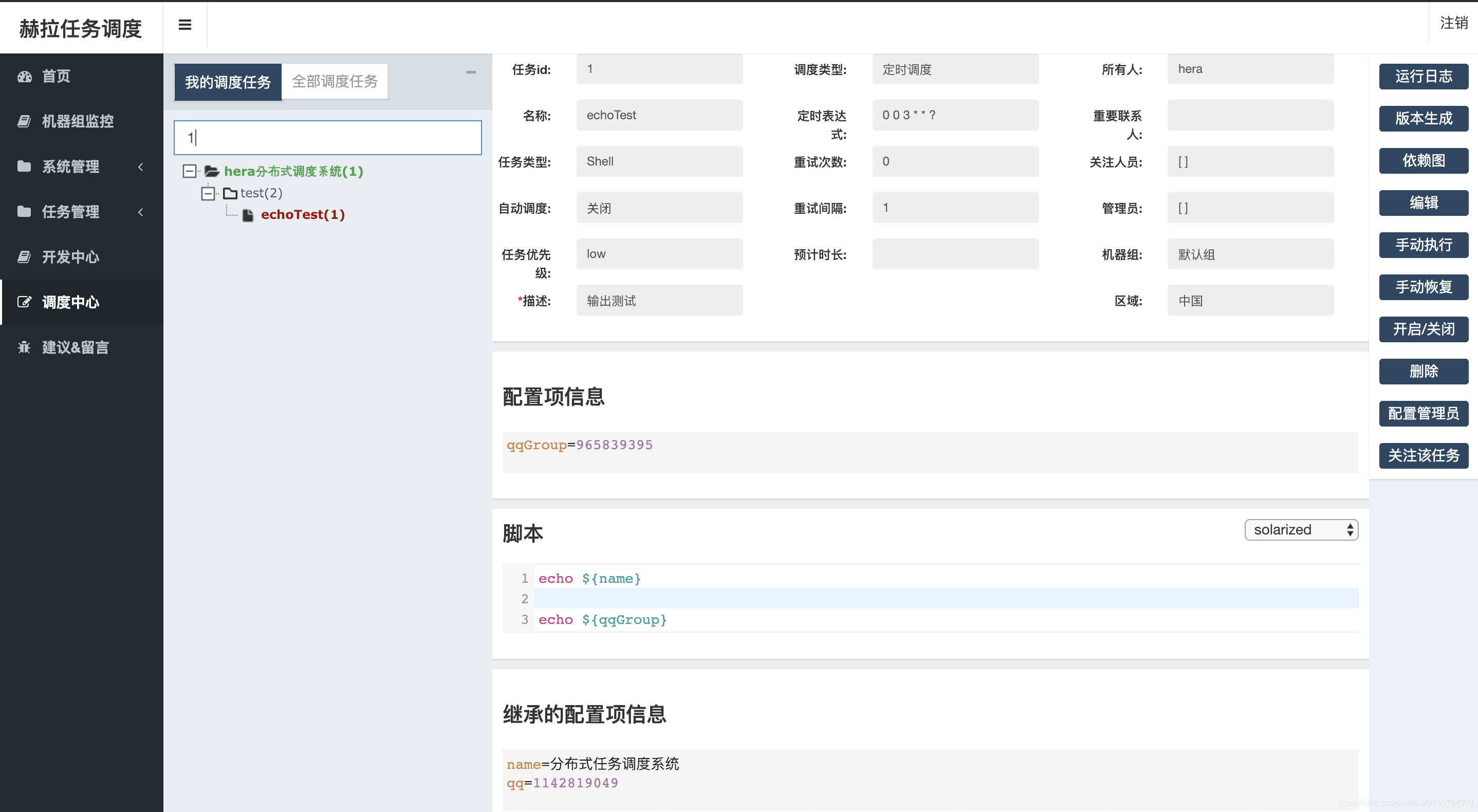
会发现一个 echoTest 任务 ,此时我们还不能执行任务,因为我们的所有任务的执行者登录用户。比如此刻我使用 hera 登录的,那么此时一定要保证你的 work 机器上有 hera 这个用户。
否则执行任务会出现 sudo: unknown user: hera 异常。
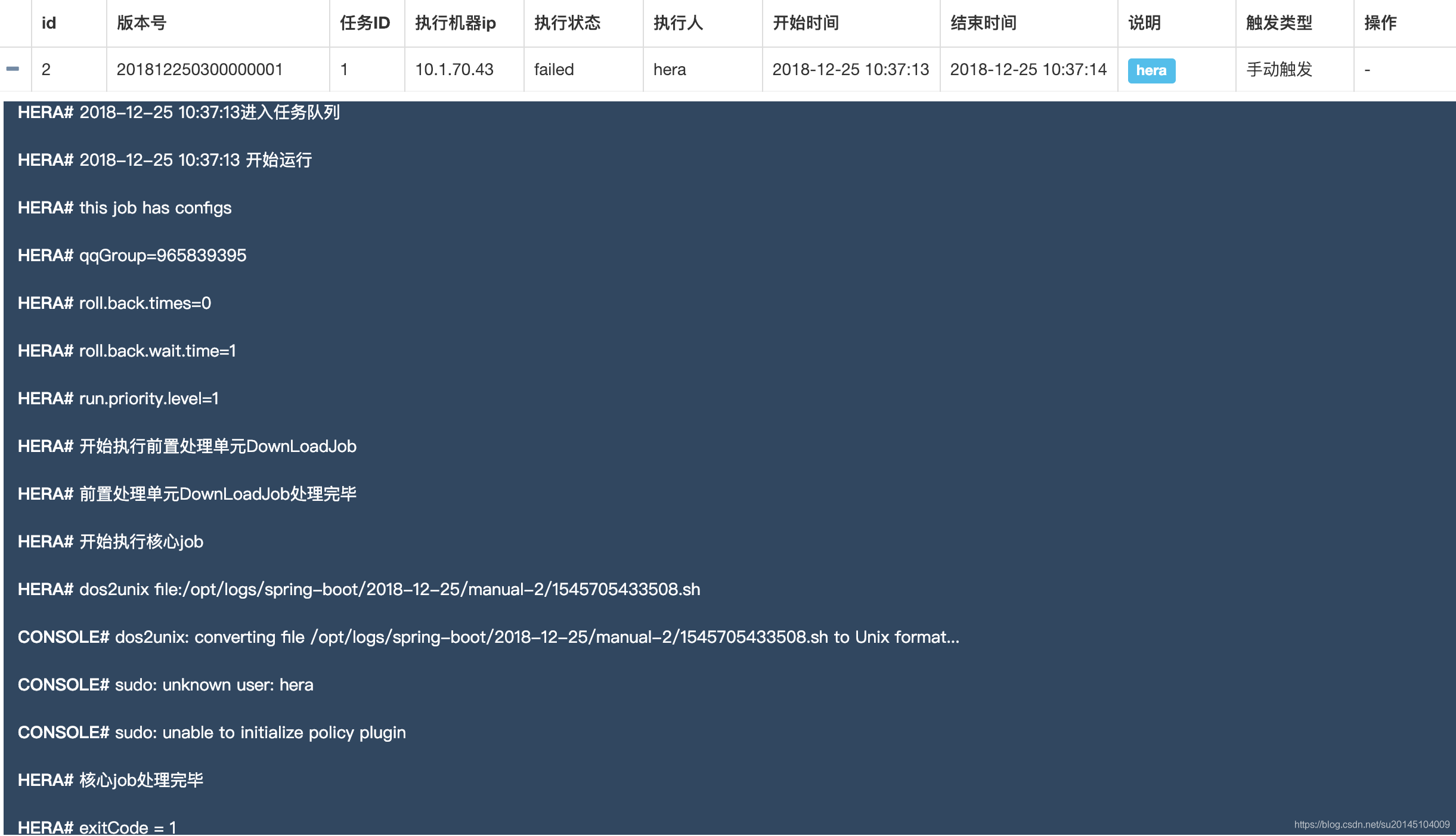
此时可以向我们填写的 work 机器上增加 hera 用户。
useradd hera
如果是 mac 系统 那么可以使用以下命令创建 hera 用户
sudo dscl . -create /Users/hera
sudo dscl . -create /Users/hera UserShell /bin/bash
sudo dscl . -create /Users/hera RealName "hera分布式任务调度"
sudo dscl . -create /Users/hera UniqueID "1024"
sudo dscl . -create /Users/hera PrimaryGroupID 80
sudo dscl . -create /Users/hera NFSHomeDirectory /Users/hera
此时点击手动执行->选择版本->执行。此时该任务会运行,点击右上角的查看日志,可以看到任务的执行记录。
此时如果任务执行失败,error 日志内容为
sudo: no tty present and no askpass program specified
那么此时要使你启动 hera 项目的用户具有 sudo -u hera 的权限(无须输入root密码,即可执行 sudo -u hera echo 1 ,具体可以在 sudo visudo 中配置)。
比如我启动 hera 应用的用户是 wyr
那么首先在终端执行 sudo visudo命令,此时会进入文本编辑
然后在后面追加一行
wyr ALL=(ALL) NOPASSWD:ALL
如下图:

root用户启动,即可跳过这段。
由于在 hera 中还用到了 dos2unix ,需要在执行任务的work上安装 dos2unix 工具。
yum install dos2unix
如果一切配置完成,那么即可看到输出任务执行成功的日志。
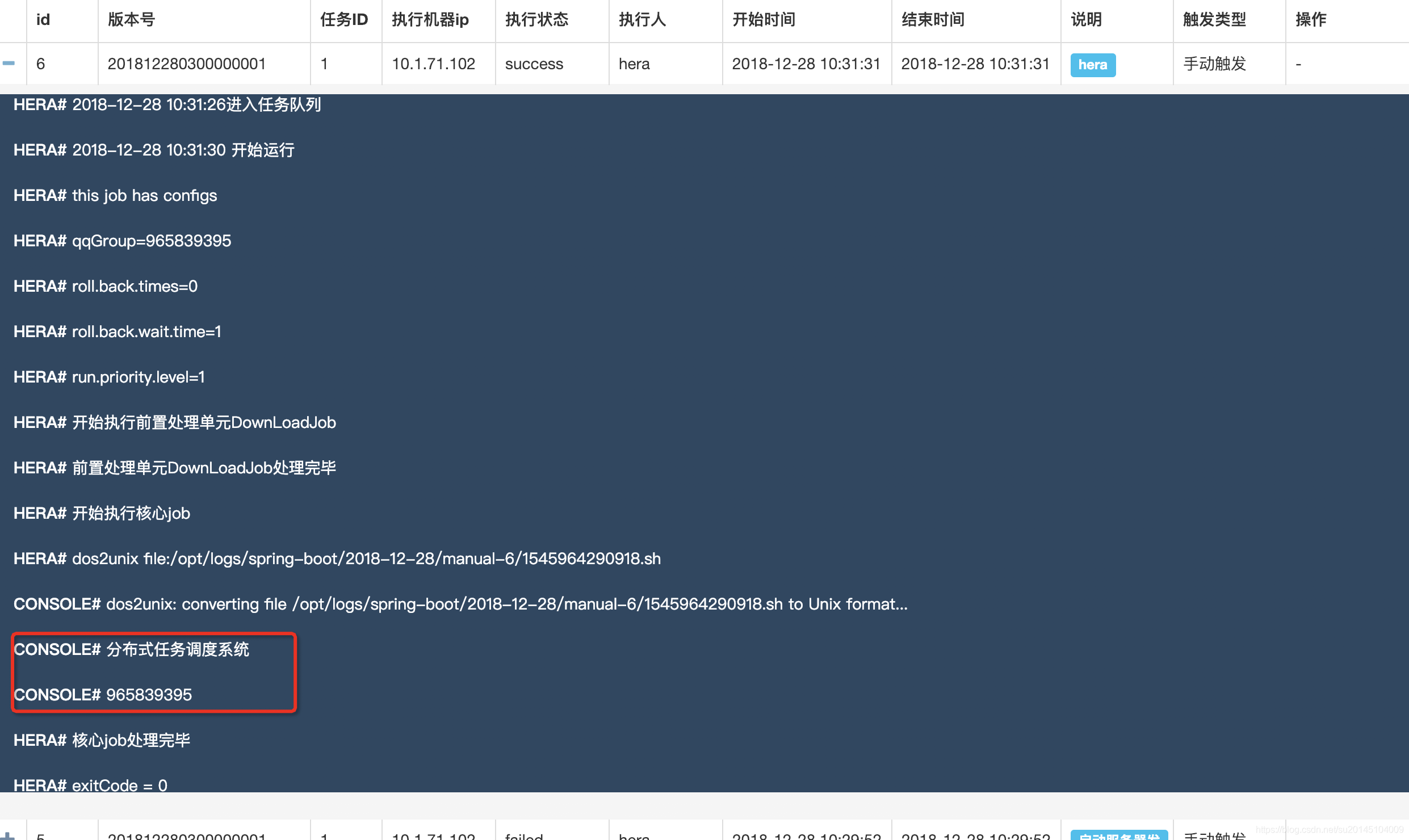
当然在部署的时候可能会出现各种状况。
比如:work 无法连接到 master,连接时抛出
java.net.NoRouteToHostException: 没有到主机的路由
这个时候请注意,我们的master使用的端口是:9887。需要在每台 hera 机器上的防火墙开启此端口(最好关闭防火墙 sudo service iptables stop )。
还有一种情况: work 可以连接上 master ,但是在master日志中发现 work 总是一段时间后断开。原因是:hera 各个机器的时间不一致,修改一下
Thanks goes to these wonderful people (emoji key):
 苏承祥 🎨 |
 凌霄 🎨 |
 akong0115 🎨 |
 Yizhong Zhang 🎨 |
 jet2007 🎨 |
This project follows the all-contributors specification. Contributions of any kind welcome!


