


Installation • Uninstallation • How to use Chatette? • Chatette vs Chatito? • Development • Credits
Chatette is a Python program that generates training datasets for Rasa NLU given template files. If you want to make large datasets of example data for Natural Language Understanding tasks without too much of a headache, Chatette is a project for you.

Specifically, Chatette implements a Domain Specific Language (DSL) that allows you to define templates to generate a large number of sentences, which are then saved in the input format(s) of Rasa NLU.
The DSL used is a near-superset of the excellent project Chatito created by Rodrigo Pimentel. (Note: the DSL is actually a superset of Chatito v2.1.x for Rasa NLU, not for all possible adapters.)
An interactive mode is available as well:
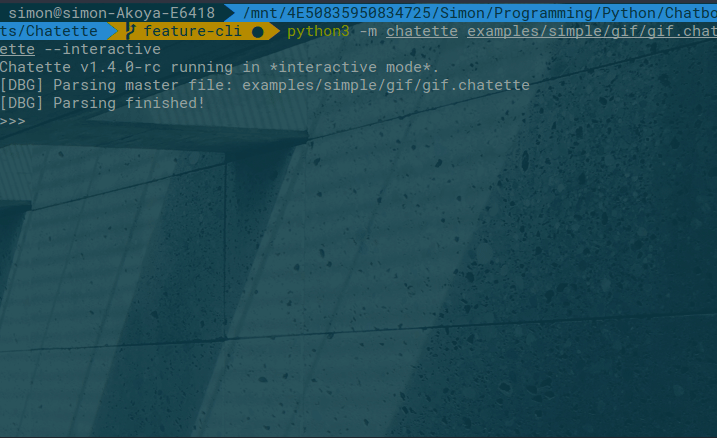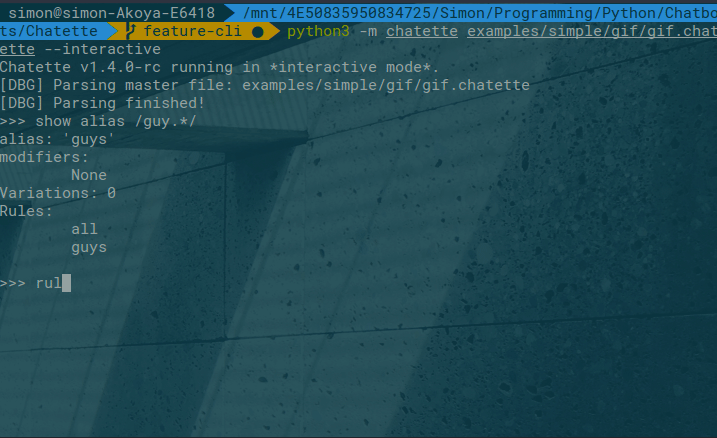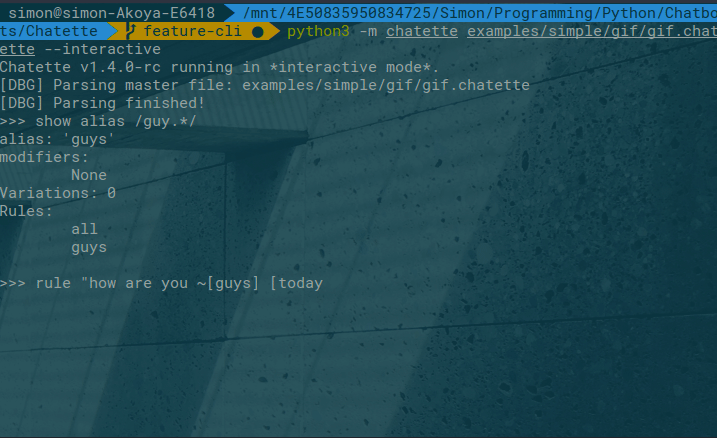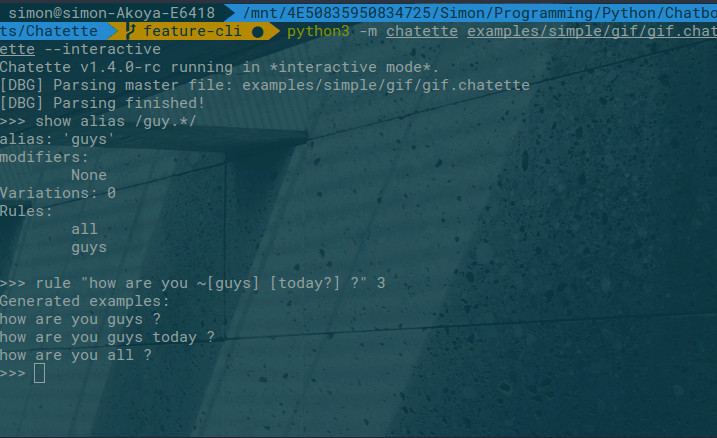
To run Chatette, you will need to have Python installed. Chatette works with both Python 2.7 and 3.x (>= 3.4).
Chatette is available on PyPI, and can thus be installed using pip:
pip install chatetteAlternatively, you can clone the GitHub repository and install the requirements:
pip install -r requirements/common.txtYou can then install the project (as an editable package) using pip, by executing the following command from the directory Chatette/chatette/:
pip install -e .You can then run the module by using the commands below in the cloned directory.
You can just use pip to uninstall Chatette:
pip uninstall chatetteThe data that Chatette uses and generates is loaded from and saved to files. You will thus have:
-
One or several input file(s) containing the templates. There is no need for a specific file extension. The syntax of the DSL to make those templates is described on the wiki.
-
One or several output file(s), which will be generated by Chatette and will contain the generated examples. Those files can be formatted in JSON (by default) or in Markdown and can be directly fed to Rasa NLU. It is also possible to use a JSONL format.
Once Chatette is installed and you created the template files, run the following command:
python -m chatette <path_to_template>where python is your Python interpreter (some operating systems use python3 as the alias to the Python 3.x interpreter).
You can specify the name of the output file as follows:
python -m chatette <path_to_template> -o <output_directory_path><output_directory_path> is specified relatively to the directory from which the script is being executed.
The output file(s) will then be saved in numbered .json files in <output_directory_path>/train and <output_directory_path>/test. If you didn't specify a path for the output directory, the default one is output.
Other program arguments and are described in the wiki.
TL;DR: main selling point: it is easier to deal with large projects using Chatette, and you can transform most Chatito projects into a Chatette one without any modification.
A perfectly legitimate question is:
Why does Chatette exist when Chatito already fulfills the same purposes?
The two projects actually have different goals:
Chatito aims to be a generic but powerful DSL, that should stay very legible. While it is perfectly fine for small projects, when projects get larger, the simplicity of its DSL may become a burden: your template file becomes overwhelmingly large, to the point you get lost inside it.
Chatette defines a more complex DSL to be able to manage larger projects and tries to stay as interoperable with Chatito as possible. Here is a non-exhaustive list of features Chatette has and that Chatito does not have:
- Ability to break down templates into multiple files
- Possibility to specify the probability of generating some parts of the sentences
- Conditional generation of some parts of the sentences, given which other parts were generated
- Choice syntax to prevent copy-pasting rules with only a few changes and to easily modify the generation behavior of parts of sentences
- Ability to define the value of each slot (entity) whatever the generated example
- Syntax for generating words with different case for the leading letter
- Argument support so that some templates may be filled by different strings in different situations
- Indentation is permissive and must only be somewhat coherent
- Support for synonyms
- Interactive command interpreter
- Output for Rasa in JSON or in Markdown formats
As the Chatette's DSL is a superset of Chatito's one, input files used for Chatito are most of the time completely usable with Chatette (not the other way around). Hence, it is easy to start using Chatette if you used Chatito before.
As an example, this Chatito data:
// This template defines different ways to ask for the location of toilets (Chatito version)
%[ask_toilet]('training': '3')
~[sorry?] ~[tell me] where the @[toilet#singular] is ~[please?]?
~[sorry?] ~[tell me] where the @[toilet#plural] are ~[please?]?
~[sorry]
sorry
Sorry
excuse me
Excuse me
~[tell me]
~[can you?] tell me
~[can you?] show me
~[can you]
can you
could you
would you
~[please]
please
@[toilet#singular]
toilet
loo
@[toilet#plural]
toilets
could be directly given as input to Chatette, but this Chatette template would produce the same results:
// This template defines different ways to ask for the location of toilets (Chatette version)
%[&ask_toilet](3)
~[sorry?] ~[tell me] where the @[toilet#singular] is [please?]?
~[sorry?] ~[tell me] where the @[toilet#plural] are [please?]?
~[sorry]
sorry
excuse me
~[tell me]
~[can you?] [tell|show] me
~[can you]
[can|could|would] you
@[toilet#singular]
toilet
loo
@[toilet#plural]
toilets
The Chatito version is arguably easier to read, but the Chatette version is shorter, which may be very useful when dealing with lots of templates and potential repetition.
Beware that, as always with machine learning, having too much data may cause your models to perform less well because of overfitting. While this script can be used to generate thousands upon thousands of examples, it isn't advised for machine learning tasks.
Chatette is named after Chatito: -ette in French could be translated to -ita or -ito in Spanish. Note that the last e in Chatette is not pronouced (as is the case in "note").
For developers, you can clone the repo and install the development requirements:
pip install -r requirements/develop.txt
Then, install the module as editable:
pip install -e <path-to-chatette-module>
-
Run pylint:
tox -e pylint -
Run pycodestyle:
tox -e pycodestyle -
Run pytest:
tox -e pytest
Disclaimer: This is a side-project I'm not paid for, don't expect me to work 24/7 on it.
Many thanks to them!



















































































































