A document similarity engine for discovering related scientifc articles using distributed representation (Doc2Vec), trained on 600,000+ articles from Arxiv.org on AWS. The vectors are used to return articles similar to a search query (which can be entire paragraphs), or any article found by browsing through the interface.
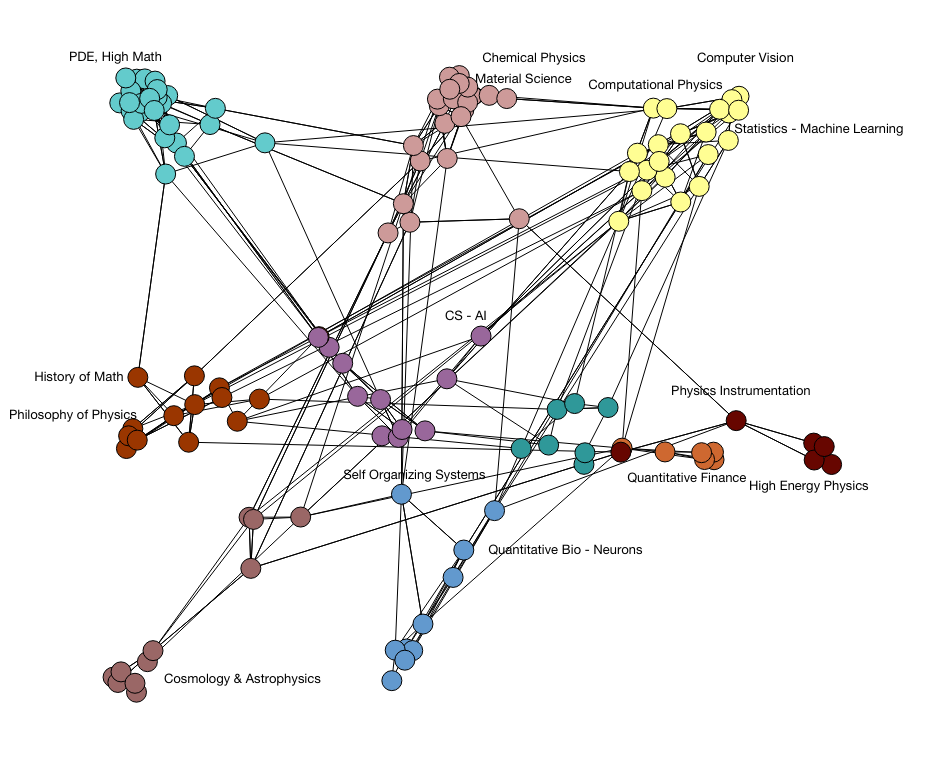
A serendipitous find was that the network of documents and the similarity between them form a weighted graph. I used a community detection algorithm on this weighted graph to visualize the relationship between topics (whose vectors were calculated by simply averaging their document vector).
Knowledge required to tackle complex problems is often siloed in disparate disciplines, each with their own unique lexica and citation communities. There's an opportunity for text-mining to find overlaps across disciplines that could lead to innovative research.
Recent advances in Natural Language Processing have given us new tools for overcoming these barriers to discovery. Specifically, a set of machine learning algorithms developed at Google (Word2Vec) learn to represent text using fixed number of dimensions, each of which encodes some aspect of that word's or document's meaning. For example, we can locate the "gender" dimension that has been automatically encoded by the algorithm, by subtracting the vector for "woman" from that of "man". Adding this dimension to "aunt" will yield "uncle", and so on.
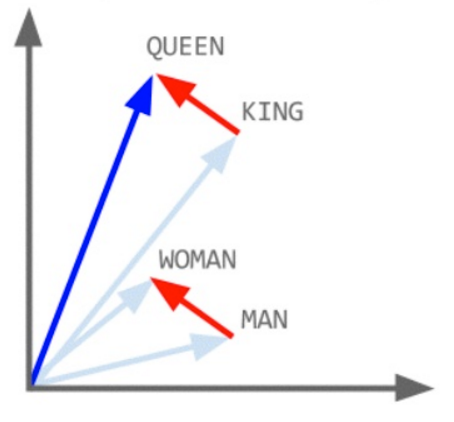
Here are some examples from pre-trained word vectors:
- Iraq - Violence = Jordan
- Human - Animal = Ethics
- Library - Books = Hall
Semantically similar words have very similar vectors, so the cosine similarity between, for example, "strong" and "powerful" will be approximately 1.
I used the Open Archives Initative's API to gather metadata and abstracts for over 600,000 articles published on Arxiv in the past 10 years. This data is parsed, cleaned, and placed into a PostGRES database.
SciExporer's engine utilizes Word2Vec and Doc2Vec, which produce word and document vectors via a simple, 2-level neural network that trains on raw text, analyzing words in their local context. Training was done on a powerful EC2 instance with several processors in an online manner that does not require loading the entire corpus into memory.
The number of hidden layer neurons is a tuning parameter that can be tweaked to yield either more exact matches or fuzzier searches. The current model employs only 100 neurons, which is actually rather few. As we scale up the data to include full-text PDFs, we can increase that number because we will have more data to train those extra features.
When a query is sent in, a vector is inferred for the document based on text the model has already seen. We then look for cosine similarity with other documents in the database that are closely matched.
The topic visualizer employs D3 and a community detection algorithm (Louvain) to find clusters of meaning, which reveals several neighborhoods that are from separate parent categories. This visualization can be used to discover neighboring topics that may overlap semantically with the user's primary interest.




































































