UAV systems are attracting the attention of researchers and companies from a wide range of industries, particularly in the last decade, due to their ability to operate in a coordinated manner in complex scenarios and to cover and speed up applications that can be dangerous or tedious for humans. Search and rescue, inspection of facilities, delivery of commodities, and surveillance are just a few examples of these in the military, commercial, and government sectors. Path planning is an important research field in the autonomous UAV that helps to find the path, avoid collisions, and navigate in the environment. In this project, I have implemented the TD3+ PER algorithm to increase the performance of the autonomous vehicle. As a result, when compared to the TD3 algorithm, TD3+PER has shown increasing stability in training and improved the performance of the autonomous UAV.
The goal of the project is to develop an autonomous UAV navigation system using reinforcement learning. The navigation of UAV include path finding in the environment without any collision. This is done by using TD3 and Prioritized experience replay (PER).
- to learn the fundamentals of unmanned aerial vehicle operation
- To investigate different path finding systems.
- To develop a Reinforcement learning algorithm which will be used to create an autonomous navigation system for UAV.
- Explore various simulators which are used drone training.
- Evaluate the results which are obtained.
- Does the prioritised experience replay method improve navigation performance?
- Does reinforcement learning, which is used in the project, improve the navigation of the UAV’s?
For this project, I am using AirSim simulator from Microsoft to simulate the environment which is used to train the proposed TD3 + PER reinforcement algorithm.
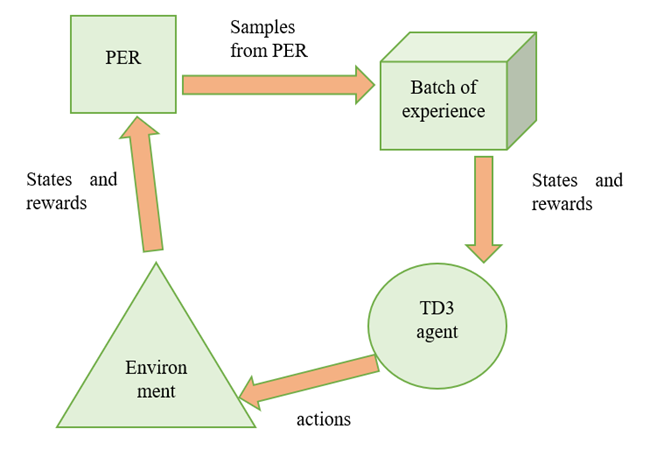
The proposed model uses TD3 reinforcement learning method with PER to help it to converge to the point quickly.In the working model, when the TD3 agent generates an action in the environment (AirSim), the agent gets rewarded. The states and rewards are then sent to PER. The PER calculates the TD and sends the required samples of actions and states to the batch of experience. This batch of experience has the knowledge of best actions and how to get the highest rewards. Then the experience is shared with the TD3 agent, which increases the performance of the algorithm by reducing the unwanted steps in training.

The libraries which are used for implementation are:
- TensorFlow: Helps in creating neural networks.
- PIL: this is an image processing library used for collecting image data from the environment (AIRsim)
- Numpy: This library is a mathematical library that is used for computation of matrices.
- Opengym: This library provides the environment wapper which is used to connect AirSim and the RL algorithm.
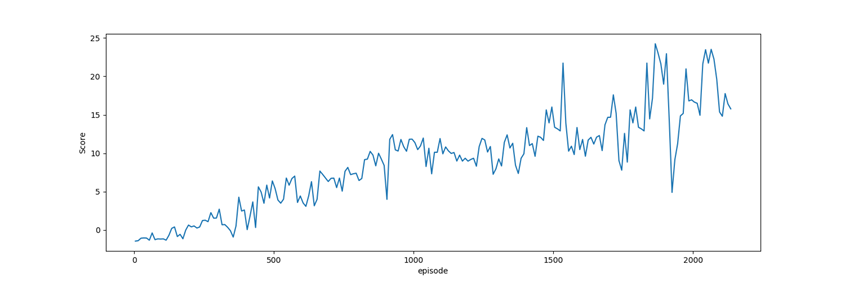
Average Q value: It's a measure of the total anticipated benefit when the agent is in state s and does action a. this is used to give the probability of success of the model to achieve its goals. The average q values are stored in stats.csv file.
TD3 + PER

only TD3

The above plots show the average Q value of TD3 algorithm and TD3+per algorithm. The proposed algorithm showed a steady growth of performance than the random performance in the TD3. This means that the PER increases the stability of the TD3 algorithms and helps to converge faster.
Total rewards: Using reward and punishment, the Reward Function instructs the agent what is right and what is wrong. Agents in RL are tasked with maximising the sum of all possible rewards. There are instances when we have to give up quick gains in order to get the most overall benefit. So, most of the RL algorithm uses total rewards as the metric to evaluate the model.
TD3 +PER
Only TD3
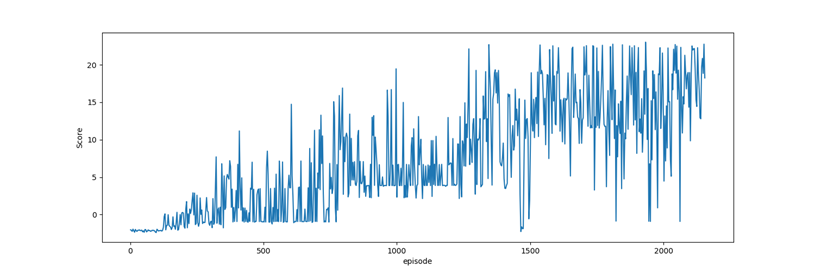
The above graphs indicate that the TD3+ PER was able to get more rewards compare to the TD3. This can be concluded that the TD3+PER algorithm was taking more precise steps and was converging to the goal more quickly. The bias introduced by the PER had an impact on the performance of the algorithm.
