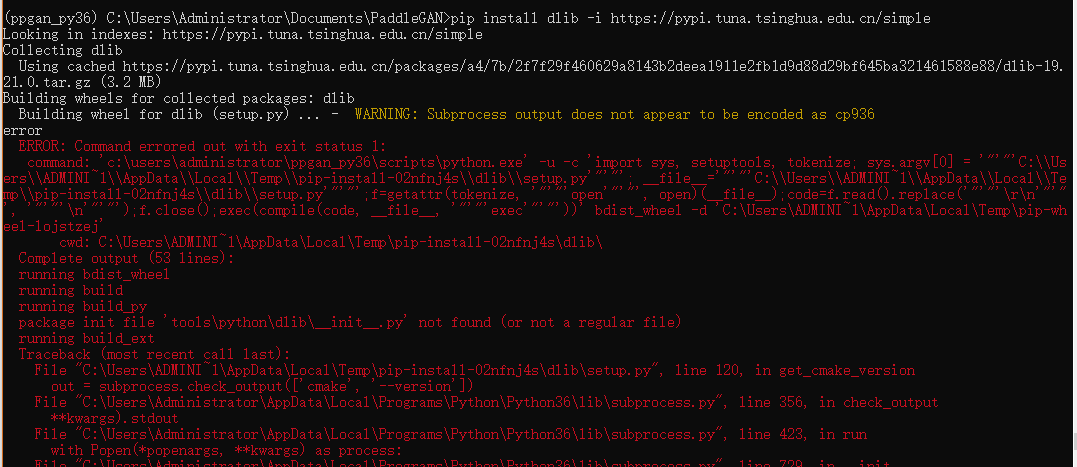
Model EDVR proccess start..
[03/25 11:23:58] ppgan INFO: Found /home/aistudio/.cache/ppgan/edvr_infer_model.tar
[03/25 11:23:58] ppgan INFO: Decompressing /home/aistudio/.cache/ppgan/edvr_infer_model.tar...
2021-03-25 11:23:58,229-WARNING: The old way to load inference model is deprecated. model path: /home/aistudio/.cache/ppgan/edvr_infer_model/EDVR_model.pdmodel, params path: /home/aistudio/.cache/ppgan/edvr_infer_model/EDVR_params.pdparams
0%| | 0/1427 [00:00<?, ?it/s]
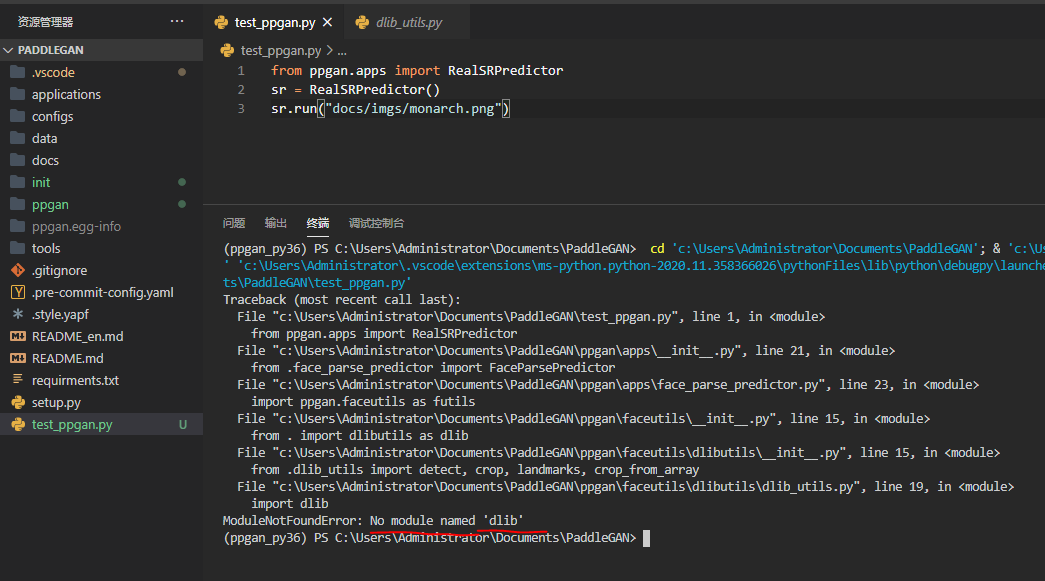
Traceback (most recent call last):
File "tools/video-enhance.py", line 114, in <module>
frames_path, temp_video_path = predictor.run(temp_video_path)
File "/home/aistudio/PaddleGAN/PaddleGAN/ppgan/apps/edvr_predictor.py", line 173, in run
outs = self.base_forward(np.array(data_feed_in))
File "/home/aistudio/PaddleGAN/PaddleGAN/ppgan/apps/base_predictor.py", line 61, in base_forward
feed=feed_dict)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1110, in run
six.reraise(*sys.exc_info())
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/six.py", line 703, in reraise
raise value
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1108, in run
return_merged=return_merged)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1238, in _run_impl
use_program_cache=use_program_cache)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1328, in _run_program
[fetch_var_name])
ValueError: In user code:
File "/root/miniconda3/envs/py37_paddle1.8/lib/python3.7/site-packages/paddle/fluid/framework.py", line 2610, in append_op
attrs=kwargs.get("attrs", None))
File "/root/miniconda3/envs/py37_paddle1.8/lib/python3.7/site-packages/paddle/fluid/layer_helper.py", line 43, in append_op
return self.main_program.current_block().append_op(*args, **kwargs)
File "/root/miniconda3/envs/py37_paddle1.8/lib/python3.7/site-packages/paddle/fluid/layers/nn.py", line 7445, in reshape
"XShape": x_shape})
File "/workspace/PaddleGAN/applications/EDVR/models/edvr/edvr_model.py", line 361, in EDVRArch
L3_fea = fluid.layers.reshape(L3_fea, [-1, N, nf, shape[3]//4, shape[4]//4])
File "/workspace/PaddleGAN/applications/EDVR/models/edvr/edvr_model.py", line 436, in net
TSA_only = self.TSA_only)
File "/workspace/PaddleGAN/applications/EDVR/models/edvr/edvr.py", line 104, in build_model
out = videomodel.net(self.feature_input[0])
File "inference_model.py", line 84, in save_inference_model
infer_model.build_model()
File "inference_model.py", line 123, in <module>
save_inference_model(args)
InvalidArgumentError: The 'shape' attribute in ReshapeOp is invalid. The input tensor X'size must be divisible by known capacity of 'shape'. But received X's shape = [5, 128, 103, 135], X's size = 8899200, 'shape' is [-1, 5, 128, 102, 135], known capacity of 'shape' is -8812800.
[Hint: Expected output_shape[unk_dim_idx] * capacity == -in_size, but received output_shape[unk_dim_idx] * capacity:-8812800 != -in_size:-8899200.] (at /paddle/paddle/fluid/operators/reshape_op.cc:208)
[operator < reshape2 > error]