English | 简体中文
PaddleGAN provides developers with high-performance implementation of classic and SOTA Generative Adversarial Networks, and supports developers to quickly build, train and deploy GANs for academic, entertainment and industrial usage.
GAN-Generative Adversarial Network, was praised by "the Father of Convolutional Networks" Yann LeCun (Yang Likun) as [One of the most interesting ideas in the field of computer science in the past decade]. It's the one research area in deep learning that AI researchers are most concerned about.

-
2021.4.15~4.22
GAN 7 Days Course Camp: Baidu Senior Research Developers help you learn the basic and advanced GAN knowledge in 7 days!
Courses videos and related materials: https://aistudio.baidu.com/aistudio/course/introduce/16651
-
👶 Young or Old?:StyleGAN V2 Face Editing-Time Machine! 👨🦳

-
🔥 Latest Release: PP-MSVSR 🔥
- Video Super Resolution SOTA models

-
😍 Boy or Girl?:StyleGAN V2 Face Editing-Changing genders! 😍

-
👩🚀 A Space Odyssey :LapStyle image translation take you travel around the universe👨🚀
-
🧙♂️ Latest Creative Project:create magic/dynamic profile for your student ID in Hogwarts 🧙♀️
-
💞 Add Face Morphing function💞 : you can perfectly merge any two faces and make the new face get any facial expressions!
-
Publish a new version of First Oder Motion model by having two impressive features:
- High resolution 512x512
- Face Enhancement
- Tutorials: https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/motion_driving.md
-
New image translation ability--transfer photo into oil painting style:
-
Complete tutorials for deployment: https://github.com/wzmsltw/PaintTransformer

-
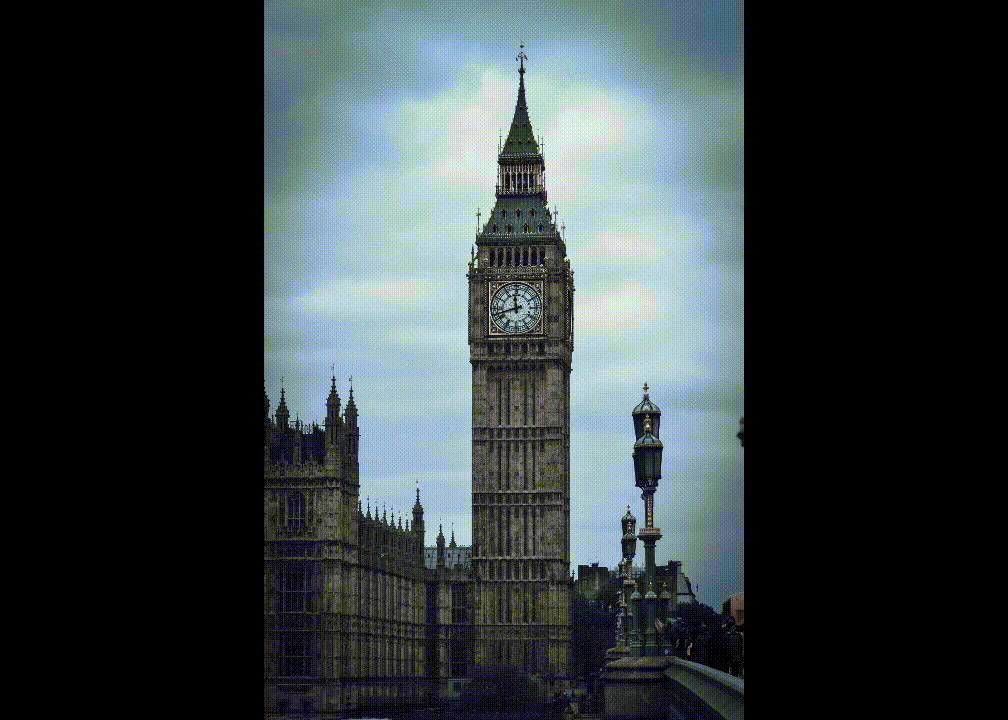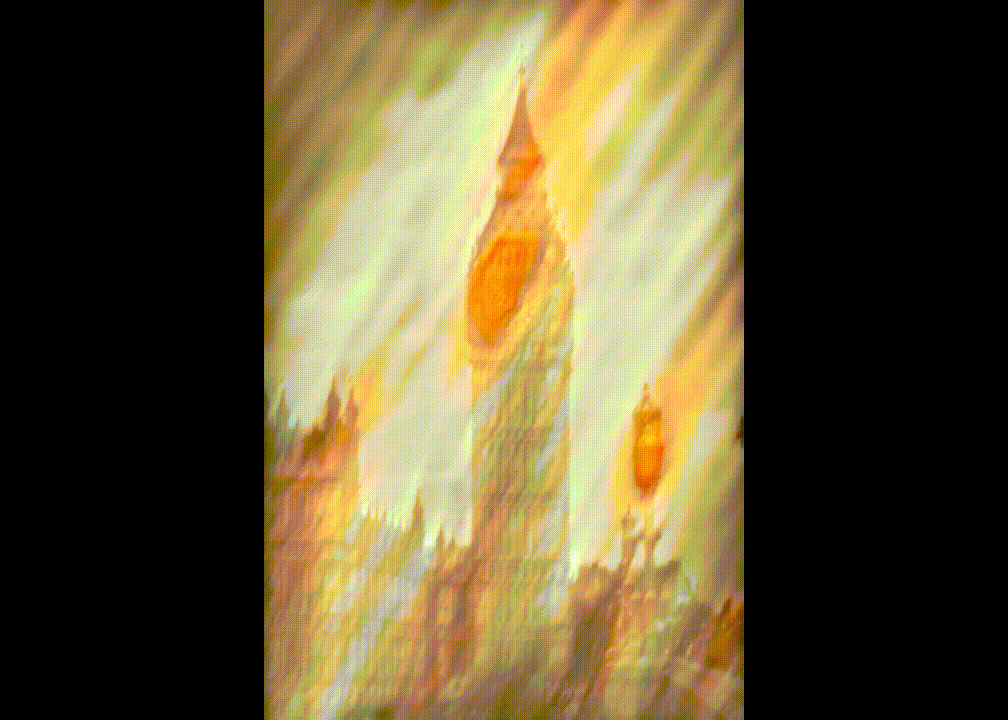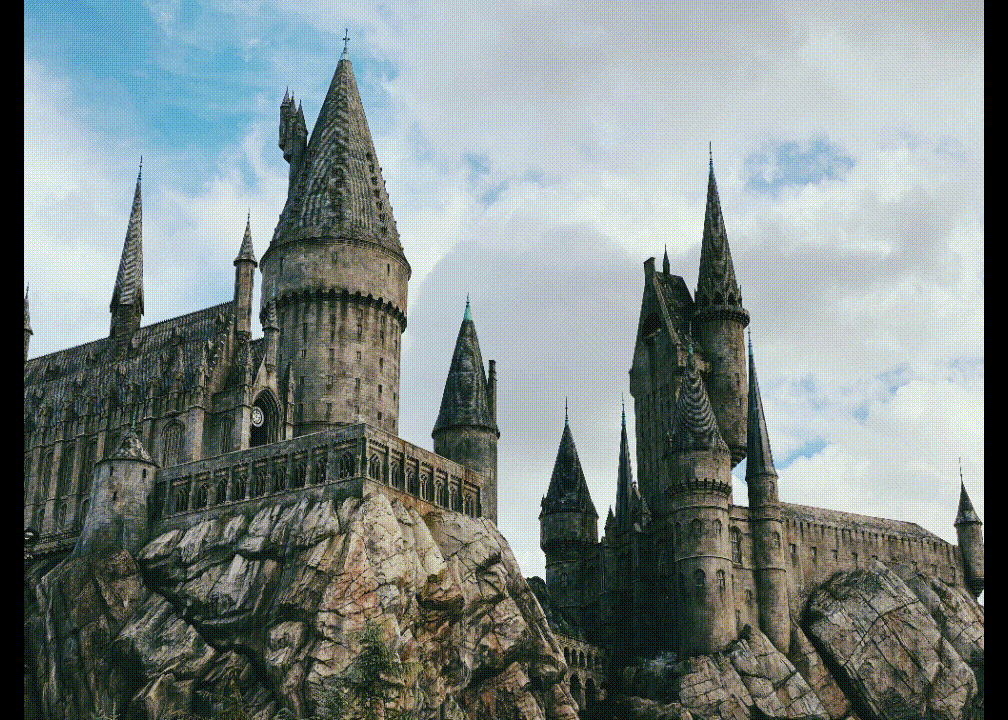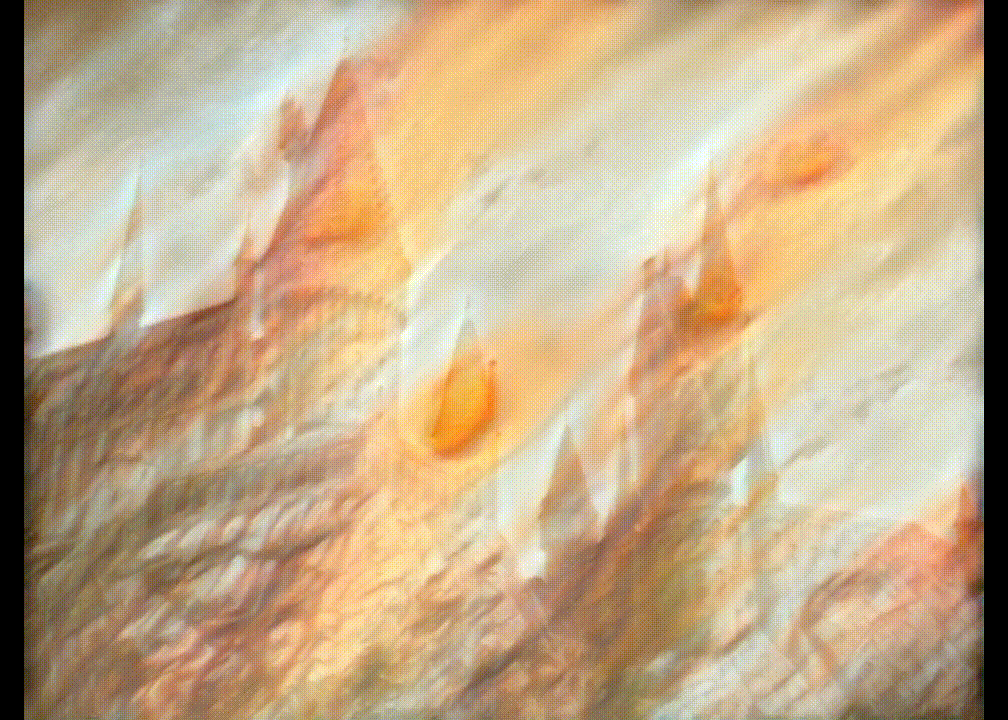




- Environment dependence:
- PaddlePaddle >= 2.1.0
- Python >= 3.6
- CUDA >= 10.1
- Full installation tutorial
- Pixel2Pixel
- CycleGAN
- LapStyle
- PSGAN
- First Order Motion Model
- FaceParsing
- AnimeGANv2
- U-GAT-IT
- Photo2Cartoon
- Wav2Lip
- Single Image Super Resolution(SISR)
- Including: RealSR, ESRGAN, LESRCNN, PAN, DRN
- Video Super Resolution(VSR)
- Including: ⭐ PP-MSVSR ⭐, EDVR, BasicVSR, BasicVSR++
- StyleGAN2
- Pixel2Style2Pixel
- StarGANv2
- MPR Net
- FaceEnhancement
- PReNet
- SwinIR
- InvDN
- AOT-GAN
- NAFNet
- GFPGan
- GPEN
You can run those projects in the AI Studio to learn how to use the models above:
| Online Tutorial | link |
|---|---|
| Motion Driving-multi-personal "Mai-ha-hi" | Click and Try |
| Restore the video of Beijing hundreds years ago | Click and Try |
| Motion Driving-When "Su Daqiang" sings "unravel" | Click and Try |










NEW try out the Lip-Syncing web demo on Huggingface Spaces using Gradio:
-
v2.1.0 (2021.12.8)
- Release a video super-resolution model PP-MSVSR and multiple pre-training weights
- Release several SOTA video super-resolution models and their pre-trained models such as BasicVSR, IconVSR and BasicVSR++
- Release the light-weight motion-driven model(Volume compression: 229M->10.1M), and optimized the fusion effect
- Release high-resolution FOMM and Wav2Lip pre-trained models
- Release several interesting applications based on StyleGANv2, such as face inversion, face fusion and face editing
- Released Baidu’s self-developed and effective style transfer model LapStyle and its interesting applications, and launched the official website experience page
- Release a light-weight image super-resolution model PAN
-
v2.0.0 (2021.6.2)
- Release Fisrt Order Motion model and multiple pre-training weights
- Release applications that support Multi-face action driven
- Release video super-resolution model EDVR and multiple pre-training weights
- Release the contents of 7-day punch-in training camp corresponding to PaddleGAN
- Enhance the robustness of PaddleGAN running on the windows platform
-
v2.0.0-beta (2021.3.1)
- Completely switch the API of Paddle 2.0.0 version.
- Release of super-resolution models: ESRGAN, RealSR, LESRCNN, DRN, etc.
- Release lip migration model: Wav2Lip
- Release anime model of Street View: AnimeGANv2
- Release face animation model: U-GAT-IT, Photo2Cartoon
- Release SOTA generation model: StyleGAN2
-
v0.1.0 (2020.11.02)
- Release first version, supported models include Pixel2Pixel, CycleGAN, PSGAN. Supported applications include video frame interpolation, super resolution, colorize images and videos, image animation.
- Modular design and friendly interface.
Scan OR Code below to join [PaddleGAN QQ Group:1058398620], you can get offical technical support here and communicate with other developers/friends. Look forward to your participation!

It was first proposed and used by ACM(Association for Computing Machinery) in 1961. Top International open source organizations including Kubernates all adopt the form of SIGs, so that members with the same specific interests can share, learn knowledge and develop projects. These members do not need to be in the same country/region or the same organization, as long as they are like-minded, they can all study, work, and play together with the same goals~
PaddleGAN SIG is such a developer organization that brings together people who interested in GAN. There are frontline developers of PaddlePaddle, senior engineers from the world's top 500, and students from top universities at home and abroad.
We are continuing to recruit developers interested and capable to join us building this project and explore more useful and interesting applications together.
SIG contributions:
- zhen8838: contributed to AnimeGANv2.
- Jay9z: contributed to DCGAN and updated install docs, etc.
- HighCWu: contributed to c-DCGAN and WGAN. Support to use
paddle.vision.datasets. - hao-qiang & minivision-ai : contributed to the photo2cartoon project.
Contributions and suggestions are highly welcomed. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring. When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA. Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA. For more, please reference contribution guidelines.
PaddleGAN is released under the Apache 2.0 license.