nightrome / cocostuff Goto Github PK
View Code? Open in Web Editor NEWThe official homepage of the COCO-Stuff dataset.
Home Page: https://arxiv.org/abs/1612.03716
The official homepage of the COCO-Stuff dataset.
Home Page: https://arxiv.org/abs/1612.03716
























































































































Hi there,
I'm trying to use your model and migrate it to tensorflow using the caffe-tensorflow repository and your caffemodel and prototxt files. The problem I face now is that the Deeplab VGG-16 model trained on COCO-Stuff that you offer on thid repository only outputs 182 different labels but as I understand it should return 183 (91 for COCO, 91 for stuff and 1 for unlabeled).
Please let me know if I'm missing something,
thank you in advance
When I curl it, I get:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="https://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip">here</a>.</p>
</body></html>
Which is to say it has moved to where it currently is supposed to be located.
Hi, could you please share me the link of coco-stuff 2017 version annotations for COCO 2017 Stuff Segmentation Task? Actually it's the version of (train 40K, val 5K, test-dev 5K, test-challenge 5K). I've searched the internet for that but I only found the version of (train 118K, val 5K, test-dev 20K, test-challenge 20K).
Thanks.
Hi,
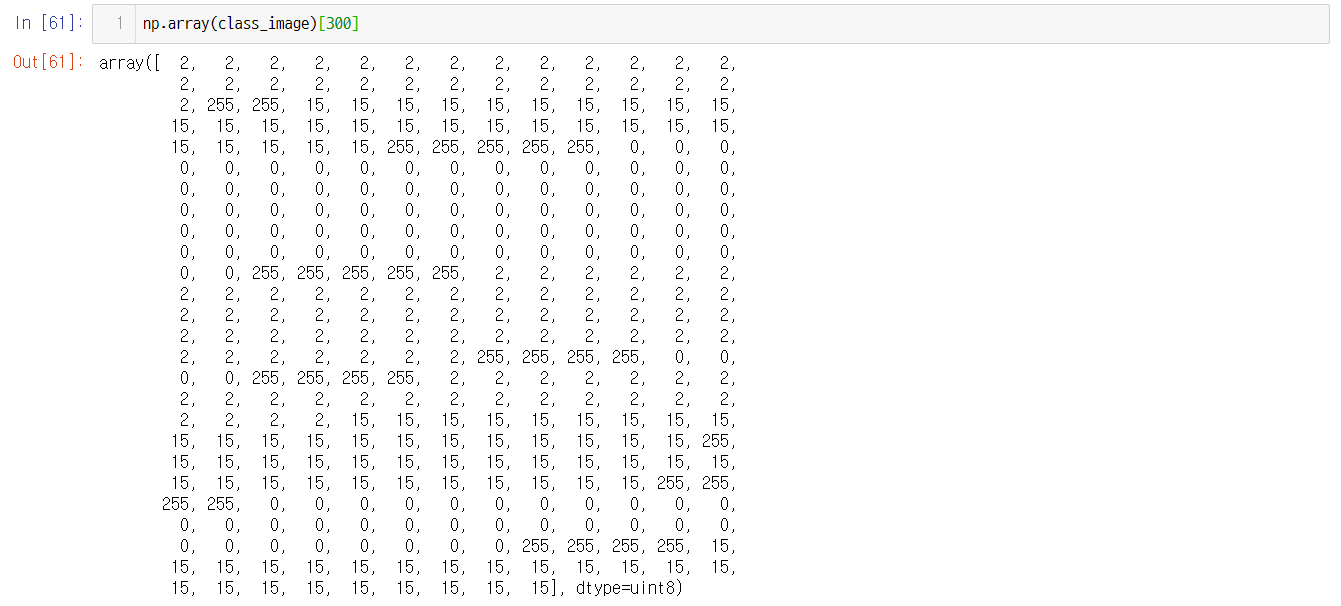
Since there are 11 classes are remove, does it mean that the labels are range from 0-170 plusing 255 ? Or does is mean that the labels are still range from 0-191, and we need to map them to 0-170 manually?
Hi Caesar,
Question for you -- I'm looking at the COCO stuff annotation for 000000351710.png:

I see in the label definitions that 0 represents unlabeled, but I can't find a definition for 255. What does the 255 intensity value represent?
Array([[180, 180, 180, 180, 95, 156, 156, 156, 156, 156, 156, 156, 156],
[ 95, 95, 180, 95, 95, 95, 156, 156, 156, 156, 156, 156, 156],
[180, 180, 180, 180, 95, 95, 95, 95, 156, 156, 156, 156, 156],
[ 95, 95, 95, 95, 95, 95, 95, 95, 168, 168, 168, 150, 150],
[ 95, 0, 95, 95, 95, 95, 95, 95, 168, 168, 95, 95, 95],
[ 96, 0, 3, 2, 139, 139, 139, 148, 148, 3, 148, 148, 148],
[141, 141, 3, 3, 255, 255, 255, 255, 148, 255, 255, 255, 148],
[148, 148, 148, 148, 255, 255, 255, 255, 255, 255, 255, 255, 148],
[148, 148, 148, 148, 255, 255, 255, 255, 255, 255, 255, 255, 141],
[148, 148, 148, 148, 148, 255, 255, 148, 148, 255, 255, 141, 141]],
dtype=uint8)
(cc'ing @liuzhuang13)
This might be a stupid question - in the Versions of COCO-Stuff section, it says "it includes all 164K images from COCO 2017 (train 118K, val 5K, test-dev 20K, test-challenge 20K)." However, I only see the train and val sets available for download in the Downloads section. Are either of the test sets available?
Hello COCO Stuff authors,
The coco stuff taxonomy here is very cool: https://raw.githubusercontent.com/nightrome/cocostuff10k/master/dataset/cocostuff-labelhierarchy.png
Could you please share the tools/code you used to plot the taxonomy? Thank you.
panoptic_semseg_train2017/000000000247.png

I want to know why the greyscale of the sky is 119, but as you have mentioned in this issue, the sky-other in the labels may 157 or 146(157-11)(some classes have been removed)?
I am so confused that how to build the mapping relationships between classes and greyscale in the .png
Hello,
Sorry if this has been answered but I am having a bit of difficulty trying to figure out which stuff classes (as specifically as possible) were included in the Coco 2017 Stuff challenge. I'm imagining the original 80 thing classes (from the 91 with some removed) are included, but which of the remaining 171 classes were included in the Stuff challenge?
Thanks
Thank you, authors, for the great work. As I've examined the annotations, it seems like the bounding boxes are provided per category rather than per instance. For example, there are 2 windows in the image but only a single box covering 2 windows. Am I correct?
If so, do you have the instance-wise annotation?
Many thanks beforehand!
Hi,
The annotation link (http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip) seems broken. Do you know how I could download the annotations ? Thank you for your help
In the Microsoft COCO: Common Objects in Context, the number of images is described as "328k". But in the README, "164K complex images from COCO".
I trained semantic segmentation model using "stuffthingmaps_trainval2017.zip"
(Stuff+thing PNG-style annotations on COCO 2017 trainval )
In this case,
thing+stuff labels cover indices 0-181 and 255 indicates the 'unlabeled' or void class.
I think the below line
https://github.com/nightrome/cocostuff/blob/master/models/deeplab/evaluate_performance.py#L98
confusion[g - 1, d - 1] += c
(this is for json format annotation,
COCO-style annotations (json file) cover indices 1-182)
should be changed to
confusion[g, d] += c
since g and d can be 0.
This modification does not change the performance on leaf category.
However, If I add metric for superclass to evaluation_performance.py based on coccostuffapi,
This modification gives me very different values for superclass category performance.
(much higher)
Do I miss something?
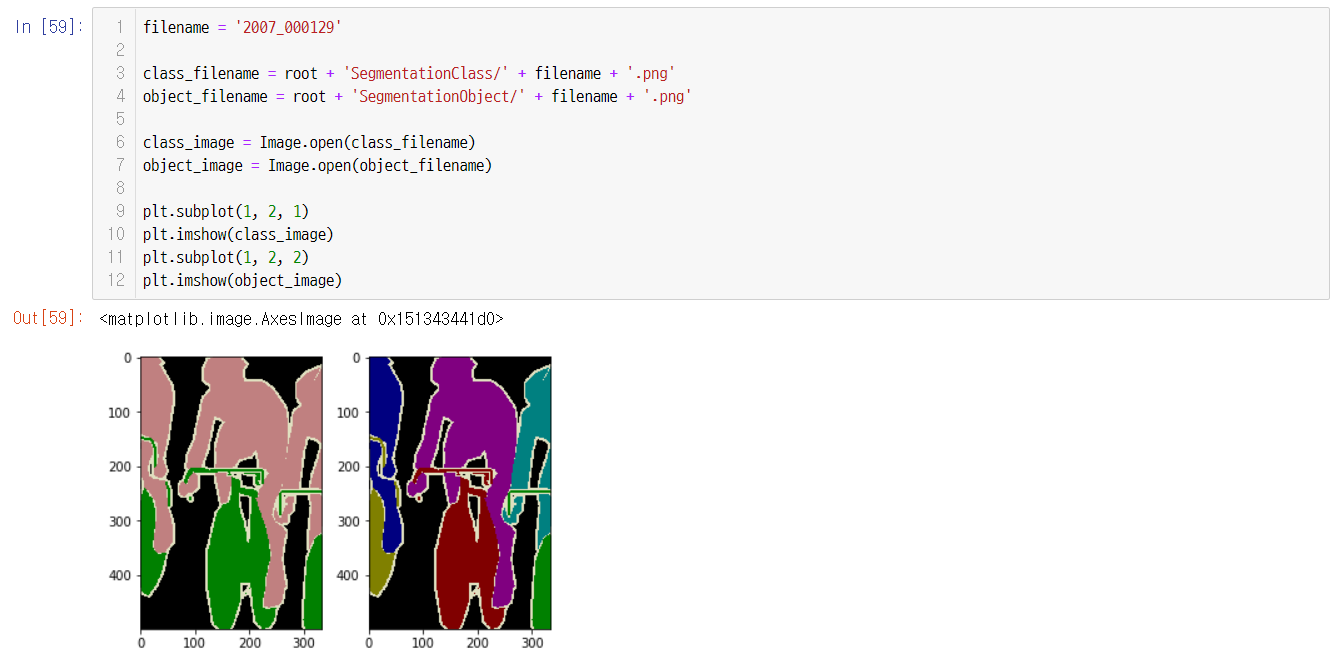
@nightrome Hello there!
I'm trying to check the class-number-wise labeled map but couldn't find anything like that.
The image below is the example of PASCAL VOC.
Doesn't cocostuff have these kind of labeled maps?
I opened the images of stuffthingmaps_trainval2017 with numpy, and it seems like they only have the value of (0,255) - which only represents the brightness.
Hello,
I'm reproducing some results in the recent papers, such as LDMs and OC-GAN, and I found that most of them conduct experiments on COCO stuff 2017 old version.
In that old version of COCO stuff, the number of training/testing data with detection annotations is about 41k/5k. Is it possible to get this version of COCO-stuff?
Thank you in advance!
Hi
could you supply with deploy.prototxt files to test.
Thanks
Hi,
I am trying to train a hybrid task cascade net (HTC) and the mask branch requires the format of cocostuff dataset. I am wondering if it is possible to convert from coco json file to a cocostuff dataset ?
I was trying to download the annotations from here and the server seems to be not responding
http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
I only want a stuff data set, How can I separate the outdoor of stuff part from this data set? Are there have a data set only includes outdoor classes in stuff? Thank you!
It's said in Caffe-compatible stuff-thing maps that thing+stuff labels cover indices 0-181 and 255 indicates the 'unlabeled' or void class.
However, the mapping in labels.txt seems not match.
annotations_trainval2017.zip | Thing-only COCO-style annotations on COCO 2017 trainval | 241 MB
This cannot be downloaded..
<Error>
<link type="text/css" id="dark-mode" rel="stylesheet" href=""/>
<style type="text/css" id="dark-mode-custom-style"/>
<Code>UserProjectAccountProblem</Code>
<Message>User project billing account not in good standing.</Message>
<Details>
The billing account for project 81,941,577,218 is disabled in state delinquent
</Details>
</Error>
This may be a stupid question, but I am trying to evaluate some models that used the COCO stuff dataset on the COCO Panoptic dataset instead. Is there an example dataloader that would help make COCO Panoptic like COCO STUFF?
Hi,
My supervisors and I are currently working on a paper analysing the COCO data set. As part of this we need to identify nouns within the COCO captions as “things” or “stuff”. In Section 4.1 of your COCO-Stuff paper, you mention that you underwent a similar process tagging the nouns by hand. I was wondering if you would please be able to share this data with us to save us having to undertake a similar venture. We would of course credit your work through appropriate citations.
Many thanks
Hi, I am running experiments on the COCO-stuff but find that you do not provide the plattete for visualization.
Could you share an array named cocostuff_pallete and _get_cocostuff_pallete like below:
from PIL import Image
def get_mask_pallete(npimg, dataset='detail'):
"""Get image color pallete for visualizing masks"""
# recovery boundary
if dataset == 'pascal_voc':
npimg[npimg==21] = 255
# put colormap
out_img = Image.fromarray(npimg.squeeze().astype('uint8'))
if dataset == 'ade20k':
out_img.putpalette(adepallete)
elif dataset == 'cityscapes':
out_img.putpalette(citypallete)
else:
out_img.putpalette(vocpallete)
return out_img
def _get_voc_pallete(num_cls):
n = num_cls
pallete = [0]*(n*3)
for j in range(0,n):
lab = j
pallete[j*3+0] = 0
pallete[j*3+1] = 0
pallete[j*3+2] = 0
i = 0
while (lab > 0):
pallete[j*3+0] |= (((lab >> 0) & 1) << (7-i))
pallete[j*3+1] |= (((lab >> 1) & 1) << (7-i))
pallete[j*3+2] |= (((lab >> 2) & 1) << (7-i))
i = i + 1
lab >>= 3
return pallete
vocpallete = _get_voc_pallete(256)
adepallete = [0,0,0,120,120,120,180,120,120,6,230,230,80,50,50,4,200,3,120,120,80,140,140,140,204,5,255,230,230,230,4,250,7,224,5,255,235,255,7,150,5,61,120,120,70,8,255,51,255,6,82,143,255,140,204,255,4,255,51,7,204,70,3,0,102,200,61,230,250,255,6,51,11,102,255,255,7,71,255,9,224,9,7,230,220,220,220,255,9,92,112,9,255,8,255,214,7,255,224,255,184,6,10,255,71,255,41,10,7,255,255,224,255,8,102,8,255,255,61,6,255,194,7,255,122,8,0,255,20,255,8,41,255,5,153,6,51,255,235,12,255,160,150,20,0,163,255,140,140,140,250,10,15,20,255,0,31,255,0,255,31,0,255,224,0,153,255,0,0,0,255,255,71,0,0,235,255,0,173,255,31,0,255,11,200,200,255,82,0,0,255,245,0,61,255,0,255,112,0,255,133,255,0,0,255,163,0,255,102,0,194,255,0,0,143,255,51,255,0,0,82,255,0,255,41,0,255,173,10,0,255,173,255,0,0,255,153,255,92,0,255,0,255,255,0,245,255,0,102,255,173,0,255,0,20,255,184,184,0,31,255,0,255,61,0,71,255,255,0,204,0,255,194,0,255,82,0,10,255,0,112,255,51,0,255,0,194,255,0,122,255,0,255,163,255,153,0,0,255,10,255,112,0,143,255,0,82,0,255,163,255,0,255,235,0,8,184,170,133,0,255,0,255,92,184,0,255,255,0,31,0,184,255,0,214,255,255,0,112,92,255,0,0,224,255,112,224,255,70,184,160,163,0,255,153,0,255,71,255,0,255,0,163,255,204,0,255,0,143,0,255,235,133,255,0,255,0,235,245,0,255,255,0,122,255,245,0,10,190,212,214,255,0,0,204,255,20,0,255,255,255,0,0,153,255,0,41,255,0,255,204,41,0,255,41,255,0,173,0,255,0,245,255,71,0,255,122,0,255,0,255,184,0,92,255,184,255,0,0,133,255,255,214,0,25,194,194,102,255,0,92,0,255]
how do know the correspondance between the training images and annotations, if all the images have a unique title?
Hi!
I'm using the annotations values and it seems like all the annotations are shifted by 1.
For example:
The person class is labeled with value 0 (but should be 1 according to your mapping list).
The skis class is labeled with value 34 (but should be 35 according to your mapping list).
The snow class is labeled with value 158 (but should be 159 according to your mapping list).
Note - I'm reading the files in Python. Maybe it has anything to do with the fact that the annotation platform is written in Matlab?
Do you have any idea for the root cause of this mismatch?
Thanks in advance.
Link to the current updated mapping list:
https://github.com/nightrome/cocostuff/blob/master/labels.md
Hi, I am working for a start-up and we are training a segmentation model based on COCO-stuff dataset.
We are not re-distributing any of the COCO images, and we are simply using the images and annotations for training. Below is what I can find regarding licenses, but I am not too sure if using the models commercially will be any breach of the licenses for below.
COCO-Stuff is a derivative work of the COCO dataset. The authors of COCO do not in any form endorse this work. Different licenses apply:
COCO images: [Flickr Terms of use](http://cocodataset.org/#termsofuse)
COCO annotations: [Creative Commons Attribution 4.0 License](http://cocodataset.org/#termsofuse)
COCO-Stuff annotations & code: [Creative Commons Attribution 4.0 License](https://creativecommons.org/licenses/by/4.0/legalcode)[](https://github.com/nightrome/cocostuff#acknowledgements)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}