![]()
Read data from a Word document (.doc or .docx) using Node.js
There are a fair number of npm components which can extract text from Word .doc files, but they often appear to require some external helper program, and involve either spawning a process or communicating with a persistent one. That raises the installation and deployment burden as well as the runtime one.
This module is intended to provide a much faster way of reading the text from a Word file, without leaving the Node.js environment.
This means you do not need to install Word, Office, or anything else, and the module will work on all platforms, without any native binary code requirements.
As of version 1.0, this module supports both traditional, OLE-based, Word files (usually .doc), and modern, Open Office-style, ECMA-376 Word files (usually .docx). It can be used both with files and with file contents in a Node.js Buffer.
yarn add word-extractor
# Or using npm...
npm install word-extractor
const WordExtractor = require("word-extractor");
const extractor = new WordExtractor();
const extracted = extractor.extract("file.doc");
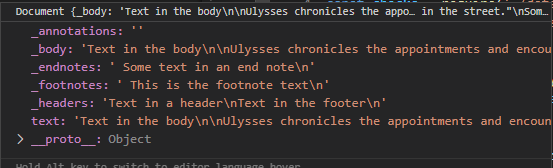
extracted.then(function(doc) { console.log(doc.getBody()); });
The object returned from the extract() method is a promise that resolves to a
document object, which then provides several views onto different parts of the
document contents.
WordExtractor#extract(<filename> | <Buffer>)
Main method to open a Word file and retrieve the data. Returns a promise which
resolves to a Document. If a Buffer is passed instead of a filename, then
the buffer is used directly, instad of reading a disk from the file system.
Document#getBody()
Retrieves the content text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Document#getFootnotes()
Retrieves the footnote text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Document#getEndnotes()
Retrieves the endnote text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Document#getHeaders(options?)
Retrieves the header and footer text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Note that by default, getHeaders() returns one string, containing all
headers and footers. This is compatible with previous versions. If you want
to separate headers and footers, use getHeaders({includeFooters: false}),
to return only the headers, and the new method getFooters() (from version 1.0.1)
to return the footers separately.
Document#getFooters()
From version 1.0.1. Retrieves the footer text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Document#getAnnotations()
Retrieves the comment bubble text from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Document#getTextboxes(options?)
Retrieves the textbox contenttext from a Word document. This will handle UNICODE characters correctly, so if there are accented or non-Latin-1 characters present in the document, they'll show as is in the returned string.
Note that by default, getTextboxes() returns one string, containing all
textbox content from both main document and the headers and footers. You
can control what gets included by using the options includeHeadersAndFooters
(which defaults to true) and includeBody (also defaults to true). So,
as an example, if you only want the body text box content, use:
doc.getTextboxes({includeHeadersAndFooters: false}).
Copyright (c) 2016-2021. Stuart Watt.
Licensed under the MIT License.
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")