mc2-project / opaque-sql Goto Github PK
View Code? Open in Web Editor NEWAn encrypted data analytics platform
License: Apache License 2.0
An encrypted data analytics platform
License: Apache License 2.0
I've built Opaque on a fresh install of Ubuntu 18.04 following the documentation. I can successfully run build/sbt test (all tests pass), but build/sbt clean coverage test gives the following error:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 2 in stage 0.0 failed 4 times, most recent failure: Lost task 2.3 in stage 0.0 (TID 5) (ryan-dev.internal.cloudapp.net executor 0): java.lang.NoClassDefFoundError: Could not initialize class edu.berkeley.cs.rise.opaque.RA
(A number of suites receive the same error)
[info] Run completed in 6 minutes, 43 seconds.
[info] Total number of tests run: 161
[info] Suites: completed 11, aborted 10
[info] Tests: succeeded 161, failed 0, canceled 0, ignored 10, pending 0
[info] *** 10 SUITES ABORTED ***
[error] Error during tests:
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionOpaqueUDFSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionJoinSuite
[error] edu.berkeley.cs.rise.opaque.tpch.MultiplePartitionTPCHSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionSubquerySuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionSortSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionUnionSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionLimitSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionFilterSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionAggregationSuite
[error] edu.berkeley.cs.rise.opaque.MultiplePartitionCreateSuite
[error] (test:test) sbt.TestsFailedException: Tests unsuccessful
Join between table A table B failed when A has more than 'same' two rows for some join attribute. and I just found error message like "multiple rows from the primary table had the same join attribute".
However, I tested on standard spark, it just works as planned.
Could you please explain why opaque has this limit?
Our previous implementation of network obliviousness using column sort was based on the old row representation (pre-Flatbuffers). There was some work on porting oblivious sort to the Flatbuffers row representation, but it did not include column sort.
The capability to decrypt arbitrary data on the server side was added for debugging only, but was never removed before Opaque's release. With this debugging function, an attacker can decrypt arbitrary data, breaking Opaque's security model.
No server-side code calls ecall_decrypt, but it is used on the client to decrypt the results of an Opaque query. Two changes are therefore needed:
#153 upgrades Opaque to version 0.12.0, but anything beyond that seems to require changing the code in ServiceProvider.cpp because of a linking issue when mbedcrypto/mbedtls and oehostverify are both present.
From #23:
Setting init value to zero (default for IntegerType currently) might not return valid results when data contains also negative values.
The existing null checks are not sufficient since they only check the nullity of the current max, not the new value.
Running into the following error: java.net.BindException: Cannot assign requested address: Service 'sparkDriver' failed after 16 retries (on a random free port)! Consider explicitly setting the appropriate binding address for the service 'sparkDriver' (for example spark.driver.bindAddress for SparkDriver) to the correct binding address. Even when these tests pass completely locally.
#204 was introduced as a possible fix, but it looks like that did not work.
Working with the Big Data Benchmark data sets. The "rankings" are fine, but there is a problem with loading encrypted " uservisits" - most likely due to incomplete support for DateField
(uservisits has a StructField("visitDate", DateType),)
The exception I get is
scala.MatchError: 7 (of class java.lang.Byte)
at edu.berkeley.cs.rise.opaque.Utils$.flatbuffersExtractFieldValue(Utils.scala:328)
=============================================
In more detail,
scala> val uvs = spark.read.format("edu.berkeley.cs.rise.opaque.EncryptedSource").schema(StructType(Seq(
| StructField("sourceIP", StringType),
| StructField("destURL", StringType),
| StructField("visitDate", DateType),
| StructField("adRevenue", FloatType),
| StructField("userAgent", StringType),
| StructField("countryCode", StringType),
| StructField("languageCode", StringType),
| StructField("searchWord", StringType),
| StructField("duration", IntegerType)))).load("/home/gidon/tmp/euvs1")
uvs: org.apache.spark.sql.DataFrame = [sourceIP: string, destURL: string ... 7 more fields]
scala> uvs.show
scala.MatchError: 7 (of class java.lang.Byte)
at edu.berkeley.cs.rise.opaque.Utils$.flatbuffersExtractFieldValue(Utils.scala:328)
Where "/home/gidon/tmp/euvs1" is created by
val uv = spark.read.schema(
StructType(Seq(
StructField("sourceIP", StringType),
StructField("destURL", StringType),
StructField("visitDate", DateType),
StructField("adRevenue", FloatType),
StructField("userAgent", StringType),
StructField("countryCode", StringType),
StructField("languageCode", StringType),
StructField("searchWord", StringType),
StructField("duration", IntegerType)))).csv("s3n://big-data-benchmark/pavlo/text/tiny/uservisits")
val euvs = uvs.encrypted
euvs.write.format("edu.berkeley.cs.rise.opaque.EncryptedSource").save("/home/gidon/tmp/euvs1")
The following message is printed:
StartEnclave failed
Error: Unexpected error occurred.
With additional instrumentation, the status code is found to be 0x4004: SGX_ERROR_SERVICE_INVALID_PRIVILEDGE ("Enclave has no privilege to get launch token").
Reported by András Méhes.
Currently, global aggregation works correctly when the input is non-empty. If the input is empty, then Opaque will return empty, but Spark SQL will return a result (e.g., return 0 for count(*)).
When performing join on encrypted data (Opaque) with another dataframe - there is a rdd.zip exception when the two dataframes are not with the same number of partitions.
Caused by: java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions: List(3, 1)
at org.apache.spark.rdd.ZippedPartitionsBaseRDD.getPartitions(ZippedPartitionsRDD.scala:57)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:248)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:246)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:246)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1930)
at org.apache.spark.rdd.RDD.count(RDD.scala:1134)
at edu.berkeley.cs.rise.opaque.execution.ObliviousUnionExec$$anonfun$executeBlocked$3.apply$mcJ$sp(operators.scala:346)
at edu.berkeley.cs.rise.opaque.execution.ObliviousUnionExec$$anonfun$executeBlocked$3.apply(operators.scala:346)
at edu.berkeley.cs.rise.opaque.execution.ObliviousUnionExec$$anonfun$executeBlocked$3.apply(operators.scala:346)
at edu.berkeley.cs.rise.opaque.Utils$.time(Utils.scala:93)
at edu.berkeley.cs.rise.opaque.execution.ObliviousUnionExec.executeBlocked(operators.scala:346)
at edu.berkeley.cs.rise.opaque.execution.EncryptedSortExec.executeBlocked(EncryptedSortExec.scala:33)
at edu.berkeley.cs.rise.opaque.execution.EncryptedSortMergeJoinExec.executeBlocked(operators.scala:296)
at edu.berkeley.cs.rise.opaque.execution.ObliviousProjectExec.executeBlocked(operators.scala:207)
at edu.berkeley.cs.rise.opaque.execution.OpaqueOperatorExec$class.executeCollect(operators.scala:147)
at edu.berkeley.cs.rise.opaque.execution.ObliviousProjectExec.executeCollect(operators.scala:200)
at org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$execute$1$1.apply(Dataset.scala:2193)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:57)
at org.apache.spark.sql.Dataset.withNewExecutionId(Dataset.scala:2546)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$execute$1(Dataset.scala:2192)
at org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collect$1.apply(Dataset.scala:2197)
at org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collect$1.apply(Dataset.scala:2197)
at org.apache.spark.sql.Dataset.withCallback(Dataset.scala:2559)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collect(Dataset.scala:2197)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:2173)
Also, Opaque rdd partitions count always returns 0.
Regular join (on non-encrypted data) works well on the same data set.
To reproduce perform a simple join on two dataframes with different partitions size.
for example, using the person dataset provided in previous join issue:
when i run build/sbt test , it gives the following error:
Cause: edu.berkeley.cs.rise.opaque.OpaqueException: StartEnclave failed. Error: The underlying platform or hardware returned an error. For example, an SGX user-mode instruction failed.
Opaque's currently implements multiple join types via broadcast nested loop join (#159), but FULL OUTER join is not yet supported.
The least squares test seems to crash when running when I run OpaqueMultiplePartitionSuite.
See this branch to recreate quickly.

When I execute at the five step ,I caught en error, the detail message as follows
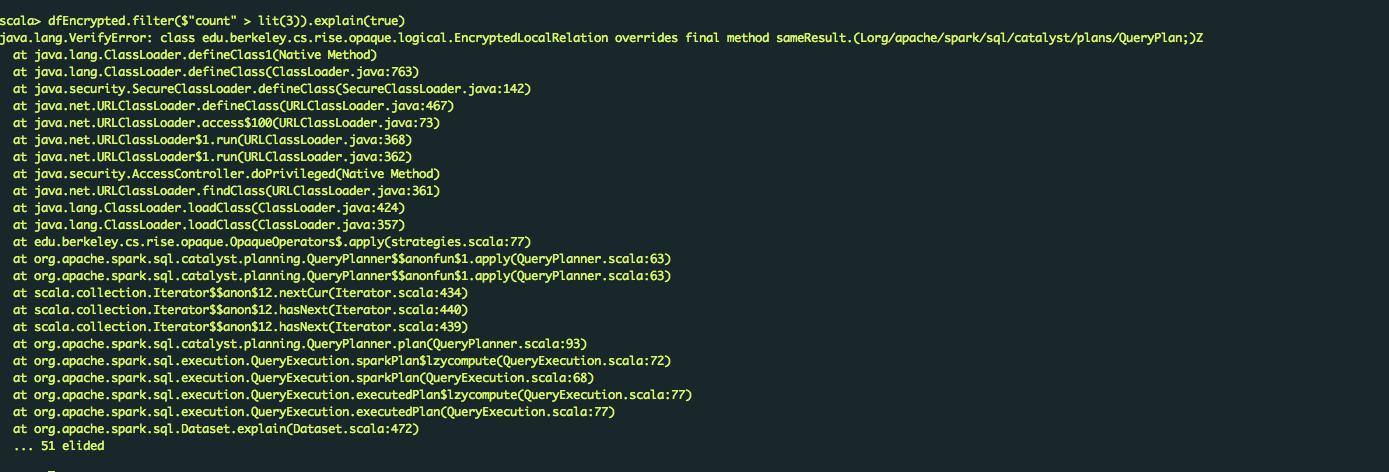
Can you help me ?Thank you!
If Opaque's environment variables are not set, then the following error occurs:
what(): basic_string::_M_construct null not valid```.
The Spark executor is also killed.
When trying to run the tests with SGX_MODE=HW, 3 tests fail with the following error message:
[info] Cause: java.lang.NoClassDefFoundError: Could not initialize class edu.berkeley.cs.rise.opaque.execution.SGXEnclave$
[info] at edu.berkeley.cs.rise.opaque.execution.SGXEnclave.<init>(SGXEnclave.scala:22)
[info] at edu.berkeley.cs.rise.opaque.Utils$.initEnclave(Utils.scala:236)
[info] at edu.berkeley.cs.rise.opaque.RA$$anonfun$initRA$1$$anonfun$2.apply(RA.scala:39)
[info] at edu.berkeley.cs.rise.opaque.RA$$anonfun$initRA$1$$anonfun$2.apply(RA.scala:38)
[info] at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:801)
[info] at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:801)
[info] at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
[info] at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
[info] at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
[info] at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
Failing tests are:
[error] edu.berkeley.cs.rise.opaque.QEDSuite
[error] edu.berkeley.cs.rise.opaque.OpaqueSinglePartitionSuite
[error] edu.berkeley.cs.rise.opaque.OpaqueMultiplePartitionSuite
// EDL
void ocall_malloc(size_t size, [out] uint8_t **ret);
// Implementation
void ocall_malloc(size_t size, uint8_t **ret) {
*ret = static_cast<uint8_t *>(malloc(size));
}uint8_t **ret could be a pointer to memory in enclave. It could casue a arbitrary memory write in enclave.
Fix:
Add a wrapper function of ocall_malloc, checking the returned value with sgx_is_inside_enclave/sgx_is_outside_enclave. There is a sample below.
void wrapper_ocall_malloc(size_t size, uint8_t **ret) {
ocall_malloc(size, ret);
if (sgx_is_inside_enclave(*ret, size)) {
// error
}
}In Step 3 of the Running the interactive shell section of Using Opaque SQL I get the following error when running edu.berkeley.cs.rise.opaque.Utils.initSQLContext(spark.sqlContext):
edu.berkeley.cs.rise.opaque.OpaqueException: Cannot begin attestation without sharedKey.
at edu.berkeley.cs.rise.opaque.RA$.initRA(RA.scala:47)
at edu.berkeley.cs.rise.opaque.RA$.attestEnclaves(RA.scala:110)
at edu.berkeley.cs.rise.opaque.Utils$.initSQLContext(Utils.scala:316)
... 49 elided
This can be fixed by starting the shell with
spark-shell --jars ${OPAQUE_HOME}/target/scala-2.12/opaque_2.12-0.1.jar --conf spark.opaque.testing.enableSharedKey=true
instead of what's specified in the docs:
spark-shell --jars ${OPAQUE_HOME}/target/scala-2.12/opaque_2.12-0.1.jar
But I'm assuming that you don't want to include that configuration flag in this section since it shouldn't be used in production. Perhaps you could specify it's necessary for local testing or something? Or am I doing something wrong?
I'll send the data samples used in this experiment.
val pers = spark.read.json("/path/json-person-rest_assured_payd_out.json"")
val idlist = spark.read.json("/path/idlist.json")
val pe = pers.encrypted
val ie = idlist.encrypted
pe.write.format("edu.berkeley.cs.rise.opaque.EncryptedSource").save("/path/encr_pers")
ie.write.format("edu.berkeley.cs.rise.opaque.EncryptedSource").save("/path/encr_idlist")
val pp = spark.read.format("edu.berkeley.cs.rise.opaque.EncryptedSource")
.schema(pers.schema).load("/path/encr_pers")
val ii = spark.read.format("edu.berkeley.cs.rise.opaque.EncryptedSource")
.schema(idlist.schema).load("/path/encr_idlist")
//Works
idlist.join(pers, pers("PersonID") === idlist("PersonId")).show
// Process crash
ie.join(pe, pe("PersonID") === ie("PersonId")).show
"N3edu8berkeley2cs4rise6opaque4tuix8LessThanE can't operate on values of different types (StringField and LongField)"
"
18/03/13 15:46:48 WARN BlockManager: Putting block rdd_74_1 failed due to an exception
18/03/13 15:46:48 WARN BlockManager: Block rdd_74_1 could not be removed as it was not found on disk or in memory
18/03/13 15:46:48 ERROR Executor: Exception in task 1.0 in stage 45.0 (TID 101)
scala.MatchError: (Stream(),Stream()) (of class scala.Tuple2)
at edu.berkeley.cs.rise.opaque.execution.ObliviousUnionExec$$anonfun$11.apply(operators.scala:340)
....
"
PARQUET-1178 will add efficient encryption support to Parquet. If Opaque were to support saving and loading in this format, it would be able to take advantage of Parquet's performance optimizations like column pruning and columnar compression.
To whom it may concern,
The edl definition for ecall_encrypt function has vulnerability due to improper boundary check for two pointers 'plaintext' and 'ciphertext'. Please notice that you used correct edl definition for encall_decrypt function but failed to correct this ecall_encrypt function.
Potential attack methodology: passing an address from 'trusted' zone to ecall_encrypt(*plaintext), then use ecall_decrypt to translate the secret back to 'untrusted zone'. In this way, SGX security promise is useless for this application.
Mitigation: change edl definition for ecall_encrypt from [user_check] to [in]. Or check the boundary like in: https://github.com/intel/linux-sgx/blob/master/SampleCode/SampleEnclave/Enclave/Edger8rSyntax/Pointers.cpp
if (sgx_is_outside_enclave(val, sz) != 1)
abort();
Please contact me anytime if you have doubt of my ticket. I can explain the POC of how OPAQUE can be attacked due to this minor flaw.
Best regards,
W
Hi,
Good morning! I notice the current version only supports openenclave sdk based DCAP attestation. However, machines without FLC can only support EPID based attestation. I wonder if I want to continue taking advantage of EPID based attestation, shall I convert back to commits before merge #92 and start my own fork? Or shall I change the existing branch? Or is there a better way in your opinion?
Thank you!
Boundary processing for join and aggregation currently occur at the client using a call into the SGX enclave. These should instead use a single worker partition, allowing the client to run on a non-SGX-enabled machine.
Currently, a MatchError with (null, BooleanType) is thrown.
Reported by András Méhes.
Error is java.lang.AssertionError: FlatBuffers: cannot grow buffer beyond 2 gigabytes. in createEncRowsVector in EncryptedBlock.java (flatbuffers generated file).
Currently, attestation is only executed as part of the initSQLContext call, which is only called once. Therefore, if a worker fails and a new worker is spawned, the driver will not re-attest the worker. This is still secure since, without attestation, the enclave cannot get the client's private key, but will trigger an exception when it tries to process data.
Aggregation seems to crash with 6 partitions but not 5.
Adding a couple print statements seems to suggest that process_bounday() is segfaulting.
See this branch to recreate easily

Integrity verification would require the following changes:
Remote attestation currently fails non-deterministically when multiple enclaves are created. This happens when there are multiple workers started.
Detailed steps:
Start the master using ./spark/sbin/start-master.sh
Start more than one worker machines using ./spark/sbin/start-slave.sh <MASTER_IP>:7077
On the master, run: ./spark/bin/spark-submit --class edu.berkeley.cs.rise.opaque.benchmark.Benchmark --deploy-mode client --master spark://<MASTER IP>:7077 /home/ubuntu/opaque/target/scala-2.12/opaque_2.12-0.1.jar
EncryptedSource currently extends SchemaRelationProvider, meaning the user must provide a schema when loading an encrypted table. This is inconvenient when accessing Opaque through pure SQL.
We should instead serialize the schema alongside the encrypted data, make EncryptedSource extend RelationProvider to remove the need for a user-specified schema, and load the saved schema in EncryptedSource#createRelation.
Primitive types:
Composite types:
Enclave check method uses std::exit if condition is not met.
As a result, each time an enclave check method fails, for example in data manipulation such as join or filter, the entire application is exited and has to be restarted.
Additionally, Utils.encrypt should use OpenSSL encryption on the driver to ensure that it uses the same key as is transferred to the worker enclaves.
Instead of inserting a blank line into a data block, we can pass it through the parameters of the function NonObliviousSortMergeJoin.
To demonstrate the error, I can simply follow the instructions from Using Opaque SQL in the documentation but substitute the given integers for floats:
scala> df.show()
+----+------+
|word| count|
+----+------+
| foo|508.41|
| bar|717.13|
| baz| 82.31|
+----+------+
scala> df.printSchema
root
|-- word: string (nullable = true)
|-- count: float (nullable = false)
If I encrypt the dataframe, then decrypt it I get the following:
scala> dfEncrypted.show()
+----+----------+
|word| count|
+----+----------+
| foo|508.410004|
| bar|717.130005|
| baz| 82.309998|
+----+----------+
scala> dfEncrypted.printSchema
root
|-- word: string (nullable = true)
|-- count: float (nullable = false)
scala> dfEncrypted.collect()
res18: Array[org.apache.spark.sql.Row] = Array([foo,508.41], [bar,717.13], [baz,82.31])
So it appears that there is an error in de-serializing the floats to a string as the displayed numbers are incorrect when using show() but not collect().
One thing I noticed when debugging is that, if I set breakpoints in the various cases here, running collect() shows that both the StringField and FloatField cases are entered (as expected), but running show() prints out that StringField is visited twice so it would seem that the float value is being turned into a string (incorrectly) somewhere in C++ code before Scala? But I am not sure.
Groupby with Max/Min throws null exception when column is other than IntegerType
More info:
scala/edu/berkeley/cs/rise/opaque/Utils.scala:
flatbuffersCreateField supports only creation of Null IntegerType (sets int value to 0)
Max and Min methods create Null Literal which currently not fully supported for all DataTypes and results in an exception.
Setting init value to zero (default for IntegerType currently) might not return valid results when data contains also negative values.
scala.MatchError: (null,LongType) (of class scala.Tuple2)
at edu.berkeley.cs.rise.opaque.Utils$.flatbuffersCreateField(Utils.scala:256)
origins - creation of Literal.create(null, child.dataType) in createInitialValuesVector
-if(NOT "$ENV{SGX_MODE}" EQUAL "HW")
+if(NOT "$ENV{SGX_MODE}" STREQUAL "HW")
Reported by András Méhes.
Hi, guys! Sorry to bother you.
I tried to fetch 1millon data using fetch-data.sh from aws. But I got
ERROR: S3 error: 403 (AccessDenied): Access Denied
Is the data no longer available or it's only my aws wrongly configured?
Thanks!
Hi I try to reproduce the benchmark but i failed to compile the whole project. Your prebuilt docker image works fine but I am afraid that benchmarking within a container may affect its best performance. Have you met this flatbuffer error before? Thanks!
./build/sbt compile
./build/sbt: line 201: [[: .: syntax error: operand expected (error token is ".")
OpenJDK 64-Bit Server VM warning: Ignoring option MaxPermSize; support was removed in 8.0
[info] Loading project definition from /home/lqp0562/opaque/project
[info] Compiling 1 Scala source to /home/lqp0562/opaque/project/target/scala-2.10/sbt-0.13/classes...
[info] Set current project to opaque (in build file:/home/lqp0562/opaque/)
[info] Executing in batch mode. For better performance use sbt's shell
[info] Generating flatbuffers for /home/lqp0562/opaque/src/flatbuffers/Expr.fbs
/home/lqp0562/opaque/target/flatbuffers/flatbuffers-1.7.0/flatc: error: Unable to generate C++ for Expr
Usage: /home/lqp0562/opaque/target/flatbuffers/flatbuffers-1.7.0/flatc [OPTION]... FILE... [-- FILE...]
--binary -b Generate wire format binaries for any data definitions.
--json -t Generate text output for any data definitions.
--cpp -c Generate C++ headers for tables/structs.
--go -g Generate Go files for tables/structs.
--java -j Generate Java classes for tables/structs.
--js -s Generate JavaScript code for tables/structs.
--ts -T Generate TypeScript code for tables/structs.
--csharp -n Generate C# classes for tables/structs.
--python -p Generate Python files for tables/structs.
--php Generate PHP files for tables/structs.
-o PATH Prefix PATH to all generated files.
-I PATH Search for includes in the specified path.
-M Print make rules for generated files.
--version Print the version number of flatc and exit.
--strict-json Strict JSON: field names must be / will be quoted,
no trailing commas in tables/vectors.
--allow-non-utf8 Pass non-UTF-8 input through parser and emit nonstandard
\x escapes in JSON. (Default is to raise parse error on
non-UTF-8 input.)
--defaults-json Output fields whose value is the default when
writing JSON
--unknown-json Allow fields in JSON that are not defined in the
schema. These fields will be discared when generating
binaries.
--no-prefix Don't prefix enum values with the enum type in C++.
--scoped-enums Use C++11 style scoped and strongly typed enums.
also implies --no-prefix.
--gen-includes (deprecated), this is the default behavior.
If the original behavior is required (no include
statements) use --no-includes.
--no-includes Don't generate include statements for included
schemas the generated file depends on (C++).
--gen-mutable Generate accessors that can mutate buffers in-place.
--gen-onefile Generate single output file for C#.
--gen-name-strings Generate type name functions for C++.
--escape-proto-ids Disable appending '_' in namespaces names.
--gen-object-api Generate an additional object-based API.
--cpp-ptr-type T Set object API pointer type (default std::unique_ptr)
--cpp-str-type T Set object API string type (default std::string)
T::c_str() and T::length() must be supported
--no-js-exports Removes Node.js style export lines in JS.
--goog-js-export Uses goog.exports* for closure compiler exporting in JS.
--go-namespace Generate the overrided namespace in Golang.
--raw-binary Allow binaries without file_indentifier to be read.
This may crash flatc given a mismatched schema.
--proto Input is a .proto, translate to .fbs.
--grpc Generate GRPC interfaces for the specified languages
--schema Serialize schemas instead of JSON (use with -b)
--bfbs-comments Add doc comments to the binary schema files.
--conform FILE Specify a schema the following schemas should be
an evolution of. Gives errors if not.
--conform-includes Include path for the schema given with --conform
PATH
--include-prefix Prefix this path to any generated include statements.
PATH
--keep-prefix Keep original prefix of schema include statement.
--no-fb-import Don't include flatbuffers import statement for TypeScript.
--no-ts-reexport Don't re-export imported dependencies for TypeScript.
FILEs may be schemas, or JSON files (conforming to preceding schema)
FILEs after the -- must be binary flatbuffer format files.
Output files are named using the base file name of the input,
and written to the current directory or the path given by -o.
example: /home/lqp0562/opaque/target/flatbuffers/flatbuffers-1.7.0/flatc -c -b schema1.fbs schema2.fbs data.json
java.lang.RuntimeException: Flatbuffers build failed.
at scala.sys.package$.error(package.scala:27)
at
at
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at
at
at scala.Function1$$anonfun$compose$1.apply(Function1.scala:47)
at sbt.$tilde$greater$$anonfun$$u2219$1.apply(TypeFunctions.scala:40)
at sbt.std.Transform$$anon$4.work(System.scala:63)
at sbt.Execute$$anonfun$submit$1$$anonfun$apply$1.apply(Execute.scala:228)
at sbt.Execute$$anonfun$submit$1$$anonfun$apply$1.apply(Execute.scala:228)
at sbt.ErrorHandling$.wideConvert(ErrorHandling.scala:17)
at sbt.Execute.work(Execute.scala:237)
at sbt.Execute$$anonfun$submit$1.apply(Execute.scala:228)
at sbt.Execute$$anonfun$submit$1.apply(Execute.scala:228)
at sbt.ConcurrentRestrictions$$anon$4$$anonfun$1.apply(ConcurrentRestrictions.scala:159)
at sbt.CompletionService$$anon$2.call(CompletionService.scala:28)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
[error] (*:buildFlatbuffers) Flatbuffers build failed.
[error] Total time: 0 s, completed Aug 14, 2020, 12:28:43 PM
There are plenty of issues when trying to run multi-partition tests using a master specified as something like local-cluster[3,1,2048] instead of local[4]. We need to investigate why this is the case to have our multi-partition tests increase their coverage (test attestation as well, etc)
Error msg: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
FlatbuffersTemporaryRow::set acquires ownership of a Rows buffer via a raw pointer but never frees the pointer, creating a memory leak when set is called again.
To prevent this kind of memory leak, FlatbuffersRowWriter::output_buffer should return a smart pointer instead of a raw pointer. We will need a custom smart pointer because the managed memory was allocated outside of the enclave and must be deallocated using ocall_free.
The current remote attestation code fails in the cluster if all nodes haven't been set up when it runs. If this is the case, then those unconnected nodes will not have been attested, and will not have the shared key required for encryption/decryption.
The client uses ecall_encrypt, ecall_decrypt, and ecall_find_range_bounds. The first two should be reimplemented using a Java AES library. The latter should be run on a worker instead of the driver.
After this is done, then ecall_decrypt can be removed (#37).
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.