![]()
![]()
![]()
![]()
![]()
![]()


A Global Service Load Balancing solution with a focus on having cloud native qualities and work natively in a Kubernetes context.
Just a single Gslb CRD to enable the Global Load Balancing:
apiVersion: k8gb.absa.oss/v1beta1
kind: Gslb
metadata:
name: test-gslb-failover
namespace: test-gslb
spec:
ingress:
ingressClassName: nginx # or any other existing ingressclasses.networking.k8s.io
rules:
- host: failover.test.k8gb.io # Desired GSLB enabled FQDN
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend-podinfo # Service name to enable GSLB for
port:
name: http
strategy:
type: failover # Global load balancing strategy
primaryGeoTag: eu-west-1 # Primary cluster geo tagGlobal load balancing, commonly referred to as GSLB (Global Server Load Balancing) solutions, has been typically the domain of proprietary network software and hardware vendors and installed and managed by siloed network teams.
k8gb is a completely open source, cloud native, global load balancing solution for Kubernetes.
k8gb focuses on load balancing traffic across geographically dispersed Kubernetes clusters using multiple load balancing strategies to meet requirements such as region failover for high availability.
Global load balancing for any Kubernetes Service can now be enabled and managed by any operations or development teams in the same Kubernetes native way as any other custom resource.
- Load balancing is based on timeproof DNS protocol which is perfect for global scope and extremely reliable
- No dedicated management cluster and no single point of failure
- Kubernetes native application health checks utilizing status of Liveness and Readiness probes for load balancing decisions
- Configuration with a single Kubernetes CRD of Gslb kind
Simply run
make deploy-full-local-setupIt will deploy two local k3s clusters via k3d, expose associated CoreDNS service for UDP DNS traffic), and install k8gb with test applications and two sample Gslb resources on top.
This setup is adapted for local scenarios and works without external DNS provider dependency.
Consult with local playground documentation to learn all the details of experimenting with local setup.
Optionally, you can run make deploy-prometheus and check the metrics on the test clusters (http://localhost:9080, http://localhost:9081).
k8gb was born out of the need for an open source, cloud native GSLB solution at Absa Group in South Africa.
As part of the bank's wider container adoption running multiple, geographically dispersed Kubernetes clusters, the need for a global load balancer that was driven from the health of Kubernetes Services was required and for which there did not seem to be an existing solution.
Yes, there are proprietary network software and hardware vendors with GSLB solutions and products, however, these were costly, heavyweight in terms of complexity and adoption, and were not Kubernetes native in most cases, requiring dedicated hardware or software to be run outside of Kubernetes.
This was the problem we set out to solve with k8gb.
Born as a completely open source project and following the popular Kubernetes operator pattern, k8gb can be installed in a Kubernetes cluster and via a Gslb custom resource, can provide independent GSLB capability to any Ingress or Service in the cluster, without the need for handoffs and coordination between dedicated network teams.
k8gb commoditizes GSLB for Kubernetes, putting teams in complete control of exposing Services across geographically dispersed Kubernetes clusters across public and private clouds.
k8gb requires no specialized software or hardware, relying completely on other OSS/CNCF projects, has no single point of failure, and fits in with any existing Kubernetes deployment workflow (e.g. GitOps, Kustomize, Helm, etc.) or tools.
Please see the extended architecture documentation here
Internal k8gb architecture and its components are described here
- General deployment with Infoblox integration
- AWS based deployment with Route53 integration
- AWS based deployment with NS1 integration
- Azure based deployment with Windows DNS integration
- General deployment with Cloudflare integration
- Local playground for testing and development
- Local playground with Kuar web app
- Metrics
- Traces
- Ingress annotations
- Integration with Admiralty
- Integration with Liqo
- Integration with Rancher Fleet
A list of publicly known users of the K8GB project can be found in ADOPTERS.md. We encourage all users of K8GB to add themselves to this list!
k8gb is very well tested with the following environment options
| Type | Implementation |
|---|---|
| Kubernetes Version | for k8s < 1.19 use k8gb <= 0.8.8; since k8s 1.19 use 0.9.0 or newer |
| Environment | Self-managed, AWS(EKS) * |
| Ingress Controller | NGINX, AWS Load Balancer Controller * |
| EdgeDNS | Infoblox, Route53, NS1 |
* We only mention solutions where we have tested and verified a k8gb installation. If your Kubernetes version or Ingress controller is not included in the table above, it does not mean that k8gb will not work for you. k8gb is architected to run on top of any compliant Kubernetes cluster and Ingress controller.
KCDBengaluru 2023 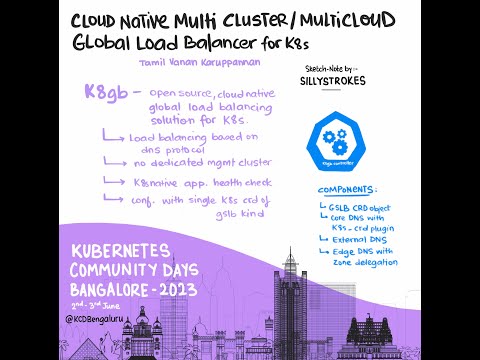 |
KubeCon EU 2023  |
|---|---|
KubeCon NA 2021  |
FOSDEM 2022  |
NS1 INS1GHTS  |
Crossplane Community Day  |
#29 DoK Community  |
AWS Containers from the Couch show  |
OpenShift Commons Briefings  |
Demo at Kubernetes SIG Multicluster  |
You can also find recordings from our community meetings at k8gb youtube channel.
See CONTRIBUTING




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")



![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")








![renovate[bot] avatar](https://avatars.githubusercontent.com/in/2740?v=4 "renovate[bot]")






















































































































{kind=link}