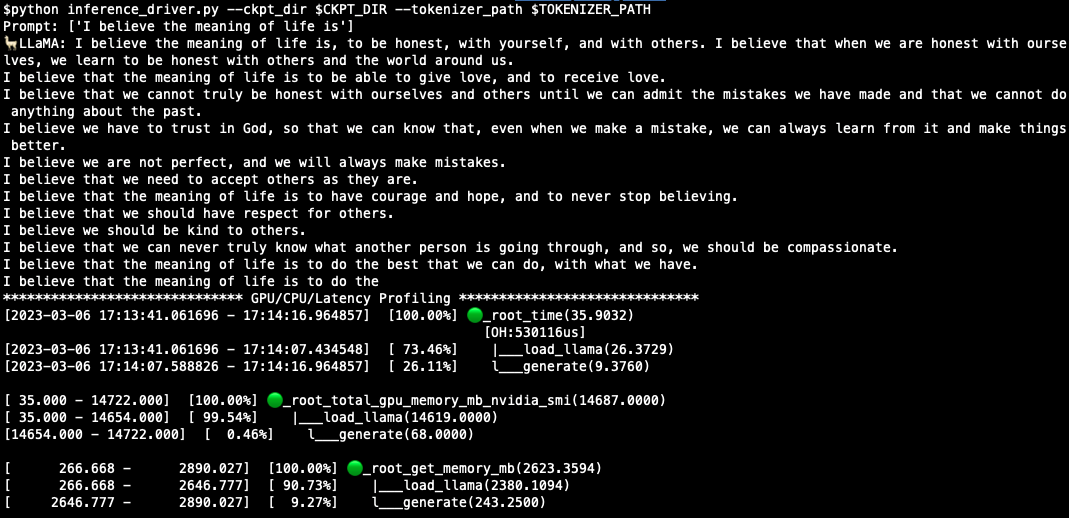
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 webapp.py --ckpt_dir ../../../llama/ckpt/13B/ --tokenizer_path ../../../llama/ckpt/tokenizer.model
`WARNING:torch.distributed.run:
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
initializing model parallel with size 2
initializing ddp with size 1
initializing pipeline with size 1
Traceback (most recent call last):
File "webapp.py", line 95, in
generator = load(
File "webapp.py", line 56, in load
model.load_state_dict(checkpoint, strict=False)
File "/data/anaconda3/envs/pyllama/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1671, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for Transformer:
size mismatch for tok_embeddings.weight: copying a param with shape torch.Size([32000, 2560]) from checkpoint, the shape in current model is torch.Size([32000, 5120]).
size mismatch for layers.0.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.0.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.0.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.0.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.0.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.0.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.0.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.1.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.1.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.1.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.1.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.1.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.1.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.1.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.2.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.2.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.2.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.2.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.2.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.2.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.2.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.3.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.3.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.3.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.3.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.3.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.3.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.3.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.4.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.4.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.4.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.4.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.4.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.4.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.4.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.5.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.5.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.5.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.5.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.5.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.5.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.5.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.6.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.6.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.6.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.6.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.6.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.6.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.6.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.7.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.7.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.7.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.7.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.7.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.7.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.7.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.8.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.8.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.8.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.8.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.8.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.8.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.8.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.9.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.9.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.9.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.9.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.9.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.9.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.9.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.10.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.10.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.10.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.10.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.10.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.10.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.10.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.11.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.11.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.11.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.11.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.11.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.11.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.11.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.12.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.12.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.12.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.12.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.12.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.12.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.12.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.13.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.13.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.13.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.13.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.13.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.13.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.13.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.14.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.14.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.14.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.14.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.14.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.14.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.14.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.15.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.15.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.15.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.15.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.15.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.15.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.15.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.16.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.16.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.16.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.16.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.16.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.16.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.16.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.17.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.17.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.17.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.17.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.17.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.17.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.17.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.18.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.18.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.18.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.18.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.18.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.18.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.18.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.19.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.19.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.19.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.19.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.19.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.19.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.19.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.20.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.20.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.20.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.20.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.20.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.20.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.20.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.21.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.21.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.21.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.21.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.21.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.21.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.21.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.22.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.22.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.22.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.22.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.22.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.22.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.22.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.23.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.23.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.23.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.23.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.23.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.23.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.23.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.24.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.24.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.24.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.24.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.24.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.24.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.24.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.25.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.25.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.25.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.25.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.25.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.25.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.25.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.26.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.26.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.26.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.26.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.26.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.26.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.26.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.27.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.27.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.27.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.27.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.27.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.27.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.27.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.28.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.28.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.28.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.28.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.28.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.28.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.28.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.29.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.29.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.29.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.29.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.29.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.29.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.29.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.30.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.30.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.30.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.30.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.30.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.30.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.30.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.31.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.31.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.31.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.31.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.31.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.31.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.31.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.32.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.32.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.32.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.32.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.32.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.32.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.32.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.33.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.33.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.33.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.33.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.33.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.33.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.33.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.34.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.34.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.34.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.34.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.34.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.34.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.34.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.35.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.35.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.35.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.35.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.35.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.35.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.35.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.36.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.36.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.36.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.36.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.36.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.36.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.36.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.37.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.37.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.37.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.37.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.37.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.37.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.37.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.38.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.38.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.38.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.38.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.38.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.38.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.38.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.39.attention.wq.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.39.attention.wk.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.39.attention.wv.weight: copying a param with shape torch.Size([2560, 5120]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.39.attention.wo.weight: copying a param with shape torch.Size([5120, 2560]) from checkpoint, the shape in current model is torch.Size([5120, 5120]).
size mismatch for layers.39.feed_forward.w1.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for layers.39.feed_forward.w2.weight: copying a param with shape torch.Size([5120, 6912]) from checkpoint, the shape in current model is torch.Size([5120, 13824]).
size mismatch for layers.39.feed_forward.w3.weight: copying a param with shape torch.Size([6912, 5120]) from checkpoint, the shape in current model is torch.Size([13824, 5120]).
size mismatch for output.weight: copying a param with shape torch.Size([16000, 5120]) from checkpoint, the shape in current model is torch.Size([32000, 5120]).`