evenmai92 / front-end-interview Goto Github PK
View Code? Open in Web Editor NEW大厂前端面试汇总
License: MIT License
大厂前端面试汇总
License: MIT License







编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
说明: 所有输入只包含小写字母 a-z 。
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
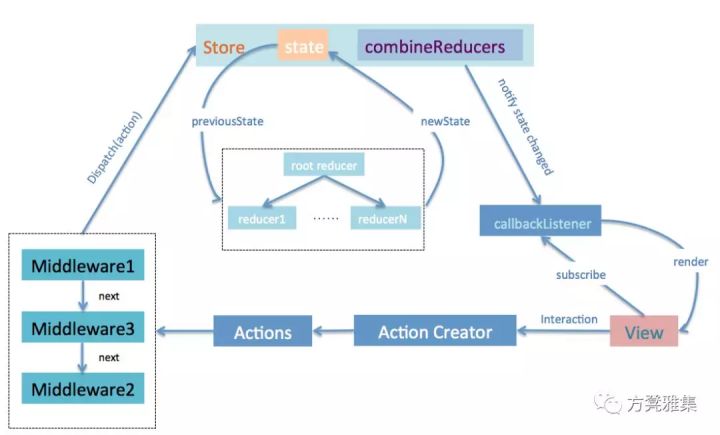
1. Store
Store 就是保存数据的地方,你可以把它看成一个容器。整个应用只能有一个 Store。
Redux 提供createStore这个函数,用来生成 Store。
import { createStore, applyMiddleware } from 'redux'
import thunk from 'redux-thunk'
const middleware = [ thunk ];
const store = createStore(
reducer,
applyMiddleware(...middleware)
)2. State
Store对象包含所有数据。如果想得到某个时点的数据,就要对 Store 生成快照。这种时点的数据集合,就叫做 State。
当前时刻的 State,可以通过store.getState()拿到。
const state = store.getState();Redux 规定, 一个 State 对应一个 View。只要 State 相同,View 就相同。你知道 State,就知道 View 是什么样,反之亦然。
3. Action
State 的变化,会导致 View 的变化。但是,用户接触不到 State,只能接触到 View。所以,State 的变化必须是 View 导致的。
Action 就是 View 发出的通知,表示 State 应该要发生变化了。
Action 是一个对象。其中的type属性是必须的,表示 Action 的名称。其他属性可以自由设置,社区有一个规范可以参考。
4. store.dispatch()
store.dispatch()是 View 发出 Action 的唯一方法。
store.dispatch({
type: 'ADD_TODO',
payload: 'Learn Redux'
})5. Reducer
Store 收到 Action 以后,必须给出一个新的 State,这样 View 才会发生变化。这种 State 的计算过程就叫做 Reducer。
Reducer 是一个纯函数,它接受 Action 和当前 State 作为参数,返回一个新的 State。只要是同样的输入,必定得到同样的输出。
纯函数是函数式编程的概念,必须遵守以下一些约束。
1. getState
redux中获取state的值,通过getState获取,从源码可以看出,只做了是否正在dispatching的校验,也就是说获取的state是可以直接修改,没任何提示,当然页面也不会刷新,因为没触发订阅者listener
function getState(): S {
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState as S
}2. dispatch
dispatch只做两件事,一:调用reducer,二:通知所有订阅者
function dispatch(action: A) {
// ...省略校验
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}3. 应用中间件applyMiddleware
function applyMiddleware(
...middlewares: Middleware[]
): StoreEnhancer<any> {
return (createStore: StoreEnhancerStoreCreator) => <S, A extends AnyAction>(
reducer: Reducer<S, A>,
preloadedState?: PreloadedState<S>
) => {
const store = createStore(reducer, preloadedState)
let dispatch: Dispatch = () => {
throw new Error(
'Dispatching while constructing your middleware is not allowed. ' +
'Other middleware would not be applied to this dispatch.'
)
}
const middlewareAPI: MiddlewareAPI = {
getState: store.getState,
dispatch: (action, ...args) => dispatch(action, ...args)
}
// 首次调用中间,并将middlewareAPI传入进去,因此每个中间都可以拿到getState和dispatch,只不过此时的dispatch是改造过的
// 因为在中间件里面调用改dispatch,都会重新再经过所有中间一遍
const chain = middlewares.map(middleware => middleware(middlewareAPI))
// middleware中间件列表中,最后一个能取到真正的dispatch,即此处传入的store.dispatch
dispatch = compose<typeof dispatch>(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}
// compose函数将所有中间件函数组合成一个按顺序调用的函数[a, b, c] => a(b(c(...args))),所以最后一个中间件能拿到传入的参数
// 也就是store.dispatch
function compose(...funcs: Function[]) {
if (funcs.length === 0) {
// infer the argument type so it is usable in inference down the line
return <T>(arg: T) => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args: any) => a(b(...args)))
}
// dispatch能传入函数参数的中间件
const thunk = ({ getState, dispatch }) => next => action => {
if(typeof action === 'function') {
action(dispatch, getState);
} else {
// 非最后一个中间件,next是上一个中间件的返回值,此处是logger的返回值,即next => action => {...};
next(action);
}
}
// 日志中间件
const logger = ({ getState, dispatch }) => next => action => {
if (process.env.NODE_ENV !== 'production') {
console.log(action);
}
// 此处的next是真正的dipatch,就是compose<typeof dispatch>(...chain)(store.dispatch)传入的store.dispatch
return next(action);
}
applyMiddleware(thunk, logger)Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。下面我们针对以下几点,对源码进行分析:
一. Vuex暴露的方法和属性及其用处
// src/index.js
export default {
Store,
install,
version: '__VERSION__',
mapState,
mapMutations,
mapGetters,
mapActions,
createNamespacedHelpers
}可以看到对外暴露Store对象、install挂载方法、version版本、以及方便在组件中获取state、mutation、getter和action的方法和初始化时用于创建命名空间别名的createNamespacedHelpers;
二. Vuex的挂载及如何与组件关联
Vuex作为Vue的插件,通过提供install方法来挂载到Vue实例上。
// src/mixin.js 导出作为install方法
export default function (Vue) {
const version = Number(Vue.version.split('.')[0])
if (version >= 2) {
Vue.mixin({ beforeCreate: vuexInit })
} else {
// override init and inject vuex init procedure
// for 1.x backwards compatibility.
const _init = Vue.prototype._init
Vue.prototype._init = function (options = {}) {
options.init = options.init
? [vuexInit].concat(options.init)
: vuexInit
_init.call(this, options)
}
}
/**
* Vuex init hook, injected into each instances init hooks list.
*/
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
// 根组件挂载$store
this.$store = typeof options.store === 'function'
? options.store()
: options.store
} else if (options.parent && options.parent.$store) {
// 从父组件获取$store
this.$store = options.parent.$store
}
}
}可以看出来,是通过调用了Vue.mixin在全局里混入了beforeCreate生命周期,那么Vue实例在初始化触发beforeCreate生命周期时,就会执行vuexInit方法。然后将我们在初始化配置Vue实例时,传入的store实例挂载到每个组件的$store上,也就是说,我们可以在任何组件里,都能通过this.$store取到相应的state状态值。
const store = new Vuex.Store({
state: {},
mutations: {}
});
const app = new Vue({
el: '#app',
// 把 store 对象提供给 “store” 选项,这可以把 store 的实例注入所有的子组件
store
})
三. Vuex初始化
export default Store {
constructor (options = {}) {
// Auto install if it is not done yet and `window` has `Vue`.
// To allow users to avoid auto-installation in some cases,
// this code should be placed here. See #731
if (!Vue && typeof window !== 'undefined' && window.Vue) {
install(window.Vue)
}
// ....
const {
plugins = [],
strict = false
} = options
// store internal state
this._committing = false
this._actions = Object.create(null) // 用于存储配置的actions
this._actionSubscribers = []
this._mutations = Object.create(null) // 用于存储配置的mutations
this._wrappedGetters = Object.create(null) // 用于存储配置的getters
this._modules = new ModuleCollection(options) // 实例化后会将我们在store初始化配置的mudule构建成属性,eg:{root: {_children: {a: module, b: module}, module}}
this._modulesNamespaceMap = Object.create(null) // 用去存储每个命令空间的模块。eg: {'a/': module, 'b/': module}
this._subscribers = []
this._watcherVM = new Vue()
// bind commit and dispatch to self
const store = this
const { dispatch, commit } = this
// 重新绑定dipatch和commit方法,强行将其执行上下文this指向store,避免用户使用时,改写this指向,导致出错
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
// strict mode
this.strict = strict
const state = this._modules.root.state
// 根据命令空间与否注册所有模块的state,mutation,getter和action(重点)
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
installModule(this, state, [], this._modules.root)
// 将state和getters变成响应式(重点)
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
resetStoreVM(this, state)
// apply plugins
plugins.forEach(plugin => plugin(this))
if (Vue.config.devtools) {
devtoolPlugin(this)
}
}
function installModule (store, rootState, path, module, hot) {
const isRoot = !path.length
const namespace = store._modules.getNamespace(path)
// register in namespace map
if (module.namespaced) {
store._modulesNamespaceMap[namespace] = module
}
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
const local = module.context = makeLocalContext(store, namespace, path)
module.forEachMutation((mutation, key) => {
const namespacedType = namespace + key
registerMutation(store, namespacedType, mutation, local)
})
module.forEachAction((action, key) => {
const type = action.root ? key : namespace + key
const handler = action.handler || action
registerAction(store, type, handler, local)
})
module.forEachGetter((getter, key) => {
const namespacedType = namespace + key
registerGetter(store, namespacedType, getter, local)
})
module.forEachChild((child, key) => {
installModule(store, rootState, path.concat(key), child, hot)
})
}
/**
* make localized dispatch, commit, getters and state
* if there is no namespace, just use root ones
*/
function makeLocalContext (store, namespace, path) {
const noNamespace = namespace === ''
const local = {
dispatch: noNamespace ? store.dispatch : (_type, _payload, _options) => {
const args = unifyObjectStyle(_type, _payload, _options)
const { payload, options } = args
let { type } = args
if (!options || !options.root) {
type = namespace + type
if (process.env.NODE_ENV !== 'production' && !store._actions[type]) {
console.error(`[vuex] unknown local action type: ${args.type}, global type: ${type}`)
return
}
}
return store.dispatch(type, payload)
},
commit: noNamespace ? store.commit : (_type, _payload, _options) => {
const args = unifyObjectStyle(_type, _payload, _options)
const { payload, options } = args
let { type } = args
if (!options || !options.root) {
type = namespace + type
if (process.env.NODE_ENV !== 'production' && !store._mutations[type]) {
console.error(`[vuex] unknown local mutation type: ${args.type}, global type: ${type}`)
return
}
}
store.commit(type, payload, options)
}
}
// getters and state object must be gotten lazily
// because they will be changed by vm update
Object.defineProperties(local, {
getters: {
get: noNamespace
? () => store.getters
: () => makeLocalGetters(store, namespace)
},
state: {
get: () => getNestedState(store.state, path)
}
})
return local
}
function resetStoreVM (store, state, hot) {
const oldVm = store._vm
// bind store public getters
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: {
$$state: state
},
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
if (hot) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation for hot reloading.
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}
}初始化时通过调用installModule方法,注册state、mutation、getter、action。在注册的过程中,会拼接上相应的命名空间。而makeLocalContext 方法将会构造不同的访问方式,当没有命名空间时,用默认的commit和action;有命名空间时,使用改造过的commit和action,其里面会拼接上命名空间的值去查找相应的mutation和action(getter和state也类似),因为我们在开发中,可以直接在组件中store.commit('increment')或模块中commit('increment'),内部会拼接上命令空间找到相应的方法,无需我们处理。
最后调用resetStoreVM将我们的state和getter设置到vue实例上,变成响应式。因此当我们在组件中访问state时,其实访问的是$$state数据,这样就会触发Vue的依赖收集,改变后也就会触发组件更新。
四. vuex更新数据的方式
Vuex异步请求放在Action处理,Action 提交的是 mutation,而不是直接变更状态,更新数据直接通过commit来操作(必须是同步函数),目的是为了devtools 能捕捉到前一状态和后一状态的快照,然后进行回溯。enableStrictMode会对state进行深度监听,如果_committing值为false,则报错提示,其中_committing可以通过_withCommit函数设置(只能提示,不能拦截掉,也就是还可以强制更新)
function enableStrictMode (store) {
// 严格模式且开发环境下,深度监听state值的变化,如果_committing为false,则报错
store._vm.$watch(function () { return this._data.$$state }, () => {
if (process.env.NODE_ENV !== 'production') {
assert(store._committing, `Do not mutate vuex store state outside mutation handlers.`)
}
}, { deep: true, sync: true })
}
_withCommit (fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}
五. vuex数据更新是异步还是同步?
从之前的源码中可以看到,Vuex本身其实是同步更新的,但是在Vue中表现出异步是因为将state的数据挂载做为Vue的响应式data数据处理,满足Vue的数据更新机制(异步更新)。
<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel="dns-prefetch" href="//www.zhix.net">
在一些浏览器的a标签是默认打开dns预解析的,在https协议下dns预解析是关闭的,加入mate后会打开。
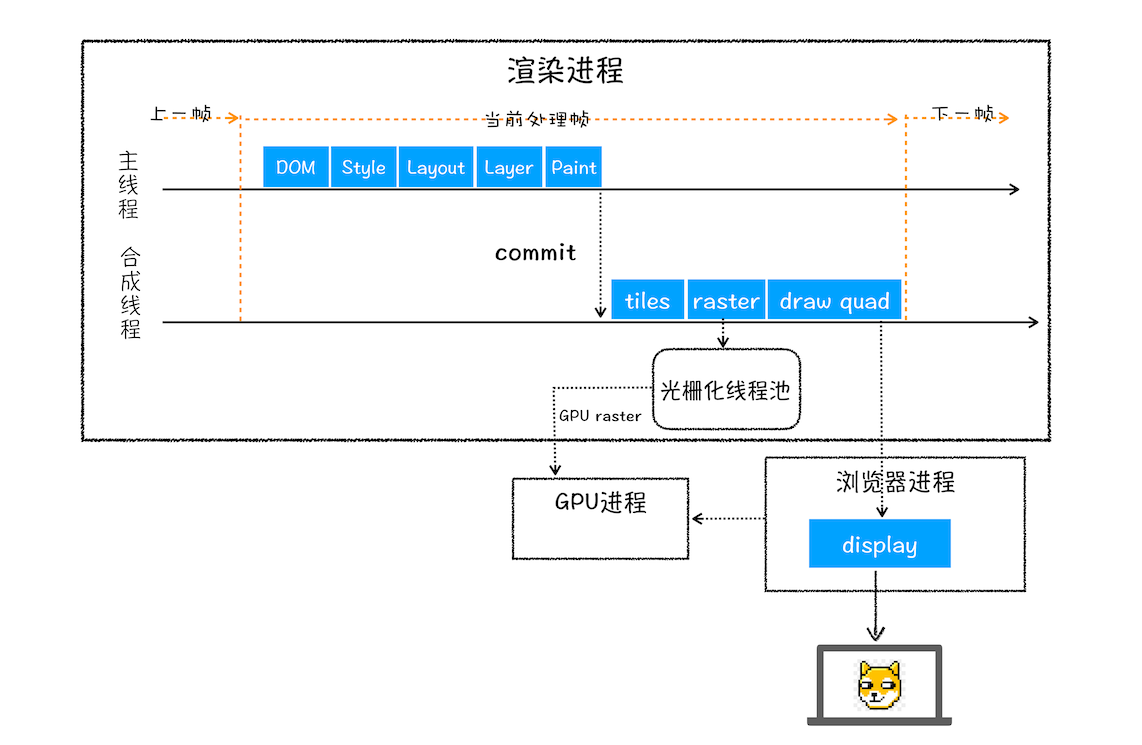
渲染进程将 HTML 内容转换为能够读懂的DOM 树结构。
渲染引擎将 CSS 样式表转化为浏览器可以理解的styleSheets,计算出 DOM 节点的样式。
创建布局树,并计算元素的布局信息。
对布局树进行分层,并生成分层树。
为每个图层生成绘制列表,并将其提交到合成线程。
合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图。
合成线程发送绘制图块命令DrawQuad给浏览器进程。
浏览器进程根据 DrawQuad 消息生成页面,并显示到显示器上。
重排:
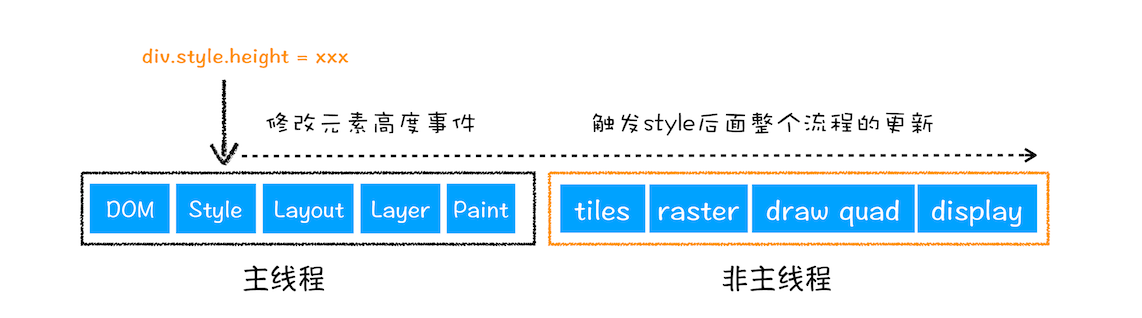
从上图可以看出,如果你通过 JavaScript 或者 CSS 修改元素的几何位置属性,例如改变元素的宽度、高度等,那么浏览器会触发重新布局,解析之后的一系列子阶段,这个过程就叫重排。无疑,重排需要更新完整的渲染流水线,所以开销也是最大的。
重绘:
接下来,我们再来看看重绘,比如通过 JavaScript 更改某些元素的背景颜色,渲染流水线会怎样调整呢?你可以参考下图:
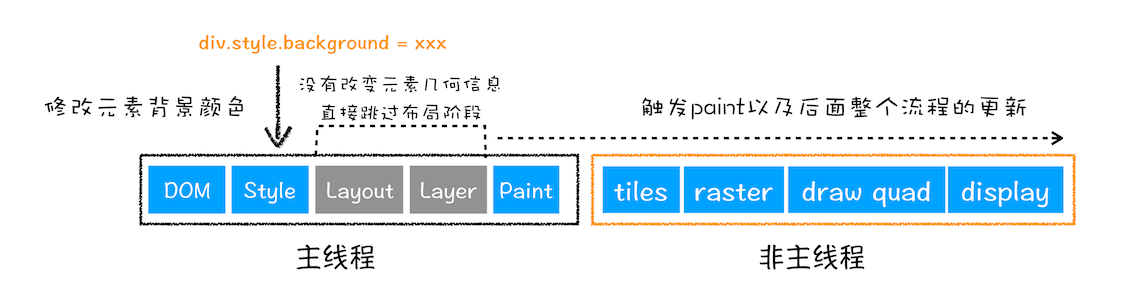
从图中可以看出,如果修改了元素的背景颜色,那么布局阶段将不会被执行,因为并没有引起几何位置的变换,所以就直接进入了绘制阶段,然后执行之后的一系列子阶段,这个过程就叫重绘。相较于重排操作,重绘省去了布局和分层阶段,所以执行效率会比重排操作要高一些。
直接合成阶段(动画性能对比):
那如果你更改一个既不要布局也不要绘制的属性,会发生什么变化呢?渲染引擎将跳过布局和绘制,只执行后续的合成操作,我们把这个过程叫做合成。具体流程参考下图:
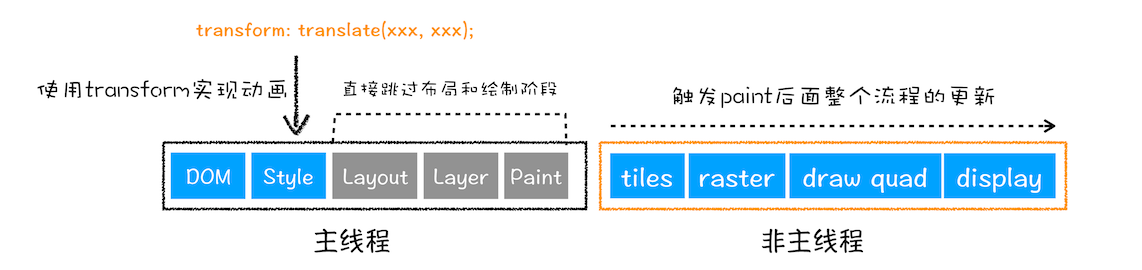
在上图中,我们使用了 CSS 的 transform 来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
/**
* @desc 函数防抖
* @param func 目标函数
* @param wait 延迟执行毫秒数
* @param immediate true - 立即执行, false - 延迟执行
*/
function debounce(func, wait, immediate) {
let timer;
return function() {
let context = this,
args = arguments;
if (timer) clearTimeout(timer);
if (immediate) {
let callNow = !timer;
timer = setTimeout(() => {
timer = null;
}, wait);
if (callNow) func.apply(context, args);
} else {
timer = setTimeout(() => {
func.apply
}, wait)
}
}
}
节流函数:只允许一个函数在N秒内执行一次。滚动条调用接口时,可以用节流throttle等优化方式,减少http请求;
/**
* @desc 函数节流
* @param func 函数
* @param wait 延迟执行毫秒数
* @param type 1 表时间戳版,2 表定时器版(其实时间戳版和定时器版的节流函数的区别就是,时间戳版的函数触发是在时间段内开始的时候,而定时器版的函数触发是在时间段内结束的时候)
*/
function throttle(func, wait, type) {
if (type === 1) {
let previous = 0;
} else if (type === 2) {
let timeout;
}
return function() {
let context = this;
let args = arguments;
if (type === 1) {
let now = Date.now();
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
} else if (type === 2) {
if (!timeout) {
timeout = setTimeout(() => {
timeout = null;
func.apply(context, args)
}, wait)
}
}
}
}
<script src="script.js"></script>
没有 defer 或 async,浏览器会立即加载并执行指定的脚本,“立即”指的是在渲染该 script 标签之下的文档元素之前,也就是说不等待后续载入的文档元素,读到就加载并执行。
<script async src="script.js"></script>
有 async,加载和渲染后续文档元素的过程将和 script.js 的加载与执行并行进行(异步),标记为async的脚本并不保证按照指定它们的先后顺序执行。对它来说脚本的加载和执行是紧紧挨着的,所以不管你声明的顺序如何,只要它加载完了就会立刻执行。。
<script defer src="myscript.js"></script>
有 defer,加载后续文档元素的过程将和 script.js 的加载并行进行(异步),但是 script.js 的执行要在所有元素解析完成之后,DOMContentLoaded 事件触发之前完成。关于 defer,我们还要记住的是它是按照加载顺序执行脚本的
// 动态加载js
function loadJS( url, callback ){
var script = document.createElement('script'),
fn = callback || function(){};
script.type = 'text/javascript';
//IE
if(script.readyState){
script.onreadystatechange = function(){
if( script.readyState == 'loaded' || script.readyState == 'complete' ){
script.onreadystatechange = null;
fn();
}
};
}else{
//其他浏览器
script.onload = function(){
fn();
};
}
script.src = url;
document.getElementsByTagName('head')[0].appendChild(script);
}
loadJS(myscript.js);
// 一开始设置
<img data-src="https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4">
// 等页面可见时
const img = document.querySelector('img')
img.src = img.dataset.src
<picture>
<source srcset="banner_w1000.jpg" media="(min-width: 801px)">
<source srcset="banner_w800.jpg" media="(max-width: 800px)">
<img src="banner_w800.jpg" alt="">
</picture>
或
@media (min-width: 769px) {
.bg {
background-image: url(bg1080.jpg);
}
}
@media (max-width: 768px) {
.bg {
background-image: url(bg768.jpg);
}
}
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use:[
{
loader: 'url-loader',
options: {
limit: 10000, /* 图片大小小于1000字节限制时会自动转成 base64 码引用*/
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
/*对图片进行压缩*/
{
loader: 'image-webpack-loader',
options: {
bypassOnDebug: true,
}
}
]
}
optimization: {
runtimeChunk: {
name: 'manifest' // 将 webpack 的 runtime 代码拆分为一个单独的 chunk。
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial'
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},
摘抄至浏览器工作原理与实践的V8工作原理部分
js有8种数据类型,分为两大类型,基本数据类型:Boolean,String,Number,undefined,null,Bigint,Symbol;引用数据类型:Object。其中基本数据类型存储在栈空间,而引用类型存储在堆空间,在栈空间中只是保留了对象的引用地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。例如以下代码:
function foo(){
var a = "极客时间"
var b = a
var c = {name:"极客时间"}
var d = c
}
foo()
内存分配的示意图如下所示:
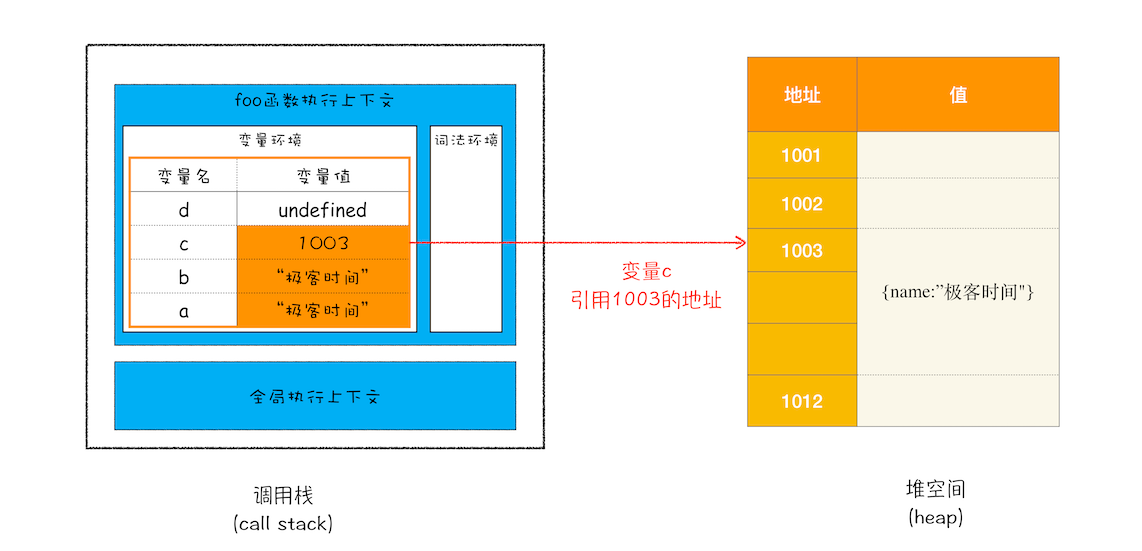
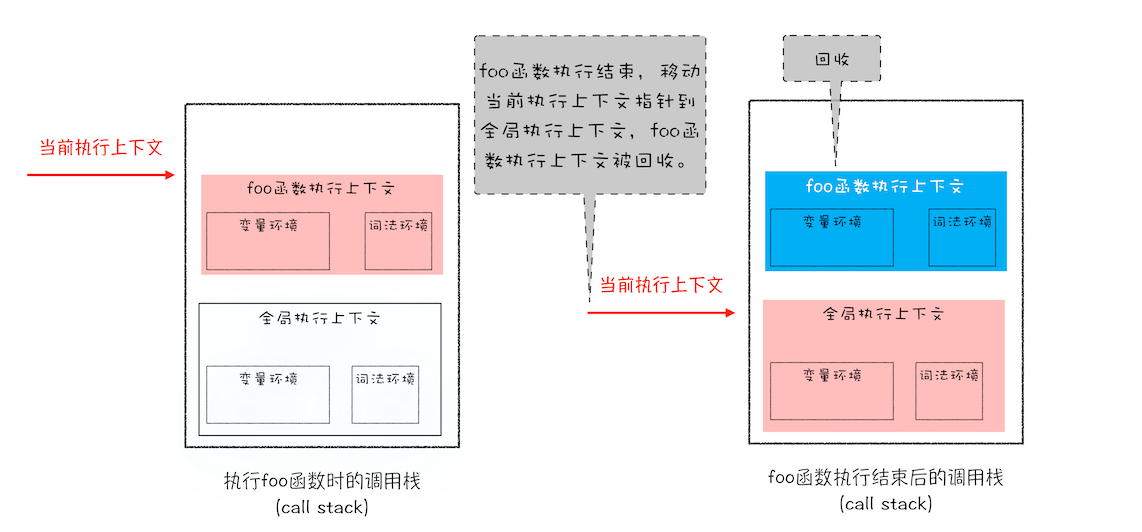
为什么不能所有数据都存储在栈空间中,而要区分栈和堆空间呢?这是因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。比如文中的 foo 函数执行结束了,JavaScript 引擎需要离开当前的执行上下文,只需要将指针下移到上个执行上下文的地址就可以了,foo 函数执行上下文栈区空间全部回收,具体过程你可以参考下图
所以通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。
不同语言的垃圾回收策略
通常情况下,垃圾数据回收分为手动回收和自动回收两种策略。
如 C/C++ 就是使用手动回收策略,何时分配内存、何时销毁内存都是由代码控制的。另外一种使用的是自动垃圾回收的策略,如 JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。对于js而言,因为数据是存储在栈和堆两种内存空间中的,所以得分别分析“栈中的垃圾数据”和“堆中的垃圾数据”是如何回收的。
调用栈中的数据是如何回收的
通过一段示例代码的执行流程来分析其回收机制,具体如下:
1 function foo(){
2 var a = 1
3 var b = {name:"极客邦"}
4 function showName(){
5 var c = 2
6 var d = {name:"极客时间"}
7 }
8 showName()
9 }
10 foo()
当执行到第 6 行代码时,其调用栈和堆空间状态图如下所:
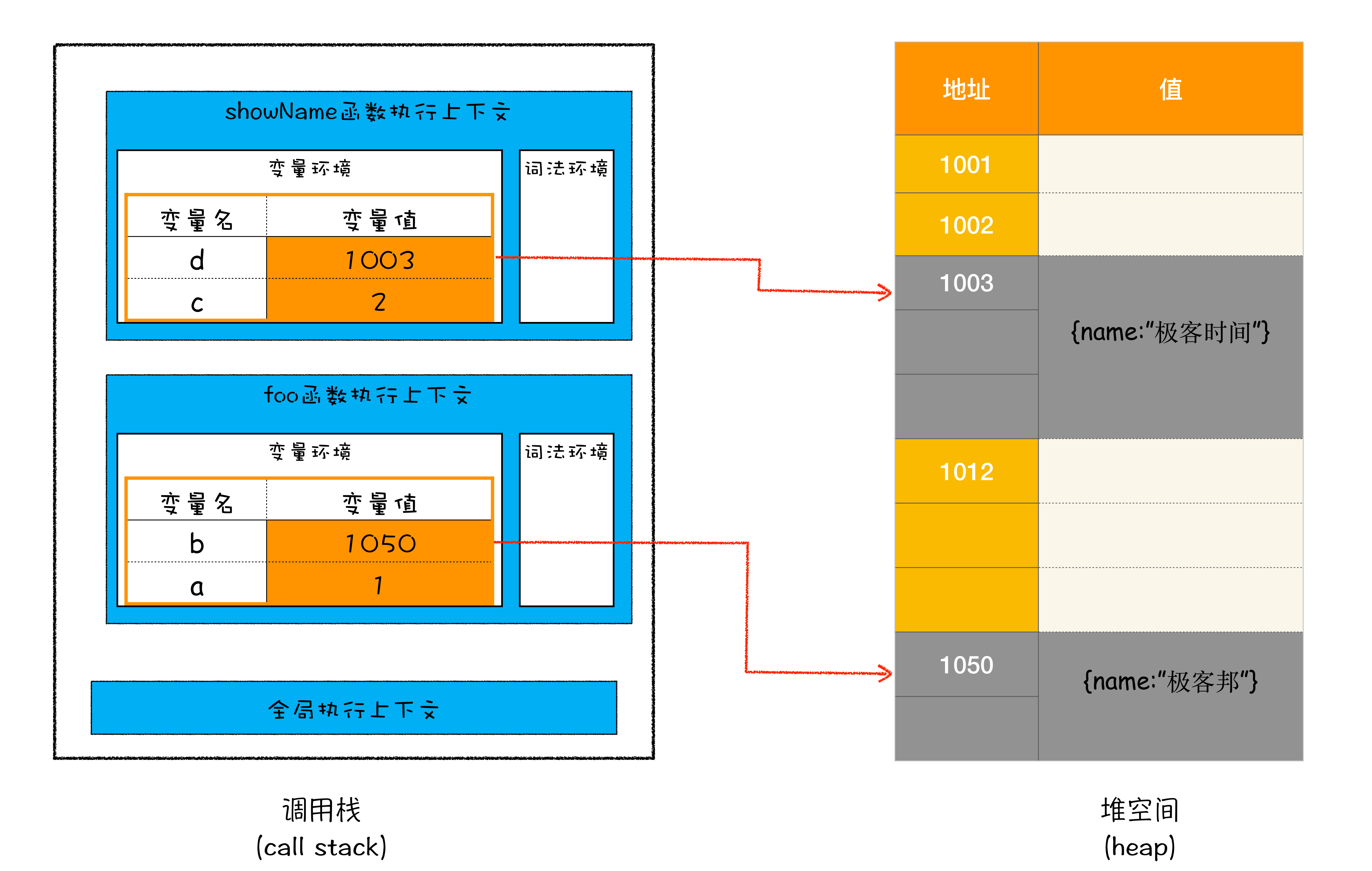
从图中可以看出,原始类型的数据被分配到栈中,引用类型的数据会被分配到堆中。当 foo 函数执行结束之后,foo 函数的执行上下文会从堆中被销毁掉,那么它是怎么被销毁的呢?
当执行到 showName 函数时,那么 JavaScript 引擎会创建 showName 函数的执行上下文,并将 showName 函数的执行上下文压入到调用栈中,最终执行到 showName 函数时,其调用栈就如上图所示。与此同时,还有一个记录当前执行状态的指针(称为 ESP),指向调用栈中 showName 函数的执行上下文,表示当前正在执行 showName 函数。
接着,当 showName 函数执行完成之后,函数执行流程就进入了 foo 函数,那这时就需要销毁 showName 函数的执行上下文了。ESP 这时候就帮上忙了,JavaScript 会将 ESP 下移到 foo 函数的执行上下文,这个下移操作就是销毁 showName 函数执行上下文的过程。
问题是ESP 指针向下移动怎么就能把 showName 的执行上下文销毁了呢?具体你可以看下面这张移动 ESP 前后的对比图:
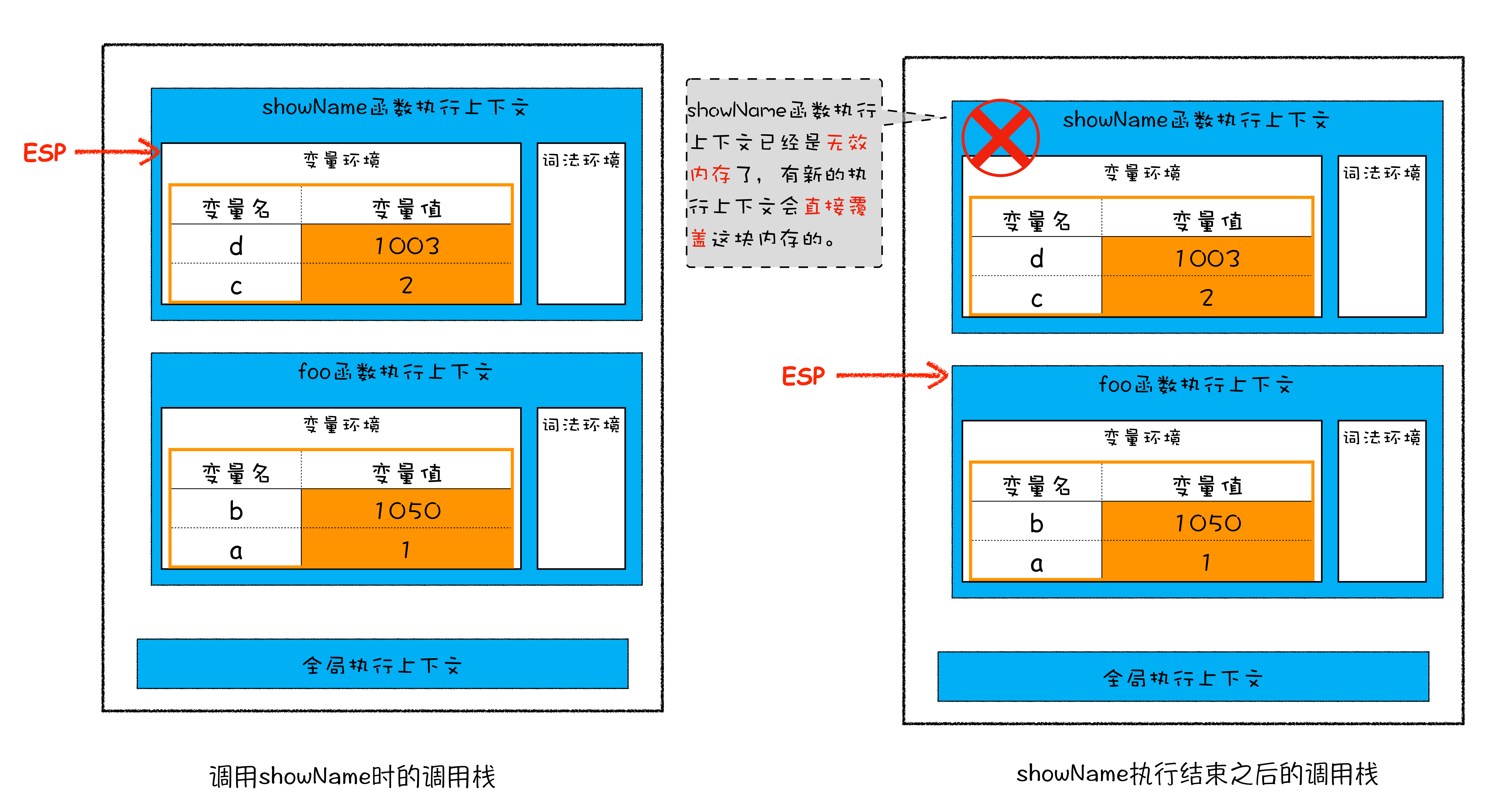
从图中可以看出,当 showName 函数执行结束之后,ESP 向下移动到 foo 函数的执行上下文中,上面 showName 的执行上下文虽然保存在栈内存中,但是已经是无效内存了。比如当 foo 函数再次调用另外一个函数时,这块内容会被直接覆盖掉,用来存放另外一个函数的执行上下文。
所以说,当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP 来销毁该函数保存在栈中的执行上下文。
堆中的数据是如何回收的
通过上面分析,上面那段代码的 foo 函数执行结束之后,ESP 应该是指向全局执行上下文的,那这样的话,showName 函数和 foo 函数的执行上下文就处于无效状态了,不过保存在堆中的两个对象依然占用着空间,如下图所示:

从图中可以看出,1003 和 1050 这两块内存依然被占用。要回收堆中的垃圾数据,就需要用到 JavaScript 中的垃圾回收器了。
所以,接下来我们就来通过 Chrome 的 JavaScript 引擎 V8 来分析下堆中的垃圾数据是如何回收的。
代际假说和分代收集
不过在正式介绍 V8 是如何实现回收之前,首先先学习下代际假说(The Generational Hypothesis)的内容,这是垃圾回收领域中一个重要的术语,后续垃圾回收的策略都是建立在该假说的基础之上的,所以很是重要。
代际假说有以下两个特点:
其实这两个特点不仅仅适用于 JavaScript,同样适用于大多数的动态语言,如 Java、Python 等。
有了代际假说的基础,我们就可以来探讨 V8 是如何实现垃圾回收的了。
通常,垃圾回收算法有很多种,但是并没有哪一种能胜任所有的场景,你需要权衡各种场景,根据对象的生存周期的不同而使用不同的算法,以便达到最好的效果。
所以,在 V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
垃圾回收器的工作流程
现在知道了 V8 把堆分成两个区域——新生代和老生代,并分别使用两个不同的垃圾回收器。其实不论什么类型的垃圾回收器,它们都有一套共同的执行流程。
第一步是标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象。
第二步是回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。
第三步是做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片,但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片,比如接下来我们要介绍的副垃圾回收器。
那么接下来,我们就按照这个流程来分析新生代垃圾回收器(副垃圾回收器)和老生代垃圾回收器(主垃圾回收器)是如何处理垃圾回收的。
副垃圾回收器
副垃圾回收器主要负责新生区的垃圾回收。而通常情况下,大多数小的对象都会被分配到新生区,所以说这个区域虽然不大,但是垃圾回收还是比较频繁的。
新生代中用 Scavenge 算法来处理。所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
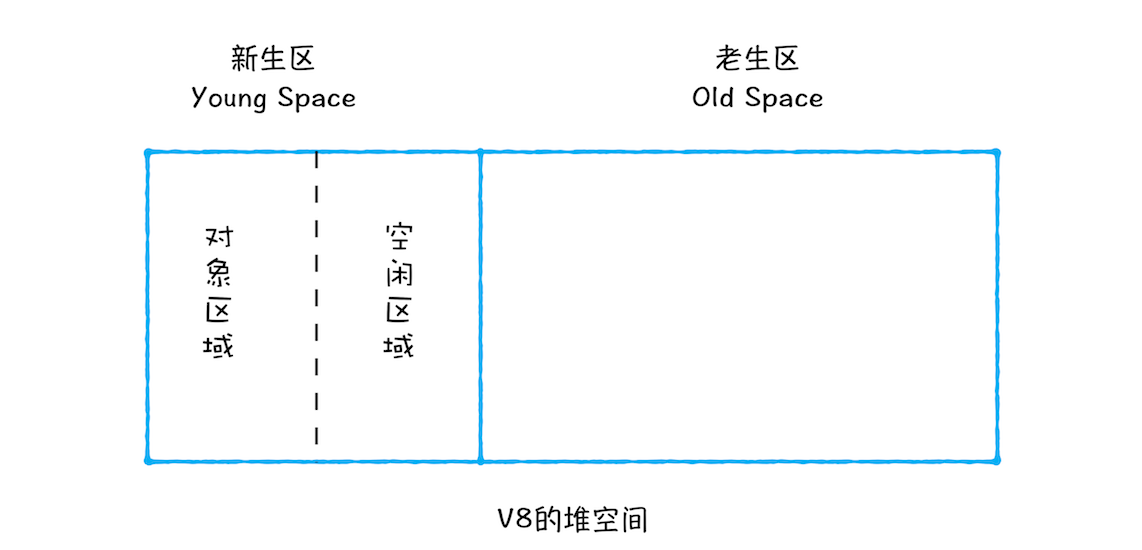
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
在垃圾回收过程中,首先要对对象区域中的垃圾做标记;标记完成之后,就进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,所以这个复制过程,也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去。
由于新生代中采用的 Scavenge 算法,所以每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域。但复制操作需要时间成本,如果新生区空间设置得太大了,那么每次清理的时间就会过久,所以为了执行效率,一般新生区的空间会被设置得比较小。
也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直接被分配到老生区。因此老生区中的对象有两个特点,一个是对象占用空间大,另一个是对象存活时间长。
由于老生区的对象比较大,若要在老生区中使用 Scavenge 算法进行垃圾回收,复制这些大的对象将会花费比较多的时间,从而导致回收执行效率不高,同时还会浪费一半的空间。因而,主垃圾回收器是采用标记 - 清除(Mark-Sweep)的算法进行垃圾回收的。下面分析该算法是如何工作的。
首先是标记过程阶段。标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
比如最开始的那段代码,当 showName 函数执行退出之后,这段代码的调用栈和堆空间如下图所示:
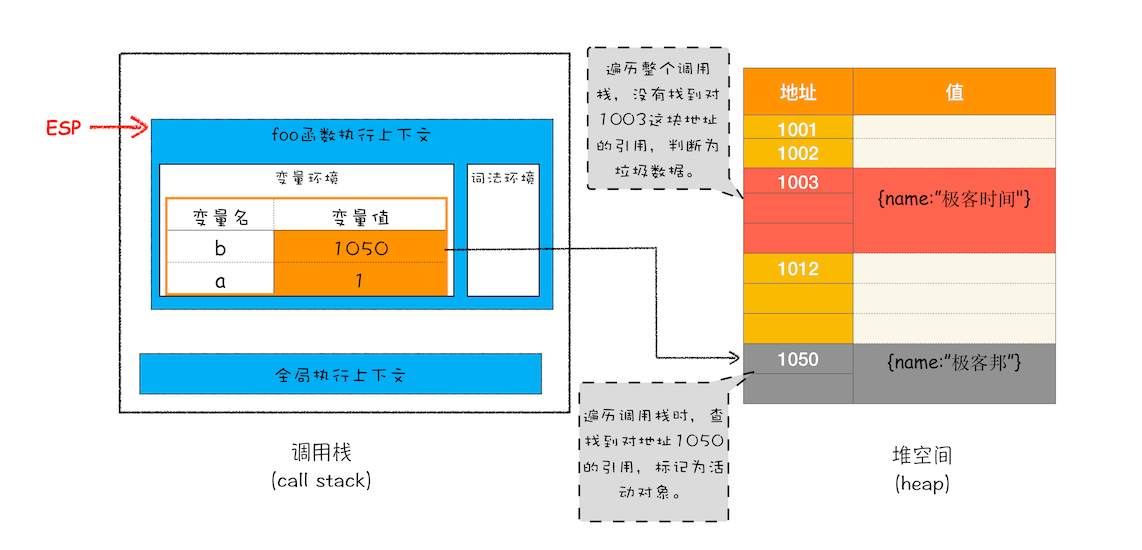
从上图你可以大致看到垃圾数据的标记过程,当 showName 函数执行结束之后,ESP 向下移动,指向了 foo 函数的执行上下文,这时候如果遍历调用栈,是不会找到引用 1003 地址的变量,也就意味着 1003 这块数据为垃圾数据,被标记为红色。由于 1050 这块数据被变量 b 引用了,所以这块数据会被标记为活动对象。这就是大致的标记过程。
接下来就是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,可以理解这个过程是清除掉红色标记数据的过程,可参考下图大致理解下其清除过程:
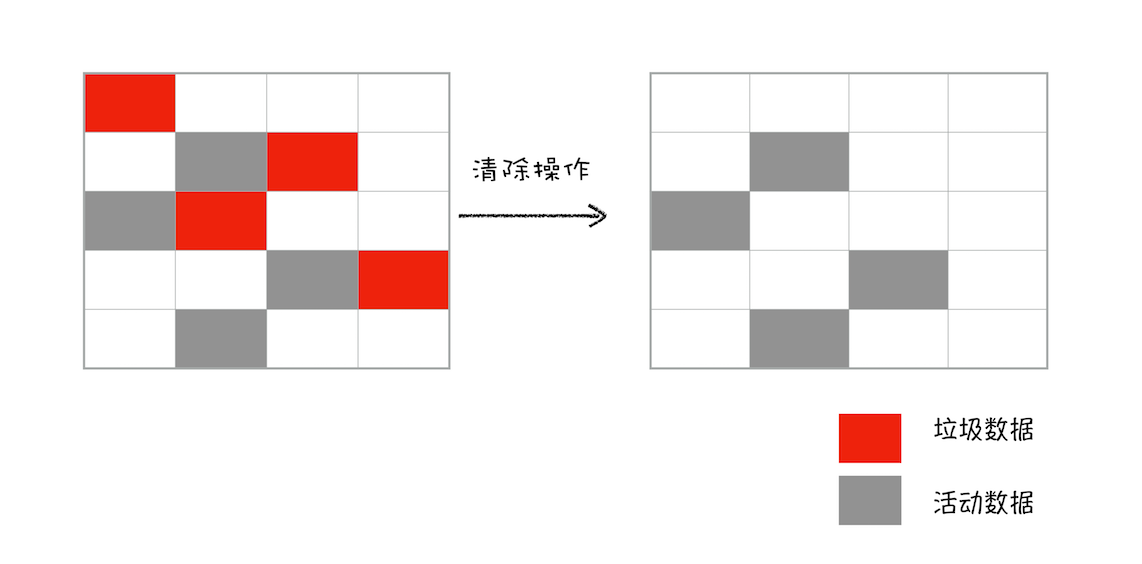
上面的标记过程和清除过程就是标记 - 清除算法,不过对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生了另外一种算法——标记 - 整理(Mark-Compact),这个标记过程仍然与标记 - 清除算法里的是一样的,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。你可以参考下图:
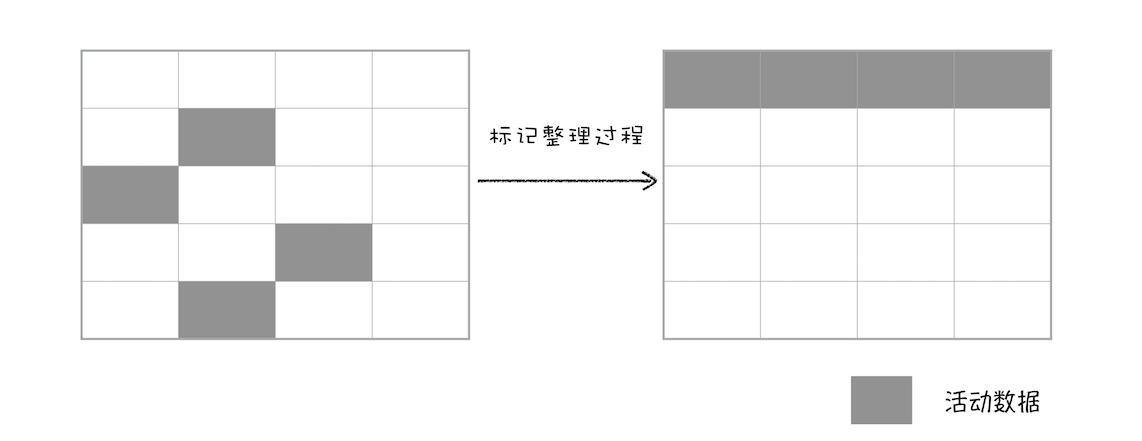
全停顿
现在知道了 V8 是使用副垃圾回收器和主垃圾回收器处理垃圾回收的,不过由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)。
比如堆中的数据有 1.5GB,V8 实现一次完整的垃圾回收需要 1 秒以上的时间,这也是由于垃圾回收而引起 JavaScript 线程暂停执行的时间,若是这样的时间花销,那么应用的性能和响应能力都会直线下降。主垃圾回收器执行一次完整的垃圾回收流程如下图所示:
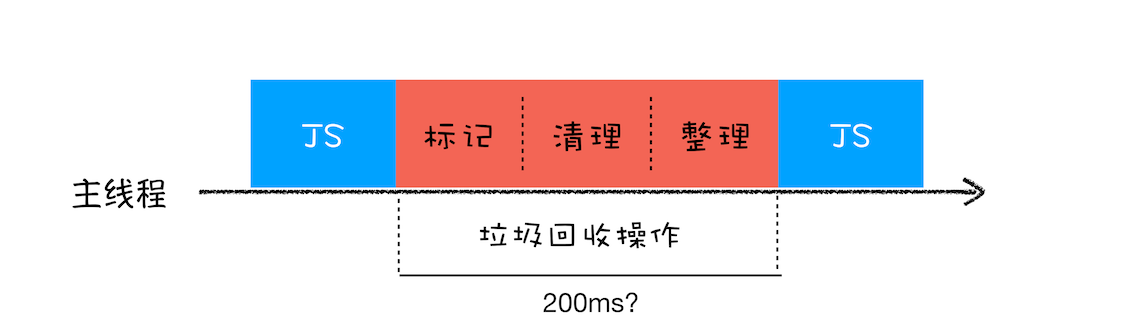
在 V8 新生代的垃圾回收中,因其空间较小,且存活对象较少,所以全停顿的影响不大,但老生代就不一样了。如果在执行垃圾回收的过程中,占用主线程时间过久,就像上面图片展示的那样,花费了 200 毫秒,在这 200 毫秒内,主线程是不能做其他事情的。比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在这 200 毫秒内无法执行的,这将会造成页面的卡顿现象。
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法。如下图所示:
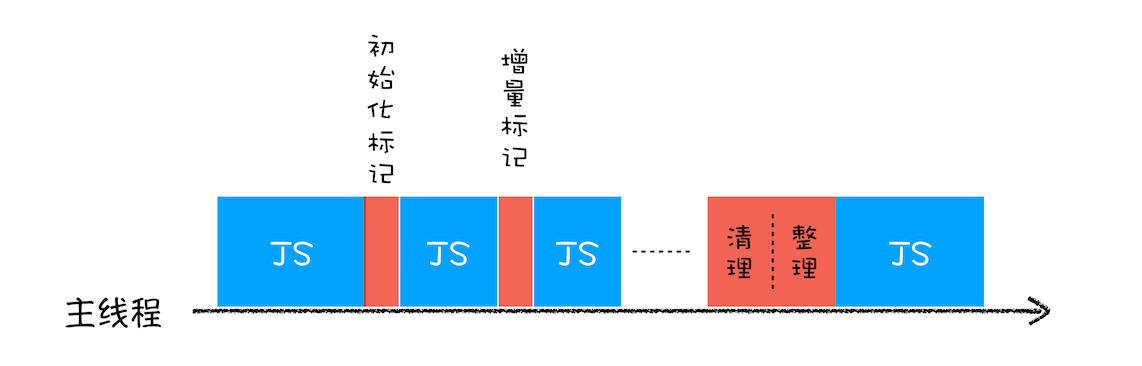
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
// 二叉搜索树
function BinaryTree() {
const Node = function(key) {
//节点函数
this.key = key;
this.left = null;
this.right = null;
};
let root = null;
// 插入
this.insert = function(key) {
// 插入节点
let insertNode = function(node, newNode) {
if (node.key > newNode.key) {
if (node.left == null) {
node.left = newNode;
} else {
insertNode(node.left, newNode);
}
} else {
if (node.right == null) {
node.right = newNode;
} else {
insertNode(node.right, newNode);
}
}
};
const newNode = new Node(key);
if (root == null) {
root = newNode;
} else {
insertNode(root, newNode);
}
};
// 获取二叉树
this.getTree = function() {
return root;
}
// 递归中序遍历 排序
this.inOrderTraverse = function(callback) {
const inOrderTraverseNode = function(node, callback) {
if (node != null) {
inOrderTraverseNode(node.left, callback);
callback(node.key);
inOrderTraverseNode(node.right, callback);
}
};
inOrderTraverseNode(root, callback);
};
// 非递归中序遍历(利用栈实现)
this.nonRecursiveInOrderTraverse = function(callback) {
const stack = [{status: 'next', node: root}];
while(stack && stack.length !== 0) {
const cur = stack.pop();
if(cur.status === 'print') {
callback(cur.node.key);
} else {
cur.node.right && stack.push({status: 'next', node: cur.node.right});
stack.push({status: 'print', node: cur.node });
cur.node.left && stack.push({status: 'next', node: cur.node.left});
}
}
}
//递归前序遍历 复制二叉树 效率高得多
this.proOrderTraverse = function(callback) {
const proOrderTraverseNode = function(node, callback) {
if (node != null) {
callback(node.key);
proOrderTraverseNode(node.left, callback);
proOrderTraverseNode(node.right, callback);
}
};
proOrderTraverseNode(root, callback);
};
// 非递归前序遍历(利用栈实现)
this.nonRecursiveProOrderTraverse = function(callback) {
const stack = [{status: 'next', node: root}];
while(stack && stack.length !== 0) {
const cur = stack.pop();
if(cur.status === 'print') {
callback(cur.node.key);
} else {
cur.node.right && stack.push({status: 'next', node: cur.node.right});
cur.node.left && stack.push({status: 'next', node: cur.node.left});
stack.push({status: 'print', node: cur.node });
}
}
}
//后续遍历 文件系统遍历
this.postOrderTraverse = function(callback) {
const postOrderTraverseNode = function(node, callback) {
if (node != null) {
postOrderTraverseNode(node.left, callback);
postOrderTraverseNode(node.right, callback);
callback(node.key);
}
};
postOrderTraverseNode(root, callback);
};
// 非递归前序遍历(利用栈实现)
this.nonRecursivePostOrderTraverse = function(callback) {
const stack = [{status: 'next', node: root}];
while(stack && stack.length !== 0) {
const cur = stack.pop();
if(cur.status === 'print') {
callback(cur.node.key);
} else {
stack.push({status: 'print', node: cur.node });
cur.node.right && stack.push({status: 'next', node: cur.node.right});
cur.node.left && stack.push({status: 'next', node: cur.node.left});
}
}
}
// 查找最大值
this.max = function() {
let node = root;
if (node) {
while (node && node.right != null) {
node = node.right;
}
}
return node.key;
};
// 查找最小值
this.min = function() {
let node = root;
if (node) {
while (node && node.left != null) {
node = node.left;
}
}
return node.key;
};
// 查找指定值
this.search = function(key) {
const searchNode = function(node, key) {
if (node == null) {
return false;
}
if (node.key > key) {
searchNode(node.left, key);
} else if (node.key < key) {
searchNode(node.right, key);
} else {
return true;
}
};
return searchNode(root, key);
};
/**
* 二叉树的删除
* 二叉树删除分三种情况
* 删除左叶子节点
* 删除右叶子节点
* 以及拥有左右两个节点的主节点删除
* 拥有左右两个节点的主节点删除要考虑到数据的可排序行需要将删掉的节点重新赋值
*/
// 移除节点
this.remove = function(key) {
const findMinNode = function(node) {
//如果存在左右两个节点的话查找右节点的最小节点
if (node) {
while (node && node.left != null) {
node = node.left;
}
return node;
}
return null;
};
const removeNode = function(node, key) {
if (node == null) {
return null;
}
if (node.key > key) {
// 递归查找左叶子节点,直接等于返回的null值
node.left = removeNode(node.left, key);
return node;
} else if (node.key < key) {
node.right = removeNode(node.right, key);
return node;
} else {
if (node.left == null && node.right == null) {
// 当只有一个节点,而且被选中
node = null;
return node;
}
if (node.left == null) {
//左节点为空
node = node.right;
return node;
} else if (node.right == null) {
//右节点为空
node = node.left;
return node;
}
// ?????
let aux = findMinNode(node.right); //查找到右节点最小节点赋值
node.key = aux.key;
node.right = removeNode(node.right, aux.key);
return node;
}
};
return removeNode(root, key);
};
}
// test
const nodes = [8, 3, 10, 2, 9, 14, 4, 7, 13];
const binaryTree = new BinaryTree();
nodes.forEach(function(key) {
binaryTree.insert(key);
});
const callback = function(key) {
console.log(key);
};
binaryTree.nonRecursivePostOrderTraverse(callback);参考一
参考二
参考三
「回溯是递归的副产品,只要有递归就会有回溯」,所以回溯法也经常和二叉树遍历,深度优先搜索混在一起,因为这两种方式都是用了递归。
回溯法就是暴力搜索,并不是什么高效的算法,最多再剪枝一下。
回溯算法能解决如下问题:
回溯法的模板:
backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
子集问题
子集问题(一)
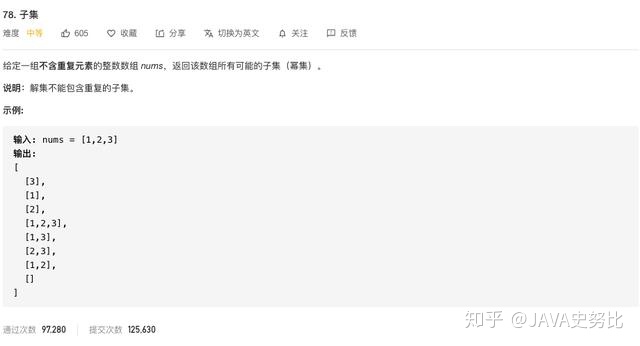
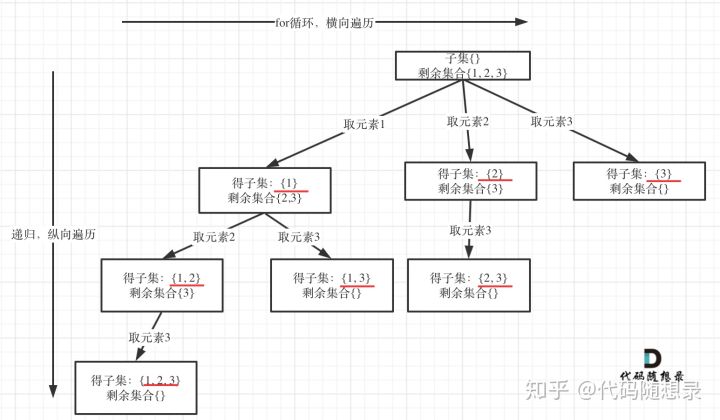
「本题其实可以不需要加终止条件」,因为start >= nums.length,本层for循环本来也结束了,本来我们就要遍历整颗树。
并不会无限递归,因为每次递归的下一层就是从i+1开始的。
如果要写终止条件,注意:result.push(nums[i]);要放在终止条件的上面,如下:
const res = []; // 结果
function subsets(nums) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums, temp);
return res;
}
function backtracking(start, nums, temp) {
res.push([...temp]);; // 收集子集,要放在终止添加的上面,否则会漏掉结果
if (start>= nums.length) { // 终止条件可以不加
return;
}
// 从start开始遍历,避免重复
for(let i = start; i < nums.length; i++) {
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i + 1, nums, temp);
// 回溯
temp.pop();
}
}
subsets([1,2,3])
子集问题(二)
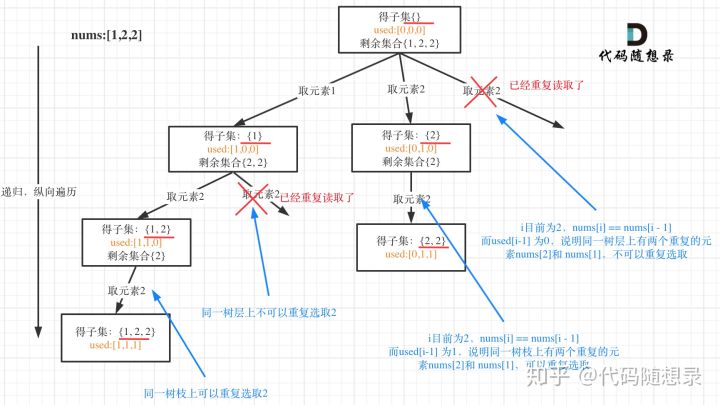
这个题目与前面的子集题目相比较,差别就在于包含重复的子集,也就是不能顺序改变而已,元素一样的子集出现。
这个题目框架还是不变的,但是,要做一下简单的剪枝操作:怎么排除掉重复的子集。
这里我通过Map数据结构来去重,如下:
const res = []; // 结果
const map = new Map(); // 用来判断是否重复
function subsets(nums) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums, temp);
return res;
}
function backtracking(start, nums, temp) {
// 去重
if(!map.has(temp.join())) {
res.push([...temp]);; // 收集子集,要放在终止添加的上面,否则会漏掉结果
map.set(temp.join(), temp);
}
// 从start开始遍历,避免重复
for(let i = start; i < nums.length; i++) {
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i + 1, nums, temp);
// 回溯
temp.pop();
}
}
subsets([1,1,2])
全排列问题
全排列问题(一)
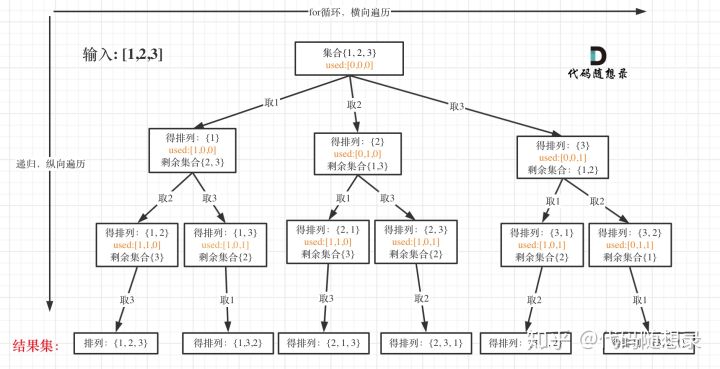
排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用start了,而且我们这边还要进行剪枝(temp集合中有的就排除)。如下:
const res = []; // 结果
function subsets(nums) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums, temp);
return res;
}
function backtracking(start, nums, temp) {
// 终止条件
if(nums.length === temp.length) {
res.push([...temp]);
return;
}
// 从0开始遍历
for(let i = 0; i < nums.length; i++) {
// 去重
if(temp.includes(nums[i])) {
continue;
}
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i + 1, nums, temp);
// 回溯
temp.pop();
}
}
subsets([1,2,3])
组合问题
组合问题(一)
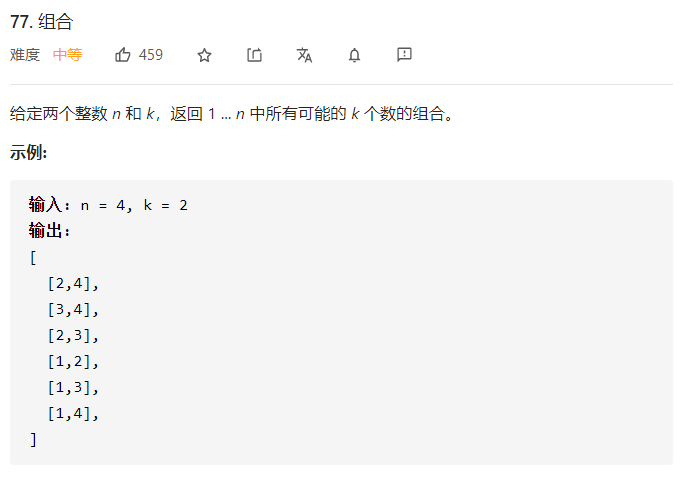
可以直观的看出其搜索的过程:「for循环横向遍历,递归纵向遍历,回溯不断调整结果集」
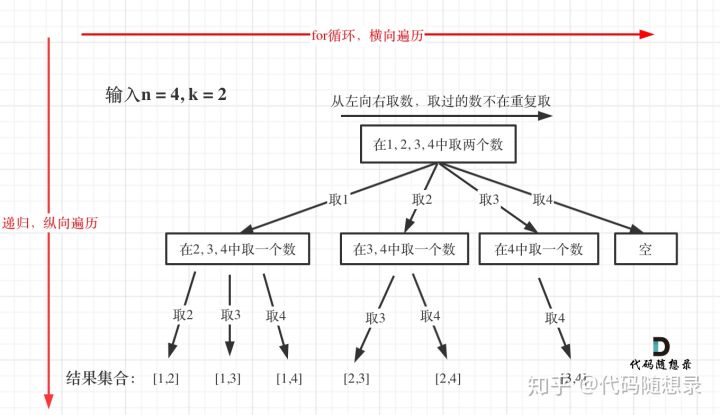
其中优化回溯算法只有剪枝一种方法,在回溯算法:组合问题再剪剪枝中把回溯法代码做了剪枝优化,树形结构如图:
「回溯算法:求组合问题!剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够题目要求的k个元素了,就没有必要搜索了」。
「在for循环上做剪枝操作是回溯法剪枝的常见套路!」,如下。
const res = []; // 结果
function subsets(nums, k) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums, k, temp);
return res;
}
function backtracking(start, nums, k, temp) {
if(k === temp.length) {
res.push([...temp]);
return;
}
// 从start开始遍历,无优化版 i < nums.length
// 剪枝优化 i < (nums.length - (k - temp.length) + 1)
for(let i = start; i < (nums.length - (k - temp.length) + 1); i++) {
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i + 1, nums, k, temp);
// 回溯
temp.pop();
}
}
subsets([1,2,3,4], 2);
组合总和(一)
这个题目跟之前的没有什么太大的区别,只是需要注意一个点:每个数字可以被无限制重复被选取,我们要做的就是在递归的时候,i的下标不是从i+1开始,而是从i开始。
const res = []; // 结果
function subsets(nums, target) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums, target, temp);
return res;
}
function backtracking(start, nums, target, temp) {
// 终止条件
if(target < 0) {
return;
}
// 获取结果
if(target === 0) {
res.push([...temp]);
}
// 从start开始遍历
for(let i = start; i < nums.length; i++) {
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i, nums, target - nums[i], temp);
// 回溯
temp.pop();
}
}
subsets([2,3,6,7], 7);
组合总和(二)
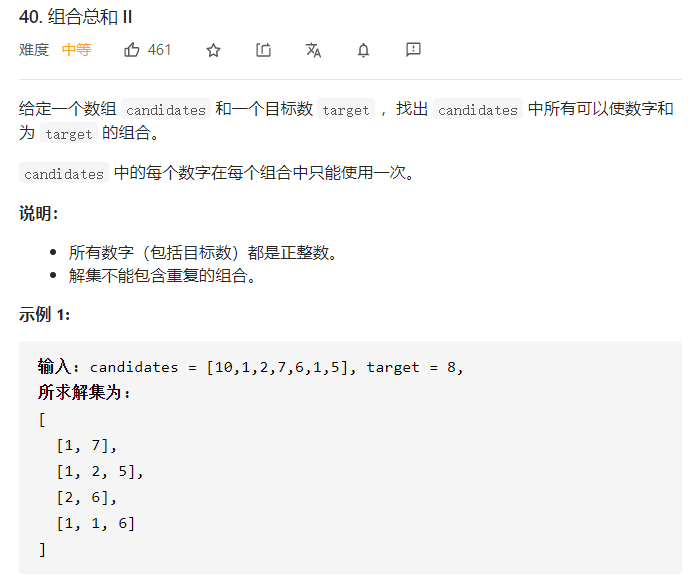
题目差不多,只不过这里只是每个数字只能用一次,同时也是不能包含重复的组合,所以,用之前Map去重方法解决.
const res = []; // 结果
const map = new Map();
function subsets(nums, target) {
if(nums.length === 0) return null;
const temp = []; // 缓存结果值
backtracking(0, nums.sort(), target, temp);
return res;
}
function backtracking(start, nums, target, temp) {
// 终止条件
if(target < 0) {
return;
}
// 获取结果(判断是否重复)
if(target === 0 && !map.has(temp.join())) {
res.push([...temp]);
map.set(temp.join(), temp);
}
// 从start开始遍历
for(let i = start; i < nums.length; i++) {
// 处理节点;
temp.push(nums[i]);
// 递归
backtracking(i + 1, nums, target - nums[i], temp);
// 回溯
temp.pop();
}
}
subsets([10,1,2,7,6,1,5], 8);
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.