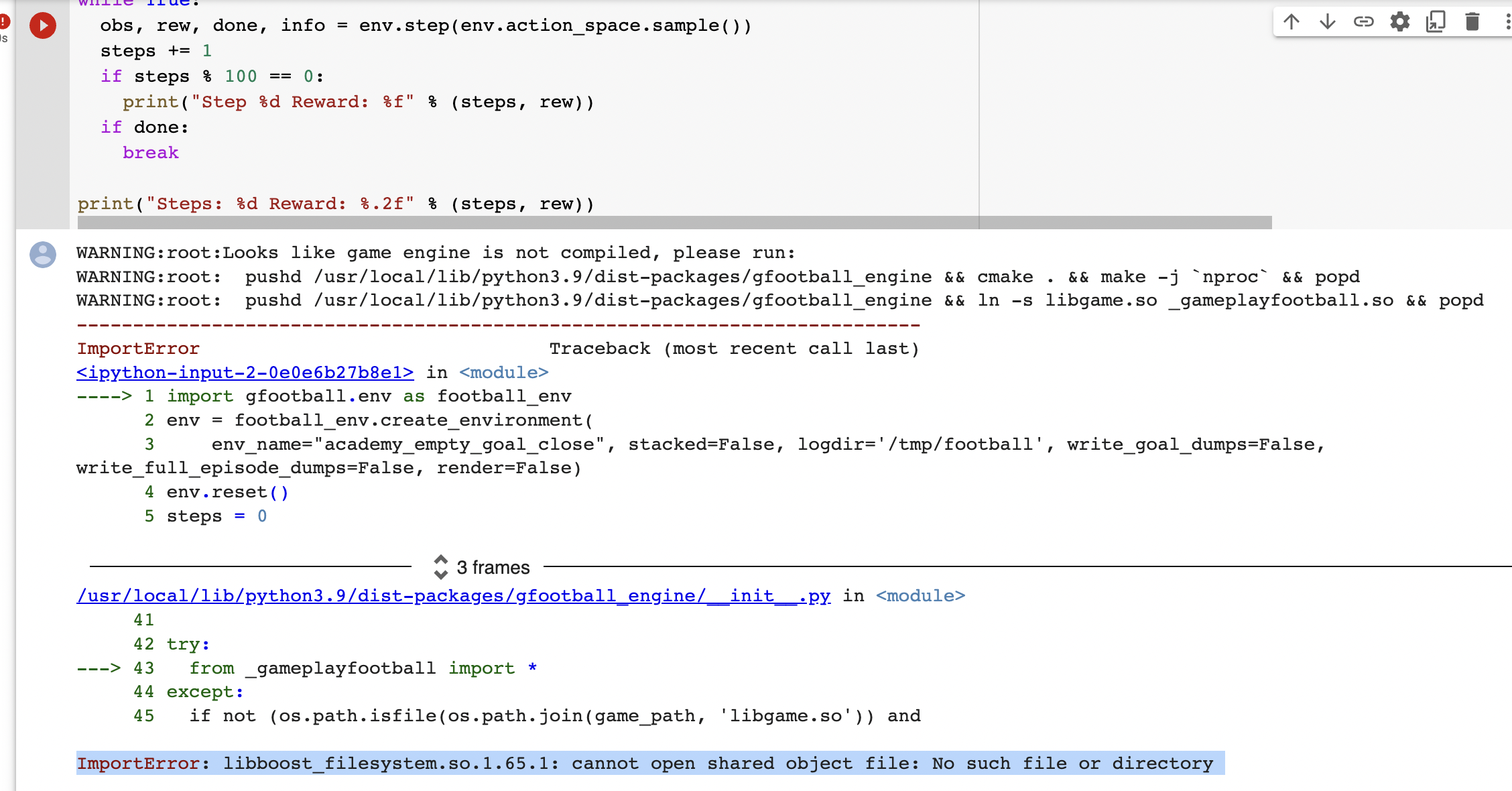
Hello and thank you for the implementation it really helps. I have an environment that is sparse and only receives a reward on task completion. I followed your code and implemented a PPO algorithm that uses a simple actor-critic network. I am attaching my code for the network and PPO here.
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.fc1 = nn.Linear(33, 128)
self.fc2 = nn.Linear(128, 128)
self.critic = nn.Linear(128, 1)
self.actor = nn.Linear(128, 3)
self.apply(init_weights)
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
return self.critic(x), F.softmax(self.actor(x), dim=-1)
class PPO():
def __init__(
self,
env,
policy,
lr,
gamma,
betas,
gae_lambda,
eps_clip,
entropy_coef,
value_coef,
max_grad_norm,
timesteps_per_batch,
n_updates_per_itr,
summary_writer,
norm_obs = True):
self.policy = policy
self.env = env
self.lr = lr
self.gamma = gamma
self.betas = betas
self.gae_lambda = gae_lambda
self.eps_clip = eps_clip
self.entropy_coef = entropy_coef
self.value_coef = value_coef
self.max_grad_norm = max_grad_norm
self.timesteps_per_batch = timesteps_per_batch
self.n_updates_per_itr = n_updates_per_itr
self.summary_writer = summary_writer
self.norm_obs = norm_obs
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.total_updates = 0
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=self.lr, betas=self.betas)
def learn(self, total_timesteps=1000000, callback=None):
timesteps = 0
while timesteps < total_timesteps:
batch_obs, batch_actions, batch_log_probs, batch_rtgs, batch_advantages, batch_lens = self.rollout()
timesteps += np.sum(batch_lens)
advantage_k = (batch_advantages - batch_advantages.mean()) / (batch_advantages.std() + 1e-10)
for i in range(self.n_updates_per_itr):
state_values, action_probs = self.policy(batch_obs)
state_values = state_values.squeeze()
dist = Categorical(action_probs)
curr_log_probs = dist.log_prob(batch_actions)
ratios = torch.exp(curr_log_probs - batch_log_probs)
surr1 = ratios * advantage_k
surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantage_k
policy_loss = (-torch.min(surr1, surr2)).mean()
value_loss = F.mse_loss(state_values, batch_rtgs)
total_loss = policy_loss + self.value_coef * value_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
self.total_updates += 1
self.summary_writer.add_scalar("policy_loss", policy_loss, self.total_updates)
self.summary_writer.add_scalar("value_loss", value_loss, self.total_updates)
self.summary_writer.add_scalar("total_loss", total_loss, self.total_updates)
if callback:
callback.eval_policy(self.policy, self.summary_writer, self.norm_obs)
def rollout(self):
batch_obs = []
batch_acts = []
batch_state_values = []
batch_log_probs = []
batch_rewards = []
batch_rtgs = []
batch_lens = []
batch_advantages = []
batch_terminals = []
timesteps_collected = 0
while timesteps_collected < self.timesteps_per_batch:
eps_rewards = []
eps_state_values = []
eps_terminals = []
obs = self.env.reset()
done = False
eps_timesteps = 0
for _ in range(50):
timesteps_collected += 1
if self.norm_obs:
obs = (obs - obs.mean()) / (obs.std() - 1e-10)
batch_obs.append(obs)
state_value, action_probs = self.policy(torch.from_numpy(obs).type(torch.float).to(self.device))
dist = Categorical(action_probs)
action = dist.sample()
act_log_prob = dist.log_prob(action)
obs, reward, done, _ = self.env.step(action.cpu().detach().item())
eps_rewards.append(reward)
eps_state_values.append(state_value.squeeze().cpu().detach().item())
eps_terminals.append(0 if done else 1)
batch_acts.append(action.cpu().detach().item())
batch_log_probs.append(act_log_prob.cpu().detach().item())
eps_timesteps += 1
if done:
break
batch_lens.append(eps_timesteps)
batch_rewards.append(eps_rewards)
batch_state_values.append(eps_state_values)
batch_terminals.append(eps_terminals)
batch_obs = torch.tensor(batch_obs, dtype=torch.float).to(self.device)
batch_acts = torch.tensor(batch_acts, dtype=torch.float).to(self.device)
batch_log_probs = torch.tensor(batch_log_probs, dtype=torch.float).flatten().to(self.device)
for eps_rewards, eps_state_values, eps_terminals in zip(reversed(batch_rewards), reversed(batch_state_values), reversed(batch_terminals)):
discounted_reward = 0
gae = 0
next_state_value = 0
next_terminal = 0
for reward, state_value, terminal in zip(reversed(eps_rewards), reversed(eps_state_values), reversed(eps_terminals)):
discounted_reward = reward + self.gamma * discounted_reward
delta = reward + self.gamma * next_state_value * next_terminal - state_value
gae = delta + self.gamma * self.gae_lambda * next_terminal * gae
batch_rtgs.insert(0, discounted_reward)
batch_advantages.insert(0, gae)
next_state_value = state_value
next_terminal = terminal
batch_rtgs = torch.tensor(batch_rtgs, dtype=torch.float).to(self.device)
batch_advantages = torch.tensor(batch_advantages, dtype=torch.float).to(self.device)
return batch_obs, batch_acts, batch_log_probs, batch_rtgs, batch_advantages, batch_lens
I am using the Generalised Advantage Estimate in my case but even when using the simpler advantage function,R-V(s) my implementation still gets stuck and will always choose the same action when I am evaluating. This is how I evaluate the policy in a deterministic way. I am not sampling from a categorical distribution.
_, action_probs = policy(torch.from_numpy(obs).type(torch.float).to(device))
action = torch.argmax(action_probs).item()
Can you provide any pointers as to where the problem might be? I have used stablebaselines3 with the same environment implementation however because I want to have more control over the model I am using I opted for a custom implementation. I can't seem to figure out where the problem might be however.