cool-cohort / cool Goto Github PK
View Code? Open in Web Editor NEWthe source code of the COOL system
Home Page: https://www.comp.nus.edu.sg/~dbsystem/cool/
License: Apache License 2.0
the source code of the COOL system
Home Page: https://www.comp.nus.edu.sg/~dbsystem/cool/
License: Apache License 2.0
















































In table.yaml, the column with float64 type should be processed with the same logic as int, but it's not supported.
We want to generate cohort query from sogamo dataset for cohortQueryProcessing unittest.
Through some simple data analysis, there some problems. we found that:
In sogamo dataset, there are only 4 players in the entire dataset which contains 10k items. Thus the cohort query in old-version code is not representative. It can not work well as a unittest. According to the CoHANA paper, the raw data is larger than the sample data current we have. I recommend use raw data to generate test cohort query.
In tpch dataset, there is a same problem. There is only 1 user in the entire dataset. Total order in this datasets is about the same user.
ENV: On MacBook Pro 11.6.5
Steps on Terminal:
Currently, the COOL system cannot support the NULL value in the INT type columns, and it will assign NULL as a separate class for String type columns.
Maybe we can add bit maps to deal with NULL values.
there is redundancy in the storage for the several features that have a one-to-one mapping with the user ID, e.g. age, gender, birth year, and other demographic information.
This system can save cohort results in a certain format, and we need to reload these cohort results to filter users when processing other cohort queries.
The CoolModel class is currently serve to keep various readstores in memory without loading the the actual chunk data. It looks like a caching layer, then there are a few issue to address.
currentCube, so it can serve the cohort of a cube at one time. This is not necessary. Multiple workers should be able to concurrently request for cohorts under different cubes with only necessary synchronizationUse checkstyle to enforce a consistent code formatting.
After executing the command with query1-0.json to obtain the specific users from the health dataset, COOL shows 8513 users. But the correct number of users should be 8592. The user ids that start with "P-19709" are all missed. The missed user ids are as follows.
P-19709, P-19712, P-19713, P-19718, P-19720, P-19721, P-19732, P-19749, P-19762, P-19767,
P-19772, P-19773, P-19776, P-19777, P-19778, P-19780, P-19782, P-19789, P-19790, P-19791,
P-19797, P-19798, P-19799, P-19801, P-19803, P-19805, P-19806, P-19809, P-19812, P-19813,
P-19820, P-19830, P-19834, P-19841, P-19842, P-19843, P-19844, P-19846, P-19860, P-19861,
P-19864, P-19872, P-19874, P-19879, P-19882, P-19887, P-19890, P-19893, P-19901, P-19902,
P-19907, P-19909, P-19910, P-19911, P-19915, P-19919, P-19923, P-19929, P-19931, P-19941,
P-19944, P-19948, P-19950, P-19952, P-19954, P-19959, P-19962, P-19964, P-19972, P-19973,
P-19975, P-19978, P-19983, P-19985, P-19989, P-19991, P-19992, P-19994, P-19998
If we use int32 to store the time(i.e., the time interval), we can only analyze 68 years because of the INT32 ranges in [-2147483648, 2147483647].
For more details, please check the problem YEAR2038.
Next, we need to support int64 storage format.
The output cohort logic has at least one bug. The users are repeatedly added to the cohort output.
cohort size recorded in the query_res.json is inconsistent with the user list size stored in all.cohort. The issue is due to missing code in de-duplication in adding users during cohort processing.
The COOL can support the following OLAP query:
SELECT cout(*), sum(O_TOTALPRICE)
FROM TPC_H WHERE O_ORDERPRIORITY = 2-HIGH AND R_NAME = EUROPE
GROUP BY N_NAME,R_NAME
HAVING O_ORDERDATE >= '1993-01-01' AND O_ORDERDATE <= '1994-01-01' The design of OLAP follows the current steps:
The project structure.

The logic visualization.

The result:
{
"status" : "OK",
"elapsed" : 0,
"result" : [ {
"timeRange" : "1993-01-01|1994-01-01",
"key" : "RUSSIA|EUROPE",
"fieldName" : "O_TOTALPRICE",
"aggregatorResult" : {
"count" : 2.0,
"sum" : 312855,
"average" : null,
"max" : null,
"min" : null,
"countDistinct" : null
}
}, {
"timeRange" : "1993-01-01|1994-01-01",
"key" : "GERMANY|EUROPE",
"fieldName" : "O_TOTALPRICE",
"aggregatorResult" : {
"count" : 1.0,
"sum" : 4820,
"average" : null,
"max" : null,
"min" : null,
"countDistinct" : null
}
}, {
"timeRange" : "1993-01-01|1994-01-01",
"key" : "ROMANIA|EUROPE",
"fieldName" : "O_TOTALPRICE",
"aggregatorResult" : {
"count" : 2.0,
"sum" : 190137,
"average" : null,
"max" : null,
"min" : null,
"countDistinct" : null
}
}, {
"timeRange" : "1993-01-01|1994-01-01",
"key" : "UNITED KINGDOM|EUROPE",
"fieldName" : "O_TOTALPRICE",
"aggregatorResult" : {
"count" : 1.0,
"sum" : 33248,
"average" : null,
"max" : null,
"min" : null,
"countDistinct" : null
}
} ]
}
Previously, each range filed had a min and max value in the DataField. Now, since we merge the invariant fields with userID, we lost those information.
There are mainly two types of cohort study: Prospective Cohort Study and Retrospective Cohort Study.
In the prospective cohort study, we need cohort analysis to study the result of some actions. While in the retrospective cohort study, cohort analysis is needed for exploring the reasons for some outcome.
The big difference between them is the definition of age. The age in the prospective cohort study is a period of time after birth time. But the age in the retrospective cohort study is a period of time before the birth time.
Now COOL supports prospective cohort study. We need to implement the retrospective cohort study as well.
map string to global id at the beginning for each cublet.
iterate through data and check if user is contained in the target cohort list for the cublet
comment out CoolTupleReader for now. The downstream exploration application is already commented
the code format of the PR(#105) has not been checked.
The next step is to clean all outdated code in the previous version and format the rest code.
In eCommerce use-cases, we always need to group users based on several events (i.e., selectors), and the COOL system should support this functionality.
Currently the implementation of DistributedController at L86 and L185 calls the reload method of CoolModel that accepts a buffer and only loads that buffer to CubeRS. Therefore, it cannot handles cubes with multiple cublets.
Moreover, this overloaded reload is only used here. It does not make much sense to reload just one cublet. We can remove that method later.
The current organization of storevector seems quite ad-hoc. The input vector is not a good abstraction, defining a set of interface methods, which aren't general enough to be used/implemented by its implementing classes.
Give a few ideas about my plan here:
get, hasnext, next. which directly works on the state of internal buffers in the implementing classes. Implementing Iterable interface and using iterator to avoid directly manipulating buffer state is a better approach, I think.Any comments?
After merging the PR #72 , we shall revisit how to store a cohort. Maybe there is a better approach than using a list of global id for subsequent processing.
Supporting append relaxes the assumption of monotonic increasing user key in a cube, which will break all analysis when a cohort input is given. The problem is that during processing, the input vector of cohort is checked from small to large userkey id only once. No retraction.
The cohort representation is also related to PR #75 as well. We no longer plan to maintain a consistent global id across cublets, thus we cannot use a list of id from a cube to represent a cohort.
One possible direction is to directly store the user key value and we do translation through metachunk of a cublet, before processing. And applies this also to the appended blocks.
As a continued efforts of code refactoring to improve the systems extensibility, it comes to our attention that we need to remove the system design built around just int and string. Many codes in the system are hardcoded and contains casting to only support int and string.
It will pave the way to support float.
Have an abstract value type that moves across different operators in cool.
Have selected types at the source and end to handle the different data types.
better code readability and extensibility.
One tuple may meet two events, but now we only consider whether the tuple meets one of the events.
need to support the list functions in the cohortselector layout.
or we need run multiple times to get the meaningful results.
according to the current code logic, a user with only one record will never be classified into any cohort. Please fix it.
In the readStore, if we traverse one field multiple times, it reads the wrong value and does not throw expectations or warnings.
For example, in RLEInputVector readStore, if we traverse it multiple times with get, the end-offset will prevent the traverse and only return the value in the last offset, which results in a wrong read.
We should either explicitly throws exceptions to prevent multiple traverses, or allow it by removing such constraint or adding reset methods to reset the offset.
In this version, MetaChunk will be continuously expanded by Cubelets. However, the MetaChunk in each cubelet should only contain the necessary information for its own storage, and we can add another storage to store the global information.
For example,
In Cubelet 1, the age range is 0 to 20. (in MetaChunk: 0-20)
In Cubelet 2, the age range is 30 to 50. (in MetaChunk: 0-50)
we should change it into
In Cubelet 1, the age range is 0 to 20. (in MetaChunk: 0-20)
In Cubelet 2, the age range is 30 to 50. (in MetaChunk: 30-50)
(in MetaChunk: 0-50 [global] )
In this way, we can skip several cubelets by checking the MetaChunk when we process cohort queries. For example, we can skip the search process in Cubelet 1 if the query is only about the users whose age is bigger than 30.
we can support the time in the "%d/%m/%Y" format, and we need to support a more fine-grained format, i.e., "%d/%m/%Y %H:%M:%S"
Please update the function and unit test for the funnel analysis
TODO
When we run the mvn clean package command, it will generate many Cubes and cohorts.
We should remove these useless files after finishing all test cases.
Many thanks for the great work !
I found some limitations of the tool in which we cannot use it in current state:
we need to add more use-cases to valid and improve our system.
The current float compression with large diff. The reason is that the xor to represent the difference will span all 32 bits. When xor is directly casted to long type, the first bit recoganized as the sign bit will be mapped to the sign bits in long which now is a 64 bit value. That would result in diffSize being 64, while it should have been 32.
The solution is to use Integer.toUsignedLong to covert int to long. Note that the casting in the other direction is ok: casting a value from long to int will take the last 32 bit as bits for the int.
We need to refactor all functionality tests in the current version.
Refering to the Paper of Cohona, we can break down a complete cohort query into five sub-query, shown in fig. The target of query is to
Given the
launchbirth action and the activity table as show in Table (check raw paper), for players who play thedwarfrole at their birth time, cohort those players based on their birth countries and report the total gold that country launch cohorts spent since they were born.
We call these five steps 1). BirthSelection 2). BirthTupleGeneration 3). AgeGeneration 4). CohortAttributeGeneration 5). CohortGenration.

Actually, we can compress step 1 and step 2 into one operation. The combination of step 1 and step 2 is called BirthSelection. As for step 4, it is not neccessary for the basic cohort query, it only add some additional attribution for a kind of cohort. For above example query, the target is to count the number of player for one country which is the cohort. From the example in paper Cohort Analysis with ease. we can see that CohortAtributeGeneration is not the basic step for a cohort query. Progress is shown in fig that step a,b,c generate data in axis-x and axis-y, step e generate lines of different color.
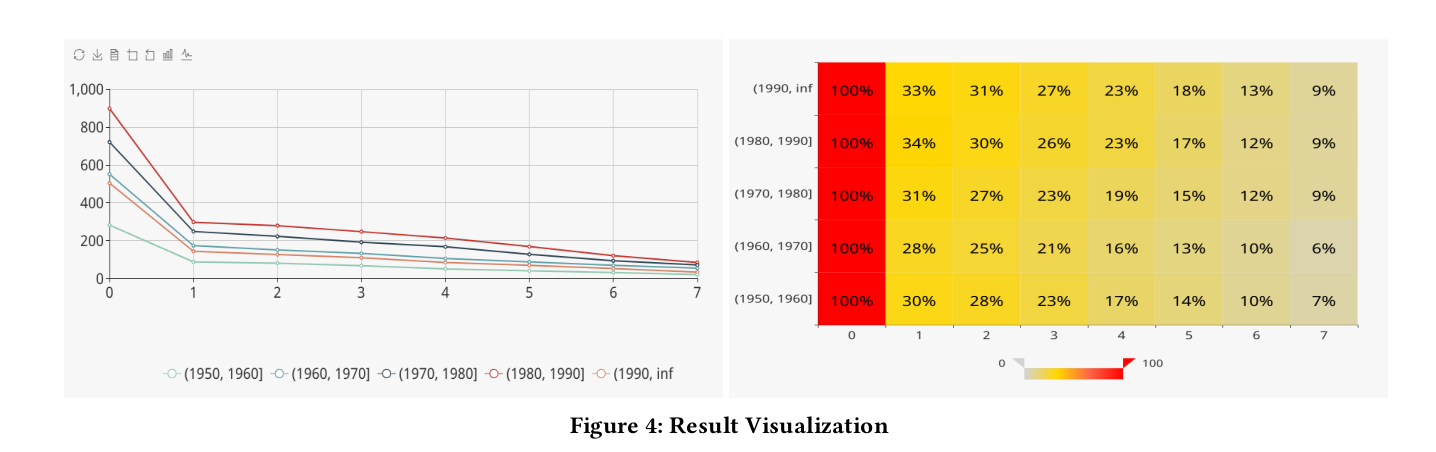
Thus we can summary the tree step of the basic cohort query, which is also the three operator in our implementation.
These three steps should be executed step by step in a CohortExecuteUnit.
(Following part is for cohort query processing only. We can consider this part as a component of the whole query processing module. If we want to maintain a good open source project, we have to support base query process in the future)
There are some assumptions before we build the query execution part.
For one table, we allow append operation to add data. The data in every append operation is called a append block. Considering the application scenarios of cohort, we assume that Every Append Block contains a bunch of behavior data item within a certain time window. For the layout of the Append Block, we also assume that tuples are clustered in userId, and for one user, its tuple is sorted in time serise. These are two constrains we set for input data.
First we create a class CohortOperator to combine above three sub-process and also CohortAttributeGeneration step. (This step can be null). For three sub-process, we can create classes separately. There is no need to allow them to implement same interface, since these three classes are all needed in Cohort Processing. However, every class have to implement init and process two functions. init load filter from query.
Simply introduce the logic of every sub-process.
The logic of BirthSelection's process
process return these HashMapThe logic of AgeGeneration's process
process return the ArrayList which contain accessible tuple. These ArrayList is the scope the rest operator applied on. Each element of this ArrayList is a Array contain accessible tuple. The index of the ArrayList is age in cohort.The logic of CohortGeneration's process
process, We maintain HashMap <Cohort - SelectedValueList>.In order to reduce the usage of memory, we can implement the CohortOperator as an iterator container. Everytime step is called, it return the i-th age's cohort data (HashMap).
Above content is the simply imagination of modular cohort query's execution processing. I think it can solve the continuous problem. Additionally, apart from cohort query, we should reconstruct the filter class in the next few days. Certainly, there are many other aspects to consider in code level, such as the memory usage and the query optimization, which are left in the future work.
Following test passed.
Csv data loader Test
Cube Reload Test
Cohort Selection Test
Cohort Analysis Test
Funnel Analysis Test
IceBerg Test
CohortProfilingTest Test
Below test build failed.
`======================== Cube List Test ========================
Applications: [sogamo, tpc-h-10g, health]
Tests run: 13, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 1.245 sec <<< FAILURE!
CohortSelectionTest(com.nus.cool.core.model.CoolModelTest) Time elapsed: 0.029 sec <<< FAILURE!
java.nio.BufferUnderflowException
at java.base/java.nio.Buffer.nextGetIndex(Buffer.java:699)
at java.base/java.nio.DirectShortBufferU.get(DirectShortBufferU.java:321)
at com.nus.cool.core.io.storevector.ZInt16Store.next(ZInt16Store.java:67)
at com.nus.cool.core.io.storevector.FoRInputVector.next(FoRInputVector.java:57)
at com.nus.cool.core.cohort.TimeUtils.getDateFromOffset(TimeUtils.java:53)
at com.nus.cool.core.cohort.ExtendedCohortSelection.getUserBirthTime(ExtendedCohortSelection.java at com.nus.cool.core.cohort.ExtendedCohortSelection.getUserBirthTime(ExtendedCohortSelection.java at com.nus.cool.core.cohort.ExtendedCohortSelection.getUserBirthTime(ExtendedCohortSelection.java:427)
at com.nus.cool.core.cohort.ExtendedCohortSelection.selectUser(ExtendedCohortSelection.java:511)
at com.nus.cool.core.cohort.CohortUserSection.process(CohortUserSection.java:150)
at com.nus.cool.model.CoolCohortEngine.selectCohortUsers(CoolCohortEngine.java:63)
at com.nus.cool.core.model.CoolModelTest.CohortSelectionTest(CoolModelTest.java:96)
Results :
Failed tests: CohortSelectionTest(com.nus.cool.core.model.CoolModelTest)
Tests run: 13, Failures: 1, Errors: 0, Skipped: 0
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for cool 0.1-SNAPSHOT:
[INFO]
[INFO] cool ............................................... SUCCESS [02:26 min]
[INFO] cool-core .......................................... FAILURE [02:30 min]
[INFO] cool-extensions .................................... SKIPPED
[INFO] parquet-extensions ................................. SKIPPED
[INFO] hdfs-extensions .................................... SKIPPED
[INFO] arrow-extensions ................................... SKIPPED
[INFO] avro-extensions .................................... SKIPPED
[INFO] cool-queryserver ................................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:57 min
[INFO] Finished at: 2022-04-18T15:58:23+05:30
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.12.4:test (default-test) on project cool-core: There are test failures.
[ERROR]
[ERROR] Please refer to /Users/i0w00to/apache/COOL/cool-core/target/surefire-reports for the individual test results.
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn -rf :cool-core
`
Create an issue and submit a corresponding PR for each one.
loadattr that mutates internal data.EcommerceDataSetSQL1 test under IcebergQueryTest assumes that CsvLoaderTest to have loaded ecommerce data loaded in the cube repo. Yet this dependency unlike CohortSelectionTest/CohortAnalysisTest is not specified.
The field sequence of the table.YAML must be the same as the sequence in each row,
This is not convenient, the data reader could read the sequence from the header of the CSV file, and then only use the other information in table.yaml instead of field sequence.
This is the version of JDK:
java -version
java version “18.0.1” 2022-04-19
Java(TM) SE Runtime Environment (build 18.0.1+10-24)
Java HotSpot(TM) 64-Bit Server VM (build 18.0.1+10-24, mixed mode, sharing)
After pull and mvn clean , build:
l0p018z@m-c02c75femd6r COOL % java -jar cool-queryserver/target/cool-queryserver-0.1-SNAPSHOT.jar datasetSource 8086
[] Dataset source folder datasetSource exists.
[] Start the Query Server (port: 8086)...
log4j:WARN No appenders could be found for logger (org.eclipse.jetty.util.log).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread “Thread-0” java.lang.ExceptionInInitializerError
at com.sun.xml.bind.v2.runtime.reflect.opt.AccessorInjector.prepare(AccessorInjector.java:83)
at com.sun.xml.bind.v2.runtime.reflect.opt.OptimizedAccessorFactory.get(OptimizedAccessorFactory.java:176)
at com.sun.xml.bind.v2.runtime.reflect.Accessor$FieldReflection.optimize(Accessor.java:282)
at com.sun.xml.bind.v2.runtime.property.ArrayProperty.(ArrayProperty.java:69)
at com.sun.xml.bind.v2.runtime.property.ArrayERProperty.(ArrayERProperty.java:88)
at com.sun.xml.bind.v2.runtime.property.ArrayElementProperty.(ArrayElementProperty.java:100)
at com.sun.xml.bind.v2.runtime.property.ArrayElementNodeProperty.(ArrayElementNodeProperty.java:62)
at java.base/jdk.internal.reflect.DirectConstructorHandleAccessor.newInstance(DirectConstructorHandleAccessor.java:67)
at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:499)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:483)
at com.sun.xml.bind.v2.runtime.property.PropertyFactory.create(PropertyFactory.java:128)
at com.sun.xml.bind.v2.runtime.ClassBeanInfoImpl.(ClassBeanInfoImpl.java:183)
at com.sun.xml.bind.v2.runtime.JAXBContextImpl.getOrCreate(JAXBContextImpl.java:532)
at com.sun.xml.bind.v2.runtime.JAXBContextImpl.(JAXBContextImpl.java:347)
at com.sun.xml.bind.v2.runtime.JAXBContextImpl$JAXBContextBuilder.build(JAXBContextImpl.java:1170)
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:145)
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:236)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:104)
at java.base/java.lang.reflect.Method.invoke(Method.java:577)
at javax.xml.bind.ContextFinder.newInstance(ContextFinder.java:171)
at javax.xml.bind.ContextFinder.newInstance(ContextFinder.java:129)
at javax.xml.bind.ContextFinder.find(ContextFinder.java:307)
at javax.xml.bind.JAXBContext.newInstance(JAXBContext.java:478)
at javax.xml.bind.JAXBContext.newInstance(JAXBContext.java:435)
at org.glassfish.jersey.server.wadl.internal.WadlApplicationContextImpl.getJAXBContextFromWadlGenerator(WadlApplicationContextImpl.java:120)
at org.glassfish.jersey.server.wadl.WadlFeature.isJaxB(WadlFeature.java:74)
at org.glassfish.jersey.server.wadl.WadlFeature.configure(WadlFeature.java:56)
at org.glassfish.jersey.model.internal.CommonConfig.configureFeatures(CommonConfig.java:728)
at org.glassfish.jersey.model.internal.CommonConfig.configureMetaProviders(CommonConfig.java:647)
at org.glassfish.jersey.server.ResourceConfig.configureMetaProviders(ResourceConfig.java:823)
at org.glassfish.jersey.server.ApplicationHandler.initialize(ApplicationHandler.java:328)
at org.glassfish.jersey.server.ApplicationHandler.lambda$initialize$1(ApplicationHandler.java:293)
at org.glassfish.jersey.internal.Errors.process(Errors.java:292)
at org.glassfish.jersey.internal.Errors.process(Errors.java:274)
at org.glassfish.jersey.internal.Errors.processWithException(Errors.java:232)
at org.glassfish.jersey.server.ApplicationHandler.initialize(ApplicationHandler.java:292)
at org.glassfish.jersey.server.ApplicationHandler.(ApplicationHandler.java:259)
at org.glassfish.jersey.server.ApplicationHandler.(ApplicationHandler.java:246)
at org.glassfish.jersey.jetty.JettyHttpContainer.(JettyHttpContainer.java:468)
at org.glassfish.jersey.jetty.JettyHttpContainerProvider.createContainer(JettyHttpContainerProvider.java:37)
at org.glassfish.jersey.server.ContainerFactory.createContainer(ContainerFactory.java:58)
at com.nus.cool.queryserver.QueryServer.createJettyServer(QueryServer.java:94)
at com.nus.cool.queryserver.QueryServer.run(QueryServer.java:49)
at java.base/java.lang.Thread.run(Thread.java:833)
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int) throws java.lang.ClassFormatError accessible: module java.base does not “opens java.lang” to unnamed module @15fef0a0
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Method.checkCanSetAccessible(Method.java:200)
at java.base/java.lang.reflect.Method.setAccessible(Method.java:194)
at com.sun.xml.bind.v2.runtime.reflect.opt.Injector$1.run(Injector.java:177)
at com.sun.xml.bind.v2.runtime.reflect.opt.Injector$1.run(Injector.java:174)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:318)
at com.sun.xml.bind.v2.runtime.reflect.opt.Injector.(Injector.java:172)
... 44 more
In OLAP queries, such as group BY and count, we don't care about the order of records.
So such an assumption adds some inconvenience in data pre-processing for OLAP queries
once the users only have one record, it will not be recorded as a validate user.
The COOL stores and compresses the DateTime column by the int values. Hence, it can only process the time step by day. If we update the storage into float type, it can process the time step by an hour, a minute, and even a second.
The current age calculation for week/month/year is based on translation to the fixed day interval:
Needs to use the date object to generate the difference directly and add tests to cover these cases.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.