cfzd / ultra-fast-lane-detection-v2 Goto Github PK
View Code? Open in Web Editor NEWUltra Fast Deep Lane Detection With Hybrid Anchor Driven Ordinal Classification (TPAMI 2022)
License: MIT License
Ultra Fast Deep Lane Detection With Hybrid Anchor Driven Ordinal Classification (TPAMI 2022)
License: MIT License
博主你好,我将curvelane数据集转换为tusimple格式后与tusimple放在一起,使用convert_tusimple.py进行分割,出现以下错误:
VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
lanes = [np.array(l['lanes']) for l in label_json_all] # 车道
Traceback (most recent call last):
File "/home/wjy/Ultra-Fast-Lane-Detection-V2/scripts/convert_tusimple.py", line 202, in
'label_data_driver_161_90frame.json', 'label_data_driver_182_30frame.json'])
File "/home/wjy/Ultra-Fast-Lane-Detection-V2/scripts/convert_tusimple.py", line 63, in get_tusimple_list
line_txt_tmp = [None] * (len(h_samples[i][valid]) + len(lanes[i][j][valid]))
TypeError: object of type 'int' has no len()
Hello,thanks for your research.
my os is windows 10
i got a problem for make culane evaluator.
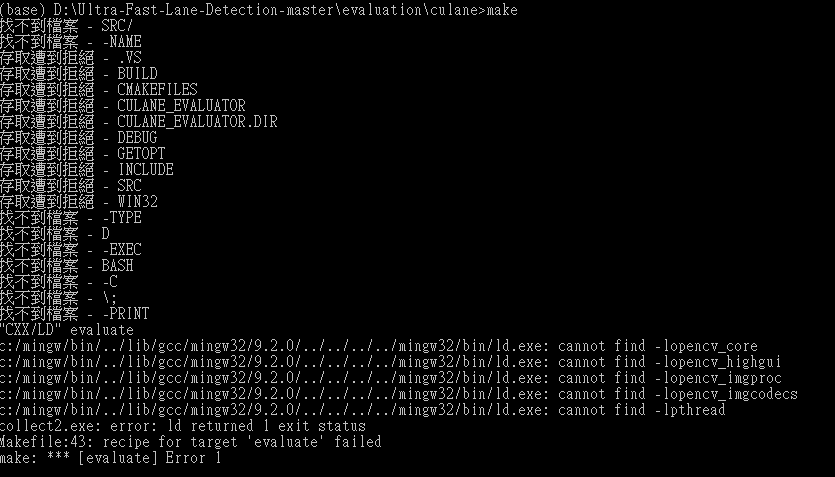
i dont know what the problem is fall
i try to use install fot the windows,but also have trouble

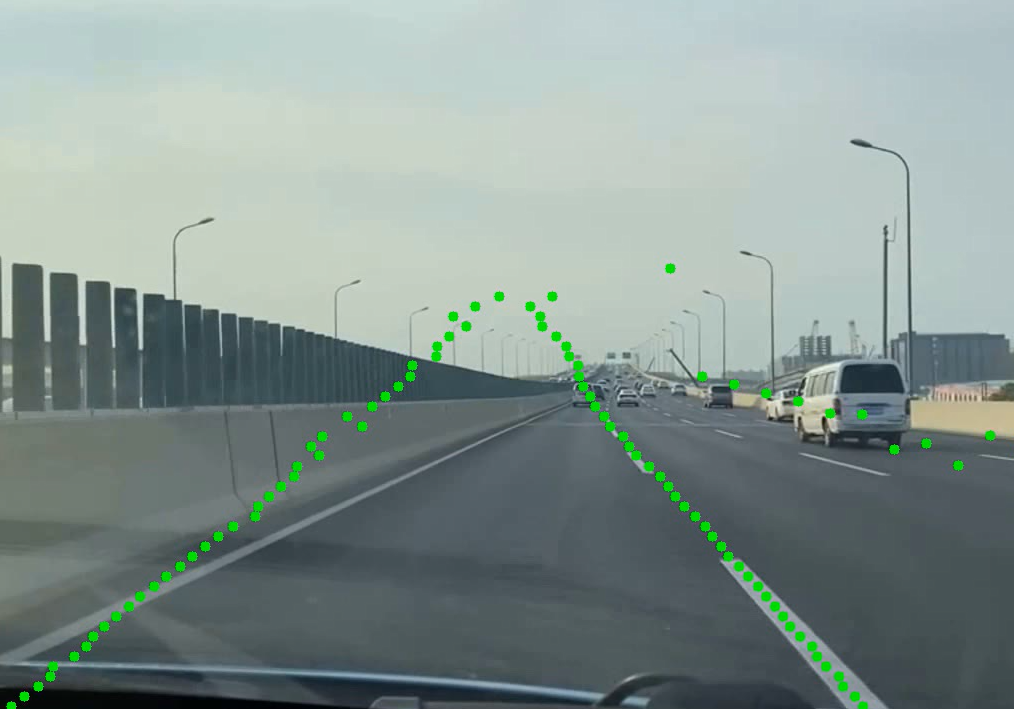
Could you please provide any pointers to how I could modify demo.py to perform inference using a video file?
How to demo the video?
Is it possible that you also share the visualization code?
FileNotFoundError: [Errno 2] No such file or directory: '/home/wjy/Ultra-Fast-Lane-Detection-V2/tmp/txt/out0_normal.txt'
Hello,
I have change the format from curvelanes to culane, but when I run the evaluation I got -1 precision. In your code , you have given the
original format of curvelanes, but can you give the changed format from curvelanes to culane ? That is the format when I run your code to change the format from curvelanes to culane

How can i change the resnet backborn to vgg16?
I see the backborn in culane.py can change to resnet18,34,50....
but in backborn.py form middle i see vgg16bn, Can the backborn change to vgg16bn?
To someone who's interested in testing multiple custom images (cut from video), save the following as infer.py and change the dataset path and output path, then run:
python infer.py configs/your_model_config.py --test_model path/to/your/model/file
import torch, os, cv2
from pylab import *
from utils.dist_utils import dist_print
from utils.common import merge_config, get_model
import tqdm
import torchvision.transforms as transforms
from data.dataset import LaneTestDataset
def pred2coords(pred, row_anchor, col_anchor, local_width = 1, original_image_width = 1640, original_image_height = 590):
batch_size, num_grid_row, num_cls_row, num_lane_row = pred['loc_row'].shape
batch_size, num_grid_col, num_cls_col, num_lane_col = pred['loc_col'].shape
max_indices_row = pred['loc_row'].argmax(1).cpu()
# n , num_cls, num_lanes
valid_row = pred['exist_row'].argmax(1).cpu()
# n, num_cls, num_lanes
max_indices_col = pred['loc_col'].argmax(1).cpu()
# n , num_cls, num_lanes
valid_col = pred['exist_col'].argmax(1).cpu()
# n, num_cls, num_lanes
pred['loc_row'] = pred['loc_row'].cpu()
pred['loc_col'] = pred['loc_col'].cpu()
coords = []
row_lane_idx = [1,2]
col_lane_idx = [0,3]
for i in row_lane_idx:
tmp = []
if valid_row[0,:,i].sum() > num_cls_row / 2:
for k in range(valid_row.shape[1]):
if valid_row[0,k,i]:
all_ind = torch.tensor(list(range(max(0,max_indices_row[0,k,i] - local_width), min(num_grid_row-1, max_indices_row[0,k,i] + local_width) + 1)))
out_tmp = (pred['loc_row'][0,all_ind,k,i].softmax(0) * all_ind.float()).sum() + 0.5
out_tmp = out_tmp / (num_grid_row-1) * original_image_width
tmp.append((int(out_tmp), int(row_anchor[k] * original_image_height)))
coords.append(tmp)
for i in col_lane_idx:
tmp = []
if valid_col[0,:,i].sum() > num_cls_col / 4:
for k in range(valid_col.shape[1]):
if valid_col[0,k,i]:
all_ind = torch.tensor(list(range(max(0,max_indices_col[0,k,i] - local_width), min(num_grid_col-1, max_indices_col[0,k,i] + local_width) + 1)))
out_tmp = (pred['loc_col'][0,all_ind,k,i].softmax(0) * all_ind.float()).sum() + 0.5
out_tmp = out_tmp / (num_grid_col-1) * original_image_height
tmp.append((int(col_anchor[k] * original_image_width), int(out_tmp)))
coords.append(tmp)
return coords
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
args, cfg = merge_config()
cfg.batch_size = 1
print('setting batch_size to 1 for demo generation')
dist_print('start testing...')
assert cfg.backbone in ['18', '34', '50', '101', '152', '50next', '101next', '50wide', '101wide']
if cfg.dataset == 'CULane':
cls_num_per_lane = 18
elif cfg.dataset == 'Tusimple':
cls_num_per_lane = 56
else:
raise NotImplementedError
net = get_model(cfg)
state_dict = torch.load(cfg.test_model, map_location='cpu')['model']
compatible_state_dict = {}
for k, v in state_dict.items():
if 'module.' in k:
compatible_state_dict[k[7:]] = v
else:
compatible_state_dict[k] = v
net.load_state_dict(compatible_state_dict, strict=False)
net.eval()
img_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((int(cfg.train_height/cfg.crop_ratio), cfg.train_width)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
pathname = "" # Dir of imgs to be detected
imgs_path = os.listdir(pathname)
i = 0
for imgname in imgs_path:
if imgname.endswith('.png') or imgname.endswith('.jpg') or imgname.endswith('.jpeg'):
img = cv2.imread(pathname + '/' + imgname)
im0 = img.copy()
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_h, img_w = img.shape[0], img.shape[1]
img = img_transforms(img)
img = img[:, -cfg.train_height:, :]
img = img.to('cuda:0')
img = torch.unsqueeze(img, 0)
with torch.no_grad():
pred = net(img)
coords = pred2coords(pred, cfg.row_anchor, cfg.col_anchor, original_image_width=img_w,
original_image_height=img_h)
for lane in coords:
for coord in lane:
cv2.circle(im0, coord, 5, (0, 255, 0), -1)
resname = " " + str(i) + '.png' # Dir of inference result
cv2.imwrite(resname, im0)
i += 1
print(imgname + " finished.")
#cv2.waitKey(0)
Many thanks to @Yutong-gannis
Hi, I'm on the verge of publishing my own paper and to provide a comparative study, I wanted to use your algorithm as an alternative method. In doing so, I need to get a custom video inference from your network but I'm struggling to obtain an accurate result. I used the file "Demo.py" with some changes from the last version of v.2 of this network but it wasn't helpful. I would highly appreciate it if you could share your visualization code.
Thank you very much for your help in advance.
Best,
Ali
如题,v1版本中是划分为num_grid来判断某个点是否存在,而在v2版本中是额外添加了一个车道线点是否存在的分支。请问改进的动机是因为对比之后效果更好吗?还是只是结构上的改进
@cfzd 请教下readme里面开源的culane_res18.pth模型是使用git仓库里面代码训练的吗,我这边碰见的问题是
我自己只是换了数据集,其他部分保持不动,使用相同脚本将开源模型和自己训练的模型转成onnx,再转tensorr,但是2个模型在fp16下结果完全不同。
我想问下作者的culane_res18.pth模型是否有过特殊处理
the cuda version must 10.2?
")"位置写错了
Traceback (most recent call last):
File "train.py", line 117, in
train(net, train_loader, loss_dict, optimizer, scheduler,logger, epoch, metric_dict, cfg.dataset)
File "train.py", line 17, in train
for b_idx, data_label in enumerate(progress_bar):
File "/home/wjy/anaconda3/envs/lane-det/lib/python3.7/site-packages/tqdm/std.py", line 1195, in iter
for obj in iterable:
File "/home/wjy/Ultra-Fast-Lane-Detection-V2/data/dali_data.py", line 246, in next
points_row = my_interp.run(points, self.interp_loc_row, 0)
AttributeError: module 'my_interp' has no attribute 'run'
Traceback (most recent call last):
File "train.py", line 8, in
from utils.common import calc_loss, get_model, get_train_loader, inference, merge_config, save_model, cp_projects
File "/home/ubuntu/user_space/Ultra-Fast-Lane-Detection-V2/utils/common.py", line 2, in
from data.dali_data import TrainCollect
File "/home/ubuntu/user_space/Ultra-Fast-Lane-Detection-V2/data/dali_data.py", line 11, in
import my_interp
ImportError: /home/ubuntu/miniconda3/lib/python3.7/site-packages/my_interp-0.0.0-py3.7-linux-x86_64.egg/my_interp.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZTIN3c1021AutogradMetaInterfaceE
and my gcc version is updated to 7.3.0, so I do not aware of the reason why this problem arise. Tks!
i got FileNotFoundError when i try to evaluate the pretrained model on Curvelanes
i run the test.py with following command
python test.py configs/curvelanes_res18.py --test_model ./work_dirs/curvelanes_res18.pth --test_work_dir ./tmp
result:
Traceback (most recent call last):
File "test.py", line 36, in
eval_lane(net, cfg)
File "/home/powei/Ultra-Fast-Lane-Detection-v2-master/evaluation/eval_wrapper.py", line 853, in eval_lane
res = call_curvelane_eval(cfg.data_root, 'curvelanes_eval_tmp', cfg.test_work_dir)
File "/home/powei/Ultra-Fast-Lane-Detection-v2-master/evaluation/eval_wrapper.py", line 1057, in call_curvelane_eval
res_all['res_curve'] = read_helper(out0)
File "/home/powei/Ultra-Fast-Lane-Detection-v2-master/evaluation/eval_wrapper.py", line 960, in read_helper
lines = open(path, 'r').readlines()[1:]
FileNotFoundError: [Errno 2] No such file or directory: './tmp/txt/out0_curve.txt'
i have successfully built culane_evaluator
Scanning dependencies of target culane_evaluator [ 20%] Building CXX object CMakeFiles/culane_evaluator.dir/src/counter.cpp.o [ 40%] Building CXX object CMakeFiles/culane_evaluator.dir/src/evaluate.cpp.o [ 60%] Building CXX object CMakeFiles/culane_evaluator.dir/src/lane_compare.cpp.o [ 80%] Building CXX object CMakeFiles/culane_evaluator.dir/src/spline.cpp.o [100%] Linking CXX executable culane_evaluator [100%] Built target culane_evaluator
导入my_interp报错
python3.8/site-packages/my_interp-0.0.0-py3.8-linux-x86_64.egg/my_interp.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor8data_ptrIfEEPT_v@cfzd 这个是CUDA版本不匹配吗
@cfzd
if name == "main":
torch.backends.cudnn.benchmark = True
args, cfg = merge_config()
cfg.batch_size = 1
print('setting batch_size to 1 for demo generation')
dist_print('start testing...')
assert cfg.backbone in ['18', '34', '50', '101', '152', '50next', '101next', '50wide', '101wide']
if cfg.dataset == 'CULane':
cls_num_per_lane = 18
elif cfg.dataset == 'Tusimple':
cls_num_per_lane = 56
else:
raise NotImplementedError
net = get_model(cfg)
state_dict = torch.load(cfg.test_model, map_location='cpu')['model']
compatible_state_dict = {}
for k, v in state_dict.items():
if 'module.' in k:
compatible_state_dict[k[7:]] = v
else:
compatible_state_dict[k] = v
net.load_state_dict(compatible_state_dict, strict=False)
net.eval()
img_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((cfg.train_height, cfg.train_width)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img_path = "D:/autodrive/images/00010.png"
img = cv2.imread(img_path)
img_h, img_w = img.shape[0], img.shape[1]
im0 = img.copy()
img = img_transforms(img)
img = img.to('cuda:0')
img = torch.unsqueeze(img, 0)
with torch.no_grad():
pred = net(img)
coords = pred2coords(pred, cfg.row_anchor, cfg.col_anchor, original_image_width=img_w,
original_image_height=img_h)
for lane in coords:
for coord in lane:
cv2.circle(im0, coord, 5, (0, 255, 0), -1)
cv2.imshow('demo', im0)
cv2.waitKey(0)”
这是我改的单张图片的推理,但是检测出的点与车道线匹配不上,似乎是你在加载图片是进行过仿射变换,可以解答一下吗
tusimple中的json文件中车道线点是按行锚来划分的,如果一条车道线是水平的,在这个行锚上就一个点,而作者用这种json文件生成tusimple_anno_cache.json文件来训练,这样作者要的纵锚不就失去了意义了吗
Error when executing Mixed operator decoders__Image, instance name: "__Image_4", encountered:
Error in thread 0: nvml error (999): A nvml internal driver error occurred
Current pipeline object is no longer valid.
有什么命令我遗漏了吗?怎么推理自己的数据集啊,或者自己的单张图片?
The paper mentions the use of the LLAMAS dataset. How should this dataset be used for model training?
作者进行用了多个数据集进行验证模型结果,包括tusimple./culane/LLAMAS等,想请问下LLAMAS数据集如何训练,有没有code提供,谢谢
I don't find this fie in my data, can you tell me where I can find the tusimple_anno_cache.json, thanks.
您好,请问在哪里能找到tusimple_anno_cache.json这个文件呢?或者是怎么生成呢
Hi~ My custom dataset contains up to 8 lanes, can ufldv2 tackle this problem like ufldv1?
out_tmp_left = (loc_row_left[batch_idx,all_ind_left,cls_idx,lane_idx].softmax(0) * all_ind_left.float()).sum() + 0.5
out_tmp_left = out_tmp_left / (num_grid-1) * 1640 + 1640./25
out_tmp_up = (loc_col_up[batch_idx,all_ind_up,cls_idx,lane_idx].softmax(0) * all_ind_up.float()).sum() + 0.5
out_tmp_up = out_tmp_up / (num_grid-1) * 590 + 32./534*590what's the meaning of the value 1640./25 and 32./534*590, if I change the dataset,how to set the value?
https://github.com/cfzd/Ultra-Fast-Lane-Detection-v2/blob/master/data/dali_data.py#L160
At data/dali_data.py from line 152-160, points are transformed with image warp, at this step points are aligned with lanes on image
After warp affine (from line 163-176), the image is resized and cropped, but there's no further transform to the points, shows that the points are not at the correct spots of the image.
Is this a bug, or you did this with some purpose?
tusimple_anno_cache.json文件是有代码convert_tusimple.py文件生成的,随之生成的还有车道线的掩码图,想请问一下在训练的过程中计算loss用的标签是tusimple_anno_cache.json中的车道线点还是掩码上的车道线点?
或者说 如何用V1版本可以训练的数据转换成目前程序可用的训练集
请问cache_dict内部存储的是什么,如何根据图像集生成cache_dict
If we have only two lanes, column anchors can't be used, is it same as the UFLDv1?
请问在训练tusimple或自定义数据集中,loss下降到多少,top3达到多少合适呢?
train.py中不使用res = eval_lane(net, cfg, ep = epoch, logger = logger)可以吗?
I found some parameters in the cls that I can't understand.
self.input_dim = input_height // 32 * input_width // 32 * 8, I am wondering why there is an 8.(cls): Sequential(
(0): Identity()
(1): Linear(in_feature=2000, out_features=2048, bias=True)
(2): Relu()
(3): Linear(in_feature=2047, out_features=39576, bias=True)
)
(pool): Conv2d(512, 8, kernel_size=(1, 1), stride(1, 1))
Why the out_features in line 5 is 39576, I know it's self.dim1 + self.dim2 + sel4.dim3 + sel4.dim4 but I just don't understand why. And why the output of line 7 is 8.
Looking forward to your reply, thanks.
I've done data training and evaluation. I can check the result of version 1 with demo.py, but what file should I check in version2 to check the detection result?
In the prev version, we could get the number of detected lanes like,
output_img, lane_points, lanes_detected = lane_detector.cfg.detect_lanes(frame)
lanes_detected = ['False', 'True', 'True', 'False']
The above would mean the two center lanes have been detected
Is there a way to do that here?
Hello, thank you for your excellent work. When will the code be released? thank you!
cached data loaded
2778
100%|██████████████████████████████| 2778/2778 [56:40<00:00, 1.22s/it, col_top1=0.039, col_top2=0.107, col_top3=0.146, ext_col=0.946, ext_row=0.936, loss=5.363, top1=0.067, top2=0.174, top3=0.251]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4335/4335 [39:22<00:00, 1.83it/s]
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
sh: 1: ./evaluation/culane/evaluate: Permission denied
Traceback (most recent call last):
File "train.py", line 120, in
res = eval_lane(net, cfg, ep = epoch, logger = logger)
File "/home/disk01/wyw/Ultra-Fast-Lane-Detection-v2/evaluation/eval_wrapper.py", line 899, in eval_lane
res = call_culane_eval(cfg.data_root, 'culane_eval_tmp', cfg.test_work_dir)
File "/home/disk01/wyw/Ultra-Fast-Lane-Detection-v2/evaluation/eval_wrapper.py", line 1022, in call_culane_eval
res_all['res_normal'] = read_helper(out0)
File "/home/disk01/wyw/Ultra-Fast-Lane-Detection-v2/evaluation/eval_wrapper.py", line 960, in read_helper
lines = open(path, 'r').readlines()[1:]
FileNotFoundError: [Errno 2] No such file or directory: 'out_culane/20220901_204530_lr_5e-02_b_32/txt/out0_normal.txt'
你好,很感谢无私你的分享!
我想请问一下 我这边使用自己数据转成tusimple格式数据集进行训练 , 车道线的点我自己在原图上画出来也是没问题,但是训练途中在读取十几张图片后 loss变成了nan,这是什么原因造成的啊
期望得到你的回复,谢谢!!!
您好,我参考了demo文件,写了个利用您训练好的culane_res18.pth,进行一张张图片的检测,可是检测出的每张图片要30ms+,
t1=time.time() #0.015 s
img = cv2.imread(img_path)
im0 = img.copy()
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_h, img_w = img.shape[0], img.shape[1]
img = img_transforms(img)
img = img[:, -cfg.train_height:, :]
t2_3=time.time() #0.005 s
img = img.to('cuda:0')
img = torch.unsqueeze(img, 0)
with torch.no_grad():
pred = net(img)
t2_2=time.time() #0.018 s
coords = pred2coords(pred, cfg.row_anchor, cfg.col_anchor, original_image_width=img_w,
original_image_height=img_h)
t2_1=time.time()
统计时间的片段代码如上。 mg_transforms这个函数要花费进15ms 网络回归花费5ms pred2coords函数花费18ms 。
您有时间,回复下吗?
大家怎么看
Hi there,
How can I perform inference on a custom dataset? I want to test my video to detect the lane.
thanks.
Hello,
I have run your code successfully. In your paper ,the precision of resnet34 is 81.34. I didn't change your parameters in config, but I only got the precision about 71 and the epoch is 50 , can you give your parameters or your result ?
I have specified the model path
python test.py configs/tusimple_res34.py --test_model pretrained_model/tusimple_res34.pth --test_work_dir ./tmp
but the code downloads model from
"https://download.pytorch.org/models/resnet34-b627a593.pth" to /home/xxx/.cache/torch/hub/checkpoints/resnet34-b627a593.pth
automatically
您好,我在部署这个项目中在安装环境中没有出现问题,但训练过程出现了标题上的问题,初步分析应该是my_interp这个包的问题,编译没有出现问题。我用的显卡是3090,所安装的pytorch必须是在cuda11以下版本的,但好像my_interp功能包依赖于cuda10.2的环境,所以一直在寻找libcudart.so.10.2这个是属于cuda10.2的软链接文件,我尝试分析my_interp包的源码,修改依赖的cuda版本,但并未找到修改的方法,答主可否提供一定的帮助,帮我解决此问题。相信在运行的过程中,也会有很多研究人员遇到相同的问题,还希望答主可否指点一二,提供解决该问题的方式,这样也让代码会更加的完美!感激不尽!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.