atoti / atoti Goto Github PK
View Code? Open in Web Editor NEWatoti issue tracking
License: Apache License 2.0
atoti issue tracking
License: Apache License 2.0
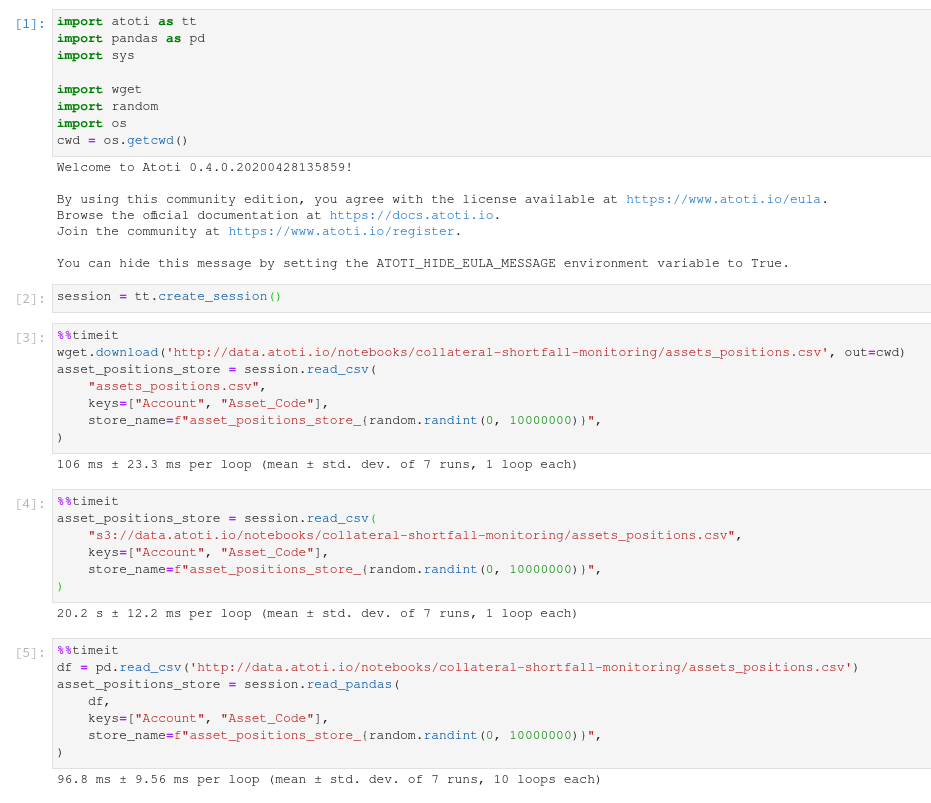
I tried to load remote data using several methods and using the s3 protocol appears 200 times slower than using wget or pandas:
| method | timing |
|---|---|
| pandas http + read_pandas | 96.8ms |
| wget http + read_csv | 106ms |
| read_csv + s3 | 20.2s |
Install python-wget and run the attached notebook main.zip
Here are the logs
Let's consider the following join:
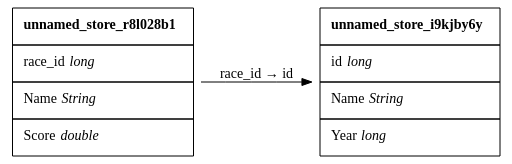
If I have some score for which there is no existing race_id, Year will default to 0.
Sample code:
import pandas as pd
main_df = pd.DataFrame(
data={
"race_id": [1, 5, 0, 2],
"Name": ["John", "Robert", "Thomas", "Mike"],
"Score": [10, 8, 5, 12],
}
)
race_df = pd.DataFrame(
data={
"id": [0, 1, 2],
"Name": ["Alpha", "Beta", "Gamma"],
"Year": [2017, 2018, 2019],
}
)
import atoti
session = atoti.create_session()
race_store = session.read_pandas(race_df)
main_store = session.read_pandas(main_df, types={"Score": atoti.types.DOUBLE})
main_store.join(race_store, mapping={"race_id": "id"})
cube = session.create_cube(main_store)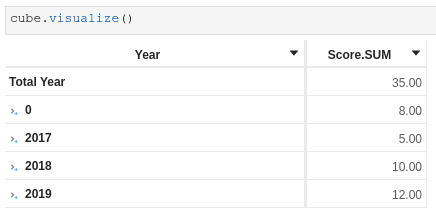
While I understand why the value is zero (the original type is int, and it would be useful if I decide to aggregate it), in this specific case described above I would like to default it to something more explicit like 2020 or N/A. I initially thought the value 0 came from the data source.
The easy fix is to force the type of Year to be a string, and then I get N/A:
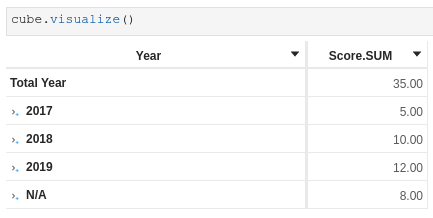
I could also alter the data to define the missing race_id or remove the data from the main store with an unknown race_id.
I might be nitpicking but even when the underlying type is INT, if I use the field in a hierarchy, I think people would prefer to see N/A rather than 0.
I've seen multiple users willing to package the library into a docker image. They however struggle to do so and face some issues in particular with ports.
Could you please provide a sample docker image? Thanks
Hello,
I'm working on a VaR notebook (you can get it gere, it downloads the necessary data itself) and I seem to have an issue with sibling aggregation on the VaR in a multi-level hierarchy: instead of aggregating only on the siblings that share the same parent level, it seems the sibling aggregation is performed on all members.

Where the VaR (values ok) is defined by:
scaled_pnl_vector = m["Quantity"] * m["pnl_vector.VALUE"]
m['Position Vector'] = atoti.agg.sum(scaled_pnl_vector, scope=atoti.scope.origin('instrument_code'))
m["Confidence Level"] = 0.95
m["VaR"] = atoti.array.percentile(m["Position Vector"], m["Confidence Level"])
Parent VaR (values ok):
m["Parent VaR"] = atoti.parent_value(m["VaR"], h["Trading Book Hierarchy"])
VaR agg on siblings (values not ok):
m["Position Vector Agg on siblings"] = atoti.agg.sum(
m["Position Vector"],
scope=atoti.scope.siblings(h["Trading Book Hierarchy"]),
)
m["VaR agg on siblings"] = atoti.array.percentile(m["Position Vector Agg on siblings"], m["Confidence Level"])
Parent VaR Ex (values not ok):
m["Parent Position Vector Ex"] = atoti.agg.sum(
m["Position Vector"],
scope=atoti.scope.siblings(h["Trading Book Hierarchy"], exclude_self=True),
)
m["Parent VaR Ex"] = atoti.array.percentile(m["Parent Position Vector Ex"], m["Confidence Level"])
And in the end the marginal VaR (values not ok):
m["Marginal VaR"] = m["Parent VaR"] - m["Parent VaR Ex"]
In this particular example, the value of the Parent VaR Ex at level Hermes should be equal to the value of the VaR at level Developed Market after having applied a filter excluding Hermes.
Thanks in advance for the help.
PS : I don't think it is related to this issue as I also tried it with cube.aggregates_cache.capacity = 0
Reported by a first time user:
in getting started I had "absolutely no idea what a cube was". Then I immediately went back to the homepage -> docs -> api reference then cube, but all I found was an autogenerated doc. It did not help me understand what a cube was.
It would be great to add in the documentation a page explaining a few OLAP concepts and what value they bring. For example:
Hello,
The Atoti documentation mentions that:
at takes the value of the given measure shifted on one of the level to the given value.
The value can be a literal value or the value of another level
And using the value of another level was working at some point as @fabiencelier uses it in https://github.com/activeviam/atoti/issues/940
But for me I cannot seem to make it work.
I am working on a soccer notebook where on one line of the facts I have Team and Opponent, managed to create a measure Team Goals and was trying to compute a measure Opponent Goals with the following line:
m["Opponent Goals"] = atoti.at(m["Team Goals"], {level["Team"]: level["Opponent"]})
But I can never see any result for the Opponent Goals measure in a pivot table, even when all hierarchies are expressed.
On the other hand if I "hardcode" the opponent doing the following:
m["Norwich Goals"] = atoti.at(m["Team Goals"], {level["Team"]: "Norwich"})
Then the measure is computed as expected.
Find below a short notebook allowing you to reproduce (1st of april atoti version):
atWithLevelIssue.zip
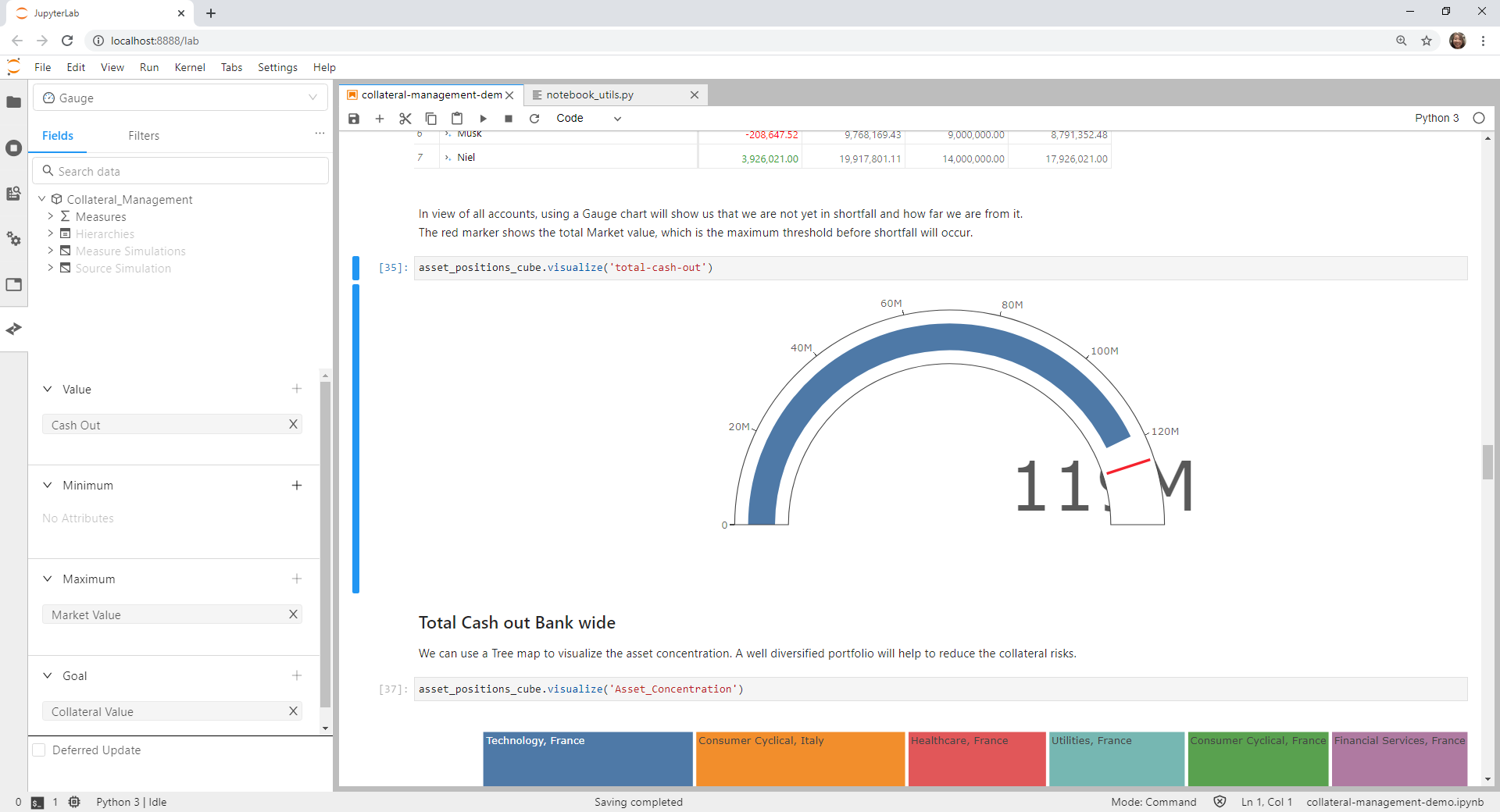
The value in gauge chart went out of alignment when the content editor is expanded.
How can I rename a level ?
Something like that would be nice:
levels["old"].name = "new"Hello, I am plotting a few charts in a notebook with atoti doing some cube.visualize() and I noticed that we do not have the x and y axis titles showing as you can see in the screenshot below:
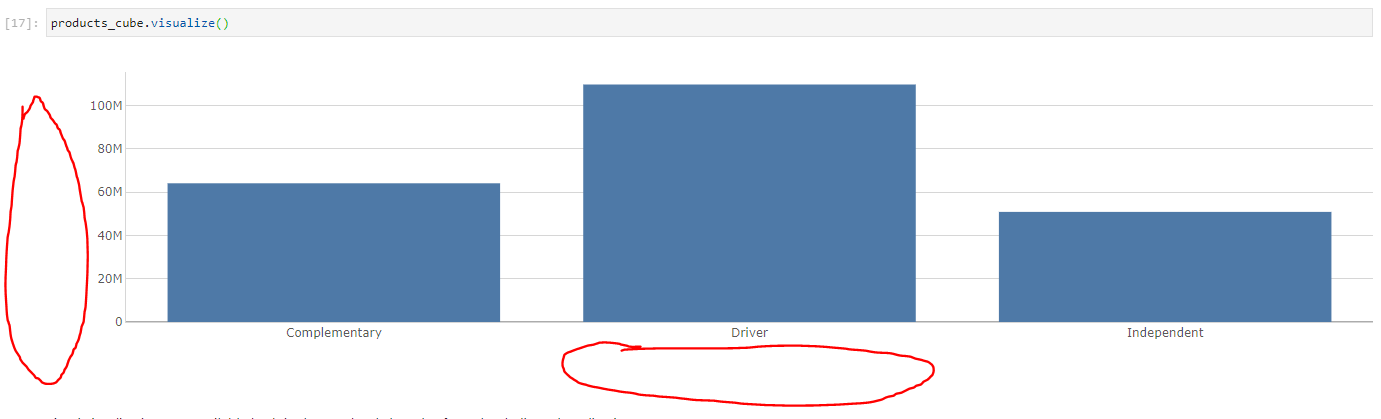
In the particular case of this example this is the margin per product category that is plotted. But since I have other indicators with the same unit as the margin (revenue for example), it is simply impossible to the user to know which measure has been plotted unless selecting the chart, then clicking on the atoti panel on the left and looking at what measure is plotted.
Would it be possible in the chart settings to be able to display axis titles ?
I am able to perform csv read using
asset_positions_store = session.read_csv(
"s3://data.atoti.io/notebooks/collateral-shortfall-monitoring/assets_positions.csv",
keys=["Account", "Asset_Code"],
store_name="asset_positions_store",
)
I tried to do the same for parquet:
assets_store = session.read_parquet(
"s3://data.atoti.io/notebooks/collateral-shortfall-monitoring/assets_attributes.parquet",
keys=["Asset_Code"],
store_name="assets_store",
)
I encountered the below error:
Py4JJavaError: An error occurred while calling o2.createStoreFromParquet.
: java.lang.IllegalArgumentException: Wrong FS: s3://data.atoti.io/notebooks/collateral-shortfall-monitoring/assets_attributes.parquet, expected: file:///
at org.apache.hadoop.fs.FileSystem.checkPath(FileSystem.java:773)
at org.apache.hadoop.fs.RawLocalFileSystem.pathToFile(RawLocalFileSystem.java:86)
at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:447)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1804)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1849)
at org.apache.hadoop.fs.ChecksumFileSystem.listStatus(ChecksumFileSystem.java:675)
at com.activeviam.chouket.loading.parquet.impl.ParquetDiscovery.doGetSingleFile(ParquetDiscovery.java:100)
at com.activeviam.chouket.loading.parquet.impl.ParquetDiscovery.getSingleFile(ParquetDiscovery.java:80)
at com.activeviam.chouket.loading.parquet.impl.ParquetDiscovery.getSchemaFromParquetFile(ParquetDiscovery.java:58)
at com.activeviam.chouket.loading.parquet.impl.ParquetDataLoaderImpl.createDataTable(ParquetDataLoaderImpl.java:85)
at com.activeviam.chouket.loading.parquet.impl.ParquetDataLoaderImpl.createStore(ParquetDataLoaderImpl.java:102)
at com.activeviam.chouket.loading.parquet.impl.ParquetDataStoreOperation.createDataTable(ParquetDataStoreOperation.java:73)
at com.activeviam.chouket.loading.parquet.impl.ParquetDataStoreOperation.lambda$load$0(ParquetDataStoreOperation.java:53)
at java.base/java.util.Collections$SingletonMap.forEach(Collections.java:4946)
at com.activeviam.chouket.loading.parquet.impl.ParquetDataStoreOperation.load(ParquetDataStoreOperation.java:50)
at com.activeviam.chouket.api.impl.ActiveViamSessionApiImpl.createStoreFromParquet(ActiveViamSessionApiImpl.java:363)
I created a pivot table with "Deferred update" selected.
I created a new measure and added to the pivot table. The "Deferred update" checkbox got removed and when I tried to adjust the column width, a lot of warnings on the "Deferred updates have been cancelled" are displayed.

Refer to
localhost-1587967183971.log
It would be nice to have the modulo operator between two measures like we have m["m1"] * m["m2"], it could be useful to have m["m1"] % m["m2"]
I know it would be feasible via / and // operators, but it is still making it more complicated.
A measure needed to divide by the number of days present in the AsOfDate year, therefore either divide by 365 or by 366.
Algorithm:
Reported by a first time user:
the exception was not clear. When
session.read_csvwas looking for the data file, it could not find it. But it throws a pretty weird exception aboutpy4jwith a java error exception and atoti java exception. Took a minute to realize the error was not from the jvm but due to the incorrect file path. This is compared to the error produced by pandas when using read_csv.
Here is the error thrown by atoti's read_csv:
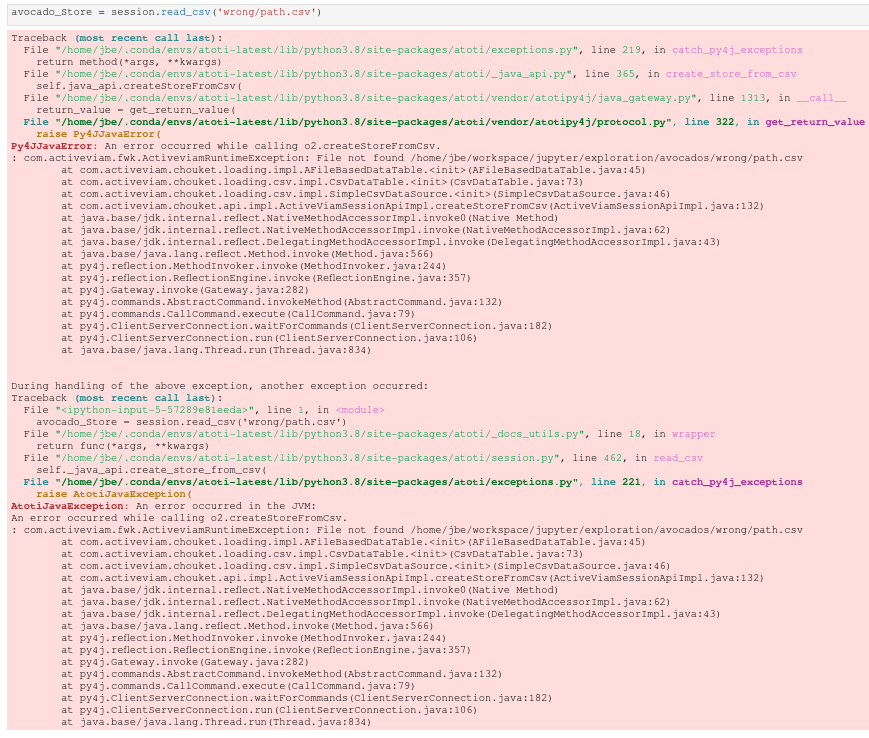
Here is the error thrown by pandas' read_csv:

I see at least two difference with pandas:
FileNotFoundErrorWe should at least fix (2.)
I have a featured values widget and a pivot table both in realTime mode.
I also have a measure simulation widget and I configured a small measure simulation in my notebook. when I edit the scenarios or when I add or delete a scenario using the widget in the UI, I don't see the impacts in my 2 other widgets.
If the 2 other widgets are in "refresh periodically" mode then I see the impact after a few seconds which is the intended behavior.
Looking at the websocket I get a successful response from the server after the change performed on the simulation.
{"status":"success","data":{"epoch":28,"headers":[{"name":"AV_Category","type":"String"},{"name":"Supplier_Simulation","type":"String"},{"name":"Supplier_Simulation_PurchasePrice.AVG_multiply","type":"double"},{"name":"Priority","type":"double"}],"rows":[["AV_Category","Base",1.0,1.0],["Cat1","Supplier Change",1.1,1.0],["Cat2","Supplier Change",0.8,1.0]],"pagination":{"currentPage":1}}}
Here is the snapshot of my view :
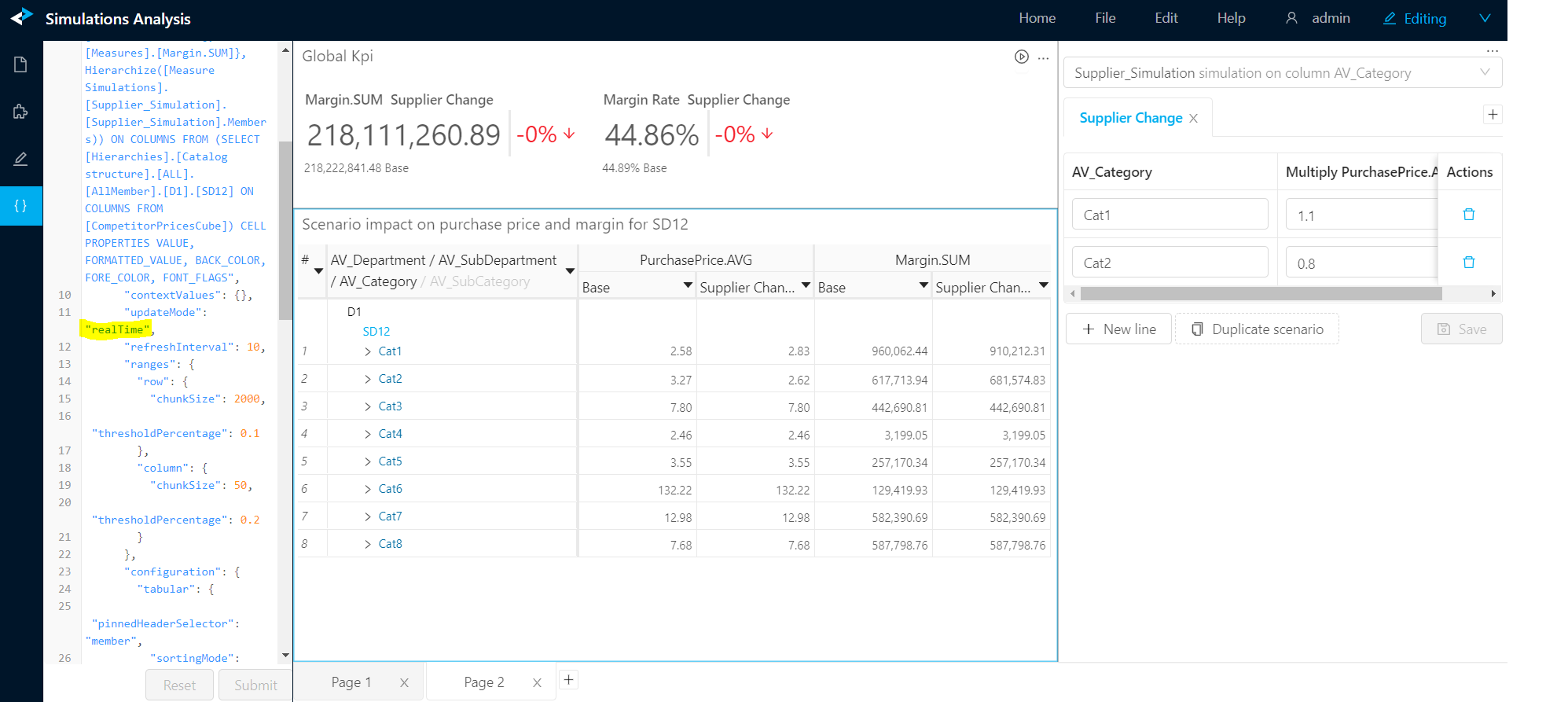
To reproduce you can get the code from github here :
https://github.com/activeviam/perso-lma-python-notebooks/tree/master/Product%20Clustering%20Demo
notebook code for simulation :
# Here we setup a simulation to multiply the purchase price of different categories
supplier_simulation = priceIndicesCube.setup_simulation(
"Supplier_Simulation",
multiply=[m["PurchasePrice.AVG"]],
per=[lvl["AV_Category"]]
)
# now let's try different scenarios
supplier_change_scenario = supplier_simulation.scenarios["Supplier Change"]
supplier_change_scenario += ("Cat1", 1.10) # 10% more expensive for Cat1
supplier_change_scenario += ("Cat2", 0.95) # 5% cheaper for Cat2
Hi team
black is recommended to be used to prettify notebooks by atoti-community team(@jbe456 ).
I'm using nb_black extension. However cube.visualize() command is breaking this extension.
I activate it in a cell as follows:
%load_ext lab_black
It will do the job fine, until I run a cell containing cube.visualize().
How to reproduce:
%load_ext lab_blacktest = {"a": 'a'} - the nb_black will successfully convert it to test = {"a": "a"}cube.visualize() - in any of the tutorialstest = {"a": 'a'} - the nb_black will start throughin exceptions and copy pasting previous cells randomly: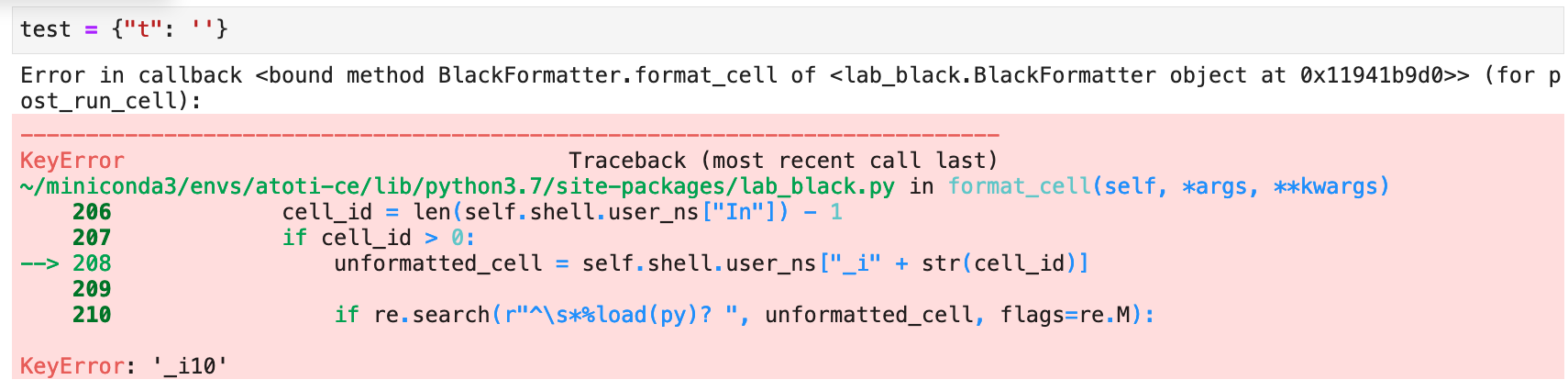
PS: I was recommended to use R&D tool but I do not know how to use it so I'm using the nb_black extension: https://github.com/activeviam/atoti/blob/673a3560b4dbabb100eb730fd5e3f05f2a405196/javascript/cli/src/commands/test/notebooks.ts
import pandas as pd
dummy_df = pd.DataFrame(
data={
"id": [0, 1, 2, 3],
"Name": ["John", "John", "Thomas", "Mike"],
"Score": [10, 8, 5, 12],
}
)
import atoti
session = atoti.create_session()
dummy_store = session.read_pandas(
dummy_df, keys=["id"], types={"id": atoti.types.STRING, "Score": atoti.types.DOUBLE}
)
cube = session.create_cube(dummy_store)
cube.measures["underlying"] = atoti.agg.single_value(
atoti.where(cube.measures["Score.SUM"] == 12, 1000),
scope=atoti.scope.origin(cube.levels["Name"]),
)
cube.measures["final"] = atoti.where(cube.measures["underlying"] == None, 'NOTHING', 'SOMETHING')The measure final returns an empty cell for Total Name although underlying has a value:

I would expect the final measure to return "SOMETHING" for "Total Name"
This bug happened when I tried to use several aggregations on different levels of origin consecutively. A first aggregation is used to sum my measure on a certain level. I then use a filter in order to get their cross product on the next level. Then I try to sum the crossed products on the top level, but instead get the sum on the bottom level, which is innacurate.
Here I reproduced the bug:
bug_agg_origin.zip

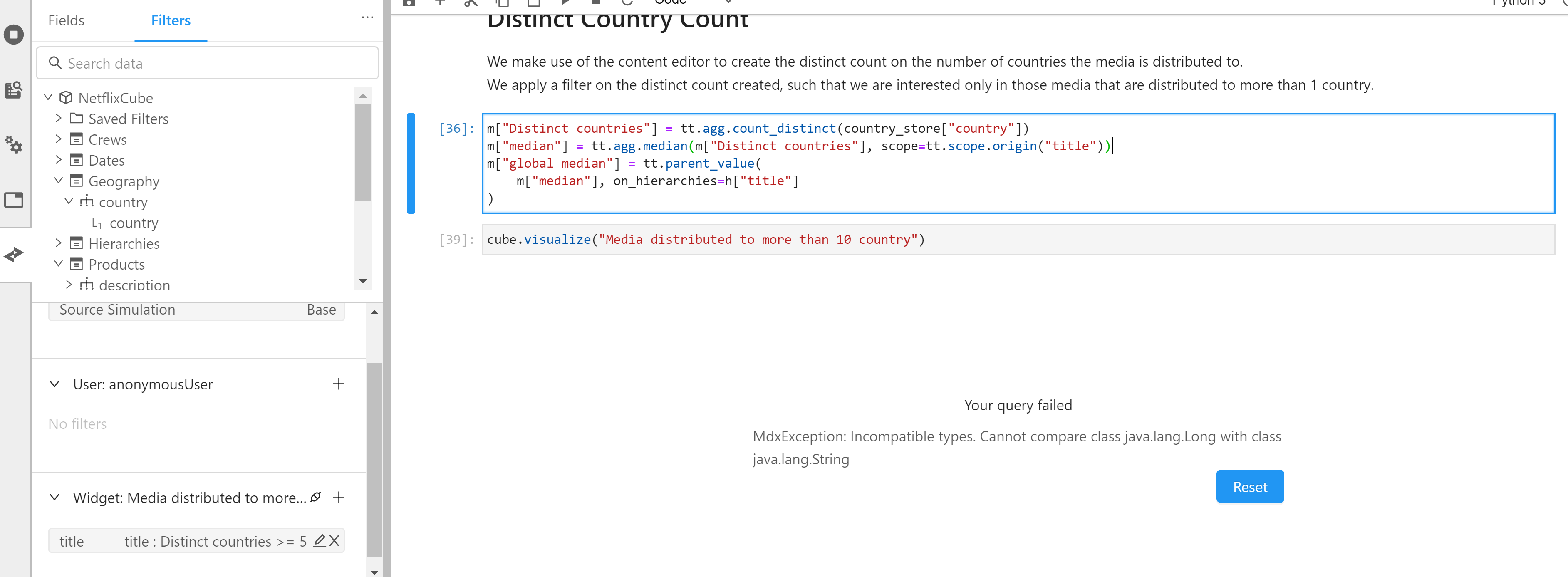
Create a measure with tt.agg.count_distinct on a level.
When I try to use the distinct count in filter, I encountered the error:
MdxException: Incompatible types. Cannot compare class java.lang.Long with class java.lang.String
Refer to attached
distinct_count.zip
import atoti
config = create_config()
session = atoti.create_session()
products_store = session.read_csv(
"s3://data.atoti.io/notebooks/products-classification/products_referential.csv",
store_name="Products_store",
sep=";",
)This will log the following message (+ missing space between sentences):
The store has been sampled because the sampling mode policy has breached.Call Session.load_all_data() to trigger the full load of the data.
We used to have the following sentence:
- "The store has been sampled because there is more than 10000 lines in the files to load.Call Session.load_all_data() to trigger the full load of the data.\n"
+ "The store has been sampled because the sampling mode policy has breached.Call Session.load_all_data() to trigger the full load of the data.\n"vendors~main.e36f9ec557b7cc383dbd.js:2 TypeError: Cannot read property 'caption' of undefined
at vendors~main.e36f9ec557b7cc383dbd.js:2
at Array.forEach (<anonymous>)
at e (vendors~main.e36f9ec557b7cc383dbd.js:2)
at e (vendors~main.e36f9ec557b7cc383dbd.js:2)
at Function.eh.fromCellSet (vendors~main.e36f9ec557b7cc383dbd.js:2)
at t.e (vendors~main.e36f9ec557b7cc383dbd.js:2)
at t.e (vendors~main.e36f9ec557b7cc383dbd.js:2)
at vendors~main.e36f9ec557b7cc383dbd.js:2
at vendors~main.e36f9ec557b7cc383dbd.js:2
at Object.e [as cb] (vendors~main.e36f9ec557b7cc383dbd.js:2)
Check out this notebook, run all cells until h["Date"].slicing = True

Only tested against 0.3.1 since I was not able to run the notebook in latest because I'm facing an other issue preventing me from executing the notebook.
After upgrading to Atoti 0.3.1, I encountered the error "Could not connect to Content Server..." during cube.visualize().
This only happens when we persist the content server
config = create_config(metadata_db="./metadata.db")
session = atoti.create_session(config=config)

Refer to attached logs.
ActiveUI_Report_4_15_2020__9_35_27_AM.zip
Hello,
I am working on a formula 1 dataset where data gives the championship standings at the end of each race. Trying to compute the championship winner for each year (so in theory driver with position == 1 at the end of the year) I am having trouble with a where statement that tests if a measure is equal to another.
It seems a where statement returns True in cases it is not supposed to. I am raising this issue after showing it to @fabiencelier
I have a first measure giving the name of winner of a round (raceNr) for a particular year:
m["First driver at round"] = tt.filter(m["Driver Name"], l["position"] == 1)
Then to have it at year level, and since we cannot use measures in filters, the idea was to have a where statement returning None when the race is not the last of the season, and the previous measure otherwise. Then leaf evaluate this where statement at round level, and aggregate with single value since there should be only one non null value.
m["1st in standings"] = tt.where(m["Nr of rounds until race"] == m["Nr of rounds in year"], m["First driver at round"], None)
m["Year Winner"] = tt.agg.single_value(m["1st in standings"], scope=tt.scope.origin("round"))
First issue is that measure m["1st in standings"] is always null (I cannot see it in a pivot table)
Second issue is that year winner is correctly computed for the last race of the season, but is also non null for some other races, even though m["Nr of rounds until race"] is not equal to m["Nr of rounds in year"]
See the result in the below picture:

Do you have any idea why ?
Find here a short notebook with the reproduction and indications
An other way of doing cube.visualize() would be to do it directly from the code like this:
Therefore you wouldn't have to go into the left bar.
When you are developing in the notebook your hands are on the keyboard because you are coding. When you want to test or see the result of a measure you've just coded, cube.visualize() is useful. However, first you have to chose which type of widget, and then you have to go into the left bar and find back the measures and relevant levels you just typed in your cell.
It would be nice to instead type cube.pivot(levels=[], columns=[], measures=[], filters=[]) or cube.graph(levels=[], columns=[], measures=[], filters=[], graph_type) and then you just have to grab (copy past) the relevant name from the cell you just coded.
Provide an API for querying directly from the datastore of an existing ActivePivot instance.
I want to use the data from existing data stores in my notebook, for doing some analysis.
use case is to get data from a datastore and update the mdx based on that data, before querying the cube.
This code sample is only useful to understand the use case of what I wanted to achieve:
import atoti as tt
import numpy as np
import pandas as pd
session = tt.create_session()
drivers_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/drivers.csv", encoding="latin-1"
)
drivers_df.rename(columns={"url": "driver_url"}, inplace=True)
drivers_df.rename(columns={"nationality": "driver_nationality"}, inplace=True)
drivers_store = session.read_pandas(
drivers_df, keys=["driverId"], store_name="F1 drivers"
)
races_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/races.csv", encoding="latin-1"
)
races_df.rename(columns={"url": "race_url"}, inplace=True)
races_df.rename(columns={"name": "race_name"}, inplace=True)
races_store = session.read_pandas(
races_df, keys=["raceId"], store_name="F1 races"
)
constructors_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/constructors.csv", encoding="latin-1"
)
constructors_df.rename(columns={"url": "constructor_url"}, inplace=True)
constructors_df.rename(columns={"name": "constructor_name"}, inplace=True)
constructors_df.rename(columns={"nationality": "constructor_nationality"}, inplace=True)
constructors_store = session.read_pandas(
constructors_df,
keys=["constructorId"],
store_name="F1 constructors",
)
resultsTypes = {
"points": tt.types.DOUBLE,
}
results_store = session.read_csv(
"s3://data.atoti.io/notebooks/formula-one/results.csv",
keys=["resultId"],
store_name="F1 results",
types=resultsTypes,
)
results_store.join(drivers_store, mapping={"driverId": "driverId"})
results_store.join(races_store, mapping={"raceId": "raceId"})
results_store.join(constructors_store, mapping={"constructorId": "constructorId"})
f1cube = session.create_cube(results_store, "F1Cube")
session.load_all_data()
lvl = f1cube.levels
m = f1cube.measures
h = f1cube.hierarchiesThe use case is to return the maximum points among all drivers given any cube location. Think of it as the value used to determine agg.max_member.
Therefore I wanted to aggregate the maximum driver's points.SUM always across all drivers: i.e. slicing by driver but also ignoring any filter on the driver level.
I thought about using scope.siblings to achieve that with a level as an argument.
m["Champion Points"] = tt.agg.max(
m["points.SUM"], scope=tt.scope.siblings(lvl["driverRef"])
)While it works when the level driver is explicitly expressed, it does not otherwise: indeed since it takes a hierarchy as an input, if the level driver is not explicitly expressed, it will return points.SUM for AllMember on the driverRef hierarchy.
I also thought at some point we could introduce something like:
m["Champion Points"] = tt.agg.max(
m["points.SUM"], scope=tt.scope.origin_ignore_filters(lvl["driverRef"])
)The "workaround" was to do the following:
driver_points_max = tt.agg.max(m["points.SUM"], scope=tt.scope.origin(lvl["driverRef"]))
m["Champion Points"] = tt.parent_value(
driver_points_max, on=[h["driverRef"]], top_value=driver_points_max
)I was able to achieve what I wanted so this is more for documentation purpose and let you decide if you want to improve the API or not.
If you decide that the above syntax is the right one, could you document it in the tutorial next to parent value? It seems a legit use case for parent_value.
When accessing the data is slow because of network issues and/or because the file is large, reading/loading the file takes time which is expected.
However, what's not expected, is that the following operations then become slow as well:
This problem has been highlighted in #26
Is there any plan to improve this?
I have data files on AWS S3 and it is accessible via a public url.
I would like to be able to use atoti session to read the file e.g.:
asset_positions_store = session.read_csv('http://data.atoti.io/notebooks/collateral-shortfall-monitoring/assets_positions.csv', keys=['Account','Asset_Code'], store_name='asset_positions_store')
Currently I am unable to do so.
Currently, there is no way to perform Drill-Through query operation using Atoti's API as documented here https://docs.atoti.io/0.3.1/lib/atoti.query.html#atoti.query.session.QuerySession.query_mdx
It will be very helpful if we want to explore the facts contributing to a given number/measure.
Take any measure using the scope siblings and pass it a level instead of a hierarchy:
m["Champion Points"] = tt.agg.max(
m["points.SUM"], scope=tt.scope.siblings(lvl["driverRef"])
)For more context see #38
It works as if it was a hierarchy, giving unexpected result if one think it accepts a level.
Since it worked without any error, I was expecting siblings to operate on the driverRef level only while in fact it was also operating on the ALL level of the driverRef hierarchy.
I would expect to:
Right now agg.single_value is documented here and says:
Perform a single value aggregation of the input measure.
I created a calculated measure and saved it.
(1) when I print the measure, it doesn't show. However in the Atoti Editor, it is available for selection.
Doesn't cube.measures contain all measures?

(2) On restart of the kernel, the saved measure is gone. Hence the cube.visualize that was built before failed with MdxException: unknown measure error.
On point 2, it is understandable since I didn't persist the db. Just thinking that users have to be aware of how the save works here.
Datasets:
import pandas as pd
matches = {
"match_id": [0, 1, 2, 3],
"Day": [1, 1, 2, 2],
"Home": ["Liverpool", "Norwich", "West Ham", "Everton"],
"Away": ["West Ham", "Everton", "Liverpool", "Norwich"],
}
matches_df = pd.DataFrame(data=matches)
goals = {
"goal_id": [0, 1, 2, 3],
"match_id": [0, 0, 0, 3],
"Team": ["Liverpool", "Liverpool", "West Ham", "Everton"],
}
goals_df = pd.DataFrame(data=goals)Create cube:
import atoti
session = atoti.create_session()
matches_store = session.read_pandas(matches_df, keys=["match_id"])
goals_store = session.read_pandas(goals_df, keys=["goal_id"])
matches_store.join(goals_store, mapping={"match_id": "match_id"})
matches_cube = session.create_cube(matches_store, "MatchesCube")
Define measures:
m = matches_cube.measures
level = matches_cube.levels
h = matches_cube.hierarchies
m["Goal.DISTINCT_COUNT"] = atoti.agg.count_distinct(goals_store["goal_id"])
m["Goal.COUNT"] = atoti.agg._count(goals_store["goal_id"])
m["Match.DISTINCT_COUNT"] = atoti.agg.count_distinct(matches_store["match_id"])
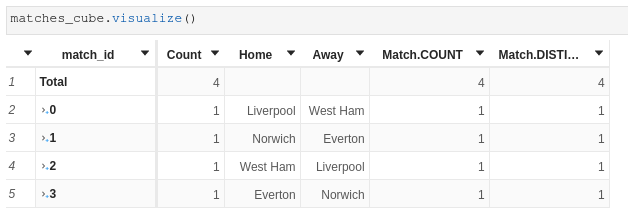
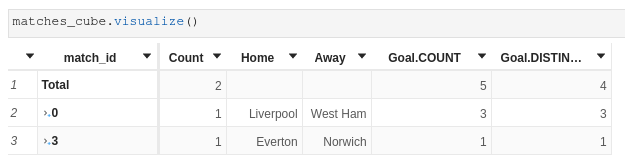
m["Match.COUNT"] = atoti.agg._count(matches_store["match_id"])Total contributors.COUNT is 4, one per match id:

If we crossjoin by goal id, we still get 4 but the count does NOT add up:

If we add the measures aggregating goals:
Goal.DISTINCT_COUNT is correctly equal to 4contributors.COUNT changed to 10 and does not add up (?)Goal.COUNT is equal to 11 and does not add up (?)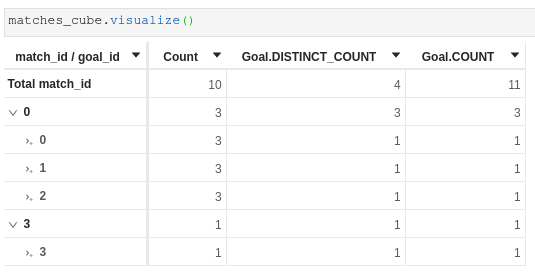
I would expect more documentation in the cases of one-to many join in this page for example https://docs.atoti.io/0.3.1/tutorial/04-advanced-store-manipulations.html#Join-stores
In particular:
contributors.COUNT supposed to be?
BaseStore.COUNT?contributors.COUNT does not add up is confusing.contributors.COUNT changes when adding the measure on the secondary store is confusing as well. What do these values represent?atoti.agg._count(goals_store['goal_id']) a valid usage? If that's the case we may want to make it public and remove the leading _.Goal.COUNT does not add up is confusing.Goal.COUNT?CREATE TABLE match_store (
match_id int,
Day int,
Home varchar(255),
Away varchar(255)
);
CREATE TABLE goal_store (
goal_id int,
match_id int,
Team varchar(255)
);
INSERT INTO goal_store
VALUES
(0,0,"Liverpool"),
(1,0,"Liverpool"),
(2,0,"West Ham"),
(3,3,"Everton");
INSERT INTO match_store
VALUES
(0,1,"Liverpool", "West Ham"),
(1,1,"Norwich", "Everton"),
(2,2,"West Ham", "Liverpool"),
(3,2,"Everton", "Norwhich");Inner join:
SELECT * from match_store INNER join goal_store on match_store.match_id=goal_store.match_id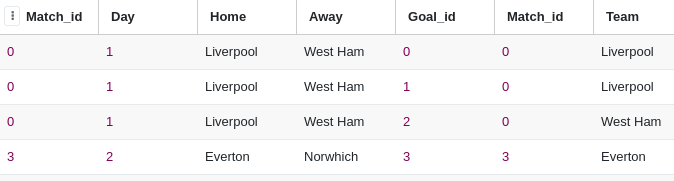
Left join:
SELECT * from match_store LEFT join goal_store on match_store.match_id=goal_store.match_id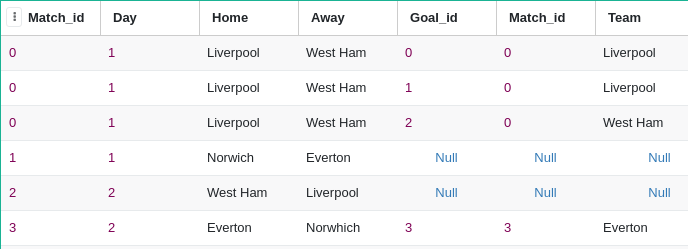
head(joined_columns=True) does not display the many to many joined fields.
This would imply displaying more rows than the initial store currently has.
Should we support it ? Or explain in the doc that it only displays many-to-one ?
import atoti as tt
import pandas as pd
base_df = pd.DataFrame({"a":["a1", "a2"], "v":[10.0, 20.0]})
joined_df = pd.DataFrame({
"a":["a1", "a2", "a1", "a2"],
"b": ["b1", "b1", "b2", "b2"],
"c":[30.0,40.0,50.0,60.0]
})
session = tt.create_session()
base = session.read_pandas(base_df, keys=["a"])
joined = session.read_pandas(joined_df, keys=["a", "b"])
base.join(joined)
base.head(joined_columns=True)| a | v |
|---|---|
| a1 | 10.0 |
| a2 | 20.0 |
Create a simulation using setup_simulation and have one of the levels be of type different than string:
import pandas as pd
dummy = {
"id": [0, 1, 2, 3],
"Name": ["John", "John", "Thomas", "Mike"],
"Score": [10, 8, 5, 12],
}
dummy_df = pd.DataFrame(data=dummy)
import atoti
session = atoti.create_session()
dummy_store = session.read_pandas(dummy_df, keys=["id"])
cube = session.create_cube(dummy_store)
cube.measures["Score"] = atoti.agg.sum(dummy_store["Score"])
simulation = cube.setup_simulation(
'DUMMY_SIMU',
levels=[cube.levels["id"]],
replace=[cube.measures["Score"]]
)java.lang.ClassCastException: Incorrect type String for tuple with value id for lookup in dictionary of type ChristmasDictionaryLong. Exception in store: DUMMY_SIMU, field: id, for tuple: [id, Base, null, 1.0].
Traceback (most recent call last):
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 219, in catch_py4j_exceptions
return method(*args, **kwargs)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/_java_api.py", line 142, in refresh
self.java_session.refresh(force_start)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/java_gateway.py", line 1313, in __call__
return_value = get_return_value(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/protocol.py", line 322, in get_return_value
raise Py4JJavaError(
Py4JJavaError: An error occurred while calling t.refresh.
: java.lang.ClassCastException: Incorrect type String for tuple with value id for lookup in dictionary of type ChristmasDictionaryLong. Exception in store: DUMMY_SIMU, field: id, for tuple: [id, Base, null, 1.0].
at com.qfs.store.transaction.impl.TransactionManager.transformToFullRecords(TransactionManager.java:1375)
at com.qfs.store.transaction.impl.TransactionManager.addAll(TransactionManager.java:1136)
at com.qfs.store.transaction.impl.DelegatingOpenedTransaction.addAll(DelegatingOpenedTransaction.java:132)
at com.qfs.store.transaction.ITransactionalWriter.addAll(ITransactionalWriter.java:117)
at com.activeviam.chouket.loading.pojo.PojoDataTable.lambda$initialLoad$0(PojoDataTable.java:60)
at com.qfs.store.transaction.impl.TransactionManager.performInTransaction(TransactionManager.java:2492)
at com.activeviam.chouket.loading.pojo.PojoDataTable.initialLoad(PojoDataTable.java:58)
at com.activeviam.chouket.loading.pojo.PojoDataTable.initialLoad(PojoDataTable.java:26)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.lambda$feed$3(SimpleActiveViamSession.java:629)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1540)
at com.activeviam.chouket.impl.SimpleActiveViamSession.feed(SimpleActiveViamSession.java:629)
at com.activeviam.chouket.impl.SimpleActiveViamSession.startFeeding(SimpleActiveViamSession.java:588)
at com.activeviam.chouket.impl.SimpleActiveViamSession.resume(SimpleActiveViamSession.java:385)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refresh(SimpleActiveViamSession.java:449)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<ipython-input-5-f9a59dd0d932>", line 1, in <module>
simulation = cube.setup_simulation(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/cube.py", line 218, in setup_simulation
simulation = Simulation(
File "<string>", line 11, in __init__
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/simulation.py", line 114, in __post_init__
self._java_api.refresh()
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 221, in catch_py4j_exceptions
raise AtotiJavaException(
AtotiJavaException: An error occurred in the JVM:
An error occurred while calling t.refresh.
: java.lang.ClassCastException: Incorrect type String for tuple with value id for lookup in dictionary of type ChristmasDictionaryLong. Exception in store: DUMMY_SIMU, field: id, for tuple: [id, Base, null, 1.0].
at com.qfs.store.transaction.impl.TransactionManager.transformToFullRecords(TransactionManager.java:1375)
at com.qfs.store.transaction.impl.TransactionManager.addAll(TransactionManager.java:1136)
at com.qfs.store.transaction.impl.DelegatingOpenedTransaction.addAll(DelegatingOpenedTransaction.java:132)
at com.qfs.store.transaction.ITransactionalWriter.addAll(ITransactionalWriter.java:117)
at com.activeviam.chouket.loading.pojo.PojoDataTable.lambda$initialLoad$0(PojoDataTable.java:60)
at com.qfs.store.transaction.impl.TransactionManager.performInTransaction(TransactionManager.java:2492)
at com.activeviam.chouket.loading.pojo.PojoDataTable.initialLoad(PojoDataTable.java:58)
at com.activeviam.chouket.loading.pojo.PojoDataTable.initialLoad(PojoDataTable.java:26)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.lambda$feed$3(SimpleActiveViamSession.java:629)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1540)
at com.activeviam.chouket.impl.SimpleActiveViamSession.feed(SimpleActiveViamSession.java:629)
at com.activeviam.chouket.impl.SimpleActiveViamSession.startFeeding(SimpleActiveViamSession.java:588)
at com.activeviam.chouket.impl.SimpleActiveViamSession.resume(SimpleActiveViamSession.java:385)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refresh(SimpleActiveViamSession.java:449)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
I would expect it to work. If not I would expect it to be documented with a better feedback.
Workaround is to force the type to string:
dummy_store = session.read_pandas(
dummy_df, keys=["id"], type={"id": atoti.types.STRING}
)Take a CSV file with the following line Evelyn_"Champagne"_King,I'll_Keep_a_Light_On,link,58 and try loading it: the store will be empty:
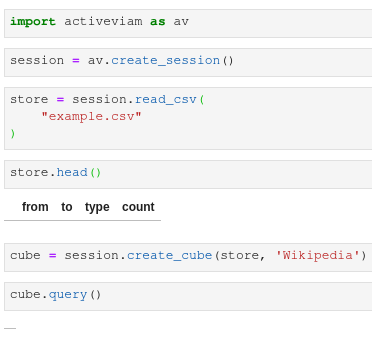
Looking at the log I can see:
INFO: Detected quote processing false differed from the input one
And indeed using process_quotes=False makes it work:
store = session.read_csv(
"example.csv",
process_quotes=False
)However I did not explicitly ask to process quotes. Would it be possible to automatically handle this use case without having to manually disable quote processing?
Attach is a notebook and a small data set to reproduce quote-csv.tar.gz
Mar 24, 2020 2:38:22 PM com.activeviam.apservicestarter.ApServiceStarterClient invokeServiceStarter
WARNING: AP_SERVICE_STARTER is not defined.
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.loading.csv.discovery.CsvDiscovery discoverFileFormat
INFO: Detecting CSV parser configuration for file /home/jbe/workspace/jupyter/issues/csv-parsing-error/example.csv
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.loading.csv.discovery.CsvDiscovery discoverFileFormat
INFO: Detected separator: ,
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.loading.csv.discovery.CsvDiscovery discoverFileFormat
INFO: Column names: [from, to, type, count]
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.loading.csv.discovery.CsvDiscovery discoverFileFormat
INFO: Detected types: [string, string, string, int]
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.loading.csv.discovery.CsvDiscovery discoverFileFormat
INFO: Detected quote processing false differed from the input one
Mar 24, 2020 2:38:22 PM com.quartetfs.biz.pivot.impl.ActivePivotManager doStop
INFO: [ActivePivotManager]: Stopped
Mar 24, 2020 2:38:22 PM com.qfs.multiversion.impl.EpochManager$DiscardOnGcTask run
INFO: Thread com.qfs.multiversion.impl.EpochManager$DiscardOnGcTask@39539b1 is interrupted!
Mar 24, 2020 2:38:22 PM ActiveViam License log
FINE: License status: Valid
Mar 24, 2020 2:38:22 PM ActiveViam License log
FINE: License: License loaded and tested successfully.
Mar 24, 2020 2:38:22 PM com.quartetfs.biz.pivot.impl.ActivePivotManager doInit
INFO: [ActivePivotManager]: Initialized
Mar 24, 2020 2:38:22 PM com.quartetfs.biz.pivot.impl.ActivePivotManager doStart
INFO: [ActivePivotManager]: Started
Mar 24, 2020 2:38:22 PM py4j.GatewayServer fireConnectionStarted
INFO: Connection Started
Mar 24, 2020 2:38:22 PM com.activeviam.chouket.util.impl.ActiveViamServerUtils$GatewayListener connectionStarted
INFO: Python connection started.
Mar 24, 2020 2:38:22 PM py4j.ClientServerConnection waitForCommands
INFO: Gateway Connection ready to receive messages
import pandas as pd
dummy = {
"ProductId": [0, 1, 2, 3],
"Class": ["Driver", "Driver", "Complementary", "Independent"],
"SellingPrice": [10.0, 8.0, 5.0, 12.0],
}
dummy_df = pd.DataFrame(data=dummy)
import atoti
session = atoti.create_session()
dummy_store = session.read_pandas(dummy_df, store_name="dummy", keys=["ProductId"])
cube = session.create_cube(dummy_store)
m = cube.measures
lvl = cube.levels
simulation = cube.setup_simulation(
"DUMMY_SIMU",
levels=[lvl["Class"], lvl["ProductId"]],
multiply=[m["SellingPrice.SUM"]],
)
test = simulation.scenarios["test"]
test += ("Complementary", "*", 5)Putting aside the double stack trace (cf #43 ), the main error message is java.lang.StringIndexOutOfBoundsException: String index out of range: -1
Traceback (most recent call last):
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 215, in catch_py4j_exceptions
return method(*args, **kwargs)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/_java_api.py", line 778, in insert_multiple_on_store_scenario
self.java_api.insertMultipleOnStoreBranch(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/java_gateway.py", line 1313, in __call__
return_value = get_return_value(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/protocol.py", line 322, in get_return_value
raise Py4JJavaError(
Py4JJavaError: An error occurred while calling o2.insertMultipleOnStoreBranch.
: com.qfs.fwk.services.BadArgumentException: [400] Invalid records to add
at com.qfs.store.service.impl.DatastoreService.parseRows(DatastoreService.java:1112)
at com.qfs.store.service.impl.DatastoreService.doInsertTransaction(DatastoreService.java:913)
at com.qfs.store.service.impl.DatastoreService.doDatastoreAction(DatastoreService.java:877)
at com.qfs.store.service.impl.DatastoreService.lambda$editDatastore$4(DatastoreService.java:827)
at com.qfs.store.transaction.impl.TransactionManager.performInTransaction(TransactionManager.java:2500)
at com.qfs.store.service.impl.DatastoreService.editDatastore(DatastoreService.java:821)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.lambda$editDatastore$0(RegisteringChouketDatastoreService.java:82)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService$DatastoreServiceOperation.initialLoad(RegisteringChouketDatastoreService.java:141)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.registerOperation(SimpleActiveViamSession.java:552)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.registerOperation(RegisteringChouketDatastoreService.java:113)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.editDatastore(RegisteringChouketDatastoreService.java:81)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.performJsonDatastoreActions(StoreOnBranchImpl.java:212)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.performJsonDatastoreAction(StoreOnBranchImpl.java:202)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.insertRows(StoreOnBranchImpl.java:103)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.insertRows(StoreOnBranchImpl.java:123)
at com.activeviam.chouket.api.impl.ActiveViamSessionApiImpl.insertMultipleOnStoreBranch(ActiveViamSessionApiImpl.java:315)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: java.lang.StringIndexOutOfBoundsException: String index out of range: -1
at java.base/java.lang.StringLatin1.charAt(StringLatin1.java:47)
at java.base/java.lang.String.charAt(String.java:693)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:368)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:392)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:424)
at com.quartetfs.fwk.format.impl.LongParser.parse(LongParser.java:30)
at com.quartetfs.fwk.format.impl.LongParser.parse(LongParser.java:23)
at com.qfs.store.service.impl.DatastoreService.parseRows(DatastoreService.java:1103)
... 28 more
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<ipython-input-5-a4c563ff8295>", line 1, in <module>
test += ("Complementary", "*", 5)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/_docs_utils.py", line 18, in wrapper
return func(*args, **kwargs)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/simulation.py", line 416, in __iadd__
self.append(row)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/_docs_utils.py", line 18, in wrapper
return func(*args, **kwargs)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/simulation.py", line 410, in append
self._java_api.insert_multiple_on_store_scenario(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 217, in catch_py4j_exceptions
raise AtotiJavaException(
AtotiJavaException: An error occurred in the JVM:
An error occurred while calling o2.insertMultipleOnStoreBranch.
: com.qfs.fwk.services.BadArgumentException: [400] Invalid records to add
at com.qfs.store.service.impl.DatastoreService.parseRows(DatastoreService.java:1112)
at com.qfs.store.service.impl.DatastoreService.doInsertTransaction(DatastoreService.java:913)
at com.qfs.store.service.impl.DatastoreService.doDatastoreAction(DatastoreService.java:877)
at com.qfs.store.service.impl.DatastoreService.lambda$editDatastore$4(DatastoreService.java:827)
at com.qfs.store.transaction.impl.TransactionManager.performInTransaction(TransactionManager.java:2500)
at com.qfs.store.service.impl.DatastoreService.editDatastore(DatastoreService.java:821)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.lambda$editDatastore$0(RegisteringChouketDatastoreService.java:82)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService$DatastoreServiceOperation.initialLoad(RegisteringChouketDatastoreService.java:141)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.registerOperation(SimpleActiveViamSession.java:552)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.registerOperation(RegisteringChouketDatastoreService.java:113)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.editDatastore(RegisteringChouketDatastoreService.java:81)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.performJsonDatastoreActions(StoreOnBranchImpl.java:212)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.performJsonDatastoreAction(StoreOnBranchImpl.java:202)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.insertRows(StoreOnBranchImpl.java:103)
at com.activeviam.chouket.edit.impl.StoreOnBranchImpl.insertRows(StoreOnBranchImpl.java:123)
at com.activeviam.chouket.api.impl.ActiveViamSessionApiImpl.insertMultipleOnStoreBranch(ActiveViamSessionApiImpl.java:315)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: java.lang.StringIndexOutOfBoundsException: String index out of range: -1
at java.base/java.lang.StringLatin1.charAt(StringLatin1.java:47)
at java.base/java.lang.String.charAt(String.java:693)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:368)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:392)
at javolution.text.TypeFormat.parseLong(TypeFormat.java:424)
at com.quartetfs.fwk.format.impl.LongParser.parse(LongParser.java:30)
at com.quartetfs.fwk.format.impl.LongParser.parse(LongParser.java:23)
at com.qfs.store.service.impl.DatastoreService.parseRows(DatastoreService.java:1103)
... 28 more
It took me a while to understand what the issue was:
"*" has been moved to None cf #50double but receives a string "*"I would therefore expect a clearer message such as Invalid type string for level ProductId: received * but expected a double
It's not obvious for somebody using the API to know when to use load_all_data.
I see two reasons to turn sampling on when using large files:
join and create_cube methods call, I'd rather do it afterwards.In https://github.com/atoti/notebooks/blob/master/retail/pricing-simulations-around-product-classes/main.ipynb I ended up writing:
# We can now load all the data so that visualizations operate on the entire dataset.
# NB: as a best practice, to optimize speed while exploring your data, we recommend keeping the default sampling mode enabled.
# Once the model is ready, as it is the case in this notebook, you may call session.load_all_data() after creating the cube.
session.load_all_data()
Can you confirm what is the best practice? Could you document it as well somewhere?
I have 2 measures simulation and 2 source simulations.
haircut_simulation = asset_positions_cube.setup_simulation(
"Haircut Simulation",
levels=[lvl["Sector"], lvl["Country"]],
replace=[m["Haircut.VALUE"]],
base_scenario="Current Market Condition",
)
market_value_simulation = asset_positions_cube.setup_simulation(
"Market Value Simulation",
levels=[lvl["Sector"], lvl["Country"]],
multiply=[m["Price.VALUE"]],
base_scenario="Current Market Condition",
)
# In Source Simulation, we do not perform simulation_setup. We just load it to the store as scenarios.
cashout_simulation = loans_positions_store.scenarios[
"Cash out Increase"
].load_pandas(loans_positions_df, truncate=True)
predictive_simulation = assets_prices.scenarios["3 months forecast"].load_pandas(
predictive_3_months, truncate=True
)
Error was thrown when I tried to create another measure simulation:
predictive_market_simulation = asset_positions_cube.setup_simulation(
"x Simulation",
levels=[lvl["Year_Month"], lvl["Sector"], lvl["Country"]],
multiply=[m["Price.VALUE"]],
replace=[m["Haircut.VALUE"]]
)
Run the attached notebook. Error is thrown from the last cell.
collateral-shortfall-monitoring.zip
Traceback (most recent call last):
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\exceptions.py", line 219, in catch_py4j_exceptions
return method(*args, **kwargs)
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\_java_api.py", line 142, in refresh
self.java_session.refresh(force_start)
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\vendor\atotipy4j\java_gateway.py", line 1313, in __call__
return_value = get_return_value(
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\vendor\atotipy4j\protocol.py", line 322, in get_return_value
raise Py4JJavaError(
Py4JJavaError: An error occurred while calling t.refresh.
: com.qfs.fwk.services.BadArgumentException: [400] the branch Cash out Increase already exists.
at com.qfs.store.service.impl.DatastoreService.createBranch(DatastoreService.java:671)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.lambda$createBranch$1(RegisteringChouketDatastoreService.java:88)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService$DatastoreServiceOperation.initialLoad(RegisteringChouketDatastoreService.java:141)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.lambda$feed$3(SimpleActiveViamSession.java:629)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1540)
at com.activeviam.chouket.impl.SimpleActiveViamSession.feed(SimpleActiveViamSession.java:629)
at com.activeviam.chouket.impl.SimpleActiveViamSession.startFeeding(SimpleActiveViamSession.java:588)
at com.activeviam.chouket.impl.SimpleActiveViamSession.resume(SimpleActiveViamSession.java:385)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refresh(SimpleActiveViamSession.java:449)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<ipython-input-66-4b95227dae0f>", line 1, in <module>
predictive_market_simulation = asset_positions_cube.setup_simulation(
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\cube.py", line 218, in setup_simulation
simulation = Simulation(
File "<string>", line 11, in __init__
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\simulation.py", line 114, in __post_init__
self._java_api.refresh()
File "C:\Apps\miniconda3\envs\atoti-0_4\lib\site-packages\atoti\exceptions.py", line 221, in catch_py4j_exceptions
raise AtotiJavaException(
AtotiJavaException: An error occurred in the JVM:
An error occurred while calling t.refresh.
: com.qfs.fwk.services.BadArgumentException: [400] the branch Cash out Increase already exists.
at com.qfs.store.service.impl.DatastoreService.createBranch(DatastoreService.java:671)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService.lambda$createBranch$1(RegisteringChouketDatastoreService.java:88)
at com.activeviam.chouket.edit.impl.RegisteringChouketDatastoreService$DatastoreServiceOperation.initialLoad(RegisteringChouketDatastoreService.java:141)
at com.activeviam.chouket.impl.SimpleActiveViamSession.loadAndWatchOperation(SimpleActiveViamSession.java:568)
at com.activeviam.chouket.impl.SimpleActiveViamSession.lambda$feed$3(SimpleActiveViamSession.java:629)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1540)
at com.activeviam.chouket.impl.SimpleActiveViamSession.feed(SimpleActiveViamSession.java:629)
at com.activeviam.chouket.impl.SimpleActiveViamSession.startFeeding(SimpleActiveViamSession.java:588)
at com.activeviam.chouket.impl.SimpleActiveViamSession.resume(SimpleActiveViamSession.java:385)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refresh(SimpleActiveViamSession.java:449)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
It seems that in latest, the simulation wild card has changed from * to None. However:
"*". So it is much more difficult to spot that there is a problem and where the problem comes from. I know you don't do deprecation warnings but it would have saved me a lot of time if you were printing a warning when running a simulation with "*" with a message like "did you mean None?". It took me a while to realize why the simulation was not working anymore and that the problem came from there.In version 0.4.0.20200507160709, I'm unable to run cube.visualize. Furthermore, any api calls after that seems to hang forever.
It seems to be a CORS issue:
Access to fetch at 'http://localhost:34009/versions/rest' from origin 'http://localhost:8888' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
Take any notebook and try to run cube.visualize. I reproduced against a clean environment on several notebooks.

Suggested by a first time user:
I imagine people using this would come from pandas or R : what would have been useful is to see a side by side "this is how you do it in pandas" vs "this is how you do it in atoti". It would decrease the steep learning curve.
This could be extended against other popular libraries as well like plotly. Example of what could be put side by side:
store.join vs dataframe.mergecube.query vs dataframe.groupby + dataframe.unstack etccube.visualize + ui manipulation vs plotly.graph_objects + go.Figure(...)cube.setup_simulation vs pandas duplicate data, redefine measures etcReported by several first time users. When following the tutorial on https://docs.atoti.io/0.3.1/tutorial.html:

It's not clear what it does and users do not know that a new folder is created. What would be great is:
${full_path}. Check out ${full_path}/01. Getting Started.ipynb"Also, should it be copy_tutorial or create_tutorial?
It is currently impossible to create a measure with atoti.filter using a constant as the output. I instead have to create a constant measure, and then filter on it :
m["example"] = tt.filter(1.0, condition)
will raise a ValueError
While :
m["one"] = 1.0
m["example"] = tt.filter(m["one"], condition)
will produce the desired output correctly.
I'm trying to create a measure that can take values according to different (4) formulas depending on conditions on other levels. Therefore, I created 4 filtered measures, one for each formula and added them to create the desired measure. Two of these formulas are just constants (1.0 and -1.0 ).
Constants can be used in atoti.where, so I could also use several layered atoti.where to get the desired measure.
This code sample is only useful to understand the use case of what I wanted to achieve:
import atoti as tt
import numpy as np
import pandas as pd
session = tt.create_session()
drivers_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/drivers.csv", encoding="latin-1"
)
drivers_df.rename(columns={"url": "driver_url"}, inplace=True)
drivers_df.rename(columns={"nationality": "driver_nationality"}, inplace=True)
drivers_store = session.read_pandas(
drivers_df, keys=["driverId"], store_name="F1 drivers"
)
races_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/races.csv", encoding="latin-1"
)
races_df.rename(columns={"url": "race_url"}, inplace=True)
races_df.rename(columns={"name": "race_name"}, inplace=True)
races_store = session.read_pandas(
races_df, keys=["raceId"], store_name="F1 races"
)
constructors_df = pd.read_csv(
"https://data.atoti.io/notebooks/formula-one/constructors.csv", encoding="latin-1"
)
constructors_df.rename(columns={"url": "constructor_url"}, inplace=True)
constructors_df.rename(columns={"name": "constructor_name"}, inplace=True)
constructors_df.rename(columns={"nationality": "constructor_nationality"}, inplace=True)
constructors_store = session.read_pandas(
constructors_df,
keys=["constructorId"],
store_name="F1 constructors",
)
resultsTypes = {
"points": tt.types.DOUBLE,
}
results_store = session.read_csv(
"s3://data.atoti.io/notebooks/formula-one/results.csv",
keys=["resultId"],
store_name="F1 results",
types=resultsTypes,
)
results_store.join(drivers_store, mapping={"driverId": "driverId"})
results_store.join(races_store, mapping={"raceId": "raceId"})
results_store.join(constructors_store, mapping={"constructorId": "constructorId"})
f1cube = session.create_cube(results_store, "F1Cube")
session.load_all_data()
lvl = f1cube.levels
m = f1cube.measures
h = f1cube.hierarchiesThe use case is to calculate the score of a given driver per year:
points.SUMScore = 8+6+6+4+3 = 27Do you know any way to achieve that today?
It could be solved for example with a topcount aggregation function:
m["Score"] = tt.agg.topcount(m["points.SUM"], lvl["raceId"], 5)Topcount is a common calculation done in MDX.
We also discussed at some point having a sort/rank function that would sort elements and return their position and then we could aggregate where rank <= 5. But I don't know if such a generalization would benefit other use cases.
In
https://docs.atoti.io/0.3.1/installation.html
6. Rebuild JupyterLab
The Windows command line should be
set NODE_OPTIONS=--max-old-space-size=4096 & jupyter lab build --dev-build=False --minimize=True
instead of
set NODE_OPTIONS=--max-old-space-size=4096 & jupyter lab build --dev-build False --minimize True
import pandas as pd
main_df = pd.DataFrame(
data={
"ProductId": [0, 1, 2],
"Class": [
"Driver",
"Driver",
"Complementary",
],
}
)
secondary_df = pd.DataFrame(
data={
"ProductId": [0, 1, 2],
"SellingPrice": [10.0, 5.0, 12.0],
}
)
import atoti
session = atoti.create_session()
main_store = session.read_pandas(main_df, store_name="main", keys=["ProductId"])
secondary_store = session.read_pandas(secondary_df, store_name="secondary", keys=["ProductId"])
main_store.join(secondary_store)
cube = session.create_cube(main_store)
m = cube.measures
lvl = cube.levels
m["SellingPrice.MEAN"]=atoti.agg.mean(m["SellingPrice.VALUE"])Throws the following error A measure aggregation cannot be performed without leaf levels:
Traceback (most recent call last):
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 215, in catch_py4j_exceptions
return method(*args, **kwargs)
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/_java_api.py", line 145, in refresh_pivot
self.java_api.refreshPivot()
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/java_gateway.py", line 1313, in __call__
return_value = get_return_value(
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/vendor/atotipy4j/protocol.py", line 322, in get_return_value
raise Py4JJavaError(
Py4JJavaError: An error occurred while calling o2.refreshPivot.
: java.lang.IllegalArgumentException: A measure aggregation cannot be performed without leaf levels
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.measurePer(AlambykBuilder.java:766)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.measurePer(AlambykBuilder.java:760)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.lambda$leafAggregatedMeasure$5(AlambykBuilder.java:798)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition$CopperAggregatedMeasure.initializeType(ACopperDefinition.java:457)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition$ACopperMeasureDefinition.doPublish(ACopperDefinition.java:352)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition.publish(ACopperDefinition.java:67)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.publishCopper(AlambykBuilder.java:1856)
at com.activeviam.chouket.postprocesssor.impl.UserCopperMeasuresDescriptionPostProcessor.accept(UserCopperMeasuresDescriptionPostProcessor.java:37)
at com.activeviam.chouket.postprocesssor.impl.UserCopperMeasuresDescriptionPostProcessor.accept(UserCopperMeasuresDescriptionPostProcessor.java:20)
at com.activeviam.copper.CopperDescriptionPostProcessor.enrichDescriptionWithCopperCalculations(CopperDescriptionPostProcessor.java:90)
at com.activeviam.chouket.pivot.impl.CubeImpl$ChouketCopperActivePivotDescriptionPostProcessor.enrichDescriptionWithCopperCalculations(CubeImpl.java:1191)
at com.activeviam.copper.CopperDescriptionPostProcessor.postProcessActivePivotDescription(CopperDescriptionPostProcessor.java:57)
at com.quartetfs.biz.pivot.impl.ActivePivotSchemaBuilder.postProcess(ActivePivotSchemaBuilder.java:964)
at com.quartetfs.biz.pivot.impl.ActivePivotManagerBuilder.postProcess(ActivePivotManagerBuilder.java:267)
at com.activeviam.chouket.pivot.impl.CubeManagerImpl.toManagerDesc(CubeManagerImpl.java:194)
at com.activeviam.chouket.impl.SimpleActiveViamSession.doRefreshPivot(SimpleActiveViamSession.java:504)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refreshPivot(SimpleActiveViamSession.java:488)
at com.activeviam.chouket.api.impl.ActiveViamSessionApiImpl.refreshPivot(ActiveViamSessionApiImpl.java:116)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<ipython-input-3-80d80df6e30c>", line 3, in <module>
m["SellingPrice.MEAN"]=atoti.agg.mean(m["SellingPrice.VALUE"])
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/measures.py", line 93, in __setitem__
self._java_api.refresh_pivot()
File "/home/jbe/.conda/envs/atoti-latest/lib/python3.8/site-packages/atoti/exceptions.py", line 217, in catch_py4j_exceptions
raise AtotiJavaException(
AtotiJavaException: An error occurred in the JVM:
An error occurred while calling o2.refreshPivot.
: java.lang.IllegalArgumentException: A measure aggregation cannot be performed without leaf levels
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.measurePer(AlambykBuilder.java:766)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.measurePer(AlambykBuilder.java:760)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.lambda$leafAggregatedMeasure$5(AlambykBuilder.java:798)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition$CopperAggregatedMeasure.initializeType(ACopperDefinition.java:457)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition$ACopperMeasureDefinition.doPublish(ACopperDefinition.java:352)
at com.activeviam.chouket.pivot.alambyk.impl.ACopperDefinition.publish(ACopperDefinition.java:67)
at com.activeviam.chouket.pivot.alambyk.impl.AlambykBuilder.publishCopper(AlambykBuilder.java:1856)
at com.activeviam.chouket.postprocesssor.impl.UserCopperMeasuresDescriptionPostProcessor.accept(UserCopperMeasuresDescriptionPostProcessor.java:37)
at com.activeviam.chouket.postprocesssor.impl.UserCopperMeasuresDescriptionPostProcessor.accept(UserCopperMeasuresDescriptionPostProcessor.java:20)
at com.activeviam.copper.CopperDescriptionPostProcessor.enrichDescriptionWithCopperCalculations(CopperDescriptionPostProcessor.java:90)
at com.activeviam.chouket.pivot.impl.CubeImpl$ChouketCopperActivePivotDescriptionPostProcessor.enrichDescriptionWithCopperCalculations(CubeImpl.java:1191)
at com.activeviam.copper.CopperDescriptionPostProcessor.postProcessActivePivotDescription(CopperDescriptionPostProcessor.java:57)
at com.quartetfs.biz.pivot.impl.ActivePivotSchemaBuilder.postProcess(ActivePivotSchemaBuilder.java:964)
at com.quartetfs.biz.pivot.impl.ActivePivotManagerBuilder.postProcess(ActivePivotManagerBuilder.java:267)
at com.activeviam.chouket.pivot.impl.CubeManagerImpl.toManagerDesc(CubeManagerImpl.java:194)
at com.activeviam.chouket.impl.SimpleActiveViamSession.doRefreshPivot(SimpleActiveViamSession.java:504)
at com.activeviam.chouket.impl.SimpleActiveViamSession.refreshPivot(SimpleActiveViamSession.java:488)
at com.activeviam.chouket.api.impl.ActiveViamSessionApiImpl.refreshPivot(ActiveViamSessionApiImpl.java:116)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:834)
First, it's not clear what a leaf level is for everyone.
Secondly, it seems we need to precise against which level we need the aggregation to occur:
As a workaround, this is working:
m["SellingPrice.MEAN"] = atoti.agg.mean(
m["SellingPrice.VALUE"], scope=atoti.scope.origin(lvl["ProductId"])
)However I saw occurences where this would work right away so I'm confused:
(1) if I redefine SellingPrice.VALUE it works fine
m["SellingPrice.VALUE"]=secondary_store["SellingPrice"]
m["SellingPrice.MEAN"]=atoti.agg.mean(m["SellingPrice.VALUE"])(1) if I create a simulation (here on SellingPrice.VALUE), the initial line works fine:
simulation = cube.setup_simulation(
"DUMMY_SIMU",
levels=[lvl["ProductId"]],
multiply=[m["SellingPrice.VALUE"]],
)
# Does not throw anymore!
m["SellingPrice.MEAN"] = atoti.agg.mean(m["SellingPrice.VALUE"])(2) in the following case (one-to-many join?):
m["SellingPrice.MEAN"] = atoti.agg.mean(m["SellingPrice.VALUE"])m["CompetitorPrice.MEAN"] = atoti.agg.mean(m["CompetitorPrice.VALUE"])
Looking at the stacktrace, "it" does not try to find the column in the store I have defined but in the store "above" (in the references).
Run all the notebook.
Notebook: Notebook.zip
Data: data.zip
java.lang.IllegalArgumentException: MtM is not part of the cube's datastore selection when trying to create a measure from the same store as above:
related_logs.txt
RuntimeException: The level 'Instrument Currency' should share its dictionary with the field 'Base Currency' whatever the MDX query sent to the server.
I have the below 3 stores:
netflix_store [key: "show_id"]
country_store [key: "show_id", "country"]
location_store [key: "country"]
neflix_store has a many-to-many relationship to country_store.
country_store has many-to-one relationship to location_store.
I am unable to see the hierarchy (country_code) and measures (longitude and latitude) from location_store after joining to country_store.

Please see attached zip
00_netflix.zip
Trying to download error reports for UI with screenshot, I encounter another error that prevents the download. Please see screenshot attached.
Check "Screenshot" in the options and click download:

Datasets:
import pandas as pd
matches = {
"match_id": [0, 1, 2, 3],
"Day": [1, 1, 2, 2],
"Home": ["Liverpool", "Norwich", "West Ham", "Everton"],
"Away": ["West Ham", "Everton", "Liverpool", "Norwich"],
}
matches_df = pd.DataFrame(data=matches)
goals = {
"goal_id": [0, 1, 2, 3],
"match_id": [0, 0, 0, 3],
"Team": ["Liverpool", "Liverpool", "West Ham", "Everton"],
}
goals_df = pd.DataFrame(data=goals)Create cube:
import atoti
session = atoti.create_session()
matches_store = session.read_pandas(matches_df, keys=["match_id"])
goals_store = session.read_pandas(goals_df, keys=["goal_id"])
matches_store.join(goals_store, mapping={"match_id": "match_id"})
matches_cube = session.create_cube(matches_store, "MatchesCube")
Define measures:
m = matches_cube.measures
level = matches_cube.levels
h = matches_cube.hierarchies
m["Goal.DISTINCT_COUNT"] = atoti.agg.count_distinct(goals_store["goal_id"])
m["Goal.COUNT"] = atoti.agg._count(goals_store["goal_id"])
m["Match.DISTINCT_COUNT"] = atoti.agg.count_distinct(matches_store["match_id"])
m["Match.COUNT"] = atoti.agg._count(matches_store["match_id"])
m["Home"]=matches_store['Home']
m["Away"]=matches_store['Away']When using measures working on the main store, things work as expected:
When using measures working on the secondary store, some facts get removed (the match that have no goals):
When using both measures working on main store and secondary store, some facts still get removed:

I would expect more documentation in the cases of one-to many join in this page for example https://docs.atoti.io/0.3.1/tutorial/04-advanced-store-manipulations.html#Join-stores
From my understanding, when joining store A (main store) onto store B (secondary store), Atoti does not really perform any join yet. But at query time:
CREATE TABLE match_store (
match_id int,
Day int,
Home varchar(255),
Away varchar(255)
);
CREATE TABLE goal_store (
goal_id int,
match_id int,
Team varchar(255)
);
INSERT INTO goal_store
VALUES
(0,0,"Liverpool"),
(1,0,"Liverpool"),
(2,0,"West Ham"),
(3,3,"Everton");
INSERT INTO match_store
VALUES
(0,1,"Liverpool", "West Ham"),
(1,1,"Norwich", "Everton"),
(2,2,"West Ham", "Liverpool"),
(3,2,"Everton", "Norwhich");Inner join:
SELECT * from match_store INNER join goal_store on match_store.match_id=goal_store.match_id
Left join:
SELECT * from match_store LEFT join goal_store on match_store.match_id=goal_store.match_id
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.