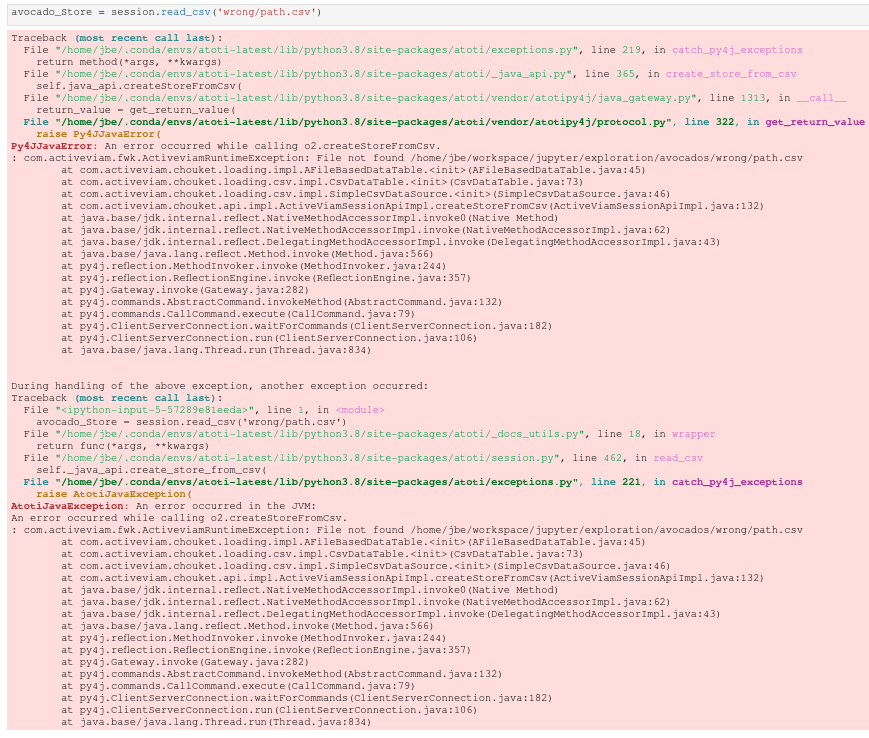
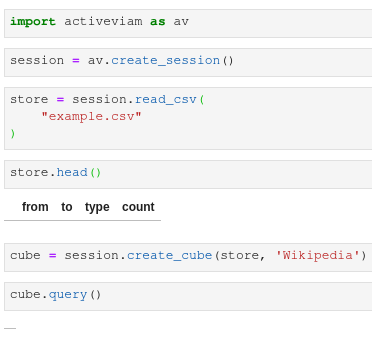
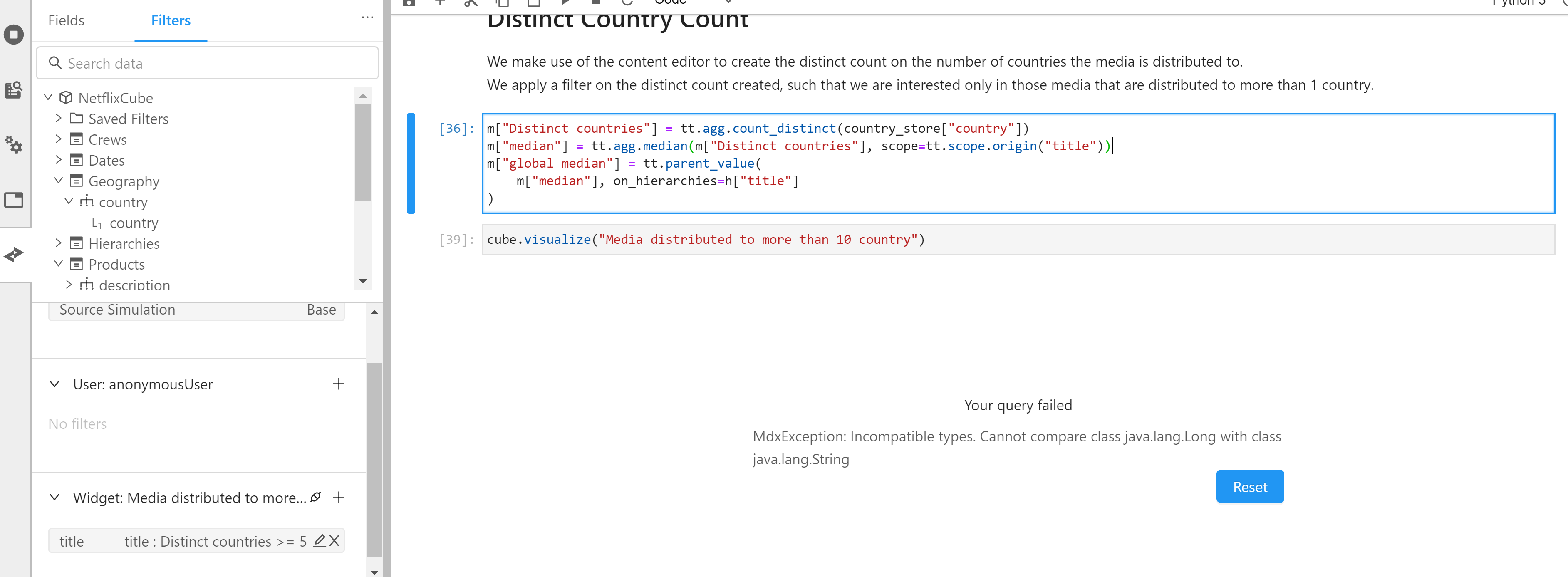
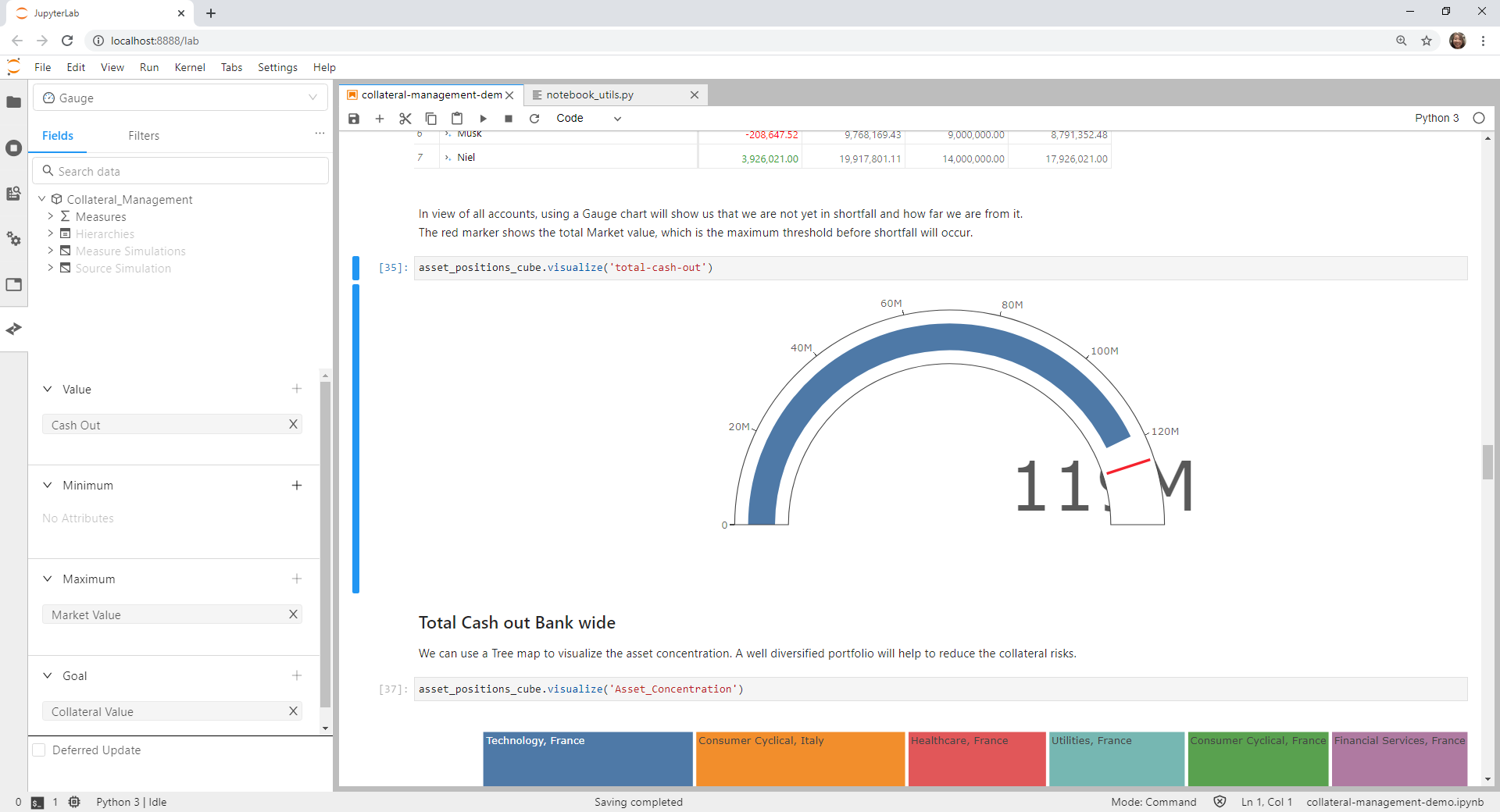
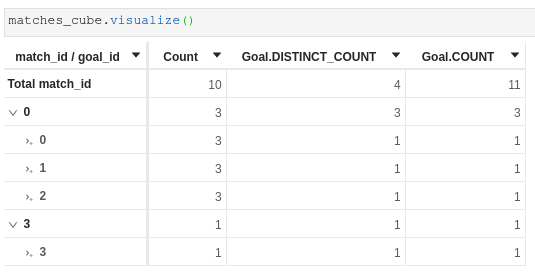
Steps to reproduce
Datasets:
import pandas as pd
matches = {
"match_id": [0, 1, 2, 3],
"Day": [1, 1, 2, 2],
"Home": ["Liverpool", "Norwich", "West Ham", "Everton"],
"Away": ["West Ham", "Everton", "Liverpool", "Norwich"],
}
matches_df = pd.DataFrame(data=matches)
goals = {
"goal_id": [0, 1, 2, 3],
"match_id": [0, 0, 0, 3],
"Team": ["Liverpool", "Liverpool", "West Ham", "Everton"],
}
goals_df = pd.DataFrame(data=goals)Create cube:
import atoti
session = atoti.create_session()
matches_store = session.read_pandas(matches_df, keys=["match_id"])
goals_store = session.read_pandas(goals_df, keys=["goal_id"])
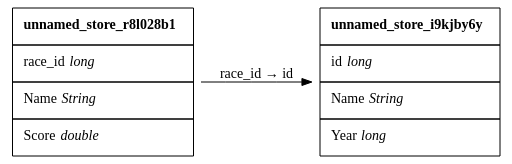
matches_store.join(goals_store, mapping={"match_id": "match_id"})
matches_cube = session.create_cube(matches_store, "MatchesCube")
Define measures:
m = matches_cube.measures
level = matches_cube.levels
h = matches_cube.hierarchies
m["Goal.DISTINCT_COUNT"] = atoti.agg.count_distinct(goals_store["goal_id"])
m["Goal.COUNT"] = atoti.agg._count(goals_store["goal_id"])
m["Match.DISTINCT_COUNT"] = atoti.agg.count_distinct(matches_store["match_id"])
m["Match.COUNT"] = atoti.agg._count(matches_store["match_id"])
m["Home"]=matches_store['Home']
m["Away"]=matches_store['Away']
Actual Result
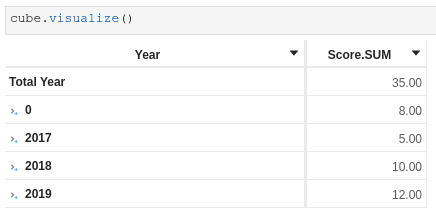
When using measures working on the main store, things work as expected:
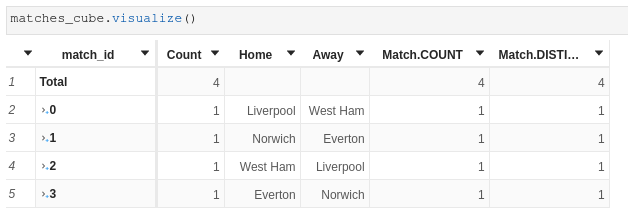
When using measures working on the secondary store, some facts get removed (the match that have no goals):
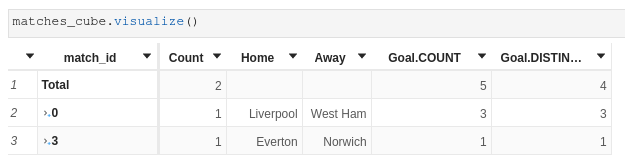
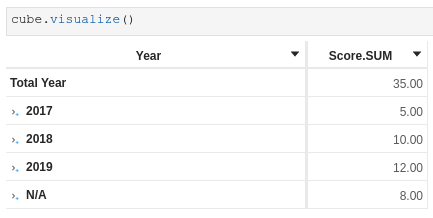
When using both measures working on main store and secondary store, some facts still get removed:

Expected Result
I would expect more documentation in the cases of one-to many join in this page for example https://docs.atoti.io/0.3.1/tutorial/04-advanced-store-manipulations.html#Join-stores
From my understanding, when joining store A (main store) onto store B (secondary store), Atoti does not really perform any join yet. But at query time:
- If I have a measure working on store A, it will resolves the join as a LEFT JOIN and then perform the calculation
- If I have a measure working on store B, it will resolves the join as an INNER JOIN and then perform the calculation
- the latter is true even if I have measures working on store A.
- Is that correct? Could you document it somewhere?
- I would not expect to have that "inner join" behavior when I have measures working against store A and B. That means users add a measure and suddenly values change and rows get removed. Is it expected?
- I would expect to have a LEFT JOIN in my case. But maybe that would not work all the time. See the SQL example below:
CREATE TABLE match_store (
match_id int,
Day int,
Home varchar(255),
Away varchar(255)
);
CREATE TABLE goal_store (
goal_id int,
match_id int,
Team varchar(255)
);
INSERT INTO goal_store
VALUES
(0,0,"Liverpool"),
(1,0,"Liverpool"),
(2,0,"West Ham"),
(3,3,"Everton");
INSERT INTO match_store
VALUES
(0,1,"Liverpool", "West Ham"),
(1,1,"Norwich", "Everton"),
(2,2,"West Ham", "Liverpool"),
(3,2,"Everton", "Norwhich");
Inner join:
SELECT * from match_store INNER join goal_store on match_store.match_id=goal_store.match_id
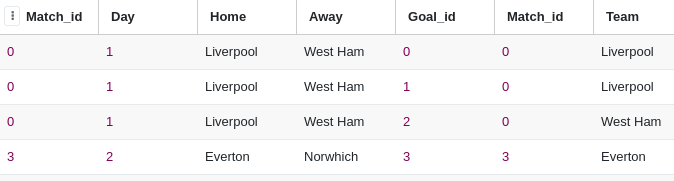
Left join:
SELECT * from match_store LEFT join goal_store on match_store.match_id=goal_store.match_id
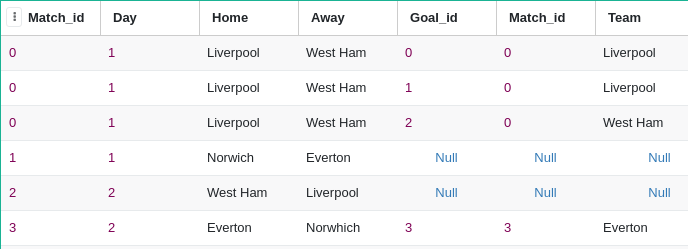
Environment
- Atoti: 0.4.0.20200511082531
- Python: 3.8.2
- Operating System: linux