apiflask / apiflask Goto Github PK
View Code? Open in Web Editor NEWA lightweight Python web API framework.
Home Page: https://apiflask.com
License: MIT License
A lightweight Python web API framework.
Home Page: https://apiflask.com
License: MIT License
Refactor the HTTPError class to support adding custom error classes, for example:
from apiflask import HTTPError
class NotAuthor(HTTPError):
status_code = 400
message = 'Only the author can perform this action!'
extra_data = {
'error_code': 1234,
'docs': 'http://example.com'
}Raise the error in the view:
@app.get('/')
def hello():
if not author:
raise NotAuthor
return 'Hello!'Find a way to reuse the get_headers() methods from Werkzeug exceptions for HTTPError.
related to #173
Originally posted by Farmer-chong October 1, 2021
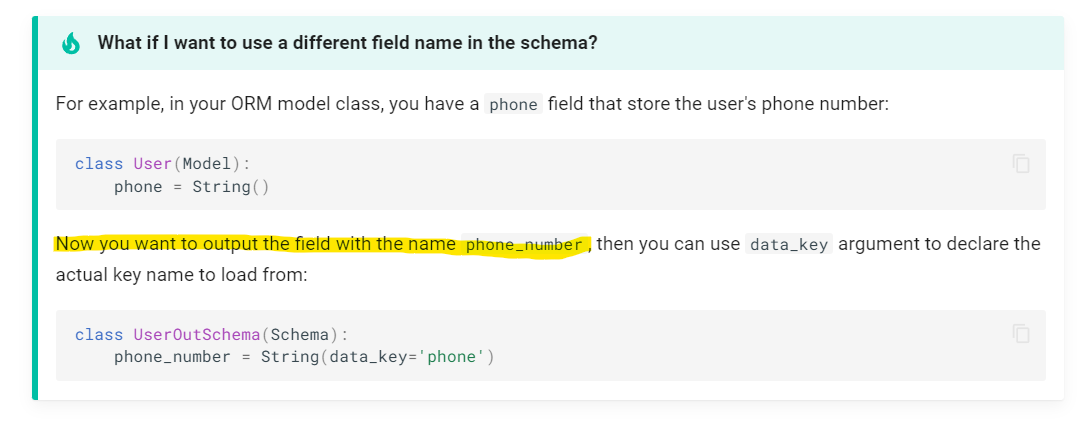
It seems that data_key argument is the output parameter?
Yes, this section should be rewritten, the data_key is the name of the external field (which we load from and dump to).
--path/-p will be more consistent with the name of the config LOCAL_SPEC_PATH:$ flask spec --path openapi.json
--output/-o will be more intuitive when using the command:$ flask spec --output openapi.json
Or --output-file:
$ flask spec --output-file openapi.json
The INFO key accepts a dict that contains the four OpenAPI info fields:
app.info = {
'description': '...',
'termsOfService': 'http://example.com',
'contact': {
'name': 'API Support',
'url': 'http://www.example.com/support',
'email': '[email protected]'
},
'license': {
'name': 'Apache 2.0',
'url': 'http://www.apache.org/licenses/LICENSE-2.0.html'
}
}The dict can be overwritten by other separate config keys.
HTTPError and HTTPException, apiflask.abort and flask.abort.Also, add an example for the error handling feature.
The flask spec generates local spec. While it will be very useful if we can update the local spec automatically when the spec changes.
We already have a LOCAL_SPEC_PATH config to get the path. Now we need to add a new config as the sync switch:
SYNC_LOCAL_SPEC: t.Optional[bool] = None
Problems:
flask spec --output ....the BASE_RESPONSE_SCHEMA not use in APIBlueprint
class BaseResponseSchema(Schema):
message = String()
status_code = Integer()
data = Field() # the data key
app.config['BASE_RESPONSE_SCHEMA'] = BaseResponseSchema
app.config['BASE_RESPONSE_DATA_KEY '] = 'data'
just return the data, like this
{
"data": {
"category": "dog",
"id": 3,
"name": "admin13"
}
}
I can’t determine whether it’s a bug or a problem with my settings
Also support syncing the file automatically.
Output to stdout (if config LOCAL_SPEC_PATH is None):
$ flask spec
Output to a file (default to using config LOCAL_SPEC_PATH):
$ flask spec -o openapi.json
Other names for the option:
-o/--output-o/--output-path-p/--path-f/--fileOther names for LOCAL_SPEC_PATH:
Add support for RapiDoc and RapiPDF, similar to marshmallow-code/flask-smorest#248.
New parameters:
APIFlask(rapidoc_path='/rapidoc')APIFlask(rapipdf_path='/rapipdf')Also, add some configs for resources and options.
Currently, the class-based view support is in a different way from Flask. In Flask, you can register the view classes with the app.add_url_route method, so that you can register all the rules in a central place for maintenance. However, in APIFlask, it forces you to use the app.route decorator on view classes. To improve this, we could:
@cbv, to collect the information for OpenAPI generating.add_url_rule for route classes, so it can collect the info then register the rule, for example, app.add_resource().Final implementation: Overwrite the add_url_rule method and collect the spec information before trigger the actual add_url_rule method. See the linked PR for more details.
In the automatic error response, there are three fields currently:
detail: It will be filled when a validation error happened.message: The HTTP reason phrase.status_code: The HTTP status code.The status_code seems unnecessary since the HTTP header already contains the status info, and some users may want it in the camel case (it can be achieved with the custom error processor though), so maybe we should just remove it. Users who need it can easily add it back via the custom error processor:
@app.error_processor
def handle_error(error):
return {
...
'status_code': error.status_code
}It would be great to be able to specify in the ApiFlask configuration which is the service basepath and the assigned host/servers.
I'm not sure if this configuration is already possible but I can't find it in the documentation.
It can be set with a links parameter in the output decorator:
@output(FooSchema, links=...)A full example:
@app.post('/pets')
@input(PetInSchema)
@output(
PetOutSchema,
201,
description='The pet you just created',
links={'getPetById': {
'operationId': 'getPet',
'parameters': {
'pet_id': '$response.body#/id'
}
}}
)
@doc(tag='Pet')
def create_pet(data):
...
@app.get('/pets/<int:pet_id>')
@output(PetOutSchema, description='The pet with given ID')
@doc(tag='Pet', operation_id='getPet')
def get_pet(pet_id):
...Can you join the support of pydantic, so that users can choose more than one, so that people who like different styles can choose freely according to their hobbies, thank you
Add a way to register an external authentication library for @auth_required.
The SPEC_FORMAT config was re-added via #66. To keep the inconsistency, the spec route should also use the value of SPEC_FORMAT.
Currently, the format will be decided based on the spec path. For example, if the spec path is foo.json, then the JSON format will be used, while the YAML will be used if the spec path is foo.yaml. This behavior will be removed in 0.7.0, now the format should be set explicitly with the SPEC_FORMAT` config.
These two keys should be AUTO_OPERATION_SUMMARY and AUTO_OPERATION_DESCRIPTION.
The idea is, if an endpoint's URL rule contains a variable, then add a 404 response for it:
@app.get('/pets/<id>')
def get_pet(id):
passSo user don't need to set a 404 response manually:
@app.get('/pets/<id>')
@doc(responses=[404])
def get_pet(id):
passAlso, add a config to control this behavior:
AUTO_404_RESPONSE: bool = True
Basic ideas:
File field.FileType, FileLength (or reuse Length?) validators.References:
Add a schema_name_resolver attribute so that user can provide their own resolver. The default schema name resolver is:
def _schema_name_resolver(schema: t.Type[Schema]) -> str:
"""Default schema name resovler."""
name = schema.__class__.__name__
if name.endswith('Schema'):
name = name[:-6] or name
if schema.partial:
name += 'Update'
return nameadd support for validate different location at once
code example 1:
@app.get('/pets/<int:pet_id>')
@input(PetInSchema, location='json')
@input(PaginationSchema, location='query')
@output(PetOutSchema)
def get_pet(pet_id, data):
if pet_id > len(pets) - 1:
abort(404)
# you can also return an ORM/ODM model class instance directly
# APIFlask will serialize the object into JSON format
return pets[pet_id]or code example 2:
@app.get('/pets/<int:pet_id>')
@input({
'json': PetInSchema,
'query': PaginationSchema
})
@output(PetOutSchema)
def get_pet(pet_id, data):
if pet_id > len(pets) - 1:
abort(404)
# you can also return an ORM/ODM model class instance directly
# APIFlask will serialize the object into JSON format
return pets[pet_id]C:\Users\chao\Documents\PROJECTS\python>flask run --reload
Traceback (most recent call last):
File "c:\python\python38-64\lib\runpy.py", line 194, in _run_module_as_main
return run_code(code, main_globals, None,
File "c:\python\python38-64\lib\runpy.py", line 87, in run_code
exec(code, run_globals)
File "C:\Python\Python38-64\Scripts\flask.exe_main.py", line 7, in
File "c:\python\python38-64\lib\site-packages\flask\cli.py", line 990, in main
cli.main(args=sys.argv[1:])
File "c:\python\python38-64\lib\site-packages\flask\cli.py", line 596, in main
return super().main(*args, **kwargs)
File "c:\python\python38-64\lib\site-packages\click\core.py", line 782, in main
rv = self.invoke(ctx)
File "c:\python\python38-64\lib\site-packages\click\core.py", line 1254, in invoke
cmd_name, cmd, args = self.resolve_command(ctx, args)
File "c:\python\python38-64\lib\site-packages\click\core.py", line 1297, in resolve_command
cmd = self.get_command(ctx, cmd_name)
File "c:\python\python38-64\lib\site-packages\flask\cli.py", line 539, in get_command
self.load_plugin_commands()
File "c:\python\python38-64\lib\site-packages\flask\cli.py", line 535, in load_plugin_commands
self.add_command(ep.load(), ep.name)
File "c:\python\python38-64\lib\site-packages\pkg_resources_init.py", line 2460, in load
self.require(*args, **kwargs)
File "c:\python\python38-64\lib\site-packages\pkg_resources_init.py", line 2483, in require
items = working_set.resolve(reqs, env, installer, extras=self.extras)
File "c:\python\python38-64\lib\site-packages\pkg_resources_init.py", line 790, in resolve
raise VersionConflict(dist, req).with_context(dependent_req)
pkg_resources.VersionConflict: (apispec 4.2.0 (c:\python\python38-64\lib\site-packages), Requirement.parse('apispec[yaml]<4,>=3.3'))
能提供一下requeirments.txt吗,我在3.8上测试不过,包冲突,重新安装apispec,你的程序报得大于4.2.0
from TestFlask.application import db
from TestFlask.module.UserModule import User
from apiflask import Schema
from apiflask.fields import Integer, String
class UserReq(Schema):
id = Integer(required=True, description="ID"), # ID
login_name = Integer(required=True, description="登录名"), # 登录名
real_name = String(required=True, description="所属项目") # 姓名
branch = String(required=True, description="所属模块") # 部门
phone = String(required=True) # 手机号
password = String(required=True) # 密码
page = Integer(required=True, description="page"), # page
pageLimit = Integer(required=True, description="page"), # pageLimit
class Meta:
model = User
exclude = ["page", "pageLimit"] # 排除字段列表
if name == 'main':
userReq = UserReq()
print(userReq)
-------------------------->
ValueError: Invalid fields for <UserReq(many=False)>: {'pageLimit', 'page'}.
when raise a subclass of HTTPError, the message field will be a list, it's different with when you raise a HTTPError directly
this is a demo
I'm not sure it's a bug or feature, but I think it should be consistent
except
{
"detail": {
},
"message": "This pet is missing."
}
current
{
"detail": {
},
"message": [
"This pet is missing."
]
}
Environment:
HTTPError object instead of separate information to the error processor function.@app.error_processor
def my_error_processor(error):
return {
'status_code': error.status_code,
'message': error.message,
'errors': error.detail
}, error.status_code, error.headerserror_processor decorator for auth classes.It could be done by adding a new config REDOC_CONFIG.
Since the generated spec is cached on the app._spec attribute, If the user access this method and attribute just after creating the app instance, when the routes are not registered yet, the subsequent requests to the spec will get the empty spec that has been cached on the first access.
from apiflask import APIFlask
app = APIFlask(__name__)
app.spec # the spec will be cached at this stageA solution would be to add a force_update parameter for the get_spec method, then clear the cached spec in app.spec:
@property
def spec(self) -> t.Union[dict, str]:
return self._get_spec(force_update=True)Then the app.spec is for users, it always returns the latest spec (need to update the openapi docs to mention this attribute); The method app.get_spec() meant to be used internally, it returns the cached spec as default, so we can rename it to app._get_spec().
Currently, the response is handled by APIFlask. Althought you can return whatever you want, but you have to return the data match the schema passed in the output decorator to generate the OpenAPI spec correctly. While some user may want to return other information more than just the data:
{
"data": {},
"message": "some message",
"code": "custom code"
}Or you want to return the same schema for both success response and validation error response:
{
"data": {},
"detail": "some detailed info",
"status_code": "200",
"message": "some message"
}Initial plan:
BASE_RESPONSE_SCHEMA = None, accepts the base schema class.BASE_RESPONSE_DATA_KEY = 'data', accepts a string to indicate the key to get/put the data.Example usage (of imagine):
from apiflask import APIFlask, Schema, input, output
from apiflask.fields import String, Integer, Field
from app.models import Pet
app = APIFlask(__name__)
class BaseResponseSchema(Schema):
data = Field()
message = String()
code = Integer()
class PetOutSchema(Schema):
...
app.config['BASE_RESPONSE_SCHEMA'] = BaseResponseSchema
@app.get('/pets/<int:pet_id>')
@output(PetOutSchema)
def get_pet(pet_id):
pet = Pet.query.get(pet_id)
return {
'data': pet,
'message': 'Get pet successfully.'
'code': '1000'
}Questions:
fields.Field?)This project currently only supports the Code-first approach, in other words, it generates the OpenAPI spec from your code and keeps the spec in sync with your code afterward. While the Spec-first approach allows you to write the spec first, when every detail of the API is discussed and confirmed, you start to code based on the spec. Both approaches have their own pros and cons. Although Code-first seems quite convenient and popular, I still hope to support the Spec-first approach for APIFlask, and it's the recommended approach by the OpenAPI initiative.
A good starting point is to support for a Semi-Spec-first approach:
After this, we can start to think of supporting the real Spec-first workflow. TBH, I don't quite familiar with the Spec-first approach, especially:
Before these happen, maybe we can recommend the user to use Connexion in the docs since it's now back to the maintenance status (spec-first/connexion#1365).
See a relevant discussion here.
Learning resources checklist:
I'm currently using APIFlask to develop the 3rd version of flog web api and the API is in an APIBlueprint. And I open /api/v3/redoc in my browser but it returns a 404 response.
What I have done:
/api/v3 url prefixWhat's expected:
When I get to /api/v3/redoc, it should display my documentation for the web api.
flask spec command to generate spec to a local file (also support syncing the file automatically)See this discussion where Grey says:
Glad to see this finally merged! After I proposed this idea and was declined in the first pallets meeting, I started to make the REST API extension I'm developing to become a framework so that I can inherit the Flask class and add these route shortcuts, now I may consider making it back to an extension...
So that we can healthily mix different extensions and not make APIFlask our main point of entry.
Can't get static files work in version 0.6.1
Example:
from apiflask import APIFlask
app = APIFlask(__name__)
@app.route("/")
def index():
return ""h1 { font-size: 16px; }File Tree:
/app-root
app.py
/static
style.css
And I GET /static/style.css in the browser, I expected to see:
h1 { font-size: 16px; }
But I got
500 Internal Server Error
What I have tried
Environment:
在apiflask内置的api文档中进行调试时,无法上传文件
demo
from apiflask import APIFlask, input, output, abort
from marshmallow.fields import Raw
app = APIFlask(__name__)
@app.post("/icon")
@input({"icon": Raw(type="file", required=True)}, location="files")
def icon(data):
print(data.get("icon"))
return {"ok": 'ok'}在docs页面有正常的选择文件按钮,但观察curl结果发现并没有将选择的文件上传至后端(network中也并没有),但当我使用Postamn等工具进行请求时,后端是正常(结果正常),因此我只能暂时将问题归结于apispec的bug
Environment:
The default error response contains three fields: detail, message, and status_code. The user can add more fields or remove existing ones by register a custom error processor with @app.error_processor. However, the abort and HTTPError only accept fixed arguments for the existing three fields.
We could collect additional keyword arguments in abort and HTTPError, store them as HTTPError.addtional_fields, and return them in error response when present.
Final implementation: Added a new keyword argument extra_data to collect the additional error information. See the linked PR for more details.
@app.get('/')
def missing():
abort(404, message='nothing', extra_data={'code': '123', 'status': 'not_found'})Currently, if the json_errors is False when creating the app instance, the error processor registered with app.error_processor will not be applied on generic HTTP errors. I think it's better to change this behavior to match the behavior of auth.error_processor and keep it explicit.
Next: Version 0.6.0 plan
Marshmallow provides some aliases for one field, for example, Str and String. To keep everything simple and consistent, I imported the fields selectively in apiflask.fields, so the IDE will not prompt Url and URL when you type "U". The following aliases were removed:
Instead, you will need to use:
Users can still import all the fields from Marshmallow, I will address this change in the docs.
Is it a good or bad idea? Feel free to leave any thoughts.
code:
@app.delete('/pets/<int:pet_id>') @output({}, 204) def delete_pet(pet_id): if pet_id > len(pets) - 1: abort_json(404) pets.pop(pet_id) return ''
shell:
curl -v -X DELETE localhost:5000/pets/0
error:
AttributeError: 'dict' object has no attribute 'many'
Hi everyone! So happy to finally public this project on the first day of April. I hope this project will make the web API development with Flask a lot easier.
Welcome to leave any ideas or suggestions for this project. I will try to make a beta release as soon as possible.
You can propose any API changes or default value changes. For example:
HTTPError to HTTPException.If needed, feel free to create a new issue (for bug/feature/advice/change/improvement) or new discussion (for question/discussion/random thoughts).
Thank you! :)
Since the docs are not versioned yet, this part should be added when the 0.8.0 version is about to release.
Related to #84.
Support to set a custom example for request parameters.
@input(PetQuerySchema, location='query', example=..., examples=[...])I have some doubt about these changes, so I keep it as a undocumentated features so far. Basically, I change the name of the following decorators from Marshamallow:
Some ideas behind these changes:
validate and validate_schema are short and clear than validates and validates_schema. It also matches the validate keyword in field classes.pre_ to before_ and from post_ to after_ was trying to follow the name convention in Flask (before_request, etc.).IMO, the new names are easier to understand and intuitive. However, this will definitely introduce "breaking" changes between APIFlask and Marshmallow. I can add a warning in the docs to inform users that they can continue to import everything from marshmallow, but notice the name changes if they want to import from APIFlask.
Is it a good or bad idea? Feel free to leave any thoughts.
Expected release date: 2021/4/20
Features:
abort_json() to abort()More docs:
Changelog: https://apiflask.com/changelog/#version-040
Next: Version 0.5.0 plan
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.