![]()
APIFlask is a lightweight Python web API framework based on Flask and marshmallow-code projects. It's easy to use, highly customizable, ORM/ODM-agnostic, and 100% compatible with the Flask ecosystem.
With APIFlask, you will have:
- More sugars for view function (
@app.input(),@app.output(),@app.get(),@app.post()and more) - Automatic request validation and deserialization
- Automatic response formatting and serialization
- Automatic OpenAPI Specification (OAS, formerly Swagger Specification) document generation
- Automatic interactive API documentation
- API authentication support (with Flask-HTTPAuth)
- Automatic JSON response for HTTP errors
- Python 3.8+
- Flask 2.0+
For Linux and macOS:
$ pip3 install apiflaskFor Windows:
> pip install apiflask- Website: https://apiflask.com
- Documentation: https://apiflask.com/docs
- PyPI Releases: https://pypi.python.org/pypi/APIFlask
- Change Log: https://apiflask.com/changelog
- Source Code: https://github.com/apiflask/apiflask
- Issue Tracker: https://github.com/apiflask/apiflask/issues
- Discussion: https://github.com/apiflask/apiflask/discussions
- Twitter: https://twitter.com/apiflask
- Open Collective: https://opencollective.com/apiflask
If you find APIFlask useful, please consider donating today. Your donation keeps APIFlask maintained and evolving.
Thank you to all our backers and sponsors!


from apiflask import APIFlask, Schema, abort
from apiflask.fields import Integer, String
from apiflask.validators import Length, OneOf
app = APIFlask(__name__)
pets = [
{'id': 0, 'name': 'Kitty', 'category': 'cat'},
{'id': 1, 'name': 'Coco', 'category': 'dog'}
]
class PetIn(Schema):
name = String(required=True, validate=Length(0, 10))
category = String(required=True, validate=OneOf(['dog', 'cat']))
class PetOut(Schema):
id = Integer()
name = String()
category = String()
@app.get('/')
def say_hello():
# returning a dict or list equals to use jsonify()
return {'message': 'Hello!'}
@app.get('/pets/<int:pet_id>')
@app.output(PetOut)
def get_pet(pet_id):
if pet_id > len(pets) - 1:
abort(404)
# you can also return an ORM/ODM model class instance directly
# APIFlask will serialize the object into JSON format
return pets[pet_id]
@app.patch('/pets/<int:pet_id>')
@app.input(PetIn(partial=True)) # -> json_data
@app.output(PetOut)
def update_pet(pet_id, json_data):
# the validated and parsed input data will
# be injected into the view function as a dict
if pet_id > len(pets) - 1:
abort(404)
for attr, value in json_data.items():
pets[pet_id][attr] = value
return pets[pet_id]You can also use class-based views based on MethodView
from apiflask import APIFlask, Schema, abort
from apiflask.fields import Integer, String
from apiflask.validators import Length, OneOf
from flask.views import MethodView
app = APIFlask(__name__)
pets = [
{'id': 0, 'name': 'Kitty', 'category': 'cat'},
{'id': 1, 'name': 'Coco', 'category': 'dog'}
]
class PetIn(Schema):
name = String(required=True, validate=Length(0, 10))
category = String(required=True, validate=OneOf(['dog', 'cat']))
class PetOut(Schema):
id = Integer()
name = String()
category = String()
class Hello(MethodView):
# use HTTP method name as class method name
def get(self):
return {'message': 'Hello!'}
class Pet(MethodView):
@app.output(PetOut)
def get(self, pet_id):
"""Get a pet"""
if pet_id > len(pets) - 1:
abort(404)
return pets[pet_id]
@app.input(PetIn(partial=True))
@app.output(PetOut)
def patch(self, pet_id, json_data):
"""Update a pet"""
if pet_id > len(pets) - 1:
abort(404)
for attr, value in json_data.items():
pets[pet_id][attr] = value
return pets[pet_id]
app.add_url_rule('/', view_func=Hello.as_view('hello'))
app.add_url_rule('/pets/<int:pet_id>', view_func=Pet.as_view('pet'))Or use async def
$ pip install -U "apiflask[async]"import asyncio
from apiflask import APIFlask
app = APIFlask(__name__)
@app.get('/')
async def say_hello():
await asyncio.sleep(1)
return {'message': 'Hello!'}See Using async and await for the details of the async support in Flask 2.0.
Save this as app.py, then run it with:
$ flask run --reloadOr run in debug mode:
$ flask run --debugNow visit the interactive API documentation (Swagger UI) at http://localhost:5000/docs:
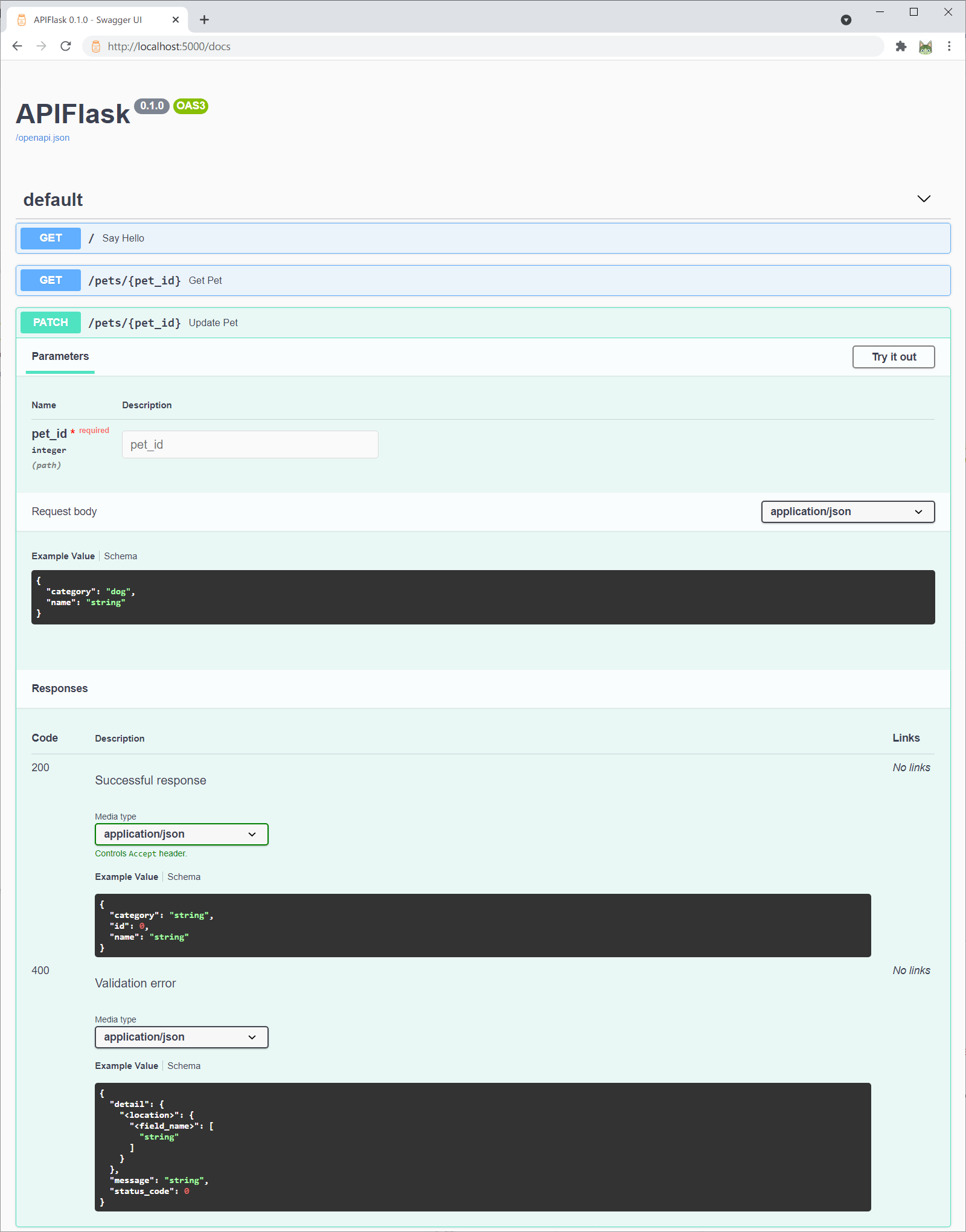
Or you can change the API documentation UI when creating the APIFlask instance with the docs_ui parameter:
app = APIFlask(__name__, docs_ui='redoc')Now http://localhost:5000/docs will render the API documentation with Redoc.
Supported docs_ui values (UI libraries) include:
swagger-ui(default value): Swagger UIredoc: Redocelements: Elementsrapidoc: RapiDocrapipdf: RapiPDF
The auto-generated OpenAPI spec file is available at http://localhost:5000/openapi.json. You can also get the spec with the flask spec command:
$ flask specFor some complete examples, see /examples.
APIFlask is a thin wrapper on top of Flask. You only need to remember the following differences (see Migrating from Flask for more details):
- When creating an application instance, use
APIFlaskinstead ofFlask. - When creating a blueprint instance, use
APIBlueprintinstead ofBlueprint. - The
abort()function from APIFlask (apiflask.abort) returns JSON error response.
For a minimal Flask application:
from flask import Flask, request
from markupsafe import escape
app = Flask(__name__)
@app.route('/')
def hello():
name = request.args.get('name', 'Human')
return f'Hello, {escape(name)}'Now change to APIFlask:
from apiflask import APIFlask # step one
from flask import request
from markupsafe import escape
app = APIFlask(__name__) # step two
@app.route('/')
def hello():
name = request.args.get('name', 'Human')
return f'Hello, {escape(name)}'In a word, to make Web API development in Flask more easily, APIFlask provides APIFlask and APIBlueprint to extend Flask's Flask and Blueprint objects and it also ships with some helpful utilities. Other than that, you are actually using Flask.
APIFlask accepts marshmallow schema as data schema, uses webargs to validate the request data against the schema, and uses apispec to generate the OpenAPI representation from the schema.
You can build marshmallow schemas just like before, but APIFlask also exposes some marshmallow APIs for convenience:
apiflask.Schema: The base marshmallow schema class.apiflask.fields: The marshmallow fields, contain the fields from both marshmallow and Flask-Marshmallow. Beware that the aliases (Url,Str,Int,Bool, etc.) were removed.apiflask.validators: The marshmallow validators.
from apiflask import Schema
from apiflask.fields import Integer, String
from apiflask.validators import Length, OneOf
from marshmallow import pre_load, post_dump, ValidationErrorAPIFlask starts as a fork of APIFairy and is inspired by flask-smorest and FastAPI (see Comparison and Motivations for the comparison between these projects).


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")














![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")