zyxelsa / inst Goto Github PK
View Code? Open in Web Editor NEWOfficial implementation of the paper “Inversion-Based Style Transfer with Diffusion Models” (CVPR 2023)
License: Apache License 2.0
Official implementation of the paper “Inversion-Based Style Transfer with Diffusion Models” (CVPR 2023)
License: Apache License 2.0











































































































debug后发现是from torch import autocast就出错了
I'm not seeing any license for this repository, can you tell me what the license it is on?
Thank you for your great work! I wonder whether we can use the content image x and style image y when training? Is it possible. In othe words, why image x is equal image y? Can you help me?
是这样的,我在学校的服务器上跑。且因为Jupyter面板看不到,所以把ipynb改成了py文件去运行的。然后训练出的embedding.pt有且路径对,content_image的路径也对的。但是style_image的路径填了却报错,和content_image填一样的也报错。

想请问大佬应该怎么解决,无限感谢!!
this may be cased by the code in line 1112 in ddpm.py, plz change the code like this, but im not sure, plz let me see the hole issue report

Originally posted by @neverenough7 in #13 (comment)
this is my issue, I do not know how to find it`s problem. please help me solve it. Thank you
8张16G的卡,也报CUDA out of memory,得多大的显存啊,训不起来
while runing InST.ipynb, I have encountered the following problem. It seems to be failing to load CLIPProcessor when loading.
Has anyone had a similar problem, please help, thanks!
Traceback (most recent call last):
File "ml_InST.py", line 68, in
model = load_model_from_config(config, f"{ckpt}")
File "ml_InST.py", line 39, in load_model_from_config
model = instantiate_from_config(config.model)
File "/home/mll/DeepLearning/InST/ldm/util.py", line 85, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()), **kwargs)
File "/home/mll/DeepLearning/InST/ldm/models/diffusion/ddpm.py", line 477, in init
self.instantiate_cond_stage(cond_stage_config)
File "/home/mll/DeepLearning/InST/ldm/models/diffusion/ddpm.py", line 553, in instantiate_cond_stage
model = instantiate_from_config(config)
File "/home/mll/DeepLearning/InST/ldm/util.py", line 85, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()), **kwargs)
File "/home/mll/DeepLearning/InST/ldm/modules/encoders/modules.py", line 169, in init
self.processor = CLIPProcessor.from_pretrained(version)
File "/home/mll/miniconda3/envs/inst/lib/python3.8/site-packages/transformers/processing_utils.py", line 186, in from_pretrained
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/home/mll/miniconda3/envs/inst/lib/python3.8/site-packages/transformers/processing_utils.py", line 230, in _get_arguments_from_pretrained
args.append(attribute_class.from_pretrained(pretrained_model_name_or_path, **kwargs))
File "/home/mll/miniconda3/envs/inst/lib/python3.8/site-packages/transformers/feature_extraction_utils.py", line 308, in from_pretrained
feature_extractor_dict, kwargs = cls.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
File "/home/mll/miniconda3/envs/inst/lib/python3.8/site-packages/transformers/feature_extraction_utils.py", line 436, in get_feature_extractor_dict
raise EnvironmentError(
OSError: We couldn't connect to 'https://huggingface.co' to load this model, couldn't find it in the cached files and it looks like openai/clip-vit-large-patch14 is not the path to a directory containing a preprocessor_config.json file.
Excellent work! How to prepare Personalized dataset when training the code? Could you please provide some detailed instructions, thank you!
Hi, expert
I used the weights you provided for testing. Why are the test results inconsistent with the results in the paper?


HI,
i am currently facing issue with torch._six module.
current torch version=
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
import torch
torch.version
'2.0.0+cu117'
ModuleNotFoundError Traceback (most recent call last)
Cell In[7], line 10
8 sys.path.append(".")
9 sys.path.append('./taming-transformers')
---> 10 from taming.models import vqgan
File ~/Desktop/Difussion_InST/InST/scripts/./taming-transformers/taming/models/vqgan.py:5
2 import torch.nn.functional as F
3 import pytorch_lightning as pl
----> 5 from main import instantiate_from_config
7 from taming.modules.diffusionmodules.model import Encoder, Decoder
8 from taming.modules.vqvae.quantize import VectorQuantizer2 as VectorQuantizer
File ~/Desktop/Difussion_InST/InST/scripts/./taming-transformers/main.py:14
11 from pytorch_lightning.callbacks import ModelCheckpoint, Callback, LearningRateMonitor
12 from pytorch_lightning.utilities import rank_zero_only
---> 14 from taming.data.utils import custom_collate
17 def get_obj_from_str(string, reload=False):
18 module, cls = string.rsplit(".", 1)
File ~/Desktop/Difussion_InST/InST/scripts/./taming-transformers/taming/data/utils.py:12
10 from taming.data.helper_types import Annotation
11 # from torch._six import str as string_classes
---> 12 import torch._six.string_classes as string_classess
13 from torch.utils.data._utils.collate import np_str_obj_array_pattern, default_collate_err_msg_format
14 from tqdm import tqdm
ModuleNotFoundError: No module named 'torch._six'
这个问题不知道怎么解决,我运行的参数如下python main.py --base configs/stable-diffusion/v1-finetune.yaml -t --actual_resume ./models/sd/sd-v1-4.ckpt -n myrun --gpus 0, --data_root .\images
我反复检查但是没能解决问题,麻烦大佬
NameError: name 'trainer' is not defined
Can you tell me which dataset you use?
Thank you for your paper, the results look amazing!!
Tried to run InST.ipynb to reproduce results published in the Comparison Data section.
As for style reference, I specified the following parameters: style_dir=andre-derain.jpg, embeddings - andre-derain_embeddings.pt_

Other parameters: content_dir=pexels-anastasiya-lobanovskaya-804952.jpg, and prompt=''
After running it with n_iter=3, got following results:

So it seems that style wasn't transferred at all in my case.
Could you please suggest whether I run InST.ipynb with the wrong parameters, or what could go not as expected in my setup?
If one use a textual inversion to describe the style image, how to separate style and content in the reference image? I understand that "content" is part of the "style"(as the paper mentioned, semantics elements are part of style). However, in Fig.4, 2rd row, InST result is totally a robot as the reference image, while the content is a human. So I am confused about the evaluation: which parts of elements of the style image are we really want to transfer to content image...
Hi expert,
As you mentioned in the paper "The training process takes about 20 minutes each image on one NVIDIA GeForce RTX3090 with a batch size of 1".
So, what the dataset you used as training data? I would like to compare with some state of art method of style transfer.
Can you run and test the project with a dedicated GPU of 10gb and a shared GPU of 32gb?
I train the embeddings.pt and use it in InST.ipynb to generate picture, but the results are bad not as good as what the author provided.
I want ask what caused it, Is it because there were other details during training?
Hi ,
Can I use your network to transform my image to a different style (anime for example) and use also textual prompt (for example 'riding a horse') and receive an image of myself in the style of anime riding a horse?
How can I do it ? I trained the network with the anime style and tried adding a prompt in the evaluation and the prompt didn't effect the image
Thank you very much in advance,
Noa
您好,请问embeddings.pt是只能自己运行main.py来生成吗?训练的数据是什么呢?这个能分享一下吗?
When I was training, I encountered the following error:
pytorch_lightning.utilities.exceptions.MisconfigurationException: No test_step() method defined to
It seems like the training has been completed, but there is no way to test it.What should I do? DoI need to modify the code?
I also want to know if the training data and test data are the same during training? Run command only have --data_root.
Thank a lot!
(ldm) lz@manager-Precision-7920-Tower:~/Documents/InST$ python main.py --base configs/stable-diffusion/v1-finetune.yaml -t --actual_resume ./models/sd/sd-v1-4.ckpt -n log1_shuimo --gpus 0, --data_root /home/lz/Documents/InST/style
Global seed set to 23
Running on GPUs 0,
Loading model from ./models/sd/sd-v1-4.ckpt
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Traceback (most recent call last):
File "main.py", line 582, in
model = load_model_from_config(config, opt.actual_resume)
File "main.py", line 29, in load_model_from_config
model = instantiate_from_config(config.model)
File "/home/lz/Documents/InST/ldm/util.py", line 85, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()), **kwargs)
File "/home/lz/Documents/InST/ldm/models/diffusion/ddpm.py", line 477, in init
self.instantiate_cond_stage(cond_stage_config)
File "/home/lz/Documents/InST/ldm/models/diffusion/ddpm.py", line 561, in instantiate_cond_stage
model = instantiate_from_config(config)
File "/home/lz/Documents/InST/ldm/util.py", line 85, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()), **kwargs)
File "/home/lz/Documents/InST/ldm/modules/encoders/modules.py", line 166, in init
self.tokenizer = CLIPTokenizer.from_pretrained(version)
File "/home/lz/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1764, in from_pretrained
raise EnvironmentError(
OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14' is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "main.py", line 795, in
if trainer.global_rank == 0:
NameError: name 'trainer' is not defined
I reported an error during training, it seems that I am missing a rewrite of the “LightningModule” method.
Could you please provide a new main.py?



When try to install packages under project folder, error occurs.
The error message is:
(base) PS C:\Users\bchan\Desktop\project\creativity-transfer> conda env create -f environment.yaml
Collecting package metadata (repodata.json): done
Solving environment: done
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Installing pip dependencies: / Ran pip subprocess with arguments:
['C:\\Users\\bchan\\Miniconda3\\envs\\ldm\\python.exe', '-m', 'pip', 'install', '-U', '-r', 'C:\\Users\\bchan\\Desktop\\project\\creativity-transfer\\condaenv.v7jnhji2.requirements.txt']
Pip subprocess output:
Pip subprocess error:
ERROR: File "setup.py" not found. Directory cannot be installed in editable mode: C:\Users\bchan\Desktop\project\creativity-transfer
failed
CondaEnvException: Pip failed
After some research online, by removing the last line in environment.yaml, that is, " - -e .", can avoid this error and successfully install the above dependencies.
OS: windows 11 22H2
Dose the stochastic inversion is only used for the inference?
And this model is only trained on embedding.pt not the diffusion model parameters?
embedding_manager save和load模型时使用的是initial_embeddings,设置为requires_grad=False,测试了一下训练过程中没有更新这个参数,只更新了attention网络。看了一下InST的代码,这里应该是保存的string_to_token_dict而不是initial_embeddings吧。

something was wrong
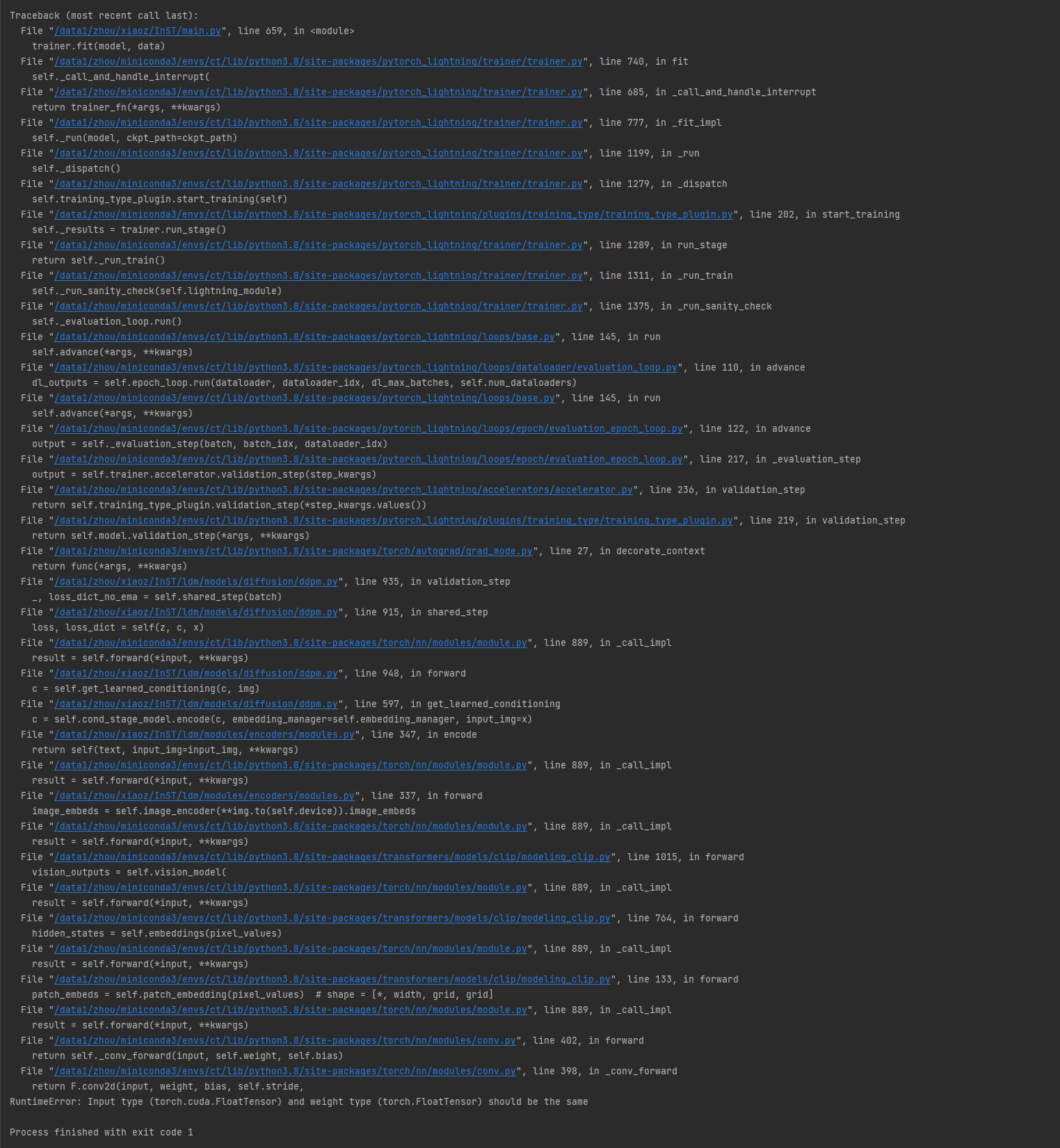
@zyxElsa
code: trainer.fit(model, data) in main.py
error: RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
I don't know how to solve the problem
The paper says "The training process takes about 20 minutes each image on one NVIDIA GeForce RTX3090 with a batch size of 1."
I used two RTX3090. However, it already cost three hours and it doesn't seem to stop.
For "v1-finetune.yaml”, which paramater specifys the number of epochs in the training process?
Thank you for your great work!
I trained an image and get results by main.py and CreativityTransfer.ipynb, but I can't get similar results to the results in the paper. Can you give specific steps or parameters in main.py?
Below is content image and my result.


Hi, thank you for sharing the code!
Can you also share some exemplar images so that we can check whether we are on the right track of training and evaluation?
Also, I tried to transfer the style of a sample image to the newly trained style of TheStarryNight and got the following.
Is this an expected result?
What should I do to change this old man into Domhnall Gleeson?

What does 'logs/{log_dir}/checkpoints/embeddings.pt' in ipynb mean? and whether has pretrained pt file for test?
model.embedding_manager.load('./logs/{log_dir}/checkpoints/embeddings.pt')
model = model.to(device)
Thanks!

Train Step: occur some errors as the following
Hello, thank you for sharing your code. But when I ran InST.ipynb for testing, I found that there was no corresponding trained model. Can you please share this test model?
First, really nice idea and results but for the style transfer case where a content reference image is given, the steps is not really explained clearly in the paper about how the content is preserved. Is the stochastic inversion related to this? If so, how?
Hi,
I run the training code main.py with reference image, but it seems doesn't work. I use the trained model to stylize the image, it always generate same images no matter what input style image I provide. And in the logs, the sampled images are all noises like this:

Really fantastic work! Respect firstly :-)
When I typed conda env create -f environment.yaml , error occured:
Installing pip dependencies: / Ran pip subprocess with arguments:
['/home/miniconda3/envs/ldm/bin/python', '-m', 'pip', 'install', '-U', '-r', '/data/application/creativity-transfer/condaenv.hx046q8u.requirements.txt']
Pip subprocess output:
Pip subprocess error:
ERROR: File "setup.py" not found. Directory cannot be installed in editable mode: /data/application/creativity-transfer
failed
CondaEnvException: Pip failed
OS: Centos7
Maybe because of missing of setup.py in repo folder?
By relying on style style screenshots in the paper to train embeddings. pt, it is impossible to achieve results that look as good as the paper,Doubt the feasibility of this method. May I ask if you can provide the embeddings. pt file for the author's training, any one is sufficient. Thank you very much!
依靠对论文里的style风格截图训练embeddings.pt,无法得到和论文一样好看的结果,怀疑这个方法的可行性。请问可以提供一下作者训练的embeddings.pt文件吗,随便一个就行。不胜感激!
It said that Cuda out of memory,how can i train it on multi-GPUs?
作者你好,我训练了几张style图片的embedding,但是在做风格转换时的效果较差,其中一个案例如下:
我的结果:

论文结果:

style图片:

请问是训练过程需要针对训练图片做参数调整还是训练时长问题?我在训练999epoch时停止训练,但效果较差,请问能否提供你所训练的embedding.pt呢?
When training with main.py, how many images are typically placed in the data_root folder? Is it one image per style? Why do I get the same output results when setting different style_dir in Inst.ipynb?

In your code, I saw that you mainly employed the textual version framework. I wanted to know the mainly difference is that you only used single image to embed the style and the textual version method used 3~5 images?
InST is a great work! Thanks for your great work and releasing your code . But i feel a little confused that content image is added the predicted noise , and why the predict noise is used instead of the stochastic noise? Thanks for your reply.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.