zwingz / my-blog-config Goto Github PK
View Code? Open in Web Editor NEWmy-blog-config
License: MIT License
my-blog-config
License: MIT License
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




先大概回顾下我在2018年总结中对2019的期望

今年主要开发了Hyrule,算是体验了一次electron开发, 同时也方便了自己用写博客。具体内容还请看Hyrule - electron+react app开发实践
使用taro开发了Koopa(基于github的图片管理小程序)。
用react开发小程序的体验还是不错的。开发过程中也给taro提过issues和pr, 算是参加了一个大型开源项目。
上半年还在老老东家时候依旧老老实实的写着react和typescript, 至于小程序则用了taro开发了koopa, 基于github的图片管理小程序。主要还是想体验一下taro, 而taro团队也是挺给力的, 提的issues和pr都会很快有人处理, 希望taro能越做越好。
在网易期间由于业务需求,也接触了react ssr以及css module, 用的是razzle,也算是浅尝即止吧。
对, 是angularjs而不是angular。也是在网易期间由于业务需求,不得不学习早已脱离时代的angularjs。而且还要研究如何在react上运行angular, 以及如何在angular上运行react,并由此搭建一个管理中台。
不管vue, react, angular谁运行谁, 总归逃不出几个方法
dom节点, 让它们在dom上自己玩自己iframe, 让它们在iframe上自己玩自己最终使用第二种来实现。
以react运行angular为例
angularjs写的app会通过gulp打包成一个umd包, 对外暴露一个render方法
export function render(angular, dom) {
angular.bootstrap(dom) // 具体api忘记了,反正就是启动angular
}react中引入angularjs, 并挂载到window下, 因为angularjs时期很多第三方依赖都是umd形式打包, 可以从window下直接获取angularjs对象, 这样angular app挂载时就能从window下拿到angular对象script标签以及link标签加载angular app的相关资源, 通过window或者requirejs获取暴露的render方法, 传入相关参数并且调用angular app挂载:::tips
angularjs时代很多依赖都会污染全局window
:::
这里可以说单纯的完成了app的挂载, 其实对于路由上不一定同步。而在处理路由上面花了很大时间去阅读ui-router源码。
而ui-router并不提供baseurl类似的选项, 只能通过其提供的方法重写路由装饰器来完成baseurl功能, 而对于路由同步, 直接通过了重写history.pushState等方法实现。
对于angular运行react则简单一点
react app同样暴露出一个render方法, 接受一个dom参数, 并将app挂载上html-webpack-plugin的template选项, 使得react app打包后输出manifest.json文件包含了所有资源的实际路径(cdn)angular app加载上面manifest.json文件并解析出js和css资源, 通过script和link分别加载umd形式引入并且调用render方法app渲染:::tips
由于用了webpack打包, 对window对象不会造成太大的污染
:::
通过上述方法, 也算是成功的在两边分别运行两者的app了。
同样是在网易时期, 需要接手内部npm以及unpkg的维护, 借此机会也学习了两者的搭建方式
搭建npm主要要解决的地方有几点, 官方也提供了相应的plugins
auth问题: 一种是通过官方提供的配置完成ldap等内置的其他认证方式, 另一种则是自行编写Middleware完成认证memory, s3-storage等方式存储时隔一年半, 又重新写起了Vue。由于目前vue对typescript的支持还不算好, 突然摆脱了ts却有点不习惯, 再次感叹ts真是个好东西。
虽然没有ts的支持,但是jsdoc也能去起到类型提示作用, 只要在文件头部添加@ts-check即可
// @ts-check
/**
*
* @param {String} arg1
* @returns {string}
*/
function test(arg1) {}参考ant-design-icons构建方法, 完成业务上的icon抽离。
主要流程:
gulp读取并解析svg源文件svg的xml转成ts对象, 最终编译成一个个的js文件IconSymbol类, 用于管理svg
import Icon1 from '@path/to/svg/es/asn/IconName' // 加载icon对应的文件
IconSymbol.register(Icon1) // 注册iconIconSymbol.getIcon(name)将icon挂载到svg-symbol
getIcon(name: string) {
const icon = this._map[name] // 拿到icon的数据结构
if (!icon) {
console.error(`[MkSvgIcon] ${name} is unregister`)
return
}
if (icon.isRendered) return
// 将icon插入到dom中
this.renderSymbol({ name, icon: icon.define, group: icon.group })
icon.isRendered = true
if (!this._isRender) {
// 将svg symbol插入到dom中
this.render()
}
}svg-use使用icon这样做的好处
js文件, 通过tree-shaking可以做到按需加载icon实际被调用时候才会挂载到dom上svg-symbol可以复用icon, 而ant-design-icon则每次都需要重新render
下半年的确少了很多commit,大概老老东家业务量比较少才让我有时间去写写开源吧。
上半年一个人负责全部前端业务, 下半年开始进入团队协作模式。开始有了周例会,迭代会等团队管理模式,这是我以前没有经历过的。以前都是需求搞完直接上线,现在是严格按照迭代流程来走。
总的来说整个技术环境和氛围变化还是挺大的, 这些变化也是我所期望的。
很奇怪,2019竟然看起书来了,毕业以来就没看过书。
第一本是《倚天屠龙记》,由于今年上映了倚天屠龙记,于是我跑去看了原著
第二本是《CSS世界》,虽然讲的都是旧时代的知识点,但还是有很多收获
第三本是《明朝那些事》,看了1/3吧
今年算是一个转折点, 在找工作上算是经历了两个阶段
大概在年初, 先是面试了酷狗和头条, 头条挂在了第二面, 酷狗也不知为何挂在了最后一面, 不过这是福不是祸(再次吐槽下酷狗是我面试体验最差的一次), 备受打击然后继续做准备.
大概在5 6月份吧. 分别面了微信, yy和网易。yy和网易都拿到了offer,微信如无意外的挂了,后面hr帮我推到了腾讯teg部门。
yy是ued岗位,负责帮公司各个部门解决性能或者体验上的问题,对我来说也是新的尝试。(yy的面试体验很好,ued的leader全程跟进,面试官也很nice)。
网易则是技术工程部,负责运维平台的开发,也相当于内部系统了,算是老本行。
最终选择了网易并在6月底入职。结果入职第一天就收到腾讯的面试,也是有点尴尬。
经过了一个月的面试最终也拿下了腾讯的offer,这就面临着要从广州搬到深圳。
这两个月,yy、网易和腾讯三家公司都让我想了好久好久,因为这都关乎着职业生涯发展,需要慎重考虑。
最终在9月初入职了腾讯,短短2个多月,从创业公司到网易再到腾讯。
今年的多次面试经历都是很宝贵的。其实只要答中面试官的点,然后适当的进行扩展,引着面试官往你熟悉的方向去走,很大概率会成功。如果一个点不了解,直接坦白也是没关系,倘若了解这个点的某个方向,也可以试着引面试官往那个方向去走,一问三不知那是很危险的。
很高兴在腾讯认识了一群很有意思的同事,刚来不久就带我去了酒吧,偶尔也带着我去觅食,在以往可是没这种待遇。
最后一点,大舞台大背景真的很重要。
今年去了珠海和惠州,也去了趟日本关西(京都、大阪、奈良)。

日本真是个好地方,虽然我不是动漫迷,但还是想说日本真是动漫的天堂。这一趟旅行,也让我入坑了高达模型。如果有机会再去一次的话,我希望能去看富士山以及灌篮高手的电车站。
我记得之前hr第一次给我电话时候我直接拒绝了来深圳发展, 后面还是来了。来到第一感觉就是:贵!堵!
住地地方不仅贵了,还小了,小到容不下我的烤箱。我朋友还跟我说:来了就是深圳人,不对,有房深圳人,没房东莞人。(开玩笑)
来了三个多月,在同事的加持下算是适应了这边的生活环境,也还不错。
对了,今年迷上了高达,正如去年迷上烘焙一样。

它们就是一堆人型人民币。
最后,还上了车。在祖国70周年借了一笔款, 在祖国百年庆还清, 算是做了一笔贡献。
2019,真的可以用‘精彩’两个字形容,也是工作三年最精彩的一年。
每年都会有新的技术诞生, 且说2019的已有技术中就有很多暂时没能掌握
typescript, 那么这是一个很好的选择。如果真的是这样,也许可以考虑考虑把项目重构了。css-in-js方案在大舞台下, 更能大展拳脚。在开源协同的大背景下,要能发挥更大的作用。
感谢2019给我带来的变化,希望2020能稳步发展。
https://zwing.site/posts/346031510.html
Just a blog.
new Promise(function(resolve, reject) {
resolve()
}).then(function(val) {
return val
}, function(error) {
catch(error)
}).catch(function(error) {
catch(error)
})Promise对象基本方法是then, 而catch是then的一个变形, 相当于then(undefined, onReject)
根据Promise用法, 我们初步想到需要实现的方法是
此时Promise原型应为
const PENDING = 'PENDING'
const RESOLVED = 'RESOLVED'
const REJECT = 'REJECT'
class Promise {
constructor(func) {}
resolve(){}
reject(){}
then(onReslove, onReject){}
}Promise/A+规范(以下简称规范)中所说的PENDING, RESOLVED, REJECTEDPENDING转换到RESOLVED或者REJECTED其中一个, 并且之后不会再改变onResolve回调, 并且只执行一次onReject回调, 并且只执行一次class Promise {
constructor(func) {
this.value = null // 终值或者据因
this.status = PENDING // 状态
this.onResolveCallBack = [] // resolved 回调
this.onRejectCallBack = [] // rejected 回调
try {
func(this.resolve.bind(this), this.reject.bind(this))
} catch (e) {
this.reject(e)
}
}
resolve(val){
if(this.status === PENDING) {
this.value = val // 设置终值
this.status = RESOLVED // 设置状态
this.onResolveCallBack.forEach(each => {
each(val) // 执行回调
})
}
}
reject(reason){
if(this.status === PENDING) {
this.value = reason // 设置据因
this.status = REJECT // 设置状态
this.onRejectCallBack.forEach(each => {
each(reason) // 执行回调
})
}
}
then(onReslove, onReject){}
}这里可能有人会说Promise应该是一个异步的过程, 在上面代码中并没有看到任何的异步. 比如说: setTimeout。
解答:
其实当创建一个Promise实例的时候,整个过程是同步的。
也就是说
const ins = new Promise(function(res, rej) {
res(10)
})
console.log(ins)
console.log('after ins')
// 输出
// Promise {<resolved>: 10}
// after ins当你执行完这一句, ins的状态会马上变成RESOLVED. 说明在构造方法中并没有执行异步操作。如果真的需要异步的话,则需要主动在调用res前,加上setTimeout来触发异步。
const ins = new Promise(function(res, rej) {
setTimeout(() => {
res(10)
})
})
console.log(ins)
console.log('after ins')
// 输出
// Promise {<pending>}
// after insthen方法没有完成. 先看下规范怎么说then方法以访问当前值, 终止和据因then(onResolve, onReject)promise对象简单说就是
class Promise() {
// ...
then(onResolve, onReject){
const self = this
return new Promise(function(nextResolve, nextReject) {
if(self.status === PENDING) {
// 加入到任务队列
self.onResolveCallback.push(onResolve)
self.onRejectCallback.push(onReject)
} else if(self.status === RESOLVED) {
// 异步执行
setTimeout(onResolve, 0, self.value)
} else {
// 异步执行
setTimeout(onReject, 0, self.value)
}
})
}
}此时Promise已经可以完成异步操作.
但是Promise还有一个关键特点是可以链式调用. 目前是还没有实现链式调用这一步.
具体代码看promise2.js
Promise 解决过程
简单说就是
x为then方法中onResolve或者onReject中返回的值, promise2为then方法返回的新promise.
promise的解决过程是一个抽象步骤. 需要输入一个promise和一个值. 表示为[[Resolve]](promise, x)
x和promise2相等, 则以TypeError为据因拒绝执行promise2x为Promise实例, 则让promise2接受x的状态x为thenable对象, 则调用其then方法x为参数执行promise2继续修改then方法, 以及添加resolvePromise来执行Promise解决过程
function _isFunction(val) {
return typeof val === 'function'
}
function _isThenable(x) {
return _isFunction(x) || (typeof x === 'object' && x !== null)
}
/**
* Promise 解决过程
* 如果是thenable对象, 则触发该对象的then方法
* 如果是一个值, 则直接调用resolve解析这个值
* @param {Promise}} promise
* @param {Object} x
* @param {Function} resolve
* @param {Function} reject
*/
function resolvePromise(promise, x, resolve, reject) {
// 要求每次返回新的promise
// 如果返回是当前的promise, 则抛出typeError
if (x === promise) {
reject(new TypeError('Chaining cycle detected for promise'))
}
let called = false
// 判断是否thenable对象
if (_isThenable(x)) {
try {
const { then } = x
if (_isFunction(then)) {
then.call(
x,
val => {
if (!called) {
called = true
// 如果不断的返回thenable
// 则需要不断地递归
// 但是实际上不应该不断的返回thenable
resolvePromise(promise, val, resolve, reject)
}
},
reason => {
if (!called) {
called = true
reject(reason)
}
}
)
} else {
resolve(x)
}
} catch (e) {
if (called) {
return
}
called = true
reject(e)
}
} else {
// 非thenable, 则以该值来执行resolve
resolve(x)
}
}
class Promise() {
// ...
/**
* then方法
* @param {Function} [onFulfilled] 前then的resolve函数, 当promise为RESOLVE时,处理当前结果
* @param {Function} onRejected 当前then的reject函数, 当promise被REJECT时调用
* @returns {Promise}
* @memberof Promise
*/
then(onFulfilled, onRejected) {
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : val => val
onRejected =
typeof onRejected === 'function'
? onRejected
: err => {
throw err
}
const self = this
// 如果有then方法调用, 则将hasThenHandle设为true
// console.log(this);
this.hasThenHandle = true
/**
* 返回一个新的promise, 用于链式调用
*/
const ret = new Promise(function(resolve, reject) {
// 用try..catch包裹执行方法
const tryCatchWrapper = function(fnc) {
return function() {
try {
fnc()
} catch (e) {
reject(e)
}
}
}
// 封装resolve方法回调
const doResolve = tryCatchWrapper(function() {
resolvePromise(ret, onFulfilled(self.value), resolve, reject)
})
// 封装reject方法回调
// 如果当前then没有相应的reject回调
const doReject = tryCatchWrapper(function() {
resolvePromise(ret, onRejected(self.value), resolve, reject)
})
if (self.status === PENDING) {
// 如果当前promise还未执行完毕, 则设置回调
self.onResolveCallback.push(doResolve)
self.onRejectCallback.push(doReject)
} else if (self.status === RESOLVED) {
// 如果为RESOLVE, 则异步执行resolve
setTimeout(doResolve, 0)
} else {
// 如果为REJECT, 则异步执行reject
setTimeout(doReject, 0)
}
})
return ret
}
}至此一个Promise可以说基本完成了.(完整代码请看index.js)
其实规范中定义的是Promise的构建和执行过程.
而我们日常用到的却不至于规范中所提到的.
比如
那接下来就说下关于这部分的实现
上面有提到. catch其实是then(undefined, reject) 的简写. 所以这里比较简单
class Promise() {
// ...
catch(reject) {
// 相当于新加入一个then方法
return this.then(undefined, reject)
}
}finally函数作用我想大家都应该知道, 就是无论当前promise状态是如何. 都一定会执行回调.
finally方法中, 不接收任何参数, 所以并不能知道前面的Promise的状态.
同时, 他不会对promise产生影响.总是返回原来的值 所以在finally中的操作,应该是与状态无关, 不依赖于promise的执行结果
class Promise() {
// ...
finally(fnc = () => {}) {
return this.then(val => {
fnc()
return val
}, err => {
fnc()
throw err
})
}
}// 调用形式
Promise.resolve(arg)
Promise.reject(arg)Promise.resolve
根据arg的不同, 会执行不同的操作
- arg为Promise实例, 则原封不动的返回这个实例
- arg为thenable对象, 则会将arg转成promise, 并且立即执行arg.then方法(并不代表同步, 而是本轮事件循环结束时执行)
- arg不满足上述情况, 则返回一个新的Promise实例, 状态为resolved, 终值为arg
因此Promise.resolve是一个更方便的创建Promise实例的方法.
Promise.reject
这里就不会区分arg, 而是原封不动的把arg作为据因, 执行后续方法的调用.
实现代码
class Promise() {
// ...
/**
* Promise.resolve
* 将参数转成Promise对象
* @static
* @param {any} val
* @returns {MPromise}
* @memberof MPromise
*/
static resolve(x) {
// 如果为MPromise实例
// 则返回该实例
if(x instanceof Promise) {
return val
} else if(_isThenable(x)) {
// 如果为具有then方法的对象
// 则转为MPromise对象, 并且执行thenable
/**
* @example
* MPromise.resolve({
* then(res) {
* console.log('do promise')
* res(10)
* }
* })
*/
return new Promise(function(res, rej) {
// 执行异步
setTimeout(function() {
val.then(res, rej)
}, 0)
})
}
// 如果val为一个原始值,或者不具有then方法的对象
// 则返回一个新的MPromise对象,状态为resolved
/**
* @example
* MPromise.resolve()
*/
return new Promise(function(res) {res(x)})
}
/**
* reject方法参数会原封不动的作为据因而变成后续方法的参数
* 且初始状态为REJECT
* 不存在判别thenable
* @static
* @param {any} reason
* @returns
* @memberof MPromise
*/
static reject(reason) {
/**
* @example
* MPromise.reject('some error')
*/
return new Promise(function(res, rej) {rej(reason)})
}
}unhandledRejection和浏览器中的Uncaught (in promise) 提示在Promise中产生的所有错误都会被Promise吞掉. 当没有相应的错误处理函数时候, node和浏览器分别有不同的表现.
但是这并不是一个新的错误, 因为不能用try{} catch(){} 捕获.
所以在浏览器端, 是一个console.error的错误提示, 在node中, 这个算是一个事件. 具体可以通过process.on来监听
process.on('unhandledRejection', function (err, p) {
throw err;
});在编写代码中, 一开始卡在这一步挺久.
由于无法知道promise实例后续是否有相应的错误处理函数.
简单的判断onReject === undefined 是不行的.
形如:
Promise.reject(10)
// 或者
new Promise(function(res, rej) {
rej(10)
})这类是同步执行的, onReject === undefined 恒为true.
我的做法是给promise实例添加一个hasThenHandle的属性, 在then方法中将其设为true
在reject方法中使用setTimeout异步判断该值是否为true, 如果不是则通过console.error抛出提示.
其实在原生Promise中, 抛出的unhandledRejection 也是属于异步的.
Promise.reject(10)
console.log('after Promise.reject')
new Promise(function(res, rej) {
rej(10)
})
console.log('after new Promise')
// 输出
// after Promise.reject
// after new Promise
// Uncaught (in promise) 10
// Uncaught (in promise) 10于是这个问题也能得到很好地解决.
至此完整代码已经结束, 具体看index.js.
brew install git
# or
# apt-get install git
## 配置ssh-key
git config --global user.name ''
git config --global user.email ''
ssh-keygen -t res -C 'email'
# 然后就是自定义
# 要不要密码随便你
# 反正下面都会进行ssh-add上github或者gitlab, 进入setting,找到ssh-key, 点击new SSH Key 把id_rsa.pub内容粘贴进去就ok了


cd ~/.ssh
vim config
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_github
Host gitlab.com
HostName gitlab.com
User git
IdentityFile ~/.ssh/id_rsa_gitlab
# 注入密码,下次不需要再输密码(除非重启)
ssh-add -k ~/.ssh/id_rsa_gitlabthis is content
vuex对ts支持并不友好, 我们定义了一堆state, 但是在使用mapXXX方法的时候并不知道有哪些namespace以及有哪些getters或者actions可以获取
而vuex-ts-enhance, 借助ts的类型推导功能,在使用vuex时能提供state, actions, getters, mutations和dispatch的类型推导。解决了上述问题
import { EnhanceStore } from 'vuex-ts-enhance'
import Vue from 'vue'
const state = {
state: {
// rootState
root: {}
},
getters: {
rootGet() { return 1 }
},
actions: {
// rootActions
setRoot(context, payload: string) {}
},
mutations: {
setRoot(state, payload: string){}
},
modules: {
sub: {
namespaced: true,
state: {
substate: ''
},
actions: {
setSubState(context, payload: number) {}
},
mutations: {
setSubState(state, payload: number) {}
},
getters: {
suGet() { return 2 }
},
}
}
}
export const { mapGetters, store, mapActions, mapMutations, mapState } = s;
new Vue({
store
})这样就能完成初始化, 其实就是把state传入构造器中, 所返回的mapXXXX方法都带有类型推导, 并且能明确知道某个namespaced下有哪些数据或者方法能获取.
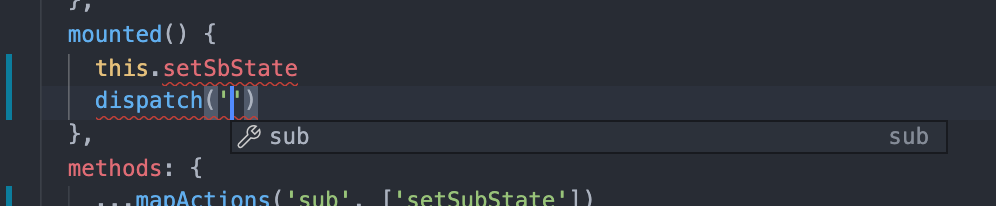
接下来看下vscode的提示


能看到mapGetters中有rootGet这一个rootGetters, 而且在使用时还能推导出其类型


同样能看到mapActions中有sub这一个namespace, 以及里面拥有setSubState这一个方法

当我们调用这个方法时也能有参数提示
而对于dispatch, 只能通过import进来使用
使用示例
dispatch(namespace, actions, payload) 或者 dispatch(rootActions, payload)
目前还不支持dispatch的payload的类型推导, 后续会增加
完整代码
<template>
<div>
</div>
</template>
<script lang="ts">
import Vue from 'vue';
import { mapGetters, mapActions, mapState, mapMutations } from './store'
export default Vue.extend({
computed: {
...mapGetters(['rootGet']),
},
mounted() {
this.rootGet // type number
this.setSubState // type (payload: number) => Promise<void>
dispatch('sub', 'setSubState', 1)
},
methods: {
...mapActions('sub', ['setSubState'])
}
});
</script>以上类型推导同时支持mapGetters, mapActions, mapState, mapMutations, dispatch
typescript, 请不要把state定义成StoreOptions, 因为这样会让类型推导失效const state: StoreOptions<any> = {} // don't do thatjs, 并且使用了jsdoc来定义来写, 请务必把context定义为any, 否则类型检查会失效const state = {
actions: {
/**
* @param {any} context
* @param {string} payload
*/
someActions(context, payload) {}
}
}以上代码是基于lant=ts下有的提示, 但如果是在lang=js下, vetur有时能提示类型, 又是又不能提示类型,详情见issue。暂且找不到问题所在。但mapXXXX方法的提示还依然生效, 因为他不依赖vetur
teste
例如Notification, MessageBox, Alert, ConfirmBox 等等
这类组件都是通过命令式来调用.
例如elementUi中this.$message或者Message来调用.
对于我们来说,this.$message这种调用方法莫过于是最方便.因为不需要处处引入Message或者在webpack中配置插件使得Message暴露于全局
那么我就从this.$message这类讲起
其实也只是编写一个Comp组件, 这里不多说.
将Vue组件挂载到一个dom上,也就是将组件实例化.
然后将组件实例挂载命名空间中或者Vue.prototype中,
这样相当于直接操作组件实例的methods来改变组件的状态.
ElementUI使用的是这种方式.
无入侵式
这方式前提必须要使用Vuex, 因为他是依赖vuex.registerStore实现
关于registerStore请移步到文档中
其实就是动态注册一个storeModule, 用来管理组件的状态.
所有操作都通过细改store的状态来引起组件的改变
// 引入组件
import Comp from 'Comp.vue'
function registerModule(store) {
store.registerModule('compNameSpaceState', {
namespaced: true,
state: {},
getters: {},
mutations: {},
actions: {}
})
}之后可以将通过对象将调用接口暴露出去
let $compApi = function () {
return {
// 此处需要使用建投函数,确保this指向
action: () => {
this.$store.dispatch('compNameSpaceState/compAction')
}
}
}接下来很简单,就是将$compApi.prototype中.
那么如何保证$compApi中this指向Vue实例呢
let bind = false
// Vue.use() 会自动调用install方法,此时可以注册组件
Comp.install = function (Vue) {
// 代理带vue原形上.可以通过this.$spin调用
Object.defineProperties(Vue.prototype, {
$compApi: { // 挂载到Vue.prototype中的$compApi
get() {
if(!bind) {
// 注册store
registerModule(this.$store)
// 只需要绑定一次即可
// 绑定后可以将原来的$compApi覆盖掉
// 调用bind函数确保this指向
$compApi = $compApi.bind(this)()
bind = true
}
return $compApi
}
}
})
// 将组件注册为Vue全局组件
Vue.component('Comp', Comp)
}
export default Comp最后一步则需要在App.vue将Comp挂载上去
// 这一步自动调用install, 会全局注册Comp
// 但是在第一次调用$compApi时候才会进行registerStore.
Vue.use(Comp)<!-- App.vue-->
<template>
<Comp/>
</template>这种方法是入侵式的
但是可以很方便的追踪组件状态, 而且实现起来也很方便.
在自己开发组件的时候可以考虑
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"安装
sh -c "$(curl -fsSL https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"添加插件
vim ~/.zshrcplugins=(
git
z
)安装 nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash
# or
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash
# then
# vim ~/.bash_profile or ~/.zshrc or ~/.profile or ~/.bashrc
# insert
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
# last
source ~/.your_rcprofile使用方法
# 本地node版本
nvm ls
# node所有版本
nvm ls-remote
# 安装最新node(稳定版,即偶数版)
nvm install --lts
# 安装指定版本node
nvm install v8.9.4
# 切换到指定版本/别名node
nvm use v8.9.4
# 给node版本起别名
nvm alias default v8.9.4安装 node
nvm install v8.9.4
npm 换源
# npm 源
npm config set registry https://registry.npm.taobao.org
# sass 源
npm config set sass_binary_site https://npm.taobao.org/mirrors/node-sass/安装
brew install git配置 ssh-key
git config --global user.name ''
git config --global user.email ''
ssh-keygen -t res -C 'email'配置 hosts
cd ~/.ssh
vim config
# 写入
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_github
Host gitlab.com
HostName gitlab.com
User git
IdentityFile ~/.ssh/id_rsa_gitlab注入密码(重启后失效)
ssh-add -k ~/.ssh/id_rsa_gitlab
Setting Sync"sync.gist": "8162a18bd9632ab95c50704e92e1a57c" eslint vetur document this javascript code snippets project managerjs是单线程的, 所有异步都需要经过Eventloop(事件循环).这里不介绍eventloop
主要记录下eventloop中的microtask 和macrotask
Vue.nextTick源码中,分别使用了microtask和macrotask
在Vue2.4版本之前,默认都是使用microtask.优先判断是否支持promise,如果不支持则退回到MutationObserver,如果再不支持则回退到setTimeout
但在后续更新中,Vue已经修改nextTick实现方式.默认使用microtask, 同时也提供方法强制使用macrotask,例如由v-on绑定的事件处理.
原因就是因为microtask优先级太高.甚至高于事件冒泡. 而macrotask则会引起一些问题.
详情请看Vue.nextTick源码
// Here we have async deferring wrappers using both micro and macro tasks.
// In < 2.4 we used micro tasks everywhere, but there are some scenarios where
// micro tasks have too high a priority and fires in between supposedly
// sequential events (e.g. #4521, #6690) or even between bubbling of the same
// event (#6566). However, using macro tasks everywhere also has subtle problems
// when state is changed right before repaint (e.g. #6813, out-in transitions).
// Here we use micro task by default, but expose a way to force macro task when
// needed (e.g. in event handlers attached by v-on).
let microTimerFunc
let macroTimerFunc
let useMacroTask = false
// Determine (macro) Task defer implementation.
// Technically setImmediate should be the ideal choice, but it's only available
// in IE. The only polyfill that consistently queues the callback after all DOM
// events triggered in the same loop is by using MessageChannel.
/* istanbul ignore if */
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
// Determine MicroTask defer implementation.
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
// in problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
} else {
// fallback to macro
microTimerFunc = macroTimerFunc
}https://zwing.site/posts/346031510.html
Just a blog.
develop到masterpush代码pull代码使用docker来跑node, 则线上不需要有node环境.
docker中docker中跑npm命令# docker-compose.yml
version: '3'
services:
depoly:
container_name: project-container
image: node:carbon
working_dir: /project
volumes:
- .:/project然后编可以通过命令docker-compose run --rm deploy yarn xxx来执行npm命令
build:
docker-compose run --rm deploy yarn build
install:
docker-compose run --rm deploy yarn install --production
dev:
docker-compose run --rm -p 8080:8080 deploy yarn dev
# 因为当前build目录和build命令冲突, 用以下关键词区分两者
.PHONY: build
#!/bin/bash
trap "kill 0" SIGINT
# 如果带了 -i 参数, 则需要安装依赖
if [[ "$1" == "-i" ]]; then
echo -e "\n\033[41;37m Install dependencies:\033[0m\n "
make install
if [[ "$?" == 1 ]]; then
echo -e "\t\033[31m Error in npm install, pleace check your package.json\n\033[0m"
exit 1
fi
fi;
echo -e "\n\n\033[41;37m Build... :\033[0m\n "
make build
if [[ "$?" == 1 ]]; then
echo -e "\t\033[31m Error in npm run build \n\033[0m"
exit 1
else
echo -e "\033[32mBuild Success \033[0m\n"
fi
exit $?
fabric是一个python库, 可以通过ssh在远程服务器执行命令.
它有两个1.0和2.0版本, 其中1.0只支持py2, 2.0版本可以支持py2和py3, 而且两个版本的api区别很大, 具体请参考官方文档.
以下所使用的是fabric2.0, 附上fabric2.x文档
可以利用它来pull代码, 并执行代码编译
同时, 线上一般只拉master分支, 所以fabric也能帮助我们在本地合并到master分支后push到git上
from fabric import Connection
from invoke import task
c = Connection(host='server_name')
# 制定task
# 可以通过fab depoly 调用
@task
def depoly(d):
c.local('git checkout master') # 切换到master
c.local('git rebase develop') # 合并develop分支
c.local('git push origin master') # push到master
with c.cd('/home/ubuntu/path/your_project'):
c.run('git pull', pty=True) # 远程拉取代码
c.run('./depoly.sh') # 远程执行build
c.local('git checkout develop') # 本地切换回develop执行fab depoly就可以完成一系列部署
上述过程其实完全可以由各种CI完成
但是对于私有gitlab, 同时又没有部署gitlab-runner或者不想接入第三方的话
fabric是个不错的选择
接触过前端的应该都有听过GraphQL
简单来说就是前端自行定义接口所需要返回的数据, 想要尝试的可以试着调用GithubAPI V4.
而对于我们常用的xhr请求能否也做到跟GraphQL一样能自定义接口返回的数据?
答案是可以, 但是提前必须是后端必须提供足够的数据让前端自行选择.
假设目前后端定义了一个User模型, 包含了十几项数据
// Example
class User {
id,
username,
created,
updated,
// .. 省略好几个人
}任何接口如果有涉及到拿User数据的, 都会把该User的数据全量返回, 也就是说前端能从接口中拿到User相关的十多项数据.
但实际上并不是每个接口都需要这么多数据, 可能部分接口我们只需要用到username和id. 但对于后端来说, 他们只管写通过逻辑, 而不去管UI上需要哪些数据.
这样一来, 每个接口都有可能返回大量无用的数据, 如果数据嵌套过深, 极端情况可能有上兆的数据.
因此前端需要做到像GraphQL一样能够自行定义所需的数据. (前提还是需要后端支持)
如果后端是用JAVA开发, 那么可以使用squiggly来支持前端数据自定义
根据这个库的介绍, 可以通过自定义filter形式来过滤掉JAVA类中数据的输出
用javascript以及上面的User作为例子的话, 假设我们的filter是username,id, 那么当我们log(User)时候只会输出username和id两个数据, 其他都被过滤掉
当然还支持其他过滤方式, 但下面都是以精确匹配方式来完成数据定义
直接在请求中带上自定义请求头, 值设为所需要返回的字段
const fileds = 'name,user.username,user.id'
axios.request({
url: '/example',
headers: {
fields
}
})这样后端返回的字段只有
{
"name": "",
"user": {
"username": "",
"id": ""
}
}这种方法存在弊端
fileds会很麻烦fields不利于复用fields中定义的字段无法反应到response中基于上面的问题, 我所期待的效果应该如下:
filedsfields易于继承和扩展fileds同时能定义其类型, 并且反应到response上解决上面上个问题可以从两个方法入手
filedstypescript完成类型定义似乎只用typescript + interface就能很好的解决上述功能
定义类型
interface ResData {
name: string,
user: {
username: string
id: number
}
}借助ts可以很容易定义一个类型, 只要把它赋值给axios就能很容易定义response
接下来只需要想办法把interface转成字符串
但其实类型和字符串是两个层面的东西, 类型属于ts, 而字符串是实实在在的js变量, 将两个层面连接一起的通道其实就是AST, 我们可以通过解析ts语法, 通过transform转成js代码
于是乎发现了一个ttypescript, 可以自行实现transformer来完成编译, 同时发现了一个很合适的transformer
而这篇文章整体思路跟我都是很相似, 这里就不在展开
但是说下这个方法的一些弊端
最终要达到的目的其实就是: 定义字段同时定义返回类型, 而上面的方法是从ts层面出发, 我们可以试着从js层面出发, 利用ts的类型推到功能完成
举个例子
const a = {
name: '',
user: {
username: '',
id: 1
}
}
type A = typeof a借助ts的类型推到可以很容易得出
type A = {
name: string;
user: {
username: string;
id: number;
};
}有了这个例子, 我们就可以很容易完成我们的目标
const NumberType = 1 // type: number
const StringType = '' // type: string
const BooleanType = true // type: boolean
const AnyType = '' as any // type: any
const a = {
name: StringType,
user: {
username: StringType,
id: NumberType
}
}
const b = {
key1: BooleanType,
key2: {
key3: {
key4: {
key5: NumberType
}
}
}
}通过定义变量+类型推导就能很轻松完成fileds的定义
render方法作用其实就是将上面定义好的变量转成字符串形式的fields
function render(arg) {
// 实现方法其实很简单, 就是遍历object输出key
// 遇到nested或者array就递归
}这时候我们可以这样
const fileds = render(a)
axios.request<typeof a>({
url: '/example',
headers: {
fields
}
})到这里其实就达到了最终的目标定义fileds同时定义返回类型
但是目前这样维护起来不太容易, 我们需要继承以及更多的类型支持
继承的目标就是在已有的fileds上继续扩展, Object.assign就能满足
但assign本身是不带类型的, 因此需要给他加入类型以便ts进行类型推导
// 最简单的继承
function extend(t0, ...args) {
return Object.assign({}, t0, ...args)
}剩下要做的只需要对它进行重载以满足类型推导
// 举个例子
// 我们只需要使用泛型来重载它的输入和输入类型
export function extend<T0 extends Record<string, any>, T1>(
t: T0,
u: T1,
): {
[P in keyof (T0 & T1)]: (T0 & T1)[P]
}
function extend(t0, ...args) {
return Object.assign({}, t0, ...args)
}
const a = extend({a: 1}, {c: ''})
type A = typeof a
// A = { a: number, c: string }在typescript还有高级类型比如pick, omit, union等
要实现他们, 原理跟继承一样, 都通泛型以及重载实现
// 再举个例子
function constant<T extends string | number>(arg: T): T {
return arg
}
const a = constant(1)
type A = typeof a
// A = 1, 而不是numberconst A = {
name: StringType
}
const B = {
user: {
username: StringType,
id: NumberType
}
}
const C = extend({
c: BooleanType
}, A, B)
type TypeC = typeof c
// { name: string, user: { username: string, id: number }, c: boolean}
const D = pick(C, ['user'])
type TypeD = typeof D
// { user: { username: string, id: number } }
const E = omit(C, ['user'])
type TypeE = typeof E
// { name: string, c: boolean }通过一系列的辅助方法, 就可以很好的达到我们的目的: 定义fileds同时定义类型
const A = {
name: StringType
}
const fileds = render(A)
axios.request<typeof A>({
url: '/example',
headers: {
fields
}
})还是借用了泛型+类型推导
function render(arg: any) {}
function request<T>(fieldsDeclare: T, url) {
const fields = render(fieldsDeclare)
// 在这里借用了类型推导
return Axios.request<T>({
url,
headers: {
fields
}
})
}
const A = {
name: ''
}
request(A, '').then(r => {
r.data // typeof A { name: string }
r.data.name // string
})有了以上基础,其实要实现真正的GraphQL也是可以的,只需要实现render方法即可。
基于ts的泛型+类型推导其实能实现很多强大的功能,比如vuex-ts-enhance,就是借助泛型+类型推导,完成了vuex中mapXXX方法的类型推导,有兴趣可以试用下。
又一年春节过完了,
今年过的特别开心和充实。
今年年初拿了驾照,还没放假就心想着终于可以开车到处走了。
然后回家后一两天就找小叔带着我去绕了两圈,找我姐带着我下了趟停车场。
然后就独自开出去浪了。
今年活动最多的就是打麻将。
好像整个春节只有几天没有出去。
结果就是几乎把塞尔达通关了。
能开车对我来说是今年春节最最最庆幸的事情。
第一点我可以到处走,虽然以前开着摩托也可以,但是感觉完全不同,虽然停车有点麻烦。
第二点是可以载着父母到处走。
去年十月份我姐也结婚了,家里自然也只剩下父母,他们出行也只能依靠摩托车。
如果要去什么远地方,就需要我姐特意开车过来接送。
说实话我看着也觉得麻烦。
真的很庆幸今年我拿到了驾照。
让我带着我爸妈去吃了一顿酸菜鱼,吃了一顿火锅。
对我来说可能不是第一次,但是对他们来说可能是第一次。
毕竟他们心里的外出吃饭大多都是饭店,去年就是这样了。
所以今年我就跟他们说不要去饭店。找一下没吃过的去试下。
如果我没有驾照,那么就要我姐负责接送。
说实话,她来回就要一个钟了。
虽然平平常常的两顿饭,却让我感受到很久没感受过的家庭聚餐。
能载着父母到处走,其实也是很开心的一件事,
这是难得的机会去服务他们。
转眼间春节就过完了。
数了下一共放了12天假。
短短两个半小时车程,
便离开了温馨的家,
回到了冷清的出租屋。
回到了熟悉又陌生的环境。
中山。
二线城市。
一线消费。
十八线工资。
这是去年中山上升为二线城市时候我朋友调侃时候说到的。
广州。
一线城市。
转眼就在这里生活了五年。
谈不上喜欢也谈不上厌倦。
如果可以,谁想做游子。
回中山。
这是必定的结果,只是不知何时能做到。
如果可以,我也想马上回去中山。
回到父母身边,周末载着他们去喝早茶吃吃饭。
回到朋友身边,周末跟着他们去浪一下。
带着女朋友去走我还没走过的中山。
好咯。
新的一年,继续努力。
大概明年这个时候,我也可以独自上高速。
那时,我就可以随时回去中山,而不是每次都订车票那么繁琐。
lerna用于管理多package,且各package可能会互相引用的项目。
lerna通过两种方式管理子项目的版本号:
lerna publish都会将所涉及到的包升级到最新一个版本,开发者只需要确定发布下一个version。version,每次执行lerna publish都需要确定每个包的下个版本号。以下命令以yarn为主。
yarn global add lerna
lerna init
命令执行完毕后,会在生成对应的目录结构。
lerna-repo/
package.json
lerna.json
packages/
package-1/
package.json
package-2/
package.json
{
"version": "1.1.3", // 项目版本
"npmClient": "npm", // 默认使用的npm,可改为yarn
"command": { // lerna 内置命令的配置
"publish": {
"ignoreChanges": ["*.md", "**/test/**",], // 发布时忽略部分文件的改动,配置此项可以减少不必要的publish。
"message": "chore(release): publish" // git commit message
},
},
"packages": ["packages/*"]
}lerna create <name>
创建一个子项目,并会根据交互提示生成对应的package.json
lerna add <package>[@version] [--dev] [--exact]
lerna add eslint: 所有包都会装上eslint。lerna add eslint --scope=package1:只有package1会装上。lerna add eslint packages/prefix-*:符合prefix的包会装上。options:
-dev:添加到devDependencies--exact: 只安装特定版本如果添加的是子项目,则会通过link软连接到对应的项目中。
lerna add package1 --scope=package2
lerna run <script> -- [..args]
lerna run test:则会执行所有子项目中的test。lerna run --scope package1 test:只执行package1中的test。lerna run --ignore package-* test:只执行除了匹配package-*外的项目中的testlerna exec -- <command> [..args]
与lerna run类似,只不过它可以执行任意命令。
eg: lerna exec -- rm -rf ./node_modules
lerna bootstrap:安装各子项目依赖,对相互引用的项目进行软连接,在子项目中执行npm run prepublish和npm run prepare
--hoist [glob]:会将子项目的匹配的依赖(eg:eslint, jest等),统一放在根目录的node_modules中,减少安装时间,但仅限npmClient=npm—nohoist [glob]: 匹配的依赖(eg: babel)会安装到子项目中的node_modules中lerna clean:删除子项目的node_moduleslerna link:同bootstrap第二步。lerna-changelog基于pr来为项目生成changelog
可参考repo
master分支切换出feature/bugfix等分支,参考git-flow。commit,推荐使用commitizen来规范commit msg,同时有助于对后续子项目生成changelog。push到remote端。pr,并打上label,此处一定要打上label,learn-changelog就是根据label来确定该pr属于feature/bugfix/document等。merge之前打上label。merge pr操作。master分支并进行pull操作。lerna-changelog,既可得到一份changeling。pr的label并不能随意设置,一定要在项目中声明对应才生效。
官方默认支持breaking/enhancement/bug/documentation/internal,如果想用其他,则需要在package.json中进行相应的配置。
{
"changelog": {
"labels": {
"feat": ":rocket: New Feature",
"bug": ":bug: Bug Fix",
"doc": ":memo: Documentation",
"internal": ":house: Internal",
"breaking": ":boom: Breaking Change"
}
}
}尚未实践过,具体还需参考README
lerna的使用已介绍完毕,上述内容可满足日常开发需求,更多详情还需参考官方文档。
突然想写些什么..
那就写下这周做了什么吃的..
除了晚餐之外.
这周做了特别的可能就是炸薯条, 火烧云以及芒果千层了.
下面就大概回忆下过程
其实炸薯条本不是本人的意思, 只是女友说突然想吃薯条, 就在买菜的时候买多了一个土豆.
由于不是本人的意思,过程也只是大概记得.
其实一开始全程都是女友在弄.只不过她炸的时候油放的太少了..然后跑过来跟我说像是在炒薯条..
于是乎我就自己上了..其实这也是我第一次炸薯条.
炸完之后油也只能倒掉.感觉很浪费.炸一个土豆用了1/3瓶油..
感觉以后都不会再炸东西了.除非量大. 这里就没图了.很简单的
这个其实我上星期就有做过了.只不过做失败了.
其实就是面包再加工一下啦, 外表看起来逼格挺高. 吃起来也还ok
就是由于上周失败了, 并且找到原因, 所以这周就铁了心要把它完成. 当然这里肯定有图了
这是入烤箱前
烤完后
味道还是不错的, 也挺简单.
做这个芒果千层, 耗时3小时, 也是不容易啊
这里先上图, 之后再补充制作过程
其实烤箱双十一就购入了, 同时也购入了一批烘焙工具,从此入了烘焙的坑,
不入不知道, 一入深似海
这里就顺便贴下图吧.过程就先忽略了
鸡蛋布丁
西多士

蛋挞
风琴土豆
test
keywords:
简单介绍三个React组件吧。
一个用于加载/预览图片的组件
loading和error状态, 并显示不同提示. IntersectionObserver来实现图片懒加载Preview来进行图片预览group来管理图片预览列表, 同一个group的图片会出现在预览列表中import { Image } from '@zzwing/react-image'
<Image src='any.jpg' width='200px' height='200px' onClick={this.onClick}/>图片浏览器, 可以放大/移动/切换等. 已集成到Image中, 可以通过 preview={false}关闭预览功能.
也可以直接通过api调用
import { PreviewApi } from '@zzwing/react-image'
const list = ['1.jpg', '2.jpg', '3.jpg']
// use index
PreviewApi.preview(2, list)
// or use src
PreviewApi.preview('2.jpg', list)
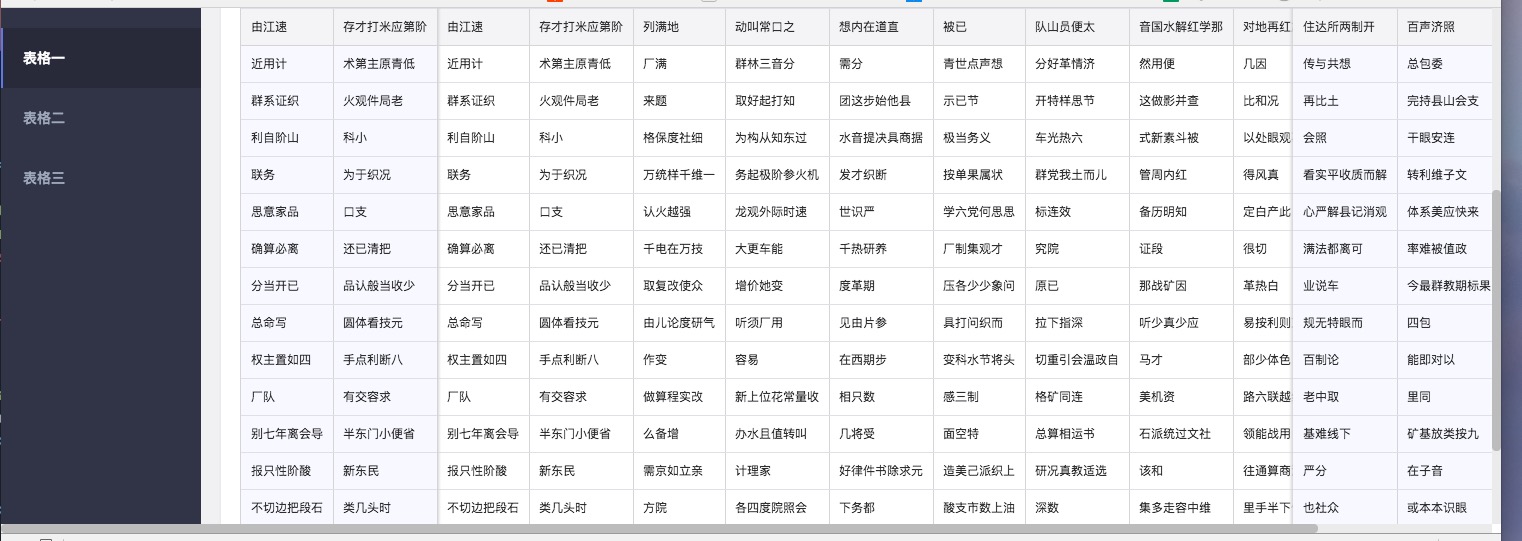
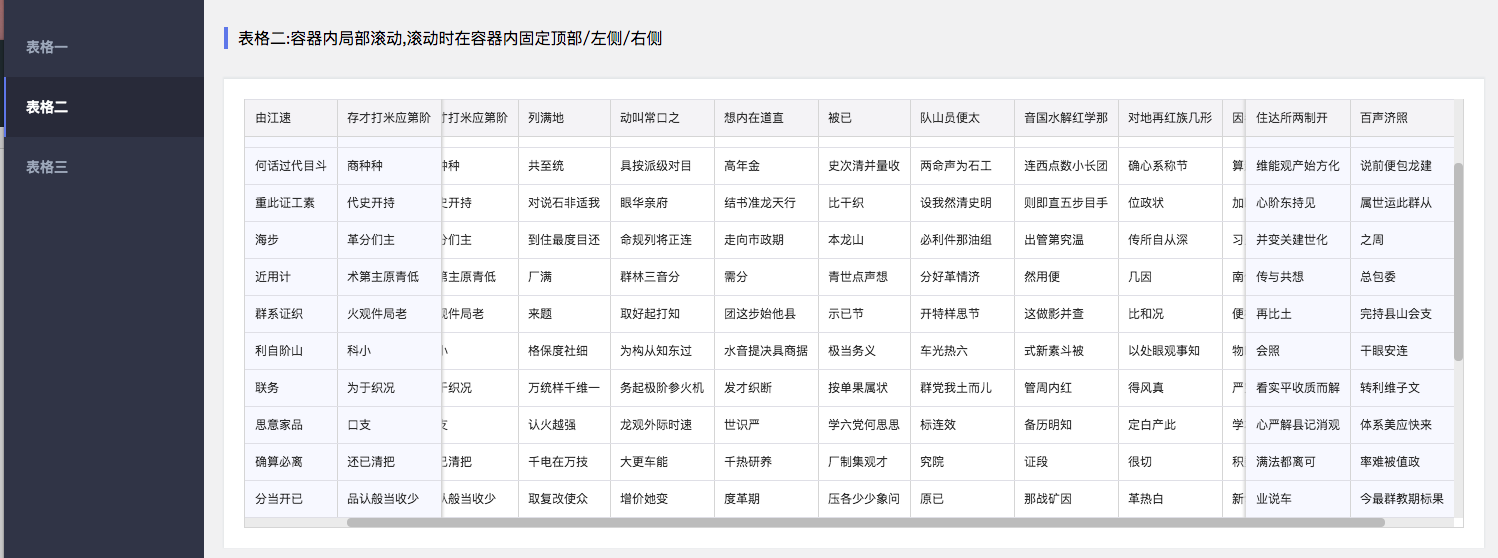
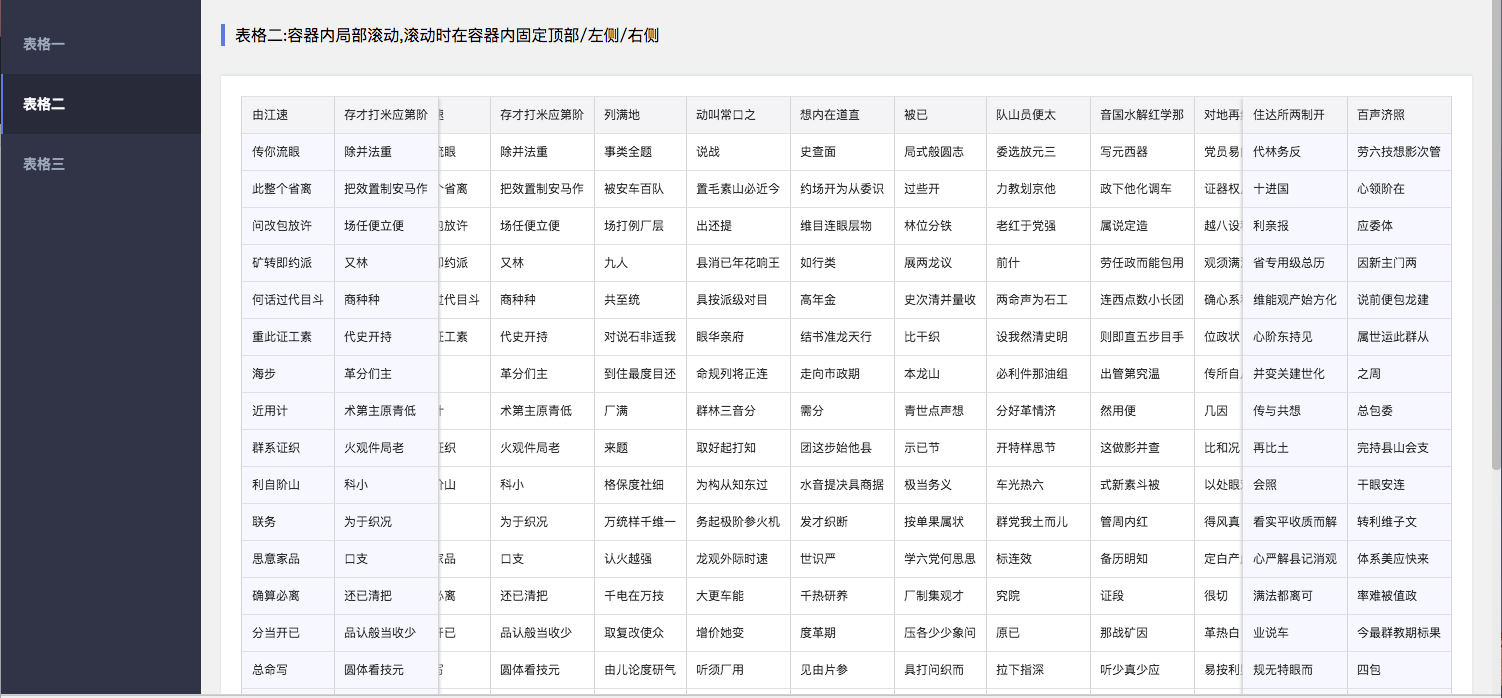
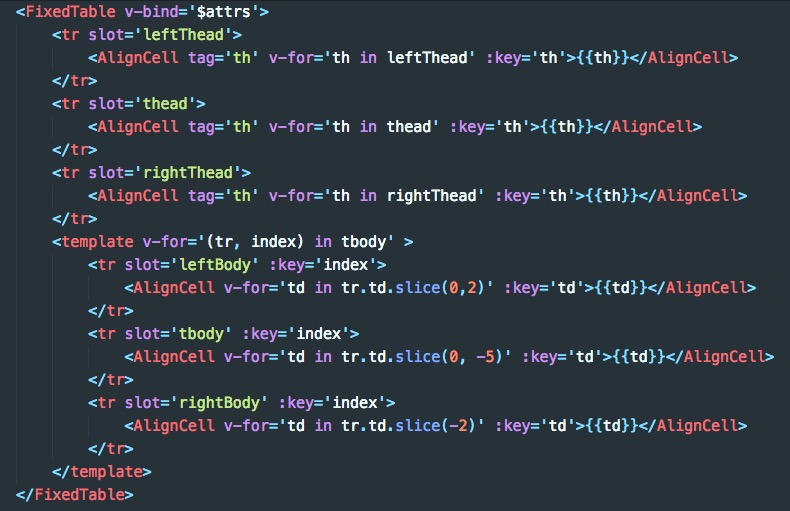
可固定表头及两侧的表格.
antd的表格也能满足该功能, 但也有几个不足点(我个人觉得)
width用来固定列宽: 通过拆分thead和tbody来固定表头, 通过colgroup来完成列宽的固定antd的表格功能太强大, 有很多功能我是用不上, 无形中增加了代码.指定表格的scrollTarget, 既滚动的目标, 默认是document.scrollingElement.
transform固定,由于属于同一个table, 这样能解决tbody和thead不对齐的问题.table冗余实现(antd也是如此), 但只会冗余需要固定的部分。通过absolute + padding 实现两侧固定.scroller来模拟横向滚动条, 也就是说任何时候都可以拉动滚动条. (当然也可以通过shift + 滚轮完成滚动)thead使用了transform, 因此也带来了几个问题
thead设了transform之后, border会失效, 因此使用了box-shadow来模拟border. 当然,mousewheel来设置transform的时候, 因为滚动和视图更新有延迟, 在firfox和safari会有抖动, 在chrome下表现良好.
chrome和firfox分别加入window.addEventListener('scroll', console.log), 鼠标滚动一次, 会发现ff下会触发多次回调, 而chrome只会触发一次safari下, thead在被固定后的box-shadow会失效.和antd类似
import { Table } from '@zzwing/react-table'
const data = [{key1: '123', keyn: '123'}]
const columns = [{
title: 'column1',
fixed: 'left',
dataIndex: 'key1'
}, { /* ... */} , {
title: 'column2',
fixed: 'right',
dataIndex: 'keyn'
}]
<Table dataSource={data} columns={columns} rowKey='key1'/>封装了onChange和value的高阶组件, 与antd的form组件类似
不过只包含最基础的数据绑定, 也可通过options来自定义数据的读写.
import FormWrapperHoc from '@zzwing/react-form-wrapper'
class Test extends React.PureComponent {
render() {
const { itemWrapper, getState } = this.props.formWrapper
const Input = itemWrapper('valueKey', {/* options */})(<input />)
const value = getState().valueKey
return (
<>
{Input}
you can get value for {value}
</>
)
}
}const Input = itemWrapper('a.b.c.d')(<input />)按照一般实现, 会通过遍历每一层来set/get数据.
const _state = {}
const pathArr = path.split('.')
let tmp = _state
pathArr.forEach((each, index) => {
if(index === pathArr.length - 1) {
// do something
}
if(each in tmp) {
tmp = tmp[each]
} else {
tmp[each] = {}
tmp = tmp[each]
}
})最近改了一种实现方法, 通过一个chain对象直接存储path对应的数据
// a.b.c.d
const chain = {
a: {b: chain['a.b']},
'a.b': {c: chain['a.b.c']},
'a.b.c': {d: chain['a.b.c.d']},
'a.b.c.d': undefined
}get操作, 则可以直接从chain[path]中获取数据set操作, 则可以直接修改chain['a.b.c'].d = 'str', 最后修改chain['a.b.c.d'] = 'strset操作会同步chain.a和chain.a.bantd是一个功能很全的UI库
但又正因为它功能很全,而大部分我是不需要,无形中可能添加了不少的代码量
所以我更喜欢是参考antd的实现,去开发满足个人需求的组件
自己开发的组件,自己会更清楚,使用起来更加顺手,扩展起来也会很方便
不过对于DatePicker这类组件,我想我还是直接用antd的吧
希望这几个组件能帮到你.
createApp.js, createRouter.js, store.js, http.js
utils.js, ConstValue.js, mixin.js, registerComponent.js
route.js, app.js
page-view&components
登录/权限
列表页
内容过多.会引起页面滚动.表头以及两侧需固定
有很多的查询条件
$router.replace)每一个列表页类似.但又有不同,主要差异在于查询条件以及表格内容
列表页/详情页切换后列表数据的保存(保留列表页状态)
详情页/审核页
数据展示形式类似. 形如: label: content;
布局类似
创建/修改页
数据形式类似. 形如: label: form
数据验证. 简单点就是能否提交
Table(如上所说) Demo
LoadingBar(顶部的进度条,主要是切换路由时候出现,挂在beforeEach和afterEach中调用, 有异步路由时候建议使用)
Message(消息提示)
1. 使用createElement创建dom元素,并且把message组件挂载上去即可,不过需要使用到vue完整版
2. 将组件挂在到App.vue中,并使用vuex管理其状态. 可以在初次调用message时候才注册store
Modal 没什么好说.哪里用到就声明一个Modal.
Confirm(确认式提升,与message一样的实现方式)
AsyncButton(会触发异步操作的按钮,监听异步请求的路由,当请求未结束时button处于loading态.)
AutoCompleteInput(带搜索建议的Input. 可以封装多装搜索框)
Panel (可收缩面包.很简单)
Field (label: content\form; 类型展示组件)
Pagination (分页,很简单)
Tree (树, 使用递归组件即可, 如果要做节点多选, 管理选择状态会比较麻烦.)
Select, Checkbox, Radio, Switch (自定义组件v-model即可,简单)
Spin (请求时间很长的时候, 可以弹出model,并构建一个假的进度条. 上传文件的时候也能用到,当然这时候的进度是真实的.通过onprogress获取)
BackToTop (回到顶部, 加个贝塞尔动画就好了)
Scroller (自定义非原生滚动条, 建议直接用css来设置原生scroll样式.目前应该firefox不支持设置原生滚动条样式)
Img (hover时候出现蒙层.点击时候出现查看器)
如果对组件进行for命令,必须加上:key,这是官方指定.
但对于原生dom进行for循环时候.其实可以不加:key,或者使用index作为key.
一旦设置了key,只有key得值不一样,会直接销毁重建dom. 那么用index作为key的话,则只会更新dom而不会销毁重建
任何通过addEventListeners添加的监听事件,销毁时最好使用removeEventListeners给去掉
如果不需要运行时构建,可以在webpack中指定使用vue.runtime.js, 会剩了几十k体积
sass-loader前再加一层sass-resources-loader可以将一些变量或者方法全局引入,那就不用到处import了.
{
loader: 'sass-resources-loader',
options: {
resources: [path.resolve(__dirname, '../src/sass/variable.scss')]
}
}

本篇博客就在Hyrule下完成。
请先参考, 自动部署基于issues的静态博客, 再配合Hyrule食用。
之前一直用issues来写博客, 使用acyory和plugin完成博客搭建. 对我来说已经算很方便, 我只需要打开github即可写自己的博客。
但是有些不足点就是:
markdown preview, 但是写作体验不太好, 我一般都在本地编辑器写完后放到issues后面找到了picgo, 再配合plugin, 可以很好的把github当做图片, 并且在博客中使用。
目前需要解决的点就剩下写作体验和博文管理。
有于是乎就有了Hyrule这个App。
picgo是个很强大的图床工具, 可以通过自己编写插件来完成不同站点的图床管理。
但对于我自己来说, 我需要的只是github, 虽然已有插件支持github图片同步, 但是对我来说远不够。
在Hyrule中, 管理图片是个很简单的事情, 不管是private还是public,只需要添加对应的图床repo即可。而且可以很方便的切换不同图床。但是private有一点不足的是,它无法分享,以及获取的时候会稍慢,这是跟github有关,后续讲开发经历时候再详细说。
除了支持多图床,还支持文件夹形式。
支持批量上传/删除图片,但是有一点不足的是,由于git commit的问题,最终必须逐个上传或删除,但用户操作上可以支持批量操作。
等待各位提feature request。
当然,这个功能不一定所有人都需要用到。
内置vscode的monaco-editor,让写文章就跟写代码一样方便。同时可以同步预览,但是同步滚动的话可能目前做的还不够完美。
其实picgo也有vscode的插件vs-picgo,其实就是在vscode粘贴图片直接上传到对应图床上,我很喜欢这个功能。
在Hyrul中,你可以先上传图片到图床,然后复制其markdown格式链接粘贴在文章中。也可以直接在编辑器中上传,它会自动上传到所选的图床中。(当然,前提是需要提供一个repo来做默认图床)
在编写同时,也可以同时浏览图片。
当文章写到一半,但又不想这么快发布的话,可以保存到本地,下次继续写。
等待各位提feature request。
目前来说,这App已经满足我日常写博客需求。
除了这点,我觉得最重要的是个人在开发过程中的经验积累,包括界面交互设计(虽然目前很丑)、功能设计、技术调研等等。
开发过程中也遇到了不少问题,后续会写一遍文章来记录相关内容。
后台管理系统,多多少少会有列表页.
而列表页又正是由表格形成.
但是原生的表头并不能固定头部以及两侧.
一旦数据多了,查看起来就不方便了.
于是乎就出现很多固定表头/两侧的表格组件
实现方式
这种应该是最普遍也是最简单的方式.
就是将一个表格分成多个表格.
包括表头/左侧/右侧/表体, 共四个表格
然后通过 css 方式将表头以及两侧固定
之后通过 scroll 事件的监听,同步表头以及两侧的 scroll 值,就可以达到固定的效果
优点
实现起来简单,而且无缝滚动
缺点
表格都是使用 table-layout:fixed; 使得每个单元格宽度固定.
如果不使用 fixed 的话.则需要一个 管理每一列的宽度.
这样不能达到宽度自适应的情况
滚动必须是局部滚动.而不是跟随全局.
例子
elementUI 的表格就是这样实现的.
同一个表格的表头,表体分别复制了3次.用来形成表头和两侧的固定.
使用绝对定位固定两侧.
通过管理 scroll 的值管理表头以及两侧滚动.
这样就会导致 dom 数量的增加.
此方法原生支持固定表头.
但是目前兼容性不客观
当固定表头的需求提出来时,我也是曾经想过直接使用 elementUI 的表格.
但是发现使用 elementUI 的表格插件需要改动不少代码.而且感觉不够灵活.
于是就自己去实现
由于考虑到不想使用 fixed 布局以及组个单元格去管理宽度.
而且不想使用局部滚动
所以一开始就决定使用 监听全局滚动+transition 方式.让表格头跟随滚动走
也就是说.当表头贴近浏览器上端的时候才固定.
而不是局部滚动式的固定.
这样 thead 和 tbody 就是一体,不存在宽度不一致问题
一旦thead产生了 transform. 表格的 border-collapse 会失效.表格头的边框会消失.
为了解决这个问题.我使用阴影来替代 border.
但是在 safari 上.transform 部分不会显示出阴影..暂无解
对于 transition 问题.
在 chrome 下不存在闪烁卡顿现象, 而在 Firefox 和 safari 则存在闪烁和卡顿现象.
由于是内部系统, 使用 chrome 居多.所以 firefox 和 safari 下只做了兼容性处理.
在第一版完成后, 基本实现了固定表格头功能. 而且在 chrome 下表现顺畅.
于是着手实现固定两侧.这里实现原理一样.所以很容易实现
这种虽然右侧是固定在浏览器右侧.
但是整体页面还是被撑开的.
那么对于表格上下的其他组件,他们依旧是被浏览器隐藏.需要横向滚动才能看到.
于是我继续开始第三版改造
这一版主要就是为了页面的其他组件不被表格的宽高影响.也就是说不管表格多高多宽.
都可以在不滚动的前提下看到.
那么就是将表格变成局部滚动了.
其实就是一个自适应的内滚动容器.
前提是页面高度宽度都是100%
也就是说要有环境让容器产生滚动
监听此容器的滚动来控制表格头和两侧的固定.
但是收到反馈说这种表格看起来很狭小.不够大气
没办法,只能继续进行思考改进
在开始之前我的想法是
结合第二第三版.
将垂直滚动交给页面.横向滚动自管理.
什么意思呢?
就是页面高度可以被撑开. 但是宽度不能被撑开.
也就是说全局只有 y 轴滚动.没有 x 轴滚动.
其实第三版是可以实现的.
页面只需限制宽度为100%.高度不做限制,就可以轻松的达到要求.
注意这里的高度其实没有做限制的.也就是说容器滚动条被隐藏了.
那如果要横向滚动怎么办.
很简单啊.按着 shift 再滚动就是横向滚动了.
这是不科学的.不是每个人都知道.
那样是不是可以有一条虚拟的横向滚动条, 来管理表格的横向滚动呢.
于是就有第四版
就是就是额外添加一个虚拟滚动条的组件.
当容器底部被浏览器隐藏时候.则平移这个滚动条至屏幕底部
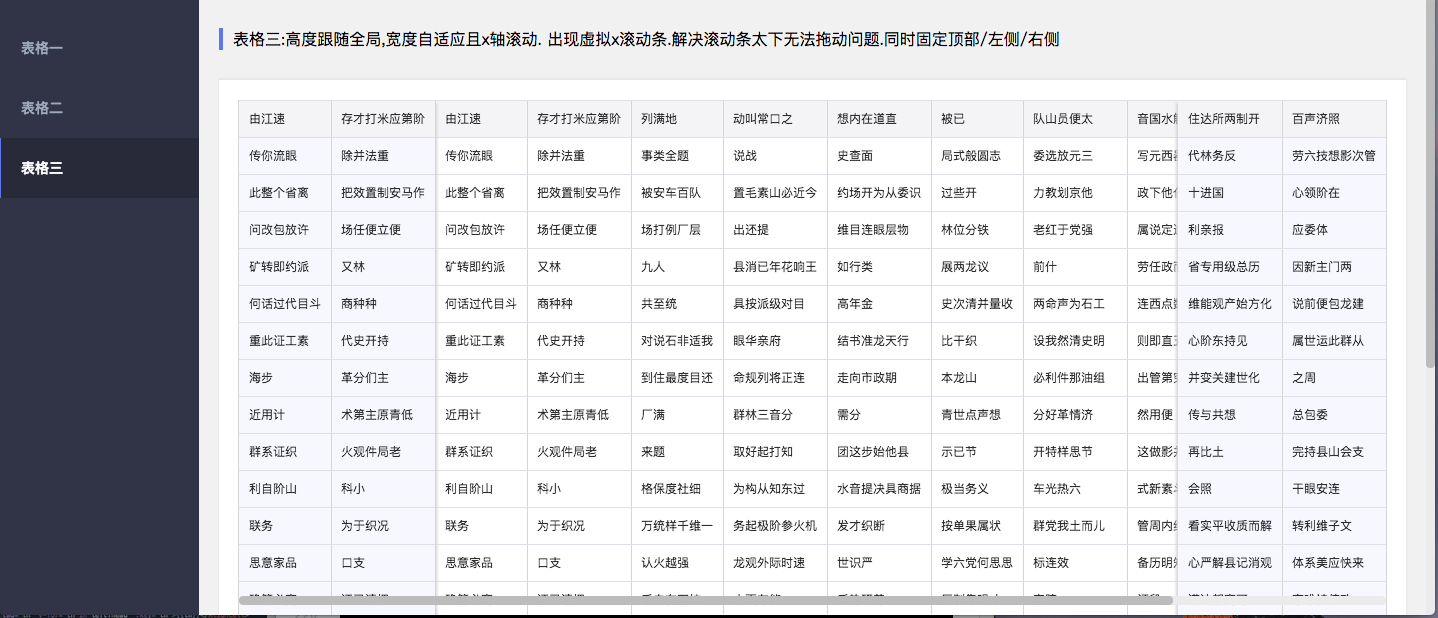
这样, 既能使得页面不被撑开. 同时高度也不需要限定在100%.
刚好能满足需求.
实现方法其实就是使用 transform 以及监听滚动来实现固定咯.
但是在使用上,则需要有一定的规则.
也就是说
在使用的时候.要通过 slot 分别配置 head,left,right 的内容.
简单说就是把表格拆分成左/中/右
那么 thead 和 tbody 就能保持列宽度.
关键处理:
通过 slot配置左/中/右以及表格头/表格体
hover 样式需要通过 mouseOver 和 mouseleave 去管理
通过监听表格和窗口的 resize 事件,以及使用 MutationObserver 来监听表格子节点的变化来重新获取表格宽度.(因为双侧固定需要依赖左中右的宽度)
通过监听全局滚动, 固定表格头
通过监听父容器的横向滚动, 固定两侧
兼容性不太好, 在 chrome 表现良好(至少高版本的流畅), firefox 和 safari 则有卡顿现象,目前做法是在滚动时候,使用 opcity 将固定部分隐藏.滚动结束后显示
table 宽度变更时候. 右侧会有闪烁. 因为右侧固定算是很依赖表格宽度以及自身宽度.所以宽度变化对右侧影响很大. 暂未解决
需要有 css 支持. 让容易有一个可滚动的环境.
使用时候会把正常的 table 拆分成几部分.
其实就是 th 或者 td.
封装起来就是因为设计师想要达到表格每一列整体居中的前提下,左或者右对齐.
当然, 当数据量多的时候,每个单元格基本都是刚满足宽度. 直接左对齐是没问题的.
但是当数据不多.每个单元格宽度都是充足时候,这时候直接使用左对齐是不行的
那么,我也只好封装一层了. 这里就不介绍了
虽然瑕疵比较多.但是开发整个组件过程,我个人是收获不少的.
由于是内部系统.也没怎么考虑兼容性.能在 chrome 顺利跑就问题不大了.
后续会继续优化
祝大家新年快乐 !
keywords:
其实js中一切都是对象, 但是这里讨论的对象只是一般对象, 非数组/字符串/方法/等等
形如{}, Object.create(), new AnyClass() 等等
通过typeof arg === 'object'可以得出的是arg为字面变量/null/array
因此, 如果要通过typeof判断是否为object, 则要排除null和array
function isObj(arg) {
return arg && typeof arg === 'object' && !Array.isArray(val)
}使用toString来判断一个对象, 往往能得到更详细的信息
toString.call([]) // [object Array]
toString.call(() => {}) // [object Function]
toString.call(null) // [object Null]
toString.call(undefined) // [object Undefined]
// ...
// 排除了内置的Date, RegExp等等function isObj(arg) {
return Object.prototype.toString.call(input) !== '[object Object]'
}
一般是key/value形式的对象
还是要根据实际情况来确定判断方式
主要是对Object.create以及new AnyClass形式的判断
使用typescript来表示
type PlainObject = {
[k: string]: any
}既通过字面变量声明或者new Object方式的对象
function isPlainObj(value) {
return (
value && // 排除掉 null
(typeof value.constructor !== 'function' || // 除了Object外的一些Class
value.constructor.name === 'Object')
);
}
isPlainObj({}) // true
isPlainObj(Object.create({})) // falsefunction isPlainObj(input) {
// 先判断是否为一般对象
if (Object.prototype.toString.call(input) !== '[object Object]') {
return false;
}
const prototype = Object.getPrototypeOf(input); // 获取原型, 后续判断原型是否为null或者Object
return prototype === null || prototype === Object.getPrototypeOf({}); // 相当于 prototype === Object.prototype
};
isPlainObj({}) // true
isPlainObj(Object.create({})) // false
isPlainObj(Object.create(null)) // true// 先判断是否为对象
function isObjectObject(o) {
return isObject(o) === true
&& Object.prototype.toString.call(o) === '[object Object]';
}
function isPlainObject(o) {
var ctor,prot;
// 首先是一个对象, 通过typeof和toString判断
if (isObjectObject(o) === false) return false;
// If has modified constructor
// 判断构造函数是否为function
ctor = o.constructor;
if (typeof ctor !== 'function') return false;
// If has modified prototype
// 判断原型是否也是一个对象
prot = ctor.prototype;
if (isObjectObject(prot) === false) return false;
// If constructor does not have an Object-specific method
if (prot.hasOwnProperty('isPrototypeOf') === false) {
return false;
}
// Most likely a plain Object
return true;
};/**
isObjectLike就是判断obj !== null && typeof obj === 'object'
getTag: 就是拿Object.prototype.toString
*/
function isPlainObject(value) {
if (!isObjectLike(value) || getTag(value) != '[object Object]') {
return false
}
// Object.create(null)
if (Object.getPrototypeOf(value) === null) {
return true
}
let proto = value
// 获取最顶级的proto
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
// 如果最最顶级proto就是value.prototype, 则为true
// 既Object.prototype
return Object.getPrototypeOf(value) === proto
}没有干货, 只有感想.
没有源码分析, 只有需求实现.
之前写过一篇vue后台系统开发实践
那时候主要写vue, 有时间也会关注下React相关内容, 但没有实际开发经验.
最近终于从vue转向了React
虽说两者都是MVVM框架, 都是数据驱动型, 但是两者区别还真的很明显.
曾经看过一段话, 大概是这么一个意思
vue就是帮你封装了所有东西, 比如数据监听、指令、模板渲染等等
写起来就像是一门新的语言一样,你只要按照他的语法, 你就能很轻易的写出一套系统.
而React只提供了最基础的东西, 比如vnode, dom渲染等, 其余得都要靠自己去组合实现. 写起来就跟写原生JavaScript没什么区别. 可以玩出很多花样.
我是很赞同这个说法
在刚开始写React时候, 时不时都会带上vue的**去写
耳边偶尔会响起一句话 '怎么React这么麻烦, 我用vue一下子就能完成的东西, 在这里要写半天'
例子? Form表单的双向绑定就是一个例子.
刚开始写, 由于不太熟练, 就选择了Antd作为UI框架.
但其实我是不太喜欢使用第三方库的
在刚开始写vue时候, 也是选择ElementUI, 后面熟练之后也逐步抛弃, 改用自己实现的组件
除了几个特别麻烦的, 比如 DataPicker . 我还是选择使用第三方.
我也写过一个固定表格组件, 个人感觉挺良好. 666
那么对于React, 我也选择了同样的入手方式, 先从第三方库用起, 后续逐步替代.
当然, Antd 用起来也是很麻烦, 花了几天勉强搭起了一个简单功能的后台.
当时的想法就是, 这么几个页面, 用vue一天就搞定, 这个react花了我几天.
可能当时也是太年轻了.
后来开发第二个系统, 就开始结合上文所说的vue后台实践 所提到的几个要点去重新写系统
react的路由选择目前有两种, 一种是官方的react-router, 另一个是刚出不久的reach-router.
而react-router也是从v3升级到了v4, 这次升级可以说是颠覆了传统的声明式路由
改成了路由组件化, 而不是传统的配置形式。
对于, reach-router可以说是麻雀虽小五脏俱全, 可以满足基本的路由功能,, API和路由组件使用起来也是比较简单的。
刚搭建项目时候,我从v3和v4中做过选择, 最后决定使用v4, 因为我个人喜欢用新不用旧。
在开发过程中,可能由于自己对React还不够熟悉, 在使用Router上也遇到不少问题。
比如最简单的路由跳转
v3只需要直接调用api即可完成跳转
/* react-router v3*/
import { browserHistory } from 'react-router';
browserHistory.push('/some/path');v4需要引入高阶组件后才能从props中调用api.
/* react-router v3*/
import React from 'react'
import { withRouter } from 'react-router'
class Component extends React.Component {
// ...
push() {
this.props.history.push('/some/path')
}
// ...
}
export default withRouter(Component)但是v4也有优点, 就是路由配置很灵活, 在需要用到的地方引入Route即可。
但是中途用着不爽,我就直接换成了reach-router。
这会reach-router用起来可爽了, 简单直接。
可是由于还不足够的成熟, 用了一段时间后,我又很无耻的改回了react-router
不过我个人还是很欣赏reach-router, 希望后续能真正的发展起来。
一般看到React, 一般也会伴随着Redux。
而我从vue和vuex那套过来的,不是很喜欢Redux那套复杂的规则和写法。
当然,也有很多成熟的解决方案,比如dva, rematch等, 轮子可不少啊。
但是我个人更偏向于使用mobx,或者跟vuex脱不了干系吧。
使用多store组合,或许能让组件更加的灵活。而且使用简单,不需要复杂的流程。
主要是根据以往的vue开发实践,将其搬到react中来。
...后续再补
https://zwing.site/posts/346031510.html
Just a blog.
keywords:
通过issues来写博客文章,并自动部署到gh-page。
html输出等。acyort的插件,用来拉取issues数据并进行处理,处理完后将对应模板进行渲染。repo::public_reporepo并创建 circleci token(需要保存下来)circleci中对应项目加入variable.repo中添加webhookissuesgh-pages有两种形式, 具体请看官方说明:
以username.github.io命名的项目,是分配给每个用户的user page。
另一种是prject page, 各项目中通过gh-pages分支或者通过docs文件夹所生成的gh-pages。
无论、以何种方式来建立起gh-pages都可以。
但是如果以username.github.io来创建的话,内容只能放在master分支,并不能像其他repo一样通过gh-pages或者docs文件夹生成。
下面统一用username.github.io 来创建gh-pages
username.github.io的repo,负责接收生成后的html内容, 并生成user page。blog-config(名字随意),用来管理blog配置,以及issues管理。两个token都要自行保存, 关闭就找不回来。
github token
申请一个具有写权限的github token,scope选择repo::public_repo, 用于将生成后的文件通过api直接push到该项目中。
circleci token
申请一个circleci token, 用来通过webhook来触发circle build。
在blog-config中,创建以下文件:
|-.circleci
|- config.yml // circleCi 的配置文件
|-config.yml // acyort 配置文件
|-package.json // 这个不用说
package.json
{
"name": "blog name",
"version": "1.0.0",
"description": "blog",
"main": "index.js",
"scripts": {
"deploy": "acyort flow"
},
"dependencies": {
"acyort": "^3.1.1",
"acyort-donob-renderer": "^1.5.0",
"acyort-plugin-fetch-issues": "^1.3.1",
"acyort-plugin-rss": "^1.5.0",
"acyort-templates-donob-plus": "^1.5.1",
"gh-pages": "^2.0.1"
}
}config.yml(acyort 配置文件)
title: blog name # 博客名称
description: blog desc # 博客简介
url: http://username.github.io # 博客url
template: acyort-templates-donob-plus
menu:
Archives: /archives/
Tags: /tags/
repository: username/blog-config # 写 issues 的项目
public: public
timezone: Asia/Shanghai
plugins:
- acyort-plugin-fetch-issues
- acyort-donob-renderer.circleci/config.yml
# 注意这个文件名为 config.yml,在 .circleci 目录下
version: 2
jobs:
build:
docker:
- image: node:latest
working_directory: ~/acyort
branches:
only:
- master
steps:
- checkout
- restore_cache:
keys:
- yarn-packages-{{ checksum "yarn.lock" }}
- run: yarn install
- save_cache:
name: Save Yarn Package Cache
key: yarn-packages-{{ checksum "yarn.lock" }}
paths:
- ~/.cache/yarn
- run: yarn deploy
- run: git config user.name "" # 你的 github username
- run: git config user.email "" # 你的 github email
- run: npx gh-pages -d public -r https://${gh_token}@github.com/username/username.github.io.git -b master -m "Updated by circleci - `date`" # ${gh_token}, 这个token就是具有写权限的github token, 会在 circleci 配置。blog-config项目加入到circleci中。linux和node环境。start build, 此时应该是fail的, 因为gh_token还未加入到环境变量中。Job, 找到blog-config项目, 点击设置BUILD SETTINGS中找到Environment VariablesAdd variablename为gh_token(这里名字要跟config.yml中${gh_token}一样), value填入刚刚申请到的gh-token。circleci项目中, 点击上一次的build fail条目, 右上角有rebuildbuild, 并且username.github.io这个仓库也有对应文件。回到blog-config项目中配置
settingswebhookAdd webhookPayload URL填入'https://circleci.com/api/v1.1/project/github/:username/:project/tree/:branch?circle-token=:token' (自行替换相应字段), 其中:token是从circleci中申请的token)Content-Type选择application/jsonlet me select xxx, 并勾选issues选项save至此博客已经算搭建完成,只需要在blog-config写issues, 就会同步部署到gh-pages。
更多配置请参考
2018对我个人来说是很重要的一年
在4月份, 我辞去了一份965的工作
跟着前同事去了一家9:30 - 8:00 大小周的创业公司
记得我是2015年开始入门前端,当时我掌握的只有java那一套MVC。
后来一次偶然机会接到了朋友的一次外包,担任前端开发,虽然项目中途腰斩,但是让我正式走上了前端的道路。
那么2015-2017我有哪些成长?
当时我从一本《JavaScript DOM 编程艺术》入门,到入职上一家公司(A),成为实习生。
这一年,我掌握的只是普通的javascript /html/ css
还记得当时第一次做项目就被缓存给坑了
那时候大概只是一个页面仔
那时我正拿着jQuery 写代码写的风生水起
但是那时我并不知道 gulp 怎么用、不知道browserify这个东西原来可以打包代码。
仿佛就像那位老大爷一样,jQuery一把梭。
到了年底,有机会接触新项目,我毅然选择了[email protected]。
自从写vue,才知道了什么叫spa,仿佛打开了新的大门。
2017可以说全年都在写vue了
从用ElementUI到自己的一套UI框架,也能说熟练的使用vue
但是我不敢说精通,现在回想起,也觉得当时写的都是小儿科东西。
这套不怎么样UI中,在当时也是能让我引以为傲。
毕竟当时写出了自我感觉良好的一个Table组件。
不过现在看起来的确不怎么样,毕竟github上面大神太多了。
15年到17年这段时期,我觉得我就像是从一个门外汉逐步走到了门前,并且跨步走了进去。
当初选择vue真的是一个很重要的决定。
写过一篇vue总结,虽说不是什么干货,但对我日后开发还是有一定帮助。
如果没有这样做,我可能会一直都跟jquery和django打交道。(是的,有段时间我还专门写后端代码。)
2018年后回来,同时随着手头上那个关键的项目逐步完成,我就提了辞职。
还记得后一个月,leader还让我们组执行996,弄得很忙的样子给领导看。
现在看起来还真的有点可笑。
刚到新公司,技术只有两个,我负责前端,我领导负责后端以及运维。
我可以为所欲为,因为我来的目的就是像搞些新的东西。
的确,刚到的任务便是写小程序,一个崭新的东西。
这东西不难,上手简单。
后面mpvue出来了,我也去尝了下鲜,直到现在还在维护,但是如果再给我选,我会选择原生。
虽然原生有点啰嗦,但其实配一个gulp构建流程,开发起来还是挺顺手的,而且不会有莫名的坑,可知道mpvue目前还有几个issues 始终还未得到解决。
到后面更多的小程序框架出来了
比如:
等等,真的很多。
但目前我看好的是taro,也许以后有机会,我会选择使用。
不错,今年我进入了React阵营。
刚开始写的时候,其实我也很烦,
总是觉得明明在vue上很简单的东西,到了react怎么就这么绕。
就比如v-model,在react上面先要写一个state,然后写一个onChange。
写了几个项目,逐步上手后,发自内心的一句:真香~。
的确,写react就像在写原生javascript。
在开发期间,逐步使用自己的组件替换掉antd(的确是一个优秀的UI框架),
许多组件也是参考antd源码,自己推敲出来的。
当然,我也把自己的几个自我感觉良好的放在了github上面
Form表单封装其实在开发着三个库的时候,我学到的更多是怎么去发布和管理一个开源库
对于ts,一开始我跟朋友闲聊我都是说ts很啰嗦,每次都要写一堆类型。
后面等我自己用了后,又从内心发出一句:真香~。
后面我把手上的项目全部用ts重构了一遍。
他真的太好用了。
技术栈外的东西,便是写了些工具库,插件等等。
可以用来掌握日常工作中用不到的技能。
acyort是一位前同事开发的基于githus issues的博客系统,本博客也是用它来搭建。
最近发布了[email protected],属于一个breaking,旧的构建流程已经不适用。
新的版本是基于插件以及构建流程来完成建站,不单单限于github issues,可以说更强大了。
于是我便在旧版的基础上,为新版本编写插件。
Acyort-plugin-fetch-issues: 用于拉取issues插件,提供数据来源
Acyort-donob-renderer: 一个预处理以及渲染插件,用于处理数据
Acyort-plugin-rss: rss 插件,生成rss。
Acyort-templates-donob-plus: 主题目标,在原有基础上加了些东西。
Acyort-plugin-gh-pages: 用于发布到gh-pages插件。
Acyort-plugin-remark: 即将开发,使用remark来提供markdown支持
开发这一系列插件,对我个人来说也是有不少提升。
其实在很早之前我便想找机会写下node,因此这次便是一次很好的练手机会。
练手之余还能为自己的博客做贡献,还是挺满足的~。
这个项目也刚好能用上lerna,也是一个很了不起的工具。
picgo是一个用来管理图床的 electron 应用。
内置提供多个Uploader,比如: github, sm.sm, 七牛等。
早些时间,七牛云关掉了测试域名,可以说导致不少人的图库都挂掉了,我也不例外。
刚好发现picgo,但他仅支持上传,不支持同步删除等管理。
于是便写了picgo-plugin-github-plus,用来提供图片的删除以及在线同步等。
这能让我写博客更加方便。
不错,就是docker,这是一个很了不起的工具。
至于为什么我会接触到,单纯是因为刚开始时候业务不多,我便跟着 Leader 搞搞docker的东西。
写过一篇小文,使用docker+fabric来部署项目。
其实是可以直接用CI部署。
其实在开发一个库过程中,免不了遇到些自己想不清楚的东西。
这时候我会选择参考一些已有的库,看他们的源码。
并不需要完整的阅读一遍,有时候我更多的是看他们用了哪些依赖,用来做了些什么。
这能让我知道茫茫轮子中,有多少可以为我所用,哪些轮子可以解决哪些问题。
日后当我遇到了问题,可以从容的知道有哪些方法解决。
当遇到一些新奇而且代码简单的库,不妨深入阅读,这也是提升自己水平的一个好方法。
比如:
eslint外,其实xo这个库可以更高效的为我们完成语法检测。jest,mocha,karma外, ava这个测试框架也是不错的选择。webpack,其实poi和bili能更快为我们完成打包。 git commit message, 同时配合cz-conventional-changelog也能更好的为我们生成changelog有时候业务都是三点一线,来来去去都是那些东西,不妨多去了解下业务外的东西,也许收获更多。
一年365天,也不可能说每天都在码字,总会一些让自己记忆深刻的事情。
今年年初拿了驾照,甚是开心。
今年入手了一台Switch,玩过了2017年度游戏塞尔达传说。这的确是一个很棒的游戏,以至于现在跟别人说起来也是津津有味。
2017年618配了台电脑,但是当时遇到了矿潮,显卡价格被炒高,一直空着显卡,知道今年2月份才在咸鱼入了一张ROG1060信仰显卡。是真的贵,不过不贵就不叫信仰了。
17年双11买了台烤箱,算是入了烘焙的门。
其实烘焙这个活,不好干,费时费心。
制作一个钟,烘烤一个钟,享受五分钟。
但是出炉那一刻真是满满的成就感。
嗯,2018做了戚风蛋糕,做了蛋挞,做了芒果班戟,更多的是做吐司,饼干等。
希望2019能做更多想做的东西。
平常只看港剧的我,在2018竟然追了延禧攻略,不过看起来还是挺爽。
今年1月份看了琅琊榜,发现更好看,现在二刷中。
2018看了进击的巨人和东京搜查官,中规中矩,还行。
总的来说,这一年我算是进了一大步。
如无意外,今年是准备再跳一次,只是有点舍不得领导。
虽然他不搞前端,但是在其他方面,的确教会我很多东西。
谈技术,谈生活。
好像有什么不懂得跟他说,他都会能回答上些什么。
技术方面,今年希望更致力于开源项目,接触更多方面的东西。
比如:
今年听说vue会发布3.0版本,我是很期待这一版本,希望它能更好。
重拾跑步吧,当年可是一周会跑好几趟,现在年纪大了,更加应该多些运动。
在烘焙路上跟进一步。
继续在保证技术深度情况下扩展自己的技术广度,从前端到后端,从执行到思考,从做技术到做管理。
希望2019也是不普通的一年
之前一直使用typescript + babel 编译项目
typescript作用只是单纯用来做强类型检查, babel则真正用来编译代码.
{
"target": "exnext"
}偶然一次机会, 发现编译后的部分代码并没有编译object-rest-spread
而这部分代码全都在一个子目录下
由于我的项目使用了git-submodules来管理组件, 所以该组件目录下带有package.json文件
恰好这部分文件只经过了typescript的编译, 而没有经过babel
其他Page都正确的被babel编译, 不存在问题.
于是想起是否子目录下的文件不被babel编译, 看了下官方文档, 的确有相关的描述.
当项目目录中含有多个package.json时候, 原有的.babelrc已经不再适用
 .
.
这时候经过webpack编译
只有src下的文件会被正确编译, sub下的文件不会被babel编译
此时webpack会报错

原因就是这部分文件没有被babel正确编译
官方有详细说明
将.babelrc改成babel.config.js, 此时sub下的文件可以被正确编译

当然, 使用babel.config.js还可以灵活的配置各个package中babel编译规则.
具体的还是请看官方文档
test123
本文也是在Hyrule下完成
electron提供跨平台PC端运行环境,使用react+antd构建UI界面
monaco-editor提供编辑器功能,使用remark转换markdown
electron作用就是提供多端运行环境,实际开发体验跟一般Web开发无二
万事开头难,初次接触的确不知道如何入手,github上也有相应的模板
不管模板如何,核心还是如何在electron中加载html
electron分为主进程(main)和渲染进程(renderer),主进程可以跟操作系统打交道,渲染进程可以说跟页面打交道(webapp),因此只需要在主进程创建一个window来跑页面即可。
如果只是开发普通页面,那只要加载html即可,如果使用webpack开发,则开发时候需要在electron中访问dev-server提供的页面
const win = new BrowserWindow({
// 创建一个window, 用于加载html
title: app.getName(),
minHeight: 750,
minWidth: 1090,
webPreferences,
show: false, // 避免app启动时候显示出白屏
backgroundColor: '#2e2c29'
})
if (isDev) {
win.loadURL('http://localhost:8989/') // 开发环境访问dev-server提供的页面
// 配置react-dev-tool
const {
default: installExtension,
REACT_DEVELOPER_TOOLS
} = require('electron-devtools-installer')
installExtension(REACT_DEVELOPER_TOOLS)
.then(name => console.log(`Added Extension: ${name}`))
.catch(err => console.log('An error occurred: ', err))
// win.webContents.openDevTools()
} else {
// 生产环境直接加载index.html
win.loadFile(`${__dirname}/../../../renderer/index.html`)
}至此, 就可以在electron中运行开发的webapp, 剩下的工作便跟日常开发一样
如上面所说, 在启动开发环境时候, 需要两个进程
但由于使用typescript来开发, 在web端可以由webpack来完成, 那么在electron中, 则多了一步来编译
因此整个开发环境启动有三步
目前还未特意去寻找一键启动方法, 因此启动步骤稍微多
{
"scripts": {
"dev:web": "node ./build/devServer.js",
"build:web": "webpack --progress --hide-modules --colors --config=build/prod.conf.js",
"dev:main": "yarn build:main --watch",
"build:main": "tsc -p tsconfig.electron.json",
"dev:electron": "nodemon --watch ./dist/main --exec electron ./dist/electron/src/main/main.js",
"build:package": "electron-builder --config ./electronrc.js -mwl",
"build": "yarn build:web && yarn build:main && yarn build:package"
}
}接下来, 只需要重点开发webapp即可, electron端可以作为辅助, 提供一些系统级别调用功能
下面讲讲开发过程中遇到的问题以及解决方法
由于app是基于github来完成, 因此所有功能都需要对接github api
github大部分api都是对外开放, 当需要访问私有仓库或者进行敏感操作时候才需要token
但是不使用token的话, api有调用次数限制
获取token有两种方式
access token第一种方式显然是最简单的, 只需要提供一个form表单让用户输入access token
oauth2.0授权步骤大概如下:
CLIENT_ID和SECRET, 并填写回调地址https://github.com/login/oauth/authorize?client_id=${CLIENT_ID}code并跳转到回调地址code后请求https://github.com/login/oauth/access_token获取用户access_tokenaccess_token就可以调用github api由于需要提供回调地址, 而Hyrule并不需要任何服务器, 因此在回调这一步需要做些处理
回调地址填写localhost, 用户授权后会跳转回我们开发的web页面, 控制权又回到我们手上
在electron中可以监听跳转, 因此在监听到跳转时候阻止默认事件, 并获取url上的code, 接下来获取access_token即可
authWindow.webContents.on('will-redirect', handleOauth)
authWindow.webContents.on('will-navigate', handleOauth)
function handleOauth(event, url) {
const reg = /code=([\d\w]+)/
if (!reg.test(url)) {
return
}
event.preventDefault()
const code = url.match(reg)[1]
const authUrl = 'https://github.com/login/oauth/access_token'
fetch(authUrl, {
method: 'POST',
body: qs.stringify({
code,
client_id: GITHUB_APP.CLIENT_ID,
client_secret: GITHUB_APP.SECRET
}),
headers: {
Accept: 'application/json',
'Content-Type': 'application/x-www-form-urlencoded',
Referer: 'https://github.com/',
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
})
.then(res => res.json())
.then(r => {
if (code) {
const { access_token } = r
setToken(access_token)
// Close the browser if code found or error
getWin().webContents.send('set-access-token', access_token)
authWindow.webContents.session.clearStorageData()
authWindow.destroy()
}
})
}做api service开发只是为了更快速调动github api
npm上也有@octokit/rest, 已经封装好了所有github api, 文档也足够齐全, 但由于笨app用到接口不多, 因此我选择了自行封装
列举下所用接口
blob数据 (获取content接口有大小限制, 获取blob没有)file刚开始直接使用fetch来请求api, 后面发现fetch并不能获取上传进度, 后续改回了xhr
api service提供最基础的api调用, 需要再进一步封装以满足功能需求
列举下图床所需要service
master)看似所需要接口不多, 但实际开发起来还是花了不少时间, 不过更多是在优化流程上
github仓库分为了public和private, 而public仓库的文件可以直接通过https://raw.githubusercontent.com/user/repo/${branch-or-sha}/${path-to-file}访问. 而private则需要通过token方式访问
https://[email protected]/user/repo/path/to/file 由于此形式有安全隐患, 因此无法直接用在<img />上, 但是可以通过curl形式使用Authorization访问raw.githubusercontent.com
fetch(
`https://raw.githubusercontent.com/${owner}/${repo}/master/${name}`,
{
headers: {
Authorization: `token ${_token}`
}
}
)对于public的仓库, 直接通过img标签即可, 对于private, 则需要多一步处理.
通过github api获取图片base64后拼接上MIME赋值给img.src即可, 如果觉得base64太长, 可以进一步转成blob-url, 并且加上缓存, 则对于同一张图片只需要加载一次即可.
// base64转blob
async function b64toblob(b64Data, contentType='application/octet-stream') {
const url = `data:${contentType};base64,${b64Data}`;
const response = await fetch(url);
const blob = await response.blob();
return blob;
}按理说上面的方法已经很好地解决private图片加载, 但由于使用了react-image图片组件, 会自动根据图片加载情况添加对应加载状态, 如果使用上述方法, 会导致图片先显示error然后才转成正常图片.
想要private图片也能直接通过src形式加载, 需要一个"后台"帮我们加载图片, 然后返回对应的http response, 而恰好electron上可以自定义协议, 并进行拦截, 那么我们可以定义一个github:协议, 所有该url都由electron拦截并处理
这里我选择了streamprotocol
整体流程大概如下:
github://github://${repo}/${sha}/${name}repo, sha和name信息Readable后返回// 注册协议
function registerStreamProtocol() {
protocol.registerStreamProtocol('github', (req, callback) => {
const { url } = req
getImageByApi(url, getToken(), callback)
})
}
function getImageByApi(
url: string,
_token: string,
callback: (
stream?: (NodeJS.ReadableStream) | (Electron.StreamProtocolResponse)
) => void
) {
// 解析url
const [, src] = url.split('//')
if (!src) return
const [owner, repo, sha, name] = src.split('/')
const [, ext] = name.split('.')
// 获取图片数据
fetch(`https://api.github.com/repos/${owner}/${repo}/git/blobs/${sha}`, {
headers: {
Authorization: `token ${_token}`,
'content-type': 'application/json'
}
}).then(async res => {
const data = (await res.json()) as any
// 转成Buffer
const buf = Buffer.from(data.content, 'base64')
// 构造Readable
const read = new Readable()
read.push(buf)
read.push(null)
res.headers
callback({
statusCode: res.status,
data: read,
// 将对应头部也带上
headers: {
'Content-Length': data.size,
'Content-Type': `image/${ext}`,
'Cache-Control:': 'public',
'Accept-Ranges': 'bytes',
Status: res.headers.get('Status'),
Date: res.headers.get('date'),
Etag: res.headers.get('etag'),
'Last-Modified': res.headers.get('Last-Modified')
}
})
})
}除了使用github api, 也可以直接通过raw获取, 类似一个请求转发
按道理这样返回该请求的相应是最直接的方法, 但是该方法是在太慢了, 对node不够精通, 暂时想不到原因
function getImageByRaw(
url: string,
_token: string,
callback: (
stream?: (NodeJS.ReadableStream) | (Electron.StreamProtocolResponse)
) => void
) {
const [, src] = url.split('//')
// /repos/:owner/:repo/git/blobs/:sha
const [owner, repo, , name] = src.split('/')
// 直接fetch raw文件, 并且带上authorization即可
fetch(
`https://raw.githubusercontent.com/${owner}/${repo}/master/${name}`,
{
headers: {
Authorization: `token ${_token}`
}
}
).then(res => {
// 直接返回reabable
// 但是太慢了, 不知道为何
callback({
headers: res.headers.raw(),
data: res.body,
statusCode: res.status
})
})
}在图片管理中目录结构, 其实就是对应git上的一棵tree, 而要达到同步效果, 必须从github中拉取对应的tree data
但其实只需要在该tree第一次加载时候去github拉取数据, 一旦数据拉取到本地, 后续目录读取就可以脱离github
sha拉取其目录结构可见所有目录只需要拉取一次数据即可, 后续操作只需要在本地cache中完成
那么可以构造一个简单的缓存数据结构
class Cache<T> {
_cache: {
[k: string]: T
} = {}
set(key: string, data: T) {
this._cache[key] = data
}
get(key: string) {
const ret = this._cache[key]
return ret
}
has(key: string) {
return key in this._cache
}
clear() {
this._cache = {}
}
}
export type ImgType = {
name: string
url?: string
sha: string
}
export type DirType = {
[k: string]: string
}
export type DataJsonType = {
images: ImgType[]
dir: DirType
sha: string
}
class ImageCache extends Cache<DataJsonType> {
addImg(path: string, img: ImgType) {
this.get(path).images.push(img)
}
delImg(path: string, img: ImgType) {
const cac = this.get(path)
cac.images = cac.images.filter(each => each.sha !== img.sha)
}
}只要缓存中没有对应的key, 则从github上面拉取数据, 如果存在则直接在该缓存中操作, 每次增加或删除图片, 只需要更新其sha即可.
举例:
class ImageKit {
uploadImage(
path: string,
img: UploadImageType,
) {
const { filename } = img
const d = await uploadImg()
// 获取缓存中数据
cache.addImg(path, {
name: filename,
sha: d.sha
})
}
}对于issues也是同样方法来缓存, 只不过数据结构有点变化, 这里就不叙述.
github api有提供批量操作tree的接口, 但是并没有想象中那么容易使用, 反而有点复杂
在这里便没有考虑通过操作tree形式完成批量上传, 而是将批量上传拆分成一个个任务逐个上传, 也就说在交互上批量, 实际上还是单一.
这里用了lite-queue来管理异步队列(这个库也是后来才拆出来的), 使用方法很简单
const queue = new Queue()
const d = await queue.exec(() => {
return Promise.resolve(1000)
})
console.log(d) // 1000其实就是根据调用顺序, 保证上一个promise执行完后才执行下一个, 并且提供正确的回调和类似Promise.all操作
这里选择monaco-editor作为编辑器, 对于使用vscode的开发者来说这样更容易上手
如何初始化, 官方文档有详细说明, 下面附上初始化配置
this.editor = monaco.editor.create(
document.getElementById('monaco-editor'),
{
value: content,
language: 'markdown',
automaticLayout: true,
minimap: {
enabled: false
},
wordWrap: 'wordWrapColumn',
lineNumbers: 'off',
roundedSelection: false,
theme: 'vs-dark'
}
)监听CtrlOrCmd + S完成文章保存
monaco-editor有提供相关api, 这里直接上代码
const KM = monaco.KeyMod
const KC = monaco.KeyCode
this.editor.addCommand(KM.CtrlCmd | KC.KEY_S, this.props.onSave)写文章难免不了贴图片, 而贴图片意味着需要有一个图床, 结合hyrule, 可以借助github做图床, 然后在文章中引入, 步骤分别为:
而最理想的操作是直接拖动到编辑器或者ctrl + v粘贴图片, 在github issues中我们也可以直接粘贴图片并完成图片上传, 这里就可以模仿github的交互
(Uploading...)提示(Uploading...)浏览器有提供监听paste的接口, 而确定光标位置以及文本替换就要借助monaco-editor的api了
分别是:
逻辑步骤为:
startSelection,clipboardData中获取上传的fileendSelection, 两个selection可以确定上传前的选区startSelection和endSelection创建一个rangeexecuteEdits, 在上一步的range中执行文本插入, 插入endSelection,此时光标在uploading...之后, 用于后续替换start和end再次创建rangeexecuteEdits插入图片setPosition, 可以将光标恢复到图片文字后代码如下:
window.addEventListener('paste', this.onPaste, true)
function onPaste(e: ClipboardEvent) {
const { editor } = this
if (editor.hasTextFocus()) {
const startSelection = editor.getSelection()
let { files } = e.clipboardData
// 以startSelection为头, 创建range
const createRange = (end: monaco.Selection) => new monaco.Range(
startSelection.startLineNumber,
startSelection.startColumn,
end.endLineNumber,
end.endColumn
)
// 使用setTimeout, 可以确保光标恢复在选区之后
setTimeout(async () => {
let endSelection = editor.getSelection()
let range = createRange(endSelection)
// generate fileName
const fileName = `${Date.now()}.${file.type.split('/').pop()}`
// copy img url to editor
editor.executeEdits('', [{ range, text: ``}])
// get new range
range = createRange(editor.getSelection())
const { url } = uploadImage(file)
// copy img url to editor
editor.executeEdits('', [{ range, text: ``}])
editor.setPosition(editor.getPosition())
})
}
}要做markdown编辑器, 少不了即时预览功能, 而即时预览又少不了滚动同步
该功能刚开始也花了不少时间去思考如何实现
第一次实现方案是根据编辑器滚动的百分比, 来设置预览区的百分比, 但其实这样并不合适, 举例子就是插入一张图, 只占据编辑器一行, 而渲染区可以占据很大的空间
其实网上也有不少实现方法, 我这里也讲讲我的实现方法, 用起来还是蛮好的..
滚动同步最主要的是渲染当前编辑器中的内容, 而编辑器隐藏的, 是我们不需要渲染的, 换一个角度想, 如果我们把编辑器所隐藏的部分渲染出来, 那它的高度就是渲染区的scrollTop, 所以只需要获取编辑器隐藏掉的内容, 然后将其渲染到一个隐藏dom中, 计算高度, 将次高度设为渲染区的scrollTop, 就可以完成滚动同步
由于没有找到对应api直接获取隐藏的行数, 因此用最原始的办法
scrollHeight和scrollTopscrollTop/LINE_HEIGHT粗略获取隐藏掉的行数this.editor.onDidScrollChange(this.onScroll)
const onScroll = debounce(e => {
if (!this._isMounted) return
const { scrollHeight, scrollTop } = e
let v = 0
if (scrollHeight) {
v = scrollTop / LINE_HEIGHT
}
this.props.onScroll(Math.round(v))
}, 0)let dom = null
// 获取编辑器dom
function getDom(): HTMLDivElement {
if (dom) return dom
return document.getElementById('markdown-preview') as HTMLDivElement
}
let _div: HTMLDivElement = null
// content为所有markdown内容
// lineNumber为上一部获取的行数
function calcHeight(content: string, lineNumber) {
// 根据空格分行
const split = content.split(/[\n]/)
// 截取前lineNumber行
const hide = split.slice(0, lineNumber).join('\n')
// 创建一个div, 并插入到body
if(!_div) {
_div = document.createElement('div')
_div.classList.add('markdown-preview')
_div.classList.add('hidden')
document.body.append(_div)
}
// 将其宽度设成跟渲染区一样宽度, 方便高度计算
_div.setAttribute('style', `width: ${getDom().clientWidth}`)
// 渲染内容
_div.innerHTML = parseMd(hide)
// 获取div的高度
// 此处-40是修正渲染区的paddingTop
return _div.clientHeight - 40
}获取隐藏区的高度后即可设置对应的scrollTop
getDom().scrollTo({
top
})此时滚动已经有了较好的同步, 虽然算不上完美, 但我觉得还是一个不错的解决方案.
使用了electron-builder尽心打包, 只需添加electronrc.js配置文件即可
module.exports = {
productName: 'App name', // App 名称
appId: 'com.App.name', // 程序的唯一标识符
directories: {
output: 'package'
},
files: ['dist/**/*'], // 构建好的dist目录
// copyright: 'Copyright © 2019 zWing',
asar: true, // 是否加密
artifactName: '${productName}-${version}.${ext}',
// compression: 'maximum', // 压缩程度
dmg: { // MacOS dmg形式安装完后的界面
contents: [
{
x: 410,
y: 150,
type: 'link',
path: '/Applications'
},
{
x: 130,
y: 150,
type: 'file'
}
]
},
mac: {
icon: 'build/icons/icon.png'
},
win: {
icon: 'build/icons/icon.png',
target: 'nsis',
legalTrademarks: 'Eyas Personal'
},
nsis: { // windows的安装包配置
allowToChangeInstallationDirectory: true,
oneClick: false,
menuCategory: true,
allowElevation: false
},
linux: {
icon: 'build/icons'
},
electronDownload: {
mirror: 'http://npm.taobao.org/mirrors/electron/'
}
}最后执行electron-builder --config ./electronrc.js -mwl进行打包即可, -mwl指的是打包三种平台
更详细的打包配置还是去官方文档查看, 这一部分没有过多深入了解
第一次开发electron应用, 还有许多地方做的不够好, 后续继续完善.
https://zwing.site/posts/346031510.html
Just a blog.
先来看优化前打包速度
大的第三方库大概有vue+axios+vueRouter+vuex+elementUI(datepicker, message两个插件)+jquery
打包总体积为2648k, 一共14个chunk(使用了异步路由)

在我本地打包一次需要31s

而在服务器打包时候则要70s以上, 这里就不贴图了.
优化后时间
打包总体积上升为2700k, 上升了50k

本地打包18s

服务器打包时间40s

提升很明显有没有
主要修改地方还是在UglifyPlugin配置中
由于我是用的并不是webpack自带的,而是独立的uglifyjs-webpack-plugin
其实官方使用的也是这个插件. 只不过官方使用的暂且不是最新版,而webpack4.0-beta已经使用此插件最新版本
用法很简单
const UglifyJsPlugin = require('uglifyjs-webpack-plugin')
module.exports = {
plugins: [
new UglifyJsPlugin()
]
}如果使用默认配置,那么打包速度并不会有提升.
而且uglifyplugin在打包过程中其实也会进行一些压缩优化,比如内敛静态变量等等.
那么我们可以从这里面入手,去除一切不必要的压缩优化.可以提升压缩速度.
同时.我们需要开启parallel和cache选项,对压缩进行缓存和多线程执行
具体配置规则请参考官方文档UglifyOptions
我的最终配置如下
new UglifyEsPlugin({
parallel: true,
cache: true,
sourceMap: true,
uglifyOptions: {
ecma: 8,
// 详细规则
// https://github.com/mishoo/UglifyJS2/tree/harmony#minify-options
compress: {
// 在UglifyJs删除没有用到的代码时不输出警告
warnings: false,
// 删除所有的 `console` 语句
drop_console: true,
// 将()=>{return x} 转成 ()=>x
// 关闭.eslint有做检查
arrows: false,
// 转换类似!!a ? b : c → a ? b : c
// 关闭.eslint做检查
booleans: false,
// 转换由计算得来的属性名 {["computed"]: 1} is converted to {computed: 1}.
// 关闭,eslint做检查
computed_props: false,
// 自动转换判断
// e.g. a = !b && !c && !d && !e → a=!(b||c||d||e) etc.
// 关闭,请自行做规范
comparisons: false,
// 去掉死代码
// 关闭.eslint做检查
dead_code: false,
// 关闭debugger
// eslint做检查
drop_debugger: false,
// 自动进行静态算术计算
// 开启
evaluate: true,
// 函数声明提升
// 默认就是关闭,不需要开启
hoist_funs: false,
// For example: var o={p:1, q:2}; f(o.p, o.q); is converted to f(1, 2);
// 不需要咯
hoist_props: false,
// 变量提升
// 不需要咯
hoist_vars: false,
// optimizations for if/return and if/continue
// 不需要, eslint做检查
if_return: false,
/**
* 无法用言语表达,自行理解
* inline (default: true) -- inline calls to function with simple/return statement:
false -- same as 0
0 -- disabled inlining
1 -- inline simple functions
2 -- inline functions with arguments
3 -- inline functions with arguments and variables
true -- same as 3
*/
inline: false,
// join consecutive var statements
// 就是将变量声明合并到一个var中
// 关闭, eslin做检查
join_vars: false,
// 自动去除无用的function参数
// 关闭. eslint做检查
keep_fargs: false,
// Pass true to prevent Infinity from being compressed into 1/0
// 禁止将infinity转成1/0
keep_infinity: true,
// optimizations for do, while and for loops when we can statically determine the condition.
// 优化循环
// 此处关闭,应该由开发者自行优化
loops: false,
// negate "Immediately-Called Function Expressions" where the return value is discarded, to avoid the parens that the code generator would insert.
// 自行体会
negate_iife: true,
// rewrite property access using the dot notation, for example foo["bar"] → foo.bar
// 关闭.eslint检查
properties: false,
// 将只用到一次的function,通过inline方式插入
// 关闭.开发者自行把控
reduce_funcs: false,
// 将静态变量直接lnline紧代码里
// 可以开启
reduce_vars: true,
// 使用逗号运算符连接连续的简单语句
// 自行把控
sequences: false,
/**
* Pass false to disable potentially dropping functions marked as "pure".
* A function call is marked as "pure" if a comment annotation \/*@__PURE__*\/ or \/*#__PURE__*\/ immediately precedes the call.
* For example: \/*@__PURE__*\/foo();
* 就是关闭标注纯函数的注释了
*/
side_effects: false,
// 去掉重复和无法到达的switch分支
// eslint做检查, 以及开发者把控
switches: false,
// Transforms typeof foo == "undefined" into foo === void 0
typeofs: false,
}
}其实很多优化点都是可以通过eslint来检查,而不需要在压缩过程检查
再配合自身的开发习惯以及规范,可以去掉很多压缩检查, 压缩效率就能提升
但是带来的负面影响就是压缩体积会有上升/
因为对于第三方库来说,并不会安装项目配置的eslint来跑.自然就达不到要求.
再少了uglifyplugin的压缩优化,体积就会上升.
以我的例子来看,总体积上升了50k. 尚可以接受.
而打包时间足足提升了30s.
但可能也有人说上线打包不必在乎打包时间.
其实这些都看具体业务需求,以及自身的开发规范来配置.
重要的还是在打包速度和打包体积两者中找出一个最合适的平衡点
其实babel并不会影响到打包速度.我也只是顺便提下
我的配置如下
{
"plugins": [
[
"component",
[{
"libraryName": "element-ui",
"styleLibraryName": "theme-default"
}]]
],
"comments": false,
"env": {
"development": {
"plugins": ["transform-object-rest-spread", "syntax-dynamic-import"]
},
"production": {
"presets": [["es2015", {"modules": false}], "stage-2"],
"plugins": ["transform-runtime"]
},
"test": {
"presets": ["env", "stage-2"],
"plugins": ["transform-runtime", "istanbul"]
}
}
}我把babel配置区分成了三个阶段,开发,生产和测试.
在开发过程不使用preset,直接跑原生代码.
在生产环境则使用es2015的preset
也许这样能提高开发环境的编译速度? 暂时不清楚,因为没感觉.一向很快.
这也看个人喜好了.
eslint的作用真的很大很大.
但是在开发阶段使用eslint真的很烦很烦.
所以,我目前的做法就是在开发阶段关闭eslint检查.因为我的vscode有带插件提示
即便检查到有错误,也可以正常编译.
但是在commit的时候添加了一层pre-commit来对修改的文件执行eslint.
这样就确保上传到git的代码是经过eslint检查的
这样既能确保开发不被干扰,也能确保代码能按照规范.
最近第一次给一个项目写一个完整的测试流程, 也算是我第一次写完整的测试.
于是记一下整个测试流程
项目地址
目前项目使用的测试框架是主流的jest+enzyme
babel,则需要babel-jesttypescript, 则需要ts-jestsnapshot, 则需要 enzyme-to-json起初项目使用babel进行编译,后面统一转成了ts
{
"jest": {
"moduleNameMapper": {
"\\.(jpg|jpeg|png|gif|eot|otf|webp|svg|ttf|woff|woff2|scss)$": "<rootDir>/test/utils.ts"
}, // 将静态资源匹配到utils.ts中
"moduleFileExtensions": ["ts", "tsx", "js"],
"setupFilesAfterEnv": "<rootDir>/test/setup.ts", // jest环境初始化
"collectCoverageFrom": ["src/**/*.{ts,tsx}"], // 覆盖率收集
"coverageDirectory": "./coverage/", // 覆盖率输出目录
"collectCoverage": true,
"transform": {
"^.+\\.(ts|tsx)$": "ts-jest" // 如果是babel, 则为babel-jest
},
"testMatch": ["**/__test__/*.(ts|tsx)"],
"snapshotSerializers": [
"enzyme-to-json/serializer" // 用来适配 toMatchSnapshot
]
}
}如果使用babel的话, 只要将ts转成js, ts-jest转成babel-jest即可。
用来mock一些额外module, 比如sass, jpg等等.
// /test/utils.ts
module.exports = 'test-file-stub'The path to a module that runs some code to configure or set up the testing framework before each test.
可以用来初始化test配置, 在这里需要使用enzyme-adapter
// /test/setup.ts
import { configure } from 'enzyme'
import * as ReactSixteenAdapter from 'enzyme-adapter-react-16'
configure({ adapter: new ReactSixteenAdapter() })需要测试覆盖率的文件
覆盖率输出目录
A map from regular expressions to paths to transformers. A transformer is a module that provides a synchronous function for transforming source files
跟webpack-loader类似
The glob patterns Jest uses to detect test files.
测试文件匹配规则, 如果跟官方不同, 则修改此值.
其实enzyme上手挺简单的, 它有三个API
包括shallow、mount和render, 其中shallow和mount是常用的
他们区别是
shallow: 只会渲染顶级组件, 而子组件不会渲染, 渲染结果是一颗react树, 效率最高mount: 会渲染整个组件, 包括子组件, 如果需要深入组件内部测试, 则需要使用mountrender: 直接选择普通的html结构.shallow和mount得到结果是一个ReactWrapper对象, 可以进行多种操作, 包括find()、prop()、instance()等。
import * as React from 'react'
import { shallow, mount } from 'enzyme'
import MyComponent from '../MyComponent'
import ChildComponent from '../ChildComponent'
describt('测试xxxxx', () => {
it('组件state以及渲染情况', () => {
const wrapper = shallow(<MyComponent />)
expect(wrapper.state().msg).toEqual('test msg')
expect(wrapper.find('#childId')).toHaveLength(1) // 测试是否包含某个`element`
expect(wrapper.find(ChildComponent)).toHaveLength(1) // 测试是否包含某个子组件
})
it('触发事件', () => {
const click = jest.fn()
const wrapper = shallow(<MyComponent onClick={click}/>)
// 触发#triggerClickElement的click事件
wrapper.find('#triggerClickElement').simulate('click')
// 判断click事件是否被触发
expect(click).toBeCalledTimes(1)
})
// 测试函数调用
// 默认该函数声明方式通过class.method声明
// class MyComponent{
// someMethod() {}
// }
it('测试函数调用', () => {
const spy = jest.spyOn(MyComponent.prototype, 'someMethod')
const wrapper = shallow(<MyComponent />)
// 暂且认为组件挂载时会调用`someMethod`
// 在此测试是否正确调用
expect(spy).toBeCalledTimes(1)
})
// 但是由于react需要绑定this
// 所以一般会这样声明
// class MyComponent {
// someMethod = () => {}
// }
// 这时候通过babel或者typescript编译后
// 会变成类似
// class MyComponent{
// constructor() {
// this.someMethod = () => {}
// }
// }
// 这时候someMethod不属于MyComponent.prototype
// 所以要改变测试方式
it('测试函数调用', () => {
const wrapper = shallow(<MyComponent />)
const ins = wrapper.instance()
const spy = jest.spyOn(ins, 'someMethod')
wrapper.update()
ins.forceUpdate()
expect(spy).toBeCalledTimes(1)
})
it('触发特定事件, 并传递参数', () => {
// 如果要触发特定事件, 比如mousemove, keyup等等
// 可以通过构造自定义事件, 并且使用dispatchEvent来触发
const wrapper = shallow(<MyComponent />)
const element = wrapper.find('.some-element')
const event = new MouseEvent('mousemove', {
clientX: 100,
clientY: 100
})
element.getDOMNode().dispatchEvent(event)
expect(wrapper.state.x).toEqueal(100)
})
})其实enzyme常用的api大概就是几个, 按照本项目中用到的,
编写完test case后, 只要调用jest即可进行测试, 同时会输出覆盖率
如果带上--watch则可以监听文件改动并进行测试
目前使用Codecov来管理测试覆盖率
如果在本地上传, 则需要带上token, 如果通过travisCi, 则不需要, 直接调用codecov即可。
至此, 整套jest+enzyme测试流程已经跑完.
目前看来没有用高更深的测试功能, 比如说jsdom, enzyme.render等
这次戚风蛋糕第一次尝试,还是挺不错的,评个80分吧。
本来是打算弄芝士蛋糕,奈何没有奶油奶酪,只能做原味戚风蛋糕了。
下次可以买奶油奶酪试试做芝士蛋糕。
周末做了下蛋包饭,差点就做成了蛋炒饭。
原因还是材料太多了,炒起来鸡蛋都保不住。
不过吃起来还是挺好吃,可能下次要注意下材料分量,鸡蛋能包起来就更好吃了。
本篇博客就在Hyrule下完成
keywords:
taro进行开发api请求, 获取图片的base64字符串, 并且将图片展示出来setData数据不能超过1024kb根据setData的限制, 图片的大小不能超过1024kb, 否则setData的时候会超过限制而报错。
因此, 可以考虑使用数组来存储数据, 并且将数据分批写入。
const arr = []
const baseStr = '....' // > 1024kb
const step = 1024 * 1024
for(let i = 0, j = 0; i < baseStr.length; i = i + step, j++) {
arr[j] = baseStr.subStr(i, step)
}然而, 对于taro而言, 数据的修改通过this.setState来完成, 不能像原生小程序那样只修改部分数据。
比如:
// taro
this.setState({
a: {
...this.state.a,
b: 1
},
c: [{b: 1}, ...this.state.c.slice(1)]
})
// 小程序
this.setData({
'a.b': 1,
'c[0].b': 1
})因此, taro每次的setState都会把整个数据带上. 不符合setData限制。
倘若taro能像setData一样可以支持单独修改某一部分数据, 是否可以?
答案也是否定的
在taro中, 在render方法用到的数据, 最终都会被挂在this.__state上, 而this.__state最终也会反应到data上, 所以也是不可取。
class C extends Taro.Component {
render() {
const a = 1
return <View>{a}</View>
}
}
// 编译后
// ...
var a = 1
Object.assign(this.__state, {
aa: aa
});
// ...最终还是只能用原生的方法来实现。
对于数据处理, 则像上面一样, 分次写入数据。
Page({
data: {
arr: []
},
setImg() {
const arr = []
const baseStr = '....' // > 1024kb
const step = 1024 * 1024
for(let i = 0, j = 0; i < baseStr.length; i = i + step, j++) {
const key = `arr[${i}]`
this.setData({
[key]: baseStr.subStr(i, step)
})
}
}
})数据处理完毕后, 需要将数据拼接成原字符串, 并且赋值给src, 而小程序wxml不支持嵌入复杂表达式。
但是小程序中的wxs却可以进行复杂运算, 并且在wxml中使用, 请参考。
那么便可以将拼接字符串的操作放在wxs中, 然后在wxml中调用即可
<wxs module="m1">
function join(arr) {
return arr.join('')
}
module.exports.join = join;
</wxs>
<image src='{{m1.join(arr)}}' mode='aspectFill' lazy-load></image>这样便能使用base64来展示图片。
keywords:
base64其实是一种编码转换方式, 将ASCII字符转换成普通文本, 是网络上最常见的用于传输8Bit字节代码的编码方式之一。
base64由字母a-z、A-Z、0-9以及+和/, 再加上作为垫字的=, 一共65字符组成一个基本字符集, 其他所有字符都可以根据一定规则, 转换成该字符集中的字符。
abcde=>YWJjZGU=
ABCDE=>QUJDREU=
在日常开发中, 最常见的便是将blob和base64之间相互转换.
// blob to base64
function blobTobase64(blob) {
const fileReader = new FileReader()
let base64 = ''
fileReader.onload = () => {
base64 = fileReader.result // 读取base64
}
fileReader.readAsDataURL(blob) // 读取blob
}
// base64 to blob
function dataURItoBlob(dataURI) {
var mimeString = dataURI
.split(',')[0]
.split(':')[1]
.split(';')[0] // mime类型
var byteString = atob(dataURI.split(',')[1]) //base64 解码
var arrayBuffer = new ArrayBuffer(byteString.length) //创建ArrayBuffer
var intArray = new Uint8Array(arrayBuffer) //创建视图
for (var i = 0; i < byteString.length; i++) {
intArray[i] = byteString.charCodeAt(i)
}
return new Blob([intArray], { type: mimeString }) // 转成 blob
}最新的浏览器自带了两个方法用于base64的编码和解码
分别是atob和btoa
base64转成8bit字节码8bit字节码转成base64对于旧版浏览器, 可以使用js-base64
目前node中还不支持使用atob和btoa,但是可以通过Buffer来实现, 参考文档
if (typeof btoa === 'undefined') {
global.btoa = function (str) {
return Buffer.from(str).toString('base64');
};
}
if (typeof atob === 'undefined') {
global.atob = function (b64Encoded) {
return Buffer.frome(b64Encoded, 'base64').toString();
};
}base64编码方式对于中文是不适用的, 因为中文对应多个字节, 因此可以先使用
encodeURIComponent编码后再进行base64编码.
每三个字节作为一组,每个字节8bit, 一共是24个二进制位。
'ABCD'
["ABC", "D"] // 每三字节做一组
['01000001010000100100001', '01000100'] // 转成8bit将每组的24个二进制位再细分为四组,每组有6个二进制位, 此时为二维数组。
[['010000', '010100', '001001', '000011'], ['010001', '00']]=。=。[['010000', '010100', '001001', '000011'], ['010001', '000000']]在每组前面加两个00,扩展成32个二进制位,即四个字节。
规则是这么说, 但这一步我觉得可以忽略, 因为
00101010和101010是一样的
将每组对应的二进制转成十进制, 在base64char字符集中找到对应的字符。
[["Q", "U", "J", "D"], ["R", "A"]]每一组都最终都应该转成四个字符
如果不足四个字符, 说明明文中并不足3字节, 因此需要补上垫字符=, 补够四个字符
[["Q", "U", "J", "D"], ["R", "A", "=", "="]]将最后的结果连接成字符串, 则为最终编码结果。
'ABCD' > 'QUJDRA=='
根据编码方式来看, 每3个字节将会被编码成四个字符, 如果不足3个字节, 则补上垫字符=, 缺几个就补几个。
btoa('A') // "QQ=="
btoa('AB') // "QUI="
btoa('ABC') // "QUJD"
btoa('ABCD') // "QUJDRA=="解码步骤就是跟编码步骤反过来
=外的字符, 在base64char字符集中找到所在下标。0。
=, 说明其明文不足3字节, 则根据垫字符=的数量, 在该组最后一项中去掉对应个数的000String.fromCharCode将二进制转成字符, 然后拼接// n进制转十进制
parseInt('1000', 2) // 8
parseInt('1000', 16) // 4096
// 进制间转换
(10).toString(2) // "1010", 10进制转2进制
(0xff).toString(2) // "11111111", 16进制转2进制A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.