zhongdeming428 / blog Goto Github PK
View Code? Open in Web Editor NEWThis repo is created for myself to write blogs.
Home Page: https://zhongdeming428.github.io/Blog
This repo is created for myself to write blogs.
Home Page: https://zhongdeming428.github.io/Blog



















最近是在所在实习公司的第一个sprint,有个朋友又请假了,所以任务比较重,一直这么久都没怎么更新了,这个周末赖了个床,纠结了一会儿决定还是继续写这个系列,虽然比较乏味,但是学到的东西还是很多的。
之前主要是针对函数处理部分的API做解读,经过那些天的努力,基本已经解读完了,现在把重点移到数组上。对于数组处理API的解读,从这篇文章开始。
flatten是一个很基础的函数,在Underscore中也算是一个工具函数,为了方便以后的讲解,今天先阅读flatten函数的源码。
首先,我们带着问题来阅读源码,如果你参加面试,考官让你手写一个展开数组的函数,你会怎么写?
我们接受的参数应该是一个数组,我们可以使用一个叫array的变量表示它,它的返回值应该是一个数组,使用result表示:
function flatten(array) {
var result = [];
// ... 展开代码
return result
}
然后我们应该对传入的数组进行类型验证,如果不是数组,我们应该抛出一个类型异常:
function flatten(array) {
var result = [];
if(Object.prototype.toString.call(array) !== '[object Array]')
throw new TypeError('Please pass a array-type object as parameter to flatten function');
else {
// ... 展开代码
}
return result
}
这样就可以保证我们接收到的参数是一个数组,接下来我们应该遍历array参数,对于它的每一项,如果不是数组,我们就将其添加到result中,否则继续展开:
function flatten(array) {
var result = [];
if(Object.prototype.toString.call(array) !== '[object Array]')
throw new TypeError('Please pass a array-type object as parameter to flatten function');
else {
for(var i = 0; i < array.length; i++) {
if(Object.prototype.toString.call(array[i]) === '[object Array]') {
// ... 继续展开。
}
else {
result.push(array[i]);
}
}
}
return result
}
当数组中的项还是一个数组时,我们应当如何展开呢?
由于不确定到底是嵌套了多少层数组,所以最好是使用递归来展开,但是有新的问题,我们的flatten函数返回一个数组结果,但是我们如何把递归结果返回给我们的result呢,是使用concat方法还是怎样?
由于函数中对象类型的参数是引用传值,所以我们可以把result传递给flatten自身,使其直接修改result即可:
function flatten(array, result) {
var result = result || [];
if(Object.prototype.toString.call(array) !== '[object Array]')
throw new TypeError('Please pass a array-type object as parameter to flatten function');
else {
for(var i = 0; i < array.length; i++) {
if(Object.prototype.toString.call(array[i]) === '[object Array]') {
// ... 递归展开。
arguments.callee(array[i], result);
}
else {
result.push(array[i]);
}
}
}
return result
}
以上函数,就基本实现了flatten的功能,再美化一下:
var flatten = function(array, result) {
var result = result || [];
var length = array.length;
var toString = Object.prototype.toString;
var type = toString.call(array);
if(type !== '[object Array]')
throw new TypeError('The parameter you passed is not a array');
else {
for(var i = 0; i < length; i++) {
if(toString.call(array[i]) !== '[object Array]') {
result.push(array[i]);
}
else {
arguments.callee(array[i], result);
}
}
}
return result;
}
大家可以把上面这段代码拷贝到控制台进行实验。
通过我们自己亲手实现一个flatten函数,阅读Underscore源码就变得简单了。
下面是Underscore中flatten函数的源码(附注释):
var flatten = function (input, shallow, strict, output) {
output = output || [];
var idx = output.length;
//遍历input参数。
for (var i = 0, length = getLength(input); i < length; i++) {
var value = input[i];
if (isArrayLike(value) && (_.isArray(value) || _.isArguments(value))) {
// Flatten current level of array or arguments object.
//如果input数组的元素是数组或者类数组对象,根据是否shallow来展开,如果shallow为true,那么只展开一级。
if (shallow) {
var j = 0, len = value.length;
while (j < len) output[idx++] = value[j++];
} else {
//如果shallow为false,那么递归展开所有层级。
flatten(value, shallow, strict, output);
idx = output.length;
}
} else if (!strict) {
//如果value不是数组或类数组对象,并且strict为false。
//那么直接将value添加到输出数组,否则忽略value。
output[idx++] = value;
}
}
return output;
};
Underscore实现的flatten更加强大,它支持类数组对象而不仅仅是数组,并且它多了两个参数——shallow和strict。
当shallow为true时,flatten只会把输入数组的数组子项展开一级,如果shallow为false,那么会全部展开。
当strict为false时,只要是非数组对象,flatten都会直接添加到output数组中;如果strict为true,那么会无视input数组中的非类数组对象。
更多Underscore源码解读:GitHub
前些天一直在学习入门Webpack,后来尝试了自己搭建一下一个简单的React开发环境,后来就在想可不可以自己写一个简单的脚手架,以免每次搭建一个简单的开发环境都需要自己一个个的配置,这样很麻烦,使用create-react-app的话,配置一大堆可能不会用到的功能,比较冗余,所以自己写一个超级简化的脚手架,只处理ES6代码、JSX语法和css模块,这样就满足了基本的使用。
后来在开发的过程中又遇到了新的麻烦,比如使用Node的child_process.spawn方法调用npm命令时,会出现错误,因为在Windows环境下,实际上要调用npm.cmd,而非npm,在这里出现了问题,还有一些其他问题,后来正好看到了@Jsonz大神写的两篇文章:探索 create-react-app 源码和create-react-app 源码解析之react-scripts,于是也照着学习了一下create-react-app脚手架的源码,基本解决了一些问题,最终写出来了一个简(can)单(fei)的React脚手架,当然还有许许多多的不足,但是这个学习的过程值得我记录下来。
这篇文章记录了以下知识:
create-react-app是一个很成功的、功能完善的脚手架,考虑到了许多方面,比如使用npm或者yarn,比如npm和Node版本、日志的记录和打印等等诸多方面,开发环境搭建的也十分完善,除了基本的React开发之外,还考虑了图片、postcss、sass、graphQL等等模块的处理。由于能力有限,本文开发的脚手架只涵盖了基本模块的处理,不包含图片、sass……等等。
脚手架的作用主要是建立一个React开发的标准目录、并且配置好webpack打包工具,使得开发过程中可以直接在标准的目录上修改,然后通过配置好的命令启动本地服务器或者打包app。所以脚手架中应该包括一个模板文件夹,里面放入应该拷贝到用户工程文件夹的所有文件或目录。在使用脚手架时,先把模板文件夹中的内容拷贝到用户工程文件夹下,然后修改package.json配置文件,最后安装所有模块。这就是我开发的脚手架所完成的基本工作。
脚手架工程目录结构如下:
ROOT
│ .gitignore
│ .npmignore
│ LICENSE
│ package-lock.json
│ package.json
│ README.md
│
├─dist
├─package
│ create-react.js
│
└─templates
│ .babelrc
│ .gitignore
│ README.md
│ webpack.base.conf.js
│ webpack.dev.conf.js
│ webpack.prod.conf.js
│
├─dist
└─src
│ index.css
│ index.html
│ index.js
│
└─components
App.js
根据我的前一篇文章,搭建React开发环境,最小化的标准目录结构应该如下:
ROOT
│ .babelrc
│ .gitignore
│ README.md
│ webpack.base.conf.js
│ webpack.dev.conf.js
│ webpack.prod.conf.js
│
├─dist
└─src
│ index.css
│ index.html
│ index.js
│
└─components
App.js
所以在脚手架根目录下的templates文件夹中应该包含以上文件,文件内的内容可以自由定制。
同样根据上一篇文章,需要安装的模块主要有:
'webpack',
'webpack-cli',
'html-webpack-plugin',
'clean-webpack-plugin',
'webpack-dev-server',
'css-loader',
'webpack-merge',
'style-loader',
'babel-preset-env',
'babel-loader',
'babel-polyfill',
'babel-preset-react'
和
'react',
'react-dom'
第一部分只需要安装在开发环境(npm i -D ...),第二部分生产环境也要安装(npm i --save ...)。
那么接下来可以通过Node实现脚手架的开发了。
首先介绍一些有用的并且会用到的模块:
cross-spawn:解决跨平台使用npm命令的问题的模块。chalk:实现控制台彩色文字输出的模块。fs-extra:实现了一些fs模块不包含的文件操(比如递归复制、删除等等)的模块。commander: 实现命令行传入参数预处理的模块。validate-npm-package-name:对于用户输入的工程名的可用性进行验证的模块。首先,在代码中引入这些基本的模块:
const spawn = require('cross-spawn');
const chalk = require('chalk');
const os = require('os');
const fs = require('fs-extra');
const path = require('path');
const commander = require('commander');
const validateProjectName = require('validate-npm-package-name');
const packageJson = require('../package.json');
然后定义我们的模板复制函数:
function copyTemplates() {
try {
if(!fs.existsSync(path.resolve(__dirname, '../templates'))) {
console.log(chalk.red('Cannot find the template files !'));
process.exit(1);
}
fs.copySync(path.resolve(__dirname, '../templates'), process.cwd());
console.log(chalk.green('Template files copied successfully!'));
return true;
}
catch(e) {
console.log(chalk.red(`Error occured: ${e}`))
}
}
fs模块首先检测模板文件是否存在(防止被用户删除),如果存在则通过fs的同步拷贝方法(copySync)拷贝到脚手架的当前工作目录(即process.cwd()),如果不存在则弹出错误信息,随后使用退出码1退出进程。
随后定义package.json的处理函数;
function generatePackageJson() {
let packageJson = {
name: projectName,
version: '1.0.0',
description: '',
scripts: {
start: 'webpack-dev-server --open --config webpack.dev.conf.js',
build: 'webpack --config webpack.prod.conf.js'
},
author: '',
license: ''
};
try {
fs.writeFileSync(path.resolve(process.cwd(), 'package.json'), JSON.stringify(packageJson));
console.log(chalk.green('Package.json generated successfully!'));
}
catch(e) {
console.log(chalk.red(e))
}
}
可以看出先是定义了一个JavaScript Object,然后修改属性之后通过fs模块将其JSON字符串写入到了package.json文件中,实现了package.json的生成。
最后安装所有的依赖,分为devDependencies和dependencies:
function installAll() {
console.log(chalk.green('Start installing ...'));
let devDependencies = ['webpack', 'webpack-cli', 'html-webpack-plugin', 'clean-webpack-plugin', 'webpack-dev-server', 'css-loader', 'webpack-merge', 'style-loader', 'babel-preset-env', 'babel-loader', 'babel-polyfill', 'babel-preset-react'];
let dependencies = ['react', 'react-dom'];
const child = spawn('cnpm', ['install', '-D'].concat(devDependencies), {
stdio: 'inherit'
});
child.on('close', function(code) {
if(code !== 0) {
console.log(chalk.red('Error occured while installing dependencies!'));
process.exit(1);
}
else {
const child = spawn('cnpm', ['install', '--save'].concat(dependencies), {
stdio: 'inherit'
})
child.on('close', function(code) {
if(code !== 0) {
console.log(chalk.red('Error occured while installing dependencies!'));
process.exit(1);
}
else {
console.log(chalk.green('Installation completed successfully!'));
console.log();
console.log(chalk.green('Start the local server with : '))
console.log();
console.log(chalk.cyan(' npm run start'))
console.log();
console.log(chalk.green('or build your app via :'));
console.log();
console.log(chalk.cyan(' npm run build'));
}
})
}
});
}
函数中,通过cross-spawn执行了cnpm的安装命令,值得注意的是其配置项:
{
stdio: 'inherit'
}
代表将子进程的输出管道连接到父进程上,及父进程可以自动接受子进程的输出结果,详情见options.stdio。
通过commander模块实现命令行参数的预处理;
const program = commander
.version(packageJson.version)
.usage(' [options]')
.arguments('<project-name>')
.action(name => {
projectName = name;
})
.allowUnknownOption()
.parse(process.argv);
其中,version方法定义了create-react-application -V的输出结果,usage定义了命令行里的用法,arguments定义了程序所接受的默认参数,然后在action函数回调中处理了这个默认参数,allowUnknownOption表示接受多余参数,parse表示把多余未解析的参数解析到process.argv中去。
最后是调用三个方法实现React开发环境的搭建:
if(projectName == undefined) {
console.log(chalk.red('Please pass the project name while using create-react!'));
console.log(chalk.green('for example:'))
console.log();
console.log(' create-react-application ' + chalk.yellow('<react-app>'));
}
else {
const validateResult = validateProjectName(projectName);
if(validateResult.validForNewPackages) {
copyTemplates();
generatePackageJson();
installAll();
//console.log(chalk.green(`Congratulations! React app has been created successfully in ${process.cwd()}`));
}
else {
console.log(chalk.red('The project name given is invalid!'));
process.exit(1);
}
}
如果接受的工程名为空,那么弹出警告。如果不为空,就验证工程名的可用性,如果不可用,就弹出警告并且退出进程,否则调用之前定义的三个主要函数,完成环境的搭建。
截止到此,使用该程序的方式仍然是node xxx.js --parameters的方式,我们需要自定义一个命令,并且最好将程序上传到npm,便于使用。
实现自定义命令并发布npm模块只需要以下几步:
修改入口文件,头部添加以下两句:
#!/usr/bin/env node
'use strict'
第二行也一定不能少!
修改package.json,添加bin属性:
// package.json
{
"bin": {
"create-react-application": "package/create-react.js"
}
}
执行以下命令:
npm link
注册npm账户(如已经注册则可以忽略)。
执行以下命令:
npm adduser
并输入账户密码。
执行以下命令:
npm publish
接下来就可以收到发布成功的邮件啦!
如果要更新你的npm模块,执行以下步骤:
使用一下命令更新你的版本号:
npm version x.x.x
再使用以下命令发布;
npm publish
执行完以上步骤之后,就可以在npm下载你的模块啦!
#!/usr/bin/env node这是Unix系操作系统中的一种写法,名字叫做Shebang或者Hashbang等等。在Wikipedia的解释中,把这一行代码写在脚本中,使得操作系统把脚本当做可执行文件执行时,会找到对应的程序执行(比如此文中的node),而这段代码本身会被解释器所忽略。
npm link在npm官方文档的解释中,npm link的执行,是一个两步的过程。当你在你的包中使用npm link时,会将全局文件夹:{prefix}/lib/node_modules/<package>链接到执行npm link的文件夹,同样也会将执行npm link命令的包中的所有可执行文件链接到全局文件夹{prefix}/bin/{name}中。
此外,npm link project-name会将全局安装的project-name模块链接到执行npm link命令的当前文件夹的node_modules中。
根据npm官方文档,prefix的值可为:
具体参考:prefix configuration和npm link
本文所开发的脚手架已经上传到了npm,可以通过以下步骤查看实际效果:
安装create-react-application
npm i -D create-react-application
或者
npm i -g create-react-application
使用create-react-application
create-react-application <project-name>
源码已经上传到了GitHub,欢迎大家一起哈啤(#手动滑稽)。
此外文中还有许多不足,比如关于npm link的解释我也还不是很清楚,欢迎大家补充指教!
入职半个月了,一直在接受业务知识以及企业文化知识的培训,下周终于要开始上岗入手项目了。由于公司使用自己搭建的 GitLab 服务作为项目版本控制器,所以我决定学习一下 GitLab,由于这货跟 GitHub 都是基于 Git,所以代码管理方面没有啥区别,主要学习的是 GitLab 服务的搭建。
输入一下命令更新源,然后安装依赖 openssh-server 和 ca-certificates。
sudo apt-get update
sudo apt-get install -y openssh-server ca-certificates
如果需要邮箱提醒服务,还需要安装 postfix,当然你也可以安装其他邮件服务。
安装方法:
sudo apt-get install -y postfix
如果没有配置过 postfix,那么安装过程中会跳出来配置选项。依次选择“Internet Site” => “确定” => 填入服务器域名 => “确定”。
安装 GitLab 包。
官网教程上面写的是使用 curl 下载一个 Shell 脚本,然后通过这个脚本安装 GitLab,但是实际上访问的时候,会提示 404 不存在的错误,所以此路不通。实际上访问 GitLab 官网的下载页面的时候,也是 404 不存在,不知道为什么官方人员还没有发现这个问题。
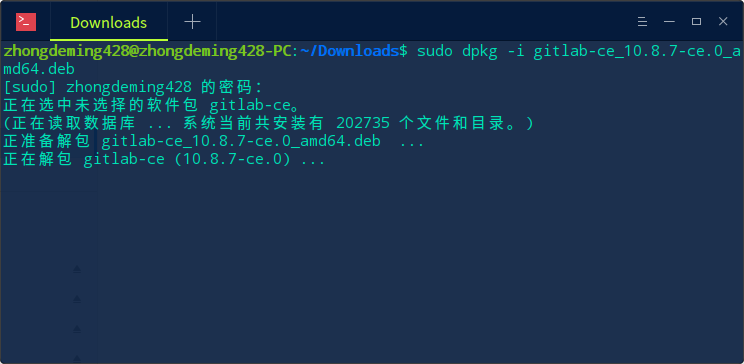
这里我使用的是手动安装,先去 GitLab 的 GitLab 仓库下载 deb 包(因为 Deepin 属于 Debian 系),然后通过 dpkg 命令进行安装。
这里最好选择社区版(gitlab-ce)。
下载之后可以有两种方法进行安装:
1.命令行安装
sudo dpkg -i gitlab-ce_xx.x.x-ce.x_amd64.deb
效果如图:
2.右键 deb 包,然后在”打开方式“中选择“深度软件包管理器”就可以了,然后就可以开始安装。
安装之后开始配置 GitLab,使用 gedit 或者 vim 打开 /etc/gitlab/gitlab.rb。然后修改 external_url 的值为你的本机ip,比如“127.0.0.1”。
然后重新配置 GitLab:
sudo gitlab-ctl reconfigure
配置完成后通过下面命令查看 GitLab 的服务状况:
sudo gitlab-ctl status
如果结果如下,则代表开启成功:
ok: run: alertmanager: (pid 9288) 1s
ok: run: gitaly: (pid 9297) 0s
ok: run: gitlab-monitor: (pid 9311) 0s
ok: run: gitlab-workhorse: (pid 9314) 1s
ok: run: logrotate: (pid 9331) 0s
ok: run: nginx: (pid 9337) 0s
ok: run: node-exporter: (pid 9347) 0s
ok: run: postgres-exporter: (pid 9349) 1s
ok: run: postgresql: (pid 9362) 0s
ok: run: prometheus: (pid 9364) 0s
ok: run: redis: (pid 9403) 0s
ok: run: redis-exporter: (pid 9444) 0s
ok: run: sidekiq: (pid 9460) 0s
ok: run: unicorn: (pid 9467) 1s
如果结果如下,则代表开启失败,还需要做处理(后文会讲到):
fail: alertmanager: runsv not running
fail: gitaly: runsv not running
fail: gitlab-monitor: runsv not running
fail: gitlab-workhorse: runsv not running
fail: logrotate: runsv not running
fail: nginx: runsv not running
fail: node-exporter: runsv not running
fail: postgres-exporter: runsv not running
fail: postgresql: runsv not running
fail: prometheus: runsv not running
fail: redis: runsv not running
fail: redis-exporter: runsv not running
fail: sidekiq: runsv not running
fail: unicorn: runsv not running
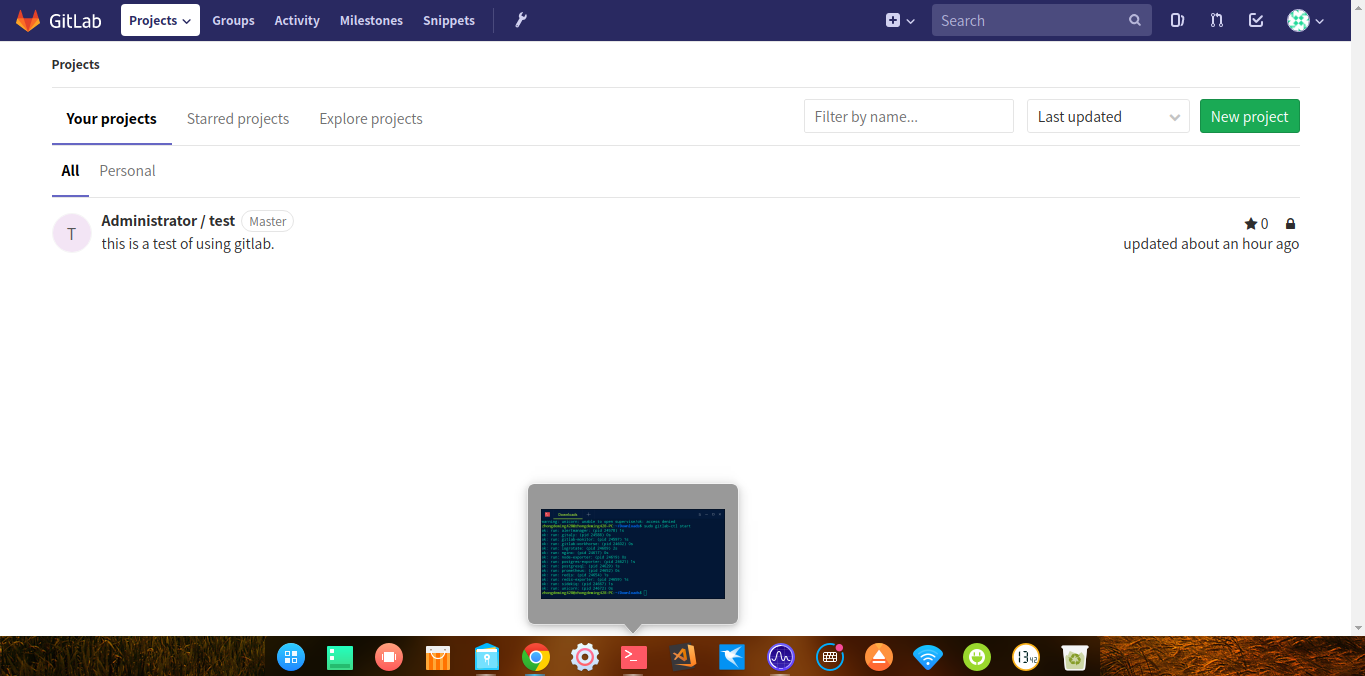
如果成功开启了 GitLab 服务,接下来就可以打开你的浏览器,输入“127.0.0.1”或者你在局域网中的 ip 进入 GitLab 的服务界面了。局域网内的其它机器也可以通过你的局域网 IP 访问你机器上的 GitLab 服务,这样就形成了一个私有的 Git 版本管理。
成功后的服务界面:
错误结果显示如下:
fail: alertmanager: runsv not running
fail: gitaly: runsv not running
fail: gitlab-monitor: runsv not running
fail: gitlab-workhorse: runsv not running
fail: logrotate: runsv not running
fail: nginx: runsv not running
fail: node-exporter: runsv not running
fail: postgres-exporter: runsv not running
fail: postgresql: runsv not running
fail: prometheus: runsv not running
fail: redis: runsv not running
fail: redis-exporter: runsv not running
fail: sidekiq: runsv not running
fail: unicorn: runsv not running
这说明 runsv 服务未开启,通过一下命令开启即可:
systemctl start gitlab-runsvdir.service
systemctl status gitlab-runsvdir.service
sudo gitlab-ctl start
界面提示“Whoops, GitLab is taking too much time to respond.”,这说明 GitLab 此时占用了过多的内存资源。你需要对服务器进行扩容,或者清理掉一些不需要的且占内存的服务。
这个问题基本没有啥办法,只能是扩展内存了,因为开启服务确确实实需要占据大量内存。
可能有些同学看到这个标题就会产生疑惑,为什么我们要判断JavaScript中的两个变量是否相等,JavaScript不是已经提供了双等号“==”以及三等号“===”给我们使用了吗?
其实,JavaScript虽然给我们提供了相等运算符,但是还是存在一些缺陷,这些缺陷不符合我们的思维习惯,有可能在使用的时候得到一些意外的结果。为了避免这种情况的出现,我们需要自己函数来实现JavaScript变量之间的对比。
在JavaScript中:
0 === 0
//true
+0 === -0
//true
相等运算符认为+0和-0是相等的,但是我们应当认为两者是不等的,具体原因源码中给出了一个链接:Harmony egal proposal.
在JavaScript中:
null == undefined
//true
null === undefined
//false
我们应当认为null不等于undefined,所以在比较null和undefined时,应当返回false。
前文有说过,NaN是一个特殊的值,它是JavaScript中唯一一个自身不等于自身的值。
NaN == NaN
//false
NaN === NaN
//false
但是我们在对比两个NaN时,我们应当认为它们是相等的。
由于在JavaScript中,数组是一个对象,所以如果两个变量不是引用的同一个数组的话,即使两个数组一模一样也不会返回true。
var a = [];
//undefined
var b = [];
//undefined
a=== b
//false
a==b
//false
但是我们应当认为,两个元素位置、顺序以及值相同的数组是相等的。
凡是涉及到对象的变量,只要不是引用同一个对象,都会被认为不相等。我们需要做出一些改变,两个完全一致的对象应当被认为是相等的。
var a = {};
//undefined
var b = {};
//undefined
a == b
//false
a === b
//false
这种情况在所有JavaScript内置对象中也适用,比如我们应当认为两个一样的RegExp对象是相等的。
在JavaScript中,数值2和Number对象2是不严格相等的:
2 == new Number(2);
//true
2 === new Number(2);
//false
但是我们在对比2和new Number(2)时应当认为两者相等。
我们实现的方法当然还是依赖于JavaScript相等运算符的,只不过针对特例需要有特定的处理。我们在比较之前,首先应该做的就是处理特殊情况。
underscore的代码中,没有直接将逻辑写在_.isEqual方法中,而是定义了两个私有方法:eq和deepEq。在GitHub用户@hanzichi的repo中,我们可以看到1.8.3版本的underscore中并没有deepEq方法,为什么后来添加了呢?这是因为underscore的作者把一些特例的处理提取了出来,放到了eq方法中,而更加复杂的对象之间的对比被放到了deepEq中(同时使得deepEq方法更加便于递归调用)。这样的做法使得代码逻辑更加鲜明,方法的功能也更加单一明确,维护代码更加简洁快速。
eq方法的源代码:
var eq = function (a, b, aStack, bStack) {
// Identical objects are equal. `0 === -0`, but they aren't identical.
// See the [Harmony `egal` proposal](http://wiki.ecmascript.org/doku.php?id=harmony:egal).
//除了0 === -0这个特例之外,其余所有a === b的例子都代表它们相等。
//应当判断0 !== -0,但是JavaScript中0 === -0。
//下面这行代码就是为了解决这个问题。
//当a !== 0或者1/a === 1/b时返回true,一旦a === 0并且1/a !== 1/b就返回false。
//而a === 0且1/a !== 1/b就代表a,b有一个为0,有一个为-0。
if (a === b) return a !== 0 || 1 / a === 1 / b;
//一旦a、b不严格相等,就进入后续检测。
//a == b成立但是a === b不成立的例子中需要排除null和undefined,其余例子需要后续判断。
// `null` or `undefined` only equal to itself (strict comparison).
//一旦a或者b中有一个为null就代表另一个为undefined,这种情况可以直接排除。
if (a == null || b == null) return false;
// `NaN`s are equivalent, but non-reflexive.
//自身不等于自身的情况,一旦a,b都为NaN,则可以返回true。
if (a !== a) return b !== b;
// Exhaust primitive checks
//如果a,b都不为JavaScript对象,那么经过以上监测之后还不严格相等的话就可以直接断定a不等于b。
var type = typeof a;
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
//如果a,b是JavaScript对象,还需要做后续深入的判断。
return deepEq(a, b, aStack, bStack);
};
对于源码的解读我已经作为注释写在了源码中。
那么根据源码,可以将其逻辑抽象出来:

deepEq的源码:
var deepEq = function (a, b, aStack, bStack) {
// Unwrap any wrapped objects.
//如果a,b是_的一个实例的话,需要先把他们解包出来再进行比较。
if (a instanceof _) a = a._wrapped;
if (b instanceof _) b = b._wrapped;
// Compare `[[Class]]` names.
//先根据a,b的Class字符串进行比较,如果两个对象的Class字符串都不一样,
//那么直接可以认为两者不相等。
var className = toString.call(a);
if (className !== toString.call(b)) return false;
//如果两者的Class字符串相等,再进一步进行比较。
//优先检测内置对象之间的比较,非内置对象再往后检测。
switch (className) {
// Strings, numbers, regular expressions, dates, and booleans are compared by value.
//如果a,b为正则表达式,那么转化为字符串判断是否相等即可。
case '[object RegExp]':
// RegExps are coerced to strings for comparison (Note: '' + /a/i === '/a/i')
case '[object String]':
// Primitives and their corresponding object wrappers are equivalent; thus, `"5"` is
// equivalent to `new String("5")`.
//如果a, b是字符串对象,那么转化为字符串进行比较。因为一下两个变量:
//var x = new String('12');
//var y = new String('12');
//x === y是false,x === y也是false,但是我们应该认为x与y是相等的。
//所以我们需要将其转化为字符串进行比较。
return '' + a === '' + b;
case '[object Number]':
//数字对象转化为数字进行比较,并且要考虑new Number(NaN) === new Number(NaN)应该要成立的情况。
// `NaN`s are equivalent, but non-reflexive.
// Object(NaN) is equivalent to NaN.
if (+a !== +a) return +b !== +b;
// An `egal` comparison is performed for other numeric values.
//排除0 === -0 的情况。
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
case '[object Date]':
//Date类型以及Boolean类型都可以转换为number类型进行比较。
//在变量前加一个加号“+”,可以强制转换为数值型。
//在Date型变量前加一个加号“+”可以将Date转化为毫秒形式;Boolean类型同上(转换为0或者1)。
case '[object Boolean]':
// Coerce dates and booleans to numeric primitive values. Dates are compared by their
// millisecond representations. Note that invalid dates with millisecond representations
// of `NaN` are not equivalent.
return +a === +b;
case '[object Symbol]':
return SymbolProto.valueOf.call(a) === SymbolProto.valueOf.call(b);
}
var areArrays = className === '[object Array]';
//如果不是数组对象。
if (!areArrays) {
if (typeof a != 'object' || typeof b != 'object') return false;
// Objects with different constructors are not equivalent, but `Object`s or `Array`s
// from different frames are.
//比较两个非数组对象的构造函数。
var aCtor = a.constructor, bCtor = b.constructor;
if (aCtor !== bCtor && !(_.isFunction(aCtor) && aCtor instanceof aCtor &&
_.isFunction(bCtor) && bCtor instanceof bCtor)
&& ('constructor' in a && 'constructor' in b)) {
return false;
}
}
// Assume equality for cyclic structures. The algorithm for detecting cyclic
// structures is adapted from ES 5.1 section 15.12.3, abstract operation `JO`.
// Initializing stack of traversed objects.
// It's done here since we only need them for objects and arrays comparison.
//初次调用eq函数时,aStack以及bStack均未被传递,在循环递归的时候,会被传递进来。
//aStack和bStack存在的意义在于循环引用对象之间的比较。
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
while (length--) {
// Linear search. Performance is inversely proportional to the number of
// unique nested structures.
if (aStack[length] === a) return bStack[length] === b;
}
// Add the first object to the stack of traversed objects.
//初次调用eq函数时,就把两个参数放入到参数堆栈中去,保存起来方便递归调用时使用。
aStack.push(a);
bStack.push(b);
// Recursively compare objects and arrays.
//如果是数组对象。
if (areArrays) {
// Compare array lengths to determine if a deep comparison is necessary.
length = a.length;
//长度不等,直接返回false认定为数组不相等。
if (length !== b.length) return false;
// Deep compare the contents, ignoring non-numeric properties.
while (length--) {
//递归调用。
if (!eq(a[length], b[length], aStack, bStack)) return false;
}
} else {
// Deep compare objects.
//对比纯对象。
var keys = _.keys(a), key;
length = keys.length;
// Ensure that both objects contain the same number of properties before comparing deep equality.
//对比属性数量,如果数量不等,直接返回false。
if (_.keys(b).length !== length) return false;
while (length--) {
// Deep compare each member
key = keys[length];
if (!(_.has(b, key) && eq(a[key], b[key], aStack, bStack))) return false;
}
}
// Remove the first object from the stack of traversed objects.
//循环递归结束,把a,b堆栈中的元素推出。
aStack.pop();
bStack.pop();
return true;
};
对于源码的解读我已经作为注释写在了源码中。
那么根据源码,可以将其逻辑抽象出来:
1 使用Object.prototype.toString方法获取两参数类型,如果两参数的原始数据类型都不同,那么可以认为两个参数不相等。
2 如果进入了第二步,那么说明两个参数的原始类型相同。针对获取到的字符串进行分类,如果是除Object和Array之外的类型,进行处理。
3 经过以上比较,所剩类型基本只剩Array和基本对象了。如果不是数组对象,那么构造函数不同的对象可以被认为是不相等的对象。
4 初始化对象栈aStack以及bStack,因为初次调用deepEq函数时不会传递这两个参数,所以需要手动初始化。因为之后比较的数组对象以及基本对象需要用到对象栈,所以现在应该把当前的a,b推入到两个栈中。
5 针对数组,先比较长度,长度不等则数组不等。长度相等再递归调用deepGet比较数组的每一项,有一项不等则返回false。
6 基本对象类型比较,先使用_.keys获取对象的所有键。键数量不同的两对象不同,如果键数目相等,再递归调用deepEq比较每一个键的属性,有一个键值不等则返回false。
7 经过所有检测如果都没有返回false的话,可以认为两参数相等,返回true。在返回之前会把栈中的数据推出一个。
有同学可能会疑惑:/[a-z]/gi与/[a-z]ig/在意义上是一样的,但是转化为字符串之后比较会不会是不相等的?
这是一个非常好的问题,同时也是underscore处理的巧妙之所在。在JavaScript中,RegExp对象重写了toString方法,所以在强制将RegExp对象转化为字符串时,flags会按规定顺序排列,所以将之前两个RegExp对象转化为字符串,都会得到/[a-z]/gi。这就是underscore可以放心大胆的将RegExp对象转化为字符串处理的原因。
underscore选择将Date对象和Boolean对象都转化为数值进行处理,这避免了纷繁复杂的类型转换,简单粗暴。而且作者没有使用强制转换方法进行转换,而是只使用了一个“+”符号,就强制将Date对象和Boolean对象转换成了数值型数据。
很多童鞋在阅读源码时,可能会很疑惑aStack以及bStack的作用在哪里。aStack和bStack用于保存当前比较对象的上下文,这使得我们在比较某个对象的子属性时,还可以获取到其自身。这样做的好处就在于我们可以比较循环引用的对象。
var a = {
name: 'test'
};
a['test1'] = a;
var b = {
name: 'test'
};
b['test1'] = b;
_.isEqual(a, b);
//true
underscore使用aStack和bStack作比较的代码:
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
while (length--) {
// Linear search. Performance is inversely proportional to the number of
// unique nested structures.
if (aStack[length] === a) return bStack[length] === b;
}
上面的测试代码中,a、b对象的test1属性都引用了它们自身,这样的对象在比较时会消耗不必要的时间,因为只要a和b的test1属性都等于其某个父对象,那么可以认为a和b相等,因为这个被递归的方法返回之后,还要继续比较它们对应的那个父对象,父对象相等,则引用的对象属性必相等,这样的处理方法节省了很多的时间,也提高了underscore的性能。
underscore的处理具有很强的优先级,比如在比较数组对象时,先比较数组的长度,数组长度不相同则数组必定不相等;比如在比较基本对象时,优先比较对象键的数目,键数目不等则对象必定不等;比如在比较两个对象参数之前,优先对比Object.prototype.toString返回的字符串,如果基本类型不同,那么两个对象必定不相等。
这样的主次分明的对比,大大提高了underscore的工作效率。所以说每一个小小的细节,都可以体现出作者的处心积虑。阅读源码,能够使我们学习到太多的东西。
我们可以在其他方法中看到underscore对ES6中新特征的支持,比如_.is[Type]方法已经支持检测Map(_.isMap)和Set(_.isSet)等类型了。但是_.isEqual却没有对Set和Map结构的支持。如果我们使用_.isEqual比较两个Map或者两个Set,总是会得到true的结果,因为它们可以通过所有的检测。
在underscore的官方GitHub repo上,我看到有同学已经提交了PR添加了_.isEqual对Set和Map的支持。
我们可以看一下源码:
var size = a.size;
// Ensure that both objects are of the same size before comparing deep equality.
if (b.size !== size) return false;
while (size--) {
// Deep compare the keys of each member, using SameValueZero (isEq) for the keys
if (!(isEq(a.keys().next().value, b.keys().next().value, aStack, bStack))) return false;
// If the objects are maps deep compare the values. Value equality does not use SameValueZero.
if (className === '[object Map]') {
if (!(eq(a.values().next().value, b.values().next().value, aStack, bStack))) return false;
}
}
可以看到其思路如下:
这段代码有一个很巧妙的地方在于它没有区分到底是Map对象还是Set对象,先直接使用a.keys().next().value以及b.keys().next().value获取Set的元素值或者Map的键。后面再进行类型判断,如果是Map对象的话,再使用a.values().next().value以及b.values().next().value获取Map的键值,Map对象还需要比较其键值是否相等。
个人认为,这段代码也有其局限性,因为Set和Map可以认为是一个数据集,这区别于数组对象。我们可以说[1,2,3]不等于[2,1,3],因为其相同元素的位置不同;但是我认为new Set([1,2,3])应该认为等于new Set([2,1,3]),因为Set是无序的,它内部的元素具有单一性。
准备了挺久,一直想要好好深入了解一下Webpack,之前一直嫌弃Webpack麻烦,偏向于Parcel这种零配置的模块打包工具一些,但是实际上还是Webpack比较靠谱,并且Webpack功能更加强大。由于上一次学习Webpack的时候并没有了解过Node.js,所以很多时候真的感觉无能为力,连个__dirname都觉得好复杂,学习过Node.js之后再来学习Webpack,就会好理解很多,这一次算是比较深入的了解一下Webpack,争取以后能够脱离create-react-app或者Vue-Cli这种脚手架工具,或者自己也能够写一套脚本自动配置开发环境。
由于写这篇笔记的时候,Webpack已经发行了最新的Webpack 4.0,所以这篇笔记就算是学习Webpack 4.0的笔记吧,笔者所用版本是webpack 4.8.3,另外使用Webpack 4.x的命令行需要安装单独的命令行工具,笔者所使用的Webpack命令行工具是webpack-cli 2.1.3,学习的时候可以按照这个要求部署开发环境。
此外,在学习webpack之前,你最好对ES6、Node.js有一定的了解,最好使用过一个脚手架。
Webpack具有四个核心的概念,想要入门Webpack就得先好好了解这四个核心概念。它们分别是Entry(入口)、Output(输出)、loader和Plugins(插件)。接下来详细介绍这四个核心概念。
Entry是Webpack的入口起点指示,它指示webpack应该从哪个模块开始着手,来作为其构建内部依赖图的开始。可以在配置文件(webpack.config.js)中配置entry属性来指定一个或多个入口点,默认为./src(webpack 4开始引入默认值)。
具体配置方法:
entry: string | Array<string>
前者一个单独的string是配置单独的入口文件,配置为后者(一个数组)时,是多文件入口。
另外还可以通过对象语法进行配置:
entry: {
[entryChunkName]: string | Array<string>
}
比如:
//webpack.config.js
module.exports = {
entry: {
app: './app.js',
vendors: './vendors.js'
}
};
以上配置表示从app和vendors属性开始打包构建依赖树,这样做的好处在于分离自己开发的业务逻辑代码和第三方库的源码,因为第三方库安装后,源码基本就不再变化,这样分开打包有利于提升打包速度,减少了打包文件的个数,Vue-Cli采取的就是这种分开打包的模式。但是为了支持拆分代码更好的DllPlugin插件,以上语法可能会被抛弃。
Output属性告诉webpack在哪里输出它所创建的bundles,也可指定bundles的名称,默认位置为./dist。整个应用结构都会被编译到指定的输出文件夹中去,最基本的属性包括filename(文件名)和path(输出路径)。
值得注意的是,即是你配置了多个入口文件,你也只能有一个输出点。
具体配置方法:
output: {
filename: 'bundle.js',
path: '/home/proj/public/dist'
}
值得注意的是,output.filename必须是绝对路径,如果是一个相对路径,打包时webpack会抛出异常。
多个入口时,使用下面的语法输出多个bundle:
// webpack.config.js
module.exports = {
entry: {
app: './src/app.js',
vendors: './src/vendors.js'
},
output: {
filename: '[name].js',
path: __dirname + '/dist'
}
}
以上配置将会输出打包后文件app.js和vendors.js到__dirname + '/dist'下。
loader可以理解为webpack的编译器,它使得webpack可以处理一些非JavaScript文件,比如png、csv、xml、css、json等各种类型的文件,使用合适的loader可以让JavaScript的import导入非JavaScript模块。JavaScript只认为JavaScript文件是模块,而webpack的设计**即万物皆模块,为了使得webpack能够认识其他“模块”,所以需要loader这个“编译器”。
webpack中配置loader有两个目标:
比如webpack.config.js:
module.exports = {
entry: '...',
output: '...',
module: {
rules: [
{
test: /\.css$/,
use: 'css-loader'
}
]
}
};
该配置文件指示了所有的css文件在import时都应该经过css-loader处理,经过css-loader处理后,可以在JavaScript模块中直接使用import语句导入css模块。但是使用css-loader的前提是先使用npm安装css-loader。
此处需要注意的是定义loaders规则时,不是定义在对象的rules属性上,而是定义在module属性的rules属性中。
配置多个loader:
有时候,导入一个模块可能要先使用多个loader进行预处理,这时就要对指定类型的文件配置多个loader进行预处理,配置多个loader,把use属性赋值为数组即可,webpack会按照数组中loader的先后顺序,使用对应的loader依次对模块文件进行预处理。
{
module: {
rules: [
{
test: /\.css$/,
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader'
}
]
}
]
}
}
此外,还可以使用内联方式进行loader配置:
import Styles from 'style-loader!css-loader?modules!./style.css'
但是这不是推荐的方法,请尽量使用module.rules进行配置。
loader用于转换非JavaScript类型的文件,而插件可以用于执行范围更广的任务,包括打包、优化、压缩、搭建服务器等等,功能十分强大。要是用一个插件,一般是先使用npm包管理器进行安装,然后在配置文件中引入,最后将其实例化后传递给plugins数组属性。
插件是webpack的支柱功能,目前主要是解决loader无法实现的其他许多复杂功能,通过plugins属性使用插件:
// webpack.config.js
const webpack = require('webpack');
module.exports = {
plugins: [
new webpack.optimize.UglifyJsPlugin()
]
}
向plugins属性传递实例数组即可。
模式(Mode)可以通过配置对象的mode属性进行配置,主要值为production或者development。两种模式的区别在于一个是为生产环境编译打包,一个是为了开发环境编译打包。生产环境模式下,webpack会自动对代码进行压缩等优化,省去了配置的麻烦。
学习完以上基本概念之后,基本也就入门webpack了,因为webpack的强大就是建立在这些基本概念之上,利用webpack多样的loaders和plugins,可以实现强大的打包功能。
按照以下步骤实现webpack简单的打包功能:
(1)建立工程文件夹,位置和名称随意,并将cmd或者git bash的当前路径切换到工程文件夹。
(2)安装webpack和webpack-cli到开发环境:
npm install webpack webpack-cli --save-dev
(3)在工程文件夹下建立以下文件和目录:
(4)安装css-loader:
npm install css-loader --save-dev
(5)配置webpack.config.js:
module.exports = {
mode: 'development',
entry: './src/index.js',
output: {
path: __dirname + '/dist',
filename: 'bundle.js'
},
module: {
rules: [
{
test: /\.css$/,
use: 'css-loader'
}
]
}
};
(6)在index.html中引入bundle.js:
<!--index.html-->
<html>
<head>
<title>Test</title>
<meta charset='utf-8'/>
</head>
<body>
<h1>Hello World!</h1>
</body>
<script src='./bundle.js'></script>
</html>
(7)在index.js中添加:
import './index.css';
console.log('Success!');
(8)在工程目录下,使用以下命令打包:
webpack
查看输出结果,可以双击/dist/index.html查看有没有报错以及控制台的输出内容。
webpack提供Node API,方便我们在Node脚本中使用webpack。
基本代码如下:
// 引入webpack模块。
const webpack = require('webpack');
// 引入配置信息。
const config = require('./webpack.config');
// 通过webpack函数直接传入config配置信息。
const compiler = webpack(config);
// 通过compiler对象的apply方法应用插件,也可在配置信息中配置插件。
compiler.apply(new webpack.ProgressPlugin());
// 使用compiler对象的run方法运行webpack,开始打包。
compiler.run((err, stats) => {
if(err) {
// 回调中接收错误信息。
console.error(err);
}
else {
// 回调中接收打包成功的具体反馈信息。
console.log(stats);
}
});
动态生成是啥?动态生成就是指在打包后的模块名称内插入hash值,使得每一次生成的模块具有不同的名称,而index.html之所以要动态生成是因为每次打包生成的模块名称不同,所以在HTML文件内引用时也要更改script标签,这样才能保证每次都能引用到正确的JavaScript文件。
为什么要添加hash值?
之所以要动态生态生成bundle文件,是为了防止浏览器缓存机制阻碍文件的更新,在每次修改代码之后,文件名中的hash都会发生改变,强制浏览器进行刷新,获取当前最新的文件。
如何添加hash到bundle文件中?
只需要在设置output时,在output.filename中添加[hash]到文件名中即可,比如:
// webpack.config.js
module.exports = {
output: {
path: __dirname + '/dist',
filename: '[name].[hash].js'
}
};
现在可以动态生成bundle文件了,那么如何动态添加bundle到HTML文件呢?
每次打包bundle文件之后,其名称都会发生更改,每次人为地修改对应的HTML文件以添加JavaScript文件引用实在是令人烦躁,这时需要使用到强大的webpack插件了,有一个叫html-webpack-plugin的插件,可以自动生成HTML文件。安装到开发环境:
npm install html-webpack-plugin --save-dev
安装之后,在webpack.config.js中引入,并添加其实例到插件属性(plugins)中去:
// webpack.config.js
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
// other configs ...
plugins: [
new HtmlWebpackPlugin({
// options配置
})
]
};
这时就可以看到每次生成bundle文件之后,都会被动态生成对应的html文件。
在上面的代码中还可以看到HtmlWebpackPlugin插件的构造函数还可以传递一个配置对象作为参数。比较有用的配置属性有title(指定HTML中title标签的内容,及网页标题)、template(指定模板HTML文件)等等,其他更多具体参考信息请访问:Html-Webpack-Plugin
由于每次生成的JavaScript文件都不同名,所以新的文件不会覆盖旧的文件,而旧的文件一只会存在于/dist文件夹中,随着编译次数的增加,这个文件夹会越来越膨胀,所以应该想办法每次生成新的bundle文件之前清理/dist文件夹,以确保文件夹的干净整洁,有以下两个较好的处理办法:
如果你是Node脚本调用webpack打包:
如果通过Node API调用webpack进行打包,可以在打包之前直接使用Node的fs模块删除/dist文件夹中的所有文件:
const webpack = require('webpack');
const config = require('./webpack.config');
const fs = require('fs');
const compiler = webpack(config);
var deleteFolderRecursive = function(path) {
if (fs.existsSync(path)) {
fs.readdirSync(path).forEach(function(file, index){
var curPath = path + "/" + file;
if (fs.lstatSync(curPath).isDirectory()) { // recurse
deleteFolderRecursive(curPath);
} else { // delete file
fs.unlinkSync(curPath);
}
});
fs.rmdirSync(path);
}
};
deleteFolderRecursive(__dirname + '/dist');
compiler.run((err, stats) => {
if(err) {
console.error(err);
}
else {
console.log(stats.hash);
}
});
可以看到在调用compiler.run打包之前,先使用自定义的deleteFolderRecursive方法删除了/dist目录下的所有文件。
如果你使用webpack-cli进行打包
这时候就得通过webpack的插件完成这个任务了,用到的插件是clean-webpack-plugin。
安装:
npm install clean-webpack-plugin --save-dev
然后在webpack.config.js文件中添加插件:
// webpack.config.js
const CleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
plugins: [
new CleanWebpackPlugin(['dist'])
]
};
之后再次打包,你会发现之前的打包文件全部被删除了。
开发环境与生产环境存在许多的差异,生产环境更讲究生产效率,因此代码必须压缩、精简,必须去除一些生产环境并不需要用到的调试工具,只需要提高应用的效率和性能即可。开发环境更讲究调试、测试,为了方便开发,我们需要搭建一个合适的开发环境。
为何要使用source maps?
因为webpack对源代码进行打包后,会对源代码进行压缩、精简、甚至变量名替换,在浏览器中,无法对代码逐行打断点进行调试,所有需要使用source maps进行调试,它使得我们在浏览器中可以看到源代码,进而逐行打断点调试。
如何使用source maps?
在配置中添加devtool属性,赋值为source-map或者inline-source-map即可,后者报错信息更加具体,会指示源代码中的具体错误位置,而source-map选项无法指示到源代码中的具体位置。
每次写完代码保存之后还需要手动输入命令或启动Node脚本进行编译是一件令人不胜其烦的事情,选择一下工具可以简化开发过程中的工作:
(1)使用watch模式
在使用webpack-cli进行打包时,通过命令webpack --watch即可开启watch模式,进入watch模式之后,一旦依赖树中的某一个模块发生了变化,webpack就会重新进行编译。
(2)使用webpack-dev-server
使用过create-react-app或者Vue-Cli这种脚手架的童鞋都知道,通过命令npm run start即可建立一个本地服务器,并且webpack会自动打开浏览器打开你正在开发的页面,并且一旦你修改了文件,浏览器会自动进行刷新,基本做到了所见即所得的效果,比webpack的watch模式更加方便给力。
使用方法:
① 安装webpack-dev-server:
npm install --save-dev webpack-dev-server
② 修改配置文件,添加devServer属性:
// webpack.config.js
module.exports = {
devServer: {
contentBase: './dist'
}
};
③ 添加命令属性到package.json:
// package.json
{
"scripts": {
"start": "webpack-dev-server --open"
}
}
④ 运行命令
npm run start
可以看到浏览器打开后的实际效果,尝试修改文件,查看浏览器是否实时更新。
此外还可以再devServer属性下指定更多的配置信息,比如开发服务器的端口、热更新模式、是否压缩等等,具体查询:Webpack
通过Node API使用webpack-dev-server:
'use strict';
const Webpack = require('webpack');
const WebpackDevServer = require('../../../lib/Server');
const webpackConfig = require('./webpack.config');
const compiler = Webpack(webpackConfig);
const devServerOptions = Object.assign({}, webpackConfig.devServer, {
stats: {
colors: true
}
});
const server = new WebpackDevServer(compiler, devServerOptions);
server.listen(8080, '127.0.0.1', () => {
console.log('Starting server on http://localhost:8080');
});
(3)使用webpack-dev-middleware
webpack-dev-middleware是一个比webpack-dev-server更加基础的插件,webpack-dev-server也使用了这个插件,所以可以理解为webpack-dev-middleware的封装层次更低,使用起来更加复杂,但是低封装性意味着较高的自定义性,使用webpack-dev-middleware可以定义更多的设置来满足更多的开发需求,它基于express模块。
这一块不做过多介绍,因为webpack-dev-server已经能够应付大多数开发场景,不用再设置更多的express属性了,想要详细了解的童鞋可以了解:使用 webpack-dev-middleware
(4)设置IDE
某些IDE具有安全写入功能,导致开发服务器运行时IDE无法保存文件,此时需要进行对应的设置。
具体参考:调整文本编辑器
热模块替换(Hot Module Replacement,HMR),代表在应用程序运行过程中替换、添加、删除模块,浏览器无需刷新页面即可呈现出相应的变化。
使用方法:
(1)在devServer属性中添加hot属性并赋值为true:
// webpack.config.js
module.exports = {
devServer: {
hot: true
}
}
(2)引入两个插件到webpack配置文件:
// webpack.config.js
const webpack = require('webpack');
module.exports = {
devServer: {
hot: true
},
plugins: [
new webpack.NamedModulesPlugin(),
new webpack.HotModuleReplacementPlugin()
]
};
(3)在入口文件底部添加代码,使得在所有代码发生变化时,都能够通知webpack:
if (module.hot) {
module.hot.accept('./print.js', function() {
console.log('Accepting the updated intMe module!');
printMe();
})
}
热模块替换比较难以掌控,容易报错,推荐在不同的开发配置下使用不同的loader简化HMR过程。具体参考:其他代码和框架
生产环境要求代码精简、性能优异,而开发要求开发快速、测试方便,代码不要求简洁,所以两种环境下webpack打包的目的也不相同,所以最好将两种环境下的配置文件分开来。对于分开的配置文件,在使用webpack时还是要对其中的配置信息进行整合,webpack-merge是一个不错的整合工具(Vue-Cli也有使用到)。
使用方法:
(1)安装webpack-merge:
npm install webpack-merge --save-dev
(2)建立三个配置文件:
其中,webpack.base.conf.js表示最基础的配置信息,开发环境和生产环境都需要设置的信息,比如entry、output、module等。在另外两个文件中配置一些对应环境下特有的信息,然后通过webpack-merge模块与webpack.base.conf.js整合。
(3)添加npm scripts:
// package.json
{
"scripts": {
"start": "webpack-dev-server --open --config webpack.dev.conf.js",
"build": "webpack --config webpack.prod.conf.js"
}
}
此外,建议设置mode属性,因为生产环境下会自动开启代码压缩,免去了配置的麻烦。
TreeShaking表示移除JavaScript文件中的未使用到的代码,webpack 4增强了这一部分的功能。通过配置package.json的sideEffects属性,可以指定哪些文件可以移除多余代码。如果sideEffects设置为false,那么表示文件中的未使用代码可以放心移除,没有副作用。如果有些文件中的冗余代码不能被移除,那么可以设置sideEffects属性为一个数组,数组内容为文件的路径字符串。
指定无副作用的文件之后,设置mode为"production",再次构建代码,可以发现未使用到的代码已经被移除。
module.rules属性中,设置include属性以指定哪些文件需要被loader处理。渐进式网络应用程序(Progressive Web Application - PWA),是一种可以提供类似于原生应用程序(native app)体验的网络应用程序(web app),在离线(offline)时应用程序能够继续运行功能,这是通过 Service Workers 技术来实现的。PWA是最近几年比较火的概念,它的核心是由service worker技术实现的在客户浏览器与服务器之间搭建的一个代理服务器,在网络畅通时,客户浏览器会通过service worker访问服务器,并且缓存注册的文件;在网络断开时,浏览器会访问service worker这个代理服务器,使得在网络断开的情况下,页面还是能够访问,实现了类似原生应用的网站开发。create-react-app已经实现了PWA开发的配置。
下面介绍如何通过webpack快速开发PWA。
(1)安装插件workbox-webpack-plugin:
npm install workbox-webpack-plugin --save-dev
(2)在配置文件中引入该插件:
// webpack.config.js
const WorkboxPlugin = require('workbox-webpack-plugin');
module.exports = {
plugins: [
new WorkboxPlugin.GenerateSW({
clientsClaim: true,
skipWaiting: true
})
]
};
(3)使用webpack进行编译,打包出service-worker.js
(4)在入口文件底部注册service worker:
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('/service-worker.js').then(registration => {
console.log('SW registered: ', registration);
}).catch(registrationError => {
console.log('SW registration failed: ', registrationError);
});
});
}
(5)打开页面,进行调试:
npm run start
(6)打开浏览器调试工具,查看控制台的输出,如果输出“SW registered: ... ...”,表示注册service worker成功,接下来可以断开网络,或者关闭服务器,再次刷新,可以看到页面仍然可以显示。
webpack确实是一个功能强大的模块打包工具,丰富的loader和plugin使得其功能多而强。学习webpack使得我们可以自定义自己的开发环境,无需依赖create-react-app和Vue-Cli这类脚手架,也可以针对不同的需求对代码进行不同方案的处理。这篇笔记还只是一篇入门的笔记,如果要真正的构建较为复杂的开发环境和生产环境,还需要了解许多的loader和plugin,好在webpack官网提供了所有的说明,可以给用户提供使用指南:
阅读脚手架的源码也有助于学习webpack,今后应该还有进行这方面的学习,但是答辩即将到来,不知道毕业之前还有没有机会^_^。
对很多人而言,虚拟 DOM 都是一个很高大上而且远不可及的专有名词,以前我也这么认为,后来在学习 Vue 源码的时候发现 Vue 的虚拟 DOM 方案衍生于本文要讲的 snabbdom 工具,经过阅读源码之后才发现,虚拟 DOM 原来就是这么回事,并没有想象中那么难以理解嘛~
这篇文章呢,就单独从 snabbdom 这个库讲起,不涉及其他任何框架,单独从这个库的源码来聊一聊虚拟 DOM。
在讲 snabbdom 之前,需要先学习 TypeScript 知识,以及 snabbdom 的基本使用方法。
在学习 snabbdom 源码之前,最好先学会用 snabbdom,至少要掌握 snabbdom 的核心概念,这是阅读框架源码之前基本都要做的准备工作。
以下内容可以直接到 snabbdom 官方文档了解。
snabbdom 主要具有一下优点:
modules 可以很容易地扩展。通过一些第三方的插件,可以很容易地支持 JSX、服务端 HTML 输出等等……
较为核心的 API 其实就四个:init、patch、 h和tovnode,通过这四个 API 就可以玩转虚拟 DOM 啦!
下面简单介绍一下这四个核心函数:
init:这是 snabbdom 暴露出来的一个核心函数,通过它我们才能开始使用许多重要的功能。该函数接受一个数组作为参数,数组内都是 module,通过 init 注册了一系列要使用的 module 之后,它会给我们返回一个 patch 函数。
patch: 该函数是我们挂载或者更新 vnode 的重要途径。它接受两个参数,第一个参数可以是 HTML 元素或者 vnode,第二个元素只能是 vnode。通过 patch 函数,可以对第一个 vnode 进行更新,或者把 vnode 挂载/更新到 DOM 元素上。
tovnode: 用于把真实的 DOM 转化为 vnode,适合把 SSR 生成的 DOM 转化成 vnode,然后进行 DOM 操作。
h: 该函数用于创建 vnode,在许多地方都能见到它的身影。它接受三个参数:
@param {string} selector|tag 标签名或者选择器
@param {object} data 数据对象,结构在后面讲
@param {vNode[]|string} children 子节点,可以是文本节点Module 是 snabbdom 的一个核心概念,snabbdom 的核心主干代码只实现了元素、id、class(不包含动态赋值)、元素内容(包括文本节点在内的子节点)这四个方面;而其他诸如 style 样式、class 动态赋值、attr 属性等功能都是通过 Module 扩展的,它们写成了 snabbdom 的内部默认 Module,在需要的时候引用就行了。
那么 Module 究竟是什么呢?
snabbdom 的官方文档已经讲得很清楚了,Module 的本质是一个对象,对象的键由一些钩子(Hooks)的名称组成,键值都是函数,这些函数能够在特定的 vnode/DOM 生命周期触发,并接受规定的参数,能够对周期中的 vnode/DOM 进行操作。
由于 snabbdom 使用 TypeScript 编写,所以在之后看代码的时候,我们可以非常清楚地看到 Module 的组成结构。
内置 Module 有如下几种:
class:动态控制元素的 class。props:设置 DOM 的一些属性(properties)。attributes:同样用于设置 DOM 属性,但是是 attributes,而且 properties。style:设置 DOM 的样式。dataset:设置自定义属性。customProperties:CSS 的变量,使用方法参考官方文档。delayedProperties:延迟的 CSS 样式,可用于创建动画之类。snabbdom 提供了丰富的生命周期钩子:
| 钩子名称 | 触发时机 | Arguments to callback |
|---|---|---|
pre |
patch 开始之前。 | none |
init |
已经创建了一个 vnode。 | vnode |
create |
已经基于 vnode 创建了一个 DOM,但尚未挂载。 | emptyVnode, vnode |
insert |
创建的 DOM 被挂载了。 | vnode |
prepatch |
一个元素即将被 patch。 | oldVnode, vnode |
update |
元素正在被更新。 | oldVnode, vnode |
postpatch |
元素已经 patch 完毕。 | oldVnode, vnode |
destroy |
一个元素被直接或间接地移除了。间接移除的情况是指被移除元素的子元素。 | vnode |
remove |
一个元素被直接移除了(卸载)。 | vnode, removeCallback |
post |
patch 结束。 | none |
如何使用钩子呢?
在创建 vnode 的时候,把定义的钩子函数传递给 data.hook 就 OK 了;当然还可以在自定义 Module 中使用钩子,同理定义钩子函数并赋值给 Module 对象就可以了。
注意
Module 中只能使用以下几种钩子:pre, create, update, destroy, remove, post。
而在 vnode 创建中定义的钩子只能是以下几种:init, create, insert, prepatch, update, postpatch, destroy, remove。为什么 pre 和 post 不能使用呢?因为这两个钩子不在 vnode 的生命周期之中,在 vnode 创建之前,pre 已经执行完毕,在 vnode 卸载完毕之后,post 钩子才开始执行。
snabbdom 提供 DOM 事件处理功能,创建 vnode 时,定义好 data.on 即可。比如:
h(
'div',
{
on: {
click: function() { /*...*/}
}
}
)如上,就定义了一个 click 事件处理函数。
那么如果我们要预先传入一些自定义的参数那该怎么做呢?此时我们应该通过数组定义 handler:
h(
'div',
{
on: {
click: [
function(data) {/*...*/},
data
]
}
}
)那我们的事件对象如何获取呢?这一点 snabbdom 已经考虑好了,event 对象和 vnode 对象会附加在我们的自定义参数后传入到 handler。
根据官方文档的说明,Thunk 是一种优化策略,可以防止创建重复的 vnode,然后对实际未发生变化的 vnode 做替换或者 patch,造成不必要的性能损耗。在后面的源码分析中,再做详细说明吧。
在首先查看源代码之前,先分析一下源码的目录结构,好有的放矢的进行阅读,下面是 src 目录下的文件结构:
.
├── helpers
│ └── attachto.ts
├── hooks.ts // 定义了钩子函数的类型
├── htmldomapi.ts // 定义了一系列 DOM 操作的 API
├── h.ts // 主要定义了 h 函数
├── is.ts // 主要定义了一个类型判断辅助函数
├── modules // 定义内置 module 的目录
│ ├── attributes.ts
│ ├── class.ts
│ ├── dataset.ts
│ ├── eventlisteners.ts
│ ├── hero.ts
│ ├── module.ts
│ ├── props.ts
│ └── style.ts
├── snabbdom.bundle.ts // 导出 h 函数和 patch 函数(注册了所有内置模块)。
├── snabbdom.ts // 导出 init,允许自定义注册模块
├── thunk.ts // 定义了 thunk
├── tovnode.ts // 定义了 tovnode 函数
└── vnode.ts // 定义了 vnode 类型
2 directories, 18 files所以看完之后,我们应该有了一个大致的概念,要较好的了解 vnode,我们可以先从 vnode 下手,结合文档的介绍,可以详细了解虚拟 DOM 的结构。
此外还可以从我们使用 snabbdom 的入口处入手,即 snabbdom.ts。
这一小节先了解 vnode 的结构是怎么样的,由于 snabbdom 使用 TypeScript 编写,所以关于变量的结构可以一目了然,打开 vnode.ts,可以看到关于 vnode 的定义:
export interface VNode {
sel: string | undefined;
data: VNodeData | undefined;
children: Array<VNode | string> | undefined;
elm: Node | undefined;
text: string | undefined;
key: Key | undefined;
}可以看到 vnode 的结构其实比较简单,只有 6 个属性。关于这六个属性,官网已经做了介绍:
sel:是一种 CSS 选择器,vnode 挂载为 DOM 时,会基于这个属性构造 HTML 元素。data:构造 vnode 的数据属性,在构造 DOM 时会用到里面的数据,data 的结构在 vnode.ts 中可以找到定义,稍后作介绍。children:这是一个 vnode 数组,在 vnode 挂载为 DOM 时,其 children 内的所有 vnode 会被构造为 HTML 元素,进一步挂载到上一级节点下。elm:这是根据当前 vnode 构造的 DOM 元素。text: 当前 vnode 的文本节点内容。key:snabbdom 用 key 和 sel 来区分不同的 vnode,如果两个 vnode 的 sel 和 key 属性都相等,那么可以认为两个 vnode 完全相等,他们之间的更新需要进一步比对。往下翻可以看到 VNodeData 的类型定义:
export interface VNodeData {
props?: Props;
attrs?: Attrs;
class?: Classes;
style?: VNodeStyle;
dataset?: Dataset;
on?: On;
hero?: Hero;
attachData?: AttachData;
hook?: Hooks;
key?: Key;
ns?: string; // for SVGs
fn?: () => VNode; // for thunks
args?: Array<any>; // for thunks
[key: string]: any; // for any other 3rd party module
}可以看出来这些属性基本上都是在 Module 中所使用的,用于对 DOM 的一些数据、属性进行定义,后面再进行介绍。
打开 hooks.ts,可以看到源码如下:
import {VNode} from './vnode';
export type PreHook = () => any;
export type InitHook = (vNode: VNode) => any;
export type CreateHook = (emptyVNode: VNode, vNode: VNode) => any;
export type InsertHook = (vNode: VNode) => any;
export type PrePatchHook = (oldVNode: VNode, vNode: VNode) => any;
export type UpdateHook = (oldVNode: VNode, vNode: VNode) => any;
export type PostPatchHook = (oldVNode: VNode, vNode: VNode) => any;
export type DestroyHook = (vNode: VNode) => any;
export type RemoveHook = (vNode: VNode, removeCallback: () => void) => any;
export type PostHook = () => any;
export interface Hooks {
pre?: PreHook;
init?: InitHook;
create?: CreateHook;
insert?: InsertHook;
prepatch?: PrePatchHook;
update?: UpdateHook;
postpatch?: PostPatchHook;
destroy?: DestroyHook;
remove?: RemoveHook;
post?: PostHook;
}这些代码定义了所有钩子函数的结构类型(接受的参数、返回的参数),然后定义了 Hooks 类型,这与我们前面介绍的钩子类型和所接受的参数是一致的。
打开 module.ts,看到源码如下:
import {PreHook, CreateHook, UpdateHook, DestroyHook, RemoveHook, PostHook} from '../hooks';
export interface Module {
pre: PreHook;
create: CreateHook;
update: UpdateHook;
destroy: DestroyHook;
remove: RemoveHook;
post: PostHook;
}可以看到,该模块先引用了上一节代码定义的一系列钩子的类型,然后用这些类型进一步定义了 Module。能够看出来 module 实际上就是几种钩子函数组成的一个对象,用于干涉 DOM 的构造。
h 函数h 函数是一个大名鼎鼎的函数,在各个框架中都有这个函数的身影。它的愿意是 hyperscript,意思是创造 HyperText 的 JavaScript,当然包括创造 HTML 的 JavaScript。在 snabbdom 中也不例外,h 函数旨在接受一系列参数,然后构造对应的 vnode,其返回的 vnode 最终会被渲染成 HTML 元素。
看看源代码:
export function h(sel: string): VNode;
export function h(sel: string, data: VNodeData): VNode;
export function h(sel: string, children: VNodeChildren): VNode;
export function h(sel: string, data: VNodeData, children: VNodeChildren): VNode;
export function h(sel: any, b?: any, c?: any): VNode {
var data: VNodeData = {}, children: any, text: any, i: number;
if (c !== undefined) {
data = b;
if (is.array(c)) { children = c; }
else if (is.primitive(c)) { text = c; }
else if (c && c.sel) { children = [c]; }
} else if (b !== undefined) {
if (is.array(b)) { children = b; }
else if (is.primitive(b)) { text = b; }
else if (b && b.sel) { children = [b]; }
else { data = b; }
}
if (children !== undefined) {
for (i = 0; i < children.length; ++i) {
if (is.primitive(children[i])) children[i] = vnode(undefined, undefined, undefined, children[i], undefined);
}
}
if (
sel[0] === 's' && sel[1] === 'v' && sel[2] === 'g' &&
(sel.length === 3 || sel[3] === '.' || sel[3] === '#')
) {
addNS(data, children, sel);
}
return vnode(sel, data, children, text, undefined);
};
export default h;可以看到前面很大一段都是函数重载,所以不用太关注,只用关注到最后一行:
return vnode(sel, data, children, text, undefined);在适配好参数之后,h函数调用了 vnode 函数,实现了 vnode 的创建,而 vnode 函数更简单,就是一个工厂函数:
export function vnode(sel: string | undefined,
data: any | undefined,
children: Array<VNode | string> | undefined,
text: string | undefined,
elm: Element | Text | undefined): VNode {
let key = data === undefined ? undefined : data.key;
return {sel: sel, data: data, children: children,
text: text, elm: elm, key: key};
}它来自于 vnode.ts。
总之我们知道 h 函数接受相应的参数,返回一个 vnode 就行了。
在讲 snabbdom.ts 之前,本来应该先了解 htmldomapi.ts 的,但是这个模块全都是对于 HTML 元素 API 的封装,没有讲解的必要,所以阅读本章之前,读者自行阅读 htmldomapi.ts 源码即可。
这是整个项目的核心所在,也是定义入口函数的重要文件,这个文件大概有接近 400 行,主要定义了一些工具函数以及一个入口函数。
打开 snabbdom.ts ,最早看到的就是一些简单的类型定义,我们也先来了解一下:
function isUndef(s: any): boolean { return s === undefined; } // 判断 s 是否为 undefined。
// 判断 s 是否已定义(不为 undefined)。
function isDef(s: any): boolean { return s !== undefined; }
// 一个 VNodeQueue 队列,实际上是 vnode 数组,代表要挂载的 vnode。
type VNodeQueue = Array<VNode>;
// 一个空的 vnode,用于传递给 craete 钩子(查看第一节)。
const emptyNode = vnode('', {}, [], undefined, undefined);
// 判断两个 vnode 是否重复,依据是 key 和 sel。
function sameVnode(vnode1: VNode, vnode2: VNode): boolean {
return vnode1.key === vnode2.key && vnode1.sel === vnode2.sel;
}
// 判断是否是 vnode。
function isVnode(vnode: any): vnode is VNode {
return vnode.sel !== undefined;
}
// 一个对象,用于映射 childen 数组中 vnode 的 key 和其 index 索引。
type KeyToIndexMap = {[key: string]: number};
// T 是一个对象,其中的每一个键都被映射到 ArraysOf 类型,键值是 T 键值的数组集合。
type ArraysOf<T> = {
[K in keyof T]: (T[K])[];
}
// 参照上面的注释。
type ModuleHooks = ArraysOf<Module>;看完了基本类型的定义,可以继续看 init 函数:
export function init(modules: Array<Partial<Module>>, domApi?: DOMAPI) {
let i: number, j: number, cbs = ({} as ModuleHooks);
const api: DOMAPI = domApi !== undefined ? domApi : htmlDomApi;
for (i = 0; i < hooks.length; ++i) {
cbs[hooks[i]] = [];
for (j = 0; j < modules.length; ++j) {
const hook = modules[j][hooks[i]];
if (hook !== undefined) {
(cbs[hooks[i]] as Array<any>).push(hook);
}
}
}
// 这中间定义了一大堆工具函数,稍后做选择性分析……此处省略。
// init 函数返回的 patch 函数,用于挂载或者更新 DOM。
return function patch(oldVnode: VNode | Element, vnode: VNode): VNode {
let i: number, elm: Node, parent: Node;
const insertedVnodeQueue: VNodeQueue = [];
// 先执行完钩子函数对象中的所有 pre 回调。
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
if (!isVnode(oldVnode)) {
// 如果不是 VNode,那此时以旧的 DOM 为模板构造一个空的 VNode。
oldVnode = emptyNodeAt(oldVnode);
}
if (sameVnode(oldVnode, vnode)) {
// 如果 oldVnode 和 vnode 是同一个 vnode(相同的 key 和相同的选择器),那么更新 oldVnode。
patchVnode(oldVnode, vnode, insertedVnodeQueue);
} else {
// 如果 vnode 不同于 oldVnode,那么直接替换掉 oldVnode 对应的 DOM。
elm = oldVnode.elm as Node;
parent = api.parentNode(elm); // oldVnode 对应 DOM 的父节点。
createElm(vnode, insertedVnodeQueue);
if (parent !== null) {
// 如果 oldVnode 的对应 DOM 有父节点,并且有同级节点,那就在其同级节点之后插入 vnode 的对应 DOM。
api.insertBefore(parent, vnode.elm as Node, api.nextSibling(elm));
// 在把 vnode 的对应 DOM 插入到 oldVnode 的父节点内后,移除 oldVnode 的对应 DOM,完成替换。
removeVnodes(parent, [oldVnode], 0, 0);
}
}
for (i = 0; i < insertedVnodeQueue.length; ++i) {
// 执行 insert 钩子。因为 module 不包括 insert 钩子,所以不必执行 cbs...
(((insertedVnodeQueue[i].data as VNodeData).hook as Hooks).insert as any)(insertedVnodeQueue[i]);
}
// 执行 post 钩子,代表 patch 操作完成。
for (i = 0; i < cbs.post.length; ++i) cbs.post[i]();
// 最终返回 vnode。
return vnode;
};
}可以看到 init 函数其实不仅可以接受一个 module 数组作为参数,还可以接受一个 domApi 作为参数,这在官方文档上是没有说明的。可以理解为 snabbdom 允许我们自定义 dom 的一些操作函数,在这个过程中对 DOM 的构造进行干预,只需要我们传递的 domApi 的结构符合预定义就可以了,此处不再细表。
然后可以看到的就是两个嵌套着的循环,大致意思是遍历 hooks 和 modules,构造一个 ModuleHooks 类型的 cbs 变量,那这是什么意思呢?
hooks 定义如下:
const hooks: (keyof Module)[] = ['create', 'update', 'remove', 'destroy', 'pre', 'post'];那就是把每个 module 中对应的钩子函数整理到 cbs 钩子名称对应的数组中去,比如:
const module1 = {
create() { /*...*/ },
update() { /*...*/ }
};
const module2 = {
create() { /*...*/ },
update() { /*...*/ }
};
// 经过整理之后……
// cbs 如下:
{
create: [create1, create2],
update: [update1, update2]
}这种结构类似于发布——订阅模式的事件中心,以事件名作为键,键值是事件处理函数组成的数组,在事件发生时,数组中的函数会依次执行,与此处一致。
在处理好 hooks 之后,init 内部定义了一系列工具函数,此处暂不讲解,先往后看。
init 处理到最后返回的使我们预期的 patch 函数,该函数是我们使用 snabbdom 的重要入口,其具体定义如下:
// init 函数返回的 patch 函数,用于挂载或者更新 DOM。
return function patch(oldVnode: VNode | Element, vnode: VNode): VNode {
let i: number, elm: Node, parent: Node;
const insertedVnodeQueue: VNodeQueue = [];
// 先执行完钩子函数对象中的所有 pre 回调。
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
if (!isVnode(oldVnode)) {
// 如果不是 VNode,那此时以旧的 DOM 为模板构造一个空的 VNode。
oldVnode = emptyNodeAt(oldVnode);
}
if (sameVnode(oldVnode, vnode)) {
// 如果 oldVnode 和 vnode 是同一个 vnode(相同的 key 和相同的选择器),那么更新 oldVnode。
patchVnode(oldVnode, vnode, insertedVnodeQueue);
} else {
// 如果 vnode 不同于 oldVnode,那么直接替换掉 oldVnode 对应的 DOM。
elm = oldVnode.elm as Node;
parent = api.parentNode(elm); // oldVnode 对应 DOM 的父节点。
createElm(vnode, insertedVnodeQueue);
if (parent !== null) {
// 如果 oldVnode 的对应 DOM 有父节点,并且有同级节点,那就在其同级节点之后插入 vnode 的对应 DOM。
api.insertBefore(parent, vnode.elm as Node, api.nextSibling(elm));
// 在把 vnode 的对应 DOM 插入到 oldVnode 的父节点内后,移除 oldVnode 的对应 DOM,完成替换。
removeVnodes(parent, [oldVnode], 0, 0);
}
}
for (i = 0; i < insertedVnodeQueue.length; ++i) {
// 执行 insert 钩子。因为 module 不包括 insert 钩子,所以不必执行 cbs...
(((insertedVnodeQueue[i].data as VNodeData).hook as Hooks).insert as any)(insertedVnodeQueue[i]);
}
// 执行 post 钩子,代表 patch 操作完成。
for (i = 0; i < cbs.post.length; ++i) cbs.post[i]();
// 最终返回 vnode。
return vnode;
};可以看到在 patch 执行的一开始,就遍历了 cbs 中的所有 pre 钩子,也就是所有 module 中定义的 pre 函数。执行完了 pre 钩子,代表 patch 过程已经开始了。
接下来首先判断 oldVnode 是不是 vnode 类型,如果不是,就代表 oldVnode 是一个 HTML 元素,那我们就要把他转化为一个 vnode,方便后面的更新,更新完毕之后再进行挂载。转化为 vnode 的方式很简单,直接将其 DOM 结构挂载到 vnode 的 elm 属性,然后构造好 sel 即可。
随后,通过 sameVnode 判断是否是同一个 “vnode”。如果不是,那么就可以直接把两个 vnode 代表的 DOM 元素进行直接替换;如果是“同一个” vnode,那么就需要进行下一步对比,看看到底有哪些地方需要更新,可以看做是一个 DOM Diff 过程。所以这里出现了 snabbdom 的一个小诀窍,通过 sel 和 key 区分 vnode,不相同的 vnode 可以直接替换,不进行下一步的替换。这样做在很大程度上避免了一些没有必要的比较,节约了性能。
完成上面的步骤之后,就已经把 vnode 挂载到 DOM 上了,完成这个步骤之后,需要执行 vnode 的 insert 钩子,告诉所有的模块:一个 DOM 已经挂载了!
最后,执行所有的 post 钩子并返回 vnode,通知所有模块整个 patch 过程已经结束啦!
不难发现重点在于当 oldVnode 和 vnode 是同一个 vnode 时如何进行更新。这就自然而然的涉及到了 patchVnode 函数,该函数结构如下:
function patchVnode(oldVnode: VNode, vnode: VNode, insertedVnodeQueue: VNodeQueue) {
let i: any, hook: any;
if (isDef(i = vnode.data) && isDef(hook = i.hook) && isDef(i = hook.prepatch)) {
// 如果 vnode.data.hook.prepatch 不为空,则执行 prepatch 钩子。
i(oldVnode, vnode);
}
const elm = vnode.elm = (oldVnode.elm as Node);
let oldCh = oldVnode.children;
let ch = vnode.children;
// 如果两个 vnode 是真正意义上的相等,那完全就不用更新了。
if (oldVnode === vnode) return;
if (vnode.data !== undefined) {
// 如果 vnode 的 data 不为空,那么执行 update。
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
i = vnode.data.hook;
// 执行 vnode.data.hook.update 钩子。
if (isDef(i) && isDef(i = i.update)) i(oldVnode, vnode);
}
if (isUndef(vnode.text)) {
// 如果 vnode.text 未定义。
if (isDef(oldCh) && isDef(ch)) {
// 如果都有 children,那就更新 children。
if (oldCh !== ch) updateChildren(elm, oldCh as Array<VNode>, ch as Array<VNode>, insertedVnodeQueue);
} else if (isDef(ch)) {
// 如果 oldVnode 是文本节点,而更新后 vnode 包含 children;
// 那就先移除 oldVnode 的文本节点,然后添加 vnode。
if (isDef(oldVnode.text)) api.setTextContent(elm, '');
addVnodes(elm, null, ch as Array<VNode>, 0, (ch as Array<VNode>).length - 1, insertedVnodeQueue);
} else if (isDef(oldCh)) {
// 如果 oldVnode 有 children,而新的 vnode 只有文本节点;
// 那就移除 vnode 即可。
removeVnodes(elm, oldCh as Array<VNode>, 0, (oldCh as Array<VNode>).length - 1);
} else if (isDef(oldVnode.text)) {
// 如果更新前后,vnode 都没有 children,那么就添加空的文本节点,因为大前提是 vnode.text === undefined。
api.setTextContent(elm, '');
}
} else if (oldVnode.text !== vnode.text) {
// 定义了 vnode.text,并且 vnode 的 text 属性不同于 oldVnode 的 text 属性。
if (isDef(oldCh)) {
// 如果 oldVnode 具有 children 属性(具有 vnode),那么移除所有 vnode。
removeVnodes(elm, oldCh as Array<VNode>, 0, (oldCh as Array<VNode>).length - 1);
}
// 设置文本内容。
api.setTextContent(elm, vnode.text as string);
}
if (isDef(hook) && isDef(i = hook.postpatch)) {
// 完成了更新,调用 postpatch 钩子函数。
i(oldVnode, vnode);
}
}该函数是用于更新 vnode 的主要函数,所以 vnode 的主要生命周期都在这个函数内完成。首先执行的钩子就是 prepatch,表示元素即将被 patch。然后会判断 vnode 是否包含 data 属性,如果包含则说明需要先更新 data,这时候会调用所有的 update 钩子(包括模块内的和 vnode 自带的 update 钩子),在 update 钩子内完成 data 的合并更新。在 children 更新之后,还会调用 postpatch 钩子,表示 patch 过程已经执行完毕。
接下来从 text 入手,这一大块的注释都在代码里面写得很清楚了,这里不再赘述。重点在于 oldVnode 和 vnode 都有 children 属性的时候,如何更新 children?接下来看 updateChildren:
function updateChildren(parentElm: Node,
oldCh: Array<VNode>,
newCh: Array<VNode>,
insertedVnodeQueue: VNodeQueue) {
let oldStartIdx = 0, newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx: any;
let idxInOld: number;
let elmToMove: VNode;
let before: any;
// 从两端开始开始遍历 children。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode might have been moved left
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx];
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) { // 如果是同一个 vnode。
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue); // 更新旧的 vnode。
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) { // 同上,但是是从尾部开始的。
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue);
api.insertBefore(parentElm, oldStartVnode.elm as Node, api.nextSibling(oldEndVnode.elm as Node));
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue);
api.insertBefore(parentElm, oldEndVnode.elm as Node, oldStartVnode.elm as Node);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (oldKeyToIdx === undefined) {
// 创造一个 hash 结构,用键映射索引。
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
}
idxInOld = oldKeyToIdx[newStartVnode.key as string]; // 通过 key 来获取对应索引。
if (isUndef(idxInOld)) { // New element
// 如果找不到索引,那就是新元素。
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm as Node);
newStartVnode = newCh[++newStartIdx];
} else {
// 找到对应的 child vnode。
elmToMove = oldCh[idxInOld];
if (elmToMove.sel !== newStartVnode.sel) {
// 如果新旧 vnode 的选择器不能对应,那就直接插入到旧 vnode 之前。
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm as Node);
} else {
// 选择器匹配上了,可以直接更新。
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue);
oldCh[idxInOld] = undefined as any; // 已更新的旧 vnode 赋值为 undefined。
api.insertBefore(parentElm, (elmToMove.elm as Node), oldStartVnode.elm as Node);
}
newStartVnode = newCh[++newStartIdx];
}
}
}
if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) {
// 没匹配上的多余的就直接插入到 DOM 咯。
if (oldStartIdx > oldEndIdx) {
// newCh 里面有新的 vnode,直接插入到 DOM。
before = newCh[newEndIdx+1] == null ? null : newCh[newEndIdx+1].elm;
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue);
} else {
// newCh 里面的 vnode 比 oldCh 里面的少,说明有元素被删除了。
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}
}updateVnode 函数在一开始就从 children 数组的首尾两端开始遍历。可以看到在遍历开始的时候会有一堆的 null 判断,为什么呢?因为后面会把已经更新的 vnode children 赋值为 undefined。
判断完 null 之后,会比较新旧 children 内的节点是否“相同”(排列组合共有四种比较方式),如果相同,那就继续调用 patchNode 更新节点,更新完之后就可以插入 DOM 了;如果四中情况都匹配不到,那么就通过之前建立的 key 与索引之间的映射来寻找新旧 children 数组中对应 child vnode 的索引,找到之后再进行具体操作。关于具体的操作,代码中已经注释了~
对于遍历之后多余的 vnode,再分情况进行比较;如果 oldCh 多于 newCh,那说明该操作删除了部分 DOM。如果 oldCh 少于 newCh,那说明有新增的 DOM。
关于 updateChildren 函数的讲述,这篇文章的讲述更为详细:vue的Virtual Dom实现- snabbdom解密 ,大家可以去读一下~
讲完最重要的这个函数,整个核心部分基本上是弄完了,不难发现 snabbdom 的秘诀就在于使用:
最后还有一个小问题,这个贯穿许多函数的 insertedVnodeQueue 数组是干嘛的?它只在 createElm 函数中进行 push 操作,然后在最后的 insert 钩子中进行遍历。仔细一想就可以发现,这个插入 vnode 队列存起来的是一个 children 的左右子 children,看下面一段代码:
h(
'div',
{},
[
h(/*...*/),
h(/*...*/),
h(/*...*/)
]
)可以看到 div 下面包含了三个 children,那么当这个 div 元素被插入到 DOM 时,它的三个子 children 也会触发 insert 事件,所以在插入 vnode 时,会遍历其所有 children,然后每个 vnode 都会放入到队列中,在插入之后再统一执行 insert 钩子。
以上,就写这么多吧~多的也没时间写了。
自从工作之后,就已经很久没有写过博客了。时间被分割得比较碎,积累了一段时间的学习成果,才写下了这篇博客。
之前有写过 Webpack4 的文章,但是都比较偏入门,唯一的一篇实战篇 —— 基于Webpack搭建React开发环境,也是比较简单的,没有涉及到 CSS 抽取,第三方库打包等功能,这篇文章相对而言比较深入。但由于作者水平有限,难免存在谬误之处,欢迎大家指正。
还有没入门的童鞋可以参考我之前的文章:
在命令行中敲入如下命令:
mkdir Webpack-Vue && cd Webpack-Vue && npm init -y
然后你就可以在你的当前路径下看到一个叫 Webpack-Vue 的文件夹,里面有一个包含默认信息的 package.json 文件,打开并修改这个文件的一些内容。
然后我们在项目文件夹中创建以下几个文件夹:
Linux 下可以输入一下命令进行快速创建:
mkdir src src/components dist build -p
其中,dist 用于存放 Webpack 打包后的项目文件、src 用于存放你的源代码文件、build 用于存放 Webpack 打包相关的配置文件。
在 src 下,创建入口文件 index.js。
Linux 下创建的命令:
touch ./src/index.js
在根目录下创建 index.html 文件,内容如下:
<!DOCTYPE html>
<html>
<head>
<title>Webpack Vue Demo</title>
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<div id="app"></div>
</body>
</html>
这将用于作为我们应用的模板,打包的 js 文件会在 Webpack 插件的处理下插入到这个文件中。
其他配置性文件根据你自己的喜好来添加了,比如 .gitignore 文件等。
要使用 Webpack,第一步当然是先安装。使用以下命令进行安装:
npm i webpack webpack-cli -D
然后你就可以看到你的项目文件夹中多了一个 node_modules 文件夹,然后 package.json 文件中多了一个 devDependencies 属性。里面包含了安装的依赖名称和依赖版本,现在暂时还只有 webpack 和 webpack-cli。
这一节我们将着手配置一个具有最基本打包功能的项目,从 src/index.js 开始对项目进行打包。
为了项目结构更加科学合理,我们把所有的 Webpack 配置相关的文件都存放在了 build 目录中。
进入 build 文件夹,然后创建以下几个文件:
在 Linux 中,可以敲入如下命令快速创建:
cd build/ && touch webpack.base.conf.js webpack.dev.conf.js webpack.prod.conf.js build.js
其中,webpack.base.conf.js 是最基础的打包配置,是开发环境和生产环境都要用到的配置。webpack.dev.conf.js 就是在开发环境要使用的配置。webpack.prod.conf.js 就是在生产环境要使用的配置了。build.js 是通过 Node 接口进行打包的脚本。
接下来我们在对应的文件中写入最基本的配置信息。
先写最基本的配置信息:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: {
bundle: path.resolve(__dirname, '../src/index.js')
},
output: {
path: path.resolve(__dirname, '../dist'),
filename: '[name].[hash].js'
},
module: {
rules: [
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, '../index.html')
})
]
};
同样写入最基本的配置信息:
const merge = require('webpack-merge');
const path = require('path');
const baseConfig = require('./webpack.base.conf');
module.exports = merge(baseConfig, {
mode: 'development',
devtool: 'inline-source-map',
devServer: {
contentBase: path.resolve(__dirname, '../dist'),
open: true
}
});
继续写入最基础的配置:
const merge = require('webpack-merge');
const CleanWebpackPlugin = require('clean-webpack-plugin');
const path = require('path');
const baseConfig = require('./webpack.base.conf');
module.exports = merge(baseConfig, {
mode: 'production',
devtool: 'source-map',
module: {
rules: []
},
plugins: [
new CleanWebpackPlugin(['dist/'], {
root: path.resolve(__dirname, '../'),
verbose: true,
dry: false
})
]
});
注意到我们上面引用了两个新的依赖,需要先进行安装才能使用:
cnpm i webpack-merge clean-webpack-plugin webpack-dev-server html-webpack-plugin -D
这个脚本用于构建生产环境,开发环境基于 webpack-dev-server 搭建,不写脚本。
接下来,写入我们的打包脚本,通过 Node 调用 Webpack 进行打包。
const webpack = require('webpack');
const config = require('./webpack.prod.conf');
webpack(config, (err, stats) => {
if (err || stats.hasErrors()) {
// 在这里处理错误
console.error(err);
return;
}
// 处理完成
console.log(stats.toString({
chunks: false, // 使构建过程更静默无输出
colors: true // 在控制台展示颜色
}));
});
这样做的好处是可以利用 Node 做一些其他的事情,另外当 Webpack 配置文件不在项目文件夹根部时方便调用。
配置 npm scripts 能够使我们更方便的使用打包命令。
在 package.json 文件的 scripts 属性中,写入如下两条:
"build": "node build/build.js",
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js"
基本的配置写完了,我们测试一下打包效果,在 src/index.js 中写入如下代码:
console.log('index.js!');
然后在命令行中输入:
npm run dev
在自动打开的网页中,我打开控制台,我们可以看到输出了一句“index.js”,符合预期。
然后输入构建命令进行构建:
npm run build
截图如下:
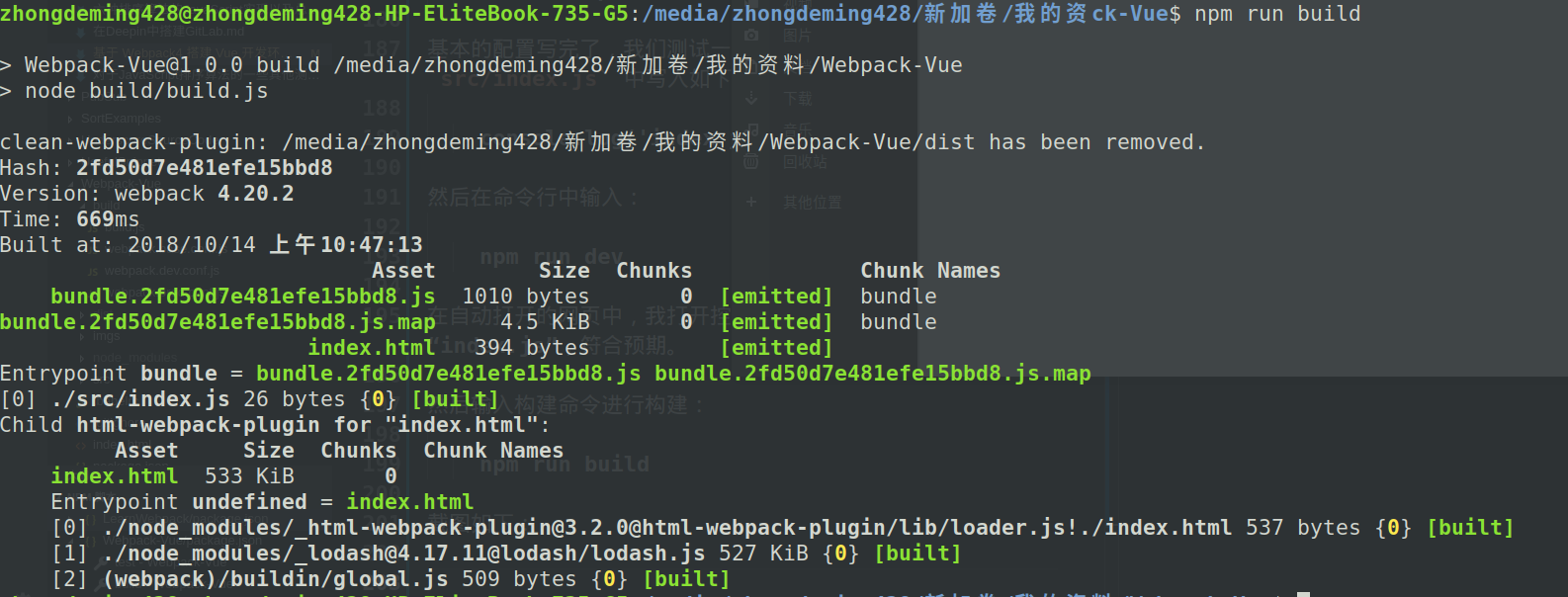
这就表示打包成功了,但是我们还只完成了最基本的打包功能,Vue 还不能使用,接下来我们将这个项目变得更加强大。
为了方便开发,我们需要引入一些 Loader,以简化我们的写法以及使我们的代码兼容更多的环境。
这一部分可以根据 Webpack 的文档来写,因为都是一些基本的东西,配置起来也不难。
为了使我们的 JavaScript 代码兼容更多环境,我们需要使用 babel-loader。
配置方法:
首先安装 babel-loader、babel-preset-env 和 babel-core。需要注意的是,如果你的 babel-loader 是 7.x 版本的话,你的 babel-core 必须是 6.x 版本;如果你的 babel-loader 是 8.x 版本的话,你的 babel-core 必须是 7.x 版本。如果不这样的话,Webpack 会报错。
安装命令如下:
npm i babel-loader@7 babel-core babel-preset-env -D
然后在 webpack.base.conf.js 的 module.rules 中新增如下对象:
{
test: /\.js$/,
use: 'babel-loader',
exclude: /node_modules/
}
我们还需要添加一个配置文件(.babelrc)在根目录下:
{
"presets": [
["env", {
"modules": false,
"targets": {
"browsers": ["> 1%", "last 2 versions", "not ie <= 8"]
}
}]
]
}
这就是 babel-preset-env 的作用,帮助我们配置 babel。我们只需要告诉它我们要兼容的情况(目标运行环境),它就会自动把代码转换为兼容对应环境的代码。
以上代码表示我们要求代码兼容最新两个版本的浏览器,不用兼容 IE 8,另外市场份额超过 1% 的浏览器也必须支持。
只需要告诉 babel-preset-env 你想要兼容的环境,它就会自动转换,是不是很爽?再也不用配置那么多了。
接下来我们试一试,把 src/index.js 中的代码改写为:
const x = 'index.js';
const y = (x) => {
console.log(x);
}
y(x);
然后使用 npm run build 进行打包,打包之后的代码中:
var x = 'index.js';
var y = function y(x) {
console.log(x);
};
y(x);
说明我们的代码已经被成功地转换了。
为了做一个对比,未配置 babel 时,转换结果如下:
const x = 'index.js';
const y = (x) => {
console.log(x);
}
y(x);
这个用于将字体文件、图片文件进行模块化。
首先安装 file-loader:
npm i file-loader -D
然后在 webpack.base.conf.js 中添加如下配置到 module.rules:
{
test: /\.(png|svg|jpg|gif)$/,
use: [
'file-loader'
]
},
{
test: /\.(woff|woff2|eot|ttf|otf)$/,
use: [
'file-loader'
]
}
当然可以简化配置信息,把两个 test 正则合并到一处。
接下来我们配置 vue-loader。
为了使用 Vue 单文件组件,我们需要对 .vue 文件进行处理,使用 vue-loader。
首先安装 vue-loader、css-loader、vue-style-loader 和 vue-template-compiler,后者也是必不可少的,少了会报错。
命令:
npm i vue-loader css-loader vue-style-loader vue-template-compiler -D
然后我们配置 webpack.base.conf.js,写入以下代码到该文件的 module.rules 属性当中:
{
test: /\.vue$/,
loader: 'vue-loader'
},
{
test: /\.css$/,
use: ['vue-style-loader', 'css-loader']
}
只有这一处配置是不行的,根据 vue-loader 官网的说明,我们还需要配置一个插件,然后还需要配置 resolve.alias 别名,不然 Webpack 没法找到 Vue 模块。
配置插件,首先在文件头部引入:
const VueLoaderPlugin = require('vue-loader/lib/plugin');
然后在 plugins 数组中添加这个插件对象:
new VueLoaderPlugin(),
随后我们还要配置别名,将 resolve.alias 配置为如下对象:
{
'vue$': 'vue/dist/vue.esm.js',
'@': path.resolve(__dirname, '../src'),
}
这可以使得 Webpack 很方便的找到 Vue,我们在 JavaScript 文件中引入依赖的时候,也可以方便地使用 @ 来代替 src,省去了写文件路径的麻烦。
我们顺便添加一个 resolve.extensions 属性,方便我们引入依赖或者文件的时候可以省略后缀:
extensions: ['*', '.js', '.json', '.vue'],
extensions 属性是一个数组。这样配置之后,我们在 JavaScript 文件中 import JavaScript 文件、json 文件和 Vue 单文件组件都可以省略后缀。
以上几步都很重要,最好不要省略。
接下来我们验证一下 Vue 单文件组件是否可用。
安装 Vue:
npm i vue --save
然后修改 index.js 文件内容如下:
import Vue from 'vue';
import App from './App';
new Vue({
el: '#app',
template: '<App/>',
components: { App }
});
然后在同级目录下创建一个 App.vue 文件,内容如下:
<template>
<h1>Hello World!</h1>
</template>
<script>
export default {
name: 'App'
}
</script>
<style>
html, body {
padding: 0;
margin: 0;
box-sizing: border-box;
font-size: 16px;
}
</style>
运行命令 npm run dev 就可以看到一个大大的一级标题 —— Hello World 啦!
到这里,我们的项目已经可以使用 Vue 单文件组件进行开发了,但是还没有完,我们还有一些任务要做。
这里我们使用 postcss 的 autoprefixer 插件为我们的 css 代码自动添加前缀以适应不同的浏览器。
首先安装依赖:
npm i postcss-loader autoprefixer -D
然后修改 module.rules 中的 css 配置项,修改之后如下:
{
test: /\.css$/,
use: ['vue-style-loader', 'css-loader', 'postcss-loader']
}
然后在我们项目的根目录下新增配置文件 postcss.config.js,内容如下:
module.exports = {
plugins: [
require('autoprefixer')
]
}
代表我们将要使用 autoprefixer 插件。
之后我们就可以愉快地写代码了,可以自己验证一下是否自动添加了前缀,这里不再赘述。
Webpack 4 开启热更新相对容易,具体步骤如下:
修改 webpack.dev.conf.js,在 devServer 属性中设置 hot 的值为 true,这就代表开启了热更新。但是只这样做还不够,需要我们添加一个插件,继续修改 webpack.dev.conf.js。
设置其 plugins 属性如下:
const webpack = require('webpack');
// 在文件头部引入 webpack 依赖
[
new webpack.HotModuleReplacementPlugin()
]
这就开启了 css 热更新(因为 vue-style-loader 封装了 style-loader,热更新开箱即用),但是 JavaScript 热更新还不能用,每次修改代码我们都会刷新浏览器,所以我们需要继续配置。
为了使得 JavaScript 模块也能进行 HMR,我们需要在我们的 入口文件(index.js) 的底部添加如下代码:
if (module.hot) {
module.hot.accept();
}
接下来就可以进行 HMR 了。
每次我们对项目进行打包时,我们都会把引用的第三方依赖给打包一遍,比如 Vue、Vue-Router、React 等等。但是这些库的代码基本都是不会变动的,我们没必要每次打包都构建一次,所以我们最好将这些第三方库提取出来单独打包,这样有利于减少打包时间。
官方插件是 DllPlugin,但是这个插件配置比较繁琐。网上有人推荐一个比较好用的插件 —— autodll-webpack-plugin,确实很好用。
下面是它的配置方法:
首先安装:
npm i autodll-webpack-plugin -D
然后在 webpack.base.conf.js 中引入:
const AutoDllPlugin = require('autodll-webpack-plugin');
然后在 plugins 属性中添加这个插件:
new AutoDllPlugin({
inject: true, // will inject the DLL bundle to index.html
debug: true,
filename: '[name]_[hash].js',
path: './dll',
entry: {
vendor: ['vue', 'vue-router', 'vuex']
}
})
inject 为 true,插件会自动把打包出来的第三方库文件插入到 HTML。filename 是打包后文件的名称。path 是打包后的路径。entry 是入口,vendor 是你指定的名称,数组内容就是要打包的第三方库的名称,不要写全路径,Webpack 会自动去 node_modules 中找到的。
每次打包,这个插件都会检查注册在 entry 中的第三方库是否发生了变化,如果没有变化,插件就会使用缓存中的打包文件,减少了打包的时间,这时 Hash 也不会变化。
使用 splitChucksPlugin 插件,这是 Webpack 自带的,不用安装第三方依赖。
使用方法:
在 webpack.base.conf.js 的 plugins 属性中添加如下插件对象;
new webpack.optimize.SplitChunksPlugin()
这代表你将使用默认的提取配置来提取你的公共代码,如果你不想使用默认配置,请给插件构造函数传入配置对象.
具体怎么配置,请参考冷星大神的博客 —— webpack4——SplitChunksPlugin使用指南,里面关于配置项的作用介绍得很清楚很详细。
我个人比较喜欢 stylus,因为写起来比较无拘无束,类似 Python,没那么多条条框框,而且用起来也不是很复杂。
引入方法:
首先下载 stylus 和 stylus-loader 依赖:
npm i stylus stylus-loader -D
然后在配置项 module.rules 中添加一个处理 stylus 文件的配置对象。
配置信息如下:
{
test: /\.styl(us)$/,
use: ['vue-style-loader', 'css-loader, 'stylus-loader', 'postcss-loader']
}
接下来只要你在 Vue 单文件组件的 style 标签加上 lang='stylus',你就可以使用 stylus 来写 CSS 了。
这个功能的配置方法在 Vue Loader 官网交代得很清楚了。
使用的是 mini-css-extract-plugin 插件,首先安装:
npm i mini-css-extract-plugin -D
然后在配置文件头部引入:
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
然后当你要抽取 CSS 的时候(比如生产环境打包),你就把原来配置文件中的所有 vue-style-loader 替换为 MiniCssExtractPlugin.loader,其他的什么 css-loader、stylus-loader 等等都不要动。
最后,修改 plugins 选项,插入如下插件:
new MiniCssExtractPlugin({
filename: "[name].css",
chunkFilename: "[id].css"
})
打包之后,你会发现所有的 CSS 代码都被抽取到了一个单独的 CSS 文件当中。
示例代码放在我的 GitHub 仓库,需要的同学可以自取。
如有错误,敬请指出!
最近在做项目的时候碰到了一个奇怪的问题,通过 Vue.mixin 方法注入到 Vue 实例的一个方法不起作用了,后来经过仔细排查发现这个实例自己实现了一个同名方法,导致了 Vue.mixin 注入方法的失效。后来查阅资料发现 Vue.mixin 注入到实例的 methods 方法会被实例中的同名方法替换,而不会依次执行。于是我就有了查看源码的想法,进而诞生了这篇文章~
本文所用源码版本为 2.2.6
首先从 Vue.mixin 这个方法入手,打开 src 目录不难找到 mixin 所在的文件:src/core/global-api/mixin.js,其内容如下:
可以看到这只是一层简单的封装,核心内容基本都在 mergeOptions 方法中,所以下面打开这个方法所在的文件:src/core/util/options.js。注意 mergeOptions 方法是通过 src/core/util/index.js 引入导出的,其源码在 options.js 中,直接看 options.js 就好了。
在 options.js 中找到 mergeOptions 方法,内容如下:
其主流程大致如下:
checkComponents 检查传入参数的合法性,后面再讲具体实现。normalizeProps 方法和 normalizeDirectives 方法对这两个属性进行规范化。extends 属性,这个属性表示扩展其它 Vue 实例,具体参考官方文档。这里为什么要检查这个属性呢?因为当传入对象具有该属性时,表示所有的 Vue 实例都要扩展它所指定的实例(Vue.mixin 的功能即是如此),那么我们在合并之前,需要先把 extends 进行合并,如果 extends 是一个 Vue 构造函数(也可能是扩展后的 Vue 构造函数),那么合并参数变为其 options 选项了;否则直接合并 extends。extends 属性之后,我们还要检查其 mixins 属性,这个属性的功能参考官方文档。因为如果传入的 Vue 配置对象仍然指定了 mixins 的话,我们需要递归的进行 merge。mixin 参数了。可以看到通过 mergeField 函数进行了合并,先遍历合并的目标对象,进行合并了;随后遍历要合并的对象,只对目标对象上不存在的属性进行合并操作。那么合并的重点就到了 mergeFiled 函数了。继续看 mergeField 函数:
function mergeField (key) {
const strat = strats[key] || defaultStrat
options[key] = strat(parent[key], child[key], vm, key)
}该函数通过 key 值在 strats 中选取合并的具体函数,这是一种典型的策略模式,所以我们看 strats是如何定义的。
options.js 中关于 strats 的定义如下:
/**
* Option overwriting strategies are functions that handle
* how to merge a parent option value and a child option
* value into the final value.
*/
const strats = config.optionMergeStrategies其中 config 对象来自于 src/core/config.js,它定义了 config 的所有类型及初始值,当然初始值都还是一些空数组之类的,所以我们要在 options.js 中看具体的实现。
下面根据 Vue 的配置属性分开讲解不同的合并方式。
el 的合并方式比较简单,因为它本身
源码如下:
/**
* Options with restrictions
*/
if (process.env.NODE_ENV !== 'production') {
strats.el = strats.propsData = function (parent, child, vm, key) {
if (!vm) {
warn(
`option "${key}" can only be used during instance ` +
'creation with the `new` keyword.'
)
}
return defaultStrat(parent, child)
}
}可以看到这里有个条件,只有在开发环境下才会定义 strats.el 方法以及 propsData 方法(propsData 文档),这是因为这两个属性比较特殊,尤其是 propsData 只在开发环境下才使用,方便测试而已。另外一个比较特殊的地方是这两者只能在 new 操作符调用 Vue 构造函数所构造的 Vue 实例中才能存在,所以当 vm 未传递时,会弹出一个警告。
这两个属性的合并方法都是 defaultStrat,其源码如下:
/**
* Default strategy.
*/
const defaultStrat = function (parentVal: any, childVal: any): any {
return childVal === undefined
? parentVal
: childVal
}可以看出在 childVal 已定义的时候直接替代 parentVal。
这个方法在后边还会用到。
data选项的合并是重中之重,因为 data 在子组件中是一个函数,它返回的也是一个特殊的响应式对象。
其源码如下:
这里分了两种情况,一种是传递了 vm 参数,一种是没传递。
当没传递 vm 参数的时候,需要校验 childVal 是否是函数,而 parentVal 不需要校验,因为它必须是函数才能通过之前的 merge 校验,到达现在这一步。确定都是函数之后,就调用这两个函数,再然后对返回的两个 data 对象通过 mergeData 做处理,这里后面再讲。
当传递了 vm 参数的时候,需要用其他方式处理,当是函数的时候,使用返回值做下一步合并;当是其他值的时候,直接使用其值进行下一步合并。
这一步要校验 childVal 和 parentVal 是否为函数。正是因为这一步校验了,所以前面所讲的情况就不再需要校验,为什么呢?
我们可以回头看 mergeOptions 的源码,发现其第三个参数 vm 是可选的,在递归的时候它会把 vm 传递给自身,这就导致当我们一开始调用 mergeOptions 的时候传递了 vm,则其后所有递归都会传递 vm;当我们一开始未传递 vm 值的时候,其后所有的递归也不会传递 vm 参数。那么是否有 vm 就取决于我们最开始调用该函数时所传递的参数是否包含 vm 了。
全局查找 mergeOptions 函数的调用,可以看到有两处:
src/core/instance/init.js,该文件也定义了 initMixin 方法,用于初始化 Vue 把传递给 Vue 构造函数的配置对象合并到 vm.$options 中。这种情况下会传递 vm,其值为当前正在构造的 Vue 实例。src/core/global-api/mixin.js,这处才是定义的全局 API。简而言之,Vue 构造函数构造 Vue 实例时,会调用 mergeOptions 并且传递 vm 实例作为第三个参数;当我们调用 Vue.mixin 进行全局混淆时是不会传递 vm 的。前者对应第二种情况,后者对应第一种情况。
当我们先构造 Vue 实例的时候,vm 被传递进而执行第二种情况,parentVal 会被校验,所以之后再调用 Vue.mixin 时第一种情况不再需要校验。
当我们先不实例化 Vue 而先调用 Vue.mixin 时,会先执行第一种情况的代码,那么会导致 bug 出现吗?答案肯定是不会,因为此时 parentVal 为 undefined,因为 Vue.mixin 调用时 parentVal 的初始值为 Vue.options,这个对象根本不包含 data 属性。
那么 data 合并的任务主要在 mergeData 函数中了,查看其源码:
可以看到这里遍历了要合并的 data 的所有属性,然后根据不同情况进行合并:
set 方法进行合并,后面讲 set。继续看 set 函数:
可以看到 set 也对 target 分了两种情况进行处理。首先判断了 target 是数组的情况,然后如果 target 包含当前属性,那么就直接赋值。接下来判断了 target 是否是响应式对象,如果是的话就会在开发环境下弹出警告,最好不要让 data 函数返回一个响应式对象,因为会造成性能浪费。如果不是响应式对象也可以直接赋值返回,其他情况下就会进一步转化 target 为响应式对象,并收集依赖。
以上大概就是 data 的合并方式,可以看出来如果实例指定了与 mixins 相同名称的 data 值,那么以实例中的为准,mixin 中执行的 data 会失效,如果都是对象但是 mixin 中新增了属性的话,还是会被添加到实例 data 中去的。
Hooks 的合并函数定义为 mergeHook 钩子,其源码如下:
/**
* Hooks and props are merged as arrays.
*/
function mergeHook (
parentVal: ?Array<Function>,
childVal: ?Function | ?Array<Function>
): ?Array<Function> {
return childVal
? parentVal
? parentVal.concat(childVal)
: Array.isArray(childVal)
? childVal
: [childVal]
: parentVal
}这个比较简单,代码注释也写得很清楚了,Vue 实例的生命周期钩子被合并为一个数组。具体有哪些钩子可以被合并被写在 src/core/config.js 中:
/**
* List of lifecycle hooks.
*/
_lifecycleHooks: [
'beforeCreate',
'created',
'beforeMount',
'mounted',
'beforeUpdate',
'updated',
'beforeDestroy',
'destroyed',
'activated',
'deactivated'
],合并 assets (components、filters、directives)的方法也比较简单,下面跳过了。
合并 watch 的函数源码如下:
这一段源码也很简单,注释也很明了,跟生命周期的钩子一样,Vue.mixin 会把所有同名的 watch 合并到一个数组中去,在触发的时候依次执行就好了。
这三项的合并都使用了相同的策略,源代码如下:
这里的处理也比较简单,可以看出来当多次调用 Vue.mixin 混淆时,同名的 props、methods、computed 会被后来者替代;但是当 Vue 构造函数传递了同名的属性时,会以构造函数所接受的配置对象为准。因为 Vue 实例化时也会调用 mergeOptions 第二个参数即为 Vue 构造函数所接受的配置对象,正如前文所述。
前文有讲到几个辅助函数,比如:checkComponents、normalizeProps、normalizeDirectives。这里简单贴一下源码:
这个函数是为了检查 components 属性是否符合要求的,主要是防止自定义组件使用 HTML 内置标签。
这个函数主要是对 props 属性进行整理。包括把字符串数组形式的 props 转换为对象形式,对所有形式的 props 进行格式化整理。
这个函数也主要是对 directives 属性进行格式化整理的,把原来的对象整理成一个新的符合标准格式的对象。
看到 Vue 的官方文档:自定义选项合并策略,它允许我们自定义合并策略,具体方式就是替换 Vue.config.optionsMergeStrategies,也就是前文所提到的那个定义在 src/core/config.js 中的属性。我们也可以看一下源代码,这一功能在 src/core/global-api/index.js 文件中的 initGlobalAPI 定义。
const configDef = {}
configDef.get = () => config
if (process.env.NODE_ENV !== 'production') {
configDef.set = () => {
warn(
'Do not replace the Vue.config object, set individual fields instead.'
)
}
}
Object.defineProperty(Vue, 'config', configDef)可以看到最后一句给 Vue 函数定义了一个 config 属性,其 property 定义为 configDef。在生产环境下不允许设置其值,但是在开发环境下,我们可以直接设置 Vue.config。那么通过设置 Vue.config.optionsMergeStrategies,我们可以改变合并策略,在后面再进行合并操作时,都会读取 config 对象中的属性,这时就可以使用我们自定义的合并策略进行合并了。
看了这些属性的合并方式以后,对 Vue.mixin 的工作方式也有了一定的了解了。个人认为基本上可以把 Vue.mixin 合并属性的方式分为三类,一类是替换式、一类是合并式、还有一类是队列式。
替换式的有 el、props、methods 和 computed,这一类的行为是新的参数替代旧的参数。
合并式的有 data,这一类的行为是新传入的参数会被合并到旧的参数中。
队列式合并的有 watch、所有的生命周期钩子(hooks),这一类的行为是所有的参数会被合并到一个数组中,必要时再依次取出。
所以对于 Vue.mixin 的使用我们也需要小心,尤其是替换式合并的属性,当你在 mixins 里面指定了以后,就不要再实例中再指定同名属性了,那样的话你的 mixins 中的属性会被替代导致失效。
作者水平有限,文章难免存在纰漏,敬请大家指正。
说起跨域的解决方案,总是会说到 JSONP,但是很多时候都没有仔细去了解过 JSONP,可能是因为现在 JSONP 用的不是很多(多数时候都是配置响应头实现跨域),也可能是因为用 JSONP 的场景一般都是用 jQuery 来实现,所以对 JSONP 知之甚少。
JSONP 的本意是 JSON with Padding,即填充式 JSON。为什么叫填充式呢?因为服务端不会直接返回 JSON 格式数据给客户端,它会拼接成一个字符串,这个字符串被拿到客户端执行。这是对于 JSON 的一种应用。
发明 JSONP 的老头子们发现虽然同源策略(CORS)限制了 ajax 对于其它服务器的访问,但是并不能限制 HTML 的资源请求。
比如在 HTML 中,img、script、link 等标签完全可以访问任何地址的资源。而其中的 script 标签为跨域请求提供了一种新的思路,因为 script 请求的是一段可执行的 JavaScript 代码。我们可以把之前直接从服务器返回的数据封装到 JavaScript 代码中,然后在前端再使用这些数据。这就是 JSONP 的实现原理。
使用 jQuery 的 $.ajax 进行 JSONP 请求时,type 属性总是选择为 GET,如果填为 POST,就会报错,这是为什么呢?其实理解 JSONP 的原理之后,这就很好理解了。原因就是 script 标签的资源请求只能是 GET 类型,目前为止我还没有见过 POST 类型的资源请求~
前端小白不理解 JSONP 的另一个原因就在于 JSONP 不只是前端这一块的任务,只靠前端是无法实现的,后端也必须做相应处理。
前端请求一个专用的接口获取数据,请求的数据会以 JavaScript 代码的形式返回,假如数据如下:
{
"name": "russ",
"age": 20
}那要构造成什么样的 JavaScript 代码才能被前端使用到呢?最容易想到的就是把数据赋值给一个全局变量,或者把数据扔到函数里面。扔给全局变量的话会导致一些问题(全局暴露、命名冲突、数据处理逻辑分散……),所以把数据扔给一个专门处理数据的函数比较合适。这也是 JSONP 所采用的方案。所以拼接出来的字符串(也是后端返回的 js 代码)基本如下:
callback({
"name": "russ",
"age": 20
})那么前端就需要在 script 请求返回之前定义好 callback 这个函数,以便在 script 返回之后可以顺利加载执行。这里需要前后端约定好回调函数的名称。当然可以前端传递回调的名称给后端,后端根据前端传递的名称进行 JavaScript 代码拼接,jQuery.ajax 就有这种实现,允许前端自定义回调的名称。
先讲讲后端实现,因为后端实现起来比较简单~
以下实现均使用 Nodejs。
Nodejs 实现代码如下:
const http = require('http');
const { parse } = require('url');
// 假设这是在数据库中找到的数据~
const data = {
name: 'russ',
age: 20,
gender: 'male'
};
const server = http.createServer((req, res) => {
const url = parse(req.url, true); // 解析 url
// 只有路由为 `/user` 的 GET 请求会被响应
if (req.method === 'GET' && url.pathname === '/user') {
const { callback } = url.query; // 获取 callback 回调名称
if (callback) // 如果传递了 callback 参数,说明是 JSONP 请求
return res.end(`${callback}(${JSON.stringify(data)})`);
else // 没传递 callback,直接当做不跨域的 GET 请求返回数据
return res.end(JSON.stringify(data));
}
return res.end('Not Found'); // 不匹配的路由返回错误
});
server.listen(3000, () => {
console.log('Server listening at port 3000...');
});可以直接在浏览器中请求查看结果~
伴随着很多功能强大的 api 的出现,我们在很多场景下都可以直接弃用 jQuery(参考nefe/You-Dont-Need-jQuery
)。而如果我们的页面没有使用 jQuery 的时候,我们就需要手动实现 JSONP 了~
前面说过 JSONP 的原理是 script 标签的资源请求,所以前端的处理就是构造 script 标签发起请求。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>JSONP</title>
</head>
<body>
<!-- 点击的时候调用 fetchJSON -->
<button onclick="fetchJSON()">Fetch</button>
</body>
<script>
// 定义了 fetchJSON 函数。
function fetchJSON() {
// 内部调用 jsonp 函数实现接口的 jsonp 访问。
jsonp('http://localhost:3000/user?').then(data => {
console.log(data);
}).catch(err => {
console.log(err);
})
}
function jsonp(url) {
let $script = document.createElement('script'), // 先构造一个 script 元素
callbackName = `callback_${Date.now()}`; // 先定义回调名称,加时间戳防止缓存
// 返回 promise 对象,方便后续处理
return new Promise((resolve, reject) => {
// 在发起请求之前,先定义好回调函数
window[callbackName] = (res) => {
// 请求结束之后清除全局变量
window[callbackName] = undefined;
// 移除之前挂载的 script 元素
document.head.removeChild($script);
// 清空 $script
$script = undefined;
resolve(res);
};
// 绑定 src,及请求地址
$script.src = `${url}callback=${callbackName}`;
// 绑定 error 处理函数
$script.onerror = err => {
reject(err);
};
// 挂在 script 元素到 head,此时才开始发起请求~
document.head.appendChild($script); // 开始请求
});
}
</script>
</html>当然上面的代码没有做兼容性处理,在低级浏览器使用时需要做一下处理,但是其他原理是一样的。
大致有两点:
一、安全性问题
JSONP 会从其它域加载 JavaScript 脚本并直接执行,如果 JavaScript 脚本中包含恶意攻击代码,那我们的网站将会受到威胁。所以当我们访问非自己维护的服务器的 JSONP 接口时,需要留心。
二、错误处理
script 标签的 onerror 函数在 HTML5 才定义,并且即使我们定义了 onerror 处理函数,我们也不容易捕捉到错误发生的原因。所以这也是一大缺点,至于具体表现可以单独运行上面的前端代码试试,看看错误发生时(后端服务未启动),前端控制台打印出来的错误对象是什么样的。
![]()
已经快一年没有碰过 React 全家桶了,最近换了个项目组要用到 React 技术栈,所以最近又复习了一下;捡起旧知识的同时又有了一些新的收获,在这里作文以记之。
在阅读文章之前,最好已经知道如何使用 Redux(不是 React-Redux)。
为了更好的解读源码,我们可以把源码拷贝到本地,然后搭建一个开发环境。Redux 的使用不依赖于 React,所以你完全可以在一个极为简单的 JavaScript 项目中使用它。这里不再赘述开发环境的搭建过程,需要的同学可以直接拷贝我的代码到本地,然后安装依赖,运行项目。
$ git clone https://github.com/zhongdeming428/redux && cd redux
$ npm i
$ npm run dev忽略项目中的那些说明文档什么的,只看 src 这个源文件目录,其结构如下:
src
├── applyMiddleware.js // 应用中间件的 API
├── bindActionCreators.js // 转换 actionCreators 的 API
├── combineReducers.js // 组合转换 reducer 的 API
├── compose.js // 工具函数,用于嵌套调用中间件
├── createStore.js // 入口函数,创建 store 的 API
├── index.js // redux 项目的入口文件,用于统一暴露所有 API
├── test
│ └── index.js // 我所创建的用于调试的脚本
└── utils // 专门放工具函数的目录
├── actionTypes.js // 定义了一些 redux 预留的 action type
├── isPlainObject.js // 用于判断是否是纯对象
└── warning.js // 用于抛出合适的警告信息可以看出来 redux 的源码结构简单清晰明了,几个主要的(也是仅有的) API 被尽可能的分散到了单个的文件模块中,我们只需要挨个的看就行了。
上一小节说到 index.js 是 redux 项目的入口文件,用于暴露所有的 API,所以我们来看看代码:
import createStore from './createStore'
import combineReducers from './combineReducers'
import bindActionCreators from './bindActionCreators'
import applyMiddleware from './applyMiddleware'
import compose from './compose'
import warning from './utils/warning'
import __DO_NOT_USE__ActionTypes from './utils/actionTypes'
// 不同的 API 写在不同的 js 文件中,最后通过 index.js 统一导出。
// 这个函数用于判断当前代码是否已经被打包工具(比如 Webpack)压缩过,如果被压缩过的话,
// isCrushed 函数的名称会被替换掉。如果被替换了函数名但是 process.env.NODE_ENV 又不等于 production
// 的时候,提醒用户使用生产环境下的精简代码。
function isCrushed() {}
if (
process.env.NODE_ENV !== 'production' &&
typeof isCrushed.name === 'string' &&
isCrushed.name !== 'isCrushed'
) {
warning(
'You are currently using minified code outside of NODE_ENV === "production". ' +
'This means that you are running a slower development build of Redux. ' +
'You can use loose-envify (https://github.com/zertosh/loose-envify) for browserify ' +
'or setting mode to production in webpack (https://webpack.js.org/concepts/mode/) ' +
'to ensure you have the correct code for your production build.'
)
}
// 导出主要的 API。
export {
createStore,
combineReducers,
bindActionCreators,
applyMiddleware,
compose,
__DO_NOT_USE__ActionTypes
}我删除了所有的英文注释以减小篇幅,如果大家想看原来的注释,可以去 redux 的项目查看源码。
可以看到在程序的头部引入了所有的 API 模块以及工具函数,然后在底部统一导出了。这一部分比较简单,主要是 isCrushed 函数有点意思。作者用这个函数来判断代码是否被压缩过(判断函数名是否被替换掉了)。
这一部分也引用到了工具函数,由于这几个函数比较简单,所以可以先看看它们是干嘛的。
除了 compose 函数以外,所有的工具函数都被放在了 utils 目录下。
actionTypes.js
这个工具模块定义了几种 redux 预留的 action type,包括 reducer 替换类型、reducer 初始化类型和随机类型。下面上源码:
// 定义了一些 redux 保留的 action type。
// 随机字符串确保唯一性。
const randomString = () =>
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
const ActionTypes = {
INIT: `@@redux/INIT${randomString()}`,
REPLACE: `@@redux/REPLACE${randomString()}`,
PROBE_UNKNOWN_ACTION: () => `@@redux/PROBE_UNKNOWN_ACTION${randomString()}`
}
export default ActionTypes可以看出就是返回了一个 ActionTypes 对象,里面包含三种类型:INIT、REPLACE 和 PROBE_UNKNOW_ACTION。分别对应之前所说的几种类型,为了防止和用户自定义的 action type 相冲突,刻意在 type 里面加入了随机值。在后面的使用中,通过引入 ActionType 对象来进行对比。
isPlainObject.js
这个函数用于判断传入的对象是否是纯对象,因为 redux 要求 action 和 state 是一个纯对象,所以这个函数诞生了。
上源码:
/**
* 判断一个参数是否是纯对象,纯对象的定义就是它的构造函数为 Object。
* 比如: { name: 'isPlainObject', type: 'funciton' }。
* 而 isPlainObject 这个函数就不是纯对象,因为它的构造函数是 Function。
* @param {any} obj 要检查的对象。
* @returns {boolean} 返回的检查结果,true 代表是纯对象。
*/
export default function isPlainObject(obj) {
if (typeof obj !== 'object' || obj === null) return false
let proto = obj
// 获取最顶级的原型,如果就是自身,那么说明是纯对象。
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
return Object.getPrototypeOf(obj) === proto
}warning.js
这个函数用于抛出适当的警告,没啥好说的。
/**
* Prints a warning in the console if it exists.
*
* @param {String} message The warning message.
* @returns {void}
*/
export default function warning(message) {
/* eslint-disable no-console */
if (typeof console !== 'undefined' && typeof console.error === 'function') {
console.error(message)
}
/* eslint-enable no-console */
try {
// This error was thrown as a convenience so that if you enable
// "break on all exceptions" in your console,
// it would pause the execution at this line.
throw new Error(message)
} catch (e) {} // eslint-disable-line no-empty
}compose.js
这个函数用于嵌套调用中间件(middleware),进行初始化。
/**
* 传入一系列的单参数函数作为参数(funcs 数组),返回一个新的函数,这个函数可以接受
* 多个参数,运行时会将 funcs 数组中的函数从右至左进行调用。
* @param {...Function} funcs 一系列中间件。
* @returns {Function} 返回的结果函数。
* 从右至左调用,比如: compose(f, g, h) 将会返回一个新函数
* (...args) => f(g(h(...args))).
*/
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
// 通过 reduce 方法迭代。
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}看完了工具函数和入口函数,接下来就要正式步入主题了。我们使用 redux 的重要一步就是通过 createStore 方法创建 store。那么接下来看看这个方法是怎么创建 store 的,store 又是个什么东西呢?
我们看源码:
import $$observable from 'symbol-observable'
// 后面会讲。
import ActionTypes from './utils/actionTypes'
// 引入一些预定义的保留的 action type。
import isPlainObject from './utils/isPlainObject'
// 判断一个对象是否是纯对象。
// 使用 redux 最主要的 API,就是这个 createStore,它用于创建一个 redux store,为你提供状态管理。
// 它接受三个参数(第二三个可选),第一个是 reducer,用于改变 redux store 的状态;第二个是初始化的 store,
// 即最开始时候 store 的快照;第三个参数是由 applyMiddleware 函数返回的 enhancer 对象,使用中间件必须
// 提供的参数。
export default function createStore(reducer, preloadedState, enhancer) {
// 下面这一段基本可以不看,它们是对参数进行适配的。
/*************************************参数适配****************************************/
if (
(typeof preloadedState === 'function' && typeof enhancer === 'function') ||
(typeof enhancer === 'function' && typeof arguments[3] === 'function')
) {
// 如果传递了多个 enhancer,抛出错误。
throw new Error(
'It looks like you are passing several store enhancers to ' +
'createStore(). This is not supported. Instead, compose them ' +
'together to a single function'
)
}
// 如果没有传递默认的 state(preloadedState 为函数类型,enhancer 为未定义类型),那么传递的
// preloadedState 即为 enhancer。
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
// 如果 enhancer 为不为空且非函数类型,报错。
throw new Error('Expected the enhancer to be a function.')
}
// 使用 enhancer 对 createStore 进行处理,引入中间件。注意此处没有再传递 enhancer 作为参数。实际上 enhancer 会对 createStore 进行处理,然后返回一个实际意义上的 createStore 用于创建 store 对象,参考 applyMiddleware.js。
return enhancer(createStore)(reducer, preloadedState)
}
// 如果 reducer 不是函数类型,报错。
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}
/*********************************************************************************/
// 在函数内部定义一系列局部变量,用于存储数据。
let currentReducer = reducer // 存储当前的 reducer。
let currentState = preloadedState // 用于存储当前的 store,即为 state。
let currentListeners = [] // 用于存储通过 store.subscribe 注册的当前的所有订阅者。
let nextListeners = currentListeners // 新的 listeners 数组,确保不直接修改 listeners。
let isDispatching = false // 当前状态,防止 reducer 嵌套调用。
// 顾名思义,确保 nextListeners 可以被修改,当 nextListeners 与 currentListeners 指向同一个数组的时候
// 让 nextListeners 成为 currentListeners 的副本。防止修改 nextListeners 导致 currentListeners 发生变化。
// 一开始我也不是很明白为什么会存在 nextListeners,因为后面 dispatch 函数中还是直接把 nextListeners 赋值给了 currentListeners。
// 直接使用 currentListeners 也是可以的。后来去 redux 的 repo 搜了搜,发现了一个 issue(https://github.com/reduxjs/redux/issues/2157) 讲述了这个做法的理由。
// 提交这段代码的作者的解释(https://github.com/reduxjs/redux/commit/c031c0a8d900e0e95a4915ecc0f96c6fe2d6e92b)是防止 Array.slice 的滥用,只有在必要的时候调用 Array.slice 方法来复制 listeners。
// 以前的做法是每次 dispatch 都要 slice 一次,导致了性能的降低吧。
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
// 返回 currentState,即 store 的快照。
function getState() {
// 防止在 reducer 中调用该方法,reducer 会接受 state 参数。
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState
}
// store.subscribe 函数,订阅 dispatch。
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected the listener to be a function.')
}
// 不允许在 reducer 中进行订阅。
if (isDispatching) {
throw new Error(
'You may not call store.subscribe() while the reducer is executing. ' +
'If you would like to be notified after the store has been updated, subscribe from a ' +
'component and invoke store.getState() in the callback to access the latest state. ' +
'See https://redux.js.org/api-reference/store#subscribe(listener) for more details.'
)
}
let isSubscribed = true
// 每次操作 nextListeners 之前先确保可以修改。
ensureCanMutateNextListeners()
// 存储订阅者的注册方法。
nextListeners.push(listener)
// 返回一个用于注销当前订阅者的函数。
return function unsubscribe() {
if (!isSubscribed) {
return
}
if (isDispatching) {
throw new Error(
'You may not unsubscribe from a store listener while the reducer is executing. ' +
'See https://redux.js.org/api-reference/store#subscribe(listener) for more details.'
)
}
isSubscribed = false
// 每次操作 nextListeners 之前先确保可以修改。
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
// store.dispatch 函数,用于触发 reducer 修改 state。
function dispatch(action) {
if (!isPlainObject(action)) {
// action 必须是纯对象。
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
if (typeof action.type === 'undefined') {
// 每个 action 必须包含一个 type 属性,指定修改的类型。
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// reducer 内部不允许派发 action。
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
try {
// 调用 reducer 之前,先将标志位置一。
isDispatching = true
// 调用 reducer,返回的值即为最新的 state。
currentState = currentReducer(currentState, action)
} finally {
// 调用完之后将标志位置 0,表示 dispatch 结束。
isDispatching = false
}
// dispatch 结束之后,执行所有订阅者的函数。
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
// 返回当前所使用的 action,这一步是中间件嵌套使用的关键,很重要。
return action
}
// 一个比较新的 API,用于动态替换当前的 reducers。适用于按需加载,代码拆分等场景。
function replaceReducer(nextReducer) {
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
// 执行默认的 REPLACE 类型的 action。在 combineReducers 函数中有使用到这个类型。
currentReducer = nextReducer
dispatch({ type: ActionTypes.REPLACE })
}
// 这是为了适配 ECMA TC39 会议的一个有关 Observable 的提案(参考https://github.com/tc39/proposal-observable)所写的一个函数。
// 作用是订阅 store 的变化,适用于所有实现了 Observable 的类库(主要是适配 RxJS)。
// 我找到了引入这个功能的那个 commit:https://github.com/reduxjs/redux/pull/1632。
function observable() {
// outerSubscribe 即为外部的 subscribe 函数。
const outerSubscribe = subscribe
// 返回一个纯对象,包含 subscribe 方法。
return {
subscribe(observer) {
if (typeof observer !== 'object' || observer === null) {
throw new TypeError('Expected the observer to be an object.')
}
// 用于给 subscribe 注册的函数,严格按照 Observable 的规范实现,observer 必须有一个 next 属性。
function observeState() {
if (observer.next) {
observer.next(getState())
}
}
observeState()
const unsubscribe = outerSubscribe(observeState)
return { unsubscribe }
},
// $$observable 即为 Symbol.observable,也属于 Observable 的规范,返回自身。
[$$observable]() {
return this
}
}
}
// 初始化时 dispatch 一个 INIT 类型的 action,校验各种情况。
dispatch({ type: ActionTypes.INIT })
// 返回一个 store 对象。
return {
dispatch,
subscribe,
getState,
replaceReducer,
[$$observable]: observable
}
}不难发现,我们的 store 对象就是一个纯 JavaScript 对象。包含几个属性 API,而我们的 state 就存储在 createStore 这个方法内部,是一个局部变量,只能通过 getState 方法访问到。这里实际上是对闭包的利用,所有我们操作的 state 都存储在 getState 方法内部的一个变量里面。直到我们的程序结束(或者说 store 被销毁),createStore 方法才会被回收,里面的变量才会被销毁。
而 subscribe 方法就是对观察者模式的利用(注意不是发布订阅模式,二者有区别,不要混淆),我们通过 subscribe 方法注册我们的函数,我们的函数会给存储到 createStore 方法的一个局部变量当中,每次 dispatch 被调用之后,都会遍历一遍 currentListeners,依次执行其中的方法,达到我们订阅的要求。
了解了 createStore 到底是怎么一回事,我们再来看看 combineReducers 到底是怎么创建 reducer 的。
我们写 reducer 的时候,实际上是在写一系列函数,然后整个到一个对象的属性上,最后传给 combineReducers 进行处理,处理之后就可以供 createStore 使用了。
例如:
// 创建我们的 reducers。
const _reducers = {
items(items = [], { type, payload }) {
if (type === 'ADD_ITEMS') items.push(payload);
return items;
},
isLoading(isLoading = false, { type, payload }) {
if (type === 'IS_LOADING') return true;
return false;
}
};
// 交给 combineReducers 处理,适配 createStore。
const reducers = combineReducers(_reducers);
// createStore 接受 reducers,创建我们需要的 store。
const store = createStore(reducers);那么 combineReducers 对我们的 reducers 对象进行了哪些处理呢?
下面的代码比较长,希望大家能有耐心。
import ActionTypes from './utils/actionTypes'
import warning from './utils/warning'
import isPlainObject from './utils/isPlainObject'
/**
* 用于获取错误信息的工具函数,如果调用你所定义的某个 reducer 返回了 undefined,那么就调用这个函数
* 抛出合适的错误信息。
*
* @param {String} key 你所定义的某个 reducer 的函数名,同时也是 state 的一个属性名。
*
* @param {Object} action 调用 reducer 时所使用的 action。
*/
function getUndefinedStateErrorMessage(key, action) {
const actionType = action && action.type
const actionDescription =
(actionType && `action "${String(actionType)}"`) || 'an action'
return (
`Given ${actionDescription}, reducer "${key}" returned undefined. ` +
`To ignore an action, you must explicitly return the previous state. ` +
`If you want this reducer to hold no value, you can return null instead of undefined.`
)
}
/**
* 工具函数,用于校验未知键,如果 state 中的某个属性没有对应的 reducer,那么返回报错信息。
* 对于 REPLACE 类型的 action type,则不进行校验。
* @param {Object} inputState
* @param {Object} reducers
* @param {Object} action
* @param {Object} unexpectedKeyCache
*/
function getUnexpectedStateShapeWarningMessage(
inputState,
reducers,
action,
unexpectedKeyCache
) {
const reducerKeys = Object.keys(reducers)
const argumentName =
action && action.type === ActionTypes.INIT
? 'preloadedState argument passed to createStore'
: 'previous state received by the reducer'
// 如果 reducers 长度为 0,返回对应错误信息。
if (reducerKeys.length === 0) {
return (
'Store does not have a valid reducer. Make sure the argument passed ' +
'to combineReducers is an object whose values are reducers.'
)
}
if (!isPlainObject(inputState)) {
return (
`The ${argumentName} has unexpected type of "` +
{}.toString.call(inputState).match(/\s([a-z|A-Z]+)/)[1] + // {}.toString.call(inputState).match(/\s([a-z|A-Z]+)/)[1]
`". Expected argument to be an object with the following ` + // 返回的是 inputState 的类型。
`keys: "${reducerKeys.join('", "')}"`
)
}
// 获取所有 State 有而 reducers 没有的属性,加入到 unexpectedKeysCache。
const unexpectedKeys = Object.keys(inputState).filter(
key => !reducers.hasOwnProperty(key) && !unexpectedKeyCache[key]
)
// 加入到 unexpectedKeyCache。
unexpectedKeys.forEach(key => {
unexpectedKeyCache[key] = true
})
// 如果是 REPLACE 类型的 action type,不再校验未知键,因为按需加载的 reducers 不需要校验未知键,现在不存在的 reducers 可能下次就加上了。
if (action && action.type === ActionTypes.REPLACE) return
if (unexpectedKeys.length > 0) {
return (
`Unexpected ${unexpectedKeys.length > 1 ? 'keys' : 'key'} ` +
`"${unexpectedKeys.join('", "')}" found in ${argumentName}. ` +
`Expected to find one of the known reducer keys instead: ` +
`"${reducerKeys.join('", "')}". Unexpected keys will be ignored.`
)
}
}
/**
* 用于校验所有 reducer 的合理性:传入任意值都不能返回 undefined。
* @param {Object} reducers 你所定义的 reducers 对象。
*/
function assertReducerShape(reducers) {
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
// 获取初始化时的 state。
const initialState = reducer(undefined, { type: ActionTypes.INIT })
if (typeof initialState === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined during initialization. ` +
`If the state passed to the reducer is undefined, you must ` +
`explicitly return the initial state. The initial state may ` +
`not be undefined. If you don't want to set a value for this reducer, ` +
`you can use null instead of undefined.`
)
}
// 如果初始化校验通过了,有可能是你定义了 ActionTypes.INIT 的操作。这时候重新用随机值校验。
// 如果返回 undefined,说明用户可能对 INIT type 做了对应处理,这是不允许的。
if (
typeof reducer(undefined, {
type: ActionTypes.PROBE_UNKNOWN_ACTION()
}) === 'undefined'
) {
throw new Error(
`Reducer "${key}" returned undefined when probed with a random type. ` +
`Don't try to handle ${
ActionTypes.INIT
} or other actions in "redux/*" ` +
`namespace. They are considered private. Instead, you must return the ` +
`current state for any unknown actions, unless it is undefined, ` +
`in which case you must return the initial state, regardless of the ` +
`action type. The initial state may not be undefined, but can be null.`
)
}
})
}
// 把你所定义的 reducers 对象转化为一个庞大的汇总函数。
// 可以看出,combineReducers 接受一个 reducers 对象作为参数,
// 然后返回一个总的函数,作为最终的合法的 reducer,这个 reducer
// 接受 action 作为参数,根据 action 的类型遍历调用所有的 reducer。
export default function combineReducers(reducers) {
// 获取 reducers 所有的属性名。
const reducerKeys = Object.keys(reducers)
const finalReducers = {}
// 遍历 reducers 的所有属性,剔除所有不合法的 reducer。
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
// 将 reducers 中的所有 reducer 拷贝到新的 finalReducers 对象上。
finalReducers[key] = reducers[key]
}
}
// finalReducers 是一个纯净的经过过滤的 reducers 了,重新获取所有属性名。
const finalReducerKeys = Object.keys(finalReducers)
let unexpectedKeyCache
// unexpectedKeyCache 包含所有 state 中有但是 reducers 中没有的属性。
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
let shapeAssertionError
try {
// 校验所有 reducer 的合理性,缓存错误。
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
// 这就是返回的新的 reducer,一个纯函数。每次 dispatch 一个 action,都要执行一遍 combination 函数,
// 进而把你所定义的所有 reducer 都执行一遍。
return function combination(state = {}, action) {
if (shapeAssertionError) {
// 如果有缓存的错误,抛出。
throw shapeAssertionError
}
if (process.env.NODE_ENV !== 'production') {
// 非生产环境下校验 state 中的属性是否都有对应的 reducer。
const warningMessage = getUnexpectedStateShapeWarningMessage(
state,
finalReducers,
action,
unexpectedKeyCache
)
if (warningMessage) {
warning(warningMessage)
}
}
let hasChanged = false
// state 是否改变的标志位。
const nextState = {}
// reducer 返回的新 state。
for (let i = 0; i < finalReducerKeys.length; i++) { // 遍历所有的 reducer。
const key = finalReducerKeys[i] // 获取 reducer 名称。
const reducer = finalReducers[key] // 获取 reducer。
const previousStateForKey = state[key] // 旧的 state 值。
const nextStateForKey = reducer(previousStateForKey, action) // 执行 reducer 返回的新的 state[key] 值。
if (typeof nextStateForKey === 'undefined') {
// 如果经过了那么多校验,你的 reducer 还是返回了 undefined,那么就要抛出错误信息了。
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
// 把返回的新值添加到 nextState 对象上,这里可以看出来,你所定义的 reducer 的名称就是对应的 state 的属性,所以 reducer 命名要规范!
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
// 检验 state 是否发生了变化。
}
// 根据标志位返回对应的 state。
return hasChanged ? nextState : state
}
}combineReducers 方法代码比较多,但是实际逻辑还是很简单的,接下来这个函数代码不多,但是逻辑要稍微复杂一点,它就是应用中间件的 applyMiddleware 函数。这个函数的**比较巧妙,值得学习。
import compose from './compose'
// 用于应用中间件的函数,可以同时传递多个中间件。中间件的标准形式为:
// const middleware = store => next => action => { /*.....*/ return next(action); }
export default function applyMiddleware(...middlewares) {
// 返回一个函数,接受 createStore 作为参数。args 参数即为 reducer 和 preloadedState。
return createStore => (...args) => {
// 在函数内部调用 createStore 创建一个 store 对象,这里不会传递 enhancer,因为 applyMiddleware 本身就是在创建一个 enhancer,然后给 createStore 调用。
// 这里实际上是通过 applyMiddleware 把 store 的创建推迟了。为什么要推迟呢?因为要利用 middleWares 做文章,先初始化中间件,重新定义 dispatch,然后再创建 store,这时候创建的 store 所包含的 dispatch 方法就区别于不传递 enhancer 时所创建的 dispatch 方法了,其中包含了中间件所定义的一些逻辑,这就是为什么中间件可以干预 dispatch 的原因。
const store = createStore(...args)
// 这里对 dispatch 进行了重新定义,不管传入什么参数,都会报错,这样做的目的是防止你的中间件在初始化的时候就
// 调用 dispatch。
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args) // 注意最后 dispatch 的时候不会访问上面报错的那个 dispatch 函数了,因为那个函数被下面的 dispatch 覆盖了。
}
// 对于每一个 middleware,都传入 middlewareAPI 进行调用,这就是中间件的初始化。
// 初始化后的中间件返回一个新的函数,这个函数接受 store.dispatch 作为参数,返回一个替换后的 dispatch,作为新的
// store.dispatch。
const chain = middlewares.map(middleware => middleware(middlewareAPI))
// compose 方法把所有中间件串联起来调用。用最终结果替换 dispatch 函数,之后所使用的所有 store.dispatch 方法都已经是
// 替换了的,加入了新的逻辑。
dispatch = compose(...chain)(store.dispatch)
// 初始化中间件以后,把报错的 dispatch 函数覆盖掉。
/**
* middle 的标准形式:
* const middleware = ({ getState, dispatch }) => next => action => {
* // ....
* return next(action);
* }
* 这里 next 是经过上一个 middleware 处理了的 dispatch 方法。
* next(action) 返回的仍然是一个 dispatch 方法。
*/
return {
...store,
dispatch // 全新的 dispatch。
}
}
}代码量真的很少,但是真的很巧妙,这里有几点很关键:
compose 方法利用 Array.prototype.reduce 实现中间件的嵌套调用,返回一个全新的函数,可以接受新的参数(上一个中间件处理过的 dispatch),最终返回一个全新的包含新逻辑的 dispatch 方法。你看 middleware 经过初始化后返回的函数的格式:
next => action => {
return next(action);
}其中 next 可以看成 dispatch,这不就是接受一个 dispatch 作为参数,然后返回一个新的 dispatch 方法吗?原因就是我们可以认为接受 action 作为参数,然后触发 reducer 更改 state 的所有函数都是 dispatch 函数。
middleware 中间件经过初始化以后,返回一个新函数,它接受 dispatch 作为参数,然后返回一个新的 dispatch 又可以供下一个 middleware 调用,这就导致所有的 middleware 可以嵌套调用了!而且最终返回的结果也是一个 dispatch 函数。
最终得到的 dispatch 方法,是把原始的 store.dispatch 方法传递给最后一个 middleware,然后层层嵌套处理,最后经过第一个 middleware 处理过以后所返回的方法。所以我们在调用应用了中间件的 dispatch 函数时,从左至右的经过了 applyMiddleware 方法的所有参数(middleware)的处理。这有点像是包裹和拆包裹的过程。
为什么 action 可以经过所有的中间件处理呢?我们再来看看中间件的基本结构:
({ dispatch, getState }) => next => action => {
return next(action);
}我们可以看到 action 进入函数以后,会经过 next 的处理,并且会返回结果。next 会返回什么呢?因为第一个 next 的值就是 store.dispatch,所以看看 store.dispatch 的源码就知道了。
function dispatch(action) {
// 省略了一系列操作的代码……
// 返回当前所使用的 action,这一步是中间件嵌套使用的关键。
return action
}没错,store.dispatch 最终返回了 action,由于中间件嵌套调用,所以每个 next 都返回 action,然后又可以供下一个 next 使用,环环相扣,十分巧妙。
这部分描述的有点拗口,语言捉急但又不想画图,各位还是自己多想想好了。
这个方法没有太多好说的,主要作用是减少大家 dispatch reducer 所要写的代码,比如你原来有一个 action:
const addItems = item => ({
type: 'ADD_ITEMS',
payload: item
});然后你要调用它的时候:
store.dispatch(addItems('item value'));如果你使用 bindActionCreators:
const _addItems = bindActionCreators(addItems, store.dispatch);当你要 dispatch reducer 的时候:
_addItems('item value');这样就减少了你要写的重复代码,另外你还可以把所有的 action 写在一个对象里面传递给 bindActionCreators,就像传递给 combineReducers 的对象那样。
下面看看源码:
/**
* 该函数返回一个新的函数,调用新的函数会直接 dispatch ActionCreator 所返回的 action。
* 这个函数是 bindActionCreators 函数的基础,在 bindActionCreators 函数中会把 actionCreators 拆分成一个一个
* 的 ActionCreator,然后调用 bindActionCreator 方法。
* @param {Function} actionCreator 一个返回 action 纯对象的函数。
* @param {Function} dispatch store.dispatch 方法,用于触发 reducer。
*/
function bindActionCreator(actionCreator, dispatch) {
return function() {
return dispatch(actionCreator.apply(this, arguments))
}
}
// 接受一个 actionCreator(或者一个 actionCreators 对象)和一个 dispatch 函数作为参数,
// 然后返回一个函数或者一个对象,直接执行这个函数或对象中的函数可以让你不必再调用 dispatch。
export default function bindActionCreators(actionCreators, dispatch) {
// 如果 actionCreators 是一个函数而非对象,那么直接调用 bindActionCreators 方法进行转换,此时返回
// 结果也是一个函数,执行这个函数会直接 dispatch 对应的 action。
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
// actionCreators 既不是函数也不是对象,或者为空时,抛出错误。
if (typeof actionCreators !== 'object' || actionCreators === null) {
throw new Error(
`bindActionCreators expected an object or a function, instead received ${
actionCreators === null ? 'null' : typeof actionCreators
}. ` +
`Did you write "import ActionCreators from" instead of "import * as ActionCreators from"?`
)
}
// 如果 actionCreators 是一个对象,那么它的每一个属性就应该是一个 actionCreator,遍历每一个 actionCreator,
// 使用 bindActionCreator 进行转换。
const keys = Object.keys(actionCreators)
const boundActionCreators = {}
for (let i = 0; i < keys.length; i++) {
const key = keys[i]
const actionCreator = actionCreators[key]
// 把转换结果绑定到 boundActionCreators 对象,最后会返回它。
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
return boundActionCreators
}这部分挺简单的,主要作用在于把 action creator 转化为可以直接使用的函数。
看了源码以后,觉得中间件并没有想象中的那么晦涩难懂了。就是一个基本的格式,然后你在你的中间件里面可以为所欲为,最后调用固定的方法,返回固定的内容就完事了。这就是为什么大多数 redux middleware 的源码都很短小精悍的原因。
看看 redux-thunk 的源码:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;是不是很短很小?那么到底干了什么让它这么受欢迎呢?
实际上 redux-thunk 可以被认为就是:
// 这就是典型的 middleware 格式。
({ dispatch, getState }) => next => action => {
// next 就是 dispatch 方法。注释所在的函数就是返回的新的 dispatch。
// 先判断一下 action 是不是一个函数。
if (typeof action === 'function') {
// 如果是函数,调用它,传递 dispatch,getState 和 多余的参数作为 aciton 的参数。
return action(dispatch, getState, extraArgument);
}
// 如果 action 不是函数,直接 nextr调用 action,返回结果就完事儿了。
return next(action);
};怎么样,是不是很简单?它干的事就是判断了一下 action 的类型,如果是函数就调用,不是函数就用 dispatch 来调用,很简单。
但是它实现的功能很实用,允许我们传递函数作为 store.dispatch 的参数,这个函数的参数应该是固定的,必须符合上面代码的要求,接受 dispatch、getState作为参数,然后这个函数应该返回实际的 action。
我们也可以写一个自己的中间件了:
({ dispatch, getState }) => next => action => {
return action.then ? action.then(next) : next(action);
}这个中间件允许我们传递一个 Promise 对象作为 action,然后会等 action 返回结果(一个真正的 action)之后,再进行 dispatch。
当然由于 action.then() 返回的不是实际上的 action(一个纯对象),所以这个中间件可能没法跟其他中间件一起使用,不然其他中间件接受不到 action 会出问题。这只是个示例,用于说明中间件没那么复杂,但是我们可以利用中间件做很多事情。
如果想要了解更加复杂的 redux 中间件,可以参考:
最后,时间紧迫,水平有限,难免存在纰漏或错误,请大家多多包涵、多多指教、共同进步。
关于 Decorator 到底是 ES 6 引入的还是 ES 7 引入的我也不是很明白了,两种说法都有,这种问题懒得纠结了……在用的时候发现这个东西很好用,平常用处可能不大,但是结合 React 就很好使了。接下来就讲一讲。
我搭建了一个 React 开发环境,结合 babel 的插件——babel-plugin-transform-decorators-legacy一起使用,这个插件可以让你写 Decorator。
GitHub 地址:https://github.com/zhongdeming428/HOC
可以通过如下命令克隆:
$ git clone https://github.com/zhongdeming428/HOC.git克隆下来以后就可以尝试啦!
装饰器本身就是一个函数,使用起来挺简单,无非就是修饰类或者类的函数。使用 @ 调用,扔在要修饰的类或者类方法前面就可以了。但是在修饰类和类函数的时候又有细微的差异。
class A {
@sayB
sayA() {
console.log('a');
}
}
function sayB(target, name, descriptor) {
// ...
}在使用装饰器装饰类函数的时候,可以接受三个参数。第一个是要修饰的对象,第二个是修饰的属性名,第三个是属性描述符。可以在我搭建的项目中进行尝试。
在用装饰器装饰类的时候,只能够接受一个参数——target。这区别于上面的情况:
@APlus
class A {
}
function APlus(target, name, descriptor) {
// ... 打印一下可以发现 name、descriptor 是 undefined。
}另外,装饰器还可以接受参数,返回一个符合装饰器规范的新函数即可,这样又可以对装饰器的装饰行为进行定制了。比如:
@attach2Prop({ name: 'A' })
class A {
}
@attach2Prop({ name: 'B' })
class B {
}
function attach2Prop(obj) {
return function(target) {
target.prototype.$data = obj;
}
}
console.log((new A()).$data.name);
console.log((new B()).$data.name);结果会输出 A 和 B。
这就就可以用同一个装饰器实现不同行为的装饰了。
那么结合 React 有什么妙用呢?
以往在使用 react-redux 时,在定义好 UI 组件后,还要定义容器组件:
class UIComponent extends React.Component {
}
const ContainerComponent = connect(mapState2Props, mapDispatch2Props)(UIComponent);
export default ContainerComponent;有了装饰器之后:
@connect(mapState2Props, mapDispatch2Props)
class UIComponent extends React.Component {
}
export default UIComponent;这样用简化的代码达到了同样的效果,还省去了给容器组件命名的麻烦……代码也更加的整洁。
上一小节中的容器组件实际上就是一个高阶组件,但是我们自己有时候也要定义一些高阶组件,实现代码的更高层次的复用。
例如:我们做了一个组件库,里面有一部分的组件是有一个功能特征的,那就是可以拖拽;又比如我们做的移动端组件,需要实现一个左滑删除功能。我们需要给每种具有这个特征的组件写一遍拖拽或者左滑删除逻辑吗?
显然是否定的,我们可以实现一个纯逻辑组件,而非 UI 组件,它的功能就是使得你的 UI 组件具有某种特定功能。比如上面提到的左滑删除或者拖拽。
这个纯逻辑组件就可以是一个装饰器,是一个高阶组件。
在我搭建的开发环境中,就实现了这样一个简单的高阶组件,让你的 UI 组件在鼠标滑入时显示为一只手。
装饰器代码如下:
// src/decorators/CursorPointer.js
import React from 'react';
export default Component => class extends React.Component {
render() {
return <div style={{cursor: 'pointer', display: 'inline-block'}}>
<Component/>
</div>
}
}这个装饰器(高阶组件)接受一个 React 组件作为参数,然后返回一个新的 React 组件。实现很简单,就是包裹了一层 div,添加了一个 style,就这么简单。以后所有被它装饰的组件都会具有这个特征。
使用这个装饰器:
import React from 'react';
import Clickable from '../decorators/CursorPointer';
@Clickable
class ClickablePanel extends React.Component {
render() {
return <div className="panel">
</div>
}
}
export default ClickablePanel;将装饰器与高阶组件相结合,可以大大优化你的 React 代码!
该文档只记录了我认为需要记录的部分,太过于基础或者细节的内容会被忽略。
Go 语言通过环境变量来指导一系列的活动,比如编译、运行、代码组织、依赖下载等等。
下面是 Go 语言中我们常用的一些环境变量及其含义:
GO111MODULE="on"
GOARCH="amd64"
GOBIN=""
GOENV="/Users/demingzhong/Library/Application Support/go/env"
GOEXE=""
GOOS="darwin"
GOPATH="/Users/demingzhong/go"
GOPRIVATE=""
GOPROXY="https://goproxy.cn,direct"
GOROOT="/usr/local/go"
GOVERSION="go1.17.3"
GOMOD="/Users/demingzhong/Documents/Work/entry-task/go.mod"参考:https://juejin.cn/post/6844903817071296525#heading-3
参考:https://blog.51cto.com/u_13107138/2767314
上一篇中讲解了Underscore中的去抖函数(_.debounced),这一篇就来介绍节流函数(_.throttled)。
经过上一篇文章,我相信很多人都已经了解了去抖和节流的概念。去抖,在一段连续的触发中只能得到触发一次的结果,在触发之后经过一段时间才可以得到执行的结果,并且必须在经过这段时间之后,才可以进入下一个触发周期。节流不同于去抖,节流是一段连续的触发至少可以得到一次触发结果,上限取决于设置的时间间隔。
通过这张我手画的图,我相信可以更容易理解函数节流这个概念。

在这张粗制滥造的手绘图中,从左往右的轴线表示时间轴,下方的粗蓝色线条表示不断的调用throttled函数(看做连续发生的),而上方的一个一个节点表示我们得到的执行func函数的结果。
从图上可以看出来,我们通过函数节流,成功的限制了func函数在一段时间内的调用频率,在实际中能够提高我们应用的性能表现。
接下来我们探究一下Underscore中_.throttle函数的实现。
我们在探究源码之前,先了解一下Underscore API手册中关于_.throttle函数的使用说明:
throttle_.throttle(function, wait, [options])
创建并返回一个像节流阀一样的函数,当重复调用函数的时候,最多每隔 wait毫秒调用一次该函数。对于想控制一些触发频率较高的事件有帮助。(注:详见:javascript函数的throttle和debounce)
默认情况下,throttle将在你调用的第一时间尽快执行这个function,并且,如果你在wait周期内调用任意次数的函数,都将尽快的被覆盖。如果你想禁用第一次首先执行的话,传递{leading: false},还有如果你想禁用最后一次执行的话,传递{trailing: false}。
var throttled = _.throttle(updatePosition, 100);
$(window).scroll(throttled);
结合我画的那张示意图,应该比较好理解了。
如果传递的options参数中,leading为false,那么不会在throttled函数被执行时立即执行func函数;trailing为false,则不会在结束时调用最后一次func。
Underscore源码(附注释):
// Returns a function, that, when invoked, will only be triggered at most once
// during a given window of time. Normally, the throttled function will run
// as much as it can, without ever going more than once per `wait` duration;
// but if you'd like to disable the execution on the leading edge, pass
// `{leading: false}`. To disable execution on the trailing edge, ditto.
_.throttle = function (func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function () {
//previous===0时,下一次会立即触发。
//previous===_.now()时,下一次不会立即触发。
previous = options.leading === false ? 0 : _.now();
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function () {
//获取当前时间戳(13位milliseconds表示)。
//每一次调用throttled函数,都会重新获取now,计算时间差。
//而previous只有在func函数被执行过后才回重新赋值。
//也就是说,每次计算的remaining时间间隔都是每次调用throttled函数与上一次执行func之间的时间差。
var now = _.now();
//!previous确保了在第一次调用时才会满足条件。
//leading为false表示不立即执行。
//注意是全等号,只有在传递了options参数时,比较才有意义。
if (!previous && options.leading === false) previous = now;
//计算剩余时间,now-previous为已消耗时间。
var remaining = wait - (now - previous);
context = this;
args = arguments;
//remaining <= 0代表当前时间超过了wait时长。
//remaining > wait代表now < previous,这种情况是不存在的,因为now >= previous是永远成立的(除非主机时间已经被修改过)。
//此处就相当于只判断了remaining <= 0是否成立。
if (remaining <= 0 || remaining > wait) {
//防止出现remaining <= 0但是设置的timeout仍然未触发的情况。
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
//将要执行func函数,重新设置previous的值,开始下一轮计时。
previous = now;
//时间达到间隔为wait的要求,立即传入参数执行func函数。
result = func.apply(context, args);
if (!timeout) context = args = null;
//remaining>0&&remaining<=wait、不忽略最后一个输出、
//timeout未被设置时,延时调用later并设置timeout。
//如果设置trailing===false,那么直接跳过延时调用later的部分。
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
return result;
};
throttled.cancel = function () {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
return throttled;
};
接下来,我们分三种情况分析Underscore源码:
在默认情况下调用throttled函数时,options是一个空的对象{},此时options.leading!==false并且options.trailing!==false,那么throttled函数中的第一个if会被忽略掉,因为options.leading === false永远不会满足。
此时,不断地调用throttled函数,会按照以下方式执行:
用now变量保存当前调用时的时间戳,previous默认为0,计算remaining剩余时间,此时应该会小于0,满足了if (remaining <= 0 || remaining > wait)。
清空timeout并清除其事件,为previous重新赋值以记录当前调用throttled函数的值。
能够进入当前的if语句表示剩余时间不足或者是第一次调用throttled函数(且options.leading !== false),那么将会立即执行func函数,使用result记录执行后的返回值。
下一次调用throttled函数时,重新计算当前时间和剩余时间,如果剩余时间不足那么仍然立即执行func,如此不断地循环。如果remaining时间足够(大于0),那么会进入else if语句,设置一个timeout异步事件,此时注意到timeout会被赋值,直到later被调用才回被赋值为null。这样做的目的就是为了防止不断进入else if条件语句重复设置timeout异步事件,影响性能,消耗资源。
之后调用throttled函数,都会按照这样的方式执行。
通过上面的分析,我们可以发现,除非设置options.leading===false,否则第一次执行throttled函数时,条件语句if (!previous && options.leading === false) previous = now;不会被执行。间接导致remaining<0,然后进入if语句立即执行func函数。
接下来我们看看设置options.leading === false时的情况。
设置options.leading为false时,执行情况与之前并没有太大差异,仅在于if(!previous && options.leading === false)语句。当options.leading为false时,第一次执行会满足这个条件,所以赋值previous=== now,间接使得remaining>0。
由于timeout此时为undefined,所以!timeout为true。设置later为异步任务,在remaining时间之后执行。
此后再不断的调用throttled方法,思路同2.1无异,因为!previous为false,所以if(!previous && options.leading === false)该语句不再判断,会被完全忽略。可以理解为设置判断!previous的目的就是在第一次调用throttled函数时,判断options.leading是否为false,之后便不再进行判断。
此时的区别在于else if中的执行语句。如果options.trailing === false成立,那么当remaining>0时间足够时,不会设置timeout异步任务。那么如何实现时间到就立即执行func呢?是通过不断的判断remaining,一旦remaining <= 0成立,那么就立即执行func。
接下来,我们手动实现一个简单的throttle函数。
首先,我们需要多个throttled函数共享一些变量,比如previous、result、timeout,所以最好的方案仍然是使用闭包,将这些共享的变量作为throttle函数的私有变量。
其次,我们需要在返回的函数中不断地获取调用该函数时的时间戳now,不断地计算remaining剩余时间,为了实现trailing不等于false时的效果,我们还需要设置timeout。
最终代码如下:
var throttle = function(func, wait) {
var timeout, result, now;
var previous = 0;
return function() {
now = +(new Date());
if(now - previous >= wait) {
if(timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(this, arguments);
}
else if(!timeout) {
timeout = setTimeout(function() {
previous = now;
result = func.apply(this, arguments);
timeout = null;
}, wait - now + previous);
}
return result;
}
}
可能大家发现了一个问题就是我的now变量也是共享的变量,而underscore中是throttled函数的私有变量,为什么呢?
我们可以注意到:underscore设置timeout时,调用的是另外一个throttle函数的私有函数,叫做later。later在更新previous的时候,使用的是previous = options.leading === false ? 0 : _.now();也就是通过_.now函数直接获取later被调用时的时间戳。而我使用的是previous = now,如果now做成throttled的私有变量,那么timeout的异步任务执行时,设置的previous仍然是过去的时间,而非异步任务被执行时的当前时间。这样做直接导致的结果就是previous相比实际值更小,remaining会更大,下一次func触发会来的更早!
下面这段代码是对上面代码的应用,大家可以直接拷贝到浏览器的控制台,回车然后在页面上滚动鼠标滚轮,看看这个函数实现了怎样的功能,更有利于你对这篇文章的理解!
var throttle = function(func, wait) {
var timeout, result, now;
var previous = 0;
return function() {
now = +(new Date());
if(now - previous >= wait) {
if(timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(this, arguments);
}
else if(!timeout) {
timeout = setTimeout(function() {
previous = now;
result = func.apply(this, arguments);
timeout = null;
}, wait - now + previous);
}
return result;
}
}
window.onscroll = throttle(()=>{console.log('yes')}, 2000);
node-delegates 是 TJ 大神所写的一个简单的小工具,源码只有 157 行,作用在于将外部对象接受到的操作委托到内部属性进行处理,也可以理解为讲对象的内部属性暴露到外部,简化我们所需要书写的代码。
安装和使用的代码在源码仓库都可以找到,这里主要先讲一下 API。
用于创建一个 delegator 实例,用于把 proto 接收到的一些操作委托给它的 prop 属性进行处理。
根据 targetProp 所包含的键,自动判断类型,把 targetProto 上的对应属性代理到 proto。可以是 getter、setter、value 或者 method。
在 proto 对象上新增一个名为 name 的函数,调用该函数相当于调用 proto 的 prop 属性上的 name 函数。
新增一个 getter 到 proto 对象,访问该 getter 即可访问 proto 的 prop 的对应 getter。
同 getter。
在 proto 上同时新增一个 getter 和一个 setter,指向 proto.prop 的对应属性。
access 的特殊形式。
delegate(proto, 'request')
.fluent('query')
// getter
var q = request.query();
// setter (chainable)
request
.query({ a: 1 })
.query({ b: 2 });/**
* Expose `Delegator`.
*/
// 暴露 Delegator 构造函数
module.exports = Delegator;
/**
* Initialize a delegator.
* 构造一个 delegator 实例
* @param {Object} proto 外部对象,供外部调用
* @param {String} target 外部对象的某个属性,包含具体处理逻辑
* @api public
*/
function Delegator(proto, target) {
// 如果没有使用 new 操作符调用构造函数,则使用 new 构造
if (!(this instanceof Delegator)) return new Delegator(proto, target);
// 构造实例属性
this.proto = proto;
this.target = target;
this.methods = [];
this.getters = [];
this.setters = [];
this.fluents = [];
}
/**
* Automatically delegate properties
* from a target prototype
* 根据 targetProp 自动委托,绑定一个属性到 Delegator 构造函数
* @param {Object} proto 接受请求的外部对象
* @param {object} targetProto 处理具体逻辑的内部对象
* @param {String} targetProp 包含要委托的属性的对象
* @api public
*/
Delegator.auto = function(proto, targetProto, targetProp){
var delegator = Delegator(proto, targetProp);
// 根据 targetProp 获取要委托的属性
var properties = Object.getOwnPropertyNames(targetProto);
// 遍历所有要委托的属性
for (var i = 0; i < properties.length; i++) {
var property = properties[i];
// 获取 targetProto 上对应属性的 descriptor
var descriptor = Object.getOwnPropertyDescriptor(targetProto, property);
// 如果当前属性的 get 被重写过,就作为 getter 委托(使用 __defineGetter__ 或者 Object.defineProperty 指定 getter 都会重写 descriptor 的 get 属性)
if (descriptor.get) {
delegator.getter(property);
}
// 同 get,如果 set 被重写过,那就作为 setter 委托
if (descriptor.set) {
delegator.setter(property);
}
// 如果当前 property 具有 value,那么判断是函数还是普通值
if (descriptor.hasOwnProperty('value')) { // could be undefined but writable
var value = descriptor.value;
if (value instanceof Function) {
// 是函数就进行函数委托
delegator.method(property);
} else {
// 是普通值就作为 getter 委托
delegator.getter(property);
}
// 如果这个值可以重写,那么继续进行 setter 委托
if (descriptor.writable) {
delegator.setter(property);
}
}
}
};
/**
* Delegate method `name`.
*
* @param {String} name
* @return {Delegator} self
* @api public
*/
Delegator.prototype.method = function(name){
var proto = this.proto;
var target = this.target;
this.methods.push(name);
// 在 proto 上定义一个 name 的方法
proto[name] = function(){
// 实际还是调用的 proto[target][name],内部的 this 还是指向 proto[target]
return this[target][name].apply(this[target], arguments);
};
return this;
};
/**
* Delegator accessor `name`.
*
* @param {String} name
* @return {Delegator} self
* @api public
*/
Delegator.prototype.access = function(name){
// 同时定义 getter 和 setter
return this.getter(name).setter(name);
};
/**
* Delegator getter `name`.
* 委托 name getter
* @param {String} name
* @return {Delegator} self
* @api public
*/
Delegator.prototype.getter = function(name){
var proto = this.proto;
var target = this.target;
this.getters.push(name);
// 使用 __defineGetter__ 绑定 name getter 到 proto
proto.__defineGetter__(name, function(){
// 注意 this 指向 proto 本身,所以 proto[name] 最终访问的还是 proto[target][name]
return this[target][name];
});
// 此处 this 指向 delegator 实例,构造链式调用
return this;
};
/**
* Delegator setter `name`.
* 在 proto 上委托一个 name setter
* @param {String} name
* @return {Delegator} self
* @api public
*/
Delegator.prototype.setter = function(name){
var proto = this.proto;
var target = this.target;
this.setters.push(name);
// 通过 __defineSetter__ 方法指定一个 setter 到 proto
proto.__defineSetter__(name, function(val){
// 注意 this 指向 proto 本身,所以对 proto[name] 设置值即为为 proto[target][name] 设置值
return this[target][name] = val;
});
// 返回自身实现链式调用
return this;
};
/**
* Delegator fluent accessor
*
* @param {String} name
* @return {Delegator} self
* @api public
*/
Delegator.prototype.fluent = function (name) {
var proto = this.proto;
var target = this.target;
this.fluents.push(name);
proto[name] = function(val){
// 如果 val 不为空,那么就作为 setter 使用
if ('undefined' != typeof val) {
this[target][name] = val;
// 完事后返回 proto 自身,实现链式调用
return this;
} else {
// 如果 val 未定义,那么作为 getter 使用,返回具体的值
return this[target][name];
}
};
return this;
};之所以会研究一下这个库是因为在看 koa 源码的时候看到使用了这个库,在 koa 中通过使用 node-delegates 把 context.request 和 context.response 上的属性都委托到了 context 自身。所以我们可以直接使用 context.query、context.status 来进行操作,简化了我们所写的代码。
koa 源码位置链接:https://github.com/koajs/koa/blob/b7fc526ea49894f366153bd32997e02568c0b8a6/lib/context.js#L191
__defineGetter__ 和 __defineSetter__ 可以设置 getter 和 setter,但是 MDN 显示这两个 API 已被 deprecated,github 也已经有人提了 issue 和 pr。另外,通过这两个 API 设置 getter 和 setter 时,传递的函数的内部 this 指向原来的属性,比如:
let a = { nickName: 'HotDog' }
a.__defineGetter__('name', function() {
return this.nickName // 此处 this 仍然指向 a
})看了 30 Seconds CSS,有了许多收获,所以写下了这篇文章,算是收藏一些代码小片段,留作后用。
CSS 代码如下:
.bounce-loading {
width: 20rem;
height: 10rem;
background-color:aqua;
display: flex;
justify-content: center;
align-items: center;
}
.bounce-loading > div {
width: 1rem;
height: 1rem;
border-radius: 0.5rem;
background-color:blueviolet;
margin: 0 0.5rem;
animation: bounce 1s infinite alternate;
}
@keyframes bounce {
0% {
transform: translateY(0);
opacity: 1;
}
100% {
transform: translateY(2rem);
opacity: 0.1;
}
}
.bounce-loading > div:nth-child(2) {
animation-delay: 0.2s;
}
.bounce-loading > div:nth-child(3) {
animation-delay: 0.4s;
}
HTML 代码如下:
<div class="bounce-loading">
<div></div>
<div></div>
<div></div>
</div>
效果如下:
CSS 代码如下:
.donut-loading {
width: 2rem;
height: 2rem;
border-radius: 2rem;
border: 3px solid rgba(0, 0, 0, 0.1);
border-left-color: #7983ff;
animation: rotate 1s infinite linear;
}
@keyframes rotate {
from {
transform: rotate(0deg)
}
to {
transform: rotate(360deg)
}
}
HTML 代码如下:
<div class="donut-loading"></div>
效果如下:
CSS 代码如下:
.reactive-height {
width: 50%;
background-color: aqua;
}
.reactive-height::before {
content: '';
float: left;
padding-top: 100%;
}
.reactive-height::after {
content: "";
clear: both;
display: table;
}
HTML 代码如下:
<div class="reactive-height"></div>
CSS 代码如下:
.custom-scrollbar {
width: 40rem;
height: 7rem;
background-color: aliceblue;
overflow-y: scroll;
}
.custom-scrollbar::-webkit-scrollbar {
width: 8px;
}
.custom-scrollbar::-webkit-scrollbar-thumb {
border-radius: 10px;
background-color:mediumpurple;
}
HTML 代码如下:
<div class="custom-scrollbar">
<p>
Pellentesque habitant morbi tristique senectus et
netus et malesuada fames ac turpis egestas.
Vestibulum tortor quam, feugiat vitae,
ultricies eget, tempor sit amet, ante.
Donec eu libero sit amet quam egestas semper.
Aenean ultricies mi vitae est. Mauris placerat
eleifend leo. Quisque sit amet est et sapien
ullamcorper pharetra. Vestibulum erat wisi,
condimentum sed, commodo vitae, ornare sit amet,
wisi. Aenean fermentum, elit eget tincidunt condimentum,
eros ipsum rutrum orci, sagittis tempus lacus enim ac dui.
Donec non enim in turpis pulvinar facilisis. Ut felis.
Praesent dapibus, neque id cursus faucibus, tortor neque
egestas augue, eu vulputate magna eros eu erat. Aliquam
erat volutpat. Nam dui mi, tincidunt quis, accumsan
porttitor, facilisis luctus, metus
</p>
</div>
效果截图如下:
CSS 代码如下:
.custom-text-selection {
width: 50%;
}
.custom-text-selection::selection {
background-color:navy;
color: white;
}
HTML 代码如下:
<p class="custom-text-selection">
Pellentesque habitant morbi tristique senectus et
netus et malesuada fames ac turpis egestas.
Vestibulum tortor quam, feugiat vitae,
ultricies eget, tempor sit amet, ante.
Donec eu libero sit amet quam egestas semper.
Aenean ultricies mi vitae est. Mauris placerat
eleifend leo. Quisque sit amet est et sapien
ullamcorper pharetra. Vestibulum erat wisi,
condimentum sed, commodo vitae, ornare sit amet,
wisi. Aenean fermentum, elit eget tincidunt condimentum,
eros ipsum rutrum orci, sagittis tempus lacus enim ac dui.
Donec non enim in turpis pulvinar facilisis. Ut felis.
Praesent dapibus, neque id cursus faucibus, tortor neque
egestas augue, eu vulputate magna eros eu erat. Aliquam
erat volutpat. Nam dui mi, tincidunt quis, accumsan
porttitor, facilisis luctus, metus
</p>
效果截图如下:
CSS 代码如下:
.disable-selection {
width: 50%;
user-select: none;
}
HTML 代码如下:
<p class="disable-selection">
Pellentesque habitant morbi tristique senectus et
netus et malesuada fames ac turpis egestas.
Vestibulum tortor quam, feugiat vitae,
ultricies eget, tempor sit amet, ante.
Donec eu libero sit amet quam egestas semper.
Aenean ultricies mi vitae est. Mauris placerat
eleifend leo. Quisque sit amet est et sapien
ullamcorper pharetra. Vestibulum erat wisi,
condimentum sed, commodo vitae, ornare sit amet,
wisi. Aenean fermentum, elit eget tincidunt condimentum,
eros ipsum rutrum orci, sagittis tempus lacus enim ac dui.
Donec non enim in turpis pulvinar facilisis. Ut felis.
Praesent dapibus, neque id cursus faucibus, tortor neque
egestas augue, eu vulputate magna eros eu erat. Aliquam
erat volutpat. Nam dui mi, tincidunt quis, accumsan
porttitor, facilisis luctus, metus
</p>
HTML 代码如下:
<p class="gradient-text">
gradient-text
</p>
CSS 代码如下:
.gradient-text {
background: -webkit-linear-gradient(pink, red);
-webkit-text-fill-color: transparent;
-webkit-background-clip: text;
}
效果截图如下:
该部分实现一个鼠标移入时的下划线变化效果,共用一段 HTML 代码,代码如下:
<p class="hover-underline-animation">
Hover Underline Animation
</p>
各部分实现效果的 CSS 代码各异,将分别给出。
CSS 代码如下:
.hover-underline-animation {
cursor: pointer;
}
.hover-underline-animation::after {
content: '';
width: 100%;
height: 2px;
display: block;
background-color: #7983ff;
transform: scaleX(0);
transition: transform 0.3s;
}
.hover-underline-animation:hover::after {
transform: scaleX(1);
}
效果截图如下:
CSS 代码如下:
.hover-underline-animation {
cursor: pointer;
}
.hover-underline-animation::after {
content: '';
width: 100%;
height: 2px;
display: block;
background-color: #7983ff;
transform: scaleX(0);
transform-origin: right;
transition: transform 0.3s;
}
.hover-underline-animation:hover::after {
transform: scaleX(1);
transform-origin: left;
}
效果截图如下:
这一部分 HTML 代码略有不同,为了展示左入左出、右入右出的效果,需要三个元素来实现,所以 HTML 代码多了两个相同的元素:
<span class="hover-underline-animation">
Hover Underline Animation
</span>
<span class="hover-underline-animation">
Hover Underline Animation
</span>
<span class="hover-underline-animation">
Hover Underline Animation
</span>
CSS 代码如下;
.hover-underline-animation {
cursor: pointer;
position: relative;
}
.hover-underline-animation::after {
content: '';
position: absolute;
right: 0;
bottom: 0;
width: 0%;
height: 2px;
display: block;
background-color: #7983ff;
transition: all 0.3s;
}
.hover-underline-animation:hover::after {
width: 100%;
}
.hover-underline-animation:hover ~ .hover-underline-animation::after {
right: 100% !important;
}
效果截图如下:
HTML 代码如下:
<ul class="not-selector" type="none">
<li>One</li>
<li>Two</li>
<li>Three</li>
<li>Four</li>
</ul>
CSS 代码如下:
.not-selector > li {
width: 20rem;
position: relative;
}
.not-selector > li:not(:last-child)::after {
content: "";
display: inline-block;
background-color: #c3c3c3;
height: 0.5px;
width: 100%;
position: absolute;
bottom: 0;
left: 0;
}
实现效果如下:
HTML 代码如下:
<div class="overflow-scroll-gradient dn">
<div>
Pellentesque habitant morbi tristique senectus et
netus et malesuada fames ac turpis egestas.
Vestibulum tortor quam, feugiat vitae,
ultricies eget, tempor sit amet, ante.
Donec eu libero sit amet quam egestas semper.
Aenean ultricies mi vitae est. Mauris placerat
eleifend leo. Quisque sit amet est et sapien
ullamcorper pharetra. Vestibulum erat wisi,
condimentum sed, commodo vitae, ornare sit amet,
wisi. Aenean fermentum, elit eget tincidunt condimentum,
eros ipsum rutrum orci, sagittis tempus lacus enim ac dui.
Donec non enim in turpis pulvinar facilisis. Ut felis.
Praesent dapibus, neque id cursus faucibus, tortor neque
egestas augue, eu vulputate magna eros eu erat. Aliquam
erat volutpat. Nam dui mi, tincidunt quis, accumsan
porttitor, facilisis luctus, metus
</div>
</div>
CSS 代码如下:
.overflow-scroll-gradient {
position: relative;
}
.overflow-scroll-gradient::before {
content: "";
display: inline-block;
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 5rem;
background: linear-gradient(rgba(255, 255, 255, 1), rgba(255, 255, 255, 0.001))
}
.overflow-scroll-gradient::after {
content: "";
display: inline-block;
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 5rem;
background: linear-gradient(rgba(255, 255, 255, 0.001), rgba(255, 255, 255, 1))
}
.overflow-scroll-gradient > div {
width: 15rem;
height: 25rem;
overflow-y: scroll;
}
效果截图如下:
HTML 代码:
<p class="system-font-stack">This text uses the system font.</p>
CSS 代码如下:
.system-font-stack {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', Helvetica, Arial, sans-serif;
}
我在 Ubuntu 系统下显示效果如下:
HTML 代码如下:
<div>
<input type="checkbox" id="toggle" class="offscreen">
<label for="toggle" class="checkbox"></label>
</div>
CSS 代码如下:
.offscreen {
display: none;
}
.checkbox {
width: 40px;
height: 20px;
border-radius: 20px;
display: inline-block;
background-color: rgba(0, 0, 0, 0.25);
position: relative;
cursor: pointer;
}
.checkbox::before {
content: "";
width: 18px;
height: 18px;
border-radius: 18px;
background-color: white;
position: absolute;
left: 1px;
top: 1px;
transition: transform .3s ease;
}
#toggle:checked + .checkbox {
background-color: #7983ff;
}
#toggle:checked + .checkbox::before {
transform: translateX(20px);
}
效果截图如下:
HTML 代码如下:
<div class="triangle"></div>
CSS 代码如下:
.triangle {
width: 0;
height: 0;
border: 1rem solid transparent;
border-bottom: 3rem solid blue;
}
利用 CSS border 的特性绘制三角形,改变 border 的宽度,可以绘制不同特性的三角形。
HTML 代码如下:
<p class="truncate-text">
This text will be truncated with ellipse ......
</p>
CSS 代码如下:
.truncate-text {
width: 19rem;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
background-color: #c3c3c3
}
效果截图如下;
前几天一直在学习webpack,总算比之前学习的时候有了点收获,所以在昨天发布了一篇webpack入门笔记,今天继续使用webpack练了练手,搭建了一个React开发环境,如果还不熟悉的童鞋可以看一下昨天发布的笔记:入门webpack笔记
在任意目录下,新建一个文件夹作为你的项目文件夹,命名随意。随后使用命令行工具,切换到该文件夹,键入npm init进行初始化(遇到的问题一直回车就好了),初始化完成之后可以看到生成了一个package.json文件。
随后在该项目文件夹下新建两个文件夹:/dist和/src,其中/src用于放置开发的源码,/dist用于放置“编译”后的代码。
随后在/src目录下新建index.html、index.css和index.js文件
通过命令行使用webpack 4需要安装两个模块:webpack和webpack-cli,都安装为开发环境依赖。
npm install -D webpack webpack-cli
安装完成之后可以看到你的package.json文件发生了变化,在devDependencies属性下多了两个包的属性。
1.安装最基本的插件:
npm install -D html-webpack-plugin clean-webpack-plugin webpack-dev-server css-loader webpack-merge style-loader
2.在项目文件夹下新建文件webpack.base.conf.js,表示最基本的配置文件,内容如下:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const CleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
entry: './src/index.js',
output: {
filename: 'bundle.[hash].js',
path: path.join(__dirname, '/dist')
},
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
}
]
},
plugins: [
new HtmlWebpackPlugin({
template: './src/index.html'
}),
new CleanWebpackPlugin(['dist'])
]
};
其中,/src/index.html是你的网站入口HTML文件,/src/index.js是你的入口js文件。
3.在项目文件夹下新建webpack.dev.conf.js文件,表示开发环境下的配置。内容如下:
const merge = require('webpack-merge');
const baseConfig = require('./webpack.base.conf.js');
module.exports = merge(baseConfig, {
mode: 'development',
devtool: 'inline-source-map',
devServer: {
contentBase: './dist',
port: 3000
}
});
4.在项目文件夹下新建webpack.prod.conf.js文件,表示生产环境的配置,内容如下:
const merge = require('webpack-merge');
const baseConfig = require('./webpack.base.conf.js');
console.log(__dirname);
module.exports = merge(baseConfig, {
mode: 'production'
});
配置了三个配置文件以满足两个不同环境下的代码构建,使用语义化较好的npm scripts来构建代码有利于简化工作。
添加新的scripts内容到package.json文件的scripts属性,记得用双引号引起来,其属性如下:
// package.json
{
"scripts": {
"start": "webpack-dev-server --open --config webpack.dev.conf.js",
"build": "webpack --config webpack.prod.conf.js"
}
}
配置完之后,可以尝试修改/src/index.html、/src/index.js或/src/index.css,运行npm scripts命令查看效果。
比如按照以下内容创建文件:
index.html
<html>
<head>
<meta charset="utf-8"/>
<title>React & Webpack</title>
</head>
<body>
<div id="root">
<h1>Hello React & Webpack!</h1>
</div>
</body>
</html>
index.css
body {
background-color: blue;
}
#root {
color: white;
background-color: black;
}
index.js
import './index.css';
console.log('Success!');
随后使用命令npm run start,即可看到效果。修改css或者js文件,保存之后可以看到浏览器自动刷新并且展示出了你刚刚所做的更改。
做到这里,一个基本的开发环境已经搭建出来了,下一步就是针对React特定的环境,配置不同的webpack来进行构建。
使用React开发,主要是ES6(虽然最近所有高级浏览器都已经支持ES6,但是还是要为低级IE做准备)和React的JSX语法需要进行转换。下面针对这两种语法进行配置。
Babel是一个优秀的JavaScript编译器(这句话源自Babel官网),通过Babel的一些插件,可以将JSX语法、ES6语法转换为ES5的语法,使得低级浏览器也可以运行我们写的代码。
通过以下命令安装Babel预设、babel-loader、babel-polyfill和babel-preset-react:
npm install -D babel-preset-env babel-loader babel-polyfill babel-preset-react
在项目文件夹的根目录下新建一个.babelrc的文件(Windows下无法直接创建,可以通过将文件命名为.babelrc.达到创建的目的),在文件内输入以下内容:
{
"presets": ["env", "react"]
}
webpack.base.conf.js在module.rules中插入一个新对象,内容如下:
{
test: /\.js$/,
use: 'babel-loader',
exclude: /node_modules/
}
react和react-dom模块npm install --save react react-dom
在/src中新建一个App.js文件,内容如下:
import React from 'react';
class App extends React.Component {
render() {
return <div>
<h1>Hello React & Webpack!</h1>
<ul>
{
['a', 'b', 'c'].map(name => <li>{`I'm ${name}!`}</li> )
}
</ul>
</div>
}
}
export default App;
清空index.js之后在其中写入如下内容:
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import './index.css';
ReactDOM.render(<App/>, document.getElementById('root'));
使用npm run start命令打开页面可以看到使用React写出来的效果了。
打开浏览器查看编译后的代码,找到App组件中的map函数这一段,可以发现ES6的语法已经被转换到了ES5的语法:
['a', 'b', 'c'].map(function (name) {
return _react2.default.createElement(
'li',
null,
'I\'m ' + name + '!'
);
})
箭头函数被写成了function匿名函数。
上面的步骤,我已经重新跑了一遍,一步一步按照来就可以搭建成功,有兴趣的童鞋可以照着跑一遍。^_^
另外如果还有错误的话,请提醒我一下,我一定会马上改正的!
Underscore中提供了_.template函数实现模板引擎功能,它可以将JSON数据源中的数据对应的填充到提供的字符串中去,类似于服务端渲染的模板引擎。接下来看一下Underscore是如何实现模板引擎的。
首先是_.template函数的配置项,Underscore源码中配置了默认的配置项:
_.templateSettings = {
// 执行JavaScript语句,并将结果插入。
evaluate: /<%([\s\S]+?)%>/g,
// 插入变量的值。
interpolate: /<%=([\s\S]+?)%>/g,
// 插入变量的值,并进行HTML转义。
escape: /<%-([\s\S]+?)%>/g
};
每一项的意思都写在了注释中,修改不同项的正则表达式,可以修改你传入的字符串模板中的占位符。默认的占位符:
源码中还写了一个不可能匹配的正则表达式:
// 一个不可能有匹配项的正则表达式。
var noMatch = /(.)^/;
一个JSON(类字典),用于映射转义字符到转义后的字符:
var escapes = {
"'": "'",
'\\': '\\',
'\r': 'r',
'\n': 'n',
'\u2028': 'u2028',
'\u2029': 'u2029'
};
以及一个匹配转义字符的正则表达式和一个转义函数。
// 匹配需要转义字符的正则表达式。
var escapeRegExp = /\\|'|\r|\n|\u2028|\u2029/g;
// 返回字符对应的转义后的字符。
var escapeChar = function (match) {
return '\\' + escapes[match];
};
接下来会使用到这些变量。
实现原理大致如下:
_.escape函数对其进行转义,同样写入字符串中。如何匹配传入字符串中的占位符是一个问题,因为一个字符串中可能包含多种或者多个占位符,这里用了String.prototype.replace方法的一种不常用的方法。
通常,我们至少用String.prototype.replace的简单用法,即第一个参数为要替换的字符串,第二个参数为用于替换它的新字符串,该函数返回替换结果,不改变原字符串。如果要将字符串中的指定字符串全部替换,那么第一个参数应该传入正则表达式,并且采用全局匹配模式g。很多人不知道String.prototype.replace还有更加灵活的第三种用法,即第二个参数传递为一个函数,这个函数的返回结果作为替代指定字符串的新字符串,且至少接收一个参数:
可以打开浏览器输入如下代码回车进行验证:
let str = 'abc';
str.replace(/a/g, function() {
console.log(arguments);
});
如果有多个匹配结果,那么回调函数会被调用多次:
let str = 'abcabc';
str.replace(/a/g, function() {
console.log(arguments);
});
回车之后,在控制台可以看到两次打印结果。那么就相当于是进行了一个循环操作,这个循环会遍历匹配到的每一项,这样就可以对于匹配到的占位符进行适当的操作了。此外,String.prototype.replace函数还有一个很优秀的特性,如果第一个参数传递为正则表达式并且含有多个捕获组(及括号),那么每个捕获组所捕获的字符串都会作为参数传递给回调函数,所以说回调函数至少接收一个参数。其参数个数可以取决于正则表达式中的捕获组个数。验证以下代码:
let str = 'abcabcabc';
str.replace(/(ab)|(c)/g, function() {
console.log(arguments);
});
可以发现回调所接受的参数个数即为3 + 正则中的捕获组个数。基于这个特性,Underscore作者对字符串进行了很好的处理。
实现代码如下:
_.template = function (text, settings, oldSettings) {
// 如果第二个参数为null或undefined。。等,那么使用oldSettings作为settings。
if (!settings && oldSettings) settings = oldSettings;
// 如果三个参数齐整,那么使用整合后的对象作为settings。
settings = _.defaults({}, settings, _.templateSettings);
// Combine delimiters into one regular expression via alternation.
// 匹配占位符的正则表达式,将配置项中的三个正则合并,每一个正则都是一个捕获组,如果配置项没有包含的话,就默认不匹配任何值。
var matcher = RegExp([
(settings.escape || noMatch).source,
(settings.interpolate || noMatch).source,
(settings.evaluate || noMatch).source
].join('|') + '|$', 'g');
// Compile the template source, escaping string literals appropriately.
var index = 0;
var source = "__p+='";
// function回调作为string.replace的第二个参数会传递至少三个参数,如果有多余捕获的话,也会被作为参数依次传入。
// string.replace只会返回替换之后的字符串,但是不会对原字符串进行修改,下面的操作实际上没有修改text,只是借用string.replace的回调函数完成新函数的构建。
text.replace(matcher, function (match, escape, interpolate, evaluate, offset) {
// 截取没有占位符的字符片段,并且转义其中需要转义的字符。
source += text.slice(index, offset).replace(escapeRegExp, escapeChar);
// 跳过占位符,为下一次截取做准备。
index = offset + match.length;
// 转义符的位置使用匹配到的占位符中的变量的值替代,构造一个函数的内容。
if (escape) {
// 不为空时将转义后的字符串附加到source。
source += "'+\n((__t=(" + escape + "))==null?'':_.escape(__t))+\n'";
} else if (interpolate) {
source += "'+\n((__t=(" + interpolate + "))==null?'':__t)+\n'";
} else if (evaluate) {
// 由于是直接执行语句,所以直接把evaluate字符串添加到构造函数的字符串中去就好。
source += "';\n" + evaluate + "\n__p+='";
}
// Adobe VMs need the match returned to produce the correct offset.
// 正常来说没有修改原字符串text,所以不返回值没有关系,但是这里返回了原匹配项,
// 根据注释的意思,可能是为了防止特殊环境下能够有一个正常的offset偏移量。
return match;
});
source += "';\n";
// source拼凑出了一个函数定义的所有内容,为后面使用Function构造函数做准备。
// If a variable is not specified, place data values in local scope.
// 指定作用域,以取得传入对象数据的所有属性。
if (!settings.variable) source = 'with(obj||{}){\n' + source + '}\n';
source = "var __t,__p='',__j=Array.prototype.join," +
"print=function(){__p+=__j.call(arguments,'');};\n" +
source + 'return __p;\n';
var render;
try {
// 通过new Function()形式构造函数对象。
// new Function(param1, ..., paramN, funcBody)
render = new Function(settings.variable || 'obj', '_', source);
} catch (e) {
e.source = source;
throw e;
}
var template = function (data) {
return render.call(this, data, _);
};
// Provide the compiled source as a convenience for precompilation.
var argument = settings.variable || 'obj';
// 为template函数添加source属性以便于进行预编译,以便于发现不可重现的错误。
template.source = 'function(' + argument + '){\n' + source + '}';
return template;
};
具体注释都已经写在代码中。
可以发现,在_.template函数中,将配置项中的三个正则合并成了一个,并且每一个正则都构成了一个捕获组,这样回调就会接受6个参数,最后一个参数被作者忽略了。在回调中,作者分别对三种匹配项进行了处理,然后拼接到了source字符串中。
构造完source字符串之后,作者就使用了new Function()的语法构造了一个render函数,通过研究source字符串可以发现,render实际上相当于函数:
function render(settings.variable || 'obj', _) {
var __t,
__p = '',
__j = Array.prototype.join,
print = function(){
__p+=__j.call(arguments,'');
};
// 如果配置了variable属性就不需要使用with块了。
with(obj || {}) {
__p += '...' + ((__t=(" + /*需要转义的变量*/ + "))==null?'':_.escape(__t)) + ((__t=(" + /*变量*/ + "))==null?'':__t) + ... ;
/*需要执行的JavaScript字符串*/;
}
return __p;
}
构造完这个render函数,基本的工作也就完成了。
这里比较巧妙的点在于作者通过String.prototype.replace函数构造函数字符串,对于每一个特定的模板定制了一个特定的函数,这个函数会构造一个对应于模板的字符串,将变量填充进去,所以返回的字符串即为我们想要的字符串。
不久前在公司写了一个基于 Hapijs 的后端项目,感觉这个框架很有自己的特点,跟 Express 和 Koa 的区别比较大,体现了配置大于编码的**。用起来很方便,据说 Walmart 团队用这个框架扛住了黑五的流量,看起来在实际项目中也有可用性,推荐大家尝试一下~
有点跑题了,这篇文章主要写我在开发过程中所遇到的一个问题,以及我从这个问题所学习到的东西,然后我是怎么解决这个问题的。
我的项目需求是写一个 App 版本管理器,前后端都由我开发。前端分为两个部分:运营人员写版本更新说明的内部系统和 App 访问的产品页;后端就是对 App 版本进行管理的 CURD 接口。重点在于三个部分的程序部署在三台服务器上,前端的两个系统在不同的服务器对第三个服务器上的接口进行数据请求,这就不可避免的涉及到了跨域。
当然,只是跨域的话也不难解决,添加 Access-Control-Allow-Origin 为要跨域的域名就 OK 了,或者直接赋值为 *。但是我的部分接口涉及鉴权,通过 JWT 进行校验,如果 JWT 不合法,那么会返回 401 Unauthorized 错误;而我的 JWT 是通过请求头的自定义字段 authorization 带到服务器的,这就导致一个更加麻烦的问题出现了 —— 预检请求。
预检请求(preflight request),是一个跨域请求,用来校验当前跨域请求能否被理解。
它使用 HTTP 的 OPTIONS 请求,一般会包括一下请求头:Access-Control-Request-Method,Access-Control-Request-Headers 和 Origin。
预检请求通常在必要的时候由浏览器自动发起,不需要程序员进行干预。
如果我们想要知道服务器是否支持一个 DELETE 请求,在发送 DELETE 请求之前,服务器通常会发送一个如下的预检请求:
OPTIONS /resource/foo
Access-Control-Request-Method: DELETE
Access-Control-Request-Headers: origin, x-requested-with
Origin: https://foo.bar.org
如果服务器允许使用 DELETE 方法的话,会返回如下响应头;其中 Access-Control-Allow-Methods 会列出 DELETE 方法,代表服务器支持这个方法。
HTTP/1.1 200 OK
Content-Length: 0
Connection: keep-alive
Access-Control-Allow-Origin: https://foo.bar.org
Access-Control-Allow-Methods: POST, GET, OPTIONS, DELETE
Access-Control-Max-Age: 86400
以上资料来源于 MDN
由此可知,预检请求是一个用于校验服务器是否支持当前方法以及是否能够理解当前请求的一种请求,它区别于一般的请求,不由代码发起,而在必要的时候由浏览器自动发出。
所以这里就出问题了,如果我们不知道什么时候浏览器会发出预检请求,那么服务器没有做处理的话就会导致 CORS 报错的出现。
接下来再深入一点。
满足以下条件的请求就是简单请求:
一、请求方法属于下面三种方法之一:
二、HTTP 的请求头信息超出一下范围:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:超出这三个的范围:
不满足以上条件的请求就是非简单请求。
如果是简单的 CORS 请求,浏览器会自动在请求头中添加一个 Origin 请求头字段,如果响应头对应的 Access-Control-Allow-Origin 没有包含 Origin 所指定的域,那么就会报 CORS 错误,请求失败。所以服务器的响应要添加对应的响应头。
如果是非简单的 CORS 请求,那么会有一次预检请求,在正是请求之前发出一个 OPTIONS 请求对服务器进行检测。
除了有 Origin 以外,预检请求的请求头还包括一下两个特殊字段:
Access-Control-Request-Method:表示 CORS 请求要用到的请求方法。
Access-Control-Request-Headers:这是一个用逗号分割的字符串,指出 CORS 请求要附加的请求头。
服务器的响应可以包含以下字段:
Access-Control-Allow-Methods:逗号分割的字符串,表示允许的跨域请求方法。
比如:
Access-Control-Allow-Methods: PUT, POST, GET, OPTIONS
Access-Control-Allow-Headers:如果浏览器请求包含 Access-Control-Request-Headers 字段,那么服务器中该响应头也是必须的,也是一个由逗号分隔的字符串,表示服务器支持的请求头。
比如:
Access-Control-Allow-Headers: authorization
Access-Control-Max-Age:可选字段,设置当前预检请求的有效期,单位为秒。
Access-Control-Allow-Credentials:可选字段。默认情况下,CORS 请求不携带 cookie,如果服务器想要 cookie,需要指定该请求头为 true。
避免出现预检请求,需要使得你的请求满足简单请求的两个条件。
比如在使用 JWT 鉴权时,可能会把你的 token 放在请求头的 authorization 字段,因为这个字段超出了简单请求的范围,所以请求会变成非简单请求。这时可以不把 token 放在 authorization 请求头中。
出现预检请求后,进行服务器配置,分别设置好 Access-Control-Allow-Origin、Access-Control-Allow-Methods 和 Access-Control-Allow-Headers,使得你的非简单请求能够通过预检请求。
如果使用 Hapijs 的话,只需要在路由配置中增加 cors: true 配置即可。
这篇文章是我阅读 Web Performance 101 之后的进行的粗糙的翻译作为笔记,英语还行的童鞋可以直接看原文。
这篇文章主要介绍了现代 web 加载性能(注意不涉及代码算法等),学习为什么加载性能很重要、有哪些优化的方法以及有哪些工具可以帮助我们对网站进行优化。
首先,加载缓慢的网站让人很不舒服!
最明显的例子就是当一个移动网站加载太慢的时候,用户体验如同观看一部恐怖电影。
图片来源: Luke Wroblewski
第二,网站性能直接影响你的产品质量。
—— 2016 年,AliExpress 将他们网站的性能提升了三分之一,然后他们收到的订单增加了 10.5%!
——2006 年,谷歌曾经尝试将他们的搜索放慢 0.5 秒然后发现用户的搜索(请求)次数减少了 25%。
——2008 年,Aberdeen 集团发现将网站放慢 1s,会导致用户满意度下降 16%。
此外还有一系列如上的数据,不管是新的还是旧的:(wpostats.com · pwastats.com)。
这就是为什么网站性能很重要。
现在,我们需要弄懂当我们说一个网站很快意味着什么。
在什么情况下可以说一个网站很快?
——它必须加载很快(文件下载、界面渲染),
——然后,在加载之后,它必须很快的执行(比如动画不跳帧、滚动很丝滑)。
网站加载很快意味着:
——服务器对于客户端请求响应很快,
——网站自身加载渲染很快。
在这篇文章中,我们将会讨论这个因素:如何让网站快速加载以及渲染。
先从 JavaScript 开始吧。通常情况下,JavaScript 是网站加载缓慢的根源。
第一种 JavaScript 优化方式是压缩,如果你已经知道了的话,直接跳过吧。
什么是压缩?在一般情况下,人们写 JavaScript 代码会使用一种方便的格式,包含缩进、富有含义的长变量名、写注释等等。因为这种方式,代码具有很高的可读性,但是多余的空格和注释会使得 JavaScript 文件变得很大。
为了解决这个问题,人们想到了代码压缩。在压缩的过程中,代码会被去掉所有不必要的字母,替换成短的变量名,去掉注释等等。在最后,代码文件变得比之前更小,但是代码的功能并不受影响。
代码压缩可以将代码文件减小大约 30% ~ 40%。
主流的代码打包工具都支持代码压缩:
—— mode: production in webpack,
—— babel-preset-minify in Babel,
—— gulp-uglify in Gulp
async 和 defer接下来,你写了一个 JavaScript 脚本,然后进行了压缩,现在想要在页面中加载它。该如何做呢?
最简单的方式就是写一个 script 标签,然后 src 属性指向你所写脚本的路径,然后它就可以照常开始工作啦!
但是,你知道这种方法有什么问题吗?
问题就在于 JavaScript 会阻塞渲染。
这是什么意思?
当你的浏览器加载页面的时候,它会转换 HTML 文档成为标签,然后构建 DOM 树。随后它会使用 DOM 树渲染页面。
问题在于,JavaScript 代码可以改变 DOM 树的构建方式。
例如,JavaScript 可以通过 document.write 写一个 HTML 注释的起始标签到文档中,然后整个 DOM 树都会被毁掉。
这就是为什么浏览器在碰到 script 标签的时候会停止渲染页面,这样做可以防止 document 做多余的工作。
从浏览器的角度来看:
——浏览器遍历文档,然后会解析它
——在某些时刻,浏览器遇到了 script 标签,然后停止了 HTML 转换,它开始下载并执行那些 script 代码
——一旦代码执行完毕,浏览器继续遍历 HTML 文档,然后渲染页面
实际上,这意味着当你添加一个 script 标签到页面中时,它后面的内容在它下载并执行完毕之前都是不可见的。如果你添加一个 script 到 head 标签中,所有的内容都会变得不可见——直到 script 被下载执行完毕。
那我们该怎么办呢?应该使用 async 和 defer 属性。
这些属性让浏览器直到 script 脚本可以在后台下载,不必阻塞文档渲染,下面是详细的介绍:
——async 让浏览器异步下载(在后台)script 代码,然后继续解析渲染 HTML。(如果在页面渲染完毕之前,script 代码已经下载好了,那么就先停止渲染,先执行 script 代码。由于下载所消耗的时间通常大于 HTML 转化,所以这种情况实际上不多见)。
——defer 会告诉浏览器在后台异步下载 script 代码,直到 HTML 转化渲染完毕才开始执行这些 script 代码。
这里有两大不同点:
——async script 标签会在下载之后尽快地执行,它们的执行顺序没有规律。这就意味着有 async 属性的 React bundle script 和 app bundle script 在同一时刻开始下载,由于 app bundle 更小所以会先下载完毕,导致 app 的 bundle script 先执行。然后网站就崩掉了~
——defer 不像 async,会在加载以及文档渲染完毕之后按照 script 标签的顺序开始执行,因此,defer 是更适合的优化方案。
继续。
很多时候,应用都是打包到一个 bundle 里面,然后每次请求都发送到客户端。但是这样做的问题在于有些页面我们见到的场景很少,但是它们的代码同样被打包到了我们的 bundle 中,这样每次页面加载的代码多于实际需要,造成了性能浪费。
这个问题通常使用代码切割进行解决,把大的 bundle 切割成一个个小的。
通过代码切割,我们把不同功能的代码打包到了不同的文件,只在必要的时候加载必要的代码。由于使用这样的做法,用户再也不会下载他们不需要用到的代码了。
那么我们怎么切割代码呢?
首先,你需要一个代码打包工具,比如 Webpack、Parcel 或者 Rollup。所有的这几个工具都支持一个特殊函数 import()。
在浏览器中,import() 接受传递给它的 JS 文件并异步下载该文件。这可以用于加载应用程序一开始不需要但是接下来可能会用到的库。
但是在打包工具中,import() 的功能又有所不同。如果你在代码中传递了一个文件给 import() 并且在之后进行打包,打包工具会把这个文件以及其所有的依赖打包到一个单独的文件中。app 运行到 import 函数时会单独下载这个文件。
因此,在上方的例子中,webpack 会把 ChangeAvatarModal.js 及其依赖打包到单独文件中。在代码执行到 import 时,这个单独文件会被下载。
这就是实际的代码切割。
第二,在 React 和 Vuejs 中,会有基于 import() 的工具能够让你的代码切割工作更加轻松。
例如,react-loadable 是一个组件,用于等待其他组件加载,在其他组件加载时,它会进行占位。React 16.6 添加了一个相似的内置功能组件,叫做 Suspense。此外 Vuejs 也已经支持异步组件一段时间了。
如果优化得很好的话,我们可以减少很多不必要的数据的下载,代码切割能够成为最重要的流量优化工具。
如果你的 app 只能做一种优化的话,那就是代码切割。
另外一个重要的优化点在于包的依赖。
——例如,momentjs 这个库,用于进行时间操作,它包含了大约 160 kb 大小的不同语言的文件包。
——React 甚至把 propTypes 包含在生产环境的包中,尽管这不是必要的。
——Lodash,你很有可能引入了整个完整的包,尽管你可能只需要其中的一两个方法。
上面这些就是把不必要的代码引入打包的情况。
为了帮助开发者移除多余的代码,作者和谷歌一起维护了一个 repo 收集关于如何在 webpack 中优化你的依赖,使用这些建议可以让你的 app 更快更轻巧!
→ GoogleChromeLabs/webpack-libs-optimizations
以上都是 JavaScript 的优化方式,总结起来就是:
——压缩你的 js 代码
——使用 async 和 defer 加载 script
——切割你的代码,让应用只加载必须的代码
——移除依赖中实际未使用的代码
接下来是如何优化 css 代码。
首先,压缩 CSS,就像 JavaScript 代码一样。删除不必要的空格和字母来使你的代码更小。
这些工具可以帮助你压缩 CSS 代码:
—— webpack’s postcss-loader with cssnano
—— PostCSS’s cssnano
—— Gulp’s gulp-clean-css
第二、styles 阻塞渲染,就像之前 script 那样。
因为没有样式的网站看起来很奇怪。
如果浏览器在样式加载之前渲染页面,那么用户就会看到上面那样的情况。
然后页面就会闪烁,然后就会看到上面截图这样子,很难说是一种好的用户体验。
这就是为什么样式加载的时候页面会是空白的。
现在有一种比较机智的优化方式。浏览器在加载样式之前保持空白页是很有理由的,我们不必从这一点下手。但是我们仍然可以想办法让页面渲染更快——让页面只加载渲染初始界面所必要的样式,剩余的样式在之后加载,这些渲染初始界面所必要的样式称为“Critical CSS”。
让我们看看是怎么做的。
1、把页面样式分为 critical 的和 non-critical 的。
2、把 critical CSS 嵌入到 HTML,真能够让它们尽快地被加载。
现在,当你加载页面的时候,页面能够很快地被渲染,但是你仍然得加载那些不重要的 CSS。
有多种方式可以加载剩余的 CSS,下面的方式是我所倾向的:
3、使用<link rel="preload"> 获取非必要的 CSS。
4、一旦文件被加载到缓存以后,把 rel 属性从 preload 切换为 stylesheet。这可以让浏览器从缓存中获取 CSS 并应用到页面中。
那我们怎么知道哪些 CSS 是必须的,哪些 CSS 是不必须的呢?通常情况下,规则如下:
移除 CSS 样式知道页面看起来变得滑稽,那么剩下的 CSS 就是必要的。
例如,页面的布局样式或者文章的文本样式是必须的,因为缺少它们会使得页面看起来很烂。而 JavaScript 弹出窗或者页脚的样式是非必须的,因为用户不会在一开始就看到它们,缺少那些样式,页面看起来仍然十分完美。
听起来可能比较复杂,但是有很多自动化工具可以帮助我们完成这项工作。
—— styled-components. It’s a CSS-in-JS library that extracts and returns critical styles during server-side rendering. It works only if you already write styles using styled-components, but if you do, it works really well.
——critical. It’s a utility that takes an HTML page, renders it in a headless browser and extracts styles for above-the-fold content. Because critical runs only over a single page, it might not work well for complex single-page apps.
—— penthouse. It’s similar to critical but works with URLs instead of HTML pages.
这种做法一般可以节约 200 ~ 500 ms 左右的首屏渲染时间。
了解更多 Critical CSS 的知识,阅读 the amazing Smashing Magazine’s guide.
这就是 CSS 优化的主要策略,总结起来就是:
——压缩 CSS 代码
——提取必要的 CSS,让页面首先加载它们
现在让我们看看 HTTP 的优化。
让 HTTP 传输较少数据的方式仍然是压缩代码,本节主要说压缩 HTML 代码,JS、CSS 的代码压缩在之前已经讲过了。
压缩代码的第二种方式是 GZIP 压缩。
Gzip 是一种算法,它可以使用复杂的归档算法压缩你发送到客户端的数据。在压缩之后,你的文件看起来像是无法打开的二进制文件,但是它们的体积会减小 60% 到 80%。浏览器接受这些文件之后会自动进行解压缩。
基本上,使用 Gzip 已经是生产环境的标准,因此如果你使用一些流行的服务器软件比如 Apache 或者 Nginx,你就可以修改配置文件开启 Gzip 压缩。
Apache instructions · Nginx instructions
注意:
使用这些说明启用 Gzip 将会导致服务器动态压缩资源,这会增加服务器响应时间。在大多数情况下你不需要关心这一点,但如果你希望提高响应时间,可以在构建的时候进行资源预压缩。
注意:
不要对文本文件之外的文件进行 Gzip 压缩!
图像、字体、视频或者其他二进制文件通常已经被压缩过了,因此对它们进行 Gzip 压缩只会延长响应时间。SVG 图片是唯一的例外,因为它也是文本。
Gzip 有一个替代品,一种叫 Brotli 的算法。
__Brotli 的优点:__同样的 CPU 载荷下,它压缩效率比 Gzip 高 20% 到 30%。就是说可以减少 30% 下载量!
__Brotli 的缺点:__它很年轻,浏览器以及服务器的支持度还不够,所以你不能用它来替代 Gzip。但是可以针对不同的浏览器使用 Gzip 或者 Brotli。
Apache 从 2.4.26 开始支持 Brotli,Nginx 有外部模块支持 Brotli。
Apache instructions · Nginx module
注意:
不要把 Brotli 的压缩等级设置到最大,那样会让它压缩得比 Gzip 慢。设置为 4 是最好的,可以让 Brotli 压缩得比 Gzip 更小更快。
现在,我们聊聊 CDN。
什么是 CDN?假设你在美国假设了一个应用。如果你的用户来自华沙,他们的请求不得不从波兰发出,一路颠簸来到美国,然后又得回到波兰。这个请求过程将会消耗很多时间:
——网络请求要跨越很长的一段距离
——网络请求要经过很多路由或者类似设备(每个设备都有一段处理时间)
如果用户想要获取 app 数据,而且只有美国的服务器知道如何处理数据,那上面这些过程好像都是必要的。但对于静态内容而言,上面的请求过程完全没有必要,因为它们请求的只是一些静态内容,完全可以部署到任何服务器上。
CDN 服务就是用来解决这个问题的。CDN 代表“Content Delivery Network(静态内容分发)”,CDN 服务在全世界提供许多服务器来 “serve” 静态文件。如果要使用的话,只需要在一个 CDN 服务注册,然后上传你的静态文件,然后更新 app 中引用的文件的地址,然后每个用户都会引用离他们最近的服务器上的静态文件了。
根据我们的经验,CDN 基本上能把每个请求的延迟从上百毫秒减少到 5-10 毫秒。考虑到当页面打开时有很多资源要加载,CDN 的优化效果是很惊人的。
你知道吗?谷歌在你开始点击搜索之前已经在加载搜索结果的第一项了。这是因为三分之一的用户会首先点击第一个搜索结果,预加载内容可以让用户更快的看到目标页面。
如果你确定你的页面或者资源会在不久之后被用到,浏览器允许你进行预加载。
有五种方法可以实现预加载,它们每一种的适用场景都不同:
——<link rel="dns-prefetch"> 提示浏览器对一个 IP 地址提前进行 DNS 请求。这对于 CDN 请求很有用,此外一些你知道域名但是不知道具体地址的资源的预加载也可以使用。
——<link rel="preconnect"> 提示浏览器提前连接到某台服务器。在 dns-prefetch 适用的场景同样适用,但它可以建立完整的连接并节约很多时间。缺点是打开新的连接很消耗资源,因此不要过度使用。
——<link rel="prefetch"> 会在后台对资源进行低优先级预加载然后缓存,这个比较有用,比如在进入 SPA 的下一个页面之前加载 bundle。
——<link rel="preload"> 会在后台对资源进行高优先级的预加载。这对于加载短时间内即将用到的资源而言比较有用。
——<link rel="prerender"> 会在后台预加载特定页面,然后在不可见的 tab 中渲染页面。当用户进入这个页面时,页面可以立马呈现在用户面前。这是谷歌用于预加载第一条搜索结果的方案。
注意:
不要过度使用预加载,虽然预加载能够提升用户体验、加速应用,但是会导致不必要的流量消耗;尤其是在移动端,用户会消耗过多的不要的流量,这同样会降低用户体验。
阅读更多:Preload, prefetch and priorities in Chrome · Prefetching, preloading, prebrowsing
HTTP 优化方式:
—— 使用 CDN 节省静态资源的下载时间
—— 预加载一会将要用到的资源
继续,说说图片优化。
图片消耗了大量的流量,但庆幸的是图片加载不阻塞渲染。但图片优化仍然是必要的,我们需要让图片加载更快、消耗更少的流量。
第一,也是最重要的一点,选择合适的图片格式。
最常见的图片格式是:svg、jpg、png、webp和 gif。
svg 最适合矢量图,比如 icon 和 logo。
jpg 最适合照片,因为它压缩图片时质量损耗最小,以至于肉眼难以发现。
png 适合没有任何质量损失的光栅图形 - 例如光栅图标或像素艺术。
webp 最适合照片或者光栅图片,因为它支持有损或者无损压缩。它的压缩比也比 jpg 和 png 更优秀。
不幸的是 webp 只能在 chrome 使用,但是你仍然可以使用 jpg 和 png 来实现一个 fallback。
上面就是具体实现。
这样写的话,支持 webp 的浏览器会加载 webp 格式的图片,不支持 webp 格式的浏览器会加载 jpg 最为备用方案。
最后是 gif。
不要使用 gif,它非常笨重。超过 1M 的 gif 最好使用视频文件代替,可以更好的压缩内容。
See also: Replace Animated GIFs with Video at WebFundamentals
除了使用合适的图片格式以外,图片压缩也可以是优化方案。下面是几种图片压缩方式:
首先是 svg:
——压缩。因为 svg 图片是文本,所以可以移除空格和注释
——简化 path,如果 svg 是自动工具生成的,其内部的 path 可能会很复杂,这种情况下,移除那些不影响 svg 样式的 path
——简化 svg 文件结构,如果 svg 是自动工具生成的,通常会包含很多多余的 meta 元素,移除它们可以减小文件体积
这些优化方式都可以直接使用 svgo 实现,它还有 UI 界面:a great UI for svgo
第二个:jpg。
——减小图片维度。根据我的经验,这是一个开发人员使用 jpg 常犯的错误
这种情况常发生于我们把一张大尺寸的图片塞进一个小尺寸的容器中时。比如我们把一张 2560 * 1440 px 的图片放到一个 533 * 300 px 的容器中。
当这种情况发生时,浏览器会加载过大的文件,然后还要花时间缩小图片,知道能够塞进去那个小小的容器,这些都是无用功。
要解决这个问题,可以直接在你的 PS 或者其他工具中对图片进行编辑;或者你也可以使用 webpack loader(比如 responsive-loader)。如果要使用大尺寸图片适配高分屏,可以通过 <picture> 或者 <img srcset> 代替。
还可以对 jpg 进行图片降维压缩,图片质量压缩到原来的 70 ~ 80,图片压缩导致的质量损失会很难发现。
上面可以看出压缩后图片质量损失不大。
但是我们可以看到图片的大小减小了很多。这就是为什么推荐对 jpg 图片进行 70-80 水平的压缩,因为图片信息损失很小,但是体积压缩很大。
除了以上方式外,我们还可以使用渐进式图片。
上方是非渐进式图片加载的方法。
这是一张渐进式的图片的加载方式。
可以通过 PS 或者 Gimp 制作渐进式图片。也可以使用 webpack-loader(比如 image-webpack-loader)或者其他工具。
注意:
渐进式图片可能比常规图片更大,而且解码更慢。
第三,png。
——使用隔行扫描 PNG。 隔行扫描 PNG 的工作方式与渐进式 JPEG 相同:它从低质量开始渲染,但在加载时进行改进。 但它不是适合所有场景。例如,逐步加载 PNG 图标看起来很奇怪 - 但它可能适用于其他某些图像。
——使用索引颜色。 通过使用索引颜色,PNG 图片将其所有颜色放入调色板中并使用它来引用每种颜色。 这使得每个像素所需的字节数更小,并且可能有助于降低整体图像权重。 由于调色板大小有限(最多256种颜色),因此此解决方案不适用于具有大量颜色的图像。
这两种方式都可以通过图片编辑器或者 image-webpack-loader 或者其他工具实现。
以上的所有优化都可以使用自动化工具完成,之前都已经提到过,但是这里再总结一下:
— webpack has image-webpack-loader which runs on every build and does pretty much every optimization from above. Its default settings are OK
— For you need to optimize an image once and forever, there’re apps like ImageOptim and sites like TinyPNG.
— If you can’t plug a webpack loader into your build process, there’re also a number of CDNs and services that host and optimize images for you (e.g., Akamai, Cloudinary, or imgix).
图片优化总结:
——通过图片降维、质量压缩或者使用渐进式图片优化图片加载时间
最后一个优化方式就是字体了。
有时候页面加载好了,所有的样式、布局都已经可见了,但是字体还没有出现或者显示异常,这就是字体问题所导致的,自定义字体尚未下载完毕,这个时候浏览器会等待几秒,如果仍然未下载,浏览器才会使用备用字体作为替代。
这种行为在某种程度上避免了字体的闪烁,但是在缓慢的网络条件下,这种行为使得页面加载变得缓慢。
我们需要了解一下如何优化这种情况。
首先,要记得设置 fallback 字体。
fallback 字体会在自定义字体无法下载或者下载时间过长时被使用。它在 CSS 的 font 或者 font-family 的第一个指定字体后面指定,比如上方的Arial, sans-serif。
fallback 字体应当是比较流行的内置字体(比如 Georgia);也可以是比较通用的字体系列(如 serif 或者 sans-serif);通常情况下,即使你指定了内置的字体作为 fallback,但是你仍然需要添加一个通用的字体系列——因为内置字体可能也会在某些设备上缺失。
没有 fallback 字体的话,一旦自定义字体缺失,浏览器会使用默认的 serif font 进行渲染。这样可能会导致页面比较难看。
使用 fallback 字体,至少你有机会定义一个和你的自定义字体相近的字体作为备用方案。
font-display第二点优化,使用 CSS 的 font-display 属性指定自定义字体。
font-display 属性会调整自定义字体的应用方式。默认情况下,它会设置为 auto,在大部分主流浏览器中,意味着浏览器会等待自定义字体加载 3s。这意味着如果网络太慢的话,用户需要等待 3s 后字体才会显示。
这很不好,为了优化这一点,指定 font-display。
Note: in Microsoft Edge, the font-display: auto behavior is different. With it, if the custom font is not cached, Edge immediately renders the text in the fallback font and substitutes the custom font later when it’s loaded. This is not a bug because font-display: auto lets browsers define the loading strategy.
有两个 font-display 的值我认为比较适用于大部分情况。
第一个是 font-display: fallback。这样指定的话,浏览器会使用最早能够获得的字体立即渲染,不管是已经缓存的自定义字体还是 fallback 字体。如果自定义字体没有被缓存的话,浏览器会下载它。如果下载得足够快(通常是 3s 内),浏览器会使用自定义字体替换 fallback 字体。
这种情况下,用户可能会在读 fallback 字体的文本时,浏览器突然进行字体替换,这对于用户体验而言并不是很差,总比不显示任何字体要强。
第二个适用的 font-display 值是 optional。使用这个值,浏览器同样会立即使用可获得的字体进行文本渲染:不管是已缓存的自定义字体还是 fallback 字体。但是当自定义字体未缓存时,在下载好自定义字体后,浏览器不会立即替换已有的 fallback 字体,直到页面下一次刷新。
这种行为意味着用户始终只会看到一种字体,不会出现字体替换的情况。
那我们该如何选择这两个值呢?
我相信这是一个品味问题。 我个人更喜欢用自定义字体展示文本,因此我选择 font-display:fallback 值。 如果你觉得访问者第一次访问时看到 fallback 字体的页面没有什么关系,那么 font-display:optional 对您来说非常有用。
Note: this font-display trick is not applicable to icon fonts. In icon fonts, each icon is usually encoded by a rarely used Unicode character. Using font-display to render icons with a fallback font will make random characters appear in their place.
字体优化方案的总结:
—— 指定合适的 fallback(备用)字体 (还有通用的字体系列)
—— 使用 font-display 来配置自定义字体的应用方式。
最后是一些有助于页面性能优化的工具。
第一个是 Google PageSpeed Insights。
第二个是 Lighthouse。
第三个是 WebPageTest。
最后一个是 webpack 插件:webpack-bundle-analyzer。
具体的介绍就没写了,点进去直接用就知道啦。
感谢阅读!
原作者推特:@iamakulov。
Thanks to Arun, Anton Korzunov, Matthew Holloway, Bradley Few, Brian Rosamilia,Rafael Keramidas, Viktor Karpov, and Artem Miroshnyk (in no particular order) for providing feedback on drafts.
译者水平有限,难免存在纰漏,敬请各位斧正。
作为一个FrontEnd Developer,谁没有写过几个博客呢?这已经不是我写的第一个博客了。之前自己在学习Vue框架的时候写过一个自己的博客,并且扔在了自己架设的阿里云服务器上面。由于是练手的项目,并且买的是廉价服务器,所以访问速度什么的都是十分的感人。所以在学习React全家桶的时候,我决定再写一个自己的博客,所以就诞生了现在这个项目。
这个博客是基于GitHub API、issues功能及React全家桶开发的,没有后台服务器,访问速度相对比我的廉价服务器快一点。源码都放在了这个repo,大家有兴趣的可以clone一下看一看,欢迎大家PR,帮助我学习改进,指出我在开发中的不足之处。
今后我会在这个博客当中写一些东西,记录我的学习笔记、生活状态或者是人生规划。
之前写过一篇 Redux 的源码解析文章,时隔几个月我又看了看 React Redux 的源码,这一次也是收获满满,所以写下了这篇博客记录一下我的收获。
React Redux 不同于 Redux,Redux 的设计目的在于提供一个独立于 UI 的数据中心,使得我们可以方便地在组件树中的任意多个组件间共享数据;Redux 独立于 React,可以脱离 React 使用。而 React Redux 是为了方便我们将 Redux 与 React 结合使用,使得我们可以在 React 组件内方便地获取 Store 中的数据并且订阅 Store 内数据的变化;当 Store 内数据变化后,能够使得我们相应的组件根据一定的条件重新渲染。
所以 React Redux 的核心点在于:
这篇文章可以就这两点围绕展开解读。
在阅读源码之前,最好熟知如何使用 React-Redux,如果对于 API 还不熟悉的话,可以阅读官网的相关文档。
另外在你的电脑上最好打开一份同版本的源代码项目,以便跟随阅读。
首先我们下载 GitHub 上的 React Redux 源码,我所阅读的源码版本是 7.1.3,读者也最好是下载该版本的源码,以免在阅读时产生困惑。
git clone https://github.com/reduxjs/react-redux.git下载下来之后我们就可以看到源码的文件结构了,src 目录具体文件结构如下:
src
├── alternate-renderers.js
├── components
│ ├── Context.js
│ ├── Provider.js
│ └── connectAdvanced.js
├── connect
│ ├── connect.js
│ ├── mergeProps.js
│ ├── mapDispatchToProps.js
│ ├── mapStateToProps.js
│ ├── selectorFactory.js
│ ├── verifySubselectors.js
│ └── wrapMapToProps.js
├── hooks
│ ├── useDispatch.js
│ ├── useReduxContext.js
│ ├── useSelector.js
│ └── useStore.js
├── index.js
└── utils
├── Subscription.js
├── batch.js
├── isPlainObject.js
├── reactBatchedUpdates.js
├── reactBatchedUpdates.native.js
├── shallowEqual.js
├── useIsomorphicLayoutEffect.js
├── useIsomorphicLayoutEffect.native.js
├── verifyPlainObject.js
├── warning.js
└── wrapActionCreators.js我们先从入口文件 index.js 开始看起。
该文件内容比较简单:
import Provider from './components/Provider'
import connectAdvanced from './components/connectAdvanced'
import { ReactReduxContext } from './components/Context'
import connect from './connect/connect'
import { useDispatch, createDispatchHook } from './hooks/useDispatch'
import { useSelector, createSelectorHook } from './hooks/useSelector'
import { useStore, createStoreHook } from './hooks/useStore'
import { setBatch } from './utils/batch'
import { unstable_batchedUpdates as batch } from './utils/reactBatchedUpdates'
import shallowEqual from './utils/shallowEqual'
setBatch(batch)
export {
Provider,
connectAdvanced,
ReactReduxContext,
connect,
batch,
useDispatch,
createDispatchHook,
useSelector,
createSelectorHook,
useStore,
createStoreHook,
shallowEqual
}主要就是从各个文件中导出我们需要使用的 API。
我们使用的最多的几个 API 是 Provider 和 connect,先从这两个看起,其他 API 放到后面看。
根据 React-Redux 官网的实例,我们在使用的时候需要引入 Provider 组件,然后将其包裹在我们的根组件外边,传入 store 数据:
它使得我们的应用可以方便地获取 store 对象,那么它是如何实现的呢?
我们知道 React 有一个概念叫 Context,它同样提供一个 Provider 组件,并且可以使得 Consumer 可以在内部的任意位置获取 Provider 提供的数据,所以这两者有非常相似的功能和特性。React-Redux 就是基于 Context API 实现的,这样顶层组件提供的 store 对象可以在内部位置获取到。
React-Redux 的 Provider 组件源码如下:
function Provider({ store, context, children }) {
const contextValue = useMemo(() => {
const subscription = new Subscription(store)
subscription.onStateChange = subscription.notifyNestedSubs
return {
store,
subscription
}
}, [store])
const previousState = useMemo(() => store.getState(), [store])
useEffect(() => {
const { subscription } = contextValue
subscription.trySubscribe()
if (previousState !== store.getState()) {
subscription.notifyNestedSubs()
}
return () => {
subscription.tryUnsubscribe()
subscription.onStateChange = null
}
}, [contextValue, previousState])
const Context = context || ReactReduxContext
return <Context.Provider value={contextValue}>{children}</Context.Provider>
}可以看到这是一个简单地函数组件,在开始的时候创建了一个 contextValue 对象,内部包含一个 store 和一个 subscription。这个 contextValue 会在最后作为 value 传入 Context API,即最后一行代码。
这里值得学习的是 contextValue 的计算方法,基于 useMemo Hook 实现了对于 contextValue 的缓存,只有当 store 发生变化的时候这个值才会重新计算,减少了计算的开支。
这个 store 对象是我们内部组件所需要的,那这个 subscription 对象是啥呢?这个 subscription 对象其实是 React-Redux 实现数据订阅的关键所在,我们之后再关注这一块,现在只需要知道这是很重要的一个内容就行。
关于 Context 的来源,可以看到是 Provider 接受到的 context props 或者内部默认的 ReactReduxContext。所以我们知道了我们可以提供一个默认的 context 组件给 Provider 来实现进一步的封装。这里多数情况下我们都是使用的 ReactReduxContext:
export const ReactReduxContext = /*#__PURE__*/ React.createContext(null)
if (process.env.NODE_ENV !== 'production') {
// 在非生产环境中可以在 devtools 中看到该组件名称
ReactReduxContext.displayName = 'ReactRedux'
}可以看到这是通过 React.createContext API 创建的一个 context 对象,平平无奇。
那么我们通过 Context.Provider 提供了我们的 contextValue 给下层组件,那么我们的下层组件是如何获取我们的 contextValue 的呢?
这个时候我们就应该想到我们的 connect 函数,肯定是它内部完成了这些工作,下面我们看看 connect 函数做了什么。
connect 函数来源于 connect.js 的 createConnect 函数调用,这是一个高阶函数,返回了我们真正使用到的 connect API:
// createConnect with default args builds the 'official' connect behavior. Calling it with
// different options opens up some testing and extensibility scenarios
export function createConnect({
connectHOC = connectAdvanced,
mapStateToPropsFactories = defaultMapStateToPropsFactories,
mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories,
mergePropsFactories = defaultMergePropsFactories,
selectorFactory = defaultSelectorFactory
} = {}) {
// 这是我们真正使用到的 connect 函数
return function connect(
mapStateToProps,
mapDispatchToProps,
mergeProps,
{
pure = true,
areStatesEqual = strictEqual,
areOwnPropsEqual = shallowEqual,
areStatePropsEqual = shallowEqual,
areMergedPropsEqual = shallowEqual,
...extraOptions
} = {}
) {
// match 函数的第二个参数是一个函数数组,通过将第一个参数作为调用参数,依次顺序调用第二个参数内的函数来获取结果
// 返回的函数就是经过包装后的对应函数
const initMapStateToProps = match(
mapStateToProps,
mapStateToPropsFactories,
'mapStateToProps'
)
const initMapDispatchToProps = match(
mapDispatchToProps,
mapDispatchToPropsFactories,
'mapDispatchToProps'
)
const initMergeProps = match(mergeProps, mergePropsFactories, 'mergeProps')
return connectHOC(selectorFactory, {
// used in error messages
methodName: 'connect',
// used to compute Connect's displayName from the wrapped component's displayName.
getDisplayName: name => `Connect(${name})`,
// if mapStateToProps is falsy, the Connect component doesn't subscribe to store state changes
shouldHandleStateChanges: Boolean(mapStateToProps),
// passed through to selectorFactory
initMapStateToProps,
initMapDispatchToProps,
initMergeProps,
pure,
areStatesEqual,
areOwnPropsEqual,
areStatePropsEqual,
areMergedPropsEqual,
// any extra options args can override defaults of connect or connectAdvanced
...extraOptions
})
}
}为什么会有这么个高阶函数来产生我们所使用的 connect 函数呢?第一段注释说得很清楚了,因为给 createConnect 函数传入不同的参数可以生成不同的 connect 函数,用于我们的测试或者其他场景,在计算我们真正使用的 connect 函数时,使用到的全部都是默认参数。
createConnect 函数返回了我们真正使用到的 connect 函数,这个函数所接受的参数我们就应该比较熟悉了。如果还不熟悉的话,可以参考 React-Redux 官方文档。
connect 函数在接受到我们传入的参数后,会执行三次 match 函数来计算初始化 mapDispatchToProps、mapStateToProps 和 mergeProps 的函数。我们看看 match 函数是如何定义的:
/*
connect is a facade over connectAdvanced. It turns its args into a compatible
selectorFactory, which has the signature:
(dispatch, options) => (nextState, nextOwnProps) => nextFinalProps
connect passes its args to connectAdvanced as options, which will in turn pass them to
selectorFactory each time a Connect component instance is instantiated or hot reloaded.
selectorFactory returns a final props selector from its mapStateToProps,
mapStateToPropsFactories, mapDispatchToProps, mapDispatchToPropsFactories, mergeProps,
mergePropsFactories, and pure args.
The resulting final props selector is called by the Connect component instance whenever
it receives new props or store state.
*/
function match(arg, factories, name) {
for (let i = factories.length - 1; i >= 0; i--) {
const result = factories[i](arg)
if (result) return result
}
return (dispatch, options) => {
throw new Error(
`Invalid value of type ${typeof arg} for ${name} argument when connecting component ${
options.wrappedComponentName
}.`
)
}
}match 函数的第一个参数是我们传入的原始的 mapStateToProps、mapDispatchToProps 或者 mergeProps 函数。第二个参数是 connect 函数传入的一个数组,第三个参数是指定的函数名称。
在 match 函数内,会遍历第二个数组参数,依次执行数组中的函数,并且将我们原始的 mapxxxToProps 或者 mergeProps 函数作为参数传入这个参数,如果返回的结果为非 False 值,就直接返回,作为我们的 init..函数。
如果数组遍历完成后还是没有得到非 False 的返回值,那么就返回一个__标准格式__ (注意返回函数的格式)的报错函数,说明用户传入的 map.. 函数不符合要求,看起来 match 函数会对我们传入的参数做一次校验。
那么上一段中提到的标准格式是什么格式呢?我们可以看一下函数定义上面的大段注释。这段注释说明 connect 函数只是 connectAdvanced 函数的一个代理人,它所做的工作就是将我们传入的参数转化为可以供 selectorFactory 使用的参数。而可以供 selectorFactory 使用的一个标准就是参数的结构符合如下定义:
(dispatch, options) => (nextState, nextOwnProps) => nextFinalProps这个结构就是我们的标准格式。
被转化为这个格式的 init 系列函数会被作为参数传入 connectAdvanced 函数,而 connectAdvanced 函数会根据传入的参数和 store 对象计算出最终组件需要的 props。
这个标准格式非常重要,因为后面的很多地方的代码都跟这个有关,所以我们需要注意一下。
我们已经知道了 match 函数的作用,所以我们接下来看一下 match 是如何通过第二个参数来计算我们的标准化后的 mapStateToProps……等函数的。
这个函数是根据下面代码计算出来的:
const initMapStateToProps = match(
mapStateToProps,
mapStateToPropsFactories,
'mapStateToProps'
)match 的原理我们已经明白了,所以标准化的关键就在于 mapStateToPropsFactories 函数数组。
我们现在看一下这个数组:
import { wrapMapToPropsConstant, wrapMapToPropsFunc } from './wrapMapToProps'
export function whenMapStateToPropsIsFunction(mapStateToProps) {
return typeof mapStateToProps === 'function'
? wrapMapToPropsFunc(mapStateToProps, 'mapStateToProps')
: undefined
}
export function whenMapStateToPropsIsMissing(mapStateToProps) {
return !mapStateToProps ? wrapMapToPropsConstant(() => ({})) : undefined
}
export default [whenMapStateToPropsIsFunction, whenMapStateToPropsIsMissing]可以看到这个函数数组一共就有两个函数,会一次传入我们的 mapStateToProps 参数进行计算,得到了结果就会返回。
第一个函数 whenMapStateToPropsIsFunction 是计算当我们的 mapStateToProps 参数为函数时的结果,第二个函数时计算当我们传入的 mapStateToProps 是一个 False 值时的默认结果(即如果我们的 mapStateToProps 为 null 时,selectorFactory 函数应该使用的函数)。
我们再深入看看 wrapMapToPropsFunc 和 wrapMapToPropsConstant 函数,其中wrapMapToPropsFunc 函数是重点。
wrapMapToPropsFunc 函数代码如下:
// Used by whenMapStateToPropsIsFunction and whenMapDispatchToPropsIsFunction,
// this function wraps mapToProps in a proxy function which does several things:
//
// * Detects whether the mapToProps function being called depends on props, which
// is used by selectorFactory to decide if it should reinvoke on props changes.
//
// * On first call, handles mapToProps if returns another function, and treats that
// new function as the true mapToProps for subsequent calls.
//
// * On first call, verifies the first result is a plain object, in order to warn
// the developer that their mapToProps function is not returning a valid result.
//
export function wrapMapToPropsFunc(mapToProps, methodName) {
return function initProxySelector(dispatch, { displayName }) {
const proxy = function mapToPropsProxy(stateOrDispatch, ownProps) {
return proxy.dependsOnOwnProps
? proxy.mapToProps(stateOrDispatch, ownProps)
: proxy.mapToProps(stateOrDispatch)
}
// allow detectFactoryAndVerify to get ownProps
// 第一次运行时将 dependsOnOwnProps 设置成 true
// 使得 detectFactoryAndVerify 在运行的时候可以获得第二个参数,等第二次运行时
// proxy.mapToProps 和 denpendsOnOwnProps 都是经过计算得到的
proxy.dependsOnOwnProps = true
proxy.mapToProps = function detectFactoryAndVerify(
stateOrDispatch,
ownProps
) {
proxy.mapToProps = mapToProps
proxy.dependsOnOwnProps = getDependsOnOwnProps(mapToProps)
let props = proxy(stateOrDispatch, ownProps)
if (typeof props === 'function') {
proxy.mapToProps = props
proxy.dependsOnOwnProps = getDependsOnOwnProps(props)
props = proxy(stateOrDispatch, ownProps)
}
if (process.env.NODE_ENV !== 'production')
verifyPlainObject(props, displayName, methodName)
return props
}
return proxy
}
}可以看到该函数返回的结果确实符合我们的标准格式,并且 proxy.mapToProps 返回的结果即为标准格式中的最终结果:nextFinalProps。
可以看到返回的 initProxySelector 函数可以接受 dispatch 函数和 options 参数,返回一个 proxy 函数对象,这个函数接受 stateOrDispatch 函数和 ownProps 参数,最终返回一个计算结果。
这里的关键在于 proxy.dependsOnOwnProps 属性,这个属性决定了我们在调用 proxy.mapToProps 函数时是否传入第二个函数。那这个 dependsOnOwnProps 属性是如何得到的呢?
继续看代码,可以发现在第一次执行 initProxySelector 函数的时候,默认 dependsOnOwnProps 参数为 true,这是为了让 detectFactoryAndVerify 函数执行时可以得到 ownProps 这个参数。而detectFactoryAndVerify 的存在是为了在第一次运行 mapToProps 函数时进行一些额外的工作,比如计算dependsOnOwnProps 属性、校验返回的 props 结果。在 detectFactoryAndVerify 函数内部会重新为 proxy.mapToProps 赋值,这意味着第二次运行 proxy.mapToProps 函数的时候,就不会重新计算那些参数了。
另外如果我们的 mapStateToProps 返回的结果是一个函数,则在后续的计算中,这个返回的函数会作为真正的 mapToProps 函数进行 props 的计算。这也是为什么官方文档中会有如下这段话:
You may define
mapStateToPropsandmapDispatchToPropsas a factory function, i.e., you return a function instead of an object. In this case your returned function will be treated as the realmapStateToPropsormapDispatchToProps, and be called in subsequent calls. You may see notes on Factory Functions or our guide on performance optimizations.
也就是除了可以返回一个纯对象以外,还可以返回一个函数。
再来看一下 getDependsOnOwnProps 函数是如何计算 dependsOnOwnProps 属性的:
// 该函数用于计算 mapToProps 是否需要使用到 props
// 依据是 function.length,如果 function.length === 1 就说明只需要 stateOrDispatch
// 如果 function.length !== 1,说明就需要 props 进行计算。
export function getDependsOnOwnProps(mapToProps) {
return mapToProps.dependsOnOwnProps !== null &&
mapToProps.dependsOnOwnProps !== undefined
? Boolean(mapToProps.dependsOnOwnProps)
: mapToProps.length !== 1
}当 mapToProps.dependsOnOwnProps 有值时就直接使用这个值作为结果,不再重新计算;如果还是没有值的话, 需要进行一次计算,计算的逻辑就是 mapToProps 函数的参数格式,即我们传递给 connect 函数的 mapStateToProps 函数的参数个数,只有当参数个数为 1 的时候才不会传入 ownProps 参数。
关于 wrapMapToPropsConstant 函数,这是用来计算当我们传入的 mapStateToProps 函数为 null 时的结果的函数。代码如下:
export function wrapMapToPropsConstant(getConstant) {
return function initConstantSelector(dispatch, options) {
const constant = getConstant(dispatch, options)
function constantSelector() {
return constant
}
constantSelector.dependsOnOwnProps = false
return constantSelector
}
}可以看到也是对结果进行了一下标准化,然后计算得到的常量 constant,返回 constantSelector 作为结果,其 dependsOnOwnProps 属性为 fasle,因为我们没有传入对应参数,也就没有依赖 ownProps 了。最终得到的结果就是一个 undefined 对象,因为这种情况下,getConstant 函数为一个空函数: () => {}。
计算该函数用到的函数数组为:
import { bindActionCreators } from 'redux'
import { wrapMapToPropsConstant, wrapMapToPropsFunc } from './wrapMapToProps'
export function whenMapDispatchToPropsIsFunction(mapDispatchToProps) {
return typeof mapDispatchToProps === 'function'
? wrapMapToPropsFunc(mapDispatchToProps, 'mapDispatchToProps')
: undefined
}
export function whenMapDispatchToPropsIsMissing(mapDispatchToProps) {
return !mapDispatchToProps
? wrapMapToPropsConstant(dispatch => ({ dispatch }))
: undefined
}
export function whenMapDispatchToPropsIsObject(mapDispatchToProps) {
return mapDispatchToProps && typeof mapDispatchToProps === 'object'
? wrapMapToPropsConstant(dispatch =>
bindActionCreators(mapDispatchToProps, dispatch)
)
: undefined
}
export default [
whenMapDispatchToPropsIsFunction,
whenMapDispatchToPropsIsMissing,
whenMapDispatchToPropsIsObject
]这里会有三个函数,分别用于处理传入的 mapDispatchToProps 是函数、null 和对象时的情况。
当传入的 mapDispatchToProps 为函数时,同样也是调用 wrapMapToPropsFunc 计算结果,这个与 initMapStateToProps 的计算逻辑一致。
当传入的 mapDispatchToProps 为 null 时,处理的逻辑同 initMapStateToProps,区别在于传入的参数不是空函数,而是一个返回对象的函数,对象默认包含 dispatch 函数,这就使得我们使用 React-Redux 以后,可以在内部通过 this.props.dispatch 访问到 store 的 dispatch API:
Once you have connected your component in this way, your component receives
props.dispatch. You may use it to dispatch actions to the store.
当传入的 mapDispatchToProps 为对象时,说明这是一个 ActionCreator 对象,可以通过使用 redux 的 bindActionCreator API 将这个 ActionCreator 转化为包含很多函数的对象并 merge 到 props。
这一个函数的计算比较简单,代码如下:
import verifyPlainObject from '../utils/verifyPlainObject'
export function defaultMergeProps(stateProps, dispatchProps, ownProps) {
return { ...ownProps, ...stateProps, ...dispatchProps }
}
export function wrapMergePropsFunc(mergeProps) {
return function initMergePropsProxy(
dispatch,
{ displayName, pure, areMergedPropsEqual }
) {
let hasRunOnce = false
let mergedProps
return function mergePropsProxy(stateProps, dispatchProps, ownProps) {
const nextMergedProps = mergeProps(stateProps, dispatchProps, ownProps)
if (hasRunOnce) {
// 这里如果 pure === true 并且新旧 props 内容未变的时候
// 就不对 mergedProps 进行赋值,这样可以确保原来内容的引用不变,
// 可以让我们的 useMemo 或者 React.memo 起作用。
if (!pure || !areMergedPropsEqual(nextMergedProps, mergedProps))
mergedProps = nextMergedProps
} else {
hasRunOnce = true
mergedProps = nextMergedProps
if (process.env.NODE_ENV !== 'production')
verifyPlainObject(mergedProps, displayName, 'mergeProps')
}
return mergedProps
}
}
}
export function whenMergePropsIsFunction(mergeProps) {
return typeof mergeProps === 'function'
? wrapMergePropsFunc(mergeProps)
: undefined
}
export function whenMergePropsIsOmitted(mergeProps) {
return !mergeProps ? () => defaultMergeProps : undefined
}
export default [whenMergePropsIsFunction, whenMergePropsIsOmitted]基本上就是直接对 stateProps、dispatchProps 和 ownProps 三者的合并,加上了一些基本的校验。
现在我们得到了三个主要的函数:initMapStateToProps、initMapDispatchToProps 和 initMergeProps。我们知道了 React-Redux 是如何通过我们传入的参数结合 store 计算出被 connect 的组件的 props 的。
下面我们再来进一步了解一下,selectorFactory 函数是如何基于我们的 init... 系列函数计算最终的 props 的。
找到文件中的 selectorFactory.js 文件,可以看到 finalPropsSelectorFactory 函数,这个就是我们的 selectorFactory 函数。
代码如下:
export default function finalPropsSelectorFactory(
dispatch,
{ initMapStateToProps, initMapDispatchToProps, initMergeProps, ...options }
) {
const mapStateToProps = initMapStateToProps(dispatch, options)
const mapDispatchToProps = initMapDispatchToProps(dispatch, options)
const mergeProps = initMergeProps(dispatch, options)
if (process.env.NODE_ENV !== 'production') {
verifySubselectors(
mapStateToProps,
mapDispatchToProps,
mergeProps,
options.displayName
)
}
const selectorFactory = options.pure
? pureFinalPropsSelectorFactory
: impureFinalPropsSelectorFactory
return selectorFactory(
mapStateToProps,
mapDispatchToProps,
mergeProps,
dispatch,
options
)
}可以看到一开始通过 init... 系列函数计算出了需要的 mapStateToProps 、mapDispatchToProps 和 mergeProps 函数。
随后根据 options.pure 的值选择不同的函数进行下一步计算。
当 options.pure === true 时,意味着我们的组件为”纯组件“。
React Redux 源码不得不提的一个点就是配置项中的 pure 参数,我们可以在 createStore 的时候传入该配置,该配置默认为 true。
当 pure 为 true 的时候,React Redux 内部有几处地方就会针对性地进行优化,比如我们这里看到的 selectFactory。当 pure 为不同的值时选择不同的函数进行 props 的计算。如果我们的 pure 为 false,则每次都进行相应计算产生新的 props,传递给我们的内部组件,触发 rerender。
当我们的 pure 为 true 的时候,React Redux 会缓存上一次计算的相应结果,然后在下一次计算后对比结果是否相同,如果相同的话就会返回上一次的计算结果,一旦我们的组件是纯组件,则传入相同的 props 不会导致组件 rerender,达到了性能优化的目的。
当 pure 为 false 时,调用 impureFinalPropsSelectorFactory 计算 props:
export function impureFinalPropsSelectorFactory(
mapStateToProps,
mapDispatchToProps,
mergeProps,
dispatch
) {
return function impureFinalPropsSelector(state, ownProps) {
return mergeProps(
mapStateToProps(state, ownProps),
mapDispatchToProps(dispatch, ownProps),
ownProps
)
}
}这样每次计算都会返回新的 props,导致组件一直 rerender。
当 pure 为 true 时,调用 pureFinalPropsSelectorFactory 计算 props:
export function pureFinalPropsSelectorFactory(
mapStateToProps,
mapDispatchToProps,
mergeProps,
dispatch,
{ areStatesEqual, areOwnPropsEqual, areStatePropsEqual }
) {
let hasRunAtLeastOnce = false
let state
let ownProps
let stateProps
let dispatchProps
let mergedProps
function handleFirstCall(firstState, firstOwnProps) {
state = firstState
ownProps = firstOwnProps
stateProps = mapStateToProps(state, ownProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
hasRunAtLeastOnce = true
return mergedProps
}
function handleNewPropsAndNewState() {
stateProps = mapStateToProps(state, ownProps)
if (mapDispatchToProps.dependsOnOwnProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
function handleNewProps() {
if (mapStateToProps.dependsOnOwnProps)
stateProps = mapStateToProps(state, ownProps)
if (mapDispatchToProps.dependsOnOwnProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
function handleNewState() {
const nextStateProps = mapStateToProps(state, ownProps)
const statePropsChanged = !areStatePropsEqual(nextStateProps, stateProps)
stateProps = nextStateProps
if (statePropsChanged)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
function handleSubsequentCalls(nextState, nextOwnProps) {
const propsChanged = !areOwnPropsEqual(nextOwnProps, ownProps)
const stateChanged = !areStatesEqual(nextState, state)
state = nextState
ownProps = nextOwnProps
if (propsChanged && stateChanged) return handleNewPropsAndNewState()
if (propsChanged) return handleNewProps()
if (stateChanged) return handleNewState()
return mergedProps
}
return function pureFinalPropsSelector(nextState, nextOwnProps) {
return hasRunAtLeastOnce
? handleSubsequentCalls(nextState, nextOwnProps)
: handleFirstCall(nextState, nextOwnProps)
}
}可以看到第一次计算时的过程跟 impureFinalPropsSelectorFactory 一致,但是多了个闭包内缓存的过程,在随后的 props 计算当中,会根据 state 和 props 的变化情况选择不同的函数进行计算,这样做是为了尽可能的减少计算量,优化性能。如果 state 和 props 都没有发生变化的话,就直接返回缓存的 props。
可以看到这段代码里面对比变量是否不同的函数有这么几个:areOwnPropsEqual、areStatesEqual、areStatePropsEqual。在前文中我们还看到过 areMergedPropsEqual 这个函数,他们都在 connect 函数定义时已经被赋值:
areStatesEqual = strictEqual,
areOwnPropsEqual = shallowEqual,
areStatePropsEqual = shallowEqual,
areMergedPropsEqual = shallowEqualstrictEqual 的定义:
function strictEqual(a, b) {
return a === b
}而 shallowEqual 的定义如下:
// 眼尖的朋友可能会发现这段代码来自于 React 源码
function is(x, y) {
if (x === y) {
return x !== 0 || y !== 0 || 1 / x === 1 / y
} else {
return x !== x && y !== y
}
}
export default function shallowEqual(objA, objB) {
if (is(objA, objB)) return true
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false
}
const keysA = Object.keys(objA)
const keysB = Object.keys(objB)
if (keysA.length !== keysB.length) return false
for (let i = 0; i < keysA.length; i++) {
if (
!Object.prototype.hasOwnProperty.call(objB, keysA[i]) ||
!is(objA[keysA[i]], objB[keysA[i]])
) {
return false
}
}
return true
}可以看到前者的对比简单粗暴,后者的对比更加细腻。
为什么 state 的对比会跟其他三者不一样呢?
这是因为 state 比较特殊,查看 Redux 的源码:combineReducers.ts。不难发现当我们的所有 reducers 返回的内容不变(维持原有的引用)时,我们最终得到的 state(Store.getState() 返回的对象)也会维持原有引用,使得 oldState === newState 成立,所以我们在 React Redux 中对于 state 的对比会比其他三个要简单许多。
为什么 Redux 能够确保 reducer 没有修改 state 的时候返回的是原来的 state,而 reducer 修改后的 state 的引用关系一定发生了变化呢?是因为 redux 要求使用者在定义 reducer 时按照这样的要求做,在 reducer 产生新数据时一定要新建对象(通过扩展语法... 或者 Object.assisgn),在没有匹配到 action.type 时一定返回旧对象。这一点可以在之前提到的 combineReducers 的源码中仍然可以看到许多针对性的检查。
看完 2.4 小节,我们其实可以发现 selectorFactory 确实符合第二大节开始时提到的标准格式:
(dispatch, options) => (nextState, nextOwnProps) => nextFinalProps我希望大家能够记住这个结论,因为有助于我们后面理解相关的代码。
了解了 selectorFactory 的工作原理之后,我们再看看在 connectAdvanced 内部是如何使用它的。
我们已经知晓了是 React Redux 如何通过 state 和 props 计算出下一次渲染所需要使用的 props。这一节回到 connectAdvenced 函数看看我们的 props 是在什么时机被计算的。
connectAdvanced 函数实际上就是我们使用到的 connect 函数,它接受相应配置以及相关组件,返回给我们一个高阶组件。
打开 src/components/connectAdvanced.js 文件,可以看到该函数在前面一小部分做了部分校验之后,直接返回了一个拥有一大段代码的函数:wrapWithConnect,这个函数大概有三百多行,它就是我们执行 connect(...) 之后返回的函数,可想而知该函数接受一个__我们定义的 UI 组件,返回给我们一个容器组件__。
我们依次看下去这段代码,拣一部分最重要的代码进行分析。
const selectorFactoryOptions = {
...connectOptions,
getDisplayName,
methodName,
renderCountProp,
shouldHandleStateChanges,
storeKey,
displayName,
wrappedComponentName,
WrappedComponent
}
const { pure } = connectOptions
function createChildSelector(store) {
return selectorFactory(store.dispatch, selectorFactoryOptions)
}首先可以看到这段代码,它根据相关参数构建了一个 selectorFactoryOptions 对象,然后新建了一个 createChildSelector 函数,这个函数用于调用我们之前分析过的 selectorFactory 函数,我们知道 selectorFactory 函数符合我们的标准格式,所以调用 selectorFactory 会得到一个新的函数,该函数接受 state 和 props,返回计算出的下一次渲染所需要的 props。所以 createChildSelector 得到的结果就是一个 props 计算函数。这里之所以要这么做是为了计算得到当前 store 需要用到的 props 计算函数,防止后面需要计算时又要重新调用。而当我们的 store 对象发生变化以后,这个函数又会被重新调用:
// childPropsSelector 函数用于根据 mapStateToProps、mapDispatchToProps 等配置
// 计算 store 更新后的组件 props
const childPropsSelector = useMemo(() => {
// The child props selector needs the store reference as an input.
// Re-create this selector whenever the store changes.
return createChildSelector(store)
}, [store])可以看到这里也使用 useMemo 进行了优化。
昨晚一些前置工作之后,内部定义了一个 ConnectFunction,这就是我们真正用于渲染的组件,最后会被 connect()() 返回。我们向容器组件传递 props 的时候,就是传递给了 ConnectFunction。
在一开始,ConnectFunction 会准备一些将要用到的数据:
const [propsContext, forwardedRef, wrapperProps] = useMemo(() => {
// Distinguish between actual "data" props that were passed to the wrapper component,
// and values needed to control behavior (forwarded refs, alternate context instances).
// To maintain the wrapperProps object reference, memoize this destructuring.
const { forwardedRef, ...wrapperProps } = props
return [props.context, forwardedRef, wrapperProps]
}, [props])
// 根据 propsContext 和 Context 计算要使用的 context,其中 propsContext 来自于外部传递,Context 来自于内部
// 如果 ContainerComponent 有接受到 context 属性,那么就是用传入的这个 context,否则使用 Context.js 定义的那个。
// 同时那也是提供 store 对象的那个 context。
const ContextToUse = useMemo(() => {
// Users may optionally pass in a custom context instance to use instead of our ReactReduxContext.
// Memoize the check that determines which context instance we should use.
return propsContext &&
propsContext.Consumer &&
isContextConsumer(<propsContext.Consumer />)
? propsContext
: Context
}, [propsContext, Context])
// 通过 useContext 使用 context,并且订阅其变化,当 context 变化时会 re-render。
// Retrieve the store and ancestor subscription via context, if available
const contextValue = useContext(ContextToUse)
// The store _must_ exist as either a prop or in context.
// We'll check to see if it _looks_ like a Redux store first.
// This allows us to pass through a `store` prop that is just a plain value.
// 检查 props 以及 context 中是否有 store,如果都没有那就没法玩了。
// 所以这里我们其实也可以给 ContainerComponent 传入一个 store props 作为我们 connect 的 store
const didStoreComeFromProps =
Boolean(props.store) &&
Boolean(props.store.getState) &&
Boolean(props.store.dispatch)
const didStoreComeFromContext =
Boolean(contextValue) && Boolean(contextValue.store)
// Based on the previous check, one of these must be true
// 使用传入的 store,如果 ContainerComponent 接收到了 store,那就用它作为 store。
// 实验证明确实可以使用 DisplayComponent 的 props 传入 store,并且如果传入了的话,该组件就会使用 props 中的 store 而非 context 中的。
const store = didStoreComeFromProps ? props.store : contextValue.store上面代码中的 props 就是我们传递给容器组件的 props,首先会从其中解析出我们的 forwardedRef、context 和 其他 props 属性。
forwardedRef 用于将我们在容器组件上设置的 ref 属性通过 React.forwardRef API 转交给内部的 UI 组件。
context 属性用于计算我们将要使用到的 context 。其他 props 用于计算 UI 组件需要用到的 props。
当决定了要使用哪个 context 的时候,就会通过 useContext API 使用其传递的值,所以我们这里用到的是 React Hooks,我们通过 useContext API 即可使用到 Provider 内部的内容,而无需使用 Consumer 组件。
上面的最后一段代码用于判断我们的 store 应该用哪个来源的数据,可以看到如果我们给我们的容器组件传递了 store 属性的话,React Redux 就会使用这个 store 作为数据来源,而不是顶层 Context 内的 store 对象。
如果我们先不考虑组件是如何订阅 store 更新的话,我们可以先看 UI 组件需要的 props 是如何计算出来并且应用的。
// childPropsSelector 函数用于根据 mapStateToProps、mapDispatchToProps 等配置
// 计算 store 更新后的组件 props
const childPropsSelector = useMemo(() => {
// The child props selector needs the store reference as an input.
// Re-create this selector whenever the store changes.
return createChildSelector(store)
}, [store])这段代码我们之前有分析过,createChildSelector 函数用于调用 selectorFactory,返回 selectorFactory 调用一次之后的结果,由于 selectorFactory 符合我们的设计规范:
(dispatch, options) => (nextState, nextOwnProps) => nextFinalProps所以 childPropsSelector 返回的函数就符合下面的规范:
(nextState, nextOwnProps) => nextFinalProps在整个函数的后半段,会有下面这段计算代码:
// If we aren't running in "pure" mode, we don't want to memoize values.
// To avoid conditionally calling hooks, we fall back to a tiny wrapper
// that just executes the given callback immediately.
const usePureOnlyMemo = pure ? useMemo : callback => callback()
// 最终使用的 props
const actualChildProps = usePureOnlyMemo(() => {
// ...忽略部分代码
return childPropsSelector(store.getState(), wrapperProps)
}, [store, previousStateUpdateResult, wrapperProps])可以看到这里也根据 options.pure 选项决定是否缓存计算结果,如果不是 true 的话会每次更新 store、previousStateUpdateResult 或者 wrapperProps 都会导致 actualChildProps 重新计算。
所以这里的 actualChildProps 就是我们上方规范中的 nextFinalProps。
计算出最终用到的 props 之后,就开始渲染我们的 UI 组件了:
// Now that all that's done, we can finally try to actually render the child component.
// We memoize the elements for the rendered child component as an optimization.
const renderedWrappedComponent = useMemo(
() => <WrappedComponent {...actualChildProps} ref={forwardedRef} />,
[forwardedRef, WrappedComponent, actualChildProps]
)上方代码中的 WrappedComponent 组件即为我们传入的 UI 组件,可以看到最后 forwardedRef(本来是容器组件的 ref)最终被指到了内部的 UI 组件上。
renderedWrappedComponent 组件就是我们渲染 UI 组件的结果,然而我们还不能直接拿去返回给用户渲染,我们还要考虑其他情况,我们接下来看看 UI 组件是如何订阅 store 更新的。
在我们的阅读源码的时候,可能经常会看到这个 subscription 对象,这个对象用于实现组件对于 store 更新的订阅,是 React Redux 实现数据更新的关键。接下来我们深入该 API 的实现及功能。
打开我们的 src/utils/Subscription.js 文件,该文件总共就两个函数:createListenerCollection 和 Subscription。前者是辅助工具,后者是我们的真正使用到的 API。
先看这个工具函数:
const CLEARED = null
const nullListeners = { notify() {} }
function createListenerCollection() {
const batch = getBatch()
// the current/next pattern is copied from redux's createStore code.
// TODO: refactor+expose that code to be reusable here?
// 此处使用两个队列,防止在 notify 的同时进行 subscribe 导致的边缘行为
// Reference: https://github.com/reduxjs/react-redux/pull/1450#issuecomment-550382242
let current = []
let next = []
return {
clear() {
next = CLEARED
current = CLEARED
},
notify() {
const listeners = (current = next)
batch(() => {
for (let i = 0; i < listeners.length; i++) {
listeners[i]()
}
})
},
get() {
return next
},
subscribe(listener) {
let isSubscribed = true
if (next === current) next = current.slice()
next.push(listener)
return function unsubscribe() {
if (!isSubscribed || current === CLEARED) return
isSubscribed = false
if (next === current) next = current.slice()
next.splice(next.indexOf(listener), 1)
}
}
}
}可以看到在这个函数返回的对象内部定义了两个队列,一个 next,一个 current,他们用于存放订阅当前对象更新的 listener,一个用于存放下一步更新后的队列。这样做是为了防止在 notify 执行后,队列被遍历时又开始调用 subscribe 或者 unsubscribe 函数导致队列发生变化导致的一些边缘问题。每次 notify 之前都会同步 current 为 next,随后的 subscribe 执行都是在 next 的基础上执行。
总而言之这是一个返回纯对象的函数,而这个对象的作用就是一个事件发布订阅中心,这是属于观察者模式的应用,我们的所有 listener 都会监听当前对象,一旦当前对象调用 notify,所有 listener 都会被执行。而这个对象的 subscribe 或者 notify 的调用时机取决于该对象的使用者。
下面是 subscription 对象的源码:
export default class Subscription {
constructor(store, parentSub) {
this.store = store
this.parentSub = parentSub
this.unsubscribe = null
this.listeners = nullListeners
// 绑定好 this,因为之后会在其他地方执行
this.handleChangeWrapper = this.handleChangeWrapper.bind(this)
}
addNestedSub(listener) {
// 先执行 trySubscribe 函数,确定当前实例的订阅目标(parentSub or store)
this.trySubscribe()
// 子订阅都集中在 this.listeners 进行管理
return this.listeners.subscribe(listener)
}
notifyNestedSubs() {
this.listeners.notify()
}
handleChangeWrapper() {
// this.onStateChange 由外部提供
if (this.onStateChange) {
this.onStateChange()
}
}
isSubscribed() {
return Boolean(this.unsubscribe)
}
trySubscribe() {
if (!this.unsubscribe) {
this.unsubscribe = this.parentSub
? this.parentSub.addNestedSub(this.handleChangeWrapper)
: this.store.subscribe(this.handleChangeWrapper)
this.listeners = createListenerCollection()
}
}
tryUnsubscribe() {
if (this.unsubscribe) {
this.unsubscribe()
this.unsubscribe = null
this.listeners.clear()
this.listeners = nullListeners
}
}
}我们先看其构造函数,总共接受了两个参数:store 和 parentSub,这个 store 就是你所想到的 store,是 Redux 的数据中心。它在该类的另一个函数 trySubscribe 中被使用到:
trySubscribe() {
if (!this.unsubscribe) {
this.unsubscribe = this.parentSub
? this.parentSub.addNestedSub(this.handleChangeWrapper)
: this.store.subscribe(this.handleChangeWrapper)
this.listeners = createListenerCollection()
}
}可以看到如果没有 unsubscribe 属性的话,会根据是否有 parentSub 属性进行下一步计算,这说明我们的 parentSub 是一个可选参数。如果没有 parentSub 的话就会直接使用 store.subscribe 来订阅 store 的更新,一旦数据更新,则会执行改类的 handleChangeWrapper 函数。如果有 parentSub 属性的话,就会执行 parentSub 的 addNestedSub 函数,因为这个函数存在于 Subscription 类上,所以可以猜想 parentSub 即为 Subscription 的一个实例。
在执行完 unsubscribe 的初始化之后,会初始化 listeners 的初始化,这里就用到了我们之前提到的那个工具函数。
我们看到订阅 store 更新的函数是 Subscription.prototype.handleChangeWrapper:
handleChangeWrapper() {
// this.onStateChange 由外部提供
if (this.onStateChange) {
this.onStateChange()
}
}而 onStateChange 函数在 Subscription 上并未被定义,只能说明这个函数在使用时被定义。等下我们阅读使用这个类的代码时可以看到。
我们再看看 Subscription 是如何使用我们的 listener 的:
addNestedSub(listener) {
// 先执行 trySubscribe 函数,确定当前实例的订阅目标(parentSub or store)
this.trySubscribe()
// 子订阅都集中在 this.listeners 进行管理
return this.listeners.subscribe(listener)
}
notifyNestedSubs() {
this.listeners.notify()
}addNestedSub 是 Subscription 的实例作为另一个 Subscription 实例的 parentSub 属性时被调用执行的函数,这个函数会把子 Subscription 实例的 handleChangeWrapper 函数注册到父 Subscription 实例的 listeners 中,当父 Subscription 实例调用 notifyNestedSub 时,所有的子 Subscription 的 handleChangeWrapper 函数都会被执行。
这就达到了一个目的,React Redux 通过 Subscription 和 listeners 可以构造一个 Subscription 实例构成的树,顶部的 Subscription 实例可以订阅 store 的变化,store 变化之后会执行 handleChangeWrapper 函数,而如果我们的 handleChangeWrapper 函数(内部执行 onStateChange)会调用 notifyNestedSub 函数的话,那不就所有的下层 Subscription 实例都会得到更新的消息?从而子 Subscription 实例的 handleChangeWrapper 函数就会被执行。这是一个由上而下的事件传递机制,确保了顶部的事件会被按层级先上后下的传递到下层。
示意图:
通过这张示意图我们就可以很清楚的看到 Subscription 是如何实现事件由上而下派发的机制了。
回过头继续看我们如何实现组件订阅 Store 数据更新。
const [subscription, notifyNestedSubs] = useMemo(() => {
if (!shouldHandleStateChanges) return NO_SUBSCRIPTION_ARRAY
// This Subscription's source should match where store came from: props vs. context. A component
// connected to the store via props shouldn't use subscription from context, or vice versa.
// 如果 store 来自于最底层的 Provider,那么 parentSub 也要来自于 Provider
const subscription = new Subscription(
store,
didStoreComeFromProps ? null : contextValue.subscription
)
// `notifyNestedSubs` is duplicated to handle the case where the component is unmounted in
// the middle of the notification loop, where `subscription` will then be null. This can
// probably be avoided if Subscription's listeners logic is changed to not call listeners
// that have been unsubscribed in the middle of the notification loop.
const notifyNestedSubs = subscription.notifyNestedSubs.bind(
subscription
)
return [subscription, notifyNestedSubs]
}, [store, didStoreComeFromProps, contextValue])这是在计算当前组件用到的 subscription 实例和 notifyNestedSub 函数。
第一行代码标识如果用户配置了不处理 store 变化的话,就不需要 subscription 这个功能了。
后面开始初始化当前组件的 subscription 对象,如果 store 来自于 props,那么当前组件就是 Subscription 树最顶层的组件,它没有 parentSub,它直接订阅 store 的变化。
如果当前 store 来自于 context,那么表示它可能不是顶层的 Subscription 实例,需要考虑 contextValue 当中有没有包含 subscription 属性,如果有的话就需要将其作为 parentSub 进行实例化。
最后计算 notifyNestedSub 函数,之所以要绑定是因为像我之前在 Subscription 树状图中画的那样,这个函数要作为 subscription 实例的 handleChangeWrapper 函数调用,所以要确保 this 的指向不变。
这里容易产生一个疑问,为什么在 contextValue 中会有一个 subscription 实例传过来呢?我们在之前查看 Provider 组件源码的时候也没看到有这个属性呀。其实是后面的代码重写了传递给下层组件的 contextValue,确保下层被 connect 的组件能够拿到上层组件的 subscription 实例,达到构建 Subscription 树的目的:
// Determine what {store, subscription} value should be put into nested context, if necessary,
// and memoize that value to avoid unnecessary context updates.
const overriddenContextValue = useMemo(() => {
if (didStoreComeFromProps) {
// This component is directly subscribed to a store from props.
// We don't want descendants reading from this store - pass down whatever
// the existing context value is from the nearest connected ancestor.
return contextValue
}
// Otherwise, put this component's subscription instance into context, so that
// connected descendants won't update until after this component is done
// 如果 store 来源于底层的 Provider,那么继续向下一层传递 subscription。
return {
...contextValue,
subscription
}
}, [didStoreComeFromProps, contextValue, subscription])这个 overriddenContextValue 属性就是被重写后的 contextValue,可以看到它把当前组件的 subscription 传到了下一层,这也就回到了 2.6 小节没有讲完的部分,也就是 ConnectFunction 的最后一段代码:
// If React sees the exact same element reference as last time, it bails out of re-rendering
// that child, same as if it was wrapped in React.memo() or returned false from shouldComponentUpdate.
const renderedChild = useMemo(() => {
if (shouldHandleStateChanges) {
// If this component is subscribed to store updates, we need to pass its own
// subscription instance down to our descendants. That means rendering the same
// Context instance, and putting a different value into the context.
return (
<ContextToUse.Provider value={overriddenContextValue}>
{renderedWrappedComponent}
</ContextToUse.Provider>
)
}
return renderedWrappedComponent
}, [ContextToUse, renderedWrappedComponent, overriddenContextValue])
return renderedChild如果我们配置了需要处理 store 更新的话,就会重新使用 Provider 包裹下一层组件(即我们的 UI 组件),组件接受到的 contextValue 就是我们重写后的 contextValue:overriddenContextValue。
所以下一层组件被 connect 之后,它的 ConnectFunction 就可以在 contextValue 中拿到它上一层组件的 subscription 对象,这样就将组件树关联起来啦,这是很重要的一步!
组件树之间的 subscription 树构建好之后,我们就需要看看他们之间是如何传递事件的。
在 ConnectFunction 内部,定义了一系列 ref:
// Set up refs to coordinate values between the subscription effect and the render logic
const lastChildProps = useRef()
const lastWrapperProps = useRef(wrapperProps)
const childPropsFromStoreUpdate = useRef()
const renderIsScheduled = useRef(false)我们知道 React 的函数组件在每一次渲染的时候都拥有一个独立的上下文环境(不知道的童鞋可以阅读:精读《useEffect 完全指南》),为了防止每次 ConnectFunction 渲染拿不到上一次渲染的相关参数,我们需要 ref 来进行状态保留。
这里的四个 ref 保留了上一次 UI 组件渲染用到的 props、上一次的 wrapperProps 数据以及两个标志变量的内容。其中 childPropsFromStoreUpdate 代表由于 Store 更新导致的新的 props,renderIsScheduled 代表是否需要进行一次 rerender。
// 最终使用的 props
const actualChildProps = usePureOnlyMemo(() => {
// Tricky logic here:
// - This render may have been triggered by a Redux store update that produced new child props
// - However, we may have gotten new wrapper props after that
// If we have new child props, and the same wrapper props, we know we should use the new child props as-is.
// But, if we have new wrapper props, those might change the child props, so we have to recalculate things.
// So, we'll use the child props from store update only if the wrapper props are the same as last time.
if (
childPropsFromStoreUpdate.current &&
wrapperProps === lastWrapperProps.current
) {
return childPropsFromStoreUpdate.current
}
// TODO We're reading the store directly in render() here. Bad idea?
// This will likely cause Bad Things (TM) to happen in Concurrent Mode.
// Note that we do this because on renders _not_ caused by store updates, we need the latest store state
// to determine what the child props should be.
return childPropsSelector(store.getState(), wrapperProps)
}, [store, previousStateUpdateResult, wrapperProps])上面这是完整的 actualChildProps 的计算过程,不难发现其中关于 childPropsFromStoreUpdate 和 lastWrapperProps 的对比以及其注释。
这段代码的作用是如果在计算过程中由于 store 的更新导致新的 props 产生,并且当前 wrapperProps 没有发生变化,那么就直接使用新的 props,如果 wrapperProps 产生了变化的话就不能直接使用了,因为 wrapperProps 的变化可能导致计算的结果发生变化。
我们继续找到 subscription 实例的订阅代码:
// Actually subscribe to the nearest connected ancestor (or store)
// 订阅上层 subscription 的通知,当接受到通知时,说明 store state 发生了变化
// 需要判断是否 re-render,此时就会执行 checkForUpdates
subscription.onStateChange = checkForUpdates
subscription.trySubscribe()这里将当前 subscription 的 onStateChange 函数设置成了 checkForUpdates,如果当前 subscription 接收到了 store 更新的消息的话,就会执行 checkForUpdates 函数进行相关状态的更新以及 rerender。
那我们继续找到 checkForUpdates 函数的实现代码:
// We'll run this callback every time a store subscription update propagates to this component
// 每次收到 store state 更新的通知时,执行这个函数
const checkForUpdates = () => {
if (didUnsubscribe) {
// Don't run stale listeners.
// Redux doesn't guarantee unsubscriptions happen until next dispatch.
return
}
const latestStoreState = store.getState()
let newChildProps, error
try {
// Actually run the selector with the most recent store state and wrapper props
// to determine what the child props should be
newChildProps = childPropsSelector(
latestStoreState,
lastWrapperProps.current
)
} catch (e) {
error = e
lastThrownError = e
}
if (!error) {
lastThrownError = null
}
// If the child props haven't changed, nothing to do here - cascade the subscription update
if (newChildProps === lastChildProps.current) {
if (!renderIsScheduled.current) {
notifyNestedSubs()
}
} else {
// Save references to the new child props. Note that we track the "child props from store update"
// as a ref instead of a useState/useReducer because we need a way to determine if that value has
// been processed. If this went into useState/useReducer, we couldn't clear out the value without
// forcing another re-render, which we don't want.
lastChildProps.current = newChildProps
childPropsFromStoreUpdate.current = newChildProps
renderIsScheduled.current = true
// If the child props _did_ change (or we caught an error), this wrapper component needs to re-render
// 如果需要更新,执行 forceComponentUpdateDispatch 函数强制更新当前组件,这样就通过 subscription 完成了
// state 的更新和组件的 re-render
forceComponentUpdateDispatch({
type: 'STORE_UPDATED',
payload: {
error
}
})
}
}可以看到 store 更新事件到达后,会先计算出一个 newChildProps,即我们新的 props,过程中如果有计算错误会被保存。
如果计算出来的 props 和当前 lastChildProps 引用的结果一致的话,说明数据没有发生变化,组件如果没有更新计划的话就需要手动触发 notifyNestedSubs 函数通知子组件更新。
如果计算出来的 props 和之前的 props 不相等的话,说明 store 的更新导致 props 发生了变化,需要更新相关引用,并触发当前组件更新,当前组件更新后 ConnectFunction 的相关计算又开始了新的一轮,所以又回到了我们之前讲的 actualChildProps 数据的计算。这也是为什么在 actualChildProps 的计算过程中还要考虑 props 和 wrapperProps 的更新。
我们看到 checkForUpdates 更新当前组件是调用了 forceComponentUpdateDispatch 函数,我们看看其实现:
function storeStateUpdatesReducer(state, action) {
const [, updateCount] = state
return [action.payload, updateCount + 1]
}
// We need to force this wrapper component to re-render whenever a Redux store update
// causes a change to the calculated child component props (or we caught an error in mapState)
// 通过 useReducer 强制更新当前组件,因为每次 dispatch 之后 state 都会发生变化
// storeStateUpdatesReducer 返回的数组的第二个参数会一直增加
const [
[previousStateUpdateResult],
forceComponentUpdateDispatch
] = useReducer(storeStateUpdatesReducer, EMPTY_ARRAY, initStateUpdates)
// 如果下层组件在使用时有捕获到错误,则在当前这层抛出
// Propagate any mapState/mapDispatch errors upwards
if (previousStateUpdateResult && previousStateUpdateResult.error) {
throw previousStateUpdateResult.error
}这里通过 useReducer Hooks 构造了一个数据和一个更新函数。
我们看到 reducer 是一个每次都会固定更新的函数(updateCount 永远自增),所以每次调用 forceComponentUpdateDispatch 都会导致当前组件重新渲染。而其数据中 error 的来源就是我们 checkForUpdates 计算下一次 props 的时候捕捉到的错误:
forceComponentUpdateDispatch({
type: 'STORE_UPDATED',
payload: {
error
}
})如果在计算过程中产生了错误,会在下一次渲染的时候抛出来。
我们需要在组件渲染之后更新之前的引用,所以会有下面这段代码:
// We need this to execute synchronously every time we re-render. However, React warns
// about useLayoutEffect in SSR, so we try to detect environment and fall back to
// just useEffect instead to avoid the warning, since neither will run anyway.
// 通过使用 useLayoutEffect 实现在 DOM 更新之后做一些操作,这里是在 DOM 更新之后更新内部的一些 ref
// 确保下一次判断时使用的 ref 是最新的
useIsomorphicLayoutEffect(() => {
// We want to capture the wrapper props and child props we used for later comparisons
lastWrapperProps.current = wrapperProps
lastChildProps.current = actualChildProps
renderIsScheduled.current = false
// If the render was from a store update, clear out that reference and cascade the subscriber update
if (childPropsFromStoreUpdate.current) {
childPropsFromStoreUpdate.current = null
notifyNestedSubs()
}
})同时可以看到在渲染完成之后,会通知所有子组件 store 数据发生了更新。
值得注意的是 useIsomorphicLayoutEffect 这个自定义 Hook:
// React currently throws a warning when using useLayoutEffect on the server.
// To get around it, we can conditionally useEffect on the server (no-op) and
// useLayoutEffect in the browser. We need useLayoutEffect to ensure the store
// subscription callback always has the selector from the latest render commit
// available, otherwise a store update may happen between render and the effect,
// which may cause missed updates; we also must ensure the store subscription
// is created synchronously, otherwise a store update may occur before the
// subscription is created and an inconsistent state may be observed
// 参考:https://reactjs.org/docs/hooks-reference.html#uselayouteffect
export const useIsomorphicLayoutEffect =
typeof window !== 'undefined' &&
typeof window.document !== 'undefined' &&
typeof window.document.createElement !== 'undefined'
? useLayoutEffect
: useEffect由于 useLayoutEffect 不适用于 SSR 的场景,所以会使用 useEffect 作为 fallback。
讲到这里,React Redux 的工作原理基本就解析完了,文章中为了避免出现大段的代码已经尽量少的粘贴源码,所以可能会导致阅读起来会存在一定困难。建议大家去我的 GitHub 上面看源码,包含有相关注释,有什么问题也可以在 issues 提出哦。
Invalid Cookie Values 解决:
ignoreErrors: true在一个多月的毕业设计之后,我再次开始了Underscore的源码阅读学习,断断续续也写了好些篇文章了,基本把一些比较重要的或者个人认为有营养的函数都解读了一遍,所以现在学习一下Underscore的整体架构。我相信很多程序员都会有一个梦想,那就是可以写一个自己的模块或者工具库,那么我们现在就来学习一下如果我们要写一个自己的Underscore,我们该怎么写?
大致的阅读了一下Underscore源码,可以发现其基本架构如下:
在ES6之前,JavaScript开发者是无法通过let、const关键字模拟块作用域的,只有函数内部的变量会被认为是私有变量,在外部无法访问,所以大部分框架或者工具库的模式都是在立即执行函数里面定义一系列的变量,完成框架或者工具库的构建,这样做的好处就是代码不会污染全局作用域。Underscore也不例外,它也使用了经典的立即执行函数的模式:
(function() {
// ...
}())
此外,Underscore采用了经典的构造器模式,这使得用户可以通过_(obj).function()的方式使用Underscore的接口,因为任意创建的Underscore对象都具有原型上的所有方法。那么代码形式如下:
(function() {
var _ = function() {
// ...
};
}())
_是一个函数,但是在JavaScript中,函数也是一个对象,所以我们可以给_添加一系列属性,即Underscore中的一系列公开的接口,以便可以通过_.function()的形式调用这些接口。代码形式如下:
(function() {
var _ = function() {
// ...
};
_.each = function() {
// ...
};
// ...
}())
_变量可以当做构造器构造一个Underscore对象,这个对象是标准化的,它具有规定的属性,比如:_chain、_wrapped以及所有Underscore的接口方法。Underscore把需要处理的参数传递给_构造函数,构造函数会把这个值赋给所构造对象的_wrapped属性,这样做的好处就是在之后以_(obj).function()形式调用接口时,可以直接到_wrapped属性中寻找要处理的值。这就使得在定义_构造函数的时候,需要对传入的参数进行包裹,此外还要防止多层包裹,以及为了防止增加new操作符,需要在内部进行对象构建,代码形式如下:
(function() {
var _ = function(obj) {
// 防止重复包裹的处理,如果obj已经是_的实例,那么直接返回obj。
if(obj instanceof _) {
return obj;
}
// 判断函数中this的指向,如果this不是_的实例,那么返回构造的_实例。
// 这里是为了不使用new操作符构造新对象,很巧妙,因为在通过new使用构造函数时,函数中的this会指向新构造的实例。
if(!(this instanceof _)) {
return new _();
}
//
this._wrapped = obj;
};
_.each = function() {
// ...
};
// ...
}())
这一段的处理很关键也很巧妙。
既然我们是在立即执行函数内定义的变量,那么_的生命周期也只存在于匿名函数的执行阶段,一旦函数执行完毕,这个变量所存储的数据也就被释放掉了,所以不导出变量的话实际上这段代码相当于什么都没做。那么该如何导出变量呢?我们知道函数内部可以访问到外部的变量,所以只要把变量赋值给外部作用域或者外部作用域变量就行了。通常为了方便实用,把变量赋值给全局作用域,不同的环境全局作用域名称不同,浏览器环境下通常为window,服务器环境下通常为global,根据不同的使用环境需要做不同的处理,比如浏览器环境下代码形式如下:
(function() {
var _ = function() {
// ...
};
_.each = function() {
// ...
};
// ...
window._ = _;
}())
这样处理之后,在全局作用域就可以直接通过_使用Underscore的接口了。
但是仅仅这样处理还不够,因为Underscore面向环境很多,针对不同的环境要做不同的处理。接下来看Underscore源码。
首先,Underscore通过以下代码根据不同的环境获取不同的全局作用域:
//获取全局对象,在浏览器中是self或者window,在服务器端(Node)中是global。
//在浏览器控制台中输入self或者self.self,结果都是window。
var root = typeof self == 'object' && self.self === self && self || typeof global == 'object' && global.global === global && global || this || {};
root._ = _;
注释写在了代码中,如果既不是浏览器环境也不是Node环境的话,就获取值为this,如果this仍然为空,就赋值给一个空的对象。这里我不太明白赋值给空对象有什么意义,这样的话外部还是无法访问到这个对象的,如果有知道的童鞋欢迎在评论中告诉我,大家一起学习!
这里值得学习的地方还有作者关于赋值的写法,十分简洁,尝试了一下,对于下面的写法:
const flag = val1 && val2 && val3 || val4 && val5;
程序会从左到右依次判断val1、val2、val3的值,假设||把与运算分为许多组,那么:
比如:
const a = 1 && 2 && 3 || 2 && 3;
// a === 3
const b = 1 && false && 2 || 2 && 3;
// b === 3
const c = 1 && false && 2 || false && 2
// c === false
const d = 1 && false && 2 || 0 && 2
// d === 0
const e = 1 && false && 2 || 1 && 2
// e === 2
除了要考虑给全局作用域赋值的差异以外,还要考虑JavaScript模块化规范的差异,JavaScript模块化规范包括AMD、CMD等。
通过以下代码兼容AMD规范:
//兼容AMD规范的模块化工具,比如RequireJS。
if (typeof define == 'function' && define.amd) {
define('underscore', [], function () {
return _;
});
}
如果define是一个函数并且define.amd不为null或者undefined,那就说明是在AMD规范的工作环境下,使用define函数导出变量。
通过以下代码兼容CommonJS规范:
//为Node环境导出underscore,如果存在exports对象或者module.exports对象并且这两个对象不是HTML DOM,那么即为Node环境。
//如果不存在以上对象,把_变量赋值给全局环境(浏览器环境下为window)。
if (typeof exports != 'undefined' && !exports.nodeType) {
if (typeof module != 'undefined' && !module.nodeType && module.exports) {
exports = module.exports = _;
}
exports._ = _;
} else {
root._ = _;
}
此外,通过以上代码可以支持ES6模块的import语法。具体原理参考阮一峰老师的教程:ES6 模块加载 CommonJS 模块。如果既不是AMD规范也不是CommonJS规范,那么直接将_赋值给全局变量。这一点可以通过将Underscore源码复制到浏览器的控制台回车后再查看_和_.prototype的值得到结论。
导出变量之后,在外部就可以使用我们定义的接口了。
许多出名的工具库都会提供链式调用功能,比如jQuery的链式调用:$('...').css().click();,Underscore也提供了链式调用功能:_.chain(...).each().unzip();。
链式调用基本都是通过返回原对象实现的,比如返回this,在Underscore中,可以通过_.chain函数开始链式调用,实现原理如下:
// Add a "chain" function. Start chaining a wrapped Underscore object.
//将传入的对象包装为链式调用的对象,将其标志位置位true。
_.chain = function (obj) {
var instance = _(obj);
instance._chain = true;
return instance;
};
它构造一个_实例,然后将其_chain链式标志位属性值为true代表链式调用,然后返回这个实例。这样做就是为了强制通过_().function()的方式调用接口,因为在_的原型上,所有接口方法与_的属性方法有差异,_原型上的方法多了一个步骤,它会对其父对象的_chain属性进行判断,如果为true,那么就继续使用_.chain方法进行链式调用的包装,在一部分在后续会继续讨论。
在许多出名的工具库中,都可以实现用户扩展接口,比如jQuery的$.extend和$.fn.extend方法,Underscore也不例外,其_.mixin方法允许用户扩展接口。
这里涉及到的一个概念就是mixin设计模式,mixin设计模式是JavaScript中最常见的设计模式,可以理解为把一个对象的属性拷贝到另外一个对象上,具体可以参考:掺杂模式(mixin)。
先看Underscore中_.mixin方法的源代码:
_.mixin = function (obj) {
// _.functions函数用于返回一个排序后的数组,包含所有的obj中的函数名。
_.each(_.functions(obj), function (name) {
// 先为_对象赋值。
var func = _[name] = obj[name];
// 为_的原型添加函数,以增加_(obj).mixin形式的函数调用方法。
_.prototype[name] = function () {
// this._wrapped作为第一个参数传递,其他用户传递的参数放在后面。
var args = [this._wrapped];
push.apply(args, arguments);
// 使用chainResult对运算结果进行链式调用处理,如果是链式调用就返回处理后的结果,
// 如果不是就直接返回运算后的结果。
return chainResult(this, func.apply(_, args));
};
});
return _;
};
这段代码很好理解,就是对于传入的obj对象参数,将对象中的每一个函数拷贝到_对象上,同名会被覆盖。与此同时,还会把obj参数对象中的函数映射到_对象的原型上,为什么说是映射,因为并不是直接拷贝的,还进行了链式调用的处理,通过chainResult方法,实现了了链式调用,所以第三节中说_对象原型上的方法与_对象中的对应方法有差异,原型上的方法多了一个步骤,就是判断是否链式调用,如果是链式调用,那么继续通过_.chain函数进行包装。chainResult函数代码如下:
// Helper function to continue chaining intermediate results.
//返回一个链式调用的对象,通过判断instance._chain属性是否为true来决定是否返回链式对象。
var chainResult = function (instance, obj) {
return instance._chain ? _(obj).chain() : obj;
};
实现mixin函数之后,Underscore的设计者非常机智的运用了这个函数,代码中只可以看到为_自身定义的一系列函数,比如_.each、_.map等,但看不到为_.prototype所定义的函数,为什么还可以通过_().function()的形式调用接口呢?这里就是因为作者通过_.mixin函数直接将所有_上的函数映射到了_.prototype上,在_.mixin函数定义的下方,有一句代码:
// Add all of the Underscore functions to the wrapper object.
_.mixin(_);
这句代码就将所有的_上的函数映射到了_.prototype上,有点令我叹为观止。
通过_.mixin函数,用户可以为_扩展自定义的接口,下面的例子来源于中文手册:
_.mixin({
capitalize: function(string) {
return string.charAt(0).toUpperCase() + string.substring(1).toLowerCase();
}
});
_("fabio").capitalize();
=> "Fabio"
在许多工具库中,都有实现noConflict,因为在全局作用域,变量名是独一无二的,但是用户可能引入多个类库,多个类库可能有同一个标识符,这时就要使用noConflict实现无冲突处理。
具体做法就是先保存原来作用域中该标志位的数据,然后在调用noConflict函数时,为全局作用域该标志位赋值为原来的值。代码如下:
// Save the previous value of the `_` variable.
//保存之前全局对象中_属性的值。
var previousUnderscore = root._;
// Run Underscore.js in *noConflict* mode, returning the `_` variable to its
// previous owner. Returns a reference to the Underscore object.
_.noConflict = function () {
root._ = previousUnderscore;
return this;
};
在函数的最后,返回了Underscore对象,允许用户使用另外的变量存储。
作为一个对象,应该有一些基本属性,比如toString、value等等,需要重写这些属性或者函数,以便使用时返回合适的信息。此外还需要添加一些版本号啊什么的属性。
做完以上所有的工作之后,一个基本的工具库基本就搭建完成了,完成好测试、压缩等工作之后,就可以发布在npm上供大家下载了。想要写一个自己的工具库的同学可以尝试一下。
另外如果有错误之处或者有补充之处的话,欢迎大家不吝赐教,一起学习,一起进步!
更多Underscore源码解析:GitHub
最近在弄毕设,研究关于固定收益债券定价方面的知识,需要使用到QuantLib这个Python金融库,但是这是一个C++编译的库,官网也只给出了源代码,安装起来十分繁琐,所以在网上找了一个简易的安装方法,给大家推荐一下。
在TA-Lib这个网站上找到别人编译好的QuantLib安装包:
为了选择合适的安装包,我们先了解包的命名含义,比如这个:
QuantLib_Python-1.11-CP36-cp36m-win32.whl
其中cp36的含义就是Python 3.6平台,win32就代表是32位Windows系统。
根据自己的环境找到合适的安装包,并下载(注意下载之后不要修改文件名)。
pip安装wheel:
pip install wheel
比如:
pip install QuantLib_Python-1.11-cp36-cp36m-win32.whl
安装成功就会提示你
Processing c:\users\administrator\desktop\quantlib_python-1.11-cp36-cp36m-win32.
whl
Installing collected packages: QuantLib-Python
Successfully installed QuantLib-Python-1.11
Array.prototype.reduce 是 JavaScript 中比较实用的一个函数,但是很多人都没有使用过它,因为 reduce 能做的事情其实 forEach 或者 map 函数也能做,而且比 reduce 好理解。但是 reduce 函数还是值得去了解的。
reduce 函数可以对一个数组进行遍历,然后返回一个累计值,它使用起来比较灵活,下面了解一下它的用法。
reduce 接受两个参数,第二个参数可选:
@param {Function} callback 迭代数组时,求累计值的回调函数
@param {Any} initVal 初始值,可选其中,callback 函数可以接受四个参数:
@param {Any} acc 累计值
@param {Any} val 当前遍历的值
@param {Number} key 当前遍历值的索引
@param {Array} arr 当前遍历的数组callback 接受这四个参数,经过处理后返回新的累计值,而这个累计值会作为新的 acc 传递给下一个 callback 处理。直到处理完所有的数组项。得到一个最终的累计值。
reduce 接受的第二个参数是一个初始值,它是可选的。如果我们传递了初始值,那么它会作为 acc 传递给第一个 callback,此时 callback 的第二个参数 val 是数组的第一项;如果我们没有传递初始值给 reduce,那么数组的第一项会作为累计值传递给 callback,数组的第二项会作为当前项传递给 callback。
示例:
对数组求和:
let arr = [1, 2, 3];
let res = arr.reduce((acc, v) => acc + v);
console.log(res); // 6如果我们传递一个初始值:
let arr = [1, 2, 3];
let res = arr.reduce((acc, v) => acc + v, 94);
console.log(res); // 100利用 reduce 求和比 forEach 更加简单,代码也更加优雅,只需要清楚 callback 接受哪些参数,代表什么含义就可以了。
我们还可以利用 reduce 做一些其他的事情,比如对数组去重:
let arr = [1, 1, 1, 2, 3, 3, 4, 3, 2, 4];
let res = arr.reduce((acc, v) => {
if (acc.indexOf(v) < 0) acc.push(v);
return acc;
}, []);
console.log(res); // [1, 2, 3, 4]统计数组中每一项出现的次数:
let arr = ['Jerry', 'Tom', 'Jerry', 'Cat', 'Mouse', 'Mouse'];
let res = arr.reduce((acc, v) => {
if (acc[v] === void 0) acc[v] = 1;
else acc[v]++;
return acc;
}, {});
console.log(res); // {Jerry: 2, Tom: 1, Cat: 1, Mouse: 2}将二维数组展开成一维数组:
let arr = [[1, 2, 3], 3, 4, [3, 5]];
let res = arr.reduce((acc, v) => {
if (v instanceof Array) {
return [...acc, ...v];
} else {
return [...acc, v];
}
});
console.log(res); // [1, 2, 3, 3, 4, 3, 5]由此可以看出,reduce 函数还是很实用的,但是 reduce 函数兼容性不是特别好,只支持到 IE 9,如果要在 IE 8 及以下使用的话就不行了,所以我们可以自己实现一下,还可以对其做一下扩展,使其能够遍历对象。
首先可以实现一个最基础的 each 函数,作为我们 reduce 的基础:
/**
* 遍历对象或数组,对操作对象的属性或元素做处理
* @param {Object|Array} param 要遍历的对象或数组
* @param {Function} callback 回调函数
*/
function each(param, callback) {
// ...省略参数校验
if (param instanceof Array) {
for (var i = 0; i < param.length; i++) {
callback(param[i], i, param);
}
} else if (Object.prototype.toString.call(param) === '[object Object]') {
for (var val in param) {
callback(param[val], val, param);
}
} else {
throw new TypeError('each 参数错误!');
}
}可以看出 each 可以遍历对象或数组,回调函数接受三个参数:
@param {Any} v 当前遍历项
@param {String|Number} k 当前遍历的索引或键
@param {Object|Array} o 当前遍历的对象或者数组有了这个基础函数,我们可以开始实现我们的 reduce 函数了:
/**
* 迭代数组、类数组对象或对象,返回一个累计值
* @param {Object|Array} param 要迭代的数组、类数组对象或对象
* @param {Function} callback 对每一项进行操作的回调函数,接收四个参数:acc 累加值、v 当前项、k 当前索引、o 当前迭代对象
* @param {Any} initVal 传入的初始值
*/
function reduce(param, callback, initVal) {
var hasInitVal = initVal !== void 0;
var acc = hasInitVal ? initVal : param[0];
each(hasInitVal ? param : Array.prototype.slice.call(param, 1), function(v, k, o) {
acc = callback(acc, v, k, o);
});
return acc;
}可以看到,我们的 reduce 函数就是在 each 上面封装了一层。根据是否传递了初始值 initVal 来决定遍历的起始项。每次遍历都接受 callback 返回的 acc 值,然后在 reduce 的最后返回 acc 累计值就可以啦!
当然,这部分代码有一个很严重的 bug,导致了我们的 polyfill 毫无意义,那就是遍历对象时的 for...in。这个语法和在 IE <= 9 环境下存在 bug,会无法获得对象的属性值,这就导致我们所实现的 reduce 无法在 IE 9 以下遍历对象,但是遍历数组还是可以的。对于 for...in 的这个 bug,可以参考 underscore 是怎么实现的,这里暂时不研究了~
之前写过一篇 Vue 异步组件的文章,最近在做一个简单项目的时候又想用到 React 异步组件,所以简单地了解了一下使用方法,这里做下笔记。
传统的 React 异步组件基本都靠自己实现,自己写一个专门的 React 组件加载函数作为异步组件的实现工具,通过 import() 动态导入,实现异步加载,可以参考【翻译】基于 Create React App路由4.0的异步组件加载(Code Splitting)这篇文章。这样做的话还是要自己写一个单独的加载组件,有点麻烦。于是想找个更简单一点的方式,没想到真给找到了:Async React using React Router & Suspense,这篇文章讲述了如何基于 React Router 4 和 React 的新特性快速实现异步组件按需加载。
2018 年 10 月 23 号,React 发布了 v16.6 版本,新版本中有个新特性叫 lazy,通过 lazy 和 Suspense 组件我们就可以实现异步组件,如果你使用的是 React v16.6 以上版本:
最简单的实现方法:
// codes from https://react.docschina.org
import React, { lazy, Suspense } from 'react';
const OtherComponent = lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
);
}从 React 中引入 lazy 方法和 Suspense 组件,然后用 lazy 方法处理我们的组件,lazy 会返回一个新的React 组件,我们可以直接在 Suspense 标签内使用,这样组件就会在匹配的时候才加载。
lazy 接受一个函数作为参数,函数内部使用 import() 方法异步加载组件,加载的结果返回。
Suspense 组件的 fallback 属性是必填属性,它接受一个组件,在内部的异步组件还未加载完成时显示,所以我们通常传递一个 Loading 组件给它,如果没有传递的话,就会报错。
所以在使用 React Router 4 的时候,我们可以这样写:
import React, { lazy, Suspense } from 'react';
import { HashRouter, Route, Switch } from 'react-router-dom';
const Index = lazy(() => import('components/Index'));
const List = lazy(() => import('components/List'));
class App extends React.Component {
render() {
return <div>
<HashRouter>
<Suspense fallback={Loading}>
<Switch>
<Route path="/index" exact component={Index}/>
<Route path="/list" exact component={List}/>
</Switch>
</Suspense>
</HashRouter>
</div>
}
}
function Loading() {
return <div>
Loading...
</div>
}
export default App;在某些 React 版本中,lazy 函数还有 bug,会导致 React Router 的 component 属性接受 lazy 函数返回结果时报错:React.lazy makes Route's proptypes fail。
我也遇到了这种 bug,具体的依赖版本如下:
"react": "^16.7.0",
"react-dom": "^16.7.0",
"react-router-dom": "^4.3.1"首次安装依赖后就再也没有更新过,所以小版本应该也是上面的小版本,不存在更新。
解决方法可以把 lazy 的结果放在函数的返回结果中:
import React, { lazy, Suspense } from 'react';
import { HashRouter, Route, Switch } from 'react-router-dom';
const Index = lazy(() => import('components/Index'));
const List = lazy(() => import('components/List'));
class App extends React.Component {
render() {
return <div>
<HashRouter>
<Suspense fallback={Loading}>
<Switch>
<Route path="/index" exact component={props => <Index {...props}/>}/>
<Route path="/list" exact component={props => <List {...props}/>}/>
</Switch>
</Suspense>
</HashRouter>
</div>
}
}
function Loading() {
return <div>
Loading...
</div>
}
export default App;上面代码和之前唯一的不同就是把 lazy 返回的组件包裹在匿名函数中传递给 Route 组件的 component 属性。
这样我们的组件都会在路由匹配的时候才开始加载,Webpack 也会自动代码进行 code split,切割成很多小块,减小了首页的加载时间以及单独一个 js 文件的体积。在工作中已经实践过了,确实好用:
如果没有使用 React v16.6 以上版本,也可以自己实现,我们可以写一个专门用于异步加载的函数:
function asyncComponent(importComponent) {
class AsyncComponent extends React.Component {
render() {
return this.state.component;
}
state = {
component: null
}
async componentDidMount() {
const { default: Component } = await importComponent();
this.setState({
component: <Component/>
});
}
}
return AsyncComponent;
}使用的方法与 React.lazy 相同,传入一个异步加载的函数即可,上面这个函数需要注意的地方就是 import() 进来的组件被包裹在 default 属性里,结构时要用 const { default: Component } = ... 这种形式。
效果如下:
总的来说:
import ~最近在读一本设计模式的书,书中的开头部分就讲了一下 JavaScript 中的继承,阅读之后写下了这篇博客作为笔记。毕竟好记性不如烂笔头。
JavaScript 是一门面向对象的语言,但是 ES6 之前 JavaScript 是没有类这个概念的。即使 ES6 引入了 class,也只是基于 JavaScript 已有的原型继承模式的一个语法糖,并没有为 JavaScript 引入新的面向对象的继承模型。
但是 JavaScript 是一门非常灵活的语言,为了实现类和继承,JavaScript Developers 已经把原型玩出了花,下面介绍一下 JavaScript 中的继承模式。
JavaScript 中已有的继承模式包括以下六种:
JavaScript 中,每个对象都有一个原型(prototype),在对象本身找不到对应属性的时候,JavaScript 就会去对象的原型上找,所以这就为 JavaScript 实现继承提供了一种方法 —— 我们只需要把父类的属性放在子类的原型上就行了。因为子类中没有对应属性的话,就会使用原型上的属性,即父类的属性,这就达到了继承的目的。
// 父类
function Person() {
this.name = 'Kevin';
this.age = 18;
}
// 子类
function Chinese() {
this.feature = 'hard-working';
}
// 指定子类的原型,实现子类继承父类。
Chinese.prototype = new Person();
// 实例化子类。
var c = new Chinese();
// 输出'hard-working'。
console.log(c.feature);
// 输出'Kevin'。
console.log(c.name);
这是一种比较简单直观的继承实现方法,但是存在着问题。所有的子类实例共享了父类实例的属性。如果父类实例的属性是引用类型的值时,将会出现牵一发而动全身的风险。
比如,我们给父类 Person 添加一个 category 的数组属性:
// 父类
function Person() {
this.name = 'Kevin';
this.age = 18;
this.category = ['yellow', 'black', 'white'];
}
// 子类
function Chinese() {
this.feature = 'hard-working';
}
// 指定子类的原型,实现子类继承父类。
Chinese.prototype = new Person();
// 实例化子类。
var c1 = new Chinese();
var c2 = new Chinese();
// 修改 c1 的 category 属性,世界上还有棕色人种。
c1.category.push('brown');
// 输出 c1 和 c2 的 category 属性。
console.log(c1.category);
// 结果是 ["yellow", "black", "white", "brown"]
console.log(c2.category);
// 结果是 ["yellow", "black", "white", "brown"]
我们只修改了 c1 的 category 属性,但是 c2.category 也跟着变化了,因为它们共享了一个 Person 实例,而这个 Person 实例的 category 值是引用类型的。
这就是一个很严重的缺陷了,这样的继承模式会使得我们的数据变得不可预测。
类式继承的致命缺陷是共享引用类型的属性导致牵一发而动全身,而问题的根源在于我们给子类的原型赋值为父类的一个实例,那现在解决这个问题就有办法了。我们可以麻烦一点,不把父类的实例赋值给原型了,直接赋值给每一个子类实例吧,这样就不会存在共享引用类型属性的问题了。
// 父类
function Person() {
this.name = 'Kevin';
this.age = 18;
this.category = ['yellow', 'black', 'white'];
}
// 子类
function Chinese() {
Person.call(this);
this.feature = 'hard-working';
}
// 实例化子类。
var c1 = new Chinese();
var c2 = new Chinese();
// 修改 c1 的 category 属性。
c1.category.push('brown');
// 输出 ["yellow", "black", "white", "brown"]
console.log(c1.category);
// 输出 ["yellow", "black", "white"]
console.log(c2.category);
可以看到,共享引用类型属性的问题确实解决了。但是这种方法也不太好,因为我们没有利用好原型。每个属性都实例化在实例的本身,造成了资源的浪费,也不符合代码复用的原则。对于一些共享的公用的方法,我们应该绑定在原型上。
为了解决第二小节的问题,出现了组合式继承。所谓组合式继承,就是综合类式继承和构造函数式继承,结合二者。
比如:
// 父类
function Person() {
this.name = 'Kevin';
this.age = 18;
this.category = ['yellow', 'black', 'white'];
}
// 子类
function Chinese() {
// 基于构造函数式继承。
Person.call(this);
this.feature = 'hard-working';
}
// 基于类式继承。
Chinese.prototype = new Person();
console.log(new Person());
console.log(new Chinese());
这样就“充分地”利用了原型。
但是什么东西都往原型塞,也是一种浪费。我们在子类构造函数中调用了父类的构造函数,在指定子类的原型时又调用了一遍,既不优雅又浪费资源,所以这种方法也不怎么样。
这是 2006 年道格拉斯.克罗克福德的一篇文章所提出来的,我们把要继承的属性放在原型中,然后再在实例上定义属性,这样就使得每个实例可以有自己特有的属性,还可以和其他实例共享必要的属性。
function inherit(o) {
function F(){}
F.prototype = o;
return new F();
}
var x = inherit({name: 'Kevin'});
x.age = 18;
// 输出 {name: 'Kevin', age: 18}
console.log(x);
这种方法首先定义了一个空白的构造函数,然后为其指定了将要继承的属性,然后返回它的一个实例,最后给每个实例指定属性。
这样节约了很多的资源,每个返回的实例也很干净纯洁。
这是一种基于原型式继承的方法,只多了一个步骤,就是给每个实例添加属性。这看起来像是第五小节代码的一种封装。
function inherit(o) {
function F(){}
F.prototype = o;
var f = new F();
f.name = 'Kevin';
f.age = 18;
return f;
}
var proto = {
sayName: function() {
console.log(this.name);
}
};
var x = inherit(proto);
// {name: "Kevin", age: 18}
console.log(x);
// Kevin
x.sayName();
这种继承方式在 underscore 中曾经使用过,具体哪里我也不记得了,感兴趣的同学可以去看看。
这是一种综合型的方法,结合了寄生式、组合式继承方法。实际上是寄生式、构造函数式、类式继承的综合体。
// 基于寄生式继承实现的原型赋值,把子类的原型赋值为父类。
function inheritProto(SubClass, SuperClass) {
function F() {}
F.prototype = SuperClass.prototype;
var f = new F();
// 赋值 prototype 会丢失 constructor 指向,重新赋值。
f.constructor = SubClass;
SubClass.prototype = f;
}
// 父类
function Person() {
this.name = 'Kevin';
this.age = 18;
}
Person.prototype.sayName = function() {
console.log(this.name);
};
function Chinese() {
// 构造函数式继承。
Person.call(this);
this.feature = 'hard-working';
this.name = '李国强';
}
// 类式继承原型。
inheritProto(Chinese, Person);
var c = new Chinese();
console.log(c);
// 输出 {name: "李国强", age: 18, feature: "hard-working"}
c.sayName();
// 输出 "李国强"。
从注释可以看出来,确实综合了三种继承模式。所以这种方法的名字就叫寄生组合式继承。
笔记一篇,时间很仓促,如果有问题欢迎指正!
所有代码可以复制到浏览器控制台执行查看输出。
代码如下:
public static bool checkFrameWork(string destVersion)
{
bool ver1 = GetVersionFromRegistry(destVersion);
if (ver1)
return true;
else
{
return Get45PlusFromRegistry();
}
}
//reference:https://docs.microsoft.com/en-us/dotnet/framework/migration-guide/how-to-determine-which-versions-are-installed
public static bool Get45PlusFromRegistry()
{
const string subkey = @"SOFTWARE\Microsoft\NET Framework Setup\NDP\v4\Full\";
using (RegistryKey ndpKey = RegistryKey.OpenBaseKey(RegistryHive.LocalMachine, RegistryView.Registry32).OpenSubKey(subkey))
{
if (ndpKey != null && ndpKey.GetValue("Release") != null)
{
return CheckFor45PlusVersion((int)ndpKey.GetValue("Release"));
}
return false;
}
}
// Checking the version using >= will enable forward compatibility.
public static bool CheckFor45PlusVersion(int releaseKey)
{
if (releaseKey >= 378389)
return true;
// This code should never execute. A non-null release key should mean
// that 4.5 or later is installed.
return false;
}
public static bool GetVersionFromRegistry(string destVersion)
{
ArrayList versions = new ArrayList();
// Opens the registry key for the .NET Framework entry.
using (RegistryKey ndpKey =
RegistryKey.OpenRemoteBaseKey(RegistryHive.LocalMachine, "").
OpenSubKey(@"SOFTWARE\Microsoft\NET Framework Setup\NDP\"))
{
// As an alternative, if you know the computers you will query are running .NET Framework 4.5
// or later, you can use:
// using (RegistryKey ndpKey = RegistryKey.OpenBaseKey(RegistryHive.LocalMachine,
// RegistryView.Registry32).OpenSubKey(@"SOFTWARE\Microsoft\NET Framework Setup\NDP\"))
foreach (string versionKeyName in ndpKey.GetSubKeyNames())
{
if (versionKeyName.StartsWith("v"))
{
RegistryKey versionKey = ndpKey.OpenSubKey(versionKeyName);
string name = (string)versionKey.GetValue("Version", "");
string sp = versionKey.GetValue("SP", "").ToString();
string install = versionKey.GetValue("Install", "").ToString();
if (install == "") //no install info, must be later.
{
Console.WriteLine(name);
versions.Add(name);
}
//Console.WriteLine(versionKeyName + " " + name);
else
{
if (sp != "" && install == "1")
{
//Console.WriteLine(versionKeyName + " " + name + " SP" + sp);
Console.WriteLine(name);
versions.Add(name);
}
}
if (name != "")
{
continue;
}
foreach (string subKeyName in versionKey.GetSubKeyNames())
{
RegistryKey subKey = versionKey.OpenSubKey(subKeyName);
name = (string)subKey.GetValue("Version", "");
if (name != "")
sp = subKey.GetValue("SP", "").ToString();
install = subKey.GetValue("Install", "").ToString();
if (install == "") //no install info, must be later.
{
//Console.WriteLine(versionKeyName + " " + name);
//Console.WriteLine(name);
versions.Add(name);
}
else
{
if (sp != "" && install == "1")
{
//Console.WriteLine(" " + subKeyName + " " + name + " SP" + sp);
//Console.Write(name);
versions.Add(name);
}
else if (install == "1")
{
//Console.WriteLine(" " + subKeyName + " " + name);
//Console.WriteLine(name);
versions.Add(name);
}
}
}
}
}
object[] verArr = versions.ToArray();
foreach (object o in verArr)
{
Version ver;
string str = o.ToString();
if (str == "")
ver = new Version("1.0");
else
ver = new Version(str);
if (ver >= new Version(destVersion))
return true;
}
}
return false;
}
其中还有一点小瑕疵,有兴趣的自己看一看修改一下就好了。
在使用的时候,我们只需要调用checkFrameWork函数就可以了。

最近寒假在家学习Node.js开发,光看书或者跟着敲代码还不够,得找一点有趣的事情来玩一玩,于是我决定写一个Node爬虫,爬取一些有意思或者说是有用的数据。这个决定只与我的兴趣有关,与Python或者Node或者Java等等谁更适合写爬虫无关,与爬取多少数据无关,与爬取的对象无关。
在写Node爬虫之前,我们先要确定爬取的网站目标。
这个目标的选择有一定的标准,首先得具有可行性,必须能够爬取到这个网站上的数据,否则一切都是空谈;其次,网站上数据的真实性或者数据量必须满足你的需求;最后,网站的响应速度也是我们需要考虑的一个因素。
基于这些标准,我选择了智联招聘网站作为我的爬取目标,爬取的数据是全国主要城市的主要软件工作岗位的招聘数据。
确定爬取目标之后,我们就可以着手写Node爬虫了。由于每一个网站的代码风格不同,我们针对不同网站所写的爬虫也会不同。
在写爬虫之前,我们需要先查看一下智联招聘网站的url风格,以及代码风格。

在智联招聘的首页,我们可以发现一个搜索栏,填入工作和地点之后,我们就可以点击搜索查看对应招聘信息,这时候我们可以探究一下智联招聘url中暗藏的秘密。当我选择珠海城市的Web开发岗位的时候,我的url是下图这样的:

多试几次,或者把鼠标放在下图中的链接上。

我们就可以发现url中参数的意义所在。
其他参数我们不用管,我们只需要知道sj是岗位代码,p是当前数据页码(搜索结果可能有很多页,智联招聘是每页60条记录),jl是城市就可以了。知道这两个参数的意义之后,我们就可以通过组合url来获取不同城市不同岗位的招聘信息了。
在Node中组合url,然后通过http模块的get方法,我们可以获取到来自智联招聘网站的响应。
function getData(pageNo, job, jobLocation, jobsCount){
var url = encodeURI(`http://sou.zhaopin.com/jobs/searchresult.ashx?bj=160000&sj=${variables.jobs[job]}&in=160400&jl=${jobLocation}&p=${pageNo}&isadv=0`);
var jobs = [];
console.log(`${job}-${jobLocation}...`);
return new Promise((resolve, reject)=>{
try{
http.get(url, (res)=>{
不难发现我们得到的响应是一个html文件,我们可以通过解析html文本来获取其中的数据信息。最直接的方法是通过RegExp,但是获取的信息较多时会比较麻烦。
我选择的是通过第三方库——cheerio,来解析HTML文本。这个库使用起来简单方便,能够让你在V8引擎中通过jQuery操作DOM节点的方式解析HTML文本信息。
$('table.newlist').each((k, v)=>{
var job = {};
job.company = $('td.gsmc', v).text();
job.salary = $('td.zwyx', v).text();
job.name = String($('td.zwmc>div', v).text()).replace(/\s/g, '');
job.location = jobLocation;
if(job.company !== '' && job.salary !== '面议'){
jobs.push(job);
}
});
上面这段代码就是我通过cheerio解析HTML文本的代码。
在同时发起多个请求时,有可能会漏掉一些请求,我认为是并发太多导致服务器没有响应,应该通过setTimeout函数延迟一下多个请求。这一点在我将处理后的数据存到LeanCloud平台时得到了验证。
我选择的是MongoDB作为我的后台数据库,因为MongoDB以文档形式存储数据,数据格式是BSON,与Node.js的亲和性很好。
MongoDB操作简单,性能很高,能够满足我的开发需求。
在官网下载MongoDB的Windows安装包之后(需要科学上网),在Windows平台安装,最好不要安装自带的可视化工具,因为会消耗相当长的时间,我们可以选择Robo 3T作为替代品。其他安装过程可以自行百度。
我们在Node中使用MongoDB需要先通过MongoDB Driver,我选择的是mongodb。
通过
npm install mongodb --save
就可以安装,然后在Node代码中通过
require('mongodb')
引入。
存储代码:
const MongoClient = require('mongodb').MongoClient;
//将数据写入数据库
function writeDB(type, realJobs){
MongoClient.connect('mongodb://localhost:27017', (e, db)=>{
assert.ifError(e);
var jobs = db.db('jobs');
var collection = jobs.collection('jobs');
realJobs.forEach((job)=>{
collection.insert(Object.assign({}, job, { type }));
});
db.close();
});
}
通过爬虫获取的数据还只是原始数据,我需要通过Node将其转化为我需要的数据,比如对深圳的Web前端开发岗位薪资取平均值。
这一过程简而言之就是将数据从MongoDB中取出来,然后取平均值。处理之后的代码我将它们存到了LeanCloud上,以便于我的前端展示页面调用。
我使用React框架写前端页面,综合React Router插件实现客户端路由,后台数据存储在LeanCloud上,通过LeanCloud的SDK即可在前端页面实现数据查询。
图表的展示我使用echarts插件,这款插件由百度团队开发,使用起来已经不比highcharts差了,性能方面表现感觉很出色。
这次开发极大地增强了我的学习兴趣,通过爬取的数据我也对软件行业在各城市的发展有了一定的了解。这一次从后端到前端的开发,让我学到了新的知识,也复习了之前学习过的旧知识,受益匪浅。
太久没更新博客了,之前一直非常忙碌,也没有心情更新博客。现在终于稳定了,也开始有心情学习了。
很久之前就已经学习了如何使用 Docker,但是一直没有输出一个自己的学习笔记,过了一段时间之后好像又会丢掉一些东西。现在复习了一波之后赶紧记录一下,让自己有一个系统的知识体系。整篇文章由浅入深,适合有一点 Docker 基础但是还没有形成知识体系的童鞋阅读。
本文不涉及如何安装 Docker,如有需要请自己查找。
Docker 是 2013 年 dotCloud 公司基于 Golang 实现的开源软件,后来 dotCloud 公司改名为 Docker Inc。现在 Docker 已经在 GitHub 上开源,由全世界开发者共同维护。目前主流操作系统基本都已支持 Docker。
Docker 基于 Linux 的多种技术提供了高效、快捷、轻量的容器方案,大大提升了工作人员及机器的工作效率,降低了各种环境兼容问题的发生几率,将传统的 SSH 部署方式转变为 DevOps 自动部署。可以说是引起了行业革命,大大地解放了生产力,所以 Docker 从开源起就广受开发及运维人员的青睐,开源没多久就有许多大型企业宣布将大力支持 Docker。到我写这篇文章的时候 Docker 已经是如日中天,尤其是大型公司对于 Docker 的使用已经相当的深入,几万十几万的实例正在生产环境一刻不停的运行着。不仅运维需要学习 Docker 如何使用,后端前端也需要学习。
那么 Docker 为什么这么火呢?它能带给我们什么?我们为什么要学习 Docker?
首先,Docker 带给我们最直接的好处就是轻量、快速。
传统的虚拟化方式我们都知道是虚拟机,可以在一台物理机上运行多个操作系统的虚拟环境。通过虚拟机技术我们也可以在不同的物理机上实现基本一致的环境。但是问题在于虚拟机技术太重了,安装一台虚拟机以及每次启动关闭虚拟机的时间都非常久,这对于追求高效的我们是不可接受的。
所以 Docker 最大的优势就是快、就是轻。结合 Linux 的 Union FS 技术,可以实现镜像的分层打包,这样 Docker 就变得尽可能的轻量了。基于 Linux 的 Control Group、namespace 及 Docker 共享系统内核的技术,使得 Docker 可以非常快速的实现一个虚拟的隔离环境,因为它不用像虚拟机一样构造一些虚拟的硬件然后运行一个独立且完善的操作系统,所有的 Docker 实例都是直接使用物理机的内核,容器内部没有自己的内核和虚拟硬件,所以运行速度、安装速度、启动速度都是非常快的。
也正因为如此,所以 Docker 对于物理机的资源利用率也比传统的虚拟机高很多,迁移也非常的快速。
另外,Docker 提供更加独立且一致的运行环境,让我们可以一次配置,到处运行。无需考虑环境的兼容问题,有利于实施 CI、CD。
此外,Docker 自身采用分层存储技术,维护和扩展非常容易,而且支持共有镜像库和私有镜像库的部署,镜像管理镜像非常简单,不用再担心你的”配置信息“散落在各个角落。

上图对比了传统了虚拟化技术和 Docker 的虚拟化技术,很容易看出来为什么 Docker 更加轻量,快速,对于物理机的压榨更加高效。
Docker 的基本概念不多,也很好掌握,就只有三个。之后的命令讲解也会基于这三个维度展开,稍微会有一些扩展。
Docker 镜像(Image),可以理解为编程语言中的 Class 类,是一种用于生成容器实例的模板,是创建 Docker 容器的基础。
Docker 镜像不仅像类一样可以生成实例(容器),而且可以实现类之间的继承(镜像分层),一个镜像可以基于另一个镜像实现,而底层的基础镜像是共用的。
Docker 镜像是类的话,我们的容器就可以理解为类的实例对象,它基于 Docker 镜像产生。
Docker 容器是一个轻量级的沙箱(Sandbox),能够隔离应用,使多个应用运行在同一台物理机上,但是应用内部没有感知,认为它们是运行在一个独立的机器上。
镜像自身是只读的,创建容器的时候会在镜像的最上层新建一个可写层,镜像本身不发生变化。
Docker 仓库用于集中管理 Docker 镜像,可以理解为我们的 npm 或者 GitHub。我们可以在 Docker Hub 上下载镜像,也可以上传我们自己的镜像到 GitHub 提供给别的开发者下载。
Docker Hub 也支持 npm 那样的私有仓库搭建,许多公司会在自己内部搭建一个 Docker 镜像仓库,对公司内部的镜像进行管理。
现在我们知道 Docker 的三个概念了,我们现在尝试从 Docker 仓库拉取一个镜像,然后在本地运行 Docker 容器吧。
通过 docker search 命令我们可以搜索 Docker Hub 公有库上的镜像。
我们搜索一下 hello-world 试试:
$ docker search hello-world结果如下:
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
hello-world Hello World! (an example of minimal Dockeriz… 1090 [OK]
kitematic/hello-world-nginx A light-weight nginx container that demonstr… 136
tutum/hello-world Image to test docker deployments. Has Apache… 65 [OK]
dockercloud/hello-world Hello World! 17 [OK]
crccheck/hello-world Hello World web server in under 2.5 MB 11 [OK]
vad1mo/hello-world-rest A simple REST Service that echoes back all t… 3 [OK]
ppc64le/hello-world Hello World! (an example of minimal Dockeriz… 2
...可以看到 search 命令给我们列出了搜索结果的名称、描述、star 数等信息,我们可以自行选择搜索结果,然后使用 docker pull 命令进行下载:
docker pull hello-world拉取成功之后可以通过 docker image ls 查看下载的镜像信息。
接下来使用 docker run 命令运行我们的镜像:
$ docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/当你看到上方信息的时候,说明 hello-world 镜像已经成功运行啦!
通过第二节我们知道了 Docker 的三个概念,所以现在我们就慢慢开始学习如何使用 Docker。要想运行一个自己的容器,首先我们要有一个自己的镜像,那么我们如何制作一个镜像呢?
第一种方法就是使用 docker commit 命令,这个命令的简介如下:
Usage: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
Create a new image from a container's changes
Options:
-a, --author string Author (e.g., "John Hannibal Smith
<[email protected]>")
-c, --change list Apply Dockerfile instruction to the
created image
-m, --message string Commit message
-p, --pause Pause container during commit (default true)它可以基于一个容器的修改创建一个新的镜像,这是什么意思呢?
比如我们现在运行一个基于 nginx 镜像创建的容器:
$ docker run -p 80:80 --name my-ng nginx运行 docker ps 查看我们运行中的容器:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bb182db11e7c nginx "nginx -g 'daemon of…" 58 seconds ago Up 57 seconds 0.0.0.0:80->80/tcp my-ng可以看到 my-ng 已经跑起来了,那我们访问本机的 80 端口查看页面:

得到如上所示的 nginx 欢迎页。
现在我们不喜欢这个页面,我们要更改一下它的内容,那我们直接进入容器修改 /usr/share/nginx/html/index.html 网页的内容即可。
首先输入 docker exec -it my-ng bash 进入容器。
然后找到我们的 /usr/share/nginx/html/index.html 文件,修改其内容:
$ echo "Hello World" > index.html然后退出容器,重新访问 localhost 查看效果:
$ curl localhost
Hello World说明此时容器内容已经做了更改,那我如果我们想要以后运行的 nginx 容器都使用这个基础页面,我们就应该基于当前修改创建一个新的镜像了。这时 docker commit 闪亮登场:
$ docker commit -m "modify index.html of nginx" my-ng new-ng然后使用 docker image ls 查看我们刚刚新建的镜像:
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
new-ng latest 660bca868911 4 seconds ago 126MB可以看到 new-ng 已经创建了。
那我们基于它运行一个新的容器吧。
$ docker run -p 80:80 new-ng重新访问 80 端口:
$ curl localhost
Hello World这就说明我们的新镜像的欢迎页都是我们修改之后的内容。我们成功地基于 my-ng 容器创建了一个符合我们需求的镜像。
通过上面的例子我们知道了 docker commit 可以基于容器制作镜像,但是这并不是推荐以及常用的做法,因为这个命令很容易造成镜像臃肿,一个简单的修改可能会引起其他多处地方的变动。另外 commit 命令制作的镜像是一个”黑箱镜像“,除了制作镜像的人以外其他人都不知道镜像修改了什么地方,所以不利于对于镜像的维护与扩展。
更多的情况下,commit 命令用于将一个容器的变动提交到另一个镜像,可以用于容器调试以及事故现场的保护。尽量不要用 commit 命令制作常用镜像。
我们更加常用的,也是官方推荐的镜像制作方法是使用 Dockerfile。你应该经常在一些开源项目的根目录下见到一个 Dockerfile 文件,这就是用于制作镜像的配置文件。
Dockerfile 由一行行的命令语句组成,而且支持 # 开头的注释,其基本语法如下:
# Comment
INSTRUCTION arguments一般而言,Dockerfile 由三部分组成,包括基础镜像指令、镜像的操作指令以及容器内进程的启动指令。
一个基本的 Dockerfile 示例如下:
FROM mhart/alpine-node
COPY ./src /data/src
WORKDIR /data/src
RUN ["npm", "install"]
EXPOSE 3000
CMD ["node", "index.js"]可以看到其中包括了 FROM 命令指定基础镜像为 mhart/alpine-node,COPY、WORKDIR、RUN、EXPOSE 等指令指定镜像的一些操作,最后的 CMD 指定容器启动进程时需要执行的命令。
接下来我们对 Dockerfile 的这些指令进行讲解。
FROM 的基本语法如下:
FROM <image>[:<tag>]image 是镜像名称,tag 是镜像的版本,比如我们之前例子中的 nginx:latest。
FROM 指令表示基于指定的基础镜像开始下一阶段的构建,并且为之后的构建指令指明了基础镜像,一个符合要求的 Dockerfile 必须以 FROM 开头(除了 ARG 指令可以在它之前)。
如果我们不需要任何的基础镜像,我们可以指定 FROM 为 scratch:
FROM scratch使用这个基础镜像,接下来的指令都作为镜像的第一层存在。
COPY 的基本语法如下:
COPY [--chown=<user>:<group>] <src>... <dest>
COPY [--chown=<user>:<group>] ["<src>",... "<dest>"]该命令用于将当前上下文(后面会讲)路径中指定的文件或文件夹(src)复制到容器内制定的路径(dest),并且会保留原来文件的元信息,比如权限信息、更改时间信息等。第二种示例适合于路径中含有空格的情况。
其中 --chown 的作用跟 bash 指令中的 chown 一致,用于修改文件权限。但是该指令只能在 Linux 下使用,Windows 下构建镜像时不能配置这一项。
值得注意的是 src 可以是相对路径,当他们是相对路径的时候,解析的基础路径是 docker build 命令指定的当前上下文。dest 也可以是相对路径,当它为相对路径时,解析的基础路径是 WORKDIR 指令指定的工作路径。
src 可以指定多个,COPY 命令会将最后一个参数视为 dest,多个 src 都会被拷贝到 dest。
dest 不存在时,Docker 会自动创建。
另外,COPY 指令支持通配符匹配文件,具体请参考 Docker 官网。
ADD 命令的基本语法与 COPY 类似:
ADD [--chown=<user>:<group>] <src>... <dest>
ADD [--chown=<user>:<group>] ["<src>",... "<dest>"]其功能也与 COPY 一致,但是新增了一些功能。
ADD 指令的 src 可以为 URL,此时 ADD 指令会到指定 URL 下载文件,然后复制到 dest 路径。
因为从 URL 下载的文件没有保留源文件的元信息,所以默认具有 600 权限(这里可以参考 chown 命令的解释,1/2/4 权限码-ugo 所有者等等)。下载文件的最后更新时间也会默认使用 HTTP 响应头中的 Last-Modified 字段。
如果 src 是一个本地压缩文件路径(identity, gzip, bzip2 或者 xz),则会被解压后复制到 dest。如果是一个压缩文件的 URL,则不会被解压缩。
dest 不存在的时候会被创建。
WORKDIR 的基本语法:
WORKDIR /path/to/workdir该指令用于指定工作路径,影响该指令之后的 RUN、CMD、COPY、ADD、ENTRYPOINT 等各种指令的路径解析。如果不存在该指令,则 Docker 会自动创建它。
Dockerfile 中可以多次使用 WORKDIR 指令,如果指定了相对路径,那么它会相对于上一条 WORKDIR 指令进行解析。
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd此时,RUN 指令的工作路径为 /a/b/c,因为后两条 WORKDIR 指令是相对路径,会相对于其上一条 WORKDIR 指令进行解析。
RUN 指令有两种语法:
RUN <command>
RUN ["executable", "param1", "param2"]该指令将在当前镜像的上一层执行所有指令,然后将执行结果提交(commit),随后生成的镜像将用于下一层指令构建。所以我们应该知道 RUN 指令执行一次,就会提交一层镜像,我们应该减少生成的镜像,减少 Dockerfile 中 RUN 指令的出现次数。
第一种形式属于 shell 形式,第二种形式属于 exec 形式,使用 Nodejs 的同学应该见到过这两种形式的命令执行。两种形式存在区别,shell 形式会直接调用 shell 进行命令执行,而 exec 形式不会。因此 shell 形式被 shell 调用时会被 shell 进行处理,包括环境变量的替换等等。比如RUN echo $HOME,该指令运行时,实际上是 shell 对 $HOME 进行了处理,而不是 docker。当你使用 exec 形式的指令时,其内部的字符串不会被 shell 处理,而如果你需要被 shell 处理时,应该使用 RUN ["sh", "-c", "echo $HOME"] 的形式显式指定处理的程序。在讲解 CMD 命令和 ENTRYPOINT 命令时,还会讲一点两者的区别。具体请参考 Dockerfile CMD shell versus exec form。
该指令的基本语法:
EXPOSE <port> [<port>/<protocol>...]该指令用于向 Docker 声明容器运行时占用的具体端口,protocol 可以是 tcp 或者 udp,默认是 tcp。
值得注意的是该指令并没有向外部暴露端口,它只是一种约定性的文档性质的指令,让开发人员和 Docker 了解该容器运行时使用的端口。使用 docker run -P ... 时,绑定的容器内的端口实际上就是 EXPOSE 指令指定的端口。
ENTRYPOINT 有两种语法形式:
ENTRYPOINT ["executable", "param1", "param2"]
ENTRYPOINT command param1 param2可以看到也是两种形式的命令执行形式。
ENTRYPOINT 指令允许你将 Docker 容器配置成一个可执行命令。
docker run -it 之后附加的命令参数会覆盖掉 CMD 指定的进程启动命令,并且如果你指定了 ENTRYPOINT 指令的话会将其附加到 ENTRYPOINT 指令的后方作为参数来执行。
如果运行 docker run -it 命令时没有指定命令参数,那么会将 CMD 指令作为参数附加给 ENTRYPOINT 指令执行。
这样的话可以让我们把容器变成一个可执行的命令工具,在 docker run -it 的时候给它传入参数,容器就可以实现不同的行为。
该指令的具体语法为:
VOLUME ["/data"]
VOLUME /var/log
VOLUME /var/log /var/db该指令用于挂载匿名卷(volume)。卷用于存储文件及数据,可以理解为硬盘,它是独立于容器的。容器向卷中写入数据,容器退出及删除的时候我们的卷依然存在,所以卷可以有效地实现数据持久化。我们在运行容器的时候应该避免向容器存储层写入大量数据,应该保持容器的无状态化,基本上容器内动态产生的数据都不应该写入容器的存储层,而应该将数据保存到卷。
为了防止用户使用镜像的时候忘记挂载卷,我们可以使用该指令指定一个匿名的默认卷,当容器启动后会向卷内写入数据。当使用 docker run 指令启动容器的时候,我们可以使用 -v 选项覆盖默认卷。
还是之前的示例,我们新增一个 VOLUME 指令:
FROM mhart/alpine-node
COPY ./src /data/src
WORKDIR /data/src
VOLUME /data/src
RUN ["npm", "install"]
EXPOSE 3000
CMD ["node", "index.js"]此时使用该镜像运行容器,应该会挂载内部的 /data/src 作为匿名卷,我们在当前目录构建一下:
$ docker build -t tmp .然后运行我们的容器:
$ docker run -p 80:3000 tmp然后我们使用 docker inspect 命令查看我们的容器信息:
$ docker inspect 347
# 容器名是 hash 缩写,docker 不要求写全,只需要能够定位到具体的 docker 容器就行看到会打印出一大堆的 JSON 信息,然后我们找到对象里的一个 Mounts 属性:
"Mounts": [
{
"Type": "volume",
"Name": "82d53d18bba2925261e256878f29880c26d3a8d4f88f0c3a00725441b3a31503",
"Source": "/var/lib/docker/volumes/82d53d18bba2925261e256878f29880c26d3a8d4f88f0c3a00725441b3a31503/_data",
"Destination": "/data/src",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],可以看到这是一个 local 类型的本地匿名卷,我们通过 docker volume inspect 查看其具体信息:
$ docker volume inspect 82d53d18bba2925261e256878f29880c26d3a8d4f88f0c3a00725441b3a31503同样会打印出来一串 JSON 数据:
[
{
"CreatedAt": "2019-12-22T09:01:20Z",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/82d53d18bba2925261e256878f29880c26d3a8d4f88f0c3a00725441b3a31503/_data",
"Name": "82d53d18bba2925261e256878f29880c26d3a8d4f88f0c3a00725441b3a31503",
"Options": null,
"Scope": "local"
}
]如果要删除卷,直接使用如下命令:
$ docker volume rm <volume>该指令使用语法如下:
ENV <key> <value>
ENV <key>=<value> ...该指令用于指定环境变量,指定了环境变量后,其后的指令都可以直接使用这些环境变量。
比如:
ENV NODE_ENV=10.15.3
RUN nvm use $NODE_ENV &&\
node scripts/build.js该指令用户指定 Dockerfile 当前环境下使用到的变量。
语法如下:
ARG <name>[=<default value>]可以理解为是定义变量的一个指令,而这个指令定义的变量可以在 build 命令构建镜像的时候使用 --build-arg <varname>=<value> 标签动态的传入参数。
USER 指令的基本格式如下:
USER <user>[:<group>] or
USER <UID>[:<GID>]用于设置当前用户或者用户组,会影响在它之后的 RUN、CMD 和 ENTRYPOINT 等指令的执行。
该指令主要有以下两种语法格式:
HEALTHCHECK [OPTIONS] CMD command # 通过在容器中执行一条指令来检查容器的健康状况
HEALTHCHECK NONE # 清除所有的 healthcheck 指令,包括从上一层基础镜像继承的这条指令用于检查容器是否还处于正常的工作状态,尤其适用于一些工作进程没有退出但是已经无法正常工作的应用。
Dockerfile 中添加了 HEALTHCHECK 指令之后,对应容器的运行状态会附加健康状态。该状态最开始是 starting,当通过健康检查之后会变为 healthy,当健康检查指令连续失败一定次数之后,会变为 unhealthy。
OPTIONS 选项可以是如下几条:
--interval=DURATION (default: 30s)
--timeout=DURATION (default: 30s)
--start-period=DURATION (default: 0s)
--retries=N (default: 3)其中,interval 代表健康检查指令会在容器启动后的每一个 interval 时间段执行一次。
timeout 代表如果单次健康检查指令的执行时间超过了 timeout 指定时间的话,会被认为执行失败。
start-period 代表在容器启动后 start-period 时间之后才开始执行健康检查指令。
retries 代表重复执行 retries 次失败之后,会将容器标记为 unhealthy。
一个 Dockerfile 只设置一条 HEALTHCHECK 指令,多次指定时只有最后一条会起作用。
指令执行的退出码对应检查状态情况如下:
0: success - 代表容器健康可用
1: unhealthy - 容器存在健康问题,影响使用
2: reserved - 不要使用这个退出码
该指令语法结构如下:
ONBUILD [INSTRUCTION]注意 ONBUILD 后面接的是 Dockerfile 语法中的指令,不是任意 command。
该指令用于指定一条构建指令,在以该镜像为基础的镜像构建的时候执行。也就是说包含这条指令的镜像构建的时候,其指定的指令并不会执行,而是会在继承该镜像的镜像构建的时候执行。其指定的指令会被延迟到下一个构建阶段。
CMD 指令有三种形式:
CMD ["executable","param1","param2"] (exec 形式,推荐使用)
CMD ["param1","param2"] (作为默认参数传递给 ENTRYPOINT)
CMD command param1 param2 (shell 形式)一个 Dockerfile 配置文件中只允许存在一条 CMD 指令,如果你制定了多条 CMD 指令,那么只有最后一条会执行。
CMD 指令的主要目的在于为可执行容器指定默认的启动指令。多数时候 CMD 是一条可执行的指令,比如 node index.js、python manage.py runserver 0.0.0.0:8000。有时候 CMD 也可以是纯参数,不包含可执行文件,但是你必须指定 ENTRYPOINT 指令,此时 CMD 参数会传递给 ENTRYPOINT 可执行指令。
如果用户通过 docker run -it 运行容器时在最后指定了执行命令,则会覆盖配置中的 CMD 指令。
LABEL 指令语法如下:
LABEL <key>=<value> <key>=<value> <key>=<value> ...它指定了一系列的键值对,添加到镜像上作为元数据。
示例如下:
LABEL "com.example.vendor"="ACME Incorporated"
LABEL com.example.label-with-value="foo"
LABEL version="1.0"
LABEL description="This text illustrates \
that label-values can span multiple lines."如果键值包含空格的话,就需要使用双引号括起来。
使用 LABEL 指令标记的镜像,实例化的容器可以通过 docker inspect 命令查看 Labels。
该指令语法结构如下:
SHELL ["executable", "parameters"]该指令必须写成 JSON 格式,用于指定构建时执行 shell 格式的命令所用到的 shell。在 Linux 下默认使用 ["/bin/bash", "-c"],Windows 下默认使用 ["cmd", "/S", "/C"]。
该命令主要格式如下:
STOPSIGNAL signal该指令用于设置发送给容器的系统调用退出命令,该命令可以是有效无符号数字(比如 9),也可以是信号名称(比如 SIGKILL)。
学习了 Dockerfile 的基本语法之后,我们就可以通过 docker build 命令来构建镜像了。
Docker 提供了非常强大的命令行工具给我们使用,这一节将讲解一些非常常用且重要的 Docker 命令。
Docker 的配置文件存放在 ~/.docker 之下,可以通过 ls -a ~/.docker 查看:
config.json daemon.json一般情况下是这两个配置文件。
在需要的时候我们可以修改这两个文件来设置 Docker 的一些行为。
制作镜像我们使用 docker build 命令。
比如我们有一个如下的 Dockerfile 文件:
FROM busybox
CMD [ "echo", "https://www.baidu.com" ]随后我们可以在当前路径下打开终端,制作镜像:
$ docker build -t temp-busybox .回车之后就会开始制作镜像。
上方的命令中,-t 代表指定镜像名称,所以制作出来的镜像名称就叫 temp-busybox。
. 代表指定 Dockerfile 构建时候的上下文,而非 Dockerfile 所在的路径。指定的上下文会被上传到 Docker Daemon(Docker 是遵循 CS 架构,镜像构建过程在 Server 端完成,后续会有介绍)。
docker build 命令的语法结构如下:
$ docker build [OPTIONS] PATH | URL | -指定上下文可以是 Git 仓库、targball 压缩包,或者是文件路径。
可以使用 docker container create 命令创建一个新的容器:
$ docker container create [OPTIONS] IMAGE [COMMAND] [ARG...]当然我们更常用的做法是使用 docker run 命令:
$ docker container run [OPTIONS] IMAGE [COMMAND] [ARG...]可以在镜像名称后方添加命令,表示在容器启动后在其内部执行一条命令。这条命令会覆盖 CMD 指令指定的命令,如果有使用到 ENTRYPOINT 指令的话,还会作为参数传递给 ENTRYPOINT 执行。
在容器内执行命令有两种方式,一种是上一节提到的 docker run 命令,还有一种是使用 docker exec 命令。这两者的区别在于 docker run 会创建新的容器,而 docker exec 只会在已经运行的容器内执行。
docker exec:
$ docker container exec [OPTIONS] CONTAINER COMMAND [ARG...]停止运行中的容器,我们使用 docker stop 命令:
$ docker container stop [OPTIONS] CONTAINER [CONTAINER...]
笔者是一枚前端开发,在学习 Linux 的时候碰到了一个问题 —— 怎么练手?因为自己电脑上面装的是 Windows 系统,所以学习 Linux 的时候没办法进行练习,而敲指令是学习 Linux 最高效的途径,这就需要我装一个 Linux 虚拟机或者双系统了。最开始的时候我用 VMWare 的虚拟机装了个 Ubuntu,后来觉得 Linux 好像确实好用,虚拟机又太耗资源,再加上我的 Windows 越来越卡顿,我决定装一个双系统。
一开始的时候,我还是安装的 Ubuntu 系统,后来发现真的用 Ubuntu 系统进行工作学习的话,好像还是有很多的困难的,首先是 QQ 官方停止了对 Linux 平台的开发支持,在 Ubuntu 上面很难装 QQ;其次,Ubuntu 的字体什么的对于中文支持都还不够完善;再者,网易云音乐在 Ubuntu 上的表现也不是很好(启动都需要使用 sudo netease-cloud-music 命令来实现,不然点击图标都没得反应)。总之,Ubuntu 对于**用户的日常使用而言,不太合适(当然人家可能压根就不是为了日常使用而开发的,更不是为了**人开发的)。为了更好的学习 Linux,在经过了解之后,我决定安装 Deepin 作为我的日常使用系统。这是由武汉深之度科技公司开发的针对**用户量身定制的 Linux 系统,预装搜狗输入法、QQ、网易云音乐等常用软件,应用商店也是应有尽有(甚至还有 Steam……虽然我没用过,详情见下图),用起来十分舒服。

好了,讲了这么多,那我们到底该怎么安装 Deepin 双系统呢?
以 Windows7 为例,大概包括以下几个步骤:
这篇文章在 Deepin 系统中完成,所以没办法重温安装过程,只能讲一个安装的大概了。如果需要了解详细,可以参考 Deepin 的官方安装教程,其中还包含视频演示。
安装系统完成之后,对计算机进行重启,开机时会进入引导界面。进入引导界面之后,可以看到前三个都是 Deepin 的选项,第四个叫做 system setup。选中这一项时,系统会报错,因为这一项是为启动 Windows 做准备的;可能由于 Deepin 的 Bug 问题,一开始是没有 Windows选项的,需要我们进入 Deepin 操作系统之后,在控制中心进行修改。
说是修改,其实也不用做什么。进入 Deepin 之后,点击“控制中心”,右侧边栏会弹出设置界面。然后选择“系统信息”,拉倒最底下可以看到“启动菜单”。随便动一动就好了,比如把一个开关打开然后关掉……这样就行了。再次重启时就可以发现引导界面的最后一项可以正确的显示 Windows 了。
作为前端开发,我最基本的开发环境包括 VS Code、Git、Node、Python、Vim 等等。现在先安装这几个软件。
安装 Git 和 Vim 比较简单,使用
sudo apt-get install git vim
就阔以了。
安装 VS Code 有两种方法,一种是在深度商店安装,一种是在 VS Code 官网下载 .deb 包,然后使用
sudo dpkg -i 包名
安装就可以了。两者的区别是官网下载的是最新版,深度商店的版本要落后于官网的版本。
安装 Node 也有两种方式。一种是通过包管理器安装、一种是官网源码安装。两者的区别是包管理器安装之后包名叫做 nodejs 而非 node,运行脚本时也是 nodejs 命令,很不习惯,如果要修改包名还需要使用其它命令更改。
我使用的是源码安装方式。首先在 Node.js 中文网 下载源代码。下载之后使用
tar -zxf node-vxx.x.x.tar.gz
解压源码,然后使用
sudo apt-get install g++
安装 gcc 源码编译器。
接下来进入解压后的源码文件夹:
cd node-vxx.x.x
运行配置文件:
./configure
然后开始编译:
make
编译后开始安装:
make install
安装完成之后就可以通过 node -v 查看所安装的 Node 版本是否正确了。
Python 的话,Deepin 本身就安装了 Python,而且 2 和 3 两个版本都有。如果要使用 Python 3.x 运行脚本,需要使用 python3 命令。切记不要卸载系统本身自带的 2 版本的 Python!另外如果要在 VS Code 中调试 Python 代码,配置文件的写法请参考我的另一篇博客。
另外推荐一个清理垃圾的软件,叫做 BleachBit,可以在深度商店直接安装,截图如下:

最近几天在系统的复习排序算法,之前都没有系统性的学习过,也没有留下过什么笔记,所以很快就忘了,这次好好地学习一下。
首先说明为了减少限制,以下代码通通运行于Node V8引擎而非浏览器,源码在我的GitHub,感兴趣的话可以下载来然后运行试试。
为了方便对比各个排序算法的性能,这里先写了一个生成大规模数组的方法——generateArray:
exports.generateArray = function(length) {
let arr = Array(length);
for(let i=0; i<length; i++) {
arr[i] = Math.random();
}
return arr;
};
只需要输入数组长度,即可生成一个符合长度要求的随机数组。
冒泡排序也成为沉淀排序(sinking sort),冒泡排序得名于其排序方式,它遍历整个数组,将数组的每一项与其后一项进行对比,如果不符合要求就交换位置,一共遍历n轮,n为数组的长度。n轮之后,数组得以完全排序。整个过程符合要求的数组项就像气泡从水底冒到水面一样泡到数组末端,所以叫做冒泡排序。
冒泡排序是最简单的排序方法,容易理解、实现简单,但是冒泡排序是效率最低的排序算法,由于算法嵌套了两轮循环(将数组遍历了n遍),所以时间复杂度为O(n^2)。最好的情况下,给出一个已经排序的数组进行冒泡排序,时间复杂度也为O(n)。
特地感谢一下评论中@雪之祈舞的优化,每次冒泡都忽略尾部已经排序好的i项。
JavaScript实现(从小到大排序):
function bubbleSort(arr) {
//console.time('BubbleSort');
// 获取数组长度,以确定循环次数。
let len = arr.length;
// 遍历数组len次,以确保数组被完全排序。
for(let i=0; i<len; i++) {
// 遍历数组的前len-i项,忽略后面的i项(已排序部分)。
for(let j=0; j<len - 1 - i; j++) {
// 将每一项与后一项进行对比,不符合要求的就换位。
if(arr[j] > arr[j+1]) {
[arr[j+1], arr[j]] = [arr[j], arr[j+1]];
}
}
}
//console.timeEnd('BubbleSort');
return arr;
}
代码中的注释部分的代码都用于输出排序时间,供测试使用,下文亦如是。
选择排序是一种原址比较排序法,大致思路:
找到数组中的最小(大)值,并将其放到第一位,然后找到第二小的值放到第二位……以此类推。
JavaScript实现(从小到大排序):
function selectionSort(arr) {
//console.time('SelectionSort');
// 获取数组长度,确保每一项都被排序。
let len = arr.length;
// 遍历数组的每一项。
for(let i=0; i<len; i++) {
// 从数组的当前项开始,因为左边部分的数组项已经被排序。
let min = i;
for(let j=i; j<len; j++) {
if(arr[j]<arr[i]) {
min = j;
}
}
if(min !== i) {
[arr[min], arr[i]] = [arr[i], arr[min]];
}
}
//console.timeEnd('SelectionSort');
return arr;
}
由于嵌套了两层循环,其时间复杂度也是O(n^2),
插入排序是最接近生活的排序,因为我们打牌时就差不多是采用的这种排序方法。该方法从数组的第二项开始遍历数组的n-1项(n为数组长度),遍历过程中对于当前项的左边数组项,依次从右到左进行对比,如果左边选项大于(或小于)当前项,则左边选项向右移动,然后继续对比前一项,直到找到不大于(不小于)自身的选项为止,对于所有大于当前项的选项,都在原来位置的基础上向右移动了一项。
示例:
// 对于如下数组
var arr = [2,1,3,5,4,3];
// 从第二项(即arr[1])开始遍历,
// 第一轮:
// a[0] >= 1为true,a[0]右移,
arr = [2,2,3,5,4,3];
// 然后1赋给a[0],
arr = [1,2,3,5,4,3];
// 然后第二轮:
// a[1] >= 3不成立,该轮遍历结束。
// 第三轮;
// a[2] >= 5不成立,该轮遍历结束。
// 第四轮:
// a[3] >= 4为true,a[3]右移,
arr = [1,2,3,5,5,3];
// a[2] >= 4不成立,将4赋给a[3],然后结束该轮遍历。
arr = [1,2,3,4,5,3];
// a[4] >= 3成立,a[4]右移一位,
arr = [1,2,3,4,5,5];
// arr[3] >= 3成立,arr[3]右移一位,
arr = [1,2,3,4,4,5];
// arr[2] >= 3成立,arr[2]右移一位,
arr = [1,2,3,3,4,5];
// arr[1] >= 3不成立,将3赋给a[2],结束该轮。
arr = [1,2,3,3,4,5];
// 遍历完成,排序结束。
如果去掉比较时的等号的话,可以减少一些步骤,所以在JavaScript代码中减少了这部分,
JavaScript实现(从小到大排序):
function insertionSort(arr) {
//console.time('InsertionSort');
let len = arr.length;
for(let i=1; i<len; i++) {
let j = i;
let tmp = arr[i];
while(j > 0 && arr[j-1] > tmp) {
arr[j] = arr[j-1];
j--;
}
arr[j] = tmp;
}
//console.timeEnd('InsertionSort');
return arr;
}
插入排序比一般的高级排序算法(快排、堆排)性能要差,但是还是具有以下优点的:
到目前为止,已经介绍了三种排序方法,包括冒泡排序、选择排序和插入排序。这三种排序方法的时间复杂度都为O(n^2),其中冒泡排序实现最简单,性能最差,选择排序比冒泡排序稍好,但是还不够,插入排序是这三者中表现最好的,对于小数据集而言效率较高。这些原因导致三者的实用性并不高,都是最基本的简单排序方法,多用于教学,很难用于实际中,从这节开始介绍更加高级的排序算法。
归并排序是第一个可以用于实际的排序算法,前面的三个性能都不够好,归并排序的时间复杂度为O(nlogn),这一点已经由于前面的三个算法了。
值得注意的是,JavaScript中的Array.prototype.sort方法没有规定使用哪种排序算法,允许浏览器自定义,FireFox使用的是归并排序法,而Chrome使用的是快速排序法。
归并排序的核心**是分治,分治是通过递归地将问题分解成相同或者类型相关的两个或者多个子问题,直到问题简单到足以解决,然后将子问题的解决方案结合起来,解决原始方案的一种**。
归并排序通过将复杂的数组分解成足够小的数组(只包含一个元素),然后通过合并两个有序数组(单元素数组可认为是有序数组)来达到综合子问题解决方案的目的。所以归并排序的核心在于如何整合两个有序数组,拆分数组只是一个辅助过程。
示例:
// 假设有以下数组,对其进行归并排序使其按从小到大的顺序排列:
var arr = [8,7,6,5];
// 对其进行分解,得到两个数组:
[8,7]和[6,5]
// 然后继续进行分解,分别再得到两个数组,直到数组只包含一个元素:
[8]、[7]、[6]、[5]
// 开始合并数组,得到以下两个数组:
[7,8]和[5,6]
// 继续合并,得到
[5,6,7,8]
// 排序完成
JavaScript实现(从小到大排序):
function mergeSort(arr) {
//console.time('MergeSort');
//let count = 0;
console.log(main(arr));
//console.timeEnd('MergeSort');
//return count;
// 主函数。
function main(arr) {
// 记得添加判断,防止无穷递归导致callstack溢出,此外也是将数组进行分解的终止条件。
if(arr.length === 1) return arr;
// 从中间开始分解,并构造左边数组和右边数组。
let mid = Math.floor(arr.length/2);
let left = arr.slice(0, mid);
let right = arr.slice(mid);
// 开始递归调用。
return merge(arguments.callee(left), arguments.callee(right));
}
// 数组的合并函数,left是左边的有序数组,right是右边的有序数组。
function merge(left, right) {
// il是左边数组的一个指针,rl是右边数组的一个指针。
let il = 0,
rl = 0,
result = [];
// 同时遍历左右两个数组,直到有一个指针超出范围。
while(il < left.length && rl < right.length) {
//count++;
// 左边数组的当前项如果小于右边数组的当前项,那么将左边数组的当前项推入result,反之亦然,同时将推入过的指针右移。
if(left[il] < right[rl]) {
result.push(left[il++]);
}
else {
result.push(right[rl++]);
}
}
// 记得要将未读完的数组的多余部分读到result。
return result.concat(left.slice(il)).concat(right.slice(rl));
}
}
注意是因为数组被分解成为了只有一个元素的许多子数组,所以merge函数从单个元素的数组开始合并,当合并的数组的元素个数超过1时,即为有序数组,仍然还可以继续使用merge函数进行合并。
归并排序的性能确实达到了应用级别,但是还是有些不足,因为这里的merge函数新建了一个result数组来盛放合并后的数组,导致空间复杂度增加,这里还可以进行优化,使得数组进行原地排序。
快速排序由Tony Hoare在1959年发明,是当前最为常用的排序方案,如果使用得当,其速度比一般算法可以快两到三倍,比之冒泡排序、选择排序等可以说快成千上万倍。快速排序的复杂度为O(nlogn),其核心**也是分而治之,它递归地将大数组分解为小数组,直到数组长度为1,不过与归并排序的区别在于其重点在于数组的分解,而归并排序的重点在于数组的合并。
基本**:
在数组中选取一个参考点(pivot),然后对于数组中的每一项,大于pivot的项都放到数组右边,小于pivot的项都放到左边,左右两边的数组项可以构成两个新的数组(left和right),然后继续分别对left和right进行分解,直到数组长度为1,最后合并(其实没有合并,因为是在原数组的基础上操作的,只是理论上的进行了数组分解)。
基本步骤:
JavaScript实现(从小到大排序):
function quickSort(arr) {
let left = 0,
right = arr.length - 1;
//console.time('QuickSort');
main(arr, left, right);
//console.timeEnd('QuickSort');
return arr;
function main(arr, left, right) {
// 递归结束的条件,直到数组只包含一个元素。
if(arr.length === 1) {
// 由于是直接修改arr,所以不用返回值。
return;
}
// 获取left指针,准备下一轮分解。
let index = partition(arr, left, right);
if(left < index - 1) {
// 继续分解左边数组。
main(arr, left, index - 1);
}
if(index < right) {
// 分解右边数组。
main(arr, index, right);
}
}
// 数组分解函数。
function partition(arr, left, right) {
// 选取中间项为参考点。
let pivot = arr[Math.floor((left + right) / 2)];
// 循环直到left > right。
while(left <= right) {
// 持续右移左指针直到其值不小于pivot。
while(arr[left] < pivot) {
left++;
}
// 持续左移右指针直到其值不大于pivot。
while(arr[right] > pivot) {
right--;
}
// 此时左指针的值不小于pivot,右指针的值不大于pivot。
// 如果left仍然不大于right。
if(left <= right) {
// 交换两者的值,使得不大于pivot的值在其左侧,不小于pivot的值在其右侧。
[arr[left], arr[right]] = [arr[right], arr[left]];
// 左指针右移,右指针左移准备开始下一轮,防止arr[left]和arr[right]都等于pivot然后导致死循环。
left++;
right--;
}
}
// 返回左指针作为下一轮分解的依据。
return left;
}
}
快速排序相对于归并排序而言加强了分解部分的逻辑,消除了数组的合并工作,并且不用分配新的内存来存放数组合并结果,所以性能更加优秀,是目前最常用的排序方案。
之前还在知乎上看到过一个回答,代码大致如下(从小到大排序):
function quickSort(arr) {
// 当数组长度不大于1时,返回结果,防止callstack溢出。
if(arr.length <= 1) return arr;
return [
// 递归调用quickSort,通过Array.prototype.filter方法过滤小于arr[0]的值,注意去掉了arr[0]以防止出现死循环。
...quickSort(arr.slice(1).filter(item => item < arr[0])),
arr[0],
...quickSort(arr.slice(1).filter(item => item >= arr[0]))
];
}
以上代码有利于对快排**的理解,但是实际运用效果不太好,不如之前的代码速度快。
如果说快速排序是应用性最强的排序算法,那么我觉得堆排序是趣味性最强的排序方法,非常有意思。
堆排序也是一种很高效的排序方法,因为它把数组作为二叉树排序而得名,可以认为是归并排序的改良方案,它是一种原地排序方法,但是不够稳定,其时间复杂度为O(nlogn)。
实现步骤:
数组构建的堆结构:
// 数组
var arr = [1,2,3,4,5,6,7];
// 堆结构
1
/ \
2 3
/ \ / \
4 5 6 7
可以发现对于数组下标为i的数组项,其左子节点的值为下标2*i + 1对应的数组项,右子节点的值为下标2*i + 2对应的数组项。
实际上并没有在内存中开辟一块空间构建堆结构来存储数组数据,只是在逻辑上把数组当做二叉树来对待,构建堆结构指的是使其任意父节点的子节点都不大于(不小于)父节点。
JavaScript实现(从小到大排序):
function heapSort(arr) {
//console.time('HeapSort');
buildHeap(arr);
for(let i=arr.length-1; i>0; i--) {
// 从最右侧的叶子节点开始,依次与根节点的值交换。
[arr[i], arr[0]] = [arr[0], arr[i]];
// 每次交换之后都要重新构建堆结构,记得传入i限制范围,防止已经交换的值仍然被重新构建。
heapify(arr, i, 0);
}
//console.timeEnd('HeapSort');
return arr;
function buildHeap(arr) {
// 可以观察到中间下标对应最右边叶子节点的父节点。
let mid = Math.floor(arr.length / 2);
for(let i=mid; i>=0; i--) {
// 将整个数组构建成堆结构以便初始化。
heapify(arr, arr.length, i);
}
return arr;
}
// 从i节点开始下标在heapSize内进行堆结构构建的函数。
function heapify(arr, heapSize, i) {
// 左子节点下标。
let left = 2 * i + 1,
// 右子节点下标。
right = 2 * i + 2,
// 假设当前父节点满足要求(比子节点都大)。
largest = i;
// 如果左子节点在heapSize内,并且值大于其父节点,那么left赋给largest。
if(left < heapSize && arr[left] > arr[largest]) {
largest = left;
}
// 如果右子节点在heapSize内,并且值大于其父节点,那么right赋给largest。
if(right < heapSize && arr[right] > arr[largest]) {
largest = right;
}
if(largest !== i) {
// 如果largest被修改了,那么交换两者的值使得构造成一个合格的堆结构。
[arr[largest], arr[i]] = [arr[i], arr[largest]];
// 递归调用自身,将节点i所有的子节点都构建成堆结构。
arguments.callee(arr, heapSize, largest);
}
return arr;
}
}
堆排序的性能稍逊于快速排序,但是真的很有意思。
通过console.time()和console.timeEnd()查看排序所用时间,通过generateArray()产生大规模的数据,最终得到如下结论:
通过对冒泡排序的测试,得到以下数据:
BubbleSort: 406.567ms
给10000(一万)条数据进行排序,耗时406毫秒。
BubbleSort: 1665.196ms
给20000(两万)条数据进行排序,耗时1.6s。
BubbleSort: 18946.897ms
给50000(五万)条数据进行排序,耗时19s。
由于机器不太好,当数据量达到100000时基本就非常漫长了,具体多久也没等过,这已经可以看出来性能非常不好了。
通过对选择排序的测试,得到以下数据:
SelectionSort: 1917.083ms
对20000(两万)条数据进行排序,耗时1.9s。
SelectionSort: 12233.060ms
给50000(五万)条数据进行排序时,耗时12.2s,可以看出相对于冒泡排序而言已经有了进步,但是远远不够。还可以看出随着数据量的增长,排序的时间消耗越来越大。
通过对插入排序的测试,得到以下数据:
InsertionSort: 273.891ms
对20000(两万)条数据进行排序,耗时0.27s。
InsertionSort: 1500.631ms
对50000(五万)条数据进行排序,耗时1.5s。
InsertionSort: 7467.029ms
对100000(十万)条数据进行排序,耗时7.5秒,对比选择排序,又有了很大的改善,但是仍然不够。
通过对归并排序的测试,得到以下数据:
MergeSort: 287.361ms
对100000(十万)条数据进行排序,耗时0.3秒,真的很优秀了hhh,
MergeSort: 2354.007ms
对1000000(一百万)条数据进行排序,耗时2.4s,绝对的优秀,难怪FireFox会使用这个来定义Array.prototype.sort方法,
MergeSort: 26220.459ms
对10000000(一千万)条数据进行排序,耗时26s,还不错。
接下来看快排。
通过对快速排序的测试,得到以下数据:
QuickSort: 51.446ms
100000(十万)条数据排序耗时0.05s,达到了可以忽略的境界,
QuickSort: 463.528ms
1000000(一百万)条数据排序耗时0.46s,也基本可以忽略,太优秀了,
QuickSort: 5181.508ms
10000000(一千万)条数据排序耗时5.2s,完全可以接受。
通过对堆排序的测试,得到以下数据:
HeapSort: 3124.188ms
对1000000(一百万)条数据进行排序,耗时3.1s,逊色于快速排序和归并排序,但是对比其他的排序方法还是不错的啦。
HeapSort: 41746.788ms
对10000000(一千万)条数据进行排序,耗时41.7s,不太能接受。
以前都认为排序方法随便用用无可厚非,现在想想确实挺naive的hhh,想到了以前实习的时候,SQL Server几百万数据几秒钟就排序完成了,这要是用冒泡排序还不得等到两眼发黑?通过这次学习总结排序算法,尤其是对于每种方法性能的测试,我深刻地认识到了算法设计的重要性,只有重视算法的设计、复杂度的对比,才能写出优秀的算法,基于优秀的算法才能写出性能出色的应用!
此外,由于对于算法复杂度的研究不够深入,理解只停留在表面,所以文中如果存在有错误,恳请大牛不吝赐教!
最后,我想说一声,支持阮老师!
《图解 HTTP》一书是日本学者上野宣所著,2014 年由于均良先生翻译并在国内出版。因为作者使用十分生动的语言和浅显易懂的案例将 HTTP 协议讲解得深入浅出,所以深受开发者喜爱。现在在网上随手一搜都可以找到很多的电子书或者读书笔记,可见该书的畅销程度。
我本人由于之前在使用 Nodejs 开发后端项目的时候有过一些障碍(比如 302、301 重定向,401 认证失败、预检请求等等),所以想要找个时间系统的学习一下 HTTP 协议,也作为之后阅读 Nodejs 框架的前瞻;所以 《图解 HTTP》自然而然也就成为了我的首选教材,于是赶紧在网上买了一本,不久之后就诞生了这个系列的读书笔记。说是一个系列,其实就是八篇长度比较适中的文章,对于书中的内容多半是精简摘抄,有些地方稍微有一点点拓展,所以看过书的童鞋就没有什么必要再浪费时间阅读了。
全书一共有 11 个大章节,其中第一章主要介绍了网络基础知识,包括 HTTP 网络协议的诞生背景、TCP/IP 协议简介、网络协议的分层以及 DNS 服务等等。第二章主要讲解了 HTTP 协议的作用、工作方式以及一些特点。第三章主要讲解 HTTP 报文的结构。第四章主要讲解 HTTP 的一系列状态码,比如 2XX 代表响应成功、3XX 代表重定向、4XX 代表客户端请求错误造成响应失败、5XX 代表服务器错误导致响应失败。第五章主要讲解 Web 服务器的一些概念,比如网关、隧道、代理以及资源缓存等等。第六章主要讲解 HTTP 首部,包括常用的通用、请求、响应、实体首部字段以及一些其他的首部字段,这一章讲解的比较多,所以内容也相对而言比较多。第七章主要讲解 HTTPS 的组成、工作原理以及网络证书等知识,对于使用 Nodejs 开发而言这一节十分重要,尤其是对证书的知识感到困惑的童鞋需要好好阅读一下这一章。第八章主要讲解身份认证,现在多半基于表单认证,主要涉及到 cookie 以及 session 的知识。第九章主要讲解一些从 HTTP 扩展的协议,最重要的是 WebSocket 协议,但是我的笔记中这一章的内容基本没写。第十章主要讲解构建 Web 内容的技术,作为一名前端开发,我很自然的跳过了这一章~~。第十一章主要讲解一些常见的 Web 攻击技术,最常见的有 XSS 跨站攻击、SQL 注入攻击、CSRF 跨站点请求伪造、DoS 攻击等等。
我的笔记大概在七章之前是每章一篇 ,然后第十一章单独一篇,中间的两篇被忽略掉了。其中我认为最重要的是第四章 HTTP 状态码、第六章 HTTP 首部、第七章 HTTPS 的知识以及 HTTP 证书的基本原理。总而言之,这是一本关于 HTTP 的相当好的入门书籍,推荐指数五颗星。具体内容还需要大家自己阅读,文章如下:
所有文章的具体内容都可以在我的 GitHub 找到,有任何有异议的地方都可以直接评论或者提起 PR。
最后,感谢您的阅读!
由于无法进入图形界面,所以需要在开机时进入恢复模式。我的机器上时在开机时通过引导选项中的recovery mode选项进入,进入之后可以看到许多选项卡,选择root,回车之后再回车,准备输入命令。
通过以下命令查看:
$dpkg -l | grep -i nvidia
如果列出来的驱动中,有名称为nvidia-common之外的驱动,则需要卸载其他驱动。
$sudo apt-get remove --purge nvidia-*
第三步中删除了nvidia-common,这里需要重新安装一下:
$sudo apt-get install ubuntu-desktop
通过以下命令,将驱动添加到/etc/modules中:
$echo 'nouveau' | sudo tee -a /etc/modules
然后找到xorg.conf文件,删除它。
这一步我也是靠猜的,不知道到底猜对了没有,我使用的命令如下:
$sudo remove /etc/X11/xorg.conf
大家最好还是自己找一找资料,这一部分我不敢保证其正确性,因为最后我重启可以进入图形界面了,所以就没有在意这部分了。
通过以下命令重新启动计算机:
$sudo reboot

最近在倒腾Ubuntu,然后想着怎么美化一下界面,于是照着网上的教程整了一下Flatabulous这个软件,然后好像/boot就满了。关机之后再开机就出现了如题所述的错误,无法开机,也无法进入recovery mode,整个系统都感觉没救了。找了一些答案好多都说需要使用live CD的方式启动,太麻烦了。后来找到了一个靠谱点的教程,现在记录一下。
首先,最好对你的系统做个备份,或者导出,确保意外发生的时候,给你的造成的损失是最小的。
出现这种错误的原因多半是/boot盘空间不够,你的Ubuntu内核做了许多的更新,而默认情况下,Ubuntu将保留旧的内核并将它们添加到可在Grub2启动加载器菜单中启动的可用内核列表中。
你可以通过以下命令来确定你的/boot是否已经爆满:
df -h
现在的情况是系统已经无法进入,连修复模式也没办法开启,所以我们要想办法。在进入引导界面的时候,可以选择Ubuntu高级选项,然后选择一个非修复模式的系统进入。当然不是所有情况下都能顺利进入系统,这个时候你只能祈祷能够顺利进入登录界面咯。
登录之后,打开命令行工具,使用以下命令查看你的当前内核:
uname -a
然后把输出结果记在你的小本本上吧,等会千万不能删除这个内核。
接下来就是通过以下命令查看你的机器上安装的所有内核:
dpkg --list | -grep linux-image
找到所有比当前内核版本低的内核。当你知道要删除哪些内核时,请继续在下面将其删除。运行以下命令删除您选择的内核:
sudo apt-get purge linux-image-xxxx-generic
或者:
sudo apt-get purge linux-image-extra-xxx-xx-generic
最后,运行下面的命令更新grub2:
sudo update-grub2
最后的最后,重启你的机器:
sudo reboot
这次在登录的时候,就可以直接使用第一个选项Ubuntu进行登录了。
$ sudo apt-get update
$ sudo apt-get install redis-serverWindows 下:
直接到 GitHub 下载 zip 包,解压出来然后把内容拷贝到你的某个目录下就可以了。
运行的时候需要把 cmd 路径切换到你的 Redis 所在的路径。如果觉得麻烦的话,可以把 Redis 所在的路径设置为环境变量。
运行以下命令:
$ redis-server或者 Windows 下直接运行 redis-server.exe。
$ redis-cli或者 Windows 下直接运行 redis-cli.exe。
我本机(Ubuntu 18.04)直接使用包管理器安装 redis,所以配置文件位于/etc/redis/redis.conf。
使用管理员权限打开该配置文件,即可进行配置:
$ sudo vim /etc/redis/redis.conf学习网站 -> try.redis.io/
Redis 基于键值对的形式存储数据,通常被认为是一种 NoSQL 数据库。
SET KEY VALUE
比如:
SET name 'fido'
GET KEY
比如:
GET name
INCR KEY
比如:
SET age 18
INCR age
自增后 age 的值为 19
DECR KEY
比如:
DECR age
自减后 age 的值为 18
**为什么会有自增和自减操作呢?**我们可以在自己的代码里面完成这些操作的啊:
x = GET age
x = x + 1
SET age x
这段代码不就完成了自增操作吗?
这样做确实可以,但是并不符合数据操作的原子性,如果多个客户端同时取出同一个数据,然后进行了更新:
这样就出现问题了,因为我们期望 age 的值变成 20,现在却只增加了 1。
这就是为什么 Redis 提供了这些原子性操作。
DEL KEY
比如
DEL age
之后 age 的值就不存在了。
SETNX KEY VALUE
表示如果 KEY 键没有对应的值存储在 Redis 中,则创建一个新的键值对进行存储。
EXPIRE KEY TIME
EXPIRE 命令可以指定某个键值对的有效时长,单位为秒。在指定的时长过后,数据将不存在。
比如:
EXPIRE age 100
该命令表示 100 秒后 age 将被销毁。
使用 TTL 命令可以查看剩余有效时长:
TTL KEY
比如:
TTL age
如果输出为 -2,表示数据已经被销毁,不再存在。如果输出为 -1,表示数据永不过期。
Redis 同样支持一些复杂点的数据结构,首先要讲的就是 list(列表),list 是一系列有序值的集合。比较重要的操作指令包括:LPUSH、RPUSH、LPOP、RPOP、LLEN 和 LRANGE。
下面分别介绍这些指令的含义。
表示在列表的尾部插入一条数据:
RPUSH friends Tom
此时 friends 即为一个 list,里面只有一条数据即为 Tom。
RPUSH friends Jerry
此时 friends 仍然是一个 list,不过内部已有两条数据,分别为 Tom 和 Jerry。
表示在列表的尾部删除一条数据
RPOP friends
这条命令会在 friends 的尾部删除一条数据,并且返回删除的数据。
所以 RPOP 的意思应为 Right POP;RPUSH 的意思应为 Right PUSH。由此可知 LPUSH、LPOP 的意思。
获取某个 list 的长度。
LLEN friends
将返回对应 list 的长度。
返回某个 list 的子集,接受两个参数指定起始索引和截止索引(索引从 0 开始)。
LRANGE friends 0 -1
上面这条命令表示返回 friends 的所有元素,其中截止索引为 -1 表示所有。
输出结果大致如下:
1) "zzz"
2) "123"
Set 与 List 的区别在于 Set 里面的元素是无序且不重复的。
主要的操作命令有SADD、SREM、SISMEMBER、SMEMBERS 和 SUNION。
SADD 命令会把指定的值添加到集合中:
SADD names 123
SREM 会把指定的值从集合中移出,意义为Set Remove。
SREM names 123
SISMEMBER 会检测给出的值是否是给定集合的元素。
SISMEMBER names 123
返回值为 1 或者 0,1 代表是,0 代表否。
SMEMBERS 返回集合的所有元素。
SMEMBERS names
输出格式大致如下:
1) "123"
SUNION 代表求出多个集合的并集。
SUNION names1 names2
返回结果是一个新的集合。
该命令表示求两个集合的交集。
SINTER names1 names2
返回结果为一个新的集合。
该命令表示求两个集合的差集。
SDIFF name1 name2
返回结果是 name1 中具有但是 name2 中没有的元素所组成的集合,即为差集。
与 SUNION 类似,但是区别于 SUNION,因为 SUNION 只会求出两个集合的交集,然后返回结果;但是 SUNIONSTORE 不仅会求出交集,还会把结果保存在目标集合中。如果目标集合已经存在,则会覆盖掉已有的集合。
SADD name1 test1
SADD name1 test2
SADD name2 test3
SUNIONSTORE name name1 name2
SMEMBERS name
执行上述命令后,name1 和 name2 的交集会保存在 name 集合中。
无序集合在实际应用中还是有一些掣肘,所以 Redis 1.2 引入了有序集合。
有序集合与普通的集合类似,但是每一项都有一个相关联的数值,这个数值用于在集合中进行排序。
ZADD 表示在一个有序集合中新增一项,ZADD 接受 3 个参数:
比如:
ZADD hackers 1912 "Alan Turing"
该命令返回有序集合的子集,与 LRANGE 类似。
ZRANGE names 0 -1
返回 names 的所有元素。
该命令返回一个子集,子集中每一项的 score 都位于 min 和 max 之间。
ZRANGEBYSCORE names 100 200
一个 Hash 可以在许多字段和字段的值之间构造映射关系,所以适合于表示对象。
该命令用于设置散列。
HSET person1 name "test"
HSET person1 age 18
HSET person1 gender "male"
该命令用于返回某个 HASH 的所有数据。
HGETALL person1
输出结果如下:
1) "name"
2) "test"
3) "age"
4) "18"
5) "gender"
6) "male"
该命令含义为 hash multiple set,即一次设置多对映射关系。
HMSET person2 name "test1" age 18 gender "female"
该命令表示获取 HASH 中某一个字段的值
HGET person1 name
同样的 HASH 结构中也有许多的原子性操作命令。
设置 HASH 中某个字段的值。
HSET person1 name "Jerry"
表示对 HASH 中的某个数值进行加操作。
HINCRBY person1 age 1
接受三个参数:
要想进行减操作时,参数 3 改成负数即可。
该命令表示删除 HASH 中的某一个属性。
HDEL person1 name
此时这个字段及其对应的值都会被删除掉。
更多 HASH 数据结构的操作命令可以参考:HASHES
Redis 事务是一系列批量执行的 Redis 命令,区别于数据库事务,Redis 事务不存在回滚机制,在某条命令执行失败后不会取消事务,对于错误之前修改的数据也不会回滚。
Redis 事务主要依赖三条命令:MULTI、EXEC, WATCH 和 DISCARD。
执行事务的步骤如下:
MULTI
SET name test1
SET name test2
GET name
EXEC
如果想取消事务,键入DISCARD 命令:
MULTI
SET name test1
SET name test2
GET name
DISCARD
WATCH 命令用于监控某个或某几个键,一旦键的值被修改,则事务取消。监控会持续到 EXEC 命令执行。
通过 WATCH 可以实现 CAS(check and set)机制,在某种程度上使操作具有原子性,防止了分布式(或多线程)同时修改数据时可能出现的错误。
Redis 单个命令的操作是原子性的,但是事务并不具有原子性,所以对于数据的操作要谨慎。
在 Node 中使用 Redis,需要通过驱动进行连接,然后进行相应的操作。最常用的驱动当属:node-redis。该模块允许你按照指定的配置连接 Redis,然后进行数据操作。也有人对 node-redis 进行了进一步的封装:redis-connection,该模块在程序中可以维持一个公用的 Redis 连接,可有效减少数据库的连接数,提高数据库的效率。
翻译了一篇关于 JWT 的教程文章~
何为去抖函数?在学习Underscore去抖函数之前我们需要先弄明白这个概念。很多人都会把去抖跟节流两个概念弄混,但是这两个概念其实是很好理解的。
去抖函数(Debounce Function),是一个可以限制指定函数触发频率的函数。我们可以理解为连续调用同一个函数多次,只得到执行该函数一次的结果;但是隔一段时间再次调用时,又可以重新获得新的结果,具体这段时间有多长取决于我们的设置。这种函数的应用场景有哪些呢?
比如我们写一个DOM事件监听函数,
window.onscroll = function(){
console.log('Got it!');
}
现在当我们滑动鼠标滚轮的时候,我们就可以看到事件被触发了。但是我们可以发现在我们滚动鼠标滚轮的时候,我们的控制台在不断的打印消息,因为window的scroll事件被我们不断的触发了。
在当前场景下,可能这是一个无伤大雅的行为,但是可以预见到,当我们的事件监听函数(Event Handler)涉及到一些复杂的操作时(比如Ajax请求、DOM渲染、大量数据计算),会对计算机性能产生多大影响;在一些比较老旧的机型或者较低版本的浏览器(尤其IE)中,很可能会导致死机情况的出现。所以这个时候我们就要想办法,在指定时间段内,只执行一定次数的事件处理函数。
说了一些概念和应用场景,但是还是很拗口,到底什么是去抖函数?
我们可以通过如下实例来理解:
假设有以下代码:
//自己实现的简单演示代码,未实现immediate功能,欢迎改进。
var debounce = function (callback, delay, immediate) {
var timeout, result;
return function () {
var callNow;
if (timeout)
clearTimeout(timeout);
callNow = !timeout && immediate;
if (callNow) {
result = callback.apply(this, Array.prototype.slice.call(arguments, 0));
timeout = {};
}
else {
timeout = setTimeout(() => {
callback.apply(this, Array.prototype.slice.call(arguments, 0));
}, delay);
}
};
};
var s = debounce(() => {
console.log('yes...');
}, 2000);
window.onscroll = s;
debounce函数就是我自己实现的一个简单的去抖函数,我们可以通过这段代码进行实验。
步骤如下:
通过以上步骤,我们可以发现当我们连续滚动鼠标时,控制台没有消息被打印出来,停止2s以内并再次滚动时,也没有消息输出;但是当我们停止的时间超过2s时,我们可以看到控制台有消息输出。
这就是去抖函数。在连续的触发中(无论时长),只能得到触发一次的效果。在指定时间长度内连续触发,最多只能得到一次触发的效果。
underscore源码如下(附代码注释):
// Returns a function, that, as long as it continues to be invoked, will not
// be triggered. The function will be called after it stops being called for
// N milliseconds. If `immediate` is passed, trigger the function on the
// leading edge, instead of the trailing.
//去抖函数,传入的函数在wait时间之后(或之前)执行,并且只会被执行一次。
//如果immediate传递为true,那么在函数被传递时就立即调用。
//实现原理:涉及到异步JavaScript,多次调用_.debounce返回的函数,会一次性执行完,但是每次调用
//该函数又会清空上一次的TimeoutID,所以实际上只执行了最后一个setTimeout的内容。
_.debounce = function (func, wait, immediate) {
var timeout, result;
var later = function (context, args) {
timeout = null;
//如果没有传递args参数,那么func不执行。
if (args) result = func.apply(context, args);
};
//被返回的函数,该函数只会被调用一次。
var debounced = restArgs(function (args) {
//这行代码的作用是清除上一次的TimeoutID,
//使得如果有多次调用该函数的场景时,只执行最后一次调用的延时。
if (timeout) clearTimeout(timeout);
if (immediate) {
////如果传递了immediate并且timeout为空,那么就立即调用func,否则不立即调用。
var callNow = !timeout;
//下面这行代码,later函数内部的func函数注定不会被执行,因为没有给later传递参数。
//它的作用是确保返回了一个timeout,并且保持到wait毫秒之后,才执行later,
//清空timeout。而清空timeout是在immediate为true时,callNow为true的条件。
//timeout = setTimeout(later, wait)的存在是既保证上升沿触发,
//又保证wait内最多触发一次的必要条件。
timeout = setTimeout(later, wait);
if (callNow) result = func.apply(this, args);
} else {
//如果没有传递immediate,那么就使用_.delay函数延时执行later。
timeout = _.delay(later, wait, this, args);
}
return result;
});
//该函数用于取消当前去抖效果。
debounced.cancel = function () {
clearTimeout(timeout);
timeout = null;
};
return debounced;
};
可以看到underscore使用了闭包的方法,定义了两个私有属性:timeout和result,以及两个私有方法later和debounced。最终会返回debounced作为处理之后的函数。timeout用于接受并存储setTimeout返回的TimeoutID,result用于执行用户传入的func函数的执行结果,later方法用于执行传入的func函数。
利用了JavaScript的异步执行机制,JavaScript会优先执行完所有的同步代码,然后去事件队列中执行所有的异步任务。
当我们不断的触发debounced函数时,它会不断的clearTimeout(timeout),然后再重新设置新的timeout,所以实际上在我们的同步代码执行完之前,每次调用debounced函数都会重置timeout。所以异步事件队列中的异步任务会不断刷新,直到最后一个debounced函数执行完。只有最后一个debounced函数设置的later异步任务会在同步代码执行之后被执行。
所以当我们在之前实验中不断的滚动鼠标时,实际上是在不断的调用debounced函数,不断的清除timeout对应的异步任务,然后又设置新的timeout异步任务。当我们停止的时间不超过2s时,timeout对应的异步任务还没有被触发,所以再次滚动鼠标触发debounced函数还可以清除timeout任务然后设置新的timeout任务。一旦停止的时间超过2s,最终的timeout对应的异步代码就会被执行。

最近在学习 Linux,前面的基础知识学习了一下,进入了 Vim 的学习环节。感觉这个编辑器还是可以的,有特色,鼠标都不用,蛮炫酷。对于基本
的使用来讲还是很方便的。下面是一些我的学习笔记,大致就是一些常用的命令吧。这个博客就是使用 Vim 写的一个 Markdown 文档,就当是给自己练练手,加深学习的印象了。
Vim 是从 vi 发展而来的一个功能强大、高度可定制的文本编辑器,是一款开源的软件。Vim 的基本功能模式如下图:
由图可知,Vim 基本包括三种工作模式:命令模式、插入模式和编辑模式。在终端中通过 vi 命令即可使用 Vim 打开对应文件,从而进入命令模式,此时输入的任何文本信息都会被当做命令,回车即可执行输入的这些命令。要想编辑文本信息,需要进入编辑模式,此时输入命令 a、o、i都可以进入插入模式。其中,a 代表在当前光标位置的后方插入,o 代表在当前光标的下面一行插入,i 代表在当前光标位置的前面插入。此外,A、O、I也可以进入插入模式,但是它们意义与其小写模式正好相反。A 代表在行尾插入,O 代表在当前光标位置的上面一行插入,I 代表在行首开始插入。进入插入模式之后,按“ESC”键即可退出插入模式,回到命令模式。
| 命令 | 含义 |
|---|---|
| a | 在光标当前所在位置的后面开始插入 |
| A | 在光标所在行行尾开始插入 |
| i | 在光标当前所在位置的前面开始插入 |
| I | 在光标所在行行首开始插入 |
| o | 在光标所在行的下一行开始插入 |
| O | 在光标所在行的上一行开始插入 |
| 命令 | 含义 |
|---|---|
| :set nu | 设置行号 |
| :set nonu | 取消行号 |
| gg | 跳转到第一行 |
| G | 跳转到最后一行 |
| nG | 跳转到第n行 |
| :n | 跳转到第n行 |
| $ | 跳转到行尾 |
| 0 | 跳转到行首 |
其中,值得注意的是,命令 :n 与命令 nG 具有同样的功能,从字面上看,:n 更容易记住,所以我一般使用 :n命令。
具体使用方法:
:100
在命令模式下,输入上方的命令,回车就回跳转到第一百行。
这些常用的跳转命令最好记住。
| 命令 | 含义 |
|---|---|
| x | 将光标所在处的字符进行剪切(删除) |
| nx | 将光标之后的n的字符进行剪切(删除) |
| dd | 将光标所在行进行剪切(删除) |
| ndd | 将光标所在行之后的n行进行剪切(删除) |
| dG | 将光标所在行到文章末尾进行剪切(删除) |
| D | 将光标所在处到行尾进行剪切(删除) |
| :n1,n2d | 将n1到n2行内容进行剪切(删除) |
常用的是 x、nx、dd 和 ndd。
| 命令 | 含义 |
|---|---|
| yy | 复制当前行 |
| nyy | 复制当前行以下的n行 |
| dd | 剪切当前行 |
| ndd | 剪切当前行之后的n行 |
| p | 粘贴在当前光标所在行下 |
| P | 粘贴在当前光标所在行上 |
| 命令 | 含义 |
|---|---|
| r | 取代光标所在处的字符 |
| R | 进入替换模式,类似于 Windows 中的 insert |
| u | 撤销上一次操作 |
注意点:
r 然后按新的字符。ESC 才能退出。| 命令 | 含义 |
|---|---|
| /string | 搜索指定字符串,如果要忽略大小写,先输入命令 :set ic |
| n | 搜索指定字符串的下一个位置 |
| :%s/old/new/g | 全文替换指定字符串 |
| :n1,n2s/old/new/g | 在指定范围内替换指定字符串 |
注意点:
| 命令 | 含义 |
|---|---|
| :w | 保存修改 |
| :w new_filename | 另存为指定文件 |
| :wq | 保存修改并退出 |
| ZZ | 保存修改并退出的快捷键 |
| :q! | 不保存修改强制退出 |
| :wq! | 保存修改并强制退出 |
| 命令 | 含义 |
|---|---|
| :r 文件名 | 将指定文件的内容导入到光标所在位置 |
| :r !命令 | 将命令运行结果导入到光标所在位置 |
| :map 快捷键 触发命令 | 自定义快捷键 |
| :ab old new | 在编辑时自动替换一些字符 |
注意点:
:r !命令 是一个很好用的命令,比如:r !date可以把当前日期时间快速导入到当前光标位置。:map 快捷键 触发命令用于自定义快捷键,在命令模式下,输入“:map ”然后输入“Ctrl+V+P”,会出现“^P”,代表快捷键为“Ctrl+P”。最后一部分触发命令是指按下快捷键后,触发的命令,比如“I#”,这代表快捷方式触发的命令为“I#”,然后按下“ESC”键。含义即为在行首添加“#”井号,快速注释。n1,n2s/^/#/g,代表将指定范围内的行首替换为“#”井号。其中,“^”代表行首。:ab是编辑时快速替换命令,当你自定义替换字符串后,当你在编辑模式下输入要替换的字符串时,空格或者回车后,这个就字符串就回立即被你定义的新字符串替换掉,很方便。Ctrl+S保存修改,在 Vim 中也喜欢按,结果按了之后就出问题了,无法输入了。解决方法就是按Ctrl+Q,退出锁屏模式。Ctrl+Z不是撤销更改,撤销更改应该进入命令模式,按u。编辑模式下按Ctrl+Z是强制将进程加入后台运行,会生成一个“.swap”交换文件。要正常编辑,可以手动删除交换文件,由于交互文件是隐藏文件,所以需要按ls -a查看。以上只是一些基本的 Vim 命令,学会使用这些命令还是能够大大地增强学习乐趣。另外要想学好 Vim,最好每个命令都自己试一试,亲身体验过后,还是觉得它非常方便的。
本文对应项目为 learn-coverage-test,可以对照项目案例进行阅读。
在写代码的时候,我们有时候会进行代码测试以保证我们代码的可执行性。但是测试代码只能保证测试案例能够通过,我们怎么样才能确保我们的测试案例基本覆盖了所有的情况呢?
比如:
const a = true;
if (a) {
return 1;
} else {
return -1;
}上面这段代码只能确保 a === true 的情况被执行,而没有执行 a === false 的情况。如果在实际使用当中,a 的值为 false,那么上面的代码可能会发生不可预知的情况。
所以我们需要引入覆盖率测试对我们的测试案例进行评估。
覆盖率用于评估在代码测试的过程中,所测试的代码的比例和程度。通常而言,测试覆盖率高的代码出错的几率比较小;测试覆盖率较低的代码出现不可预知行为的几率比较大。
根据维基百科的资料,基本的代码覆盖率有 4 种:函数覆盖率、语句覆盖率、分支覆盖率和条件覆盖率。
其中:
比如现在有一个函数:
function foo(x, y) {
let res = 0;
if (x > 0 && y > 0) {
res = x;
}
return res;
}对于上面这个函数,我们在测试时:
foo(1, 2)foo(1, 2),因为 res = x 也被执行了。x > 0 的值为 true 和 false 的情况,以及 y > 0 为 true 和 false 的情况,那么条件覆盖率被满足。比如:foo(1, -1) 和 foo(-1, 1)。以上案例来自维基百科
Mocha 是 JavaScript 项目的测试工具,Istanbul 是 JS 测试覆盖率报告的生成工具。
该节介绍如何结合二者测试代码并生成代码测试覆盖率报告。
nyc 是 Istanbul 的命令行接口,我们将其作为开发依赖安装在项目中:
$ npm i -D nyc然后在我们的 package.json 文件的 scripts 对象中新增如下属性:
"coverage": "node_modules/.bin/nyc --reporter=html --reporter=text node_modules/mocha/bin/_mocha"当然,根据项目情况不同,上面的命令可以不一致,具体可以参考文档进行配置。
这样当你在 npm run test 之后就可以在测试结果之后看到输出的覆盖率报告,而且还会额外生成覆盖率报告页面文件到项目的 coverage 目录下。
点击 coverage/index.html 可以看到详细的覆盖率测试结果:
首先要对你的 GitHub 账号开通 Codecov 权限,访问 Codecov,然后使用 GitHub 账号登录。之后将会自动同步一些你的 GitHub 信息,按照指引进行即可。
此后还需要在 GitHub 进行设置,对某个 repo 开通 Codecov 的服务。具体可以在 GitHub marketplace 中找到 Codecov,然后点击 configure 进行配置。
Travis CI 脚本中需要添加几句命令,以便安装对应依赖和上传覆盖率报告。
.travis.yml 具体配置大约如下:
language: node_js
node_js:
- "7"
install:
- npm i
- npm i -g codecov
script:
- npm run coverage
- node_modules/.bin/nyc report --reporter=text-lcov > coverage.lcov
- codecov
cache:
directories:
- node_modules可以看到安装的依赖为 codecov,并且是全局安装。然后使用 node_modules/.bin/nyc report --reporter=text-lcov > coverage.lcov 命令生成了报告。
配置好之后,当你每次对项目进行 PR 的时候,Codecov 会自动测试覆盖率,然后将报告评论在 PR 中:
如果 Contributor 没有对新增代码写对应的测试案例,你就可以一眼看出来。如果测试覆盖率太低,你可以修改 PR,重新合并。
我在 PR 中修改了测试代码,提高了测试覆盖率,Codecov 在我合并 PR 之前就已经把覆盖率报告评论在了 PR 下方了,可以明显地看到覆盖率得到了提升,确实十分的方便。
在 Codecov 官网登录后找到你的 repo,然后点击进去,依次找到 Settings -> Badge,复制对应的代码即可。
本文只讨论 CommonJS 规范,不涉及 ESM
我们知道 JavaScript 这门语言诞生之初主要是为了完成网页上表单的一些规则校验以及动画制作,所以布兰登.艾奇(Brendan Eich)只花了一周多就把 JavaScript 设计出来了。可以说 JavaScript 从出生开始就带着许多缺陷和缺点,这一点一直被其他语言的编程者所嘲笑。随着 BS 开发模式渐渐地火了起来,JavaScript 所要承担的责任也越来越大,ECMA 接手标准化之后也渐渐的开始完善了起来。
在 ES 6 之前,JavaScript 一直是没有自己的模块化机制的,JavaScript 文件之间无法相互引用,只能依赖脚本的加载顺序以及全局变量来确定变量的传递顺序和传递方式。而 script 标签太多会导致文件之间依赖关系混乱,全局变量太多也会导致数据流相当紊乱,命名冲突和内存泄漏也会更加频繁的出现。直到 ES 6 之后,JavaScript 开始有了自己的模块化机制,不用再依赖 requirejs、seajs 等插件来实现模块化了。
在 Nodejs 出现之前,服务端 JavaScript 基本上处于一片荒芜的境况,而当时也没有出现 ES 6 的模块化规范(Nodejs 最早从 V8.5 开始支持 ESM 规范:Node V8.5 更新日志),所以 Nodejs 采用了当时比较先进的一种模块化规范来实现服务端 JavaScript 的模块化机制,它就是 CommonJS,有时也简称为 CJS。
这篇文章主要讲解 CommonJS 在 Nodejs 中的实现。
在 Nodejs 采用 CommonJS 规范之前,还存在以下缺点:
这几点问题的存在导致 Nodejs 始终难以构建大型的项目,生态环境也是十分的贫乏,所以这些问题都是亟待解决的。
CommonJS 的提出,主要是为了弥补当前 JavaScript 没有模块化标准的缺陷,以达到像 Java、Python、Ruby 那样能够构建大型应用的阶段,而不是仅仅作为一门脚本语言。Nodejs 能够拥有今天这样繁荣的生态系统,CommonJS 功不可没。
CommonJS 对模块的定义十分简单,主要分为模块引用、模块定义和模块标识三个部分。下面进行简单介绍:
示例如下:
const fs = require('fs')在 CommonJS 规范中,存在一个 require “全局”方法,它接受一个标识,然后把标识对应的模块的 API 引入到当前模块作用域中。
我们已经知道了如何引入一个 Nodejs 模块,但是我们应该如何定义一个 Nodejs 模块呢?在 Nodejs 上下文环境中提供了一个 module 对象和一个 exports 对象,module 代表当前模块,exports 是当前模块的一个属性,代表要导出的一些 API。在 Nodejs 中,一个文件就是一个模块,把方法或者变量作为属性挂载在 exports 对象上即可将其作为模块的一部分进行导出。
// add.js
exports.add = function(a, b) {
return a + b
}在另一个文件中,我们就可以通过 require 引入之前定义的这个模块:
const { add } = require('./add.js')
add(1, 2) // print 3模块标识就是传递给 require 函数的参数,在 Nodejs 中就是模块的 id。它必须是符合小驼峰命名的字符串,或者是以.、..开头的相对路径,或者绝对路径,可以不带后缀名。
模块的定义十分简单,接口也很简洁。它的意义在于将类聚的方法和变量等限定在私有的作用于域中,同时支持引入和导出功能以顺畅的连接上下游依赖。
CommonJS 这套模块导出和引入的机制使得用户完全不必考虑变量污染。
以上只是对于 CommonJS 规范的简单介绍,更多具体的内容可以参考:CommonJS规范
Nodejs 在实现中并没有完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了一些自身需要的特性。接下来我们会探究一下 Nodejs 是如何实现 CommonJS 规范的。
在 Nodejs 中引入模块会经过以下三个步骤:
在了解具体的内容之前我们先了解两个概念:
fs、url、http 等Koa、Express 等核心模块在 Nodejs 源代码的编译过程中已经编译进了二进制文件,Nodejs 启动时会被直接加载到内存中,所以在我们引入这些模块的时候就省去了文件定位、编译执行这两个步骤,加载速度比文件模块要快很多。
文件模块是在运行的时候动态加载,需要走一套完整的流程:路径分析、文件定位、编译执行等,所以文件模块的加载速度比核心模块要慢。
在讲解具体的加载步骤之前,我们应当知晓的一点是,Nodejs 对于已经加载过一边的模块会进行缓存,模块的内容会被缓存到内存当中,如果下次加载了同一个模块的话,就会从内存中直接取出来,这样就省去了第二次路径分析、文件定位、加载执行的过程,大大提高了加载速度。无论是核心模块还是文件模块,require() 对同一文件的第二次加载都一律会采用缓存优先的方式,这是第一优先级的。但是核心模块的缓存检查优先于文件模块的缓存检查。
我们在 Nodejs 文件中所使用的 require 函数,实际上就是在 Nodejs 项目中的 lib/internal/modules/cjs/loader.js 所定义的 Module.prototype.require 函数,只不过在后面的 makeRequireFunction 函数中还会进行一层封装,Module.prototype.require 源码如下:
// Loads a module at the given file path. Returns that module's
// `exports` property.
Module.prototype.require = function(id) {
validateString(id, 'id');
if (id === '') {
throw new ERR_INVALID_ARG_VALUE('id', id,
'must be a non-empty string');
}
requireDepth++;
try {
return Module._load(id, this, /* isMain */ false);
} finally {
requireDepth--;
}
};可以看到它最终使用了 Module._load 方法来加载我们的标识符所指定的模块,找到 Module._load:
Module._cache = Object.create(null);
// 这里先定义了一个缓存的对象
// ... ...
// Check the cache for the requested file.
// 1. If a module already exists in the cache: return its exports object.
// 2. If the module is native: call
// `NativeModule.prototype.compileForPublicLoader()` and return the exports.
// 3. Otherwise, create a new module for the file and save it to the cache.
// Then have it load the file contents before returning its exports
// object.
Module._load = function(request, parent, isMain) {
let relResolveCacheIdentifier;
if (parent) {
debug('Module._load REQUEST %s parent: %s', request, parent.id);
// Fast path for (lazy loaded) modules in the same directory. The indirect
// caching is required to allow cache invalidation without changing the old
// cache key names.
relResolveCacheIdentifier = `${parent.path}\x00${request}`;
const filename = relativeResolveCache[relResolveCacheIdentifier];
if (filename !== undefined) {
const cachedModule = Module._cache[filename];
if (cachedModule !== undefined) {
updateChildren(parent, cachedModule, true);
return cachedModule.exports;
}
delete relativeResolveCache[relResolveCacheIdentifier];
}
}
const filename = Module._resolveFilename(request, parent, isMain);
const cachedModule = Module._cache[filename];
if (cachedModule !== undefined) {
updateChildren(parent, cachedModule, true);
return cachedModule.exports;
}
const mod = loadNativeModule(filename, request, experimentalModules);
if (mod && mod.canBeRequiredByUsers) return mod.exports;
// Don't call updateChildren(), Module constructor already does.
const module = new Module(filename, parent);
if (isMain) {
process.mainModule = module;
module.id = '.';
}
Module._cache[filename] = module;
if (parent !== undefined) {
relativeResolveCache[relResolveCacheIdentifier] = filename;
}
let threw = true;
try {
module.load(filename);
threw = false;
} finally {
if (threw) {
delete Module._cache[filename];
if (parent !== undefined) {
delete relativeResolveCache[relResolveCacheIdentifier];
}
}
}
return module.exports;
};我们可以先简单的看一下源代码,其实代码注释已经写得很清楚了。
Nodejs 先会根据模块信息解析出文件路径和文件名,然后以文件名作为 Module._cache 对象的键查询该文件是否已经被缓存,如果已经被缓存的话,直接返回缓存对象的 exports 属性。否则就会使用 Module._resolveFilename 重新解析文件名,再查询一边缓存对象。否则就会当做核心模块来加载,核心模块使用 loadNativeModule 方法进行加载。
如果经过了以上几个步骤之后,在缓存中仍然找不到 require 加载的模块对象,那么就使用 Module 构造方法重新构造一个新的模块对象。加载完毕之后还会缓存到 Module._cache 对象中,以便下一次加载的时候可以直接从缓存中取到。
从源码来看,跟我们之前说的没什么区别。
我们知道标识符是进行路径分析和文件定位的依据,在引用某个模块的时候我们就会给 require 函数传入一个标识符,根据我们使用的经历不难发现标识符基本上可以分为以下几种:
http、fs 等connect、koa 等标识符类型不同,加载的方式也有差异,接下来我将介绍不同标识符的加载方式。
核心模块的加载优先级仅次于缓存,前文提到过由于核心模块的代码已经编译成了二进制代码,在 Nodejs 启动的时候就会加载到内存中,所以核心模块的加载速度非常快。它根本不需要进行路径分析和文件定位,如果你想写一个和核心模块同名的模块的话,它是不会被加载的,因为其加载优先级不如核心模块。
当标识符为路径字符串时,require 都会把它当做文件模块来加载,在根据标识符获得真实路径之后,Nodejs 会将真实路径作为键把模块缓存到一个对象里,使二次加载更快。
由于文件模块的标识符指明了模块文件的具体位置,所以加载速度相对而言也比较快。
自定义模块是一个包含 package.json 的项目所构造的模块,它是一种特殊的模块,其查找方式比较复杂,所以耗时也是最长的。
在 Nodejs 中有一个叫做模块路径的概念,我们新建一个 module_path.js 的文件,然后在其中输入如下内容:
console.log(module.paths)然后使用 Nodejs 运行:
node module_path.js我们可以看到控制台输入大致如下:
[ 'C:\\Users\\UserName\\Desktop\\node_modules',
'C:\\Users\\UserName\\node_modules',
'C:\\Users\\node_modules',
'C:\\node_modules' ]此时我的 module_path.js 文件是放在桌面的,所以可以看到这个文件模块的模块路径是当前文件同级目录下的 node_modules,如果找不到的话就从父级文件夹的同名目录下找,知道找到根目录下。这种查找方式和 JavaScript 中的作用域链非常相似。可以看到当文件路径越深的时候查找所耗时间越长,所以这也是自定义模块加载速度最慢的原因。
在 Windows 环境中,Nodejs 通过下面函数获取模块路径:
Module._nodeModulePaths = function(from) {
// Guarantee that 'from' is absolute.
from = path.resolve(from);
// note: this approach *only* works when the path is guaranteed
// to be absolute. Doing a fully-edge-case-correct path.split
// that works on both Windows and Posix is non-trivial.
// return root node_modules when path is 'D:\\'.
// path.resolve will make sure from.length >=3 in Windows.
if (from.charCodeAt(from.length - 1) === CHAR_BACKWARD_SLASH &&
from.charCodeAt(from.length - 2) === CHAR_COLON)
return [from + 'node_modules'];
const paths = [];
var p = 0;
var last = from.length;
for (var i = from.length - 1; i >= 0; --i) {
const code = from.charCodeAt(i);
// The path segment separator check ('\' and '/') was used to get
// node_modules path for every path segment.
// Use colon as an extra condition since we can get node_modules
// path for drive root like 'C:\node_modules' and don't need to
// parse drive name.
if (code === CHAR_BACKWARD_SLASH ||
code === CHAR_FORWARD_SLASH ||
code === CHAR_COLON) {
if (p !== nmLen)
paths.push(from.slice(0, last) + '\\node_modules');
last = i;
p = 0;
} else if (p !== -1) {
if (nmChars[p] === code) {
++p;
} else {
p = -1;
}
}
}
return paths;
};代码和注释都写得很明白,大家看看就行,常量都放在 /lib/internal/constants.js 这个模块。
我们在引用模块的很多时候,传递的标识符都不会携带扩展名,比如
// require('./internal/constants.js')
require('./internal/constants')很明显下面的方式更简洁,但是 Nodejs 在定位文件的时候还是会帮我们补齐。补齐的顺序依次为:.js、.json 和 .node,在补齐的时候 Nodejs 会依次进行尝试。在尝试的时候 Nodejs 会调用 fs 模块来判断文件是否存在,所以这里可能会存在性能问题,如果在引用模块的时候加上扩展名,可以使得模块加载的速度变得更快。
在 Nodejs 源码 中,我们可以看到当解析不到文件名的时候,会尝试使用 tryExtensions 方法来添加扩展名:
if (!filename) {
// Try it with each of the extensions
if (exts === undefined)
exts = Object.keys(Module._extensions);
filename = tryExtensions(basePath, exts, isMain);
}而尝试的扩展名就是 Module._extensions 的键值,检索代码不难发现代码中依次定义了 .js、.json、.node、.mjs 等键,所以 tryExtensions 函数会依次进行尝试:
// Given a path, check if the file exists with any of the set extensions
function tryExtensions(p, exts, isMain) {
for (var i = 0; i < exts.length; i++) {
const filename = tryFile(p + exts[i], isMain);
if (filename) {
return filename;
}
}
return false;
}其中又调用了 tryFile 方法:
function tryFile(requestPath, isMain) {
const rc = stat(requestPath);
if (preserveSymlinks && !isMain) {
return rc === 0 && path.resolve(requestPath);
}
return rc === 0 && toRealPath(requestPath);
}
// Check if the file exists and is not a directory
// if using --preserve-symlinks and isMain is false,
// keep symlinks intact, otherwise resolve to the
// absolute realpath.
function tryFile(requestPath, isMain) {
const rc = stat(requestPath);
if (preserveSymlinks && !isMain) {
return rc === 0 && path.resolve(requestPath);
}
return rc === 0 && toRealPath(requestPath);
}
// 这个函数在其他地方还有用到,比较重要
function toRealPath(requestPath) {
return fs.realpathSync(requestPath, {
[internalFS.realpathCacheKey]: realpathCache
});
}可以看到最终还是依赖了 fs.realpathSync 方法,所以这里就跟之前说的是一样的,可能会存在性能问题,如果我们直接带上了扩展名的话,直接就可以解析出 filename,就不会去尝试扩展名了,这样可以稍微提高一点加载速度。
我们写的文件模块可能是一个 npm 包,此时包内包含许多 js 文件,所以 Nodejs 加载的时候又需要定位文件。Nodejs 会查找 package.json 文件,使用 JSON.stringify 来解析 json,随后取出其 main 字段之后对文件进行定位,如果文件名缺少扩展的话,也会进入扩展名尝试环节。
如果 main 字段指定的文件名有误,或者压根没有 package.json 文件,那么 Nodejs 会将 index 当做默认文件名,随后开始尝试扩展名。
Nodejs 中每一个模块就是一个 Module类实例,Module 的构造函数如下:
function Module(id = '', parent) {
this.id = id;
this.path = path.dirname(id);
this.exports = {};
this.parent = parent;
updateChildren(parent, this, false);
this.filename = null;
this.loaded = false;
this.children = [];
}编译和执行是引入文件模块的最后一个环节,定位到具体文件后,Nodejs 会新建一个模块对象,然后根据路径载入缓存以后进行编译,扩展名不同,编译的方式也不同,它们的编译方法都注册在了 Module._extensions 对象上,前文有提到过:
.js 文件:通过同步读取文件内容后编译执行.json 文件:通过 fs 模块读取文件,之后使用 JSON.parse 转化成 JS 对象.node 文件:这是使用 C/C++ 编写的扩展模块,通过内置的 dlopen 方法加载最后编译生成的文件.mjs 文件:这是 Nodejs 支持 ESM 加载方式的模块文件,所以使用 require 方法载入的时候会直接抛出错误在 Nodejs 的 辅助函数模块 中,通过以下代码把 Module._extensions 传递给了 require 函数:
// Enable support to add extra extension types.
require.extensions = Module._extensions;所以我们可以通过在模块中打印 require.extensions 查看当前 Nodejs 能够解析的模块:
console.log(require.extensions)
// { '.js': [Function], '.json': [Function], '.node': [Function] }另外我们可以看到上面第二段代码中的注释:Enable support to add extra extension types,也就是说我们可以通过修改 require.extensions 对象来注册模块的解析方法。
比如我们有一个 .csv 文件,我们想把它解析成一个二维数组,那么我们就可以写一下方法注册:
const fs = require('fs')
// 注册解析方法到 require.extensions 对象
require.extensions['.csv'] = function(module, filename) {
// module 是当前模块的 Module 实例,filename 是当前文件模块的路径
const content = fs.readFileSync(filename, 'utf8'),
lines = content.split(/\r\n/)
const res = lines.map(line => line.split(','))
// 注意导出是通过给 module.exports 赋值,而不是用 return
module.exports = res
}
/*
* demo.csv 的内容为:
* 1,2,3
* 2,3,4
* 5,6,7
*/
const arr = require('./demo.csv')
console.log(arr)
// output
// [ [ '1', '2', '3' ], [ '2', '3', '4' ], [ '5', '6', '7' ] ]但是在 v0.10.6 开始 Nodejs 就不再推荐使用这种方式来扩展加载方式了,而是期望现将其他语言转化为 JavaScript 以后再加载执行,这样就避免了将复杂的编译加载过程引入到 Nodejs 的执行过程。
接下来我们了解一下 Nodejs 内置的几种模块的加载方式。
在我们编写 Nodejs 模块的时候我们可以随意的使用 require、module、module、__dirname 和 __filename 等变量,仿佛它们都是 Nodejs 内置的全局变量一样,但是实际上他们都是局部变量。在 Nodejs 加载 JavaScript 模块的时候,会自动将模块内的所有代码包裹到一个匿名函数内,构成一个局部作用域,顺便把 require……等变量传入了匿名函数内部,所以我们的代码可以随意使用这些变量。
假设我们的模块代码如下:
exports.add = (a, b) => a + b经过 Nodejs 加载之后,代码变成了下面这样:
(function(exports, require, module, __filename, __dirname) {
exports.add = (a, b) => a + b
})这样看起来的话,一切都变得很顺其自然了。这也是为什么每个模块都是独立的命名空间,在模块文件内随便命名变量而不用担心全局变量污染,因为这些变量都定义在了函数内部,成为了这个包裹函数的私有变量。
弄明白 Nodejs 加载 JavaScript 的原理之后,我们很容易就可以弄明白为什么不能给 exports 直接赋值了,根本原因就在于 JavaScript 是一门按值传递(Pass-by-Value)的语言,不管我们给变量赋值的是引用类型还是原始类型,我们得到变量得到的都是一个值,只不过赋值引用类型时,变量得到的是一个代表存储引用类型的内存地址值(可以理解为指针),而我们使用变量时 JavaScript 会根据这个值去内存中找到对应的引用类型值,所以看起来也像是引用传递。而一旦我们给 exports 这种变量重新赋值的时候,exports 就失去了对原来引用类型的指向,转而指向新的值,所以就会导致我们赋给 exports 的值并没有指向原来的引用类型对象。
看看下面这段代码:
function changeRef(obj) {
obj = 12
}
const ref = {}
changeRef(ref)
console.log(ref) // {}可以看到函数内对 obj 重新赋值根本不影响函数外部的 ref对象,所以如果我们在模块内(及包裹函数内)修改 exports 的指向的话,外部的 module.exports 对象根本不受影响,我们导出的操作也就失败了。
下面我们稍微看一下 Nodejs 源码是如何编译执行 JavaScript 代码的。
首先根据 Module._extensions 对象上注册的 .js 模块加载方法找到入口:
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
const content = fs.readFileSync(filename, 'utf8');
module._compile(content, filename);
};可以看到加载方法听过 fs.readFileSync 方法同步读取了 .js 的文件内容之后,就把内容交给 module 的 _compile 方法去处理了,这个方法位于 Module 类的原型上,我们继续找到 Module.prototype._compile 方法:
// Run the file contents in the correct scope or sandbox. Expose
// the correct helper variables (require, module, exports) to
// the file.
// Returns exception, if any.
Module.prototype._compile = function(content, filename) {
let moduleURL;
let redirects;
if (manifest) {
moduleURL = pathToFileURL(filename);
redirects = manifest.getRedirects(moduleURL);
manifest.assertIntegrity(moduleURL, content);
}
const compiledWrapper = wrapSafe(filename, content);
var inspectorWrapper = null;
if (getOptionValue('--inspect-brk') && process._eval == null) {
if (!resolvedArgv) {
// We enter the repl if we're not given a filename argument.
if (process.argv[1]) {
resolvedArgv = Module._resolveFilename(process.argv[1], null, false);
} else {
resolvedArgv = 'repl';
}
}
// Set breakpoint on module start
if (!hasPausedEntry && filename === resolvedArgv) {
hasPausedEntry = true;
inspectorWrapper = internalBinding('inspector').callAndPauseOnStart;
}
}
const dirname = path.dirname(filename);
const require = makeRequireFunction(this, redirects);
var result;
const exports = this.exports;
const thisValue = exports;
const module = this;
if (requireDepth === 0) statCache = new Map();
if (inspectorWrapper) {
result = inspectorWrapper(compiledWrapper, thisValue, exports,
require, module, filename, dirname);
} else {
result = compiledWrapper.call(thisValue, exports, require, module,
filename, dirname);
}
if (requireDepth === 0) statCache = null;
return result;
};可以看到最后还是交给了 compiledWrapper 方法来处理模块内容(inspectWrapper 是做断电调试用的,咱们可以不管它),继续看 compiledWrapper 方法。
compiledWrapper 方法来源于 wrapSafe 的执行结果:
const compiledWrapper = wrapSafe(filename, content);而 wrapSafe 函数的定义如下:
function wrapSafe(filename, content) {
if (patched) {
const wrapper = Module.wrap(content);
return vm.runInThisContext(wrapper, {
filename,
lineOffset: 0,
displayErrors: true,
importModuleDynamically: experimentalModules ? async (specifier) => {
const loader = await asyncESM.loaderPromise;
return loader.import(specifier, normalizeReferrerURL(filename));
} : undefined,
});
}
const compiled = compileFunction(
content,
filename,
0,
0,
undefined,
false,
undefined,
[],
[
'exports',
'require',
'module',
'__filename',
'__dirname',
]
);
if (experimentalModules) {
const { callbackMap } = internalBinding('module_wrap');
callbackMap.set(compiled.cacheKey, {
importModuleDynamically: async (specifier) => {
const loader = await asyncESM.loaderPromise;
return loader.import(specifier, normalizeReferrerURL(filename));
}
});
}
return compiled.function;
}
// Module.wrap
// eslint-disable-next-line func-style
let wrap = function(script) {
return Module.wrapper[0] + script + Module.wrapper[1];
};
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
Object.defineProperty(Module, 'wrap', {
get() {
return wrap;
},
set(value) {
patched = true;
wrap = value;
}
});上面这段代码可以看到 wrapSafe 方法通过 Module.wrap 将模块代码构造成了一个匿名函数,随后扔给了 vm.runInThisContext 或者 compileFunction 去执行,这两函数都开始涉及到 JavaScript 跟 C/C++ 的底层了,作者水平渣渣,不再进行下一步解读,感兴趣的童鞋可以自己找到源码继续阅读。
Nodejs 通过调用 process.dlopen 加载和执行 C/C++ 模块,该函数在 Window 和 *nix 系统下有不同的实现,通过 linuv 兼容层进行了封装。
实际上 .node 模块不需要编译,因为是根据 C/C++ 编译而成的,所以只有加载和执行过程。编写 C/C++ 模块能够提高 Nodejs 的扩展能力和计算能力,我们知道 Nodejs 是单线程异步无阻塞的语言,优势在于 IO 密集型场景而非计算密集型场景。当我们有大量的计算操作需要执行时,我们可以将计算操作放到 C/C++ 模块中执行,这样可以提升 Nodejs 在计算密集型场景下的表现。但是 C/C++ 的编程门槛比 Nodejs 高很多,所以这也是一大缺点。
Nodejs 在 v10.x 中引入了 Worker Threads 特性,并且这一特性在 v12.x 中开始默认启用,大大提高了 Nodejs 在计算密集型场景下的表现,在某种程度上减少了开发者所需要编写的 C/C++ 代码量。
JSON 文件的编译是最简单的,通过 fs.readFileSync 读取文件内容后,调用 JSON.parse 转化成 JavaScript 对象导出就行了。
由于作者水平有限,关于核心模块以及 C/C++ 模块的书写和编译不再讲解。
通过这篇文章,我们至少学习到了以下几点:
CommonJS 模块化规范的基本内容
CommonJS 规范主要包括 模块引用、模块定义 和 模块标识,规定了一个模块从引入到消费以及导出的整个过程。通过给 require 方法传递模块标识符(路径字符串或者模块名称)来引入 CJS 模块,导出时给 module.exports 或者 exports 赋值或者添加属性即可。
Nodejs 引入模块的加载顺序和基本步骤
1、加载顺序和速度:
require 函数接收到模块标识符时,会优先检查内存中是否已经有缓存的模块对象,有的话直接返回,没有就继续查找。所以缓存的加载优先级和加载速度是最高的,其次是核心模块,因为核心模块已经被编译到了 Nodejs 代码中,Nodejs 启动的时候就已经把核心模块的内容加载到了内存中,所以核心模块的加载顺序和加载速度位于第二,仅次于内存。然后就是文件模块,Nodejs 通过找到文件然后使用对应的方法加载文件中的代码并执行。最后才是自定义模块。
2、加载基本步骤:
加载步骤大概有路径分析、文件定位和编译执行三个过程。
Nodejs 在拿到模块标识符之后,会进行路径分析,获得了入口文件的绝对路径之后就会去内存检索,如果内存中没有缓存的话就会进入下一步,进行文件定位。注意自定义模块会有个 模块路径 的概念,加载自定义模块时会首先在当前文件的同级 node_modules 目录下查找,如果没有找到的话就向上一级继续查找 node_modules,直到系统根目录(Windows 的盘符目录,比如 C:\ 或者 *nix 的根目录 /),所以自定义模块的加载耗时最长。
路径分析之后会进行文件定位,尝试多种不同的扩展名然后判断文件是否存在,如果最终都不存在的话就会继续把这个模块当做自定义模块进行加载,如果还是找不到就直接报错。扩展判断的顺序依次为 .js、.json 和 .node。
Nodejs 对于不同模块的编译方式
JSON.parse 转化为 JavaScript 对象然后返回结果process.dlopen 函数加载执行require() Actually Works最近一直忙于实习以及毕业设计的事情,所以上周阅读源码之后本周就一直没有进展。今天在写完开题报告之后又抽空看了一眼Underscore源码,发现上次没有看明白的一个函数忽然就豁然开朗了,于是赶紧写下了这篇笔记。
关于如何绑定函数this指向,一直是JavaScript中的高频话题,面试时考官也喜欢问如何绑定函数this的指向,以及如何试现一个bind函数,今天我们就从Underscore源码来学习如何实现一个bind函数。
在学习源码之前,我们最好先了解一下函数中this的指向,我在这个系列之前有写过一篇文章,比较完善的总结了一下JavaScript函数中this的指向问题,详情参见:博客园。
另外,在学习_.bind函数之前,我们需要先了解一下Underscore中的重要工具函数——restArgs。就在我的上一篇文章中就有介绍到:理解Underscore中的restArgs函数。
在学习_.bind函数之前,我们先来看一下Underscore中的另一个工具函数——executeBound。因为这是一个重要的工具函数,涉及到bind的实现。
executeBound源码(附注释):
// Determines whether to execute a function as a constructor
// or a normal function with the provided arguments.
//执行绑定函数,决定是否把一个函数作为构造函数或者普通函数调用。
var executeBound = function (sourceFunc, boundFunc, context, callingContext, args) {
//如果callingContext不是boundFunc的一个实例,则把sourceFunc作为普通函数调用。
if (!(callingContext instanceof boundFunc)) return sourceFunc.apply(context, args);
//否则把sourceFunc作为构造函数调用。
//baseCreate函数用于构造一个对象,继承指定的原型。
//此处self就是继承了sourceFunc.prototype原型的一个空白对象。
var self = baseCreate(sourceFunc.prototype);
var result = sourceFunc.apply(self, args);
//这里之所以要判断一下是因为如果构造函数有返回值并且返回值是一个对象,那么新构造的对象就会是返回值,而非this所指向的值。
if (_.isObject(result)) return result;
//只有在构造函数没有返回值或者返回值时非对象时,才返回this所指向的值。
return self;
};
首先我们先看为什么在executeBound函数结尾需要判断一下result,原因已经写明在注释里,请大家一定仔细注意!
举一个帮助理解的例子:
var A = function() {
this.name = 'A';
return {};
}
var B = function() {
this.name = 'B';
}
var C = function() {
this.name = 'C';
return 'C';
}
var a = new A();
var b = new B();
var c = new C();
在浏览器中输出a、b、c,看看你会发现什么?然后再来仔细思考代码中注释的部分吧。
其次回到我们这篇文章的重点,这个函数的功能非常好理解,就是根据实际情况来决定是否把一个函数(sourceFunc)当做构造函数或者普通函数来调用。这个根据的条件就是看callingContext参数是否是boundFunc函数的一个实例。如果callingContext是boundFunc的一个实例,那么就把sourceFunc当做一个构造函数来调用,否则就当做一个普通函数来调用,使用Function.prototype.apply来改变sourceFunc中this的指向。
单独开这个函数可能会使我们变得疑惑,为什么要这么做呢?这个callingContext跟boundFunc是什么关系?为什么要根据这两个参数的关系来决定是否以构造函数的形式调用sourceFunc。
接下来我们根据实际情景来解析这段源码。
在Underscore源码中,使用ctrl + F键查找executeBound字段,共有三处结果。其中一处是上方源码所示的executeBound函数声明。另外两处是调用,其形式都如下所示:
var bound = restArgs(function (callArgs) {
return executeBound(func, bound, context, this, args.concat(callArgs));
});
可以注意到实际调用时,第四个参数(callingContext)都是this,代表当前bound函数执行作用域,而第二个参数是bound自身,这样的写法着实奇怪。
其实考虑到我们的目的也就不难理解为什么这么写了,因为当我们把bound函数当做构造函数调用时,构造函数(此时也就是bound函数)内部的this会指向新构造的对象,而这个由bound函数新构造的对象自然就是bound函数的一个实例了,此时就会把sourceFunc当做构造函数调用。
接下来我们再看_.bind函数,一起深入理解该函数的同时,顺便理解一下executeBound函数中为什么要根据callingContext和boundFunc的关系来确定sourceFunc的调用方式。
我们先看_.bind函数的源码(附注释):
// Create a function bound to a given object (assigning `this`, and arguments,
// optionally). Delegates to **ECMAScript 5**'s native `Function.bind` if
// available.
//将指定函数中的this绑定到指定上下文中,并传递一些参数作为默认参数。
//其中args是默认参数,以后调用新的func时无需再次传递这些参数。
_.bind = restArgs(function (func, context, args) {
if (!_.isFunction(func)) throw new TypeError('Bind must be called on a function');
var bound = restArgs(function (callArgs) {
return executeBound(func, bound, context, this, args.concat(callArgs));
});
return bound;
});
我们看到在_.bind函数的内部定义了一个bound函数,然后返回了这个函数,即为闭包。闭包的好处即在于内部的函数是私有函数,可以访问外部函数作用域,在内部函数调用之前,整个外部函数的作用域都是存在且对于内部函数而言是可访问的。在restArgs函数的参数(即匿名函数)中并没有处理如何调用func,因为我们要根据情况来决定。当我们使用_.bind函数绑定一个函数的this时,会返回bound函数作为新的func函数,而bound函数会根据其调用的方式,来决定如何调用func,而此处的闭包能够保证在bound执行之前,func是一直存在的。当我们使用new来操作bound函数构造新的对象时,bound内的this指向新构造的对象(即为bound的新实例),executeBound函数内部就会把func当做构造函数来调用;如果以普通函数形式调用bound,那么内部的this会指向外部调用bound函数时的作用域,自然就不是bound的一个实例了,这就是为什么会给executeBound第四个参数传递this的原因。
口说无凭,我们自己写个代码探究一下闭包内部函数中this的指向问题:
var test = function() {
var bound = function() {
this.name = 'bound';
console.log(this);
}
return bound;
}
var Bound = test();
var b = new Bound();
var b = Bound();
//bound { name: 'bound' }
//window
大家可以将上面这段代码拷贝到浏览器控制台试一试,看看结果是不是跟上面的注释一样。
通过上面的学习,我们知道了原来bind函数还要考虑到特殊情况——被绑定过this的函数作为构造函数调用时的情况。
接下来我们手动实现一个简单的bind函数:
var _bind = function(func, context) {
var bound = function() {
if(this instanceof bound) {
var obj = new Object();
obj.prototype = func.prototype;
obj.prototype.constructor = func;
var res = func.call(obj);
if(typeof res == 'function' || typeof res == 'object' && !!res)
return res;
else
return obj
}
else {
return func.call(context);
}
};
return bound;
}
在阅读这篇文章之前,你会如何实现一个bind函数呢?
更多Underscore源码解读:GitHub
Go 语言通过 MPG 模型实现并发,MPG 模型的主要几个概念如下:
M:Machine ,Go 语言对内核线程的抽象,内核线程由操作系统内核分配给用户程序,线程的分配调度由操作系统负责,由于分配内核线程需要系统调用并将 CPU 切换到内核态,所以存在一定的开销。M 可以被系统调度分配给不同的 CPU 进行处理,所以可以并行执行而不是并发执行,效率会更高一些。M 的具体数量取决于执行时具体的并发规模以及设定的 runtime.GOMAXPROCS 变量的值,M 的数量最大也不会超过 runtime.GOMAXPROCS 变量的值。
P:Processor ,我理解为是 Go 语言实现的用户线程,也可以理解为是 Go 语言对于 CPU 的抽象,由 Go runtime 负责创建以及调度,这一过程的开销比 M 的创建开销要小,但是多个 P 的运行可能关联在同一个 M 上,所以并不能够保证能够实现并行执行。在运行时会将 P 分配给真正的内核线程 M 进行运行。
G:Goroutine ,Go 协程,可以理解为是并发的基本单元,由 P 负责执行。P 和 G 之间也是一对多的关系。
MPG 的关系图:

程序初始化过程中只会创建一个 M(申请一个内核线程),随着用户创建越来越多的协程,M 的数量也会随之增加,但是最多不会超过 runtime.GOMAXPROCS 的值。
当 M 当前没有绑定到任何 G 时,它将从全局可运行 G 队列中选择一个来运行。如果 G 在运行时被阻塞,比如系统调用,那么运行这个 G 的 M 就会被阻塞。这时会在全局空闲的 M 队列中唤醒一个 M 去运行其余被阻塞的 G(G 队列上的剩余),这样可以保证当某个 M 被阻塞时,该 M 的运行队列中剩余的 G 不会被阻塞,可以切换到另一个 M 运行。当 G0 从系统调用中返回时,M0 会试图从其他地方拿一个 P 来继续执行 G0,如果拿不到的话就会把 G0 放到全局的可运行 G 队列中等待空闲的 P 把它捞起来继续执行。

上图中(左边)的 M0 在执行 G0 时发现 G0 由于系统调用被阻塞了,所以 M0 上的其余 G 会分配给一个新的 M 去执行(右图),避免剩余的 G 因为 G0 的阻塞而被阻塞。
阻塞在 channel 的 G 的处理方式和阻塞在系统调用的 G 的处理方式时不一样的,阻塞在系统调用的 G 必须等待内核数据返回之后才能继续执行,所以需要一直在 M 上等待。但是 channel 是 Go 语言自己实现的模型,与内核无关,当 G 阻塞在 channel 时不需要挂在 M 上继续等待,这个 G 会被 runtime 标记为 waiting,然后 M 继续执行其他 G;当 channel 不再阻塞时,G 会被重新标记为 runnable 并等待挂载到 M 上继续执行。
Go 还有均衡的分配策略,当 M 之间挂载的 G 数量差异较大,任务分配不均衡时,会让任务少的 M 直接从任务多的 M 中拿一部分过来运行。
参考:
Go 在一开始的设计当中没有考虑要设计 G 之间的抢占式调度,用户需要主动通知 runtime 让出执行权,这里存在的一个问题就是当一个 G 死循环阻塞在 M 上的时候,后续的其他工作就可能会被阻塞,比如 GC。
为了解决这个问题,Go 在 1.14 版本引入了基于信号量的抢占式调度机制。Go程序启动时,runtime会去启动一个名为 sysmon(应该是 system monitor 的意思?) 的 M(一般称为监控线程),该 M 无需绑定 P 即可运行,在整个 Go 程序的运行过程中至关重要:
//$GOROOT/src/runtime/proc.go
// The main goroutine.
func main() {
... ...
systemstack(func() {
// newm 创建了一个新的 M 去执行 sysmon
newm(sysmon, nil)
})
.... ...
}
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
// If a heap span goes unused for 5 minutes after a garbage collection,
// we hand it back to the operating system.
scavengelimit := int64(5 * 60 * 1e9)
... ...
if .... {
... ...
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
... ...
}
}sysmon每 20us~10ms 启动一次,它需要做的事情有很多,其中很重要的一件事就是发现执行时间过长的 G 并抢占它的执行权。
// forcePreemptNS is the time slice given to a G before it is
// preempted.
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
... ...
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
if pd.schedwhen+forcePreemptNS > now {
continue
}
preemptone(_p_)
... ...
}可以看到当一个 G 运行的时间超过了 10ms,会被抢占调度并放入等待运行的 G 队列中。这样就确保了 G 被阻塞时不会影响到其他工作的进行。
参考:https://www.cnblogs.com/sunsky303/p/11058728.html
简单的函数可能会被编译器内联优化以提高程序性能。
内联优化是指将简单的函数调用修改成直接执行函数体内的代码,避免了函数运行带来的栈操作的开销,缺点在于会增加代码的体积。
性能优化验证代码:
//go:noinline
func maxNoinline(a, b int) int {
if a < b {
return b
}
return a
}
func maxInline(a, b int) int {
if a < b {
return b
}
return a
}
func BenchmarkNoInline(b *testing.B) {
x, y := 1, 2
b.ResetTimer()
for i := 0; i < b.N; i++ {
maxNoinline(x, y)
}
}
func BenchmarkInline(b *testing.B) {
x, y := 1, 2
b.ResetTimer()
for i := 0; i < b.N; i++ {
maxInline(x, y)
}
}如果想要禁用内联优化,只需要在程序代码中的函数声明前增加一行 //go:noinline 即可。
参考:https://segmentfault.com/a/1190000039146279
range 遍历数据结构时,暂存元素的变量是同一个:

存在的问题是会导致如果内部有匿名函数调用的话,访问的数据是同一片内存地址,异步执行的函数访问到的变量的值可能与预期不符。
为了解决这个问题,在执行匿名函数时,通过函数入参传参的形式将外部变量的值拷贝赋值后传入到匿名函数内部。
在迭代过程中删除 slice 元素会导致迭代过程不符合预期,所以最好不要在迭代过程中操作切片,如果需要对切片进行过滤等操作,可以新建一个切片。
slice 是引用数据类型,其底部引用数组存放数据,如果我们从同一个数组进行切割创建多个切片,多个切片底层引用的会是同一个数组。当我们修改这几个切片的数据时,会引起其他切片数据以及原数组数据的变化,这不是我们期望的行为。
当我们从一个大数组切割创建小的切片时,如果我们不释放小切片的内存,原来的大数组的数据也一直不会被回收,这种场景可能会导致内存泄漏。
切片频繁 append 可能会导致性能问题,当 append 操作导致切片底层数组不足以存放新数据的时候,会进行扩容:先申请一个容量为原来两倍或者 2.25 倍(容量大于 1024 的时候)的新的数组,然后将原数组的数据拷贝到新的数组,这一过程会引起较大的开销。所以频繁对 slice 进行 append 操作时需要注意,最好在一开始创建 slice 的时候就设置一个合理的 cap 值,避免频繁扩容。
本质上上面的三个问题都是由于切片引用底层数组所导致的。
Go 语言没有类,方法和类型通过 receicer 联系在一起,Go 语言方法的本质还是函数,在实际调用时方法的 receiver 会被作为第一个参数传入对应的方法。
type T struct {
a int
}
func (t T) Get() int {
return t.a
}
func (t *T) Set(a int) int {
t.a = a
return t.a
}上方的方法在实际编译后等价于下方函数:
func Get(t T) int {
return t.a
}
func Set(t *T, a int) int {
t.a = a
return t.a
}这一过程由编译器在编译过程中实现。
所以 Go 语言中方法的本质是一个以方法所绑定类型实例为第一个参数的普通函数。
参考:https://www.helloworld.net/p/b3wAImKtj2ij5
接口在 Go 语言中是一个很重要的概念,接口的存在使得 Go 语言代码可以变得十分优雅,隐式的接口实现也使得 Go 语言的接口继承更加简洁。
下面关注下 Go 语言接口的声明与实现以及简单的接口实现原理。
声明一个接口很简单:
type Person interface {
Eat (food string)
Drink (liquid string)
Sleep (start, end time.Time)
}实现上方的接口:
type Pers struct{}
func (p Pers) Drink(liquid string) {
println("dundundun!")
}
func (p Pers) Eat(food string) {
println("yummy!")
}
func (p Pers) Sleep(start, end time.Time) {
fmt.Printf("sleep from %v to %v", start, end)
}
var p Person = Pers{}上方通过实现 receiver 为 Pers 结构体的方法来实现接口,所以我们还可以通过结构体指针的形式初始化 p:
var p Person = &Pers{} // this is ok但是当我们通过实现 receiver 为 Pers 结构体指针的方法来实现接口时,就只能通过结构体指针的形式初始化 p 变量:
type Pers struct{}
func (p *Pers) Drink(liquid string) {
println("dundundun!")
}
func (p *Pers) Eat(food string) {
println("yummy!")
}
func (p *Pers) Sleep(start, end time.Time) {
fmt.Printf("sleep from %v to %v", start, end)
}初始化 Pers 结构体实现 Person 接口:
var p Person = &Pers{} // this is ok
var p Person = Pers{} // error! cannot use (Pers literal) (value of type Pers) as Person value in variable declaration: missing method Drink (Drink has pointer receiver)这是因为当我们通过实现 receiver 为结构体指针的方法来实现接口,方法内部可能会通过 receiver 修改结构体内部的值,如果初始化 p 变量时传递的是一个结构体而非指针,编译器不能根据结构体推导出结构体指针来传入方法内部(按值传递,结构体的地址不等同于最开始初始化时的结构体地址了),也就不能说结构体类型的值实现了这个接口了。
实现接口和初始化接口变量的四种场景:
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 不通过 |
Go 语言的空接口不是任意类型。 当我们声明一个空接口类型的值时,表示我们在使用时暂不关心传入类型的值的类型,到了运行时才去判断。
Go 的编译器如何在运行时知道对应变量的类型呢?
Go 通过下面的数据结构表示空接口类型的变量:
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}data 是指向数据值的具体指针,_type 字段表示值的真实类型;_type类型是 Go 表示数据类型的数据结构,包含了很多类型的元信息, 比如类型的大小、哈希、对齐以及种类等。
所以 Go 在运行时可以同时获取到空接口变量的类型信息和原始数据,这也是 Go 实现反射的基础之一。
回顾前文提到的问题:
package main
func main() {
var a *string
var b interface{} = a
println(a == nil, b == nil) // true false
}这是因为当我们将 a 赋值给 b 时会发生类型转换,b 会存储 a 变量的类型信息(*string)和数据信息(nil),只有当 b 的类型信息和数据信息都为 nil 时,b 才等于 nil。所以上方的代码中 b != nil。
非空接口的运行时表示如下:
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}data 同样表示指向原始数据值的指针,tab 存储的信息很多,包含接口方法(fun 数组)、数据类型(inter 和 _type)等。
参考:https://draveness.me/golang/docs/part2-foundation/ch04-basic/golang-interface
之前做一个小项目,使用C#检验这些软件的版本,到处找了一些代码,也能作用,记录一下,以防以后用到。
public static bool checkIIS(string destVersion)
{
try
{
RegistryKey rk = Registry.LocalMachine;
RegistryKey ver = rk.OpenSubKey(@"SOFTWARE\Microsoft\InetStp");
int majorVersion = Convert.ToInt32(ver.GetValue("majorversion"));
int minorVersion = Convert.ToInt32(ver.GetValue("minorversion"));
Version versionStr = new Version(majorVersion + "." + minorVersion);
if (versionStr >= new Version(destVersion))
return true;
return false;
}
catch
{
return false;
}
}
public static bool checkSQLServer(string destVersion)
{
RegistryKey localKey;
if (Environment.Is64BitOperatingSystem)
localKey = RegistryKey.OpenBaseKey(RegistryHive.LocalMachine, RegistryView.Registry64);
else
localKey = RegistryKey.OpenBaseKey(RegistryHive.LocalMachine, RegistryView.Registry32);
RegistryKey sub = localKey.OpenSubKey(@"SOFTWARE\Microsoft\Microsoft SQL Server");
object keyInst = null;
if (sub != null)
keyInst = sub.GetValue("InstalledInstances");
if (keyInst != null)
{
try
{
Version SQLVer = null;
foreach (string str in (string[])keyInst)
{
RegistryKey subSQL = localKey.OpenSubKey(@"SOFTWARE\Microsoft\Microsoft SQL Server\Instance Names\SQL");
object keySQL = subSQL.GetValue(str);
RegistryKey subVer = localKey.OpenSubKey(@"SOFTWARE\Microsoft\Microsoft SQL Server\" + (string)keySQL + @"\Setup");
object keyVer = subVer.GetValue("Version");
//get version numer
SQLVer = new Version((string)keyVer);
}
//SQL Version should >= 12.1.4100.1
Version tagVer = new Version(destVersion);
if (SQLVer >= tagVer)
{
return true;
}
else
{
return false;
}
}
catch
{
return false;
}
}
else
return false;
}
public static bool checkSilverLight(string destVersion)
{
try
{
Version version;
RegistryKey rk = Registry.LocalMachine;
RegistryKey ver = rk.OpenSubKey(@"SOFTWARE\Microsoft\Silverlight");
if (ver == null)
ver = rk.OpenSubKey(@"SOFTWARE\Wow6432Node\Microsoft\Silverlight");
version = new Version(ver.GetValue("Version").ToString());
//version >= 5.1
if (version >= new Version(destVersion))
return true;
return false;
}
catch
{
return false;
}
}
之前看了一下 TypeScript 的知识,但是一直没有上手,最近开始结合 React 和 TypeScript 一起尝试了一下,感受还是很好的,所以写一下笔记。
环境配置没有参考其他东西,就是看了下 Webpack 和 TypeScript 的官方文档,使用 Webpack 进行构建还是比较简单的。
创建一个项目目录,然后切换当前目录到项目目录下:
$ mkdir tsc && cd ./tsc然后使用 npm 初始化项目:
$ npm init -y然后创建一些项目文件:
$ mkdir build src
$ touch build/webpack.base.conf.js build/webpack.dev.conf.js build/webpack.prod.conf.js index.html src/index.tsx tsconfig.json接下来,就可以安装一些依赖了:
$ npm i webpack webpack-cli webpack-merge webpack-dev-server -D
$ npm i html-webpack-plugin clean-webpack-plugin typescript ts-loader style-loader css-loader @types/react @types/react-dom -D
$ npm i react react-dom -S可以注意到我们没有安装 babel 转译器,如果我们只写 .ts 或者 .tsx 文件,可以不安装 babel。如果要转译处理 .js 文件的话,还是要使用到 babel。
我们先写基础配置:
webpack.base.conf.js
const path = require('path');
const htmlWebpackPlugin = require('html-webpack-plugin');
const cleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
entry: path.resolve(__dirname, '../src/index.tsx'),
output: {
filename: '[name].[hash].js'
},
resolve: {
extensions: ['*', '.js', '.json', '.ts', '.tsx']
},
module: {
rules: [
{
test: /\.tsx?$/,
use: 'ts-loader',
exclude: /node_modules/
},
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
}
]
},
plugins: [
new htmlWebpackPlugin({
inject: true,
template: path.resolve(__dirname, '../index.html')
}),
new cleanWebpackPlugin(['dist'])
]
};然后可以构造开发环境下的配置文件:
webpack.dev.conf.js
const merge = require('webpack-merge');
const path = require('path');
const baseConfig = require('./webpack.base.conf');
module.exports = merge(baseConfig, {
mode: 'development',
devtool: 'source-map',
devServer: {
port: 9999,
open: true,
contentBase: path.resolve(__dirname, '../dist')
}
});然后添加 npm 脚本到 package.json 中:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack-dev-server --config ./build/webpack.dev.conf.js"
}然后添加我们的 ts 配置到 tsconfig.json:
{
"compilerOptions": {
"outDir": "./dist/", // 打包输出目录
"noImplicitAny": true, // 默认必须为变量指定类型
"module": "es6", // 使用 ESM 模块化方案
"target": "es5", // 代码编译成 ES 5
"jsx": "react", // 开启 JSX,使用 react 方式编译,如果要使用 babel 编译,那就将 jsx 设置为 ‘preserve’
"allowJs": true, // 允许编译 js 代码
"sourceMap": true, // 编译后同时产出 map 文件
"removeComments": true // 移除注释
}
}更多的配置项解释,参考:翻译 | 开始使用 TypeScript 和 React。
写完了以后我们就可以添加内容到我们的开发文件中了:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<div id="root"></div>
</body>
</html>src/index.tsx
import * as React from 'react';
import * as ReactDOM from 'react-dom';
ReactDOM.render(
<h1>Hello TSX!</h1>,
document.getElementById('root') as HTMLElement
);可以注意到引入 React 和 ReactDOM 的方式和之前有一些不同。
另外由于 TypeScript 的强制转换符 <> 和 JSX 的元素相冲突,所以使用 as 作为强制转换符。
运行 npm run dev,可以查看效果。
使用 TypeScript 以后,项目配置要稍微简单一点。配置好开发环境以后,就可以写代码啦!
我以一个 Header 组件为例,效果如下:
新建一个 Header.tsx 文件和一个 Header.css 文件到 src/components 下。
由于头部栏的标题文字应该是可以修改的,然后右边的 menu 应该是可以自定义的,所以这些数据应该都可以通过 props 传入我们的 Header 组件。
写我们的 Header 组件:
// Header.tsx
// 引入 React
import * as React from 'react';
// 引入我们的组件样式
import './Header.css';
// 定义的接口,用于规范 Header 组件的 props,向外界公开,
// 便于在其他组件中引用时实现这个接口,减少错误
export interface HeaderProps {
title: string; // 必须给定 title,一个 string 类型的值
menus?: MenuItemProps[]; // menus 是可选属性,是一个符合 MenuItemProps 接口规范的对象的数组
height?: string; // 问号都代表可选项
bgColor?: string;
}
// 这个接口定义了 MenuItem 组件的 props 规范,同时也定义了
// HeaderProps 中 menus 数组的元素的规范
interface MenuItemProps {
name: string; // 给定 menu 的名称
href: string; // 给定 menu 要跳转的链接
}
// 定义了 Header 组件的 state 的规范
interface HeaderState {
isVisible: boolean // 代表 Header 组件是否可见
}
// Header 组件
// 注意 React.Component 后面的泛型,就是我们上方定义的接口,它们分别制定了组件的 props 和 state 的规范
class Header extends React.Component<HeaderProps, HeaderState> {
// 指定组件实例的 state,必须符合 HeaderState 的规范
state = {
isVisible: true
}
render() {
const {
title,
menus = [],
height = '50px',
bgColor = 'lightblue'
} = this.props; // 从 props 获取值,其中可选项都有默认值
const style = {
height,
backgroundColor: bgColor
}; // 构造 Header 内联样式
return this.state.isVisible ? <div style={style} className="header">
<span>{title}</span>
<div className="header-menus">
{
menus.map(item => <MenuItem {...item}/>)
}
</div>
</div> : null;
}
}
// MenuItem 组件
// state 的规范是一个 object,未指定具体接口类型
class MenuItem extends React.Component<MenuItemProps, object> {
render() {
const { name, href } = this.props;
return <a className="header-menu-item" href={href} key={href}>
{name}
</a>
}
}
// 最后向外部暴露 Header 组件
export default Header;可以看到 TypeScript 结合 React 其实很好用,尤其在规范 props 的时候很好用,能够避免很多编程时候的错误。而 IDE 的提示能够更加地方便我们开发。写起来何止舒服,简直舒服啊~
然后在 Header.css 写一下我们的样式:
html,
body,
div {
margin: 0;
padding: 0;
font-size: 16px;
}
.header {
font-size: 1.5rem;
line-height: 1rem;
padding: 1rem;
box-sizing: border-box;
position: relative;
}
.header-menus {
position: absolute;
right: 1rem;
top: 50%;
transform: translateY(-50%);
}
.header-menu-item {
margin: 0 .5rem;
}这里仅仅是做个示例,排版没有在意太多的通用性,大家看看就好~
然后我们就可以在 index.tsx 中使用我们的 Header 组件了:
import * as React from 'react';
import * as ReactDOM from 'react-dom';
import Header, { HeaderProps } from './components/Header'; // 引入接口规范和组件
// 构造 Header 组件的 props,必须符合 HeaderProps 接口规范。
// 在写的过程中 IDE 也能给我们很多的提示,方便了开发
const headerProps: HeaderProps = {
title: 'Hello TSX!',
menus: [{
name: 'menu1',
href: 'https://www.zhongdeming.fun'
}, {
name: 'menu2',
href: 'https://www.baidu.com'
}],
bgColor: 'lightyellow'
};
ReactDOM.render(
<Header {...headerProps}/>,
document.getElementById('root') as HTMLElement
);这样一个组件就写完了,可以感受到 TypeScript 确实能够加速我们的开发,减少开发中的错误。
下面是一些利用 TypeScript 开发的时候 IDE 给出的提示的截图:
最近在做一个 Vue 项目的时候,突然发现了一个有意思的知识点。
有几位客服反馈说在点击某个链接跳转的时候,老是没得反应,导致选不了选项。我就很奇怪,内网环境下是没有问题的,所以代码出问题的可能性不大,怎么外网就有这种问题呢?后来仔细看了一下才发现,原来是运维那边出了点纰漏导致外网有些客户的 JavaScript 资源加载不出来,进而导致无法跳转。这里涉及到了 Vue 的异步组件知识,只有当切换到某个组件时,其单独打包的资源才会被加载。不同于统一打包的情况,这样做可以利用代码切割减少首屏加载时的资源大小,能够提升一定的加载速度,优化用户体验。接下来就自己重新做一下这个异步组件。
以下命令行操作均在 Linux 环境下进行。
先切换到你的项目根目录下,此时应该是一个空文件夹。
然后用 npm 命令初始化,添加具有一些默认选项的 package.json 文件。
$ npm init -y然后开始创建必要的文件:
$ sudo touch .babelrc index.htmlindex.html 中写入一下代码,作为固定模板:
<!DOCTYPE html>
<html lang="zh-ch">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Async Components</title>
</head>
<body>
<div id="app"></div>
</body>
</html>.babelrc 是配置 babel 转译器的,等会再来配置。
接下来创建必要的文件夹:
$ sudo mkdir -p build dist src/components src/routers 在 build 目录下创建三个文件,作为 Webpack 打包的配置文件:
然后安装必要的依赖:
$ npm i -D babel-loader@7 babel-core babel-preset-env webpack webpack-cli clean-webpack-plugin css-loader html-webpack-plugin vue-loader vue-style-loader vue-template-compiler webpack-dev-server webpack-merge$ npm i -S vue vue-router然后把下面的配置代码扔到对应的配置文件中:
// webpack.base.conf.js
const path = require('path');
const htmlWebpackPlugin = require('html-webpack-plugin');
const cleanWebpackPlugin = require('clean-webpack-plugin');
const VueLoaderPlugin = require('vue-loader/lib/plugin');
module.exports = {
target: 'web',
entry: {
index: path.resolve(__dirname, '../src/index.js')
},
output: {
filename: '[name].[hash].js',
path: path.resolve(__dirname, '../dist/')
},
resolve: {
extensions: ['.vue', '.js', '.json', '.css'],
alias: {
'@': path.resolve(__dirname, '../src'),
'vue': 'vue/dist/vue.js',
'components': path.resolve(__dirname, '../src/components')
}
},
node: {
fs: 'empty'
},
module: {
rules: [
{
test: /\.m?js$/,
exclude: /node_modules/,
use: 'babel-loader'
},
{
test: /\.css$/,
use: ['vue-style-loader', 'css-loader']
},
{
test: /\.vue$/,
use: 'vue-loader'
}
]
},
plugins: [
new htmlWebpackPlugin({
inject: true,
template: path.resolve(__dirname, '../index.html')
}),
new cleanWebpackPlugin(['dist'], {
root: path.resolve(__dirname, '../'),
verbose: true,
dry: false
}),
new VueLoaderPlugin()
]
};// webpack.dev.conf.js
const merge = require('webpack-merge');
const path = require('path');
const baseConfig = require('./webpack.base.conf.js');
module.exports = merge(baseConfig, {
mode: 'development',
devServer: {
contentBase: path.resolve(__dirname, '../dist/'),
port: 8888,
open: true,
// hot: true
watchOptions: {
watch: true
}
},
devtool: 'inline-source-map'
});// webpack.prod.conf.js
const merge = require('webpack-merge');
const path = require('path');
const baseConfig = require('./webpack.base.conf.js');
module.exports = merge(baseConfig, {
mode: 'production',
devtool: 'source-map'
});具体怎么配置这里就不赘述了,之前也写过这类型的博客,可以参考一下:基于 Webpack 4 搭建 Vue 开发环境。
然后配置 babel:
在 .babelrc 中写入以下内容:
{
"presets": [
"babel-preset-env"
]
}
然后就可以准备开发了。
在 src 目录下创建一个 index.js 文件作为打包入口文件,然后:
// /src/index.js
import Vue from 'vue';
import VueRouter from 'vue-router';
import App from './App';
import routerConfig from '@/routers';
Vue.use(VueRouter);
const routers = new VueRouter(routerConfig);
new Vue({
el: '#app',
components: { App },
router: routers,
template: '<div><App/></div>'
});其中引用了一个同级目录下的 App 作为子组件,App.vue 代码:
<template>
<div>
<router-view></router-view>
<router-link to="/javascript">JavaScript</router-link>
<router-link to="/java">Java</router-link>
<router-link to="/python">Python</router-link>
</div>
</template>
<script>
export default {
name: 'app'
}
</script>
<style scoped>
h1 {
color: blue
}
</style>
注意到我们的 Vue-Router 配置写在 /src/routers/index.js 中,代码如下:
module.exports = {
mode: 'hash',
routes: [
{
path: '/javascript',
component: (resolve) => {require(['components/javascript'], resolve)}
},
{
path: '/java',
component: (resolve) => {require(['components/java'], resolve)}
},
{
path: '/python',
component: (resolve) => {require(['components/python'], resolve)}
},
{
path: '/*',
redirect: '/javascript'
}
]
}然后在 components 目录下写我们对应的三个组件:
// java.vue
<template>
<h1>Java</h1>
</template>
<script>
export default {
name: 'java'
}
</script>// javascript.vue
<template>
<h1>JavaScript</h1>
</template>
<script>
export default {
name: 'javascript'
}
</script>// python.vue
<template>
<h1>Python</h1>
</template>
<script>
export default {
name: 'python'
}
</script>npm scripts 的定义如下:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack-dev-server --config ./build/webpack.dev.conf.js",
"build": "webpack --config ./build/webpack.prod.conf.js"
},最后运行起来本地测试服务器:
$ npm run dev打开浏览器的开发者工具,切换到 Network 选项卡,点击不同的链接,可以看到在加载切换路由时,会加载对应打包出来的 js 资源。
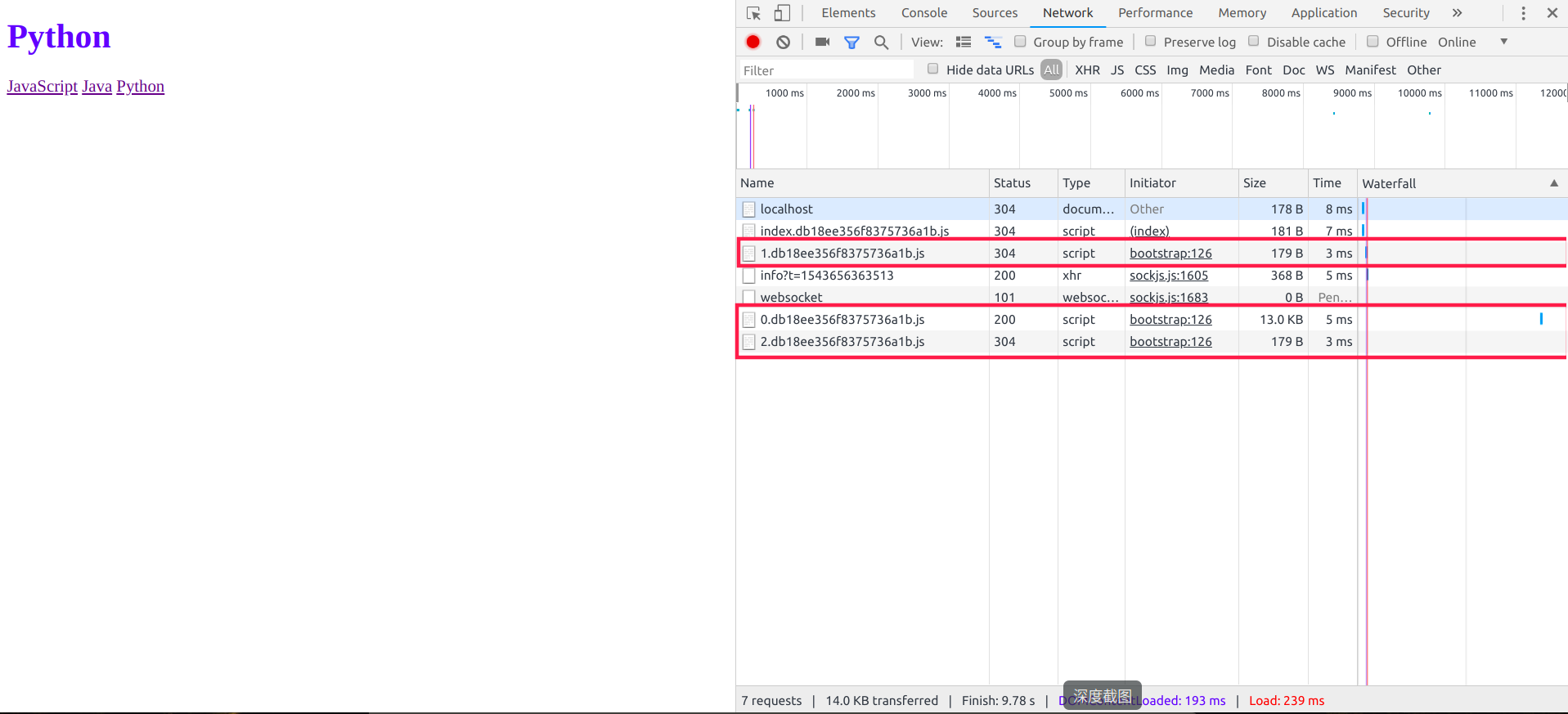
运行 npm run build,可以看到打包出来了多个 js 资源文件:
是一个 Webpack 打包 Vue 项目的优化点,通过异步组件,可以切割我们的代码,提升用户体验。
异步组件切割代码实现简单,只需要改变配置 Vue-Router 的方式即可,指定路由对应的组件时,使用如下方式:
{
path: '/XXX',
component: resolve => {
require(['./XXX.vue'], resolve);
}
}简单记录一下我从头写一个 Servlet 的过程。
我安装的是 Tomcat 7 版本,在 Ubuntu 18.04 上运行,IDE 为 Intellij IDEA。
首先创建一个 Java Web 项目,进入你的 IDEA,然后点击 Create New Project。如下图所示:
选择完毕之后点击下一步。
然后给你的项目取个名字,第一个就叫 HelloWorld 好了。
第三步是新建一个 Java 类文件,在你的 src 路径下,新建包和 Java 类文件,然后在类文件中开始写一个 Servlet。
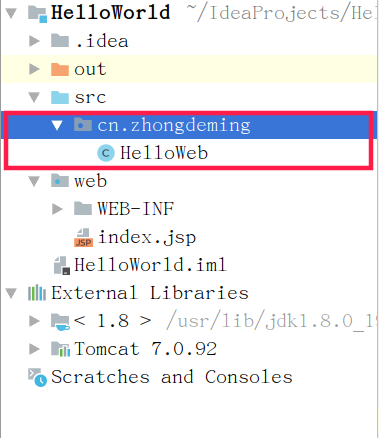
写一个最简单的 Servlet,只实现一个 Get 请求,这就需要我们的 Servlet 类继承 HttpServlet 父类,然后重写 doGet 方法。
具体代码如下:
package cn.zhongdeming;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.Writer;
public class HelloWorld extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// super.doGet(req, resp);
Writer writer = resp.getWriter();
((PrintWriter) writer).print("<h1>Hello World!</h1><p>This is from a Java Servlet!</p>");
}
}在 doGet 方法中,我们通过 resp 对象的 getWriter 方法,获取到了一个 PrintWriter 对象。然后我们可以通过这个对象向客户端浏览器做出回应。
我们传回去了一个字符串,是一个标题和一段文字。
写好了 Servlet 还不够,还要配置 Servlet,让 Tomcat 容器能够知道我们的 Servlet 的信息。
写好我们的 web.xml:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>HelloWorld</servlet-name>
<servlet-class>cn.zhongdeming.HelloWorld</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorld</servlet-name>
<url-pattern>/HelloWorld</url-pattern>
</servlet-mapping>
</web-app>需要我们写的代码是 servlet 节点和 servlet-mapping 节点以及它们所有的子节点。分别交代了我们的 HelloWorld Servlet 的位置,以及其对应的前端路由。
接下来我们就可以启动我们的 Tomcat 查看效果了。
点击右上角的运行按钮,启动 Tomcat:
然后在我们的浏览器中输入 localhost:8080/HelloWorld,即可看到效果如下:
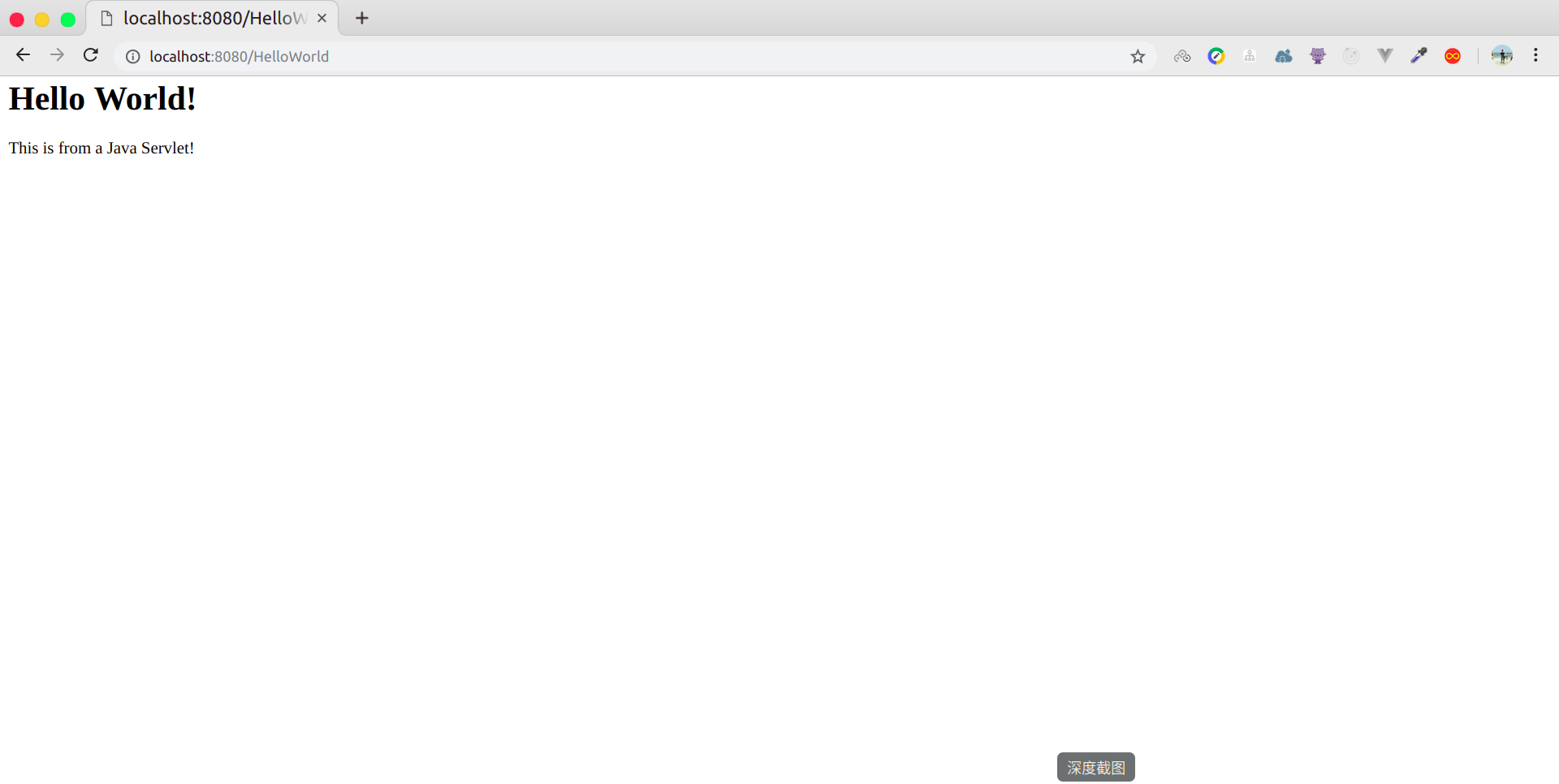
javax.servlet,需要手动导入 Tomcat 安装目录下的 lib 文件夹中的 servlet-api.jar 包。A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.