知乎:https://www.zhihu.com/people/zhangyachen
朋友们可以关注下我的公众号,获得最及时的更新:

zhangyachen's blog
知乎:https://www.zhihu.com/people/zhangyachen
朋友们可以关注下我的公众号,获得最及时的更新:





































































































































<?php
$var = "BBB";
$str = "AAA".$var."CCC";
echo $str;通过vld查看Opcodes
Finding entry points
Branch analysis from position: 0
Return found
filename: C:\AppServ\www\Untitled-1.php
function name: (null)
number of ops: 9
compiled vars: !0 = $var, !1 = $str
line # * op fetch ext return operands
---------------------------------------------------------------------------------
3 0 > EXT_STMT
1 ASSIGN !0, 'BBB'
4 2 EXT_STMT
3 CONCAT ~1 'AAA', !0
4 CONCAT ~2 ~1, 'CCC'
5 ASSIGN !1, ~2
5 6 EXT_STMT
7 ECHO !1
8 > RETURN 1
branch: # 0; line: 3- 5; sop: 0; eop: 8
path #1: 0,
找到concat对应的函数concat_function
if (result==op1) { /* special case, perform operations on result */
uint res_len = Z_STRLEN_P(op1) + Z_STRLEN_P(op2);
Z_STRVAL_P(result) = erealloc(Z_STRVAL_P(result), res_len+1);
memcpy(Z_STRVAL_P(result)+Z_STRLEN_P(result), Z_STRVAL_P(op2), Z_STRLEN_P(op2));
Z_STRVAL_P(result)[res_len]=0;
Z_STRLEN_P(result) = res_len;
} else {
Z_STRLEN_P(result) = Z_STRLEN_P(op1) + Z_STRLEN_P(op2);
Z_STRVAL_P(result) = (char *) emalloc(Z_STRLEN_P(result) + 1);
memcpy(Z_STRVAL_P(result), Z_STRVAL_P(op1), Z_STRLEN_P(op1));
memcpy(Z_STRVAL_P(result)+Z_STRLEN_P(op1), Z_STRVAL_P(op2), Z_STRLEN_P(op2));
Z_STRVAL_P(result)[Z_STRLEN_P(result)] = 0;
Z_TYPE_P(result) = IS_STRING;
}可以看出,concat_function函数会根据两个字符串的长度重新分配内存,并执行两次拷贝操作,将两个字符串拷贝到新的内存空间。
<?php
$var = "BBB";
$str = "AAA{$var}CCC";
echo $str;通过vld查看Opcodes
Finding entry points
Branch analysis from position: 0
Return found
filename: C:\AppServ\www\Untitled-1.php
function name: (null)
number of ops: 10
compiled vars: !0 = $var, !1 = $str
line # * op fetch ext return operands
---------------------------------------------------------------------------------
3 0 > EXT_STMT
1 ASSIGN !0, 'BBB'
4 2 EXT_STMT
3 ADD_STRING ~1 'AAA'
4 ADD_VAR ~1 ~1, !0
5 ADD_STRING ~1 ~1, 'CCC'
6 ASSIGN !1, ~1
5 7 EXT_STMT
8 ECHO !1
9 > RETURN 1
branch: # 0; line: 3- 5; sop: 0; eop: 9
path #1: 0,
在添加变量时,如果添加的变量不是字符串,会通过zend_make_printable_zval将变量转换成字符串输出
ADD_STRING和ADD_VAR对应的函数都是add_string_to_string
ZEND_API int add_string_to_string(zval *result, const zval *op1, const zval *op2) /* {{{ */
{
int length = Z_STRLEN_P(op1) + Z_STRLEN_P(op2);
char *buf = str_erealloc(Z_STRVAL_P(op1), length + 1);
memcpy(buf + Z_STRLEN_P(op1), Z_STRVAL_P(op2), Z_STRLEN_P(op2));
buf[length] = 0;
ZVAL_STRINGL(result, buf, length, 0);
return SUCCESS;
}add_string_to_string函数的实现过程是针对即将生成的字符串的大小重新通过PHP内核的内存管理扩展内存空间,并将新的字符串复制到原始字串后面内存空间的过程。
一种编程模式,即从表里查找信息而不使用逻辑语句。
当你的代码中为了实现一个功能或者计算一个数值而出现了大量的if和else时,我们可以考虑使用表驱动法。
比较笨拙的用法:
if($month = 1){
$days = 31;
}elseif ($month = 2){
$days = 28;
}elseif ($month = 3){
$days = 31;
}
...
elseif ($month = 12){
$days = 31;
}我们可以使用表驱动法来省掉一大堆的if/else语句:
$daysPerMonth = array(31,28,31,30,31,30,31,31,30,31,30,31);
$days = $daysPerMonth[$month - 1];如果考虑润年的情况,我们可以再针对润年定义一个数组,根据是否是润年访问不同的数组。
我们想要根据用户到年龄,性别,婚姻,吸烟与否来判断保险费率。
/**
* @desc 获取保险费率
* @param $gender 0 | 1
* @param $marital 0 | 1
* @param $smoking 0 | 1
* @param $age
*/
function getRates($gender,$marital,$smoking,$age){
if($gender == 0){
if($marital == 0){
if($smoking == 0){
if($age < 18){
$rate = 200;
}elseif ($age == 18){
$rate = 250;
}
...
elseif($age > 65){
$rate = 450;
}
}
}
}
...
}大家应该已经看出来了,每一个条件都会使判断增加一倍。
我们可以使用表驱动法来更加简洁的书写流程判断逻辑:
/**
* @desc 获取保险费率
* @param $gender 0 | 1
* @param $marital 0 | 1
* @param $smoking 0 | 1
* @param $age
* @return float
*/
function getRates($gender,$marital,$smoking,$age){
$rateTable = array(
0 => array( //性别
0 => array( //婚姻
0 => array( //吸烟状况
18 => 200,
19 => 300,
...
),
1 => array(
18 => 300,
19 => 350,
)
),
1 => array(
....
)
),
1 => array(
....
),
);
return $rateTable[$gender][$marital][$smoking][$age];
}但是有一个问题:age是一个范围,一个人的年龄能从0到100左右,我们不能将键值复制100份,一个有效的办法是把键值转换提取成独立的子程序,比如keyFromAge(),返回年龄对应的键值。
现在假如我们要输入打印一份存储在文件中的消息,文件中会存储大约500条消息,而每份文件中会有大约20种不同的消息。文件中的消息假如是如下的格式:
1 26.8 25~30 5 大连 2016-08-07 22:00:00
2 38.0 45.0 2016-08-07 21:00:00
...
12 67.0 23.3 67 2016-08-07 20:30:00
每条消息的第一个字段是ID,告诉你该条消息属于这20条消息中的哪一种。
每个字段都是以\t分隔。
打印的难点在于:每种消息的格式都是不一样的,我们必须根据每种消息的具体格式来输出具体的打印信息,比如:
1 平均温度:26.8 温度范围:25~30 采样点数:5 位置:大连 测量时间:2016-08-07 22:00:00
2 纬度:38.0 经度:45.0 测量时间:2016-08-07 21:00:00
...
12 纬度:67.0 经度:23.3 深度:67 测量时间:2016-08-07 20:30:00
如果按照传统的思维来做的话,我们会这样做:
但是缺点在于:如果有20种消息,就要特制20种消息打印程序。因为每种消息的字段和描述都是不一样的。
我们可以利用表驱动的方式来解决这个问题:在数组种定义每种消息的消息描述,然后调用同一个子程序来解释该消息。
<?php
$messageDescription = array(
0 => array(
"平均温度:",
"温度范围:",
"采样点数:",
"位置:",
"测量时间:",
),
1 => array(
"纬度::",
"经度:",
"测量时间:",
),
...
);
//读取文件的一行,利用explode("\t",$line)将一行中的字段打散为数组,赋值给$messageLine
$messageLine = array(1,26.8,"25~30",5,"大连","2016-08-07 22:00:00");
$type = $messageLine[0]; //第一个字段为消息类型
$message = $messageDescription[$type - 1]; //该消息类型对应的消息描述
array_shift($messageLine);
printMessage($message, $messageLine);
/**
* @desc 打印消息体
* @param $message 该类消息的消息描述
* @param $messageLine 消息体
*/
function printMessage($message,$messageLine){
foreach ($message as $key => $val){
echo $val.$messageLine[$key]."\t";
}
echo "\n";
}当要添加消息类型时,我们只需要在$messageDescription数组中添加对应的消息描述,而不用单独添加一种打印消息的子程序。
比如我们正在开发一个评级的应用程序,等级区间如下:
>90% A
<90% B
<75% C
<65% D
<50% F
我们面临的困难在于:如果使用表驱动法,我们无法将数组的key值设置为区间,而且key值还有可能是浮点数字。
我们可以将每一个区间的上限写入一张表中,然后写一个循环,每当分数超过上限时,就知道相应的等级了。
<?php
$rangeLimit = array(50,65,75,90,100);
$grade = array("F","D","C","B","A");
$maxGradeLevel = count($grade) - 1;
$gradeLevel = 0;
$studentGrade = "A";
$studentScore = 85; //测试值
while ($gradeLevel < $maxGradeLevel){
if($studentScore < $rangeLimit[$gradeLevel]){
$studentGrade = $grade[$gradeLevel];
break;
}
$gradeLevel++;
}
echo $studentGrade;为什么要初始化$studentGrade为A?试想如果用户得分为100,那么根据$studentScore < $rangeLimit[$gradeLevel]的比较条件,该用户将无法匹配到正确的结果,因为比较符号是<而不是<=。
需要注意的细节:
参考资料:代码大全2
Security Enhanced Linux的缩写,安全强化Linux 的意思。
有的时候在linux上想要访问文件,但是却出现了"Permission Denied"。于是为了省事情,干脆直接chmod 777 file/dir. 如果这是一个普通测试文件还好办,但是如果是Web服务器的根目录,代表所有程序均可对该目录存取,万一你真的有启动 WWW 服务器软件,那么该软件所触发的程序将可以写入该目录, 而该程序却是对整个 Internet 提供服务的!只要有心人接触到这支程序,而且该程序刚好又有提供使用者进行写入的功能, 那么外部的人很可能就会对你的系统写入东西,如果是恶意文件那就不好办了。
我们把如上不合理的做法叫员工资源误用,为了防止如上的操作带来损失,美国国家安全局 (NSA) 开发selinux,使得linux更加安全。
自主式存取控制 (Discretionary Access Control),根据程序的拥有者与文件资源的 rwx 权限来决定有无存取的能力。 但是会有如下的缺点:
强访问控制(Mandatory Access Control, MAC),可以针对特定的程序与特定的文件资源来进行权限的控管。这样即使某个用户取得了root权限,但是在访问不同的程序时,取得的权限不一定是root,这要根据程序的配置而决定。
在DAC中,我们根据用户的身份或者属组来判断用户是否有权限。但是在MAC中,我们控制的是程序。这样一来,我们控制的主体就是程序而不是用户。
强调:如果恶意用户以root用户本地或者远程登录机器,那么selinux无法阻止其访问文件。说白了selinux是防止用户通过某一种程序或者服务(比如http)恶意访问其他文件。
参考资料:http://vbird.dic.ksu.edu.tw/linux_basic/0440processcontrol_5.php
SQL语句:
mysql> explain extended SELECT * FROM recent_answer WHERE deleted=0 AND uid=130759605 AND (bit&1)=0 ORDER BY ctime limit 10;
+----+-------------+---------------+------+-----------------------------------------+---------+---------+-------------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------+------+-----------------------------------------+---------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | recent_answer | ref | f_uid,s_rself,s_rpublic,s_rgood,s_aself | s_rself | 5 | const,const | 7084 | 100.00 | Using where |
+----+-------------+---------------+------+-----------------------------------------+---------+---------+-------------+------+----------+-------------+表结构:
Create Table: CREATE TABLE `recent_answer` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`qid` int(10) unsigned NOT NULL DEFAULT '0',
`rid` int(10) unsigned NOT NULL DEFAULT '0',
`uid` int(10) unsigned NOT NULL DEFAULT '0',
`rootField` int(10) unsigned NOT NULL DEFAULT '0',
`field` int(10) unsigned NOT NULL DEFAULT '0',
`finished` tinyint(3) unsigned NOT NULL DEFAULT '0',
`deleted` tinyint(3) unsigned NOT NULL DEFAULT '0',
`status` int(10) unsigned NOT NULL DEFAULT '0',
`goodValue` int(10) unsigned NOT NULL DEFAULT '0',
`ctime` int(10) unsigned NOT NULL DEFAULT '0',
`bit` bigint(20) unsigned NOT NULL DEFAULT '0',
`ext` varbinary(5000) NOT NULL DEFAULT '',
`authTime` int(10) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `f_qid` (`qid`),
KEY `f_uid` (`uid`,`rid`),
KEY `s_rself` (`uid`,`deleted`,`ctime`),
KEY `s_rpublic` (`uid`,`deleted`,`status`,`ctime`),
KEY `s_rgood` (`uid`,`deleted`,`status`,`goodValue`),
KEY `s_field` (`rootField`,`deleted`,`status`,`ctime`),
KEY `s_aself` (`uid`,`deleted`,`authTime`,`bit`)
) ENGINE=InnoDB AUTO_INCREMENT=8286690 DEFAULT CHARSET=gbk为什么没有filesort
问了下DBA,猜测是mysql是先根据索引KEY s_rself (uid,deleted,ctime)进行排序,然后根据排序结果去逐个判断bit字段((bit&1)=0),然后返回结果
MySQL排错指南 第二章
为什么mysql -uroot提示“ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/home/iknow/mysql5/tmp/mysql.sock'”
mysql -hxxx -uroot就可以连接上
[[email protected] ~]$ mysql -uroot
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)查看mysql读取配置文件的顺序
[iknow@cp01-qm-iknow-qatest05-1.epc.baidu.com ~]$ mysql --help | grep my.cnf
/etc/my.cnf /var/lib/mysql/my.cnf ~/.my.cnf查看my.cnf(注意--socket的值)
[[email protected] home]$ vi /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Default to using old password format for compatibility with mysql 3.x
# clients (those using the mysqlclient10 compatibility package).
old_passwords=1
[mysql.server]
user=mysql
basedir=/var/lib
[mysqld_safe]
err-log=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid查看mysqld进程(注意--socket的值)
[[email protected] home]$ ps -ef | grep mysqld
iknow 12623 21175 0 14:17 pts/1 00:00:00 grep mysqld
iknow 17053 1 0 2015 ? 00:00:00 /bin/sh ./bin/mysqld_safe
iknow 17142 17053 0 2015 ? 00:28:33 /home/iknow/local/mysql5/libexec/mysqld --basedir=/home/iknow/local/mysql5 --datadir=/home/iknow/local/mysql5/var/ --pid-file=/home/iknow/local/mysql5/var/mysql.pid --skip-external-locking --port=3306 --socket=/home/iknow/local/mysql5/tmp/mysql.sock将/etc/my.cnf里的socket值改变一下,重启mysql:
[mysqld]
datadir=/var/lib/mysql
socket=/home/iknow/local/mysql5/tmp/mysql.sock
# Default to using old password format for compatibility with mysql 3.x
# clients (those using the mysqlclient10 compatibility package).
old_passwords=1
[mysql.server]
user=mysql
basedir=/var/lib
[mysqld_safe]
err-log=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid或者启动时指定socket文件路径:
[[email protected] ~]$ mysql -uroot -S /home/iknow/local/mysql5/tmp/mysql.sock后续:读下启动文件mysqld_safe,因为发现在~/.my.cnf中添加配置项不能覆盖/etc/my.cnf的配置项
[[email protected] mysql5]$./bin/mysqld_safe start
Starting mysqld daemon with databases from /home/iknow/local/mysql5/var/
STOPPING server from pid file /home/iknow/local/mysql5/var/mysql.pid
161002 10:55:17 mysqld ended
解决方法:
[[email protected] mysql5]$./bin/mysqld_safe &
[1] 17495
[[email protected] mysql5]$Starting mysqld daemon with databases from /home/iknow/local/mysql5/var/
[[email protected] mysql5]$
[[email protected] mysql5]$ps aux | grep mysql
work 16580 0.0 0.0 8404 1956 pts/2 T 10:59 0:00 mysql -uroot
iknow 17495 0.0 0.0 52836 1132 pts/3 S 11:00 0:00 /bin/sh ./bin/mysqld_safe
iknow 17510 13.7 0.4 1126484 158640 pts/3 Sl 11:00 0:00 /home/iknow/local/mysql5/libexec/mysqld --basedir=/home/iknow/local/mysql5 --datadir=/home/iknow/local/mysql5/var/ --pid-file=/home/iknow/local/mysql5/var/mysql.pid --skip-external-locking --port=3306 --socket=/home/iknow/local/mysql5/tmp/mysql.sock
iknow 17660 0.0 0.0 51160 728 pts/3 S+ 11:00 0:00 grep mysql
ACID
简单但使用最频繁的事务。所有的操作都处于同一层次,由BEGIN/START TRANSACTION开始事务,由COMMIT/ROLLBACK结束,且都是原子的,要么都执行,要么都回滚。
扁平事务的主要限制是不能提交或者回滚事务的某一部分。如果某一事务中有多个操作,在一个操作有异常时并不希望之的操作全部回滚,而是保存前面操作的更改。扁平事务并不能支持这样的事例,因此就出现了带有保存节点的扁平事务。
允许事务在执行过程中回滚到较早的一个状态,而不是回滚所有的操作。保存点用来通知系统应该记住事务当前的状态,以便当之后发生错误时,事务能回到保存点当时的状态。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from a;
+----+------+
| id | data |
+----+------+
| 1 | 1 |
| 2 | 0 |
| 3 | 3 |
| 4 | 4 |
| 5 | 0 |
| 6 | 3 |
| 7 | 0 |
| 8 | 10 |
| 20 | 10 |
| 21 | 23 |
+----+------+
10 rows in set (0.00 sec)
mysql> update a set data=100 where id=21;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> savepoint p1;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into a(data) values(100);
Query OK, 1 row affected (0.00 sec)
mysql> rollback to p1;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from a;
+----+------+
| id | data |
+----+------+
| 1 | 1 |
| 2 | 0 |
| 3 | 3 |
| 4 | 4 |
| 5 | 0 |
| 6 | 3 |
| 7 | 0 |
| 8 | 10 |
| 20 | 10 |
| 21 | 100 |
+----+------+
10 rows in set (0.00 sec)其余事务类型先暂时不做介绍了。
为了实现事务的持久性。由两部分组成:内存中的redo log buffer、磁盘中的redo log file。
当事务begin到commit的过程中,事务修改页的过程写到redo log buffer中,当事务提交时,通过Force Log at Commit机制实现事务的持久性,即将redo log buffer中的内容写入到磁盘中进行持久化。
为了确保每次日志都写入磁盘,在每次将buffer写入磁盘中时,引擎都要调用一次fsync操作,但是buffer首先写入的是操作系统文件buffer,然后再写入磁盘。
redo log buufer -> os file buffer -> disc
控制日志刷新到磁盘的策略:
0:事务提交时不进行磁盘持久化,这个操作仅在master thread中完成,每隔一秒进行fsync
2:事务提交时将重做日志写入操作系统的文件缓存中,但是不进行fsync操作。如果数据库宕机但是操作不宕机时,并不会导致事务的丢失,但是操作系统宕机时,重启数据库后会丢失从未从文件缓存刷新到磁盘的那部分。
使用w命令查看登录用户正在使用的进程信息
w命令用于显示已经登录系统的用户的名称,以及他们正在做的事。该命令所使用的信息来源于/var/run/utmp文件。w命令输出的信息包括:
$ w
23:04:27 up 29 days, 7:51, 3 users, load average: 0.04, 0.06, 0.02
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
ramesh pts/0 dev-db-server 22:57 8.00s 0.05s 0.01s sshd: ramesh [priv]
jason pts/1 dev-db-server 23:01 2:53 0.01s 0.01s -bash
john pts/2 dev-db-server 23:04 0.00s 0.00s 0.00s w
$ w -h
ramesh pts/0 dev-db-server 22:57 17:43 2.52s 0.01s sshd: ramesh [priv]
jason pts/1 dev-db-server 23:01 20:28 0.01s 0.01s -bash
john pts/2 dev-db-server 23:04 0.00s 0.03s 0.00s w -h
$ w -u
23:22:06 up 29 days, 8:08, 3 users, load average: 0.00, 0.00, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
ramesh pts/0 dev-db-server 22:57 17:47 2.52s 2.49s top
jason pts/1 dev-db-server 23:01 20:32 0.01s 0.01s -bash
john pts/2 dev-db-server 23:04 0.00s 0.03s 0.00s w -u
$ w -s
23:22:10 up 29 days, 8:08, 3 users, load average: 0.00, 0.00, 0.00
USER TTY FROM IDLE WHAT
ramesh pts/0 dev-db-server 17:51 sshd: ramesh [priv]
jason pts/1 dev-db-server 20:36 -bash
john pts/2 dev-db-server 1.00s w -s
使用who命令查看(登录)用户名称及所启动的进程
who命令用于列举出当前已登录系统的用户名称。其输出为:用户名、tty号、时间日期、主机地址。
$ who
ramesh pts/0 2009-03-28 22:57 (dev-db-server)
jason pts/1 2009-03-28 23:01 (dev-db-server)
john pts/2 2009-03-28 23:04 (dev-db-server)
如果只希望列出用户,可以使用如下语句:
$ who | cut -d' ' -f1 | sort | uniq
john
jason
ramesh
补充:users命令,可用于打印输出登录服务器的用户名称。该命令除了有help和version选项外,再没有其他选项。如果某用户使用了多个终端,则相应的会显示多个重复的用户名。
$ users
john jason ramesh
使用whoami命令查看你所使用的登录名称
whoami命令用于显示登入的用户名。
$ whoami
john
whoami命令的执行效果和id -un的效果完全一样,例如:
$ id -un
john
whoami命令能显示当前登入的用户名称,以及当前所使用的tty信息。该命令的输出结果包括如下内容:用户名、tty名、当前时间日期,同时还包括用户登录系统所使用的链接地址。
$ who am i
john pts/2 2009-03-28 23:04 (dev-db-server)
$ who mom likes
john pts/2 2009-03-28 23:04 (dev-db-server)
Warning: Don't try "who mom hates" command.
当然,如果你使用su命令改变用户,则该命令(whoami)所显示的结果将随之改变。
随时查看系统的历史信息(曾经使用过系统的用户信息)
last命令可用于显示特定用户登录系统的历史记录。如果没有指定任何参数,则显示所有用户的历史信息。在默认情况下,这些信息(所显示的信息)将来源于/var/log/wtmp文件。该命令的输出结果包含以下几列信息:
$ last jason
jason pts/0 dev-db-server Fri Mar 27 22:57 still logged in
jason pts/0 dev-db-server Fri Mar 27 22:09 - 22:54 (00:45)
jason pts/0 dev-db-server Wed Mar 25 19:58 - 22:26 (02:28)
jason pts/1 dev-db-server Mon Mar 16 20:10 - 21:44 (01:33)
jason pts/0 192.168.201.11 Fri Mar 13 08:35 - 16:46 (08:11)
jason pts/1 192.168.201.12 Thu Mar 12 09:03 - 09:19 (00:15)
jason pts/0 dev-db-server Wed Mar 11 20:11 - 20:50 (00:39
以上转自:http://blog.csdn.net/wudiyi815/article/details/8061459
id命令:
查看显示目前登陆账户的uid和gid及所属分组及用户名
id [-gGnru][--help][--version][用户名称]
单纯通过refer来防盗链感觉并不靠谱,refer也可以伪装
location ~* \.(gif|jpg|png|swf|flv)$ {
valid_referers none blocked *.baidu.com;
if ($invalid_referer) {
return 403;
}
} 浏览器根本就不计算内容的高度,除非内容超出了视窗范围(导致滚动条出现)。或者你给整个页面设置一个绝对高度。否则,浏览器就会简单的让内容往下堆砌,页面的高度根本就无需考虑。
因为页面并没有缺省的高度值,所以,当你让一个元素的高度设定为百分比高度时,无法根据获取父元素的高度,也就无法计算自己的高度。换句话说,父元素的高度只是一个缺省值:height: auto;。当你要求浏览器根据这样一个缺省值来计算百分比高度时,只能得到undefined的结果。也就是一个null值,浏览器不会对这个值有任何的反应。
解决方法:给父元素设置一个高度的有效值
博客
记录下不能RSS的博客
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
Unicode码可以采用UCS-2格式直接存储。以汉字"严"为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
Unicode定义了所有可以用来表示字符的数值集合(称之为Code Point)。UTF-8和UTF-16等UTF标准定义了这些数值和字符的映射关系。Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
Unicode用一个2字节数字表示每个字符(定长),从0到65535。每个 2 字节数字表示至少在一种世界语言中使用的一个唯一字符。(在多种语言中都使用的字符具有相同的数字码。)这样就确保每个字符一个数字,并且每个数字一个字符。Unicode数据永远不会模棱两可。Unicode使用相同的数字表示ASCII和ISO-8859-1中的字符。只是这两种编码用一个字节表示,而Unicode用两个字节表示。所以Unicode表示这两种编码的字符时只要用低字节就可以了,高字节为0。
UTF-8是一种变长的编码方式,每个UTF-8的编码可以是1至6个字节长。它将Unicode编码的字符采用变长的方式进行编码。对Unicode中属于ISO-8859-1的编码采用和ISO-8859-1相同的单字节编码。其他字符采用两字节以上的编码。实际上对于两个字节的Unicode编码,UTF-8只要三个字节即可表示。第一个字节由n个1(1< n <= 6)开始, n表示编码的字节数,后面每个字节都以10开始,后面6位为有效位。将第一位的剩余位和后面的所有字节的后六位连接起来就是对应的Unicode编码的数值。例如汉字“中”的编码:
Unicode: 4E 2D
01001110 00101101
UTF-8: E4 B8 AD
11100100 10111000 10101101
用记事本创建一个文本文件,输入汉字“中”分别保存为Unicode格式和UTF-8格式。 将UltraEdit的自动识别UTF-8文件格式选项禁止,然后用其打开这两个文件,选用二进制查看方式
UTF-8格式文件编码为“EF BB BF E4 B8 AD”。其中有个三字节的前缀“EF BB BF”,这是UTF-8格式文本文件的标识。不过这个前缀不要,某些文本查看软件也可以通过编码判断出UTF-8格式。“E4 B8 AD”就是“中”的UTF-8编码。
Unicode格式的文件的完整编码是“FF FE 2D 4E”。前面有个双字节前缀“FF FE”,这是Unicode格式文本文档的编码标识。而我们看到的编码是“2D 4E”,而不是如我前面所说的“4E 2D”,为什么呢?因为数字是按照低字节在先高字节在后的顺序存储的,所以实际的Unicode编码恰恰是“4E2D”。
UTF-16比较好理解,就是任何字符对应的数字都用两个字节来保存.我们通常对Unicode的误解就是把Unicode与UTF-16等同了.但是很显然如果都是英文字母这做有点浪费.明明用一个字节能表示一个字符为啥整两个啊.
于是又有个UTF-8,这里的8非常容易误导人,8不是指一个字节,难道一个字节表示一个字符?实际上不是.当用UTF-8时表示一个字符是可变的,有可能是用一个字节表示一个字符,也可能是两个,三个.当然最多不能超过3个字节了.反正是根据字符对应的数字大小来确定.
于是UTF-8和UTF-16的优劣很容易就看出来了.如果全部英文或英文与其他文字混合,但英文占绝大部分,用UTF-8就比UTF-16节省了很多空间.而如果全部是中文这样类似的字符或者混合字符中中文占绝大多数.UTF-16就占优势了,可以节省很多空间.另外还有个容错问题,等会再讲
看的有点晕了吧,举个例子.假如中文字"汉"对应的unicode是6C49(这是用十六进制表示,用十进制表示是27721为啥不用十进制表示呢?很明显用十六进制表示要短点.其实都是等价的没啥不一样.就跟你说60分钟和1小时一样.).你可能会问当用程序打开一个文件时我们怎么知道那是用的UTF-8还是UTF-16啊.自然会有点啥标志,在文件的开头几个字节就是标志.
EF BB BF 表示UTF-8
FE FF 表示UTF-16.
用UTF-16表示"汉"
假如用UTF-16表示的话就是01101100 01001001(共16 bit,两个字节).程序解析的时候知道是UTF-16就把两个字节当成一个单元来解析.这个很简单.
用UTF-8表示"汉"
用UTF-8就有复杂点.因为此时程序是把一个字节一个字节的来读取,然后再根据字节中开头的bit标志来识别是该把1个还是两个或三个字节做为一个单元来处理.
0xxxxxxx,如果是这样的01串,也就是以0开头后面是啥就不用管了XX代表任意bit.就表示把一个字节做为一个单元.就跟ASCII完全一样.
110xxxxx 10xxxxxx.如果是这样的格式,则把两个字节当一个单元
1110xxxx 10xxxxxx 10xxxxxx 如果是这种格式则是三个字节当一个单元.
这是约定的规则.你用UTF-8来表示时必须遵守这样的规则.我们知道UTF-16不需要用啥字符来做标志,所以两字节也就是2的16次能表示65536个字符.
而UTF-8由于里面有额外的标志信息,所有一个字节只能表示2的7次方128个字符,两个字节只能表示2的11次方2048个字符.而三个字节能表示2的16次方,65536个字符.
由于"汉"的编码27721大于2048了所有两个字节还不够,只能用三个字节来表示.
所有要用1110xxxx 10xxxxxx 10xxxxxx这种格式.把27721对应的二进制从左到右填充XXX符号(实际上不一定从左到右,也可以从右到左,这是涉及到另外一个问题.等会说.
刚说到填充方式可以不一样,于是就出现了Big-Endian,Little-Endian的术语.Big-Endian就是从左到右,Little-Endian是从右到左.
由上面我们可以看出UTF-8需要判断每个字节中的开头标志信息,所以如果一当某个字节在传送过程中出错了,就会导致后面的字节也会解析出错.而UTF-16不会判断开头标志,即使错也只会错一个字符,所以容错能力强.
Windows早期(至少是95年以前的事情了)是ANSI字符集的,也就是说一个中文文本,在Windows简体中文版显示的是中文,到Windows日文版显示的就不知道是什么东西了。
后来,Windows支持了Unicode,但当时大部分软件都是用ANSI编码的,unicode还不流行,怎么办?Windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是unicode的时候,就用默认语言编码解释。(在区域和语言选项里可以改默认语言)
这个默认语言,在不同Windows语言版本里是不同的,在简体中文版里,是GBK,在繁体中文版里,是BIG5,在日文版里是JIS
而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本也不甘心这样,所以它要支持Unicode,但是有一个问题,一段二进制编码,如何确定它是GBK还是BIG5还是UTF-16/UTF-8?记事本的做法是在TXT文件的最前面保存一个标签,如果记事本打开一个TXT,发现这个标签,就说明是unicode。标签叫BOM,如果是0xFF 0xFE,是UTF16LE,如果是0xFE 0xFF则UTF16BE,如果是0xEF 0xBB 0xBF,则是UTF-8。如果没有这三个东西,那么就是ANSI,使用操作系统的默认语言编码来解释。
Unicode的好处就是,不论你的TXT放到什么语言版本的Windows上,都能正常显示。而ANSI编码则不能。(UTF-8的好处是在网络环境下,比较节约流量,毕竟网络里英文的数据还是最多的)
http://www.ruanyifeng.com/blog/2010/02/url_encoding.html
在验证情况2时,发现传输时使用的为utf-8编码(谷歌浏览器,火狐浏览器),不知道是什么原因。难道做了优化?

这个标签的作用是声明客户端的浏览器用什么字符集编码显示该页面,xxx可以为GB2312,GBK,UTF-8(和MySQL不同,MySQL是 UTF8)等等。因此,大部分页面可以采用这种方式来告诉浏览器显示这个页面的时候采用什么编码,这样才不会造成编码错误而产生乱码。但是有的时候我们会 发现有了这句还是不行,不管xxx是哪一种,浏览器采用的始终都是一种编码,这个情况我后面会谈到。
请注意,是属于html信息的,仅仅是一个声明,它起作用表明服务器已经把HTML信息传到了浏览器。
这个函数header()的作用是把括号里面的信息发到http标头。
如果括号里面的内容为文中所说那样,那作用和标签基本相同,大家对照第一个看发现字符都差不多的。但是不同的是如果有这段 函数,浏览器就会永远采用你所要求的xxx编码,绝对不会不听话,因此这个函数是很有用的。为什么会这样呢?那就得说说HTTP标头和HTML信息的差 别了:
HTTP标头是服务器以HTTP协议传送HTML信息到浏览器前所送出的字串。
因为meta标签是属于html信息的,所以header()发送的内容先到达浏览器,通俗点就是header()的优先级高于meta(不知道可 不可以这样讲)。加入一个php页面既有header("content-type:text/html; charset=xxx"),又有,浏览器就只认前者http标头而不认meta了。当然这个函数只能在php页面内使用。
Apache 根目录的 conf 文件夹里,有整个Apache的配置文档httpd.conf。
打开httpd.conf,有AddDefaultCharset xxx,xxx为编码名称。这行代码的意思:设置整个服务器内的网页文件https标头里的字符集为你默认的xxx字符集。有这行,就相当于给每个文件都 加了一行header("content-type:text/html; charset=xxx")。这下就明白为什么明明meta设置了是utf-8,可浏览器始终采用gb2312的原因。
如果网页里有header("content-type:text/html; charset=xxx"),就把默认的字符集改为你设置的字符集,所以这个函数永远有用。如果把AddDefaultCharset xxx前面加个“#”,注释掉这句,而且页面里不含header("content-type…"),那这个时候就轮到meta标签起作用了。
优先级:
header("content-type:text/html; charset=xxx")
AddDefaultCharset xxx
META
如果没有约定,该如何猜测编码方式?
很多字符编码不像UTF-8编码存在明显规律,例如Big5、GBK、GB2312等。识别这些编码可以使用的方法是通过编码范围来识别。例如GB2312的编码范围是0xA1A1-0×7E7E,如果某个字符串中有字节不在此范围内,就可以认为该字符串不是GB2312编码。
通过编码范围识别的方法误差很大,原因是很多双字节编码的编码范围重合度很高,一个字符串同时落在几个编码的编码范围就很难确定。ISO-8859-1编码占用了0×00-0xff内所有空间,所以无法通过编码范围来识别。
基于语义识别字符编码的方法的本质是把文本流当作什么编码来理解更符合语义,具体可以根据字频、词频、上下文环境等方式识别。例如某段文本中“B5C4(’的’字的GBK编码)”两个字节出现的频度比较高,则该段文本是GBK编码的可能性就非常大。基于语义的识别准确度取决于供识别的文本流长度和所采用的识别语料。
一旦传输过程中某一字节丢失,则之后的文本语义将会全部发生变化,且不易被发现,因为字节还可以和之后的字节进行组合

鸟哥文章:http://www.laruence.com/2008/04/17/110.html
参考:http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html
http://blog.sina.com.cn/s/blog_4bb59dc40102vffj.html
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
在数据库中,lock与latch都可以成为锁,但两者有截然不同的含义。
latch 一般称为闩锁(轻量级的锁) 因为其要求锁定的时间非常短,若持续时间长,则应用性能非常差,在InnoDB存储引擎中,latch有可以分为mutex(互斥锁)和rwlock(读写锁)其目的用来保证并发线程操作临界资源的正确性,并且没有死锁检测的机制。
lock的对象是事务,用来锁定的是数据库中的对象,如表、页、行。并且一般lock对象仅在事务commit或rollback后进行释放(不同事务隔离级别释放的时间可能不同),此外lock正如大多数数据库中一样,是有死锁机制的。
将锁定的对象分为多个层次,意味着事务希望在更细粒度上进行加锁。
比如如果对一个数据对象加IS锁,表示它的子结点有意向加 S锁。例如,要对某个元组加 S锁,则要首先对关系和数据库加 IS锁。
数据库的层级结构如下:
由于InnoDB存储引擎支持的是行级别的锁,因此意向锁其实是不会阻塞除全表扫以外的任何请求。意向锁只是说明该事务有意向对子节点加某个锁。
意向锁与行级锁的兼容性如下:
引进意向锁是为了提高封锁子系统的效率。该封锁子系统支持多种封锁粒度。原因是:在多粒度封锁方法中一个数据对象可能以两种方式加锁 ― 显式封锁和隐式封锁。因此系统在对某一数据对象加锁时不仅要检查该数据对象上有无(显式和隐式)封锁与之冲突,还要检查其所有上级结点和所有下级结点,看申请的封锁是否与这些结点上的(显式和隐式)封锁冲突,显然,这样的检查方法效率很低。为此引进了意向锁。
一致性非锁定读(consistent nonlocking read)是指InnoDB存储引擎通过多版本控制(multi versionning)的方式来读取当前执行时间数据库中行的数据,如果读取的行正在执行DELETE或UPDATE操作,这是读取操作不会因此等待行上锁的释放。相反的,InnoDB会去读取行的一个快照数据。
上面展示了InnoDB存储引擎一致性的非锁定读。之所以称为非锁定读,因为不需要等待访问的行上X锁的释放。
但是在不同的事务隔离级别下,读取的方式不同,并不是每个事务隔离级别下都是采用非锁定的一致性读,此外,即使使用非锁定的一致性读,但是对于快照数据的定义也各不相同。
在事务隔离级别RC和RR下,InnoDB存储引擎引擎使用非锁定的一致性读。然而,对于快照数据的定义却不相同。在RC事务隔离级别下,对于快照数据,非一致性读总是被锁定行的最新一份快照数据。而在RR事务隔离级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本。即:RC级别再其他事务提交之后即能看到数据的最新版本。RR级别总是读取事务开始时的行数据,即使其他事务提交了也是如此。(不做演示了)。
Next-Key Lock是结合Gap Lock和Record Lockd 一种锁定算法,在Nex-Key Lock算法下,InnoDB对于行的查询都是采用这种锁定算法,例如一个索引有10 11 13 20这四个值,那么该索引可能被Next-Key Locking的区间为:
(-∞,10]
(10,11]
(11,13]
(13,20]
(20,+∞)
当查询的索引含有唯一属性时,InnoDB会对Next-Key Lock进行优化,降级为Reord Lock,即仅锁住索引本身,而不是范围。
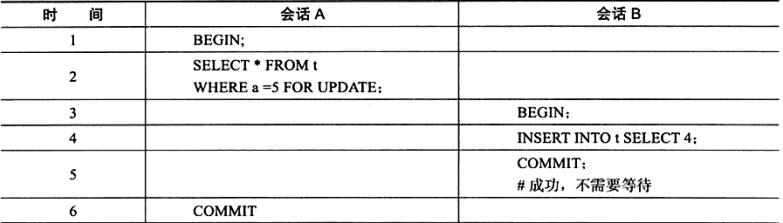
表t共有1 2 5 三个值,在会话A中首先对a=5进行了X锁定。而由于a是主键且唯一,因此锁定的仅是5这个值,而不是(2,5)这个范围,这样在会话B中插入4不会阻塞,可以立即插入并返回,及锁定由Next-Key Lock算法降级为了Record Lock,从而提高应用的并发性。
正如前面介绍,Next-Key Lock 降级为Record Lock仅在查询的列是唯一索引的情况下,如果是辅助索引,则有不同:
>create table z(a INT,b INT, PRIMARY KEY(a),KEY(b));
>INSERT INTO z SELECT 1,1;
>INSERT INTO z SELECT 3,1;
>INSERT INTO z SELECT 5,3;
>INSERT INTO z SELECT 7,6;
>INSERT INTO z SELECT 10,8;表z的列b是辅助索引,若在会话A中执行下面的SQL语句:
>SELECT * FROM z WHERE b=3 FOR UPDATE;很明显,这是SQL语句通过索引b进行查询,因此使用传统的Next-Key Locking技术加锁,并且由于有两个索引,其需要分别进行锁定。对于聚集索引,其仅对列a等于5的索引加Record Lock(b=3对应的列中a的值),而对于辅助索引,其加上了Next-Key Lock,锁定的范围是(1,3)特别需要注意的是,InnoDB存储引擎还会对辅助索引的下一个键值加上gap lock,即还有一个辅助索引范围为(3,6)的锁。因此在会话B中运行下面语句会被阻塞:
>SELECT * FROM z WHERE a=5 LOCK IN SHARE MODE;
>INSERT INTO z SELECT 4,2;
>INSERT INTO z SELECT 6,5;用户可以通过以下两种方式来显式的关闭Gap Lock:
但需要牢记,上述设置破坏了事务的隔离性,并且对于replication,可能会导致主从不一致。此外,从性能上看,RC也不会优于默认的事务隔离级别RR。
需要再次提醒,对于唯一键值的锁定,Next-Key Lock降级为Record Lock仅仅存在于查询所有的唯一索引列。若唯一索引由多个列组成,而查询仅是查找多个唯一索引列中的其中一个,那么查询其实是range类型查询,而不是point类型查询,故InnoDB存储引擎依然使用Next-Key Lock进行锁定。
注意:通过主键或则唯一索引来锁定不存在的值,也会产生GAP锁定。
以下示例中id为主键。
mysql> select * from a;
+----+------------+
| id | data |
+----+------------+
| 1 | 1 |
| 2 | 0 |
| 3 | 3 |
| 4 | 4 |
| 5 | 0 |
| 6 | 3 |
| 7 | 4294967295 |
+----+------------+
7 rows in set (0.04 sec)| Time | 用户1 | 用户2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | mysql> select * from a where id=10 for update; Empty set (0.03 sec) | |
| 3 | insert into a(id,data) values(8,10); #等待 |
读到其他事务未提交的数据,生产环境不会使用,不解释了。
读到其他事务已经提交的数据。RC隔离环境会出现此问题。
但是,一般来说,不可重复读是可以接收的,因为其读到的是已经提交的数据,本身不会带来很大的问题,因此很多数据库产商将其事务隔离级别默认设置成RC,在这种隔离级别下允许不可重复读的现象发生。
在InnoDB存储引擎中,通过Next-Key Lock算法来避免不可重复读的问题,在MySQL官方文档将不可重复读的问题定义为Phantom Problem,即幻像问题。在Next-Key Lock算法下,对于索引的扫描,不仅是锁住扫描的索引,还是锁住这些索引覆盖的范围gap,因此这个范围内的插入都是不允许的,这样就避免了另外的事务在这个范围内插入数据导致不可重复读的问题。因此InnoDB存储引擎的默认事务隔离级别是RR,采用Next-Key Lock算法,避免不可重复读的现象。
一个事务的更新操作会被另一个事务的更新操作锁覆盖,从而导致数据的不一致。
事务T1将行记录r更新为v1,但是事务T1并未提交
与此同时,事务T2将行记录r更新为v2,事务T2未提交
事务T1提交
事务T2提交
但是在当前数据库的任何隔离级别下,都不会导致数据库理论上的丢失更新问题。这是因为,即使是READ UNCOMMITTED的事务隔离级别,对于行的DML操作,需要对行或者其他粗粒度级别的对象加锁,因此在上述步骤B中,事务T2并不能对行记录r进行更新操作,其余被阻塞,直到事务T1提交。
虽然数据库能阻止丢失更新问题的产生,但是在生产应用中还有另一个逻辑意义的丢失更新问题,而导致该问题并不是因为数据库本身的问题。实际上,在所有多用户计算机系统环境下都有可能产生这个问题。简单来说,出现下面的情况,就会发生丢失更新。
事务T1查询一行数据,放入本地内存,并显示给一个终端用户User1
事务T2也查询该行数据,并将取得的数据显示给终端用户User2
User1修改这行的记录,更新数据库并提交
User2修改这行的记录,更新数据库并提交
我们以12306为例:如果用户要购买票,应用程序应该为先查询此时的余票,如果余票>0,用户再进行购买。
查询余票数量 select 余票 into tickets
if(tickets > 0){
数据库进行余票数量更新 update 票数 = tickets - 1
}
两个用户1与2同时登录12306进行购买,即触发了两个事务T1与T2。此时T1与T2查询到的余票数量是一样的,比如都是1,T1与T2进行update,所以用户1与2都买票成功。但是一个问题是:买之前余票都是1,但是有两个用户买票成功。
要避免丢失更新发生,需要将事务在这种情况下操作变成串行化,而不是并行操作。
| Time | 用户1 | 用户2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select ticket into @ticket from xx where id=xx for update(相当于应用程序中有变量存储余票数量) | |
| 3 | select ticket into @ticket from xx where id=xx for update #等待中... | |
| 4 | update xx set ticket=@ticket-1 where id=xx | |
| 5 | commit | |
| 6 | update xx set ticket=@ticket-1 where id=xx | |
| 7 | commit |
阻塞不是一件坏事,是为了保证事务可以并发并且正常的运行。
在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来控制等待的时间(默认50秒),innodb_rollback_on_timeout用来设定是否在等待超时时对进行中的事务进行回滚操作(默认为OFF,代表不会滚)。参数innodb_lock_wait_timeout是动态的,可以在运行中调整。
>set @@innodb_lock_wait_timeout=60;而innodb_rollback_on_timeout是静态的,不可在启动时进行修改。
mysql> set @@innodb_rollback_on_timeout=on;
ERROR 1238 (HY000): Variable 'innodb_rollback_on_timeout' is a read only variable当发生超时,MySQL会抛出一个1205的错误。
>BEGIN
>SELECT * FROM t WHERE a=1 FOR UPDATE;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction需要牢记,在默认情况下,InnoDB存储引擎不会由于超时而引发回滚,其实InnoDB存储引擎在大部分情况下都不会对异常进行回滚,如在一个会话中添加了如下语句:
会话A:
>SELECT * FROM t;
>BEGIN;
>SELECT * FROM t WHERE a<4 FOR UPDATE;在会话A中开启一个事务,在Next-key Lock算法下锁定小于4的所有记录(其实也锁定了4这个记录本身)在另一个会话B中执行以下语句
>BEGIN;
>INSERT INTO t SELECT 5;
>INSERT INTO t SELECT 3;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction可以看到,在会话B中插入记录5是可以的,但是插入记录为3的时候,因为会话A中Next-Key Lock算法的关系,需要等待会话A中事务释放这个资源,所以等待后产生超时,但是在超时后用户再进行SELECT操作时发现,5这个记录依然存在。
这是因为会话B中事务虽然抛出异常,但是既没有进行COMMIT操作,也没有进行ROLLBACK。而这是非常危险的状态,因此用户必须判断是否需要COMMIT还是ROLLBACK,之后在进行下一步操作。
指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。
最简单的一种方法是超时,当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务回滚,另一个等待的事务就能继续运行了,在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来设置超时时间。
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式处理,或者说其是根据FIFO的顺序选择回滚对象,但若超时的事务所占权重比较大,如事务操作更新了很多行,占用了较多的undo log,这是采用FIFO方式,就显得不合适了,因为回滚这个事务的时间相对另一个事务所占用的时间可能会更多。
除了超时机制,当前的数据库还采用wait-for graph(等待图)的方式来进行死锁检测,较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也是采用这种方式。wait-for graph要求数据库保存以下两种信息:
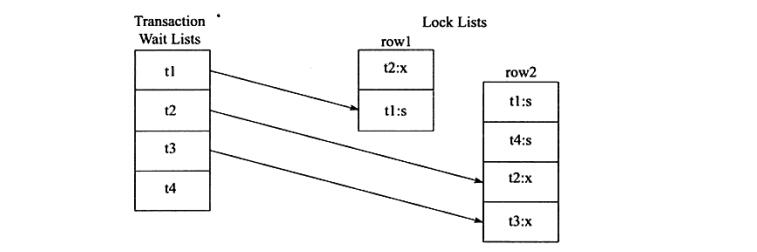
我们可以看出一共有4个事务。
row1行被t2占用的x锁,t1在等待t2释放x锁。
row2行被t1、t4同时占用s锁,t2在等待t1、t4释放s锁,同理t3在等待t1、t4、t2。
所以wait-for-graph图如下:
如图,可以发现回路(t1,t2)因此存在死锁。通过上述介绍,可以发现wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说,InnoDB存储引擎会选择回滚undo量最小的事务。
| Time | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN | |
| 2 | select * from t where id=1 for update | begin |
| 3 | select * from t where id=2 for update | |
| 4 | select * from t where id=2 for update #等待 | |
| 5 | select * from t where id=1 for update ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
在上述操作中,会话B中的事务会抛出1213的错误,即表示发生死锁,死锁的原因是会话A和会话B的资源在互相等待。大多数死锁InnoDB存储引擎本身可以侦测到,不需要人为干预,但是在上述例子中,在会话B中的事务抛出死锁异常后,会话A中马上得到了记录为2的这个资源,这其实是因为会话B中的事务发生了回滚,否则会话A中的事务是不可能得到该资源的,InnoDB存储引擎是不会回滚大部分的错误异常,但是死锁除外。发生死锁后,InnoDB存储引擎会马上回滚一个事务,这点需要注意,因此如果在应用程序中捕获1213这个错误,其实并不需要对其进行回滚。
此外还存在另一种死锁,即当前事务持有了待插入记录的下一个记录的X锁,但是在等待队列中存在一个S锁的请求,则可能发生死锁,来看一个例子:
| Time | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN | |
| 2 | begin | |
| 3 | select * from t where a=4 for update | |
| 4 | select * from t where a<=4 lock in share mode | |
| 5 | insert into t values(3); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
A获得a=4的x锁,B在a=1,2,3上加上s锁后,等待A释放x锁。在事件5中A想要插入a=3,需要等待B释放a=3的s锁,死锁就此发生。
指将当前锁的粒度降低。
比如说,数据库可以把一个表的1000个行级锁升级为一个页锁,或者将页锁升级为表锁,因为这样可以避免锁的开销。
SQL Server在以下情况下可能发生锁的升级:
但是锁升级会带来并发性的降低。
InnoDB存储引擎不存在锁升级的问题,因为其不是根据每个记录来产生行锁的,相反,其根据每个事务访问的每个页对锁进行管理的,采用的位图的方式。因此不管一个事务锁住页的一个记录还是多个记录,其开销通常是一致的。
参考资料:《MySQL技术内幕-InnoDB存储引擎》
http://baike.baidu.com/link?url=ZYqMGtJ-urHQzkfER91GmTkIZfgmNobdHLk2rsrI4e11EmQIdnrp2HAMxvp7jVt9srKg6dnXahWt4MBCrtXu3q
为了弹性布局。更准确的说是界面元素根据浏览器字体大小而进行整体缩放。
用户可以根据他们的需要而调整浏览器字体大小,例如有的人视力不好,可能需要改变浏览器的默认字体大小。
这时,我们希望页面元素的宽度、外边距、内边距等尺寸元素也会根据字体大小而进行成比例的缩放,这时我们需要使用em单位而不是px单位,因为px单位是固定的,一旦赋值元素的尺寸就不会变化。
em单位是相对于_使用em单位的元素_的字体大小。即1em总是等于当前使用em元素的字体大小。
如果当前使用em的元素没有设置字体大小,例如:
<body>
<div id="father">
......
</div>
</body>body{
font-size:20px;
}
#father{
width:20em;
border:1px solid red;
}根据1em总是等于当前使用em元素的字体大小,当前元素的字体大小是从body继承来的20px,所以1em=20px。继而算出width等于20*20=400px。
但是如果当前使用em的元素设置了字体大小,还是上面的例子,只不过加了font-size的设置:
body{
font-size:20px;
}
#father{
font-size:2em;
width:20em;
border:1px solid red;
}当前元素的font-size等于2em,在这种情况下,元素本身的font-size=父元素的font-size乘以em值,
即20*2=40px。
再根据1em总是等于当前使用em元素的字体大小,当前元素的字体大小是40px,所以1em=40px。继而算出width等于20*40=800px。
总之:先找到计算出当前元素的font-size值。如果当前元素的font-size也使用了em单位,那么当前元素的font-size=父元素的font-size*font-size的em值。
em可以设置在margin、padding、width、height等值上。
我们查看本页面的css源码,搜索em:
也是一种字体单位,类似于em,但是rem转化为像素的大小取决于页根元素的字体大小,即 html 元素的字体大小。
使用em时,我们需要知道使用em元素的字体大小。如果本身没有设置,我们需要依据继承性寻找父元素的字体大小甚至是爷爷级元素的字体大小,很繁琐。但是rem单位只需知道html元素的字体大小即可,html元素的字体大小相当于唯一的标杆。
根元素字体大小乘以你 rem 值就是px值。
<body>
<div id="father">
......
</div>
</body>html{
font-size:20px;
}
#father{
font-size:1.5rem;
width:20em;
border:1px solid red;
}此时#father元素的font-size为20_1.5=30px。width为20_20=400px。
一定是依据html的字体大小,不是body的字体大小。
试验此代码时还发现谷歌浏览器的最小字体是12px,即使字体设置为10px也会被强制设置成12px。o(╯□╰)o
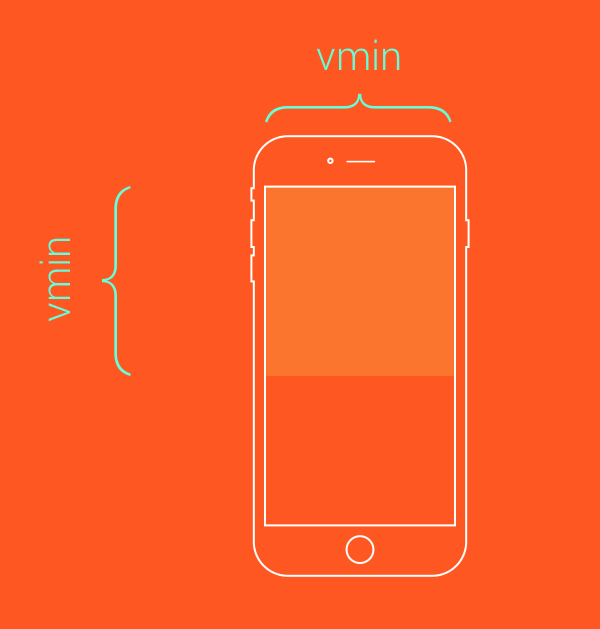
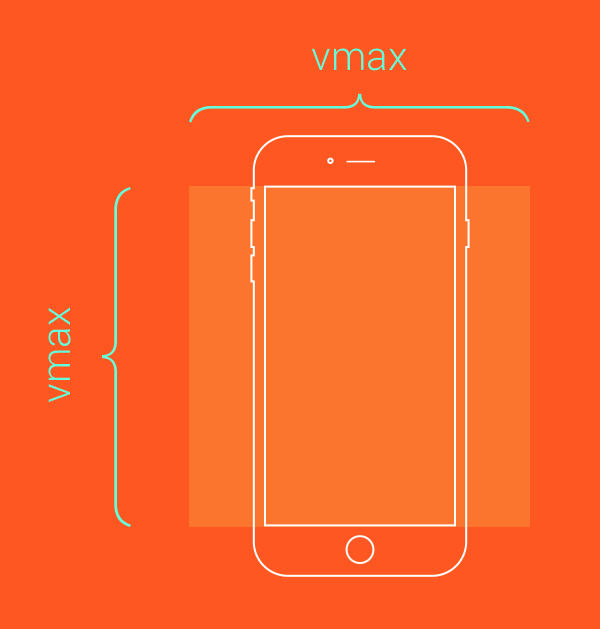
注意这里的viewport指的是浏览器内部的可视区域大小,不包含任务栏标题栏以及底部工具栏的浏览器区域大小。
如果想做一个占满高度的区域:
.slide {
height: 100vh;
}所以你什么时候可能用到这些值?
设想你需要一个总是在屏幕上可见的元素。使用高度和宽度设置为低于100的vmin值将可以实现这个效果。例如,一个正方形的元素总是至少接触屏幕的两条边可能是这样定义的:
.box {
height: 100vmin;
width: 100vmin;
}如果你需要一个总是覆盖可视窗口的正方形(一直接触屏幕的四条边),使用相同的规则只是把单位换成vmax。
.box {
height: 100vmax;
width: 100vmax;
}兼容性:http://caniuse.com/ 搜索上面的单位即可。
参考资料:http://www.w3cplus.com/css/px-to-em
http://webdesign.tutsplus.com/zh-hans/tutorials/comprehensive-guide-when-to-use-em-vs-rem--cms-23984
http://www.w3cplus.com/css/7-css-units-you-might-not-know-about.html
http://www.zhangxinxu.com/wordpress/2012/09/new-viewport-relative-units-vw-vh-vm-vmin/
这个是什么?为什么要用?怎么用?什么时候用?
1.Oh, god. Dad, please talk some sense into your wife.
译文:老天,爸,拜托你劝你老婆几句吧。
talk sense
Why don't you talk sense!
talk some sense into sb
给某人讲讲道理;开导某人
2.Wilson: Be yourself…cold, uncaring, distant.
House: Please, don’t put me on a pedestal.
Wilson:做你自己吧,冷漠、不关心人、拒人千里。
House:拜托,不要崇拜我。
put somebody on a pedestal
If you idolize a girl and put her on a pedestal, she will sense it instantly.
uncaring 无同情心的;无爱心的
distant (人)不亲密的;冷淡的;矜持的
idolize 将(某人)当作偶像崇拜
3.Puts a burden on the rest of us
译文:加重其他人的负担
burden n.
Too many children are a burden
4.I swear to God, Sheldon, one day I’m going to get the hang of talking to you.
译文:我对上帝发誓,Sheldon,总有一天我要学会跟你说话的窍门。
get the hang of something
I’ll teach you how to use the design program – you’ll get the hang of it after a while.
5.I worked my ass off to get to where I am today. I want to be somebody.
译文:我玩命工作到今天的位置,就是想出人头地。
somebody
Alex points out that we are all somebodies and nobodies.
somebody 重要人物,当权人物
6.My father, God rest his soul.
我的父亲,愿他的灵魂安息。
rest his soul
To this day, the smell of stale air reminds me of him, God rest his soul.
stale (食物)不新鲜的;走味的;变硬的;发霉的;干的
7.I didn’t play. I’m still feeling sluggish.
译文:我没打,可还是觉得浑身无力。
sluggish:adj. 行动迟缓的, 不机警的, 不活泼的, 无精打采的
8.I’m dragging my feet.I’m afraid,once I get it done,she’s gonna make me live out there.
译文:我总是拖拖拉拉的,我怕如果一旦我把车库清理干净了,她会让我住在那里。
Drag one’s feet 拖延不走, 迟迟不行动; 故意拖拉
I drag my feet for another two weeks.
9.Randy, you’re an absolute knockout.
译文:Randy, 你已经长成了大美人。
knockout n. (尤指拳击中)击倒对手取胜 〈美俚〉击倒的,引人注目的,杰出的,迷人的
Her dress was a knockout.
10.I mean, you make sure they’re going to decent parents
译文:你能确保孩子是去的正经人家吗?
decent ˈdi:sənt adj.
The majority of residents here are decent citizens.
majority məˈdʒɔriti n.多数, 大多数; 半数以上
resident n.定居的; 常驻的
11.Clean up when she goes berserk.
译文:她发飙时候负责善后。
go berserk bəˈsɜ:k 狂怒的;激动得控制不住的;疯狂似的;狂暴的
A worker went berserk and killed his boss.
12.Are you sure it’s not because you are a little jealous of me and Molly?.
译文:你确定你不是因为有点嫉妒我和Molly?
be jealous of ˈdʒeləs
She was jealous of his wealth.
13.Fitz:I’m getting divorced.
Pope: She just had your baby.They will crucify you.
Fitz: 我准备离婚。
Pope:她刚生了你的孩子,人们会唾弃你的。
crucify ˈkru:səˌfaɪ v.
The prime minister was crucified in the press for his handling of the affair.
divorced adj 离婚的
divorce n. 离婚
prime minister 总理,首相
14.He certainly can turn his back on someone suffering.
译文:他绝对可以漠视那些受苦受难的人。
turn one’s back on someone:
Jessie’s already in the gym[dʒim], and when she sees me walk in with Eva she just turns her back on me and ignores[iɡˈnɔ:] ] me.
15.You’d browbeat them until they made the choice you knew was right.
译文:你也会逼迫他们做出你认为正确的决定。
browbeat v. ˈbraʊˌbi:t 对…声色俱厉地进行威胁,吓唬
She was determined to browbeat everyone into believing her.
16.We are seriously screwed. And I am freaking out that you're not freaking out.
译文:我们真的完蛋了。而且我很担心你一点都不上心。
freak out (使)强烈反应,震惊,畏惧
I remember the first time I went onstage. I freaked out completely.
17.Did I accidentally hit a nerve?
译文:我是不是无意中冒犯了谁?
hit a nerve
The newspaper article touched a raw nerve - people still resent the closure of the local school.
nerve 神经,神经质,神经紧张;情绪不安,提心吊胆
raw (食物)生的,未经烹煮的/刺痛的
resent [riˈzent] 对…感到愤怒
18.I'm not fat. I just haven't grown into my body yet, you skinny bitch!
译文:我不是胖。我只是还没发育,你这个皮包骨贱人!
grow into 长成(内在,外在)
He's grown into a fine, responsible young man.
skinny 皮包骨的
19.I’m trying to do my part to preserve the integrity of our penal system
译文:我正在努力维护我国刑罚制度的公正性。
integrity [ɪnˈtɛgrɪti] n. 正直; 诚实, 诚恳
She had the integrity to refuse to compromise on matters of principle
preserve vt. 保护,维护
compromise 妥协,折中方法
20.deferred
adj.延期的
caution money
保证金
settle
解决,定居
21.precedence
n.优先,局先
initate
n.初启
stricken
adj. 患病的;受挫折的;受…侵袭的;遭殃的
residual
n. 剩余;残渣
adj. 剩余的;残留的
irrespective
adj. 无关的;不考虑的;不顾的
predicate
vt. 断定为…;使…基于
retrieve
vt. [计] 检索;恢复;重新得到
credential
n. 证书;凭据;国书
consecutive
adj.连续的
ruin
n.毁坏
dedicated
adj.专注的
foundation
n.(喻)基座,基础,地基
mechanism ˈmekənizəm
n.构造, 机制,办法, 技巧, 途径
significantly sɪ gˈnɪfəkəntlɪ
adv.重要的;显著的, 有特定含义的;表示…的
equivalent ɪˈkwɪv(ə)l(ə)nt
adj.(价值、数量、功能、意义等)相等的,相同的,等同的
replication
n. 复制品,仿样
term
n.专门名词
statement
n. 陈述,声明
nested
adj.嵌套的
backward
adj.向后的
compatibility kəmˌpætəˈbɪlətɪ
n.适合,一致;互换性; 通用性, 兼容性
semantics
n.语义学,语义
predictable
adj.可预言的;可预料的,可预计的
deterministic diˌtə:miˈnistik
adj. 确定性的
propagate prɔpəɡeit
vt. & vi. 繁衍, 增殖
precisely prɪˈsaɪsli:
adv. 精确地;恰好;细心地
concurrency
n.并发性
eliminate iˈlimineit
vt.消除, 排除
potentially pəˈtenʃəlɪ
adv.潜在地;可能地
duration djuəˈreiʃən
n. 持续, 持续的时间, 期间
excess
adj. 超重的, 过量的; 额外的
interleaved
adj.交叉存取的,隔行扫描的
monotonic
adj.单调的; 无变化的
seek
vt.寻求;寻找;探索;搜索
strategy 'strætɪdʒɪ
n.战略,策略
restrict
vt. 限制;约束;限定
misleading
令人误解的
adequate 'ædɪkwət
adj. 充足的;适当的;胜任的
fallen
阵亡者
synopsis sɪ'nɒpsɪs
n. 概要,大纲
cluster
n. 群;簇;丛;串
underlying
adj. 潜在的;根本的;在下面的;优先的
deficiencies dɪ'fɪʃənsi
n. 缺乏,不足;缺陷(deficiency的复数形式)
distributing
v. 分配;散布(distribute的ing形式)
adj. 分配的
operand ɒpərænd
n. [计] 操作数;[计] 运算对象
criteria kraɪ'tɪərɪə
n. 标准,条件(criterion的复数)
subset
子集
extracted iks'træktid
adj. 萃取的;引出的
vt. 提取(extract的过去式及过去分词)
corresponding
adj. 相当的,相应的;一致的;通信的
uncorrelated ʌn'kɔrileitid
adj. 不相关的
compose
vt. 构成;写作;使平静;排…的版
wildcard
通配符
selectivity
n. 选择性;分离性;选择度
walkthrough
n. 预排,预排工作,演练
separately 'sep(ə)rətlɪ
adv. 分别地;分离地;个别地
phase feɪz
n. 相;阶段;[天] 位相
vt. 使定相;逐步执行
vi. 逐步前进
aggregate ægrɪgət
vi. 集合;聚集;合计
refinement
n. 精制;文雅;[化工][油气][冶] 提纯
simplification sɪmplɪfɪ'keɪʃən
n. 简单化;单纯化
infer
推断
tricky
adj. 狡猾的;机警的
collation kə'leɪʃ(ə)n
n. 校对;斋日的点心;牧师职务
workaround
n. 工作区;变通方案;权变措施
disjoint
vt. 解体;使脱臼
vi. 脱臼;解体
estimate
vi. 估计,估价
inherently ɪn'hɪrəntli
adv. 内在地;固有地;天性地
tuple
n. [计] 元组,重数
individually ndɪ'vɪdjʊ(ə)lɪ
adv. 个别地,单独地
sufficient sə'fɪʃ(ə)nt
adj. 足够的;充分的
recap riːkæp
n. 翻新的轮胎
vt. 翻新胎面;扼要重述
trivial trɪvɪəl
adj. 不重要的,琐碎的;琐细的
exhaustive ɪg'zɔːstɪv
adj. 详尽的;彻底的;消耗的
greedy
adj. 贪婪的;贪吃的;渴望的
prune pruːn
vi. 删除;减少
vt. 修剪;删除;剪去
statistics stə'tɪstɪks
n. 统计;统计学;[统计] 统计资料
cardinality kɑːdɪ'nælɪtɪ
n. 基数;集的势
uniform
adj. 统一的;一致的;相同的;均衡的;始终如一的
multiply
乘
arithmetic ə'rɪθmətɪk
n. 算术,算法
troubleshooting
n. 解决纷争;发现并修理故障
derive dɪ'raɪv
adj. 导出的;衍生的,派生的
generalizing
归纳
constraint kən'streɪnt
n. [数] 约束;局促,态度不自然;强制
theoretically θiə'rɛtɪkli
adv. 理论地;理论上
interpretation
n. 解释;翻译;演出
artifact
人工制品,手工艺品,加工品; 石器;
lessen
vt. 使…变小;使…减轻;使…变少
likelihood
n. 可能性,可能
emphasis emfəsɪs
n. 重点;强调;加强语气
blockquote
n. 引用;用来设定一段较长的文字段落
relevant
adj. 相关的;切题的;中肯的;有重大关系的;有意义的,目的明确的
sequential sɪ'kwenʃ(ə)l
adj. 连续的;相继的;有顺序的
iterate
vt. 迭代;重复;反复说;重做
accumulate ə'kjuːmjʊleɪt
vi. 累积;积聚
vt. 积攒
scenario sɪ'nɑːrɪəʊ
n. 方案;情节;剧本
illustrate ɪləstreɪt
vt. 阐明,举例说明;图解
vi. 举例
portion
n. 部分;一份;命运
vt. 分配;给…嫁妆
to the extent
到......程度
notation
nəʊ'teɪʃ(ə)n
subscribe
vi. 订阅;捐款;认购;赞成;签署
vt. 签署;赞成;捐助
get in the way
挡路; 妨碍;
traverse trævəs
n. 穿过;横贯;横木
vt. 穿过;反对;详细研究;在…来回移动
partitioned
adj. 分割的;分区的;分段的
vt. 划分(partition的过去分词);[数] 分割;把…分成部分
sane
adj. 健全的;理智的;[临床] 神志正常的
subsequent 'sʌbsɪkw(ə)nt
adj. 后来的,随后的
draft
n. 汇票;草稿;选派;
vt. 起草;制定;征募
milestone
n. 里程碑,划时代的事件
contrary
adj. 相反的;对立的
investigate
v. 调查;研究
cavity
n.腔,蛀牙
benchmark
n. 基准;标准检查程序
vt. 用基准问题测试(计算机系统等)
deprecate deprɪkeɪt
vt. 反对;抨击;轻视;声明不赞成
practical
adj. 实际的;实用性的
malformed mæl'fɔrmd
adj. 畸形的,难看的
demonstrate demənstreit
vt. 证明;展示;论证
vi. 示威
记录下sed编译器的常见使用方法。
sed编辑器基于输入到命令行的或者是存储在文本文件中的命令来处理数据流中的数据。每次从输入中读取一行,用编辑器命令匹配数据,修改数据,输出到STDOUT。在流编辑器将所有命令与一行数据匹配之后,它会读取下一行数据并重复此过程。
s/pattern/replacement/flags关于flags:
其中:-n和p一起使用,只会输出被substitute命令修改过的行
$ echo -e "This is test test\nThis is no" | sed -n 's/test/no/p'
This is no test默认,sed使用的命令会作用于所有行,使用行寻址使命令作用于特定的行。
两种方式:
[address]command或者
address {
command1
command2
command3
}$ echo -e "one 1\ntwo 1\nthree 1" | sed "2,$ s/1/2/"
one 1
two 2
three 2/pattern/commandpattern可以为正则表达式。
$ echo -e "one 123\ntwo 456\nthree 789" | sed "/one/s/123/number/"
one number
two 456
three 789 $ echo -e "one 123\ntwo 456\nthree 789" | sed "2{
s/two/hehe/
s/456/444/
}"
one 123
hehe 444
three 789或者:
$ echo -e "one 123\ntwo 456\nthree 789" | sed "2{s/two/hehe/;s/456/444/}"
one 123
hehe 444
three 789上面的两种方法均适用。
$ echo -e "one\ntwo\nthree\nfour" | sed "/two/d"
one
three
four使用两个文本模式删除某个范围内的行
$ echo -e "one\ntwo\nthree\nfour" | sed "/one/,/three/d"
foursed '[address]command\
new line' $ echo -e "one\ntwo\nthree\nfour" | sed "$ a\five"
one
two
three
four
five $ echo -e "one\ntwo\nthree\nfour" | sed "3c\change"
one
two
change
four使用区间:
$ echo -e "one\ntwo\nthree\nfour" | sed "1,2c\change"
change
three
foursed会用这一行文本替换这两行,而不是逐一修改。
转换命令是唯一可以处理单个字符的sed编辑器命令。
[address]y/inchars/outchars将inchars和outchars进行一对一映射,如果长度不同,会产生一条错误消息。
转换命令是全局命令,会自动替换文本行中找到的指定字符的所有实例。
$ echo -e "1\n2\n3\n4" | sed "y/123/789/"
7
8
9
4 $ echo -e "one\ntwo\nthree\nfour" | sed -n '3{
p
s/three/substitude/p
}'
three
substitude同时显示原来的和新的行文本。
$ echo -e "one\ntwo\nthree\nfour" | sed -n '3{
=
p
}'
3
threel允许打印数据流中的文本和不可打印的ASCI字符。任何不可打印的字符都用他们的八进制前加一个反斜线或者标准C命名法。
$ echo -e "one\ntwo\nthree\nfour" | sed -n 'l'
one$
two$
three$
four$[address]w filename $ echo -e "one\ntwo\nthree\nfour" | sed "1,2w data"
one
two
three
four
$ cat data
one
two[address]r filename不能对读取命令使用地址区间,而只能使用单独一个行号或者文本模式地址,sed会将文件中的文本插入到地址之后。
$ cat data
one
two
$ echo -e "one\ntwo\nthree\nfour" | sed "3r data"
one
two
three
one
two
four可以和删除命令一起使用来用另一个文件的数据替换文件中的占位文本。
$ cat data
Would the following people:
LIST
please report to the office
$ sed '/LIST/{
r list
d
}' data
Would the following people:
Zhangyachen
please report to the office模式空间是一块活动缓冲区,在sed编译器执行命令时它会保存sed编译器要检验的文本。
sed编辑器还利用了另一块缓冲区域,称作保持空间。你可以在处理模式空间中其他行是用保持空间来临时保存一些行。
| 命令 | 描述 |
|---|---|
| h | 将模式空间复制到保持空间 |
| H | 将模式空间附加到保持空间 |
| g | 将保持空间复制到模式空间 |
| G | 将保持空间附加到模式空间 |
| x | 交换两个空间的内容 |
小写的n命令会告诉sed编辑器移动到数据流中的下一文本行,而不用重新回到命令的最开始再执行一遍。
删除第一行之后的空白。
$ cat data
one
two
three
$ sed '/one/{
> n
> d
> }' data
one
two
three多行版本的next命令N会将下一文本加到已在模式空间中的文本上。将两个文本行合并到同一模式空间,文本行仍然用换行符分隔,但是sed编辑器现在会将两行文本当做一行来处理。
待续。。。
当前mysql执行的策略很简单:mysql对任何关联都执行嵌套循环操作,即mysql先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻打匹配的行,依次下去,直到描述到所表表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。mysql会尝试在最后一个关联表中打到所有匹配的行,如果最后一个关联表无法找到更多的行以后,mysql返回到上一层次关联表,看是否能够找到更多的匹配记录,依此类推迭代执行。
按照这样的方式查找第一条表记录,再嵌套查询下一个关联表,然后回溯到上一个表,在mysql中是通过嵌套循环的方式来实现的--正如其名‘嵌套循环关联’。请看下面的例子中的简单查询:
select tbl1.col1,tbl2.col2
from tbl1 inner join tbl2 using(col3)
where tbl1.col1 in(5,6);假设mysql按照查询中的表顺序进行关联操作,我们则可以用下面的伪代码表示mysql将如何完成这个查询:
outer_iter = iterator_over tbl1 where col1 in(3,4)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3=outer_row.col3
inner_row = inner_iter.next
while inner_row
output[outer_row.col1,inner_row.col2]
inner_row = inner_iter.next
end
out_row = outer_iter.next
end
上面的执行计划对于单表查询和多表关联查询都适用,如果是一个单表查询,那么只需要完成上面的外层的基本操作。对于外连接和上面的执行过程任然适用。例如我们将上面的查询修改如下:
SELECT tbl1.col1 ,tbl2.col2 FROM tbl1 left outer join tbl2 using (col3) WHERE tbl1.col1 in (3,4)对应的伪代码:
outer_iter = iterator over tbl1 where col1 in(3,4)
outer row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
if inner row -> 手动加粗
while inner_row
out_put [outer_row.col1,inner_row.col2]
inner_row = inner_iter.next
end
else -> 手动加粗
out_put[outer_row.col1,NULL] -> 手动加粗
end
outer_row = outer_iter.next
end
从上面两个例子也可以看出,对于主表来说,是先进行主表的where条件筛选,再进行表联接,而不是先进行整表联接再进行where条件的筛选。
举个例子:
数据表结构:
mysql> create table a(
-> id int unsigned not null primary key
-> );
mysql> create table b like a;表中数据:
mysql> select * from a;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+----+
5 rows in set (0.00 sec)
mysql> select * from b;
+----+
| id |
+----+
| 4 |
| 5 |
| 6 |
| 7 |
+----+
4 rows in set (0.00 sec)explain查询:
mysql> explain select a.id as aid,b.id as bid from a left join b using(id) where a.id>3;
+----+-------------+-------+--------+---------------+---------+---------+----------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+----------+------+--------------------------+
| 1 | SIMPLE | a | range | PRIMARY | PRIMARY | 4 | NULL | 3 | Using where; Using index |
| 1 | SIMPLE | b | eq_ref | PRIMARY | PRIMARY | 4 | com.a.id | 1 | Using index |
+----+-------------+-------+--------+---------------+---------+---------+----------+------+--------------------------+
2 rows in set (0.00 sec)可以看出,首先在a表上进行范围查询,筛选出a.id>3的数据,然后在进行"嵌套查询"。
注意,on后面的筛选条件主要是针对的是关联表,而对于主表筛选并不适用,比如:
mysql> select a.id as aid,b.id as bid from a left join b on a.id=b.id and a.id>3;
+-----+------+
| aid | bid |
+-----+------+
| 1 | NULL |
| 2 | NULL |
| 3 | NULL |
| 4 | 4 |
| 5 | 5 |
+-----+------+
5 rows in set (0.00 sec)
mysql> explain select a.id as aid,b.id as bid from a left join b on a.id=b.id and a.id>3;
+----+-------------+-------+--------+---------------+---------+---------+----------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+----------+------+-------------+
| 1 | SIMPLE | a | index | NULL | PRIMARY | 4 | NULL | 5 | Using index |
| 1 | SIMPLE | b | eq_ref | PRIMARY | PRIMARY | 4 | com.a.id | 1 | Using index |
+----+-------------+-------+--------+---------------+---------+---------+----------+------+-------------+
2 rows in set (0.00 sec)我们发现a表的id<=3的数据并未被筛选走,explain的结果是a表进行了index类型的查询,即主键索引的全部扫描。
如果在on的筛选条件是针对b表的呢,情况会怎么样?
下面的例子数据表结构和数据变了,我们只关注查询的结果区别:
mysql> select * from a left join b on a.data=b.data and b.id<=20;
+----+------+------+------+
| id | data | id | data |
+----+------+------+------+
| 1 | 1 | NULL | NULL |
| 2 | 2 | NULL | NULL |
| 3 | 3 | NULL | NULL |
| 4 | 4 | 1 | 4 |
| 4 | 4 | 6 | 4 |
| 4 | 4 | 11 | 4 |
| 4 | 4 | 16 | 4 |
| 5 | 5 | 2 | 5 |
| 5 | 5 | 7 | 5 |
| 5 | 5 | 12 | 5 |
| 5 | 5 | 17 | 5 |
+----+------+------+------+
11 rows in set (0.00 sec)
mysql> select * from a left join b on a.data=b.data where b.id<=20;
+----+------+------+------+
| id | data | id | data |
+----+------+------+------+
| 4 | 4 | 1 | 4 |
| 5 | 5 | 2 | 5 |
| 4 | 4 | 6 | 4 |
| 5 | 5 | 7 | 5 |
| 4 | 4 | 11 | 4 |
| 5 | 5 | 12 | 5 |
| 4 | 4 | 16 | 4 |
| 5 | 5 | 17 | 5 |
+----+------+------+------+
8 rows in set (0.00 sec)由此,我们可以根据伪码来分析两者的区别:
outer_iter = iterator over a
outer row = outer_iter.next
while outer_row
inner_iter = iterator over b where data = outer_row.date where id<=20
inner_row = inner_iter.next
if inner row
while inner_row
out_put [outer_row,inner_row]
inner_row = inner_iter.next
end
else
out_put[outer_row,NULL]
end
outer_row = outer_iter.next
end
outer_iter = iterator over a
outer row = outer_iter.next
while outer_row
inner_iter = iterator over b where data = outer_row.date ->手动加粗
inner_row = inner_iter.next
if inner row
while inner_row
out_put [outer_row,inner_row]
inner_row = inner_iter.next
end
else
out_put[outer_row,NULL]
end
outer_row = outer_iter.next
end
left join的结果集中 where b.id<=20 ->手动加粗
参考资料:《高性能MySQL》
通过精心构造数据,使得所有数据全部碰撞,人为将哈希表变成一个退化的单链表,此时哈希表各种操作的时间均提升了一个数量级,因此会消耗大量CPU资源,导致系统无法快速响应请求,从而达到拒绝服务攻击(DoS)的目的。
POST攻击的防护
针对POST方式的哈希碰撞攻击,目前PHP的防护措施是控制POST数据的数量。在>=PHP5.3.9的版本中增加了一个配置项max_input_vars,用于标识一次http请求最大接收的参数个数,默认为1000。因此PHP5.3.x的用户可以通过升级至5.3.9来避免哈希碰撞攻击。5.2.x的用户可以使用这个patch:http://www.laruence.com/2011/12/30/2440.html。
另外的防护方法是在Web服务器层面进行处理,例如限制http请求body的大小和参数的数量等,这个是现在用的最多的临时处理方案。具体做法与不同Web服务器相关,不再详述。
其它防护
上面的防护方法只是限制POST数据的数量,而不能彻底解决这个问题。例如,如果某个POST字段是一个json数据类型,会被PHPjson_decode,那么只要构造一个超大的json攻击数据照样可以达到攻击目的。理论上,只要PHP代码中某处构造Array的数据依赖于外部输入,则都可能造成这个问题,因此彻底的解决方案要从Zend底层HashTable的实现动手。一般来说有两种方式,一是限制每个桶链表的最长长度;二是使用其它数据结构如红黑树取代链表组织碰撞哈希(并不解决哈希碰撞,只是减轻攻击影响,将N个数据的操作时间从O(N^2)降至O(NlogN),代价是普通情况下接近O(1)的操作均变为O(logN))。
目前使用最多的仍然是POST数据攻击,因此建议生产环境的PHP均进行升级或打补丁。至于从数据结构层面修复这个问题,目前还没有任何方面的消息。
[email protected]:nginx_trans^_^ $ ./sbin/nginx -h
nginx version: nginx/1.2.4
Usage: nginx [-?hvVtq] [-s signal] [-c filename] [-p prefix] [-g directives]
Options:
-?,-h : this help
-v : show version and exit
-V : show version and configure options then exit
-t : test configuration and exit
-q : suppress non-error messages during configuration testing
-s signal : send signal to a master process: stop, quit, reopen, reload
-p prefix : set prefix path (default: /home/iknow/nginx_trans/)
-c filename : set configuration file (default: /home/iknow/nginx_trans/conf/nginx.conf)
-g directives : set global directives out of configuration file关注 -g directives : set global directives out of configuration file
-g是指定一些全局配置项。全局配置项见:http://nginx.org/en/docs/ngx_core_module.html
http://www.tuicool.com/articles/a2MbMzQ
参考资料:http://nginx.org/en/docs/http/server_names.html
https://www.nginx.com/blog/thread-pools-boost-performance-9x/
http://blog.csdn.net/historyasamirror/article/details/5778378
允许多个http请求通过一个套接字同时被输出 ,而不用等待相应的响应。
非幂等请求(POST等)不应该使用管道化连接,因为一旦出错,无法安全的重试POST这样的请求。
如果一个事务,不管执行一次还是多次,得到的结果都相同,这个事务就是等幂的。可以认为GET,HEAD,PUT,DELETE,TRACE,OPTIONS方法共享这一特性
Syntax : open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time];
open_log_file_cache off;
Default : open_log_file_cache off;
Context : http, server, location该指令用于设置缓存,该缓存用于存储带有变量的日志文件路径而又频繁使用的文件描述符,这些被频繁使用的文件描述符将会被存储在缓存中。
server {
listen 8080;
location /foo {
echo "foo = [$foo]";
}
location /bar {
set $foo 32;
echo "foo = [$foo]";
}
}$ curl 'http://localhost:8080/foo'
foo = []
$ curl 'http://localhost:8080/bar'
foo = [32]
$ curl 'http://localhost:8080/foo'
foo = []$args支持被改写,但是$arg_XXX变量也会随之发生变化。location /test {
set $orig_a $arg_a;
set $args "a=5";
echo "original a: $orig_a";
echo "a: $arg_a";
}$ curl 'http://localhost:8080/test?a=3'
original a: 3
a: 5 location /main {
echo_location /foo;
echo_location /bar;
}
location /foo {
echo foo;
}
location /bar {
echo bar;
}$ curl 'http://localhost:8080/main'
foo
bar该模块的作用是针对一个指定的key值限制其连接数量,尤其针对一个特定的ip。并不是所有的连接都会被计数,只有当请求正在被服务端处理并且请求头全部被服务器读取时才算。
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
...
server {
...
location /download/ {
limit_conn addr 1;
}Syntax: limit_conn_zone key zone=name:size;
Default: —
Context: http设置一片共享内存区域来保存不同key值的状态,状态中包括了当前连接数量。key值可以是文本,变量或者这两者的组合,空值将不会被考虑。
1.7.6之前的版本,key值只能包含一个变量
例如:
limit_conn_zone $binary_remote_addr zone=addr:10m;该例子表明的key值是 $binary_remote_addr,注意不是$remote_addr,因为$binary_remote_addr更加节省空间。如果共享区域被耗尽,那么之后的请求都会返回503错误码。
Syntax: limit_conn zone number;
Default: —
Context: http, server, location指定一块已经设定的共享内存空间,以及每个给定键值的最大连接数。当连接数超过最大连接数时,服务器将会返回 503 错误。
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /download/ {
limit_conn addr 1;
}同一 IP同一时间只允许有一个连接。
也可以同时设置:
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}该模块使用漏桶算法限制了对于一个特定的key值的处理频率,尤其对于一个特定的IP。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
...
server {
...
location /search/ {
limit_req zone=one burst=5;
}
Syntax: limit_req_zone key zone=name:size rate=rate;
Default: —
Context: httplimit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;表示平均每秒请求次数最多是1次。其余同ngx_http_limit_req_module的limit_conn_zone
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: —
Context: http, server, location设置对应的共享内存限制域和允许被处理的最大请求数阈值。 如果请求的频率超过了限制域配置的值,请求处理会被延迟,所以所有的请求都是以定义的频率被处理的。 超过频率限制的请求会被延迟,直到被延迟的请求数超过了定义的阈值 这时,这个请求会被终止,并返回503错误。这个阈值的默认值等于0。
limit_req_zone $binary_remote_addr zone=one:10m rate=20r/s;
server {
location /search/ {
limit_req zone=one burst=5;
}限制平均每秒不超过20个请求,同时允许超过频率限制的请求数不多于5个。
如果不希望超过的请求被延迟,可以用nodelay参数:
limit_req zone=one burst=5 nodelay;个人理解burst和nodelay是:burst相当于一个缓冲,超过频率的请求都放入这个缓冲中。如果不设置此nodelay参数,严格使用平均速率限制请求数。比如说如上的例子,如果不设置nodelay,那么第一秒有25个请求时,多余的5个只能在第二秒执行。如果设置nodelay,那么25个请求将都在第1秒执行。但是平均处理频率都是20r/s,所以第2秒超过20的请求返回503错误。
盗用网上两张图:
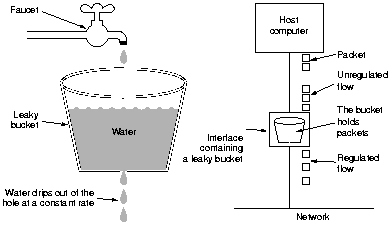
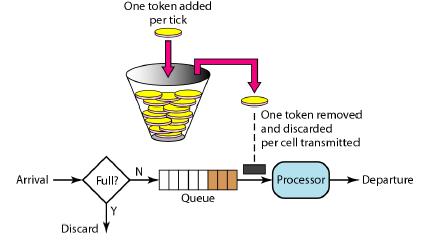
该模块检查请求链接的可靠性,保护资源免遭未经授权的访问,并限制连接的有效期。
Syntax: secure_link expression;
Default: —
Context: http, server, location定义一个字符串变量,链接的校验值和有效期从其中提取。
校验值会和secure_link_md5指令定义的MD5值进行比较。如果值不同,那么$secure_link变量置为空字符串。如果值一样,再比较过期时间,如果时间过期,$secure_link为0,否则为1。请求传递过来的MD5值会经过base64url进行编码。
请求传递过来的过期时间会保存在$secure_link_expires变量中。
Syntax: secure_link_md5 expression;
Default: —
Context: http, server, location定义一个字符串,nginx会将其MD5值与请求传入的值进行比较。
该表达式应该包含应该被保护部分以及加密部分。如果链接具有有效时间,表达也应包含$secure_link_expires(否则可以通过修改url中的过期时间参数来修改链接的过期时间)
为了防止未经授权的请求,表达式应该包含客户端的一些信息,例如ip地址或者浏览器版本等。
location /s/ {
secure_link $arg_md5,$arg_expires;
secure_link_md5 "$secure_link_expires$uri$remote_addr secret";
if ($secure_link = "") {
return 403;
}
if ($secure_link = "0") {
return 410;
}
...
}例如:
location /sec/ {
root /soft/xlongwei;
secure_link $arg_st,$arg_e;
secure_link_md5 segredo$uri$arg_e; #segredo为密码样例
if ( $secure_link = "" ) {
return 402;
}
if ( $secure_link = "0" ) {
return 405;
}
}$secret = 'segredo'; // secret,该部分不应泄露
$path = "/".$_REQUEST["f"]; // ?f=path
$expire = time()+10; // add ? seconds to be available,这里是10妙内访问有效
$md5 = base64_encode(md5($secret . $path . $expire, true)); // Using binary hashing.
$md5 = strtr($md5, '+/', '-_'); // + and / are considered special characters in URLs
$md5 = str_replace('=', '', $md5); // When used in query parameters the base64 padding character is considered special.
$url = "http://cms.xlongwei.com$path?st=$md5&e=$expire"; nginx计算segredo$uri$arg_e的MD5值,并与$_GET['st']中传递来的值进行比较来判断是否是授权的请求。$e参数表示该链接10秒内有效($_GET['e']参数表示到期时间,即使手动修改url中的e参数也无效,因为这样会造成md5值不一致)
http://www.ruanyifeng.com/blog/2008/06/base64.html
在上面的例子中:
$md5 = base64_encode(md5($secret . $path . $expire, true)); // Using binary hashing.
$md5 = strtr($md5, '+/', '-_'); // + and / are considered special characters in URLs
$md5 = str_replace('=', '', $md5); // When used in query parameters the base64 padding character is considered special.由于base64转码后的字符在[a-zA-Z0-9+/=]之间,而+/=并不适合作为url进行传输,需要将他们替换掉(+容易引起歧义,服务器端获取+时会将+转为空格,容易引起歧义)。
分为域名劫持和数据劫持。
域名劫持是针对传统DNS解析的常见劫持方式。用户在浏览器输入网址,即发出一个HTTP请求,首先需要进行域名解析,得到业务服务器的IP地址。使用传统DNS解析时,会通过当地网络运营商提供的Local DNS解析得到结果。域名劫持,即是在请求Local DNS解析域名时出现问题,目标域名被恶意地解析到其他IP地址,造成用户无法正常使用服务。
数据劫持基本针对明文传输的内容发生。用户发起HTTP请求,服务器返回页面内容时,经过中间的运营商网络,页面内容被篡改或加塞内容,强行插入弹窗或者广告。
防范域名劫持的办法是将DNS服务器手动设置为优秀的公共DNS服务器地址(例如google的8.8.8.8),这样DNS解析就不走ISP的Local DNS,有效的防止Local DNS的域名劫持。
防范数据劫持的办法是使用SSL/TLS进行加密传输。
SELECT thread_id FROM thread_5 WHERE id = 11074781 AND status = 0 AND thread_type = 0 ORDER BY post_time LIMIT 0, 50
增加在id 、status、thread_type 、post_time上的4字段复合索引。
原因:通过优化前后的执行计划对比可发现,优化后消除了filesort,直接利用索引的有序性避开额外的排序操作


当不能使用索引生成排序结果的时候,MYSQL需要自己进行排序,如果数据量小则在内存中进行,如果数据量则需要使用磁盘,不过MYSQL将这个过程统一称为文件排序(filesort),即使完全是内存排序不需要任何磁盘文件时也是如此。
如果需要排序的数据量小于排序缓冲区,MYSQL使用内存进行快速排序操作,如果内存不够排序,那么MYSQL会先将数据分块,对独立的块使用快速排序进行排序,并将各个块的排序结果放在磁盘上,然后将各个排序好的块进行合并,最后返回排序结果。
MYSQL有2中排序算法:(不再赘述2种排序的意思)
2次排序传输
单次排序传输
MYSQL在进行文件排序的时候需要使用的临时存储空间可能比想象的大许多。因为MYSQL在排序时,对每一个排序记录都会分配一个足够长的定长空间来存放。这个定长空间必须足够长以容纳最长的字符串。
在关联查询的时候如果需要排序,MYSQL会分为2中情况来处理:如果order by子句的所有列都来自关联的第一个表,那么MYSQL在关联处理第一个表的时候就进行文件排序,Explain的结果可以看到Extra字段有using filesort。除此之外的情况,MYSQL将关联的结果放到一个临时表中,然后在所有关联结束之后,再进行文件排序。Extra的结果时using temporary;using filesort。如果有limit,也在排序之后应用,所以即使返回较少的数据,也会非常耗时。
引用自:http://s.petrunia.net/blog/?p=24
SELECT c.cust_id cust_id FROM tb_aband_cust_contact c, tb_aband_phone p WHERE c.contact_id = contact_or_recipId AND p.full_phone=88123121 AND c.del_flag=0 AND p.flag=0 AND p.del_flag=0;
建立full_phone、flag、del_flag上的3字段复合索引
MYSQL一次查询只能使用一个索引
DELETE FROM mydownload WHERE create_time<1271913480;
建立基于create_time的索引,并使用LIMIT修改为分批的执行,减少锁的时间。
DELETE FROM mydownload WHERE create_time<1271913480 LIMIT 50000
删除操作不会重新整理整个表,只是把行标记为删除,在表中留下“空洞”。
尽管MyISAM是表级锁,但是依然可以一边读取,一边并发追加新行。这种情况下只能读取到查询开始时的所有数据,新插入的数据时不可见的。这样可以避免不一致读。
然而表中间的数据变动的话,还是难以提供一致读。MVCC是解决这个问题的最流行的办法。可是MyISAM不支持MVCC,除非插入操作在表的末尾,否则不能支持并发插入。
通过配置concurrent_insert变量,可以配置MyISAM打开并发插入
0:不允许并发插入,所有插入都会对表加互斥锁。
1:只要表中没有空洞,MyISAM就允许并发插入
2:5.0及以后,强制插入到表的末尾,即使表中有空洞。如果没有线程从表中读取数据,MySQL将把新行放在空洞里。
MyISAM存储引擎的读锁和写锁是互斥的,读写操作是串行的。那么,一个进程请求某个 MyISAM表的读锁,同时另一个进程也请求同一表的写锁,MySQL如何处理呢?答案是写进程先获得锁。不仅如此,即使读请求先到锁等待队列,写请求后 到,写锁也会插到读锁请求之前!这是因为MySQL认为写请求一般比读请求要重要。
max_write_lock_count:
缺省情况下,写操作的优先级要高于读操作的优先级,即便是先发送的读请求,后发送的写请求,此时也会优先处理写请求,然后再处理读请求。这就造成一个问题:一旦我发出若干个写请求,就会堵塞所有的读请求,直到写请求全都处理完,才有机会处理读请求。此时可以考虑使用max_write_lock_count:
max_write_lock_count=1
有了这样的设置,当系统处理一个写操作后,就会暂停写操作,给读操作执行的机会。
low-priority-updates:
我们还可以更干脆点,直接降低写操作的优先级,给读操作更高的优先级。
low-priority-updates=1
http://www.cnblogs.com/coser/archive/2011/11/08/2241674.html
http://www.cnblogs.com/zhengyun_ustc/archive/2013/11/29/slowquery3.html
依赖子查询
select_type为DEPENDENT SUBQUERY,子查询的第一个select依赖外部的查询。
replace没有保留旧值,而on duplicate key update类似于update,保留了旧值
http://www.path8.net/tn/archives/5613
http://blog.itpub.net/26250550/viewspace-1076292/
http://dev.mysql.com/doc/refman/5.0/en/server-status-variables.html
http://www.fromdual.com/mysql-handler-read-status-variables
个人理解:
Handler_read_first:从头到尾扫描一个索引的次数
Handler_read_key:访问索引的次数
Handler_read_last:从尾到头扫描一个索引的次数
Handler_read_next:按照索引的顺序读取下一行次数,经常发生在范围查找或者扫描索引的情况中。
Handler_read_prev:按照索引的顺序读取前一行次数,经常发生在ORDER BY ... DESC
Handler_read_rnd:这个变量比较费解。。。,手册中说:
The number of requests to read a row based on a fixed position. This value is high if you are doing a lot of queries that require sorting of the result. You probably have a lot of queries that require MySQL to scan entire tables or you have joins that do not use keys properly.
全表扫描该值不会增加,不利用索引的排序也不会增加,只有在临时表中进行排序该值才会增加。
Handler_read_rnd_next:从数据文件中读取下一行的次数。
最后两个值应该越大越不好。
select user(),current_user()
user()函数会返回当前用户连接到服务器使用的连接参数。
current_user()会返回从权限表中选择的与访问权限相关的用户名和主机名对
user表排序工作如下,假定user表看起来像这样:
+-----------+----------+-
| Host | User | …
+-----------+----------+-
| % | root | …
| % | jeffrey | …
| localhost | root | …
| localhost | | …
+-----------+----------+-
当服务器读取表时,它首先以最具体的Host值排序。主机名和IP号是最具体的。'%'意味着“任何主机”并且是最不特定的。有相同Host值的条目首先以最具体的User值排序(空User值意味着“任何用户”并且是最不特定的)。最终排序的user表看起来像这样:
+-----------+----------+-
| Host | User | …
+-----------+----------+-
| localhost | root | … ...
| localhost | | … ...
| % | jeffrey | … ...
| % | root | … ...
+-----------+----------+-
当客户端试图连接时,服务器浏览排序的条目并使用找到的第一匹配。对于由jeffrey从localhost的连接,表内有两个条目匹配:Host和User值为'localhost'和''的条目,和值为'%'和'jeffrey'的条目。'localhost'条目首先匹配,服务器可以使用。
mysqld启动时,所有授权表的内容被读进内存并且从此时生效。
当服务器注意到授权表被改变了时,现存的客户端连接有如下影响:
表和列权限在客户端的下一次请求时生效。
数据库权限改变在下一个USE db_name命令生效。
全局权限的改变和密码改变在下一次客户端连接时生效。
如果用GRANT、REVOKE或SET PASSWORD对授权表进行修改,服务器会注意到并立即重新将授权表载入内存。
如果你手动地修改授权表(使用INSERT、UPDATE或DELETE等等),你应该执行mysqladmin flush-privileges或mysqladmin reload告诉服务器再装载授权表,否则你的更改将不会生效,除非你重启服务器。
如果你直接更改了授权表但忘记重载,重启服务器后你的更改方生效。这样可能让你迷惑为什么你的更改没有什么变化!
当你修改授权表的内容时,确保你按你想要的方式更改权限设置是一个好主意。要检查给定账户的权限,使用SHOW GRANTS语句。例如,要检查Host和User值分别为pc84.example.com和bob的账户所授予的权限,应通过语句:
mysql> SHOW GRANTS FOR 'bob'@'pc84.example.com';
一个有用的诊断工具是mysqlaccess脚本,由Carlier Yves 提供给MySQL分发。使用--help选项调用mysqlaccess查明它怎样工作。注意:mysqlaccess仅用user、db和host表检查存取。它不检查tables_priv、columns_priv或procs_priv表中指定的表、列和程序级权限。
mysql> explain select * from recent_answer where id=7;
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE noticed after reading const tables |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
mysql实际访问一遍primary key或者unique key(sql语句必须用到了primary key或者unique key),发现没有这条记录,返回Impossible WHERE noticed after reading const tables
没有明确指出谁持有锁,但是可以显示出事务在等待锁
当前出现的锁,但是无法得出哪个事务持有锁,哪个事务等待锁
显示哪个事务持有锁,哪个事务等待锁,但是无法显示正在阻塞中的事务的MySQL进程ID
可以查看MySQL进程的ID
show engine innodb status
查找LATEST DETECTED DEADLOCK
关注WAITING FOR THIS LOCK TO BE GRANTED(事务在等待哪个锁)和HOLDS THIS LOCKS(阻塞事务的锁的信息)
当事务开始时,它会获取所有需要使用的表上的元数据锁,并在事务结束后释放锁,所有其他想要修改这些表定义的线程都需要等待事务结束。(5.5.3版本之后)
http://blog.itpub.net/26250550/viewspace-1071987/
翻译自:http://dev.mysql.com/doc/refman/5.1/en/innodb-auto-increment-handling.html
插入的行数会被提前计算出来
例如:不包括嵌套子查询的insert和replace
插入的行数不会被提前计算出来
例如:INSERT ... SELECT, REPLACE ... SELECT, LOAD DATA
包括:在插入时指定自增列的值
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d'); //c1是自增列
INSERT ... ON DUPLICATE KEY UPDATE,可能分配给该语句的值没有被用到(更新)
表锁
“块插入”使用表锁。
简单插入仅锁定分配自增值的过程,一次性分配所需的数量
均不使用表锁,仅锁定分配自增值的过程。
仅能保证唯一并且单调自增,但是不保证连续。
但是可能会造成主从不一致。
http://dev.mysql.com/doc/refman/5.1/en/explain-extended.html
The filtered column indicates an estimated percentage of table rows that will be filtered by the table condition. That is, rows shows the estimated number of rows examined and rows × filtered / 100 shows the number of rows that will be joined with previous tables. Before MySQL 5.7.3, this column is displayed if you use EXPLAIN EXTENDED. As of MySQL 5.7.3, extended output is enabled by default and the EXTENDED keyword is unnecessry.
要想过滤掉A中的数据,必须使用where,即使on中包含有A表中的列的限制条件,也不会过滤A的任何数据
Created_tmp_disk_tables:在磁盘上建立临时表的次数。如果无法在内存上建立临时表,MySQL则将临时表建立到磁盘上。内存临时表的最大值是tmp_table_size和max_heap_table_size values中偏小的那个。
Created_tmp_files:MySQL建立的临时文件。
Created_tmp_tables:建立临时表的数目。另外,每当执行 SHOW STATUS,都会使用一个内部的临时表,Created_tmp_tables的全局值都会增加。
翻译自:http://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
ICP应用的场合是当MySQL利用索引获取表数据。在没有ICP时,存储引擎利用索引定位数据,将数据返回给服务器,在服务器端利用where条件过滤数据。当ICP启用时,MySQL可以在索引端利用where条件过滤不需要的数据,不需要在服务器端过滤。
MySQL只有当type值为range、 ref、 eq_ref或者ref_or_null并且需要去表中取数据时才会用到ICP(在MySQL5.6中分区表不能使用ICP,在5.7中修复)。当表是InnoDB时,索引必须是二级索引(一级索引可以直接取数据,不必去表中取数据)
ICP是默认开启的,通过设置optimizer_switch变量里的index_condition_pushdown 标记来开启ICP
mysql > set optimizer_switch=’index_condition_pushdown=on|off
假设有一张表,有如下索引:key(zipcode, lastname, firstname),sql语句如下:
SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%';如果没有ICP,会在表中扫描所有zipcode='95054'的用户,索引不会帮助过滤不符合lastname LIKE '%etrunia%'的行。当启用ICP时,MySQL会在索引中过滤lastname LIKE '%etrunia%'的行(个人认为可以从explain的key_len字段看出来是否使用了lastname字段来过滤),减少了IO操作
取自http://s.petrunia.net/blog/?p=101 的一张图,其实看了这张图就知道ICP是干嘛的了:
前台线程的程序,必须等所有的前台线程运行完毕后才能退出;而后台线程的程序,只要前台的线程都终止了,那么后台的线程就会自动结束并推出程序。
一般前台线程用于需要长时间等待的任务,比如监听客户端的请求;后台线程一般用于处理时间较短的任务,比如处理客户端发过来的请求信息。
每一个服务器端进程在该表中都有一行,表明是否启用监控和历史事件日志
mysql> SELECT * FROM threads\G
*************************** 1. row ***************************
THREAD_ID: 1
NAME: thread/sql/main
TYPE: BACKGROUND
PROCESSLIST_ID: NULL
PROCESSLIST_USER: NULL
PROCESSLIST_HOST: NULL
PROCESSLIST_DB: NULL
PROCESSLIST_COMMAND: NULL
PROCESSLIST_TIME: 80284
PROCESSLIST_STATE: NULL
PROCESSLIST_INFO: NULL
PARENT_THREAD_ID: NULL
ROLE: NULL
INSTRUMENTED: YES
HISTORY: YES
CONNECTION_TYPE: NULL
THREAD_OS_ID: 489803
...
*************************** 4. row ***************************
THREAD_ID: 51
NAME: thread/sql/one_connection
TYPE: FOREGROUND
PROCESSLIST_ID: 34
PROCESSLIST_USER: isabella
PROCESSLIST_HOST: localhost
PROCESSLIST_DB: performance_schema
PROCESSLIST_COMMAND: Query
PROCESSLIST_TIME: 0
PROCESSLIST_STATE: Sending data
PROCESSLIST_INFO: SELECT * FROM threads
PARENT_THREAD_ID: 1
ROLE: NULL
INSTRUMENTED: YES
HISTORY: YES
CONNECTION_TYPE: SSL/TLS
THREAD_OS_ID: 755399
...当Performance Schema库初始化时,会将已经存在的线程填充到threads表中。从那之后,每当服务器新创建一个线程,就对应得在threads表中新增加一行。
在新创建的线程中,INSTRUMENTED和HISTORY列的值由setup_actors表决定。
当线程结束时,在threads表中对应的行将被移除。
和INFORMATION_SCHEMA.PROCESSLIST与SHOW PROCESSLIST的区别:
重要的字段:
PROCESSLIST_ID:PROCESSLIST_ID 与INFORMATION_SCHEMA.PROCESSLIST的ID值、SHOW PROCESSLIST的ID值相同、select connection_id()返回值相同
INSTRUMENTED:被线程执行的事件是否被MySQL监控(Whether events executed by the thread are instrumented,不知道理解的对不对。。。),值为YES或者NO
当被监控的事件执行时,一定会有如下的事实:
History:与INSTRUMENTED类似
其余字段的值看参考资料吧。
参考资料:http://dev.mysql.com/doc/refman/5.7/en/threads-table.html
setup_instruments存储着一系列监控器对象,代表着什么事件会被收集。(The setup_instruments table lists classes of instrumented objects for which events can be collected)
mysql> SELECT * FROM setup_instruments;
+------------------------------------------------------------+---------+-------+
| NAME | ENABLED | TIMED |
+------------------------------------------------------------+---------+-------+
...
| wait/synch/mutex/sql/LOCK_global_read_lock | YES | YES |
| wait/synch/mutex/sql/LOCK_global_system_variables | YES | YES |
| wait/synch/mutex/sql/LOCK_lock_db | YES | YES |
| wait/synch/mutex/sql/LOCK_manager | YES | YES |
...
| wait/synch/rwlock/sql/LOCK_grant | YES | YES |
| wait/synch/rwlock/sql/LOGGER::LOCK_logger | YES | YES |
| wait/synch/rwlock/sql/LOCK_sys_init_connect | YES | YES |
| wait/synch/rwlock/sql/LOCK_sys_init_slave | YES | YES |
...
| wait/io/file/sql/binlog | YES | YES |
| wait/io/file/sql/binlog_index | YES | YES |
| wait/io/file/sql/casetest | YES | YES |
| wait/io/file/sql/dbopt | YES | YES |
...每一个在源码中的监控器都会在表中有一行,即使该监控器代码没有被执行。当一个监控器代码被启用并且执行,就会创造一个监控器实例,在 *_instances表中可见。
参考资料:http://dev.mysql.com/doc/refman/5.7/en/setup-instruments-table.html
setup_consumers表用于配置事件的消费者类型,即收集的事件最终会写入到哪些统计表中。(The setup_consumers table lists the types of consumers for which event information can be stored and which are enabled)
mysql> SELECT * FROM setup_consumers;
+----------------------------------+---------+
| NAME | ENABLED |
+----------------------------------+---------+
| events_stages_current | NO |
| events_stages_history | NO |
| events_stages_history_long | NO |
| events_statements_current | YES |
| events_statements_history | YES |
| events_statements_history_long | NO |
| events_transactions_current | NO |
| events_transactions_history | NO |
| events_transactions_history_long | NO |
| events_waits_current | NO |
| events_waits_history | NO |
| events_waits_history_long | NO |
| global_instrumentation | YES |
| thread_instrumentation | YES |
| statements_digest | YES |
+----------------------------------+---------+参考资料:http://dev.mysql.com/doc/refman/5.7/en/setup-consumers-table.html
http://www.cnblogs.com/cchust/p/5022148.html
setup_actors表决定着是否为前台进程(和客户端连接有关的进程)开启监控和历史事件日志。最多有100记录,可以通过修改performance_schema_setup_actors_size系统变量最大值。
mysql> SELECT * FROM setup_actors;
+------+------+------+---------+---------+
| HOST | USER | ROLE | ENABLED | HISTORY |
+------+------+------+---------+---------+
| % | % | % | YES | YES |
+------+------+------+---------+---------+对于每一个前台进程,会根据用户名和主机名在setup_actors表中进行匹配。如果匹配成功,ENABLED和HISTORY列的值就会被分别赋给threads表中的INSTRUMENTED和HISTORY列。这能够让用户启用监控器和历史事件日志。如果没有在setup_actors表中匹配到,ENABLED和HISTORY列的值会被赋值为NO。
对于setup_actors表的改变不会影响现有的线程,只会改变现有线程创建的子线程。如果想要改变现有的线程,改变threads表中对应行的 INSTRUMENTED和HISTORY的值。
参考资料:http://dev.mysql.com/doc/refman/5.7/en/setup-actors-table.html
http://dev.mysql.com/doc/refman/5.7/en/performance-schema-instrument-naming.html
如下例子示例了如何像SHOW PROFILES和SHOW PROFILE一样分析数据。
1.默认的,MySQL允许所有前台线程监控和收集历史事件。
mysql> SELECT * FROM setup_actors;
+------+------+------+---------+---------+
| HOST | USER | ROLE | ENABLED | HISTORY |
+------+------+------+---------+---------+
| % | % | % | YES | YES |
+------+------+------+---------+---------+可以做如下改变:
mysql> UPDATE performance_schema.setup_actors SET ENABLED = 'NO', HISTORY = 'NO'
-> WHERE HOST = '%' AND USER = '%';
mysql> INSERT INTO performance_schema.setup_actors (HOST,USER,ROLE,ENABLED,HISTORY)
-> VALUES('localhost','test_user','%','YES','YES');mysql> SELECT * FROM performance_schema.setup_actors;
+-----------+-----------+------+---------+---------+
| HOST | USER | ROLE | ENABLED | HISTORY |
+-----------+-----------+------+---------+---------+
| % | % | % | NO | NO |
| localhost | test_user | % | YES | YES |
+-----------+-----------+------+---------+---------+2.确保statement and stage监控器在setup_instruments表中启用。
mysql> UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
-> WHERE NAME LIKE '%statement/%';
mysql> UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
-> WHERE NAME LIKE '%stage/%';3.确保events_statements_* 和events_stages_*启用。
mysql> UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'
-> WHERE NAME LIKE '%events_statements_%';
mysql> UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'
-> WHERE NAME LIKE '%events_stages_%';4.运行想要分析的语句:
mysql> SELECT * FROM employees.employees WHERE emp_no = 10001;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
+--------+------------+------------+-----------+--------+------------+5.通过events_statements_history_long表确定EVENT_ID
mysql> SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT
-> FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%10001%';
+----------+----------+--------------------------------------------------------+
| event_id | duration | sql_text |
+----------+----------+--------------------------------------------------------+
| 31 | 0.028310 | SELECT * FROM employees.employees WHERE emp_no = 10001 |
+----------+----------+--------------------------------------------------------+6.一个语句很可能会触发很多事件,这些事件都是循环嵌套的,每个阶段的事件记录有一个nesting_event_id列,包含父表的event_id。(Query the events_stages_history_long table to retrieve the statement's stage events. Stages are linked to statements using event nesting. Each stage event record has a NESTING_EVENT_ID column that contains the EVENT_ID of the parent statement.
求翻译,MLGB)
mysql> SELECT event_name AS Stage, TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration
-> FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=31;
+--------------------------------+----------+
| Stage | Duration |
+--------------------------------+----------+
| stage/sql/starting | 0.000080 |
| stage/sql/checking permissions | 0.000005 |
| stage/sql/Opening tables | 0.027759 |
| stage/sql/init | 0.000052 |
| stage/sql/System lock | 0.000009 |
| stage/sql/optimizing | 0.000006 |
| stage/sql/statistics | 0.000082 |
| stage/sql/preparing | 0.000008 |
| stage/sql/executing | 0.000000 |
| stage/sql/Sending data | 0.000017 |
| stage/sql/end | 0.000001 |
| stage/sql/query end | 0.000004 |
| stage/sql/closing tables | 0.000006 |
| stage/sql/freeing items | 0.000272 |
| stage/sql/cleaning up | 0.000001 |
+--------------------------------+----------+
15 rows in set (0.00 sec)参考资料:http://dev.mysql.com/doc/refman/5.7/en/performance-schema-query-profiling.html
http://blog.51yip.com/mysql/1056.html
变长字段需要额外的2个字节,固定长度字段不需要额外的字节。而null都需要1个字节的额外空间,所以以前有个说法:索引字段最好不要为NULL,因为NULL让统计更加复杂,并且需要额外的存储空间。这个结论在此得到了证实。
key_len的长度计算公式:
varchr(10)变长字段且允许NULL:10 * (Character Set:utf8=3,gbk=2,latin1=1) + 1(NULL) + 2(变长字段)
varchr(10)变长字段且不允许NULL:10 * (Character Set:utf8=3,gbk=2,latin1=1) + 2(变长字段)
char(10)固定字段且允许NULL:10 * (Character Set:utf8=3,gbk=2,latin1=1) + 1(NULL)
char(10)固定字段且允许NULL:10 * (Character Set:utf8=3,gbk=2,latin1=1)
参考资料:http://www.ittang.com/2014/0612/13360.html
http://dev.mysql.com/doc/refman/5.7/en/dynindex-sysvar.html
http://dev.mysql.com/doc/refman/5.6/en/innodb-parameters.html

http://www.cnblogs.com/rollenholt/p/3776923.html
http://blog.csdn.net/sxingming/article/details/52628531
http://blog.itpub.net/7728585/viewspace-2132521
http://blog.sina.com.cn/s/blog_4de07d5e01010jc4.html
来看一下通过http发送请求的场景:
但是此种情况下,信用卡号就很有可能被窃听。于是,我们可以使用SSL或者TLS作为对通信进行加密的协议,然后在此之上承载http。通过对此两种协议的叠加,我们就对HTTP的通信进行加密,防止窃听。
以上面的例子为例,如果我们想要达到安全的通信,必须达到以下几点:
以上问题抽象出来就是:
通过文章最开始提到的密码技术,我们可以想到机密性可以用对称密码解决(这里的窃听不是指发送内容不能被攻击者得到,而是攻击者即使得到发送内容也不能理解或者破译)。由于对称密码不能被攻击者预测,因此我们使用伪随机数生成器来生成密钥。若要将对称密码的密钥发送给通信方而不被攻击者窃听,可以使用公钥密码或者Diffie-Hellman密钥交换。
识别篡改可以使用消息认证码技术.
对通信对象的认证,可以使用对公钥加上数字签名所生成的证书。
我们需要一个“框架”将上述工具组合起来,SSL/TLS协议就扮演了这样一个框架的角色。
上面的例子是SSL/TLS承载HTTP协议,其实SSL/TLS还可以承载很多协议,例如:SMTP、POP3。
SSL是1994年网景公司设计的一种协议,并在该公司的Web浏览器中进行了实现。随后很多Web浏览器都采用了这一种协议,使其成为了事实上的行业标准。SSL已经于1995年发布了3.0版本。
TLS是IETF在SSL3.0的基础上设计的协议。在1999年作为RFC2246发布的TLS1.0,实际上相当于SSL3.1。
TLS协议分为TLS记录协议和TLS握手协议。位于底层的TLS记录协议负责进行加密,位于上层的TLS握手协议负责加密以外的其他操作。而上层的TLS握手协议又分为4个子协议。
负责消息的压缩、加密以及数据的认证。
处理过程如下:
负责生产共享密钥以及交换证书。
握手协议主要分为4个子协议:握手协议、密码规格变更协议、警告协议和应用数据协议。
负责在客户端和服务器之间协商决定密码算法和共享密钥。基于证书的认证也在这一步完成。这段协议相当于下面的会话:
客户端:“你好,我能理解的密码套件有RSA/3DES,或者DSS/AES,请问我们使用哪一种?”
服务器:“你好,我们使用RSA/3DES吧,这是我的证书。”
协商之后,就会互相发出信号来切换密码。负责发出信号的就是下面介绍的密码规格变更协议。
负责向通信对象传达变更密码方式的信号。
客户端:“我们按照刚才的约定切换密码吧。1,2,3”
中途发生错误时,就会通过下面的警告协议传达给对方。
负责向通信对象传达变更密码方式的信号。
客户端:“我们按照刚才的约定切换密码吧。1,2,3”
中途发生错误时,就会通过下面的警告协议传达给对方。
服务器:“刚才的消息无法正确解析哦。”
将TLS上面承载的应用数据传达给通信对象的协议。
(图片太长了,截了两次,o(╯□╰)o)
一些重要握手过程:
客户端向服务器发出加密通信的请求。
在这一步,客户端主要向服务器提供以下信息。
“会话ID”是当客户端和服务器希望重新使用之前建立的会话(通信路径)时所使用的信息。
服务器收到客户端请求后,向客户端发出回应。服务器的回应包含以下内容。
服务器发送Certificate消息。包含以下内容
当Certificate消息不足以满足需求时(例如匿名方式通信),服务器会通过ServerKeyExchange消息向客户端发送一些必要信息。
当使用RSA时,服务器发送N与E,也就是公钥。
当使用DH算法时,服务器发送P、G、G的x次方modP(DH算法的公开参数)
客户端从服务器的证书中取出服务器的公钥,然后向服务器发送以下信息。
非常重要的一个数值,TLS密码通信的机密性和数据的认证全部依靠这个数值。
主密码依赖如下信息计算出来:
当使用RSA公钥密码时,客户端在发送ClientKeyExchange消息时,将经过加密的预备主密码一起发送给服务器。
当使用DH密钥交换时,客户端在发送ClientKeyExchange消息时,将DH的公开值一起发送给服务器。根据这个值,客户端和服务器会各自生成预备主密码。
当根据预备主密码计算主密码时,会使用两个单向散列函数(MD5和SHA-1)组合而成的伪随机数生成器。之所以用两个单向散列函数,是为了提高安全性。
引用dog250的理解
不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于SSL协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。
对于RSA密钥交换算法来说,pre-master-key本身就是一个随机数,再加上hello消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。
pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么pre master secret就有可能被猜出来,那么仅适用pre master secret作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上pre master secret三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。
主密码用于生成下列6种信息:
这部分还没涉猎过,先找个文章mark下。
https://imququ.com/post/optimize-tls-handshake.html
参考资料:《图解密码技术》
http://www.ruanyifeng.com/blog/2014/02/ssl_tls.html
http://www.ruanyifeng.com/blog/2014/09/illustration-ssl.html
对于其他用户,只有读权限。
[root@localhost www]# ll -d dlslpp
drwxr-xr--. 2 root root 4096 Jul 10 13:59 dlslpp
此时切换到其他用户,想要进入该目录时,提示权限不足,因为没有执行权限。
[dlslpp@localhost www]$ cd dlslpp
-bash: cd: dlslpp: Permission denied
在添加执行权限时,其他用户可以进入该目录,但是如果没有读权限,不能列出目录下的文件。
[dlslpp@localhost www]$ ll -d dlslpp
drwxr-x--x. 2 root root 4096 Jul 10 13:59 dlslpp
[dlslpp@localhost dlslpp]$ ls
ls: cannot open directory .: Permission denied
对目录没有x权限,无法查看目录下文件的内容。
[dlslpp@localhost www]$ ll -d dlslpp
drwxr-xrw-. 2 root root 4096 Jul 10 16:14 dlslpp
[dlslpp@localhost www]$ cat dlslpp/test.php
cat: dlslpp/test.php: Permission denied
加上对目录的x权限,但是没有文件的r权限,也无法查看文件的内容。
[dlslpp@localhost dlslpp]$ ll test.php
-rw-r---wx. 1 root root 17 Jul 10 16:14 test.php
[dlslpp@localhost dlslpp]$ cat test.php
cat: test.php: Permission denied
和上面差不多,不做实验了。
有些文件是需要执行权限的,比如脚本文件必须要有执行权限才可以的。比如有一个文件a.sh,它的权限是rw-,你是无法 使用"./a.sh" 来运行的,会提示你没有权限,只能用sh a.sh的方式运行。 加上x权限,chmod u+x a.sh 之后,就可以以 ./a.sh 来执行这个脚本了。
[root@localhost dlslpp]# ll a.sh
-rwxr--r--. 1 root root 9 Jul 10 17:17 a.sh
[root@localhost dlslpp]# ./a.sh
11
[root@localhost dlslpp]# chmod u-x a.sh
[root@localhost dlslpp]# ./a.sh
-bash: ./a.sh: Permission denied
使用sh a.sh方式时,如果用户对sh命令也没有执行权限,那么同样无法执行文件。
参考:《鸟哥的Linux私房菜》
http://www.xker.com/page/e2012/0925/120748.html
核心代码如下:
/* {{{ php_trim()
* mode 1 : trim left
* mode 2 : trim right
* mode 3 : trim left and right
* what indicates which chars are to be trimmed. NULL->default (' \t\n\r\v\0')
*/
PHPAPI char *php_trim(char *c, int len, char *what, int what_len, zval *return_value, int mode TSRMLS_DC)
{
register int i;
int trimmed = 0;
char mask[256];
if (what) {
php_charmask((unsigned char*)what, what_len, mask TSRMLS_CC);
} else {
php_charmask((unsigned char*)" \n\r\t\v\0", 6, mask TSRMLS_CC);
}
//从左开始
if (mode & 1) {
for (i = 0; i < len; i++) {
if (mask[(unsigned char)c[i]]) { //该位置有第二个参数对应的值
trimmed++;
} else {
break;
}
}
len -= trimmed;
c += trimmed;
}
if (mode & 2) {
for (i = len - 1; i >= 0; i--) {
if (mask[(unsigned char)c[i]]) {
len--;
} else {
break;
}
}
}
if (return_value) {
//把c指针现在指向的位置以后的len个字符返回
RETVAL_STRINGL(c, len, 1);
} else {
return estrndup(c, len);
}
return "";
}可以看出,在php_trim函数内部调用了php_charmask函数
/* {{{ php_charmask
* Fills a 256-byte bytemask with input. You can specify a range like 'a..z',
* it needs to be incrementing.
* Returns: FAILURE/SUCCESS whether the input was correct (i.e. no range errors)
*/
static inline int php_charmask(unsigned char *input, int len, char *mask TSRMLS_DC)
{
unsigned char *end;
unsigned char c;
int result = SUCCESS;
memset(mask, 0, 256); //初始化一个长度为256的hash表
for (end = input+len; input < end; input++) {
c=*input;
if ((input+3 < end) && input[1] == '.' && input[2] == '.'
&& input[3] >= c) {
memset(mask+c, 1, input[3] - c + 1);
input+=3;
} else if ((input+1 < end) && input[0] == '.' && input[1] == '.') {
/* Error, try to be as helpful as possible:
(a range ending/starting with '.' won't be captured here) */
if (end-len >= input) { /* there was no 'left' char */
php_error_docref(NULL TSRMLS_CC, E_WARNING, "Invalid '..'-range, no character to the left of '..'");
result = FAILURE;
continue;
}
if (input+2 >= end) { /* there is no 'right' char */
php_error_docref(NULL TSRMLS_CC, E_WARNING, "Invalid '..'-range, no character to the right of '..'");
result = FAILURE;
continue;
}
if (input[-1] > input[2]) { /* wrong order */
php_error_docref(NULL TSRMLS_CC, E_WARNING, "Invalid '..'-range, '..'-range needs to be incrementing");
result = FAILURE;
continue;
}
/* FIXME: better error (a..b..c is the only left possibility?) */
php_error_docref(NULL TSRMLS_CC, E_WARNING, "Invalid '..'-range");
result = FAILURE;
continue;
} else {
//对应的位置为1
mask[c]=1;
}
}
return result;
}可以看出trim函数的逻辑:
1 声明一个长度为256的hash表。
2 将character_mask中每个字节转化为ascii码,将hash表中ascii码对应key的value设置为1。
3 从头部遍历str中每个字节,若遍历到字节对应的ascii码在hash表中存在,则str长度位置减1;若不存在,就中断循环。
4 从尾部遍历str中每个字节,逻辑同3。
案例分析:
trim("广东省","省")导致乱码
首先获得"广东省"的十六进制表示
<?php
// 文件utf-8编码
// 获取字符串编码
function get_hex_str($str) {
$hex_str = '';
for ($i = 0; $i < strlen($str); $i ++) {
$ord = ord($str[$i]);//转换为ascii码
$hex_str .= sprintf("\x%02X", $ord);//以十六进制输出,2为指定的输出字段的宽度.如果位数小于2,则左端补0
}
return $hex_str;
}$str = "广东省";
printf("str[%s] hex_str[%s]\n", $str, get_hex_str($str));
$str = trim($str, "省");
printf("str[%s] hex_str[%s]\n", $str, get_hex_str($str));
输出:
str[广东省] hex_str[\xE5\xB9\xBF\xE4\xB8\x9C\xE7\x9C\x81]
str[广hex_str[\xE5\xB9\xBF\xE4\xB8]
utf-8编码下汉字对应三个字节,“东”的编码为e4 b8 9c,“省”的编码为e7 9c 81。
trim("广东省", "省"); 函数处理时不是以我们看到的中文字符为一个单位,而是以字节为单位。
相等于从e5 b9 bf e4 b8 9c e7 9c 81开头和结尾去掉包含在e7 9c 81的字节,这样“东”的第三个字节就会被切掉,就会有上述的输出了。
如果想将中文字符串中部分字符去掉,建议使用str_replace。
负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲(INSERT BUFFER),UNDO页的回收。
负责IO请求的回调。
事物被提交后,其所使用的undolog可能不再需要,因此需要Purge Thread来回收并且分配新的undo页。1,1版本之前purge操作在Master Thread中完成。之后是独立的线程。
[mysqld]
innodb_purge_threads=11.2之后支持多个Purge Thread
1.2.x引入。脏页的刷新操作都放入到单独的线程中来完成。
运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
运行级别2:多用户状态(没有NFS,NFS就是网络文件系统)
运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
运行级别4:系统未使用,保留
运行级别5:X11控制台,登陆后进入图形GUI模式
运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
注意:ubuntu系统下,运行级别2-5提供的服务是一样的,即2-5级别没有差别,所以ubuntu系统下0表示关机,1表示维护模式,2-5表示GUI界面的系统,6表示重启系统。
如果想要修改默认的运行级别,修改/etc/inittab文件。( ubuntu系统默认没有/etc/inittab文件,在/etc/init/rc-sysinit.conf文件中指定了默认运行级别。)
id:3:initdefault:
将数字改为需要的运行级别即可。
不同运行级别之间的 差别的在于系统默认起动的服务的不同。例如运行级别1会关闭网络服务,运行级别3默认不启动X图形界面服务,而运行级别5却默认起动。
[root@localhost ~]# runlevel
N 3
使用runlevel命令可以显示前次和当前的运行级别,中间使用空格符隔开,如果没有前次运行级别则显示N。例如,系统默认运行级别是2,且用户没有切换过运行级别,那么运行runlevel命令后,系统显示为N 2。如果当前运行级别为2,用户使用init 3切换到运行级别3,那么runlevel命令显示为2 3。
每个运行级别在/etc下都对应一个rcN.d目录,N的范围是0-6。系统启动时,根据默认的运行级别执行相应rcN.d目录下的服务。为了管理方便,该目录下所有的服务实际是软链接到/etc/init.d目录下相应的脚本文件。由init.d目录下的脚本文件完成服务的启动和关闭功能。
rcN.d目录下文件的格式为:[SK]NNname。S表示启动该服务,K表示关闭该服务;NN表示启动顺序号,最小的数字最先被启动,最大的数字最后被启动。name表示服务名称。
[root@localhost etc]# cd rc3.d/
[root@localhost rc3.d]# ls
K01smartd K15httpd K69rpcsvcgssd K76ypbind K89rdisc S02lvm2-monitor S12rsyslog S23NetworkManager S26acpid S64mysqld S90crond
K02oddjobd K30spice-vdagentd K73winbind K84wpa_supplicant K92pppoe-server S08ip6tables S13cpuspeed S24nfslock S26haldaemon S80postfix S95atd
K05wdaemon K50dnsmasq K74ntpd K86cgred K95firstboot S08iptables S13irqbalance S24rpcgssd S26udev-post S82abrt-ccpp S97rhnsd
K10psacct K50kdump K75cgconfig K87restorecond K95rdma S10network S13rpcbind S25blk-availability S28autofs S82abrtd S97rhsmcertd
K10saslauthd K60nfs K75ntpdate K88sssd K99rngd S11auditd S15mdmonitor S25cups S50bluetooth S84php-fpm S99certmonger
K15htcacheclean K61nfs-rdma K75quota_nld K89netconsole S01sysstat S11portreserve S22messagebus S25netfs S55sshd S85nginx S99local
[root@localhost rc0.d]# ll
total 0
lrwxrwxrwx. 1 root root 20 Apr 5 18:20 K01certmonger -> ../init.d/certmonger
lrwxrwxrwx. 1 root root 16 Apr 5 18:23 K01smartd -> ../init.d/smartd
lrwxrwxrwx. 1 root root 17 Apr 5 18:20 K02oddjobd -> ../init.d/oddjobd
lrwxrwxrwx. 1 root root 19 Apr 5 18:20 K02rhsmcertd -> ../init.d/rhsmcertd
lrwxrwxrwx. 1 root root 15 Apr 5 18:19 K03rhnsd -> ../init.d/rhnsd
lrwxrwxrwx. 1 root root 13 Apr 5 18:20 K05atd -> ../init.d/atd
lrwxrwxrwx. 1 root root 17 Apr 5 18:25 K05wdaemon -> ../init.d/wdaemon
我们注意到,在运行级别为3的时候,nginx服务默认是启动的。
[root@localhost rc3.d]# ls | grep nginx
S85nginx
如果想要开机时不启动nginx,输入下列命令:
[root@localhost rc3.d]# chkconfig nginx off
则nginx服务开机时就不自动启动了。
[root@localhost rc3.d]# ls | grep nginx
K15nginx
用来更新(启动或停止)和查询系统服务的运行级信息
chkconfig [--list] [--type type][name]
chkconfig --add name
chkconfig --del name
chkconfig --override name
chkconfig [--level levels] [--type type] name <on|off|reset|resetpriorities>
chkconfig [--level levels] [--type type] name
具体用法见http://roclinux.cn/?p=51 或者 man chkconfig
参考资料:http://blog.csdn.net/luomoweilan/article/details/20290165
总结下《图解密码技术》的核心点,自己忘的时候瞅一眼。
加密和解密使用同一密匙。
加密和解密使用不同密钥的方式。
计算散列值,保证的不是机密性,而是完整性。
确认消息是否被篡改,而且能够确认消息是否来自所期待的通信对象。
为了防止通信方的否认
模拟产生随机数的算法
1977年美国联邦信息处理标准所采用的一种对称密码,现在已经能被暴力破解。
DES是一种将64比特的明文加密成64比特密文的对称密码算法,密匙长度是56比特。但由于每隔7比特会设置用于错误检查的比特,因此密匙长度实际是56比特。
DES基本结构也被称为Feistel网络,加密的各个步骤称为轮,整个加密的过程就是进行若干次轮的循环。DES是一种16轮循环的Feistel网络。
但是这样一来右侧根本没有加密,因此我们需要用不同的子密匙对一轮的处理重复若干次,并在两轮处理之间将左侧和右侧数据对调。
DES破解消息:http://wenku.baidu.com/link?url=0UrkWjEU0SsXN4uA059-vm_e32e3YxflhD4X6J3dU_aupbTSog70EabsJ4u6YMldfygILs8BX1q7DI0GuAhdw2Qud6IywUVXt04ybUrB44K
取代DES成为新标准的一种对称密码算法。在2000年从候选算法中选出了一种名为Rijndael的对称密码算法。
分组长度是128比特。在AES规格中,密匙长度只有128、1192、256比特三种。
Rijndael需要重复进行10~14轮计算。
目前为止还没有出现针对Rijndael的有效攻击。
分组密码只能加密固定长度的分组,但是我们要加密的长度可能会超过分组密码的分组长度,这是就需要对分组密码算法进行迭代,迭代的方法就是分组密码的模式。
相同的明文会被转换为相同的密文。只要观察一下密文,就知道明文存在怎样的重复组合,并以此为线索破解密码。并且在ECB模式中,每个明文分组都各自独立的加密和解密,攻击者可以改变密文分组的顺序。
不推荐使用。
每次加密时都会随机产生一个不同的比特序列来作为初始化向量。
前8字节为nonce,这个值在每次加密时必须不同(防止具有相同的分组序号的相同明文加密后产生相同的密文)。后8字节为分组序号,这个部分会逐次累加。
能够以任意顺序处理分组,就意味着能够实现并行计算。
解决密匙配送问题:
公钥密码处理速度只有对称密码的几百分之一。
一种公钥算法。
http://www.ruanyifeng.com/blog/2013/06/rsa_algorithm_part_one.html
一旦发现了对大整数进行质因数分解的高效算法,RSA就能被破译。
仅靠公钥密码本身,是无法防御中间人攻击的。要防御中间人攻击,还需要一种手段来确认所收到的公钥是否真的属于Bob,这种手段称为认证。
公钥密码的问题:
混合密码系统的组成机制:
用对称密码提升明文的加密速度,用公钥密码提升对称密码的密匙的安全性(因为对称密码的密匙长度相对于明文长度很短,所以公钥密码速度慢的问题可以被忽略)。
也叫消息摘要函数,哈希函数或者杂凑函数。
用来确认明文的完整性,或者是否被篡改。
单向散列函数有一个输入和输出,输入称为消息,输出称为散列值。
找到和该消息具有相同散列值的另一条消息是非常困难的。
找到相同散列值的两条不同的消息是非常困难的。
MD4产生128比特的散列值,现在已经不安全。
MD5产生28比特的散列值,目前MD5的强碰撞性已经被攻破。
SHA-1产生160比特的散列值,强碰撞性于2005年被攻破。
SHA-256、SHA-384、SHA-512统称SHA-2,散列长度分别为256,384,512比特。
SHA-2尚未被攻破。
查看php支持的哈希函数
<?php
print_r(hash_algos());php使用哈希函数范例:
<?php
echo hash('sha256', 'abc');
echo hash('sha512', 'abc');
// md5, sha1.. 等等也都可以用此寫法
echo hash('md5', 'abc');
echo hash('sha1', 'abc');单向散列函数并不是加密算法
为了破解弱抗碰撞性,可以使用暴力破解。以SHA-1为例,散列值长度值为160比特,因此最多尝试2的160次方就能找到目标消息了。
为了破解强抗碰撞性。
设想在N个人中,如果要保证至少两个人的生日一样的概率大于二分之一,N至少多少?
先算N个人生日全都不一样的概率(过程略了),N=23。
当Y非常大时,N约等于Y的平方根。
以160比特的散列值为例,N=2^80时,生日攻击有二分之一的概率成功。
单向散列函数可以辨别篡改,但是无法辨别伪装。此时我们需要认证技术。
参考:php处理密码的几种方式
https://jellybool.com/post/php-password-hash-in-the-right-way
message authentication code(MAC),输入包括消息和共享密钥,可以输出固定长度的数据。
但是还是那个恒久的问题:共享密钥配送问题。如果共享密钥落入第三方手中,消息认证码就无法发挥作用了(解决方法还是上面提过的四种解决方法)。
H是HASH的意思。
防御方法:
消息认证码之所以无法防止否认,是因为发送者和接受者共享密钥。对于第三方来说,我们无法证明这条消息是由发送发生成的,因为接收方也可以伪造此消息。
所以,我们可以模仿公钥密码,发送方使用只有自己知道的密钥。这样只有发送方可以正确解密的消息,这样就可以防止发送方的否认。
但是如果数字签名的生成者说:“我的私钥被别人窃取了”,怎么办?报警吧,哈哈哈
但是数字签名还是无法防止中间人攻击,要防止,必须确认自己得到的公钥是否真的属于自己的通信对象。可以打电话核对公钥的散列值,也可以使用公钥证书。
公钥证书记有姓名、组织、邮箱地址等个人信息,以及属于此人的公钥,并由认证机构(CA)施加数字签名。只要看到公钥证书,我们就知道认证机构认定该公钥的确属于此人。
其中(1)(2)(3)仅在注册新公钥才会进行,并不是每次通信需要,(4)仅在发送方第一次用公钥密码向接受者发送消息才会进行,公钥可以保存在电脑中。
公钥基础设施,为了更有效的运用公钥而制定的一系列规范和规格的总称。
规范包括证书由谁颁发,如何颁发,私钥泄露时应该如何作废证书,计算机之间的数据交换应该采用怎样的格式。
认证机构的工作:
做作废证书,认证机构需要制作一张证书作废清单CRL,PKI用户需要从认证机构获取最新的CRL,并查询自己要用于验证签名的公钥是否作废。

伪随机数生成器的算法是公开的,但是种子是保密的。
仅靠软件无法生成真随机数。
不具备不可预测性,不可用于密码技术。C语言的库函数rand,Java的java.util.Random类采用此方法。
具备不可预测性。
要破解不可预测性,必须破译密码。
如果被攻击者知道了种子,那么就能知道这个伪随机数生成器生成的全部伪随机数列。
要避免种子被攻击者知道,我们需要使用不可重现性的真随机数作为种子。例如Linux系统中的/dev/random文件就是一个根据硬件设备驱动收集的背景噪声存储真随机数的随机数池。
会话密钥:仅限于本次通信,下次通信不能使用。
主密钥:一直被重复使用。
我们需要保证消息的重要性,需要用密钥(CEK)对消息进行加密,但是需要保证CEK的机密性,用另一个密钥(KEK)对CEK进行加密,但是还是需要保证KEK的机密性,陷入了死循环?
防御字典攻击。字典攻击是一种实现进行计算并准备好候选密钥列表的方法。
字典攻击:http://baike.baidu.com/link?url=Zma4cc9nFzhmdM0cmLiHLvGm65dUQRXzfLiK_o5SRPge05lCfh1MQnLGgx937mZuRMycHWJ_njK9zfX3KA-ISK
在这篇文章中,我们会讨论nginx的代理能力。包括nginx的负载均衡,buffer和cache
使用代理的一个理由是它可以扩展你的机器。nginx具有很大的并发处理能力。这使得nginx成为一个理想的接入层(point-of-contact)。接入层可以将请求传递给任意数量的后端机器来处理,这样可以很好的分担负载压力,并且可以很灵活的添加后端机器或者将它们下线进行维修。
使用代理的另一个理由是许多服务器并不像nginx一样具有高性能。将nginx作为这些服务器的上游会具有更好的用户体验并且更加安全。
proxy_pass指令一般出现在location和limit_except中,如果一个请求匹配到了location中的proxy_pass指令,请求就会被转发到给定的URL。
# server context
location /match/here {
proxy_pass http://example.com;
}
. . .
在上面的配置片段中,proxy_pass中没有给出URI。如果URL中不包含URI,nginx服务器不会改变原地址的URI。
举个例子,如果请求是/match/here/please,那么被发送到example.com的URI将是http://example.com/match/here/please
来看另一个例子:
# server context
location /match/here {
proxy_pass http://example.com/new/prefix;
}
. . .在上面的例子中,proxy_pass中给出了URI(/new/prefix),如果在proxy_pass给出了URI,那么请求中匹配到location的部分将会被proxy_pass中的URI替代。
例如:如果请求是/match/here/please,那么请求将被转成http://example.com/new/prefix/please。/match/here将被替换成/new/prefix
有时,上述的情况不会发生。proxy_pass中的URI将会被忽略,此时原始的URI或者被其他指令改变后的URI将会被传递。
例如:如果location使用正则表达式进行匹配,那么nginx不能决定哪部分URI匹配到了正则表达式,所以nginx发生原始的URI。另一个例子时如果在同一个location中还使用到了rewrite,那么将会导致客户端的URI被rewrite,这时被rewrite后的URI将会被传递到下游。
如果你想让后端服务器正确的处理请求,那么仅仅传递URI是不够的。当Nginx代表客户端传递请求和客户端直接传递请求是不一样的。最主要的原因是会有headers伴随着请求。
当nginx代理一个请求时,它会自动做出一些调整:
underscores_in_headers变量标记为on$proxy_host的值,该值是传递给后端机器的IP(或者名字)加上端口号。我们从上面推断的第一点就是如果有我们不想传递的请求头,我们应该将他们置为空字符串。空请求头会被nginx移除。
第二点是为了确保服务器正确的处理带有下划线的非标准请求头,将underscores_in_headers指令的值置为on
在绝大多数代理情况下,"Host"的值都是十分重要的,该值会被改写成$proxy_host
"Host"头部绝大多数情况下都是如下的值:
$proxy_host$http_host:来自客户端请求头部的Host值。尽管该值大多数情况下该值能够工作,但是当客户端请求没有携带Host头部时,那么就无能为力了。$host:该值按照如下顺序进行设置:来自请求行的主机名(暂时没懂,请求行哪来的host name)、来自客户端的Host头部、匹配请求的server name绝大多数情况下会将Host头部的值设置为$host。因为这是最灵活的处理方式并且能够提供给被代理服务器一个尽可能正确的Host头部。
待续。。
用户输入:英特尔® 酷睿™ i7处理器大显身手
$value = iconv("UTF-8","GBK//TRANSLIT",$value);结果:
英特尔(R) 酷睿(TM) i7处理器大显身手
$value = iconv("UTF-8","GBK//IGNORE",$value);结果:
英特尔 酷睿 i7处理器大显身手
$value = iconv("UTF-8","GBK",$value);结果:
英特尔
mb_convert_encoding($value, "GBK","UTF-8");结果:
英特尔? 酷睿? i7处理器大显身手
iconv ( string $in_charset , string $out_charset , string $str )
大端序又叫网络字节序。大端序规定高位字节在存储时放在低地址上,在传输时高位字节放在流的开始;低位字节在存储时放在高地址上,在传输时低位字节放在流的末尾。
小端序规定高位字节在存储时放在高地址上,在传输时高位字节放在流的末尾;低位字节在存储时放在低地址上,在传输时低位字节放在流的开始。
网络字节序是指大端序。TCP/IP都是采用网络字节序的方式,java也是使用大端序方式存储。
主机字节序代表本机的字节序。一般是小端序,但也有一些是大端序。
主机字节序用在协议描述中则是指小端序。
当想要解析一个二进制的字符串或者将想要传递的值编码成二进制。
pack(format,args+)
其中,format的可能值有:
| 值 | 描述 |
|---|---|
| a | 将字符串空白以 NULL 字符填满 |
| A | 将字符串空白以 SPACE 字符 (空格) 填满 |
| h | 16进制字符串,低位在前以半字节为单位 |
| H | 16进制字符串,高位在前以半字节为单位 |
| c | 有符号字符 |
| C | 无符号字符 |
| s | 有符号短整数 (16位,主机字节序) |
| S | 无符号短整数 (16位,主机字节序) |
| n | 无符号短整数 (16位, 大端字节序) |
| v | 无符号短整数 (16位, 小端字节序) |
| i | 有符号整数 (依赖机器大小及字节序) |
| I | 无符号整数 (依赖机器大小及字节序) |
| l | 有符号长整数 (32位,主机字节序) |
| L | 无符号长整数 (32位,主机字节序) |
| N | 无符号长整数 (32位, 大端字节序) |
| V | 无符号长整数 (32位, 小端字节序) |
| f | 单精度浮点数 (依计算机的范围) |
| d | 双精度浮点数 (依计算机的范围) |
对于a,A,h,H,跟随在后面的数字暗示着字符串的长度。比如说,A25意味着一个有25个字符的字符串,字符串空白以 SPACE 字符 (空格) 填满。对于其他格式,跟随在后面的数字表示在字符串中该类型的格式化连续出现的次数。
其中,常用的有a、A、c、C、n、N
当接受到信号时,进程会根据信号的响应动作执行相应的操作,信号的响应动作有以下几种:
考虑如下命令:
kill 2563发送SIGTERM 信号给进程。一旦进程接受到此信号,会有情况之一:
应用程序可以决定当接受到此信号时去做什么。大多数应用程序会是第二种情况,但是也有一些不是。当接受到此信号时,一些应用程序会去做完全不同的事情。如果应用程序在等待I/O处理时接受到此信号,它可能不会对此信号做出任何的反应。
当进程不对SIGTERM信号做出回应时,大多数系统管理员可能会求助一个更加生硬的信号。
kill -9 2563-9会通知kill命令你想发送SIGKILL信号。该信号不能被进程所忽略。事实上,进程不会意识到SIGKILL信号的来临,因为SIGKILL信号直接被init接受,init会终止该进程。进程不会得到任何机会去捕捉SIGKILL信号。
然而,内核在一些情况下并不会杀死进程。如果进程在等待网络或者磁盘I/O,内核并不能停止它们。僵尸进程和普通进程处在uninterruptible sleep的状态下是不能被内核停止的。此时,你需要重启计算机。
该状态不会立即处理接受到的信号,只有当获取等待的资源或者超时(如果在进入slepp状态时指定)进程才会苏醒。这种情况大多发生在设备驱动在等待磁盘或者网络I/O(输入/输出)。
UNIX中,D代表此状态。
另:SIGINT VS SIGTERM
前者与字符ctrl+c关联,后者没有任何控制字符关联。
前者只能结束前台进程,后者则不是。
待续。。
主启动文件,只要登录了Linux系统,bash就会执行/etc/profile文件中的命令。
此文件设置的变量有:
pathmunge () {
case ":${PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
...
# Path manipulation
if [ "$EUID" = "0" ]; then
pathmunge /sbin
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
pathmunge /sbin after
fiMAIL="/var/spool/mail/$USER"if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`id -u`
UID=`id -ru`
fi
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
```shell
* HOSTNAME:依据主机的hostname命令决定此变量内容
```shell
HOSTNAME=`/bin/hostname 2>/dev/null`HISTSIZE=1000注意此行:
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL此处保证了这些环境变量对这个登录shell创建的子进程都有效。
另外,profile文件会逐一访问/etc/profile.d里的文件。它为linux提供了一个集中存放用户登录时要执行的应用专属的启动文件的地方。
for i in /etc/profile.d/*.sh ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null 2>&1
fi
fi
doneprofile.d目录下的文件:
root@localhost www]# ll /etc/profile.d/
total 76
-rw-r--r--. 1 root root 605 Apr 2 2013 bash_completion.sh
-rw-r--r--. 1 root root 1127 Jul 16 2014 colorls.csh
-rw-r--r--. 1 root root 1143 Jul 16 2014 colorls.sh
-rw-r--r--. 1 root root 92 Jun 24 2013 cvs.csh
-rw-r--r--. 1 root root 78 Jun 24 2013 cvs.sh
-rw-r--r--. 1 root root 192 Sep 10 2014 glib2.csh
-rw-r--r--. 1 root root 192 Sep 10 2014 glib2.sh
-rw-r--r--. 1 root root 58 May 4 2015 gnome-ssh-askpass.csh
-rw-r--r--. 1 root root 70 May 4 2015 gnome-ssh-askpass.sh
-rw-r--r--. 1 root root 1745 Apr 10 2015 lang.csh
-rw-r--r--. 1 root root 2706 Apr 10 2015 lang.sh
-rw-r--r--. 1 root root 123 Jun 4 2014 less.csh
-rw-r--r--. 1 root root 121 Jun 4 2014 less.sh
-rw-r--r--. 1 root root 976 Jul 18 2011 qt.csh
-rw-r--r--. 1 root root 912 Jul 18 2011 qt.sh
-rw-r--r--. 1 root root 2142 Mar 4 2015 udisks-bash-completion.sh
-rw-r--r--. 1 root root 105 Mar 31 2015 vim.csh
-rw-r--r--. 1 root root 269 Mar 31 2015 vim.sh
-rw-r--r--. 1 root root 169 May 20 2009 which2.sh
| 组合键 | 约定使用 |
|---|---|
| Ctrl+C | 非常规终端,终止前台进程 |
| Ctrl+D | 输入完成的正常信号 |
| Ctrl+L | 清屏 |
| Ctrl+U | 删除当前行 |
| Ctrl+Z | 挂起前台进程 |
向读取进程发送“信息传递完毕”信号。
[root@localhost ~]# wc
1
2
3
4
//输入Ctrl+D
4 4 8
擦除当前行。比如输入命令错误较多,懒得修改,不如使用Ctrl+U重新输入。或者输入密码时输入错了,但是很难改动,因为密码不会在屏幕上显示,使用Ctrl+U全部擦除。
临时目录,系统会在几天后自动清理。清理时使用tmpwatch,使用方法见 man tmpwatch或者http://www.runoob.com/linux/linux-comm-tmpwatch.html
保存配置文件
一般用户使用的命令位于这两个目录中。
系统必备的核心工具命令如ls、cd、cp等在/bin中。辅助工具如编译器、浏览器等位于/usr/bin中。
核心用户使用的命令文件保存在这两个目录中,包括安装和删除硬件、启动和关闭系统以及进行系统维护的命令。
位于/bin和/etc中的命令和配置文件基本上不变,但是另一些文件通常会变化,包括收发电子邮件、系统日志、新闻组等。这些内容通常变化的文件和目录位于/var中。
[root@localhost dlslpp]# touch file1
[root@localhost dlslpp]# ls
file1
[root@localhost dlslpp]# ls > file2
[root@localhost dlslpp]# ls
file1 file2
[root@localhost dlslpp]# cat file2
file1
file2
为什么file2会显示file1和file2呢?因为这些命令的执行顺序导致的结果。顺序如下:
[root@localhost dlslpp]# vi /etc/group
...
dlslpp:x:500:
nginx:x:492:
mysql:x:27:
test:x:501:
a:x:502:test
...
主要组在/etc/passwd的第四个字段定义。
次要组在/etc/group的第四个字段定义。
不能直接修改/etc/group文件来添加用户到一个组,而要使用usermod命令。
以其他身份来执行一条命令。在/etc/sudoers中设置了可执行sudo指令的用户。
who which host=(whom) command //表示某个用户在哪台主机上以哪个用户的身份执行什么命令
比如我们需要redhat用户可以执行passwd命令,配置如下:
redhat ALL=(root) /usr/sbin/useradd
其余更详细的用法在配置文件中都有例子。
重新读取用户环境相关配置文件,具体的来说就是执行下用户目录下.bash_profile和.bashrc文件,这个我们成为全切换。
su
执行这个命令的时候系统不读取以上两个文件,所以我们一般称它为半切换,这样切换过去之后,redhat用户使用的依旧是此前用户的环境配置信息
hash在开发中经常用到,而现在time33算是最流行的哈希算法。
算法:对字符串的每个字符,迭代的乘以33
原型: hash(i) = hash(i-1)*33 + str[i] ;
在使用时,存在一个问题,对相似的字符串生成的hashcode也类似,有人提出对原始字符串,进行MD5,然后再计算hashcode。
最简单的版本:
uint32_t time33(char const *str, int len)
{
unsigned long hash = 0;
for (int i = 0; i < len; i++) {
hash = hash *33 + (unsigned long) str[i];
}
return hash;
}为什么是33:因为33和17, 31, 63, 127,129等数字可以被移位所替代
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
/* variant with the hash unrolled eight times */
for (; nKeyLength >= 8; nKeyLength -= 8) {
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
}
switch (nKeyLength) {
case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 1: hash = ((hash << 5) + hash) + *arKey++; break;
case 0: break;
EMPTY_SWITCH_DEFAULT_CASE()
}
return hash;
}关于unrolled,鸟哥在博客中这样解释的:
然后, 特别要主意的就是使用的unrolled, 我前几天看过一片文章讲Discuz的缓存机制, 其中就有一条说是Discuz会根据帖子的热度不同采用不同的缓存策略, 根据用户习惯,而只缓存帖子的第一页(因为很少有人会翻帖子).
于此类似的**, PHP鼓励8位一下的字符索引, 他以8为单位使用unrolled来提高效率, 这不得不说也是个很细节的,很细致的地方.
参考资料:
http://www.laruence.com/2009/08/23/1065.html
http://segmentfault.com/a/1190000000718519
http://blog.csdn.net/a600423444/article/details/8850617
ZEND_API int _zend_hash_init(HashTable *ht, uint nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
uint i = 3;
SET_INCONSISTENT(HT_OK);
//判读大小是否超过上限
if (nSize >= 0x80000000) {
/* prevent overflow */
ht->nTableSize = 0x80000000;
} else {
while ((1U << i) < nSize) { //初始化一个空数组或不足8个元素的数组,都会被创建8个长度的HashTable。同样创建100个元素的数组,也会被分配128长度的HashTable
i++;
}
ht->nTableSize = 1 << i;
}
ht->nTableMask = 0; /* 0 means that ht->arBuckets is uninitialized */
ht->pDestructor = pDestructor;
ht->arBuckets = (Bucket**)&uninitialized_bucket;
ht->pListHead = NULL;
ht->pListTail = NULL;
ht->nNumOfElements = 0;
ht->nNextFreeElement = 0;
ht->pInternalPointer = NULL;
ht->persistent = persistent;
ht->nApplyCount = 0;
ht->bApplyProtection = 1;
return SUCCESS;
}ZEND_API int _zend_hash_index_update_or_next_insert(HashTable *ht, ulong h, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC)
{
uint nIndex;
Bucket *p;
#ifdef ZEND_SIGNALS
TSRMLS_FETCH();
#endif
IS_CONSISTENT(ht);
CHECK_INIT(ht);
if (flag & HASH_NEXT_INSERT) {
h = ht->nNextFreeElement;
}
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
//循环遍历
while (p != NULL) {
if ((p->nKeyLength == 0) && (p->h == h)) { //数字索引的nKeyLength=0
if (flag & HASH_NEXT_INSERT || flag & HASH_ADD) {
return FAILURE;
}
ZEND_ASSERT(p->pData != pData);
HANDLE_BLOCK_INTERRUPTIONS();
if (ht->pDestructor) {
ht->pDestructor(p->pData);
}
UPDATE_DATA(ht, p, pData, nDataSize);
HANDLE_UNBLOCK_INTERRUPTIONS();
if (pDest) {
*pDest = p->pData;
}
return SUCCESS;
}
p = p->pNext;
}
p = (Bucket *) pemalloc_rel(sizeof(Bucket), ht->persistent);
p->arKey = NULL;
p->nKeyLength = 0; /* Numeric indices are marked by making the nKeyLength == 0 */
p->h = h;
INIT_DATA(ht, p, pData, nDataSize);
if (pDest) {
*pDest = p->pData;
}
CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex]);
HANDLE_BLOCK_INTERRUPTIONS();
ht->arBuckets[nIndex] = p;
CONNECT_TO_GLOBAL_DLLIST(p, ht);
HANDLE_UNBLOCK_INTERRUPTIONS();
if ((long)h >= (long)ht->nNextFreeElement) {
ht->nNextFreeElement = h < LONG_MAX ? h + 1 : LONG_MAX;
}
ht->nNumOfElements++;
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
return SUCCESS;
}ZEND_API int _zend_hash_add_or_update(HashTable *ht, const char *arKey, uint nKeyLength, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC)
{
ulong h;
uint nIndex;
Bucket *p;
#ifdef ZEND_SIGNALS
TSRMLS_FETCH();
#endif
IS_CONSISTENT(ht);
ZEND_ASSERT(nKeyLength != 0);
CHECK_INIT(ht);
h = zend_inline_hash_func(arKey, nKeyLength); //将字符串型索引进行转换
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
//循环的目的在于找出相同的key值,便于覆盖相同key值的value
while (p != NULL) {
if (p->arKey == arKey ||
((p->h == h) && (p->nKeyLength == nKeyLength) && !memcmp(p->arKey, arKey, nKeyLength))) {
if (flag & HASH_ADD) {
return FAILURE;
}
ZEND_ASSERT(p->pData != pData);
HANDLE_BLOCK_INTERRUPTIONS();
if (ht->pDestructor) {
ht->pDestructor(p->pData);
}
UPDATE_DATA(ht, p, pData, nDataSize);
if (pDest) {
*pDest = p->pData;
}
HANDLE_UNBLOCK_INTERRUPTIONS();
return SUCCESS;
}
p = p->pNext;
}
if (IS_INTERNED(arKey)) {
p = (Bucket *) pemalloc(sizeof(Bucket), ht->persistent);
p->arKey = arKey;
} else {
p = (Bucket *) pemalloc(sizeof(Bucket) + nKeyLength, ht->persistent);
p->arKey = (const char*)(p + 1);
memcpy((char*)p->arKey, arKey, nKeyLength);
}
p->nKeyLength = nKeyLength;
INIT_DATA(ht, p, pData, nDataSize);
p->h = h;
CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex]);
if (pDest) {
*pDest = p->pData;
}
HANDLE_BLOCK_INTERRUPTIONS();
CONNECT_TO_GLOBAL_DLLIST(p, ht);
ht->arBuckets[nIndex] = p;
HANDLE_UNBLOCK_INTERRUPTIONS();
ht->nNumOfElements++;
ZEND_HASH_IF_FULL_DO_RESIZE(ht); /* If the Hash table is full, resize it */
return SUCCESS;
}ZEND_API int zend_hash_find(const HashTable *ht, const char *arKey, uint nKeyLength, void **pData)
{
ulong h;
uint nIndex;
Bucket *p;
IS_CONSISTENT(ht);
h = zend_inline_hash_func(arKey, nKeyLength);
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while (p != NULL) {
if (p->arKey == arKey ||
((p->h == h) && (p->nKeyLength == nKeyLength) && !memcmp(p->arKey, arKey, nKeyLength))) {
*pData = p->pData;
return SUCCESS;
}
p = p->pNext;
}
return FAILURE;
}两行文字基线之间的距离。

基线的位置可以看成x字母下边缘的位置。
不同字体的基线位置会有微小的差别。


一行文本的行高为:上间距 + 文本的高度+下间距,并且上间距是等于下间距的。
我们还可以基本上这样认为:行高是两行文字基线之间的距离,也是两行文字顶线之间的距离,两行文字中线之间的距离。
围绕盒子看不见的区域,大小与font-size相关,高度就是上面图示中的文本高度。我们可以理解成选中文字之后的变色区域。

内容区域只与字号与字体有关,与行高无关!
在宋体字体下,内容区域高度 = 字体大小。在其他字体下,内容区域高度 ≈ 字体大小
内联盒子不会让内容成块显示,而是显示成一行,如果外部包含inline标签的话(span,a,em等),则属于内联盒子。如果只有文字的话,就是"匿名内联盒子"。

每一行就是一个行框盒子,每个行框盒子都是由一个个内联盒子组成的。

由一行一行的行框盒子组成的。

总之:包含盒子包括行框盒子包括内联盒子
取决于用户代理。桌面浏览器(包括火狐浏览器)使用默认值,约为1.2,这取决于元素的 font-family。
line-height: normal;所用的值是无单位数值乘以元素的 font size。计算出来的值与使用数值指定的一样。大多数情况下,使用这种方法设置line-height是首选方法,在继承情况下不会有异常的值。
line-height: 3.5;指定 用于计算 line box 的高度。
line-height: 3em;与元素自身的字体大小有关。计算出的值是给定的百分比值乘以元素计算出的字体大小。
line-height: 34%;IE8+
input框等元素默认行高是normal,可以使用
line-height: inherit ;让元素可控性更强。
em的效果跟%是一样的。
所有可继承元素根据font-size重新计算行高。
<div id="father">
<div id="son">
我的font-size为60px
</div>
</div>#father{
font-size:12px;
line-height:1.5;
width:300px;
}
#son{
font-size:60px;
color:white;
}
此时,#son元素的line-height为60*1.5=75px;
当前元素根据font-size计算行高,将计算出来的值继承给下面的元素。
<div id="father">
<div id="son">
我的font-size为60px
</div>
</div>#father{
font-size:12px;
line-height:150%;
width:300px;
}
#son{
font-size:60px;
color:white;
}
此时#son元素的line-height为12px*150%=18px。因为#son元素的文本框高度是60px,所以#son元素的半行间距约等于(18-60)/2 = -21px;所以#son元素内的两行字重合在一起了。
推荐使用无单位数值给line-height赋值
<div>
<img src="muke/resource/photo/1_0.jpeg">
</div>div{
background-color: #abcdef;
}
img{
width: 300px;
height: 300px;
}
注意到图片下方有很窄的一条空隙,使得图片的高度不能填充父容器的高度。
现在在图片之后加入一些文字的话:
<div>
<img src="muke/resource/photo/1_0.jpeg">
<span>xxxx我是图片之后的文字</span><br>
</div>div{
background-color: #abcdef;
}
img{
width: 300px;
height: 300px;
}
span{
background-color: white;
}
注意到图片底部是与字母x的下边缘(基线)对齐的,所以我们可以联想到,图片为了与之后文字的基线对齐(图片之后没有文字可以想象成有文字),所以图片下面才有了一小段空隙。为什么图片要与文字的基线对齐呢?因为vertical-align的属性默认是baseline。以后有时间再细细研究一下vertical-align这个属性。
img{
width: 300px;
height: 300px;
vertical-align:bottom;
}这样的话图片就与文字的底线对齐,也就消除了空隙。
img{
width: 300px;
height: 300px;
display:block;
}因为vertical-align这个属性只对行内元素有效,所以将图片变为块状元素可以使得vertical-align:baseline失效。
div{
background-color: #abcdef;
line-height:0;
}
这里有个疑问,此时基线按理说应该比图片底端还要向上,为什么图片没有与基线对齐?
<div>
单行文本垂直居中
</div>div{
background-color: #abcdef;
height: 300px;
line-height: 300px;
}
文字居中,即文字内容区域的一半 + 内容区域顶部到父容器上边缘 = 父容器高度的一半。而内容区域顶部到父容器上边缘 = 上间距 = 下间距,所以文字内容区域 + 上间距 + 下间距 = 父容器高度。因为文字内容区域 + 上间距 + 下间距 = line-height,所以当line-height = height时,单行文本居中。也就是文本的中线与父容器的中间线近似重合。
<div id="father">
<div id="son">多行文本垂直居中<br>多行文本垂直居中<br>多行文本垂直居中<br></div>
</div>#father{
line-height:300px;
background-color: #abcdef;
height: 300px;
}
#son{
line-height: normal;
display: inline-block;
vertical-align: middle;
border: 1px red solid;
}
多行文本居中,我们可以将这多行文本看成一个整体,即一行,问题转换为上面的单行文本居中,所以我们让父元素的height = line-height。为了覆盖掉继承过来的line-height,我们在#son元素中使用line-height:normal。看下效果:

貌似偏上了一些,为了让整体文本的中线与父容器的中间线近似重合。我们可以添加vertical-align: middle。让整体放置于父元素的中部,效果就是本节开始的那张图片的效果。
参考资料:http://www.imooc.com/learn/403
http://www.imooc.com/article/7767
https://developer.mozilla.org/zh-CN/docs/Web/CSS/line-height
函数的执行环境
struct _zend_execute_data {
struct _zend_op *opline;
zend_function_state function_state;
zend_op_array *op_array;
zval *object;
HashTable *symbol_table;
struct _zend_execute_data *prev_execute_data;
zval *old_error_reporting;
zend_bool nested;
zval **original_return_value;
zend_class_entry *current_scope;
zend_class_entry *current_called_scope;
zval *current_this;
struct _zend_op *fast_ret; /* used by FAST_CALL/FAST_RET (finally keyword) */
zval *delayed_exception;
call_slot *call_slots;
call_slot *call;
};在解释成中间代码时,静态变量是存放在CG(active_op_array)->static_variables中的。
struct _zend_op_array {
/* Common elements */
zend_uchar type;
const char *function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
/* END of common elements */
zend_uint *refcount;
zend_op *opcodes;
zend_uint last;
zend_compiled_variable *vars;
int last_var;
zend_uint T;
zend_uint nested_calls;
zend_uint used_stack;
zend_brk_cont_element *brk_cont_array;
int last_brk_cont;
zend_try_catch_element *try_catch_array;
int last_try_catch;
zend_bool has_finally_block;
/* static variables support */
HashTable *static_variables;
zend_uint this_var;
const char *filename;
zend_uint line_start;
zend_uint line_end;
const char *doc_comment;
zend_uint doc_comment_len;
zend_uint early_binding; /* the linked list of delayed declarations */
zend_literal *literals;
int last_literal;
void **run_time_cache;
int last_cache_slot;
void *reserved[ZEND_MAX_RESERVED_RESOURCES];
};每次执行时都会从该符号表中查找相应的值,由于op_array在程序执行时始终存在。 所有对静态符号表中数值的修改会继续保留,下次函数执行时继续从该符号表获取信息。 也就是说Zend为每个函数(准确的说是zend_op_array)分配了一个私有的符号表来保存该函数的静态变量。
一种简单的设计方式是在因特网上使用一个DNS服务器,该服务器包含所有的映射。在这种集中式设计中,客户端将所有的查询发往同一台的DNS服务器。但是,这种设计方式的问题如下:
基于以上几点,DNS采用分布式设计方案。
为了处理规模问题,DNS使用了大量的DNS服务器,他们以层次方式组织,并且分布在全世界的范围内。大致来说,有三种类型的DNS服务器:
根,TLD和权威DNS服务器都处在DNS层级结构中,还有另外一种重要的DNS,叫作本地DNS服务器。本地DNS服务器严格来说并不属于DNS服务器的层级结构,但是它对DNS层级结构是很重要的。主机的本地DNS服务器通常邻近本主机。对于机构ISP而言,本地DNS服务器可能就与主机在同一个局域网中,对于居民区ISP来说,本地DNS服务器通常与主机相隔不超过几个路由器。当主机发出DNS请求时,该请求被发往本地DNS服务器,它起着代理的作用,并将该请求转发到DNS服务器层级结构中。
举个如上图的例子,主机cis.poly.edu想要知道主机gais.cs.umass.edu的IP地址,主机先向本地DNS服务器发送查询报文,本地DNS服务器将报文转发到根DNS服务器,根DNS服务器注意到edu前缀并向本地DNS服务器返回负责edu的TLD的IP地址列表。本地DNS服务器再次向这些TLD服务器发送查询报文,该TLD服务器注意到umass.edu前缀,并用权威DNS服务器的IP地址进行响应,我们先假设权威服务器的IP地址是dns.umass.edu。最后,本地DNS服务器直接向权威服务器重发查询报文,并获得目的主机的IP。在此过程中,共发送8份报文:4份查询报文和4份回答报文。
在上面的分析过程中,我们假设TLD服务器知道每台主机的权威DNS服务器的IP地址,但是一般情况下不是这样的。相反,TLD服务器只知道中间的某个DNS服务器,该中间的DNS服务器依次才能知道用于该主机的权威DNS服务器的IP地址。同样是上面的例子,当中间的DNS服务器收到对某主机的请求时,该主机名是以cs.umass.edu结尾的,它向本地DNS服务器返回dns.cs.umass.edu的IP地址(上面的例子是dns.umass.edu),后者是所有以cs.umass.edu结尾的主机的权威DNS服务器。本地DNS服务器再向dns.cs.umass.edu发送查询,获得结果。再这个例子中,共发送10份报文。
上面的例子运用了迭代查询和递归查询。从请求主机到本地DNS是递归,后继3个查询都是迭代查询。理论上讲,任何查询既可以是迭代也可以是递归。下图的查询都是递归查询。
实际中,查询通常是请求主机到本地DNS是递归,其余是迭代。
为了改善性能并减少在因特网上到处传输的DNS报文数量,DNS广泛的使用了缓存技术。在请求链中,当一个DNS服务器收到一个DNS回答,DNS服务器能将回答中的信息缓存在本地存储器。DNS服务器会在一段时间后(通常设置为2天)将丢弃缓存的信息。
实现DNS分布式数据库的所有DNS服务器共同存储着资源记录(Resource Record,RR)。RR提供了主机名到IP地址的映射,每个DNS回答报文包含了一条或者多条资源记录。
资源记录是一个包含了下列字段的4元组:
(Name,Value,Type,TTL)
TTL是该记录的生存时间,决定了资源记录应当从缓存中删除的时间下面给出的例子中我们先忽略TTL字段。Name和Value取决于Type:
如果一台DNS服务器是某特定主机的权威DNS服务器,那么该DNS服务器就会包含一条A型记录。(即使不是DNS服务器,也可能在缓存中有A型记录)。如果DNS服务器不是某个主机名的权威DNS服务器,那么该主机将包含一条NS记录,还将包含一条A记录。例如,edu TLD服务器不是主机gaia.cs.umass.edu的权威DNS服务器,则该服务器将包含一条包括主机cs.umass.edu的域记录,如(umass.edu,dns.umass.edu,NS),还包括一条A记录,如(dns.umass.edu,128.119.40.111,A)。
工具软件dig可以显示整个DNS查询过程。
[root@localhost ~]# dig zhidao.baidu.com
输出如下信息:
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6 <<>> zhidao.baidu.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 189
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;zhidao.baidu.com. IN A
;; ANSWER SECTION:
zhidao.baidu.com. 5 IN CNAME iknow.baidu.com.
iknow.baidu.com. 5 IN CNAME iknow.n.shifen.com.
iknow.n.shifen.com. 5 IN A 123.125.115.90
iknow.n.shifen.com. 5 IN A 123.125.65.91
;; Query time: 28 msec
;; SERVER: 192.168.183.2#53(192.168.183.2)
;; WHEN: Thu Jul 7 01:44:35 2016
;; MSG SIZE rcvd: 115
第一段是查询参数和统计:
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6 <<>> zhidao.baidu.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 189
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 0
第二段是查询内容:
;zhidao.baidu.com. IN A
查询zhidao.baidu.com的A记录。
第三段是DNS服务器的答复:
;; ANSWER SECTION:
zhidao.baidu.com. 5 IN CNAME iknow.baidu.com.
iknow.baidu.com. 5 IN CNAME iknow.n.shifen.com.
iknow.n.shifen.com. 5 IN A 123.125.65.91
iknow.n.shifen.com. 5 IN A 123.125.115.90
第四段是DNS服务器的一些传输信息:
;; Query time: 29 msec
;; SERVER: 192.168.183.2#53(192.168.183.2)
;; WHEN: Thu Jul 7 02:09:40 2016
;; MSG SIZE rcvd: 115
上面结果显示,本机的DNS服务器是192.168.183.2,查询端口是53(DNS服务器的默认端口),以及回应长度是115字节。
如果不想看到这么多内容,可以使用+short参数:
[root@localhost ~]# dig +short zhidao.baidu.com
iknow.baidu.com.
iknow.n.shifen.com.
123.125.115.90
123.125.65.91
+trace参数可以显示DNS的整个分级查询过程:
[root@localhost ~]# dig +trace zhidao.baidu.com
第一段列出根域名.的所有NS记录,即所有根域名服务器。
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6 <<>> +trace zhidao.baidu.com
;; global options: +cmd
. 5 IN NS l.root-servers.net.
. 5 IN NS b.root-servers.net.
. 5 IN NS j.root-servers.net.
. 5 IN NS m.root-servers.net.
. 5 IN NS g.root-servers.net.
. 5 IN NS h.root-servers.net.
. 5 IN NS c.root-servers.net.
. 5 IN NS i.root-servers.net.
. 5 IN NS f.root-servers.net.
. 5 IN NS d.root-servers.net.
. 5 IN NS k.root-servers.net.
. 5 IN NS a.root-servers.net.
. 5 IN NS e.root-servers.net.
;; Received 228 bytes from 192.168.183.2#53(192.168.183.2) in 1544 ms
根据内置的根域名服务器IP地址,DNS服务器向所有这些IP地址发出查询请求,询问zhidao.baidu.com顶级域名服务器com.的NS记录。最先回复的根域名服务器将被缓存,以后只向这台服务器发请求。
com. 172800 IN NS h.gtld-servers.net.
com. 172800 IN NS b.gtld-servers.net.
com. 172800 IN NS f.gtld-servers.net.
com. 172800 IN NS e.gtld-servers.net.
com. 172800 IN NS d.gtld-servers.net.
com. 172800 IN NS a.gtld-servers.net.
com. 172800 IN NS j.gtld-servers.net.
com. 172800 IN NS m.gtld-servers.net.
com. 172800 IN NS i.gtld-servers.net.
com. 172800 IN NS g.gtld-servers.net.
com. 172800 IN NS k.gtld-servers.net.
com. 172800 IN NS c.gtld-servers.net.
com. 172800 IN NS l.gtld-servers.net.
;; Received 494 bytes from 192.112.36.4#53(192.112.36.4) in 3203 ms
上面结果显示.com域名的13条NS记录,同时返回的还有每一条记录对应的IP地址。
然后,DNS服务器向这些顶级域名服务器发出查询请求,询问zhidao.baidu.com的次级域名baidu.com的NS记录。
baidu.com. 172800 IN NS dns.baidu.com.
baidu.com. 172800 IN NS ns2.baidu.com.
baidu.com. 172800 IN NS ns3.baidu.com.
baidu.com. 172800 IN NS ns4.baidu.com.
baidu.com. 172800 IN NS ns7.baidu.com.
;; Received 204 bytes from 192.43.172.30#53(192.43.172.30) in 692 ms
然后,DNS服务器向上面这四台NS服务器查询math.stackexchange.com的主机名。
zhidao.baidu.com. 1200 IN CNAME iknow.baidu.com.
iknow.baidu.com. 1200 IN CNAME iknow.n.shifen.com.
n.shifen.com. 86400 IN NS ns1.n.shifen.com.
n.shifen.com. 86400 IN NS ns3.n.shifen.com.
n.shifen.com. 86400 IN NS ns5.n.shifen.com.
n.shifen.com. 86400 IN NS ns4.n.shifen.com.
n.shifen.com. 86400 IN NS ns2.n.shifen.com.
;; Received 253 bytes from 220.181.38.10#53(220.181.38.10) in 662 ms
dig命令的-x参数用于查询PTR记录(用于从IP地址查询域名)
[root@localhost ~]# dig -x 192.30.252.153
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6 <<>> -x 192.30.252.153
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 44848
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;153.252.30.192.in-addr.arpa. IN PTR
;; ANSWER SECTION:
153.252.30.192.in-addr.arpa. 5 IN PTR pages.github.com.
;; Query time: 619 msec
;; SERVER: 192.168.183.2#53(192.168.183.2)
;; WHEN: Thu Jul 7 05:40:10 2016
;; MSG SIZE rcvd: 75
[root@localhost ~]# host zhidao.baidu.com
zhidao.baidu.com is an alias for iknow.baidu.com.
iknow.baidu.com is an alias for iknow.n.shifen.com.
iknow.n.shifen.com has address 123.125.115.90
iknow.n.shifen.com has address 123.125.65.91
用于互动式地查询域名记录。
[root@localhost ~]# nslookup
> www.baidu.com
Server: 192.168.183.2 //连上的DNS服务器
Address: 192.168.183.2#53
Non-authoritative answer: //没有从权威服务器中寻找答案,即从上连DNS服务器的本地缓存中读取出的值,而非实际去查询到的值
www.baidu.com canonical name = www.a.shifen.com.
Name: www.a.shifen.com
Address: 61.135.169.125
Name: www.a.shifen.com
Address: 61.135.169.121
更详细的使用方法:http://roclinux.cn/?p=2441
DNS有2中报文:查询和回答报文。并且具有相同的格式。
各字段语义如下:
前12个字节是首部区域。
标识符是一个16比特的数字,用于标识该查询,该标识符会被复制到回答报文中,以便让客户机用它来匹配发送的请求和收到的回答。
标志字段中含有若干标志。
4个数量字段:表示首部后面的4类数据区域出现的数量。
问题区域包含着正在进行的查询信息。格式如下:
该区域包括:
回答区域包含了对最初请求的名字的资源记录。格式如下:
参考资料:
《计算机网络-自顶向下方法(原书第4版)》
http://blog.chinaunix.net/uid-24875436-id-3088461.html
http://www.ruanyifeng.com/blog/2016/06/dns.html
http://www.cnblogs.com/xiaoluo501395377/archive/2013/06/03/3116064.html
https://msdn.microsoft.com/zh-cn/library/cc775637(v=ws.10).aspx
http://www.cnblogs.com/cobbliu/archive/2013/04/02/2996333.html
对《代码大全2》第11章《变量名的力量》中的一些重要点做一下记录。
浮动,绝对定位元素,inline-blocks, table-cells, table-captions,和overflow的值不为visible的元素,(除了这个值已经被传到了视口的时候)将创建一个新的块级格式化上下文。
会产生BFC的元素:
BFC特性:
HTML:
<p></p>
<p></p>
<p></p>CSS:
p {
background: red;
width: 200px;
height:200px
}效果:
几个p元素都属于同一个BFC(html元素),所以发生了外边距折叠的现象。为了防止此现象,我们可以使他们不属于同一个BFC。
HTML:
<div id="bfc">
<p></p>
</div>
<p></p>
<p></p>CSS:
#bfc{
overflow:hidden;
}
p {
background: red;
width: 200px;
height:200px
}HTML:
<div class="aside"></div>
<div class="main"></div>CSS:
.aside {
width: 100px;
height: 150px;
float: left;
background: blue;
}
.main {
height: 200px;
background: #f00;
}效果:
In a block formatting context, each box’s left outer edge touches the left edge of the containing block (for right-to-left formatting, right edges touch). This is true even in the presence of floats (although a box’s line boxes may shrink due to the floats), unless the box establishes a new block formatting context (in which case the box itself may become narrower due to the floats).
在BFC中,每一个盒子的左外边距会触碰到包含块的左边框。在有浮动元素的情况下也是如此(即使是盒子的文本内容由于浮动元素而被压缩)。如果不想有如上的效果,盒子需要建立一个新的BFC(此时盒子会因为浮动元素的存在而变窄)。
HTML不变。
.aside {
width: 100px;
height: 150px;
float: left;
background: blue;
}
.main {
height: 200px;
background: #f00;
overflow:hidden;
}
HTML:
<div class="BFC">
<div class="box"></div>
<div class="box"></div>
</div>CSS:
.BFC {
border: 5px solid #f00;
width: 300px;
}
.box {
border: 5px solid blue;
width:100px;
height: 100px;
float: left;
}
根据:计算BFC的高度时,浮动元素也参与计算。我们让父元素建立一个BFC,包含浮动元素的高度。(以前一直不懂,现在明白了)
HTML不变。
CSS:
.BFC {
border: 5px solid #f00;
width: 300px;
overflow:hidden;
}
.box {
border: 5px solid blue;
width:100px;
height: 100px;
float: left;
}
参考资料:http://www.w3cplus.com/css/understanding-bfc-and-margin-collapse.html
https://www.sitepoint.com/understanding-block-formatting-contexts-in-css/
http://www.html-js.com/article/1866
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.