blog's People
Stargazers

Watchers

Forkers
flshersblog's Issues
WebPack Hooks 列表
WebPack 的编译过程(compilation process)提供了很多钩子(hook),可以通过钩子来介入编译过程 。
以下罗列了WebPack内部使用的钩子以及其调用源码地址。(调用方式:hooks.xxx.call)。
Mapbox GL JS主流程解析
Mapbox GL JS作为web端矢量地图渲染开源方案之一,没有太多对手,拥有诸多自建规则(适量瓦片等),mapbox矢量数据配套了一整套各端渲染方案,本文主要解析GL JS。
配置即可生成地图
大家对配置的力量都不陌生,在各种前端领域,通过配置即可实现方案的栗子很多。
但是地图领域几乎可以没有通过配置完全生成地图的方案。
mapbox 通过约定实现了地图的配置化mapbox样式规范。
以下是来自官方的示例:
{
"version": 8,
"name": "Mapbox Streets",
"sprite": "mapbox://sprites/mapbox/streets-v8",
"glyphs": "mapbox://fonts/mapbox/{fontstack}/{range}.pbf",
"sources": {...}, // 资源配置
"layers": [...] // 你要绘制的图层以及数据
}
MapBox中的一些概念
样式管理Syle
由于支持多种加载style的方式,所以需要一个管理器来管理用户配置的样式。
painer绘制管理
改类用于管理绘制,设计webgl绘制相关内容以及流程管理。
资源Source
传统地图实现方式: 讲资源之前,需要知道传统地图实现方式,传统的地图(腾讯百度等) ,都是利用在线图片显示指定区域地图,这叫栅格图。 但这种数据是一种不够先进的方案(无法支持无级缩放、高精地图应用等)。
在MapBox中,它可以支持多种类型资源来展现地图,比如(图片形式来展现地图,video形式展现在地图中,矢量数据来展现地图)。
资源类型有以下几种:vector, raster, raster-dem, geojson, image, video, canvas.
图层Layer
传统地图实现方式中,就是一个dom层 承载图片,就可以完成地图绘制。
在适量地图领域肯定不是这么回事,所以MapBox设计了图层,来承载绘制多种图形方案。
支持图层类型有: background, fill, line, symbol, raster, circle, fill-extrusion, heatmap, hillshade.
业务相关
地图业务: 在看到一张地图的时候 ,我们会看到各种类型建筑物、地面、绿地、水,他们地图数据里面都是有不同含义的。
比如一个道路:我们如何绘制这条道路呢?他很像一条线,联系上面的图层: line,这就可以确定 ,该道路的数据可以分配一个图层类型:line。 那么该道路数据格式是什么呢?我们可以指定为资源: 图片或者资源:vector(矢量),只要这个道路数据以确定好的格式产出,就可以被mapbox支持。
Mapbox绘制方式
在mapbox中,根据你定义layers来绘制,每个layer类型 可以是上面的图层类型中的一种。mapbox会把你的layers依次绘制。详细的绘制策后面在讲述。
layers = [ layer1 , layer2]
------layer 1-----
------layer 2-----
主程序流程
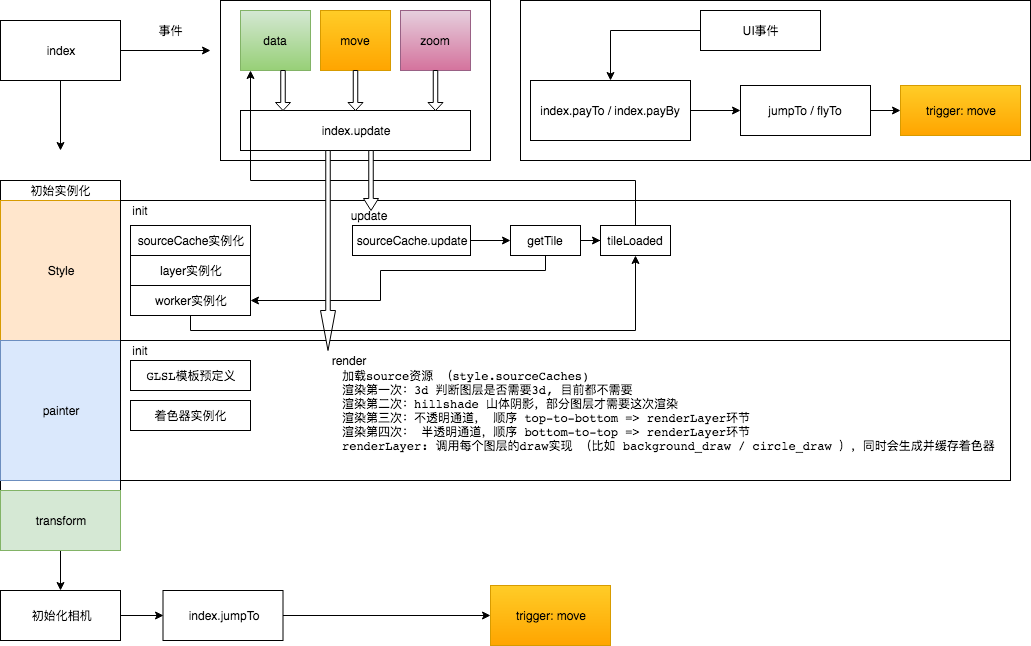
Mapbox Painter类解析
javaScript异常监控
前言:
JavaScript作为当前web前端主力语言,承担着非常重要的责任,用户体验与其息息相关,但作为一个脚本语言,它有着天然的弱点,弱类型带来的类型检查导致无法提前发现异常,特定的用户环境、特定的设备、特定的网路以及特定的用户都可能造成JavaScript的异常。
本文主要讲述如何实现浏览器端javascript异常监控。
为什么要做异常监控
公开的web服务可供任何人访问,用户的环境千差万别,跟开发者的环境可以差距很大,很多开发时没出现的异常就会展露。这时候只能通过用户投诉来被动的接受信息。
在很多时候在开发人员环境无法出现某些JS异常,有些小范围的异常在特定的设备、特定的网络状况、特定的用户场景下才能复现。
在这样的场景下做一个异常收集监控就很有必要,让FE主动知悉线上异常状况,尽快解决。
页面如何捕获异常
window.error
浏览器端提供了用于捕获异常的方式window.onerror
window.onerror = function(msg, url, row, col, error){
report({
msg, // 错误信息
url, // 发生错误对应的脚本链接
row, // 行号
col // 列号
})
}
如上所示,一个简单的上报方案就完成了。但还很不完善,msg提供的信息不够丰富:Uncaught ReferenceError: c is not defined 这样的信息还不足以帮助我们追踪异常。
注: onerror兼容性有问题,ie10 & safari6+ 才完整支持以上全部参数。
error.stack
这时候我们发现error.stack可以追踪异常栈,异常栈有很详细的信息来告知我们的发生异常的顺序以及函数细节:
Uncaught ReferenceError: c is not defined
at f (error.js:23)
at e (error.js:19)
at d (error.js:15)
at error.js:13
到此为止已经可以上报&追踪异常了。
进一步优化
- stack处理,便于后期展示与解析
const _processStackMsg = error => {
let stack = error.stack
.replace(/\n/gi, '') // 去掉换行
.replace(/\bat\b/gi, '@') // chrome中是at,ff中是@
.split('@') // 以@分割信息
.slice(0, 10) // 最大堆栈长度 Error.stackTraceLimit 10
.map(v => v.replace(/^\s*|\s*$/g, '')) //取出多余空格
.join('~') // 手动添加分隔符 便于后期展示
.replace(/\?[^:]+/gi, ''); // 去除js文件多余参数(?x=1之类)
let msg = error.toString();
if (stack.indexOf(msg) < 0) {
stack = msg + '~' + stack;
}
return 'STACK:' + stack;
};
-
无stack兼容方案(部分浏览器无stack): 利用
arguments.callee.caller递归得出调用堆栈。 -
支持自定义上报异常(常常与
try...catch配合):
var typeError = new Error('something error')
// Report opt must be an error object!
window.wmErrorReport && window.wmErrorReport(typeError);
『Script error.』
现代的大中型网站中,静态资源一般都是CDN部署方式,存放在另外的域名下,与使用该资源的网站不属于同域。
当引用的非同域JS文件中产生异常以后,会得到一个『Script error.』异常,无法得到更多信息,这属于浏览器做的一个限制。
解决方法:
CDN资源头设置Access-Control-Allow-Origin: *<script src="https://stb0.waimai.baidu.com/x.js" crossorigin></script>脚本新增crossorigin属性。
Ajax Error
很多时候web请求也会造成服务异常,请求的监控也是有必要的。
在这里我们学习了一些框架中的做法,做简单的HOOK:
XMLHttpRequest.prototype.open = function(){
// do something
}
XMLHttpRequest.prototype.send = function(){
// do something
registerComplete(this)
}
registerComplete = xhr => {
xhr.addEventListener('readystatechange',()=>{
// do something
})
}
通过hookXMLHttpRequest的原型方法以及监听readystatechange方法可以监控资源请求异常状况,进行上报操作。
其他捕获问题
- setTimeout/setInterval
- 业务入口包裹try...catch
- define/require
- fetch
link
webfont 中文字体应用
2016-05 webfont 中文字体应用
web网站字体设定
font-family 可设定值有哪些?
特定字体: 微软雅黑、arial、方正系列等等
通用字体设定:衬线字体、非衬线字体、等宽字体、手写字体、梦幻字体
wmcrm(某平台)的字体设定: font-family: "Helvetica Neue",Helvetica,"PingFang SC","Hiragino Sans GB","Microsoft YaHei","微软雅黑",Arial,sans-serif;
华文细黑(Mac),微软雅黑(Win)是这两个平台的默认中文字体.
css3 font-face
@font-face {
font-family: 'FZZzhongjw';
src: url('../font/fzzzhongjw.eot'); /* IE9*/
src: url('../font/fzzzhongjw.eot?#iefix') format('embedded-opentype'), /* IE6-IE8 */
url('../font/fzzzhongjw.woff') format('woff'), /* chrome firefox */
url('../font/fzzzhongjw.ttf') format('truetype'), /* chrome firefox opera Safari, Android, iOS 4.2+*/
url('../font/fzzzhongjw.svg#fzzzhongjw') format('svg'); /* iOS 4.1- */
}
所需字体格式ttf/svg/eot/woff
TTF
TrueTypeFont, 常见的矢量字体封装格式(SFNT)。
操作系统支持的最常见的格式。mac window
woff
Web Open Font Format, 基于SFNT格式打包压缩版本. MIME: application/x-font-woff
万维网联盟推进的标准。 web最佳webkit浏览器支持,ie9支持,chrome5 ,Safari5.1 支持
eot
Embedded Open Type,还是基于SFNT格式的版本,IE4+开始支持。
svg
可缩放矢量图形(Scalable Vector Graphics)。利用svg可以制作字体。
<glyph glyph-name="uni4E14" unicode="且" d="M11 -13 L11 0 L44 0 L44 192 L211 192 L211 0 L245 0 L245 -13 L11 -13 ZM66 50 L66 0 L190 0 L190 50 L66 50 ZM66 178 L66 129 L190 129 L190 178 L66 178 ZM66 114 L66 65 L190 65 L190 114 L66 114 Z" />
使用中文字体的问题
英文字库只有26个字母,可以组合出很多单词。 体积就小了很多。
中文字体库庞大,很多字体库4M、2M。加载资源耗费宽带资源和增大等待时间,但使用量很少,得不偿失。
微软雅黑 20902个中文字符
中文webfont解决方案
- 字体子集化: 把需要的中文文字单独从字体中提取出来做成一个新的字体文件,由于字库小了很多,所以字体文件自然也就小了
- dynamic subsetting : 根据页面字体返回子集,动态更新。
字体格式转化 fontmin
核心思路 : ttf -> eot / ttf -> woff / ttf -> svg
fontmin 字体压缩,字体转换器。
glyph — Compress ttf by glyph.
ttf2eot — Convert ttf to eot.
ttf2woff — Convert ttf to woff.
ttf2svg — Convert ttf to svg.
css — Generate css from ttf, often used to make iconfont.
svg2ttf — Convert font format svg to ttf.
svgs2ttf — Concat svg files to a ttf, just like css sprite.
otf2ttf — Convert otf to ttf.
link
锤子官网中文字体应用
字蛛 核心依赖 fontmin模块
有字库在线字体
google字体库
360字体库
思源字体-开源
css 字体
计算机字体历史
svg字体
hyperscript 源码解析
hyperscript
hyperscript 是一个帮助构建dom的js类库,可以运行于服务端以及客户端,在virtual-dom中就利用它来生成虚拟DOM。
它的典型用法是h('h1', 'Hello World!') 会返回一个标准dom节点<h1>Hello World!</h1>。
hyprscript 类库并不大,源代码总共160+行。
以下为源码解读:
// 一个跨浏览器的split实现
var split = require('browser-split')
// 跨浏览器的class list实现
var ClassList = require('class-list')
// 如果不是客户端 就使用 shim(一个HTMLElement实现,支持一些方法比如createElement)
var w = typeof window === 'undefined' ? require('html-element') : window
var document = w.document
var Text = w.Text
以上一段是为了支持server端可用使用的基本方法(因为client端方法都有不需要额外引入)。
紧接着就到了核心函数实现 既h('h1', 'Hello World!')实现:
// 用例
// 基本结构生成
h('h1', 'Hello World!')
// 带attribute的dom
h('a', {href: 'https://npm.im/hyperscript'}, 'hyperscript')
// 带事件的dom
h('a', {href: '#',
onclick: function (e) {
alert('you are 1,000,000th visitor!')
e.preventDefault()
}
}, 'click here to win a prize')
// 带style的dom
h('h1.fun', {style: {'font-family': 'Comic Sans MS'}}, 'Happy Birthday!')
// child生成
h('h1', [1,2,3,4].map(k=>{
return h('span',k)
}))
以上为该函数的用例,基本上实现方式就是围绕这个来构建的。
function h() {
// 参数解析
var args = [].slice.call(arguments),
// element 提前声明
e = null
// dom生成核心函数
function item(l){
///
}
// 将每个参数传递给 item来生成dom结构
while (args.length)
item(args.shift())
return e
}
// 接下来看 item实现
function item(l) {
// 结果存储 提前声明
var r ;
// 解析dom string里面的选择器 class or id ,
// 并生成element `e = document.createElement(xx) `
// 或者 在element上增加选择器属性 ` e.setAttribute('id',xx)`
function parseClass(){
// some code
}
// 接下来开始解析参数
// 如果没参数 不作处理
if (l == null)
;
// 如果是字符串 开始解析
else if ('string' === typeof l) {
// 如果element不存在 生成element
if (!e)
parseClass(l)
else
// 如果存在 说明这个是子级文字节点
e.appendChild(r = document.createTextNode(l))
}
// 如果是 数字、布尔、date、正则,都解析为文字节点
else if ('number' === typeof l
|| 'boolean' === typeof l
|| l instanceof Date
|| l instanceof RegExp) {
e.appendChild(r = document.createTextNode(l.toString()))
}
// 如果是数据,则遍历处理
else if (isArray(l))
forEach(l, item)
// 如果是node ,插入节点
else if (isNode(l))
e.appendChild(r = l)
// 如果是文字 ,插入节点
else if (l instanceof Text)
e.appendChild(r = l)
// 如果是对象
else if ('object' === typeof l) {
for (var k in l) {
if ('function' === typeof l[k]) {
// 绑定事件
if (/^on\w+/.test(k)) {
} else {
// 生成时候可执行函数 。后面可用cleanup清除
// observable
e[k] = l[k]()
cleanupFuncs.push(l[k](function (v) {
e[k] = v
}))
}
}
}
// 样式
else if (k === 'style') {
}
// 属性
else if (k === 'attrs') {
}
// data标准属性
else if (k.substr(0, 5) === "data-") {
}
// 最后补偿措施 一些属性直接存储dom上
else {
e[k] = l[k]
}
}
// 最后是function 一般用户批量生成子节点
else if ('function' === typeof l) {
//assume it's an observable!
var v = l()
e.appendChild(r = isNode(v) ? v : document.createTextNode(v))
cleanupFuncs.push(l(function (v) {
if (isNode(v) && r.parentElement)
r.parentElement.replaceChild(v, r), r = v
else
r.textContent = v
}))
}
return r;
}
高性能JavaScript - Others
loop循环
在 JavaScript 提供的四种循环类型中,只有一种循环比其他
循环明显要慢:for-in 循环。
优化循环工作量的第一步是减少对象成员和数组项查找的次数。
每个迭代中倒序循环会比正序循环少2此操作
基于函数的迭代forEach,比基于循环的迭代要慢一些。每个数组项要关联额外的函数 调用是造成速度慢的原因。
条件表达式
条件数量较大,倾向于使用 switch 而不是 if-else
优化条件判断的方式之一 可以使用查表法(可使用数组或者普通对象实现)
字符串连接
str += "one" + "two";慢于str = str + "one" + "two";
响应接口
一个单一的 JavaScript 操作应当使用的总时间(最大)是 100 毫秒, 如果一个js操作在100 毫秒内响应用户输入,用户认为自己是“直接操作用户界面中的对象。”
定时器可用于安排代码推迟执行,它使得你可以将长运行脚本分解成一系列较小的任务。
Web Workers
它允许你在 UI 线程之外运行 JavaScript 代码而避免锁定 UI
请求数据
• XMLHttpRequest (XHR)
• Dynamic script tag insertion 动态脚本标签插入 • iframes
• Comet
• Multipart XHR 多部分的 XHR
MXHR
请求一个url,当 readyState 3 第一次发出时,启动了一个定时器。每隔 15 毫秒检查一次响应报文中的新数据。数据片段被收集起来直到发现一个分隔符,然后一切都作为一个完整的资源处理。
使用此技术有一些缺点,其中最大的缺点是以此方法获得的资源不能被浏览器缓存。
高性能JavaScript - 2 数据访问
数据访问
在 JavaScript 中有四种基本的数据访问位置:
- 直接量
直接量仅仅代表自己,而不存储于特定位置。
JavaScript的直接量包括:字符串,数字,布尔值,对象,数组,函数,正则表达式,具有特殊意义的空值,以及未定义。
- 变量
使用
var/let/const关键字创建用于存储数据值。
- 数组项
具有数字索引,存储一个 JavaScript 数组对象
- 对象成员
具有字符串索引,存储一个 JavaScript 对象。
每一种数据存储位置都具有特定的读写操作负担。大多数情况下,对一个直接量和一个局部变量数据访问的性能差异是微不足道的。访问数组项和对象成员的代价要高一些,具体高多少,很大程度上依赖于浏览器
管理作用域
- 作用域链和标识符解析
每一个函数都是对象,内部有一个属性
[[Scope]]
内部[[Scope]]属性包含一个函数被创建的作用域中对象的集合。此集合被称为函数的作用域链,它决定哪些数据可由函数访问。
- 函数的每次调用都会产生
运行上下文,每次执行完毕会销毁运行上下文。- 当
运行上下文创建以后,作用域链被初始化,连同运行函数的[[Scope]]属性中所包含的对象。这些值按照它们出现在函数中的顺序,被复制到运行期上下文的作用域链中。- 此时
ActivationObject激活对象就创建好了,它包含访问所有局部变量,命名参数,参数集合,和 this的接口。- 在函数运行过程中,每遇到一个变量,标识符识别过程要决定从哪里获得或者存储数据。此过程搜索运行期上下文的作用域链,查找同名的标识符。
- 搜索工作从运行函数的激活目标之作用域链的前端开始。如果找到了,那么就使用这个具有指定标识符的变量;如果没找到,搜索工作将进入作用域链的下一个对象。
- 正是这种搜索过程影响了性能。
在运行期上下文的作用域链中,一个标识符所处的位置越深,它的读写速度就越慢。所以,函数中局部变量的访问速度总是最快的,而全局变量通常是最慢的
一个好的经验法则是:用局部变量存储本地范围之外的变量值,如果它们在函数中的使用多于一次。
局部变量比域外变量快,因为它位于作用域链的第一个对象中。变量在作用域链中的位置越深,访问所需的时间就越长。全局变量总是最慢的,因为它们总是位于作用域链的最后一环。
改变作用域链
- with 表达式为所有对象属性创建一个默认操作变量。
- try-catch 表达式的 catch 子句(当 try 块发生错误时,程序流程自动转入 catch 块,并将异常对象推入作用域链前端的一个可变对象中)
动态作用域
无论是 with 表达式还是 try-catch 表达式的 catch子句,以及包含()的函数,都被认为是动态作用域。一个动态作用域只因代码运行而存在,因此无法通过静态分析(察看代码结构)来确定(否存在动态作用域)
function execute(code) {
(code);
function subroutine(){
return window;
}
var w = subroutine();
//what value is w?
};
execute()函数看上去像一个动态作用域,因为它使用了()。w 变量的值与 code 有关。大多数情况下,w将等价于全局的 window 对象,但是请考虑如下情况:
execute("var window = {};")
// 这种case下 不运行这段代码不会知道具体情况。
一些引擎企图通过通过静态分析代码来确定哪些变量应该在任意时刻被访问,来加快标识符识别过程。但是对动态作用域不生效,会降低识别速度,所以不推荐使用动态作用域
闭包,作用域,和内存
通常,一个函数的激活对象与运行期上下文一同销毁。当涉及闭包时,激活对象就无法销毁了,因为引用仍然存在于闭 包的[[Scope]]属性中。这意味着脚本中的闭包与非闭包函数相比,需要更多内存开销。
原型链
一个属性或方法在原形链中的位置越深,访问它的速度就越慢。
嵌套对象
window.location.href 每遇到一个点号, JavaScript引擎就要在对象成员上执行一次解析过程。
成员嵌套越深,访问速度越慢
将经常使用的对象成员,数组项,和域外变 量存入局部变量中。然后,访问局部变量的速度会快于那些原始变量:var doc = window.document; // use doc
BEM - css命名方法
BEM代表块(Block),元素(Element),修饰符(Modifier)。
目前BEM命名方式已经被很多框架使用,从维护性易用性上来说,BEM很不错。
.block{} // 代表了更高级别的抽象或组件。
.block__element{} // 代表.block的后代,用于形成一个完整的.block的整体。
.block--modifier{} // 代表.block的不同状态或不同版本。
组件开发
从BEM的划分上来说,组件的CSS命名使用时最佳的。不同层级的组件利用该方式可以实现语义更清晰,开发者更容易理解和使用。
问题: 组件划分可能出现多级element(后代)的情况 , 可能的命名就变成了 B+E+E+E+M
解决:BEM不进行嵌套命名,只能出现B+E+M这样的情况,后代问题用B的命名来解决。
.weui-tab // B
.weui-tab__body // B+E
.weui-tab__body--error // B + E + M
// 子级
.weui-tab-body__header // B + E
.weui-tab-body__header--error // B + E + M
并非所有都要运用BEM
并不是所有的命名都要遵循
BEM,clearfix这样的就无需遵循BEM约定。
FIS3 VS WebPack (使用npm来进行前端资源管理与开发)
NPM
NPMNode Package Manager (初期定位是Node.js 包管理工具, 目前已经成为了JS包管理工具)
安装Node.js就会自带npm
npm install -g npm //更新npm
npm init // 初始化一个npm package
npm install jquery --save // 安装jquery,并将模块保存到 package.json 下 dependencies 项(产品依赖)
npm install jquery --save-dev //安装jquery,并将模块保存到 package.json 下devDependencies项(开发依赖)
npm publish
npm start // script 模式
16年之前,大部分前端资源的管理都没有一个公认的规范和约束。
前端类库资源的统一管理方面,有一些方案存在,比如bower/
spm(符合cmd规范的模块管理工具)/npm(Node.js包管理工具)近期比较流行的 react+redux+babel 、 vue + vuex 等前端技术都以webpack为基础来做构建,以npm为基础来做前端资源管理。
当前开发中需考虑的点
- lint语法校验
- DSL编译(less/scss等等)
- 雪碧图
- 文件合并&压缩
- 前端资源文件名MD5并覆写到模板文件中
- 模块化
- dev server功能
- data mock功能
- 模板开发的话需要—前后联调功能
WebPack
一个基础的webpack配置
module.exports = {
//插件项
plugins: [commonsPlugin],
//页面入口文件配置
entry: {
index : './src/js/page/index.js'
},
//入口文件输出配置
output: {
path: 'dist/js/page',
filename: '[name].js'
},
module: {
//加载器配置
loaders: [
{ test: /\.css$/, loader: 'style-loader!css-loader' },
{ test: /\.js$/, loader: 'jsx-loader?harmony' },
{ test: /\.scss$/, loader: 'style!css!sass?sourceMap'},
{ test: /\.(png|jpg)$/, loader: 'url-loader?limit=8192'}
]
},
//其它解决方案配置
resolve: {
root: 'E:/github/flux-example/src', //绝对路径
extensions: ['', '.js', '.json', '.scss'],
alias: {
AppStore : 'js/stores/AppStores.js',
ActionType : 'js/actions/ActionType.js',
AppAction : 'js/actions/AppAction.js'
}
}
};
- 构建工具 && 模块打包工具
- 基于entry配置的编译,单入口文件构建为主,多入口支持不够好
- 所有资源都构建成模块
- hot module replacement
- dev-server
- 公共模块智能提取
- npm资源全支持
- loader众多
- 当下热门开发方案都是用webpack( react vue)
FIS3
- 资源定位、cdn 部署、资源加 md5 戳和 css 雪碧图
- 并非单文件构建,比webpack好,能更好的支持前端多文件开发模式
- match机制自由度更高,自由定制
- 自由定制pack
- deploy方便前后端联调
- map.json 静态资源映射表
- 内置server
- 后端模板结合方案
优缺比较
webpack 所有资源都走js模块(通过js load、 也有输出成文件的方案),但这样局限性也很大。
fis3 会产出静态资源表map.json,通过后端框架来读取管理静态资源
webpack 是通过entry 设定来进行查找(通过入口查找所有用到的资源,进行打包),,做单页应用比较合适。 多页应用就比较复杂。
fis3 是面向前端开发工程的,是面向所有资源的,我们可以设定各种规则来对资源进行各种处理。
公共模块打包:
wbepack 会对多个entry依赖的部分进行抽离,生成一个common。单页模式ok,多页模式下公共部分抽离就会不那么好用。fis3可以自由定制公共依赖部分,管控性更强。 fis3可以实现多页情况下 每个页只加载自己需要的部分。
webpack构建中提供给外部的介入流程不多,loader/plugins 这2个方式来对文件进行各种处理
fis3 构件流程中提供了较多介入机会,lint、parser、preprocessor、standard、postprocessor、optimizer、prepackager、packager、spriter、postpackager
热加载插件:
单页应用会比较需要,webpack支持比较好fis3暂时没有该功能。
NPM 支持
webpack 支持
FIS3 为了支持NPM 提出了 hook_node_modules方案
END
在2个构建工具都支持NPM前端资源管理的情况下,FIS3无疑对工程化支持的更好。
LINK
300 毫秒点击延迟的来龙去脉(转存)
转存自THX
快速响应是所有 UI 实现的重中之重。研究表明,当延迟超过 100 毫秒,用户就能感受到界面的卡顿。 然而,出于对手指触摸滑动的区分,移动端页面对于触摸事件会有 300 毫秒的延迟,导致多数用户感觉移动设备上基于 HTML 的 web 应用界面响应速度慢。 本文主要讨论上述延时的来历,浏览器生产商的考虑,以及我们作为开发者,当前应该如何处理这个问题。
300 毫秒延迟的来历
这要追溯至 2007 年初。苹果公司在发布首款 iPhone 前夕,遇到一个问题 —— 当时的网站都是为大屏幕设备所设计的。于是苹果的工程师们做了一些约定,应对 iPhone 这种小屏幕浏览桌面端站点的问题。
这当中最出名的,当属双击缩放(double tap to zoom)。这也是会有上述 300 毫秒延迟的主要原因。
双击缩放
双击缩放,顾名思义,即用手指在屏幕上快速点击两次,iOS 自带的 Safari 浏览器会将网页缩放至原始比例。
下面以这篇网站响应时间的文章页面为例,刚一打开页面,除了文章本身,我们还看到顶部通栏、菜单等非关键性要素。

iPhone 上展现被缩小的文章页面
我们进入这个页面的目的显然是为了阅读这篇文章。所以当我们双击屏幕时,Safari 会相当智能地缩放至主体文章。

同一张页面在 iPhone 上双击放大后的效果,聚焦在文章主体内容
上述例子表明,iOS Safari 在双击后准确地定位到页面主体文章,并将其缩放至适合比例展现。这也相当符合个人使用习惯。
那么这和 300 毫秒延迟有什么联系呢?
假定这么一个场景。用户在 iOS Safari 里边点击了一个链接。由于用户可以进行双击缩放或者双击滚动的操作,当用户一次点击屏幕之后,浏览器并不能立刻判断用户是确实要打开这个链接,还是想要进行双击操作。因此,iOS Safari 就等待 300 毫秒,以判断用户是否再次点击了屏幕。
于是,300 毫秒延迟就这么诞生了。
后 iPhone 时代的 300 毫秒延迟
鉴于 iPhone 的成功,其他移动浏览器都复制了 iPhone Safari 浏览器的多数约定,包括双击缩放。几乎现在所有的移动端浏览器都有这个功能。 六年前,一个人们还在为通过移动设备上网而惊叹的时期,如此性能损失并无大碍。然而如今,是个移动端开发的 web 应用性能可以同原生应用匹敌的时代,所有的单击事件都有 300 毫秒延迟,必然是不可接受的。此外,随着响应式设计的逐步推进,开发者们已经根据设备本身的尺寸对站点进行了优化,也就逐渐淘汰了诸如双击缩放的约定。
可喜的是,浏览器开发商已经意识到这个问题,并已相继提出了一些解决方案。
注:iOS Safari 还有一个鲜为人知的约定。用户可以在靠近屏幕顶部或底部约 1/4 范围内的区域双击来滚动页面内容。当你在一个放大了的页面内竖向滚动的时候,是否有过不小心将页面横向滚动的经历?双击滚动正是为解决这个问题而生的。尽管后续出现的移动端浏览器复制了双击缩放这一行为,它们并未复制双击滚动的行为。这是我们稍后将会讨论到的很重要的一点。
浏览器开发商提供的解决方案
避免点击延迟,提供一个响应迅速的移动端浏览器,可以说这是浏览器开发商的当务之急(当然,苹果公司除外)。因此,开发商们提供了一些比较有意思的解决方案。
禁用缩放
首先来看一个一目了然的解决方案。既然双击缩放仅对那些可被缩放的页面来说有存在意义,那对于不可缩放的页面,直接去掉点击延迟,何乐而不为呢?这里所说的不可缩放,是指使用了下述 标签的页面。
<meta name="viewport" content="user-scalable=no">
<meta name="viewport" content="initial-scale=1,maximum-scale=1">
Android 平台的 Chrome 浏览器率先做出了这一改变,Android 平台的 Firefox 浏览器随后实践之。其他浏览器开发商对这点优化暂无明确计划。
然而这个解决方案看似完美,但也带来一个明显的缺陷 —— 你必须完全禁用缩放来达到目的,而从移动端站点的可用性和可访问性来看,缩放是相当关键的一环。你很可能已经遇到过这个问题,即你想要放大一张图片或者一段字体较小的文本,却发现无法完成操作。
只能说 Android 平台上的 Chrome 和 Firefox 浏览器提供的禁用缩放优化,仅适用于 web 游戏等某些特定的场景,但多数网站并不能从中获益。
不过,Google Chrome 开发团队最近提出了更好的方式。
width=device-width Meta 标签
除了双击缩放的约定外,iPhone 诞生时就有的另一个约定是,在渲染桌面端站点的时候,使用 980 像素的视口宽度,而非设备本身的宽度(iPhone 是 320 像素宽)。
下面是一个非常简单的页面,展现一张小猫的照片,照片宽为 320 像素。
<!doctype html>
<html>
<head><title>Kitty!</title></head>
<body>
<img src="http://placekitten.com/320/320">
</body>
</html>
由于默认的视口宽度是 980 像素,在 iPhone 上会看到我们的小猫蜷缩在了左上角。

当然,我们可以继续用 标签来进行配置。
<meta name="viewport" content="width=device-width">
这条代码告诉浏览器将视口大小设为设备本身的尺寸。这在 iPhone 上的效果就是把视口宽度从默认的 980 像素改为 320 像素。下面的截图,即为添加这条代码之后的效果,现在这张照片就撑满整个屏幕宽度了。

注:上述默认视口尺寸的约定,也被后续其他浏览器开发商所复制。因此上述现象不止是针对 iPhone 和 iOS Safari 浏览器。
那这一约定又和 300 毫秒点击延迟有什么联系呢?
Chrome 开发团队不久前宣布,在 Chrome 32 这一版中,他们将在包含 width=device-width 或者置为比 viewport 值更小的页面上禁用双击缩放。当然,没有双击缩放就没有 300 毫秒点击延迟。
深入之后,我们会发现这一做法还是相当有道理的。在我们还不知道响应式设计为何物的时代,双击缩放的诞生解决了在移动设备上浏览桌面端站点的问题。既然站点内包含了 width=device-width 这一 标签,也就意味着这个网站采用了响应式设计,因此也就消除了在该站点上可能潜在的双击缩放需求。
这一解决方案的另一个关键之处在于它只是去除了双击缩放,但用户仍可以使用双指缩放 (pinch to zoom)。可见,缩放功能并非被完全禁用,也就不存在可用性和可访问性的问题了。
在我看来,这是一个令人振奋的方案,很好地提升了移动端站点的性能。当然,主要的问题是 width=device-width 这一优化目前仅被 Chrome 32 所支持。
那么其他浏览器是否也会实现这一优化?它所带来的性能提升显而易见,Firefox 很有可能会随后跟上。至于 Internet Explorer,除非其开发团队只看好指针事件 (pointer events,即将在下一节介绍)。这里最举棋不定的还属 iOS。
除了双击缩放,前面还提到 iOS Safari 是唯一一个提供双击滚动的移动端浏览器。如果 iOS 要实现上述优化,那势必要去掉双击滚动。结果如何,还留待时间为我们解答。
以上就是使用 标签配置视口信息来解决 300 毫秒点击延迟的全部内容了,但别急,还有一个值得讨论的方案 —— 指针事件。
指针事件 (Pointer Events)
指针事件最初由微软提出,现已进入 W3C 规范的候选推荐标准阶段 (Candidate Recommendation)。指针事件是一个新的 web 事件系列,相应的规范旨在使用一个单独的事件模型,对所有输入类型,包括鼠标 (mouse)、触摸 (touch)、触控 (stylus) 等,进行统一的处理。
例如,你可以只去监听一个元素的 pointerdown 事件,无需分别监听其 touchstart 和 mousedown 事件。对指针事件的深入解析已经超出了本文的讨论范围,但有一个和点击延迟直接相关的实现 —— 一个名为 touch-action 的新 CSS 属性。
根据规范,touch-action 属性决定 “是否触摸操作会触发用户代理的默认行为。这包括但不限于双指缩放等行为”。
从实际应用的角度来看,touch-action 决定了用户在点击了目标元素之后,是否能够进行双指缩放或者双击缩放。因此,这也相当完美地解决了 300 毫秒点击延迟的问题。
touch-action 的默认值为 auto,将其置为 none 即可移除目标元素的 300 毫秒延迟。例如,下面的代码在 IE10 和 IE11 上移除了所有链接和按钮元素的点击延迟。
a[href], button {
-ms-touch-action: none; /* IE10 /
touch-action: none; / IE11 */
}
你甚至可以在 元素上设置 touch-action: none,这就彻底禁用了双击缩放 (注:这也同时禁用了双指缩放,因此也会带来前面讨论到的可访问性和可用性问题。)
但就目前而言,只有 Internet Explorer 实现了指针事件,不过近期 Chrome 也宣布了将在未来的版本中提供支持。
好消息是,我们现在已经有一些指针事件的 polyfills 可以在项目中使用了。接下来我们将讨论当下可用的 polyfill 以及其他解决 300 毫秒延迟的方案。
当前如何避免延迟
尽管浏览器开发商针对 300 毫秒延迟问题提出了一些解决方案,但目前并没有简单通用的方案。不过,已经有好多开发者考虑过这一问题,并带来了一些基于 JavaScript 的跨平台解决方案。这些方案可以归为两类 —— 针对指针事件的 polyfill 和“快速点击 (fast click)”。
首先来说说指针事件的 polyfill。
指针事件的 polyfill
指针事件的 polyfill 比较多,以下列出比较流行的几个。
Google 的 Polymer
微软的 HandJS
@Rich-Harris 的 Points
为避免 300 毫秒点击延迟,我们主要关心这些 polyfill 是如何在非 IE 浏览器中模拟 CSS touch-action 属性的,这其实是一个不小的挑战。由于浏览器会忽略不被支持的 CSS 属性,唯一能够检测开发者是否声明了 touch-action: none 的方法是使用 JavaScript 去请求并解析所有的样式表。HandJS 也正是这么做的,但不管是从性能上来看还是其他一些复杂的方面,这都会遇到问题。
Polymer 则是通过判断标签上的 touch-action 属性 (attribute),而非 CSS 代码。下面的代码展示了 Polymer 是如何在链接上模拟 CSS touch-action: none 属性的。
Google
这对于我们开发者来说意味着什么?如果你比较感兴趣,想深入指针事件,那上述 polyfill 就非常适合应用到手头的项目中。然而,你若只想寻求一个解决 300 毫秒点击延迟的方法,上述方案可能就有点过了,因为它们要么是资源密集型的方案,要么是 touch-action 属性的非标准化模拟。所以,接下去我们要来看一些专门针对 300 毫秒延迟而生的解决方案。
注:上面这一节内容大多参考自 Points 这个 Polyfill 的README 文件。感兴趣的话不妨深入阅读之。
FastClick
FastClick 是 FT Labs 专门为解决移动端浏览器 300 毫秒点击延迟问题所开发的一个轻量级的库。简而言之,FastClick 在检测到 touchend 事件的时候,会通过 DOM 自定义事件立即触发一个模拟 click 事件,并把浏览器在 300 毫秒之后真正触发的 click 事件阻止掉。
FastClick 的使用方法非常简单,在 window load 事件之后,在 上调用 FastClick.attach() 即可。
window.addEventListener( "load", function() {
FastClick.attach( document.body );
}, false );
attach() 方法虽可在更具体的元素上调用,直接绑定到 上可以确保整个应用都能受益。当 FastClick 检测到当前页面使用了基于 标签或者 touch-action 属性的解决方案时,会静默退出。可以说,这是真正的跨平台方案出来之前一种很好的变通方案。
就目前而言,FastClick 非常实际地解决 300 毫秒点击延迟的问题。唯一的缺点可能也就是该脚本的文件尺寸 (尽管它只有 10kb)。如果你非常在意这点文件大小,可以尝试一下 Filament Group 的 Tappy!,或者 tap.js。两者都相当轻量,能够通过监听 tap 而非 click 事件来绕过 300 毫秒延迟
Kendo UI Mobile
最后一点,如果你是 Kendo UI Mobile 的用户,那你完全不必担心上述问题。一个自定义的点击延迟解决方案已经作为 Touch widget 的一部分打包好了。这个 touch widget 是一个跨平台的 API,帮助处理所有平台的用户点击事件,所有的 Kendo UI Mobile 组件都会默认调用它。
实际上,这也是为什么在 HTML5 Mobile Challenge 中,我们制作的这个名为 cuteness 的应用,很难分辨出它到底是一个 web 应用还是原生应用。如果你是第一次听说,现在就可以在手机上打开 cuteness.io 来体验一下。
小结
尽管苹果公司创造的双击缩放行为,是一种在移动设备上访问桌面端站点的不错的解决方案,但随之引入的 300 毫秒点击延迟也成为了移动端网站让用户感觉卡顿的罪魁祸首之一。
与此同时,浏览器开发商也提出了一些解决方案。对于缩放被禁用的网站,Android 平台上的 Chrome 和 Firefox 浏览器会禁用双击缩放功能;如果站点内配置了内容为 width=device-width 的 标签,Chrome 32 及以上版本的浏览器也会禁用双击缩放功能;Internet Explorer 则对元素引入了全新的 CSS 属性,touch-action,若将其置为 none,也会取消该元素上的点击延迟。
由于这些解决方案较为零碎,社区里也有一些基于 JavaScript 的解决方案,包括一些指针事件的 polyfill,诸如 FastClick 之类专门为这个问题而生的脚本,以及类似 Kendo UI Mobile 等自主方案。
虽然 JavaScript 的方案很好地解决了延迟问题,但毕竟只是临时的措施。浏览器本身所提供的方案,例如 Chrome 的 width=device-width 优化以及 Internet Explorer 的指针事件等,更属长久之计。
未来发展如何,让我们拭目以待。
高性能JavaScript - 1 加载和运行
#1. 加载和运行
浏览器使用单进程处理UI更新和JavaScript运行等多个任务,而同一时间只能有一个任务被执行。这意味着
script的出现会使页面等待其加载执行完成再响应用户。
浏览器在遇到<body>标签之前,不会渲染页面的任何部分
当一个script标签正在下载外部资源时,不会阻塞其他script标签,但仍然阻塞其他资源
有几种方式可以减少js对性能的影响:
script放在页面底部,body闭合标签之前。- 脚本合并,
script数量越少,加载就越快。(HTTP/2对每个服务器只使用一个连接,而不是每个文件一个连接。这样,就省掉了多次建立连接的时间,所以http2下脚本合并并不能提升性能) - 以非阻塞的方式下载js
script添加defer属性,可以并行下载js文件,并在文档加载完成以后执行。
async 属性标注的脚本是异步脚本,即异步下载脚本时,不会阻塞文档解析,但是一旦下载完成后,立即执行,阻塞文档解析。
<script src="xxx" defer type="text/javascript"></script>
- 动态创建
script标签,用它下载并执行代码
var script = document.createElement ("script");
script.type = "text/javascript";
script.src = "file1.js";
document.getElementsByTagName("head")[0].appendChild(script);
- 用
XHR下载文件,并注入到页面中执行
var xhr = new XMLHttpRequest();
xhr.open("get", "file1.js", true);
xhr.onreadystatechange = function(){
if (xhr.readyState == 4){
if (xhr.status >= 200 && xhr.status < 300 || xhr.status == 304){
var script = document.createElement ("script");
script.type = "text/javascript";
script.text = xhr.responseText;
document.body.appendChild(script);
}
}
};
xhr.send(null);
推荐姿势:
// 优先加载一个加载器(body关闭标签之前)
// 使用加载器加载文件
<script type="text/javascript" src="loader.js"></script>
<script type="text/javascript">
loadScript("the-rest.js", function(){
Application.init();
});
</script>
// 或者
加载函数直接inline到页面中,避免一次http请求
The LazyLoad library: LazyLoad.js / LAB.js
Mapbox Style类解析
傅里叶变换
傅里叶--学习
学习知乎 Heinrich的文章 地址
时域分析:
从我们出生,我们看到的世界都以时间贯穿,股票的走势、人的身高、汽车的轨迹都会随着时间发生改变。这种以时间作为参照来观察动态世界的方法我们称其为时域分析
这个静止的世界就叫做频域。
下图是音乐在时域的样子

下图是 音乐在频域的样子

在时域,我们观察到钢琴的琴弦一会上一会下的摆动,就如同一支股票的走势;而在频域,只有那一个永恒的音符。
贯穿时域与频域的方法之一,就是传中说的傅里叶分析。傅里叶分析可分为傅里叶级数(Fourier Serie)和傅里叶变换(Fourier Transformation)
正弦波叠加
来看一个图,各种正弦波叠加

第一幅图是一个郁闷的正弦波cos(x)
第二幅图是2个卖萌的正弦波的叠加cos(x)+a.cos(3x)
第三幅图是4个发春的正弦波的叠加
第四幅图是10个便秘的正弦波的叠加
着正弦波数量逐渐的增长,他们最终会叠加成一个标准的矩形,但是要多少个正弦波叠加起来才能形成一个标准90度角的矩形波呢?不幸的告诉大家,答案是无穷多个。
再看一幅图

最前面黑色的线就是所有正弦波叠加而成的总和,也就是越来越接近矩形波的那个图形。
换个角度看

那么可能你看到的是这样子:
矩形波在频域的样子

再清楚一点

想象一下,世界上每一个看似混乱的表象,实际都是一条时间轴上不规则的曲线,但实际这些曲线都是由这些无穷无尽的正弦波组成。我们看似不规律的事情反而是规律的正弦波在时域上的投影,而正弦波又是一个旋转的圆在直线上的投影。
傅里叶分析究竟是干什么用的?
下面大家尝试一件事:
先在纸上画一个sin(x),不一定标准,意思差不多就行。不是很难吧。
好,接下去画一个sin(3x)+sin(5x)的图形。
别说标准不标准了,曲线什么时候上升什么时候下降你都不一定画的对吧?
好,画不出来不要紧,我把sin(3x)+sin(5x)的曲线给你,但是前提是你不知道这个曲线的方程式,现在需要你把sin(5x)给我从图里拿出去,看看剩下的是什么。这基本是不可能做到的。
但是在频域呢?则简单的很,无非就是几条竖线而已。 所以很多在时域看似不可能做到的数学操作,在频域相反很容易。这就是需要傅里叶变换的地方。尤其是从某条曲线中去除一些特定的频率成分,这在工程上称为滤波,是信号处理最重要的概念之一,只有在频域才能轻松的做到。
相位谱
通过时域到频域的变换,我们得到了一个从侧面看的频谱,但是这个频谱并没有包含时域中全部的信息。因为频谱只代表每一个对应的正弦波的振幅是多少,而没有提到相位。基础的正弦波A.sin(wt+θ)中,振幅,频率,相位缺一不可,不同相位决定了波的位置,所以对于频域分析,仅仅有频谱(振幅谱)是不够的,我们还需要一个相位谱。那么这个相位谱在哪呢?我们看下图,这次为了避免图片太混论,我们用7个波叠加的图。

鉴于正弦波是周期的,我们需要设定一个用来标记正弦波位置的东西。在图中就是那些小红点。小红点是距离频率轴最近的波峰,而这个波峰所处的位置离频率轴有多远呢?为了看的更清楚,我们将红色的点投影到下平面,投影点我们用粉色点来表示。当然,这些粉色的点只标注了波峰距离频率轴的距离,并不是相位.
时间差并不是相位差。如果将全部周期看作2Pi或者360度的话,相位差则是时间差在一个周期中所占的比例。我们将时间差除周期再乘2Pi,就得到了相位差。

在完整的立体图中,我们将投影得到的时间差依次除以所在频率的周期,就得到了最下面的相位谱。所以,频谱是从侧面看,相位谱是从下面看。

傅里叶变换
傅里叶变换,
是将一个时域非周期的连续信号,转换为一个在频域非周期的连续信号。

Performance API
Performance API 是W3C推荐标准。已经被主流浏览器实现。 它可以帮助开发者来监测页面加载性能。
window.performance
{
memory: MemoryInfo,
navigation:PerformanceNavigation,
onresourcetimingbufferfull:null,
onwebkitresourcetimingbufferfull:null,
timing: PerformanceTiming
}
timing
它包含了各种与浏览器性能有关的时间数据,提供浏览器处理网页各个阶段的耗时。
利用timeing API可以获取以下信息:
- DNS查找
domainLookupEnd - domainLookupStart
- 建立链接
connectEnd - domainLookupEnd
- 首字节到达(tcp链接结束到服务端返回首字节)
responseStart - connectEnd
- HTML传输完成
responseEnd - responseStart
- 页面加载耗时
loadEventStart - navigationStart
- 解析DOM树耗时
domComplete - domInteractive
WebPack runtime
webpack注入运行时分析
大体框架
构建好的模块会以数组(modules)形式传递给运行时函数。
运行时函数内部会处理modules
(function(modules){
// 模块加载运行时 代码
// 在此处理modules。
// 返回入口模块的exports
return entryModule.exports //(伪代码)
})(
// 构建好的模块,每一个即一个函数, 跟前端项目中的js模块文件一一对应
[
function(module, exports, __webpack_require__){
// module1 code
},
function(module, exports, __webpack_require__){
// module2 code
}]
)
运行时函数
大体框架
function (modules) {
// JSONP回调函数,每一个加载的外部模块都会调用此函数来注册模块
function webpackJsonpCallback(data) {}
// 模块缓存
var installedModules = {};
// 标记模块是否被加载
var installedChunks = {
1: 0
};
// script path function
// 异步加载模块函数。使用了公共路径来加载外链模块
function jsonpScriptSrc(chunkId) {
return __webpack_require__.p + "" + chunkId + ".main.js"
}
// 加载模块主函数
function __webpack_require__(moduleId) {}
// !!同时存在很多属性用来辅助,具体请看下面分析
__webpack_require__.s
__webpack_require__.p
// 注册jsonp 函数,并且做一些绑定工作
var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
jsonpArray.push = webpackJsonpCallback;
jsonpArray = jsonpArray.slice();
for (var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]);
var parentJsonpFunction = oldJsonpFunction;
// require入口函数, 返回入口函数的exports
// Load entry module and return exports
return __webpack_require__(__webpack_require__.s = 3);
}
具体分析
__webpack_require__函数
此为主要的实现,大量代码均为实现require的能力,具体分析可以看前一篇。
webpackJsonpCallback
每一个异步加载的模块,都会以
webpackJsonp为开头注入源码,以实现回调注册模块能力。
某文件源码:
(window["webpackJsonp"] = window["webpackJsonp"] || [])
.push([[1],{moduleID:function(){}}])
而webpackJsonpCallback就是该回调函数真正执行方法。
jsonpScriptSrc
如果使用了异步加载,则一定会用到该函数,里面存储了异步模块的数据(id:name键值对)。还使用了公共路径:webpack_require.p
function jsonpScriptSrc(chunkId) {
return __webpack_require__.p + "" + ({
chunkId:'filename'
}[chunkId] || chunkId) + ".main.js"
}
- 模块
我们的源码模块,被转换以后,整整齐齐的存放到了运行时函数的参数(数组)中。
// 模块列表
[
function(module, exports, __webpack_require__){
// module1 code
},
function(module, exports, __webpack_require__){
// module2 code
}
]
post css
React组件开发 2015-07
2015-07 分享 React组件开发
前端工程化
WebPack运行时require能力解析
在
Webpack构建好的js文件中,我们可以看到其实现的简版模块加载方式,__webpack_require__是我们很容易猜到功能,约等于import能力,可以加载某模块。
我们的各种模块化加载语法最后都会变成__webpack_require__来加载。
__webpack_require__函数
// The require function
function __webpack_require__(moduleId) {
// 检测是否存在缓存
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 不存在则生成新的模块
var module = installedModules[moduleId] = {
i: moduleId,
l: false, // 是否加载
exports: {}
};
// call的方式加载模块 this转交,参数转交,对应其打包构建好的每个模块的参数结构。
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 表示已加载
module.l = true;
// 返回模块的exports
return module.exports;
}
__webpack_require__各属性
以下是__webpack_require__各属性以及对应能力,会经常出现在加载模块的语法中,可以帮助我们加深对__webpack_require__的理解。
// 入口模块的ID
__webpack_require__.s = the module id of the entry point
//模块缓存对象 {} id:{ exports /id/loaded}
__webpack_require__.c = the module cache
// 所有构建生成的模块 []
__webpack_require__.m = the module functions
// 公共路径,为所有资源指定一个基础路径
__webpack_require__.p = the bundle public path
//
__webpack_require__.i = the identity function used for harmony imports
// 异步模块加载函数,如果没有再缓存模块中 则用jsonscriptsrc 加载
__webpack_require__.e = the chunk ensure function
// 设定getter 辅助函数而已
__webpack_require__.d = the exported property define getter function
// 辅助函数而已 Object.prototype.hasOwnProperty.call
__webpack_require__.o = Object.prototype.hasOwnProperty.call
// 给exports设定attr __esModule
__webpack_require__.r = define compatibility on export
// 用于取值,伪造namespace
__webpack_require__.t = create a fake namespace object
// 用于兼容性取值(esmodule 取default, 非esmodule 直接返回module)
__webpack_require__.n = compatibility get default export
// hash
__webpack_require__.h = the webpack hash
//
__webpack_require__.w = an object containing all installed WebAssembly.Instance export objects keyed by module id
// 异步加载失败处理函数 辅助函数而已
__webpack_require__.oe = the uncaught error handler for the webpack runtime
// 表明脚本需要安全加载 CSP策略
__webpack_require__.nc = the script nonce
以上只是完成了基本的__webpack_require__认识。后续还要结合runtime的其它源码一起解读Webpack。
高性能JavaScript - 3 DOM编程
DOM编程
dom访问和修改
你访问 DOM 越多,代码的执行速度就越慢. 尽可能一次性的修改dom,而不是多次。
innerHTML 与 DOM 方法比较
在所有浏览器中,innerHTML 速度更快一些
节点克隆
element.cloneNode() 比createElement 更有效率,但提高不多
HTML Collections
HTML 集合是用于存放 DOM 节点引用的类数组对象, 它们不是数组,但有length属性。
例如:document.images/document.links/document.forms
当遍历一个集合时,第一个优化是将集合引用存储于局部变量,并在循环之 外缓存 length 属性
元素节点
node.nodeType可以获取节点类型nodeType===1表示元素节点nodeType===3表示文本属性 其他12个属性略过。许多现代浏览器提供了 API 函数只返回元素节点。如果可用最好利用起来,因为它们比你自己在 JavaScript 中写的过滤方法要快:
childrenfirstElementchildElementCountlastElementChildnextElementSiblingpreviousElementSibling
重绘和重排版
当 DOM 改变影响到元素的几何属性(宽和高) 会发生重新排版 reflow
发生重排的情况:
- 添加或删除可见的 DOM 元素
- 元素位置改变
- 元素尺寸改变
- 内容改变
- 最初页面渲染
- 浏览器窗口改变尺寸
以下获取布局信息的操作将会导致重新排版(用以获得最新数据):
• offsetTop, offsetLeft, offsetWidth, offsetHeight
• scrollTop, scrollLeft, scrollWidth, scrollHeight
• clientTop, clientLeft, clientWidth, clientHeight
• getComputedStyle() (currentStyle in IE)(在 IE 中此函数称为 currentStyle)最小化重绘和重排版:
- 样式修改
- 合并多次样式修改,只修改 DOM 一次
- 使用css类名来修改样式
- 批量修改DOM
- 从文档流中摘除该元素(3中摘除方法)
1.隐藏元素,进行修改,然后再显示它。
2.使用一个文档片断将已存 DOM 之外创建一个子树,然后将它拷贝到文档中。
3.将原始元素拷贝到一个脱离文档的节点中,修改副本,然后覆盖原始元素。- 对其应用多重改变
- 将元素带回文档中
缓存布局信息: 尽量减少对布局信 息的查询次数,查询时将它赋给局部变量,并用局部变量参与计算。
动画:
- 使用绝对坐标定位页面动画的元素,使它位于页面布局流之外。
- 启动元素动画。当它扩大时,它临时覆盖部分页面。这是一个重绘过程,但只影响页面的一小部分,避
免重排版并重绘一大块页面。- 当动画结束时,重新定位,从而只一次下移文档其他元素的位置。
事件托管:
事件逐层冒泡总能被父元 素捕获。采用事件托管技术之后,你只需要在一个包装元素上挂接一个句柄,用于处理子元素发生的所有 事件。
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.