

Xplainable makes tabular machine learning transparent, fair, and actionable.
In machine learning, there has long been a trade-off between accuracy and explainability. This drawback has led to the creation of explainable ML libraries such as Shap and Lime which make estimations of model decision processes. These can be incredibly time-expensive and often present steep learning curves making them challenging to implement effectively in production environments.
To solve this problem, we created xplainable. xplainable presents a
suite of novel machine learning algorithms specifically designed to match the
performance of popular black box models like XGBoost and LightGBM while
providing complete transparency, all in real-time.
You can interface with xplainable either through a typical Pythonic API, or using a notebook-embedded GUI in your Jupyter Notebook.
Xplainable has each of the fundamental tabular models used in data science teams. They are fast, accurate, and easy to use.
| Model | Python API | Jupyter GUI |
|---|---|---|
| Regression | ✅ | ✅ |
| Binary Classification | ✅ | ✅ |
| Multi-Class Classification | ✅ | 🔜 |
You can install the core features of xplainable with:
pip install xplainable
to use the xplainable gui in a jupyter notebook, install with:
pip install xplainable[gui]
- Visit our General Documentation to learn how to get the best out of xplainable
- Vist our API Documentation for additional support with using our API
Basic Example
import xplainable as xp
from xplainable.core.models import XClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
# Load data
data = xp.load_dataset('titanic')
X, y = data.drop(columns=['Survived']), data['Survived']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
# Train a model
model = XClassifier()
model.fit(X_train, y_train)
# Explain the model
model.explain()Xplainable helps to streamline development processes by making model tuning and deployment simpler than you can imagine.
We built a comprehensive suite of preprocessing transformers for rapid and reproducible data preprocessing.
| Feature | Python API | Jupyter GUI |
|---|---|---|
| Data Health Checks | ✅ | ✅ |
| Transformers Library | ✅ | ✅ |
| Preprocessing Pipelines | ✅ | ✅ |
| Pipeline Persistance | ✅ | ✅ |
from xplainable.preprocessing.pipeline import XPipeline
from xplainable.preprocessing import transformers as xtf
pipeline = XPipeline()
# Add stages for specific features
pipeline.add_stages([
{"feature": "age", "transformer": xtf.Clip(lower=18, upper=99)},
{"feature": "balance", "transformer": xtf.LogTransform()}
])
# add stages on multiple features
pipeline.add_stages([
{"transformer": xtf.FillMissing({'job': 'mode', 'age': 'mean'})},
{"transformer": xtf.DropCols(columns=['duration', 'campaign'])}
])
# Fit and transform the data
train_transformed = pipeline.fit_transform(train)
# Apply transformations on new data
test_transformed = pipeline.transform(test)pp = xp.Preprocessor()
pp.preprocess(train)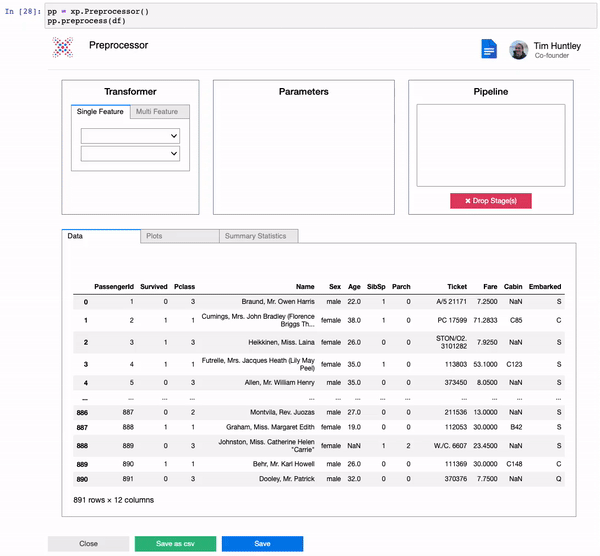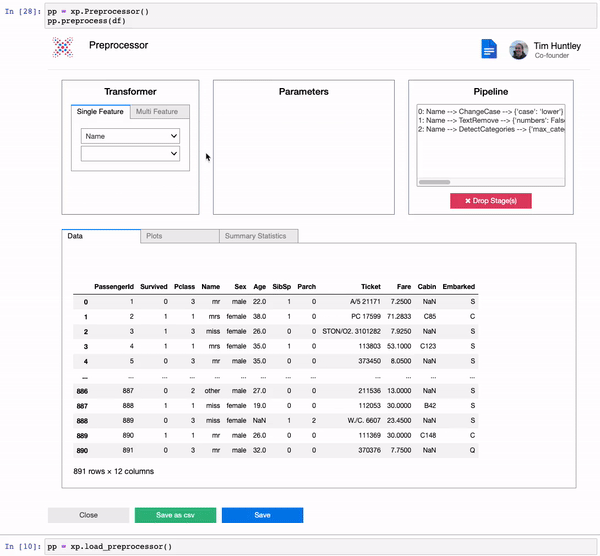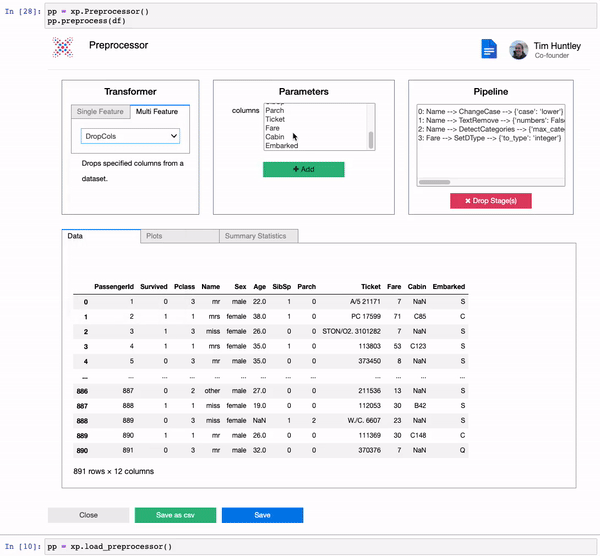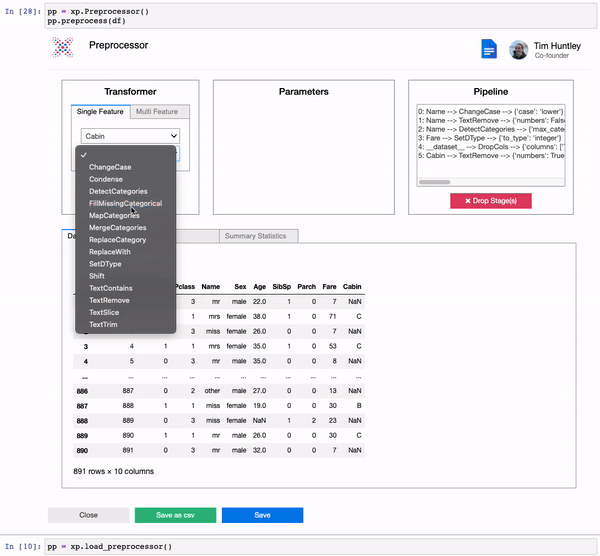
Xplainable models can be developed, optimised, and re-optimised using Pythonic APIs or the embedded GUI.
| Feature | Python API | Jupyter GUI |
|---|---|---|
| Classic Vanilla Data Science APIs | ✅ | - |
| AutoML | ✅ | ✅ |
| Hyperparameter Optimisation | ✅ | ✅ |
| Partitioned Models | ✅ | ✅ |
| Rapid Refitting (novel to xplainable) | ✅ | ✅ |
| Model Persistance | ✅ | ✅ |
import xplainable as xp
from xplainable.core.models import XClassifier
from xplainable.core.optimisation.bayesian import XParamOptimiser
from sklearn.model_selection import train_test_split
import pandas as pd
# Load your data
data = xp.load_dataset('titanic')
# note: the data requires preprocessing, so results may be poor
X, y = data.drop('Survived', axis=1), data['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Optimise params
opt = XParamOptimiser(metric='roc-auc')
params = opt.optimise(X_train, y_train)
# Train your model
model = XClassifier(**params)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Explain the model
model.explain()model = xp.classifier(train)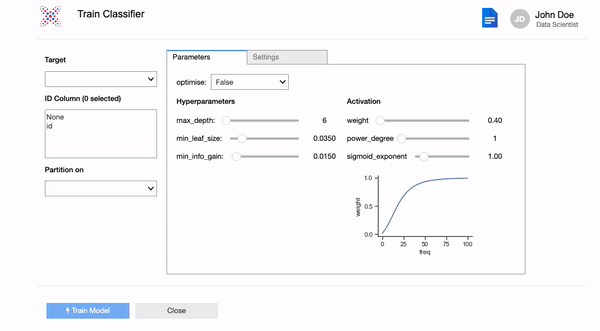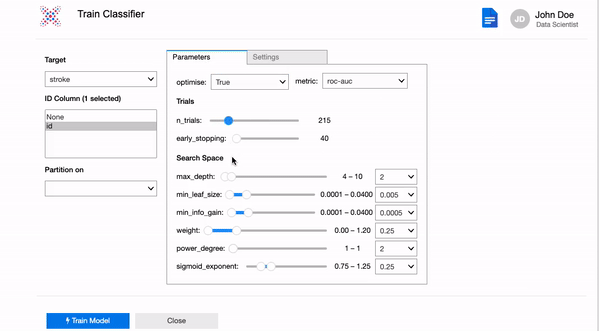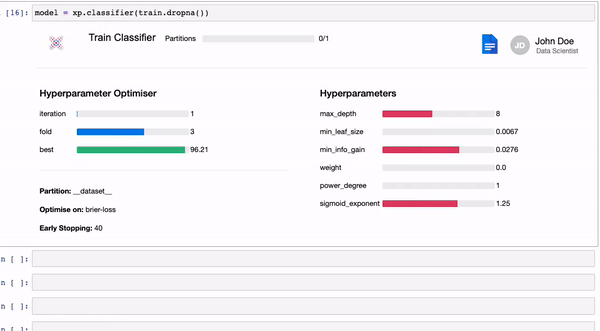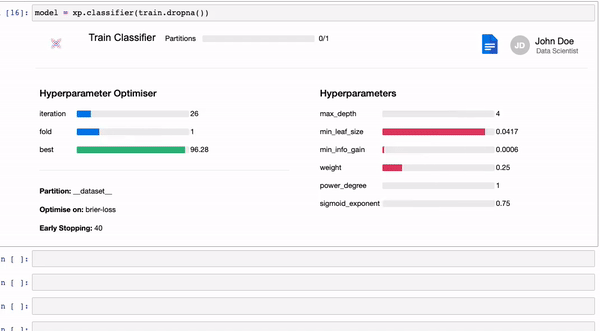
Fine tune your models by refitting model parameters on the fly, even on individual features.
new_params = {
"features": ['Age'],
"max_depth": 6,
"min_info_gain": 0.01,
"min_leaf_size": 0.03,
"weight": 0.05,
"power_degree": 1,
"sigmoid_exponent": 1,
"x": X_train,
"y": y_train
}
model.update_feature_params(**new_params)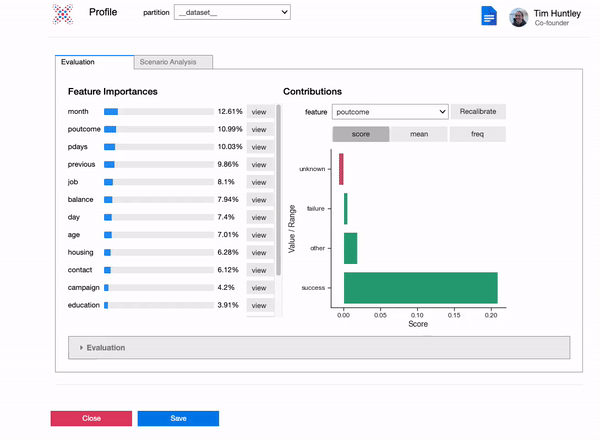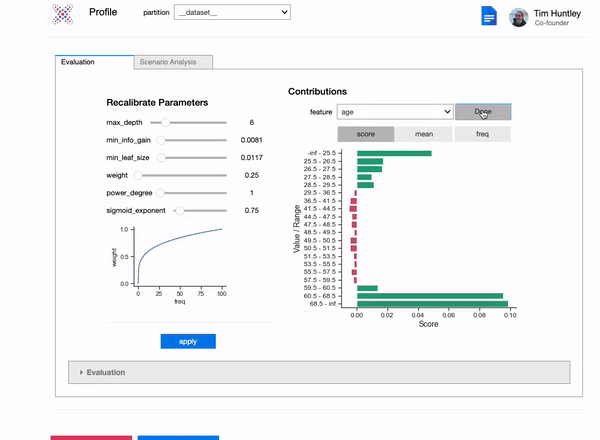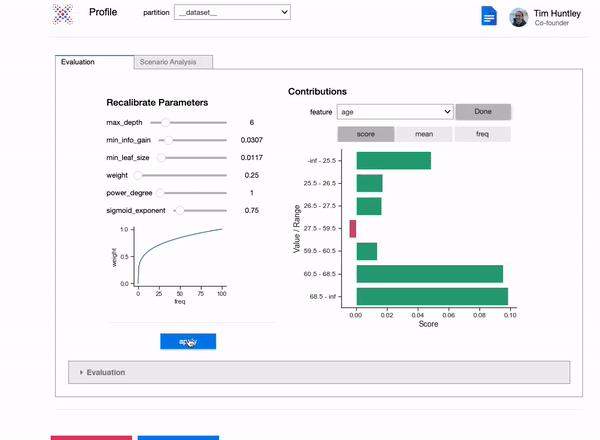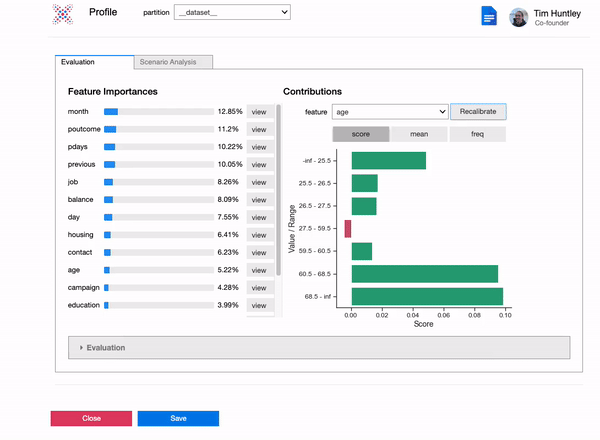
Models are explainable and real-time, right out of the box, without having to fit surrogate models such as Shap orLime.
| Feature | Python API | Jupyter GUI |
|---|---|---|
| Global Explainers | ✅ | ✅ |
| Regional Explainers | ✅ | ✅ |
| Local Explainers | ✅ | ✅ |
| Real-time Explainability | ✅ | ✅ |
model.explain()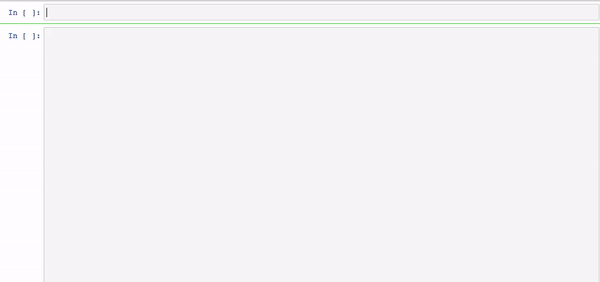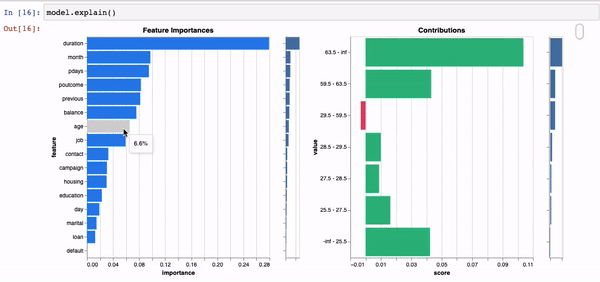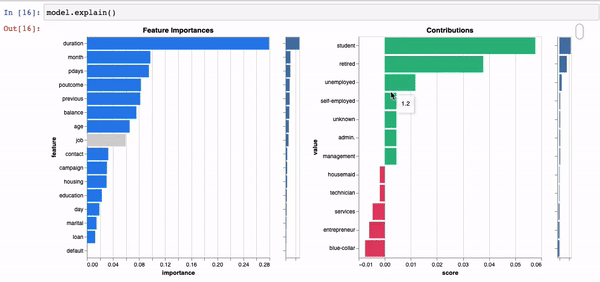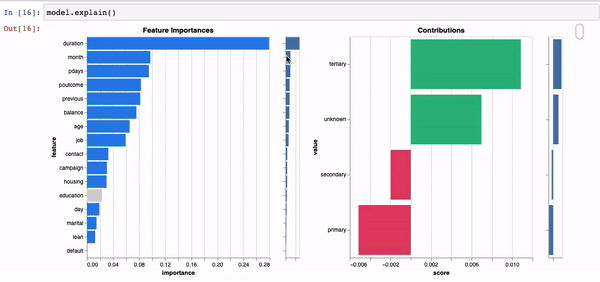
We leverage the explainability of our models to provide real-time recommendations on how to optimise predicted outcomes at a local and global level.
| Feature | |
|---|---|
| Automated Local Prediction Optimisation | ✅ |
| Automated Global Decision Optimisation | 🔜 |
Xplainable brings transparency to API deployments, and it's easy. By the time your finger leaves the mouse, your model is on a secure server and ready to go.
| Feature | Python API | Xplainable Cloud |
|---|---|---|
| < 1 Second API Deployments | ✅ | ✅ |
| Explainability-Enabled API Deployments | ✅ | ✅ |
| A/B Testing | - | 🔜 |
| Champion Challenger Models (MAB) | - | 🔜 |
We promote fair and ethical use of technology for all machine learning tasks. To help encourage this, we're working on additional bias detection and fairness testing classes to ensure that everything you deploy is safe, fair, and compliant.
| Feature | Python API | Xplainable Cloud |
|---|---|---|
| Bias Identification | ✅ | ✅ |
| Automated Bias Detection | 🔜 | 🔜 |
| Fairness Testing | 🔜 | 🔜 |
This Python package is free and open-source. To add more value to data teams within organisations, we also created Xplainable Cloud that brings your models to a collaborative environment.
import xplainable as xp
import os
xp.initialise(api_key=os.environ['XP_API_KEY'])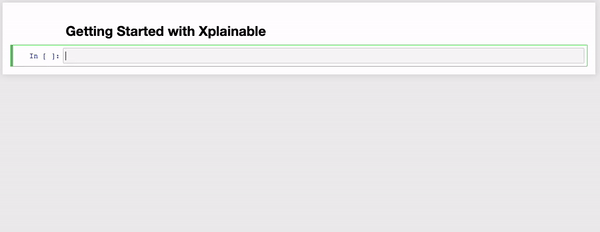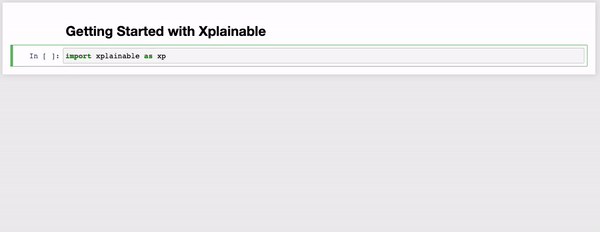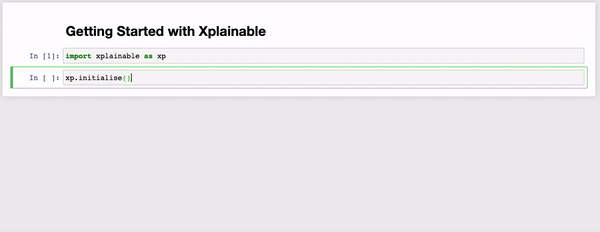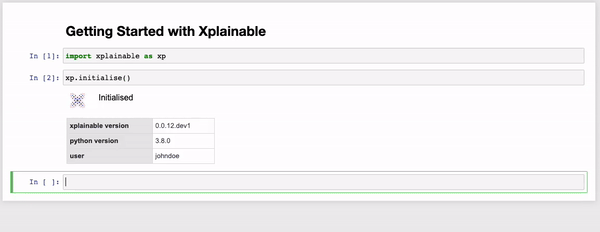
We'd love to welcome contributors to xplainable to keep driving forward more transparent and actionable machine learning. We're working on our contributor docs at the moment, but if you're interested in contributing, please send us a message at [email protected].
Thanks for trying xplainable!
Made with ❤️ in Australia
© copyright xplainable pty ltd
























































