use Ceph as storage backend
本文简述使用ceph/ceph-docker项目docker创建的Docker image来部署Ceph机群的方法。
Ceph是一个统一的、分布式的文件存储系统,可以提供高性能,高可靠性和高可扩展性。“统一”是指Ceph系统可以提供对象存储、块存储和文件系统存储三种功能,“分布式”是指集群没有中心并且有集群规模有很好的可扩展性,节点间可以互相通信,动态实现数据的复制和分发,从而管理海量数据。 与任何经典的分布式文件系统中一样,放入集群中的文件是条带化的,依据一种称为Ceph Controlled Replication Under Scalable Hashing(CRUSH)的伪随机的数据分布算法crush放入集群节点中。
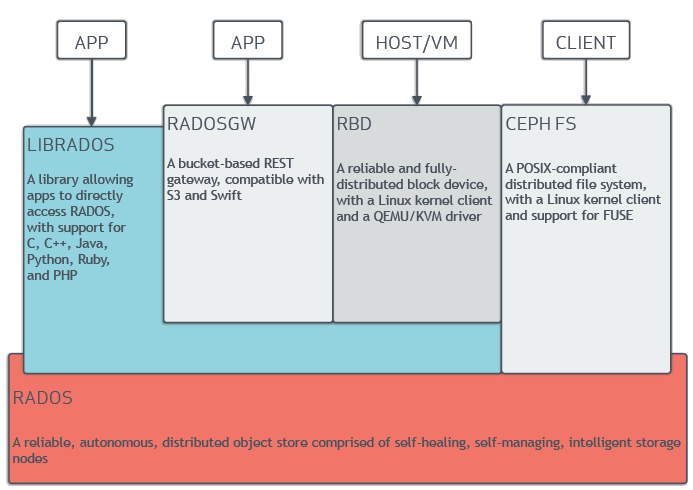
底层是基础存储系统RADOS(Reliable Autonomic Distributed Object Store),基于RADOS,Ceph可以提供理论上没有上限的集群规模可扩展性。 上层与Ceph集群的交互方式有:
- RADOSGW(RADOS Gateway)是一种RESTful接口,应用程序与其通信,将对象存储在集群中。
- RBD(RODOS Block Device)是一个完全分布式的块存储。
- CephFS是一个分布式文件系统。
- LIBRADOS库允许程序直接访问RADOS。

在Ceph存储集群中,Client 是 Ceph 文件系统的用户客户端,Metadata Daemon(MDS)提供了元数据服务器,而Object Storage Daemon(OSD) 提供了实际存储(对数据和元数据两者),Monitor(MON)提供了集群管理。
Ceph Storage Cluster包括两种类型的daemons: OSD daemon将数据作为对象存储到存储节点,MON daemon维护集群映射的master版本。

-
OSDs: OSD daemon存储数据,处理数据复制、恢复、填充、再平衡,通过检查其他Ceph OSD daemons 的heartbeat来提供监测信息给Ceph monitors。当集群做数据拷贝(默认是做数据的三个拷贝,但可调整)时,一个ceph存储集群需要至少两个ceph OSD daemons来获得一个active+clean的状态。
-
Mons: monitor维护集群状态的映射,包括monitor映射,OSD映射,Placement Group(PG)映射和CRUSH映射,Ceph也维护Mons、OSDs 和PGs中每个状态改变的历史(也叫epoch)
-
MDSs: metadata server代表Filesystem存储metadata(注意Ceph block devices和Ceph object storage不用MDS),Ceph metadata servers使得POSIX文件系统用户可以执行基本指令包括ls, find等,而不会给Ceph存储集群造成大的负担。
一个Ceph存储集群需要至少一个Ceph monitor和至少两个Ceph OSD,当运行Ceph filesystem clients时需要MDS。

Ceph将客户端数据作为对象存储在存储池中,通过CRUSH算法,Ceph计算哪个placement group应该保存对象,进一步计算哪个ceph OSD daemon可以保存placement group。CRUSH算法使得Ceph存储集群可以做到规模化、再平衡、动态恢复。
用一个Monitor和两个OSD daemons建立一个ceph storage cluster后,一旦集群达到active+clean状态,通过增加第三个OSD、一个MDS和两个Mon来扩大集群,为了达到最好的结果,在你的admin node创建一个目录来保存配置文件和ceph-depoy为集群生成的keys。
Ceph支持三种存储Ceph filesystem, Ceph object storage和 Ceph block devices,他们从Ceph storage cluster中读写数据。
在此之前先保证Ceph storage cluster在active + clean状态,基于块的存储接口是最常见的用rotating media,如硬盘/CDs/floppy disks,来存储数据的方法。Ceph block devices是厚磁盘,大小可调节,在集群的多OSD中存储条带化数据。 rbd用于操作rados block device(RBD)镜像,被linux rbd driver和rbd storage driver用于QEMU/KVM。
Filesystem是一个POSIX-compliant文件系统,使用Ceph storage cluster来存储数据,它用同样的Ceph storage cluster系统作为Ceph block devices, Ceph object storage,with its S3和Swift APIs或native binding.用Filesystem需要在你的Ceph storage Cluster上至少有一个MDS,MDS代表Filesystem存储metadata。
基于RADOS,Ceph storage cluster是所有Ceph deployments的基础,对于通过众多客户端或网关(RADOSGW、RBD 或 CephFS)执行的每个操作,数据会进入 RADOS 或者可以从中读取数据。Ceph storage cluster包括两种类型的daemons: 一个Ceph OSD 将数据作为对象存储到存储节点,一个Ceph monitor维护集群映射的master版本。一个Ceph storage cluster可能包括数千个Storage nodes,一个最小系统至少有一个Ceph monitor和两个Ceph OSD来实现data replication。
Ceph storage cluster从Ceph clients接收数据,不管这个数据来自Ceph bloak device, Ceph object storage, Ceph filesystem还是你通过librados创造的指令,它都将数据存储为对象,每个对象对应文件系统中的一个文件,被存储在Object storage device中。OSD在存储磁盘中执行读写操作,图1所示

- The Monitor map:包括集群fsid,每个monitor的位置,命名地址和端口号,它指明集群当前的epoch,map的创建时间和最后修改时间,通过执行ceph mon dump命令来查看
- The OSD map:包括集群fsid,map的创建和上次修改时间,pools列表,复制规模,PG数量,OSDs列表和状态。通过执行ceph osd dump命令来查看
- The PG map:包括PG版本,时间戳,上次OSD map的epoch,全比例,每个PG的详细信息,比如PG ID,UP Set,Acting Set,PG状态和每个pool的数据使用统计
- The CRUSH map:包括存储设备,故障域层级,存储数据时遍历层级的规则。
- The MDS map:包含当前MDS map epoch,map创建,最后修改时间,存储元数据的pool,元数据服务器列表及其状态。执行ceph mds dump查看MDS map。

在Clients读写数据前,他们必须与Monitor通信来获取集群映射的最近拷贝。Ceph storage cluster可以只有单个monitor,然而,这样容易出问题。为了增加可靠性和容错性,Ceph支持monitors集群。在monitors集群中,延迟和其他故障会造成一个或多个monitor落后于集群当前的状态。因此,Ceph通常使用大部分monitors和Paxos算法来建立monitors关于当前集群状态的一致性。
所有Ceph storage clusters至少一个monitor,monitor配置文件比较一致,你可以添加,删除或取代集群中的一个monitor。 Ceph Monitors有一个cluster map的“master copy”,Client仅仅通过链接一个Monitor,获取当前的cluster map就可以确定所有Mon,OSD ,MDS的位置。计算目标位置的能力使得Client可以与OSD daemons直接通信,这是Ceph高扩展性和高性能的一个重要方面。 Monitor的主要角色式维护cluster map的master copy,它将monitor services的所有变化写到单个Paxos,Paxos再写到key/value存储。 Monitors可以在同步操作期间查询cluster map的最近版本。
Clients和其他Ceph daemons通过Ceph配置文件发现monitors,monitors通过monitor map(monmap)来发现彼此,而不是配置文件。对Ceph monitor有更新的操作后,Ceph通过一个被称作Paxos的分布式一致性算法来相应修改monmap。
Monitors默认存储数据的路径为 /var/lib/ceph/mon/$cluster-$id,这个路径不建议修改。为了是的Ceph storage cluster有最好的性能,推荐在分开的hosts上运行Monitors,从OSD daemons中驱动。 Ceph0.59之前的版本,将数据存储在文件中,可以通过ls和cat查看,但没有强一致性。以后的版本,Monitors将数据存储为键值对,
假设一个集群中,有33个Ceph Nodes, 每台主机有一个OSD Daemon, 每个OSD Daemon从3TB驱动中读写数据,这样集群最大的实际容量是99TB,如果mon osd full ratio为0.95,当剩余容量到5TB时,集群就不会容许Clients继续读写数据,集群的可操作容量为95TB,而非99TB。
Ceph提供了cephx认证系统来认证用户和daemons,Note, The cephx protocol does not address data encryption in transport (e.g., SSL/TLS) or encryption at rest.Cephx使用共享私钥来认证,这意味着客户端和monitor集群都可以有client的私钥拷贝。 Ceph可扩展性的关键特征是避免集中式接口,clients必须直接与OSDs交互。 用户恳求客户端来与monitor交互,不同于kerberos,每个monitor可以认证用户并分发keys,因此当用cephx时,没有单个节点失败或有瓶颈。monitor返回一个包含session key的认证数据结构给用户,这个session key被用户永久的私钥加密,因此只有这个用户可以从monitor索取service,客户端用session key来向monitor索取想要的service,monitor提供客户端一个ticket,这个ticket授权客户端连接到OSDs(OSDs才是真正处理数据的),monitor和OSDs共享这个secret,client可以利用monitor提供的ticket与任意OSD或metadata服务器相连。类似kerberos,cephx ticket有期限,
Client和Monitor的key文件分别是/etc/ceph/ceph.client.admin.keyring和ceph.mon.keyring.
在某台机器上运行mon后,在/etc/ceph/和/var/lib/ceph生成配置文档,需要把配置文件分布到其他机器。
- 在k8s集群中用etcd写入/etc/ceph/下四个配置文件和/var/lib/ceph/bootstrap-rgw|bootstrap-mds|bootstrap-osd/ceph.keyring三个keyring文件,其他机器安装mon时从etcd中读取。这种方法的缺点是要指定第一台机器,不能全自动安装。
- ceph支持etcd和consul两种KV backends,所有的机器执行相同的脚本,实现全自动化安装。
在你安装和配置完Ceph存储集群后,下一个任务是存储供应,这个过程是以block,file或object存储的形式分配存储空间或容量给物理或虚拟服务器。 linux内核在2.6.34以后集成了CEPH的模块。使用Ceph的块存储有两种路径,一种是利用QEMU走librbd路径,librbd是基于librados的块设备接口实现,通过librbd创建一个块设备,rbd_aio_read()/rdb_aio_write()读写数据到osd;另一种是使用kernel module,走kernel的路径。前者主要为虚拟机提供块存储设备,后者主要为Host提供块设备支持。
librados 就是一个该协议的编码库形式的实现。所有的 Ceph clients 要么使用 librados 要么使用其封装的更高层 API 与对象存储进行交互。比如,librbd 使用 librados 提供 Ceph 客户端与 RBD 交互 API。 一个 Ceph client 通过 librados 存放或者读取数据块到 Ceph 中,需要经过以下步骤:
Client 调用 librados 连接到 Ceph monitor,获取 Cluster map。
当 client 要读或者写数据时,它创建一个与 pool 的 I/O Context。该 pool 关联有 ruleset,它定义了数据在 Ceph 存储集群中是怎么存放的。
client 通过 I/O Context 提供 object name 给 librados,它使用该 object name 和 cluster map 计算出 PG 和 OSD 来定位到数据的位置。
client 直接和 OSD Deamon 交互来读或者写数据。

- 拥有/访问对象
- 副本的个数,ceph osd dump | grep 'replicated size'
- PG的数量
- CRUSH规则表 Ceph客户端从Monitor获取Cluster Map,将对象写入pools池中。副本个数,CRUSH规则表以及PG数量决定Ceph如何存放数据。

三次映射: File是用户要存储的对象,映射为RADOS存储的对象Object。 PG对object的存储进行组织和位置映射,PG和object之间是“一对多”映射关系,一个PG负责组织若干个object。 PG和OSD之间是“多对多”映射关系。RADOS采用CRUSH算法将PG映射得到n个OSD,n可配置,在生产环境下通常为3。一个OSD的PG可达到百个。
- lsb_release -a , uname -r
- modprobe rbd---检查kernel对RBD的支持。
- 安装ceph,ceph-common来使用rbd命令行
client需要Ceph keys来连接Ceph集群,Ceph会创建一个默认的用户client.admin,它可以全连接到Ceph集群,
不推荐将client.admin keys与client节点共享。更好的方法是创建有独立keys的新用户,连接到指定的Ceph pools。
--name client.rbd表示新建的一个用户。
- 拷贝集群中的配置文件ceph.conf到client scp {ceph-mon}:/etc/ceph/ceph.client.admin.keyring {ceph-client}/etc/ceph/
- 修改ceph-client上ceph-conf
- ceph -s #查询ceph状态
rbd实际是kernel module的方法,下面介绍docker rbd和linux rbd两种操作方法
- rbd create rbd1 --size 10240 --name client.rbd;
- rbd ls --name client.rbd;
- rbd --image rbd1 info --name client.rbd;
- sudo docker run --rm -v /etc/ceph:/etc/ceph ceph/rbd ls
- sudo docker run --rm -v /etc/ceph:/etc/ceph ceph/rbd info docker-registry
rbd map --image rbd1 --name client.rbd https://bugs.launchpad.net/ubuntu/+source/ceph/+bug/1578484
作为对象存储,Ceph类似Swift 作为文件存储,类似HDFS,可以替代HDFS,但HDFS是流式存储,即一次写多次读,想使用Ceph文件存储的化,每台host上还要运行MDS。 Ceph对比HDFS优势在于易扩展,无单点。 作为块存储,类似Cinder,作为块设备像硬盘一样直接挂载。
Ceph的结构,对象存储由LIBRADOS和RADOSGW提供,块存储由RBD提供,文件系统由CEPH FS提供,而RADOSGW, RBD, CEPH FS均需要调用LIBRADOS的接口,而最终都是以对象的形式存储于RADOS里。
每一个架构都有其位置,根据应用场景去选择。
- 缺点:不适合低延迟数据访问、无法高效存储大量小文件、不支持多用户写入及任意修改文件
- 优点:适合存储大问题,ChunkSize通常64M,不适合小文件,比如几M的图片。hadoop及HDFS设计的初衷是批处理,大量数据的Map-Reduce。
- 是一个支持大量小文件和随机读写的分布式文件系统。
- ceph官方文档 http://docs.ceph.com/docs/master/
- Ceph: A Scalable, High-Performance Distributed File System http://ceph.com/papers/weil-ceph-osdi06.pdf
- http://www.ibm.com/developerworks/cn/cloud/library/cl-openstackceph/
- rados论文 http://ceph.com/papers/weil-rados-pdsw07.pdf
- CRUCH-Controlled,Scalable,Decentralized Placement of Replicated Data http://ceph.com/papers/weil-crush-sc06.pdf
- rbd-voluem https://github.com/ceph/ceph-docker/tree/master/rbd-volume
- docker https://github.com/ceph/ceph-docker/blob/master/ceph-releases/jewel/ubuntu/14.04/daemon/README.md
Ceph支持object, block和file storage三种存储方式,Client可以通过RESTful,block和POSIX三种接口分别对这三种存储方式访问,参考http://docs.ceph.com/docs/master/architecture/ 架构图。以块存储为例:
- 用block接口访问块存储,这种方式是为Host和虚拟机提供服务(架构图中的HOST/VM),参考。RADOS Block Devices (RBD)通过kernel 模块或librbd库与OSDs交互,由RBD管理RADOS Block Devices(RBD)的镜像。前面comment中的访问方式2应该就属于这种方式,如果在Docker container中运行参考前面comment中的访问方式2。
- 此外,用户可以不限于这三种接口,利用librados建立自己的接口来对集群访问,用户自己写程序(架构图中librados的APP),程序如何写,参考http://docs.ceph.com/docs/master/rados/api/librados-intro/ 即前面comment中的访问方式1。
在上述方式中,Client需要连接Monitor机器获取ceph.client.admin.keyring,从而与Ceph集群建立连接。另外,如果我们是通过etcd的方式建立集群的,Client还可以通过读取etcd来获取ceph.client.admin.keyring,这个我之前没有读取成功,总理说路径不对。
补充:linux内核在2.6.34以后集成了Ceph的模块



