weidian-inc / weidian-tech-blog Goto Github PK
View Code? Open in Web Editor NEW微店技术团队
微店技术团队


































































Success isn’t about how your life looks to others. It’s about how it feels to you.
全栈化技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募投稿,主题不限,向社区发出你的声音吧!
松本行弘:编程语言的设计与实现(推荐者: 刘远洋)
秒杀系统设计与实现(推荐者: 刘远洋)
快速学习正则(推荐者: 刘远洋)
scrcpy: 用于展示 Android 设备(推荐者: 刘远洋)
苹果发布 iPadOS / iOS 13 Beta 7 都有哪些新变化(推荐者: 刘远洋)
Dropbox 一直使用C++编写手机代码,同时支持iOS和安卓,这样只写一次代码就够了。现在它也放弃了,不得不改用 Swift 和 Kotlin 各写一次。主要原因之一是,招不到同时懂前端和 C++ 的程序员。(来自阮一峰的 twitter @ruanyf)
Github 推出了自己的持续集成服务(推荐者: 刘远洋)
自 Java 8 以来的新语言功能(推荐者: 刘远洋)
我发布了自己的 Visual Studio 代码扩展包,这也是你可以做到的(推荐者: 刘远洋)
轻量级货币转换库,money.js 的继承者 Cashify(推荐者: 刘远洋)
从命令行程序实时管道输出到 Web(推荐者: 刘远洋)
一个时间跟踪器,每 10 分钟询问一下你正在做什么(推荐者: 刘远洋)
一款能将 Markdown 文档转成高大上 PPT 的开源工具,支持图表、流程图、数学符号、自定义主题配色以及样式等等(推荐者: 刘远洋)
Canvas API 中文文档首页地图 @张鑫旭(推荐者: 刘远洋)
陆奇最新演讲:没有学习能力,看再多世界也没用(推荐者: 张燕玲)
白鸦内部培训:企业服务类产品的底层逻辑,和“有赞产品设计原则”(推荐者: 车明君)
如何写好函数(推荐者: 罗炜)
Vue 项目性能优化 — 实践指南(网上最全 / 详细)(推荐者: 刘远洋)
原文链接: luoway/blog#11
这要从结果上来评价一个函数的好坏。先考虑写完一个函数,它有哪些结果?
可执行
这是最基本的,函数不能运行那就没有意义。
保障函数可执行,要从两个方面考虑:函数本身逻辑、函数执行环境。函数本身逻辑可执行不用多说,函数执行环境是容易遗漏并出错的:函数如果接收参数,那么就要考虑参数的数据类型是否符合运行要求;函数如果调用外部变量、函数,就要考虑外部变量是否存在且符合要求,外部函数是否能正常工作。对这些情况的处理能力称为健壮性。
换个角度考虑,如果写的这个函数在程序中没有被调用过,那它就是应当删除的冗余代码,应当减少。如果这个函数被调用一次以上,它就是有价值的代码。如果被多次调用,那它就具备复用性,价值进一步提升。
完成功能
这是第二个基本,函数没有完成它该有的功能,那它的意义也是值得怀疑的。
进一步考虑,如果函数没有完成被期望的功能,却干了别的出人意料的事,那它简直是老鼠屎,扰乱了程序的执行逻辑。
提炼一下:“被期望的功能”意味着函数是有姓名的,在函数名中应当体现出来,这就是语义。函数不应当做出“别的出人意料的事”,这就是副作用,应当避免。
可阅读
衡量可阅读程度的名词,一般称为可读性。可读性是现代程序语言发展的根本,从二进制,到汇编等低级语言,到今天百家争鸣的高级语言,可读性一路攀升。按理说,高级语言的可读性已经远高于低级语言了,为什么编程时还要注意可读性?
试想一下反面例子:Web前端如何保护代码资产?
就目前客户端浏览器“三大件”HTML、CSS、JavaScript而言,保护代码资产是不可能实现的。所有的解决方案归纳为“降低可读性”,让人难以阅读,就一定程度上做到了保护代码资产,不让人理解进而进行修改和维护。
相反地,提高可读性,就是为了方便自己或他人理解以及进行修改和维护。
由此,一个好的函数,它应当是
本文以JavaScript为例,从健壮性、复用性、语义、副作用、可读性五个方面举例说明。
坏的例子
function numberPlusOne(val){
return val + 1
}期望是对输入数字,返回数字加1后的结果。但如果输入的不是数字,而是数字字符串,或者是非数字的其他内容呢?
好的例子
function numberPlusOne(val){
if(typeof val === 'string') {
val = parseFloat(val)
}
if(typeof val === 'number'){
if(!isNaN(val)) return val + 1
}
return NaN
}如果有大数相加需要,还得进一步考虑JavaScript计算精度问题。
坏的例子
function formatProductPrice(productInfo){
if(!productInfo) return productInfo
if(productInfo.price){
if(typeof productInfo.price === 'string') {
productInfo.price = parseFloat(productInfo.price)
}
productInfo.price = isNaN(productInfo.price) ? '0.00' : productInfo.price.toFixed(2)
}
//复制粘贴得到下一段,并替换price为originalPrice
if(productInfo.originalPrice){
if(typeof productInfo.originalPrice === 'string') {
productInfo.originalPrice = parseFloat(productInfo.originalPrice)
}
productInfo.originalPrice = isNaN(productInfo.originalPrice) ? '0.00' : productInfo.originalPrice.toFixed(2)
}
return productInfo
}期望是格式化产品的两个价格字段price、originalPrice,两个字段处理方式一致。
好的例子
function formatProductPrice(productInfo){
if(!productInfo) return productInfo
formatPrice(productInfo, 'price')
formatPrice(productInfo, 'originalPrice')
return productInfo
}
function formatPrice(obj, key){
if(!obj[key]) return
let val = obj[key]
if(typeof val === 'string') val = parseFloat(val)
obj[key] = val.toFixed && val.toFixed(2) || '0.00'
}复用性的基本内容就是避免重复代码。但在编程过程中,它应当是值得考虑的优化方案,而不是奉为圭臬的必须方案。提前考虑复用,结果由于各种原因没有被复用到,实际是没有提高复用性,反而可能降低开发效率。
坏的例子
function add(a, b){
return a + b
}期望是计算两数相加(add)的结果,即求和(sum)。
好的例子
function sum(a, b){
return a + b
}那么add应当如何满足其语义呢?
Number.prototype.add = function(val){
return this + val
}
let a = 1, b = 2
a.add(b) //3add语义是“增加”,sum语义是“合计”,意义是不同的。编程所需的语义,是建立在能够正确理解语言意义基础上的。所以说,程序员是需要学好英语的。
上例说明的是函数名的语义不恰当问题,编程中常见的问题是给常量、变量、字段命名,有时候还会纠结多个相似的值,如何区分命名。
//对象合并
const obj1 = { a: 1 }
const obj2 = { b: 2 }
function extendWithSideEffect(obj1, obj2){
Object.assign(obj1, obj2)
return obj1
}
function extend(obj1, obj2){
return Object.assign({}, obj1, obj2)
}期望是“对象合并”,两个函数都实现了对象合并,并返回合并后的对象。extendWithSideEffect的副作用是会改变输入参数obj1对象内容,在当前期望中是副作用,应当避免。
坏的例子
function oneDayOfWorker(){
init() //非常想吐槽的函数名init
}
function init(){
leaveHome()
}
//假设以下行为均是异步的
function leaveHome(){
doSomeThing(work)
}
function work(){
doSomeThing(goHome)
}
function goHome(){
doSomeThing(sleep)
}好的例子
function oneDayOfProgramer(){
leaveHome(()=>{
work(()=>{
goHome(sleep)
})
})
}
function leaveHome(callback){
doSomeThing(callback)
}
function work(callback){
doSomeThing(callback)
}
function goHome(callback){
doSomeThing(callback)
}更好的例子
async function oneDayOfProgramer(){
await leaveHome()
await work()
await goHome()
sleep()
}
function transformPromise(fn){
return new Promise(resolve=>{
fn(resolve)
})
}
function leaveHome(){
return transformPromise(doSomeThing)
}
function work(){
return transformPromise(doSomeThing)
}
function goHome(){
return transformPromise(doSomeThing)
}这个例子主要说明的可读性问题是,避免“链式”编写函数,而应当以“总-分”的结构去组织函数。
设主函数为main,A、B、C、D是需要有序调用的子函数定义,a、b、c、d是子函数调用。
“链式”编写函数:
main[a], A[b]→B[c]→C[d]→D
描述为主函数中只调用开始的子函数,在子函数定义中去调用其他子函数,形成“链表”结构。代码读者需要逐个子函数地查看以理解主函数main的功能逻辑。
“总-分”结构组织的函数:
main[a→b→c→d], A, B, C, D
描述为主函数中描述了子函数调用顺序,子函数定义各自实现功能。代码读者可以根据主函数main,结合子函数名的语义理解功能逻辑。
上面的问题是一种影响可读性的典型问题。可读性需要注意的问题不止一种,还有些问题可能存在争议需要统一意见,因此有着“代码风格”之说,不同风格有差异也有共同之处,多做了解和比较,整理出自己心目中的最佳实践吧!
“如何写好函数”是一个偏主观的话题,在编程实践中程序员们积累了大量客观的评价指标,其中有些指标可能是相互制约的,例如复用性、可扩展性、可读性,三者就不容易共同提高。所以这类问题鲜少有“最佳实践”的讨论。
但是,写好函数的重要性是不言而喻的。“编程一时爽,重构火葬场”,坏的函数要么影响程序员上班的心情,要么提前下次重构的计划到来,两者都不是什么好事。何以解忧?唯有换行。嗯,换行是有条提升可读性的代码风格规范。
反观自身,如何评价自己的代码好不好?笔者的建议是,阅读当前编程语言最流行的一些框架、库的源码,阅读过程中去思考如果自己来写,能不能写得更好。本文正是读源码过程中有感而发。

祝大家中秋快乐!
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
命令行输错命令是件比较常见的事情,安利一个工具,它叫 fuck[允悲],没错,fuck,输错以后,立即键入 fuck,它会帮你自动纠正。
GitHub Actions 是 GitHub 的持续集成服务。这些天,我一直在试用,觉得非常强大,有创意,比 Travis CI 玩法更多。
23世纪世界的主流趋势仍然是和平及商业,人类-安立柯帝国-翡翠文明三方的恒星际贸易联系维持着经济的繁荣,而这种繁荣已经持续了超过一个甲子。 安立柯帝国对地球特产葡萄酒、巧克力和机器人的庞大需求拉动着人类世界六国集团的经济,而六国集团内部的市场需求和太阳系殖**义也拉动着地球剩余国家的自然资源和人力资源的出口。这就是所谓的第一拉动和第二拉动,维持着人类文明的繁荣。
但是,表面的和平与繁荣掩盖不了隐藏的矛盾和冲突。六国集团内各国对殖民地的争夺愈发激烈;被锁死在地球的南方国家对六国集团垄断太阳系殖民和星际贸易日益不满;而在殖民地的新世界,殖民者与匪帮之间围绕据点不断上演旷日持久的拉锯战。发生在全太阳系范围的局部冲突或小型战争层出不穷,而谁也不知道这些矛盾、冲突和零星战火会将23世纪的世界带往何处。
【人类文明】**、美联、欧罗巴、英国、斯拉夫和以色列此六国在人类政治经济生态链中居于高级地位,他们毫无疑问地、强有力地控制着太阳系的每一寸空间,没有此六国的应许,其余国家的企业或公民无法在太阳系随意开展业务和迁移,更遑论通过星门前往安立柯星系。太阳系殖民浪潮的确波澜壮阔,但与六国集团之外的人们无关。
在第一次接触后引发的科技浪潮推动下,**率先于21世纪中后期启动了对月球和火星的殖民计划,在22世纪上半页完成了工业基地月球化,并与美欧英斯以一同执行了致力于将火星地球化的“盖亚计划”,而在整个22世纪**企业在太阳系中兴建了大量空间站和太空城市,这些持续一个世纪以上的投资、开拓和基础设施建设都支撑着**人在23世纪成为数量最多的人类地外殖民者。查看**完整词条
在21世纪中叶的北极战争后,美联吸取了美国的教训:**阶层纵容利益集团绑架政府实行帝国主义政策从而导致战线过长和树敌众多,最终导致内部矛盾被海外战争激化而招致社会撕裂和内战。从而,美联的国策在此后一百多年都维持着某种程度的孤立主义,“北美洲是北美洲人的北美洲,至于其他地方?谁在乎?”这种观点一直保留在22世纪美联人的头脑中。不过,在太阳系殖民浪潮开始后,美联人前辈当年拓荒西部的精气神全部得到唤醒,北美人开拓地外殖民地的劲头毫不亚于**人。查看北美联邦完整词条
欧罗巴通过与俄罗斯的合并将领土范围向东扩张到了太平洋海岸,但不久后就将叶尼塞河以东领土全部卖给了**,并最终将东部边界固定在乌拉尔山脉一带。欧洲大陆紧接着在21世纪40年代爆发了惨绝人寰的七年动乱,基督徒在欧罗巴军政府和天主教世界的支持下大量屠杀和驱逐欧洲的穆斯林,最终将后者全部赶到西撒哈拉。此后几十年,欧洲大陆终于迎来了安宁,高压的提高生育率政策提高了人口基数,统一的市场带来了经济潜力的持续释放,欧罗巴赶上了第一次接触带来的技术爆发,参加了盖亚计划,投入到太阳系殖民浪潮之中,这一切都令西方文明的核心地带在23世纪成为人类最强大国家之一。查看欧罗巴完整词条
英国人在21世纪末重新整合陈旧的摇摇欲坠的英联邦体系,将这个共主邦联组织彻底改革成一个邦联制国家,用英镑统一了成员国的货币,将来自各个成员国的代表选入伦敦的议会和政府,英军重新部署到这些成员国并作为防务主力,白厅成为成员国的外交、国防、贸易和教育政策制定者。英国随后在以色列出售可控核聚变能源技术给其余几个大国的过程中继续发挥协调人的角色,在22世纪的盖亚计划和太阳系航运竞赛中,英国人愈发焕发出数百年前的活力并成功取得一些成就,这直接推动英国人将其帝国时期的海洋战略放在太空中实施,他们倾举国之力建起了舰队和运输舰队,到了23世纪初这些英国太空船逐渐成为了太阳系内的一支强大力量并掌控了一些关键航道。查看英国完整词条
在一小撮政治野心家和几名民族主义资本家的领导和支持下,在欧俄合并后诞生的俄罗斯复国主义武装入侵格陵兰并成功在此建立了“新俄罗斯”。在21世纪50年代的北极战争后,新俄罗斯的领袖决定担起泛斯拉夫主义的旗帜,号召全球——主要是东欧和南欧的欧罗巴加盟邦中的斯拉夫人和对新政权心怀不满的俄罗斯精英来到格陵兰参与建立一个泛斯拉夫主义国家“斯拉夫共和国”(Slavyanskaya Respublika)。此后一百多年间,斯拉夫通过援助马尔代夫建立人工陆地的方式,获得了在赤道的重要航天发射场,并参与了第一次接触和盖亚计划,在22世纪后凭借航天领域的积累和政策支持,与英国人展开了太阳系航运竞赛,为南方国家提供防务服务,并在23世纪跻身六国集团之列。查看斯拉夫完整词条
21世纪20年代被伊斯兰联军击败并丢失国土的以色列国内各种矛盾爆发,经过多年混战后军政府上台收拾局面。军政府在部分美国犹太集团和欧洲犹太人的支持下稳定了以色列政局,并策划了将持续五十年的“救赎计划”,计划除了做出重建国家的总体规划外,还明确要求哈瑞迪派必须世俗化并为以色列重建提供合格劳动力否则将被集体流放到非洲,同时计划也明确了军政府为以色列国的政体。 此后以色列逐渐恢复活力,在21世纪中叶与中美欧英斯一同获取了第一次接触的科技成果,也作为参与者投入了盖亚计划,并在21世纪末成功开发出可控核聚变中的关键约束技术。以色列将这个能源革命的钥匙卖给列强后获得巨额资金,军政府顺势将救赎计划再延期一百年,以便集**力对小行星带的谷神星地球化改造。在22世纪中叶,谷神星被改造成了“迦南行星”,以色列人开始陆续从马达加斯加迁移到这个全新的星球,直至23世纪初已有85%以上的以色列公民生活在迦南行星。查看以色列完整词条
其余有一定影响力的区域大国还包括:伊斯兰世界联盟、太平洋共和国、墨萨克斯共和国、日本、巴西、西非联邦。此外,一些防务巨头和国际组织也是23世纪人类世界的主要玩家,包括:维索卡、联合地球、地球儿女等。
**【安立柯文明】**数千年来,神权政治下的安立柯帝国皇帝将土地分封给七个最大的家族,这些家族又各自控制着数量庞大的地方贵族领主,让他们在自己的领地里建立军队和**。人类在安立柯帝国境内各行省的贸易和探索活动不断增多,通过取悦掌控行省的大家族和贿赂领主,人类商队和探险队在帝国境内的活动为人类的葡萄酒、巧克力和机器人出口创造着源源不断的需求。
皇帝依靠庞大的地方贵族领主,让他们在自己的领地里建立军队和**,全帝国范围内一共有约1200个领主,而他们绝大部分从属于七个最大的家族,皇室从而以一种低成本的方式建立起了金字塔般的**基础。
安立柯帝国的核心美仑奇斯行星距离地球约两千光年,作为一颗气态巨行星的卫星,这个行星的体积是地球的三倍,南北半球拥有辽阔的大陆,赤道附近是连绵不绝的浅海——安立柯人就是从浅海中的一种鱼类进化而来,而他们的绝大部分生活区域至今也是在浅海和大陆的海岸地区。
**【翡翠文明】**较之人类和安立柯,翡翠是一个十分古老的文明,自从人类在21世纪中期历史性地与翡翠文明进行第一次接触后,这个古老文明在21世纪末作为中间人安排了人类与安立柯两大文明的交往。翡翠作为比人类和安立柯更高级的文明,掌控着连通太阳系与安立柯星系的星门,但却与这两个文明保持着若即若离的关系。
以下是根据“涅槃计划”中的材料翻译得出的关于翡翠文明的部分概况,注意这只是人类翻译的版本,是否与事实相符则未得到翡翠文明的明确答复。
翡翠文明原本只是庞大翡翠星系中的一个行星文明,在五万年前崛起并逐步对星系中的其他文明发动**,一个不断扩张的帝国也随之建成。伴随着历史长河中的无数次分裂和战争,翡翠帝国的生产力已经提高到整个星系最高的水平,其人口也位居星系之最,其他文明种族要不是处于奴役状态就是已经消亡。大约在两万年前,翡翠文明成为了该星系占据绝对主导地位的种族并发展到生产力超高的阶段,物质达到极大的丰富程度,翡翠人无需付出劳动即可获得无限供给的物质,翡翠社会的共识是深度开发每个人的精神世界。翡翠文明在23世纪的两大使命分别是发展大功率恒星级探测器来探索整个银河系的文明分布状况、以及展开进阶哲学研究。
从来没有人类见到过翡翠人的真实面目,因为他们在每次与人类接触之时都会将其身体和外貌展现为该人类所在种族的样子,他们的说法是这样能最大程度上尊重双方的自然基因。目前的主流观点是翡翠文明对人类没有恶意,且比较热心地向人类分享其高超的科学技术,动机可能是为了提高人类在整个银河系中的文明程度,进而达成翡翠文明的某种使命。
23世纪人类文明的工业和社会生产主要依靠超级核聚变和空间太阳能提供能源动力。此时,人类普遍从安立柯帝国进口一种称为“精炼源”的矿物质来提高超级托卡马克核聚变过程中约束等离子磁场的稳定性。从而实现持久可控的核聚变并继而以此作为大型机械和城市的主要发电方式。太空大国普遍以核聚变能源作为其主力能源。另一方面,几个大国及其企业在环绕地球的轨道上设置大量太阳能板接收太阳能,在空间站转换为电能后用无线输电技术发回到地面上的电能接收站,再通过电网送到各个使用终端。空间太阳能的使用范围主要在地球与月球殖民地。太空城、地球上的小国和资源匮乏国家是空间太阳能的主要服务对象,太空大国为其在轨道上建立电站然后将电能传输到这些国家的城市。而出于地缘政治考量,大国本身不会过多使用空间太阳能。
人类从22世纪开始进入了太空殖民时代,太阳系、南门二、安立柯星系、翡翠星系是人类足迹已到的几个恒星系。不过,后两个星系由于是外星文明的势力范围,因此人类仍无法对其殖民和开发,而只是拥有航道通行权。人类的殖民地和空间开发主要仍在太阳系和南门二。其中以月球和火星的开发最为成熟,这两个地方已经遍布人类殖民点和城市,环木星轨道、土卫六、小行星带和柯伊伯带也渐渐吸引了大量人类殖民者前往开发。值得一提的是,以色列人更是把谷神星直接地球化后改造成了迦南行星。而南门二则只有潘朵拉行星上有殖民据点。除了行星,还有大量空间站和太空城市充斥着太阳系,其中最大的是柯伊伯带星门附近的边缘港,人口已达两百万以上。
23世纪人类飞船的主流推进方式主要是核聚变、光压、磁压这三种推进系统。由于恒星际间的旅行依靠星门作为枢纽,因此飞船并不需要装备支持超长时间航行以及近光速级别的推进系统。
机器人三定律在23世纪发挥了重要作用。不过由于对安立柯出口机器人的利润更高,这反而导致人类的机器人产能大部分配置在生产对安出口型机器人上,留给人类世界消费的机器人供应并不十分充裕。
出于对AI和硅基文明的潜在崛起的担心,人类各主要国家都除了对AI的使用实行分级机制外,还立法限制机器人公司或相关运营机构私自提高AI及机器人的能力,而且也不允许AI擅自联网。
人类文明的货币系统是商品本位占绝对主导,世界各国政府都基于黄金和克里普(KREEP)的混合物质(比例为1比1)作为货币的价值,货币形式是电子货币形式,由各国**银行管理的大规模分布式服务器阵列作为电子货币的发行基础。而与之相反,安立柯帝国的货币系统是信用货币星元,星元的发行并没有真实的商品作为基础,它在人类、翡翠文明、安立柯帝国三边贸易中被确立为基础货币的无锚定信用凭证。
由世界各国入股的国际货币基金组织(IMF)在全人类范围内发行信用点(Credit Point, 简称CP),CP以一揽子货币为基础,包括:人民币、欧元、联邦美元(Federal Dollar,简称FEDA)、第纳尔、英镑和高级谢克尔(Senior Sheqel)。人类文明范围内的贸易以及与IMF的结算都以CP为基础货币。
23世纪的人类商业组织主要分为三种:作坊、行会、超级企业。
作坊是23世纪最普遍的商业组织形态,某个公民或家庭依靠3D打印设备、机器人和互联网便能成立作坊。作坊可以为市场提供各种商品或服务,但受限于竞争力太弱和精力有限,作坊往往无法涉足除本地社区外的更大市场。因此,作坊往往会选择加入某个行会,由后者负责其产品的批量生产、统一销售和大规模市场营销,作坊本身只负责创意和生产。
行会是作坊的联合体,它代表某个地区或者行业众多作坊的利益。大型行会的形态更类似于某种卡特尔,它们往往有一定实力在商业层面上与超级企业抗衡,但受制于没有私人武装和政治影响力,行会无法在更高层面上与超企对抗。行会往往被视作二十世纪大企业的翻版,但二者仍有很大不同:一,行会不直接从事产品制造和服务业务;二,行会没有庞大的员工福利压力需要承担;三,行会没有股东和董事会,只有一个附属的共同基金和合伙人团队,而后者也分为普通合伙人和有限合伙人。行会一般有如下特点:一,往往以行业和地区注册;二,作坊有随时加入和退出的权利;三,行会议会有强大权力随时干涉合伙人的决策。
超级企业类似于近代的康采恩,它们往往面向庞大的海外殖民市场,拥有私人武装和强大的政治影响力。超企的业务主要集中于需要庞大资本和劳动力,作坊和行会无力涉足的领域,例如矿业、重型制造业、金融业和航运业等。超企内部的组织结构与二十世纪的组织结构比较接近,呈金字塔形且等级分明,不同之处在于机器人和AI系统在超企中被广泛应用。超企有以下特点:一,资产庞大;二,业务覆盖广阔的市场;三,拥有私人武装;四,在殖民地普遍拥有政治权力(例如制定法律、收税和司法仲裁等);五,政府一般拥有其比例不等的股权。查看人类超级企业榜
从21世纪末开始,六大国就在太阳系积极奉行领土扩张政策,地球化成功的几个外星球(尤其是火星)都纷纷成为这些大国的开拓处女地,这构成了太阳系殖**义的核心。有几个原因支撑着太阳系殖**义:一,领土是国家利益的基本保障,外星球上的金属、矿产和水源等都是重要战略资源;二,领土扩张需要大量人口进行开拓,这能创造大量就业机会,尤其是提供给社会中下层人口;三,领土扩张后能容纳更多人口移民,间接扩大了民族发展空间,也有利于提高生育率。为了激励社会中下层成为拓荒者前往殖民地开拓空间,六大国都出台了力度不一的鼓励政策,最常用的就是拓荒者可以获得土地或获得大部分的土地开发收益,拓荒者也可以将已经开拓到一定规模的土地卖给后来的殖民者或企业从而实现套现。
>查看原文










借地打扰了……
你们的前端工程师把 dev build 发到线上了。而且前端的 authentication 校验是在 router 的 after hooks 里触发的,也就是说会先跳到登录后页面再跳转回来。


Less/No Code 让业务跑的更快
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
quick-open-url(生产力平台 @王一鸣 出品)
解析你的代码,快速帮你打开特定的链接,如从 js 中打开特定的node包的git地址,从 vue template 中打开组件文档。
如何提高Vue组件的可复用性和扩展性,组合式组件的写法或许是一种不错的思路(推荐者:@张尚金)
让一群AI玩“捉迷藏”,它们会想出啥战术来?(推荐者:@侯彪)
超级强大的动画制作生成工具(推荐者:@张尚金)
AE 制作动画,Bodymovin 解析,lottie-web 生成动画(安卓,lodash 都有),再也无惧复杂动画的实现啦
W3C 重点工作报告(2019年9月版)汇总了 W3C 近半年的工作要点以及在各标准领域的进展:支付、出版、媒体娱乐、WebRTC、汽车、WoT、HTML、CSS、SVG、WebAssembly、字体、音频、性能、测试、数据、安全隐私、国际化、无障碍等
苹果公司正式发布 iPadOS,现在就可以安装升级。它将一些桌面电脑的功能引入了 iPad,比如 程序坞 dock 和支持直接插入 U 盘。
现在,苹果公司的产品线有四个操作系统:MacOS、iOS、iPadOS、WatchOS。
来自 @ruanyf
我的父亲母亲(任正非著文章)(推荐者:@蒋迪)
开源 React Native 组件库 beeshell 2.0发布(推荐者:@张燕玲)
Vue源码拆解——说说虚拟 DOM 补丁算法(推荐者:罗炜)
趣闻
我这位同事一定只有7分钟记忆。问:那个 token 的格式能给个例子吗?答:就是标准 jwt,并丢过去一个在我们 spec 里面的连接。过了几个问题。问:那个 token 不包含 xx 信息吗?答:不包含,就是标准 jwt,并丢过去同一个链接。又过了几个问题。问:那个 token 格式是啥?答:就是标准 jwt,并丢过去同一个链接。
@生产力平台技术部 - 刘远洋
原文链接:hoperyy/blog#147

非视觉指标(Non-Visual Metrics)
感官指标(Visual Metrics)
First Paint Time (First Non-Blank Paint Time)
文档中任一元素首次渲染的时间
FCP: First Contentful Paint Time
代表文档中内容元素(文本、图像、Canvas,或者 SVG)首次渲染的时间。
它通常情况下是无意义的渲染,比如头部和导航条。
FMP: First Meaningful Paint Time
首次有意义的渲染时间(它的统计在重大的布局变化之后,往往代表了用户所关心的首次渲染时间)。
First Interactive Time
首次可交互时间
Consistently Interactive Time
持续可交互时间
Fisrt Visual Change
首次视觉发生变化的时间点
Last Visual Change
最后一次视觉发生变化的时间点
Speed Index (SI)
视觉速度:Mean Pixel-Histogram Difference 算法。
算法如下,它代表了我们页面在加载过程中视觉上的变化速度,其值越小代表感官性能越好:

PSI: Perceptual Speed Index(PSI)
视觉速度:Structural Similarity Image Metric 算法。
更贴近用户的真实感受。
非视觉指标(Non-Visual Metrics)
感官指标(Visual Metrics)
开发阶段
生产状态
Chrome 对速度的描述
https://developers.google.com/web/tools/lighthouse/audits/speed-index
Navigation_timing_API
https://developer.mozilla.org/en-US/docs/Web/API/Navigation_timing_API
Speed Index 算法
 别人的看法都是狗屁,你是谁只有你自己说了才算 --《哪吒之魔童降世》
别人的看法都是狗屁,你是谁只有你自己说了才算 --《哪吒之魔童降世》
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
vue3.0 面向函数写法的思考(推荐者: @张尚金)
面向函数的写法为什么能方便的解决逻辑复用的问题(vue 目前版本存在的痛点),看看尤大是怎么思考的吧!
架构师技术图谱,助你早日成为架构师(推荐者: @张尚金)
架构师技术图谱包括:分布式、前端、大数据、存储、微服务、推荐系统、框架 、消息队列、编程语言、设计模式、重构、集群等内容。
前端离线化探索(推荐者: @张尚金)
高速公路、地铁隧道、楼道角落,以及诸多日常信号不稳定区域,这些场景日常经常碰见,那我们该如何改善用户的焦虑,带给他们更好体验,从而提升用户留存与口碑呢?
利用 SVG 来创建 Logo 动画的一篇教程,给 Logo 加点动画,网站或许会更吸引人哦~
这里汇总了丰富的布局场景和案例,对于新手,可以快速的入门 css 布局,对于老手,也能学到一些更好的布局处理方式。
为应对越来越丰富的动画场景,浏览器有个专门用来处理动画的 GPU 进程,这其中就包含一个专门处理 3D 动画的绘图协议 WebGL,这篇文章就是介绍了如何通过引入 WebGL 来使我们的 slider 组件更加顺滑流畅。
GitHub 公布托管平台与美国贸易管制的相关细节 (推荐者: @刘远洋)
HTTP 安全 Headers - 完整指南?(推荐者: @罗炜)
介绍了常用的事关安全的 headers
Vue 源码拆解(一):实现计算属性和侦听器(推荐者: @罗炜)
构建自己的文本编辑器简明教程(推荐者: @刘远洋)
详细介绍 Apache Licene 2.0 协议(推荐者: @刘远洋)
学习 underscorejs 整体架构,打造属于自己的函数式编程类库(推荐者: @刘远洋)
[译] 愿未来没有 Webpack(推荐者: @赵兴)
深入理解 Node.js 中的进程与线程(推荐者: @何会会)
JS Promises: race vs all vs allSettled(推荐者: @张尚金)
promise 的一些你可能不知道的使用细节
前端进阶必备,github 优质资源整理分享!(推荐者: @刘远洋)
程序员工作法(推荐者: @张尚金)
掌握主动权,忙到点子上,8 条程序员工作法助你职场上的我们
应急响应实战笔记(推荐者: @张尚金)
面对各种各样的安全事件,我们该怎么处理?这是一个关于安全事件应急响应的项目,从系统入侵到事件处理,收集和整理了一些案例进行分析。
提升网站体验的一些设计思考(推荐者: @张尚金)
良好的用户体验能够留下更多的用户,所以我们应该为追求好的体验而不断努力改进
一些能够提供设计效率的 sketch 插件汇总(推荐者: @张尚金)
好的工具真的能大大的提升工作效率,这里汇总了一些很有用的 sketch 插件,比如可以快速的从 Unsplash 里面选取照片用于 UI 设计等
原文链接:hoperyy/blog#145
微店前端工程化起步于一个内部产品 vbuilder,对外我们有一个开源版本 bio-cli。
去年我们也写过一篇文章介绍该产品: bio: 一站式前端开发工具。
这么长时间过去了,我们在前端工程化方面有了哪些变化、遇到了哪些问题、用怎样的方案解决这些问题等等,值得为大家再分享。
这里也就是介绍下背景,为什么我们会开发 vbuilder。
总体思路就是:将重复性工作集成化。
当时,团队面临几个问题:
packge.json 中的依赖既有脚手架的依赖,也有业务依赖,难以区分总结为下图:
基于以上问题,我们开始了 vbuilder 的研发。
最终产品以命令行的形式发布。
此时的 vbuilder 为 V0.0 状态。
vbuilder V1.0 提供了以下能力:
mock / update / help 等vue / react / angular / weex 等),开放接入不同技术栈vbuilder 的不断推进下,我们欣喜地看到,团队发生了一些变化:
weex / vms / 后台管理 / serverside project 等总结为下图:
V1.0 出现后,推进的很顺利,在推进过程中秉持如下原则:
V1.0 基本解决了以下角色的痛点:
封闭性
高度定制化的工程配置需求实现难度增大
脚手架配置的主题被隐藏,虽然仍然开放给开发者一些配置性文件,对于高度定制化的配置需求而言依然杯水车薪。
此时,就必须新开一个脚手架,重新接入 vbuilder 体系。
在 “开放性” 来说,打了折扣。
插件开发的冲突
由于 vbuilder 是基于命令行开发,插件开发者扩展自定义命令式,依然是自定义命令行,团队规模不断扩大的状态下,很容易出现不同插件使用同一个命令,被同时安装的状态下,重复执行该命令。
V2.0 至少要解决 V1.0 存在的问题,同时需要有更明确的发展方向。
不过,V2.0 依然基于命令行。
V1.0 的思路是 “闭合”,虽然有一定的开放性,但仍然不够。
V2.0 新增 “开放” 的能力,脚手架配置可以被隐藏,也可以随时在需要的时候暴露在工程配置中,进行定制化开发。
当然,会遇到脚手架难以统一管理的问题,这一点仍然有办法可以解决。
因为被暴露的工程配置是 vbuilder 提供的,vbuilder 得以方便地统计哪些项目使用了自定义的脚手架,将通用型工具包下发给该工程。
问题 1:插件间的冲突
举个例子,有两个插件中,都有一个命令 run。如果用户安装了这两个插件,在执行 run 命令的时候,两个插件的逻辑均会触发。
在某些情况下,这不是用户希望看到的场景,可能 TA 希望的只是运行插件 A 的命令 run。
问题 2:插件命令集与内置命令的冲突
例如,内置命令集中有命令 init,而某个插件也有 init。
那么在用户执行 init 命令时,依然会执行两遍逻辑。
怎样解决?
我们组合使用了以下方案:
vbuilder 检测是否有重复命令,如有,提示用户是都运行、还是选择运行某一个插件中的命令
为命令圈定生效条件
vbuilder 的命令行基于 commander。我们基于 commander 扩展了一些方法。
假如我们希望,插件中的命令 show 只在工程目录中 xx.show 文件存在的情况下生效,那么代码如下:
commander
.command('show [param]')
.effect(cwd => fs.existsSync(path.join(cwd, 'xx.show'))) ---- 这是我们扩展的命令
.description('我的自定义命令')
.action((param, options) => {
console.log('my show');
});为内置命令集声明其为“内置命令”,插件命令可以阻止内置命令执行
假如插件中有个命令 init,而 vbuilder 内置命令中也有 init,我们希望插件中的 init 命令生效,内置命令不生效,该怎么做呢?
我们扩展了 commander 的 2 个方法:declareDefault 声明内置命令、preventDefault 阻止内置命令执行。
定义内置命令时,代码如下:
commander
.command('init [param]')
.declareDefault() --- 声明内置命令
.description('内置的 init 命令')
.action((param, options) => {
console.log('init inside');
});开发插件命令时,代码如下:
commander
.command('init [param]')
.preventDefault() --- 阻止内置命令执行
.description('内置的 init 命令')
.action((param, options) => {
console.log('init inside');
});Commander 的源码只有 1000 行左右,逻辑还是很清晰的,扩展起来非常方便,这里不再列举实现。
在命令行这个场景下,我们把 vbuilder 定义为公司内部开发的一个“水电煤”性质的基础设施。
通过 vbuilder,我们新增了以下场景:
得益于插件化,通过充分调动开发者积极性,我们可以将其能力无限延展。
我们目前还没有进入 3.0 的开发,但有一些方向是我们可以尝试的:
这是目前我们在微店前端工程化领域的一些实践和思考,希望对大家有帮助。
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
使用TensorFlow.js进行图像对象检测
@viva是我问:23世纪的能源主要靠什么?人类对宇宙的开发大致到什么地步了?
答:23世纪人类文明的工业和社会生产主要依靠超级核聚变和空间太阳能提供能源动力。此时,人类普遍从安立柯帝国进口一种称为“精炼源”的矿物质来提高超级托卡马克核聚变过程中约束等离子磁场的稳定性。从而实现持久可控的核聚变并继而以此作为大型机械和城市的主要发电方式。太空大国普遍以核聚变能源作为其主力能源。另一方面,几个大国及其企业在环绕地球的轨道上设置大量太阳能板接收太阳能,在空间站转换为电能后用无线输电技术发回到地面上的电能接收站,再通过电网送到各个使用终端。空间太阳能的使用范围主要在地球与月球殖民地。太空城、地球上的小国和资源匮乏国家是空间太阳能的主要服务对象,太空大国为其在轨道上建立电站然后将电能传输到这些国家的城市。而出于地缘政治考量,大国本身不会过多使用空间太阳能。
人类从22世纪开始进入了太空殖民时代,太阳系、南门二、安立柯星系、翡翠星系是人类足迹已到的几个恒星系。不过,后两个星系由于是外星文明的势力范围,因此人类仍无法对其殖民和开发,而只是拥有航道通行权。人类的殖民地和空间开发主要仍在太阳系和南门二。其中以月球和火星的开发最为成熟,这两个地方已经遍布人类殖民点和城市,环木星轨道、土卫六、小行星带和柯伊伯带也渐渐吸引了大量人类殖民者前往开发。值得一提的是,以色列人更是把谷神星直接地球化后改造成了迦南行星。而南门二则只有潘朵拉行星上有殖民据点。除了行星,还有大量空间站和太空城市充斥着太阳系,其中最大的是柯伊伯带星门附近的边缘港,人口已达两百万以上。
@低熵的高熵体问:行星际与恒星际飞船的推进方式是怎么样的?六大国的在轨打击能力如何?机器人有机器人三定律的限制吗?地球气候如何?大都会新闻目前有多少成员?
答:23世纪人类飞船的主流推进方式主要是核聚变、光压、磁压这三种推进系统。由于恒星际间的旅行依靠星门(一种由翡翠文明发明并维护的能压缩空间的人造黑洞)作为枢纽,因此飞船并不需要装备支持超长时间航行以及近光速级别的推进系统。
六大国在23世纪都有完整的太空舰队和太空战斗能力,其中英国、以色列和斯拉夫的太空运输能力最高,他们的战舰也最多,他们的舰队承运了超过一半的恒星际货物运输,所以被称为“人类马车夫”。不过,**、美联和欧罗巴由于人口众多、工业结构完整以及殖民地广阔,因此拥有最全面和综合度最高的太空打击力量。有其擅长夸空间和行星表面的立体作战。
机器人三定律在23世纪发挥了重要作用。不过,出于对AI和硅基文明的潜在崛起的担心,人类各主要国家都立法限制机器人公司或相关运营机构私自提高AI及机器人的能力,而且也不允许AI擅自联网。
23世纪的地球环境十分优美,这是因为:
一,大部分工业都已经转移到月球和太空城;
二,化石能源不再是能源主流;
三,核聚变和太阳能不会产生环境破坏;
四,社会的环保意识很强(甚至是矫枉过正)。
大都会新闻目前只有一个成员。
@左舷炮手寞寞寂问:翡翠文明对地球的影响体现在哪?
答:翡翠文明作为一个超越人类数万年的先进文明,对人类文明在21世纪第一次接触后的走向产生了深刻影响。
主要表现在几个方面:
1,引起了人类社会的宗教回归思潮。由于第一次接触的强大震撼感,也由于地球几个主要宗教修正了其教义,把外星文明纳入宗教体系中,很多原本已经疏离了宗教的人以及无神论证开始重新找回宗教信仰。与此同时,也催生了大量小众宗教。宗教回潮运动导致的直接后果是很多国家和社会的宗教团体和势力重新取得了强势地位。
2,向人类引荐了安立柯文明。翡翠文明是人类和安立柯文明接触、交流以至发生贸易关系的中间人,这直接引发了人类历史上最长的经济繁荣周期,大大加速了人类开发太阳系和探索其他恒星系的速度。
3,向人类传授了大量科学知识。翡翠文明在接触后不久就为人类制定了“涅槃计划”,通过学校、企业、政府、NGO和特使等各种渠道向人类有系统、有步骤地传授其掌握
的科学知识,此举直接推动了人类文明的发展。
@樊元树问:货币体系是什么样子?
答:23世纪人类文明的货币系统是商品本位占绝对主导,世界各国政府都基于黄金和克里普(KREEP)作为货币的价值,货币形式是电子货币形式,由各国**银行管理的大规模分布式服务器阵列作为电子货币的发行基础。而与之相反,安立柯帝国的货币系统是信用货币星元,星元的发行并没有真实的商品作为基础,它在人类、翡翠文明、安立柯帝国三边贸易中被确立为基础货币的无锚定信用凭证。国际货币基金组织(IMF)在全人类范围内发行信用点(Credit Point, 简称CP),CP以一揽子货币为基础,包括人民币、欧元、联邦美元(Federal Dollar,简称FEDA)、卢布、英镑和高级谢克尔(Senior Sheqel)等。人类文明范围内的贸易以及与IMF的结算都以CP为基础货币。每个国家可将与安立柯帝国贸易所收到的星元与IMF兑换为CP。
@正-魔之左手问:日本交出了什么样的代价才成为**的“盟国”呢?
答:日本的地缘环境和民族性格注定了他们不是倒向**就是倒向美联,自从21世纪美军撤出亚太地区以及紧跟着的美国解体后,日本就意识到倒向**已是必然,尤其是与朝鲜在一场惨烈的本土战争后,日本人成为亚太一极的愿望也最终落空了,因此便与朝鲜,还有独立的琉球一同成为大中华经济圈的重要一员。
@lightman-韬问:之前说过好像要推出游戏,是什么类型的,什么时候可以运营?
答:23世纪游戏预计会在2015年开放公测,是战略类型多人在线网页游戏,形态有点儿类似于travian和文明的结合,不过会有很多创新的玩法在其中。游戏会与大都会新闻的主线直接挂钩,玩家在游戏中的行为与主线间会产生相互影响。
我知道有部分粉丝的问题还没回答,这是因为一来问题比较敏感,二来我也没有想好,所以留待以后再回答。此外,我会在2015年推出一本详细说明23世纪人类文明情况的书,有兴趣的读者届时可以留意大都会新闻的动态。
>查看原文

祝大家万圣节快乐,Happy Halloween!
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @刘远洋 / @胡彬
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
Google工作法(推荐者:@胡彬)
看完后很有启发的一篇文章,平时的工作中、学习中需要更多的思考如何提高自己的效率。
Server-X:一款可能提升你十倍工作效率的工具(推荐者:@胡彬)
Vue3 中的数据侦测(推荐者:@胡彬)
「前端进阶」高性能渲染十万条数据(虚拟列表)(推荐者:@胡彬)
写给新手前端的各种文件上传攻略,从小图片到大文件断点续传(推荐者:@胡彬)
超级齐全的上传攻略,妈妈再也不用担心我不会写上传了。
深入浅出 Babel 上篇:架构和原理 + 实战(推荐者:@胡彬)
超全 Chrome 插件汇总(推荐者:@刘远洋)
量子计算:区块链的末日到来?(推荐者:@罗炜)
Get Over With the Machine Learning Hype(推荐者:@罗炜)
看清机器学习的炒作。 机器学习是计算机算法、离散数学和概率的结合。
The problems of shared mutable state and how to avoid them(推荐者:@张尚金)
这篇文章指出了数据共享存在的问题以及从浅入深的探讨了解决这种问题的方式
JavaScript 模块化(推荐者:@罗炜)
code-server(推荐者:@刘远洋)
code-server is VS Code running on a remote server, accessible through the browser.
网页端的 VSCode 编辑器。
https://unsplash.com/(推荐者:@刘远洋)
一个没有版权问题的图片网站。
celeb-detection-oss(推荐者:@刘远洋)
GIPHY 开源了一个表情包识别器,可以分清楚超过 2300 个名人,而且它识别的还是动图,准确率超过 98%。
谷歌推出了远程桌面软件,可以在手机和桌面浏览器里面,访问远程电脑的桌面,进行各种操作。
这个网站真的很 NB:https://bruno-simon.com
来自:技术部 - IT徐胖子
1 靠谱
在工作中,我们肯定希望合作伙伴做事情靠谱,不知大家有没有想过,靠谱这个词究竟表达的是什么意思呢?
有人说靠谱是指工作能力强,有人说是指言出必行,也有人说是指保质保量完成任务。我认为这些说法都有一定的道理。
如果让我谈谈靠谱的定义,我的答案是:符合预期并且状态稳定。这个定义中有两个关键词:符合预期,状态稳定。
2 符合预期
如果小明是初级工程师,那么你对小明的预期就应该是初级工程师所达到的水平。如果他可以把初级工程师的事情做完做好,这就叫达到预期。
当然如果小明在工作中不仅完成了本职工作,而且给你带了惊喜,达到了更高层级的水平,那么小明升职加薪自然也不会遥远。遇到这样的小明固然是惊喜,没有遇到也属于正常。
大多数的小明们可能在工作中只能达到初级工程师的水平,这是正常的。所以在合作中,你一定要调整自己的预期,不能不切实际,幻想着小明有着高级工程师的水平,再反过来埋怨小明没有把事情做好,那就是你的不对了。
做到超过层级的事情叫惊喜,做到符合层级的事情叫符合预期。
下面我将会用比较多的篇幅来讨论另一个词:状态稳定。
3 麦当劳
每个城市都有很多家麦当劳的连锁店,你在A连锁店吃到的薯条的味道,应该不会比B连锁店差。你在C店吃到汉堡包的尺寸,应该也不会比D店小。每当进入麦当劳,你可以保持稳定的预期值去点餐。
这是因为麦当劳有一套严格的操作流程,摘录一段罗振宇老师关于麦当劳工作流程的描述:可口可乐的温度必须保持在4摄氏度,牛肉饼的成分必须是83%的牛肩肉和17%的五花肉,其中脂肪含量不能超过19%,最终做出来的牛肉饼,必须直径是95.8毫米,厚度5.65毫米,重量47.32克。
大家可能会觉得有点过了,可乐5摄氏度和4摄氏度有什么区别呢?牛肉饼重量48克又会有什么影响呢?
其实麦当劳用这种近乎苛刻的方法,在保证一件事情:让客人在全世界所有麦当劳,吃到的可乐和牛肉饼都是同一个味道。
这种工作方式称为标准化,这种产品的质量称为匀质。我们其实经常忽视一点:匀质也是优质的一种。
4 大数定律
下面我们会用到一些数学知识,先介绍一个定律:大数定律。我们以两个班级同学的身高分析为例。
现在有A班和B班两个班级,经过统计调查,两个班级的身高分布图如下:
从图中不难分析,在两个班级中,个子高和个子矮的同学都属于少数,个子中等的同学属于大多数。这就是正态分布。其中170cm的同学人数最多。
此时我们就要引出大数定律的定义:当样本足够多时,实验结果的平均值会无限接近于一个数值,我们把这个数值称之为期望值。170cm就是这两个班级身高期望值。
5 标准差
仔细观察两张图还会发现一个细节:A班身高分布较广,图像显得比较矮胖。B班身高分布较窄,图像显得比较瘦高。这说明了什么问题?
这说明在B班,身高偏离期望值170cm的同学比较少。而在A班,身高偏离期望值170cm的同学比较多,分布比较广。
这就引入了另一个概念:标准差。标准差反映了一个数据集的离散程度,即数据偏离期望值的程度。期望值相同的两组数据,标准差未必相同。在本例中,A班的标准差大,B班的标准差小。
假设你是一名新来的校长,你要从A班和B班中,挑选一个班级的全体同学参加仪仗队,仪仗队需要队伍中每个同学的身高都差不多。如果你对两个班级的了解只有上述的身高分布图,你会怎么选择?
你肯定会选择B班。因为标准差小,数据离散程度低,偏离期望值样本少,才更有可能符合你的预期。
标准差代表风险,标准差越小,风险越小。
6 状态稳定
介绍了这些概念,终于回到我们对靠谱的定义:符合预期并且状态稳定。我认为状态稳定就是标准差小,不会偏离期望值太多。
在篮球赛场上,可以被称为球星的,一般都是每场比赛都可以稳定贡献20分以上的运动员,即使有几场发挥不佳,但总体可以提供稳定的预期,这样的运动员才可以被称为球队的核心。
在足球比赛中,怎么样衡量一位门将是否优秀呢?A门将经常有扑出点球的神勇发挥,但是也常有扑球失误。B门将扑点球没有那么擅长,但是不失误,稳如泰山。那么可以坐稳主力位置的一定是B门将。
7 风险对冲
万维钢老师在《对冲风险的数学原理》这篇文章中有一个精彩案例:
A公司是户外用品商店,天气好时盈利百分之40,天气不好时亏损百分之20,假设天气好和天气不好的时间各占一半,那么A公司利润数学期望是:0.5x0.4-0.5x0.2=0.1,即百分之10的利润。
B公司是室内用品商店,盈利情况正好和A公司相反。天气不好时盈利百分之40,天气好时亏损百分之20,那么B公司利润数学期望是:0.5x0.4-0.5x0.2=0.1,也是百分之10的利润。
假设你有100元钱,想购买A公司或B公司的股票,你盘算着,百分之10的利润还不错,但是有可能一下子亏掉百分之20,风险有点高。此时你应该怎么办呢?
答案是你应该50元买A公司的股票,50元买B公司的股票。
假设天气好,A公司盈利50x0.4=20,B公司亏损50x0.2=10,总利润是20-10=10元。
假设天气不好,B公司盈利50x0.4=20,A公司亏损50x0.2=10,总利润还是20-10=10元。
你的利润依然是百分之10,但是标准差即风险变成了0。这就是大名鼎鼎的对冲投资,即投资的领域的运动形态最好为负相关,这样可以抹平风险。
8 文章总结
再回到我对靠谱的定义:符合预期并且状态稳定。符合预期告诉我们要摆正心态,不要做不切实际的幻想。状态稳定告诉我们要管控风险,不要过多偏离期望值。愿我们都成为靠谱的人,并可以遇到靠谱的伙伴。
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
前后端参数统一处理方案(推荐者: @何会会)
前端校验防小白,后端校验防黑客,双重保障,系统更安全
一种实现简单且舒服的前端接口异常处理方案(推荐者: @刘远洋)
提升开发幸福感的 10 条 JS 技巧(推荐者: @刘远洋)
JS 最新基本数据类型:BigInt(推荐者: @何会会)
Vue 代码风格指南(推荐者: @刘远洋)
详解 React 16 的 Diff 策略(推荐者: @刘远洋)
不到 0.3s 完成渲染!360 信息流正文“闪开”优化实践(推荐者: @赵兴)
深入浅出 Vue 响应式原理 (推荐者: @何会会)
Vue 3.0 即将到来,你准备好了么?(推荐者: @张明)
[视频]Vue.js作者在VueConf现场发布RFC(推荐者: @张明)
前端离线化探索(推荐者: @刘远洋)
面试再问 ThreadLocal,别说你不会(推荐者: @何会会)
ArrayList 源码分析(扩容机制 jdk8)(推荐者: @何会会)
ArrayList是不是你感觉用的很熟悉了,方便又简单,但你知道他的实现原理吗?如何扩容的,还是可以无限的往集合里放入元素,性能瓶颈等。
从单体应用到微服务的开发旅程(推荐者: @何会会)
这是一个由 simviso 团队进行的关于架构演进的云原生分享的翻译文档,这个主要是关于Service Mesh 的分享,分享者是Kong这家公司的CTO。
the-art-of-command-line(推荐者: @刘远洋)
熟练使用命令行是一种常常被忽视,或被认为难以掌握的技能,但实际上,它会提高你作为工程师的灵活性以及生产力。本文是一份作者在 Linux 上工作时,发现的一些命令行使用技巧的摘要。有些技巧非常基础,而另一些则相当复杂,甚至晦涩难懂。这篇文章并不长,但当你能够熟练掌握这里列出的所有技巧时,你就学会了很多关于命令行的东西了。
这次要是讲不明白 Spring Cloud 核心组件,那我就白编这故事了(推荐者: @何会会)
灵魂拷问:Java 对象的内存分配过程是如何保证线程安全的?(推荐者: @何会会)
learn-regex/README-cn.md at master · ziishaned/learn-regex!(推荐者: @刘远洋)
一万八千多颗星的正则表达式教程
在工作中常用到的 SQL(推荐者: @何会会)
HashSet、LinkedHashSet、TreeSet的使用方法及区别 (推荐者: @何会会)
基于 github webhook 的代码自动部署工具(推荐者: @何会会)
推荐一款阿里开源的 Java 诊断工具,好用到爆! (推荐者: @何会会)
杀手级 AI 补代码工具问世,支持 23 种语言及 5 种主流编辑器,程序员沸腾了(推荐者: @神秘客)
四部门印发 《关于加强数学科学研究工作方案》(推荐者: @刘远洋)
从沟通反馈到高效能研发(推荐者: @何会会)
原文链接:https://juejin.im/post/5d410e85f265da03dd3d4ee8
数据模型是数据特征的抽象,用来抽象定义一个业务对象。假如现在有一个用户模型,如果要抽象的描述这个用户对象,可以按照如下来定义:
const UserModel = {
name:{
type:String,
property:'name',
value:'zhangshang'
},
age:{
type:Number,
property:'age',
value:26
}
}其中,type声明数据的类型,property指明映射路径,value是默认值。这里先有个大概的概念就行,后面我会通过实例来详细展开。
前面介绍了数据模型的定义,那和前端开发又有什么关系呢?前端又不需要和数据库打交道,前端开发主要就是拿到数据显示就完了,那为什么需要数据模型呢?它是怎么助力前端开发的呢?我们先来看一下以下几个场景。
我们在前端开发中,通过ajax请求拿到服务端数据,然后将数据显示在视图上,经常会写如下代码:
如示例,假如我们要显示用户头像,通过取到headUrl的值绑定在src属性上即可。因为是异步加载获取的数据,在最终获取到headUrl的值之前,我们需要先判断cardData.buyerExperienceInfo的存在性,然后才能取值,否则在视图初次渲染之前会报如下错误:
在这种场景下,我们在开发中就不得不写一些防御性的代码,久而久之,项目中类似代码会越来越多,碰到层级深的,防御性代码就会写的越来越恶心。另外还有的就是,如果服务端在这中间某个字段删掉了,那就又得特殊处理了,否则会有一些未知的非空错误报错,这种编码方式会导致前端严重依赖服务端定义的数据结构,非常不利于后期维护。
平时开发中,我们拿到了服务端返回的数据,有些不是标准格式的,是无法直接在视图上直接使用的,是需要而外格式化处理的,比如我司服务端返回的的价格字段单位统一是分,跟时间相关的字段统一是毫秒值,这个时候我们在组件的生命周期内,就不得不而外增加一些对数据处理的逻辑,还有就是这部分处理在很多组件都是公用的,我们就不得不频繁编写类似的代码,数据处理逻辑没有得到复用。
在用户做了一些交互后,需要将一些数据存储到服务端,这个时候我们拿到的数据往往也是非标准的,就比如你要提交个表单,其中有个价格字段,你拿到价格单位可能是百位的,而服务端需要的单位必须是分位的,这个时候在提交数据之前,你又得对这部分数据进行处理,还有就是有些接口的参数是json字符串形式的,可能是多级嵌套的,你还要需要特意构造这样的参数数据格式,导致开发中编写了太多与业务无关的逻辑,随着项目逐渐扩大或者维护人员更迭,项目会越来越不好维护。
在碰到这么多痛点之后,我就在想如何解决,回顾以上场景,总结下来存在以下几个问题:
所以,这里我引入了数据模型的概念,那通过数据模型如何解决这类问题呢?下面我将通过两个实际案例来进一步呈现上述场景,以及引入了数据模型之后是如何解决的。
......
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
今年的一半诺贝尔物理学奖颁给了系外行星的研究
Pornhub Web 开发者访谈(推荐者:@罗炜)
Pronhub是什么网站?哈哈,我只能说是“成年人的福音,未成年人的禁忌”,可以查看介绍,了解完之后你就会知道维护如此大流量的网站是件多么具有挑战性的工作。
FastJson 序列化对于重复和循环引用的处理(推荐者:@何会会)
阿里巴巴数据中台实践分享(推荐者:@张川)
闲鱼如何打造高效 CEP 系统及 DSL 编程语言(推荐者:@蒋迪)
代码仓库的提交信息怎么写?这里有一份规范标准(推荐者:@刘远洋)
HTTP 的前世今生(推荐者:@刘远洋)
libuv 中文教程(推荐者:@刘远洋)
如何在生产环境中部署 ES2015+(推荐者:@罗炜)
webpack5 即将到达战场(推荐者:刘远洋)
说说虚拟 DOM 补丁算法(推荐者:@罗炜)
京东 PC 首页 2019 改版前端总结(邵凯鸣)
图解 web 开发中的知识点,生动形象(推荐者:@张尚金)
Html Head 标签里面的元素没有你想的那么简单(推荐者:@张尚金)
vue 3.0 框架功能增强以及改进提前预览(推荐者:@张尚金)
作为 JavaScript 开发人员学习 Redux 的原因(推荐者:@张尚金)
JavaScript 命名规范(变量,类名,函数等)(推荐者:@张尚金)
使用用 js 来构建依赖树(推荐者:@张尚金)
数据可视化鼻祖 Tableau 深度解析(蒋迪)(推荐者:@张尚金)
响应至上:打造无卡顿的滚动列表(推荐者:@张尚金)
Vue2 与 Vue next 响应式原理(推荐者:@罗炜)
本期暂无投稿
数据模型是数据特征的抽象,用来抽象定义一个业务对象。假如现在有一个用户模型,如果要抽象的描述这个用户对象,可以按照如下来定义:
const UserModel = {
name:{
type:String,
property:'name',
value:'zhangshang'
},
age:{
type:Number,
property:'age',
value:26
}
}其中,type声明数据的类型,property指明映射路径,value是默认值。这里先有个大概的概念就行,后面我会通过实例来详细展开。
前面介绍了数据模型的定义,那和前端开发又有什么关系呢?前端又不需要和数据库打交道,前端开发主要就是拿到数据显示就完了,那为什么需要数据模型呢?它是怎么助力前端开发的呢?我们先来看一下以下几个场景。
我们在前端开发中,通过ajax请求拿到服务端数据,然后将数据显示在视图上,经常会写如下代码:
如示例,假如我们要显示用户头像,通过取到headUrl的值绑定在src属性上即可。因为是异步加载获取的数据,在最终获取到headUrl的值之前,我们需要先判断cardData.buyerExperienceInfo的存在性,然后才能取值,否则在视图初次渲染之前会报如下错误:
在这种场景下,我们在开发中就不得不写一些防御性的代码,久而久之,项目中类似代码会越来越多,碰到层级深的,防御性代码就会写的越来越恶心。另外还有的就是,如果服务端在这中间某个字段删掉了,那就又得特殊处理了,否则会有一些未知的非空错误报错,这种编码方式会导致前端严重依赖服务端定义的数据结构,非常不利于后期维护。
平时开发中,我们拿到了服务端返回的数据,有些不是标准格式的,是无法直接在视图上直接使用的,是需要而外格式化处理的,比如我司服务端返回的的价格字段单位统一是分,跟时间相关的字段统一是毫秒值,这个时候我们在组件的生命周期内,就不得不而外增加一些对数据处理的逻辑,还有就是这部分处理在很多组件都是公用的,我们就不得不频繁编写类似的代码,数据处理逻辑没有得到复用。
在用户做了一些交互后,需要将一些数据存储到服务端,这个时候我们拿到的数据往往也是非标准的,就比如你要提交个表单,其中有个价格字段,你拿到价格单位可能是百位的,而服务端需要的单位必须是分位的,这个时候在提交数据之前,你又得对这部分数据进行处理,还有就是有些接口的参数是json字符串形式的,可能是多级嵌套的,你还要需要特意构造这样的参数数据格式,导致开发中编写了太多与业务无关的逻辑,随着项目逐渐扩大或者维护人员更迭,项目会越来越不好维护。
在碰到这么多痛点之后,我就在想如何解决,回顾以上场景,总结下来存在以下几个问题:
所以,这里我引入了数据模型的概念,那通过数据模型如何解决这类问题呢?下面我将通过两个实际案例来进一步呈现上述场景,以及引入了数据模型之后是如何解决的。
这个案例使用Vue开发,功能很简单,就是通过ajax请求从服务端拿到数据,然后通过vue视图进行展现,效果如下:
代码只展示主要功能代码,非完整实现
在created生命周期内,向服务端请求数据。
获取到数据之后,因为拿到的数据和最终UI上显示的格式不一致,需要转化一下数据格式。
给当前Vue实例赋值,然后在template里通过模板语法进行渲染
可以看到常规写法,模板语法里面的写法特别不优雅,各种保护性代码(条件判断)
首先,我们可以专门建一个名叫model的文件夹,专门用来存放模型,然后定义卡片模型cardModel,其中数据定义格式如下:
type 必填,用来描述该字段的类型,支持String、Number、Date等类型property 必填,数据路径,对应服务端数据结构的取值路径value 选填,数据默认值,可不填通过new Model()进行初始化,后续只需要通过model.parse(data)或者model.traverse(data)这个两个方法就可以完成正向映射和反向映射的过程。
具体的使用方式可以查看API
通过axios请求接口,在拿到数据之后,调用parse方法解析数据,在解析的过程中会去做赋值操作以及数据格式化。
拿到数据,赋值给vue组件实例后,在template模板里面直接使用我们事先定义好的数据字段,不需要再去写类似a&a.b&a.b.c这样的代码,且不管服务端数据字段如何变化,视图渲染都不受影响,从而实现和服务端数据结构进行解耦。
与此同时,针对类似价格、时间等需要格式化的数据,我们可以直接使用,不需要再去写对应的格式化处理逻辑,从而专注于视图组件渲染处理。
通过引入数据模型,我们可以看到在模板里面引入变量的时候不需要进行各种判断,写法非常优雅,而且健壮性很强,即使服务端某个字段没有返回,我们这里也不会因此存在报错的可能性。且在脚本里面没有了数据格式化处理代码,从而不会因为数据处理逻辑代码可能存在的错误,打断UI的渲染。从而带来的更大好处是,随着项目的不断迭代,数据和视图有着清晰的划分,前端和后端进行了解耦,项目的可维护性得到保证。
在库里面,还提供了traverse方法,和parse方法类似,区别是traverse是反向数据生成以及格式还原。
最后,我来讲讲这个数据模型库(ducker-model)的实现原理,源码总共不到200行,还是简单的,可以通过这里下载查看,主要实现逻辑如下:
Model的类。new Model(options),传入模型结构,初始化数据模型属性,对外主要使用的是parse和traverse方法,parse方法的实现过程就是遍历模型数据结构,拿到每个属性的数据路径,然后根据这个路径去取传入的的数据里面的数据,最后给事先定义好的属性赋值,在赋值的过程中,可以根据type格式化一些类似时间、价格类型的数据。traverse方法刚好和parse相反,同样是遍历数据模型结构,拿到每个属性的数据路径,然后根据这个数据路径去设置一个新对象的值,这期间,反向格式化数据类型,最后返回这个新对象。目前这个库还很基础,只支持了一些常规的功能,能做的事情还很多,比如:
watch这个解析之后的数据,做到数据变动,视图变动呢?文章末尾会提供模型库下载地址,有需要的可以在此基础上进行扩展,欢迎一起完善这个库,另外,案例demo的地址也提供了,欢迎下载学习理解。
模型库:ducker-model


没毛病
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
谷歌官方:Chrome 浏览器的工作原理
命令行老是输入错误?试试 fuck
微软正式宣布新的适应于终端工具和编辑器的新字体:Cascadia Code,支持编程连字特性,是一款开源字体
Firefox 宣布,发布周期从 6 周改成 4 周,每个月发一个大版本。相比之下,Chrome 现在是 6 周一个大版本。
这就是前端的速度。一年可以从 v69 变成 v81,也就是说,如果你的知识一年不更新,就会遥遥落后最新进展。
by @阮一峰
从 ECMAScript 6 到 ECMAScript 10,看看 5 个版本的标准中都陆续新增了哪些新的特性:
下面工具可以自动生成英语文本。你输入一句话,然后按 Tab 键,就得到一整段。
输入 My name is 按 Tab,会有惊喜。
transformer.huggingface.co/doc/gpt2-large
本期暂无投稿
本文发表在 微店前端团队 blog
在前端性能数据的获取方法上,现在业内大多使用手动埋点的方式,即在代码中,人工判断首屏完成的位置,并在该处添加首屏记录的代码,类似:firstscreen.report() 这样。
这样做的简单省事,但缺点也很明显:
和业务代码混用
通用的监控需求混入了业务代码中
覆盖不完整
需要页面开发者自觉手动添加埋点代码,在业务中埋点覆盖率不一定能达到 100%
准确性不一定高
由于需要开发者自行判断统计脚本放置的位置,就会存在一些不准确的情况,因为每个人对首屏的理解不同
基于上面的分析,我们近期尝试了一些方案,试图将首屏时间计算自动化,节省人力、并提高准确性。
对首屏时间的定义,每个公司可能会有所不同,在本文中,首屏时间指的是:
如果页面首屏有图片
首屏时间 = 首屏图片全部加载完毕的时刻 - window.performance.timing.navigationStart
如果页面首屏没有图片
首屏时间 = 页面处于稳定状态前最后一次 dom 变化的时刻 - window.performance.timing.navigationStart
总体思路为:
从页面加载开始,按照一定的间隔打点,不断记录各个时刻下页面首屏图片列表和其他信息
问题:按照怎样的间隔打点?
找出页面首屏处于稳定状态的时刻 T1(到这个时刻为止,页面首屏可能已经稳定了一段时间)
问题:如何找出这个 T1?
以 T1 时刻的首屏图片数量为准,向前倒推,找到所有打点中最后一次和 T1 时刻首屏图片一致的打点时刻 T2
统计 T2 时刻的所有图片加载完成时间 T3
T3 即为首屏完成的时刻,进行上报
下面,一个个解决上文中提到的问题:
问题:如何找出首屏处于稳定状态的时刻 T1?
我们将页面从加载到渲染分为两大阶段:1. 获取数据;2. 数据获取完毕,渲染页面。
这个逻辑符合绝大部分的页面逻辑:先获取数据,再渲染页面。
解决方案:
通过 AOP 切面方式监听 XHR 的 send 对象,抓取页面中的第一个 XHR 请求,以第一个 XHR 请求发出的时刻为起点,统计在 1000ms 以内所有发出的请求到数组 Request 中。
我们认为可能影响首屏的请求在 [第一个 xhr 请求发出的时刻,第一个 xhr 请求发出的时刻 + 1000ms] 的时间段内均已发出。
针对串联型的请求(即下一个请求依赖上一个请求的返回数据),同时统计每个请求返回后,500ms 以内新发出的请求到数组 Request 中。
有些页面的数据请求方式是串行的,可能经过两个串联的请求后首屏的数据才能加载。
影响首屏的请求可能也会以这样的形式发出。
数组 Request 中统计到的请求,基本包含了所有影响首屏的数据请求,同时也包含了部分不影响首屏的数据请求。
针对上述统计到的请求,找到所有数据返回的时刻 T1,然后,T1 = T1 + 300ms,保证页面接收数据后渲染完毕(300ms 用于一次渲染足够了)。
此时的 T1 时刻,页面首屏被认为处于稳定状态。
问题:按照怎样的间隔打点?
MutationObserver
大家都知道 MutationObserver 对象用于捕捉页面 dom 变化,因此在脚本中,我们使用了 MutationObserver 监听 dom 变化,并在每次 dom 变化时触发一次打点(统计该时刻首屏图片信息)
setInterval
setInterval 也能实现定时打点
MutationObserver 和 setInterval 组合
但 MutationObserver 回调函数的触发时机开发者并不可控,有几种情况:
img 的 src 发生了变化或元素的 background-image 发生了变化,并不会触发在 MutationObserver 的回调,导致统计失误因此,我们现在的方案是结合 MutationObserver 和 setInterval,在 MutationObserver 回调的间歇,启动 setInterval,保证页面加载过程中打点间隔不会过长,提高统计准确率。
即使使用了上述复杂的打点与判断,误差仍然存在,那么,误差到底在哪里?
如下图所示:
不稳定状态(1 images) 稳定状态2(2 images) 稳定状态1(2 images)
| | |
|________________________|_______________________|
t1 t2 t3
按照上面的理论,我们会取 t2 时刻为可以统计首屏的时刻,两张图片加载完成的时刻即为首屏完成的时刻。
t2 和 t1 时刻差了 1 张图片。
按照我们的理论,首屏完成时间一定在 t2 之后的某个时刻 t2.n。
而实际相差的那张图片,什么时候加载完成的,我们不得而知,可能在 t2 前已经加载完毕了,也可能已经发出请求,但还没加载完毕。
误差就在这里,它总会存在。
但我们需要统计的是在误差可以接受范围内的首屏数据,根据在公司业务实践的反馈来看,数据可靠性很高。
我们也开源了这个小工具:
github: https://github.com/hoperyy/auto-compute-first-screen-time
npm: https://www.npmjs.com/package/auto-compute-first-screen-time
欢迎小伙伴们使用,吐槽,改进。
作者:刘远洋
公司:微店 - 前端团队
日期:2018-03-05
微店技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,发出你的声音吧!
周刊同步在 微店技术团队 github,欢迎关注:https://github.com/weidian-inc/weidian-tech-blog
康奈尔笔记法: 让你的学习更高效
康奈尔笔记系统把一页纸分成了三部分:

uber 开源的一个 数据可视化控件库:预览
Node.js 终端的实时 ASCII 三维渲染器。Github

Chrome 正在实现一个原生文件系统 API。资料
用 JavaScript 实现的 13kb 以内的游戏:链接
前端: Object.assign 和 Object Spread 之争, 用谁?(推荐者:@张川)
投稿人:生产力平台技术部 - 刘远洋
Babel 是 JavaScript 编译器(来自官网描述)。它将高版本 ECMAScript 语法编译为浏览器都支持的 ES5 语法。
Babel 毫无疑问是目前前端极其重要的基础设施之一了,在介绍 Babel 之前,我们简要梳理下 JavaScript 发展史。
1990 年底,万维网(WWW)诞生,可以在命令行查看网页。但通过命令行看网页,也是不太方便的。
1992 年底,美国国家超级电脑应用中心(NCSA)开始开发一个独立的浏览器,叫做 Mosaic。这是人类历史上第一个浏览器,从此网页可以在图形界面的窗口浏览。
1994 年 10 月,Mosaic 通信公司成立,不久后改名为 Netscape,其主要开发面向普通用户的新一代浏览器 Netscape Navigator。
1994 年 12 月,Netscape Navigator 发布了 1.0 版。该版本很受欢迎,但缺乏一种脚本语言,用于控制浏览器的行为。
1995 年,程序员 Brendan Eich 受雇于 Netscape 公司,只用了 10 天就开发出 JavaScript 1.0 版本,当时命名为 Mocha,1995 年 9 月改名为 LiveScript。
1995 年 12 月,Netscape 公司与 Sun 公司(Java语言的发明者和所有者)达成协议,后者允许将 LiveScript 叫做 JavaScript。对于两个公司而言都有益处:NetScape 公司可以借助 Java 的声势,而 Sun 公司则将自己的影响力扩展到了浏览器。
1996 年 3 月,Navigator 2.0 浏览器正式内置了 JavaScript 脚本语言。
1996 年 8 月,微软模仿 JavaScript 开发了一种相近的语言,取名为 JScript,首先内置于 IE3.0。
1996 年 11 月,Netscape 公司决定将 JavaScript 提交给国际标准化组织 ECMA(European Computer Manufacturers Association),希望 JavaScript 能够成为国际标准,以此抵抗微软。
1997 年 7 月,ECMAScript 1.0 版发布。
ECMA 组织发布 262 号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript。
由于 ECMA 的开放和中立性,ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的实现。
ECMA-262 标准后来也被另一个国际标准化组织 ISO(International Organization for Standardization)批准,标准号是 ISO-16262。
1998 年 6 月,ECMAScript 2.0 版发布。
1999 年 12 月,ECMAScript 3.0 版发布,成为 JavaScript 的通行标准,得到了广泛支持。
2007 年 10 月,ECMAScript 4.0 版草案发布,但该版本过于激进,分歧很大。
2008 年,Google 公司为 Chrome 浏览器而开发的 V8 编译器诞生。
2009 年,Node.js 诞生。Node.js 的出现促进了前端工程化的快速发展,前端由石器时代快速进入了工业时代。
2009 年 12 月,ECMAScript 5.0 版正式发布。截止 2012 年底,已得到绝大部分浏览器支持。
2010 年,NPM、BackboneJS 和 RequireJS 的出现,标志着 JavaScript 进入模块化开发时代。
2013 年 5 月,Facebook 发布 UI 框架库 React,引入了新的 JSX 语法,使得 UI 层可以用组件开发。
2015 年 6 月,ECMAScript 6.0 版正式发布,并更名为: ECMAScript 2015 标准。
2016 年 6 月,ECMAScript 2016 标准发布。
2017 年 6 月,ECMAScript 2017 标准发布,正式引入了 async 函数,使得异步操作的写法出现了根本的变化。
ECMAScript 标准目前保持每年一次发布的速度更新,相应的,部分浏览器对标准的支持会显得有些滞后。
于是,基于对高版本语法转译为低版本语法的各种工具被开发了出来。
下一步,我们来了解下 JavaScript 引擎。
JavaScript 引擎是一个专门处理 JavaScript 脚本的虚拟机,负责解析 Javascript 语言。
对于浏览器而言,其内核包括:渲染引擎(layout engineer 或者 Rendering Engine)、JavaScript 引擎等。
渲染引擎负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入 CSS 等),以及计算网页的显示方式,然后会输出至显示器或打印机。
浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。
下面是一些 JavaScript 引擎:
在了解了 JavaScript 及其引擎的各项背景后,我们来了解下 Babel。
Babel 是 JavaScript 编译器(来自官网描述)。它将高版本 ECMAScript 语法编译为浏览器都支持的 ES5 语法。
开发者编写的 JavaScript 代码,与浏览器等容器内运行的 JavaScript 通常是不同的,比如为了兼容低版本浏览器,需要将编写时代码转译为运行时代码。
举例:
// 这种语法,在 IE7 等低版本浏览器中是无法识别的,会报语法错误
const fn = (a, b) => a + b;
// 经过 Babel 及其插件编译为 ES5 后,IE7 等浏览器可以识别下面的代码
var fn = function(a, b) {
return a + b;
};Babel 发展史
2014 年,Facebook 的澳大利亚的工程师 Sebastian McKenzie 发布了 6to5 这个库,用于将 ES6 转为 ES5,它使用的 AST 转换引擎 fork 自 acorn。
2015 年 2 月 15 日,6to5 和 Esnext 的团队决定一起开发 6to5,并改名为 Babel,解析引擎改为 Babylon。后来,Babylon 移入到 @babel/parser。
2015-03-31,Babel 5.0 发布。
2015-10-30,Babel 6.0 发布。
Babel 自 6.0 起,就不再对代码进行修改。从这个版本开始,Babel 主要负责 Parse 和 Generate 流程,修改代码的 transform 过程全都交给插件去做。也就是说,Babel 只是一个语法解析器。
2018-08-27,Babel 7.0 发布。
Babylon、Babel 的含义**
创世记第 11 章 1-9 句记录了“巴别城”的故事。当时地上的人们都说同一种语言,当人们离开东方之后,他们来到了示拿之地。在那里,人们想方设法烧砖好让他们能够造出一座城和一座高耸入云的塔来传播自己的名声,以免他们分散到世界各地。上帝来到人间后看到了这座城和这座塔,说一群只说一种语言的人以后便没有他们做不成的事了;于是上帝将他们的语言打乱,这样他们就不能听懂对方说什么了,还把他们分散到了世界各地,这座城市也停止了修建。这座城市就被称为“巴别城”。
圣经是这样描写的:
4 他们说,“来吧,我们要建造一座城和一座塔,塔顶通天,为了扬我们的名,免得我们被分散到世界各地。”
5 但是耶和华降临看到了世人所建造的城和塔。
6 耶和华说,“看哪,他们都是一样的人,说着同一种语言,如今他们既然能做起这事,以后他们想要做的事就没有不成功的了。”
7 让我们下去,在那里打乱他们的语言,让他们不能知晓别人的意思。
8 于是耶和华使他们分散到了世界各地,他们也就停止建造那座城。
9 因为耶和华在那里打乱了天下人的言语,使众人分散到了世界各地,所以那座城名叫巴别。
——创世记11:4–9
Babel 本质上就是一个编译器,将一份代码编译为另一份代码。
Babel 的编译流程和大部分编译器的编译流程是相似的,包括三个过程:
第一阶段:解析( Parsing )
解析 是将最初原始的代码转换为一种更加抽象的表示( AST )。
它包括:词法解析( Lexical Analysis )和语法解析( Syntactic Analysis )。
第二阶段:转换( Transormation )
转换阶段会对 AST 进行遍历,在这个过程中对节点进行增删改查。
第三阶段:重新生成代码( Code Generation )
编译器有很多种,我们先不考虑其他类型的编译器,先详细了解下 Babel 的整个编译过程。
编译过程如下图:

Babel 在编译过程用到了一些工具集,如下图:

本文,我们从最简单的案例入手理解编译原理,不去深究 Babel 各个模块的源码。
解析 是将最初原始的代码转换为一种更加抽象的表示( AST )。
包括:词法解析( Lexical Analysis )和语法解析( Syntactic Analysis )。
2.1.1 词法解析( Lexical Analysis )
词法解析器( Tokenizer ) 在这个阶段将字符串形式的代码转换为 Tokens (令牌),这个过程由词法解析器( Tokenizer 或 Lexer )完成。
令牌( Tokens )是扁平化的语法片段数组,每个数组项包含了:代码片段( value )、代码位置( start / end )、类型( type ) 等信息,这些信息有助于后续的语法分析。
如 n*n 经过词法解析后,转换成的令牌如下:
// n*n
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
...
]每一个 type 有一组属性来描述该令牌:
{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
}
}词法解析器( Tokenizer )本质上就是一个字符串处理方法,入参是字符串,返回结果是数组。
function Tokenizer() {
const tokens = [];
// 字符串解析,并将结果
// processing
// 返回 Token 数组
return tokens;
}语法解析( Syntactic Analysis )
语法解析器( Parser ) 会把 Tokens 转换为抽象语法树( Abstract Syntax Tree, AST )。
AST 就是 JavaScript 中的一个 Object Tree,用于表示代码的语法结构。
举个例子:
const a = 1;
const b = 2;
console.log(a + b);会被解析为:

其中,Program、VariableDeclarator、CallExpression 等表示节点类型,每个节点都是一个语法单元。
节点类型的属性描述了节点的详细信息。
JavaScript 中的节点类型非常多,再加上 JSX、Flow 等,我们不需要记忆它们,在需要的时候,ASTExplorer( https://astexplorer.net/ )可以帮助我们快速查看代码的 AST。
很显然,语法解析器接收 Token 数组,转为 AST,本质上是一个转换方法:
function parser(tokens) {
const ast = {
type: 'Program',
body: []
};
// tokens to ast
// processing
return ast;
}这个过程 Babel 会对 AST 进行遍历,并且进行增删改查等转换动作。
Babel 所有插件都是在这个阶段工作, 比如语法转换、代码压缩等。
由于 AST 有众多类型的节点,在遍历 AST 过程中,需要用到 深度遍历 和 Visitor。
深度遍历,就是递归遍历 AST 对象;
Visitor,也就是访问者模式,它是一个对象,其 key 即为各个节点类型,值为各个处理方法。
转换过程如下:
// 转换器定义
function traverse(ast, visitor) {
// 递归遍历
// dfs(ast, visitor)
}
// 转换器执行
traverse(ast, {
Program(node, parent) {
// ...
},
CallExpression(node, parent) {
// ...
},
NumberLiteral(node, parent) {
// ...
}
});把 AST 转换回字符串形式的 Javascript,同时这个阶段还会生成 Source Map。
转换器接收一个 AST,并将其转为代码字符串。本质上是对象转字符串的方法。
function transformer(ast) {
let code = '';
// 遍历 AST,拼接 code 字符串
return code;
}了解了这个过程,我们就可以发挥其威力,做一些很酷的事情,比如自动添加埋点代码、代码压缩、自定义语法糖等等。
参考资源如下:

人工智能,重新定义未来
全栈化技术周刊整理每周有趣有用有料的各类内容,为大家呈现多样的技术世界。
周刊编辑:@何会会 / @张尚金 / @杨力 / @赵兴 / @刘远洋
周刊招募内容作者,主题不限,向团队发出你的声音吧!
flexbox解决一些经典的布局问题的方式(推荐者: @张尚金)
JavaScript modules(推荐者: @张尚金)
JS可选链(推荐者: @罗炜)
Java中lombok @Builder注解使用详解(推荐者: @何会会)
类react hooks写法的vue composition api完整指南(推荐者: @张尚金)
一文带你解锁Web应用中的图片优化技巧!(推荐者: @张燕玲)
liyasthomas/postwoman(推荐者: @刘远洋)
重磅!滴滴跨端框架Chameleon 1.0正式发布(推荐者: @张燕玲)
webpack插件模块tapable(推荐者: @罗炜)
TS 中的内置类型简述(推荐者: @蒋迪)
2019TLC大会精彩回顾—大前端·信息流(推荐者: @罗炜)
Vuex原理及应用场景分析(推荐者: @罗炜)
TensorFlow(一)(推荐者: @张燕玲)
TensorFlow(二)(推荐者: @张燕玲)
原文链接:https://www.cnblogs.com/accordion/p/11381033.html
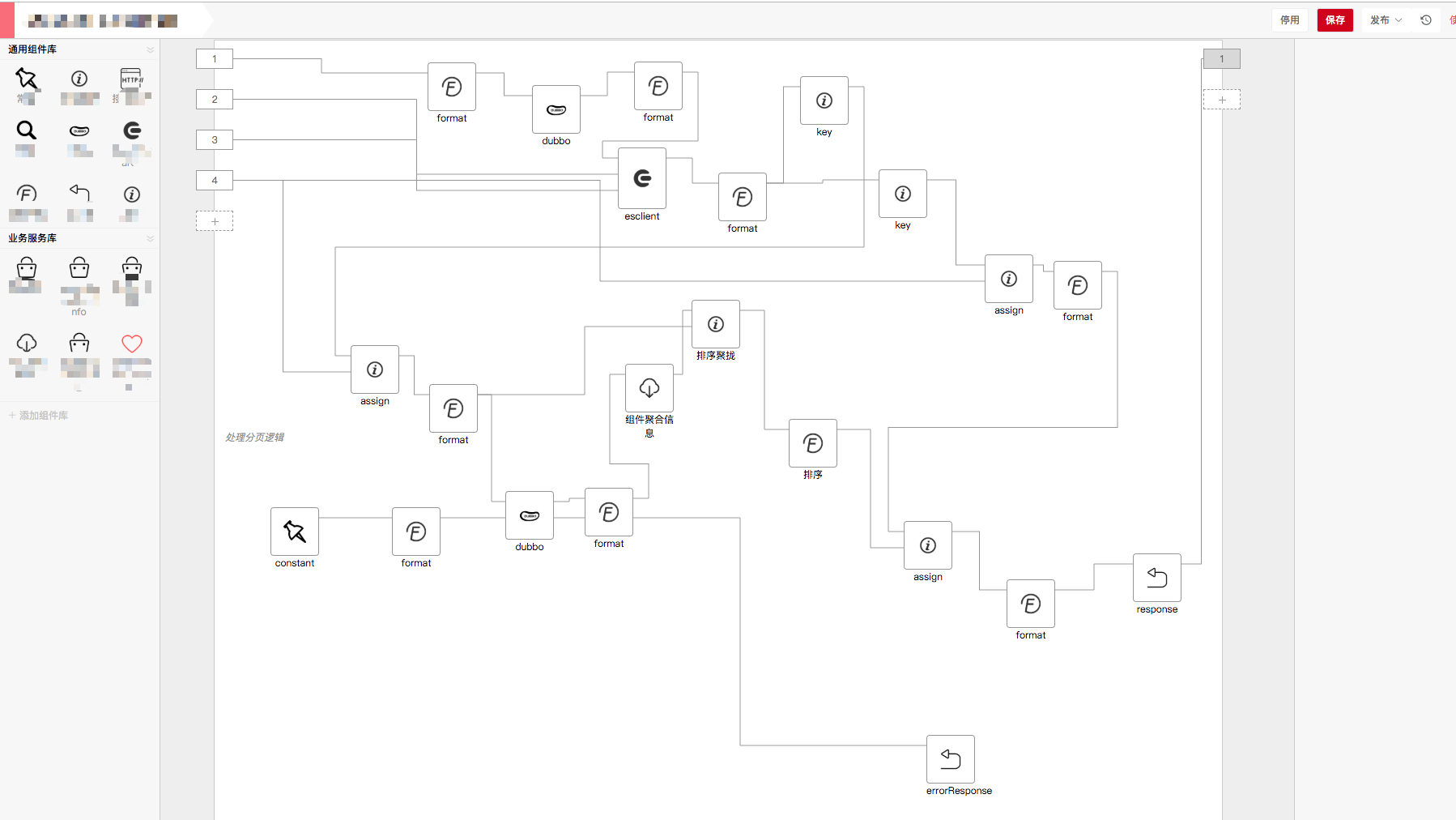
目前微店中台团队为了满足公司大部分产品、运营以及部分后端开发人员的尝鲜和试错的需求,提供了一套基于图形化搭建的服务端接口交付方案,利用该方案及提供的系统可生成一副包含运行时环境定义可立即运行的工程代码,最后,通过 “某种serverless平台” 实现生成后代码的部署、CI、运行、反向代理、进程守、日志上报、进程分组扩容等功能。
这样,产品和运营人员可基于此种方式搭建的接口配合常用的cms系统实现简单查询需求如活动大促的自主“研发”上线,代码的可靠性、稳定性由中台研发侧提供的“某种serverless平台”保障,有效支撑了多个业务快速上线,节省后端开发人员的人力与硬件资源的开销(大多数需求下,nodejs业务对虚拟机的资源开销小于java业务)。
此处并不讲解接口搭建系统的原理与实现,只说明其与上文提到的 “某种serverless平台” 的关系。
这是系统的全貌,部分细节由于敏感信息而省略。平台使用方可基于每个功能组件搭建出一套复杂的业务流,在搭建阶段,提供在线debug和日志功能,可用于排错;在部署CI阶段,可集成不同的运行时平台,既可以是自主实现的运行时,也可是第三方云平台;在运行阶段,通过使用agentool工具实时监控当前服务的性能,并可通过traceId一览请求在各系统的全貌。
本节以资源隔离粒度为度量,介绍了我对三种serverless方案的取舍以及最终为何选择了隔离程度更高的kubeless云平台。
Parse Server提供了基础功能:基于类与对象的权限控制、基于document的nosql存储、简易的用户身份认证、基于hook的自定义逻辑等,但经过笔者的调查与论证,最终并没有采用类似单进程下基于函数隔离的Parse Server及类似方案,这有几点原因:
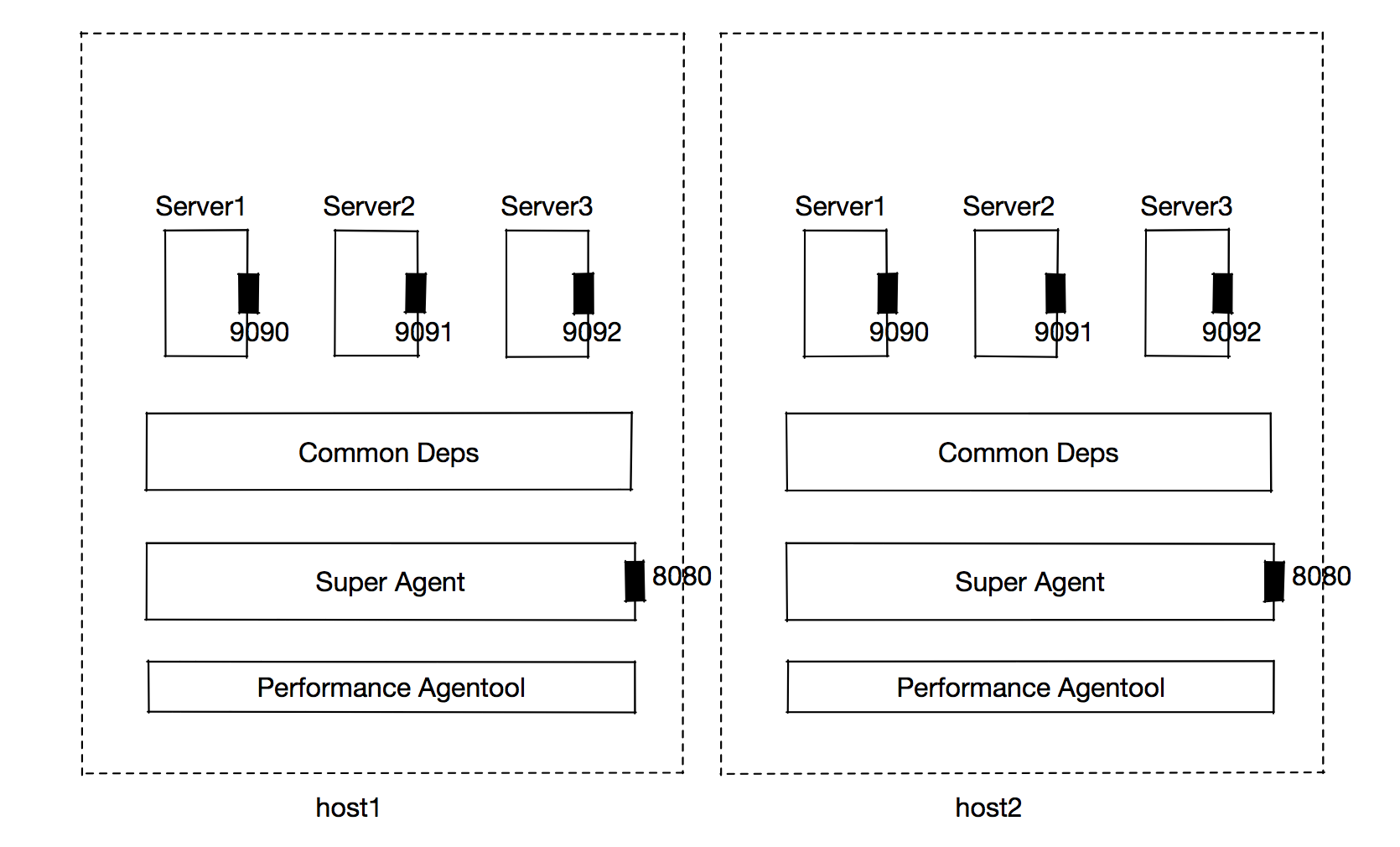
为了解决多个服务抢占libuv的问题,我选择了自主研发的 super-agent方案,通过其名称便可知它是一个超级代理,但它不仅是代理,还是一个具有极简功能且可靠的发布系统和运行时容器;它是一个分布式应用,节点间功能划分明确;它同时提供实时调试功能。
super-agent是一个多角色分布式系统,它即可以看做node容器,也可看成serverless的node实现,它以进程为粒度管理服务。它分为“协调者”和“参与者”,协调者实现 应用CI部署、启动、进程维护与管理和反向代理功能,参与者实现 业务请求代理、接受协调者调度。
在super-agent架构中,端口是区分服务的唯一标识,端口对客户端而言是透明的,这层端口资源的隔离由super-agent来做掉,因此多个服务可避免在libuv层的互相竞争,提供水平扩容的可能性。
super-agent最核心的功能在于反向代理。由于每个服务都被包装成有单独端口的独立HTTP应用,因此当用户请求流量经过前端转发层后进入super-agent,由其根据相关规则做二次转发,目前支持基于 “路径、端口”规则的转发。
后端应用部署需要进行 “优雅降级、流量摘除、健康检查、应用初始化完毕检查、流量导入、所有参与节点的部署状态查询” 等步骤,需要妥善处理;同时,协调者负责协调众多参与节点全部完成部署操作,这是一个分布式事务,需要做好事务出错后的相关业务补偿。
上图并未画出节点角色的区别,实际上只有参与者节点才真正接受用户请求。
协调者流量全部来自于内部系统,包括接受 “接口搭建系统”调用或者其他系统实现的dashboard服务;同时其会向参与者发送相关信令信息,如部署、扩容、下线、debug等。
参与者流量来自于内部系统和外部流量,其中大部分来自于外部流量。内部流量则承载协调者的信令信息。
服务的水平扩容重要性不言而喻。super-agent方案中,协调者负责管理服务的扩容与逻辑分组。
此处的服务是通过服务搭建平台通过拖拽生成的nodejs代码,它是一个包含复杂业务逻辑的函数,可以是多文件。具体的,super-agent通过将该服务包装成一个HTTP服务在单独的进程中执行。因此,如果要对服务进行水平扩容,提供多种策略的选择:
这些策略对下游应用透明,只需选择相关策略即可。
水平扩容的缺点:每台虚拟机或物理机资源有上限,一个正常的node进程最多消耗1.4GB内存,计算资源共享,在一台8C16G的虚拟机上,最多可同时运行16个服务。及时通过分组扩容的方式,每当扩展新的虚拟机或物理机,都需要由super-agent根据分组信息实现进程守护,同时每次服务CI部署也同样如此。运维管理上需要配合非常清晰明了的dashboard后台才能快速定位问题,这点在多服务的问题上尤其突出。
super-agent提供消息机制,由搭建平台中组件开发人员使用提供的serverless-toolkit工具debug相关逻辑,最终可在super-agent的协调者后台查看实时debug结果。
super-agent是符合常规的基于业务进程隔离的解决方案,它有效的支撑了微店的几个活动及产品,虽然峰值QPS不高(100左右),但它也论证了super-agent的稳定性及可靠性(线上无事故,服务无重启,平稳升级)。
但是,super-agent仍然存在几个问题,它让我们不得不另觅他法:
基于kubeless的方案则是隔离最为彻底的解决方法,kubeless是建立在K8s之上的serverless框架,因此它可以利用K8s实现一些非常有用的特性:
其中,自动伸缩则解决了 super-agent 的痛点。
kubeless中与我们紧密相关的有两个概念:“function和runtime” ,function是一个统称,它包括运行时代码、依赖以及其他配置文件;runtime则定义运行时依赖的环境,是一个docker镜像。
若要接入kubeless平台,我们需要解决如下几个问题:
因此,前进的道路仍然很曲折,而且很多需求需要自己从源码上去寻找解决方法。
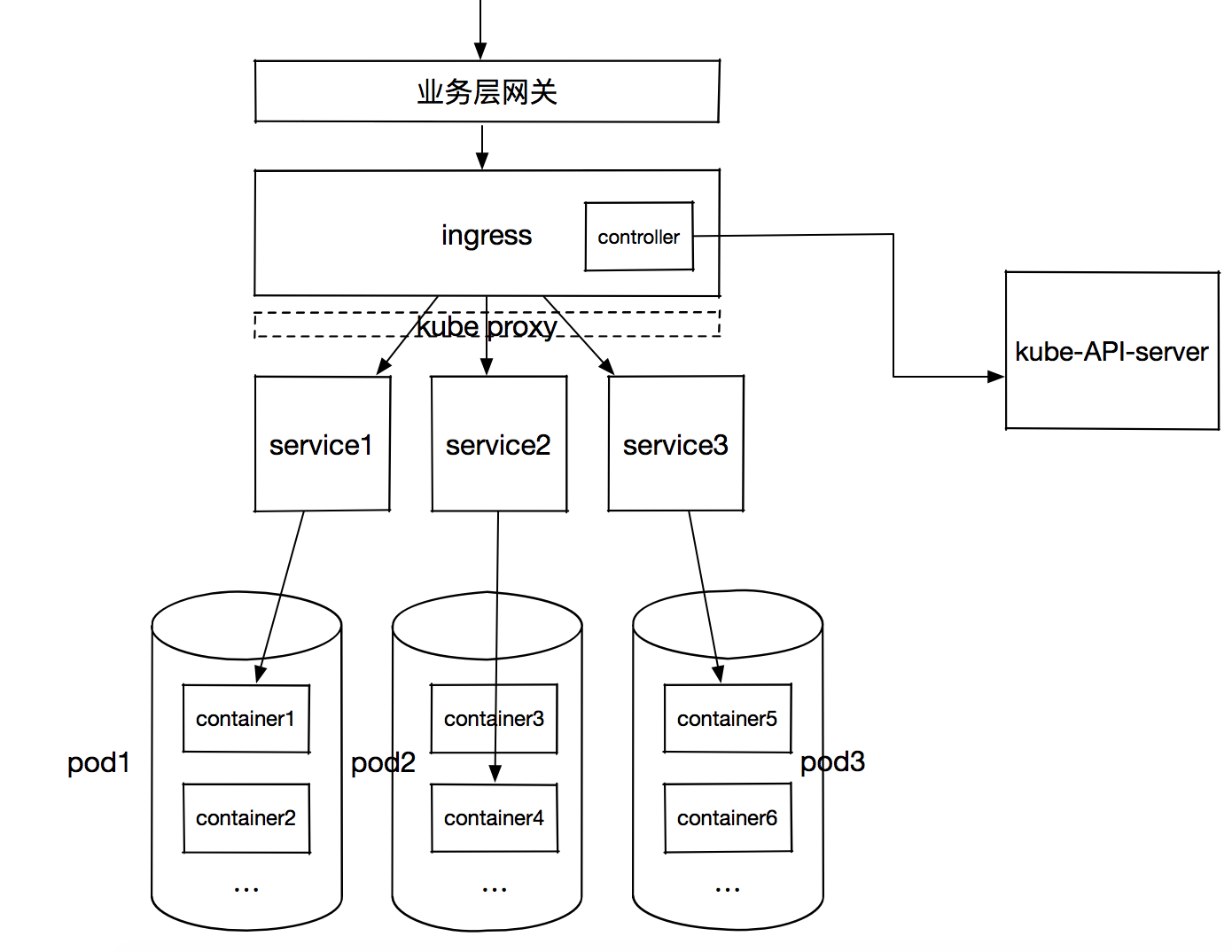
kubeless实现的serverless体系中,function所在pod中的所有容器共享网络和存储namespace,但是默认外网是不可访问k8s集群的所有pods,因此需要通过一层代理实现请求的转发,这就是“Service”。Service负责服务发现及转发(iptables四层),因此在Kubeless或者K8s中不会直接通过pod IP来访问服务,而是通过Service转发四层流量完成。Service有K8s分配的cluserIp,clusterIp是集群内部虚拟IP,无法被外部寻址,而是通过Kube-Proxy在容器网络之上又抽象了一层虚拟网络,Kube-Proxy负责Service的路由与转发(关于kube-proxy细节,请看参考资料)。
Service后端对应是一个或多个pods,这些pods中的一个容器则运行相同的业务代码。那么流量是如何路由至Service上来呢?这就涉及到Service的“发布”,常用的是Ingress。Ingress包括HTTP代理服务器和ingress controller,代理服务器负责将请求按照规则路由至对应Service,这层需要Kube-Proxy实现虚拟网络的路由;ingress controller负责从K8s API拉取最新的HTTP匹配规则。
运行在kubeless 中的函数和运行在super-agent的代码没有什么不同,可是周边的环境准备可大大不同。为了让kubeless中的function可以接入公司内部中间件服务,笔者费了不少功夫,主要集中在日志及收集部分。好在事在人为,解决的办法总是多于失败的方法。
目前,super-agent方案已承载了10+个线上应用或活动,稳定运行4个月,资源使用率符合预期;
kubeless方案还未正式接入流量,等待进一步做相关异常测试。
本文发表在 微店前端团队 blog
注意:bio 目前只兼容 Mac 平台
前端开发一站式解决方案。
使用 bio,您将只需关注业务逻辑,无需关注脚手架配置信息,即可快速完成前端开发。
额外地,bio 提供了 eslint、styleint 检测、mock 服务。
当前项目为 bio 客户端,bio 核心功能模块地址:https://github.com/weidian-inc/bio-core
github: https://github.com/weidian-inc/bio-cli
npm: https://www.npmjs.com/package/bio-cli

安装 Node.js(>= 8.9.1)
安装 bio
npm install bio-cli -g
第 1 步:创建项目目录
mkdir demo
cd demo
第 2 步:初始化各类项目
bio init bio-scaffold-vue: 初始化 vue 项目bio init bio-scaffold-react:初始化 react 项目bio init bio-scaffold-pure: 初始化 非 vue / 非 react 项目第 3 步:调试
bio run dev-daily
bio init <脚手架在 npm 源上的名称>
功能
初始化项目目录。
该命令会完成以下动作:
/Users/用户名/.bio/)README.md),该命令会为生成 demo 文件。npm install。脚手架
bio 目前内置了三个脚手架:
bio-scaffold-vue
bio-scaffold-react
bio-scaffold-pure
bio 使用 npm 托管脚手架,默认托管在 npm 官方源,您可自行设置托管源,代码地址
脚手架昵称
bio 为内置的三个脚手架都取了昵称:
bio-scaffold-vue --> vue
bio-scaffold-react --> react
bio-scaffold-pure --> pure
所以所有涉及脚手架名称的命令,均可以用昵称代替。
您也可以自行添加昵称,代码地址
bio run <脚手架支持的任务> [-n, --no-watch]
功能
启动脚手架任务。
bio 会启动脚手架,并透传任务名称到脚手架,以完成各类任务。
所以,任务名称是可变的,只要脚手架支持就可以。
我们默认提供的三个脚手架都提供了以下 6 种任务:
dev-daily -- 调试日常环境
dev-pre -- 调试预发环境
dev-prod -- 调试线上环境
build-daily -- 打包日常环境
build-pre -- 打包预发环境
build-prod -- 打包线上环境
详细信息可查看:bio 内置脚手架任务名称。
举例:初始化完 bio-scaffold-vue 项目后,启动它的 dev-daily 任务,命令即为:
bio run dev-daily
选项 -n, --no-watch 介绍:
bio 默认会 启动 一个文件监听服务,同步当前目录文件到脚手架目录,保证脚手架目录与业务目录始终是父子关系,供脚手架编译。(资料:(为什么要保证父子关系?))
-n, --no-watch 会关闭同步当前目录到脚手架目录的文件监听服务。
举例:
bio run build-daily -n 打包日常环境,并关闭文件同步监听服务
bio mock [端口]
启动本地 mock 服务,默认端口是 7000
如果希望指定端口号,可以直接指定,如:bio mock 8000
bio lint init [-t, --type [value]]
功能
初始化 lint,会自动在 git commit 前挂载 lint 执行钩子
选项 [-t, --type [value]] 介绍
默认初始化 es6 规则,如果希望在某个目录初始化 es5 功能,可以进入该目录,执行:
bio lint init -t es5
目前支持两种类型:es5、es6
bio lint [--fix] [-w, --watch]
执行 lint 检查,bio 会为你生成 lint 结果页面进行查看
--fix:自动修正源码中的代码格式。-w, --watch:启动文件监听,文件一旦有变化,会触发 lint 检查bio scaffold show <脚手架在 npm 源上的名称>
打开脚手架所在的本地目录。
bio scaffold create
创建脚手架,会提示你新的脚手架名称
bio help
help 信息


MIT
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.