

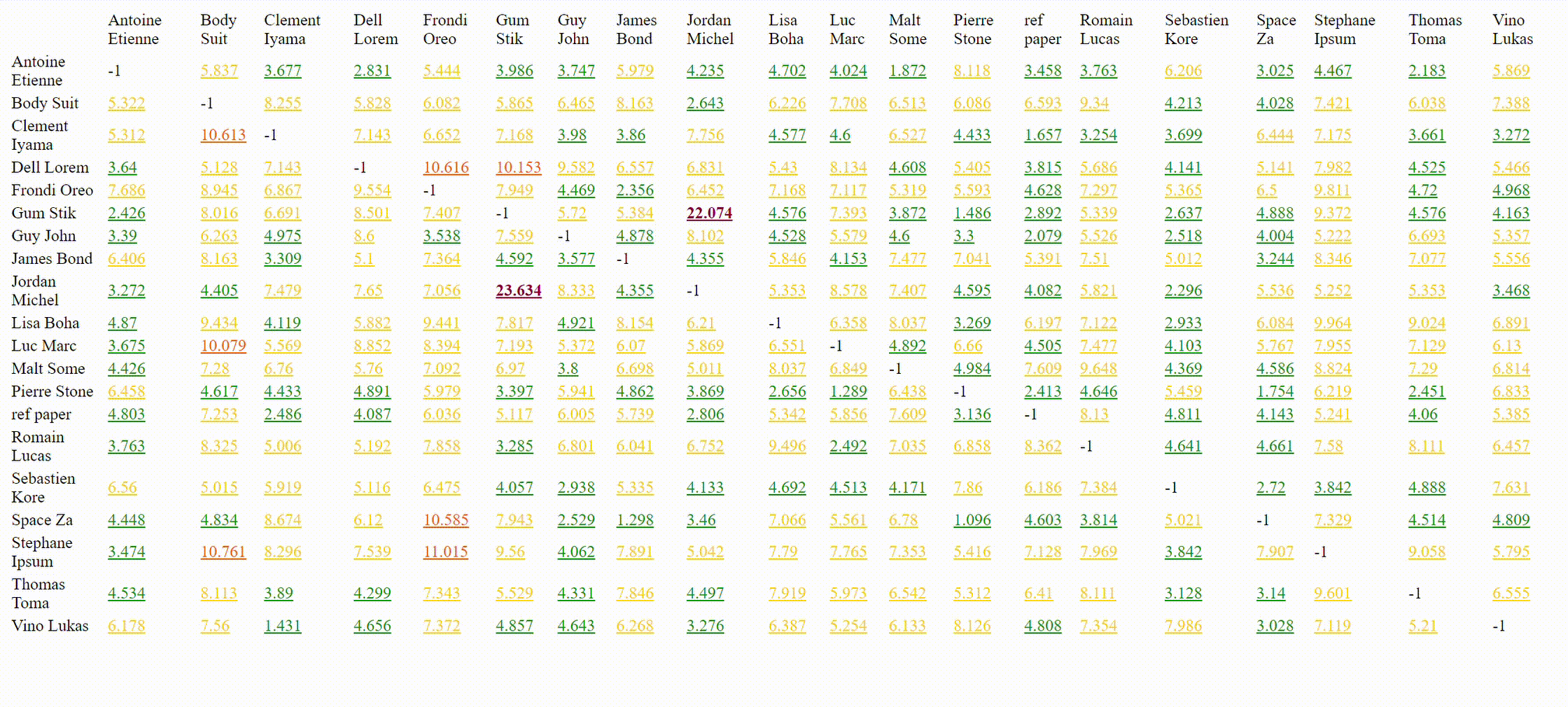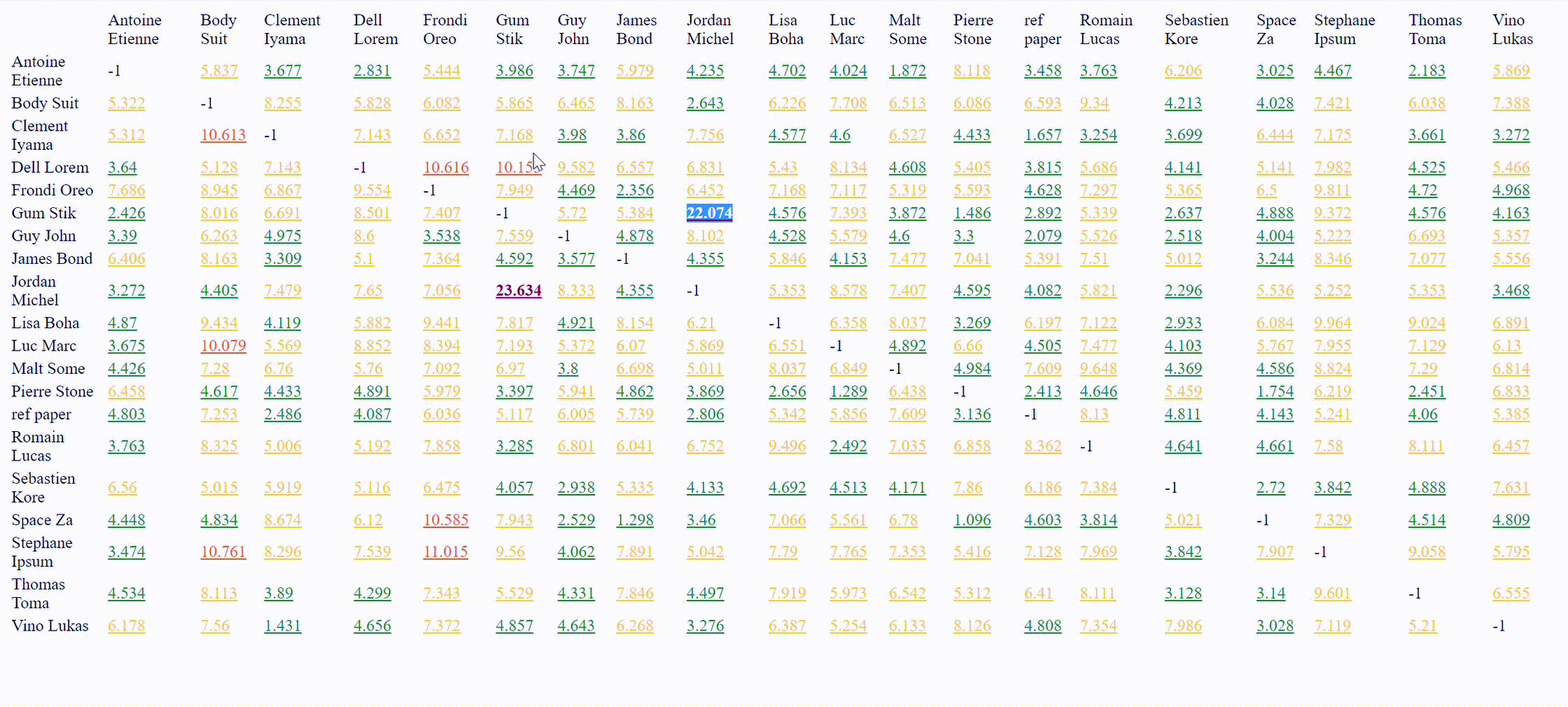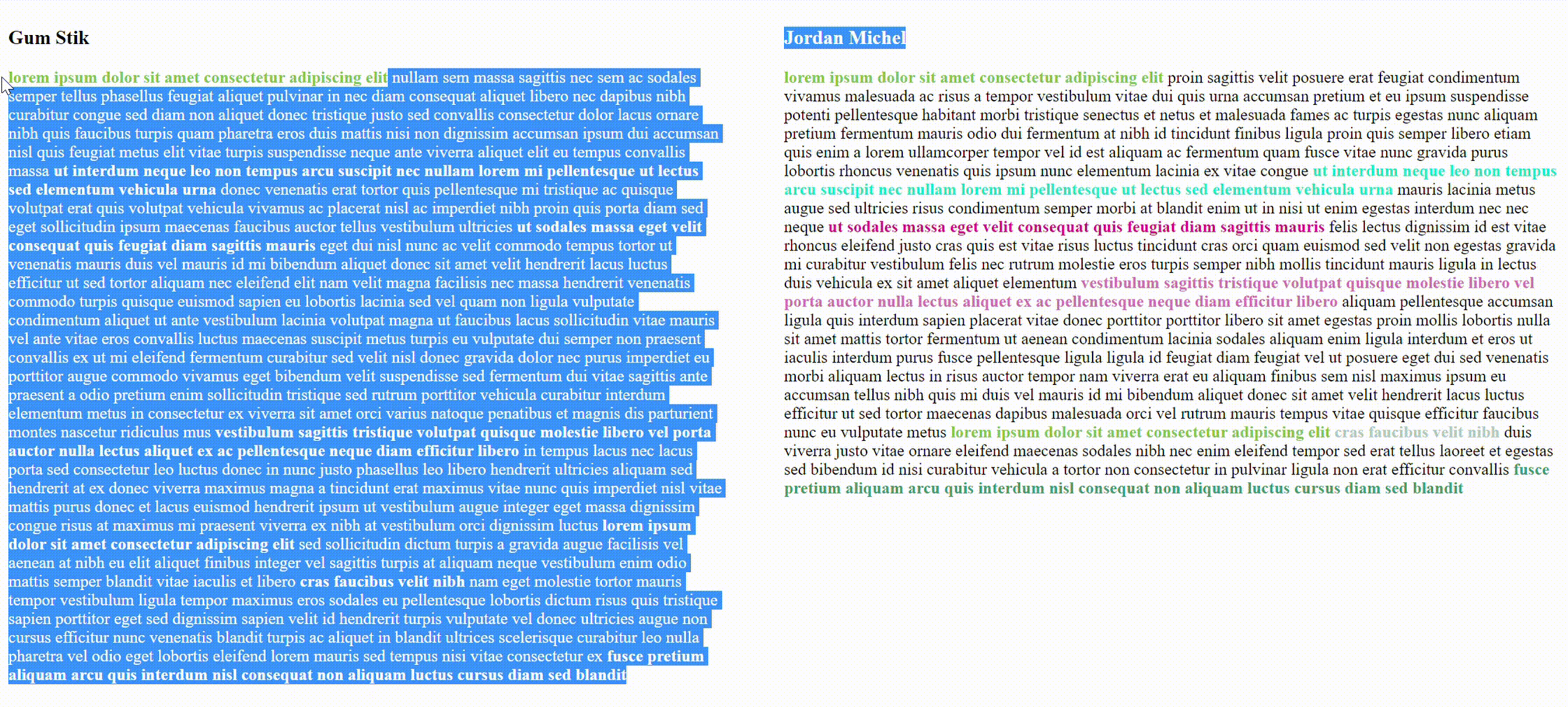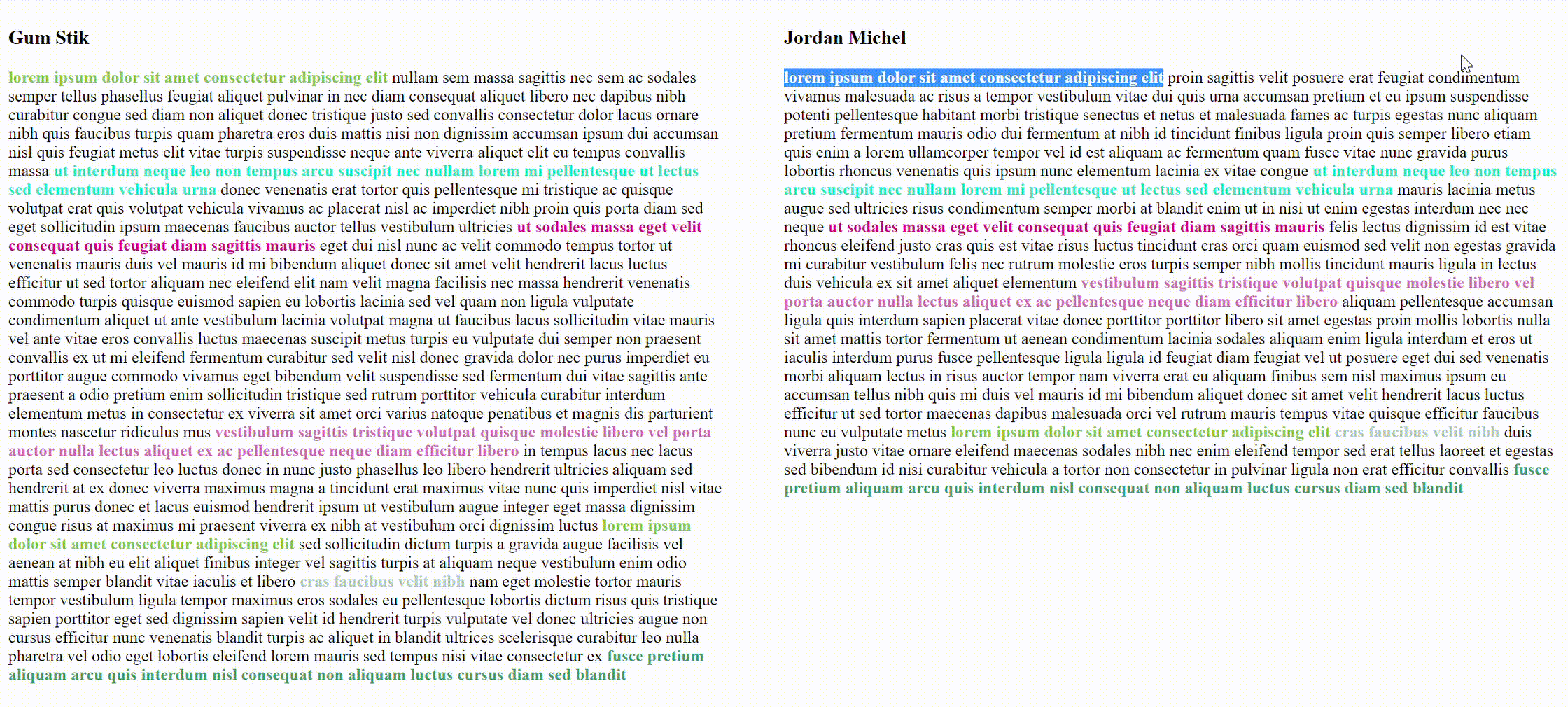
This program will process pdf, txt, docx, and odt files that can be found in the given input directory, find similar sentences, calculate similarity percentage, display a similarity table with links to side by side comparison where similar sentences are highlighted.
$ pip install copy-spotter
$ copy-spotter [-s] [-o] [-h] input_directoryPositional Arguments:
input_directory: One directory that contains all files (pdf, txt, docx, odt) (seedata/pdf/plagiarismfor example)
input_directory/
│
├── file_1.docx
├── file_2.pdf
└── file_3.pdf
Optional Arguments:
-s,--block-size: Set minimum number of consecutive and similar words detected. (Default is 2)-o,--out_dir: Set the output directory for html files. (Default is creating a new directory called results)-h,--help: Show this message and exit.
# Analyze documents in 'data/pdf/plagiarism', with default settings
$ copy-spotter data/pdf/plagiarism
# Analyze with custom block size and specify output directory
$ copy-spotter data/pdf/plagiarism -s 5 -o results/output# Clone this repository
$ git clone https://github.com/Wazzabeee/copy_spotter
# Go into the repository
$ cd copy_spotter
# Install requirements
$ pip install -r requirements.txt
$ pip install -r requirements_lint.txt
# Install precommit
$ pip install pre-commit
$ pre-commit install
# Run tests
$ pip install pytest
$ pytest tests/
# Run package locally
$ python -m scripts.main [-s] [-o] [-h] input_directory- Please make sure that all text files are closed before running the program.
- In order to get the best results please provide text files of the same languages.
- Pdf files that are made from scanned images won't be processed correctly.
- Ensure you have writing access when using the package
- If a specific file is not processed correctly feel free to contact me so that I can address the issue.
- Add more tests on existing functions
- Implement OCR with tesseract for scanned documents
- Add custom naming option for pdf files
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")






































