从零开始





下面的图都可以点击查看大图
EventLoop是HTML规范,SecAgent、Execute Context、Promise这些是ECMA规范。EventLoop、任务队列、宏任务、微任务等概念,不是简单的一对一关系。一个执行上下文有一个EventLoop,而一个EventLoop可以生成多个任务(Task或MacroTask)队列。宏任务通常指的是任务队列里的任务,而微任务是一个独立的任务列表,可以理解为一个优先任务集合。Task -> MicroTask -> render的方式运行每次循环,但render不是必须的。
一些细节:
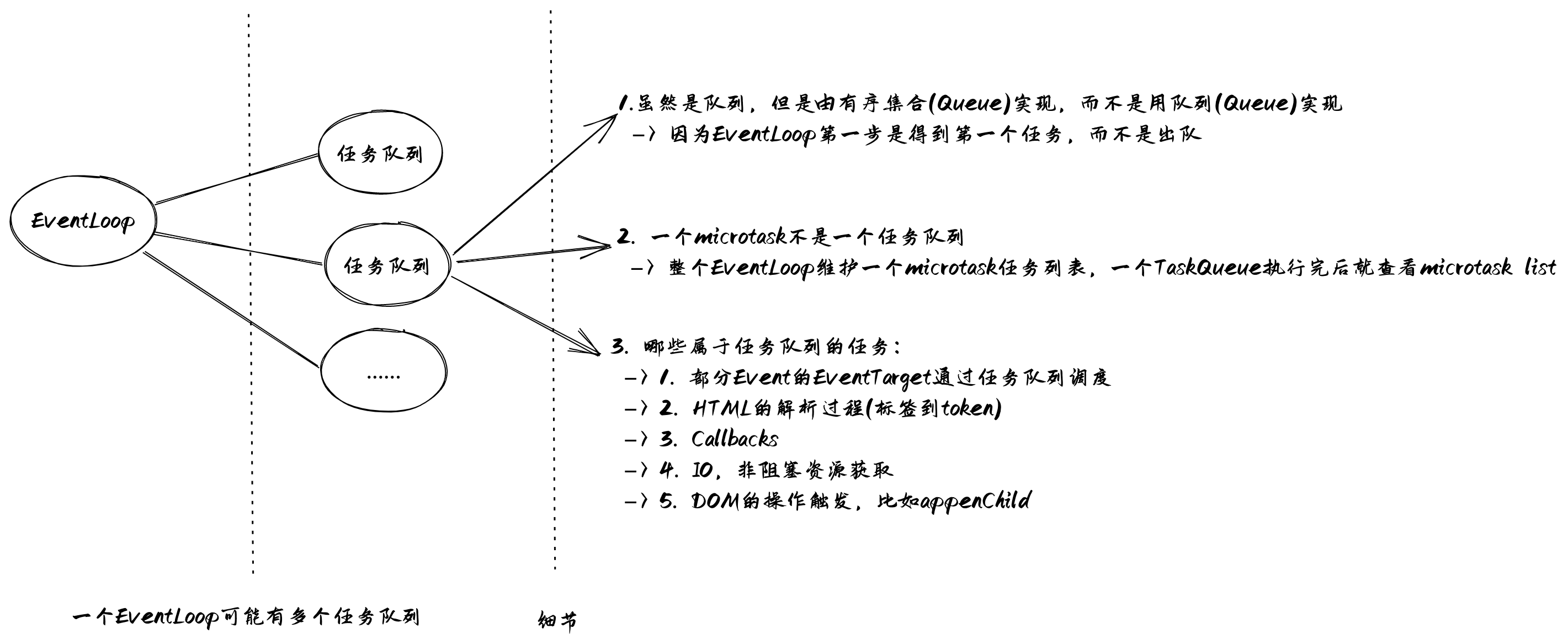
Promise标准里面没有规定必须是MicroTask,因此有的浏览器版本里面Promise的then方法还是一个MacroTask,不过现在的浏览器都统一了then为一个MicroTask;另外就是node环境和window环境的实现也是不一样的,这是由不同环境的需求决定的。EventLoop都有一个正在运行的Task,Task也可以是null,null后可以开始新的事件循环EventLoop都有一个MicroTask队列,由自定的算法生成MicroTask,每一个TaskQueue(宏任务队列)执行完毕后,就去查看是否有MicroTask等待执行,有的话就执行所有的MicroTask。事件循环的流程、步骤
TaskQueue成为一个任务队列,一个任务队列必须包含一个可运行的任务,如果没有,则跳到微任务流程(7)OldestTask)作为第一个可运行的任务,然后从TaskQueue中删除它EventLoop的当前执行任务为这个OldestTaskTaskStartTime为当前高分辨时间(current high resolution time)OldestTaskEventLoop的当前执行任务为nullMicroTask。触发微任务检查,从MicroTaskQueue中查询是否存在微任务,存在则依次取出执行hasARenderingOpportunity = falsecurrent high resolution time)OldestTask执行时间。计算方式:top-level browsing contexts为一个空集合TaskStartTime、now等参数来计算执行时间render)。如果是window环境,执行下面的步骤docs为该事件循环关联的DocumentRenderingOpportunity,没有渲染机会的更新,docs会被删掉。关联知识点:渲染阻塞、动画渲染原理、合并渲染等概念hasARenderingOpportunity = trueDocument依次运行全局的任务,flush autofocus candidates、resize steps、scroll steps、evaluate media queries and report changes、update animations and send events、fullscreen stepscanvas相关的方法,并更新animations frame callbacks)update intersection observations stopsmark paint timingwindow环境、当前活跃的Document关联的EventLoop的任务队列没有任务、微任务列表为空、hasARenderingOpportunity = false,则对当前用户代理下的任意Window对象,都执行一个idle period algorithm表示浏览器渲染器空闲worker线程的EventLoop,那么执行worker相关的流程微任务检查和执行流程
EventLoop如果performing a microtask checkpoint = true,返回performing a microtask checkpoint = true。一个微任务可能生成更多的微任务,因此有一个变量来避免重新进入同一个微任务的执行。MicroTaskQueue不为空:oldestMicrotask从MicroTaskQueue中出队EventLoop的当前执行任务为oldestMicrotaskoldestMicrotaskEventLoop的每一个环境变量,通知那些reject的任务IndexedDB事物ClearKeptObjects()。和WeakRef.prototype.deref()有关,可以让这个方法返回值被垃圾回收。performing a microtask checkpoint = false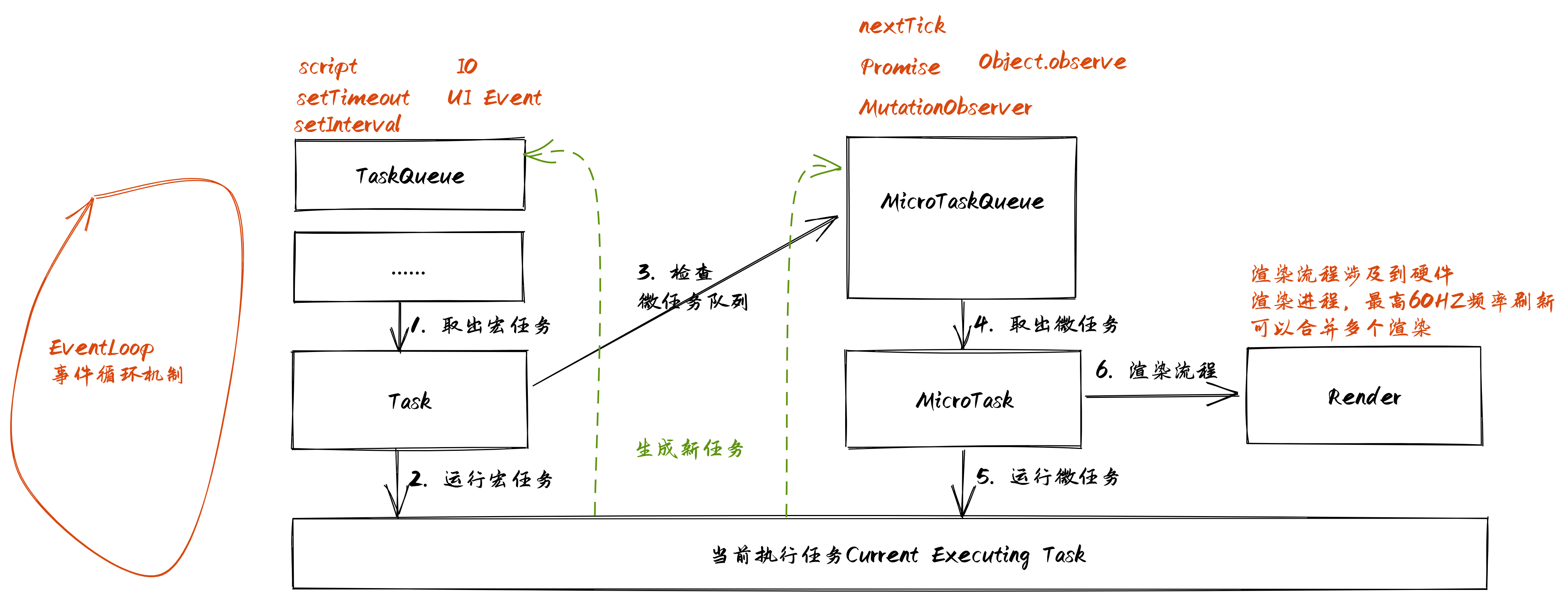
browsing context浏览器上下文一个执行上下文,如一个页签、一个iframe,和worker的上下文有区别,实现上就是相互独立的。然后event loop是在一个执行上下文下的,同源的浏览器上下文可以共用event loop,这样互相之间就可以通信。
JavaScript是单线程的,在函数执行的时候,运行时会有一个Execute context(ECMA标准,执行上下文),执行上下文存储了函数的参数、局部变量等信息,执行上下文位于栈顶,执行时有新的函数调用,会压栈,函数调用完毕,会弹栈。
执行dom.style.width = "100px"是同步更新还是异步更新?
-> 宏任务执行时提交给Render过程,由浏览器渲染线程决定是本次渲染还是合并到下次渲染。是同步过程,但是如果是下一个周期再渲染,看起来就像是异步的。
异步的含义?比如setTimeout
-> 定时器相当于一个工人,在特定时间会把回调任务加入到任务队列中去,至于任务何时被调用,是不关心的,是由事件循环调度的。
宏任务和微任务的区别?
-> 大部分操作都会生成新的宏任务:UI事件、键盘事件、原生回调相关的操作、ajax相关操作,宏任务队列可以有多个,而整个线程内的微任务队列只有一个,每个宏任务队列调度完毕都会访问和检查微任务队列。合理运用微任务可以优化我们的代码执行(减少因单线程造成的阻塞)。
UI渲染为什么会阻塞JS执行?
-> 当前执行任务(可以是宏任务,也可以是微任务)结束后会提交给渲染器,渲染器可以合并多次提交来优化渲染流程,但整体来 说虽然渲染器和JS线程是独立线程,但是渲染任务也是属于一次任务的过程,渲染没有完成,下一次宏任务调度就等待。从使用的角度来说,UI渲染和JS完全异步的话,可能会造成我JS取的元素和实际元素有偏差,因此都是按照同步的方式实现的。浏览器通过合并UI计算来减少渲染次数。
动画的第一帧/过渡效果在有些时候没有出现?
-> 有可能就是因为UI渲染合并了。可以通过设置初始值、增加一个任务(宏任务、微任务)触发回流来让动画不丢帧。
其实搞懂了它的标准,就知道90%的问题答案了。很明显标准里面描述的都是同步执行的过程,是一步步地执行任务、渲染,只是说渲染这个过程,和硬件也有关系,做了一些合并运算的优化而已。另外就是你不管它是宏任务还是微任务,它都是当前执行任务,它产生的不同类型的新任务,会添加到对应的任务队列中去。
ECMAScript 2015规范引入了箭头函数,它没有this,没有arguments。只能作为一个表达式(expression)而不能作为一个声明式(statement),表达式产生一个箭头函数引用,这个引用仍然有name和length属性,分别表示箭头函数的名字、形参(arguments)长度。
// const语句把表达式x=>x的值输出到标识符id
const id = x => x;
console.log(id.name, id.length) // id 1
const x = id;
console.log(x.name, x.length) // id 1 表明name和length是原始引用携带,不因标识符改变而改变做一些简单的运算
// 加法
const add_1 = (x, y) => x + y;
const add_2 = x => x + y; // y来自外部(闭包引用外部参数)
const add_3 = x => y => x + y; // 可以用闭包串联参数(即柯里化)
const add_4 = b => a => a + b; // 参数命名和算式结果无关这是直接针对数字(基本数据类型)的情况,如果是针对函数(引用数据),事情就变得有趣起来了
const fn_1 = x => y => x(y); // 存储函数,延迟执行。这也是函数式编程「惰性计算」的来源
const fn_2 = f => x => f(x); // 替换变量名字,结果一样
const add_1 = (f => f(5))(x => x + 2); // 7 = 2 + 5
const add_2 = (x => y => x + y)(2)(5); // 7 = 2 + 5
const add_3 = (x => x + 2)(5); // 7 = 2 + 5
const add_4 = 2 + 5;fn类型,表明我们可以利用函数内的函数,当函数被当作数据传递的时候,就可以对函数进行操作(apply),生成更高阶的操作。
add类型表明,一个运算式可以有很多不同的路径来实现。
我们回到数学,用抽象符号来表示上面我们用到的运算式
// λx.x
const id = x => x;λ表示后面是一个运算式λx表示这个运算式的输入为x,参数命名可以替换,和我们写函数变量一样.x中.的右半部分表示运算式的主体,这里是直接返回xλx.x整个表示一个lambda表达式λx.x y表示将y传入lambda表达式计算,术语称为应用(apply)学到这个记法后,我们可以有更多的表示
// λx.x + 1 运算体
const addOne = x => x + 1;
// λx.λy.x + y 多参数表达/等价表示
const add_1 = (x, y) => x + y;
const add_2 = x => y => x + y;
// (λx.λy.x + y) 1 2 表达运算
const three = (x => y => x + y)(1)(2);lambda表达式是左结合的(left associate),在不产生歧义的情况下可以去掉括号。也就是说
// (λx.λy.x + y) 1 2 表达运算
// 实际是
// (((λx.λy.x + y) 1) 2) 表达运算
const three = (x => y => x + y)(1)(2);数学家阿隆佐·邱奇在上世纪30年代提出了λ演算,它可以让我们从抽象的角度来描述「计算」这件事,λ演算和图灵机是等价的,都可以描述我们的计算过程。
比如上面我们提到的加法运算,如果是三位数字参与运算,由于加法有交换律,因此a + b + c和c + a + b得到的结果是一样的,我们更关心「计算」这件事本身,而不是参数的顺序。用λ表示为
// λx.λy.λz.x + y + z
const add = x => y => z => x + y + z;这是一种抽象的表述,这种抽象可以把复杂的「计算」过程变得更加简单。
考虑一个运算式
// λx.x 记住,x只是一个记号
// λf.f
const id = x => x;
// λx.x x
const x = 1;
const y = id(x); // 1
// (λx.x x)(λx.x x)
// 如果用f表示函数,这里会比较清晰一点
// (λf.f x)(λf.f x) f为函数,表示λ运算参数和返回都是函数,x为一个函数
const x = id;
const y = id(x)(id(x)) // id这个id函数的应用((λx.x x))称为ω 组合子,在很多函数式语言中,被称为identity、id函数,它表明我们运算式可以进行组合。((λx.x x)(λx.x x))被称为Ω。
之前我们讲过monad,monad对自己使用id函数,得到自己。这是一个定律。
应用场景-自运算/简化参数
const arr = ['1', '2', '3']
const res_1 = arr.map(Number) // [1, 2, 3]
const res_2 = arr.map(parseInt) // [1, NaN, NaN]这里的Number函数就是一个类似的id函数(如果你把Number看成一个Monad类型),它把x映射到Number域上。不过这个比喻并不恰当。
id函数的意义在于创建了一个演算系统的基本数据,比如自然数里面1(0)就是最基本的,只要我们定义+1方法,就可以遍历到所有的自然数。
也就是说数学抽象了基本数据和方法,这对应我们在monad中学到的概念Number(1) -> Just(1)。
const id = x => x
const addOne = f => () => f() + 1;
const zero = id(() => 0); // () => 0
const one = addOne(zero); // () => 1
const tow = addOne(one); // () => 2前面我们提到了柯里化,它把多参数的函数转换为一个单参数函数调用链
// 简单实现
const curry = function (fn) {
let len = fn.length;
let params = [];
return function apply(x) {
params.push(x);
if (params.length === len) {
return fn(...params);
} else {
return apply
}
}
}
const add = (x, y) => x + y;
const chainAdd = curry(add);
// λx.λy.x + y
chainAdd(1)(2); // 3通过「映射关系」来思考,可以把事情变简单。
// 这个箭头,你可以理解为一个映射: x -> x 从一个域x映射到另一个域x,这里两个x相等
const id = x => x;
// 左边为集合{x, y},映射到{x + y}:(x, y) -> x + y
const add_1 = (x, y) => x + y;
// 柯里化 x -> y -> x + y;
const add_2 = x => y => x + y;现在你可以这么理解(就像我们讲范畴论的时候一样),所有的程序都等于一个数据x加上对他的操作E。
也就是λ演算: λx.E。E是对参数x的应用。
归纳一些重要的点
lambda函数实际上,在λx.x中,x大部分情况下都是函数,也就是说一个lambda函数作用于另一个lambda函数,得到新的lambda函数。
λx.x的表示方式和λy.y的表示方式是等价的
λx.x不存在自由变量,λx.xy则存在自由变量y
(λx.T)S形式的应用可以简化为T[x:=S]形式。其中(T/S都是lambda表达式)
(λx.x)s -> x[x:=s] -> s
(λx.y)s -> y[x:=s] -> y
归约就是不断地代换参数的过程。
上面我们说的id(id)这个是个特殊的规约,永远不会停止。
lambda演算是Haskell的基础。后面我们将学习一下Haskell语言。体会什么叫真正的函数是第一等公民。
总的来说,λ演算就是我们抽象「计算」过程的一种方式,就像我们可以把微积分、复数等概念从自然中抽象出来一样。编程中的核心应用就是一切数据都是函数。
./js-design/json.parse.js和./js-design/json.stringify.js。leetcode 1448
二叉树要统计xx节点、计算xx高度、进行xx排序,都需要遍历二叉树。就像数组你要排序就总会遍历一下数组本身。这里也是。所以核心是遍历过程中什么可以作为我们的判断依据。
核心:没有比该节点大的数字。暗示了我们在遍历过程中仅需要记录最大值就行了。
代码使用先序遍历,遍历时,给定一个max初始值,每次访问到一个节点,就比较节点和链路max节点的大小,以此更新cnt和max
/**
* Definition for a binary tree node.
* function TreeNode(val, left, right) {
* this.val = (val===undefined ? 0 : val)
* this.left = (left===undefined ? null : left)
* this.right = (right===undefined ? null : right)
* }
*/
/**
* @param {TreeNode} root
* @return {number}
*/
var goodNodes = function(root) {
if (!root) return 0
let cnt = 0;
function dfs(root, max) {
if (!root) return root;
if (root.val >= max) {
cnt++;
max = root.val;
}
dfs(root.right, max);
dfs(root.left, max);
}
dfs(root, root.val);
return cnt
};# 下面的注释
# 1. 示例使用alpine;更换发行版需要自己重新配置。
# 2. option开头的都可以不配置
# 表明自己是基于哪个镜像/这里是alpine linux最新版;包管理器为apk
FROM alpine:latest
# option 环境变量设置
ENV RUNNING_IN_DOCKER true
# 安装基本依赖
# apk update更新包索引
# apk add --no-cache 添加包/不缓存
# git和openssh-server必选,自己开发能用
# bash必选,用其他的终端,vscode远程过来会报错;zsh可选
# curl/wget可以二选一,也可以都装
RUN apk update && apk add --no-cache \
git \
curl \
bash \
wget \
zsh \
openssh-server
# vscode server依赖包
RUN apk add --no-cache gcompat libstdc++ grep dropbear-scp dropbear-ssh
# 安装最新版本的 Node.js。apk中nodejs和npm是分开的两个包,需要都安装
RUN apk add --no-cache nodejs npm
# option 安装pnpm,节省磁盘空间
# option 安装nestjs,开发后台服务需要
RUN npm i -g n pnpm @nestjs/cli
# option 安装最新版本的 Neovim。如果你不用nvim,可以不装;当然也可以装vim
RUN apk add --no-cache neovim
# 初始化 git 自己替换下面的字符串
RUN git config --global user.name "Name"
RUN git config --global user.email "[email protected]"
# 设置 SSH 服务器;chpasswd前的用户名密码可以自己更换
RUN mkdir /var/run/sshd
RUN echo "root:admin123" | chpasswd # 登录用户名密码
RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config # 允许root登录
RUN sed -i 's/AllowTcpForwarding no/AllowTcpForwarding yes/' /etc/ssh/sshd_config # 允许端口转发,方便vscode remote-ssh
RUN ssh-keygen -A # 生成key
# 设置工作目录;/app可以替换为你自己喜欢的目录,会创建在用户名下面:/root/app
WORKDIR /app
# option 环境变量
# RUN sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
# 启动 SSH 服务器和终端。终端使用bash,不然vscode远程上来有问题
CMD /usr/sbin/sshd -D && /bin/bash
# rc 服务管理 添加sshd服务,方便你后面改sshd_config后,使用rc-service sshd restart来重启
RUN apk add --no-cache openrc
RUN rc-update add sshd
RUN rc-status
如果你已经适应了函数式编程,尤其是了解副作用和纯函数,那么你可以跳到"展开讲讲monads"
函数式编程是一个经常有相当多的“包袱”的话题,对monads(单子)来说更是如此。当被这些主题后面的形式化术语或数学轰炸时,就很容易在google搜索中迷失,尤其是很多函数式编程迷都认为形式化术语和数学是了解FP/monads的最基本要求。
听我说:你不需要计算机或者数学的学位证书就可以沉浸于函数式编程,并进一步采用monads相关的思维方式。形式术语和数学在你需要深入了解FP/monads时可以提供更丰富和深入的经验知识,但你并不需要一开始就从它们开始来学习FP/monads(除非你想这样!)
你曾写过这样的代码吗?
const FPBookNames = [];
for (const record of data) {
if (record.topic == "FP") {
FPBookNames.push(record.bookName);
}
}这就是我们通常意义上说的“命令式”代码风格。这对大多数人来说是熟悉的。但它只关注于如何完成一个任务。为了理解这段代码发生了什么或者为什么这么写,你必须在大脑中执行这段代码并推测它的含义。只有读完这段代码后,你才可能了解到:“这段代码的意思是把主题为FP的记录筛选出来并把它们的bookName放到数组里面去”
如果你的代码可以更“声明式”,并且状态的是什么和为什么可以一瞥下来就更清楚,也不再强调为什么,为什么只作为一个不那么重要的实现细节,会怎么样呢?
这就是函数式编程存在的意义。
举个例子,想象你有一个字符串值,你想把它转为大写。
function uppercase(str) { return str.toUpperCase(); }
var greeting = "Hello, friend!";
console.log( uppercase(greeting) ); // HELLO, FRIEND!这个实现相当直接。当假设你现在有多个字符串要转为大写。你可以手动对每个字符串调用uppercase(..)。但是当我们有多个值,把它们放到数组里面,才是最方便的。处理字符串数组的命令式方式:
// assumed: function uppercase(str) { .. }
// assumed: `listOfStrings` (array of string values)
for (let i = 0; i < listOfStrings.length; i++) {
listOfStrings[i] = uppercase(listOfStrings[i]);
}这里,我们修改数组中的原始字符串条目,用大写版本替换它们。在函数式编程中,我们通常更希望不去修改或者重新赋值,而是创建新的值。创建新的值是一种减少那些可以导致程序出现bug的意外的副作用的方式。让我们用这种方式来创建一个list:
// assumed: function uppercase(str) { .. }
// assumed: `listOfStrings` (array of string values)
let listOfUpperStrings = [];
for (let i = 0; i < listOfStrings.length; i++) {
listOfUpperStrings[i] = uppercase(listOfStrings[i]);
}这代码相当好。但是当你第一次遇到它,为了了解这段代码是什么,你不得不在脑海中执行该代码并推测它的目的。然后,你可以断言,“这段代码取一个数组中的每个字符串,然后产生一个新的大写版本的字符串数组。”
给数组的每一个值执行一个相同的操作,是一个相当通用的编程任务。以至于我们为这个任务命名并为它发明了众所周知的工具程序map(..)。我们来看一下:
// assumed: function uppercase(str) { .. }
// assumed: `listOfStrings` (array of string values)
const listOfUpperStrings = listOfStrings.map(uppercase);数组的map(..)操作只有一个单独的函数作为输入,这个函数接受一个单独的值,函数返回一个值。uppercase(..)适合这个参数格式,所以我们就直接传递给map(..)。map(..)给我们一个新的数组,数组的值是所有调用提供的函数uppercase(..)后从原始值生成的新的值。
一个通常的对FP的断言是:一个循环调用数组的机制,这个机制对数组的每个值调用一个函数来处理,众所周知的是这种方式(循环处理)不需要在代码中显式编写。
FP已经识别出了大量这种公共的任务,并将它们命名和实现为了公用的程序。
举个例子,filter(..)做了和map(..)相似的操作,但是它不产出新的值,它只判定一个值是否应该保存在新的数组中。
// assumed: `listOfStrings` (array of string values)
function isLongEnough(str) { return str.length > 50; }
const listOfLongStrings = listOfStrings.filter(isLongEnough);listOfLongStrings是一个新数组,仅包含原始listOfStrings数组中那些长度大于50的字符串。这个结果应该和我们用for循环命令式地实现等效操作相比而言,更易阅读。
我们甚至可以“组合”map(..)和filter(..)操作:
// assumed: function uppercase(str) { .. }
// assumed: function isLongEnough(str) { .. }
// assumed: `listOfStrings` (array of string values)
listOfStrings.filter(isLongEnough).map(uppercase);现在我们有一个足够长的大写字符串数组!
这就是进入FP带给你的一些早期的被采用的思维模型。这是巨型冰山的一角。
如果你好奇,但是FP概念对你来说是新的,我推荐你看一下-至少前几章-我的免费在线FP书Functional-Light JavaScript。
这里有一些high-quality video courses about FP on Frontend Masters,包括:
Bianca Gandolfo's "From Fundamentals To Functional JS"
Anjana Vakil's "Functional JavaScript First Steps"
My "Functional-Light JavaScript" -- a companion course to my book of the same name
我认为你的第一个大目标应该是理解FP并对这些主题感到舒适:
你怎么知道你是从FP到monads转变过程中走在正确的路线上并且感到舒适?这个指南上,我没有好的方式来回答读者的这个问题。但是我至少希望能够提供一些简要概览或者一些提示给你,而不是留下一些不满意的话,“看情况而定”。
当然,在FP方式中,一开始有很多方法来实现完成FPBookNames代码片段的处理。我不会去断言有一个“最正确的方式”。
但是在FP中有些常见的方式,它依赖链式表达式和组合(柯里化)函数,被称为“point-free风格”,可能就像这样:
const FPBookNames = data
.filter(
compose(
eq("FP"),
getProp("topic")
)
)
.map( getProp("bookName") );再次声明,不要去说这是“最正确”的方式来处理这个逻辑,但是,像这样的代码代表了来自FP的**组合,我认为这将帮助你准备接受monads的概念。特别是我在接下来的部分中将贯通展示它们。
当代码写得就像“和你说话”,我认为是时候带你进入monads的海洋了。
在这份指导之外,我推荐看一下这个视频 recording of my conference talk, "Mo'problems, Mo'nads".
Monad是"范畴论"广泛概念中的一个小概念。你可以简要地、不完整地描述范畴论为一个基于事物在组合和转换中的表现来分类和分组事物的方法。
Monad类型是一种在程序中表示值或者操作的方法,它将某些特性行为和那个值或者操作相关联。通过对原始值增加操作,这些额外的行为作为一种“保证”,规定如何与程序中其他Monad表示的值/操作来进行可预测的交互。
这是概念上定义monads是什么。但你可能想看一些代码。
我们在js中能实现这种概念的最简要方式是什么?这个怎么样:
function Identity(v) {
return { val: v };
}
function chain(m,fn) {
return fn(m.val);
}这就是monad最基础的实现。特别的是,“Identity”这个monad,意味着它会保留一个值,在你想要用的时候,不用去直接使用这个值。(而是通过Identity来操作)
const myAge = Identity(41); // { val: 41 }我们只在一个对象容器中放置一个值,这样我们就可以识别该值为单子化(monadically)的。这个容器是一个方便的实现单子的方式,但是实际上这不是必须的。
chain(..)函数提供了一个最小的兼容操作monad实例的方式。比如,想象我们想要41的一元表示,并且产生另一个从41增加到42的monad实例。
const myAge = Identity(41); // { val: 41 }
const myNextAge = chain( myAge, v => Identity(v + 1) ); // { val: 42 }值得注意的一个重点是,即使我在这里使用Identity和chain,但这只是简单的一个选择而已。Monad对我们用什么命名事物而言,并没有明确的要求。但是如果我们使用他人常用的名字来命名,它有助于创造一个提升我们交流方式的熟悉环境。仅此而已。
chain(..)函数看起来非常基础,但是他是非常重要的(不管你用什么名字来表示它)。我们将深入了解一下它。
我敢肯定这段代码似乎让大多数读者都感到印象深刻。为什么不简单的使用41和42,而要用{val: 41}和{val: 42}呢?使用mondas的为什么好像不是很明确。你必须和我一起再聊聊其他的才能开始谈为什么。
但希望我至少从根本上已经展示给你看了,monad并不是什么神秘或复杂的东西
Monads以前被用各种听起来愚蠢的比喻来描述,比如墨西哥卷饼。有的叫monads为“包装盒”或者“盒子”,或者“数据结构”...事实是,这些描述monad的方式都是片面的。就想看一个魔方,你可以从一个面看到方块,然后转向后看另一个不同的面,以得到更整体的认知。
一个完整的理解需要熟悉各个方面,但是完整的理解并不是一个单一的原子事件。它通常是基于许多小的理解建立起来的,就像每次只能看到魔方的一个面一样。
现在,我只想你专注于这个事:你可以给一个值42或者一个操作console.log("Hello, friend")增加/关联额外的行为来增强它们,给他们超能力。
这有另外一个可能的阐释monads的方式,使用Monio带来的能力。
const myAge = Just(41);Monio相关文档看: Just
上面的代码展示了一个Just(..)函数,它和Identity(..)之前展示的函数很像。Just这个monad的行为就像一个构造器(单元)
并且
const printGreeting = IO(() => console.log("Hello, friend!"));我们看另一个Monio的IO(..)函数,它表现得像是一个IOmonad的构造器(保留函数)
回想我们之前的草稿,你可以大体认为myAge就像{value: 41},printGreeting就像{ val: () => console.log("Hello, friend!") }。Monio的表示方式比仅仅一个对象更加复杂,但它的底层并没有什么不同。
我将在这个指南的剩余部分使用Monio。这是很方便来利用的例子,并且更容易来说明。但是请记住在这所有展示之外,我们可以做更直接的事情,比如定义一个对象{val: 41}
考虑数组的map(..)方法的概念。它的任务是对所有关联数组的值应用一个映射(值转换)操作。
[ 1, 2, 3 ].map(v => v * 2); // [ 2, 4, 6 ]注意:这个功能(map)相关的技术术语是函子(Functor)。事实上,所有的monads都是Functors,但是目前不要太担心这个术语。只需要你脑海有这个概念即可。
这个映射操作在我们数组只有一个元素的时候也当然成立,对吧?
[ 41 ].map(v => v + 1); // [ 42 ]一个很容易被我们忽略的极其重要的细节就是,map(..) 函数并不产生42,而是产生[42]给我们。为什么?因为map(..)的任务是产生一个它调用的原始容器相同类型的实例。从这个意义上说,如果你使用数组的map(..),你就是总会得到一个数组。
但是如果我们的容器是一个monad实例呢?如果这个monad下只有一个值41?因为monad也是一个Functor(可以被映射),我们应该可以期待一个相同类型的输出吧,对吗?
const myAge = Just(41);
const myNextAge = myAge.map(v => v + 1); // Just(42)希望这里有实际的意义,myNextAge应该是另一个Just的实例,这个新的Just表示有一个底层的值42
还记得上一章中的这个简单示例吗?
// assumed: function Identity(val) { .. }
// assumed: myAge ==> { val: 41 }
const myNextAge = chain( myAge, v => Identity(v + 1) ); // { val: 42 }用Monio的实现来替换就是:
const myNextAge = myAge.chain(v => Just(v + 1));所以map(..)和chain(..)之间的关系是什么?让我们把它们写到一起来看看:
myAge.map( v => v + 1 ); // Just(42)
myAge.chain( v => Just(v + 1) ); // Just(42)现在你明白了吗?map(..)设定它的返回值需要在一个容器实例中被自动包装,而chain的返回值需要是一个已经被包装为正确容器类型的值。
map(..)函数根本不需要被命名来满足monad实例的Functor行为。实际上,你甚至根本不需要一个map(..)函数,如果你有一个chain(..)函数的话,可以实现一个map(..):
function JustMap(m,fn) { return m.chain(v => Just(fn(v))); }
fortyOne.map( v => v + 1); // Just(42)
JustMap(fortyOne,v => v + 1); // Just(42)有一个map(..)函数(不论它真名叫什么)比起chain(..)函数本身来说,是很方便的事情,但map(..)函数并不是必须的。
chain(..)函数有时候是另外的名字(在其他库或者语言中对monad概念进行实现时),比如flatMap(..)或bind(..)。在Monio的monads中,所有的这三个方法是等效的,任意选一个来用就行了。
命名flatMap(..)可以加强这个操作和map(..)之间关系的理解。(map(..)自动装箱,flatMap(..)手动装箱)
Just(41).map( v => Just(v + 1) ); // Just(Just(42)) -- oops!?
Just(41).flatMap( v => Just(v + 1) ); // Just(42) -- phew!如果我们从map(..)返回一个Just实例,它就会在外层还有一层Just包装,所有我们就得到一个嵌套两层的monad值。这个是合法的操作,有时候我们就希望如此,但通常情况下我们不希望这样。如果我们用flatMap(..)返回相同的类型(也叫chain(..)/bind(..)),这就没有嵌套。本质上,flatMap(..)函数将返回值扁平化了一层!
chain(..)方法旨在为提供的函数返回一个与调用该方法的函数相同类型的monad。然而,Monio通常不执行显示类型强制,因此没有严格组织这种monad类型较差的情况。(比如Just和Maybe)是否遵循这些机制的隐含类型特征取决于开发者自己。
我已经断言chain(..)(不论你称为什么名字)是作为单子(monadic things)最重要的概念。然而,即使像chain(..)看起来实现起来一样简单(see earlier),它却提供了一种特别的方式来保障一个monad如何和其他的monad实例作交互。这些相互作用和转换对于构建一个没有混乱的monads程序而言是至关重要的。
Monad魔方的另一面是这些保证。它们被确保为定律一样的东西,所有符合monad实现的事物都必须遵守:
这些定律的形式和数学重要性现在并不重要,但是用我们微不足道的Monio的Just(identity monad)来非常简单地说明一下这些定律:
// helpers:
const inc = v => Just(v + 1);
const double = v => Just(v * 2);
// (1) "left identity" law
Just(41).chain(inc); // Just(42)
// (2) "right identity" law
Just(42).chain(Just); // Just(42)
// (3) "associativity" law
Just(20).chain(inc).chain(double); // Just(42)
Just(20).chain(v => inc(v).chain(double)); // Just(42)这里我用Monio的chain方法,这仅仅是个方便的演示说明。monad的定律是用chain操作来表述的,不论你选择怎么称呼它。
归根结底的是,Monad类型只是要求做这两件事情:
Just Maybe)chain操作,满足交换律和结合律你在本指南中的代码片段中看到的,比如包装monad实例、指定方法名称、"friends of monads" behaviors等,所有的方便提供的类型都来自于Monio。
但从这个狭隘的角度来看,一个monad并不需要是一个“容器”(比如包装一个object或class实例),也并不需要一个具体的值(比如42)。一个“包装着一个值的容器”是一个可观察的潜在有用的魔方面(包装的容器是观察理解monad的一个例子),它并不是monad的全部样貌。在你的思维中不要有太多“包装”相关的想法!
你可能仍然奇怪:我们如何提取值(比如基本数据类型42)--或者实际上,如何把monad所代表的一切--从单子表示(monadic representation)中提取出来?目前看起来好像每个单子操作都只是产生另一个monad实例。从某种意义上说,我们可能需要一个实际的数字42来打印,或者插入数据库,对吧?!
一个FP的重要概念(尤其是monads里面),是延迟我们对底层值的需求到最后的时刻。对于monads,我们更希望尽可能长地保持所有的“提升”在单子空间(monadic space)。
但又是我们确实需要转换一个monad到“真实”的值。有很多方式可以完成这个操作,但是这有一个方式,预览我们将在talk about later in the guide中说的。为了从一个monad(比如Just) 中“提取”值,我们可以使用一个Monio提供的方法fold(..)
const identity = v => v;
const myAge = Just(41);
const myNextAge = myAge.map(birthday);
// later:
const ageIsJustANumber = myNextAge.fold(identity);
console.log(`I'm about to be ${ ageIsJustANumber } years old!`);
// I'm about to be 42 years old!所以,这里有一个“逃逸值”(fold(identity)),让我们可以从我们的Just中退出。
但是记住:monads可以和其他monads很好的交互(and their friends!),所以最好的方式是尽可能地保持值在单子空间。让我们推迟丢弃monad表示的方式,直到我们必须这么做!
同时记住:fold(..)方法提供给Monio的众多monads,它并不是Monad类型的行为。它来自于from a friend called Foldable
Monio 相关文档看: Maybe
Just单子可能并不那么神奇。它很可爱,也许有点聪明,但它有点不起眼。实践中,我们几乎不会直接创建一个Just单子实例。
这些只是基础。它本身并不应该看起来具有革命性,因为这将呈现出太高的一个悬崖,而我们可能高不可攀。如果您小时候第一个数字不是2或者3,而是 √2或π,你可能会发现在小时候学习基础数学非常难!
如果Just对你来说看起来太简单了,那可能是一件好事!你可能正在“学会”monads。但是不要让它简单到让你觉得枯燥,觉得没有值得你花时间的知识。是有这样的知识的!
在这个基础的monad概念之上,有很多变体/增强的概念,会让事情变得更加有趣。我可以花很多时间和很多页来详细说明他们的例子。但是让我通过简单的演示另外的一些建立在Identity单子之上的monads的例子来逐步进行。
你可能之前命令式的程序里面写过这种样式的代码:
const shippingLabel = (
(record != null && record.address != null && record.address.shipping != null) ?
formatLabel(record.address.shipping) :
null
);当我们对这些期望他们不是null的值进行操作时,我们必须在整个程序中使用!= null检查来避免js异常。
然而,最新的js(ES2020)增加了一个“可选链”(optional chaining)操作,可以简单地做这些事情:
const shippingLabel = (
(record?.address?.shipping != null) ?
formatLabel(record.address.shipping) :
null
);?.操作(而不是.),是一个短路操作符,当左值为null时就跳过操作。这意味着我们不需要record != null或者record.address != null检查,因为?.帮我们做了这个事。
我们的操作现在就被保护起来了,不会在null上操作,但record.address.shipping仍然可能是空的,我们想要在这种场景下跳过formatLabel(..)操作,因此最后我们还有一个!= null的检查。
Maybe单子,有时候在其他库和语言内被称为Option或者Optional,允许我们定义一个行为来讲这些!= null完全委托给monad的行为,将我们从这些行为中解放出来。
为了了解Maybe,让我们先在我们之前讨论过的Just Identity单子之外增加一个monad类型:琐碎而不起眼的monad,我们称为Nothing(表示空)。Nothing比Just做的事情还少:它使得你在它上面调用的任意方法短路。就像一个方法黑洞,可以安全地跳过有危害的操作。Nothing是安全的,它就像是单子化的null或者undefined。
Maybe是一个Sum Type,它表示这两种monad类型(Just Nothing)的对偶性。这并不是说Maybe同时是两种类型,而是说它要么是其中一个,要么是其中的另一个。
注意:大多数monad实现不会暴露Just和Nothing作为单独的monad类型,而是只有一个Maybe类型。Monio选择分开表示他们同时也可以用Maybe结合他们,是为了方便演示的目的。
在Maybe:Just和Maybe:Nothing之间做选择在一开始可能会有一些迷惑性。你可能期望决策本身来源于一个单元构造器Maybe(..)。实际上,大多数受欢迎的monad教程/博客都是这么做的,因为这样令Maybe的演示更加方便也令人满意。
但这并不是合适的monad方式。Monio做了更恰当的事情,并将决策从Maybe(..)/Maybe.of(..)构造器转移到一个名为Maybe.from(..)的独立帮助函数中。Maybe.from(null)将得到一个Maybe:Nothing实例,Maybe.from(42)将得到一个Maybe:Just实例。
相比之下,调用Maybe(..)/Maybe.of(..)不会做任何条件选择,而只会将任何非Maybe的值表示为Maybe:Just。
此外,Maybe.from(..)为Nothing.isEmpty(..)代理了这个问题,“它是空的吗?”。Nothing.isEmpty(..)函数会执行== null检查,但是你可以覆盖他以重新定义什么值你想定义为Maybe.from(..)的空。
所以我们用Maybe.from(..)来创建Maybe:Just或Maybe:Nothing实例。下面的代码中,.chain(..)调用将因此带来副作用令一个和另一个相对(Maybe本身仅作为一个薄弱的传递包装器)
const shippingLabel = (
Maybe.from(record)
.chain( record => Maybe.from(record.address) )
.chain( address => Maybe.from(address.shipping) )
.chain( shipping => Maybe.from(formatLabel(shipping)) )
);shippingLabel就是一个Maybe类型。它要么表示Maybe:Just,有一个值,要么表示Maybe:Nothing,为空。
但是不论它表示哪个,都不影响我们写monad风格的代码串!如果Maybe.from(..)在这个链的任意位置产生一个Maybe:Nothing,任意子序列的chain(..)操作将跳过,因此把我们的代码从因bull造成异常的情况下保护起来。
Maybe安全抽象了我们之前关于对保护操作不引发异常的条件决策逻辑的担心。
上面的代码可能有些繁琐,让我们用一些帮助函数来清理它:
// assumed:
// function formatLabel(label) { .. }
// helpers:
const getPropSafe = prop => obj => Maybe.from(obj[prop]);
const formatLabelSafe = v => Maybe.from(formatLabel(v));
const shippingLabel = (
Maybe.from(record)
.chain( getPropSafe("address") )
.chain( getPropSafe("shipping") )
.chain( formatLabelSafe )
);这代码看起来更棒一些。而且这里没有让我们代码显得杂乱的!= null检查。
我们的shippingLabel单子现在准备好和其他monads行为交互了,并且这些交互会安全可预期,不论它具体是Maybe:Just还是Maybe:Nothing。
我们代码更进一步的提升可以用Monio提供的便利。一个monad的帮助函数,pipe(..):
const shippingLabel = (
Maybe.from(record)
.chain.pipe(
getPropSafe("address"),
getPropSafe("shipping"),
formatLabelSafe
)
);我们看到,chain.pipe(..)允许你组合多个.chain(..)序列为一个按序排列参数的调用。在Monio的monads上,你可以用.map.pipe(..)和.ap.pipe(..) .concat.pipe(..)做同样的事情。除了增加便利性之外,在某种程度上,它也稍微更有效率/性能更好。
顺便提一下,Maybe也是Foldable,所以可以用fold(..)退出,获得逃逸值。但因为Maybe是一个Sum Type,这里的fold(..)有两个函数,第一个Maybe:Nothing时调用,第二个Maybe.Just时调用。更多看:using Foldable and other adjacent behaviors later
你可能希望开始看一些monad表示值和表达式带来的更多好处。
Monio Reference: IO (and variants)
目前为止,我们已经看到那些表示直接基本数据类型比如42或者表示对象的例子。但是monads不仅仅是“值包装器”。
monads也可以被认为是一种“行为包装器”,表示一些操作,比如那些我们认为不可靠的,可能产生副作用的方法或者函数。这就是IO单子所做的事!
Monio的核心是IO单子的实现。它被设计为一个超级强大的Sum Type,它包含了各种有用的行为,有点像Scala's ZIO。我认为Monio的IO是js中最强大的IO实现。但我知道这只是一个令人生畏的主张。
别担心,为了继续,我们现在要专注于一小块IO功能,这样我们就不会不知所措。
你在IO中传入的那个函数,在执行时将开始一些副作用操作。它并不必须是副作用操作。它可以是静态的、纯函数,就像普通函数一样返回一个值。
最重要的概念是IO单子类型是惰性的,它并不即时做任何事情(就像你调用普通方法一样自动执行并返回值)。你必须评估IO能执行的操作。
For example:
const greeting = IO(() => console.log("Hello, friend!"));
// later (nothing has happened yet!)
greeting.run();
// Hello, friend!An IO, once evaluated, can also produce a value:
一个IO,一但运行了,可以产生一个值。
const customerName = IO(() => (
document.getElementById("customer-name-input").value
));
customerName.run(); // "Kyle"run(..)方法可以认为有点像Just和Maybe上的fold(..)。它帮助你执行IO单子,并把副作用行为从单子空间逃逸出来。
就像我们已经断定过几次的那样,“最佳实践”的重要目标是保持我们程序的副作用为IO操作,并只在程序需要的最后一刻消耗他们(逃逸/运行/执行)。
这有个复杂的例子串联一些IO在一起
// helpers:
const getProp = prop => obj => obj[prop];
const assignProp = prop => val => obj => obj[prop] = val;
const getElement = id => IO(() => document.getElementById(id));
const getInputValue = id => getElement(id).map( getProp("value") );
const renderTextValue = id => val => (
getElement(id).map( assignProp("innerText")(val) )
);
const renderCustomerNameIO = (
getInputValue("customer-name-input")
.chain( renderTextValue("customer-name-display") )
);
// later:
renderCustomerNameIO.run();你可以看到,这里我们组合了一些副作用操作在一起,就像我们之前组合数字和对象一样可预测。monads确实是一种变革性的、革命性的思考我们程序的方式。
为了方便,IO.of(..)通常是IO(() => ..)的等效操作。在两种情况下,你都得到一个惰性的IO。但是请注意细微的差别/陷阱:在IO.of(..)下,任何被提供的表达式都会被立即执行,然而当你用IO(() => ..),你需要手动装箱你的表达式,不论是什么,都要装箱为一个函数,这样它就不会被立即执行。
这样情况下,IO.of(..)应该仅当你已经有一个固定的非副作用的值表达式时使用,当你的表达式是一个副作用时你应该总是使用IO(() => ..)
为什么要把所有副作用操作都放到IO实例里面?
最根本的回答是:我们需要在不同副作用之间的到一个可预测的交互!(和保证!)。
当副作用直接且同步的,比如从DOM中的到一个元素,或者注入元素内容,可预测性和保证性似乎对我们没有太大的好处。
所以我最想放在这里的问题是:为什么Monio的IO单子是特别的?
我强烈认为我们代码中最复杂的副作用来源于异步操作,比如ajax请求,执行一个定时器,监听一个事件,执行一段动画等等。一个像Monio这样的IO实现可以提供一个处理代码中异步操作的通用模型,因此得到一个在异步操作中可预测和得到保证的程序是一个改变规则的处理方式。
Monio的IO自动转换和消化js的Promise,并在任何异步操作发生时提升一个IO链为一个Promise。对事件流(单Promise不能适用的场景),IOx就像是IO加Observable.
如果这还不足以引起您的兴趣,那么程序面临的另一个挑战(无论您是否意识到),Monio 的 IO 像冠军一样给出:如何将一组操作与环境隔离(如 DOM 等),以便您可以为代码运行提供环境/上下文?这对于防止程序中出现意外副作用至关重要,但它也是创建 TESTABLE 副作用代码的最有效方法。
Monio 的 IO 也包含 Reader monad 类型的行为。这意味着IO(无论链有多长/涉及多长时间)携带一个提供的“环境”,作为参数传递给run(..)。
您可以将整个程序定义为一个“IO”实例,并且如果您调用“run(window)”,您将在浏览器的 DOM 上下文中运行您的程序。但是在您的测试套件中,您可以在同一个 IO 上调用 run(fakeDOMglobal),现在所有代码和副作用都会自动通过该替代环境进行线程化。
It's effectively passing the entire "global" (aka, universe/scope-of-concern) into your program, whatever appropriate value that is, instead of the program automatically assuming which "global" it should apply against.
它有效地将整个“全局”(global)(又名,universe全局/scope-of-concern关联作用域)传递到您的程序中,无论是什么适当的值,而不是程序自动假设它应该适用于哪个“全局”。
但最终,Monio 的 IO 的真正力量 甚至没有包含在我们迄今为止讨论的内容中。 pièce de résistance 是 IO 提供了一座桥梁,让您回到熟悉和舒适的更命令式编码。
你喜欢使用 if 和 try..catch 和 for..of 循环吗?您可能已经注意到 FP 和 monads 似乎将所有这些东西都扔到了窗外,有利于长链的柯里化和组合函数调用。如果您可以获得“IO”的所有功能,但在有帮助的情况下选择使用更典型的命令式代码风格会怎样?
IO.do(..) 需要一个 JS 生成器,其代码看起来像大多数 JS 开发人员非常熟悉的 async..await 样式。当你 yield 一个值时,如果它是一元的,它会自动链接和解包(就像你有一个 IO 到 chain(..) 的来源)。如果结果是异步的(承诺),生成器内的代码会自动暂停以“等待”完成。
结合其所有方面,Monio 的 IO(和 IOx 超集)是“一个**它们的单子”。
好吧,如果你已经做到了这一步,请深呼吸。说真的,也许去散步让其中的一些安顿下来。也许重新阅读它,几次。“一个**他们所有人的单子”。
我们已经看到了单子概念的一个不错的(如果是基本的)说明。而且我们没有涵盖 Either —— 另一个 Sum Type 像 Maybe,但它在双方都持有值。 Either 通常用于表示同步的 try..catch 样式异常处理。我们也没有介绍 AsyncEither,它扩展了 Either 以异步操作(通过 Promise),与 IO 转换/处理它们的方式相同。 AsyncEither 本质上是 Monio 对 Promise/Future 类型的表示。
但是与 monad 适合的范畴论的广阔相比,它本身就是一个相当狭窄的概念。有许多来自范畴论的相邻(并且有些相关)概念,更具体地说,是“代数数据类型”(ADT)——或者至少是从它的一部分改编而来的。这些“朋友”包括:
那里还有很多很多其他主题,但这是 Monio 关注的主要三个“朋友”(并与它的 monad 混合)
需要明确的是,这三个不是单子行为。我称它们为“单子的朋友”,因为我发现单子与这些其他行为混合在我的 JS 代码中比单独的单子(或任何其他类型)更有用/实用;我认为正是这些类型行为的组合使 monad 对我们的程序具有吸引力和强大的解决方案。
我知道 FP 领域的许多人更喜欢完全独立地考虑每种类型。如果它对他们有效,那没关系。但我发现这些组合更具吸引力。
混入(大部分)Monio 的 monad 中的 fold(..) 方法正在实现“可折叠”类型的行为。值得注意的是,IO 及其变体不是直接可折叠的,但那是因为当您调用 run(..) 时,IO 的本质已经在做某种 fold(..)。
我们已经看到了前面几次引用的 fold(..)。这只是 Monio 提供的名称,但就像 chain(..) vs flatMap(..) vs bind(..),名称本身并不重要,只有预期的行为.
我们没有谈论 List 类型的 monad(因为 Monio 不提供这样的),但当然可以存在。在这种 List monad 的上下文中可折叠将在列表中的所有值上应用提供的函数,通过将每个值折叠到累加器中来逐步累加单个结果(任何类型)。 JS 数组有一个 reduce(..) 方法,它基本上是 List 的可折叠的实现(Foldable)。
相比之下,在单值 monad(如 Just)的上下文中,Foldable 使用其单个关联/基础值执行提供的函数。它可以被认为是通用 List 可折叠的一个特例,因为它不需要跨多次调用“累积”其结果。
类似地,像 Maybe 和 Either 这样的 Sum Types 在 Monio 中也是可折叠的;这是进一步的特化,这里的 fold(..) 有两个函数,但只会执行其中一个。如果关联值为“Maybe:Nothing”,则应用第一个函数,否则(当关联值为“Maybe:Just”时),应用第二个函数。 Either:Left 调用第一个函数和 Either:Right 调用第二个函数也是如此。
但是我们如何实际使用 Foldable 呢?
正如我在本指南前面几次暗示的那样,一种这样的转换是通过将标识函数(例如,v => v)传递给 fold (..)。
Just(42).fold(identity); // 42Rather than using Foldable to extract the value itself, we'll more often prefer to use fold(..) to define a natural transformation from one kind of monad to another. To illustrate, let's revisit this example from earlier:
现在,如果你仔细观察,像 Just、fold(..) 和 chain(..) 这样的单值 monad 似乎具有相同的行为(甚至实现几乎相同)。你可能想知道为什么我们应该在 Just 上提供看似重复的 fold(..) 而不是仅提供 chain(..)?
正如我在单子链里解释的,chain(..)函数总是返回一个和调用container相同的container类型(函数签名)。换句话说,haskell风格的类型签名本质上是chain: m a -> (a -> m b) -> m b。类型/种类 m 的 monad 可能在内部与在 chain(..) 调用之前到之后的不同类型值(a 与 b)相关联,但它仍然应该是一个m 种单子。
所以调用 Just(42).chain(identity) 得到逃逸值违反了这个隐含的类型签名——尽管 Monio 没有强制执行它并且操作可以正常工作。另一方面,fold(..) 没有那种隐含的类型签名,因为它旨在让您“折叠”(取到内部值)到任何任意类型,而不仅仅是另一个 monad 实例。 fold(..) 是一个更灵活的路径,它允许我们“提取”关联/基础值。
此外,Foldable 在 Sum Types Maybe 和 Either 上的 fold(..) 与它们的 chain(..) 方法有一个非常不同的签名,因此它们根本不会相互重复.
与其使用 Foldable 来提取值本身,我们更喜欢使用 fold(..) 来定义从一种 monad 到另一种的自然转换。为了说明,让我们回顾一下之前的这个例子:
// assumed:
// function formatLabel(label) { .. }
// helpers:
const getPropSafe = prop => obj => Maybe.from(obj[prop]);
const formatLabelSafe = v => Maybe.from(formatLabel(v));
const shippingLabel = (
Maybe.from(record)
.chain.pipe(
getPropSafe("address"),
getPropSafe("shipping"),
formatLabelSafe
)
);如果我们想渲染shipping标签,但前提是它实际上是有效/定义的,否则打印默认通知,我们可以像这样安排我们的程序:
// assumed:
// function formatLabel(label) { .. }
// helpers:
const identity = v => v;
const getPropSafe = prop => obj => Maybe.from(obj[prop]);
const assignProp = prop => val => obj => (
Maybe.from(obj).map(o => o[prop] = val)
);
const getElement = id => IO(() => document.getElementById(id));
const renderTextValue = id => val => (
getElement(id).map(el => (
Maybe.from(el).fold(
IO.of,
assignProp("innerText")(val)
)
))
);
const formatLabelSafe = v => Maybe.from(formatLabel(v));
// ----
const renderShippingLabel = v => (
v.fold(
() => IO.of("--no address--"),
identity
)
.chain( renderTextValue("customer-shipping-label") )
);
const renderIO = renderShippingLabel(
Maybe.from(record)
.chain.pipe(
getPropSafe("address"),
getPropSafe("shipping"),
formatLabelSafe
)
);
renderIO.run();A key aspect of the snippet is Maybe's fold(..) call in the renderShippingLabel(..) function, which folds down to either a fallback IO value if the shipping address was missing, or the computed IO holding the valid shipping address, and then chain(..)s off whichever IO was folded to. There's a similar thing happening in renderTextValue(..). Both fold(..) calls are expressing a natural transformation from the Maybe monad to the IO monad.
Again, Foldable is distinct from monads. But I think this discussion illustrates how useful it is when paired with a monad. That's why it's an honored friend.
花点时间阅读和分析该代码。它说明了我们的 monad 类型如何以有用的方式进行交互。我保证,即使一开始这段代码看起来令人头晕目眩——它对我来说确实如此! -- 最终你会理解甚至更喜欢这样的代码!
这段代码片段的一个关键方面是 renderShippingLabel(..) 函数中的 Maybe 的 fold(..) 调用,如果shipping address丢失,它会折叠为备用 IO 值,或者计算出的 IO 包含有效的送货地址,然后 chain(..) 关闭任何 IO 被折叠到的位置。在 renderTextValue(..) 中也发生了类似的事情。两个 fold(..) 调用都表达了从 Maybe monad 到 IO monad 的自然转换。
同样,Foldable 与 monad 不同。但我认为这个讨论说明了与 monad 配对时它是多么有用。这就是为什么它是尊敬的朋友。
Concatable,正式称为 Semigroup(幺半群),是 monad 的另一个有趣的朋友。您不一定会经常看到它显式使用,但它可能很有用,尤其是在使用 foldMap(..)(它是 reduce(..) 的抽象)时。
Monio 选择在其 monad 上实现 Concatable 作为 concat(..) 方法。该名称不是类型所必需的,当然,Monio 就是这样做的。
这里的基本**是一个值类型是“可连接的”,如果它的两个或多个值可以连接在一起。例如,原始的、非 monad 值类型(如字符串和数组)是可连接的,实际上它们甚至公开了相同的 concat(..) 方法名称:
"Hello".concat(", friend!"); // "Hello, friend!"
[ 1, 2, 3 ].concat( [ 4, 5 ] ); // [1,2,3,4,5]由于 Monio 的所有 monad 都是可连接的,它们都有 concat(..) 方法。因此,如果任何这样的 monad 实例与一个值相关联,该值也有一个符合 concat(..) 方法的值——例如,另一个 monad,或者像字符串或数组这样的非 monad 值——然后调用monad 的 concat(..) 方法将委托对关联/基础值调用 concat(..)。这个对底层 concat(..) 的委托是递归的。
For example:
Just("Hello").concat(Just(", friend!")); // Just("Hello, friend!")
Just([1,2,3]).concat(Just([4,5])); // Just([1,2,3,4,5])
Just(Just([1,2,3])).concat(Just(Just([4,5]))); // Just(Just([1,2,3,4,5]))
// `fold(..)` and `foldMap(..)` provided in
// Monio's util module
fold(Just("Hello"),Just(", friend!")); // Just("Hello, friend!")
foldMap(
v => v.toUpperCase(),
[
Just("Hello"),
Just(", friend!")
]
); // Just("HELLO, FRIEND!")与 chain(..) 一样,Monio 的 concat(..) 应该用于两个相同种类的 monad 之间。但是没有明确的类型强制来防止交叉类型(例如,在 Maybe 和 Either 之间)。
注意: 尽管名称重叠,但 MonioUtil 模块提供的独立 fold(..) 和 foldMap(..) 实用程序不 与 [可折叠类型](# foldable) 的 fold(..) 方法出现在 Monio monad 实例上。
此外,术语 Monoid 表示可连接/半群加上连接的“空”(恒等式)值。例如,字符串连接是一个带有空 "" 字符串的幺半群。数组连接是一个带有空 [] 数组的幺半群。即使是数字加法也是一个带有“0”“空”数字的幺半群。
将这种幺半群的概念扩展到最初看起来不像“可连接”的东西的一个例子是将多个布尔值组合在一个 && 或 || 逻辑表达式中。对于逻辑与运算,“空”值为“真”,而对于逻辑或运算,“空”值为“假”。这些值的“连接”是计算的逻辑结果(true 或 false)。
Monio 提供 AllIO 和 AnyIO 作为 IO 变体,它们是 monoids —— 同样,“空”值和 concat(..) 方法。特别是,这两个 IO 变体上的 concat(..) 方法旨在计算两个布尔结果 IO 之间的逻辑与/逻辑或(分别)。这使得 AllIO 和 AnyIO 易于与前面提到的 fold(..) 和 foldMap(..) 实用程序一起使用。
Monio Reference: AllIO, AnyIO
下面是通过 fold(..) / foldMap(..) 连接这些 monoid 的示例:
const trueIO = IO.of(true);
const falseIO = IO.of(false);
fold( AllIO.fromIO(trueIO), AllIO.fromIO(falseIO) ).run(); // false
fold( AnyIO.fromIO(falseIO), AllIO.fromIO(trueIO) ).run(); // true
const IObools = [
trueIO,
trueIO,
trueIO,
falseIO,
trueIO
];
foldMap( AllIO.fromIO, IObools ).run(); // false
foldMap( AnyIO.fromIO, IObools ).run(); // true作为额外的便利,Monio 的 IOHelpers 模块还提供了 iAnd(..) 和 iOr(..),它会自动应用此逻辑与/逻辑-或 foldMap(. .) 对两个或更多提供的 IO 实例的逻辑:
const trueIO = IO.of(true);
const falseIO = IO.of(false);
iAnd( trueIO, trueIO, falseIO, trueIO ).run(); // false
iOr( trueIO, trueIO, falseIO, trueIO ).run(); // true我正在说明使用直接的 true 和 false 值创建 IO 实例,但这并不是您实际使用这些机制的方式。由于它们都是 IO 实例,因此布尔结果(true 或 false)可以在它们各自的 IO 中延迟(并且异步!)计算,即使是由于复杂的副作用。
例如,您可以定义代表 DOM 元素状态的几个 IO 实例的列表,如下所示:
// helpers:
const getElement = id => IO(() => document.getElementById(id));
const getCheckboxState = id => getElement(id).map(el => !!el.checked);
const options = [
getCheckboxState("option-1"),
getCheckboxState("option-2"),
getCheckboxState("option-3")
];
const allOptionsChecked = iAnd( ...options ).run(); // true / false
const someOptionsChecked = iOr( ...options ).run(); // true / false额外练习:考虑在没有选中任何复选框时如何计算 noOptionsChecked - true。
Applicative 比 Semigroup 更不寻常(根据我的经验,不太常见)。但有时它会有所帮助。 Monio 选择使用 ap(..) 方法在其大多数 monad 上实现此行为。
Applicative 是一种模式,用于在 monad 中保存一个函数,然后“应用”来自另一个 monad 的值作为函数的输入,将结果返回给另一个 monad。如果该功能需要多个输入,则可以多次执行此“应用程序”,一次提供一个输入。
但我认为解释 Applicative 的最佳方式是只显示具体代码:
const add = x => y => x + y;
const addThree = Just(add(3)); // Just(y => 3 + y)
const four = Just(4); // Just(4)
addThree.ap(four); // Just(7)如果一个 monad 持有一个函数,例如这里显示的 curried/partially-applied add(..),你可以将它“应用”到另一个 monad 中持有的值。注意:我们在源函数持有的 monad (addThree) 上调用 ap(..),而不是在目标值持有的 monad (four) 上调用。
这两个表达式大致等价
addThree.ap(four);
four.map( addThree.fold(fn => fn) );回想一下 可折叠,将标识函数传递到 Monio monad 的 fold(..) 中,本质上是从 monad 中提取值。如图所示,ap(..) 有点像“提取”第二个 monad 中保存的映射函数,并针对第一个 monad 中保存的值运行它(通过 map(..))。
用单个表达式表达上述内容的另一种方式:
const add = x => y => x + y;
Just(add) // Just(x => y => x + y)
.ap( Just(3) ) // Just(y => 3 + y)
.ap( Just(4) ); // Just(7)我们将 add(..) 本身放入了 Just 中。第一个 ap(..) 调用“提取”该函数,将 3 传递给它,然后使用返回的 y => 3 + x 函数创建另一个 Just。然后第二个 ap(..) 调用与前面的代码片段执行相同的操作,提取 y => 3 + x 函数并将 4 传递给它。 4 => 3 + 4 的最终结果是 7,然后将其放回到 Just 中。
与 chain(..) 和 concat(..) 一样,Monio 的 ap(..) 应该 传递与调用方法相同类型的 monad。但是没有明确的类型强制来防止交叉类型(例如,在 Maybe 和 Either 之间)。
Monio 的所有非IO monad 都是 Applicative。同样,您可能不会非常频繁地使用这种行为,但希望您现在能够在它出现时认识到需求。
我们现在已经触及了 monad(以及几个 朋友)的表面。这绝不是对该主题的完整探索,但我希望你开始觉得它们不那么神秘或令人生畏了。
monad 是与值(数据值)或操作(函数)相关联的一组狭窄的行为(“几个定律”要求)。范畴论产生了其他相关的行为约束,例如可以增强这种表示的能力的可折叠(Foldable)和可连接(Concatable)。
这组特定的行为改进了其他monad或者按monad约定的数据结构之间的协调/交互操作,使得结果更可预测。这些行为还提供了许多机会来抽象(转变为行为定义)某些通常会使我们的命令式代码混乱的逻辑(例如空值检查)。
Monads 当然不能解决我们在代码中可能遇到的所有问题,但我认为通过进一步探索它们有很多有趣的力量可以解锁。我希望本指南能激励您继续挖掘,也许在您的探索中,您会发现 Monio 库很有帮助。
重要问题
关键词:并查集 find union,环检测
/**
* @param {character[][]} grid
* @return {boolean}
*/
var containsCycle = function(grid) {
// 并查集-查询 得到任意元素的根结点位置
function find(x, parent) {
// 根结点
if (parent[x] === x) {
return x;
} else {
// 更新根节点
// 路径压缩算法,可以让平均查找根节点的速度变快
parent[x] = find(parent[x], parent);
return parent[x]
}
}
// 并查集-合并 合并任意两个元素为同一个集合,相当于树合并
function union(x, y, parent) {
let xRoot = find(x, parent);
let yRoot = find(y, parent);
// x y本来就属于同一个集合
if (xRoot === yRoot) {
return true;
} else {
// 把x的根结点挂载到y的根结点上
// 挂载后x,y拥有同一个根节点
parent[xRoot] = yRoot;
return false;
}
}
let m = grid.length;
let n = grid[0].length;
// 并查集,parent为不交集森林,每个元素都是唯一的一棵树,自己为根结点
// 我们需要搜索二维数组,但是并查集是一维的不交集森林
let parent = new Array(m * n).fill(0).map((_, len) => len);
// 从左上角遍历到右下角,任意元素都更新到对应的树里面(任意树的各个元素拥有相同的字符)
// 角标映射公式
// k = i * n + j
for(let i = 0; i < m; i++) {
for(let j = 0; j < n; j++) {
// 上边
// 上下字符一样,则执行一次合并
if (i > 0 && grid[i][j] === grid[i - 1][j]) {
if (union(i * n + j, (i - 1) * n + j, parent)) {
// 合并前两个元素的根就一样,说明就是同一个树上
// 由于我们的路径只能查找上边和左边的元素是否相同,碰到两个树的根相等,就说明环路已经形成
return true
}
}
// 左边
if (j > 0 && grid[i][j] === grid[i][j - 1]) {
if (union(i * n + j, i * n + (j - 1), parent)) {
return true;
}
}
}
}
return false
// let a = containCycle([
// ["c","c","c","a"],
// ["c","d","c","c"],
// ["c","m","e","c"],
// ["c","c","c","c"]
// ]);
// let b = containCycle([
// ["a","s","a","a"],
// ["a","s","b","a"],
// ["a","b","b","a"],
// ["a","a","a","a"]
// ])
// console.log(a, b)
};最近有大佬开源了完全lua的neovim配置,昨天(2022/01/13)参照这个配置把自己的dotfile改了,很不错,推荐使用。
translate-shelltldr: 一个man命令的替代,快速掌握unix命令用法gtop: rust写的一个top命令替代,图形界面好用tmux: 终端分形神器,现在已经离不开了,配合neovim使用,替换掉vscodegitui: 图形化的git命令行把软件当作一个黑盒子,从软件的行为而不是内部结构的角度来测试软件。现在大多数的测试手段(俗称点点点测试),都是黑盒测试,测试人员是不懂得软件内部结构的,只是测试这个软件的行为是否符合预期效果。
设计者可以看到软件系统的内部结构,并且使用软件的内部知识来指导测试数据及方法的选择。白盒测试需要测试人员了解软件的内部结构,从软件本身的结构角度来测试。java测试人员要读懂java代码,js测试人员要读懂js代码,并根据语音和结构来选择测试方式。
介于黑盒和白盒之间
点点点测试,人工进行各种条件的触发,并观察软件的运行效果
使用软件代替人工,触发不同的场景。(API测试)
开发人员对自己编写的方法或函数进行软件测试。
单元测试是保证软件功能的第一步,前端的单元测试可以选择的有Mocha、Jest等
测试人员对功能模块进行测试
测试人员对几个集成在一起的功能模块进行测试。
前端有e2e端到端测试,还有一些自动化测试工具:Enzyme等
具体业务场景流程测试
对系统全功能测试。前后端应用一般有一个集成环境,用于测试。
对前端页面来说,系统集成测试,也可以用自动化的手段来触发,并使用window.performance来记录运行的流畅度。
测试人员对生产环境的软件进行系统、全面的测试
用户在生产环境测试
验证软件在超过负载设计的情况下仍能返回正确的结果,没有崩溃。
压力测试一般是针对服务器进行的,服务器有QPS指标,每秒访问的量增大后看服务器是否崩溃。
前端页面一般没有压测的概念,前端的页面一般用首屏渲染时间、流畅度帧数FPS等来衡量。
大公司一般在上线前都会有压力测试,压力测试时看服务器的CPU、内存、硬盘等指标,同时看请求的响应速度有没有下降。
测试软件在特定负载情况下能否正常工作。
通常不限制软件的吞吐量,在一定的负载情况下判断系统的瓶颈在哪。比如是缺内存,还是缺算力(CPU),还是硬盘容量不够用。
测试软件的性能。比如聊天软件,通常服务器服务1000个人同时聊天,性能测试的时候就跑满甚至超出这个量,持续运行,看服务的性能指标有没有下降。比如消息处理速度、发送速度、查询速度等。
开发人员对软件的功能做一个自我验证。开发每日构建版本,进行主功能测试,不用做深入的测试。这一步最好是用自动化手段来实现。
对一个新的版本,重新运行以往的测试用例,看看新版本和已知的版本相比是否有退化 (regression)
partial函数划分区域

今天做了这么个比较,发现还是原生js牛逼一点,这给了我极大的困惑。看来要专门找一下这方面的资料了!
chroma.js 色彩管理库,加深变淡
按16年去海能达报道的日子,目前已经工作整五年了。五年光阴啊!希望下一个五年,是一个新纪元!
官网:TAURI
主要是和electron比较,使用的Chromium + nodejs和Rust + webview是两种不同的跨平台方案。区别主要是不同平台的适配程度、打包大小、系统API调用能力以及语言上的区别。
作为原生API和JS之间的桥梁,挂载方法到window上给js使用,webview大致等于一个DOM渲染 + js运行时
因为是webview的,体积小、内存占用小,未来可以支持ios和android
很快将支持ios和安卓
对我来说,目前最主要的是去做。
reactwebpackRxjsleetcode 133.cloneGraph
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
关键点 记录遍历过的节点,防止重复访问
/**
* // Definition for a Node.
* function Node(val, neighbors) {
* this.val = val === undefined ? 0 : val;
* this.neighbors = neighbors === undefined ? [] : neighbors;
* };
*/
/**
* @param {Node} node
* @return {Node}
*/
var cloneGraph = function(node) {
const cloned = new Map();
if (!node) return node;
return bfs(node)
function dfs(n) {
// 已经克隆过,直接返回
if (cloned.has(n)) return cloned.get(n);
if (n) {
const m = new Node(n.val, []);
// 记录克隆事件
cloned.set(n, m)
for(const x of n.neighbors) {
const y = dfs(x);
if (y) {
m.neighbors.push(y);
}
}
return m
}
}
function bfs(n) {
// 第一个节点先克隆
const queue = [n];
cloned.set(n, new Node(n.val, []))
while(queue.length) {
// 当前节点。宽度优先队列,优先访问邻接节点,然后增加克隆节点的对应邻接节点值
const x = queue.shift();
// 遍历到邻接节点y
for(const y of x.neighbors) {
// 没克隆过(没访问过)
if (!cloned.has(y)) {
// 克隆(访问)
const z = new Node(y.val, [])
cloned.set(y, z);
// 入队(便于访问他的邻接节点)
queue.push(y);
}
// 当前节点增加邻接节点
cloned.get(x).neighbors.push(cloned.get(y))
}
}
return cloned.get(n)
}
};JS语言发展迅速,各种框架层出不穷,我们有这么一个形象的描述。

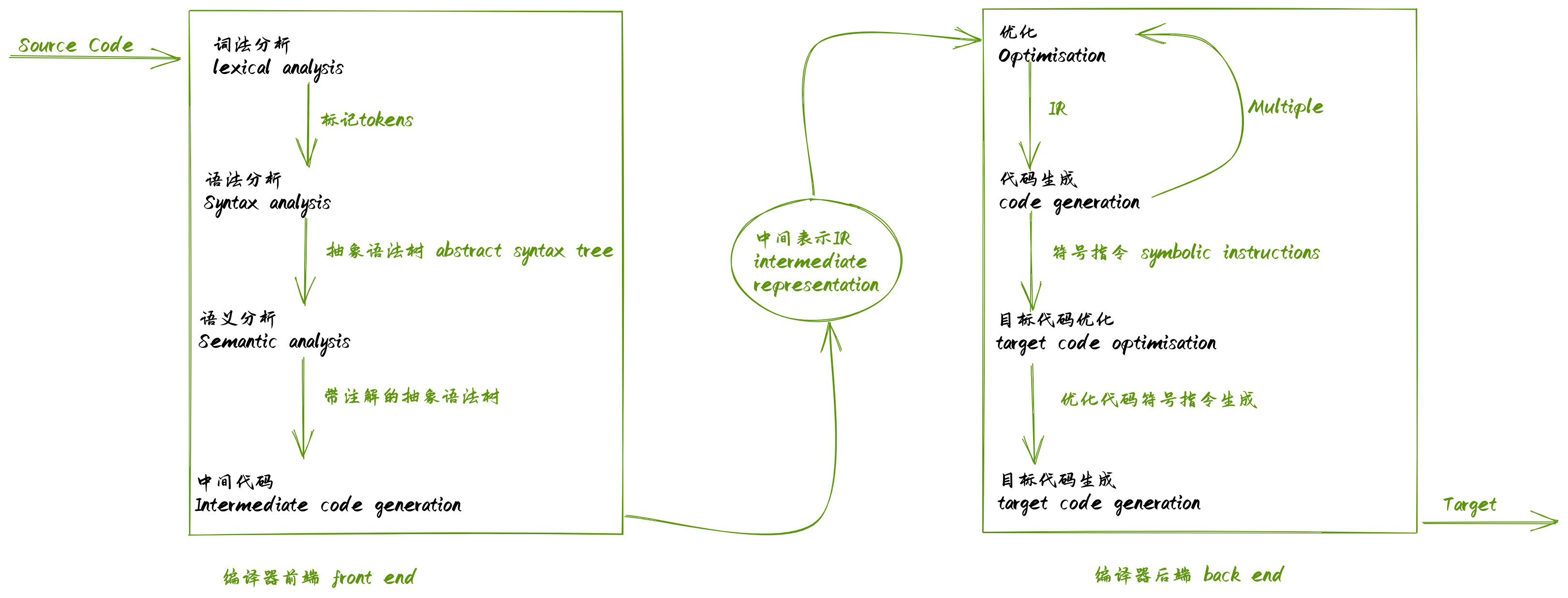
但我坚信,所有的高级描述都需要坚实的基础来夯实。因此我还是坚持学习基础,今天我们要学习编译原理和JSON的序列化和反序列化。

首先,我个人对编译原理也只是一种“还没开始学习或正在入门”的阶段,因此我讲这个的话,可能会有很多谬误,所以我就选择最简单的,找了一个架构图,我们来看着架构图来读我们的js代码。
这个图我们可以随时回来看一下,明确我们的工作已经做到哪一步了。
图灵完备:在可计算性理论,如果一系列操作数据的规则(如指令集、编程语言、细胞自动机)可以用来模拟任何图灵机,那么它是图灵完备的。这意味着这个系统也可以识别其他数据处理规则集,图灵完备性被用作表达这种数据处理规则集的一种属性。---wikipedia
图灵机:由一些基本演算规则定义的一系列演算过程,可以模拟真实世界的任意演算过程。 --- 我的归纳
图灵机等价性:等价的计算模型有
λ演算,生命游戏···
DSL有很多好处,比如JSON格式目前在我们用到的主流编程语言里面都得到了支持,实际上它就可以作为不同的语言、服务器之间通信的桥梁,至少比单纯的二进制或者文本要易懂得多。
如果要开发一门DSL语言,在前端场景下,可能有这么一些用法
java bean自动转为typescript interface,这个dsl作为中间桥梁,即java -> dsl -> typescript。自动转换接口模型,让前后端省去对接的最后一步(复制、粘贴、转换模型)aaabbbccc为a2b2c2,或者像graphql(也是一种DSL)一样用。词法解析过程就是一个一个字符地把数据录入,当然,会根据一定的规则,忽略掉空格。
var name = "wander";
function sayHello(to) {
console.log(name, ": Hello, ", to);
}
sayHello("JDT")比如这一段代码,var,name,=,"wander"等你能看到的独立的一串字符都会被解析为token。就像我们自然语言里面可以划分主语、谓语、宾语等,是一个意思,这里实际上就是模拟我们的自然语言。
有了一些符号,编译器就可以每次从数组里面取一个或一系列的token,看是否可以构成语义。在javascript语言环境下,语义就包括了我们的块级上下文(比如语法规则里面await暂时不能用于顶级模块),语句(条件控制语句、赋值语句、声明语句),表达式(运算符连接,产生运算结果,运算结果可以作为语句的一部分,比如const a = 1 + 1;整体是个赋值语句,但右侧为一个表达式)
等。
{
"type": "Program",
"start": 0,
"end": 100,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 20,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 19,
"id": {
"type": "Identifier",
"start": 4,
"end": 8,
"name": "name"
},
"init": {
"type": "Literal",
"start": 11,
"end": 19,
"value": "wander",
"raw": "\"wander\""
}
}
],
"kind": "var"
},
{
"type": "FunctionDeclaration",
"start": 21,
"end": 83,
"id": {
"type": "Identifier",
"start": 30,
"end": 38,
"name": "sayHello"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 39,
"end": 41,
"name": "to"
}
],
"body": {
"type": "BlockStatement",
"start": 43,
"end": 83,
"body": [
{
"type": "ExpressionStatement",
"start": 46,
"end": 81,
"expression": {
"type": "CallExpression",
"start": 46,
"end": 80,
"callee": {
"type": "MemberExpression",
"start": 46,
"end": 57,
"object": {
"type": "Identifier",
"start": 46,
"end": 53,
"name": "console"
},
"property": {
"type": "Identifier",
"start": 54,
"end": 57,
"name": "log"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "Identifier",
"start": 58,
"end": 62,
"name": "name"
},
{
"type": "Literal",
"start": 64,
"end": 75,
"value": ": Hello, ",
"raw": "\": Hello, \""
},
{
"type": "Identifier",
"start": 77,
"end": 79,
"name": "to"
}
],
"optional": false
}
}
]
}
},
{
"type": "ExpressionStatement",
"start": 85,
"end": 100,
"expression": {
"type": "CallExpression",
"start": 85,
"end": 100,
"callee": {
"type": "Identifier",
"start": 85,
"end": 93,
"name": "sayHello"
},
"arguments": [
{
"type": "Literal",
"start": 94,
"end": 99,
"value": "JDT",
"raw": "\"JDT\""
}
],
"optional": false
}
}
],
"sourceType": "module"
}可以看到,AST对不同的字符串,标记了不同的类型,甚至还包括了起始和终止位置。这个时候如果我们去修改AST的话,比如把name属性改为n属性(js代码压缩的原理也是在此),最后得到的代码就和我们最原始的不一样了(但结构还是一样的),像babel拿到AST之后,有很多插件就可以在这一步介入,比如修改class语法为prototype实现以适配更多的浏览器版本,这个时候我们拿到的最后结果,就连结构也和源代码不一样了。
语法产生了AST,让我们知道一个源码的代码结构,但仅有结构也不足以让你的代码能够正常运行。比如
好了
这样一句话,人类可以根据语境上下文去判定它的主语,比如(您要我办的事)好了,(我的代码)好了(可以运行)。但计算机不行,计算机的上下文是在硬件资源里面的,必须要我们去设定一个软件变量的上下文。比如
// es5
a = 1; // 🙆♂️ 可以生效,语义上没有发现变量声明,但是发现了变量赋值,通过作用域链找到了上下文window,并默认把变量赋值的语义改为window.a = 1;
// es6+
a = 1; // 🙅♂️ 不可以生效,在es6的语义中,a的作用域内没有找到变量声明,就即时抛出错误,并不会挂载到window上也就是说我们的很多js语法错误,都是在这个阶段产生的,编译器已经不认识你的意图了,比如上面的es6语境下,编译器可以识别到“你正在给一个作用域内没有发生过变量声明的变量进行赋值”,就可以抛出错误了。其实这个也好理解,变量声明会在栈内存内开辟一个空间用于存储这个变量,而变量赋值会去栈内存上寻找这个地址,找到了就赋值给它,就像是邮寄包裹,如果没有这个地址,你的包裹也就无从寄出。
经过上面的那些步骤,生成的代码已经可以给机器识别了(词法合格,语法合格,带有语义),这个时候的代码,可以经过多次中间处理来产生不同的结果,一般来说从一门语言编译到另一门语言,会经过这一步,而且IR是可以多次进行的,你可以有不同的IR。比如
# WebAssembly技术,从一门语言编译到另一门语言
rust -> compiler -> wasm
c++ -> compiler -> wasm
# 理论上来说还可以这么玩
c -> compiler front -> compiler back -> IR -> IR -> ... -> IR -> JavaScript
编译器后端对合法的语法进行优化,比如我们的V8引擎里面的Turbo Fan,它可以把循环调用优化为机器码,直接给机器运行,这是一种IR结果,引擎的其他部分有的可以把JavaScript直接解释执行,有的可以把JavaScript代码编译为字节码,比直接解释执行更高效
终于到了我的主题。以上的各个章节都属于笔记类型,下面开始我的输出。

首先是要明确我们的词法,语法和语义,JSON的格式非常简单,支持对象嵌套、数组嵌套、基本的几种数据类型,不支持函数类型,key也要包裹双引号,字符串都使用双引号。
{
"name": "wander",
"age": 20,
"male": true,
"companies": [
{"name": "hytera", years: 2 },
{"name": "jdt", years: 2.7 }
],
"desc": {
"hobby": ["code", "cook", "fitness"],
"website": "https://github.com/WanderHuang",
"haircut": "short",
"favico": "xxx"
}
}JSON.stringify原生的stringify还支持replacer函数和indent空格缩进的参数,我们为了简单起见,先不支持这些,仅支持input -> JsonString
首先,我们有明确一下输入,原生的代码是可以支持对象和数组以外的数据类型的
JSON.stringify(true) // "true"
JSON.stringify(false) // "false"
JSON.stringify(null) // "null"
JSON.stringify(undefined) // 没有输出
JSON.stringify(1) // "1"
JSON.stringify("2") // "\"2\""除了字符串类型额外增加了转义字符之外,其他基本类型的值基本都是调用String(x)的结果(除了undefined类型不处理)
因此我们先来实现这些primitive值的转换。
// 字符串类型,直接增加一个转义字符,并输出
function string2String(obj) {
return `\"${obj}\"`;
}

// 布尔类型,直接调用String,装饰为字符串
function boolean2String(obj) {
return String(obj);
}
// 数字类型,直接调用String,装饰为字符串
function number2String(obj) {
return String(obj);
}然后我们来看对象的定义,首先对象由一对大括号包裹{},其次,大括号内的数据为:分隔的键值对,其中键值对的键由字符串包裹,右边部分递归定义为JSON数据。
JsonObject ->
Key -> JsonObject
然后就是语句分隔(一对合法的键值对分隔)使用,。
由于存在递归定义,我们实现的时候也需要递归调用
// 处理Json对象转为字符串,不同类型调用不同的处理器
function object2String(obj, str = "") {
if (isPrimitive(obj, "string")) { // 字符串类型
str += string2String(obj);
} else if (isPrimitive(obj, "boolean")) { // 布尔类型
str += boolean2String(obj);
} else if (isPrimitive(obj, "number")) { // 数字类型
str += number2String(obj);
} else if (is(obj, "Object")) { // 对象类型
str += "{";
let cache = [];
for (const [key, value] of Object.entries(obj)) {
if (obj.hasOwnProperty(key)) {
if (!is(value, "Function") && !is(value, "Undefined")) {
let row = "";
row += string2String(key);
row += ":";
row = object2String(value, row);
cache.push(row);
}
}
}
if (cache.length) {
str += cache.join(",");
}
str += "}";
} else if (is(obj, "Array")) { // 数组类型
str += array2String(obj);
} else if (is(obj, "Null")) { // Null类型
str += "null";
}
// 其他类型直接略过不处理,比如我们之前讨论到的undefined类型
return str;
}
然后是数组。数组也是类似的递归调用,我们这里直接给答案
// 数组的递归实现
function array2String(obj) {
let res = "[";
for (const [i, o] of obj.entries()) {
if (!is(o, "Undefined")) {
res = object2String(o, res); // 递归处理每一个元素,每个元素都是JsonObject来处理
} else {
res += "null";
}
if (i !== obj.length - 1) {
res += ",";
}
}
res += "]";
return res;
}以上代码的辅助函数(比如is函数,判断是否是xxx类型)没有给出,可以自己实现。
最终就把数据直接通过object2string返回
function stringify(obj) {
return object2String(obj);
}写一个见到的JSON.stringify没有想象中那么难,主要要理清楚词法和语法规则,然后就是递归地处理每一种数据类型。
测试代码
var obj = {
name: "wander",
age: 20,
male: true,
companies: [
{ name: "hytera", years: 2 },
{ name: "jdt", years: 2.7 },
],
desc: {
hobby: ["code", , "cook", "fitness"],
website: "https://github.com/WanderHuang",
haircut: "short",
favico: "xxx",
},
x: null,
y: undefined,
say: function () {
console.log("u can't c this function");
},
};
var arr = [1, 2, null, undefined, obj, [1, 2]]
// 转换对象
console.log(stringify(obj));
console.log(JSON.stringify(obj));
console.log(JSON.parse(stringify(obj)));
// 转换数组
console.log(stringify(arr));
console.log(JSON.stringify(arr));
console.log(JSON.parse(stringify(arr)));
// 转换字符串
console.log(stringify("123"))
// 转换数字
console.log(stringify(123))
// 转换空值
console.log(stringify(null))
console.log(stringify(undefined))
// 转换函数
console.log(stringify(function call() {console.log("call function")}))这里由于我是一个简单的实现,默认数据来源和JSON.stringify一致,只需要去实现序列化就行了。实际上如果你要实现编译器,读入一个.json文件,再输出转换的结果,你就需要逐个字符地去读,然后给对应的每种类型赋值。
好在JSON.parse有点类似于这种模式,我们来看一下吧。
JSON.parse我们实现JSON.parse,是可以通过生成token的方式,不过json数据本身就只有几种数据类型,直接输出也可以。
首先我们需要厘清最基本的一些状态
i变量JSON内是语法无关的,因此在词法和语法外的空格,我们应该可以去掉(i++),合理的空格至少有" "和\n,先来实现一个全局环境
// 转换字符串
function parse(str) {
// 1. 强转为字符串,比如parse(null) => "null",让方法能够对不同类型输出
str = String(str);
// 2. 全局变量,当前读到第几个数字
let i = 0;
let len = str.length;
// 最外层的数据格式
let top;
// 3. 去掉空格
if (i < len) {
filterSpace();
}
// 4. 空指针判定
if (i < len) {
if (str[i] === "{") { // 对象
top = parseObject();
} else if (str[i] === "[") { // 数组
top = parseArray();
} else { // 字符串
top = parseString();
}
}
return top;
}以上方法对第一层,也就是传入的数据做了解析。当然4.步应该可以用while替换
然后我们来实现一些辅助函数(空格过滤)
/** 过滤空格符号 */
function filterSpace() {
while (i < len && (str[i] === " " || str[i] === "\n")) {
i++;
}
}
/** 过滤逗号 */
function filterColon() {
while (str[i] === ",") {
i++;
}
}实现基本数据的转换
String(x)得到的,我们可以用对应的方式转回来。数字直接用Number(x),布尔函数用true|false直接转{开头,以}结尾,递归调用[开头,以]结尾,递归调用token直接至少是可以过滤空格的,使用filterSpace方法"包裹字符串类型
/** 转换String类型 */
function parseString() {
let res = "";
if (str[i] === '"') {
i++;
}
// char[i] => String
// 这里有个坑,那就是转义字符在这里要提前结束掉字符串匹配,目前还没有处理。比如`'"' === "\""`为true
while (str[i] !== '"' && i < len) {
res += str[i++];
}
i++;
return res;
}数字类型
function parseNumber() {
let x = i;
// 语法条件,没有碰到结尾符号,就一直算作当前的token
while (
i < len &&
str[i] !== "," &&
str[i] !== " " &&
str[i] !== "}" &&
str[i] !== "]"
) {
i++;
}
let y = i;
// 取巧的方式转换为数字
return Number(str.substring(x, y));
}数字类型可用的解析规则

对象转换
/** 转换对象 */
function parseObject() {
// 1. 返回值
let obj = {};
// 2.起始判定
if (str[i] === "{") {
i++;
}
// 3. 没有到语法结束,则一直读取
while (str[i] !== "}" && i < len) {
filterSpace(); // 空格过滤
// 4. 对象的键。也有"\""的坑需要填
if (str[i] === '"') {
i++;
}
let key = parseString();
filterSpace();
// 5. 键值对分隔符
if (str[i] === ":") {
i++;
}
filterSpace();
// 6. 值读取。前面说到值也是递归定义的JsonObject,因此下面的一段都是递归调用
if (str[i] === '"') { // 字符串
obj[key] = parseString();
} else if (str.substring(i, i + 4) === "true") { // "true"
obj[key] = true;
i += 4;
} else if (str.substring(i, i + 5) === "false") { // "false"
obj[key] = false;
i += 5;
} else if (str[i] === "{") { // 对象
obj[key] = parseObject();
} else if (str[i] === "[") { // 数组
obj[key] = parseArray();
} else if (
str[i] === "-" ||
str[i] === "+" ||
(Number(str[i]) >= 0 && Number(str[i]) <= 9)
) { // 数字
obj[key] = parseNumber();
}
// 语法无关字符过滤
filterSpace();
filterColon();
filterSpace();
}
filterSpace();
filterColon();
filterSpace();
if (str[i] === "}") { // 对象结束
i++;
}
return obj;
}数组转换,和对象一样,进行递归调用
/** 数组类型解析 */
function parseArray() {
// 1. 数组开始
if (str[i] === "[") {
i++;
}
let res = [];
filterSpace();
// 2. 语法环境没有结束
while (str[i] !== "]" && i < len) {
filterSpace();
if (str[i] === ",") { // 空字符
res.push();
i++;
} else if (str[i] === '"') { // 字符串
res.push(parseString());
} else if (str.substring(i, i + 4) === "true") { // "true"
res.push(true);
} else if (str.substring(i, i + 5) === "false") { // "false"
res.push(false);
} else if (str[i] === "{") { // 对象
res.push(parseObject());
} else if (str[i] === "[") { // 数组
res.push(parseArray());
} else if (
str[i] === "-" ||
str[i] === "+" ||
(Number(str[i]) >= 0 && Number(str[i]) <= 9)
) { // 数字
res.push(parseNumber());
}
}
filterSpace();
// 3. 语法环境结束
if (str[i] === "]") {
i++
}
return res;
}核心要点
测试代码
var obj = {
name: "wander",
age: 20,
male: true,
companies: [
{ name: "hytera", years: 2 },
{ name: "jdt", years: 2.7 }
],
desc: {
hobby: ["code", "cook", "fitness"],
website: "https://github.com/WanderHuang",
haircut: "short",
favico: "xxx"
}
}
var str = JSON.stringify(obj);
var o = parse(str) // 用我们自己写的parse,可以把原生的JSON.stringify序列化的数据解析出来
console.log(str)
console.log(o)
console.log(parse(true), parse(false), parse(1), parse(" t.")) // 它也可以很好地解析数字类型、布尔类型、字符串类型之前有调研过JSON Schema的格式,其实这也是一种DSL,属于对JSON的一种加强,想要达到的效果是从JSON 或者JSON Schema格式读取token然后转为typescript的interface类型。不过当时由于一些原因搁置了,下半年这个可以是一个研究的方向。目标就是让前端的模板代码解放人手写。当然前端本身会有一些自己的类型需要处理,如果做的好,也可以给前端自己用。
// 动态规划 把问题分解为子问题,并利用子问题的重叠性,对计算进行简化,每个子问题叠加为最优解答。
// 解决问题
// 1. 最优子结构。如果一个最优解所包含的子问题解也是最优的,称为最优子结构性质。
// 2. 无后效性。子问题解决后,不受其他子问题的求解决策影响。
// 3. 子问题重叠性。有些子问题会被重复求解,就可以被缓存,减少求解次数。
// 最长回文字串: 找到一个字符串的最长回文子串
// a b c d c e f g k g <--- str
// 0 1 2 3 4 5 6 7 8 9 <--- index
// - i -> <- j - <--- 双指针探测
// f(i, j) = f(i + 1, j - 1) <--- str[i] === str[j] 一个字串,如果是回文串,则去掉头尾,也是一个回文串
// f(i, j) = 0 <--- str[i] !== str[j] 一个子串的头尾如果不相等,则一定不是回文串
//
// 最坏情况
// i = j = str.length - 1 <--- 回文串[0, str.length - 1] 长度str.length
// 最好情况
// i = j = 0 <--- 回文串[0, 0] 长度1
const lcs = str => {
const length = str.length;
// 构造数组
const cache = [];
for (let i = 0; i < length; i += 1) {
cache[i] = [];
cache[i].length = length;
// 每个单个字符是最小回文
cache[i][i] = 1;
// 两个字符相连的情况也是回文,缓存备用
// 简单数据备用,避免后面再多一次循环
if (i < length) {
if (str[i] === str[i + 1]) {
cache[i][i + 1] = 1;
}
}
}
// 由于上面的转移方程f(i, j)是依赖于f(i + 1, j - 1)的
// 因此我们求解就要从字串长度最小3(1、2不考虑,已经被缓存)开始由小变大构造所有子问题的解
// delta表示字串长度,即j - i + 1 = j和i限定的长度 = delta
for (let delta = 3; delta <= length; delta += 1) {
// 左指针
let i = 0;
// 右指针 总是从最小长度开始
let j = delta + i - 1;
while (j < length) {
cache[i][j] = str[i] === str[j] && cache[i + 1][j - 1] ? 1 : 0;
i++;
j = delta + i - 1;
}
}
return cache;
};
// =================
// =====test========
// =================
const print = (srouce, result) => {
const arr = result;
const chars = srouce.split('');
chars.unshift('|');
chars.unshift('%');
let charLen = chars.join(' ');
console.log('matrix[i, j]');
console.log(charLen);
console.log('- |', new Array(charLen.length - 4).fill('-').join(''));
chars.shift();
chars.shift();
for (let i = 0; i < arr.length; i++) {
const row = [chars[i], '|'];
for (let j = 0; j < arr[i].length; j++) {
row[j + 2] = arr[i][j] || 0;
}
console.log(
row
.toString()
.split(',')
.join(' '),
);
}
};
const source = 'abcdcefgkg';
// const source = '923n23sssasssnn9u99u95345nkj129';
const result = lcs(source);
print(source, result);
// matrix[i, j]
// % | a b c d c e f g k g
// - | -------------------
// a | 1 0 0 0 0 0 0 0 0 0
// b | 0 1 0 0 0 0 0 0 0 0
// c | 0 0 1 0 1 0 0 0 0 0
// d | 0 0 0 1 0 0 0 0 0 0
// c | 0 0 0 0 1 0 0 0 0 0
// e | 0 0 0 0 0 1 0 0 0 0
// f | 0 0 0 0 0 0 1 0 0 0
// g | 0 0 0 0 0 0 0 1 0 1
// k | 0 0 0 0 0 0 0 0 1 0
// g | 0 0 0 0 0 0 0 0 0 1
// 引申
// 这里输出有很明显的特征
// 1. 稀疏矩阵
// 2. 字串在稀疏矩阵上半部
// 3. 上半部取1,并与同一行对角线上的1,包夹形成回文串,如abcdcefgkg -> 0010100000 -> cdc
// 4. 其实在生成数组时,下半部是没有值的,我们在print函数内把undefined赋值为了0
// 针对这个结果,可以有一些优化
// 1. cache[i]的长度不一定要固定为length,只取上半部就可以了,即cache[i].length = length - i, 然后存储时从cache[i][i]开始
// 2. 稀疏矩阵可以压缩
// 3. 有了这个稀疏矩阵,可以知道任意回文串,包括长度、起止位置、
// 再贴一个字符串比较长的
// const source = '923n23sssasssnn9u99u95345nkj129';
// matrix[i, j]
// % | 9 2 3 n 2 3 s s s a s s s n n 9 u 9 9 u 9 5 3 4 5 n k j 1 2 9
// - | -------------------------------------------------------------
// 9 | 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// 2 | 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// 3 | 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// n | 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// 2 | 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// 3 | 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// a | 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// s | 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// n | 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// n | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
// 9 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0
// u | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0
// 9 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0
// 9 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0
// u | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
// 9 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0
// 5 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
// 3 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
// 4 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
// 5 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
// n | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
// k | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
// j | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
// 1 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
// 2 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
// 9 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
// 这个更明显, 大量的空间没有被有效利用,应该还有更好的方法
// 1. 额外空间占用 n * n
// 2. 时间耗费 n * n
// 因此动态规划来解决最长回文字串的问题,还是比较耗费时间和空间效率的。还有一些更好的算法需要另外探索。in quest to / lifelong learner / keep up with / date withSome of the top developers are lifelong learners. They are always in the quest to learn new skills and keep themselves up to date with the current trends.
一些顶尖的开发人员是终身学习者。他们一直在寻求学习新技能并保持与时俱进的最新动态。
mao/cn/dang。最善良和赤诚的初心,在非尽头(sulian)受震撼、美好的世界破碎。(年轻人-阿廖沙和喀秋莎都在边境-中苏-死去)。从火车产子开始,逐步进入疯癫状态,并在世人眼见之外构建了一个乌托邦(洞穴),最后自杀表明时代结束了,乌托邦内也被行了苟且之事,梦境落幕。资本(唐妻、天鹅绒)开始进入底层(李东方、草纸)。妈给儿子造了一个乌托邦,在儿子发现那天,她自杀了,儿子毁了乌托邦,也毁了自己。
农民。东方就是太阳升起的地方,照常升起表明这些日子啥都没有变,李东方十年后还是啥也不知道,历史停止。魔幻化出生代表最开始是有希望的。
军队。拥护和崇拜(说妈把婴儿一个人带到村里 不可思议) mao/dang
知识分子,软弱代表。环境把人逼疯、自杀。
知识分子,圆滑代表。在环境中得过且过,随波逐流,内心饱含对真实世界的排斥。搞破鞋、打猎(老婆出轨、枪杀农民)
破鞋代表(皮鞋刚开始不能穿、唐老师搞大一号)不关心政治,或者说是被政治逼到回归私欲,纵欲,反政治代表
知识分子,堕落代表。只会歌功颂德,甩锅,伟光正,奴颜
压抑的女性代表。每天过政治生活,没有个人私欲,嫉妒压抑下人格扭曲
代表十年间毁掉的一代,只会爬树偷鸟蛋,回到原始社会
女知识分子代表,独立人格,不关心政治和军队,只关心生活(怕枪声、穿着得体、喂野鸡、私欲放纵-由时代逼迫)
上帝视角,世界变成这个样子,是人们自作自受,人格、家庭、社会是自己放弃自己。
实际是空的,但是叫不空。表明是人们想要证明存在,但并不存在的价值,比如“最可爱的人”(政治口号,让女人们去爱这些军人,形成畸形的婚姻:崇拜和遗弃。疯妈和唐妻),比如和苏联的感情(苏联人检查所有信件,意味着不信任),越是想要证明存在的价值,它越没有价值,人们都成了它的牺牲品。
大跃进开始、欢乐进入共产主义
农民被资本主义抛弃,被社会主义拾起,起名东方,寓意希望。一切的出发点是好的
代表社会主义开始探索 受到军队拥护 逐步政治化
原始人性,鞋丢了 人疯了
捯四旧、反传统
乌托邦、一个喷嚏就破碎,mao想象中的**,在这乌托邦里最后行苟且之事,表面一切,十几年的光阴,什么都没有变过,被压抑的的情绪总有一天会爆发
对传统和美好记忆的追思,空悠悠,逝去的不会再回来
红色(dang)代表什么不言而喻,赤脚在上面走,表明要鱼水相亲
虚幻的世界。儿子在游泳,妈在上面刨,“大海航行靠舵手”,上门有个舵手,下面的人就自由自在。但这一切是想象中的,因为舵手用的是锄头,但没有打到儿子身上。
多次出现,整洁的衣物代表权威仍然在(tian an men, bing guan),但在水里,会逐步远去,最终唐老师(知识分子)崩了小队长(农),旧世界彻底落幕
新奇和流行(去北京找天鹅绒)的世界,资本主义(外地才有)的世界、私欲(女性的肚皮)的世界。小队长拿了锦旗以为是天鹅绒,表明绝大多数农min知识水平、认知都被这十几年禁锢了,愚昧和蒙蔽的日子将永远下去,于是唐老师开抢了。
寓意整个**,其中北,用的是gugong,寓意很明确,朋友告诉唐老师的话,寓意领导对这十几年的定性(弯路、自己犯的错)。南部是愚昧(乡村)、西部是激进(石油)、东部是小资(学校)、北部是政治(故宫)。
寒来暑往,十几年,年轻人的信念、青春、理想一步步消逝
针对每个问题的性能分析方案
页面运行时用户觉得卡顿、不流畅,原因有很多,根本原因
排查方法
// 堆内存限制
performance.memory.jsHeapSizeLimit
// 总占用堆内存
performance.memory.totalJSHeapSize
// 存活堆内存
performance.memory.usedJSHeapSize
// 从系统运行到当前的时间
performance.now()
// 各个数据的时间线, 文档加载完成、事件完成、网络请求耗时等等,都可以计算
performance.timing
// 可以前后加performance.now(),计算方法执行时间 单位为ms
let start = performance.now();
run()
console.log(performance.now() - start);解决方案
上面已经提及了的问题发声方式,基本都有对应的解决方案。另外还有一些方案可以采用

彩色版本
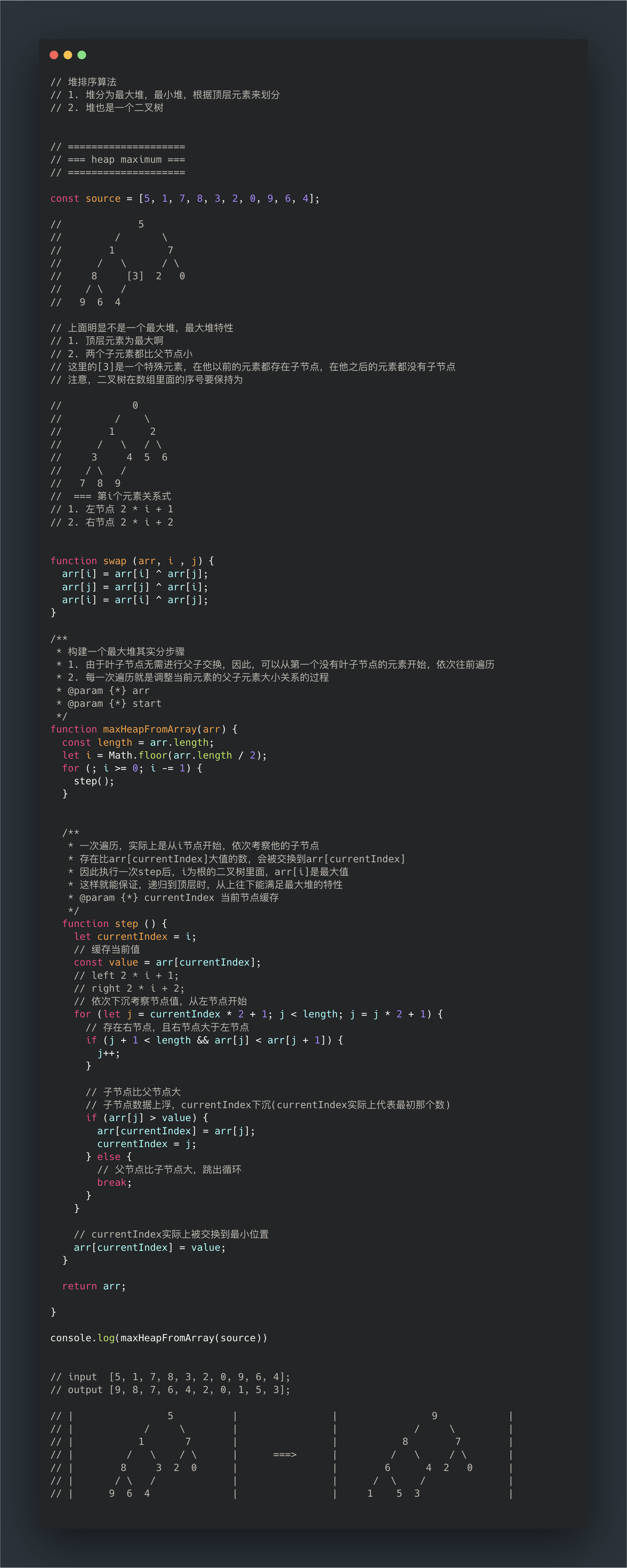
文字版本
// 堆排序算法
// 1. 堆分为最大堆,最小堆,根据顶层元素来划分
// 2. 堆也是一个二叉树
// ====================
// === heap maximum ===
// ====================
const source = [5, 1, 7, 8, 3, 2, 0, 9, 6, 4];
// 5
// / \
// 1 7
// / \ / \
// 8 [3] 2 0
// / \ /
// 9 6 4
// 上面明显不是一个最大堆,最大堆特性
// 1. 顶层元素为最大啊
// 2. 两个子元素都比父节点小
// 这里的[3]是一个特殊元素,在他以前的元素都存在子节点,在他之后的元素都没有子节点
// 注意,二叉树在数组里面的序号要保持为
// 0
// / \
// 1 2
// / \ / \
// 3 4 5 6
// / \ /
// 7 8 9
// === 第i个元素关系式
// 1. 左节点 2 * i + 1
// 2. 右节点 2 * i + 2
function swap(arr, i, j) {
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[j] ^ arr[i];
arr[i] = arr[i] ^ arr[j];
}
/**
* 构建一个最大堆其实分步骤
* 1. 由于叶子节点无需进行父子交换,因此,可以从第一个没有叶子节点的元素开始,依次往前遍历
* 2. 每一次遍历就是调整当前元素的父子元素大小关系的过程
* @param {*} arr
* @param {*} start
*/
function maxHeapFromArray(arr) {
const length = arr.length;
let i = Math.floor(arr.length / 2);
for (; i >= 0; i -= 1) {
step();
}
/**
* 一次遍历,实际上是从i节点开始,依次考察他的子节点
* 存在比arr[currentIndex]大值的数,会被交换到arr[currentIndex]
* 因此执行一次step后,i为根的二叉树里面,arr[i]是最大值
* 这样就能保证,递归到顶层时,从上往下能满足最大堆的特性
* @param {*} currentIndex 当前节点缓存
*/
function step() {
let currentIndex = i;
// 缓存当前值
const value = arr[currentIndex];
// left 2 * i + 1;
// right 2 * i + 2;
// 依次下沉考察节点值,从左节点开始
for (let j = currentIndex * 2 + 1; j < length; j = j * 2 + 1) {
// 存在右节点,且右节点大于左节点
if (j + 1 < length && arr[j] < arr[j + 1]) {
j++;
}
// 子节点比父节点大
// 子节点数据上浮,currentIndex下沉(currentIndex实际上代表最初那个数)
if (arr[j] > value) {
arr[currentIndex] = arr[j];
currentIndex = j;
} else {
// 父节点比子节点大,跳出循环
break;
}
}
// currentIndex实际上被交换到最小位置
arr[currentIndex] = value;
}
return arr;
}
console.log(maxHeapFromArray(source));
// input [5, 1, 7, 8, 3, 2, 0, 9, 6, 4];
// output [9, 8, 7, 6, 4, 2, 0, 1, 5, 3];
// | 5 | | 9 |
// | / \ | | / \ |
// | 1 7 | | 8 7 |
// | / \ / \ | ===> | / \ / \ |
// | 8 3 2 0 | | 6 4 2 0 |
// | / \ / | | / \ / |
// | 9 6 4 | | 1 5 3 |There are two syntactic forms(句法形式) for creating an arrayA repeat expression [x; N], which produces an array with N copies of x. The type of x must be 'Copy'[0, 10] means 0(inclusive) to 10(inclusive)函子是范畴论的一个概念,理解函子,先要理解范畴。基本的概念我们从wiki获得,然后再加上我(非数学专业/计算机专业毕业)的理解。
范畴论(英语:Category theory)是数学的一门学科,以抽象的方法处理数学概念,将这些概念形式化成一组组的“对象”及“态射”。数学中许多重要的领域可以形式化为范畴。使用范畴论可以令这些领域中许多难理解、难捉摸的数学结论更容易叙述证明。
范畴最容易理解的一个例子为集合范畴,其对象为集合,态射为集合间的函数。但需注意,范畴的对象不一定要是集合,态射也不一定要是函数;一个数学概念若可以找到一种方法,以符合对象及态射的定义,则可形成一个有效的范畴,且所有在范畴论中导出的结论都可应用在这个数学概念之上。
注意几点:
函子首先现身于代数拓扑学,其中拓扑空间的连续映射给出相应的代数对象(如基本群、同调群或上同调群)的代数同态。在当代数学中,函子被用来描述各种范畴间的关系。“函子”(英文:Functor)一词借自哲学家鲁道夫·卡尔纳普的用语[1]。卡尔纳普使用“函子”这一词和函数之间的相关来类比谓词和性质之间的相关[2]。对卡尔纳普而言,不同于当代范畴论的用法,函子是个语言学的词汇。对范畴论者来说,函子则是个特别类型的函数。
注意几点
我们再来看一下数学定义:

明确几点数学定义
再看一下haskell中的定义
class Functor f where
fmap :: (a -> b) -> f a -> f b
(<$) :: a -> f b -> f ahaskell的函子是一个类,并带有两个方法
fmap:得到一个映射关系a -> b,和一个函子f a,输出一个函子f b<$:这是haskell的中缀表达式,用前缀表达式表示就是id函数,表示函子值为a(f a),并接受一个函子f b,返回f a也就是说,如果我们把代码放到范畴下解决,所有的数据都统一为函子的话,函子和函子之间可以使用fmap和id函数通信。当然,我们需要给函子扩展更多的函数才能满足程序中奇奇怪怪的需求,但这不在本文讨论中。我们只关注函子。
函子的定律haskell实现
id :: a -> a
fmap id = id
fmap (f . g) = fmap f . fmap g直接上代码
// Just为我们的一个“函子”
function Just(value) {
return {
value, // 保存值
// 值为基本数据,支持映射到范畴(Just)内其他元素
// addOne = x => x + 1
// 比如 Just(1).map(addOne) -> Just(2)
map: function map(fn) {
return Just(fn(value))
},
// 值为基本数据,支持映射到自身范畴
// 比如 Just(1).flatMap(addOne) -> 2
flatMap: function flatMap(fn) {
return fn(value);
},
// 值为函数(映射),支持映射到范畴(Just)内的其他元素
// 比如Just((x) => x + 1).fmap(Just(2)) -> Just(3)
fmap: function fmap(just) { // 函子 Just(compose(b, a)) = composeJust(Just(b), Just(a));
return just.map(value)
}
}
}实现了fmap之后,我们要实现复合函数compose
// compound 复合函数 属于Number范畴
function compose(g, f) {
return x => g(f(x))
}
// compound 复合函数 属于Just范畴
function composeJust(Justg, Justf) {
return jx => Justg.fmap(Justf.fmap(jx))
}实现了复合函数,则我们就满足了结合律。即Number范畴复合后再态射与函数复合前分别态射再在Just范畴上复合,得到的结果是一样的。
课后作业:
compose函数的意义function partial(arr, start, end) {
if (start >= end) return start
let pivot = arr[start];
while (start < end) {
while (arr[end] >= pivot && start < end) end--;
if (start < end) {
arr[start] = arr[end];
start++;
}
while (arr[start] <= pivot && start < end) start++;
if (start < end) {
arr[end] = arr[start];
end--;
}
}
arr[start] = pivot;
return start;
}
function quickSort(arr, start, end) {
let mid = partial(arr, start, end);
// console.log(mid, start, end)
if (mid - 1 > start) quickSort(arr, start, mid - 1);
if (mid + 1 < end) quickSort(arr, mid + 1, end);
return arr;
}
var arr = [9, 1, 4, 7, 3, 2, 6, 8, 0];
console.table(quickSort(arr, 0, arr.length - 1));
《haskell趣学指南》概要
特性
工具链
函数分为两种类型
-- 中缀表达式
1 + 1
-- 前缀表达式
min 2 4-- baby.hs
-- doubleMe x 函数名加参数列表
-- = x + x 函数体
doubleMe x = x + x使用ghci调用
ghci> :l baby
[1 of 1] Compiling Main ( baby.hs, interpreted )
Ok, modules loaded: Main.
ghci> doubleMe 9
18
ghci> doubleMe 8.3
16.6if语句的else不可省略,更像是JavaScript中的三元表达式
testIf x = (if x > 100 then 100 else x) + 1List类型使用[1, 2, 3]的语法表示,而字符串是List的语法糖,比如hello是一个List ['h', 'e', 'l', 'l', 'o']。单引号扩字符,双引号扩字符串,这和JavaScript中一样。
-- ++ 连接List
-- [1, 2]
[1] ++ [2]
-- :首部添加元素
-- [1, 2]
1:[2]
-- !!取索引
-- 1
[2, 1] !! 1
-- head 取头部
-- 1
head [1, 2]
-- tail 除头部之外的部分
-- [2]
tail [1, 2]
-- last 取最后一个元素
-- 1
last [2, 1]
-- init 除尾部之外的部分
-- [1]
init [1, 2]
-- length 取长度
-- 2
length [0, 1]
-- null 检查是否为空
-- True
null [1]
-- reverse 反转
-- [2, 1]
reverse [1, 2]
-- take 取前x个元素
-- [1, 2]
take 2 [1, 2, 3, 4]
-- maximum 最大值 minimun最小值
-- 2
maximum [1, 2, 1]
-- sum 和
-- 3
sum [1, 1, 1]
-- product 积
-- 4
product [2, 1, 2]
-- elem 是否存在x元素
-- True
4 `elem` [1, 2, 3, 4]一个List可以用Range表示,[1..4],这个表示方式也是惰性的,用到的时候才会计算为[1,2,3,4]。也可以指定间隔[2, 1..5]生成[1,3,5]。
-- cycle 循环生成
-- [1,2,1,2]
take 4 (cycle [1, 2])
-- repeat 指定重复次数
-- [1,2,1,2]
repeat 2 [1,2]一个List可以用集合的方式来表示,规则相当丰富。也要记住这里也是惰性的。
-- [2, 4, 6, 8]
[x * 2 | x <- [1..4]]`这种方式|左边指定运算,右边指定数据范围。x <- [1..4]表示x为List [1..4]。运算和范围都支持多个,用逗号隔开,,也支持多个参数x y z...
-- [2, 6]
[x * y | x <- [1..4], x `mod` 2 == 1, y <- [2]]
元组类型。和List有点区别,也有点像,不过元组生成时大小固定,类型固定(多个参数可以为不同类型)
(1, 2)
(1, 'a')
([1,2], 'a', 3)元组操作
-- fst 返回第一个
-- 8
fst (8, 9)
-- snd 返回尾部 只对两元组生效
-- 2
snd (1, 2)
-- zip 生成元组 就像拉链一样,一边取一个生成元组
-- [(1, 2), (2, 2), (3, 2)]
zip [1, 2, 3] [2, 2, 2]本章我们来学习一些更「高级」的概念
上一文我们学习了如何快速使用vim做这些操作
现在,我们要一起来厘清一些基本的概念,这样后续的操作才会更加顺畅。
你可能好奇为什么vim的键位设计是这样的,比如hjkl用来移动光标,Ctrl用来绑定映射,\用来做leader键,@用来调用宏...
直到你看到这块键盘...

因为vi(vim作为vi的改进)的创造者Bill Joy键盘是这样的!
现在的键盘布局和他的是不一样的,但我们可以通过「改键」来实现操作的流畅性~
关于vim文档中使用到的符号,你可以通过**:h notation**来查看帮助文档中所使用的示例符号。
[] # 可选的
[count] # 重复后续command的次数,比如5x,重复五次光标字符删除
["x] # "表示寄存器,x可选[a-zA-Z0-9#%]等字符,"a表示调用寄存器a
# :reg<Enter> 可以查看寄存器情况
# 寄存器存储了一些命令集合
{motion} # motion表示一个光标操作
# w b j k 等都属于一个motion 可以和[count]结合 [count]{motion}
# 可以和操作结合 operator {motion} 比如删除操作db表示delete backwords,向后删除
<BS> # 输入删除键
<Space> # 输入空格键
<Home> # home键
<Enter> # 按下回车键 vimrc文件中使用<CR>
<Tab> # 按下Tab键
<End> # end键
<C-a> # 按下Ctrl + A键
<S-a> # 按下Shift + A键
<M-a> # 按下Alt + A键 或者说Meta + A键
# 这个比较特殊,有的终端本身用到了meta,比如iterm,这时候就需要配置终端允许发送到界面内
# 建议不使用这个键位映射,不然多端可能要重新调试
<F1>-<F12> # 按下F1...F12键
<Up> # 上
<Down> # 下
<Left> # 左
<Right> # 右

后续我们配置自己的vim时,有一些坑需要避免再踩

用任意一个产品,都要阅读它的帮助手册。比如vscode也是,很多人都不知道可以Ctrl+N/Ctrl+P来移动光标。我们要多使用vim的help。只需要**:h {TEXT}**就可以得到原生的帮助。
:h motion # 第一章我们讲过了motion,可以试着自己看看
:h buffer # buffer是vim处理文件缓存的方式
:h tab # tab和浏览器、vscode的tab一样
:h window # 窗口的概念 和窗口相关的是split,窗口分割
:h # 当然可以打开整个帮助手册
:h z # z命令帮助

在帮助页面,可以使用**:syntax on**打开语法高亮,这样你可以快速找到那些带有链接的字符。找到链接后,有跳转方案可以让你浏览起来更顺畅
# 帮助文档是只读模式,不能使用vim的插入模式,在Normal模式下可以用的命令,在帮助页面也可以用
<C-]> # Ctrl + ] 跳转进入链接页面
<C-o> # Ctrl + o 跳转回到上一次的光标地址
<C-i> # Ctrl + i 跳转回到执行<C-o>之前的光标地址

所有的配置项都可以通过**:options查看。配置项指的是你的软件配置,就像你使用word、typora等软件有个人偏好设置一样,vim也有自带的配置选项,这就是配置项。配置项使用:set**来配置
比如最常见的一些配置
:set number # 显示行号
:set bg=dark # 可选dark light |背景为dark模式
:set nocp # 可选nocp cp |非兼容(兼容vi)模式
:set shiftwidth=4 # 输入tab键入的空格个数,默认为8
:set filetype=javascript # 设置文件类型

命令可以通过Terminal模式执行,比如**:set :h :syntax :filetype :map**
:syntax on # 开启语法高亮
:filetype on plugin indent # 自动匹配文件类型
:h map # 打开map的帮助页面
:nmap # 直接执行一个命令,可以查看详情,比如这里是查看nmap配置
:e ~/.config/nvim/init.vim # 打开init.vim文件hints
在命令行中使用tab可以得到命令补全,命令可选参数可以通过唤醒提示

通过**:h usr_05可以看到vim配置文件的帮助手册。mac上nvim的配置文件地址为~/.config/nvim/init.vim** 你也可以使用下面的命令来得到配置地址
:echo stdpath('config') # 输出配置地址
:exe 'edit' stdpath('config').'/init.vim' # 编辑配置文件
VimScript是一个脚本语言,我们之前在Terminal模式使用的命令,都是脚本语言的一个内置指令。比如
" VimScript使用"作为注释
set number " 左侧显示行号
设置行号后,可以保存退出(:wq),再重新打开init.vim(vim init.vim),你会看到行号的出现。
我们来配置第一份配置
syntax on " 语法高亮
filetype plugin indent on " 文件格式自动检测
colorscheme delek " 主题色
set number " 显示行号
set rnu " 显示相对行号,凭个人喜好设置
set bg=dark " 黑色背景
set scrolloff=8 " 光标开始滚动的偏移行号(这样就不用在底部滚动)
set shiftwidth=4 " tab宽度
现在你的页面就有了色彩和定制的一些基础功能,不那么枯燥了。

仅仅有一些简单的键位还不够支撑我们的需求,而且也不够「酷」。有组合键位之后,我们才能做更多的事情。
" 配置组合键的格式常用的有这些
:nm[ap] {lhs} {rhs}
:vm[ap] {lhs} {rhs}
:im[ap] {lhs} {rhs}
:cm[ap] {lhs} {rhs}
:tm[ap] {lhs} {rhs}
之前我们解释过了[x]表示可选的字符,这里解释一下其他的
我们来看几个例子,通过例子来认识一下。
nmap <F1> :h<CR> " F1唤醒帮助
nmap <tab> V> " 缩进单行
vmap <tab> >gv " 缩进选中行 gv表示选中上一个选中的区域
nmap <leader>; A;<Esc>_ " 行末添加分号
最后一个例子,我们用到了,原生的键是****,如果键盘不好按,可以改成
let mapleader = " " " 这里是设置mapleader的字符输入,因此空格字符表示<space>键
nmap <leader>h :h<CR> " 打开帮助菜单
接下来你就可以使用一些简单的键位映射来处理快捷键的问题了。如果你感觉使用Ctrl键位不舒服,或者使用原生的leader键位不舒服,mac系统上可以调整你的键盘布局。键位映射也没有银弹,按自己最舒服的方式来就行了。

第二天,我们了解了这些内容
第三天,我们要学习复制/搜索/redo/undo/跳转/跳转列表/多行编辑等稍微智能一点的编辑器功能
最近几天,之前入职的同事们,陆续开始做述职报告,他们大多数都是3-5年经验的前端工程师,我摘录一些重要的问题并记录下来,作为之后职场路的一个指引。
一场述职报告,主要分为两部分:表述自我和问答。这里的记录包括了这两部分。
这些内容我分为这几类
基本能力是技术和业务之外的,它不在你的产出上有绩效占比,但你的所有产出都有它们带来的影响。
比如日常记录,我目前每天的时间就很碎片化,没有章法。可能某天在看A书,还没有深入了解,就到B书上了。为了写好你的「述职报告」,你必须学会记录每天做了什么,记上一个月,你就知道该怎么安排时间了。我们目前的时间安排都很满,但大致上一周的80%时间是在业务开发上,另外20%时间都是看个人发挥,有很多技术项目、规范文档的事情要做。想想还是很头疼的事情。
另外有很多提问也讲到了「沟通」这件事,跨部门的资源协调、产品方案讨论设计,做前端的研发,很多时候对这些是没有概念的。而实际问题是,你写的代码可能一文不值(在业务不值钱的情况下)。那么一个人如何去融入团队?如何产生代码之外的价值?就值得深思了。有一个案例是,产品线A需要做a产品时,研发x及时指出之前在产品线B做a产品类似的b产品时失败的经历,很可能就会阻止a产品的设计和开发。
当然基本能力只能靠积累,一个最好的办法就是看别人怎么做。多看,少说,多思考。
总结一下
这方面问的最多的问题有
核心方向只有一个:技术需要有广度和深度,也要有温度。
广度是你知道自己在做什么,深度是你知道你还可以做什么,温度是你知道你给到了用户哪些好处。
这些需要下来再继续积累。总结一下
这方面主要关心和用户贴近的方面
目前我对这些问题也没有明确的答案,或许能清晰回答这些问题,已经可以成为一个独立开发者了。
但还是要总结一下
目前还看得太少,长期的职业发展,还需要继续思考沉淀。本文有个核心观点
围绕发现问题和解决问题,一切出发点都是好的,能够更有动力去做每天的工作。要相信,我们的工作在一定程度上是不可替代的。
速度与激情里面有个名场面,「Don老大带着大家在后院吃火鸡。开饭前一起缅怀先人【祷告】,然后就是开怀一笑,和家人吃鸡喝酒」。「家人」这个概念和开源「社区」多少有点类似,不管你来自哪里,犯过什么事,只要你能成为「家人」,一切就都不重要了;开源「社区」也是如此,不论你有什么背景,好像用同一个软件,一起给它做贡献,就是「家人」。今天写下这些文字,预计后续会一直更新,一则是记录自己的学习过程,二来也是介绍给大家,毕竟用vim,我们就是「家人」了。
Bram Moolenaar's website - home
vim是作为vi的替代产品开发出来的文本编辑器,作为代码编辑器最初(21世纪涌现了很多IDE/编辑器)广泛在程序员中使用。vim和emacs并列(peace & love)为类unix系统用户最喜欢的编辑器。
虽然vim有很多中模式,但vim和其他图形化的编辑器有很大的不同,它所有的模式下都可以使用键盘进行IO操作,对于文字录入者或者程序员来说,就可以大大提高工作效率。人们通常对他的称赞就是「思考到哪里,输入就到哪里」。
然鹅,程序员tarruda给7.0版本的vim提交patch,希望vim增加异步执行命令的功能,但是被Bram拒绝了,tarruda因此fork了一个分支出来开发并维护,这个fork出来的项目就是neovim。neovim兼容大多数vim的操作,但是基于vim做了很多重构和升级,虽然vim 8.0也开始支持异步了,但现在很多人都用neovim了。
noevim的特性
实际开发中,你愿意使用vim和neovim都可以。我一般使用neovim(neovim + lsp基本媲美IDE了)。后面的行文中我只使用vim来表达这个(vim或neovim)编辑器。
我的主要开发环境是mac + neovim。
brew install neovimmac环境下vim使用**/.vimrc**,neovim使用**/.config/nvim/init.vim作为入口,若使用lua作为noevim的配置语言的话,配置入口对应为~/.config/nvim/init.lua**。
# 安装的neovim原生命令是nvim,这里配置一下shell
alias vim="nvim"
# 打开一个文件
vim ~/hello.md
# 打开一个目录
vim ~/some-directory/
# 不使用配置打开 -u NONE表示不使用vimrc文件启动,-N表示启动nocompatible选线防止进入vi兼容模式
vim -u NONE -N
# 当然你可以加载特定的vimrc
vim -u ~/your/path/to/vimrc/init.vim
# vim +command表示打开后执行一个命令等同于打开后:command<Enter>
vim +checkhealth # 用于检查运行情况/插件依赖等
vim +Tutor # 教学另外还有一些派生的模式,日常使用中我们主要用到普通模式、插入模式、可视模式、命令模式这四个模式。
普通模式主要用来移动光标,以及不需要打字输入的场景,比如y复制、p粘贴、翻页等。
进入vim界面后,默认为普通模式。普通模式可以使用许多命令来移动光标、处理文本。这里先举几个例子来感受一下。
# 移动
h 光标左移动一格
j 光标下移动一格
k 光标上移动一格
l 光标l移动一格
w 光标移动到下一个单词
b 光标移动到上一个单词开头
0 光标移动行首
$ 光标移动到行末尾
zz 当前光标定位到屏幕**
_ 光标移动到行首第一个非空格
gg 光标移动到文件头部
G 光标移动到文件尾部
dd 删除当前行
C-d 向下翻页
C-u 向上翻页
插入模式主要用于我们需要录入文字的场景。
有几种方式可以从普通模式进入插入模式。
i 字面意思 insert。光标位置前一个位置插入
I 行首插入
a 下一个位置插入
A 行末插入
o 增加一行,并进入插入模式
O 向上增加一行,并进入插入模式
<ESC> 退出插入模式
<C-c> 退出插入模式
可视模式就像是你有了光标,可以通过键盘来选择区域。可视模式中可以使用普通模式的光标移动键位来定义圈选范围。
几种方式进入可视模式。
v 进入可视模式
V 进入可视模式,选中当前行
<C-v> 多行光标
执行命令,可以执行vim的命令、插件命令、环境命令(终端命令等)。这个命令很重要,当你想要学习某条命令的时候可以帮助你快速记忆。
在普通模式下输入:进入命令
: 后直接跟命令,回车执行,比如进入帮助a的页面:h a 设置高亮:syntax on
:! 后直接跟环境命令,如:!echo 1
:<C-c> 命令模式下按<C-c>退出命令模式利用好内置的文档
:h a a命令帮助 插入
:h c c命令帮助 修改
:map 查看所有映射
:nmap 查看普通模式下映射
:vmap 查看可视模式下映射
:h 进入帮助页面
退出vim有两种方式,一种是关闭终端,另一种是重启电脑。
退出vim有两种方式,一种是保存退出,另一种是强制保存退出。
:w 保存文件 字面意思 write
:w! 强制保存文件
:wa 保存所有文件,针对你打开buffer过多的情况
:q 退出
:q! 强行退出
:wq 保存并退出
:qa 退出所有buffer 学会上面的操作,你基本上可以开始使用vim,并编辑文章或者程序了。但这些并不是vim给你带来的优势,你在其他编辑器上也可以做。接下来要讲的就有点意思了。
motion
在vim里面,一个光标的移动操作,被视为一个motion,比如
b 光标移动到上一个单词头
w 光标移动到下一个单词首而motion是可以被组合的,比如自然语言里面,「我想跳跑一步」,叠加次数后就会变成,「我想跑一万步」。motion的组合类似这个意思。
9b 光标向前移动9个单词
8<C-d> 翻页操作8次
operator
顾名思义,操作,就像是我们自然语言里面的动词一样。「我吃饭」,「吃」就是我们的操作,vim里面是一样的。这些是一些简单的操作
c change 修改
d delete 删除
y yank 复制到寄存器(后面讲)
~ 切换光标字符的大小写
gu 切换为小写
gU 切换为大写
gq 文本格式化
gw 文本格式化,不移动光标
< 块移动,左移动
> 块移动,右移动
针对motion和operator的技巧很多,现在你仅需要记住,他们都是可以组合的就行了。举几个例子,可以反应这种组合。
# 可用的介词 around in to
diw delete in word 删除一个单词
di" delete in " 删除"word"中的word
daw delete around word 删除一个单词和包裹
cb change back 向前删除到单词头部,并进入插入模式,即修改
cis change in sentence 修改句子
ci< change in < 修改<word>中的word
ca< change around < 修改<word>
# 甚至你可以组合命令进来
d:call EndParagraph() 删除到EndParagraph()执行结果的位置
dfa delete find a 删除到找到第一个a
大写命令
上面已经涉及到大部分的使用场景,现在学习一个简单的记忆规则。一个命令,小写和大写,往往是相反或者加强的。
o/O 下起一行/上起一行
a/A 光标后插入/光标行末插入
t/T 向后->直到../向前<-直到.. dta/dTa => delete to a/delete back to a
x/X 光标位置字符删除/光标前一个字符删除
p/P 向后粘贴/向上粘贴第一天,我们了解了这些内容
下一次,我们要学习一些高级操作/组合
/**
* @param {number} capacity
*/
var LRUCache = function(capacity) {
this.cap = capacity;
// 缓存节点信息
this.map = new Map();
this.len = 0;
this.head = new Node(0, 0);
this.tail = new Node(0,0);
this.head.next = this.tail;
this.tail.prev = this.head;
// node 插入尾部
this.insertLast = function (node) {
if (this.len === this.cap) {
this.unshiftFirst();
}
node.prev = this.tail.prev;
node.next = this.tail;
this.tail.prev.next = node;
this.tail.prev = node;
// 添加进map
this.map.set(node.key, node);
this.len++
}
this.unshiftFirst = function () {
if (this.head.next !== this.tail) {
let node = this.head.next;
this.head.next = node.next;
node.next.prev = this.head;
if (this.map.has(node.key)) {
this.map.delete(node.key)
}
this.len--
return node
}
}
this.remove = function (node) {
node.prev.next = node.next;
node.next.prev = node.prev;
this.len--;
this.map.delete(node.key)
}
};
/**
* @param {number} key
* @return {number}
*/
LRUCache.prototype.get = function(key) {
if (this.map.has(key)) {
let node = this.map.get(key);
this.remove(node)
this.insertLast(node);
return node.val
}
return -1;
};
/**
* @param {number} key
* @param {number} value
* @return {void}
*/
LRUCache.prototype.put = function(key, value) {
let node;
if (this.map.has(key)) {
node = this.map.get(key);
node.val = value;
this.remove(node);
} else {
node = new Node(key, value)
}
this.insertLast(node);
};
function Node(key, val) {
this.key = key;
this.val = val;
this.prev = null;
this.next = null;
}
/**
* Your LRUCache object will be instantiated and called as such:
* var obj = new LRUCache(capacity)
* var param_1 = obj.get(key)
* obj.put(key,value)
*/
本章我们学习寄存器/跳转列表等知识,以及他们的应用:复制/粘贴/撤销/重做/跳转,同时介绍一个各个GUI编辑器都支持的多行编辑。
本章我们要利用好已经学过的能力。首先来复习一下如何使用原生的帮助文档
:h # 打开帮助
:h y # 查看y命令帮助
["x]y{motion} # y命令前可选一个寄存器,后面需要搭配motion使用
{Visual}["x]y # 在Visual模式下使用y命令,y命令前可选一个寄存器
<C-]> # 文档跳转
<C-o> # 跳回
y/Y # 一个命令的小写和大写往往有关联,比如o向下另起一行,O向上另起一行。
{count}{motion} # 执行{count}次{motion}
利用好这些能力可以帮助我们阅读好文档。
寄存器是程序中用于存储特定数据的单元,使用**:reg命令可以查看当前寄存器情况。vim中用[”x**]表示寄存器,x表示寄存器名字。
一共有这十种寄存器:
1. 未命名寄存器[””] d/c/s/x/y命令处理的文本除了被其他寄存器处理外,还被存储在未命名寄存器,就像是未命名寄存器指向了最后一个使用的寄存器一样。
2. 10个数字编号的寄存器[”0]-[”9] 和yank/delete命令相关的文本被存储在数字寄存器。0/1寄存器分别存储yank和delete产生的最新文本,就文本被依次序传入2/3/4...9,最多到9。
3. 删除号寄存器[”-] 存储删除文本少于一行的
4. 26个字母寄存器,不区分大小写[”a]-[”z] 存储自定义的文本,小写字母覆盖,大写字母添加
5. 三个只读寄存器[”,] [”.] [”%] 存储文件、当前行、当前命令等。只能和p/P命令结合使用
6. 可选缓存寄存器[”#] 存储当前窗口可选文件的名字
7. 表达式寄存器[”=] 存储命令字符串
8. 选择区域寄存器[”*] [”+] 存储选择的文本。"*y可以把选区复制到系统剪切板
9. 黑洞(the black hole)寄存器[”_] 这个寄存器不做任何事情
10. 上一次搜索模式寄存器[”/] 存储上次搜索的模式匹配字符串
vim的寄存器你可以理解为内存中的一个缓存机制,它类似于一些程序语言中的buffer,但它确实和汇编里面的寄存器很相似。
:reg命令输出格式
Type Name Content
c "0 123
l "" aaa这是实现强大的自动化能力的方式。我们要用到这两个命令
q # 实现宏定义,q["x]{motion}q 可以把你的motion定义到x寄存器
@ # 调用寄存器,并执行寄存器内的命令最简单的宏录制:新增一百行。
qao<Esc>q # q["x]{motion}q 给寄存器存储o<Esc>命令
100@a # {count}@a 调用count次寄存器a的命令
在这个基础上,可以复杂一点,新增一百行,并给出序号
o1.<Esc> # 写入1.
qayypj_<C-a>q # 复制当前行到下一行,移动到新行头部,增加数字。操作记录入寄存器a
100@a # 得到结果
除了在以后的VimScript中我们会使用到寄存器外,正常的编辑行为也支持快捷键。
<C-r>0 # 读取寄存器信息并粘贴到光标处也就是说你可以在Insert模式中使用命令调用指定寄存器的内容,上述文本表示我们取用了[”0]寄存器,得到最后一次被yank(vim的复制)的内容。

现在我们来看一下复制粘贴命令。vim里面的复制,使用英文yank表示,简写为y复制命令实际是把文本转存到某个寄存器里面了,复制命令支持指定寄存器复制。
["x]y{motion} # 如果没有文本可以被复制,则复制motion,复制地点为[x]寄存器。比如"ay,复制到a寄存器
["x]yy # 复制行,可以带{count},复制多行
["x]Y # 复制光标到行结尾,不带换行符
{Visual}["x]y # 复制选区文本
{Visual}["x]Y # 复制选区行,多行
["x]p # 可以带{count} 把寄存器的内容粘贴到光标后面 {count}多次
["x]P # 可以带{count} 把寄存器的内容粘贴到光标前面 {count}多次
当你不清楚哪个寄存器存入了数据,你可以使用**:reg查看寄存器状态,然后通过[”x]p**来粘贴对应的内容。根据我们第一节讲到的寄存器概念,实际上p就是””p的缩写~,也就是说p会得到最后一次yank或者delete的内容。

这里需要明确一个概念,就是vim中的复制粘贴都是相对寄存器来说的,你可以看到命令的定义都是基于寄存器的,因此要想实现操作系统的剪贴板复制粘贴,可以自定义命令。
{Visual}"*y # 把选取内容复制到[*]寄存器。这个寄存器同时也复制到操作系统
{Normal}"*y{motion} # 普通模式执行,把motion的结果复制到寄存器,同时也复制到操作系统
"*p # 把[*]寄存器的内容取出并粘贴
使用「{Normal}"*y{motion}」复制两行到剪贴板:

[*] [+]寄存器就是你和操作系统的剪贴板交互的功能。因此你可以映射一下
vmap Y "*y " Visual模式下Y命令把选区复制到剪贴板
nmap PP "*p " Normal模式下PP命令把剪贴板内容粘贴
编辑器里面,通用的撤销和重做英文对应undo/redo。vim直接就用了这两个单词的首字母。同样你可以用{count}表示需要undo/redo的次数。
u # 撤销上一个动作
<C-r> # 取消上一个撤销动作
除了使用u/之外,你的文本编辑状态是被vim记录了的,因此你还可以在任意状态中穿梭。
:undol[ist] # 查看可以使用的undo清单
g- # 进入上一个编辑状态 对应:earlier
g+ # 进入下一个编辑状态 对应:after
:earlier {count} # {count}个状态之前
:earlier {N}s # N秒之前的状态,同理可以用s/m/h/d 秒/分/时/天
:after{count} # {count}个状态之后
:after {N}s # N秒之后的状态,同理可以用s/m/h/d 秒/分/时/天
不过日常写代码,用的最多的还是u/组合
之前我们提到过多行编辑的功能。使用命令可以进入块选择模式,需要多行编辑可以
这里需要注意,退出不会检查缩写,也不会执行InsterLeave的自动触发事件,因此必须用或<C-[>进行退出
在vim世界,光标位置也是被记录的,自然也可以查看历史位置、调用历史位置。跳转列表就像是一个函数调用栈,在这个栈里面你可以用JumpIn/JumpOut的方式读取一个函数的内容。而生成跳转列表的逻辑,就是motion。motion触发光标转移,转移前后的位置被跳转列表记录,生成一个调用链。
:ju[mps] # 可以查看当前的跳转列表
:cle[arjumps] # 清除当前的跳转列表
跳转列表显示如下
jump line col file/text
3 1 0 some text
2 70 0 another text
1 1154 23 end.
几列分别表示跳转列表的第几个/光标行号/光标列号/对应的文件或文本。
你可以使用下面两个组合来在跳转表中进行跳转
<C-i> # 跳入,往前跳
<C-o> # 跳出,往后跳
以下常用命令可以进行跳转(类型上属于text motion文本光标操作),你可以用/进行组合使用
gg # 跳转到文件头部
G # 跳转到文件尾部
[[ # 往上章节section跳转
]] # 往下章节section跳转
{ # 往上段落paragraph跳转
} # 往下段落paragraph跳转
( # 往上句子sentence跳转
) # 往下句子sentence跳转
实际上,你可以理解为一些大幅度跳转光标的操作,都会被跳转列表记录。现在你只需要记住这一点,然后在实践中多运用和两个命令。
同时,所有的修改也被记录到了列表,形成了修改记录
:changes # 查看当前的修改列表
修改列表和跳转列表类似,行号表示修改产生的光标位置。
change line col text
3 16 0 abcdef
2 35 3 abc
1 7 3 aadf6
有很多方式可以产生一个change,新增/修改/删除都算,新增文本可以是insert(i)也可以是paste(p),修改可以是change(c),删除可以是x/X
你可以使用下面的组合来跳转
g; # {count}个以前的修改位置
g, # {count}个以后的修改位置

今天我们学习了几个重要的概念,以及一些高级的编辑器操作,赶快去运用一下吧~
有了这些概念,你可以做一些更丰富的操作了,特别是寄存器,可以让你任意存/取文本。
下一次我们将讲讲搜索/替换(搜索和替换会用到更深入的知识)
链表有很多种。
处理链表就是处理各种指针之间的关系,常见处理
操作
阅读本文,假设你已经熟练运用
async/await和promise了
最近在Code Review中,有同学提出说async/await比promise好,应该统一转为async/await,当时我认为这只是两种写法风格的问题,下来也研究了两者的区别。本文探讨两种写法的适用场景,仍然不做结论性输出,仅供使用者参考。
我们知道async/await是promise的语法糖,在底层执行的时候,它仍然遵循promise的逻辑,只是在书写上,让我们能够写出更多直白的代码。今天我们来对比一下两种写法的优缺点,帮助我们
async/await在写前后有依赖的异步代码时,不仅写起来很舒服,阅读起来也很高效:
async function test() {
let a = await callPromise();
let b = await callPromise(a);
return b;
}这段代码一目了然,我们逐行得到运行结果。这种功能如果用promise写就变成这样
function test() {
return callPromise()
.then(a => callPromise(a))
}这里多余的心智负担是要去思考链式调用的每个节点。不过从两种风格来看,这里没有优劣。
这两种风格,我称为
async/await)promise)错误处理依旧是继承自语法的区别,命令式错误处理需要对命令做解析处理,函数式错误处理需要对函数结果做错误处理。
async function test() {
try {
return await callPromise();
} catch(e) {
console.log(e);
return somethingDefault;
}
}使用promise处理大概为
function test() {
return callPromise()
.then(doSomething)
.catch(e) {
console.log(e);
return somethingDefault;
}
}这里我们依然无法分出优劣,只能说命令式的方式try...catch...更加直观,而函数式的错误处理必须要理解.catch函数在链式调用中的作用。
一种观点说的是async/await让分支结构走得更顺畅,比如
async function test() {
let a = await callPromise();
let b = doSomething(a);
if (b) {
let c = await callPromise(b);
console.log(c)
return c;
} else {
return []
}
}这种带有if...else...选择的方式,其实也继承自命令式编程,很多人觉得这时候在.then里面写分支判断再返回值,会增加心智负担。实际上此时的函数式写法应该是这样的
function test() {
const leftOrRight = (left, right) => val => val ? right(val) : left;
const tap = fn => x => {
fn(x);
return x;
}
const left = [];
const right = b => callPromise(b).then(tap(console.log))
return callPromise()
.then(doSomething)
.then(leftOrRight(left, right))
}其中leftOrRight是函数式编程里面的Either概念,left表示函数出错的情况,right表示函数正确执行。正常情况下这种分支结构需要传入两个函数作为异常处理和正确处理的后续,此处为了简略,把left作为默认值处理,而right继承了正确的值并进行输出。
tap函数也是函数式编程中的概念,用于连接数据流,并在不影响输入输出的情况下执行副作用操作,比如这里我们用到的console.log
可以看到,分支结构在命令式编程和函数式编程里面有对应的模型。
以下是被诟病的promise冗长、不易阅读的问题,不建议使用:
function test() {
return callPromise()
.then(a => {
let b = doSomething(a);
if (b) {
return callPromise(b)
.then(c => {
console.log(c);
return c
})
} else {
return []
}
})
}当链式调用比较复杂的情况下,需要我们做取舍,比如条件a+条件b得到条件c
async function test() {
let a = await callPromiseA();
let b = await callPromiseB(a);
return callPromiseC(a, b);
}像这种a -> b -> a +b的调用方式,使用async/await极大减少我们阅读的负担。这种情况对应链式调用
function test() {
const apply = (fn) => (arr) => fn(...arr)
return callPromiseA()
.then(a => Promise.all([a, callPromiseB(a)]))
.then(apply(callPromiseC))
}可以看到,使用promise也并不是那么不堪,我们仍然使用更加函数的方式来解决了这个问题,甚至这里的a => Promise.all([a, callPromiseB(a)])也可以抽象出来称为一个单独的函数,方便进行组合。
而单纯并行任务的话,await无法做到,await模拟了链式调用,但并行任务并没有对应的处理方案。
async function test() {
let a = await callPromise();
let b = await callPromise(a);
return b;
}
// 等价于
function test() {
return callPromise.then(callPromise)
}
// 无法实现
Promise.all([callPromise(a), callPromise(b)])这里又要涉及到macro task和micro task了。我们知道一个宏任务是一个循环取用的队列,每次宏任务执行完毕会查看微任务队列,如果存在任务就执行。意思是从宏任务和微任务生成的微任务,总是存在一个固定的队列,每当一个宏任务执行完毕就批量按先后顺序执行微任务。也就是说我们的async/await和promise.all如果执行的是Promise.resolve(1)这种纯微任务,先后执行和并行执行,对浏览器来说差别不大,都是阻塞在微任务队列里面,而如果执行的是fetch操作(宏任务返回微任务,宏任务中产生更多的宏,最终返回微任务),那么差别就很大。Promise.all在后一种情况可以支持多个宏任务异步执行(比如并行发送http请求),而async/await只能依次执行(串行发送http请求)。
很多人说.then函数不好调试,很多时候你写箭头函数,必须要去把函数改为{}(一个区块),然后在里面增加console.log来调试,或者增加debugger。这其实是不对的,我们使用tap函数可以在不改变原有结构的情况下进行调试。
Promise.resolve(1).then(tap(console.log));
Promise.resolve(1)
.then(tap((x) => {
debugger
}))
.then(result => {
// doSomething
})await语法async/await封装了链式调用Promise.race/Promise.all/..等方法可以很好地组合async/await简化了函数式风格的链式调用,将其转为命令式风格,更加直观一种范式的产生,一定是有它的道理的。并且语言也在不断的进化,很可能我们信以为至高信仰的语法糖,又会被别的语法糖替代掉。关键是掌握其核心原理。我们日常Code Review不必纠结写法的区别(除非差异非常巨大),因为写法风格是从编程范式里面继承下来的,我们更应该关注核心要点:





新装的windows电脑,性能好很多。于是想利用wsl2来设置一个开发环境。
根据官方文档,把wsl2安装好。我安装的发行版是ubuntu

React 15带来了Virtual DOM,React 16带来了Fiber。学习原理,天天向上!
Virtual DOM直接学习此仓库https://github.com/Matt-Esch/virtual-dom,源码结构相当清晰!

Fiber阅读了这篇文章An Introduction to React Fiber - The Algorithm Behind React。
学习Fiber之前建议先学习Virtual DOM,Fiber是对Virtual DOM的一种升级。
Virtual DOM使用栈来调度需要更新的内容,中间无法中断、暂停。Fiber支持中断,在浏览器渲染帧里面分片执行更新任务。Fiber解构让虚拟节点记录父节点、兄弟节点、子节点,形成链表树,你可以从任意顶点遍历到任意子节点,并返回。Fiber的分片操作使用requestAnimationFrame(高优先级任务)和requestIdleCallback(低优先级任务)Fiber对任务的执行优先级进行标记,高优先级的任务可以先执行,实现架构上的无阻塞requestAnimationFrame模拟任务分片执行MDN: window.requestAnimationFrame() 告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。
这里的动画可以理解为浏览器的刷新帧(对应电影里面的帧),大多数应该都是16ms
// 模拟任务中断分片执行
var tasks = new Array(100).fill(0).map((x, i) => i);
// 函数可以拿到当前执行的时刻,该值和performance.now()得到的值一致
function callFrame(timestamp) { // 片段内任务同步执行
let t = tasks.pop();
console.log("当前执行任务", t)
let end = timestamp;
// 模拟阻塞。因此这里受限于实际执行的脚本,如果运行200ms,则会阻塞下一次动画
while(tasks.length && end - timestamp < 200) {
end = performance.now()
}
// 下一帧是否需要继续运行
if (tasks.length) {
requestAnimationFrame(callFrame);
}
}
requestAnimationFrame(callFrame);requestIdleCallback模拟任务分片执行MDN: window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。
这里的空闲,我们大多理解为一帧,但实际上间隔要大一些,实际测试最小有十几毫秒,最大有几十毫秒。
requestIdleCallback是一个实验特性,因此在利用它做任务分片的工作时,最好有一些兜底方案,比如
setTimeoutrequestAnimationFrame// 模拟任务中断分片执行
var tasks = new Array(100).fill(0).map((x, i) => i);
// deadline可以获取当前剩余的空闲时间
function call(deadline) {
let start = performance.now();
let t = tasks.pop();
console.log("当前执行任务", t)
let end = start;
// 模拟阻塞
while(tasks.length && end - start < 20) {
end = performance.now()
// deadline.timeRemaining()可以获取当前剩余时间
// 我们实际运行的时候,可以用这个deadline.timeRemaining()来判断是否要执行下一个任务
console.log("deadline remaining", deadline && deadline.timeRemaining())
}
// 下一帧是否需要继续运行
if (tasks.length) {
requestIdleCallback(call);
}
}diff算法这个就是树或者图的遍历,建议多刷leetcode就行了。
patch算法对节点进行具体的增删改
vdomvnode本来想写一下rust转换js的json数据的(场景:如果用在wasm内,会不会比js快),看了一早上后搁浅了(现在我的rust能力还很菜,需要先阅读其他人的代码,然后写点简单的开始)。
serde.rs 一个rust的序列化库format!这个宏来拼接字符串切片&strlet s = format!("You need a {} {}", "Mac", "Book")neon.rs 一个把rust编译为nodejs的api的库,可以用rust来给node写扩展,同类型的还有napi.rs(一个原字节员工写的)extern crate xxx,很多库的README里面还有这个,实际上使用use语法引入就行了,编译器自动检查deno安装下来完了一下,感觉除了包在远端,没什么区别。实际上去deno run的时候,也需要download到本地,那么为什么要用deno呢?用npm管理的话,还可以直接看到依赖图,远端的包感觉更难控制,**仓库一挂,全生态ggvim 可以使用:noh来关闭当前查找数据后留下的高亮11.4了,UI看起来还不错,重点是存储释放了几十个G,不用买硬盘来扩展了。本页搜集工具链
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.