voff2014 / wxblog Goto Github PK
View Code? Open in Web Editor NEWwxblog
License: Apache License 2.0
wxblog
License: Apache License 2.0









思考
NSQ: realtime distributed message processing at scale
NSQ is a realtime message processing system designed to operate at bitly’s scale, handling billions of messages per day.
It promotes distributed and decentralized topologies without single points of failure, enabling fault tolerance and high availability coupled with a reliable message delivery guarantee.
Operationally, NSQ is easy to configure and deploy (all parameters are specified on the command line and compiled binaries have no runtime dependencies). For maximum flexibility, it is agnostic to data format (messages can be JSON, MsgPack, Protocol Buffers, or anything else). Go and Python libraries are available out of the box.
This post aims to provide a detailed overview of NSQ, from the problems that inspired us to build a better solution to how it works inside and out. There’s a lot to cover so let’s start off with a little history…
Background
Before NSQ, there was simplequeue, a simple (shocking, right?) in-memory message queue with an HTTP interface, developed as part of our open source simplehttp suite of tools. Like its successor, simplequeue is agnostic to the type and format of the data it handles.
We used simplequeue as the foundation for a distributed message queue by siloing an instance on each host that produced messages. This effectively reduced the potential for data loss in a system which otherwise did not persist messages by guaranteeing that the loss of any single host would not prevent the rest of the message producers or consumers from functioning.
We also used pubsub, an HTTP server to aggregate streams and provide an endpoint for multiple clients to subscribe. We used it to transmit streams across hosts (or datacenters) and be queued again for writing to various downstream services.
As a glue utility, we used ps_to_http to subscribe to a pubsub stream and write the data to simplequeue.
There are a couple of important properties of these tools with respect to message duplication and delivery. Each of the N clients of a pubsub receive all of the messages published (each message is delivered to all clients), whereas each of the N clients of a simplequeue receive 1 / N of the messages queued (each message is delivered to 1 client). Consequently, when multiple applications need to consume data from a single producer, we set up the following workflow:
old school setup
The producer publishes to pubsub and for each downstream service we set up a dedicated simplequeue with a ps_to_http process to route all messages from the pubsub into the queue. Each service has its own set of “queuereaders” which we scale independently according to the service’s needs.
We used this foundation to process 100s of millions of messages a day. It was the core upon which bitly was built.
This setup had several nice properties:
producers are de-coupled from downstream consumers
no producer-side single point of failures
easy to interact with (all HTTP)
But, it also had its issues…
One is simply the operational overhead/complexity of having to setup and configure the various tools in the chain. Of particular note are the pubsub > ps_to_http links. Given this setup, consuming a stream in a way that avoids SPOFs is a challenge. There are two options, neither of which is ideal:
just put the ps_to_http process on a single box and pray
shard by consuming the full stream but processing only a percentage of it on each host (though this does not resolve the issue of seamless failover)
To make things even more complicated, we needed to repeat this for each stream of data we were interested in.
Also, messages traveling through the system had no delivery guarantee and the responsibility of re-queueing was placed on the client (for instance, if processing fails). This churn increased the potential for situations that result in message loss.
Enter NSQ
NSQ is designed to (in no particular order):
provide easy topology solutions that enable high-availability and eliminate SPOFs
address the need for stronger message delivery guarantees
bound the memory footprint of a single process (by persisting some messages to disk)
greatly simplify configuration requirements for producers and consumers
provide a straightforward upgrade path
improve efficiency
To introduce some NSQ concepts, let’s start off by discussing configuration.
Simplifying Configuration and Administration
A single nsqd instance is designed to handle multiple streams of data at once. Streams are called “topics” and a topic has 1 or more “channels”. Each channel receives a copy of all the messages for a topic. In practice, a channel maps to a downstream service consuming a topic.
Topics and channels all buffer data independently of each other, preventing a slow consumer from causing a backlog for other channels (the same applies at the topic level).
A channel can, and generally does, have multiple clients connected. Assuming all connected clients are in a state where they are ready to receive messages, each message will be delivered to a random client. For example:
nsqd clients
NSQ also includes a helper application, nsqlookupd, which provides a directory service where consumers can lookup the addresses of nsqd instances that provide the topics they are interested in subscribing to. In terms of configuration, this decouples the consumers from the producers (they both individually only need to know where to contact common instances of nsqlookupd, never each other), reducing complexity and maintenance.
At a lower level each nsqd has a long-lived TCP connection to nsqlookupd over which it periodically pushes its state. This data is used to inform which nsqd addresses nsqlookupd will give to consumers. For consumers, an HTTP /lookup endpoint is exposed for polling.
To introduce a new distinct consumer of a topic, simply start up an NSQ client configured with the addresses of your nsqlookupd instances. There are no configuration changes needed to add either new consumers or new publishers, greatly reducing overhead and complexity.
NOTE: in future versions, the heuristic nsqlookupd uses to return addresses could be based on depth, number of connected clients, or other “intelligent” strategies. The current implementation is simply all. Ultimately, the goal is to ensure that all producers are being read from such that depth stays near zero.
It is important to note that the nsqd and nsqlookupd daemons are designed to operate independently, without communication or coordination between siblings.
We also think that it’s really important to have a way to view, introspect, and manage the cluster in aggregate. We built nsqadmin to do this. It provides a web UI to browse the hierarchy of topics/channels/consumers and inspect depth and other key statistics for each layer. Additionally it supports a few administrative commands such as removing and emptying a channel (which is a useful tool when messages in a channel can be safely thrown away in order to bring depth back to 0).
nsqadmin
Straightforward Upgrade Path
This was one of our highest priorities. Our production systems handle a large volume of traffic, all built upon our existing messaging tools, so we needed a way to slowly and methodically upgrade specific parts of our infrastructure with little to no impact.
First, on the message producer side we built nsqd to match simplequeue. Specifically, nsqd exposes an HTTP /put endpoint, just like simplequeue, to POST binary data (with the one caveat that the endpoint takes an additional query parameter specifying the “topic”). Services that wanted to switch to start publishing to nsqd only have to make minor code changes.
Second, we built libraries in both Python and Go that matched the functionality and idioms we had been accustomed to in our existing libraries. This eased the transition on the message consumer side by limiting the code changes to bootstrapping. All business logic remained the same.
Finally, we built utilities to glue old and new components together. These are all available in the examples directory in the repository:
nsq_pubsub - expose a pubsub like HTTP interface to topics in an NSQ cluster
nsq_to_file - durably write all messages for a given topic to a file
nsq_to_http - perform HTTP requests for all messages in a topic to (multiple) endpoints
Eliminating SPOFs
NSQ is designed to be used in a distributed fashion. nsqd clients are connected (over TCP) to all instances providing the specified topic. There are no middle-men, no message brokers, and no SPOFs:
nsq clients
This topology eliminates the need to chain single, aggregated, feeds. Instead you consume directly from all producers. Technically, it doesn’t matter which client connects to which NSQ, as long as there are enough clients connected to all producers to satisfy the volume of messages, you’re guaranteed that all will eventually be processed.
For nsqlookupd, high availability is achieved by running multiple instances. They don’t communicate directly to each other and data is considered eventually consistent. Consumers poll all of their configured nsqlookupd instances and union the responses. Stale, inaccessible, or otherwise faulty nodes don’t grind the system to a halt.
Message Delivery Guarantees
NSQ guarantees that a message will be delivered at least once, though duplicate messages are possible. Consumers should expect this and de-dupe or perform idempotent operations.
This guarantee is enforced as part of the protocol and works as follows (assume the client has successfully connected and subscribed to a topic):
client indicates they are ready to receive messages
NSQ sends a message and temporarily stores the data locally (in the event of re-queue or timeout)
client replies FIN (finish) or REQ (re-queue) indicating success or failure respectively. If client does not reply NSQ will timeout after a configurable duration and automatically re-queue the message)
This ensures that the only edge case that would result in message loss is an unclean shutdown of an nsqd process. In that case, any messages that were in memory (or any buffered writes not flushed to disk) would be lost.
If preventing message loss is of the utmost importance, even this edge case can be mitigated. One solution is to stand up redundant nsqd pairs (on separate hosts) that receive copies of the same portion of messages. Because you’ve written your consumers to be idempotent, doing double-time on these messages has no downstream impact and allows the system to endure any single node failure without losing messages.
The takeaway is that NSQ provides the building blocks to support a variety of production use cases and configurable degrees of durability.
Bounded Memory Footprint
nsqd provides a configuration option --mem-queue-size that will determine the number of messages that are kept in memory for a given queue. If the depth of a queue exceeds this threshold messages are transparently written to disk. This bounds the memory footprint of a given nsqd process to mem-queue-size * #_of_channels_and_topics:
message overflow
Also, an astute observer might have identified that this is a convenient way to gain an even higher guarantee of delivery by setting this value to something low (like 1 or even 0). The disk-backed queue is designed to survive unclean restarts (although messages might be delivered twice).
Also, related to message delivery guarantees, clean shutdowns (by sending a nsqd process the TERM signal) safely persist the messages currently in memory, in-flight, deferred, and in various internal buffers.
Note, a channel whose name ends in the string #ephemeral will not be buffered to disk and will instead drop messages after passing the mem-queue-size. This enables consumers which do not need message guarantees to subscribe to a channel. These ephemeral channels will also not persist after its last client disconnects.
Efficiency
NSQ was designed to communicate over a “memcached-like” command protocol with simple size-prefixed responses. All message data is kept in the core including metadata like number of attempts, timestamps, etc. This eliminates the copying of data back and forth from server to client, an inherent property of the previous toolchain when re-queueing a message. This also simplifies clients as they no longer need to be responsible for maintaining message state.
Also, by reducing configuration complexity, setup and development time is greatly reduced (especially in cases where there are >1 consumers of a topic).
For the data protocol, we made a key design decision that maximizes performance and throughput by pushing data to the client instead of waiting for it to pull. This concept, which we call RDY state, is essentially a form of client-side flow control.
When a client connects to nsqd and subscribes to a channel it is placed in a RDY state of 0. This means that no messages will be sent to the client. When a client is ready to receive messages it sends a command that updates its RDY state to some # it is prepared to handle, say 100. Without any additional commands, 100 messages will be pushed to the client as they are available (each time decrementing the server-side RDY count for that client).
Client libraries are designed to send a command to update RDY count when it reaches ~25% of the configurable max-in-flight setting (and properly account for connections to multiple nsqd instances, dividing appropriately).
nsq protocol
This is a significant performance knob as some downstream systems are able to more-easily batch process messages and benefit greatly from a higher max-in-flight.
Notably, because it is both buffered and push based with the ability to satisfy the need for independent copies of streams (channels), we’ve produced a daemon that behaves like simplequeue and pubsub combined . This is powerful in terms of simplifying the topology of our systems where we would have traditionally maintained the older toolchain discussed above.
Go
We made a strategic decision early on to build the NSQ core in Go. We recently blogged about our use of Go at bitly and alluded to this very project - it might be helpful to browse through that post to get an understanding of our thinking with respect to the language.
Regarding NSQ, Go channels (not to be confused with NSQ channels) and the language’s built in concurrency features are a perfect fit for the internal workings of nsqd. We leverage buffered channels to manage our in memory message queues and seamlessly write overflow to disk.
The standard library makes it easy to write the networking layer and client code. The built in memory and cpu profiling hooks highlight opportunities for optimization and require very little effort to integrate. We also found it really easy to test components in isolation, mock types using interfaces, and iteratively build functionality.
Overall, it’s been a fantastic project to use as an opportunity to really dig into the language and see what it’s capable of on a larger scale. We’ve been extremely happy with our choice to use golang, its performance, and how productive we are using it.
EOL
We’ve been using NSQ in production for several months and we’re excited to share this with the open source community.
Across the 13 services we’ve upgraded, we’re processing ~35,000 messages/second at peak through the cluster. It has proved both performant and stable and made our lives easier operating our production systems.
There is more work to be done though — so far we’ve converted ~40% of our infrastructure. Fortunately, the upgrade process has been straightforward and well worth the short-term time tradeoff.
We’re really curious to hear what you think, so grab the source from github and try it out.
Finally, this labor of love began as scratching an itch — bitly provided an environment to experiment, build, and open source it… we’re always hiring.
by snakes (shoutout to jehiah who co-designed/developed NSQ, dan and pierce for contributing, and mccutchen for tirelessly proofreading this beast)
#9 October 2012
因为前缀树在hbase中使用到,特别是在基于前缀查询rowkey时用到,这是先学习一下。
类1:
public class PrefixTree {
private PreNode root;
public PrefixTree() {
this.root = new PreNode();
}
public void insert(String str) {
if (str == null) {
return ;
}
PreNode currentNode = root;
for (int i =0;i < str.length();i ++) {
char cha = str.charAt(i);
PreNode findNode = currentNode.find(cha);
if (findNode != null) {
currentNode = findNode;
} else {
PreNode newNode = new PreNode(cha);
currentNode.addChild(newNode);
if (i+1 == str.length()) {
newNode.setLast(true);// 标记为最后一个节点
}
currentNode = newNode;
}
}
}
public String search(String str) {
if (str == null) {
return null;
}
PreNode currentNode = root;
StringBuffer sb = new StringBuffer();
for (int i =0;i < str.length();i ++) {
char cha = str.charAt(i);
PreNode findNode = currentNode.find(cha);
if (findNode != null) {
sb.append(findNode.getValue());
if ((i+1) ==str.length()) {
return sb.toString();
}
} else {
// continue;
}
currentNode = findNode;
}
return null;
}
/**
* 主要还是用做前缀匹配查询
*
* @param str
* @return
*/
public List<String> getStartWith(String str) {
List<String> result = new ArrayList<String>();
if (str == null) {
return null;
}
PreNode currentNode = root;
StringBuffer sb = new StringBuffer();
for (int i =0;i < str.length();i ++) {
char cha = str.charAt(i);
PreNode findNode = currentNode.find(cha);
if (findNode != null) {
sb.append(findNode.getValue());
if ((i+1) ==str.length()) {
result.add(sb.toString());
// 增加字节点
//遍历所有子节点
result.addAll(getAllChild(findNode, sb.toString()));
}
currentNode = findNode;
} else {
// continue;
}
}
return result;
}
public List<String> getAllChild(PreNode node, String str) {
List<String> result = new ArrayList<String>();
deep(node, str, result);
return result;
}
private void deep(PreNode node, String str, List<String> finds) {
StringBuffer sb1 = new StringBuffer();
sb1.append(str);
if (node.getChildNodeList() != null) {
for (PreNode p :node.getChildNodeList()) {
sb1.append(p.getValue());
if (p.isLast()) {
finds.add(str + p.getValue());
}
if (p.getChildNodeList()!= null) {
deep(p, sb1.toString(), finds);
}
}
}
}
public static void main(String[] args) {
PrefixTree prefixTree = new PrefixTree();
prefixTree.insert("abc");
prefixTree.insert("ab994");
for (int i = 0;i < 10000; i++) {
prefixTree.insert("ab" + i);
}
prefixTree.insert("abcd");
prefixTree.insert("abcd你好");
prefixTree.insert("eadc");
prefixTree.insert("你好c");
long startTime = System.currentTimeMillis();
System.out.println(prefixTree.getStartWith("ab995"));
System.out.println("costs" +(System.currentTimeMillis() - startTime));
}
}类2:
public class PreNode {
private boolean isRoot;
private boolean isLast;
private char value;
private List<PreNode> childNodeList;
public boolean isRoot() {
return isRoot;
}
public PreNode() {
}
public PreNode(char c) {
this.value = c;
}
public void addChild(PreNode childNode) {
if (childNodeList == null) {
childNodeList = new ArrayList<PreNode>();
}
childNodeList.add(childNode);
}
public PreNode find(char cha) {
if (isRoot) {
return null;
}
if (childNodeList != null && childNodeList.size() > 0) {
for (PreNode node : childNodeList) {
if (node.value == cha) {
return node;
}
}
}
return null;
}
public void setRoot(boolean isRoot) {
this.isRoot = isRoot;
}
public boolean isLast() {
return isLast;
}
public void setLast(boolean isLast) {
this.isLast = isLast;
}
public char getValue() {
return value;
}
public void setValue(char value) {
this.value = value;
}
public List<PreNode> getChildNodeList() {
return childNodeList;
}
public void setChildNodeList(List<PreNode> childNodeList) {
this.childNodeList = childNodeList;
}
}As Twitter has grown into a global platform for public self-expression and conversation, our storage requirements have grown too. Over the last few years, we found ourselves in need of a storage system that could serve millions of queries per second, with extremely low latency in a real-time environment. Availability and speed of the system became the utmost important factor. Not only did it need to be fast; it needed to be scalable across several regions around the world.
Over the years, we have used and made significant contributions to many open source databases. But we found that the real-time nature of Twitter demanded lower latency than the existing open source products were offering. We were spending far too much time firefighting production systems to meet the performance expectations of our various products, and standing up new storage capacity for a use case involved too much manual work and process. Our experience developing and operating production storage at Twitter’s scale made it clear that the situation was simply not sustainable. So we began to scope out and build Twitter’s next generation distributed database, which we call Manhattan. We needed it to take into account our existing needs, as well as put us in a position to leapfrog what exists today.
Different databases today have many capabilities, but through our experience we identified a few requirements that would enable us to grow the way we wanted while covering the majority of use cases and addressing our real-world concerns, such as correctness, operability, visibility, performance and customer support. Our requirements were to build for:
Reliability: Twitter services need a durable datastore with predictable performance that they can trust through failures, slowdowns, expansions, hotspots, or anything else we throw at it.
Availability: Most of our use cases strongly favor availability over consistency, so an always-on eventually consistent database was a must.
Extensibility: The technology we built had to be able to grow as our requirements change, so we had to have a solid, modular foundation on which to build everything from new storage engines to strong consistency. Additionally, a schemaless key-value data model fit most customers’ needs and allowed room to add structure later.
Operability: As clusters grow from hundreds to thousands of nodes, the simplest operations can become a pain and a time sink for operators. In order to scale efficiently in manpower, we had to make it easy to operate from day one. With every new feature we think about operational complexity and the ease of diagnosing issues.
Low latency: As a real-time service, Twitter’s products require consistent low latency, so we had to make the proper tradeoffs to guarantee low latent performance.
Real-world scalability: Scaling challenges are ubiquitous in distributed systems. Twitter needs a database that can scale not just to a certain point, but can continue to grow to new heights in every metric — cluster size, requests per second, data size, geographically, and with number of tenants — without sacrificing cost effectiveness or ease of operations.
Developer productivity: Developers in the company should be able to store whatever they need to build their services, with a self service platform that doesn’t require intervention from a storage engineer, on a system that in their view “just works”.
Developers should be able to store whatever they need on a system that just works.
Tweet
Reliability at scale
When we started building Manhattan, we already had many large storage clusters at Twitter, so we understood the challenges that come from running a system at scale, which informed what kinds of properties we wanted to encourage and avoid in a new system.
A reliable storage system is one that can be trusted to perform well under all states of operation, and that kind of predictable performance is difficult to achieve. In a predictable system, worst-case performance is crucial; average performance not so much. In a well implemented, correctly provisioned system, average performance is very rarely a cause of concern. But throughout the company we look at metrics like p999 and p9999 latencies, so we care how slow the 0.01% slowest requests to the system are. We have to design and provision for worst-case throughput. For example, it is irrelevant that steady-state performance is acceptable, if there is a periodic bulk job that degrades performance for an hour every day.
Because of this priority to be predictable, we had to plan for good performance during any potential issue or failure mode. The customer is not interested in our implementation details or excuses; either our service works for them and for Twitter or it does not. Even if we have to make an unfavorable trade-off to protect against a very unlikely issue, we must remember that rare events are no longer rare at scale.
With scale comes not only large numbers of machines, requests and large amounts of data, but also factors of human scale in the increasing number of people who both use and support the system. We manage this by focusing on a number of concerns:
if a customer causes a problem, the problem should be limited to that customer and not spread to others
it should be simple, both for us and for the customer, to tell if an issue originates in the storage system or their client
for potential issues, we must minimize the time to recovery once the problem has been detected and diagnosed
we must be aware of how various failure modes will manifest for the customer
an operator should not need deep, comprehensive knowledge of the storage system to complete regular tasks or diagnose and mitigate most issues
And finally, we built Manhattan with the experience that when operating at scale, complexity is one of your biggest enemies. Ultimately, simple and working trumps fancy and broken. We prefer something that is simple but works reliably, consistently and provides good visibility, over something that is fancy and ultra-optimal in theory but in practice and implementation doesn’t work well or provides poor visibility, operability, or violates other core requirements.
Building a storage system
When building our next generation storage system, we decided to break down the system into layers so it would be modular enough to provide a solid base that we can build on top of, and allow us to incrementally roll out features without major changes.
We designed with the following goals in mind:
Keep the core lean and simple
保持核心精益与简单
Bring value sooner rather than later (focus on the incremental)
尽快带来价值,同时关注增量
Multi-Tenancy, Quality of Service (QoS) and Self-Service are first-class citizens
多租户,服务的质量,自助服务是一等公民
Focus on predictability
关注可预测性
Storage as a service, not just technology
存储是一个服务,不是一项科技
We have separated Manhattan into four layers: interfaces, storage services, storage engines and the core.
Core
The core is the most critical aspect of the storage system: it is highly stable and robust. It handles failure, eventual consistency, routing, topology management, intra- and inter-datacenter replication, and conflict resolution. Within the core of the system, crucial pieces of architecture are completely pluggable so we can iterate quickly on designs and improvements, as well as unit test effectively.
Operators are able to alter the topology at any time for adding or removing capacity, and our visibility and strong coordination for topology management are critical. We store our topology information in Zookeeper because of it’s strong coordination capabilities and because it is a managed component in our infrastructure at Twitter, though Zookeeper is not in the critical path for reads or writes. We also put a lot of effort into making sure we have extreme visibility into the core at all times with an extensive set of Ostrich metrics across all hosts for correctness and performance.
Consistency model
Many of Twitter’s applications fit very well into the eventually consistent model. We favor high availability over consistency in almost all use cases, so it was natural to build Manhattan as an eventually consistent system at its core. However, there will always be applications that require strong consistency for their data so building such a system was a high priority for adopting more customers. Strong consistency is an opt-in model and developers must be aware of the trade-offs. In a strongly consistent system, one will typically have a form of mastership for a range of partitions. We have many use cases at Twitter where having a hiccup of a few seconds of unavailability is simply not acceptable (due to electing new masters in the event of failures). We provide good defaults for developers and help them understand the trade-offs between both models.
Achieving consistency
To achieve consistency in an eventually consistent system you need a required mechanism which we call replica reconciliation. This mechanism needs to be incremental, and an always running process that reconciles data across replicas. It helps in the face of bitrot, software bugs, missed writes (nodes going down for long periods of time) and network partitions between datacenters. In addition to having replica reconciliation, there are two other mechanisms we use as an optimization to achieve faster convergence: read-repair, which is a mechanism that allows frequently accessed data to converge faster due to the rate of the data being read, and hinted-handoff, which is a secondary delivery mechanism for failed writes due to a node flapping, or being offline for a period of time.
Storage engines
One of the lowest levels of a storage system is how data is stored on disk and the data structures kept in memory. To reduce the complexity and risk of managing multiple codebases for multiple storage engines, we made the decision to have our initial storage engines be designed in-house, with the flexibility of plugging in external storage engines in the future if needed.
This gives us the benefit of focusing on features we find the most necessary and the control to review which changes go in and which do not. We currently have three storage engines:
seadb, our read-only file format for batch processed data from hadoop
sstable, our log-structured merge tree based format for heavy write workloads
btree, our btree based format for heavy read, light write workloads
All of our storage engines support block-based compression.
Storage services
We have created additional services that sit on top of the core of Manhattan that allow us to enable more robust features that developers might come to expect from traditional databases. Some examples are:
Batch Hadoop importing: One of the original use cases of Manhattan was as an efficient serving layer on top of data generated in Hadoop. We built an importing pipeline that allows customers to generate their datasets in a simple format in HDFS and specify that location in a self service interface. Our watchers automatically pick up new datasets and convert them in HDFS into seadb files, so they can then be imported into the cluster for fast serving from SSDs or memory. We focused on making this importing pipeline streamlined and easy so developers can iterate quickly on their evolving datasets. One lesson we learned from our customers was that they tend to produce large, multi-terabyte datasets where each subsequent version typically changes less than 10-20% of their data. We baked in an optimization to reduce network bandwidth by producing binary diffs that can be applied when we download this data to replicas, substantially reducing the overall import time across datacenters.
Strong Consistency service: The Strong Consistency service allows customers to have strong consistency when doing certain sets of operations. We use a consensus algorithm paired with a replicated log to guarantee in-order events reach all replicas. This enables us to do operations like Check-And-Set (CAS), strong read, and strong write. We support two modes today called LOCAL_CAS and GLOBAL_CAS. Global CAS enables developers to do strongly consistent operations across a quorum of our datacenters, whereas a Local CAS operation is coordinated only within the datacenter it was issued. Both operations have different tradeoffs when it comes to latency and data modeling for the application.
Timeseries Counters service: We developed a very specific service to handle high volume timeseries counters in Manhattan. The customer who drove this requirement was our Observability infrastructure, who needed a system that could handle millions of increments per second. At this level of scale, our engineers went through the exercise of coming up with an agreed upon set of design tradeoffs over things like durability concerns, the delay before increments needed to be visible to our alerting system, and what kind of subsecond traffic patterns we could tolerate from the customer. The result was a thin, efficient counting layer on top of a specially optimized Manhattan cluster that greatly reduced our requirements and increased reliability over the previous system.
Interfaces
The interface layer is how a customer interacts with our storage system. Currently we expose a key/value interface to our customers, and we are working on additional interfaces such as a graph based interface to interact with edges.
Tooling
With the easy operability of our clusters as a requirement, we had to put a lot of thought into how to best design our tools for day-to-day operations. We wanted complex operations to be handled by the system as much as possible, and allow commands with high-level semantics to abstract away the details of implementation from the operator. We started with tools that allow us to change the entire topology of the system simply by editing a file with host groups and weights, and do common operations like restarting all nodes with a single command. When even that early tooling started to become too cumbersome, we built an automated agent that accepts simple commands as goals for the state of the cluster, and is able to stack, combine, and execute directives safely and efficiently with no further attention from an operator.
Storage as a service
A common theme that we saw with existing databases was that they were designed to be setup and administered for a specific set of use-cases. With Twitter’s growth of new internal services, we realized that this wouldn’t be efficient for our business.
Our solution is storage as a service. We’ve provided a major productivity improvement for our engineers and operational teams by building a fully self-service storage system that puts engineers in control.
Engineers can provision what their application needs (storage size, queries per second, etc) and start using storage in seconds without having to wait for hardware to be installed or for schemas to be set up. Customers within the company run in a multi-tenant environment that our operational teams manage for them. Managing self service and multi-tenant clusters imposes certain challenges, so we treat this service layer as first-class feature: we provide customers with visibility into their data and workloads, we have built-in quota enforcement and rate-limiting so engineers get alerted when they go over their defined thresholds, and all our information is fed directly to our Capacity and Fleet Management teams for analysis and reporting.
By making it easier for engineers to launch new features, we saw a rise in experimentation and a proliferation of new use-cases. To better handle these, we developed internal APIs to expose this data for cost analysis which allows us to determine what use cases are costing the business the most, as well as which ones aren’t being used as often.
Focus on the customer
Even though our customers are our fellow Twitter employees, we are still providing a service, and they are still our customers. We must provide support, be on call, isolate the actions of one application from another, and consider the customer experience in everything we do. Most developers are familiar with the need for adequate documentation of their services, but every change or addition to our storage system requires careful consideration. A feature that should be seamlessly integrated into self-service has different requirements from one that needs intervention by operators. When a customer has a problem, we must make sure to design the service so that we can quickly and correctly identify the root cause, including issues and emergent behaviors that can arise from the many different clients and applications through which engineers access the database. We’ve had a lot success building Manhattan from the ground up as a service and not just a piece of technology.
Multi-Tenancy and QoS (Quality of Service)
Supporting multi-tenancy — allowing many different applications to share the same resources — was a key requirement from the beginning. In previous systems we managed at Twitter, we were building out clusters for every feature. This was increasing operator burden, wasting resources, and slowing customers from rolling out new features quickly.
As mentioned above, allowing multiple customers to use the same cluster increases the challenge of running our systems. We now must think about isolation, management of resources, capacity modeling with multiple customers, rate limiting, QoS, quotas, and more.
In addition to giving customers the visibility they need to be good citizens, we designed our own rate limiting service to enforce customers usage of resources and quotas. We monitor and, if needed, throttle resource usage across many metrics to ensure no one application can affect others on the system. Rate limiting happens not at a coarse grain but at a subsecond level and with tolerance for the kinds of spikes that happen with real world usage. We had to consider not just automatic enforcement, but what controls should be available manually to operators to help us recover from issues, and how we can mitigate negative effects to all customers, including the ones going over their capacity.
We built the APIs needed to extract the data for every customer and send it to our Capacity teams, who work to ensure we have resources always ready and available for customers who have small to medium requirements (by Twitter standards), so that those engineers can get started without additional help from us. Integrating all of this directly into self-service allows customers to launch new features on our large multi-tenant clusters faster, and allows us to absorb traffic spikes much more easily since most customers don’t use all of their resources at all times.
Looking ahead
We still have a lot of work ahead of us. The challenges are increasing and the number of features being launched internally on Manhattan is growing at rapid pace. Pushing ourselves harder to be better and smarter is what drives us on the Core Storage team. We take pride in our values: what can we do to make Twitter better, and how do we make our customers more successful? We plan to release a white paper outlining even more technical detail on Manhattan and what we’ve learned after running over two years in production, so stay tuned!
Acknowledgments
We want to give a special thank you to Armond Bigian, for helping believe in the team along the way and championing us to make the best storage system possible for Twitter. The following people made Manhattan possible: Peter Schuller, Chris Goffinet, Boaz Avital, Spencer Fang, Ying Xu, Kunal Naik, Yalei Wang, Danny Chen, Melvin Wang, Bin Zhang, Peter Beaman, Sree Kuchibhotla, Osama Khan, Victor Yang Ye, Esteban Kuber, Tugrul Bingol, Yi Lin, Deng Liu, Tyler Serdar Bulut, Andy Gross, Anthony Asta, Evert Hoogendoorn, Lin Lee, Alex Peake, Yao Yue, Hyun Kang, Xin Xiang, Sumeet Lahorani, Rachit Arora, Sagar Vemuri, Petch Wannissorn, Mahak Patidar, Ajit Verma, Sean Wang, Dipinder Rekhi, Satish Kotha, Johan Harjono, Alex Young, Kevin Donghua Liu, Pascal Borghino, Istvan Marko, Andres Plaza, Ravi Sharma, Vladimir Vassiliouk, Ning Li, Liang Guo, Inaam Rana.
之前试用了各种markdown软件,都没有感觉用atom+markdown语法好。
现在发现了一个开源的macdown软件,试用了一下,感觉还不错,其中最大的一个原因是:左边的markdown语法也被加工放大了,比较有立体感。
对象用户:移动开发者
服务器推送:推送消息。比如动态消息推送。
客户端提交数据,得到返回数据:比如下载图片
这个过程中都需要回执。

MQTT stands for MQ Telemetry Transport. It is a publish/subscribe, extremely simple and lightweight messaging protocol, designed for constrained devices and low-bandwidth, high-latency or unreliable networks. The design principles are to minimise network bandwidth and device resource requirements whilst also attempting to ensure reliability and some degree of assurance of delivery. These principles also turn out to make the protocol ideal of the emerging “machine-to-machine” (M2M) or “Internet of Things” world of connected devices, and for mobile applications where bandwidth and battery power are at a premium.
如何适应现有网络的不可靠,很好的保障数据发送可靠性
如何降低网络流量,从而节省网络成本
如何降低对设备能力的要求,特别是适应计算和存储弱的设备
如何降低对设备电量的消耗,满足设备电源能力的不足
如何降低平台依赖性,真正实现跨移动设备平台
缺少对数据安全性的保障,特别是对服务器的掌控
缺少对大量数据的监测,优化
推送服务在很多领域都有发展,但特别在移动领域,由于其飞速发展,给推送服务带来了很多新的机遇和挑战。首先,移动市场规模越来越大,终端种类和数量越来越多,使得推送服务的的重要性越来越凸显;其次,传统的"伪推送"模式已越来越不能满足其需要,需要发展新的推送的技术,这促使了很多新的协议和框架的出现;但是,由于移动领域的终端设备和网络情况的特点,对推送的协议和框架又提出了新的挑战,比如:移动终端的计算和存储资源的限制,移动终端的电量消耗的限制,移动网络流量和成本的控制等等。主流的移动推送解决方案如下:
https://github.com/opensensorsio/azondi/
不过只实现了QoS level 0级,也就是:至多发送一次,发送即丢弃。没有确认消息,也不知道对方是否收到.
http://code.google.com/p/moquette-mqtt/
实现了QoS level 0, QoS level 1,QoS level 2,感觉不错,呆会试体验一下。
http://git.eclipse.org/c/paho/org.eclipse.paho.mqtt.java.git/
https://code.google.com/p/naga/
http://www.blogjava.net/yongboy/archive/2014/02/15/409893.html
http://www.ibm.com/developerworks/cn/websphere/library/techarticles/1308_xiangr_mqtt/1308_xiangr_mqtt.html
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
$ wget http://www.scala-lang.org/files/archive/scala-2.10.4.tgz
$ sudo tar xvfz scala-2.10.4.final.tgz --directory /opt/
$ vim ~/.bashrc
$ export SCALA_HOME=/opt/scala-2.8.1.final
$ export PATH=$SCALA_HOME/bin:$PATH附:
Scala 语言由 Ecole Polytechnique Federale de Lausanne(瑞士洛桑市的两所瑞士联邦理工学院之一)开发。它是 Martin Odersky 在开发了名为 Funnel 的编程语言之后设计的,Funnel 集成了函数编程和 Petri net 中的创意。在 2011 年,Scala 设计团队从欧洲研究委员会 (European Research Council) 那里获得了 5 年的研究经费,然后他们成立新公司 Typesafe,从商业上支持 Scala,接收筹款开始相应的运作。
http://www.scala-sbt.org/release/docs/Getting-Started/Setup.htmlCreate a script to run the jar, by creating ~/bin/sbt with these contents:
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"Make the script executable:
$ chmod u+x ~/bin/sbt$ wget http://d3kbcqa49mib13.cloudfront.net/spark-0.9.1.tgz$ sbt/sbt update compile $ sbt/sbt assembly此外还有一篇不错的文章:
http://www.tuicool.com/articles/2uA773
<receiver android:name="com.avos.avoscloud.AVBroadcastReceiver">
<intent-filter>
<action android:name="android.intent.action.BOOT_COMPLETED" />
<action android:name="android.intent.action.USER_PRESENT" />
</intent-filter>
</receiver>USER_PRESENT:屏幕解锁是通过这个动作发出来的。
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
--- 手机识别码,通话状态
<uses-permission android:name="android.permission.GET_TASKS" />
--- 允许一个程序获取信息有关当前或最近运行的任务,一个缩略的任务状态,是否活动等等
<uses-permission android:name="android.permission.VIBRATE"/>
--- 允许访问振动设备
<!-- 保留权限,后续添加功能需要用到 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS" />
--- 允许程序读取或写入系统设置
<uses-permission android:name="android.permission.ACCESS_DOWNLOAD_MANAGER" />
---
<uses-permission android:name="android.permission.DOWNLOAD_WITHOUT_NOTIFICATION" />
<uses-permission android:name="android.permission.DISABLE_KEYGUARD" />
--- 允许程序禁用键盘锁
<uses-permission android:name="android.permission.SYSTEM_ALERT_WINDOW" />
--- 允许一个程序打开窗口使用 TYPE_SYSTEM_ALERT,显示在其他所有程序的顶层
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
--- 允许一个程序访问CellID或WiFi热点来获取粗略的位置
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
--- 许一个程序访问精良位置(如GPS)我的问题是:做一个基础的推送服务需要多少个基础的权限?
最近在做sql解析时,虽然采用开源的sqlParser来处理,但发现对编译原理还是一知半解的。这里打算重新学习一下。
常规的步伐:
开源的一个表达式例子,还是写得很清晰的。
http://code.taobao.org/p/QLExpress/wiki/index/
词法分析,语法分析,生成语法树,生成指令,指令的执行,这一步还不是很理解。
写一个最简单的四则运算demo:
物质生产方式的变革是社会历史变革的根本原因。由于生产方式中生产力和生产关系的矛盾运动,到了一定阶段,当生产关系由促进生产力的发展形式变成了阻碍生产力发展的桎梏时,社会革命的时代就到来了。随着经济基础的变更,整个社会庞大的上层建筑也或快或慢地发生变革。新的生产方式代替了旧的生产方式,原来旧的社会制度也就为另一种更高、更先进的社会制度所代替。社会发展的二历史,说到底就是生产方式变革更替的历史。
pc时代是否会长期存在?
根据马克思的理论来看,现在pc时代在办公与编程领域,特别是打字输入pc效率比手机强,从当前效率来看,pc还不会被淘汰。但如果未来手机,能支持大屏幕,同时又能支持虚拟键盘,性能与电脑产不多时,pc与笔记本都会被淘汰。
是否把握了移动入口,就把握了未来?
社交与电商是否能合二为一?
为什么小米手机现在还在pc进行抢购?淘宝目前来看,还是有海量高质量的购买流量。
除了折扣,是否还有其它方式来吸引顾客?
当下o2o,是否有发展前景?
如果通过折扣,贴钱的方式进行,不可长久。
线下需要流量与数据?
海外是否有发展前景?
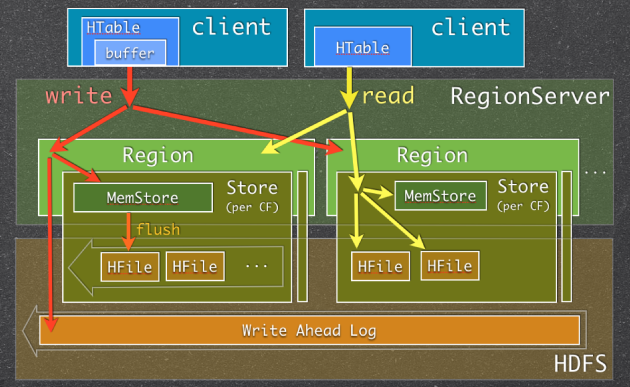
hbase在内存中存储数据,就是用的ConcurrentSkipListMap来存储数据的。
Skip List是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。Skip List可以很好解决有序链表查找特定值的困难。
/*
* @param set Set to walk back in. Pass a first in row or we'll return
* same row (loop).
* @param state Utility and context.
* @param firstOnRow First item on the row after the one we want to find a
* member in.
* @return Null or member of row previous to <code>firstOnRow</code>
*/
private Member memberOfPreviousRow(NavigableSet<KeyValue> set,
final GetClosestRowBeforeTracker state, final KeyValue firstOnRow) {
NavigableSet<KeyValue> head = set.headSet(firstOnRow, false);
if (head.isEmpty()) return null;
for (Iterator<KeyValue> i = head.descendingIterator(); i.hasNext();) {
KeyValue found = i.next();
if (state.isExpired(found)) {
i.remove();
continue;
}
return new Member(head, found);
}
return null;
}插入磁盘前的比较器:
enum PureJavaComparer implements Comparer<byte[]> {
INSTANCE;
@Override
public int compareTo(byte[] buffer1, int offset1, int length1,
byte[] buffer2, int offset2, int length2) {
// Short circuit equal case
if (buffer1 == buffer2 &&
offset1 == offset2 &&
length1 == length2) {
return 0;
}
// Bring WritableComparator code local
int end1 = offset1 + length1;
int end2 = offset2 + length2;
for (int i = offset1, j = offset2; i < end1 && j < end2; i++, j++) {
int a = (buffer1[i] & 0xff);
int b = (buffer2[j] & 0xff);
if (a != b) {
return a - b;
}
}
return length1 - length2;
}
}CFLAGS= -Wall -Werror
LDFLAGS=-lcurl
all: crawl_url
crawl_url: crawl_url.c
$(CC) $(CFLAGS) -o crawl_url crawl_url.c $(LDFLAGS)craw_url代码
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <curl/curl.h>
int main(void)
{
CURL *curl;
CURLcode res;
curl = curl_easy_init();
if (curl) {
curl_easy_setopt(curl, CURLOPT_URL, "http://www.baidu.com");
res = curl_easy_perform(curl);
if (res != CURLE_OK) {
fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res));
} else {
fprintf(stderr, "curl result is : %d\n", res);
}
curl_easy_cleanup(curl);
}
return 0;
}他们需要队列的特性:
Here's that list:
Persistence 持久化的
See what's pending 可以查等待的队列
Modify pending jobs in-place 可以修改等待的队列
Tags
Priorities 优先级
Fast pushing and popping 快速push/pop
See what workers are doing 可以查看正在做的worker
See what workers have done 可以查看那些任务做完了
See failed jobs 查看失败的任务
Kill fat workers
Kill stale workers 杀死过期的worker
Kill workers that are running too long 杀死耗时的worker进程
Keep Rails loaded / persistent workers
Distributed workers (run them on multiple machines) 分布式的,能够在多台机器执行
Workers can watch multiple (or all) tags
Don't retry failed jobs 错误的jos不再重试
Don't "release" failed jobs 不释放错误的job
查看正在执行中的任务,没有更新。
优先级不支持
有些任务指定在一些特定的机器上执行。要支持tag标记。
比如将一些文件下载,并且打包,则需要指定任务在同一台机器执行。
include"" 优先会加载本地目录的文件,<>先优先加载库里的文件 .
命名空间是什么意思?
There is a lot of inspiration floating around on the internet. I for myself use Behance and Dribbble a lot (I was a designer before I became a programmer). But it’s not only great designs and photos which inspire my work, but also architecture and nature with its colourful nuances.
When it comes to programming, I read a lot of source code from open-source projects and spoke with other developers, as well as being active in the community. This broadens my mind and helps me find new and creative solutions for my engineering problems.
多阅读一些源代码,同时与开发者交流,并在一些社区活跃,这开阔了我的思路,同时帮助我去发现一些新的且有创造力的解决方案来解决一些技术问题。
原文地址: http://tech.naver.jp/blog/?p=1420
背景介绍:Line
连我(国际名称:LINE)是由韩国NHN株式会社在日本的子公司连我 株式会社开发的一个智能手机应用程序,在2011年6月发布。用户间可以通过互联网与其他用户进行语音通话或传送短信。
原因:消息的量在指数据级的增长,需要一个存储来满足需求。
消息的业务特性是:时间序列的数据增长,并且大部分数据是冷数据。
见图:
2012年已经增长到了50亿/天的量,平均1.6亿的消息量。
line的同学挑了几个nosql产品进行选择。这些产品是Hbase,Cassandra,MongoDB.
不选择Cassandra的原因是:
不选择MongoDB的原因是:
选择Hbase的原因:
见图片:
Line同学首先在业务方面垂直分了通信录,消息Hbase集群。
Hbase非常适合时间纬度的海量数据存储与查询。淘宝的历史订单查询,阿里云的计量数据收集,包括微信自主研发类hbase的key/value存储,都是非常好的业务应用场景。
Kiji
亚马逊有一个设计原则,要把fail当作一件正常的事情。服务不可用是一个必然会发生的事情。所以对服务不可用的监控,非常的关键与重要。
一般对服务不可用有两种处理:
- 自动恢复,通过软件自动切换,比如通过zk来自动切换主备。达到自动恢复。
- 人工恢复。通过监控报警,来提示人去手工恢复,这种情况目前也比较常见。
当一个项服务可用性不能达到100%时,同时又做不自动恢复时,你必须要监控,并且要报警。
就三者来说:很多业务方都不具备,而且有如下痛点:
- 每一个业务方都需要这个监控失败的功能,但自己却不能多花精力去做这个事
- 监控url的功能很难找到好的实现方
- 短信提醒,要mc申请,审批很麻烦,并且很难使用
假设每5分钟, 要监控url是否可用?如果大家都接入这个应用,则会有很多的监控url,并且要在同一时间内监控? 监控的及时性如何实现?
既然找到可用的解决方案,找不到适合的解决方案,那只有自己来?
每一个监控url实例,第一次初始化一次,以后每次监控完成时,生成下一个监控任务,并且上个监控任务删除(或者更新)。这里可以采用延时队列实现或者schedule实现。
这个方案有一个缺点:放进队列与本身执行mnitor不能在同一个事务中完成,所以也要有一个异常保证。
持久化的线程扫描是一个不错的解决方式,tbschedule则是一个很好的解决工具。
| 监控任务 | 监控url | 监控频率 | 监控提醒 | |
|---|---|---|---|---|
| github | github.com | 5min | voff2014 | memo |
- 我们需要共享的云服务,降低研发与维护成本,更加专注我们自本身的方向。
- 我们要基于网络的消息通道,不再需要传统的短信通知,我们应用自己的移动办公app
- 我们需要专业成熟的解决方案,而不是多造轮子
在移动时代来临了,你要摒弃*短信,邮件*这种传统pc时代的通信方式,采用移动时代的通信。
构建集团私有云的建设,私有云运行不错,可以转为公有云服务。
学习1:Could not find any version that matches com.android.support:appcompat-v7:+.
解决方法:
If this happens, just go to Tools -> Android -> Android SDK Manager, then check “Android Support Repository” and “Android Support Library” under “Extra” and install them. That should take care of the error.
学习2:写共享数据
SharedPreferences类似过去Windows系统上的ini配置文件。
有三种权限:
一、SharedPreferences pf = getSharedPreferences(“voff12”, MODE_PRIVATE);
只有创建这个SharedPreferences的Activity与权限读写它。
二、SharedPreferences pf = getSharedPreferences(“ voff12”, MODE_WORLD_READABLE );
其他Activity对这个SharedPreferences具有可读权限。
三、SharedPreferences pf = getSharedPreferences(“ voff12”, MODE_WORLD_WRITEABLE);
其他Activity对这个SharedPreferences也具有可读可写的权利。如果涉及至多个线程读写,就要防止并发操作了。
San Diego – For architects who believe detailed advanced planning will be the key to a successful SOA implementation, an alternative approach is offered by Werner Vogels, vice president, world-wide architecture and CTO at Amazon.com.
Safe Harbor
Simplicity is the hardest design criteria. Designing a service we ask constantly: Is this the simplest service we can build?
Werner Vogels
Vice President, World-Wide Architecture and CTOAmazon.com
"Amazon does a lot of research, but we don't call it research, we call it development," Vogels said in a keynote at the opening the Gartner Inc. Enterprise Architecture Summit this week. He offered an almost anti-model for SOA development that includes hard work, failures, more hard work, successes and more hard work.
He laced his presentation with tongue-in-cheek humor starting with the title: "Order in the Chaos: Building the Amazon.com Platform."
Vogels pointed out that in 1995 when Amazon started with a simple Web ordering application running on a single server, the architecture was so simple it was literally drawn on a cocktail napkin. There was no grand plan to build an SOA platform that today features as many as 150 Web services on its home page alone.
The massive online retail Web site evolved from a modest attempt to sell books on the Web, into this year's version that hosts 1 million merchant partners ranging from small used book stores to Target Inc., which in virtual retailing is now bigger than Wal-Mart, Vogels said.
"We more or less naturally became a platform," Vogels said of the technological evolution.
In a brief history of Amazon's technology, he showed how one server for databases of customer information and inventory grew to two servers, one for customer info and one for inventory. As the business got bigger with more customers and more products, more and more database servers were added.
When database performance became an problem, a fast talking salesman told Amazon to buy a mainframe. Big iron did not prove to be the answer, a technology misstep that still leaves Vogels chagrined.
"This is an Internet company in 1999 and we bought a mainframe," he said. When it failed to meet the scalability, reliability and performance needs after a year, Amazon pulled the plug on that hardware.
Vogels said there is a lot of talk about what is the "secret sauce" that makes Amazon so popular. In his opinion, "The secret sauce is operating reliably at scale."
To serve its 60 million customers and keeping them all happy requires scalability and reliability, that may go beyond what most SOA developers and architects need to factor into their platforms, Vogels said. For example, while most customers may feel they're buying a lot of stuff if they have 20 books and gadgets in their online shopping cart, he said Amazon has to be prepared for the one customer in 60 million with 20,000 items in their shopping cart.
After the mainframe debacle in 1999, Amazon reached the point around 2001 where the only way to achieve the reliability and scalability it needed was to use Web services to insulate the databases from being overwhelmed by direct interaction with online applications.
"We were doing SOA before it was a buzz word," the Amazon CTO said.
Unlike most speakers at analyst conferences, Vogels doesn't mince words as to whether SOA is a good strategy or a workable theory. Upfront, he told his audience "Service orientation works."
For all the talk of how Amazon is succeeding with blade servers running Linux, the CTO says, "We never could have built that platform without service orientation."
Giving a glimpse into how the developers at Amazon are organized, Vogels said it involves teamwork. Each Web service has one team of developers responsible for it. And they are not just responsible for writing the service and then tossing it over the wall for testing and eventual entry into production where some poor maintenance geek has to look after it.
The Amazon CTO tells his Web services team members: "You build it. You own it."
That means the team is responsible for its Web service's on-going operation. If a Web service stops working in the middle of the night, team members are called to fix it.
This policy that there is "no wall at the end of development" encourages developers to make their Web services as bulletproof as possible.
Since complexity is notoriously the enemy of reliability, Vogels encourages developers to keep their Web services simple.
"Simplicity is the hardest design criteria," Vogels said. "Designing a service we ask constantly: Is this the simplest service we can build?"
Another design criterion the chief technology officer emphasizes is not getting attached to any one technology or standard. Amazon developers start with what the customer needs and then work back to what technology will work for them, Vogels said.
我们一个重要的设计标准是,不依赖于某项技术或者标准,开发人员都是从客户需求开始,然后回到技术中去并让他们工作。
This includes the implementation of Web services standards. If one retail partner wants to use SOAP and another wants to use Representational State Transfer (REST), they each get the standard they request.
"Our developers don't care if it's REST or SOAP," Vogels said. "It's all about customers."
sql的解析有两种,一种是通过语法树,一种是通过正则表达式。
正则表达式,是有局限性的,不过可以做最简单的匹配。
一个开源的sql解释引擎:JSqlParser
https://github.com/JSQLParser/JSqlParser
个人觉得接口不太易用,不过想着能节省时间,还可以接受。
贴一个普通的sql解释
引入pom文件
<dependency>
<groupId>com.github.jsqlparser</groupId>
<artifactId>jsqlparser</artifactId>
<version>0.8.5</version>
</dependency>普通sql解释
try {
String sql = "select * from bpm_light_task where StartTime < '2014-04-20' and StartTime > '2014-04-22' limit 100;";
Statement statement = CCJSqlParserUtil.parse(sql);
Select selectStatement = (Select) statement;
PlainSelect ps = (PlainSelect)selectStatement.getSelectBody();
System.out.println(ps.getFromItem());
System.out.println(ps.getWhere()); // 再次解释一下where语句就行了
System.out.println(ps.getLimit());
System.out.println(ps.getSelectItems());
} catch (JSQLParserException e) {
e.printStackTrace();
}如果你希望对where里的语句进行再次解释:
则要:
final List<String> wheres = new ArrayList<String>();
ExpressionDeParser deparser = new ExpressionDeParser() {
@Override
public void visit(AndExpression andExpression) {
if (andExpression.getLeftExpression() instanceof AndExpression) {
andExpression.getLeftExpression().accept(this);
} else {
wheres.add(andExpression.getLeftExpression().toString());
}
wheres.add(andExpression.getRightExpression().toString());
}
};
StringBuilder b = new StringBuilder();
deparser.setBuffer(b);
expression.accept(deparser);
System.out.println(wheres);业务需求要求多个app共享一个app进程。
Intent aidlIntent = new Intent(); // 会自动创建服务
aidlIntent.setAction("****.CloudChannelService");
startService(aidlIntent);
Boolean result = bindService(aidlIntent, connection, Context.BIND_AUTO_CREATE);// 自动绑定服务intent不能放进class,如果放进class则会起多个进程。
一般RPC的实现原理
个人看了hbase的rpc设计代码,觉得写得还是很不错的。
在client向远方服务器tcp建立链接时,启动一个读response的线程:
@Override
public void run() {
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": starting, having connections "
+ connections.size());
try {
while (waitForWork()) {//wait here for work - read or close connection
receiveResponse();
}
} catch (Throwable t) {
LOG.warn("Unexpected exception receiving call responses", t);
markClosed(new IOException("Unexpected exception receiving call responses", t));
}
close();
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": stopped, remaining connections "
+ connections.size());
}不断的读服务端发送过程的应答:
如果发现有结果,找到请求的call,然后发送notify,让请求线程取得结果返回。
protected void receiveResponse() {
if (shouldCloseConnection.get()) {
return;
}
touch();
try {
// See HBaseServer.Call.setResponse for where we write out the response.
// It writes the call.id (int), a flag byte, then optionally the length
// of the response (int) followed by data.
// Read the call id.
int id = in.readInt();
if (LOG.isDebugEnabled())
LOG.debug(getName() + " got value #" + id);
Call call = calls.get(id);
// Read the flag byte
byte flag = in.readByte();
boolean isError = ResponseFlag.isError(flag);
if (ResponseFlag.isLength(flag)) {
// Currently length if present is unused.
in.readInt();
}
int state = in.readInt(); // Read the state. Currently unused.
if (isError) {
if (call != null) {
//noinspection ThrowableInstanceNeverThrown
call.setException(new RemoteException(WritableUtils.readString(in),
WritableUtils.readString(in)));
}
} else {
Writable value = ReflectionUtils.newInstance(valueClass, conf);
value.readFields(in); // read value
// it's possible that this call may have been cleaned up due to a RPC
// timeout, so check if it still exists before setting the value.
if (call != null) {
call.setValue(value);
}
}
calls.remove(id);
} catch (IOException e) {
if (e instanceof SocketTimeoutException && remoteId.rpcTimeout > 0) {
// Clean up open calls but don't treat this as a fatal condition,
// since we expect certain responses to not make it by the specified
// {@link ConnectionId#rpcTimeout}.
closeException = e;
} else {
// Since the server did not respond within the default ping interval
// time, treat this as a fatal condition and close this connection
markClosed(e);
}
} finally {
if (remoteId.rpcTimeout > 0) {
cleanupCalls(remoteId.rpcTimeout);
}
}
}至少要启动三个线程。
一个监控客服端的请求线程。
一个处理线程的处理线程,
一个将处理结果回复client的线程。
hbase rpc中的处理
/**
* Starts the service threads but does not allow requests to be responded yet.
* Client will get {@link ServerNotRunningYetException} instead.
*/
@Override
public synchronized void startThreads() {
responder.start();
listener.start();
handlers = startHandlers(callQueue, handlerCount);
priorityHandlers = startHandlers(priorityCallQueue, priorityHandlerCount);
replicationHandlers = startHandlers(replicationQueue, numOfReplicationHandlers);
}服务端通用的做法是利用反射来取得结果:
@Override
public Writable call(Class<? extends VersionedProtocol> protocol,
Writable param, long receivedTime, MonitoredRPCHandler status)
throws IOException {
try {
Invocation call = (Invocation)param;
if(call.getMethodName() == null) {
throw new IOException("Could not find requested method, the usual " +
"cause is a version mismatch between client and server.");
}
if (verbose) log("Call: " + call);
status.setRPC(call.getMethodName(), call.getParameters(), receivedTime);
status.setRPCPacket(param);
status.resume("Servicing call");
Method method =
protocol.getMethod(call.getMethodName(),
call.getParameterClasses());
method.setAccessible(true);
//Verify protocol version.
//Bypass the version check for VersionedProtocol
if (!method.getDeclaringClass().equals(VersionedProtocol.class)) {
long clientVersion = call.getProtocolVersion();
ProtocolSignature serverInfo = ((VersionedProtocol) instance)
.getProtocolSignature(protocol.getCanonicalName(), call
.getProtocolVersion(), call.getClientMethodsHash());
long serverVersion = serverInfo.getVersion();
if (serverVersion != clientVersion) {
LOG.warn("Version mismatch: client version=" + clientVersion
+ ", server version=" + serverVersion);
throw new RPC.VersionMismatch(protocol.getName(), clientVersion,
serverVersion);
}
}
Object impl = null;
if (protocol.isAssignableFrom(this.implementation)) {
impl = this.instance;
}
else {
throw new HBaseRPC.UnknownProtocolException(protocol);
}
long startTime = System.currentTimeMillis();
Object[] params = call.getParameters();
Object value = method.invoke(impl, params);
int processingTime = (int) (System.currentTimeMillis() - startTime);
int qTime = (int) (startTime-receivedTime);
if (TRACELOG.isDebugEnabled()) {
TRACELOG.debug("Call #" + CurCall.get().id +
"; Served: " + protocol.getSimpleName()+"#"+call.getMethodName() +
" queueTime=" + qTime +
" processingTime=" + processingTime +
" contents=" + Objects.describeQuantity(params));
}
rpcMetrics.rpcQueueTime.inc(qTime);
rpcMetrics.rpcProcessingTime.inc(processingTime);
rpcMetrics.inc(call.getMethodName(), processingTime);
if (verbose) log("Return: "+value);
HbaseObjectWritable retVal =
new HbaseObjectWritable(method.getReturnType(), value);
long responseSize = retVal.getWritableSize();
// log any RPC responses that are slower than the configured warn
// response time or larger than configured warning size
boolean tooSlow = (processingTime > warnResponseTime
&& warnResponseTime > -1);
boolean tooLarge = (responseSize > warnResponseSize
&& warnResponseSize > -1);
if (tooSlow || tooLarge) {
// when tagging, we let TooLarge trump TooSmall to keep output simple
// note that large responses will often also be slow.
logResponse(call, (tooLarge ? "TooLarge" : "TooSlow"),
status.getClient(), startTime, processingTime, qTime,
responseSize);
// provides a count of log-reported slow responses
if (tooSlow) {
rpcMetrics.rpcSlowResponseTime.inc(processingTime);
}
}
if (processingTime > 1000) {
// we use a hard-coded one second period so that we can clearly
// indicate the time period we're warning about in the name of the
// metric itself
rpcMetrics.inc(call.getMethodName() + ABOVE_ONE_SEC_METRIC,
processingTime);
}
return retVal;
} catch (InvocationTargetException e) {
Throwable target = e.getTargetException();
if (target instanceof IOException) {
throw (IOException)target;
}
IOException ioe = new IOException(target.toString());
ioe.setStackTrace(target.getStackTrace());
throw ioe;
} catch (Throwable e) {
if (!(e instanceof IOException)) {
LOG.error("Unexpected throwable object ", e);
}
IOException ioe = new IOException(e.toString());
ioe.setStackTrace(e.getStackTrace());
throw ioe;
}
}xcode的智能提示效果比较差,VVDocumenter-Xcode是一个不错的插件。
xcode写出的代码,风格优化插件:
一些recipes
http://nscookbook.com/recipes/
Android NDK 安装配置指南
1、下载Android NDK压缩包,下载地址:
wget -c http://dl.google.com/android/ndk/android-ndk-r5-linux-x86.tar.bz2
2、解压,将Android NDK压缩包解压到主目录/home/wx/下。
tar jxvf android-ndk-r5-linux-x86.tar.bz2
解压后目录结构为:/home/wx/android-ndk-r5
3、配置PATH路径:
命令行执行sudo gedit /etc/profile,在文件末尾加入如下内容:
export NDK_HOME=/home/snowdream/android-ndk-r5
export PATH=$NDK_HOME:$PATH
保存后,重启机器。至此 android NDK 安装配置完毕。
4、编译sample工程:
执行命令
cd /home/wx/android-ndk-r5/samples/hello-jni
进入示例项目根目录,然后执行如下命令:
ndk-build
您将看到系统会编译出libhello-jni.so
采用这种方式非常方便.
In order to make HTTP requests go faster SPDY makes several improvements:
The first, and arguably most important, is request multiplexing. Rather than sending one request at a time over one TCP connection, SPDY can issue many requests simultaneously over a single TCP session and handle responses in any order, as soon as they're available.
最重要的一个改进是,在单一个 tcp session 里,改变了一个 tcp 连接里,一次只发一个请求的方式。SPDY 会一次发多个请求。
Second, SPDY compresses both request and response headers. Headers are often nearly identical to each other across requests, generally contain lots of duplicated text, and can be quite large. This makes them an ideal candidate for compression.1
第二个改进是:压缩请求与响应的头。
Finally, SPDY introduces server push.2 This can allow a server to push content that the client doesn't know it needs yet. Such content can range from additional assets like styles and images, to notifications about realtime events.
第三个改进是,服务器有主动推的功能。
参照:http://abloz.com/hbase/book.html#quickstart 在本地搭建一个hbase.
在bin/hbase脚本中
增加debug启动参数:
elif [ "$COMMAND" = "master" ] ; then
CLASS='org.apache.hadoop.hbase.master.HMaster'
if [ "$1" != "stop" ] ; then
HBASE_OPTS="$HBASE_OPTS $HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=10444"
fi下载稳定版代码:
http://svn.apache.org/repos/asf/hbase/tags/0.94.18
导入idea中远程debug.
信息来源:http://flyingdutchman.iteye.com/blog/1846808
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为row key的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为row key,这样能保证新写入的数据在读取时可以被快速命中。
有一篇文章,也专门讲了这个问题,并且画了漫画。



总结其**是,如果不倒序,则会使得regionServer不均匀,一些机器很岠,一些机器很闲。
Salting Row Key. To prevent hot spotting on writes, the row key may be “salted” by inserting a leading byte into the row key which is a mod over N buckets of the hash of the entire row key. This ensures even distribution of writes when the row key is a monotonically increasing value (often a timestamp representing the current time).
翻译过来,就是为了防止写的热点,对整个key的进行了基于N桶进行了取模,这个可以保证像单一时间递增rowkey可以保证分部式写。
openstack的开放计量服务里,ceilometer给出了这段代码:
def reverse_timestamp(dt):
"""Reverse timestamp so that newer timestamps are represented by smaller
numbers than older ones.
Reverse timestamps is a technique used in HBase rowkey design. When period
queries are required the HBase rowkeys must include timestamps, but as
rowkeys in HBase are ordered lexicographically, the timestamps must be
reversed.
"""
epoch = datetime.datetime(1970, 1, 1)
td = dt - epoch
ts = td.microseconds + td.seconds * 1000000 + td.days * 86400000000
return 0x7fffffffffffffff - ts这段代码的含义是通过Long.maxValue减去时间unixtimestamp的时间进行倒序。
这段代码的核心**是:因为rowkeys在hbase中是字典排序,如果查询是基于时间类查询,最好倒序,以提高查询速度?
现在我最大的疑问是:不这么做会有什么影响?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.