Hello ! Ce projet est une petite application des connaissances acquises sur Snowflake. Pour faire simple, je récupère de la data via l'API Twitter (#RIP l'API gratuite), je la stocke sur AWS S3 puis je la récupère et la prépare dans Snowflake.
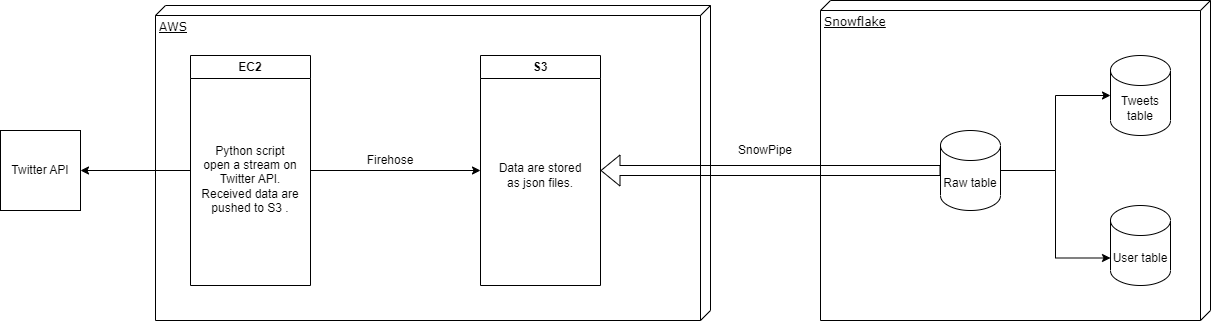
Ce script s'execute sur EC2 (un VPS) d'AWS.
J'utilise Tweepy pour faciliter les appels à l'API Tweeter.
Je redéfini la fonction on_data() du Stream de Tweepy pour ne récupérer que les clefs qui m'intéressent dans la réponse et les envoyer dans le Firehose AWS pré-défini. Ce Firehose met les données sous forme de fichiers dans S3.
J'applique également un filtre sur l'appel API pour sélectionner quelques mots clefs :
stream.filter(track=['$UOS','$ATOM','$ENJ','$COTI','$SAND'], stall_warnings=True)
La table twt_user contiendra tous les tweetos avec les informations sur leur compte mis à jour à date du dernier tweet récupéré.
CREATE OR REPLACE TABLE twt_user (
screen_name STRING PRIMARY KEY,
username STRING NOT NULL,
user_favourites_count NUMBER NOT NULL,
user_followers_count NUMBER NOT NULL,
user_friends_count NUMBER NOT NULL,
user_listed_count NUMBER NOT NULL,
user_statuses_count NUMBER NOT NULL,
verified STRING NOT NULL,
verified_type STRING NOT NULL,
last_updated DATETIME NOT NULL
);La table twt_tweet contient l'ensemble des tweets récupérés. Les informations de _count n'ont pas vraiment de valeur car sont récupérées peu après le tweet. Le champ text (contenu du tweet) peut être utile pour des analyse plus approfondies. On pourra également lier nos deux tables avec le champ user_screen_name.
CREATE OR REPLACE TABLE twt_tweet (
id STRING PRIMARY KEY,
created_at DATETIME NOT NULL,
user_screen_name STRING NOT NULL,
text STRING NOT NULL,
tweet_favorite_count NUMBER NOT NULL,
tweet_quote_count NUMBER NOT NULL,
tweet_reply_count NUMBER NOT NULL,
tweet_retweet_count NUMBER NOT NULL
);Le stage est créé pour donner accès au S3.
CREATE OR REPLACE STORAGE INTEGRATION s3_twt
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<number>:user/snowflake-user'
STORAGE_ALLOWED_LOCATIONS = ('s3://snowflake-udemy-vmzl/');
CREATE OR REPLACE STAGE twt_stage
URL = 's3://snowflake-udemy-vmzl/'
STORAGE_INTEGRATION = s3_twt
FILE_FORMAT = json_twt_fileformat;Puis on définit notre snowpipe pour consommer directement les nouveaux fichiers notifiés dans notre table twt_raw.
CREATE OR REPLACE PIPE twt_pipe
auto_ingest = TRUE
AS
COPY INTO twt_raw
FROM @twt_stage;On définit notre stream sur twt_raw en APPEND_ONLY.
CREATE OR REPLACE STREAM twt_raw_stream
ON TABLE twt_raw
APPEND_ONLY = TRUE;On schedule nos tasks :
- TWT_PARSE_RAW_STREAM : On parse nos raw data en colonnes qu'on met dans la table twt_parsed, toutes les 5 minutes.
- TWT_FILL_USER : child de TWT_PARSE_RAW_STREAM, on utilise twt_parsed pour ajouter et mettre à jour les informations des tweetos dans twt_user.
- TWT_PARSE_RAW_STREAM : child de TWT_PARSE_RAW_STREAM, on utilise twt_parsed pour ajouter les tweets dans twt_tweet.
CREATE OR REPLACE TASK TWT_PARSE_RAW_STREAM
WAREHOUSE = COMPUTE_WH
SCHEDULE = '5 MINUTE'
AS
CREATE OR REPLACE TABLE twt_parsed as
SELECT DISTINCT
RAW:id::STRING as id,
RAW:created_at::DATETIME as created_at,
RAW:screenname::STRING as screen_name,
RAW:username::STRING as username,
RAW:user_favourites_count::NUMBER as user_favourites_count,
RAW:user_followers_count::NUMBER as user_followers_count,
RAW:user_friends_count::NUMBER as user_friends_count,
RAW:user_listed_count::NUMBER as user_listed_count,
RAW:user_statuses_count::NUMBER as user_statuses_count,
RAW:verified::STRING as verified,
RAW:verified_type::STRING as verified_type,
RAW:text::STRING as text,
RAW:tweet_favorite_count::NUMBER as tweet_favorite_count,
RAW:tweet_quote_count::NUMBER as tweet_quote_count,
RAW:tweet_reply_count::NUMBER as tweet_reply_count,
RAW:tweet_retweet_count::NUMBER as tweet_retweet_count
FROM twt_raw_stream;
CREATE OR REPLACE TASK TWT_FILL_USER
WAREHOUSE = COMPUTE_WH
AFTER TWT_PARSE_RAW_STREAM
AS
MERGE INTO twt_user u
USING
(SELECT * FROM twt_parsed
QUALIFY row_number() over (
partition by
screen_name
order by
created_at desc
) = 1 ) p ON u.screen_name = p.screen_name
WHEN MATCHED THEN UPDATE
set u.username = p.username,
u.user_favourites_count = p.user_favourites_count,
u.user_followers_count = p.user_followers_count,
u.user_friends_count = p.user_friends_count,
u.user_listed_count = p.user_listed_count,
u.user_statuses_count = p.user_statuses_count,
u.verified = p.verified,
u.verified_type = p.verified_type,
u.last_updated = p.created_at
WHEN NOT MATCHED
THEN INSERT
(screen_name,username,user_favourites_count,user_followers_count,user_friends_count,user_listed_count,user_statuses_count,verified,verified_type,last_updated)
VALUES
(screen_name,username,user_favourites_count,user_followers_count,user_friends_count,user_listed_count,user_statuses_count,verified,verified_type,created_at);
CREATE OR REPLACE TASK TWT_FILL_TWEET
WAREHOUSE = COMPUTE_WH
AFTER TWT_PARSE_RAW_STREAM
AS
MERGE INTO twt_tweet t
USING twt_parsed p ON t.id = p.id
WHEN NOT MATCHED
THEN INSERT
(id,created_at,user_screen_name,text,tweet_favorite_count,tweet_quote_count,tweet_reply_count,tweet_retweet_count)
VALUES
(id,created_at,screen_name,text,tweet_favorite_count,tweet_quote_count,tweet_reply_count,tweet_retweet_count);Et ça marche bien ! Plus qu'à connecter un outil BI et à vous de jouer les Data Analystes !
