vibing / blog Goto Github PK
View Code? Open in Web Editor NEW博客,记录平常的所学所想
博客,记录平常的所学所想
安装 webpack-oss-upload-plugin
npm install webpack-oss-upload-plugin -D在 webpack config 中使用
const prefix = `${dir}/${projectName}/${version}/`;
{
output:{
publicPath: `http://e-package.oss-cn-shanghai.aliyuncs.com/${prefix}`
},
plugins: [
new WebpackOssUploadPlugin({
// oss 的配置
oss: {
region: 'region',
endpoint: 'endpoint',
accessKeyId: 'accessKeyId',
accessKeySecret: 'accessKeySecret',
bucket: 'bucket'
},
// 上传后的文件路径为:publicPath/{prefix}/your-file.js
prefix,
// 上传完成后会调用该回调
onComplete: (complication) => {
}
})
]
}在 onComplete 的参数暴露了 complication 对象,里面包含当前打包的信息,你可以合理使用它
选项说明
prefix: a/c/c/,那么上传后你的文件位置是:publicPath/a/b/c/your-file.jscomplication 对象,里面包含当前打包的信息,你可以合理使用它github 地址:https://github.com/Vibing/webpack-oss-plugin
如果你有其他需求或好的建议,请在 issue 中提给我
gRPC 是谷歌开源的一套多语言 RPC 框架,用官网的一句话来概括就是:
A high-performance, open-source universal RPC framework
翻译过来就是:一个高性能、开源通用的 RPC 框架。gRPC 也是一个遵循server/client模型的框架
先安装 grpc 和 @grpc/proto-loader
yarn add grpc @grpc/proto-loader
由于 gRPC 使用谷歌特有的 Protocol Buffer,用于序列化结构化数据的自动化过程,只需要定义如何组织你的结构化数据一次,就可以使用 protoc 轻松的根据这个定义生成语言相关的源代码(支持多种语言),以便于读写结构化数据。
这里通过 @grpc/proto-loader 来解析 proto 文件
关于 protoc buffer ,可以参考 Protocol Buffer是什么? 这篇文章
protoBuffer 目前有 2 和 3 两个版本,这里我们用版本 3
// 使用 proto3
syntax = "proto3";
// 定义包名
package helloworld;
// 定义Hello服务
service Hello {
// 定义 sayHello 方法
rpc sayHello (HelloReq) returns (HelloRes);
}
// 定义 sayHello 方法的传值
message HelloReq {
// 传入 name,1表示第一个参数
string name = 1;
// 传入 age,2表示第二个参数
int32 age = 2;
// 传入 job
string job = 3;
}
message HelloRes {
string message = 1;
}protobuf 书写较为严格,不要忘记分号。
需要注意的是,以 string name = 1;为例,这里的 1 表示第一个参数,其实在JSON格式里表示第一个 key ,比如:
message HelloReq {
// 传入 name,1表示第一个参数
string name = 1;
// 传入 age,2表示第二个参数
int32 age = 2;
}
// 对应的 JSON, 第一个 key 必须是 name ,第二个是 age
{
name: '',
age: 20
}RPC 分为 Server 端和 Client 端,我们先写 Server 端代码
首先就是引入 grpc 和 @grpc/proto-loader,先使用 proto-loader 加载 proto 文件生成对应的 package,然后通过 grpc 加载这个包,并通过.helloworld来返回 helloword 这个包(对应的是 proto 文件里的 package helloworld;)
const grpc = require('grpc')
const protoLoader = require('@grpc/proto-loader')
const path = require('path')
// 加载 proto 文件并配置
const packageDefinition = protoLoader.loadSync(
path.resolve(__dirname, '../proto/hello.proto'),
{
// 保留现场大小写而不是转换为驼峰格式
keepCase: true,
// 长转换类型。有效值为String和Number(全局类型)。默认情况下将复制当前值,这是一个不安全的数字,如果不带{@link Long}且带有长库的话。
longs: String,
// 枚举值转换类型。唯一有效的值是`String`(全局类型)。默认情况下复制当前值,即数字ID。
enums: String,
// 在结果对象上设置默认值
defaults: true,
// 包括设置为当前字段名称的虚拟oneof属性(如果有的话)
oneofs: true
}
)
// 使用 grpc 加载包
const helloProto = grpc.loadPackageDefinition(packageDefinition).helloworld上面这部分仅仅是对 proto 文件的处理,由于 Server 端和 Client 都用同一份 proto,所以这部分代码是服务端和客户端都要用到的。
现在 proto 已经解析好了,我们接着上面的代码开始写一个服务:
// 创建 server
const server = new grpc.Server()
// 添加服务, 这里的服务名叫Hello
server.addService(helloProto.Hello.service, {
// 实现sayHello方法
sayHello
})
// sayHello 方法,call 用来获取请求信息,callback 用来向客户端返回信息
function sayHello(call, callback) {
try {
// 获取 name 和 age
const { name, age, job } = call.request
console.log('收到客户端传值:', name, age, job)
// 按 proto 约定传值,返回`我叫${name},年龄${age}`
callback && callback(null, { message: `我叫${name},年龄${age}` })
} catch (error) {
console.log('服务出错', error)
callback && callback(error)
}
}
// 异步启动
server.bindAsync('0.0.0.0:50051', grpc.ServerCredentials.createInsecure(), () => {
server.start()
console.log('server start...')
})打开控制台,输入 node server/index.js运行该服务
因为 Client 也需要解析 proto,上文已经有相关代码,这里只写 Client 余下的代码:
// 创建客户端
const client = new helloProto.Hello(
'localhost:50051',
grpc.credentials.createInsecure()
)
// 调用 sayHello 方法
client.sayHello({ name: '张三', age: 30, job: 'teacher' }, (err, response) => {
if (err) {
console.log(err)
return
}
const { message } = response
console.log(message)
})客户端就这么简单。
现在运行 node client/index.js
客户端调用 sayHello 方法,并传入{ name: '张三', age: 30, job: 'teacher' } ,服务端接收到参数后通过 sayHello 处理,并返回给客户端 我叫张三,年龄30
完整代码见:https://github.com/Vibing/node-grpc
至此,gRPC 一个简单的调用就完成了,就是这么简单。
react的火热程度已经达到了94.5k个start,本系列文章主要用简单的代码来实现一个react,来了解JSX、虚拟DOM、diff算法以及state和setState的设计。
提到react,当然少不了vue,vue的api设计十分简单 上手也非常容易,但黑魔法很多,使用起来有点虚, 而react没有过多的api,它的深度体现在设计**上,使用react开发则让人比较踏实、能拿捏的住,这也是我喜欢react的原因之一。
写react怎么少的了JSX,JSX是什么,让我来看个例子
现在有下面这段代码:
const el = <h3 className="title">Hello Javascript</h3>这样的js代码如果不经过处理会报错,jsx是语法糖,它让这段代码合法化,通过babel转化后是这样的:
const el = React.createElement(
'h3',
{ className: 'title' },
'Hello Javascript'
)这种例子官网首页也有demo
开始编码之前,先介绍两个东西:parcel和babel-plugin-transform-jsx,等会我们用parcel搭建一个开发工程,babel-plugin-transform-jsx是babel的一个插件,它可以将jsx语法转成React.createElement(...)。
下面我们开始
parcel这里就不介绍了,一句话概况就是为你生成一个零配置的开发环境。
yarn global add parcel-bundler 或 npm install -g parcel-bundlersimple-reactsimple-react中执行 yarn init -y 或 npm init -y 生成package.jsonindex.htmlsrc文件夹 再在src下创建index.js 然后再index.html中引入index.js如果你先麻烦,可以直接下载源码修改。
以上步骤完可能不完整,最好参考parcel里的内容。以上工作完成后,我们需要安装babel-plugin-transform-jsx:
npm insatll babel-plugin-transform-jsx --save-dev
或者
yarn add babel-plugin-transform-jsx --dev然后添加.babelrc文件,并在该文件中加入下面这段代码:
{
"presets": ["env"],
"plugins": [["transform-jsx", { "function": "React.createElement" }]]
}上面代码的意思是 使用transform-jsx插件,并配置为使用React.createElement方法来解析JSX,当然你也可以不用React.createElement和自定义方法,比如preact使用的h方法。
现在我们在index.js里开始编码。
首先写入代码:
const el = <h3 className="title">Hello Javascript</h3>;
console.log(el);我们在什么都不写的情况下,打印看看el是什么。

打印报错:React没有定义。 这是因为在.babelrc文件中,我们使用的这段代码起了作用:
["transform-jsx", { "function": "React.createElement" }]上面说过,它会通过React.createElement方法来转译JSX,那么我们就给出这个方法:
我们把刚才那段代码改变一下:
const React = {
createElement: function(...args) {
return args[0];
}
};
const el = <h3 className="title">Hello Javascript</h3>;
console.log(el);上面代码添加了一个React对象,并在其中添加一个createElement方法,现在再执行一下看看打印出什么:

由打印结果可以看出,jsx在使用React.createElement方法转译时,createElement方法应该是这样的:
createElement({ elementName, attributes, children });现在我们改写一下createElement方法,让key的名称简单一点:
const React = {
createElement: function({ elementName, attributes, children }) {
return {
tag: elementName,
attrs: attributes,
children
};
}
};现在可以看到打印结果是:

我们再打印个复杂点的DOM结构:
const el = (
<div style="color:red;">
Hello <span className="title">JavaScript</span>
</div>
);
console.log(el);
和我们想要的结构一样。
其实上面打印出来的就是虚拟DOM,现在我们要做的就是如何把虚拟DOM转成真正的DOM对象并显示在浏览器上。
要想将虚拟dom转成真实dom并渲染到页面上,就需要调用ReactDOM.render,比如:
ReactDOM.render(<h1>Hello World</h1>, document.getElementById('root'));这段代码转换后的样子:
ReactDOM.render(
React.createElement('h1', null, 'Hello World'),
document.getElementById('root')
);这时,react会将<h1>Hello World</h1>挂载到id为root的dom下,从而在页面上显示出来。
现在我们实现render方法:
function render(vnode, container) {
const dom = createDom(vnode); //将vnode转成真实DOM
container.appendChild(dom);
}上面代码中先调用createDom将虚拟dom转成真实DOM,然后挂载到container下。
我们来实现createDom方法:
function createDom(vnode) {
if (vnode === undefined || vnode === null || typeof vnode === 'boolean') {
vnode = '';
}
if (typeof vnode === 'string' || typeof vnode === 'number') {
return document.createTextNode(String(vnode));
}
const dom = document.createElement(vnode.tag);
//设置属性
if (vnode.attrs) {
for (let key in vnode.attrs) {
const value = vnode.attrs[key];
setAttribute(dom, key, value);
}
}
//递归render子节点
vnode.children.forEach(child => render(child, dom));
return dom;
}由于属性的种类比较多,我们抽出一个setAttribute方法来设置属性:
function setAttribute(dom, key, value) {
//className
if (key === 'className') {
dom.setAttribute('class', value);
//事件
} else if (/on\w+/.test(key)) {
key = key.toLowerCase();
dom[key] = value || '';
//style
} else if (key === 'style') {
if (typeof value === 'string') {
dom.style.cssText = value || '';
} else if (typeof value === 'object') {
// {width:'',height:20}
for (let name in value) {
//如果是数字可以忽略px
dom.style[name] =
typeof value[name] === 'number' ? value[name] + 'px' : value[name];
}
}
//其他
} else {
dom.setAttribute(key, value);
}
}现在render方法已经完整的实现了,我们将创建ReactDOM对象,将render方法挂上去:
const ReactDOM = {
render: function(vnode, container) {
container.innerHTML = '';
render(vnode, container);
}
};这里在调用render之前加了一句container.innerHTML = '',就不解释了,相信大家都明白。
那么万事具备,我们来测试一下,直接上一个比较复杂的dom结构并加上属性:
const element = (
<div
className="Hello"
onClick={() => alert(1)}
style={{ color: 'red', fontSize: 30 }}
>
Hello <span style={{ color: 'blue' }}>javascript!</span>
</div>
);
ReactDOM.render(element, document.getElementById('root'));打开页面,是我们想要的结果:

再看看控制台的dom:

很完美,这是我们想要的东西
使用root登录
mysql -h 主机名(默认为localhost) -u 用户名(root) -p显示当前用户下所有数据库
mysql> show databases;退出登录
mysql> exit;创建用户(登录root后)
CREATE USER '用户名’@'主机名' IDENTIFIED BY ‘密码’;查看当前登录的用户
select current_user();查看mysql下所有用户
select user from mysql.user; 查看mysql用户的所有字段
desc mysql.user;销毁用户
drop user 用户名@主机名给某个用户分配权限
例如:grant all privileges on 数据库名称.* to wanghao@localhost; (为wanghao@localhost分配某个数据库下所有表的所有权限)
GRANT 权限 ON 数据库/表 TO ‘用户'@'主机名' [IDENTIFED BY '密码’]; 让权限生效
flush privileges;查看某用户拥有的权限
show grants for 用户名@主机名;吊销权限
revoke 权限(多个权限逗号分开) on 数据库.表名 from ‘用户'@'主机名’;重置某个用户登录密码
set password for ‘用户名’@‘主机名’ = password(‘新密码’);以下内容可以参考:MySQL 教程 | 菜鸟教程
创建数据库
create database 数据库名称;查看数据库
show databases;删除数据库
drop database <数据库名>;
进入(使用)某个数据库
use 数据库名称;查看当前数据库下的表
show tables;查看某个表的所有字段
show columns from 表名;查看某个表的描述
describe 表名称;添加字段到第一个位置(默认添加到最后)
alter table 表名 add 字段名 INT(10) first;修改表名
alter table 表名1 rename 表名2;删除表内某字段
alter table 表名 drop 字段名;修改表字段
alter table 表名 change 字段名1 字段名2 INT(10);删除表
drop table 表名;本文并不介绍 Buffer 和 Stream 使用的api,而是把对 Buffer 和 Stream 的理解带给大家。
之前发了篇文章《Nodejs核心模块简介》,笼统的介绍了下 Events模块、fs模块、stream的使用、http模块。
文章也在我的 github 博客上,欢迎订阅。
因为想学好 node 这些东西几乎是必须掌握的。这篇文章来说一下在 node 中几乎无处不在的 Buffer 和 Stream,什么是 Buffer 以及它和 Stream 到底什么关系? 马上揭晓。
Buffer 是个类数组的对象,可以把它当做数组更好理解些,只不过里面存的是二进制数据。
先创建个 buffer 来看看它打印出来的样子:
const str = 'hello';
const buf = Buffer.from(str);
console.log(buf); // <Buffer 68 65 6c 6c 6f>buf 里装的数据是字符串 hello,而 buf 的长度为 5 ,hello 的长度也是 5,所以 Buffer 中每个元素占一个字节(英文每个字母是一个字节)。
从代码使用来看,Buffer 是类数组对象。
从内存角度看,Buffer 是在内存中开辟的一块区域。
Buffer 翻译过来是缓冲器,它主要用来暂存数据。
为了更好理解,用大白话把上面哪句翻译一下:Buffer 就是我们常坐的公交车,人就是数据,人上车就表示在 Buffer 中输入数据, 到站了人就下车,Buffer 里的数据就会输出
比如我们填写完表单,发送 http 请求到服务端,我们的数据就会暂存在 Buffer 中,服务端取的数据就是从暂存的 Buffer 里取的
废话!装的当然是数据了!没错 是数据...
<Buffer 68 65 6c 6c 6f>, 从刚才打印结果看,Buffer 显示的每个元素都是十六进制,但这只是为了方面查看,在控制台显示时是十六进制而已。。。
这里问问大家,数据在内存中是什么? 没错 是二进制,就是类似010101这样的东西。
为什么以二进制存在?因为电脑读写的数据都是电信号! 而电信号就是 0和1。
好在我们可以把二进制、十进制、十六进制等进行转换,所以 Buffer 的每个元素看上去是十六进制,其实内存里存的都是二进制。
Buffer 的每个元素取值范围是多少呢?
255 这个数字肯定见过不少,比如 css 中的 rgba 每个值的范围是 0-255
而 255 其实跟 ASCII码 紧紧相连,回顾一下上面代码中打印 hello 的 buffer :<Buffer 68 65 6c 6c 6f>,然后对照下面这个 ASCII 表

再对照 buffer 里的每个元素:

是不是一下就明白了, 原来数据就是这样纸的呀。
当然,上面的 hello 使用的是国际统一码,是 0 - 127,后128个(128—255)称为扩展ASCII码,目前许多基于x86的系统都支持使用扩展(或“高”)ASCII。
亲! 先把进制问题和ASCII码放一边,现在你的脑子里只有人和公交车。
Stream 翻译过来就是流,流动的意思,《Nodejs核心模块简介》里也简单的介绍了这块内容,有兴趣可以看看。
既然 Stream 是流动的,那它跟 Buffer 到底有啥联系?
现在回到 人和公交车 的问题,上面说 人是数据,公交车本身是 Buffer,Buffer 里有没有数据 取决于人在不在里面。
注意,我上面说的是公交车本身,没有说公交车有没有在跑。
所以,聪明的你猜到了,跑着的公交车就是 Stream。
流的原则是:有源头、有终点、源头流向终点。
公交车就是这样,从起点发车,载着数据(人)往终点跑。
光说不行,来看一段代码:
const fileReadStream = fs.createReadStream('./logs/hello.log');
const fileWriteStream = fs.createWriteStream('./logs/hello2.log');
fileReadStream.on('data', chunk => {
console.log(chunk);
fileWriteStream.write(chunk);
});打印结果如下:

从图看出,hello.log数据很多,一个 buffer(公交车) 装不完, 打印了好几次的 chunk 才完成写入,每个 chunk 都是一个buffer,都填满了数据(人)。 流可以看成是公交司机,流的作用就是将 buffer 从一个地方(起点)运送的另一个地方(终点)。
现在捋一下:
这是一种至关重要的行为设计模式,它定义了对象之间的一对多依赖关系,以便当一个对象(发布者)更改其状态时,所有其他依赖对象(订阅者)都将得到通知并自动更新。这也称为PubSub(发布者/订阅者)或Event Dispatcher / Listeners Pattern。发布者有时称为主题,订阅者有时称为观察者。
如果您已经使用addEventListener或jQuery编写事件处理代码,那么您可能已经有点熟悉此模式了。它也对反应式编程(RxJS)有影响。
在示例中,我们创建了一个简单的Subject类,该类具有用于Observer从订户集合中添加和删除类的对象的方法。另外,一种fire将Subject类对象中的任何更改传播到订阅的Observers的方法。的Observer类,在另一方面,有其内部状态和基于从传播的改变更新其内部状态的方法Subject它已经预订。
Observer.js
class Subject {
constructor() {
this._observers = [];
}
subscribe(observer) {
this._observers.push(observer);
}
unsubscribe(observer) {
this._observers = this._observers.filter(obs => observer !== obs);
}
fire(change) {
this._observers.forEach(observer => {
observer.update(change);
});
}
}
class Observer {
constructor(state) {
this.state = state;
this.initialState = state;
}
update(change) {
let state = this.state;
switch (change) {
case 'INC':
this.state = ++state;
break;
case 'DEC':
this.state = --state;
break;
default:
this.state = this.initialState;
}
}
}
// usage
const sub = new Subject();
const obs1 = new Observer(1);
const obs2 = new Observer(19);
sub.subscribe(obs1);
sub.subscribe(obs2);
sub.fire('INC');
console.log(obs1.state); // 2
console.log(obs2.state); // 20npm i --registry=http://10.21.200.55:7001 #单次使用私有源
npm list -g --depth=0 #查看全局包列表,不考虑依赖
npm config ls -l #查看npm配置
npm i [email protected] #安装指定版本的包
npm update node-sass #更新包
npm search node-sass #搜索一个包是否存在
npm cache clean #清理本地包缓存
npm init --yes #快速创建一个package.json
npm install -g npm #更新npm
npm publish <本地路径> #发布包
npm outdated #查看包的版本状态
npm root -g #查看全局包位置prebuild build的前置钩子
build
postbuild build的后置钩子npm i 的时候会去读取本地项目的rc文件,没有就读~目录registry=https://registry.npm.taobao.org #设置淘宝镜像
sass_binary_site=https://npm.taobao.org/mirrors/node-sass/ #设置sass来源
phantomjs_cdnurl=http://npm.taobao.org/mirrors/phantomjs
electron_mirror=http://npm.taobao.org/mirrors/electron/假设你的梯子在你本地机器上开启了一个第三方服务器 127.0.0.1:1080,只需按照下面的方法配置一下就能正常安装 node-sass 了
npm config set proxy http://127.0.0.1:1080
npm i node-sass
下载完成后删除 http 代理
npm config delete proxy
这样下来就能正常安装了
从我接触 js 的时候,经常听到一句话:js 是单线程的。
单线程意味着 js 代码在执行时,只能按编码顺序从上到下执行(暂时抛开异步方法),如果遇到计算量大、耗时长的任务,用户就能感觉到卡顿。
JavaScript 的主线程主要作用是服务与 UI 构建,如果遇到繁重任务阻塞了 UI 主线程,就会感觉到卡。
一般我们解决的方法有两个:异步、使用Web Worker
异步暂时不讨论,这里主要说 Web Worker
既然主线程用于构建 UI,那么为了不阻塞 UI 构建,我们将繁重任务从主线程剥离出来放到其他线程里执行,不就OK了?
使用 Web Worker 可以将 js 运行在后台线程中,由于它独立于主线程,所以不会阻塞 UI 的构建
专用线程(Dedicated Web Worker) 和共享线程(Shared Web Worker)。
专用线程只能由创建它的单个脚本使用,共享线程可以由多个脚本使用。
目前统计,目前约有 97.48% 的浏览器支持专用线程
而共享线程只有大约 36.75% 的浏览器支持
所以我们在使用它们时,不要忘记判断浏览器是否支持:
if (Worker) {
//...
}if (ShareWorker) {
//...
}由于共享线程浏览器支持情况较差,本章我们只介绍专用线程。
我们创建一个文件夹,并在里面创建 index.html 和 worker.js
目录如下:
.
├── index.html
└── worker.js
index.html 代码:
<input type="text" id="ipt" value="" />
<div id="result"></div>
<script>
const ipt = document.querySelector('#ipt');
const worker = new Worker('worker.js');
ipt.onchange = function() {
// 通过postMessage发送消息
worker.postMessage({ number: this.value });
};
// 通过onmessage接收消息
worker.onmessage = function(e) {
document.querySelector('#result').innerHTML = e.data;
};
</script>worker.js 代码:
// 这里的 self 类似主线程中的 window
self.onmessage = function(e) {
self.postMessage(e.data.number * 2);
};在主线程中处理错误:
// 主线程
worker.onerror = function () {
// ...
}
// 主线程使用专用线程
worker.onmessageerror = function () {
// ...
}在专用线程中处理错误:
// worker 线程
onerror = function () {
}Web Worker 提供了 importScripts() 方法,能够将外部脚本文件加载到 Wroker 中。
importScript('script1.js')
importScript('script2.js')
// 上面写法等同于
importScript('script1.js','script2.js')Worker 可以生成子 Worker,但有两点要注意:
目前没有一类标签可以使 Worker 的代码像 <script> 元素一样嵌入网页中,但我们可以通过 Blob() 将页面中的 Worker 代码进行解析。
<script id="worker" type="javascript/worker">
// 这段代码不会被 JS 引擎直接解析,因为类型是 'javascript/worker'
// 在这里写 Worker 线程的逻辑
</script>
<script>
var workerScript = document.querySelector('#worker').textContent
var blob = new Blob(workerScript, {type: "text/javascript"})
var worker = new Worker(window.URL.createObjectURL(blob))
</script>JSON Web Token (JWT)是一个开放标准(RFC 7519),它定义了一种紧凑的、自包含的方式,用于作为JSON对象在各方之间安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。
本文只讲Koa2 + jwt的使用,不了解JWT的话请到这里进行了解。
要使用koa2+jwt需要先有个koa的空环境,搭环境比较麻烦,我直接使用koa起手式,这是我使用koa+typescript搭建的空环境,如果你也经常用koa写写小demo,可以点个star,方便~
koa-jwt主要作用是控制哪些路由需要jwt验证,哪些接口不需要验证:
import * as koaJwt from 'koa-jwt';
//路由权限控制 除了path里的路径不需要验证token 其他都要
app.use(
koaJwt({
secret: secret.sign
}).unless({
path: [/^\/login/, /^\/register/]
})
);上面代码中,除了登录、注册接口不需要jwt验证,其他请求都需要。
执行npm install jsonwebtoken安装jsonwebtoken
相关代码:
import * as jwt from 'jsonwebtoken';
const secret = 'my_app_secret';
const payload = {user_name:'Jack', id:3, email: '[email protected]'};
const token = jwt.sign(payload, secret, { expiresIn: '1h' });上面代码中通过jwt.sign来生成一个token,
参数意义:
import * as crypto from 'crypto';
import * as jwt from 'jsonwebtoken';
async login(ctx){
//从数据库中查找对应用户
const user = await userRespository.findOne({
where: {
name: user.name
}
});
//密码加密
const psdMd5 = crypto
.createHash('md5')
.update(user.password)
.digest('hex');
//比较密码的md5值是否一致 若一致则生成token并返回给前端
if (user.password === psdMd5) {
//生成token
token = jwt.sign(user, secret, { expiresIn: '1h' });
//响应到前端
ctx.body = {
token
}
}
}前端通过登录拿到返回过来的token,可以将它存在localStorage里,然后再以后的请求中把token放在请求头的Authorization里带给服务端。
这里以axios请求为例,在发送请求时,通过请求拦截器把token塞到header里:
//请求拦截器
axios.interceptors.request.use(function(config) {
//从localStorage里取出token
const token = localStorage.getItem('tokenName');
//把token塞入Authorization里
config.headers.Authorization = `Bearer ${token}`;
return config;
},
function(error) {
// Do something with request error
return Promise.reject(error);
}
);前端发送请求携带token,后端需要判断以下几点:
关于上面两点,需要在后端写一个中间件来完成:
app.use((ctx, next) => {
if (ctx.header && ctx.header.authorization) {
const parts = ctx.header.authorization.split(' ');
if (parts.length === 2) {
//取出token
const scheme = parts[0];
const token = parts[1];
if (/^Bearer$/i.test(scheme)) {
try {
//jwt.verify方法验证token是否有效
jwt.verify(token, secret.sign, {
complete: true
});
} catch (error) {
//token过期 生成新的token
const newToken = getToken(user);
//将新token放入Authorization中返回给前端
ctx.res.setHeader('Authorization', newToken);
}
}
}
}
return next().catch(err => {
if (err.status === 401) {
ctx.status = 401;
ctx.body =
'Protected resource, use Authorization header to get access\n';
} else {
throw err;
}});
}); 上面中间件是需要验证token时都需要走这里,可以理解为拦截器,在这个拦截器中处理判断token是否正确及是否过期,并作出相应处理。
后端更换新token后,前端也需要获取新token 这样请求才不会报错。
由于后端更新的token是在响应头里,所以前端需要在响应拦截器中获取新token。
依然以axios为例:
//响应拦截器
axios.interceptors.response.use(function(response) {
//获取更新的token
const { authorization } = response.headers;
//如果token存在则存在localStorage
authorization && localStorage.setItem('tokenName', authorization);
return response;
},
function(error) {
if (error.response) {
const { status } = error.response;
//如果401或405则到登录页
if (status == 401 || status == 405) {
history.push('/login');
}
}
return Promise.reject(error);
}
);原在我的 Github 上,欢迎订阅。
其他文章:
数据源于生活,数据之间的关系也是从生活里映射过来的。
比如:一个老师可以教很多学生,一个学校有很多老师,一个人只能有一个身份证等等。
总结下来,所有的数据之间有三种关系:
一对一就是,我只有你,你只有我。
比如:
即使是一对一也要明确主从关系,比如人与身份证的关系,人是主,身份证是从,因为没有人哪里来的身份证呢?再比如 没有商品哪来的商品信息呢?
这里用人与身份证的关系来举例,我们新建 person 表:
CREATE TABLE person
id INT UNSIGNED PRIMARY KEY auto_increment,
name CHAR(30) DEFAULT NULL
)再建id_card表,并通过外键person_id与主表关联:
CREATE TABLE id_card(
id INT UNSIGNED PRIMARY KEY auto_increment,
card_no VARCHAR(20) NOT NULL,
person_id INT UNSIGNED,
CONSTRAINT id_card_person FOREIGN KEY (person_id) REFERENCES person(id)
)然后添加点数据:
person 表:
| id | name |
|---|---|
| 1 | 小A |
| 2 | 小B |
| 3 | 小C |
id_card 表:
| id | card_no | person_id |
|---|---|---|
| 1 | 34xxxxxxxxxxxx0912 | 1 |
| 2 | 34xxxxxxxxxxxx1108 | 2 |
| 2 | 34xxxxxxxxxxxx0422 | 3 |
然后查询所有人的姓名和对应的身份证号:
SELECT a.name,b.card_no
FROM person a LEFT JOIN id_card b
ON a.id=b.person_id;查询结果:
| name | card_no |
|---|---|
| 小A | 34xxxxxxxxxxxx0912 |
| 小B | 34xxxxxxxxxxxx1108 |
| 小C | 34xxxxxxxxxxxx0422 |
一对多,即主表的一个数据可以有多个从表的数据。
举个例子:班级和学生,一个班级有多个学生,主表是班级,从表是学生。
我们创建班级表class:
CREATE TABLE class(
id INT UNSIGNED PRIMARY KEY auto_increment,
class_name VARCHAR(30) COMMENT '班级名'
);再创建学生表student:
CREATE TABLE student(
id INT UNSIGNED PRIMARY KEY auto_increment,
student_name CHAR(30) COMMENT '学生名',
class_id INT UNSIGNED DEFAULT NULL COMMENT '班级id',
CONSTRAINT student_class FOREIGN KEY (class_id) REFERENCES class(id)
)创建学生表时,每个学生都有一个班级,我们用class_id作为表示,然后和class表建立外键约束(这一步也可不要,看开发情况而定)。
添加数据后
class 表:
| id | class_name |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
| 3 | 三班 |
student 表:
| id | student_name | class_id |
|---|---|---|
| 1 | 李安安 | 1 |
| 2 | 陈小帅 | 1 |
| 3 | 张力克 | 3 |
然后查一下所有班级和班级的学生数量:
SELECT c.class_name ,COUNT(s.student_name) student_num
FROM class c LEFT JOIN student s ON c.id=s.class_id
GROUP BY c.class_name;结果:
| id | student_num |
|---|---|
| 一班 | 2 |
| 三班 | 1 |
| 二班 | 0 |
三种关系里,多对多是最复杂的。
多对多举例:一篇文章有可以有多种分类,一种分类可以有多篇文章。
由于多对多的关系比较复杂,我们一般会添加一张中间表专门来记录他们的关系。
新建tag(文章分类)表:
CREATE TABLE tag(
id INT UNSIGNED PRIMARY KEY auto_increment,
tag_name VARCHAR(50) NOT NULL
)新建article(文章)表:
CREATE TABLE article(
id INT UNSIGNED PRIMARY KEY auto_increment,
title VARCHAR(100) NOT NULL
)再建立tag和article的关系表:
CREATE TABLE tag_article(
id INT UNSIGNED PRIMARY KEY auto_increment,
tag_id INT UNSIGNED DEFAULT NULL,
article_id INT UNSIGNED DEFAULT NULL,
FOREIGN KEY(tag_id) REFERENCES tag(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY(article_id) REFERENCES article(id) ON DELETE CASCADE ON UPDATE CASCADE,
UNIQUE(tag_id,article_id)
)然后添加了些数据后:
tag表:
| id | tag_name |
|---|---|
| 1 | 文学 |
| 2 | 科技 |
| 3 | 编程 |
article表:
| id | title |
|---|---|
| 1 | 青青河边草 |
| 2 | 我国在航空领域取得重大成就 |
| 3 | PHP是世界上最好的语言 |
tag_article关系表:
| id | tag_id | article_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 1 | 2 |
开发中通过tag_article关系表来进行查询
比如查询tag_id=1的所有文章:
SELECT a.title
FROM article a INNER JOIN tag_article t
ON a.id=t.article_id
WHERE tag_id=1查询结果:
| title |
|---|
| 青青河边草 |
| 我国在航空领域取得重大成就 |
一对一、一对多、多对多的关系很好理解,在开发中只要分清关系类型,分清主表从表就能清晰的对数据有很好的了解。
其实学到这里,基本已经算入门了,后面我会对mysql里的常用函数和一些字句进行学习,也会写成文章分享给大家。
我们慢慢脱离了jQuery的**,迎接有React、Vue、新Angular的时代。
React的出现改了前端的革命。组件化、虚拟dom等**在它身上体现的淋漓尽致。
我们在使用任何框架的时,避免不了出现优化的问题,毕竟框架为我们提供的是方便,在方便的同时如何使你的项目性能更好,效率更高是我们程序员一生解决不完的bug。
Immutable也是Facebook旗下和React同时期出现的一个库,只是React太火了,导致当时没多少人了解Immutable。
Immutable:Immutable collections for JavaScript
翻译过来就是:JavaScript的不可变集合
而JavaScript里的对象正好相反,都是可变的(Mutable)
下面我们来解释一下不可变
现在我们有一个数据是这样的:
const data = {
name: 'Jack',
age: 25
}我们修改它的属性时一般是这样:
data.name = 'Tom'这时你会发现,data(数据源)被改变了,因为JavaScript使用的是引用赋值,这样做虽然可以节省内存,但是当应用变得复杂后,会存在很大的隐患。
为了不让data改变,一般会使用shallowCopy(浅拷贝)或 deepCopy(深拷贝)创建副本来避免被修改,但这样做造成了 CPU 和内存的浪费。
Immutable可以解决这个问题。
刚才说Immutable可以解决这个问题,意思是:Immutable可以创建新的数据副本,并且不会造成CPU和内存的浪费。
那么Immutable是通过什么玩意来实现这么牛叉的功能的?
这里先写个列子:
import { Map } from 'immutable';
const data1 = Map({
name: 'Jack',
age: 25
});
//将name修改为Tom
const data2 = data1.set('name', 'Tom');代码中,我们使用Immutable的Map创建一个Immutable Data,然后修改 data1 中的 name = 'Tom',此时打印 data1 却还是之前的数据。
Immutable Data 一旦创建,就不能再被修改,对Immutable Data的任何操作(增删改)都会创建一个新的Immutable对象,它的实现原理是持久化数据结构(Persistent Data Structure),为了避免深拷贝把所有节点都复制一遍带来的性能消耗,Immutable 使用了结构共享(Structural Sharing)。
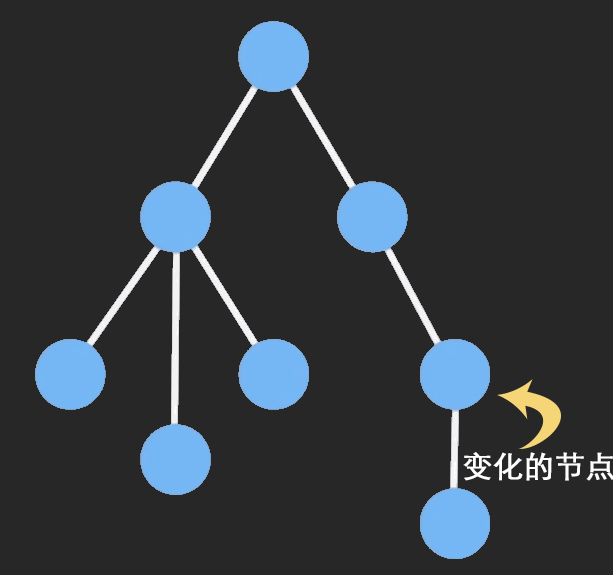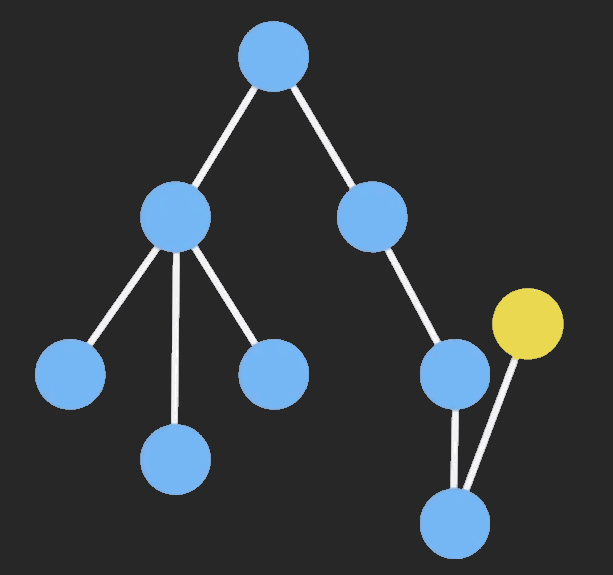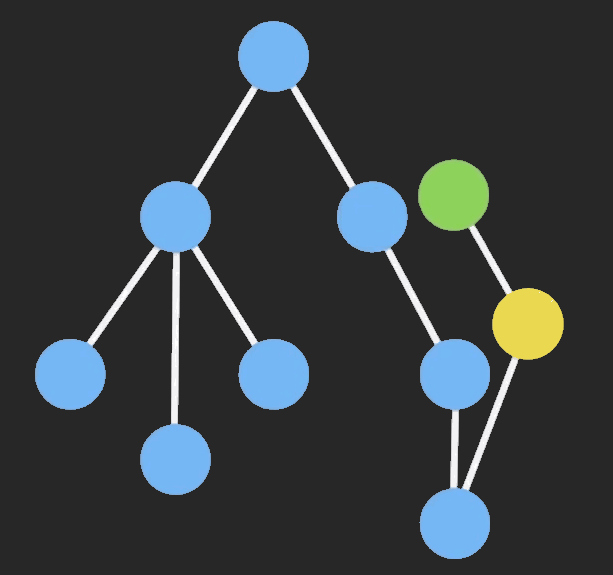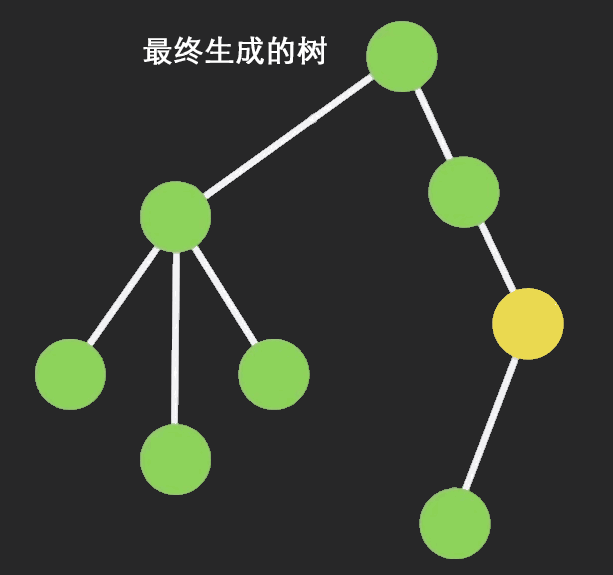
结构共享: 即数据的对象树中,一个节点的数据发生变化后,只修改这个节点本身和受它影响的父级节点,其他节点仍然共享,通过下面这个图可以了解的比较清楚
Immutable 的数据不可变性,给经常产生变化的对象带了福音,第一眼想到的是 React 的 state,毕竟我们在使用React开发项目时,最最最经常操作的不就是状态吗?
React官方也建议把 this.state当成 immutable的,那么我们来写个简单的例子:
使用 Immutable 之前:
class Demo extends React.Component {
constructor(props){
super(props);
this.state = {
data: {
count: 0
}
}
}
handerAdd = () => {
this.setState({
count: this.state.data.count+1
})
}
//...
}使用Immutable之后:
import { Map } from 'immutable'
//...
constructor(props){
super(props);
this.state = {
data: Map({
count: 0
})
}
}
handerAdd = () =>{
this.setState(({data})=>({
data: data.updata('count',c => c+1)
}))
}React 组件更新时,会调用 componentShouldUpdate 声明周期方法,这个方法默认会返回true,即使你的state和props没有发生变化也会重新render,这往往会带来比较大的开销。
React 提供了一个 PureComponent,会在componentShouldUpdate里执行一次浅比较来减少不必要的render(其实卵用不大)。
现在有了 Immutable,我们使用它来帮我们彻底解决这个问题。 Immutable提供了 is 方法,来比较两个 Immutable对象是否完全相同,我们用这个来实现:
import { is } from 'immutable';
shouldComponentUpdate(nextProps, nextState){
return !(this.props === nextProps || is(this.props, nextProps)) ||
!(this.state === nextState || is(this.state, nextState));
}使用 Immutable 后,如下图,当红色节点的 state 变化后,不会再渲染树中的所有节点,而是只渲染图中绿色的部分:
这样就可以大大的减少组件不必要的 render 啦~
本文简单介绍了Immutable 的使用,以及在 React 中使用 Immutable 如何做优化,还有其他功能没有介绍,比如 Cursor 等,Immutable 的应用还有很多,只要是跟数据操作有关的,都可以使用它来提高性能。
这是一种行为设计模式,它允许对象根据对其内部状态的更改来更改其行为。状态模式类返回的对象似乎更改了其类。它为一组有限的对象提供特定于状态的逻辑,其中每种对象类型代表一种特定的状态。
状态模式的核心是:
状态模式需要一个主题类 Context 用来作为状态的载体,这个类记用于 get 和 set 状态;
状态模式需要状态类 State ,里面包含具体的状态变化的逻辑;
在生活中,红绿灯就是状态模式的体现,灯颜色的变化会触发汽车或行人的行为
先定义 State 类,它用于红绿灯颜色变化和相应的逻辑处理:
class State {
constructor(color){
this.color = color;
}
/**
* 用于处理切换逻辑
*/
handle(context){
// 逻辑处理
console.log(`跳到:${this.color} 灯`)
// 调用 Context 的 setState 来改变状态
context.setState(this)
}
}再看看 Context 类,它抽象出来 用于获取和设置当前 state
class Context {
constructor() {
this.state = null;
}
getState() {
return this.state
}
setState(state) {
this.state = state;
}
}将状态抽离出来保存在 Context 中,具体的状态逻辑在 State 中,来看看调用:
// use
const context = new Context();
// 红灯
const redLight = new State('红灯')
redLight.handle(context) // 跳到红灯了
// 绿灯
const redLight = new State('绿灯')
redLight.handle(context) // 跳到绿灯了
// 黄灯
const redLight = new State('黄灯')
redLight.handle(context) // 跳到黄灯了在 vue2.x 版本中使用 Object.definedProperty 来劫持数据,实现数据双向绑定。我们来实现一个简单的数据劫持:
function observer(obj) {
if (typeof obj === 'object') {
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
listener(obj, key);
}
}
}
}
function listener(obj, key) {
let curValue = obj[key];
observer(curValue); // 如果curValue是对象,进入递归
Object.defineProperty(obj, key, {
get() {
console.log('get-->', curValue);
return curValue;
},
set(newVal) {
console.log('set-->', newVal);
curValue = newVal;
}
});
}上面写了个简单版的数据劫持,现在我们来测试一下:
const obj = {
name: 'Jack',
age: 20
};
observer(obj)现在我们将 obj.name 改为 Tom:
灰常好,set 方法执行了,我们在更改数据前,劫持了数据。
我们再看看获取 name:
灰常好,get 方法也执行了,我们在获取数据前,劫持了数据。
看上去很美好,但 Object.definedProperty 并不是完美的,它在有些情况下无法劫持数据:
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
const p = new Proxy(target, handler)还记得 Object.defineProperty 的语法吗:
Object.defineProperty(obj, key, options);从语法上就能发现一个最大的不同点:Object.defineProperty 监听的是对象的属性,而 Proxy 监听的是整个对象
所以我们不需要遍历对象,而是直接监听对象:
const obj = {
arr: []
}
const handler = {
get(target, key, receiver){
console.log('get->', target[key])
if(typeof target[key] === 'object' && target[key] !== null) {
return new Proxy(target[key], handler)
}
return target[key]
},
set(target, key, value){
console.log('set->', key, value)
return Reflect.set(target, key, value)
}
}
const p = new Proxy(obj, handler)上面我们监听的是一个空的对象,我们直接添加属性看看:
p.name = 'Jack';这里注意,我们代理的是 obj,返回的是 p,所以要对 p 进行操作:
真好,set 触发了。
我们再看看获取 name:
真好,get 也触发了。
我们再看看数组:
都可以非常好的监听到 get 、set,太强大了
关于 Proxy 的更多用法和说明,请看 https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Proxy
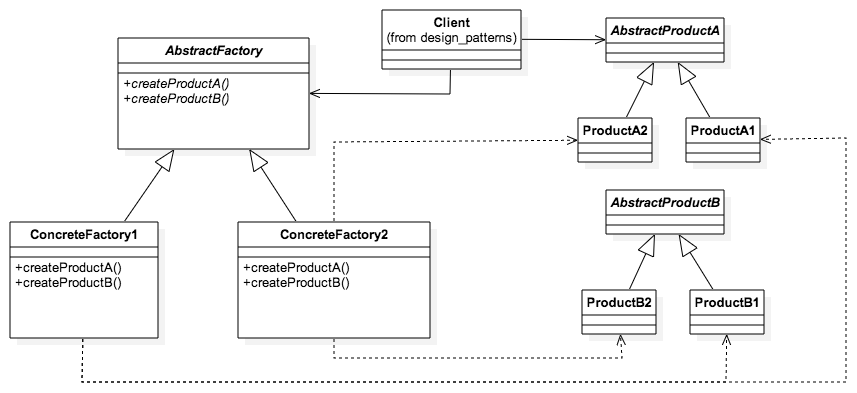
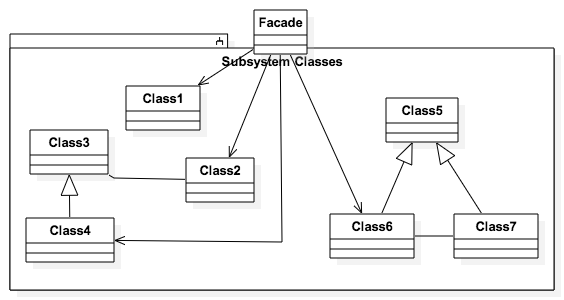
在这个项目中,我们介绍EcmaScript 6中的软件设计模式。
图像由StarUML从staruml-design-patterns项目中的.mdj文件生成。
'use strict';
class AbstractFactory {
constructor() {
}
createProductA (product) {
}
createProductB (product) {
}
}
class ConcreteFactory1 extends AbstractFactory {
constructor() {
super()
facade.log("ConcreteFactory1 class created");
}
createProductA (product) {
facade.log('ConcreteFactory1 createProductA')
return new ProductA1()
}
createProductB (product) {
facade.log('ConcreteFactory1 createProductB')
return new ProductB1()
}
}
class ConcreteFactory2 extends AbstractFactory {
constructor() {
super()
facade.log("ConcreteFactory2 class created");
}
createProductA (product) {
facade.log('ConcreteFactory2 createProductA')
return new ProductA2()
}
createProductB (product) {
facade.log('ConcreteFactory2 createProductB')
return new ProductB2()
}
}
class AbstractProductA {
constructor() {
}
}
class AbstractProductB {
constructor() {
}
}
class ProductA1 extends AbstractProductA {
constructor() {
super()
facade.log('ProductA1 created')
}
}
class ProductA2 extends AbstractProductA {
constructor() {
super()
facade.log('ProductA2 created')
}
}
class ProductB1 extends AbstractProductB {
constructor() {
super()
facade.log('ProductB1 created')
}
}
class ProductB2 extends AbstractProductB {
constructor() {
super()
facade.log('ProductB2 created')
}
}
function init_AbstractFactory() {
var factory1 = new ConcreteFactory1()
var productB1 = factory1.createProductB()
var factory2 = new ConcreteFactory2()
var productA2 = factory2.createProductA()
}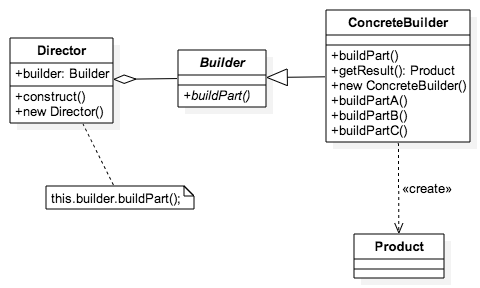

'use strict';
class Director {
constructor() {
this.structure = ['Maze','Wall','Door'];
facade.log("Director class created");
}
Construct (){
for(var all in this.structure){
let builder = new ConcreteBuilder()
builder.BuildPart(this.structure[all]);
builder.GetResult()
}
}
}
class Builder {
constructor() {
}
BuildPart (){
}
}
class ConcreteBuilder extends Builder {
constructor() {
super()
facade.log("ConcreteBuilder class created");
}
BuildPart (rawmaterial){
facade.log("ConcreteBuilder BuildPart()");
var material = rawmaterial
this.product = new Product(material)
}
GetResult (){
facade.log(JSON.stringify(this.product))
return this.product
}
}
class Product {
constructor(material) {
facade.log("Product class created");
this.data = material
}
}
function init_Builder() {
let director = new Director()
director.Construct()
}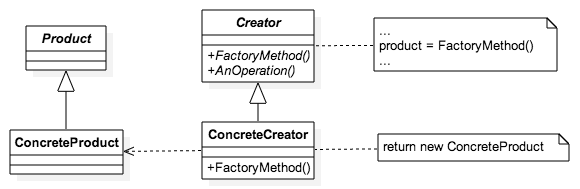
'use strict';
class Productt {
constructor() {
}
}
class ConcreteProduct extends Productt {
constructor() {
super()
facade.log('ConcreteProduct created')
}
}
class Creator {
constructor() {
}
FactoryMethod (){
}
AnOperation (){
facade.log("AnOperation()")
this.product = this.FactoryMethod()
facade.log(this.product instanceof ConcreteProduct)
}
}
class ConcreteCreator extends Creator {
constructor() {
super()
facade.log('ConcreteCreator created')
}
FactoryMethod (){
return new ConcreteProduct();
}
}
function init_FactoryMethod() {
var factory = new ConcreteCreator()
factory.AnOperation()
}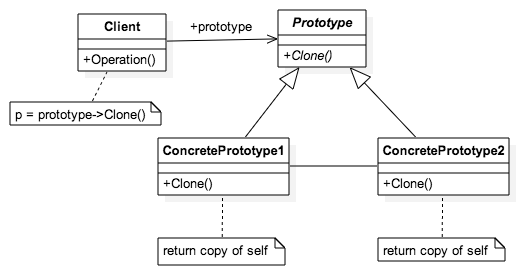
'use strict';
class Prototype {
constructor(prototype) {
}
Clone (){
}
}
class ConcretePrototype1 extends Prototype {
constructor() {
facade.log("ConcretePrototype1 created");
super()
this.feature = "feature 1"
}
setFeature(key, val) {
this[key] = val
}
Clone (){
facade.log('custom cloning function')
let clone = new ConcretePrototype1()
let keys = Object.keys(this)
keys.forEach(k => clone.setFeature(k, this[k]))
facade.log("ConcretePrototype1 cloned");
return clone;
}
}
class ConcretePrototype2 extends Prototype {
constructor() {
facade.log("ConcretePrototype2 created");
super()
}
Clone (){
facade.log("ConcretePrototype2 cloned");
return clone;
}
}
function init_Prototype () {
var proto1 = new ConcretePrototype1()
proto1.setFeature('feature', "feature 22")
var clone1 = proto1.Clone()
facade.log(clone1.feature)
}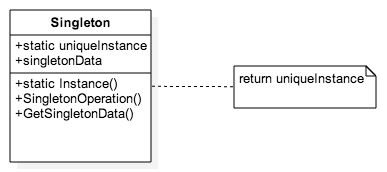
'use strict';
let _singleton = null
class Singleton {
constructor (data) {
if(!_singleton) {
this.data = data
_singleton = this
}
else
return _singleton
facade.log("Singleton class created")
}
SingletonOperation () {
facade.log('SingletonOperation')
}
GetSingletonData () {
return this.data
}
}
function init_Singleton() {
var singleton1 = new Singleton("data1")
var singleton2 = new Singleton("data2")
facade.log(singleton1.GetSingletonData())
facade.log(singleton2.GetSingletonData())
facade.log(singleton1 instanceof Singleton)
facade.log(singleton2 instanceof Singleton)
facade.log(singleton1 === singleton2)
}
'use strict';
class Target {
constructor(type) {
let result
switch(type) {
case 'adapter':
result = new Adapter()
break
default:
result = null
}
return result
}
Request() {
}
}
class Adaptee {
constructor() {
facade.log('Adaptee created')
}
SpecificRequest () {
facade.log('Adaptee request')
}
}
class Adapter extends Adaptee {
constructor() {
super()
facade.log('Adapter created')
}
Request (){
return this.SpecificRequest()
}
}
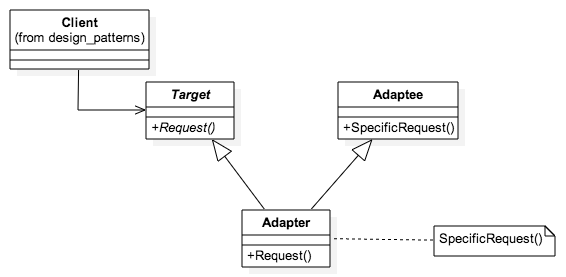
function init_Adapter() {
var f = new Target("adapter")
f.Request()
}
'use strict';
class Abstraction {
constructor() {
}
Operation (){
this.imp.OperationImp();
}
}
class RefinedAbstraction extends Abstraction {
constructor() {
super()
facade.log('RefinedAbstraction created')
}
setImp (imp) {
this.imp = imp
}
}
class Implementor {
constructor() {
}
OperationImp (){
}
}
class ConcreteImplementorA extends Implementor {
constructor() {
super()
facade.log('ConcreteImplementorA created')
}
OperationImp (){
facade.log('ConcreteImplementorA OperationImp')
}
}
class ConcreteImplementorB extends Implementor {
constructor() {
super()
facade.log('ConcreteImplementorB created')
}
OperationImp (){
facade.log('ConcreteImplementorB OperationImp')
}
}
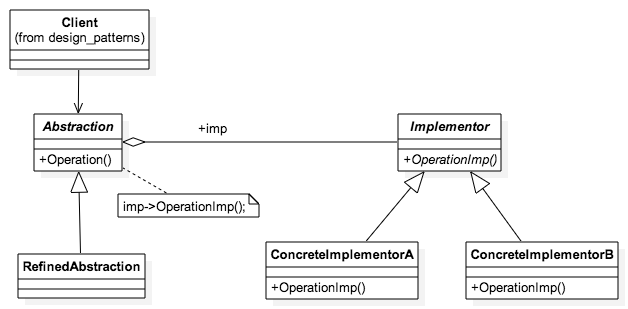
function init_Bridge() {
var abstraction = new RefinedAbstraction()
var state = Math.floor(Math.random()*2)
if(state)
abstraction.setImp(new ConcreteImplementorA())
else
abstraction.setImp(new ConcreteImplementorB())
abstraction.Operation()
}
'use strict';
class Component {
constructor() {
}
Operation (){
}
Add (Component){
}
Remove (Component){
}
GetChild (key){
}
}
class Leaf extends Component {
constructor(name) {
super()
this.name = name
facade.log('Leaf created')
}
Operation (){
facade.log(this.name)
}
}
class Composite extends Component {
constructor(name) {
super()
this.name = name
this.children = []
facade.log('Composite created')
}
Operation (){
facade.log('Composite Operation for: ' + this.name)
for(var i in this.children)
this.children[i].Operation()
}
Add (Component){
this.children.push(Component)
}
Remove (Component){
for(var i in this.children)
if(this.children[i] === Component)
this.children.splice(i, 1)
}
GetChild (key){
return this.children[key]
}
}
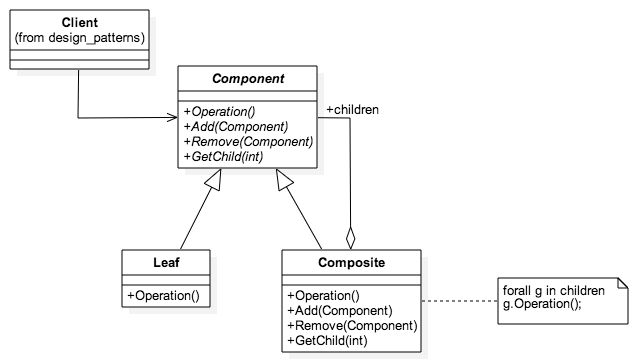
function init_Composite() {
var composite1 = new Composite('C1')
composite1.Add(new Leaf('L1'))
composite1.Add(new Leaf('L2'))
var composite2 = new Composite('C2')
composite2.Add(composite1)
composite1.GetChild(1).Operation()
composite2.Operation()
}
'use strict';
class Componentt {
constructor() {
}
Operation (){
}
}
class ConcreteComponent extends Componentt {
constructor() {
super()
facade.log('ConcreteComponent created')
}
Operation (){
facade.log('o o')
}
}
class Decorator extends Componentt {
constructor(component) {
super()
this.component = component
facade.log('Decorator created')
}
Operation (){
this.component.Operation()
}
}
class ConcreteDecoratorA extends Decorator {
constructor(component, sign) {
super(component)
this.addedState = sign
facade.log('ConcreteDecoratorA created')
}
Operation (){
super.Operation()
facade.log(this.addedState)
}
}
class ConcreteDecoratorB extends Decorator {
constructor(component, sign) {
super(component)
this.addedState = sign
facade.log('ConcreteDecoratorA created')
}
Operation (){
super.Operation()
facade.log(this.addedState + this.addedState + this.addedState + this.addedState + this.addedState)
}
AddedBehavior (){
this.Operation()
facade.log('|........|')
}
}
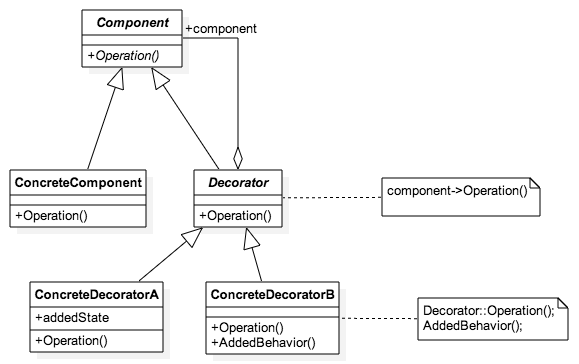
function init_Decorator() {
var component = new ConcreteComponent()
var decoratorA = new ConcreteDecoratorA(component, '!!!')
var decoratorB = new ConcreteDecoratorB(component, '.')
facade.log('component: ')
component.Operation()
facade.log('decoratorA: ')
decoratorA.Operation()
facade.log('decoratorB: ')
decoratorB.AddedBehavior()
}
'use strict';
class Facade {
constructor () {
this.log("Facade class created");
this.htmlid = null;
}
log (text) {
if(typeof this.htmlid === null){
console.log(text);
}
else{
$('#'+this.htmlid).append(text+'</br>');
}
}
erase () {
$("#"+this.htmlid).html('');
}
test_dp (dp) {
switch(dp){
case "Facade":
this.htmlid = "test_Facade"
this.erase()
this.log("This is the Facade")
break
case "AbstractFactory":
this.htmlid = "test_AbstractFactory"
this.erase()
init_AbstractFactory()
break
case "Builder":
this.htmlid = "test_Builder"
this.erase()
init_Builder()
break;
case "Factory":
this.htmlid = "test_Factory"
this.erase()
init_FactoryMethod()
break
case "Prototype":
this.htmlid = "test_Prototype"
this.erase()
init_Prototype()
break
case "Singleton":
this.htmlid = "test_Singleton"
this.erase()
init_Singleton()
break
case "Adapter":
this.htmlid = "test_Adapter"
this.erase()
init_Adapter()
break
case "Bridge":
this.htmlid = "test_Bridge"
this.erase()
init_Bridge()
break
case "Composite":
this.htmlid = "test_Composite"
this.erase()
init_Composite()
break
case "Decorator":
this.htmlid = "test_Decorator"
this.erase()
init_Decorator()
break
case "Flyweight":
this.htmlid = "test_Flyweight"
this.erase()
init_Flyweight()
break
case "Proxy":
this.htmlid = "test_Proxy"
this.erase()
init_Proxy()
break
case "ChainofResponsibility":
this.htmlid = "test_ChainofResponsibility"
this.erase()
init_ChainofResponsibility()
break
case "Command":
this.htmlid = "test_Command"
this.erase()
init_Command()
break
case "Interpreter":
this.htmlid = "test_Interpreter"
this.erase()
init_Interpreter()
break
case "Iterator":
this.htmlid = "test_Iterator"
this.erase()
init_Iterator()
break
case "Mediator":
this.htmlid = "test_Mediator"
this.erase()
init_Mediator()
break
case "Memento":
this.htmlid = "test_Memento"
this.erase()
init_Memento()
break
case "Observer":
this.htmlid = "test_Observer"
this.erase()
init_Observer()
break
case "State":
this.htmlid = "test_State"
this.erase()
init_State()
break
case "Strategy":
this.htmlid = "test_Strategy"
this.erase()
init_Strategy()
break
case "TemplateMethod":
this.htmlid = "test_TemplateMethod"
this.erase()
init_TemplateMethod()
break
case "Visitor":
this.htmlid = "test_Visitor";
this.erase();
init_Visitor()
break;
default:
console.log("nothing to test");
}
}
}
'use strict';
class FlyweightFactory {
constructor() {
this.flyweights = {};
facade.log('FlyweightFactory created')
}
GetFlyweight (key){
if(this.flyweights[key]){
return this.flyweights[key];
}
else{
this.flyweights[key] = new ConcreteFlyweight(key);
return this.flyweights[key];
}
}
CreateGibberish (keys) {
return new UnsharedConcreteFlyweight(keys, this)
}
}
class Flyweight {
constructor() {
}
Operation (extrinsicState){
}
}
class ConcreteFlyweight extends Flyweight {
constructor(key) {
super()
this.intrinsicState = key
facade.log('ConcreteFlyweight created')
}
Operation (extrinsicState){
return extrinsicState + this.intrinsicState
}
}
class UnsharedConcreteFlyweight extends Flyweight {
constructor(keys, flyweights) {
super()
this.flyweights = flyweights
this.keys = keys
facade.log('UnsharedConcreteFlyweight created')
}
Operation (extrinsicState){
var key, word = ''
for(var i = 0; i < extrinsicState; i++) {
//random key
key = this.keys[Math.floor(Math.random() * (this.keys.length))]
word = this.flyweights.GetFlyweight(key).Operation(word)
}
facade.log('UnsharedConcreteFlyweight Operation: ')
facade.log(word)
}
}
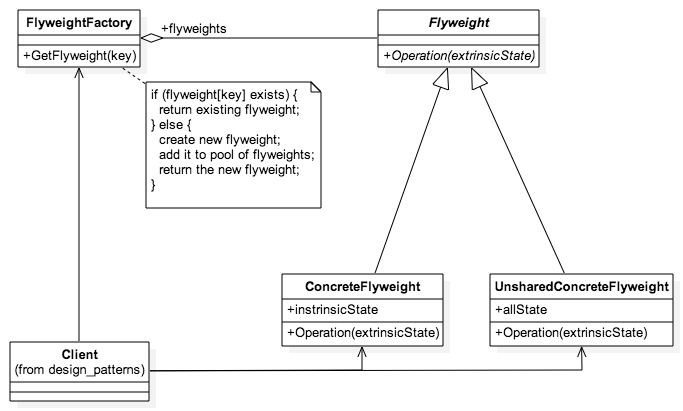
function init_Flyweight() {
var flyweights = new FlyweightFactory()
var gibberish = flyweights.CreateGibberish(['-', '+', '*'])
gibberish.Operation(5)
gibberish.Operation(10)
}
'use strict';
class Subject {
constructor() {
}
Request (){
}
}
class RealSubject extends Subject {
constructor() {
super()
facade.log('RealSubject created')
}
Request (){
facade.log('RealSubject handles request')
}
}
class Proxy extends Subject {
constructor() {
super()
facade.log('Proxy created')
}
Request (){
this.realSubject = new RealSubject();
this.realSubject.Request();
}
}
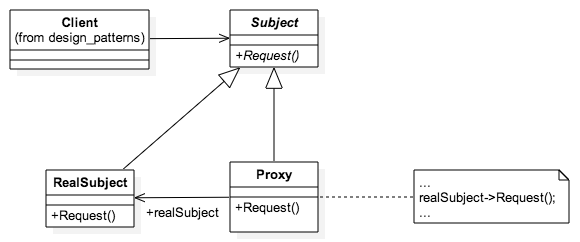
function init_Proxy() {
var proxy = new Proxy()
proxy.Request()
}
'use strict';
class Handler {
constructor() {
}
HandleRequest() {
}
}
class ConcreteHandler1 extends Handler {
constructor() {
super()
facade.log('ConcreteHandler1 created')
}
setSuccessor (successor) {
this.successor = successor
}
HandleRequest(request) {
if (request === 'run')
facade.log('ConcreteHandler1 has handled the request')
else {
facade.log('ConcreteHandler1 calls his successor')
this.successor.HandleRequest(request)
}
}
}
class ConcreteHandler2 extends Handler {
constructor() {
super()
facade.log('ConcreteHandler2 created')
}
HandleRequest(request) {
facade.log('ConcreteHandler2 has handled the request')
}
}
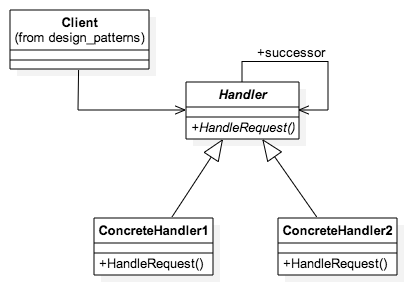
function init_ChainofResponsibility() {
let handle1 = new ConcreteHandler1()
let handle2 = new ConcreteHandler2()
handle1.setSuccessor(handle2)
handle1.HandleRequest('run')
handle1.HandleRequest('stay')
}
'use strict';
class Invoker {
constructor() {
facade.log('Invoker created')
}
StoreCommand(command) {
this.command = command
}
}
class Command {
constructor() {
}
Execute() {
}
}
class ConcreteCommand extends Command {
constructor(receiver, state) {
super()
this.receiver = receiver
facade.log('ConcreteCommand created')
}
Execute() {
facade.log('ConcreteCommand Execute')
this.receiver.Action();
}
}
class Receiver {
constructor() {
facade.log('Receiver created')
}
Action() {
facade.log('Receiver Action')
}
}
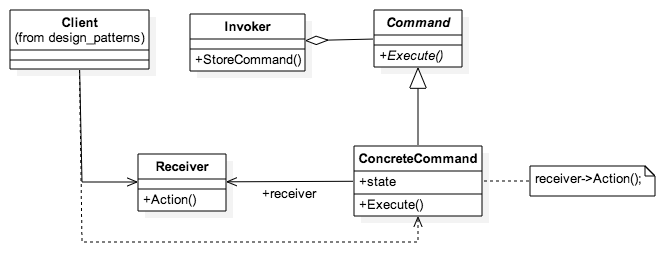
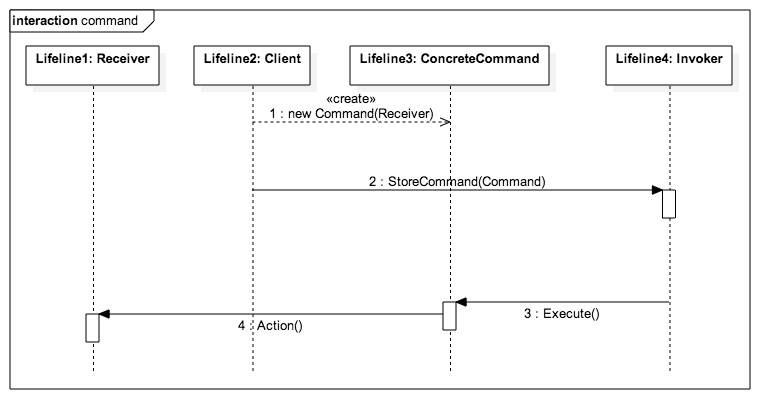
function init_Command() {
var invoker = new Invoker()
var receiver = new Receiver()
var command = new ConcreteCommand(receiver)
invoker.StoreCommand(command)
invoker.command.Execute()
}
'use strict';
class Context {
constructor(input) {
this.input = input
this.index = 0
this.output = null
}
Lookup(expr) {
//return this.
}
}
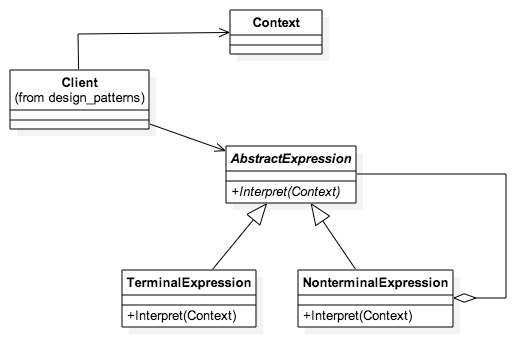
class AbstractExpression {
constructor() {
}
Interpret (context){
}
}
class TerminalExpression extends AbstractExpression {
constructor(name) {
super()
this.name = name
facade.log('TerminalExpression created')
}
Interpret (context){
}
}
class NonterminalExpression extends AbstractExpression {
constructor() {
super()
this.name = '+'
facade.log('NonterminalExpression created')
}
Interpret (context){
return terminal1.Interpret() + terminal2
}
}
function init_Interpreter() {
//var context = new Context('A+B+A')
facade.log('Not implemented')
}
'use strict';
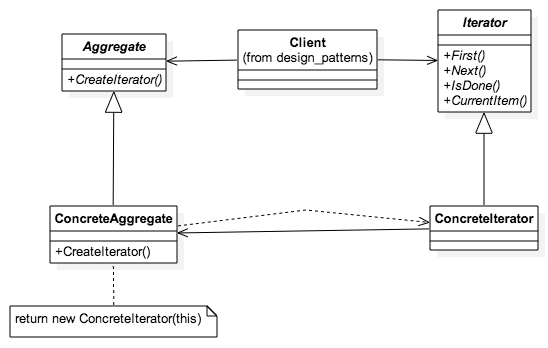
class Iterator {
constructor() {
}
First (){
}
Next (){
}
IsDone (){
}
CurrentItem (){
}
}
class ConcreteIterator extends Iterator {
constructor(aggregate) {
super()
facade.log('ConcreteIterator created')
this.index = 0
this.aggregate = aggregate
}
First (){
return this.aggregate.list[0]
}
Next (){
this.index += 2
return this.aggregate.list[this.index]
}
CurrentItem (){
return this.aggregate.list[this.index]
}
}
class Aggregate {
constructor() {
}
CreateIterator (){
}
}
class ConcreteAggregate extends Aggregate {
constructor(list) {
super()
this.list = list
facade.log('ConcreteAggregate created')
}
CreateIterator (){
this.iterator = new ConcreteIterator(this);
}
}
function init_Iterator() {
var aggregate = new ConcreteAggregate([0,1,2,3,4,5,6,7])
aggregate.CreateIterator()
facade.log(aggregate.iterator.First())
facade.log(aggregate.iterator.Next())
facade.log(aggregate.iterator.CurrentItem())
}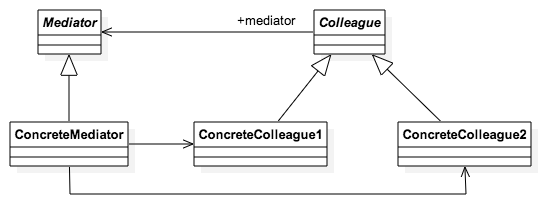
'use strict';
class Mediator {
constructor() {
}
ColleagueChanged(colleague) {
}
}
class ConcreteMediator extends Mediator {
constructor() {
super()
facade.log('ConcreteMediator created')
this.colleague1 = new ConcreteColleague1(this)
this.colleague2 = new ConcreteColleague2(this)
}
ColleagueChanged(colleague) {
switch(colleague) {
case this.colleague1:
facade.log('ConcreteColleague1 has Changed -> change ConcreteColleague2.feature: ')
this.colleague2.setFeature('new feature 2')
break
case this.colleague2:
facade.log('ConcreteColleague2 has Changed, but do nothing')
break
default:
facade.log('Do nothing')
}
}
}
class Colleague {
constructor() {
}
Changed() {
this.mediator.ColleagueChanged(this)
}
}
class ConcreteColleague1 extends Colleague {
constructor(mediator) {
super()
facade.log('ConcreteColleague1 created')
this.mediator = mediator
this.feature = "feature 1"
}
setFeature(feature) {
facade.log('ConcreteColleague1 Feature has changed from ' + this.feature + ' to ' + feature)
this.feature = feature
this.Changed()
}
}
class ConcreteColleague2 extends Colleague {
constructor(mediator) {
super()
facade.log('ConcreteColleague2 created')
this.mediator = mediator
this.feature = "feature 2"
}
setFeature(feature) {
facade.log('ConcreteColleague2 Feature has changed from ' + this.feature + ' to ' + feature)
this.feature = feature
this.Changed()
}
}
function init_Mediator() {
var mediator = new ConcreteMediator()
mediator.colleague1.setFeature("new feature 1")
}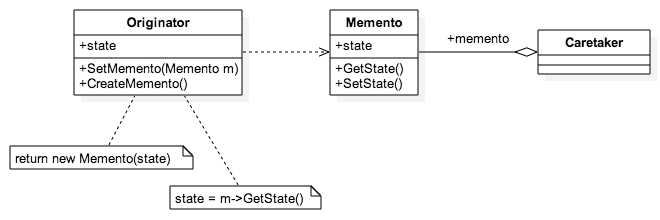
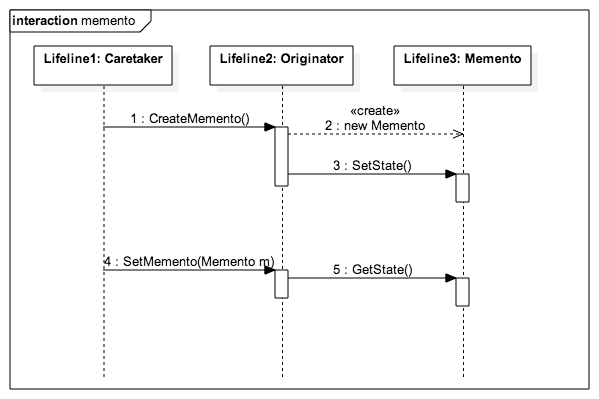
'use strict';
class Originator {
constructor() {
facade.log('Originator created')
this.state = 'a';
facade.log('State= ' + this.state)
}
SetMemento (Memento){
this.state = Memento.GetState()
facade.log('State= ' + this.state)
}
CreateMemento (state){
return new Memento(state);
}
}
class Memento {
constructor(state) {
this.state = state
facade.log('Memento created. State= ' + this.state)
}
GetState (){
return this.state;
}
SetState (state){
this.state = state;
}
}
class Caretaker {
constructor() {
facade.log('Caretaker created')
this.mementos = []
}
AddMemento(memento) {
facade.log('Caretaker AddMemento')
this.mementos.push(memento)
}
SetMemento() {
return this.mementos[this.mementos.length-1]
}
}
function init_Memento() {
let caretaker = new Caretaker()
let originator = new Originator()
caretaker.AddMemento(originator.CreateMemento('b'))
originator.SetMemento(caretaker.SetMemento())
facade.log(originator.state)
}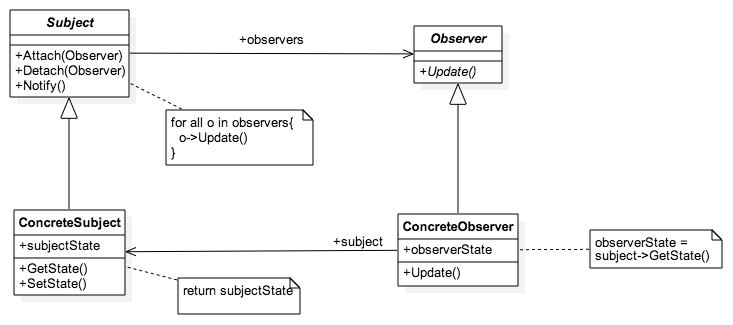
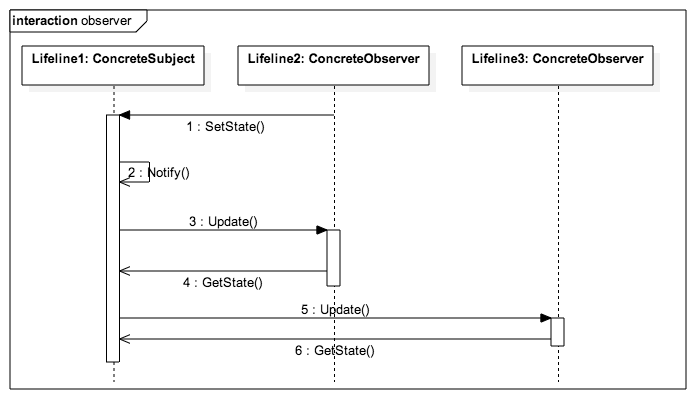
'use strict';
class Subjectt {
constructor() {
}
Attach (Observer){
this.observers.push(Observer);
facade.log('Observer attached')
}
Dettach (Observer){
for(var i in this.observers)
if(this.observers[i] === Observer)
this.observers.splice(i, 1)
}
Notify (){
facade.log('Subject Notify')
for(var i in this.observers){
this.observers[i].Update(this);
}
}
}
class ConcreteSubject extends Subjectt {
constructor() {
super()
this.subjectState = null
this.observers = []
facade.log('ConcreteSubject created')
}
GetState() {
return this.subjectState;
}
SetState(state) {
this.subjectState = state;
this.Notify()
}
}
class Observer {
constructor() {
}
Update (){
}
}
class ConcreteObserver extends Observer {
constructor() {
super()
this.observerState = '';
facade.log('ConcreteObserver created')
}
Update (Subject){
this.observerState = Subject.GetState();
facade.log('Observer new state: ' + this.observerState)
}
}
function init_Observer() {
var observer1 = new ConcreteObserver()
var observer2 = new ConcreteObserver()
var subject = new ConcreteSubject()
subject.Attach(observer1)
subject.Attach(observer2)
subject.SetState('state 1')
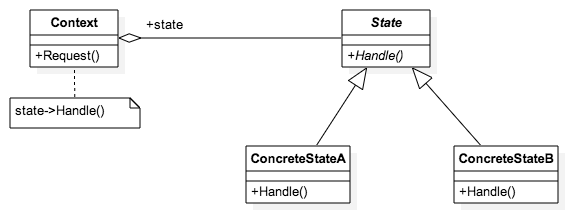
}
'use strict';
class Contextt {
constructor(state) {
switch(state) {
case "A":
this.state = new ConcreteStateA()
break
case "B":
this.state = new ConcreteStateB()
break
default:
this.state = new ConcreteStateA()
}
}
Request (){
this.state.Handle(this);
}
}
class State {
constructor() {
}
Handle (){
}
}
class ConcreteStateA extends State {
constructor() {
super()
facade.log('ConcreteStateA created')
}
Handle (context){
facade.log('ConcreteStateA handle')
}
}
class ConcreteStateB extends State {
constructor() {
super()
facade.log('ConcreteStateB created')
}
Handle (context){
facade.log('ConcreteStateB handle')
}
}
function init_State() {
let context = new Contextt("A")
context.Request()
}
'use strict';
class Contexttt {
constructor(type){
switch(type) {
case "A":
this.strategy = new ConcreteStrategyA()
break
case "B":
this.strategy = new ConcreteStrategyB()
break
default:
this.strategy = new ConcreteStrategyA()
}
}
ContextInterface (){
this.strategy.AlgorithmInterface()
}
}
class Strategy {
constructor() {
}
AlgorithmInterface (){
}
}
class ConcreteStrategyA extends Strategy{
constructor() {
super()
facade.log('ConcreteStrategyA created')
}
AlgorithmInterface (){
facade.log('ConcreteStrategyA algorithm')
}
}
class ConcreteStrategyB extends Strategy{
constructor() {
super()
facade.log('ConcreteStrategyB created')
}
AlgorithmInterface (){
facade.log('ConcreteStrategyB algorithm')
}
}
function init_Strategy() {
let contextA = new Contexttt("A")
contextA.ContextInterface()
let contextB = new Contexttt("B")
contextB.ContextInterface()
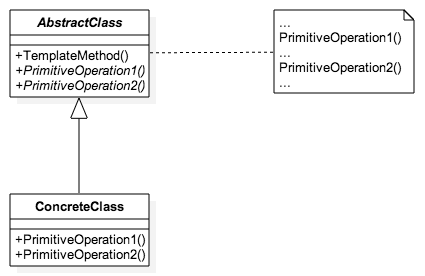
}
'use strict';
class AbstractClass {
constructor() {
}
TemplateMethod (){
this.PrimitiveOperation1();
this.PrimitiveOperation2();
}
PrimitiveOperation1 (){
}
PrimitiveOperation2 (){
}
}
class ConcreteClass extends AbstractClass {
constructor() {
super()
facade.log("ConcreteClass created")
}
PrimitiveOperation1 (){
facade.log('ConcreteClass PrimitiveOperation1')
}
PrimitiveOperation2 (){
facade.log('ConcreteClass PrimitiveOperation2')
}
}
function init_TemplateMethod() {
let class1 = new ConcreteClass()
class1.TemplateMethod()
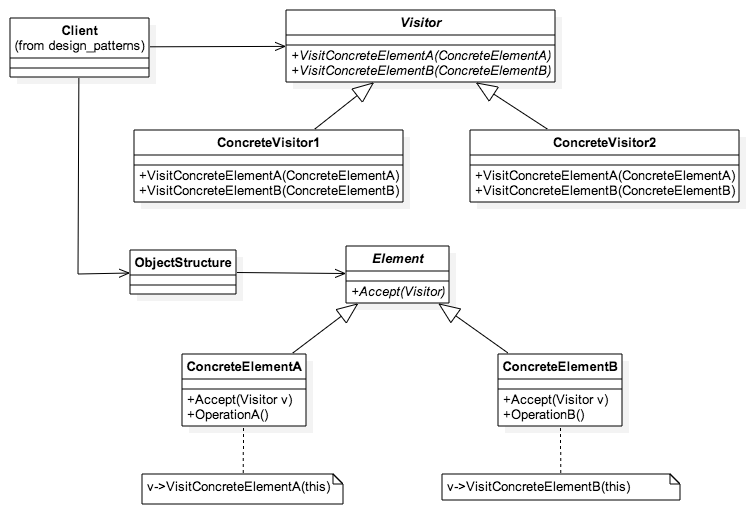
} 
'use strict';
class Visitor {
constructor() {
}
VisitConcreteElementA (ConcreteElementA){
}
VisitConcreteElementB (ConcreteElementB){
}
}
class ConcreteVisitor1 extends Visitor {
constructor() {
super()
facade.log("ConcreteVisitor1 created");
}
VisitConcreteElementA (ConcreteElementA){
facade.log("ConcreteVisitor1 visited ConcreteElementA");
}
VisitConcreteElementB (ConcreteElementB){
facade.log("ConcreteVisitor1 visited ConcreteElementB");
}
}
class ConcreteVisitor2 extends Visitor {
constructor() {
super()
facade.log("ConcreteVisitor2 created");
}
VisitConcreteElementA (ConcreteElementA){
facade.log("ConcreteVisitor2 visited ConcreteElementA");
}
VisitConcreteElementB (ConcreteElementB){
facade.log("ConcreteVisitor2 visited ConcreteElementB");
}
}
class ObjectStructure {
constructor() {
facade.log("ObjectStructure created");
}
}
class Element {
constructor() {
}
Accept (visitor){
}
}
class ConcreteElementA extends Element {
constructor() {
super()
facade.log("ConcreteElementA created");
}
Accept (visitor){
visitor.VisitConcreteElementA(this);
}
OperationA (){
facade.log("ConcreteElementA OperationA");
}
}
class ConcreteElementB extends Element {
constructor() {
super()
facade.log("ConcreteElementB created");
}
Accept (visitor){
visitor.VisitConcreteElementB(this);
}
OperationB (){
facade.log("ConcreteElementB OperationB");
}
}
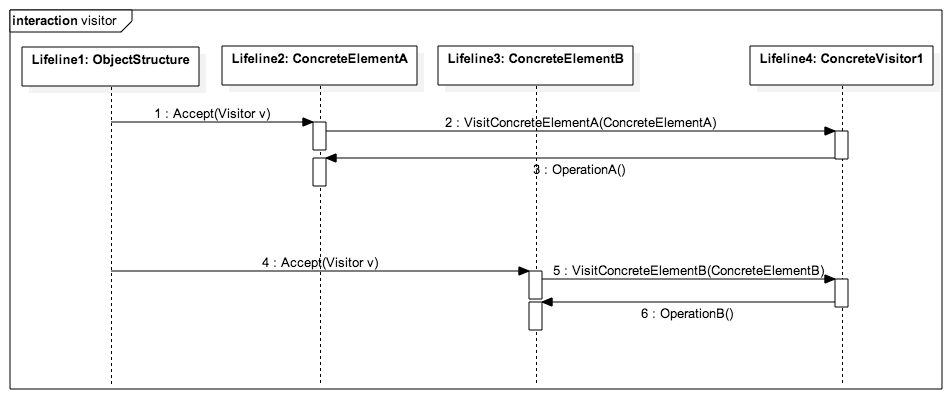
function init_Visitor() {
let visitor1 = new ConcreteVisitor1();
let visitor2 = new ConcreteVisitor2();
let elementA = new ConcreteElementA();
let elementB = new ConcreteElementB();
elementA.Accept(visitor1);
elementB.Accept(visitor2);
}原文在我的 Github 中,欢迎订阅。
前几篇文章
之所以把数据查询单拉一个文章,是因为查询牵扯的知识点比较多,可以说在增删改查里,查的复杂度也是最高的。
之前已经了解一点像WHERE id=2 这种非常简单的条件语句。
单表查询非常简单,但开发中更多的是多表查询,那我们以多表查询来说道说道。
我们在处理数据时通过某个字段来查另一个跟它有关的信息,除了在数据库中经常这样操作,在前端也有类似情况。
先看一段前端经常遇到的数据:
{
province:'江苏省',
citys:[
'南京市',
'苏州市',
'无锡市'
]
}上面是把省市都揉到一起了,只嵌套了两层,但如果嵌套个四五层,就像这样:
{
province:'江苏省',
children:[
{
name:'城市1',
children:[
name:'江宁区',
children:[
name:'XX小区'
]
]
},
{
name:'城市2',
children:[
name:'AA区',
children:[
name:'BB小区'
]
]
}
]
}这种数据解析起来会疯。
我们一直说数据扁平化,来 我们扁平一把:
// 省
const provice = [
{
province:'江苏省',
province_id: 1001
},
{
province:'浙江省',
province_id: 1002
},
...
]
// 市
const citys = [
{
name:'南京市',
province_id: 1001
},
{
name:'苏州市',
province_id: 1001
},
{
name:'杭州市',
province_id: 1002
},
{
name:'嘉兴市',
province_id: 1002
},
...
]
//找到江苏省下所有的城市
const result = citys.filter(i => i.province_id === 1001);数据扁平化的好处就是,当不需要找城市的时候,citys 数据跟我无关,只需关心 province 就可以了,而且在查找性能上更快(有时候能免了递归)。
上面的例子引出下面这句话:在数据库中,通过某些字段将表与表关联起来,这就是关系型数据库的核心。
在图中可以看到 student 表里有 class_id,这样 学生 和 班级 通过 class_id就有了关联,在开发中,我们可以通过它来查找class信息。
我们通过上面几个表来查询几个需求:
马的老师的个数马上来老师课的学生姓名我们一个一个来并分析。
SELECT t1.student_name, t2.number FROM
student t1 LEFT JOIN score t2 ON t1.id=t2.student_id
WHERE t2.number>60;先看结果:
得到了正确数据。
分析语句:
t1和t2分别是 student 和 score 的别名。
细心的同学能看出,我把上面的 sql 语句用三行来显示,这是有寓意的哟:
WHERE条件语句也就是说,它依然是符合通用语法:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]只不过第二行生成了一个临时表。
这里牵扯到了 JOIN ON 语法,我会在后面的章节中专门细说,这里推荐几篇相关文章:
SELECT COUNT(id) AS teacher_num FROM teacher WHERE teacher_name LIKE '马%';解析:
%使用,模糊搜索,如果不用%相当于精确搜索。*这个查询比较复杂,我们先上 sql :
SELECT
t1.student_name,
IFNULL(t2.course_num,0) AS course_num,
IFNULL(t2.sum_number,0) AS sum_number FROM
student t1
LEFT JOIN
(SELECT student_id,count(id) course_num, SUM(number) AS sum_number FROM score GROUP BY student_id) t2
ON t1.id=t2.student_id;再看下结果:
先!不!要!慌! 我们一点一点来解析。
现在你脑海里应该先浮现出通用查询语句:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]而图中的查询语句翻译过来就是:
SELECT 学生名, 选课数量, 成绩总和 FROM 表;然后我们来拆分上图中的查询:
先看 SELECT student_id,count(id) course_num, SUM(number) AS sum_number FROM score GROUP BY student_id,我们单独来执行这句看看结果:
这条语句为我们生成了一个表,它显示了 学生id、选课数、总成绩,所以这张表示核心,但需求是让我们展示所有的学生,所以我们必须依赖student查。
如果把上图中查出来的结果 命名为t2,就会变成:
SELECT
t1.student_name, IFNULL(t2.course_num,0) AS course_num, IFNULL(t2.sum_number,0) AS sum_number
FROM student t1 LEFT JOIN t2
ON t1.id=t2.student_id;再去掉些“多余”的部分:
SELECT
t1.student_name, t2.course_num, t2.sum_number
FROM student t1 LEFT JOIN t2
ON t1.id=t2.student_id;哈哈,是不是一下就看懂了呢?
这里再介绍下语句里没见过的东东:
关于GROUP BY有几篇文章可以看看:
下面是几个表的建表语句:
-- 班级表
CREATE TABLE class(
id INT UNSIGNED PRIMARY KEY auto_increment,
caption VARCHAR(30) COMMENT '班级名'
);
-- 学生表
CREATE TABLE student(
id INT UNSIGNED PRIMARY KEY auto_increment,
student_name CHAR(30) COMMENT '学生名',
gender CHAR(30) DEFAULT NULL COMMENT '学生性别',
class_id INT DEFAULT NULL COMMENT '班级id'
);
-- 老师表
CREATE TABLE teacher(
id INT UNSIGNED PRIMARY KEY auto_increment,
teacher_name CHAR(30) COMMENT '教师名'
);
-- 课程表
CREATE TABLE course(
id INT UNSIGNED PRIMARY KEY auto_increment,
course_name CHAR(30) COMMENT '课程名',
teacher_id INT DEFAULT NULL COMMENT'教师id'
);
-- 成绩表
CREATE TABLE score(
id INT UNSIGNED PRIMARY KEY auto_increment,
number INT DEFAULT NULL COMMENT '分数',
student_id INT DEFAULT NULL COMMENT '学生id',
course_id INT DEFAULT NULL COMMENT '课程id'
);
这篇文章主要了解查询,然而这也只是一个练习而已,实际开发中比这难的查询有很多,需要自己平常没事多练习。
今天工作比价忙,文章写的可能有点糙,如果有哪里不正确的地方欢迎指正。
我们团队正在做一个XX系统,技术栈是React,目前该系统日渐庞大,开发及维护成本加大,且每次必须把整个项目一起打包,费时费力。经考虑后决定将其拆分成多个项目,由它们组合成一个完整系统,微前端架构是非常好的选择。
微前端差不多有以下几个好处:
商品模块单拉出来形成一个项目,它可以由一个小组单独维护,实现良好解耦对我们来说最大的好处是单项目维护。
我们将整个微前端分为两个部分:
注意看地址栏变化,其中包含 /app1/xxx和/app2/xxx,乍一看这是一个项目中两个页面的切换,实际上是来自两个独立的项目,app1 和 app2 来自不同的 git 仓库。
整个流程大概为:用户访问 index.html, 此时运行模块加载器Js,加载器会根据整个系统的配置文件(project.config) 去注册各个项目,系统会先加载主项目(Main),然后会根据路由前缀动态加载对应的子项目
我们这个架构也参考了网上很多好的文章,其中核心文章可参考 https://alili.tech/archive/11052bf4/
大概如下
[
{
isBase: false,
name: 'app1',
version: '1.0.0',
//通过该路由前缀匹配加载当前入口文件
hashPrefix: '/app1',
//入口文件
entry: 'http://www.xxxx.com/app1/dist/singleSpaEntry.js',
//顶级Store
store: 'http://www.xxxx.com/main/dist/store.js'
}
......
]我们找了些实现微前端的仓库,对比后决定使用single-spa。
我们技术栈是 react,在子项目入口中需要使用 single-spa-react 来构建,关键代码如下:
import singleSpaReact from 'single-spa-react';
const reactLifecycles = singleSpaReact({
React,
ReactDOM,
rootComponent: Root,
domElementGetter
});
export function bootstrap(props) {
return reactLifecycles.bootstrap(props);
}
export function mount(props) {
return reactLifecycles.mount(props);
}
export function unmount(props) {
return reactLifecycles.unmount(props);
}如果你使用 vue,可以使用 single-spa-vue
然后在系统入口文件中,把所有的项目注册进来:
import * as singleSpa from 'single-spa';
singleSpa.registerApplication(
'app1',
() => SystemJS.import('app1-entry.js'),
() => location.hash.startsWith(`#/app1`),
props
);具体可参考 single-spa 官网 https://single-spa.js.org 这里有很多例子
我们使用的 lerna 统一管理所有项目的依赖包,所有依赖包的版本统一,这样非常方便维护。
使用 webpack 的 dll 功能,将所有项目的公用依赖包抽离,比如 react、react-dom、react-router、mobx等
为了方便项目动态加载,我们也参考网上大佬的想法,使用了systemjs,只不过我们使用的是 0.20.19 版本,配合 systemjs ,在 Webpack 中需要改一下 libraryTarget:
output: {
publicPath: 'http://www.xxxxx.com/',
filename: '[name].js',
chunkFilename: '[name].[chunkhash:8].js',
path: path.resolve(__dirname, 'release'),
libraryTarget: 'amd', //注意 这里使用 amd 的规范
library: 'app1'
},我们没有使用 umd 规范,也没有使用 systemjs 里的 Import Maps
功能,而是直接通过 project.config 来动态加载模块入口。
关于这个也看了一些大佬的方案,大概就是所有的项目里有个 store,在注册入口时将所有 store 放进队列,需要更新 store 里的状态时,调用 dispatch 将所有 store 同步。
我的做法和传统单页应用一样,一个系统应该只有一个顶级 Store,由于顶级 Store 里存的一般是整个系统的公用状态 比如菜单、用户信息等,我把它放在 Main项目里,但打包时这个Store是单独抽离的:
entry: {
singleSpaEntry: './src/singleSpaEntry.js',
store: './src/store' //单独一个入口
},在注册时,将这个 Store 传入每个项目中:
//顶级Store
const mainStore = await SystemJS.import(storeURL);
singleSpa.registerApplication(
'app1',
() => SystemJS.import('http://www.x.com/app1/entry.js'),
hashPrefix('/app1'),
{ mainStore }
);
singleSpa.registerApplication(
'app2',
() => SystemJS.import('http://www.x.com/app2/entry.js'),
hashPrefix('/app1'),
{ mainStore }
);这样就可以达到只管理这一个 Store 就可以,非常方便。
注意:我使用的是 Mobx 作为状态管理
我们部署的方式非常简单,我自己写了一个 webpack 插件用于把打包后的 dist 传到 OSS 然后将项目信息传给服务端,服务端根据我传入的项目信息组织成 project.config,然后用户在访问 index.html 时会获取 project.config,此时 single-spa 根据配置注册所有项目,然后根据路由来拉取对应的项目入口文件js文件。
我们的需求是 Main 作为整个项目的 Layout,其中子项目的挂载 Dom 也在 Main项目里,这就必须等到 Main 项目完全渲染完成后,才能挂载子项目。我参考了网上有些微前端的实现,把 domElementGetter 方法借鉴了过来:
function domElementGetter() {
let el = document.getElementById('sub-module-wrap');
if (!el) {
el = document.createElement('div');
el.id = 'sub-module-wrap';
}
let timer = null;
timer = setInterval(() => {
if (document.querySelector('#content-wrap')) {
document.querySelector('#content-wrap').appendChild(el);
clearInterval(timer);
}
}, 100);
return el;
}demo地址:https://github.com/Vibing/micro-frontend
这是我们第一次玩微前端,可能有很多地方不完美,还望各位大佬多多包涵
忽略 docker 安装
从 docker hub 仓库拉取最新的 nginx 镜像:docker pull nginx:latest
下载完成后通过 docker images查看本地镜像:
docker run -d -p 8080:80 --name mynginx nginx
-d:后台运行,不要阻塞shell指令创建窗口
-p:指定内外端口映射,-p 8080:80 宿主机为8080 容器为80
--name: 为当前启动的容器命名
通过 docker ps 查看当前启动的容器:
现在在浏览器打开:127.0.0.1:8080,可以看到 nginx 的访问页面:
我们进入 nginx 容器内部,修改刚才访问的页面试试。
通过docker exec -i -t mynginx bash 在容器 mynginx 中开启一个交互模式的终端:
nginx 的默认页面在 /usr/share/nginx/html/ 文件夹内:
我们看一下 index.html:
然后通过echo hello nginx > index.html修改 index.html 里的内容:
修改完成后,再次访问127.0.0.1:8080:
完美
Docker这两年非常火热,也是各大厂必用的好东西,这两天没事玩了一下感觉很不错,学起来也不难 写下此文共勉学习。
Docker 可理解为跑在宿主机上的非常精简、小巧、高度浓缩的虚拟机。 它可以将容器里的进程安稳的在宿主机上运行。
Docker重要的三个概念必须要知道:
为了好理解 我们从 Docker的 Logo 入手:

图片是一条鲸鱼游在海里 身上载着N个集装箱,下面是Docker字样。OK 图片描述完毕
图片给出的信息:
之所以用鲸鱼,可能是它在海里没什么天敌 体型又巨大而且游泳速度很快,毕竟Docker使用GO语言写的呢。
上文中只说了Container,而Image与Container的关系 就像类与实例的关系:
var p1 = new Person(); 即:p1是容器、Person是镜像。 至于仓库嘛 就相当于github的代码仓库,github是存代码的仓库,相应的 Docker 仓库就是存放镜像的。
只有理解上面的镜像(Image)、容器(Container)、仓库(Repository)才能破解下面的图:

上图分了三个块:
从左往右看,Client 中执行了几个命令,这些命令都与 Docker daemon(Docker的守护进程) 有交互,然后 Docker daemon 会根据相应命令做对应的动作。
Docker分社区版(Community Edition,缩写为 CE)和企业版(Enterprise Edition,缩写为 EE)
社区版是免费的,所以我们用CE版就可以了。
Docker CE具体安装参考官网文档:CentOS、MacOS、Windows
下载完成后 打开终端运行:docker run hello-world 成功运行则表示安装成功了。
下篇文章《使用Docker部署NodeJs应用》会说Docker常用的命令及使用Docker部署NodeJs
代码并让它运行起来,敬请期待
要想使用 nest 开发,你必须了解 module ,否则无法下手,也搞不懂模块间的引用逻辑。
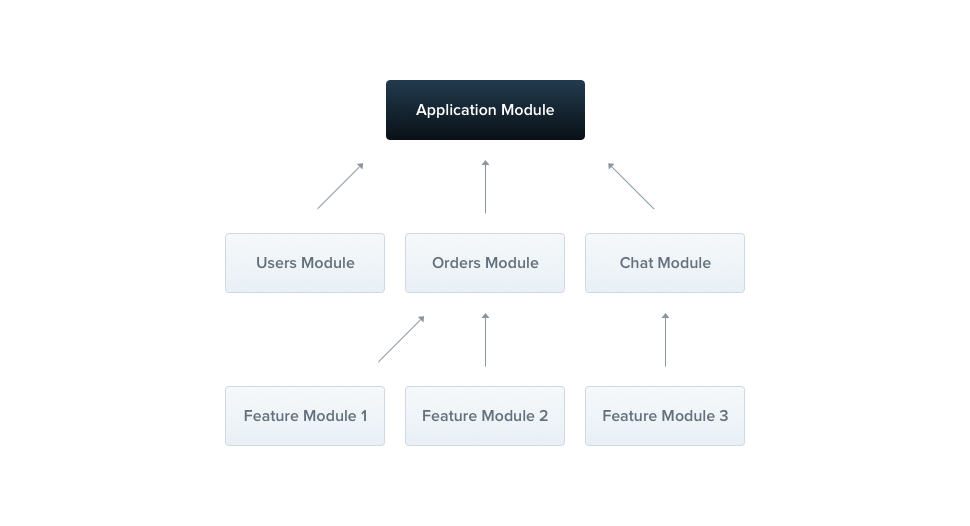
如果你不懂 nest 里的模块,可以这样理解:它类似组件化概念里的组件,比如在写 React 时,我们有一个根组件,一个 React 应用由多个组件构成的; 在 nest 应用中,也有一个根模块( app.module, 即上图中的 Application Module ),整个 nest 应用由多个模块和一个根模块构成;
来看一个模块:
import { Module } from '@nestjs/common';
import { CatsController } from './cats.controller';
import { CatsService } from './cats.service';
@Module({
imports: [],
controllers: [CatsController],
providers: [CatsService],
exports: []
})
export class CatsModule {}仔细看,当一个类被 @module 装饰时,那么这个类就是一个模块类。@module 参数中有 imports、controllers、providers、exports 四个参数,这几个参数的内容,就是该模块的所有。比如 CatsController 和 CatsService 属于同一个应用程序域,那么就应该把它们都归属到一个模块下。
总结一下,一个完整的 Module 由 imports, controllers, providers, exports 构成,模块可以引入其他模块,从而使用跟多功能,也可以导出当前模块的提供者,为其他模块提供服务
react hooks 的使用需要在 function component 组件中,本文讲述在使用 react hooks 中你需要注意的一些事情
可能导致:函数的每次执行,其内部定义的变量和方法都会重新创建,也就是说会从新给它们分配内存,这会导致性能受到影响
看下面这个例子:
import React, { useState, ReactElement } from 'react'
import { Button } from 'antd'
let num = 0; // 用于记录当前组件执行次数
export default (): ReactElement => {
console.log('render num: ', ++num) // 打印执行次数
let [count, setCount] = useState(0)
const handleClick = () => {
setCount(++count)
}
return (
<>
<p>count: {count}</p>
<Button type="primary" onClick={handleClick}>
Button
</Button>
</>
)
}初始化时执行了一次:
现在我点三次按钮,让 count 状态改变:
可见,每改变一次 count, 该组件对应的整个 function 会重新执行,其内部变量和方法会重新创建,从而影响性能。
解决方法:
使用方法:
const handleClick = useCallback(()=>{
// 业务代码
},[ count ])useCallback 的作用:组件初始化时,将第一个参数函数“缓存”起来,只有在第二个参数(数组中的值)有变化时,被包裹的函数才会重新被创建,否则不会重新创建。
总结:变量尽量放在组件外部定义,函数使用 useCallback 包裹起来,避免组件 render 时重复创建。
再看个例子,我们把上面例子作为父组件,在里面添加一个子组件.
父组件:
export default (): ReactElement => {
let [count, setCount] = useState(0)
const handleClick = useCallback(() => {
setCount(++count)
}, [count])
return (
<>
<p>count: {count}</p>
{/* 这里添加一个子组件 */}
<ChildrenComponent />
<Button type="primary" onClick={handleClick}>
Button
</Button>
</>
)
}子组件代码:
export default (): ReactElement => {
console.log('children render')
return <div>children component</div>
}现在我再点三次按钮,让父组件 render 三次:
大爷的,子组件打印三次,表示执行了三次。
这肯定不是我想要的,我想要的是子组件需要被渲染的时候再去执行,那么如何解决?
答:使用 React.memo。
React.memo 类似 class 组件里的 PureComponent , 能帮助我们控制合适重新渲染组件。
注意:说它类似,但不完全一样,它更像是 PureComponent + shouldComponentUpdate 的结合。
PureComponent 通过 props 和 state 的浅比较来判断要不要重新渲染组件。
那么在 react hooks 里如何去写呢
我们把子组件加上 React.memo :
export default React.memo(
(): ReactElement => {
console.log('children render')
return <div>children component</div>
},
)现在再点三次按钮:
可见,子组件不再打印,也就是不再执行了。
React.memo 也提供了 shouldComponentUpdate 功能,用于自定义比较来决定是否渲染:
React.memo(MyComponent, (prevProps, nextProps)=>{
// 如果传递 nextProps 渲染会返回与传递 prevProps 渲染相同的结果,则返回 true,否则返回 false.
// return true:不渲染 return false:渲染
})如果有更好的建议,请留言,多谢
本人想学数据库了,于是有了这个Mysql系列。
本系列主要用于本人学习Mysql的记录,我把它当做学习笔记。
没有从安装数据库及用户新增和权限分配等知识开始,而是侧重于Mysql表操作、数据增删改查及其他相关知识。
为学习方便,以下将以student(学生表)、class(班级表)、lesson(课程表) 为导向进行学习。
另外,本人所用可视化工具是Navicat Premium
还有一点:该篇文章用到一些简单的数据类型字段,如:INT、TINYINT、VARCHAR 只需知道它是数字类型和字符串类型。
关于数据类型请阅读《数据类型》。
建表通用语句:
CREATE TABLE table_name (column_name column_type);翻译过来就是:CREATE TABLE 表名 ( 字段名 字段类型等 );
使用上面通用语句来建学生表:
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增主键',
student_name VARCHAR(30) COMMENT '学生姓名',
age TINYINT DEFAULT 0 COMMENT '年龄',
sex CHAR(5) NOT NULL DEFAULT '0' COMMENT '性别',
create_time timestamp DEFAULT CURRENT_TIMESTAMP()
) ENGINE=InnoDB DEFAULT CHARSET=utf8;运行上面 sql 后,建表成功:
分析一下建表语句,先看除字段以外的部分:
CREATE TABLE student (
...
) ENGINE=InnoDB DEFAULT CHARACTER=utf8;ENGINE=InnoDB DEFAULT CHARACTER=utf8;是数据库默认的可以不用写,但作为新手应该知道,这句是指:数据库引擎使用的是InnoDB, 默认的字符编码是utf8。
下面再来看看字段定义部分:
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增主键',
student_name VARCHAR(30) COMMENT '学生姓名',
age TINYINT DEFAULT 0 COMMENT '年龄',
sex CHAR(5) NOT NULL DEFAULT '0' COMMENT '性别',
create_time timestamp DEFAULT CURRENT_TIMESTAMP()总结一下公式大概就是:
字段名称 + 字段类型 + [ 默认值、主键设置、自增、注释...... ]
[ ]内为可选项
以上是建表时常用的命令,[]内的......表示还有其他命令,但上面对我这个入门者已经够了。
注意:建表时还需要考虑表之间的关联和 foreign key(外键) ,这里暂时不介绍,后面会有章节专门来说这块。
表是建好了,但随着开发进行 之前建好的表很可能不满足未来需求,所以对表的修改是必须的
同样,修改表也有通用语句:
ALTER TABLE <表名> [修改选项]下面是修改选项语法
添加字段:
ADD COLUMN <列名> <类型> ...修改字段名:
CHANGE COLUMN <旧列名> <新列名> <新列类型> ...优化(修改)字段类型
MODIFY COLUMN <列名> <类型> ...删除字段
DROP COLUMN <列名> ...修改表名
RENAME TO <新表名>对于 MODIFY 和 CHANGE可能有疑问,这里说明下:MODIFY主要用于修改字段类型等,不能修改字段名称,而CHANGE是把旧字段换成新字段 当然也可以修改字段类型。
简单来说MODIFY是对原有字段做类型修改,CHANGE是直接将整个字段换掉 包括类型等
下面动手操作一把,首先是对表添加字段:
ALTER TABLE student ADD COLUMN hobby VARCHAR(100);上面语句为 student 表添加了一个字段hobby(爱好) ,该字段数据类型是字符串(100字符)。
下图表示 hobby 字段添加成功:
ALTER TABLE student CHANGE COLUMN hobby hobby_num TINYINT;上面语句将旧字段 hobby 替换成新字段 hobby_num 字段类型为数字类型;
执行完后的结果如下:
上面说过,MODIFY不能修改字段名,一般用于修改字段类型等操作,下面我们把刚才的hobby_num从数字类型改为字符串类型:
ALTER TABLE student MODIFY COLUMN hobby_num VARCHAR(30);
可以看到,类型已经成功修改为VARCHAR类型。
删除字段非常简单,这里我们删除 hobby_num 字段:
ALTER TABLE student DROP COLUMN hobby_num;执行成功,下图中 hobby_num 已经被删除:
修改表名的操作频率非常低,但还是要知道一下。
我们把 student 表名改为 students:
ALTER TABLE student RENAME students;执行后可以看到,表名已经修改成功:
删表的操作除了在学习中常用到,真正在开发中操作频率也非常低。
删表语句如下:
DROP TABLE table_name;我们把 students 表给删了:
DROP TABLE students;看下结果:
OK,表没了...没了...了...
本篇学习了:
可能的疑惑:
建表的时候用了很多数据类型,光数字类型就出现了INT、TINYINT,字符串类型出现了CHAR、VARCHAR。
所以下篇文章我们来学习《数据类型》来了解它们。
本文接着上篇 Mysql入门第一课《建表、改表、删表》 继续学习。
要建一个优秀的表,选择合适的数据类型非常重要,如果数据类型选择不当,不仅开发起来给自己找麻烦,而且还会造成数据库性能低下。
比如给student(学生表)添加age字段,选择TINYINT类型就够了,它的范围是 0-255(无符号) 比较适合,如果使用 INT 也可以满足条件,但INT占 4 个字节,而TINYINT只占 1 个字节,相比较当然TINYINT性能更好。
刚才提到了UNSIGNED(无符号),我会在下文说明。
Mysql支持多种类型,大致分为三类:数值、字符串、日期/时间类型。
我们各个击破
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1字节 | (-128, 127) | (0, 255) | 小整数值 |
| SMALLINT | 2字节 | (-32768, 32767) | (0, 65535) | 大整数值 |
| MEDIUMINT | 3字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308), 0, (2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D, 为M+2否则为D+2 |
依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
这里解释下上面提到的有符号、无符号:
对于平常开发来说,整数类型其实到 INT 的数值范围已经很大了。
建表时经常看到类似 INT(5) 后面有个 5,它表示显示宽度(M),M 的值不能大于取值范围长度。
举个例子: 如果age字段类型是INT(5) UNSIGNED ZEROFILL,插入一条数据age为99,最后显示为:00099
UNSIGNED 为无符号, ZEROFILL 的作用是用 0 填充没有数字的位置。
我问过一些同事,在开发时为了方便,很多字段应该用数字类型 他们选择用字符串类型。这句话看看就好
字符串类型是建表时最最最常用的,下面看下它有哪些类型:
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
通常情况下,二进制的数据用的很少,一般像图片、音频都是存在 CDN 或 云服务器里,用的比较多的就是CHAR、VARCHAR、TEXT了。
光看表格没啥概念,但可以知道字符串主要以字节来提现大小,我们开发中用的字符串一般就是英文字母和汉字,那就需要知道字节与它们的关系:
在 Mysql 的UTF8编码下:
所以当我们存名称、简介和文章时,可以通过占用字节数选择合适的类型了,完美。
这个类型我们用的也很多,像生日、创建时间、修改时间等等都需要它。
| 类型 | 大小 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3字节 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3字节 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1字节 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8字节 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4字节 | 1970-01-01 00:00:00/2038 (结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07) | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
在开发中,常用的是 DATETIME 和 TIMESTAMP 也有使用INT来记录时间,下面从可读性、存储空间、操作性上来分析:
DATETIME 和 TIMESTAMP 直观。INT要方便很多,可以直接比较,加减等运算,其余两种需要利用代码工具进行计算和比较,此时性能最好的是INT综合考虑,个人比较偏向TIMESTAMP,占用空间小,可读性强,如果对性能不是非常苛刻,在代码帮助下操作也很简单,但使用时要考虑它的时间范围!
结合 Mysql入门第一课《建表、改表、删表》 和本篇文章,有几处出现了约束条件,这里有必要说一下:
本篇文章主要介绍数据类型 以及在开发中 如何使用合适的数据类型,然后在番外中介绍了下建表时出现的条件约束。
下篇文章将开始 Mysql入门第三课《数据的增删改》 欢迎阅读。
React 的渲染主要分两种:首次渲染和重渲染。
首次渲染就是第一次渲染,这是无法避免的就不讨论了,重复渲染是指由于状态改变或 props 改变等原因造成的渲染。
React 默认的渲染特性:当父组件渲染时,会递归渲染下面所有的子组件(让人诟病的特性)
如下:
const App = () => {
const [count, setCount] = React.useState(0);
const [name, setName] = React.useState('Tom');
React.useEffect(() => {
setInterval(() => {
setCount(s => s + 1);
}, 1000);
}, []);
return (
<>
<h3>count: {count}</h3>
<Child name={name} />
</>
);
};
function Child(props: { name: string }) {
console.log('child render', props.name);
return <div>name: {props.name}</div>;
}React 对这种行为可以说是不负责任,不管你三七二十八,只要父组件渲染,所有它下面的子组件都会渲染,这种方式简单而粗暴。
既然如此,那么这块只能我们这些负责任的开发者去优化了。
React 把优化问题抛给开发者,它给我们提供了三个用于性能优化的 API。
用于 class 写法的组件,它会对传入组件的 props 进行浅比较,如果比较的结果相同,则不会去渲染组件
与 React.PurComponent 一样,用于函数组件
在 js 中,数据主要分两种:
基本类型的数据属于原始值(primitive value),它直接存储在栈内存中,
引用类型的数据存在于堆内存中,通过存在栈内存中的指针来调用它
var a = 1;
var b = 1;
a === b // true
var a = {};
var b = {};
a === b // false 比较的是引用 所以不相等 对于对象,不仅有引用比较,也有深比较和浅比较
const a = {num: 1};
const b = {num: 1};
a === b // false 引用不相等
a.num === b.num // true 对象的一级相等
const a = { p: {num: 1}, t: 2 }
const b = { p: {num: 1}, t: 2 }
a === b // false 引用不相等
shallowEqual(a, b) // false a.p === b.p 引用不等 浅比较为false
deepEqual(a, b) // true 深比较相等如果对象的一级属性中存在引用比较,则不相等。
对象的深比较跳过了引用比较,仅仅是比较相同层级下的属性值。
React.memo 可以让 props 在变化时,该组件才会发生有意义的重新渲染
我们将子组件用 React.memo 包起来,只要 props 不变,在父组件更新时,子组件也不会重渲染
const Child = React.memo((props: { name: string }) => {
console.log('child render', props.name);
return <div>name: {props.name}</div>;
});看起来问题解决了,React.memo 将前后的 props 进行浅比较,这基本能解决大多数问题。但如果 props 中含有对象数据,在浅比较时比较的是引用,这种方式就行不通了,好在 React.memo 提供了第二个参数,可以自定义比较前后的 props
浅比较行不通,那么深比较呢
const Child = React.memo((props) => {
return <div>{props.name}</div>;
}, (prev, next) => {
// 深比较
return deepEqual(prev,next)
});这样的确可以达到效果,但如果是比较复杂的对象,就会存在较大的性能问题,甚至直接挂掉,因此不建议使用深比较去进行性能优化
还有一种方式:如果能保证对象的值相等,再保证对象的引用相等,就可以保证子组件在 props 没变的情况下不会渲染。
React.useRef 的返回值是固定的常量,我们可以使用它来做为对象的引用
const Child = React.memo(({ obj }) => {
console.log('child render', obj, obj.name);
return <div>name: {obj.name}</div>;
});
const App = () => {
const [count, setCount] = React.useState(0);
React.useEffect(() => {
setInterval(() => {
setCount(s => s + 1);
}, 1000);
}, []);
const obj = React.useRef({
name: 'Jack'
});
return (
<>
<h3>count: {count}</h3>
<Child obj={obj.current} />
</>
);
};这样还是存在一个严重的问题:如果 name 改变了,但 obj 没有变,导致子组件不会重新渲染,数据与UI界面不一致。 看来 useRef 只能用于常量
那我们只要保证 name 不变的时候 obj 和上次一样, name 才让子组件更新就可以了。没错,就是 useMemo。
useMemo 的特性就是保证依项不变时,对应的对象也不会变,只有依赖项变化时,对应的对象才会变
const App = () => {
const [count, setCount] = React.useState(0);
const [name, setName] = React.useState('');
React.useEffect(() => {
setInterval(() => {
setCount(s => s + 1);
}, 1000);
}, []);
// 只有当 name 变化时,obj才会变化
const obj = React.useMemo(
() => ({
name
}),
[name]
);
return (
<>
<h3>count: {count}</h3>
<input
type="text"
value={name}
onChange={e => {
setName(e.target.value);
}}
/>
<Child obj={obj} />
</>
);
};上面的方式算是一种解决方案,现在我们来看看其他的东西。
我们在 class 组件中更新状态,只需要一个 setState 就行,不管你传入什么 state,组件都会刷新
// class 的 setState 传什么都会更新组件
this.setState({
name: 'Jack'
})但在 hooks 里, 如果前后两次的引用相等,就不会更新组件
const [state, setState] = useState({})
// 同一个引用,不会更新
setState(s => {
s.name = 'Tom'
return s
})
// 生成新应用,可以更新
setState(s => {
const newState = {
...s,
name: 'Tom'
};
return newState;
})在 hooks 中,如果你想修改状态对象,必须保证前后修改的对象引用不等。这就要求我们不能直接更新老的 state,而是要保持老的 state 不变,去生成一个新的 state,也就是 immutable 方式。
老的 state 保持不变,也就意味着该 state 应该是 immutable obj
const state = [
{
name: 'Tom',
age: 20
},
{
name: 'Jack',
age: 30
}
]
state[0].name = 'Alen'
// hooks中需要如下写法
const newState = [
{
...state[0],
name: 'Alen'
},
...state
]immutable 的写法过于繁琐,这不是我们想要的
其实,综上来说,我们的需求很简单:
第一个冲上脑门的答案就是:先深拷贝,然后做 mutable 修改就可以了
const state = [
{
name: 'Tom',
age: 20
},
{
name: 'Jack',
age: 30
}
]
const newState = deepClone(state);
newState[0].name = 'Alen'深拷贝有两个缺点:
const state = [
{
name: 'Tom',
age: 20
},
{
name: 'Jack',
age: 30
}
]
const newState = lodash.cloneDeep(state)
state === newState // false
state[0] === newState[0] // false可以发现,所有对象的结构都被破坏,在 React 中使用这种方式,即使对象属性没有任何变化,也会导致没有意义的重新渲染,仍会导致比较严重的性能问题
深拷贝是非常糟糕的
这么看来,更新状态还要其他的需求。
我们将 oldState 视为一个属性树,改变其中某节点时,能返回一个新的对象
遗憾的是,JavaScript 并没有内置这种对 immutable 数据的支持,更不用说对 immutable 数据更新了,但可以使用一些三方库来解决这个问题,比如:immer 和 immutablejs
import Immutable from 'immutable'
var state = Immutable.Map({
a: 1,
b: 2
})
var newState = state.set('a', 3) Immutable 数据使用结构共享的方式,只更新修改了子节点的引用,不会去修改未更改的子节点引用,达到我们想要的需求
我们平常写React是这样的:
class HelloMessage extends React.Component {
constructor(props) {
super(props);
this.handleClick = this.handleClick.bind(this); //绑定this
}
handleClick(){
console.log( this )
}
render() {
const { count } = this.state;
return (
<button onClick={ this.handleClick } >Hello</button>
);
}
}
ReactDOM.render(
<HelloMessage/>,document.getElementById('root')
);上面代码可以完好运行,handleClick 绑定好 this 后,打印如下:
HelloMessage {props: {…}, context: {…}, refs: {…}, updater: {…}, _reactInternalFiber: Hr, …}
context: {}
props: {}
refs: {}
state: null
updater: {isMounted: ƒ, enqueueSetState: ƒ, enqueueReplaceState: ƒ, enqueueForceUpdate: ƒ}
_reactInternalFiber: Hr {tag: 1, key: null, elementType: ƒ, type: ƒ, stateNode: HelloMessage, …}
__proto__: b
我们把.bind(this)去掉,再打印一次:
undefined
OK,果然this就没有任何东西了。
但是如果把 handleClick 改为箭头函数的写法,就不需要 bind(this) 了:
handleClick = () => {
console.log( this )
}更改后,this 也能正常打印出来。
我们先看一下render方法中被Babel编译后的样子:
render() {
return React.createElement(
'button',
{ onClick: this.handleClick },
'Hello'
);
}React 通过 React.createElement 方法模拟 document.createElement 来创建 DOM(当然React创建的是虚拟DOM)。 属性中 onClick 指向 this.handleClick 方法,看起来都没有问题。
下面我们不用 React 来实现上面 this 的现象:
// 创建DOM
function createElement(dom, params) {
var domObj = document.createElement(dom);
domObj.onclick = params.onclick;
domObj.innerHTML = 'Hello';
document.body.appendChild(domObj);
}
// Demo类
class Demo {
handleClick() {
console.log(this);
}
render() {
createElement('button', {
onclick: this.handleClick
});
}
}
// 执行render
new Demo().render();小伙伴们猜猜,这里的 this 指向什么(手动滑稽)?
来打印结果:
<button>Hello</button>啊哈哈哈啊,没错 this 并不是 undefined,也没有指向 Demo 对象,而是创建的 button DOM对象本身。
现在再把 handleClick 改为箭头函数:
// Demo类
class Demo {
handleClick = () => {
console.log(this);
}
render() {
createElement('button', {
onclick: this.handleClick
});
}
}
// 执行render
new Demo().render();来看看这次打印的 this :
Demo {handleClick: ƒ}
handleClick: () => { console.log(this); }
__proto__: Object
卧槽,居然指向了 Demo 对象,这样就可以在 handleClick 里随意访问 Demo 里的属性和方法了!
其实,如果你 JavaScript 基础够扎实,我想你是不会点进来看这篇文章的。
这里的问题无非就牵扯到两个点:
我打赌,上面的 Demo 实例很多人看的云里雾里的,所有我把它转成 ES5 的写法:
function createElement(dom, params) {
var domObj = document.createElement(dom);
domObj.onclick = params.onclick;
domObj.innerHTML = 'Hello';
document.body.appendChild(domObj);
}
// 创建 Demo 类,相当于 class Demo {} 的写法
function Demo() {
}
// 在原型上挂载 handleClick 方法
Demo.prototype.handleClick = function() {
console.log(this);
};
Demo.prototype.render = function() {
createElement('button', {
onclick: this.handleClick
});
};
new Demo().render(); // 运行 render 方法打印结果:
<button>Hello</button>**严重注意:在ES6 class 内定义方法时,如果不是箭头函数,方法是挂载在 prototype 原型对象上的! **
那么下面,把 handleClick 用箭头函数的方式写出来:
function createElement(dom, params) {
var domObj = document.createElement(dom);
domObj.onclick = params.onclick;
domObj.innerHTML = 'Hello';
document.body.appendChild(domObj);
}
// 创建 Demo 类,相当于 class Demo {} 的写法
function Demo() {
// 相当于箭头函数 不了解的同学请恶补一下吧
var _this = this;
this.handleClick = function(){
console.log( _this );
}
}
Demo.prototype.render = function() {
createElement('button', {
onclick: this.handleClick
});
};
new Demo().render(); // 运行 render 方法这时候再打印:
Demo {handleClick: ƒ}
handleClick: ƒ ()
__proto__: Object
厉害了哈~ this 指向了想要的对象环境中。
通过以上代码解析,能知道 React 中,在不适用箭头函数时,需要通过 bind 将函数内 this 指向当前对象才能正常访问。
而使用箭头函数时,由于箭头函数的特性,函数内的 this 就是当前对象上下文,所以不需要 bind 来指向。
如果哪里有不对的地方,欢迎指正,感谢!
玩过React的同学都知道,render()方法除了第一次组件被实例化,其他情况绝大多数是state改变触发的。
而render方法的执行,所带来的负担就是重新对比Virtual DOM(虚拟DOM树),也就是重新执行Diff算法,然后把要修改的的DOM重新update。
而我们总是在开发过程中会产生非常多不必要的重新渲染
如何减少render的触发,是提升项目性能的关键之一。
减少render的入口在哪?当然是要知道哪些情况会触发render啦~
根据个人了解,触发render有以下两种情况:
那么我们从这两点入手
在《React和Immutable》中,提到了使用Immutable配合React的componentShouldUpdate生命周期函数来减少不必要的render,效果非常明显,这里就不说了,建议大家一定去看一下
除了使用 Immutable ,还有其他方法来避免render执行吗?
先看看正常开发中,使用setState的情况:
constructor(props) {
super(props);
this.state = {};
}
render() {
console.log('render');
return (
<div>
<input onChange={this.change} />
<button onClick={this.submit}>提交</button>
</div>
);
}
change = e => {
this.setState({
value: e.target.value
});
};
submit = () => {
console.log(this.state.value);
};执行上面代码,然后在input里输入123,看看控制台上发生了什么:

对没错,执行了3次render,我们想象一下,用户在登录界面输入账号和密码时,render 会执行多少次啊啊啊 简直要命。
那有什么方法可以解决呢?
防抖函数应用在高频率操作时,能避免无意义的代码执行,从而提高性能。
constructor(props) {
super(props);
this.state = {
inputVal: ''
};
}
render() {
console.log('render');
return (
<div style={{ margin: 50 }}>
<input onChange={this.change} />
<button onClick={this.submit}>提交</button>
</div>
);
}
timer = null;
change = e => {
//获取inputVal
const inputVal = e.target.value;
//防抖处理
clearTimeout(this.timer);
this.timer = setTimeout(() => {
//set值
this.setState({
inputVal
});
}, 200);
};
submit = () => {
console.log(this.state.inputVal);
};我们依然将inputVal挂在state上面,由于onChange事件可以频繁的触发setState,所以我们从这里下手,在onChange事件里使用防抖来避免频繁触发setState,从而避免多次render带来的性能消耗。
我们在文本框里输入值,然后看看控制台打印的结果:

Yes! 可以看到 我们输入 Hello,控制台只打印出了一次 render ,非常好!
在开发中可以将防抖函数放在工具函数中方便调用哟~
现在我们改变一种写法:不使用setState而是换成私有属性this.inputVal来代替:
constructor(props) {
super(props);
this.inputVal;
}
render() {
console.log('render');
return (
<div style={{ margin: 50 }}>
<input onChange={this.change} />
<button onClick={this.submit}>提交</button>
</div>
);
}
change = e => {
this.inputVal = e.target.value;
};
submit = () => {
console.log(this.inputVal);
};我们仍然输入123,然后看看控制台:

哇塞~~ render一次都没执行,现在点击提交,打印结果是 123,这正是我们想要的。
聪明的同学能发现一个问题,其实这样的优化有一个缺点:不能使用双向绑定。
在开发中,真正使用双向绑定的表单元素,一般会有其他效果必须依赖该表单元素的数据,比如省市区级联,市区的变化必须依赖省的数据。
所以如果没有必要使用双向绑定的,请尽量避免使用。
减少render的执行次数,可以使用:
原文在我的Github里,欢迎订阅。
之前已经学习了Mysql入门第一课《建表、改表、删表》 和 Mysql入门第二课《数据类型》,今天继续学习 如果对表数据进行增加、修改和删除的操作。
依然以 student 表为例。
执行以下 sql 新建一个空的 student表:
CREATE TABLE student(
id INT UNSIGNED PRIMARY KEY auto_increment,
name VARCHAR(10),
age TINYINT(3)
) ENGINE=INNODB DEFAULT CHARSET=utf8;先看下新增数据通用语法:
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );field为字段名称,value是要插入的值,把它看做给变量赋值就行了。
下面为student表插入一条数据:
INSERT INTO student (name, age) VALUES ('赵云', 26);上面是每次插入一条数据,在开发中往往会遇到批量新增数据的情况。
下面我们一次性新增 5 条数据:
INSERT INTO student (name, age) VALUES ('张飞', 30),('刘备', 32),('关羽', 33),('马超', 28),('诸葛亮', 35)执行上面语句后,看下结果:
修改数据通用语法:
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause]修改数据要注意一个前提:对谁修改
上面语法中的[WHERE Clause]就是条件语句,用来控制要修改的哪些数据。
下面来实操一把。
现在表里的三国人物都是男的,我们把张飞改成貂蝉,让其他男的 happy 一下(邪恶脸):
UPDATE student SET name='貂蝉', age=18 WHERE id=2;之前张飞那条数据的 id 是 2,我们使用 WHERE 语句找到了id=2 的数据,然后把name和age都修改了。
这下把赵云高兴坏了,因为貂蝉在他下面。
OK,刚才可以看出,要对谁修改,是看条件语句怎么写。
现在我要把刘备和关羽都变成小乔:
UPDATE student SET name='小乔', age=16 WHERE id=3 OR id=4;上面都是通过 WHERE 来确定对某些数据修改,那如不写条件语句会怎么样?
UPDATE student set name='王昭君', age=17;没错!如果不加条件语句,会把整个表都修改了!一定要注意!
通用语法:
DELETE FROM table_name [WHERE Clause]删除数据跟 UPDATE 有点像,是根据条件语句来删除对应数据。
比如我要删除 id=1 的 王昭君。
DELETE FROM student WHERE id=1;看下结果,id=1 的王昭君不见了,好桑心:
至于批量删除跟 WHERE 语句有关,比如删除 id>3 的王昭君:
DELETE FROM student WHERE id>3;更多王昭君不见了,更伤心了:
现在不加条件语句:
DELETE FROM student;很好,全删了,眼不见为净!
本篇介绍了如何对数据表进行增加数据、修改数据、删除数据。
下面文章介绍 查询数据~
敬请期待
一句话概括:提供唯一一个对象,可以供外界访问。
我们在封装一些工具方法时,喜欢用这种方式:
const util = {
ajax: function(){},
random: function(){},
...
}最简单的就是使用字面量的创建一个对象,里面包含一些属性和方法,util暴露给外界访问。
上面的代码有个问题,如果有私有属性或方法不想暴露出来那就不行了,我们改一下:
const utilSpace = function() {
//私有变量
const _privateName = 'hello';
//私有方法
function _showPrivateName() {
console.log( _privateName )
}
//暴露给外界的对象
return {
showName: function(){
_showPrivateName();
},
publicVar: "hello, I'm Tom"
}
}
const single = utilSpace(); //向外界暴露single即可
single.showName(); // hello
single.publicVar; // hello, I'm Tom其实上面的代码已经够用了,如果你想用更优雅或更合理的写法可以这样:
(function(){
var instance; // 该变量用于缓存实例
// 定义 Util 类
var Util = function() {
if( instance ) return instance;
instance = this;
//其他属性或方法
this.xxx = 0;
this.name = 'Tom';
}
window.Util = Util;
})();
var a = new Util();
var b = new Util();
console.log( a === b ) //true上面代码中,定义一个Util类, 并用 instance 变量将 Util 实例缓存起来,当使用 new Util 时,如果 instance 已经缓存了实例,则直接将该实例返回,这样就保证不管 new 多少次,始终只会返回一个实例,达到单例的目的。
前端开发中我们遇到的单例模式有很多,比如:Dialog、Tips、Toast 等都是可以通过单例模式来搞定的。
W3C性能工作组规定:将执行时间超过50ms任务定义为长任务(Long Task)。
长任务由于长时间阻塞主线程,会让用户感觉到卡顿。
而解决长任务的方式大致有两种:
时间分片并不是某个 api,而是一种技术方案,它可以把长任务分割成若干个小任务执行,并在执行小任务的间隔中把主线程的控制权让出来,这样就不会导致UI卡顿。
React 的 Fiber 技术核心**也是时间分片,Vue 2.x 也用了时间分片,只不过是以组件为单位来实施分片操作,由于收益不高 Vue 3 把时间分片移除了。
在早期,时间分片充分利用了“异步”来实现,例如:
btn.onclick = function (){
someTask(); //50ms
setTimeout(function() {
otherTask(); //50ms
})
}上面代码,本来应该执行 100ms 的长任务,被拆分成了两个 50ms 的任务。
Generator是 ES6 里的语法,它提供了一个生成器函数来生成迭代器对象,我们利用 Generator 函数提供的 yield 关键字来让函数暂停,通过使用迭代器对象的 next 方法让函数继续执行。
如果我们用 Generator 函数,则可以这么写:
btn.onclick = ts(function* (){
someTask();
yield;
otherTask();
})这样就可以通过 yield 把一个长任务拆分成两个短任务。
我们也可以将 yield 关键字放在循环里:
btn.onclick = ts(function* (){
while (true) {
someTask();
yield;
}
})上面虽然是个死循环,但依然不会阻塞主线程,所以浏览器不会卡死。
基于 Generator 函数的执行特性,我们很容易使用它来实现一个时间分片函数:
function ts(gen) {
if (typeof gen === 'function') gen = gen();
if (!gen || typeof gen.next !== 'function') return;
return function next() {
const res = gen.next();
if (res.done) return;
setTimeout(next);
};
}代码核心**:通过 yield 关键字可以将任务暂停执行,并让出主线程的控制权;通过setTimeout将未完成的任务重新放在任务队列中执行。
为了好理解,先写段长任务代码,将主线程阻塞一段时间:
const start = performance.now();
let count = 0;
while (performance.now() - start < 1000) {}
console.log('done!');该段脚本霸占主线产长达 1s 的时间,如果把这段长任务分解成多个小任务执行呢。
我们通过这种方式来看一下,将长任务使用时间分片来处理:
ts(function* (){
const start = performance.now();
let count = 0;
while (performance.now() - start < 1000) {
yield;
}
console.log('done!');
})()从图里看到,一个长任务虽然切成了诺干个小任务,但时间颗粒度过小,这样会导致执行任务的总时长增加,而W3C定义超过 50ms 为长任务,所以我们要控制一下任务时长,让它在一个合理的时间内,这样不会导致任务总时长过长。
为了保证切割的任务接近 50ms,可以在 ts 函数中根据任务的指向时间判断是否应该一次性执行多个任务。
修改一下 ts 函数:
function ts(gen) {
if (typeof gen === 'function') gen = gen();
if (!gen || typeof gen.next !== 'function') return;
return function next() {
const start = performance.now();
const res = null;
do {
res = gen.next();
} while (!res.done && performance.now() - start < 25);
if (res.done) return;
setTimeout(next);
};
}上面代码中,做了一个 do while:如果当前任务执行时间低于 25ms 则多个任务一起执行,否则作为一个任务执行,一直到 res.done = true 为止。
现在,我们再测试一下看看结果:
可以看到,时间切片的颗粒度变的正常了,总时间也会相应缩短,完美!
时间分片的概念以及技术方案让长任务分割成多个短任务,并且将控制权放给主线程,不会造成主线程卡顿
通过使用 Generator 函数特性,很方便的实现了 ts 函数。
上篇《前端也要学Docker啊!》介绍了Docker及它的三个主要概念:Image(镜像)、Container
(容器)、Registry(仓库) 以及Docker安装。
本篇我们来动手实践:在本地创建一个自己的镜像(Node应用),使用该镜像创建容器并执行容器中的Node应用。
在根目录创建index.js
//index.js
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
ctx.body = 'Hello Docker O(∩_∩)O~~';
});
app.listen(3000);创建 Docker 镜像需要用到 docker build命令,而docker build命令又是根据 Dockerfile 配置文件来构建镜像,所以我们要在项目根目录创建一个 Dockerfile 文件:
#Dockerfile
FROM node:10.13-alpine #项目的基础依赖
MAINTAINER chenLong #项目维护者
COPY . . #将本机根目录所有文件拷贝到容器的根目录下 这个可以根据喜好调节路径
EXPOSE 3000 #容器对外暴露的端口
RUN npm i #安装node依赖
CMD npm start #在容器环境里执行的命令
你可以到 Docker 官网查看详细的Dockfile说明
上面 Node 代码已经完成了,我们使用 yarn init -y或 npm init -y 完成package.json初始化,然后安装一个koa依赖:执行yarn add koa或 npm i koa。
然后我们在本地跑一下 node 程序:node index.js,打开浏览器输入 localhost:3000 ,可以看到浏览器中成功显示了 Hello Docker O(∩_∩)O~~ 。

程序没问题,我们开始构建这个镜像,执行命令:docker build -t docker-demo/hello-docker:v1 . (注意最后有个 "." 是必须的)
--tag简写,镜像的名字及标签,通常 name:tag 或者 name 格式;可以在一次构建中为一个镜像设置多个标签。上面的 docker-demo/hello-docker是我们定义的镜像名称,v1是标签名称(类似版本号)

图中蓝色框表示 Dockerfile 的执行步骤。此时一个名为docker-demo/hello-docker的镜像已经创建完成了,现在我们执行docker images查看一下:

表示本地的镜像列表中已经有了我们刚才创建的docker-demo/hello-docker
上面已经创建好了镜像,里面包含着我们写的代码,现在我们需要把代码运行起来。
非常简单,我们使用docker run命令使用镜像创建一个容器实例(此刻脑海中浮现 var p1 = new Person() )。
我们执行命令: docker run -i -t -p 8080:3000 docker-demo/hello-docker:v1

打开浏览器,运行localhost:8080:
完美,容器里的代码已经跑起来了!
当项目越做越大时,体积过大导致加载速度过慢,性能问题直接影响用户体验。
这时我们会考虑将代码拆分。
拆分,顾名思义就是将一个大的东西拆分成N个小的东西,用公式表示就是:Sum = n * Sub
代码拆分基于动态导入
什么是动态导入?就是我需要什么,你给我什么,我不需要的时候,你别给我,我嫌重。
动态导入可以将模块分离成一个单独的文件 在需要的时候加载进来。
对于动态导入,webpack 提供了两个类似的技术。
import() 语法。 require.ensure。从webpack 2以后,一般使用第一种。
由于import()方法返回的是Promise对象,我们为了能方便的返回组件,
这里推荐使用react-loadable插件
例子代码:
import Loadable from 'react-loadable';
import Loading from './my-loading-component';
const LoadableComponent = Loadable({
loader: () => import('./my-component'),
loading: Loading,
});
export default class App extends React.Component {
render() {
return <LoadableComponent/>;
}
}代码里有熟悉的 import() 方法。react-loadable 使用 webpack 的动态导入,调用Loadable方法可以方便的返回要使用的组件。
下面我将以我本人的项目经历,来讲解代码拆分(code splitting)
当初还是小白的我,一开始哪知道有代码拆分这个技术啊,就一个人负责一个小项目,一开始项目不大,跑起来也是嗖嗖的,这里先贴一下路由代码:
import Home from './home';
import Page1 from './page1';
import Page2 from './page2';
<Route exact path="/" component={Home}/>
<Route path="/page1" component={Page1}/>
<Route path="/page2" component={Page2}/>懂行的人一看就明白,这里没有使用动态导入,而是直接将所有页面静态引入进来,然后赋到对应路由上。
这么做的坏处就是:打包时,整个项目所有的页面都会打包成一个文件中,随着页面增多,这个文件也越来越大,最后我看了一下,达到了近25M(我吓得打开度娘...)。
如果用一张图来表示的话,这张图在适合不过了:

打开度娘的我脸色渐渐有了好转,通过搜索,看到了webpack有个code splitting功能(代码拆分),
前面说过,代码拆分其实就是使用动态导入的技术实现的,那么我们就使用动态导入来优化一把之前的路由:
import Loadable from 'react-loadable';
import Loading from './my-loading-component';
const loadComponent = path =>
Loadable({
loader: () => import(`${path}`),
loading: Loading
});
<Route exact path="/" render={this.loadComponent('./home') } />
<Route path="/page1" render={this.loadComponent('./page1') } />
<Route path="/page2" render={this.loadComponent('./page2') } />我们不再使用 import module from 'url' 来静态引入模块,而是使用 loadComponent 来动态导入,它返回的是Loadable的结果,也就是我们想要的组件,我们把再把组件给对应的路由,这就完成了基于路由的代码拆分。
使用以后,鄙人怀着激动的心情开始打包项目,当我看到控制台的打包日志时,我的表情是这样的:

咳咳,这种好事情当然要分享一下啦,你要的结果:

可以看到,webpack打包时已经将之前的一个臃肿文件按路由拆分成了三个文件,当我们点击一个路由时,会动态加载对应的文件。
比如我点击home页面的路由时:

我再点击page1时:

嗯,是按照路由来拆分的代码,完美~
这样看来,我们需要将之前的那张图改成这样的:

看着项目加载速度变快了,心里真特么高兴 
其实基于路由的代码拆分已经可以满足绝大多数项目了,再大的项目也能满足。
但随着项目做的多了,慢慢的发现了一个问题:代码浪费。
比如我要做一个Tab切换的功能,像酱紫的:

对应的代码大概是酱紫的:
import { Tabs } from 'antd';
import TabOne from './component/tab1';
import TabTwo from './component/tab2';
import TabThree from './component/tab3';
const TabPane = Tabs.TabPane;
export default class Home extends Component {
render() {
return (
<Tabs defaultActiveKey="1">
<TabPane tab="Tab 1" key="1">
<TabOne />
</TabPane>
<TabPane tab="Tab 2" key="2">
<TabTwo />
</TabPane>
<TabPane tab="Tab 3" key="3">
<TabThree />
</TabPane>
</Tabs>
);
}
}Tab切换,每个前端小伙伴都做过,其实说白了,就是显示隐藏的效果。
但是在这个页面中,已经把每个Tab里的代码都加载进来了,如果用户只看第一个Tab,其他Tab不点击,就造成了代码浪费。
如何解决这个问题呢?还是那句话:我需要什么,你给我什么,我不需要的时候,你别给我,我嫌重。
我们使用动态导入的方式改造一下代码:
import { Tabs } from 'antd';
import Loadable from 'react-loadable';
import TabOne from './component/tab1';
import Loading from './component/loading';
const TabPane = Tabs.TabPane;
const loadComponent = path =>
Loadable({
loader: () => import(`${path}`),
loading: Loading
});
const Tab2 = loadComponent('./component/tab2.tsx');
const Tab3 = loadComponent('./component/tab3.tsx');
export default class Home extends Component {
render() {
return (
<Tabs defaultActiveKey="1">
<TabPane tab="Tab 1" key="1">
<TabOne />
</TabPane>
<TabPane tab="Tab 2" key="2">
<Tab2 />
</TabPane>
<TabPane tab="Tab 3" key="3">
<Tab3 />
</TabPane>
</Tabs>
);
}
}同样 我们不再使用import module from 'url'的方式,而是使用 loadComponent 方法动态导入。
由于TabOne是第一个默认显示的,所以没必要动态导入。
现在我们来点击Tab 2看看效果:

非常棒,正是我们想要的。
再点击Tab 3 :

简直完美!😄
到目前为止,我们基于模块的代码拆分就完成了,我们把之前的拆分图再改一下:

看上去爽朗了很多啊!
基于路由的代码拆分可以很大程度上减轻代码的臃肿,但依然会存在不会被使用的组件被import进来,导致代码浪费。
本人认为,既然是组件化时代,那么就应以组件为核心,将动态导入颗粒化到组件而不是路由,将会带来更合理,性能更高的项目优化。
一般业务流程是:验证用户登录信息没问题后,会签发一个 token 给用户 用于之后的接口请求。
nest 中使用 @nestjs/jwt 来给用户签发 jwt
yarn add @nestjs/jwt在 auth 模块中引入 jwt 模块
// auth/auth.module.ts
import { Module } from '@nestjs/common';
import { JwtModule } from '@nestjs/jwt';
import { UsersModule } from '../users/users.module';
import { AuthService } from './auth.service';
import { AuthController } from './auth.controller';
@Module({
imports: [
UsersModule,
// 引入 Jwt 模块并配置秘钥和有效时长
JwtModule.register({
secretOrPrivateKey: 'll@feifei',
signOptions: { expiresIn: '60s' }
}),
],
providers: [AuthService],
exports: [AuthService],
controllers: [AuthController]
})
export class AuthModule {}在 auth.controller 中新建一个 login 路由用于用户登录
import { Body, Controller, Post, Request } from '@nestjs/common';
import { AuthService } from './auth.service';
import { LoginDto } from './auth.dto'
@Controller()
export class AuthController {
constructor(private readonly authService: AuthService) {}
@Post('/login')
async getHello(@Body() data: LoginDto) {
return await this.authService.login(data);
}
}再看看 service 中怎么使用 jwt
import { Injectable, UnauthorizedException } from '@nestjs/common';
import { JwtService } from '@nestjs/jwt';
import { UsersService } from '../users/users.service';
@Injectable()
export class AuthService {
constructor(
private readonly usersService: UsersService,
// 引入 JwtService
private readonly jwtService: JwtService,
) {}
async login(data) {
const { username, password } = data;
const user = (await this.usersService.findOne(username))[0];
if (!user) {
throw new UnauthorizedException('用户不存在');
}
if (user.password !== password) {
throw new UnauthorizedException('密码不匹配');
}
const { id } = user;
const payload = { id, username };
// 生成token
const token = this.signToken(payload);
return {
...payload,
token,
};
}
signToken(data) {
return this.jwtService.sign(data);
}
}现在使用请求localhost:3000/login
正常返回了当期登录信息 token,
接下来,按照登录流程,成功发放了 token 给前端后,前端在请求其他数据时需要把 token 给后端,后端经过审核 token 有效才会正常返回接口数据。
一般情况下,前端把 token 放在请求头的 Authorization 字段中,使用 Authorization = 'Bearer tokenString'的方式请求数据
passport 是一个非常好的处理 jwt 的包,在 nestjs 中使用 passport-jwt 策略来完成 token 的安检,现在我们来添加这个策略:
在 auth/jwt.strategy.ts 中添加 JwtStrategy 策略,需要继承 PassportStrategy(Strategy) ,注意:Strategy 是 passport-jwt 包里的
import { PassportStrategy } from '@nestjs/passport';
import { ExtractJwt, Strategy, VerifiedCallback } from 'passport-jwt';
import { SECRET } from './secret';
export class JwtStrategy extends PassportStrategy(Strategy) {
constructor() {
super({
// 配置从头信息里获取token
jwtFromRequest: ExtractJwt.fromAuthHeaderAsBearerToken(),
// 忽略过期: false
ignoreExpiration: false,
// secret必须与签发jwt的secret一样
secretOrKey: SECRET,
});
}
// 实现 validate,在该方法中验证 token 是否合法
async validate(payload: any) {
console.log('payload:', payload);
return payload;
}
}写好 jwt 策略后,需要在模块中引入 PassportModule,在 providers 中加入 JwtStrategy,否则无法使用策略:
import { Module } from '@nestjs/common';
import { JwtModule } from '@nestjs/jwt';
import { PassportModule } from '@nestjs/passport';
import { UsersModule } from '../users/users.module';
import { AuthService } from './auth.service';
import { AuthController } from './auth.controller';
import { JwtStrategy } from './jwt.strategy';
import { SECRET } from './secret';
@Module({
imports: [
UsersModule,
JwtModule.register({
secret: SECRET,
signOptions: { expiresIn: '60s' },
}),
// 引入并配置PassportModule
PassportModule.register({
defaultStrategy: 'jwt',
}),
],
controllers: [AuthController],
// 引入JwtStrategy
providers: [AuthService, JwtStrategy],
exports: [AuthService],
})
export class AuthModule {}现在添加一个路由来验证一下
import { Body, Controller, Get, Post, UseGuards } from '@nestjs/common';
import { AuthGuard } from '@nestjs/passport';
import { AuthService } from './auth.service';
@Controller()
export class AuthController {
constructor(private readonly authService: AuthService) {}
@Post('login')
async getHello(@Body() data) {
return await this.authService.login(data);
}
@Get('test')
// 使用路由级守卫
@UseGuards(AuthGuard())
async test() {
return 'test';
}
}需要注意的是,在路由中需要添加 @nestjs/passport 中的 AuthGuard 守卫,否则会直接请求到控制器里面,需要 AuthGuard 守卫来检测 jwt 是否合法,如果合法会放行到控制器中
看看结果:
请求成功了,控制台也成功打印了 payload 信息:
payload: { id: 2, username: 'admin', iat: 1619766245, exp: 1619766305 }上文使用的是路由级别的守卫 使用 AuthGuard 来处理 JWT,但一般项目中,绝大多数接口都是要处理 JWT 的,如果每个接口都写上一遍无疑是一个较大的工程
所以我要使用全局的 AuthGuard 来完成这个功能,但也有些接口不需要 jwt 验证(比如 login、register),所以我们不直接使用全局的 AuthGuard,而是创建一个新的守卫:
import { Injectable, CanActivate, ExecutionContext } from '@nestjs/common';
import { Observable } from 'rxjs';
@Injectable()
export class JwtAuthGuard implements CanActivate {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
return true;
}
}新建的守卫需要实现 CanActivate,这就遇到一个麻烦,怎么把 AuthGuard 拿进来使用呢?
仔细一想, AuthGuard 也是守卫,它内部已经实现了 CanActivate,现在我要用 AuthGuard 的功能,只需要让 JwtAuthGuard 来继承 AuthGuard() 就好了
import { ExecutionContext, Injectable } from '@nestjs/common';
import { AuthGuard } from '@nestjs/passport';
import { Observable } from 'rxjs';
@Injectable()
export class JwtAuthGuard extends AuthGuard('jwt') {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
const request = context.switchToHttp().getRequest();
const whitelist = ['/login'];
if (whitelist.find((url) => url === request.url)) {
return true;
}
return super.canActivate(context);
}
}代码中通过 request 拿到当前请求的 url,通过与白名单(whitelist)对比达到排除不需要 jwt 认证的接口,非白名单内的接口仍需要通过 super.canActivate(context)。 ps: 这里白名单的处理不全面,建议配合 path-to-regexp 来使用
全局使用 JwtAuthGuard 有两种方式,一种在 app.module.ts 中通过 providers 注册全局提供者:
providers: [ { provide: APP_GUARD, useClass: JwtAuthGuard, }]还有一种是在 main.js 中添加全局使用:
app.useGlobalGuards(new JwtAuthGuard());对于两种方式,官网上是这么说的:
相关链接:https://docs.nestjs.com/guards
这里我们随便用哪种方式都能满足 , Ps: 记得把路由级别的 AuthGuard 去掉~
其他文章:
外键约束是mysql提供的表与表之间的关联,使用它可以保证数据的一致性和完整性。
但是我问过同事,他们现在开发中不会使用外键约束,主要原因是数据量大或请求很频繁时会导致一些性能问题,实际开发中是通过业务代码来代替外键约束的功能。
但这不代表不需要学它,如果你的项目数据量不是很大,用外键约束还是非常方便的。
通过之前学习和练习,外键其实已经出现过,比如在student表中:
学生表中包含一个class_id,它指向class(班级表)的id,于是我们可以通过class_id来查找这个学生的班级信息。
此时,对于student表来说class_id就是它的外键,外键字面意思就是指向外部的某个键,这里就是指向外部class表的id
多了“约束”两个字。 有约束代表着不能对含有外键关联的表随意删除和修改了,举个例子:
学生表 和 班级表 相互关联并有约束条件,如果有一天,你要删除某个班级,那班级里的学生怎么办呢?默认数据库会不让你删,因为班里还有学生存在。
OK,我们实际操作一把,现在把学生表和班级表加个外键约束:
ALTER TABLE student ADD CONSTRAINT student_class FOREIGN KEY (class_id) REFERENCES class(id);解析一下上面的语句:
看下结果:
为了好理解再看下 ER 图:
ON DELETE 和 ON UPDATE 表示删除时 和 更新时 要处理的方式。
上面图里有删除时和更新时,这是数据删除和更新时的处理方式:
来看下设置为 NO ACTION 或 RESTRICT 时,我们删除和更新数据试试:
id=1 的班级表中有对应的学生,我们来删除这个班级:
DELETE FROM class WHERE id=1;更新也是一样:
UPDATE class SET id=10 WHERE id=1;CASCADE: 对父表删除或更新时,子表同时删除或更新
我们来试一把。
先修改外键约束:
ALTER TABLE student DROP FOREIGN KEY student_class;
ALTER TABLE student ADD
CONSTRAINT student_class
FOREIGN KEY (class_id)
REFERENCES class(id)
ON DELETE CASCADE
ON UPDATE CASCADE;
可以看到已经改为CASCADE了。
需要注意的是,要先删除外键约束 然后再重新生成。
现在我们来删除id=2的班级:
DELETE FROM class WHERE id=2;然后来看看班级和学生:
班级表中 id=2 的数据已经没有了
再看看学生表:
class_id=2 的学生也一起删了
现在修改一下试试,我们把id=1 的班级修改为 id=10:
UPDATE class SET id=10 WHERE id=1;修改成功:
再看看原本class_id=1的学生怎么样了:
class_id 也变成 10 了
SET NULL:对父表删除或更新时,子表设置为NULL
先把外键约束改成 SET NULL 的处理方式:
ALTER TABLE student DROP FOREIGN KEY student_class;
ALTER TABLE student
ADD CONSTRAINT student_class
FOREIGN KEY (class_id)
REFERENCES class(id)
ON DELETE SET NULL
ON UPDATE SET NULL;为了演示方便,在student表中添加一条数据:
现在我们删除 id=3 的班级:
id=3的班级已经被删除,再看看 class_id=3 的学生怎么样了:
从图中看到,由于class_id=3这个班级被删除,这个班里的学生没有了班级,所以class_id为NULL了。
我们再看下更新:
UPDATE class SET id=100 WHERE id=10;上面语句是把id=10的班级改为id=100:
班级修改成功了,再看看这个班级下的学生:
原本 class_id=10 的学生现在也没有了班级,class_id 也置为 NULL 了。
本篇学习了什么是外键约束,以及外键约束的几个处理方式:
常见调用,比如 web 端和远程服务器交互,这是客户端与服务器之间的交互
RPC 是指服务器和服务器之间的调用
依赖中间件做数据交互,比如 MySQL、RabbitMQ、Redis 等作为中间依赖的调用方式,A 服务器向 B 服务器发送请求时 需要经过中间件,这类交互形式不需要 B 服务器立刻给出处理结果,一般适合处理数据挤压类型的架构,比如双十一订单量巨大,B 服务器处理能力有限,先把订单数据积压在中间件中,然后 B 服务器慢慢去处理。
直接交互,没有中间件,通过 HTTP、RPC、WS 等方式进行通信,这类架构的特点就是快速相应,A 服务器发送请求到 B 服务器,并会一直等待 B 服务器响应。
RPC 有 Server(一般叫Provider) 和 Client(一般叫Consumer) 的概念,只不过两者都是服务器, Client 服务器属于服务消费者,Server 属于服务提供者
RPC 可以理解为:服务器可以像调用本地方法一样调用远程方法
除了 Google 的 gRpc 和 Facebook 的 thrift 支持多语言,其他框架都只支持 Java
gRpc 和 thrift 都是通过借助代码生成工具,根据服务的描述文件来生成不同语言的 Client 和 Server 的代码,gRpc 和 thrift 都用自家的 protobuf 和 thrift 格式的文件来序列化。
RPC 整个架构分为三块:
RPC 的调用过程是这样的:
PS:注册中心并不是必须的模块,Client 也可以把 Server 的信息直接写死,然后直接调用 Server;
也就是说,RPC 中最关键的是调用这一环。
这个过程就是图中的 1-10 ,视频解释
所以,整个 RPC 调用,一般由 客户端、存根代理、服务端、网络传输、序列换与反序列化 这几个模块构成
总结:RPC 架构本质就是服务器调用另外一个服务器上的方法,文章通篇是对 RPC 架构的大致理解,后面会抽时间使用 Google 的 gRPC + Nodejs 来完成一个简单的 rpc 调用
文件上传如果加上进度条会有更好的用户体验(尤其是中大型文件),本文使用Nodejs配合前端完成这个功能。
前端我们使用 FormData 来作为载体发送数据。
<input type="file" id="file" />
<!-- 进度条 -->
<progress id="progress" value="0" max="100"></progress>// 获取 input file 的 dom 对象
const inputFile = document.querySelector('#file');
// 监听 change 事件
inputFile.addEventListener('change', function() {
// 使用 formData 装载 file
const formData = new FormData();
formData.append('file', this.files[0]);
// 上传文件
upload(formData);
})下面我们实现upload 方法。
const upload = ( formData ) => {
const xhr = new XMLHttpRequest();
// 监听文件上传进度
xhr.upload.addEventListener('progress', function(e) {
if (e.lengthComputable) {
// 获取进度
const progress = Math.round((e.loaded * 100) / e.total);
document.querySelector('#progress').setAttribute('value', progress);
}
},false);
// 监听上传完成事件
xhr.addEventListener('load', ()=>{
console.log('😄上传完成')
}, false);
xhr.open('post', 'http://127.0.0.1:3000/upload');
xhr.send(formData);
}jQuery 目前的使用量依然庞大,那么使用 jQuery 的 ajax 如何监听文件上传进度呢:
const upload = ( formData ) => {
$.ajax({
type: 'post',
url: 'http://127.0.0.1:3000/upload',
data: formData,
// 不进行数据处理和内容处理
processData: false,
contentType: false,
// 监听 xhr
xhr: function() {
const xhr = $.ajaxSettings.xhr();
if (xhr.upload) {
xhr.upload.addEventListener('progress', e => {
const { loaded, total } = e;
var progress = (loaded / total) * 100;
document.querySelector('#progress').setAttribute('value', progress);
},
false
);
return xhr;
}
},
success: function(response) {
console.log('上传成功');
}
});
}axios 使用量非常大,用它监听文件上传更简单,代码如下:
const upload = async ( formData ) => {
let config = {
// 注意要把 contentType 设置为 multipart/form-data
headers: {
'Content-Type': 'multipart/form-data'
},
// 监听 onUploadProgress 事件
onUploadProgress: e => {
const {loaded, total} = e;
// 使用本地 progress 事件
if (e.lengthComputable) {
let progress = loaded / total * 100;
document.querySelector('#progress').setAttribute('value', progress);
}
}
};
const { status } = await axios.post('http://127.0.0.1:3000/upload', formData, config);
if (res.status === 200) {
console.log('上传完成😀');
}
}这部分比较简单,其实就是单纯的文件上传,我们用 Koa 来实现.
这里使用 koa2,安装以下依赖包:
const Koa = require('koa');
const Router = require('@koa/router');
const koaBody = require('koa-body');
const path = require('path');
const fs = require('fs');
const cors = require('@koa/cors');
const app = new Koa();
const router = new Router();
router.all('/upload', async ctx => {
// 处理文件上传
const res = await dealFile(ctx);
res && (ctx.body = {
status: 200,
msg: 'complete'
});
});
// 中间件部分
app.use(cors());
app.use(
koaBody({
multipart: true,
formidable: {
maxFileSize: 2000 * 1024 * 1024 //最大2G
}
})
);
app.use(router.routes());
app.use(router.allowedMethods());
app.listen(3000);出于性能考虑,我们操作file 毫无疑问要使用stream。
我们要监听end事件,没办法在事件回调里返回响应,因为会报 404,所以需要使用 Promise 来封装一下,然后用 async、await
const dealFile = ctx => {
const { file } = ctx.request.files;
const reader = fs.createReadStream(file.path);
const writer = fs.createWriteStream(
path.resolve(__dirname, './image', file.name)
);
return new Promise(resove => {
reader.pipe(writer);
reader.on('end', () => {
resove(true);
});
});
};到这里就全部完成了。
注意:前端监听文件进度不需要后端有什么特殊处理,后端仅仅是做了文件流的写入而已。
docker pull jenkins/jenkins:2.249.3-lts-centos7这里用的2.249.3-lts-centos7版本
在 run 镜像之前,需要修改下目录权限, 因为当映射本地数据卷时,/www/jenkins_home目录的拥有者为 root 用户,而容器中 jenkins user 的 uid 为 1000
执行下面命令
sudo chown -R 1000:1000 /www/jenkins_home然后 run jenkins 镜像
docker run -p 8080:8080 -p 50000:50000 -p 3333:3333 -d -v /www/jenkins_home:/var/jenkins_home jenkins/jenkins:2.249.3-lts-centos7/var/jenkins_home与宿主机的/www/jenkins_home映射启动容器后即可在浏览器访问 Jenkins,初始化需要填写一个秘钥(秘钥在命令工具中会给你,复制一下就ok)。
登录进去后,安装推荐的插件,然后在 系统管理->插件管理安装Nodejs插件,用于跑 nodejs 项目。
然后在系统管理->全局工具配置中安装 nodejs :
构建一个自由风格的软件项目点击确定后是这样的页面:
输入当前的任务描述,然后在源码管理中选择Git:
这里使用 sshkey 的方式来拉去代码
初始化时,Credentials(证书) 没有选项,它是用来验证 git 权限的,需要添加一个私钥,点击添加:
对于如何生成秘钥请看:Git 目录下的 git ssh秘钥这篇文章。
然后将 git 拉下来的代码检出到本地子目录,这里写的是sub_dir
这里是 Nodejs 环境,配置一下就好
上面配置完了 git 代码的拉取、nodejs 的运行环境,下面执行一些 shell ,这些 shell 主要用来定义环境变量、安装 nodejs 项目依赖包、启动 nodejs 项目。
最后点击保存,到首页即可点击构建,就开始执行对应的任务。任务执行的细节可以通过控制台输出来查看。
它属于行为设计模式,定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换
一个基于策略模式的程序至少由两部分组成:
要做到这点,说明 Context 中要维持对某个策略对象的引用;
条条大路通罗马,现在人们出去旅游会选择各种方式,这里通过策略模式来完成不同需求下的旅游
先建立几组策略类,这些策略是旅游出行的方式,有的人有时间选择徒步,有的人旅游地方远或时间紧就选飞机,有的人享受自驾:
/**
* 定义多个策略类 每个策略算法不同
*/
class Foot {
trigger() {
console.log('时间很长 徒步旅行');
}
}
class Car {
trigger() {
console.log('开车自驾游')
}
}
class Plain {
trigger() {
console.log('地方远时间紧 飞机旅游')
}
}具体的策略有了,现在需要一个环境类 Context 来接收策略,根据不同场景委托给对应的策略:
/**
* 定义环境类 接收请求 把请求委托给策略类 让策略类去处理
* @class Context
*/
class Context {
constructor(stragegieInstance) {
// 传入具体某个策略实例
this.stragegieInstance = stragegieInstance;
}
handle() {
this.stragegieInstance.trigger();
}
}此时根据不同请求来委托不同的策略:
// Context根据不同请求 来使用不同的策略
// 案例1:我有很长时间,想徒步看世界 则使用 Foot 策略
const FootInstance = new Foot();
const context = new Context(FootInstance);
context.handle();
// 案例2:我想自驾旅游 则使用 Car 策略
const CarInstance = new Car();
const context = new Context(CarInstance);
context.handle();
// 案例3:旅游地方远时间也紧 则使用 Plain 策略
const PlainInstance = new Plain();
const context = new Context(PlainInstance);
context.handle();策略模式的核心是:通过一个 Context 类接收请求,将请求委托给具体的策略类
实际开发中使用策略模式的地方很多,比如表单验证有很多验证策略,比如页面要根据不同的用户显示不同的内容,这也是策略模式
JavaScript作为一门高级编程语言,不像其他语言(例如C语言)需要开发者手动的去管理内存,在 JavaScript 中,系统会自动为你分配内存,在几乎任何一种语言中,内存的生命周期主要分三个阶段:
JavaScript数据类型分两大类:基本类型、引用类型。
字符串、数字、布尔值等属于基本类型,对象类型都属于引用类型。
栈是一种先进后出、后进先出的数据结构,
举个例子,乒乓球盒子(先进后出,后进先出):
堆是一种树的结构,所以它是“无序”的,可以从任何地方将数据取出来,比如书架里的书
// 基本类型
const a = 'hello world';
// 引用类型
const obj = {}栈内存中存的数据大小必须是固定的,所以基本类型都会存储在栈内存中,这种存储方式属于简单存储,也叫静态内存,所以它的效率是很高的。
堆内存中存的是引用类型的对象数据,比如 JSON、Function、Array 等等,因为引用类型数据没有固定大小,所以不能存在于栈内存,在运行时的访问方式是通过存在栈内存里的指针(地址)去堆里寻找对应的对象数据,也称它为动态内存,堆内存的效率是比栈内存要低。
我们在使用引用类型数据时,系统会在栈内存中存一个地址,该地址指向堆内存空间中你需要找的对象。
常听说内存泄漏,到底什么是内存泄漏? 从本质上说,内存泄漏可以定义为:不再被应用程序所需要的内存,出于某种原因,它不会被GC回收
在 JavaScript 中,对于没有声明的变量,则会在全局范围中创建一个新的变量并对其进行引用,在浏览器中,全局对象是 window,例如:
function foo(arg) {
bar = "some text";
this.book = 'JavaScript';
}等价于:
function foo(arg) {
window.bar = "some text";
window.book = 'JavaScript'
}如果这种意外的全局变量过多,则会导致内存溢出
你可以使用更严格的use strict模式来避免它,或者你必须能确保将其指定为null
常用的定时器,比如setInterval
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); //每五秒会执行一次定时器里有对 id 为 renderer 的 DOM 进行引用,试想如果未来在某处将该 DOM 删掉,会导致定时器内部的代码变得不再需要,但由于定时器仍在运行,所以导致里面的处理程序所占内存不能被 GC 回收,也意味着 serverData 不能被回收。
所以我们在不适用定时器的时候,务必使用clearInterval将该定时器清除,断开其内部代码的引用,可以让 GC 收集和回收。
闭包是内部函数使用外部函数的变量
let thing = null;
const fun1 = function () {
const oThing = thing;
const unused = function () {
if(oThing) // 引用了oThing
console.log('hi')
}
thing = {
longStr: new Array(10000).join('*'),
someMethod: function (){
console.log('message')
}
}
}
setInterval(fun1, 1000)unused函数内引用了外部的oThing,在fun1中调用了thing。
在thing中,为 someMethod 创建的作用域可以被 unused 共享。
该闭包的形成,阻止了oThing的回收。
而且在定时器中被循环执行,thing的内存大小将会稳定增长,而且每个作用域都间接引用了一个longStr这个大数组,造成了相当大的内存泄漏。
const elements = {
button: document.getElementById('button'),
image: document.getElementById('image')
}
function setSrc() {
elements.image.src = 'http://exmaple.com/image_name.jpg'
}
function removeImage(){
// image是body元素的直接子元素
document.body.removeChild( document.getElementById('image') )
// 此时,虽然 image 元素被删了,但全局对象中仍然引用#image,仍在内存中,GC无法收集它
}使用ssh-keygen命令生成 ssh 秘钥:
➜ ~ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/aa/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /Users/aa/.ssh/id_rsa.
Your public key has been saved in /Users/aa/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:vJ43VKHgqjiQVorBY4tZL6f2wXX6V8l6F/DjN8iLJ8o aa@AAdeMacBook-Pro
The key's randomart image is:
+---[RSA 3072]----+
| |
| . . |
|. . . . . |
|.+.. .. . o |
|+==. ..S o + |
|*+..o..o .. + + |
|.. =o.. .. o...o |
| = .. o..=.o+o..|
| . o. +E.+oo...|
+----[SHA256]-----+
查看刚才生成的秘钥:
➜ ~ ls ~/.ssh
id_rsa id_rsa.pub known_hosts
一般 ssh 需要公钥,查看公钥:
➜ ~ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDJthVQyVKP+4gGIyTH9zrd/0Ak2n0PAnHED71VZx/HgdOue/HfzXVgfO2pLnq/rzO9W/GUEOetdOwyhDRsB/x1bFGvYRn6dKXQh8I949pc4uj5jHG6s0eiKG3e4Kahckxj8y0LxQ1VG+erYQ05FeXo/27iFXRYe4At13GS2QHQ+a3Lbh6O0whl2qITzOWO8IIH3g1HLkjlPL8cmOz1gpgcqh1LQ/HjERIlxDiFtn1Y8J/G9R1RGh21lNaRbXX7rzGUfuaToB1kifNcz8VzDbpNZgXl8BFuFLfHMcpay113Y1kg588/ESh166MPDQngHp1YjkZLNgDwQsXJ+qyTjnfi3kOo56loCr+y653BtJqSa86f7n/tTdKw7lCicRhDzrFHRNV9lBApIp7dAfdIV03HuKHJ5JRBtCKNRN/mziWaxi0oE1IZdPK76Ehzh0FuPRpe8fbTc8qir6xYnMGOthmMcOtwAoWi+Lcb4JIekRcLsJo9F05xUzvNj3KxwSteehU= aa@AAdeMacBook-Pro
以 github 为例,进入用户-> settings -> SSH and GPG keys,新建一个 ssh key,将刚才的 ssh 公钥复制进去即可
学习nodejs必须要掌握其核心,就像学JavaScript必须掌握函数、对象、数据类型、BOM、DOM等。
nodejs核心也不少,这里介绍几个核心:Events模块、fs模块、stream的使用、http模块。
事件驱动、非阻塞异步IO是nodejs的特点,所以Events是非常重要的模块。并且node中绝大多数模块都继承了Events。
事件是发布订阅模式的实现。在浏览器中,比如click事件
$('button').on('click',()=>{
//处理click响应
})当然你也可以自定义事件:
//自定义事件
$('div').bind('hello',()=>{
alert('hello')
});
//触发事件
$('div').trigger('hello');那么在 node 中如何使用 Events 模块的呢?
我们定义一个类,让它继承 Events
const EventEmit = require('events');
//定义一个播放器类
class Player extends EventEmit { }
const player = new Player();
//定义播放事件
player.on('play', ( param )=>{
console.log(`播放器播放《${param}》`)
})
play.emit('play','海阔天空'); // 播放器播放《海阔天空》
play.emit('play','七里香'); // 播放器播放《七里香》如果你想让事件只执行一次,可以使用 once :
//定义播放事件
player.once('play', ( param )=>{
console.log(`播放器播放《${param}》`)
})
play.emit('play','海阔天空');
play.emit('play','七里香'); 此时 只会打印出 播放器播放《海阔天空》
上面也说了 node 中绝大多数模块都继承了 Events,比如 stream、fs、http等等,它们就像浏览器里的 click,是原生就有的,如果你接着往下看 会对发现很多用到事件的地方。
fs 全拼是 file system 即文件系统。
既然是文件系统,它的主要作用就是操作文件,比如文件的新增、修改内容、读写文件内容等。
查看文件夹信息
fs.stat('./logs', (err, stats) => {
if (err) {
console.log(err);
return;
}
console.log('目录:', stats.isDirectory());
console.log('文件:', stats.isFile());
console.log('大小:', stats.size);
});
//打印结果
目录: true
文件: false
大小: 160查看文件信息
fs.stat('./fs.js', (err, stats) => {
if (err) {
console.log(err);
return;
}
console.log('目录:', stats.isDirectory());
console.log('文件:', stats.isFile());
console.log('大小:', stats.size);
});
//打印结果
目录: false
文件: true
大小: 2087// 创建目录
fs.mkdir("./logs", err => {
if (err) {
console.log(err);
return;
}
console.log("logs目录创建成功");
});fs.mkdir 是异步方法,如果你想同步创建可以使用 fs.mkdirSync
fs.mkdirSync('./logs2'); //同步创建文件夹fs.writeFile('./logs2/hello.log', '你好~', err => {
if (err) {
console.log(err);
return;
}
console.log('写入成功');
});注意: 若文件不存在则创建文件 若文件中有内容则覆盖
有时候我们不希望内容被覆盖,而是追加,那么可以使用 appendFile 方法。
fs.appendFile("./logs/hello.log", "hello~\n我是程序员", err => {
if (err) {
console.log(err);
return;
}
console.log("写入成功");
});// 读取文件内容
fs.readFile("./logs/hello.log", "utf8", (err, stats) => {
if (err) {
console.log(err);
return;
}
console.log(stats);
});// 读取文件夹
fs.readdir("./logs", (err, files) => {
if (err) {
console.log(err);
return;
}
console.log(files); //返回一个包含所有文件名称的数组
});
//打印结果
[ 'data-write.json', 'data.json', 'traking.log' ]// 修改名称 把hello.log修改为tranking.log
fs.rename("./logs/hello.log", "./logs/traking.log", err => {
if (err) {
console.log(err);
return;
}
console.log("改名成功");
});// 删除目录下文件
fs.readdirSync("./logs").map(file => {
// 删除文件unlink
fs.unlink(`./logs/${file}`, err => {
if (err) {
console.log(err);
return;
}
console.log("文件删除成功");
});
});// 只能删除空目录 若目录里不为空则会报错 所以要先删除里面的文件 再删除文件夹
fs.rmdir("./logs", err => {
if (err) {
console.log(err);
return;
}
console.log("目录删除成功");
});流,可理解为水流。只不过这里是数据流。
流的意义在于三点:
const fs = require('fs');
const fileReadStream = fs.createReadStream('./logs/data.json');
const fileWriteStream = fs.createWriteStream('./logs/data-write.json');
/* 通过文件流的事件方式 */
fileReadStream.on('data', chunk => {
fileWriteStream.write(chunk); // 可写流写入文件 如果文件不存在则创建文件
});
fileReadStream.on('error', err => {
console.log('错误:', err);
});
fileReadStream.on('end', () => {
console.log('结束');
});上面代码中建立了一个流:可读流--->可写流。它满足了上面说的三点:有源头(可读流)、有终点(可写流)、从源头到终点(一个文件里的数据流到了另一个文件里)。
代码中也能看出,Stream 其实也继承了 Events,它含有data、error、end等事件。
我们把上面代码改一下
// 监听pipe事件
fileWriteStream.on('pipe', source => {
console.log(source);
});
/* 通过pipe方式 */
fileReadStream.pipe(fileWriteStream);pipe 可理解为水管,在可读流和可写流之间连接了水管,不需要再监听 data 事件,使用起来很方便 能达到同样的效果。
http 模块主要用于搭建 http 服务,处理用户请求信息等
const http = require('http');
// 使用发送http请求
const options = {
protocol: 'http:',
hostname: 'www.baidu.com',
port: '80',
method: 'GET',
path: '/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg'
};
let responseData = '';
const request = http.request(options, response => {
console.log(response.statusCode); // 获取链接请求的状态码
response.setEncoding('utf8');
response.on('data', chunk => {
responseData += chunk;
});
response.on('end', () => {
console.log(responseData);
});
});
request.on('error', error => {
console.log(error);
});
request.end();// 使用http创建服务器
const port = 3000;
const host = '127.0.0.1';
const server = http.createServer();
server.on('request', (request, response) => {
response.writeHead(200, {
'Content-Type': 'text/plain'
});
response.end('Hello World\n');
});
server.listen(port, host, () => {
console.log(`Server running at http://${host}:${port}/`);
});关于 Node 核心模块还有很多,比如 Buffer、crypto加密、global全局变量、net网络、os操作系统等等,只不过上面介绍的是使用频率非常高的模块。
后面文章会继续介绍,详情的api使用请参考官网
babel 在转译时,会将源码分为两个部分来处理,分别是: syntax 和 api
{
"presets": [ ["@babel/preset-env"] ]
}preset-env可以使用最新的 JavaScript Api ,它是许多 preset 的集合(es2015+),通过配置来智能使用 JavaScript。
但随着 ECMA 的发展会一直更新和增加里面的内容,比如今年(2021年)它包含的预设由:es2020、es2019、... es2015。到了明年,它的 preset 可能就多包含一个 es2021
默认情况下,preset-env 跟 babel-preset-latest 是等同的;
在发中,如果需要支持特定的浏览器,可以通过 targets 来配置,preset-env 会根据配置生成相符合的代码:
{
"presets":[
["@babel/preset-env", {
"targets": {
"chrome": 88
}
}]
]
}合理的配置,能减少很多无用的代码;
对于 preset-env ,syntax 语法很容易就转好了,但 api 不会做任务处理,比如:
const 属于 syntax 语法,但 includes 并没有被转译。如果运行在不支持 includes 的浏览器中就会报错。
babel 使用 polyfill 来处理 api,@babel/preset-env 中有个配置选项 useBuiltIns,用来告诉 babel 如何处理 api,它的默认值是 false,即默认不处理任何 api。
{
"presets":[
["@babel/preset-env",{
"useBuiltIns": "usage"
}]
]
}useBuiltIns 还有一个选项是entry, 即在项目入口处把整个 polyfill 引入,这样会导致包非常大,而我们需要的仅仅是能支持 includes 而已。所以不用 entry 而使用 usage ,它会根据使用 api 的情况来按需加载需要用到的 polyfill 。这里的 polyfill 来自 core-js这个库,所以完整配置如下:
{
"presets":[
["@babel/preset-env",{
"useBuiltIns": "usage",
"corejs" 3
}]
]
}babel 在转译 syntax 时,会经常使用一些辅助函数来帮忙转译,比如 class 语法中,babel 自定义了 _classCallCheck 这个辅助函数;typeof 则被重新自定义了一个 _typeof 辅助函数。这些函数叫做 helpers,一个项目中如果每个文件都有这些函数,显然会不合理。
@babel/plugin-transform-runtime就是为了解决这个问题:
yarn add @babel/plugin-transform-runtime @babel/runtime -D然后配置一下
"plugins":[
["@babel/preset-env",{
"useBuiltIns": "usage",
"corejs" 3
}]
]babel 在转译过程中,对 syntax 语法的处里非常好,但有很多 api 是不转译的,比如数组的 includes 方法
preset-env 转译 JavaScript ,可以通过 useBuiltIns 来设置 core-js ,用于解决 api 的 polyfill
babel 转译时,会自定义一些 helpers 函数,可以通过 @babel/plugin-transform-runtime 来抽离这些 heplers 统一导入
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.