Using python3.8, create programs for training and testing in pictures.
| 🔢 | Ход работы | ℹ️ |
|---|---|---|
| 1️⃣ | Установить библиотеки sklearn, h5py, mahotas | ✅ |
| 2️⃣ | Скачать датасет с покемонами по варианту (для каждого покемона отдельная директория). | ✅ |
| 3️⃣ | Выбрать фичи («признаки»), для сравнения изображений (цвет, размер, форма, наличие хвоста, бровей и т.д). | ✅ |
| 4️⃣ | Подобрать фильтры для каждой фитчи. | ✅ |
| 5️⃣ | Извлечь фичи из каждой картинки обучающей выборки и записать в отдельный датасет. | ✅ |
| 6️⃣ | Разделить датасет на обучающую и тестовую выборку. | ✅ |
| 7️⃣ | Построить модели GaussianNB, Logistic Regression, Decision Tree, SVM, Random Forest, обучить, оценить полноту, точность и аккуратность и визуализировать с помощью «ящика с усами». | ✅ |
| 8️⃣ | Выбрать несколько картинок покемонов (не входящих в обучающую и тестовую выборки), определить их класс с помощью лучшего классификатора и подписать на картинках. | ✅ |
С помощью python3.8 создать программы для обучения и для тестинга на картинках с пакемонами.
В файле predict.py содержится программа для обучения на картинках. В ней содержатся функции, которые выявляют признаки и фитчи объектов расположенных на картинках.
Некоторые из наиболее часто используемых дескрипторов глобальных функций:
- Цвет - статистика цветового канала (среднее значение, стандартное отклонение) и цветовая гистограмма
- Форма - Hu Moments
- Моменты Зернике
- Текстура - Текстура Haralick
- Локальные двоичные паттерны (LBP)
- Гистограмма ориентированных градиентов (HOG)
- Статистика порогового соответствия (TAS)
Дескрипторы локальных функций - это дескрипторы функций, которые количественно определяют локальные области изображения. Точки интереса определяются на всем изображении, а участки / области изображения, окружающие эти точки интереса, рассматриваются для анализа.
Некоторые из наиболее часто используемых дескрипторов локальных функций:
- SIFT (масштабное инвариантное преобразование признаков)
- SURF (ускоренные и надежные функции)
- ORB (Ориентированная быстрая и вращающаяся КРАТКАЯ ИНФОРМАЦИЯ)
- КРАТКИЙ ОБЗОР (Двоичные надежные независимые элементарные функции)
- Объединение глобальных функций
Есть два популярных способа комбинировать эти векторы признаков.
Для глобальных векторов признаков мы просто объединяем каждый вектор признаков, чтобы сформировать один глобальный вектор признаков. Это подход, который мы будем использовать в этой лабораторной. Для локальных векторов признаков, а также для комбинации глобальных и локальных векторов признаков нам понадобится «Пакет визуальных слов» (BOVW). Обычно он использует построитель словаря, кластеризацию K-средних, линейную SVM и векторизацию Td-Idf.
- Hu Moments
Чтобы извлечь функции Hu Moments из изображения, мы используем функцию cv2.HuMoments (), предоставляемую OpenCV. Аргументом этой функции являются моменты изображения cv2.moments () сглаженным. Это означает, что мы вычисляем моменты изображения и конвертируем его в вектор с помощью flatten (). Перед этим мы конвертируем наше цветное изображение в изображение в оттенках серого, поскольку в моменты ожидания изображения будут в оттенках серого.
def fd_haralick(image):
def fd_hu_moments(image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
feature = cv2.HuMoments(cv2.moments(image)).flatten()
return feature- Текстуры Haralick
Чтобы извлечь из изображения особенности текстуры Haralick, мы используем библиотеку mahotas. Мы будем использовать функцию mahotas.features.haralick (). Перед этим мы конвертируем наше цветное изображение в изображение в градациях серого, поскольку дескриптор функции haralick ожидает, что изображения будут в оттенках серого.
def fd_haralick(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
haralick = mahotas.features.haralick(gray).mean(axis=0)
return haralick- Цветовая гистограмма
Чтобы извлечь функции цветовой гистограммы из изображения, мы используем функцию cv2.calcHist (), предоставляемую OpenCV. Аргументы, которые он ожидает, - это изображение, каналы, маска, histSize (ячейки) и диапазоны для каждого канала [обычно 0-256). Затем мы нормализуем гистограмму с помощью функции normalize () OpenCV и возвращаем сглаженную версию этой нормализованной матрицы с помощью flatten ().
def fd_histogram(image, mask=None):
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
cv2.normalize(hist, hist)Важно: чтобы получить список обучающих меток, связанных с каждым изображением, в рамках нашего обучающего пути у нас должны быть папки с названиями с названиями соответствующих видов цветов, внутри которых хранятся все изображения, принадлежащие этой метке.
После извлечения, объединения и сохранения глобальных функций и меток, из нашего набора обучающих данных, пора обучить нашу систему. Для этого нам нужно создать наши модели машинного обучения. Для создания нашей модели машинного обучения мы используем scikit-learn.
| 🔢 | В качестве наших моделей машинного обучения выберем |
|---|---|
| 1️⃣ | Логистическую регрессию |
| 2️⃣ | Линейный дискриминантный анализ |
| 3️⃣ | Метод K-ближайших соседей |
| 4️⃣ | Деревья решений |
| 5️⃣ | Случайные леса |
| 6️⃣ | Гауссовский наивный байесовский анализ |
| 7️⃣ | Машину опорных векторов |
Чтобы понять эти алгоритмы, пройдите потрясающий курс по машинному обучению профессора Эндрю Н.Г. на Coursera или посмотрите этот потрясающий плейлист доктора Нуреддина Садави.
Кроме того, мы будем использовать функцию train_test_split, предоставляемую scikit-learn, чтобы разделить наш обучающий набор данных на train_data и test_data. Таким образом, мы обучаем модели с помощью train_data и тестируем обученную модель с невидимыми test_data. Размер разделения определяется параметром test_size.
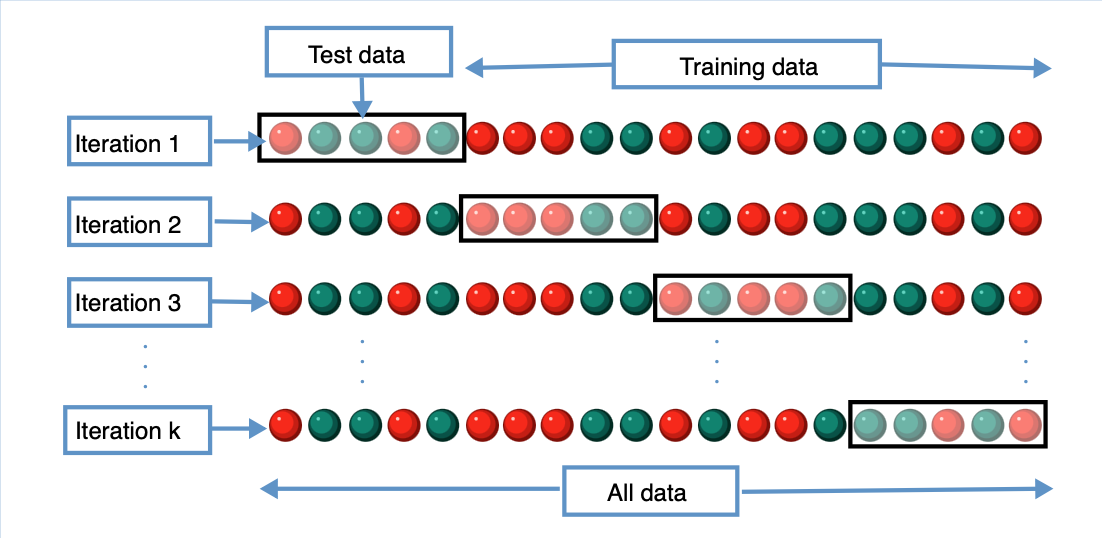
Мы также будем использовать метод под названием K-Fold Cross Validation, метод проверки модели, который является лучшим способом прогнозирования точности модели машинного обучения. Короче говоря, если мы выберем K = 10, то мы разделим все данные на 9 частей для обучения и 1 часть для уникального тестирования в каждом раунде до 10 раз. Чтобы узнать больше об этом, перейдите по этой ссылке.
Импортируем все необходимые библиотеки для работы и создаем список моделей. В этом списке будут все наши модели машинного обучения, которые будут обучены нашим локально сохраненным функциям. Во время импорта наших функций из локально сохраненного файла формата .h5 всегда рекомендуется проверять его форму. Для этого мы используем функцию np.array (), чтобы преобразовать данные .h5 в массив numpy, а затем распечатать его форму.
h5f_data = h5py.File('features/data.h5', 'r')
h5f_label = h5py.File('features/labels.h5', 'r')
global_features_string = h5f_data['dataset_1']
global_labels_string = h5f_label['dataset_1']
global_features = np.array(global_features_string)
global_labels = np.array(global_labels_string)
h5f_data.close()
h5f_label.close()
(trainDataGlobal, testDataGlobal, trainLabelsGlobal, testLabelsGlobal) = train_test_split(np.array(global_features),В файле get_feature.py содержится программа для проверки нашей программы после обучения. В соответсвии с моим вариантом мне нужно было определить 6-х пакемонов: Pikachu, Raichu, Drowzee, Clefable, Clefairy, Ditto. Для этого я скачал изображения загрузил в отдельную папку под названием "test" и после выполнения подписанные картинки будут сохранены в папку "saved"












Так же напоминаю для тех кому интересно выполнить задание самому или протестировать данную программу, то прошу перейти сюда