論文のまとめをIssueで管理しています。
論文をテーマごとにまとめています。
What I read
論文のまとめをIssueで管理しています。
論文をテーマごとにまとめています。




































http://proceedings.mlr.press/v95/tao18a.html
http://www.toshiba.co.jp/about/press/2018_11/pr_j1401.htm
Yaling Tao, Kentaro Takagi, Kouta Nakata / TOSHIBA
Proceedings of The 10th Asian Conference on Machine Learning, PMLR 95:49-64, 2018.
http://musyoku.github.io/2016/12/10/Distributional-Smoothing-with-Virtual-Adversarial-Training/
提案手法(以下VAT)は、予測分布p(y∣x)を最も狂わすノイズr_{v−adv}を計算により求め、p(y∣x+r_{v−adv})をp(y∣x)に近づけることでモデルの頑健性を高める手法です。
データxから求まる予測分布p(y∣x,θ)と、ノイズrを加えたデータx+rから求まる予測分布p(y∣x+r,θ)に対し、両者のKL距離を最小化します。
https://qiita.com/yuzupepper/items/e2d093f05adccbe1b7f1
各学習データ周辺における事後確率の分布を滑らかにすることでネットワークの汎化性能を向上させる手法です。Virtual Adversarial TrainingはAdversarial Trainingから派生した手法で、学習データの正解ラベルから計算した損失の代わりに事後確率同士の距離から計算した損失を用いることでラベルなしのデータも学習に活用する事ができます。
http://shunk031.me/paper-survey/summary/cv/Unsupervised-Deep-Embedding-for-Clustering-Analysis
高次元で規模の大きいデータセットに対しても効率的にクラスタリングできるよう特徴量を学習する
but it is sometimes sensitive to the initial location of centroids, especially in the case of imbalanced data, where the minor class has less chance to be assigned a good centroid.
VATや各ハイパーパラメータの効果を検証している
https://arxiv.org/abs/1507.00677
end-to-endの方法で分散表現を使用する埋め込みベースのニュース推薦手法の提案
http://www.kdd.org/kdd2017/papers/view/embedding-based-news-recommendation-for-millions-of-users
Shumpei Okura (Yahoo! JAPAN);Yukihiro Tagami (Yahoo Japan Corporation);Shingo Ono (Yahoo Japan Corporation);Akira Tajima (Yahoo! Japan)
KDD2017
RNNモデルを採用することで、ブラウジング履歴から各ユーザの特徴を表現し、高精度の推薦を可能にした
ニュース以外の分野(広告)などにも推薦技術を応用していきたい
NULL

Qian Yang, Jina Suh, Nan-Chen Chen, Gonzalo Ramos
Proceeding of the 2018 Designing of Interactive Systems Conference
June 2018
Yoshifumi Seki (Gunosy Inc.), and Mitsuo Yoshida (Toyohashi University of Technology).
Analysis of Bias in Gathering Information Between User Attributes in News Application. 2018.
2018
Null
https://www.aclweb.org/anthology/C96-1009
Katerina T. Franzi and Sophia Ananiadou
In Proceedings of the 16th International Conference on Computational Linguistics (COLING ‘96), pp. 41-46, 1996.
1996
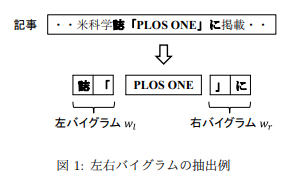
日本語の科学ニュース記事では,研究成果がわかりやすく述べられるが,出典となる文献情報は明記されない傾向にある.このことは,読者が研究の詳細を知ることへの障壁となっている.一方,研究内容が掲載された雑誌名は記事中に明記されることが多く,雑誌名を自動抽出することで対象の文献情報を探索する手がかりが得られる.
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/P11-6.pdf
菊地真人, 吉田光男, 梅村恭司 (豊橋技科大)
言語処理学会第24回年次大会(NLP2018)
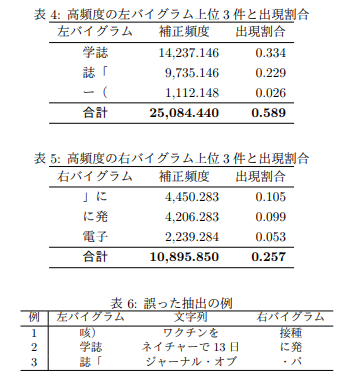
ウェブから収集した科学ニュース記事から雑誌名を抽出し,提案手法の性能を定量的に評価
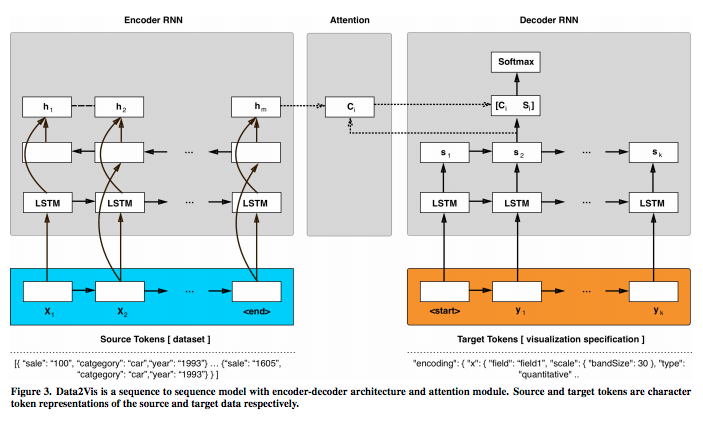
Data2Vis: Automatic Generation of Data Visualizations Using Sequence to Sequence Recurrent Neural Networks
https://arxiv.org/abs/1804.03126
Victor Dibia, Çağatay Demiralp
https://arxiv.org/abs/1805.07470
Stephen McAleer, Forest Agostinelli, Alexander Shmakov, Pierre Baldi
arXiv
[v1] Fri, 18 May 2018 23:07:31 GMT
https://arxiv.org/abs/1810.09591
Malay Haldar, Mustafa Abdool, Prashant Ramanathan, Tao Xu, Shulin Yang, Huizhong Duan, Qing Zhang, Nick Barrow-Williams, Bradley C. Turnbull, Brendan M. Collins, Thomas Legrand
arXiv
http://search.ieice.org/bin/summary.php?id=j102-d_2_34&category=-&lang=J&year=2019&abst=
矢野 正基, 大賀 隆裕, 大西 正輝,
電子情報通信学会論文誌 D Vol. J102–D No. 2 pp. 34–52
2019/02/01
https://arxiv.org/abs/1905.03151
Giles Hooker, Lucas Mentch
arXiv
Submitted on 1 May 2019
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/A1-3.pdf
小林健 (ヤフー), 小林隼人 (ヤフー/理研AIP), 村尾一真, 増山毅司 (ヤフー)
言語処理学会第24回年次大会(NLP2018)
実験結果の細部について議論
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/B3-3.pdf
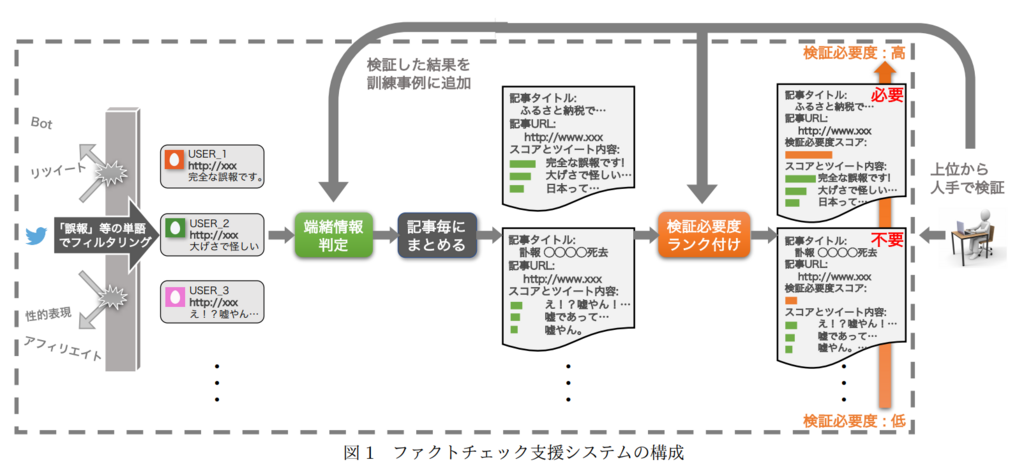
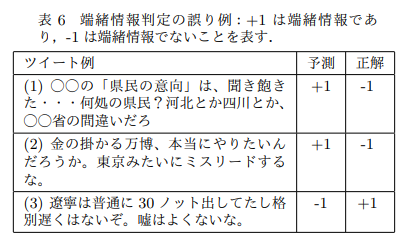
田上翼, 浅野広樹 (東北大), 楊井人文, 山下亮 (日本報道検証機構), 小宮篤史, 藤村厚夫 (スマートニュース), 町野明徳 (フリー), 乾健太郎 (東北大)
言語処理学会第24回年次大会(NLP2018)
インターネット上の誤情報を検出する研究は行われているものの [1, 2, 9],幅広いドメインから端緒情報を抽出し,要検証記事を収集する研究は本研究が初
NULL
https://arxiv.org/abs/1802.07398
眼底写真を用いた糖尿病性網膜症の診断を、deep learningアルゴリズムで自動化。2種類のデータセットでの実験を通じて、高精度で検知できると分かった。
https://jamanetwork.com/journals/jama/fullarticle/2588763
Varun Gulshan et al.
JAMA. 2016;316(22):2402-2410. doi:10.1001/jama.2016.17216
December 13, 2016
(データセットが違うので単純な比較はできないが)sensitibityとspecificityが高い。
deep convolutional neural network
Sensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function:
- Sensitivity (also called the true positive rate, the recall, or probability of detection[1] in some fields) measures the proportion of positives that are correctly identified as such (e.g. the percentage of sick people who are correctly identified as having the condition).
- Specificity (also called the true negative rate) measures the proportion of negatives that are correctly identified as such (e.g. the percentage of healthy people who are correctly identified as not having the condition).
NULL
https://arxiv.org/abs/1712.07136v2
http://www.orsj.or.jp/~nc2019s/wp-content/uploads/2019/02/2019s-2-A-1.pdf
日本オペレーションズ・リサーチ学会 2019年 春季研究発表会
先行研究 [1]では,商品閲覧履歴から各顧客の閲覧商品に対する「最新度」と「頻度」を数量化し,形状制約のもとで最新度と頻度の組に対して閲覧商品が購買される確率(商品選択確率)を推定する手法が提案された.しかし,この手法では顧客の閲覧履歴が最新度と頻度の 2 次元に縮約されるため,商品閲覧に関する多くの情報が失われてしまう.
提案手法の長所:先行研究の手法よりも詳細な情報を保持できる
短所:学習データの不足により過剰適合を生じやすい
過剰適合抑制のため,閲覧数列の順序関係に基づく推定値の補正方法を提案
[1] Iwanaga, J., Nishimura, N., Sukegawa, N., & Takano, Y. (2016). Estimating product-choice
probabilities from recency and frequency of page views. Knowledge-Based Systems, 99,
157–167.
決算短信特有の言語的な特徴を考慮した「事業セグメント情報抽出手法」を提案し、その有用性について実データを用いて評価
伊藤友貴 (東大), 小林暁雄, 関根聡 (理研AIP)
言語処理学会第24回年次大会(NLP2018)
各事業セグメントに関する説明を記載している文は以下に分類できる
| 分類 | 説明 | 数 |
|---|---|---|
| 単一型 | 文中に単一の事業セグメントの情報のみ含むもの | 450 |
| Forward型 | 一文中に複数の事業セグメントの説明があり,「セグメント名」,「セグメント説明」の順でセグメント情報が記載されるもの | 90 |
| Backword型 | 一文中に複数の事業セグメントの説明があり,「セグメント説明」,「セグメント名」の順でセグメント情報が記載されるもの | 27 |
数=検証データ320文書中のセグメント説明を含む分580文のうちの数
この性質を踏まえて、以下のように抽出する
一連の処理を通した事業セグメント説明文抽出の精度を改善したい
NULL
Microsoft Azure, Amazon AWSといったMachine Learning as a Service (MLaaS)の利便性が増しているが、ユーザのプライバシー保護の観点からMLaaSのサーバへのアップロードがはばかられる場合も多く、プライバシー保護のため暗号化されたデータを用いるとDNNモデルの性能を十分に発揮できない。
本研究では、"Paillier homomorphic cryptosystem"という暗号化の仕組みを用いた Privacy-Preserving Deep Neural Networks (2P-DNN) を提案。暗号化したMNISTデータセットでの分類性能が97%を示し、既存のプライバシー保護DNNよりも高い性能を発揮した。

https://arxiv.org/abs/1807.08459
Qiang Zhu, Xixiang Lv / School of Cyber Engineering, Xidian University, Xian 710071, China
arXiv
[v1] Mon, 23 Jul 2018 07:32:12 GMT (563kb)
https://link.springer.com/chapter/10.1007/978-3-319-23528-8_13
Dal Pozzolo, Andrea & Caelen, Olivier & Bontempi, Gianluca
Novel Decompositions of Proper Scoring Rules for Classification: Score Adjustment as Precursor to Calibration
September 2015
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/P1-25.pdf
高津弘明, 横山勝矢 (早大), 本田裕 (本田技研), 藤江真也 (千葉工大), 林良彦, 小林哲則 (早大)
言語処理学会第24回年次大会(NLP2018)
システム発話の工夫によって相互行為を活性化させようとする観点では,聞き手からの相槌やうなずきなどを誘発する研究が行われているが,これも韻律制御に留まっており,間の制御までは扱っていない [3]
NULL
ニュースコーパスからトピック (知りたい事柄) に関連するテーマを抽出し,そのテーマに関連する文が時系列順に並んだ文集合 (ストーリーライン) を出力するシステムを提案
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/P7-14.pdf
谷口祐太郎, 小林哲則, 林良彦 (早大)
言語処理学会第24回年次大会(NLP2018)
単語の重要度(文集合におけるある単語の出現頻度を,コーパス全体における出現頻度で正規化したもの)
NULL
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/C7-2.pdf
中島寛人, 山田剛(日本経済新聞社)
Yahoo!の方の言語処理学会2019の論文。Yahoo!ニュースのコメント欄で上位に表示するコメントの決め方を工夫。今は単純に「いいね」順にしているが、初速が大事になったりバイアスがかかったりで不健全。コメントの「建設度」を提唱して、この建設度を用いた表示方法を検証。「返信コメントを更に見る」ボタンのCTRが上がったとのこと。
http://anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P7-33.pdf
言語処理学会2019
グノシーにおけるユーザ行動履歴を用い、政治に関するニュース記事の閲覧傾向が世代によってどのように異なるのかを分析。最初に世代ごとのPVランキングを作成し、後に順位の差分が大きい記事を取り上げることで、若い世代は政策に中高年は政局に関心があるといった世代ごとの傾向が示唆された。
https://confit.atlas.jp/guide/event-img/jsai2018/3O2-OS-1b-04/public/pdf?type=in
関 喜史1 (1. 株式会社Gunosy)
2018年度人工知能学会全国大会
アンケートを用いたような調査は存在するものの,若年層の政治的関心がどのように他の世代と異なるのかについて,実際の行動に基づいた調査はほとんど行われていない
今回の分析はあくまでグノシー内の行動であり,一般化できるものではない.
https://confit.atlas.jp/guide/event/jsai2018/subject/4Pin1-14/advanced
岩崎 祐貴1 (1. (株) サイバーエージェント)
2018年度人工知能学会全国大会(第32回)
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/A1-2.pdf
Jan Wira Gotama Putra (東工大), Hayato Kobayashi (ヤフー/理研AIP), Nobuyuki Shimizu (ヤフー)
言語処理学会第24回年次大会(NLP2018)
上記に記載
文献[14]に基づき、以下のように定義する
Topic sentence contains the core elements ⟨subject, verb, object⟩ and at least one subordinate element time or location
NULL
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/B6-3.pdf
Jason Bennett, 野原崇史 (三井住友アセットマネジメント), Fei Cheng (NII), ○石田隆 (三井住友アセットマネジメント), 宮尾祐介 (NII)
言語処理学会第24回年次大会(NLP2018)
経済記事の分類に関する研究はセンチメント分類やイベント検出など様々あるが、不祥事検知については前例がない
実務上の目的に向けて、精度の向上だけでなく「解釈性の担保」「頑健性」「再学習の必要性」などの課題に取り組んでいる
過去のデータのみを使って学習させた場合、時が経つにつれて適合率や再現率が低下していくと分かった
※ このグラフの凡例が合っているか分からない。学習期間の月数が少ないほど精度が低いのは何故だ。。。
NULL
https://research-lab.yahoo.co.jp/nlp/20180606_higurashi.html
日暮 立、小林 隼人、村尾 一真、増山 毅司
2018年度 人工知能学会全国大会(第32回)(JSAI2018), 2018/6
2018/6
課題をランク学習の枠組みに落とし込んで、クラウドソーシングによる訓練用データ生成を可能にした

今後は, ランク学習の他にも深層学習を取り入れた手法の検討を行なっていく予定である. また, ランク学習によって生成した見出しのユーザーの回答率やクリック率への影響をオンラインで検証していくことも検討している
<script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>アダルトサイトの広告画像の世界で adversarial example が使われているという話 from S&P19。
— Tatsuya Mori (@valdzone) January 10, 2019
画像を見た人にはそれと認識できる(つまり広告として有効である)が、アダルトコンテンツ検知から逃れられるよう画像を加工するというもの(まだ概要を斜め読みしただけ)。https://t.co/jE8SqUpisH
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/E5-4.pdf
尾崎諒介, 前田竜冶 (福井大), 宇津呂武仁 (筑波大), 村瀬一之 (福井大)
言語処理学会第24回年次大会(NLP2018)
NULL
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=635861
Taejong Kim
KDI School of Public Policy and Management
Yoichi Okita
National Graduate Institute for Policy Studies
KDI School of Pub Policy & Management Paper No. 04-18
June 30, 2004
https://rss.onlinelibrary.wiley.com/doi/abs/10.1111/rssb.12243
Deep Neural Networkの特徴量の重要度を推定する手法の評価ベンチマーク「ROAR, RemOve And Retrain」を提唱。下図の通り、各推定器に基づいて最も重要と思われる特徴量の一部を削除し、再学習したときのモデルの精度の変化を測定する。

https://arxiv.org/abs/1806.10758
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim / Google Brain
[v1] Thu, 28 Jun 2018 03:46:57
29グループ(計61人)のデータアナリストに、同じデータセットと同じ質問を与えたときの分析アプローチのバラツキを分析。質問は「サッカーの主審は、肌の白い選手に比べて肌の黒い選手にレッドカードを与える可能性が高いですか?」。
分析アプローチはチーム間で大きく異なり、オッズ比で0.89から2.93の範囲だった(**値は1.31)。20チーム(69%)が統計的に有意な正の結果を示した一方で、9チーム(31%)は有意な関係を示さなかった。

これらの知見は、たとえ真摯な専門家集団であっても、複雑なデータの分析結果に主観的な要素が入り込むのは避け難いことを示唆している。 分析を透明化する手段として、同じ研究課題を同時に調査するために多数の研究チームを採用する「クラウドソーシング」が有用であると提言している。
http://journals.sagepub.com/doi/10.1177/2515245917747646
https://www.researchgate.net/publication/320041452_Many_analysts_one_dataset_Making_transparent_how_variations_in_analytical_choices_affect_results
R. Silberzahn et.al
SAGE Journals
First Published August 23, 2018

上位チームの傾向が遅攻スタイル,サッカー用語を使うとポゼッションサッカーと呼ばれる
パスを繋ぎ,ボールを相手に渡さずに攻めるチームが多いと見られる為,下位チームは素早く攻撃を行うカウンターサッカーの傾向からポゼッションサッカーにスタイル変更を行うことが上位進出への手掛かりになると見られる
(所感:スタイル変更→上位進出の手がかりという因果方向で良いのか?)
http://www.orsj.or.jp/~nc2019s/wp-content/uploads/2019/02/2019s-1-B-3.pdf
東海大学
日本オペレーションズ・リサーチ学会 2019年 春季研究発表会
特徴を一つずつ外した時に全体の誤差がどの程度変化するかを見ることで重要度を見いだす
To select proper features tailored for particular network, we decided to use a well known sensitivity based method developed by Moody [4]. It is called Sensitivity based Pruning (SBP) algorithm. It evaluates a change in training mean squared error (MSE) that would be obtained if ith input’s influence was removed from the network. The removal of influence of input is simply modeled by replacing it by its average value.
International Conference on Adaptive and Intelligent Systems 2014: Adaptive and Intelligent Systems pp 11-19 | Cite as
大学機関に所属する100以上のTwitterユーザを分析したところ、フォロワー1000人以上のユーザは、フォロワーの科学者以外の割合が高く研究のアウトリーチに効果的な状況になっていると分かった。

https://doi.org/10.1139/facets-2018-0002
Isabelle M. Côté, Emily S. Darling
FACETS, published by Canadian Science Publishing.
28 June 2018
Twitterのオンラインプロフィール情報をもとに、ユーザの各フォロワーの属性(科学者、メディア関係者、意思決定者など)を予想した。
https://www.jstage.jst.go.jp/article/jnlp/24/1/24_95/_pdf/-char/ja
フェイクニュースの検出に関して、例えば「○○議員が××と発言した」というニュースの真偽を判断するためには、一次情報である議会会議録などを用いて○○議員の実際の発言を調査すればよい。本研究では、新聞記事で引用されている箇所をどのように探せばよいか検討するため、地方議会会議録コーパスを利用し、会議録の発言がどのように新聞記事に記述されているかを明らかにする。具体的には、日経電子版の記事から「豊洲問題」に関する記事 67 点を収集し、そのうち発言文 (会議録要約文) が載る 32 点の記事から 150 の対応関係を抽出し、分析を行った。引用箇所の約95%はBoWなどの語句レベルの一致により推定できると示唆された。
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/B3-2.pdf
木村泰知, 戸嶋咲穂, 渋木英潔
言語処理学会 第24回年次大会 発表論文集 (2018年3月)
我々は,従来から,全国の自治体の地方議会会議録を収集・整理する手法を確立し,「地方議会会議録コーパス」の構築を進めてきた
特になし。
特になし。
対応箇所を自動的に推定する難しさの観点から、32記事における 150 文を以下のように分類した。
(1) は語句が連続しているかどうかの問題はあるが、引用箇所に該当する表現が全て発言箇所に存在しており、exact match により推定できると考えられる。(1) は最も簡単に対応関係を推定できる場合であり、調査対象の 22.7%(34/150 文)を占めた。
(2) は、引用箇所をBag of Words(BoW)として表現することで対応関係が推定できそうなものである。
(3) は、対応関係にある箇所全体の意味を考慮しなくてはならず、語句レベルの対応関係を超えているため最も難しい推定となる。しかしながら(3) は調査対象の 5.3%(8/150文)と少なかった。
特になし。検出に向けた続報が出たら読みたい。
http://www.anlp.jp/proceedings/annual_meeting/2018/pdf_dir/A7-4.pdf
大倉俊平, 小野真吾 (ヤフー)
言語処理学会第24回年次大会(NLP2018)
|*抽出法|説明|
|TF-All|全ての品詞を含む全単語から,記事中の出現頻度が高い順にキーフレーズとする|
|TF-Noun|TF-Allで品詞を名詞だけに制限|
|TF-IDF-Noun|各名詞の出現頻度に逆記事頻度(IDF)をかけ,値が高い順にキーフレーズとする|
|TF-IDF-Phrase|キーフレーズ候補を連続する名詞からなるフレーズとする.フレーズを構成する各名詞毎に TF-IDF を計算しその和をスコアとし、高い順にキーフレーズとする|
|PosRank|グラフベースの教師なしキーフレーズ抽出法である PositionPank[1] を用いたもの.キーフレーズ候補は「[形容詞][名詞]+」の形をしたフレーズである.ウィンドウサイズは5とした|
|PosRank-Noun|PosRank において,キーフレーズ候補を名詞 1 単語のみとしたもの|
K: 抽出キーフレーズ数, P: Precision, R: Recall, F: F値
[1] C. Florescu and C. Caragea. Positionrank: An unsupervised approach to keyphrase extraction from scholarly documents. In Proceedings of the 55th Annual Meeting of the ACL, volume 1, pages 1105–1115, 2017.
サッカー選手のプレイデータから速報テキストを生成
http://anlp.jp/proceedings/annual_meeting/2018/pdf_dir/A3-2.pdf
谷口泰史 (東工大), 高村大也 (東工大/産総研), 奥村学 (東工大)
言語処理学会第24回年次大会(NLP2018)
汎化タグに変換するだけでなく,単語の結合も行うことで,生成文の質が上がっていた
https://arxiv.org/abs/1709.02418
Whitehill, J.
https://dl.acm.org/citation.cfm?id=2971718
Proceeding
UbiComp '16 Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing
Pages 752-757
September 12 - 16, 2016

https://arxiv.org/abs/1810.06640
David Donahue, Anna Rumshisky / University of Massachusetts Lowell
arxiv
[v1] Thu, 11 Oct 2018 22:50:38 GMT
Null
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.