tongxinv / onebook Goto Github PK
View Code? Open in Web Editor NEW记录自己的知识框架,有时写写BLOG CSDN博客地址
Home Page: https://blog.csdn.net/TongxinV
记录自己的知识框架,有时写写BLOG CSDN博客地址
Home Page: https://blog.csdn.net/TongxinV


















































































链接器主要有两个作用,一是将若干输入文件(.o文件)根据一定规则合并为一个输出文件(例如ELF格式的可执行文件);一是将符号与地址绑定(当然加载器也要完成这一部分工作)
程序从源代码到二进制可执行文件需要经历:

预处理用预处理器,编译用编译器,汇编用汇编器,链接用链接器
其中链接器主要有两个作用,一是将若干输入文件(.o文件)根据一定规则合并为一个输出文件(例如ELF格式的可执行文件);一是将符号与地址绑定(当然加载器也要完成这一部分工作)。链接器有一个编译到其二进制代码中的默认链接脚本,大多数情况下使用它链接输入文件并生成目标文件
我们也可以自己书写合并规则,即自己写链接脚本。uboot更需要规则,因为涉及到重定位问题,重定位相关代码必须要放到前16KB之前。(此外,链接脚本还可以自己定义自己的段实现按段排列顺序执行程序,需源码有相关代码支持)
uboot链接脚本简单分析:

在设计一个程序时,会给这个程序指定一个运行地址(链接地址)。就是说在编译程序时其实心里是知道程序将来被运行时的地址(运行地址)的,而且必须给编译器链接器指定这个地址(链接地址)才行。最后得到的二进制程序理论上是和指定的运行地址有关的,将来这个程序被执行时必须放在当时编译链接时给定的那个地址(链接地址)下才行,否则不能运行(位置有关代码)。但是有个别特别的指令他可以跟指定的地址(链接地址)没有关系,也就是说这些代码实际运行时不管放在哪里都能正常运行(位置有关代码)
参考链接:http://blog.csdn.net/qq_33233768/article/details/64906265
(1)ifconfig查看MAC地址(如这里的为00:0c:29:6d:ec:39):
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.78.165 netmask 255.255.255.0 broadcast 192.168.78.255
inet6 fe80::20c:29ff:fe6d:ec39 prefixlen 64 scopeid 0x20<link>
inet6 2017:4444:5554:6664:20c:29ff:fe6d:ec39 prefixlen 64 scopeid 0x0<global>
inet6 2017:1111:2222:3333:20c:29ff:fe6d:ec39 prefixlen 64 scopeid 0x0<global>
ether 00:0c:29:6d:ec:39 txqueuelen 1000 (Ethernet)
RX packets 1325 bytes 106633 (104.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 137 bytes 17090 (16.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(2)修改文件/etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:6d:ec:39
TYPE=Ethernet
UUID=e3b8eebf-2bf3-432f-a197-548338ae19c5
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.78.165
NETMASK=255.255.255.0
GATEWAY=192.168.78.129
DNS1=223.5.5.5
这边有个疑问:UUID是什么?
(3)重新启动;
(4) 更新,没配置mac地址的时候,即时设置了DNS也不能解析域名
参考:http://blog.csdn.net/pearhuaer/article/details/8681359
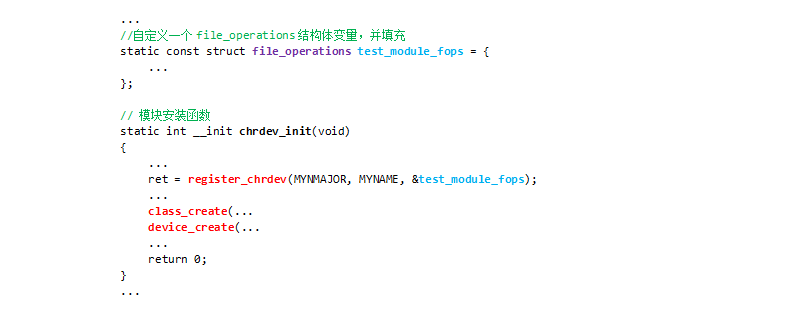
仿效真实驱动中,用结构体封装的方式来进行单次多个寄存器的地址映射。即代替文章《随笔--Linux字符设备驱动开发基础》中动态映射操作LED一节的基础动态映射方式
#include <linux/io.h>
#include <linux/ioport.h>
......
typedef struct GPJ0REG
{
volatile unsigned int gpj0con;
volatile unsigned int gpj0dat;
}gpj0_reg_t;
//#define GPJ0CON_PA 0xe0200240
//#define GPJ0DAT_PA 0xe0200244
#define GPJ0_REGBASE 0xe0200240
//unsigned int *pGPJ0CON; //指针类型才能接受ioremap返回的地址
//unsigned int *pGPJ0DAT;
gpj0_reg_t *pGPJ0REG;
...
// 模块安装函数
static int __init chrdev_init(void)
{
//注册字符设备驱动
...
#if 0
// 使用动态映射的方式来操作寄存器
if (!request_mem_region(GPJ0CON_PA, 4, "GPJ0CON"))
return -EINVAL;
if (!request_mem_region(GPJ0DAT_PA, 4, "GPJ0DAT"))
return -EINVAL;
pGPJ0CON = ioremap(GPJ0CON_PA, 4);
pGPJ0DAT = ioremap(GPJ0DAT_PA, 4);
*pGPJ0CON = 0x11111111;
*pGPJ0DAT = ((0<<3) | (0<<4) | (0<<5)); // 亮
#endif
// 2步完成映射
if (!request_mem_region(GPJ0_REGBASE, sizeof(gpj0_reg_t), "GPJ0REG"))
return -EINVAL;
pGPJ0REG = ioremap(GPJ0_REGBASE, sizeof(gpj0_reg_t));
// 映射之后用指向结构体的指针来进行操作
// 指针使用->结构体内元素 的方式来操作各个寄存器
pGPJ0REG->gpj0con = 0x11111111;
pGPJ0REG->gpj0dat = ((0<<3) | (0<<4) | (0<<5)); // 亮
...
}
// 模块卸载函数
static void __exit chrdev_exit(void)
{
...
// 解除映射
#if 0
iounmap(pGPJ0CON);
iounmap(pGPJ0DAT);
release_mem_region(GPJ0CON_PA, 4);
release_mem_region(GPJ0DAT_PA, 4);
#endif
iounmap(pGPJ0REG);
release_mem_region(GPJ0_REGBASE, sizeof(gpj0_reg_t));
...
//注销字符设备驱动
...
}动态映射结构体方式操作寄存器:在结构体中添加相应成员就可以,不用像之前的那么麻烦
更改文件/etc/apt/sources.list内容
deb http://mirrors.aliyun.com/ubuntu/ trusty main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-security main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main multiverse restricted universe保存退出,输入sudo apt-get update更新刚配置的路径
怎么删除issues
目前接触过的两种驱动实现方式是attribute路线和file_operations路线(自己取的)。
attribute的实现方式是学习驱动框架的时候接触到的,如文《驱动框架基础》所示,file_operations方式则比较常见,如文《字符设备驱动基础》中的led驱动实现测试代码。两者都是以led这种简单设备为例子。

分析使用attribute方式的LED驱动框架源码的时候,我们知道了led的一种驱动实现方式--attribute路线。源码中没有register_chrdev,只有class_create和device_create。通过对register_chrdev代码实现的分析,我们知道有register_chrdev一定走的是file_operations路线。详情点击这里:__register_chrdev_region分析
所以猜测attribute路线是一条不依赖于内核维护的255字符设备数组的驱动实现方式。让我困惑的是走attribute方式的LED驱动框架中的device_create的参数设备号0代表什么。我们都知道使用device_create的最大目的是提供相应信息给udev,让udev在用户空间下去创建设备节点以便我们能在用户空间下去访问内核驱动(当然,device_create的作用不仅仅是这个)。
比较之前的file_operations路线实现驱动方式:先使用register_chrdev注册一个设备号,然后使用class_create和device_create来自动创建设备文件节点。那我们现在谈论的attribute方式实现驱动是否也会创建相应的设备文件节点,是否一样能通过设备文件节点来访问到内核空间的驱动?
实际测试发现使用attribute方式的驱动模块leds-s5pv210模块安装后,lsmod控制台会打印出相应的模块安装信息,但是/dev下并没有产生相应的设备节点
所以我的猜测是:虽然给了它一个设备号,但是这个设备号是没有意义的(而且这个设备号是写死在内核源码中,并且当我们用attribute方式去实现一个驱动的时候你不需要像用file_operations方式时那样去指定设备号)。
;真正能解释的就是去看驱动源码,时间有限,没有具体分析源码。留个空再补充总结:
(1)device_create要能实现自动创建设备节点这一部分作用需要真正的主设备号的存在
(2)使用attribute的驱动实现方式不能通过设备节点来访问内核的对应驱动,只能通过/sys/class/xxx下的属性文件来访问
分析的源码:九鼎为s5pv210移植过的
linux+qt4.8的kernel,内核版本号2.6.35
建立映射表的三个关键部分:
具体物理地址和虚拟地址的值相关的宏定义,也就是文章《随笔--Linux字符设备驱动开发基础》中静态映射操作LED一节提到的静态映射表。实际工作中我们也只要明白静态映射表的意义就可以编写相关的代码
该函数负责由(1)中的映射表来建立MMU所能识别的页表映射关系。
在kernel/arch/arm/mach-s5pv210/mach-smdkc110.c中的smdkc110_map_io函数:

结论:经过分析,真正的内核移植时给定的静态映射表在arch/arm/plat-s5p/cpu.c中的s5p_iodesc,本质是一个结构体数组,数组中每一个元素就是一个映射,这个映射描述了一段物理地址到虚拟地址之间的映射。这个结构体数组所记录的几个映射关系被iotable_init所使用,该函数负责将这个结构体数组格式的表建立成MMU所能识别的页表映射关系,这样在开机后可以直接使用相对应的虚拟地址来访问对应的物理地址。
开机时(kernel启动时)
smdkc110_map_io怎么被调用的?

在分析驱动源码之前,首先要找到我们要分析的源码
在分析驱动源码之前,首先要找到我们要分析的源码。可源代码那么多怎么知道开发板装载的是哪一个呢?有以下几种方法
到编译过的内核源码树找xxx.o文件
...
到开发板下找对应设备的设备文件中的name,然后用name为索引找到对应的文件
...
[TOC]
在学习C++面对对象程序设计的时候,会把C++类的使用和C结构体的使用作比较。以下内容是学习过程中思考的问题,从而总结出为什么要设计出C++的封装继承和多态。因为自己写C程序的时候也是以面对对象的**来写(看过内核源码你就知道我在说什么),我们都知道C++是C语言的继承,而C++最明显的特征就是面对对象,那么C++是如何继承的,这是我思考的出发点
以下内容只是个人观点,不一定对,或者说只是想说只是想说服自己更好的理解C++
显然封装没有区别,为了完整性,把封装给贴出来了
首先明白什么是对象Object
Objects = Attributes + Services
程序里的封装就是对象Services的设计。封装的意义在于不直接操作数据。程序员很容易犯这样的错误,写着写着就伸到那个对象的里面去,直接去操数据
问题:C编程使用结构体嵌套,那么C++类的嵌套是什么?:一种就是——继承。在学习Linux设备驱动模型时,kobject就相当于是一个父类!!另外一种重要的方式是——组合。两种都可以使用,并没有谁是最好的,谁更合适应根据上下文决定或者混合使用。比如造车,继承应该是拿一个最基本的车来做父类,组合则是拿轮子拿引擎来拼装。再比如串口设备,应该是继承类device,然后组合串口。
例子较简单就不写了可以尝试一个类引用另一个类,即C编程中的结构体里面使用一个结构体类型的指针,真正需要用到时再malloc。参考博客:http://blog.csdn.net/kelvin_yan/article/details/44653145
问题:C编程结构体内使用函数指针进行封装。比如open函数指针,不同设备open的方式不同,所以在C编程的时候,我可以定义几个不同的xxx_open函数然后再把地址给结构体里面的open?那么在C++类中要实现这种用法具体怎么做呢?:多态
C version:
struct A{
void (*open)(void);
...
};
struct A xxx;xxx.open = xxx_open;
struct A yyy;yyy.open = yyy_open;
struct A zzz;zzz.open = zzz_open;C plus version:
class A{
public:
virtual void open();
};
class XXX:public A{
public:
virtual void open();
};
class YYY:public A{
public:
virtual void open();
};
class ZZZ:public A{
public:
virtual void open();
};通俗的讲,指针作为某一函数的实参,在函数内部发生改变后,外部的值也能跟着发生变化
以下内容是小项目开发随笔:(与标题相关内容在错误3)
错误1:
built-in.o: In function `main':
/root/winshare/ImagePlayer/main.c:17: undefined reference to `fb_open'
但是明明有定义啊?不是这个原因,而是文件没添加到工程中来
Makefile:
#添加顶层目录下的子文件夹(注意目录名后面加一个/)
obj-y += display/
然后子文件夹下添加相应规则
(子)Makefile
obj-y += framebuffer.o
错误2:
...
###错误3:
编译通过,但执行发生段错误,指针出错。通过这一错误进一步加深了对指针的使用
类比外部的int a作为函数形参并能够传出来,要用指针形式
外部的指针作为函数形参并能够传出来,要使用指针的指针作为形参类型
如下案例:
<textarea cols="80" rows="5" name="code" class="javascript"> 程序1: void myMalloc(char *s) //在函数中分配内存,再返回 { s=(char *) malloc(100); } void main() { char *p=NULL; myMalloc(p); //这里的p实际还是NULL,p的值没有改变 if(p) free(p); } 程序2: void myMalloc(char **s) //指针的指针,双重指针类型 { *s=(char *) malloc(100); } void main() { char *p=NULL; myMalloc(&p); //这里的p可以得到正确的值 if(p) free(p); } </textarea>###附.重要:
实际开发中,更喜欢利用结构体指针。因为如果不使用结构体指针,那么函数里面将会有一堆的解引用
结构体指针作为函数参数
void fb_open(struct framebuffer *fb)//指针
{
...
}
void main()
{
struct framebuffer fb0;
fb_open(&fb0);//取地址符&
struct framebuffer* fb1;//需要给这个指针分配实体
fb1 = (struct framebuffer*)malloc();
fb_open(fb1);//这时就不用取地址符,fb1中的成员的值在fb_open中被改变会影响
}###详细例子说明
#include <stdio.h>
#include <stdlib.h>
struct test_t{
int *p;
int a;
int b;
int c;
int d;
};
//函数外部使用malloc测试函数 (函数形参为结构体类型)
void func1(struct test_t * test)
{
test->a += 1;
printf("test->a = %d.\n", test->a);
}
/* 以下为函数内部使用malloc测试函数 (函数形参为结构体类型) */
void func2(struct test_t * test)
{
test = (struct test_t *)malloc(sizeof(struct test_t));
test->b = 1;
printf("test->b = %d.\n", test->b);
}
//...func3...
void func4(struct test_t **test)
{
*test = (struct test_t *)malloc(sizeof(struct test_t));
(*test)->d = 1;
printf("test->d = %d.\n", (*test)->d);
}
void func_p(struct test_t * test)
{
test->p = (int *)malloc(sizeof(struct test_t));
}
int main(void)
{
//使用案例1:函数外malloc
struct test_t * t1;
t1 = (struct test_t *)malloc(sizeof(struct test_t));
t1->a = 1;
func1(t1);//这样使用,t1->a的值就会改变,和func4(struct test_t **test)区分
printf("test->a = %d.\n", t1->a);
free(t1);
//有时候需要在函数里面malloc,如下:
#if 0
//使用案例2:错误使用,编译通过,运行触发段错误
struct test_t * t2;
func2(t2);
printf("test->b = %d.\n", t2->b);
free(t2);
#endif
#if 1
//但是可以在结构体里声明一个指针成员,然后如下使用
//(实际上原理和案例1是一样的,外部需要有实体,但是这里还提出来,是因为想说一下free的问题)
//为结构体内部的指针分配内存还是经常遇到的,包含该指针的结构体也是malloc而来的,但是有时只记得free最外层的指针
struct test_t * t0;
t0 = (struct test_t *)malloc(sizeof(struct test_t));
func_p(t0);
printf("test->p = %p.\n", t0->p);
free(t0->p);//不会触发段错误,注意free这个指针,还要注意先free这个指针,再free t0
free(t0);
#endif
#if 0
//使用案例3:
struct test_t * t3;
t3 = 返回值为struct test_t *的func3函数;
...
#endif
//使用案例4:(func4形参使用双重指针类型)
struct test_t * t4;
func4(&t4);
printf("test->d = %d.\n", t1->d);
free(t4);
//个人常用的就上面几种,当然还有这里没列出来的使用方式
//总结,(返回值,双重指针)多多编程多多体会
return 0;
}
打印内容:
test->a = 2.
test->a = 2.
test->p = 0x81ed020.
test->d = 1.
test->d = 1.另外:在C语言中,使用结构体的时候 "->" 和 “." 有什么区别?
定义的结构体如果是指针,访问成员时就用->
如果定义的是结构体变量,访问成员时就用.
例如:
struct AAA {
int a;
char b;
};
struct AAA q; 访问成员就用:q.a;
struct AAA *p; 访问成员就用:p->a;
以subsys_initcall和module_init为例
subsys_initcall是一个宏,定义在linux/init.h中。经过对这个宏进行展开,发现这个宏的功能是:将其声明的函数放到一个特定的段:.initcall4.init
subsys_initcall
__define_initcall("4",fn,4)
以下文件在/include/linux/init.h:

分析module_init宏,可以看出它将函数放到.initcall6.init段
module_init
__initcall
device_initcall
__define_initcall("6",fn,6)
打开编译过的内核源码树中的的/arch/arm/kernel/vmlinux.lds文件(没编译没有这个文件):
SECTIONS
{
. = 0xC0000000 + 0x00008000;
.init : { /* Init code and data */
_stext = .;
_sinittext = .;
*(.head.text)
*(.init.text) *(.cpuinit.text) *(.meminit.text)
......
. = ALIGN(16); __setup_start = .; *(.init.setup) __setup_end = .;
__initcall_start = .; *(.initcallearly.init) __early_initcall_end = .;
*(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init)
*(.initcall2.init) ... __initcall_end = .;
......
内核在启动过程中需要顺序的做很多事,内核如何实现按照先后顺序去做很多初始化操作。内核的解决方案就是给内核启动时要调用的所有函数归类,执行内核某一个函数然后每个类就会按照一定的次序被调用执行。这些分类名就叫.initcallx.init。x的值从1到8。内核开发者在编写内核代码时只要将函数设置合适的级别,这些函数就会被链接的时候放入特定的段,内核启动时再按照段顺序去依次执行各个段即可(通过某一个函数,链接脚本只是规定了某一程序段在内存中的存放位置)。
内核源代码:
以下文件在/init/main.c
extern initcall_t __initcall_start[], __initcall_end[], __early_initcall_end[];
static void __init do_initcalls(void)
{
initcall_t *fn;
for (fn = __early_initcall_end; fn < __initcall_end; fn++)
do_one_initcall(*fn);
/* Make sure there is no pending stuff from the initcall sequence */
flush_scheduled_work();
}执行do_initcalls就会按照设定好的顺序去执行,通过函数的内容可以猜测出其原理就是链接脚本设置好的顺序,然后do_initcalls执行就会去按照链接脚本设置好的顺序一个个遍历。
经过分析,可以看出,subsys_initcall和module_init的作用是一样的,只不过前者所声明的函数要比后者在内核启动时的执行顺序更早
另外:do_initcalls怎么被调用,简单看下调用过程
start_kernel() -> rest_init() ->kernel_init() -> do_basic_setup() ->do_initcalls()
arm是IO与内存统一编址,其他平台如x86是IO与内存独立编址访问方式不一样,使用内核提供的寄存器读写接口具有可移植性
在文章随笔--Linux字符设备驱动开发基础前面写的驱动在静态映射操作寄存器,都用#define rGPJ0CON *((volatile unsigned int *)GPJ0CON)的方式来访问寄存器,这样的做法在驱动中并不是很好,因为这样的做法在不同平台的情况下不具有可移植性。现在写的驱动是在ARM平台下去写的,ARM属于内存和IO统一编址的,在读写寄存器的时候即为进行IO操作,进行IO操作是和读写内存是一样的(IO也有个地址),这就叫统一编址。但是还有另外一些CPU(像x86)是非统一编址的,这种CPU在进行IO操作时的方法跟进行内存的读写的方法是不一样的。那么在这种情况下就有一种问题,如果写的驱动不仅要求在ARM下能够运行,还要求在X86下也要能够运行,如果还用#define rGPJ0CON *((volatile unsigned int *)GPJ0CON)的方式显然是不合适的,需要进行比较大的修改。我们要怎样才能够使他能够具有很强的移植性呢?——内核已经帮我们想好了办法,即内核提供访问寄存器的读写接口(函数),使用这些函数具有可移植性。其实现的原理就是用条件编译,如下比较:

代码示例(静态映射):
...
#include <mach/regs-gpio.h> //虚拟地址映射表
#include <mach/gpio-bank.h>
#include <linux/io.h>
#include <linux/ioport.h>
#define GPJ0CON S5PV210_GPJ0CON
#define GPJ0DAT S5PV210_GPJ0DAT
...
...
writel(0x11111111, GPJ0CON);
writel(((0<<3) | (0<<4) | (0<<5)), GPJ0DAT);
...代码示例(动态映射):
#include <linux/io.h>
#include <linux/ioport.h>
...
#define GPJ0CON_PA 0xe0200240
#define S5P_GPJ0REG(x) (x)
#define S5P_GPJ0CON S5P_GPJ0REG(0)
#define S5P_GPJ0DAT S5P_GPJ0REG(4)
static void __iomem *baseaddr; // 寄存器的虚拟地址的基地址,用来保存 ioremap的返回值
...
...
if (!request_mem_region(GPJ0CON_PA, 8, "GPJ0BASE"))
return -EINVAL;
baseaddr = ioremap(GPJ0CON_PA, 8);
writel(0x11111111, baseaddr + S5P_GPJ0CON);
writel(((0<<3) | (0<<4) | (0<<5)), baseaddr + S5P_GPJ0DAT);
...platform总线的注册是由platform_bus_init函数完成的,主要的内容是注册bus_type结构体类型的变量
Linux设备模型--设备驱动模型和sysfs文件系统解读http://www.cnblogs.com/Ph-one/p/5052191.html
该函数在内核启动阶段被调用,简单看下调用过程:
start_kernel()->rest_init()->kernel_init()->do_basic_setup()->driver_init()->platform_bus_init()
注:kernel_init()是在rest_init函数中创建内核线程来执行的
源代码:kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
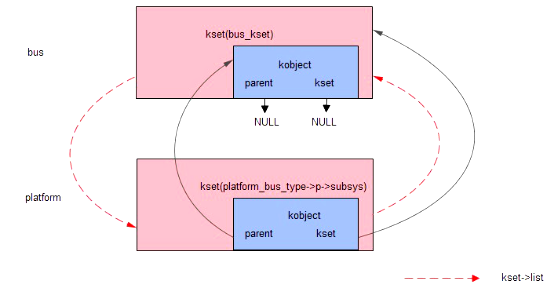
platform_bus_init:

bus_register:

函数中,首先调用kobject_set_name设置了bus对象的subsys.kobject->name 为 platform,也就是说会建立一个名为platform的目录
在这里还用到了bus_kset这个变量,这个变量就是在buses_init函数中建立bus目录所对应的kset对象
接着,priv->subsys.kobj.kset = bus_kset,设置subsys的kobj在bus_kset对象包含的集合中,也就是说bus目录下将包含subsys对象所对应的目录,即platform
紧接着调用了kset_register,参数为&priv->subsys。该函数在......在该函数的调用过程中,将调用kobj_kset_join函数,该函数将kojbect添加到kobject->kset结构(也就是他的上一级目录bus)中的链表当中
kset_register函数执行完成后,将在/sys/bus/下建立目录platform。此刻,我们先来看下kset和kobject之间的关系
然后,调用了bus_create_file函数在/sys/bus/platform/下建立文件uevent
接着调用了2次kset_create_and_add,分别在/sys/bus/platform/下建立了文件夹devices和drivers
这里和我们之前讲/sys下创建bus目录时用到的kset_create_and_add时的最主要一个区别就是:
此时的parent参数不为NULL,而是&priv->subsys.kobj
也就是说,将要创建的kset的kobject->parent = &priv->subsys.kobj,也即新建的kset被包含在platform文件夹对应的kset中
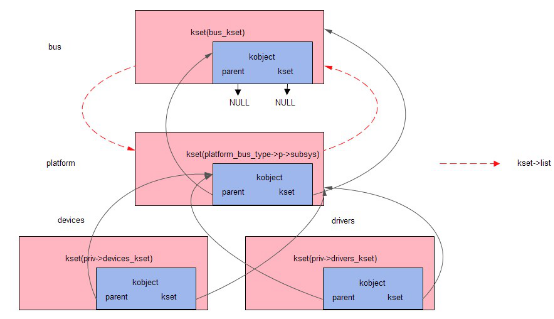
随后,调用了add_probe_files创建了属性文件drivers_autoprobe和drivers_probe
好了,整个bus_register调用完成了,我们来看下sysfs中实际的情况
[root@yj423 platform]#pwd
/sys/bus/platform
[root@yj423 platform]#ls
devices drivers drivers_autoprobe drivers_probe uevent
最后,我们对整个bus_register的过程进行一个小结:

container_of宏:得到外层结构体变量的地址,宏计算的结果是一个地址。还需注意宏的参数类型
ptr:指向结构体元素member的指针,type是结构体类型,member是结构体中的一个元素名
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })1.定义一个临时的数据类型(通过typeof( ((type *)0)->member )获得)与ptr相同的指针变量__mptr,然后用它来保存ptr的值(不能直接使用ptr,原因自己想)
2.用(char *)__mptr减去member在结构体中的偏移量,得到的值就是整个结构体变量的首地址(整个宏的返回值就是这个首地址)
container_of宏主要是用了一个技巧--求出内层结构体字段到外层的偏移量,如何得到member在结构体中的偏移量?offsetof宏
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)1.让0地址指向一个TYPE类型结构体变量:(type *)0
2.以0为基址的结构体变量指向结构体成员member的位置:(type *)0)->member
3.将member的地址强制转换成数字
[TOC]
password authentication failedR:切换到root用户
1 vim /etc/ssh/sshd_config
把PasswordAuthentication设成yes
把#PermitRootLogin no改为PermitRootLogin yes
2 重启服务器端的sshd服务
/etc/init.d/sshd restart
3 重启客服端的SecureCRT程序
附:同时我还把虚拟机防火墙关闭了:sudo ufw disable
R:16.04的服务是使用systemd进行管理了,查了一下相关的资料,发现重启服务的命令如下:
sudo systemctl restart smbd.service
进入root用户模式,更改.vimrc文件,没有就创建
vim /etc/vim/.vimrc
添加内容如下:
set encoding=utf-8
set termencoding=utf-8
set fileencoding=chinese
set fileencodings=ucs-bom,utf-8,chinese
gsettings set com.canonical.Unity.Launcher launcher-position Bottom
设置的时候提示失败,切换到root用户,并在命令前面前面加sudo。设置重启生效
没有经验,遇到问题乱改一通,但还是不行。境遇和上面那篇博客中的大兄弟一样。最后重头来
1.安装sudo apt-get install samba samba-common
2.修改配置文件vim /etc/samba/smb.conf
samba 配置文件 smb.conf 不用改什么东西,只在末尾加几条即可:
[share]
path = /home/share
available = yes //vailable用来指定该共享资源是否可用
browsable = yes //browseable用来指定该共享是否可以浏览
public = yes //public用来指定该共享是否允许guest账户访问
writable = yes //writable用来指定该共享路径是否可写
3.到/home新建文件夹share并修改权限为777
4.重启samba服务sudo service samba restart
ubuntu1604版本使用sudo systemctl restart smbd.service命令重启
5.到windows下打开命令终端,输入相应虚拟机上的linux系统的ip
我这里利用桥接方式,之前桥接上不了网是自己没配DNS(这时去星网锐捷实习的时候ZZJ告诉我的)。
另外如果你是用无线来上网的,记得去虚拟机上的网络首选项里的桥接选择无线的网卡,VMware默认桥接的网卡是有线网卡
最后可以看到网络中的文件夹,但是无法访问,网上找了找解决办法:
1.sudo apt-get install daemon重启后解决不了
2.sudo apt-get install libtalloc2重启后解决了
最后的最后还有一个问题,客户端(即windows)下无法修改服务端(即ubuntu)创建的文件
参考了博客Ubuntu 14.04 Samba客户端不能修改文件的解决办法
原因是客户端创建出来的文件所属user是nobdoy, group是nogroup, 而服务端的user/group是root/root(获取了root情况下)
两个不同用户和不同组不能相互修改
smb.conf提供了另外一个配置叫force user,它表示客户端默认创建的文件所属用户,只要和服务端设置成一样,那么就直接可以创建和修改所有文件了
所以去配置文件下添加:
[share]
path = /home/share
...
...
force user = root //直接设置成最高权限root
以上的设置方式是文件夹的访问的读写是完全开放的,显然是不合理,所以接下来又琢磨了如何设置访问权限的问题
打开配置文件vim /etc/samba/smb.conf修改为:
[share]
path = /home/share
available = yes
browsable = yes
writable = yes
public = yes
valid users = root //设置为只允许
force user = root
添加samba客户端访问用户root,同时会让你填写密码:(网上说添加的访问用户要事先存在于linux系统的中用户)
smbpasswd -a root
参考博客1:http://yuanbin.blog.51cto.com/363003/115761/
参考博客2:http://blog.csdn.net/fyh2003/article/details/7280119
[TOC]
参考文档:网上的《传志播客Python安装教程参考文档》,根据自己实际安装过程进行相应的添加修改,感谢分享。搭建环境是其次,重要的是理解命令的使用,这样才能举一反三
ubuntu16.04自带python的环境,不用进行python环境安装。但是默认安装的版本是Python2,想在其上做python3的开发会出现问题,比如使用pip安装软件包时,默认安装的时python2的包。想要安装python3的包就需要用到virtualenv工具,创建独立的python的环境,解决python2和python3两个环境之间的干扰问题。
1.安装并升级python包管理工具pip
# 安装pip
sudo apt-get install python-pip
# 更新pip
pip install --upgrade pip
2.virtualenv工具安装
安装virtualenv和virtualenvwrapper(更便于虚拟环境的集中管理)
sudo apt-get install python-virtualenv
sudo easy_install virtualenvwrapper
上述工具装好后找不到mkvirtualenv命令,需要执行以下环境变量设置
# 创建目录用来存放虚拟环境
mkdir $HOME/.virtualenvs
# 在~/.bashrc中添加行:
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
# 运行:
source ~/.bashrc
3.virtualenvwrapper基本使用
mkvirtualenv [虚拟环境名称]
workon
workon [虚拟环境名称]
deactivate
rmvirtualenv [虚拟环境名称]
创建python2的虚拟开发环境
mkvirtualenv -p /usr/bin/python2.7 py2
使用python2.7+django1.7.8环境,你应该安装如下环境:
(py2)python@ubuntu:~$ pip freeze list
pip==9.0.1
Django==1.7.8
ipdb==0.8.1
ipython==3.2.0
Pillow==2.8.2
把以上包名存储到package_py2.txt,在你的python虚拟环境中,运行:
pip install -r package_py2.txt
安装完成后可以使用pip freeze list查看;有些安装并不是最新版本,使用pip list --outdated检查哪些包需要更新,然后使用pip install --upgrade [安装包名称]选择更新
其实:这样做也没有比较方便,因为最后还是要更新,所以可以选择直接安装,系统会自动选择最新版本,当然也不是越新越好,根据具体需要选择吧:
pip install [安装包名称]
创建python3的虚拟开发环境
mkvirtualenv -p /usr/bin/python3.5 py3
使用python3.5+django1.9.4环境,你应该安装如下环境:
(py3)python@ubuntu:~$ pip freeze list
pip==9.0.1
Django==1.9.4
ipdb==0.8.1
ipython==4.1.2
Pillow==2.8.2
把以上包名存储到package_py3.txt,在你的python虚拟环境中,运行:
pip install -r package_py3.txt
注意:安装上述环境到安装到Pillow时会出现failed building wheel for ...错误,解决办法,使用常规安装命令进行安装:
pip install Pillow
问题1:使用pip list会有提示:
DEPRECATION: The default format will switch to columns in the future. You can use --format=(legacy|columns) (or define a format=(legacy|columns) in your pip.conf under the [list] section) to disable this warning
告诉你以后pip list的默认格式会采用columns。可以不用管,但还是很烦,解决如下:
在~/pip/pip.conf配置文件中(没有就自己创建)加入下面的语句,避免这类警告:
[list]
format=columns
| - | - |
|---|---|
| 查看已安装的包 | pip show --files SomePackage |
| 检查哪些包需要更新 | pip list --outdated |
| 升级包 | pip install --upgrade SomePackage |
| 卸载包 | pip uninstall SomePackage |
| 参数解释 | pip --help |
对链表进行封装
理解本部分内容需要配合《整理--Misc类设备驱动》这一文中链表的相关使用示例以及基本链表的知识。使用内核链表需要定义一个链表头,然后在需要管理的结构体中内嵌链表节点(通常又叫做链表入口entry,我是觉得挺形象的,更易于理解)
以下内容位于include/linux/List.h
分为链表头的初始化和入口entry的初始化


这里有一些小插曲,一开始,直接把函数参数替换掉展开,头插入的时候发现没有问题,但是尾插入的时候发现有不对劲:
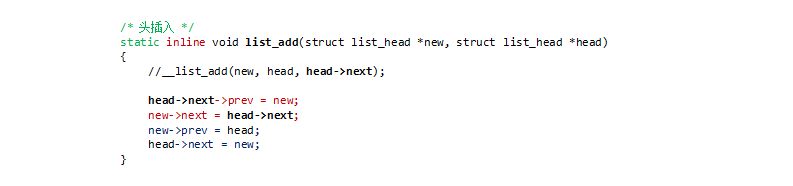

仔细分析**__list_add函数,函数形参struct list_head *prev struct list_head *next保存了相对于当前要处理的entry**的上一个和下一个的struct list_head变量的地址。
简化了问题,更易于理解,头插入和尾插入变成了只要给出对应前后节点对应的地址就能简便处理,和之前的接触过的链表不一样在于以前的链表没有连接成环
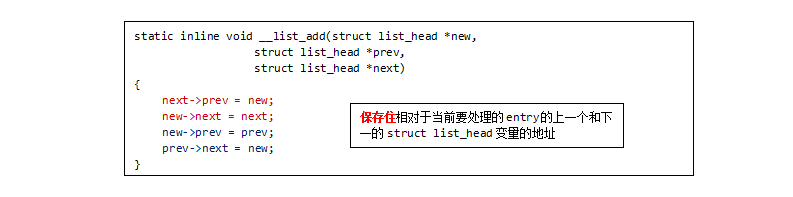
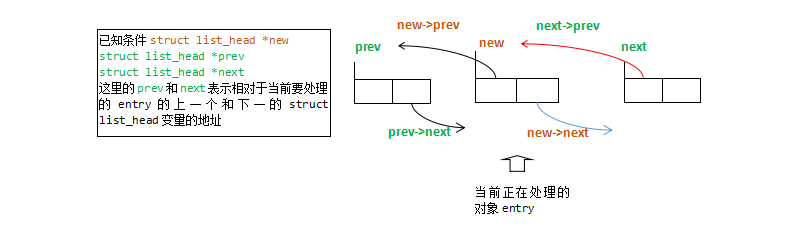

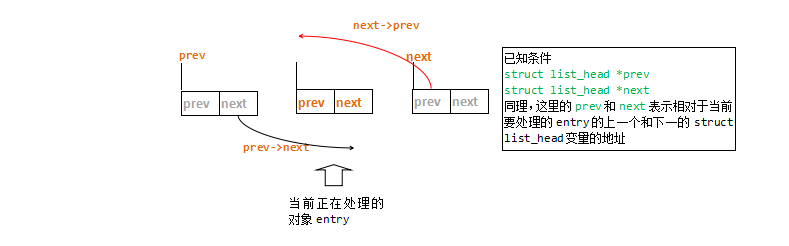

container_of宏:#17
完成uboot的编译,编译前需要进行相应的配置(通过对Makefile的分析知道了一个很重要的文件
configs/$1.h)
Makefile结构概览以及与配置的关系:

Makefile:

理解以上内容需要对其他知识有了解,如下附录:
驱动会以两种形式存在,野生家养。所谓野生的就是一个驱动源文件再加上一个Make file。野生驱动在很多情况下是非常流行的。譬如说我今天买了一个USB的网卡,那么这个USB网卡的厂家就要给我提供一个USB网卡的驱动。那么这个驱动从哪里来呢,我可以从他的官网上去下载.c文件和Makefile。这个 Makefile 是需要自己修改的,比如:
Makefile:
# 开发板的linux内核的源码树目录
KERN_DIR = /root/driver/kernel /*这边需要改,改成你自己的内核源码树目录*/
obj-m += leds-s5pv210.o
all:
make -C $(KERN_DIR) M=`pwd` modules
cp:
cp *.ko /root/x210_porting/rootfs/rootfs/driver_test
.PHONY: clean
clean:
make -C $(KERN_DIR) M=`pwd` modules clean然后make 生成一个.ko文件,然后insmod这样开发板上就可以使用USB网卡了
家养:像内核就有很多家养的驱动,DM9000等
实际上我们一个驱动文件是家养的还是野生跟我们驱动文件本身是没有任何关系的,就是我这个.c文件写好了我可以是野生的也可以是家养的,这只是一个存在形式而已,跟自身的代码是没有关系的。所以我们可以把一个家养的驱动文件从内核提出来变成一个野生的,也可以...
(1)野生,优势是方便调试开发,所以在开发阶段都是这种
(2)家养,优势可以在内核配置时make menuconfig决定内核怎么编译,方便集成
(1)以模块的形式在外部编写、调试
(2)将调试好的驱动代码集成到kernel中
(1)关键点:Kconfig、Makefile、make menuconfig
(2)操作步骤:
第1步:将写好的驱动源文件放入内核源码中正确的目录下
第2步:在Makefile中添加相应的依赖
obj -$(CONFIG_LEDS_S5PV210) += leds-s5pv210.o
第3步:在Kconfig中添加相应的配置项
我们在内核移植的课程中讲到过make menuconfig 和 Kconfig 、.config文件的对应关系
config LEDS_S5PV210 //名字取LEDS_S5PV210,CONFIG_是系统帮我们添加的
tristate "LED Support for S5PV210(X210)"
//tristatete 三态;后面那一串是在meuconfig配置的名字
//depends on MFD_88PM860X //依赖,可以去掉因为我们这个确实可以不依赖什么
help
This option enables support for on-board LED drivers found on S5PV210
最后生成的.config内容形式如下
CONFIG_MISC_FILESYSTEMS=y
# CONFIG_ADFS_FS is not set
注:弄成模块,.ko 文件在相应的文件夹下
头文件包含应该注意:是底层的头文件包含上层的头文件还是上层的头文件包含底层的头文件;我认为是后者,底层的东西提供给上层调用,上层应该配合底层。
这边的理解应该是错误的,UaMedia已经是上层,h224Session应该理解为上UaMedia的底层。所以应该是UaMedia调用h224来实现具体的业务
模块的层次划分,在编码的时候,我在H224Session函数中调用了Media的函数,这样是不适宜的,但是某些情况下确实是需要在H224中调用media的函数,怎么解决?用回调函数的方式
详细和ZZJ谈论了一些框架性的东西,有时为了层次或者包含关系,或者模块内部子模块与父模块的关联性要求,不直接调用底层接口。多封装一层甚至多封装多层。
config.mk的主要内容是编译属性和链接属性预处理属性,这些是交叉工具链本身的一些特征,这里只选择性分析
config.mk在主Makefile中被包含:
...
include $(TOPDIR)/config.mk
主要完成内容概览:
include $(TOPDIR)/config.mk
├── (1)编译工具定义 CC = $(CROSS_COMPILE)gcc
├── (2)包含开发板配置文件:sinclude $(OBJTREE)/include/autoconf.mk
├── (3)指定连接脚本LDSCRIPT
├── (4)uboot 链接地址TEXT_BASE
├── (5)自动推导规则
...
详细代码分析:

文章《随笔--Linux字符设备驱动开发基础》字符设备驱动注册代码分析一节中我们对旧接口
register_chrdev和新接口register_chrdev_region/alloc_chrdev_region进行了对比,发现其内部都调用了__register_chrdev_region,通过分析归纳出简单字符设备驱动在内核的工作原理
下列代码位于/fs/Char_dev.c

__register_chrdev_region最后返回一个char_device_struct结构体类型的指针变量(存放一个char_device_struct结构体类型的变量的地址),且其值(地址)被放入到内核维护的一个char_device_struct结构体类型的指针数组的某一元素中。应用层以设备号为索引去遍历指针数组从而找到对应驱动,具体如下(即简单字符设备驱动在内核的工作原理):
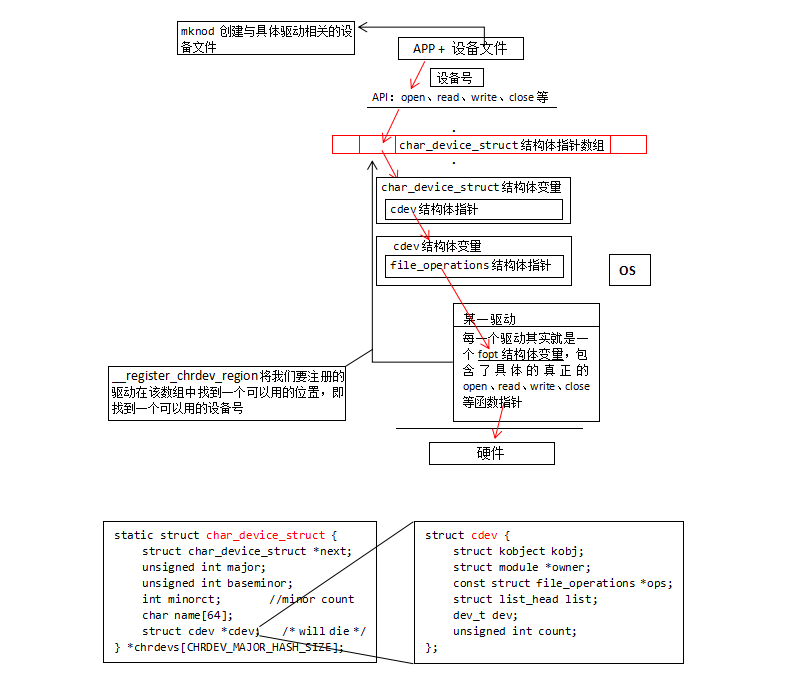
---- 路虽远,不行不至
对简单的库的移植的一般性归纳
1.移植后存放文件位置一般选择opt/目录下新建一个文件夹,比如opt/lib-codec
2.配置选项一般需要确定编译工具和链接工具,以及声明编译环境和移植的库最终在什么CPU和OS下运行,还需要指明编译库后生成的文件的存放位置。比如:
./configure CC=arm-linux-gcc LD=arm-linux-ld --prefix=/opt/lib-codec --exec-prefix=/opt/lib-codec
--enable-shared --enable-static -build=i386 -host=arm-linux
--prefix= 指定编译后的动态库.so,静态库.a,头文件.h存放位置(配置之前确定目录是存在的)
--exec-prefix= 指定可执行文件存放位置
--enable-shared=:使能共享,猜测生成动态链接库.so
--enable-static=:使能静态,猜测生成静态链接库.a和头文件.h
-build=:编译环境的设置
-host=:运行环境CPU和系统设置
3.有时候需要自己建立相应的目录,比如include目录lib目录等,具体需要去检查Makefile中具体的选项,一般xxxdir变量后面的值就是要建立的目录
4.移植的目的是由源码得到三个东西:动态库.so,静态库.a,头文件.h。下面举例说明动态链接库的使用
移植好的.h位于
opt/lib-codec/include;.so和,a文件位于opt/lib-codec/lib
/usr/lib目录下cp复制时使用 `-a` 或`-d`选项保留链接。`-a`选项通常在拷贝目录时使用,它保留链接、文件属性,
并递归地拷贝目录,其作用等于dpR选项的组合
CFLAGS添加相应的头文件路径 CFLAGS += -I $(shell pwd)/include -I/opt/lib-codec/include
LDFLAGS添加相应的链接库的路径(就是指明.h文件中声明的函数实体的位置) CFLAGS += -I $(shell pwd)/include -I/opt/lib-codec/include
LDFLAGS := -ljpeg -L/opt/lib-codec/lib
-l是链接选项(LDFLAGS),用来指定链接额外的库(如用到了数学函数,用-lm,链接器就会去链接libm.so
那么我们使用了libjpeg,对应的库名字就叫libjpeg.so,就需要用-ljpeg选项去链接)
-L是链接选项(LDFLAGS中指定),用来告诉链接器到哪个路径下面去找动态链接库。
例: LDFLAGS := -ljpeg -L/opt/lib-codec/lib
总结:-l是告诉链接器要链接的动态库的名字,而-L是告诉链接器库的路径(配合使用)
注意区分编译链接器需要的动态链接库的路径和使用动态链接时程序运行需要动态链接库的路径
注1:配置生成的Makefile的内容可以帮助你理解
注2:有时候,有些库不支持某些配置选项,比如./configure CC=arm-linux-gcc ...会跟你说不支持,那怎么办呢?使用export 命令临时性导出:
export CC=arm-linux-gcc
注3:有时候移植A库的时候需要B库的支持,B库移植好后过来继续A库的移植,发现还是报错:xxxlib not installed。原因是因为没有导出相关环境变量,所以A库在配置的时候找不到刚才移植的B库的库文件和头文件,解决办法就是使用epport临时性的导出
# export LDFLAGS="-L/opt/lib-codec/lib" ;B库动态链接和静态链接文件
# export CFLAGS="-I/opt/lib-codec/include";B库头文件
# export CPPFLAGS="-I/opt/lib-codec/include"
附:更详细的内容可以访问以下内容帮助理解
ImagePlayer开发日记之开源库使用
ImagePlayer开发日记之libjpeg移植
ImagePlayer开发日记之libpng移植
可以改写??
mount /dev/cdrom /media
提示mount:block device /dev/sr0 is write-protecter, mounting read-only
cd VMware\ Tools/
ls
cp VMwareTools-9.0.0. (按Tab补全) /tmp
cd /tmp
ls
[root@Webmail media]# cp VMwareTools-8.6.0-425873.tar.gz /tmp
[root@Webmail media]# cd /tmp/
[root@Webmail tmp]# ls
[root@Webmail tmp]# chmod +x VMwareTools-8.6.0-425873.tar.gz
[root@Webmail tmp]# tar zxf VMwareTools-8.6.0-425873.tar.gz
[root@Webmail tmp]# cd vmware-tools-distrib/
[root@Webmail vmware-tools-distrib]# ./vmware-install.pl 开始安装
接着一路回车
安装完成后,显示信息Found VMware Tools CDROM mounted at /media. Ejecting device /dev/sr0 ... ,找到安装在/ media的VMware Tools CDROM。 弹出设备/ dev / sr0 ...。意思为自动帮我们弹出设备,不放心可以自己弹出
[root@Webmail ~]# cd /
[root@Webmail /]# umount /media
参考博文1:http://jingyan.baidu.com/article/a17d52851ab9f98099c8f262.html
编译时make通不过,提示错误:
gcc: error: //source/cs/main/main.c: No such file or directory
但是进入那个文件夹下查看文件是存在的。经过排查,发现是我使用软连接的问题。
源工程代码存放路径/mnt/mcu/mcu/(我这里使用mount的方式挂载挂载到/mnt/mcu下)
源代码的目录结构是这样的:
├── include
│ ├── auth
│ ├── base
│ ├── ...
├── main
├── product
│ └── mcu
└── source
├── base
├── cps
└── cs
product是编译目录,编译时会去相应include和source目录下查找需要的文件。那么makefile可能或者一定是使用cd ..这种方式去进入相应的目录。所以想到了可能是我使用软连接的问题。我在linux下用ln -s /mnt/mcu/mcu/product/mcu/ mcu 在~ 目录建立了一个软链接,然后直接进入mcu目录编译。
按照这种方式进入编译目录是不行的,使用cd ..发现直接就进入了~ 目录
后面按照全路径 /mnt/mcu/mcu/product进入编译目录就没有报错了
在编译uboot之前需要进行配置(带参数执行mkconfig脚本+其他)
以make x210_sd_config 为例:主要完成的内容
make x210_sd_config时会相应的去执行Makefile中的:
x210_sd_config : unconfig
@$(MKCONFIG) $(@:_config=) arm s5pc11x x210 samsung s5pc110
@echo "TEXT_BASE = 0xc3e00000" > $(obj)board/samsung/x210/config.mk
@$(MKCONFIG)就表示调用目录下的mkconfig脚本,后面是mkconfig脚本的6个参数,不是五个
$(@:_config=) arm s5pc11x x210 samsung s5pc110
$和@结合: 是Makefile自动变量的一种,会被替换成目标x210_sd
冒号表示加工,怎么加工呢?就是把目标中的_config等于空(等号后面没东西表示空)。即x210_sd_config里的_config部分用空替换,得到:x210_sd,这就是第一个参数,则:
$1: x210_sd
$2: arm
$3: s5pc11x
$4: x210
$5: samsumg
$6: s5pc110
所以,$# = 6
TEXT_BASE = 0xc3e00000:指定uboot的链接地址,因为uboot中启用了虚拟地址映射,因此这个C3E00000地址就等于0x23E00000(也可能是33E00000具体地址要取决于uboot中做的虚拟地址映射关系
下面打开mkconfig脚本分析:

uboot编译前的配置(mkconfig脚本+其他)主要完成的内容:
1.创建符号链接,用于将来在写代码过程中能自动索引具体平台的文件
2.在include目录下创建config.mk文件并向里面写内容(其实就是把$2到$6的内容写入)让主Makefile去包含
3.在include目录下创建config.h文件并向里面写内容(其实就一行#include <configs/$1.h>)用于Makefile作为生成autoconf.mk的依赖和让start.S去包含
4.直接创建 $(obj)board/samsung/x210/config.mk文件并向里面写内容(TEXT_BASE = 0xc3e00000)让根目录下的config.mk去包含
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.