
- 🔭 I’m currently working on bert4torch.
- 🌱 I’m currently learning NLP and REC.
- 📫 How to reach me:
- Email:[email protected]
- Wechat:Tongjilibo
An elegent pytorch implement of transformers
Home Page: https://bert4torch.readthedocs.io/
License: MIT License





















































































































92行应该是 last_optimizer.pt 吧
bert4torch/examples/tutorials/tutorials_small_tips.py
Lines 92 to 93 in 6ed4973

您好,通过您给定convert_t5_pegasus转化成立pytorch_model.bin,此处config.json我沿用了base版本的config.json,这个错把
"hidden_act": ["gelu", "linear"]改成"hidden_act": "gelu"后出这个错

望解答,谢谢!

好像该json文件中确实没有 'hidden_size', 'num_hidden_layers', 'num_attention_heads', 'intrmediate_size', and 'hidden_act'这样几个参数
想要使用模型最后几层的输出作为输出结果,现在bert4torch能实现吗
看了模型定义没找到方法
你好,波哥,请问你做文本摘要的csl数据集是10K样本还是3K样本的那个呢,我跑的时候F1值到60%左右就不动了,跑不到68%
请教下,tensorrt trtexec把onnx转换成fp32的trt时,是没有问题的,但是转换成fp16,误差很大,基本不可用;不知道你这边有没有转成fp16的trt,有没有问题?
class RoPEPositionEncoding(nn.Module):
"""旋转式位置编码: https://kexue.fm/archives/8265
"""
def __init__(self, max_position, embedding_size):
super(RoPEPositionEncoding, self).__init__()
position_embeddings = get_sinusoid_encoding_table(max_position, embedding_size) # [seq_len, hdsz]
# cos_position = position_embeddings[:, 1::2].repeat(1, 2)
# sin_position = position_embeddings[:, ::2].repeat(1, 2)
cos_position = position_embeddings[:, 1::2].repeat_interleave(2, dim=-1) # 修改后
sin_position = position_embeddings[:, ::2].repeat_interleave(2, dim=-1) # 修改后
self.register_buffer('cos_position', cos_position)
self.register_buffer('sin_position', sin_position)
def forward(self, qw, seq_len_dim=1):
dim = len(qw.shape)
assert (dim >= 2) and (dim <= 4), 'Input units should >= 2 dims(seq_len and hdsz) and usually <= 4 dims'
seq_len = qw.shape[seq_len_dim]
# qw2 = torch.cat([-qw[..., 1::2], qw[..., ::2]], dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[..., ::2]], dim=-1).reshape_as(qw) # 修改后
if dim == 2:
return qw * self.cos_position[:seq_len] + qw2 * self.sin_position[:seq_len]
if dim == 3:
return qw * self.cos_position[:seq_len].unsqueeze(0) + qw2 * self.sin_position[:seq_len].unsqueeze(0)
else:
return qw * self.cos_position[:seq_len].unsqueeze(0).unsqueeze(2) + qw2 * self.sin_position[:seq_len].unsqueeze(0).unsqueeze(2)大佬你好,bert4torch的RoPE在实现上是不是有点问题,按照苏神的博客应该是上面修改后的代码吧
提问时请尽可能提供如下信息:
请教下,tensorrt trtexec把onnx转换成fp32的trt时,是没有问题的,但是转换成fp16,误差很大,基本不可用;不知道你这边有没有转成fp16的trt,有没有问题?
# 请在此处贴上你的核心代码# 请在此处贴上你的调试输出此处请贴上你的自我尝试过程
麻烦您给个链接,我想看看移植过来之前的源码。
主要是想知道转移矩阵这里为什么要+2:
init_transitions = torch.zeros(self.num_labels + 2, self.num_labels + 2)
因为看过其他实现,头一次看到+2的情况,您在代码中也注释了是要加首尾,但我不知道加首尾是要解决什么问题。
如题

这个example中
输入:[CLS]科学[MASK][MASK]是第一生产力[SEP]
预测出来的结果是,,两个逗号,而不是技术
使用的模型是hugging face 模型库中的bert-base-chinese。
模型加载过程中出现大量警告:

请问只是啥问题?
使用task_sequence_labeling_ner_global_pointer.py脚本做尝试
修改位置及代码如下
1、加载bert模型为huggingface上面的模型权重
self.bert_dir = "/home/BERT/bert_torch/bert-base-chinese/"
self.config_path = self.bert_dir + 'config.json'
self.checkpoint_path = self.bert_dir + 'pytorch_model.bin'
self.dict_path = self.bert_dir + 'vocab.txt'
2、修改model.fit参数
model.fit(train_dataloader, epochs=20, steps_per_epoch=5, callbacks=[evaluator])
3、完全运行结果,部分截图如下
1/5 [=====>........................] - ETA: 0s - loss: 2.5862
2/5 [===========>..................] - ETA: 0s - loss: 2.5127
3/5 [=================>............] - ETA: 0s - loss: 2.7961
4/5 [=======================>......] - ETA: 0s - loss: 2.8367
5/5 [==============================] - 1s 125ms/step - loss: 2.4887
[val] f1: 0.00000, p: 0.00000 r: 0.00000 best_f1: 0.00000
============Finish Training=============
Process finished with exit code 0
系统:ubuntu 20.0.4
pytorch版本:1.11.0+cu113
python: 3.7
想请教下是哪里的问题,导致f1结果一直为0
hi,我在使用您这边实现的bart的seq2seq模型时候,报错:init() missing 4 required positional 'hidden_size','num_attention_heads', 查看了下config问句确实是没有这些信息的,现在的bart模型地址:https://huggingface.co/fnlp/bart-base-chinese, 请问是不是框架还没有支持bart ?
咨询波哥一个问题哦。
对比测试了几个模型,比如分类,序列标注,文本生成等。使用bert4torch和hugging face中的tokenizer和model load,
hugging face版本的会在五六轮左右出现一个比较好的效果
bert4torch需要20轮以上效果才可以
而最终的模型评估效果是hugging face略高1~2个点
对比代码,暂时没找到原因。比较疑惑
不少issue是关于预训练模型加载出错的,包含报warning和config参数不对,解释如下
1、basic_language_model_CDial_GPT.py 文件测试的时候显示生成的文字杂七杂八的。

解决方法: @AutoRegressiveDecoder.wraps(default_rtype='probas') 中的probas改为logits
2、basic_language_model_nezha_gpt_dialog.py 文件测试的时候报错

解决:主要问题是model的转换,之前是自己写的,有些层写的不对,参看convert中的转换就没问题。另外相对距离的计算,波哥在配置文件中添加了,bert4keras则是在代码里实现。
提问时请尽可能提供如下信息:

bert4torch能不能保存训好的torch权重?
比如这个代码case:
你能提供预测新的文本的inference代码吗?
#! -- coding:utf-8 --
from bert4torch.tokenizers import Tokenizer
from bert4torch.models import build_transformer_model, BaseModel
from bert4torch.snippets import sequence_padding, Callback, text_segmentate, ListDataset
import torch.nn as nn
import torch
import torch.optim as optim
import random, os, numpy as np
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
maxlen = 256
batch_size = 16
config_path = 'F:/Projects/pretrain_ckpt/bert/[google_tf_base]--chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = 'F:/Projects/pretrain_ckpt/bert/[google_tf_base]--chinese_L-12_H-768_A-12/pytorch_model.bin'
dict_path = 'F:/Projects/pretrain_ckpt/bert/[google_tf_base]--chinese_L-12_H-768_A-12/vocab.txt'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
writer = SummaryWriter(log_dir='./summary') # prepare summary writer
seed = 42
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
tokenizer = Tokenizer(dict_path, do_lower_case=True)
class MyDataset(ListDataset):
@staticmethod
def load_data(filenames):
"""加载数据,并尽量划分为不超过maxlen的句子
"""
D = []
seps, strips = u'\n。!?!?;;,, ', u';;,, '
for filename in filenames:
with open(filename, encoding='utf-8') as f:
for l in f:
text, label = l.strip().split('\t')
for t in text_segmentate(text, maxlen - 2, seps, strips):
D.append((t, int(label)))
return D
def collate_fn(batch):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for text, label in batch:
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
batch_token_ids = torch.tensor(sequence_padding(batch_token_ids), dtype=torch.long, device=device)
batch_segment_ids = torch.tensor(sequence_padding(batch_segment_ids), dtype=torch.long, device=device)
batch_labels = torch.tensor(batch_labels, dtype=torch.long, device=device)
return [batch_token_ids, batch_segment_ids], batch_labels.flatten()
train_dataloader = DataLoader(MyDataset(['E:/Github/bert4torch/examples/datasets/sentiment/sentiment.train.data']), batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
valid_dataloader = DataLoader(MyDataset(['E:/Github/bert4torch/examples/datasets/sentiment/sentiment.valid.data']), batch_size=batch_size, collate_fn=collate_fn)
test_dataloader = DataLoader(MyDataset(['E:/Github/bert4torch/examples/datasets/sentiment/sentiment.test.data']), batch_size=batch_size, collate_fn=collate_fn)
class Model(BaseModel):
def init(self) -> None:
super().init()
self.bert, self.config = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, with_pool=True, return_model_config=True)
self.dropout = nn.Dropout(0.1)
self.dense = nn.Linear(self.config['hidden_size'], 2)
def forward(self, token_ids, segment_ids):
_, pooled_output = self.bert([token_ids, segment_ids])
output = self.dropout(pooled_output)
output = self.dense(output)
return output
model = Model().to(device)
model.compile(
loss=nn.CrossEntropyLoss(),
optimizer=optim.Adam(model.parameters(), lr=2e-5), # 用足够小的学习率
metrics=['accuracy']
)
def evaluate(data):
total, right = 0., 0.
for x_true, y_true in data:
y_pred = model.predict(x_true).argmax(axis=1)
total += len(y_true)
right += (y_true == y_pred).sum().item()
return right / total
class Evaluator(Callback):
"""评估与保存
"""
def init(self):
self.best_val_acc = 0.
# def on_batch_end(self, global_step, batch, logs=None):
# if global_step % 10 == 0:
# writer.add_scalar(f"train/loss", logs['loss'], global_step)
# val_acc = evaluate(valid_dataloader)
# writer.add_scalar(f"valid/acc", val_acc, global_step)
def on_epoch_end(self, global_step, epoch, logs=None):
val_acc = evaluate(valid_dataloader)
test_acc = evaluate(test_dataloader)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
# model.save_weights('best_model.pt')
print(f'val_acc: {val_acc:.5f}, test_acc: {test_acc:.5f}, best_val_acc: {self.best_val_acc:.5f}\n')
if name == 'main':
evaluator = Evaluator()
model.fit(train_dataloader, epochs=10, steps_per_epoch=None, callbacks=[evaluator])
else:
model.load_weights('best_model.pt')
Epoch 1/50
2000/2000 [==============================] - 534s 267ms/step - loss: 0.0394
Evaluation: 100%|██████████| 1159/1159 [01:34<00:00, 12.25it/s]
[val] f1: 0.00000, p: 0.00000 r: 0.00000
这个地方没有将随机种子赋值给seed
bert4torch/bert4torch/snippets.py
Line 1275 in ab4f74b
您好呀,尝试在模型上添加对抗训练,添加完成后,代码的f1值一直是0
这样预测时候 model.load_weights('../../output/best_model.pt'),报错
Traceback (most recent call last):
File "/opt/pycharm-2021.1.3/plugins/python/helpers/pydev/pydevd.py", line 1483, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "/opt/pycharm-2021.1.3/plugins/python/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/home/gallup/study/search/kuafu/kuafu/matching/run_poly_encoders.py", line 149, in
model.load_weights('../../output/' + args.model_name + '_best_model.pt')
File "/home/gallup/anaconda3/envs/tf2-torch1/lib/python3.6/site-packages/bert4torch/models.py", line 272, in load_weights
self.load_state_dict(state_dict, strict=strict)
File "/home/gallup/anaconda3/envs/tf2-torch1/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1455, in load_state_dict
state_dict = state_dict.copy()
File "/home/gallup/anaconda3/envs/tf2-torch1/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1178, in getattr
type(self).name, name))
AttributeError: 'BiEncoder' object has no attribute 'copy'
python-BaseException

这个模块中输入的pytorch_model.bin文件是使用convert_nezha_gpt_dialog.py这个脚本对苏神提供的tf版的chinese_nezha_gpt_L-12_H-768_A-12模型进行转换而来的吗?
例如:
想象keras一样直接将自定义函数作为模型的评估函数该怎么做?
该如何修改
def accuracy(y_pred, y_true):
y_pred = torch.where(y_pred>0.5,torch.ones_like(y_pred,dtype = torch.float32),
torch.zeros_like(y_pred,dtype = torch.float32))
acc = torch.mean(1-torch.abs(y_true-y_pred))
return acc
model.compile(
loss=nn.CrossEntropyLoss(),
optimizer=optim.Adam(model.parameters(), lr=2e-5),
metrics={LogLoss}
)

在关系抽取模型casrel中,如果在模型结构中加入了其他的网络结构,在def forward(self, inputs)中添加了使用过程。那么需要在class Model(BaseModel)下的def predict_subject(self, inputs)和def predict_object(self, inputs)下添加这个网络结构的使用嘛吗
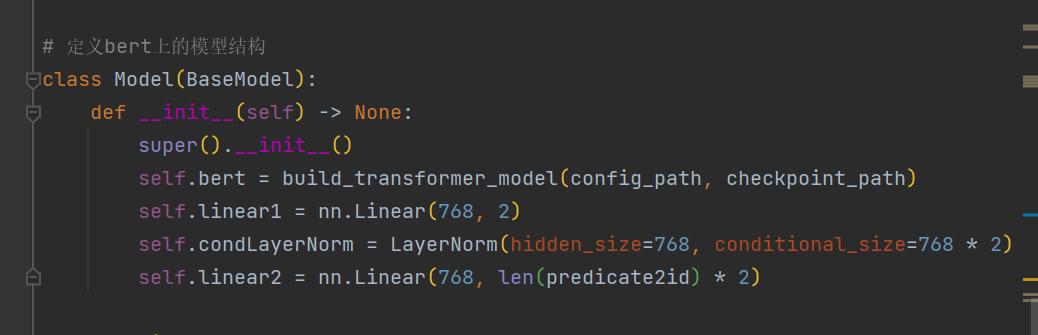
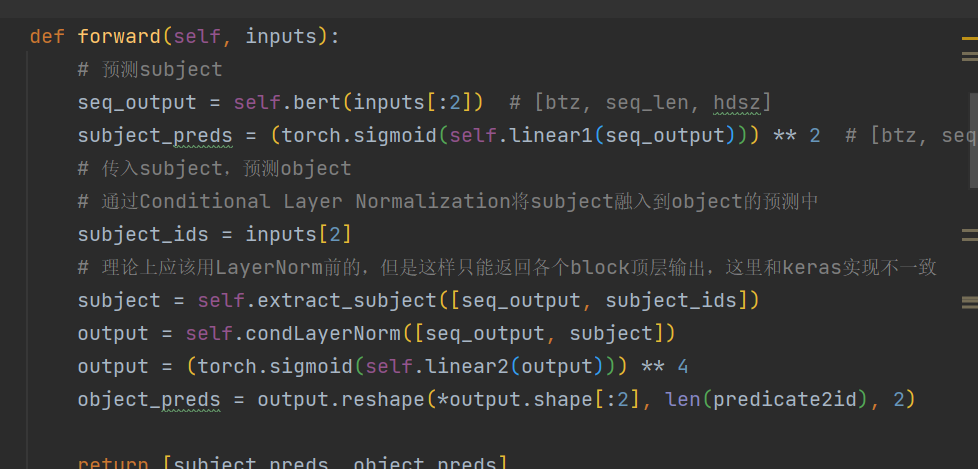

我跑的是task_sequence_labeling_ner_global_pointer.py
我的代码里就改了我下载的bert的路径(我用的是绝对路径)和在定义bert这一行(加了个model="bert")
config_path = '/mnt/hdd0/lsn/bert/bert-base-uncased/config.json'
checkpoint_path = '/mnt/hdd0/lsn/bert/bert-base-uncased/pytorch_model.bin'
dict_path = '/mnt/hdd0/lsn/bert/bert-base-uncased/vocab.txt'
self.bert = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, model='bert', segment_vocab_size=0)然后运行后报一堆[warning],类似下面这样的
[WARNIMG] bert.embeddings.LayerNorm.weight not found in pretrain models
[WARNIMG] bert.embeddings.LayerNorm.bias not found in pretrain models
[WARNIMG] bert.encoder.layer.0.attention.output.LayerNorm.weight not found in pretrain models
[WARNIMG] bert.encoder.layer.0.attention.output.LayerNorm.bias not found in pretrain models
[WARNIMG] bert.encoder.layer.0.output.LayerNorm.weight not found in pretrain models
[WARNIMG] bert.encoder.layer.0.output.LayerNorm.bias not found in pretrain models
global_pointer示例在分词后没有添加cls和sep, token加了之后指标会提高,不知是故意去掉还是疏忽了。
115 行被注释掉了, 后面inference要用到这个文件
bert4torch/examples/tutorials/tutorials_small_tips.py
Lines 108 to 116 in 5953abe
你好!
非常感谢作者编写的这套torch框架,gradient-checkpointing是种可以节省显存的训练方法,对于资源紧张下训练大模型有比较大的帮助作用,在苏神的博客上也有介绍,huggingface的transformers也内置了相关支持,是否能在后期加上这个功能?
你好,我想用t5_pegasus_small做一个seq2seq任务,config.json文件如下:
{
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 1024,
"num_attention_heads": 6,
"attention_head_size": 64,
"num_hidden_layers": 8,
"vocab_size": 50000,
"hidden_act": "gelu",
"relative_attention_num_buckets": 32
}
,但是运行时在layer层会抛assert hidden_size % num_attention_heads == 0 错误,请问是配置文件哪里不对吗
提问时请尽可能提供如下信息:
# 请在此处贴上你的核心代码# 请在此处贴上你的调试输出此处请贴上你的自我尝试过程
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/bert_crf/train.py", line 191, in
model.fit(train_dataloader, epochs=20, steps_per_epoch=None, callbacks=[evaluator])
File "D:\python36\lib\site-packages\bert4torch\models.py", line 213, in fit
output, loss, loss_detail = self.train_step(train_X, train_y, grad_accumulation_steps)
File "D:\python36\lib\site-packages\bert4torch\models.py", line 131, in train_step
loss_detail = self.criterion(output, train_y)
File "D:\python36\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/Administrator/Desktop/bert_crf/train.py", line 122, in forward
return model.crf.neg_log_likelihood_loss(*outputs, labels)
File "D:\python36\lib\site-packages\bert4torch\layers.py", line 913, in neg_log_likelihood_loss
forward_score, scores = self._forward_alg(feats, mask)
File "D:\python36\lib\site-packages\bert4torch\layers.py", line 862, in _forward_alg
masked_cur_partition = cur_partition.masked_select(mask_idx) # [x * tag_size]
您好,请问能否发一下您用于训练和测试的原始数据集呢?主要是想了解一下您是如何跑出如此高的准确率的,谢谢!
请问torch版本应该选择多少?
112行
bert4torch/examples/tutorials/tutorials_small_tips.py
Lines 111 to 112 in a1d66a7
在脚本layers.py中55行,cond = cond.unsqueeze(dim=1),这里的dim应该是等于0吧,调试发现是不太对的,老哥确认下
您好,波哥,我想在关系抽取模型上添加对抗训练方法,预训练模型使用的是ernie模型,请问需要改预训练模型的embding层嘛,因为我换了预训练模型后使用对抗训练没有效果

大佬,我用你examples中的人民日报数据跑,在task_sequence_labeling_ner_W2NER 上的结果并不好,不知道是哪里出问题了,在验证集上F1值只有90一点。我用的是windows系统3090显卡,torch=1.11.3,bert4torch=0.2.2,Python=3.8
[val-token level] f1: 0.91029, p: 0.89145 r: 0.93052
[val-entity level] f1: 0.90059, p: 0.91598 r: 0.88571 best_f1: 0.90154
============Finish Training=============
你好,波哥,请问为啥self.evaluate(valid_dataset.data[:valid_len]),第一次推理验证集时速度快,第二次推理同样的验证集时速度只有前一次的二十分之一左右,evaluate代码如下
def evaluate(self, data):
total = 0
rouge_1, rouge_2, rouge_l, bleu = 0, 0, 0, 0
for title, content in tqdm(data):
total += 1
title = ' '.join(title).lower()
# with torch.no_grad():
pred_title = ' '.join(autosumm.generate(content)).lower()
if pred_title.strip():
scores = self.rouge.get_scores(hyps=pred_title, refs=title)
rouge_1 += scores[0]['rouge-1']['f']
rouge_2 += scores[0]['rouge-2']['f']
rouge_l += scores[0]['rouge-l']['f']
bleu += sentence_bleu(references=[title.split(' ')], hypothesis=pred_title.split(' '),
smoothing_function=self.smooth)
rouge_1, rouge_2, rouge_l, bleu = rouge_1 / total, rouge_2 / total, rouge_l / total, bleu / total
return {'rouge-1': rouge_1, 'rouge-2': rouge_2, 'rouge-l': rouge_l, 'bleu': bleu}

我使用同样的权重文件,同样的测试数据,使用如下代码可以生成摘要:
model = MT5ForConditionalGeneration.from_pretrained(args.pretrain_model).to(device)
gen = model.generate(max_length=args.max_len_generate,
eos_token_id=tokenizer.sep_token_id,
decoder_start_token_id=tokenizer.cls_token_id,
**content)
使用Autotitle 示例中的generate输出为空,后来发现是beam_search中预测的第一个值就是end_id [SEP]
class AutoSummarize(AutoRegressiveDecoder):
"""seq2seq解码器
"""
@AutoRegressiveDecoder.wraps(default_rtype='logits')
def predict(self, inputs, output_ids, states):
# inputs中包含了[decoder_ids, encoder_hidden_state, encoder_attention_mask]
return model.decoder.predict([output_ids] + inputs)[-1][:, -1, :] # 保留最后一位
def generate(self, text):
gc.collect()
torch.cuda.empty_cache()
token_ids, _ = tokenizer.encode(text, maxlen=args.max_c_len)
token_ids = torch.tensor([token_ids], device=device)
encoder_output = model.encoder.predict([token_ids])
output_ids = self.beam_search(encoder_output, topk=1) # 基于beam search
return tokenizer.decode([int(i) for i in output_ids.cpu().numpy()]
不知道是不是因为states为空呢,我发现encoder_output里并没有states
提问时请尽可能提供如下信息:
# 请在此处贴上你的核心代码# 请在此处贴上你的调试输出此处请贴上你的自我尝试过程
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.